Quantized Visual Geometry Grounded Transformer
------
This project is the official implementation of our QuantVGGT: "Quantized Visual Geometry Grounded Transformer".

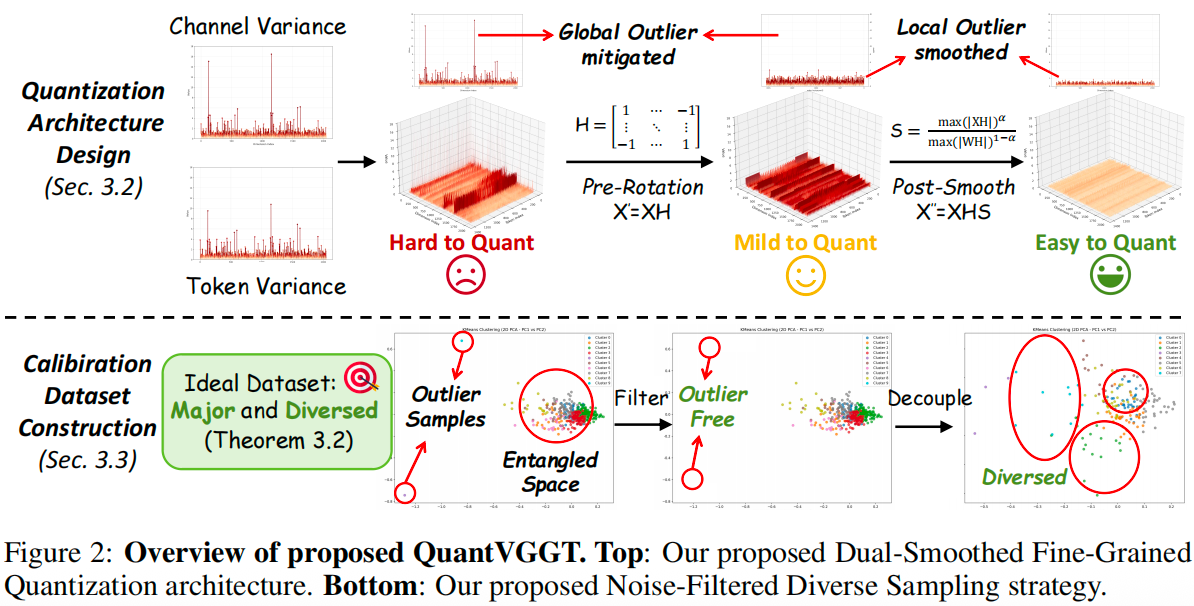
------
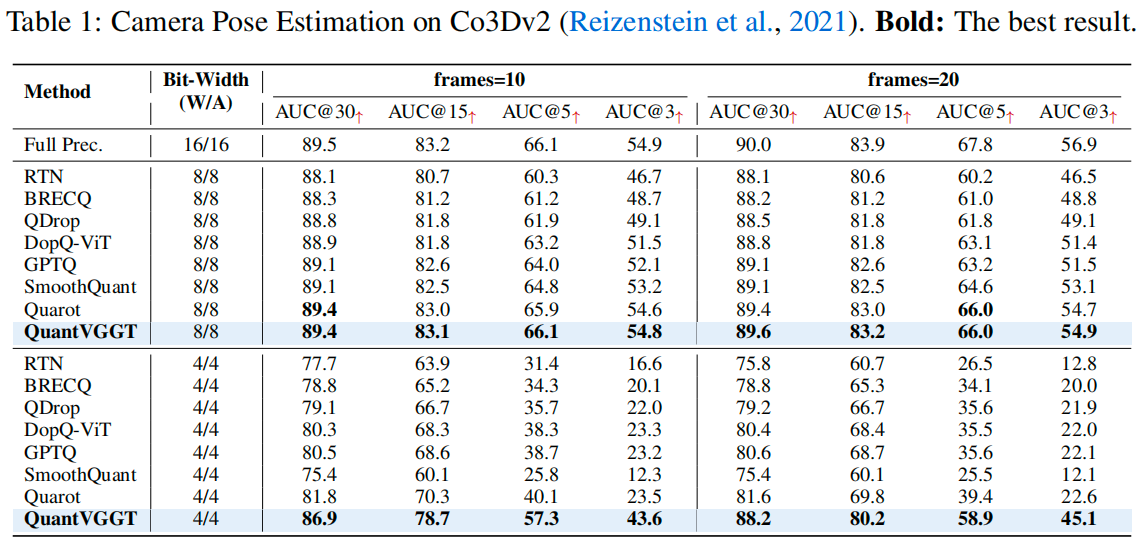
Results
Updates
- [October 10, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available.
Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
git clone git@github.com:wlfeng0509/QuantVGGT.git
cd QuantVGGT
pip install -r requirements.txt次に、VGGTで提供されている事前学習済みの重みをダウンロードし、こちらに従ってCo3Dデータセットを準備します。
次に、huggingfaceから事前学習済みのW4A4量子化パラメータをダウンロードし、ダウンロードしたフォルダをevaluation\outputs\w4a4ブランチの下に配置します。
提供されたスクリプトを推論に使用できます (スクリプト内のデータパスを変更することを忘れないでください) 。
cd evaluation
bash test.shコメント
BibTeX
QuantVGGTがあなたの研究に役立った場合は、ぜひこの論文を引用してください。
@article{feng2025quantized,
title={Quantized Visual Geometry Grounded Transformer},
author={Feng, Weilun and Qin, Haotong and Wu, Mingqiang and Yang, Chuanguang and Li, Yuqi and Li, Xiangqi and An, Zhulin and Huang, Libo and Zhang, Yulun and Magno, Michele and others},
journal={arXiv preprint arXiv:2509.21302},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-01-01 ---