s3 - 透過強化學習訓練高效且有效的搜尋代理人
你不需要大量資料來訓練搜尋代理人
![]()
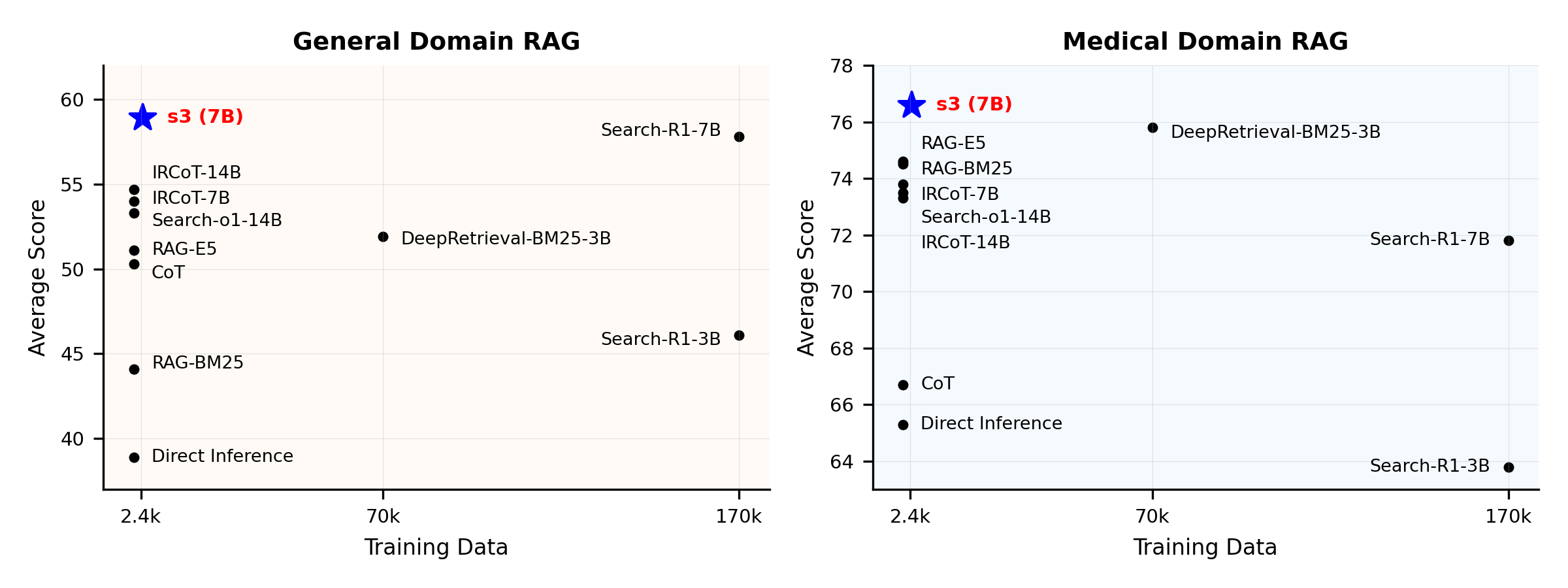
效能概覽:
什麼是 s3?
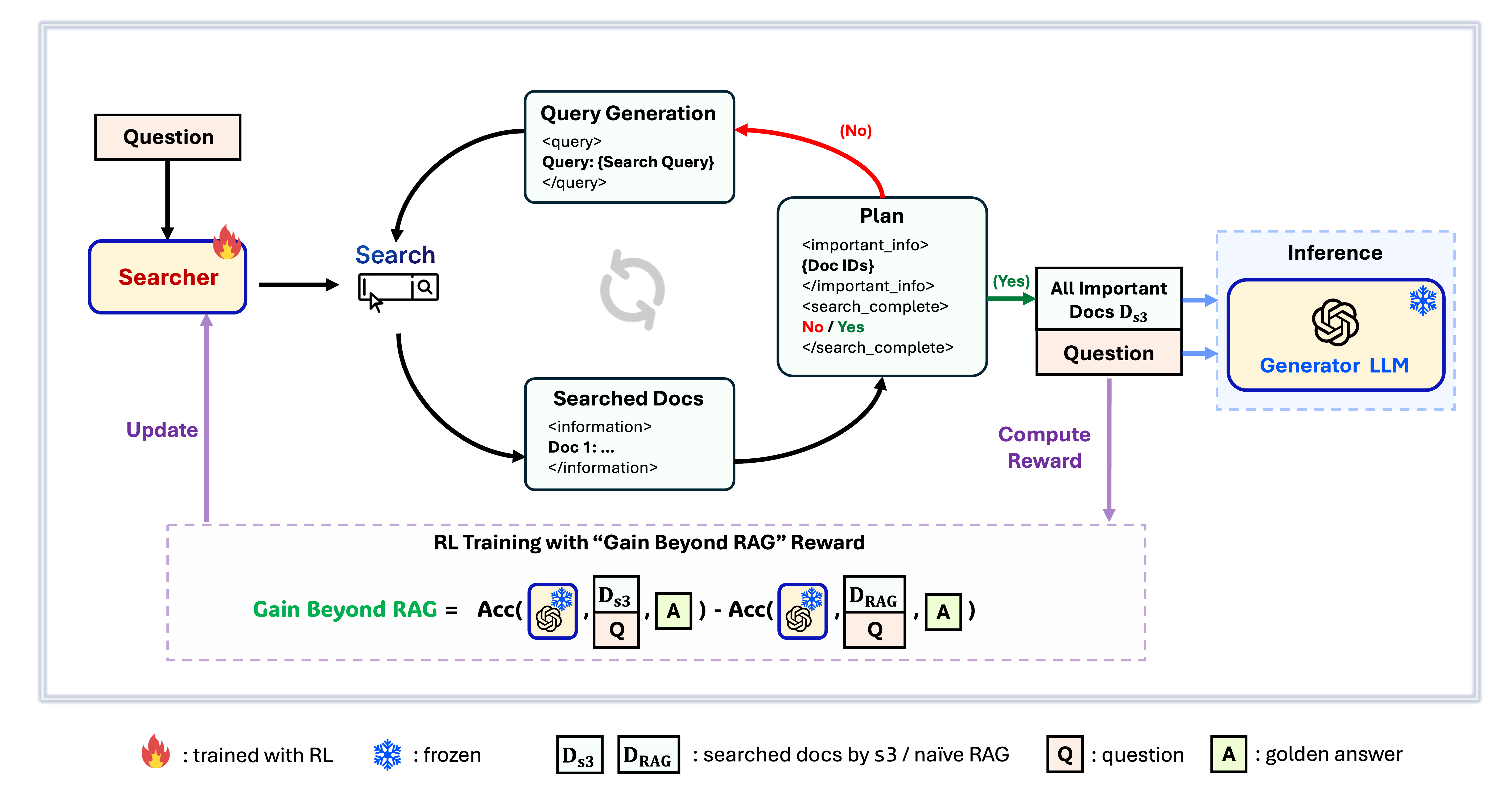
s3 框架
s3 是一個簡潔且強大的框架,用於訓練搜尋代理於檢索增強生成(RAG)中。它教導語言模型如何更有效地搜尋——而不需要改變生成器本身。通過只專注於搜尋組件,s3 能以遠少於先前方法所需資料量,在問答任務中取得卓越表現。它模組化、高效能,並設計可無縫搭配任何黑箱 LLM 使用。
目錄
📦 安裝
搜尋器與生成器環境
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 準備
下載索引與語料庫python scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gz預先計算 Naïve RAG 初始化(或者你可以在這裡下載我們處理過的資料:huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ 執行訓練
此步驟用於 S3 的訓練# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 執行搜尋/檢索
此步驟用於 s3 / 基線的內容收集s3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.sh基線
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 執行評估
此步驟用於 s3 / 基線模型的評估bash scripts/evaluation/run.sh問答集
自訂資料?
如果您想在自己的語料庫/資料集上測試 s3,您可以參考此提交記錄來瞭解建立自己的流程需要做什麼:commit 8420538結果復現?
已有多位開發者成功復現了我們的結果。如果您有任何疑問或遇到問題,歡迎提交問題——我們很樂意提供實際指導(可參考此範例)。雖然自行復現模型很簡單——而且我們實際上推薦從零開始訓練,因為評估通常比訓練更耗時——我們也提供了一個參考檢查點:s3-8-3-3-20steps,約一小時即可訓練完成。
引用
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---