Quantized Visual Geometry Grounded Transformer
------
This project is the official implementation of our QuantVGGT: "Quantized Visual Geometry Grounded Transformer".

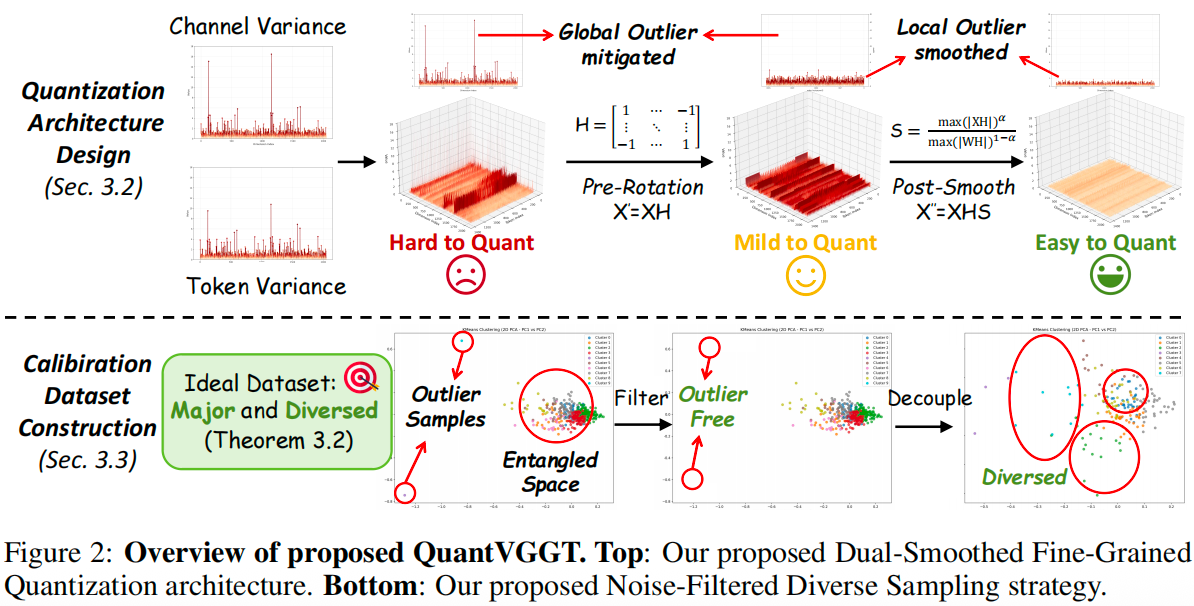
------
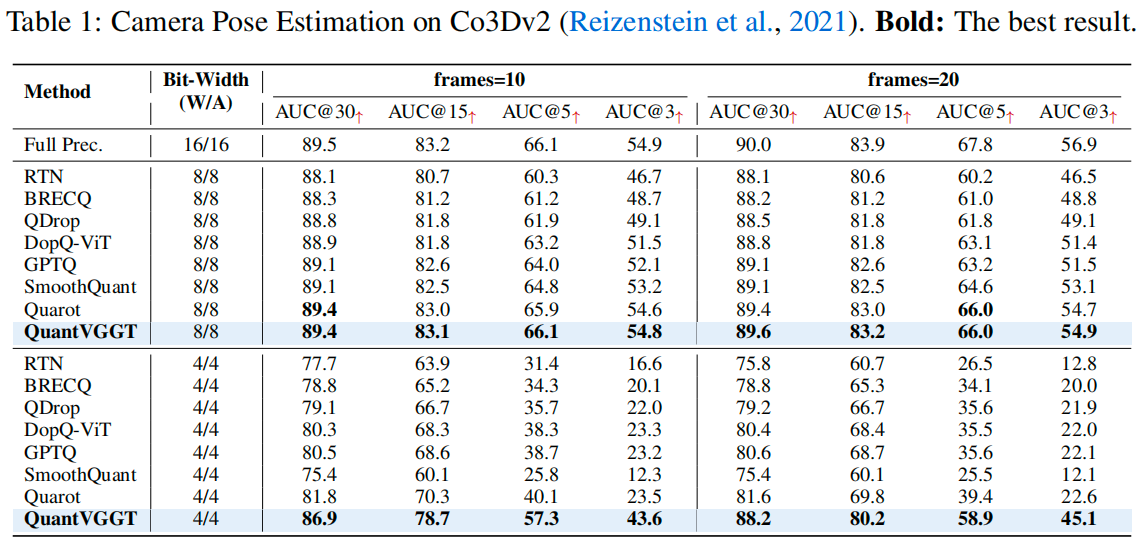
Results
Updates
- [October 10, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available.
Quick Start
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
git clone git@github.com:wlfeng0509/QuantVGGT.git
cd QuantVGGT
pip install -r requirements.txtThen download the pre trained W4A4 quantization parameters from huggingface and place the downloaded folder under evaluation\outputs\w4a4 branch.
We can now use the provided script for inference (remember to change the data path within the script).
cd evaluation
bash test.shAlso, you can use the quantized model for predicting other 3D attributes following the guidance here.
Comments
BibTeX
If you find QuantVGGT is useful and helpful to your work, please kindly cite this paper:
@article{feng2025quantized,
title={Quantized Visual Geometry Grounded Transformer},
author={Feng, Weilun and Qin, Haotong and Wu, Mingqiang and Yang, Chuanguang and Li, Yuqi and Li, Xiangqi and An, Zhulin and Huang, Libo and Zhang, Yulun and Magno, Michele and others},
journal={arXiv preprint arXiv:2509.21302},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2026-01-01 ---