Quantized Visual Geometry Grounded Transformer
------
This project is the official implementation of our QuantVGGT: "Quantized Visual Geometry Grounded Transformer".

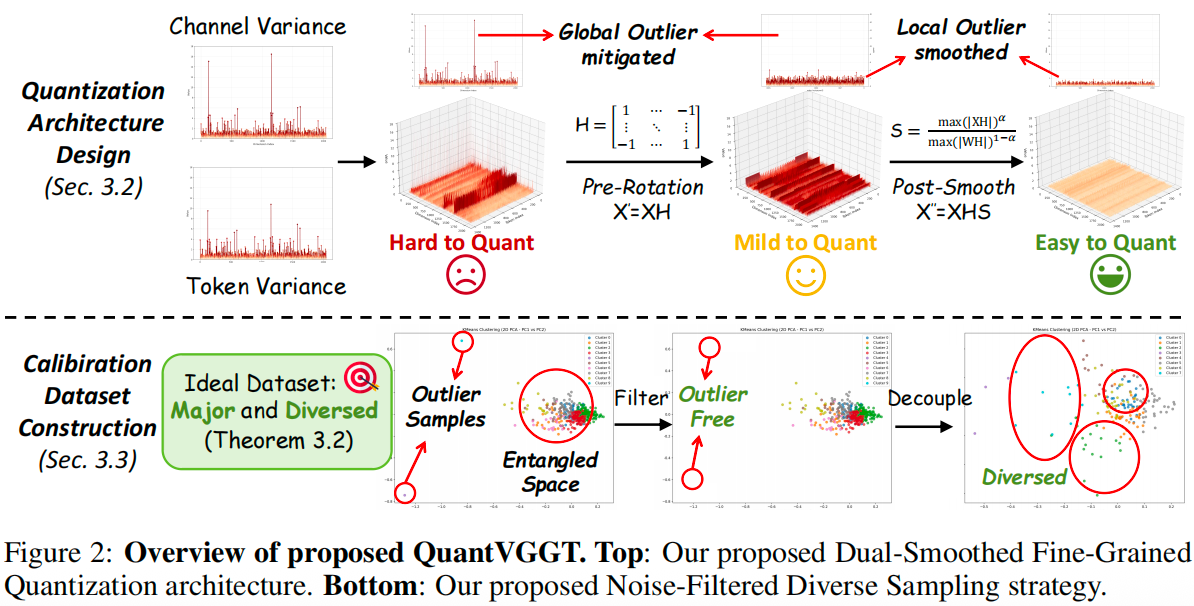
------
Results
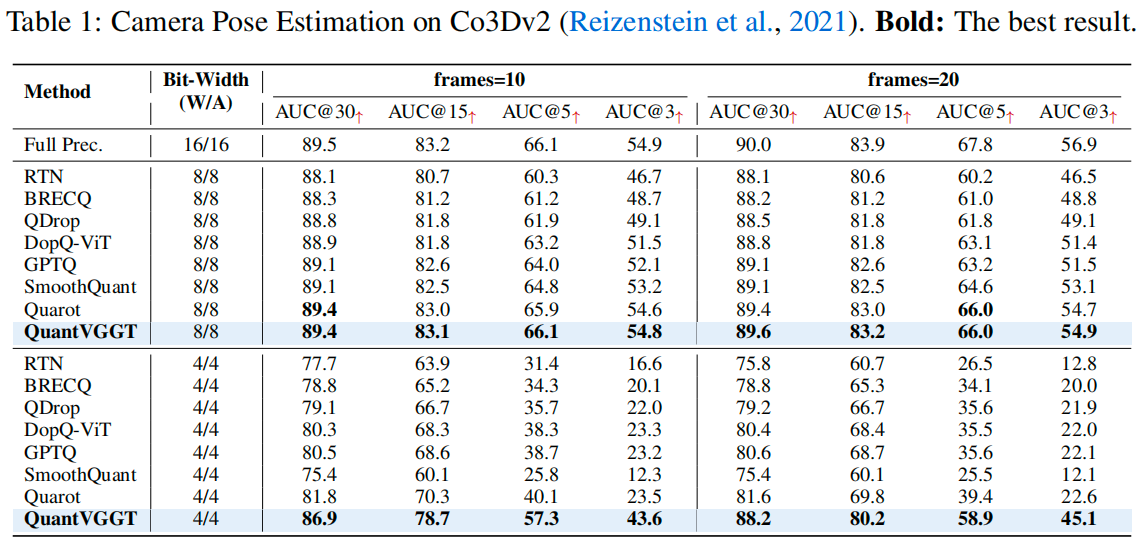
Updates
- [October 10, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available.
Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
git clone git@github.com:wlfeng0509/QuantVGGT.git
cd QuantVGGT
pip install -r requirements.txtLuego descargue los pesos preentrenados proporcionados por VGGT y prepare el conjunto de datos Co3D siguiendo esto.
Luego descargue los parámetros de cuantización W4A4 preentrenados de huggingface y coloque la carpeta descargada bajo la rama evaluation\outputs\w4a4.
Ahora podemos usar el script proporcionado para la inferencia (recuerde cambiar la ruta de datos dentro del script).
cd evaluation
bash test.shTambién, puedes usar el modelo cuantificado para predecir otros atributos 3D siguiendo la guía aquí.
Comentarios
- Nuestra base de código se construye en gran medida sobre VGGT y QuaRot. ¡Gracias por hacerlos de código abierto!
BibTeX
Si encuentras que QuantVGGT es útil y beneficioso para tu trabajo, por favor cita amablemente este artículo:
@article{feng2025quantized,
title={Quantized Visual Geometry Grounded Transformer},
author={Feng, Weilun and Qin, Haotong and Wu, Mingqiang and Yang, Chuanguang and Li, Yuqi and Li, Xiangqi and An, Zhulin and Huang, Libo and Zhang, Yulun and Magno, Michele and others},
journal={arXiv preprint arXiv:2509.21302},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-01-01 ---