Quantized Visual Geometry Grounded Transformer
------
This project is the official implementation of our QuantVGGT: "Quantized Visual Geometry Grounded Transformer".

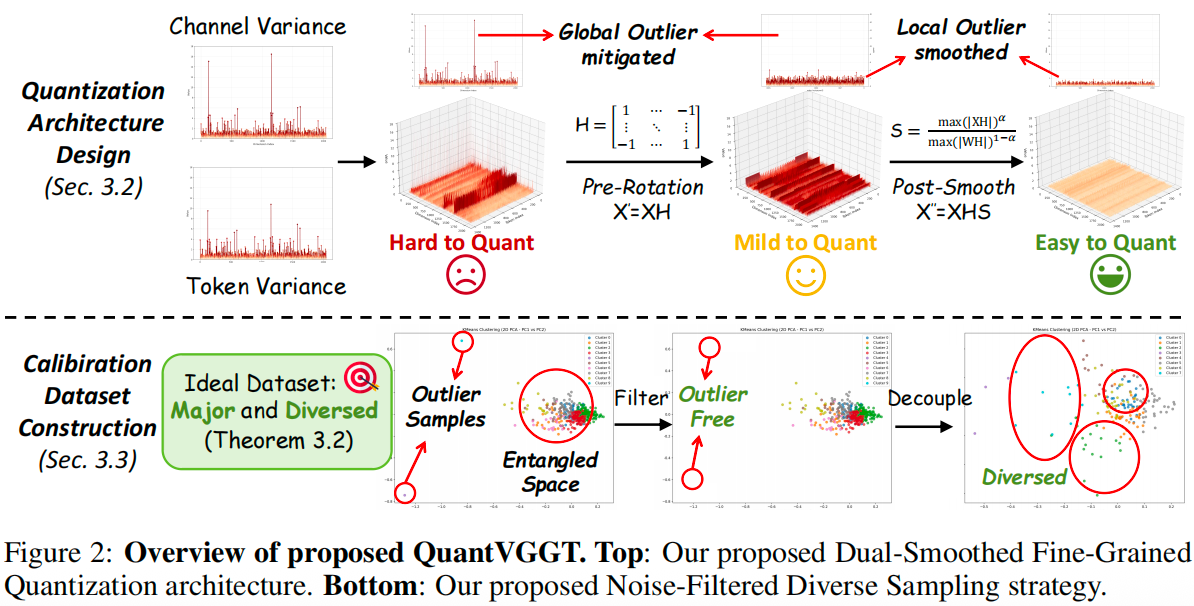
------
Results
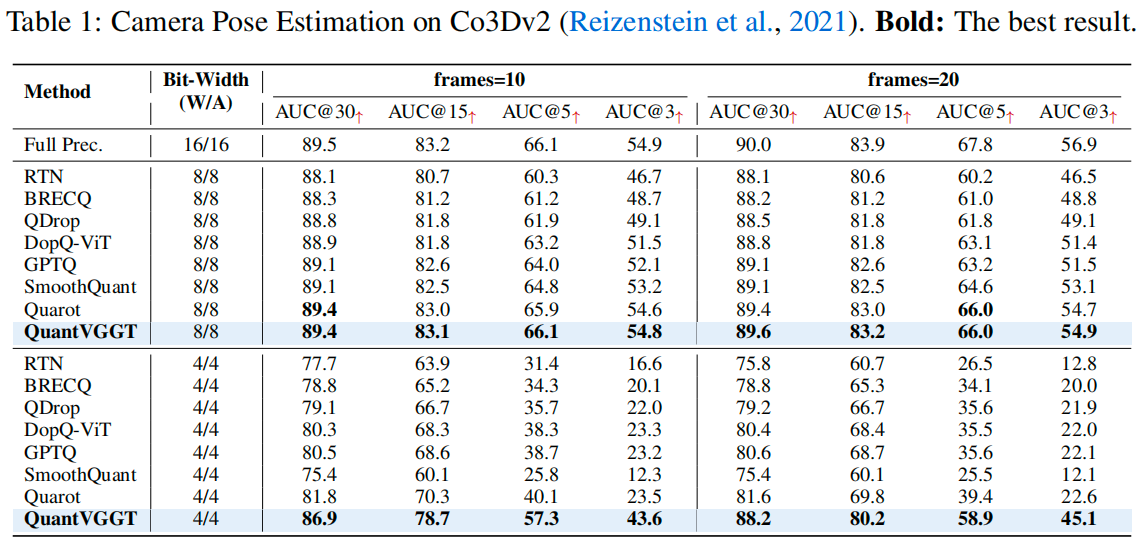
Updates
- [October 10, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available.
Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
git clone git@github.com:wlfeng0509/QuantVGGT.git
cd QuantVGGT
pip install -r requirements.txtTéléchargez ensuite les poids pré-entraînés fournis par VGGT et préparez le jeu de données Co3D en suivant ce guide.
Téléchargez ensuite les paramètres de quantification W4A4 pré-entraînés depuis huggingface et placez le dossier téléchargé sous la branche evaluation\outputs\w4a4.
Nous pouvons maintenant utiliser le script fourni pour l'inférence (n'oubliez pas de modifier le chemin des données dans le script).
cd evaluation
bash test.shVous pouvez également utiliser le modèle quantifié pour prédire d'autres attributs 3D en suivant les instructions ici.
Commentaires
BibTeX
Si vous trouvez que QuantVGGT est utile et bénéfique pour votre travail, veuillez citer cet article :
@article{feng2025quantized,
title={Quantized Visual Geometry Grounded Transformer},
author={Feng, Weilun and Qin, Haotong and Wu, Mingqiang and Yang, Chuanguang and Li, Yuqi and Li, Xiangqi and An, Zhulin and Huang, Libo and Zhang, Yulun and Magno, Michele and others},
journal={arXiv preprint arXiv:2509.21302},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-01-01 ---