Quantized Visual Geometry Grounded Transformer
------
This project is the official implementation of our QuantVGGT: "Quantized Visual Geometry Grounded Transformer".

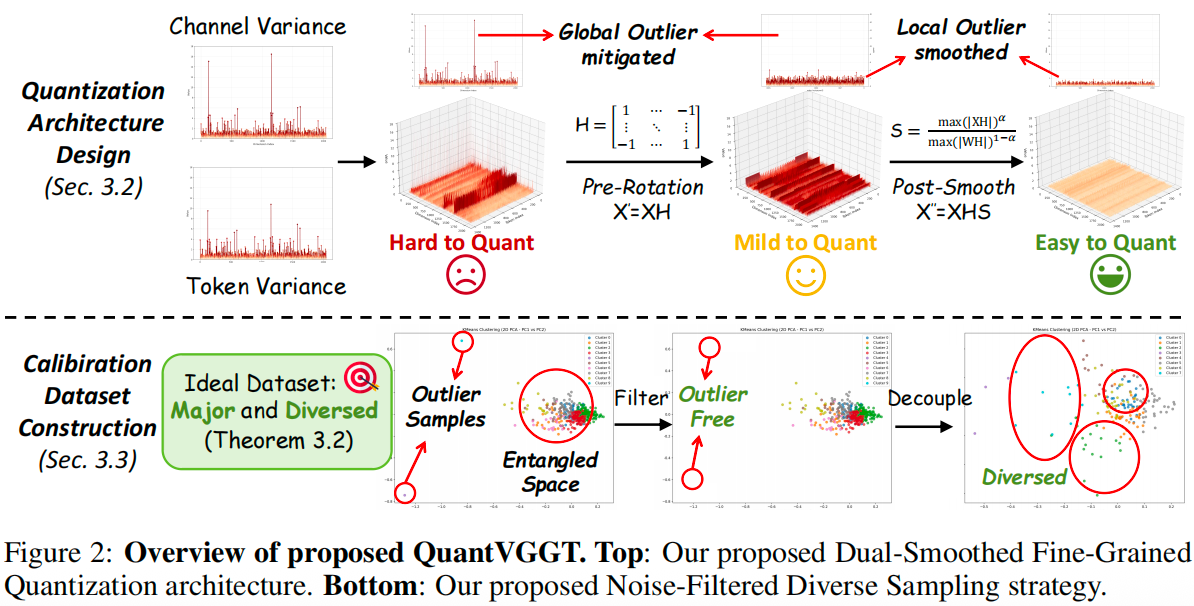
------
Results
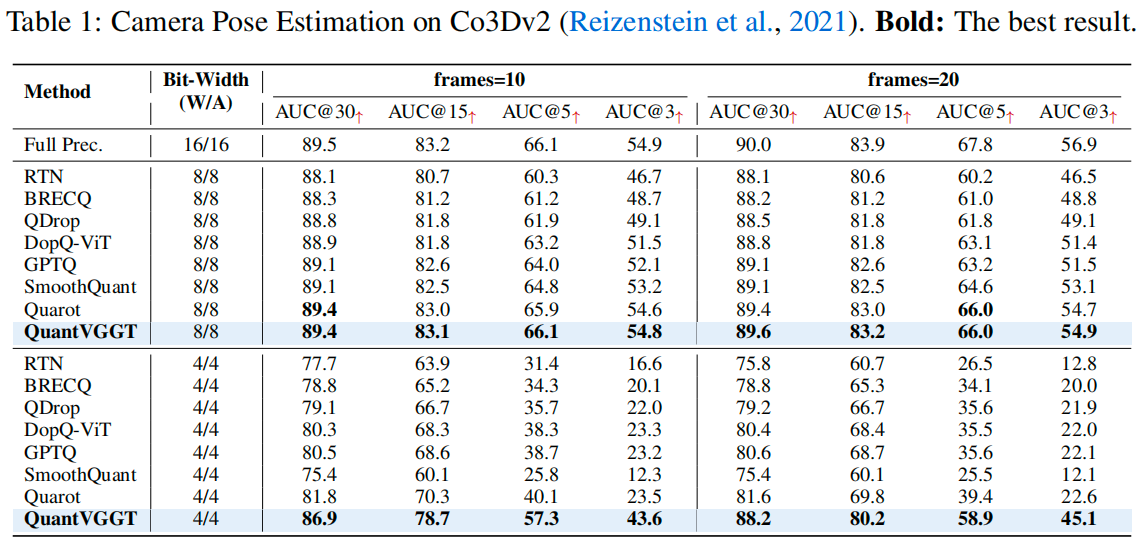
Updates
- [October 10, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available.
Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
git clone git@github.com:wlfeng0509/QuantVGGT.git
cd QuantVGGT
pip install -r requirements.txt然后下载由 VGGT 提供的预训练权重,并按照 此处 准备 Co3D 数据集。
然后从 huggingface 下载预训练的 W4A4 量化参数,并将下载的文件夹放置在 evaluation\outputs\w4a4 分支下。
现在我们可以使用提供的脚本进行推理 (记得修改脚本中的数据路径)。
cd evaluation
bash test.sh备注
BibTeX
如果您发现QuantVGGT对您的工作有用且有帮助,请引用本文:
@article{feng2025quantized,
title={Quantized Visual Geometry Grounded Transformer},
author={Feng, Weilun and Qin, Haotong and Wu, Mingqiang and Yang, Chuanguang and Li, Yuqi and Li, Xiangqi and An, Zhulin and Huang, Libo and Zhang, Yulun and Magno, Michele and others},
journal={arXiv preprint arXiv:2509.21302},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-01-01 ---