s3 - Đào Tạo Tác Nhân Tìm Kiếm Hiệu Quả Bằng RL
Bạn Không Cần Quá Nhiều Dữ Liệu Để Đào Tạo Một Tác Nhân Tìm Kiếm
![]()
Tổng quan Hiệu suất:
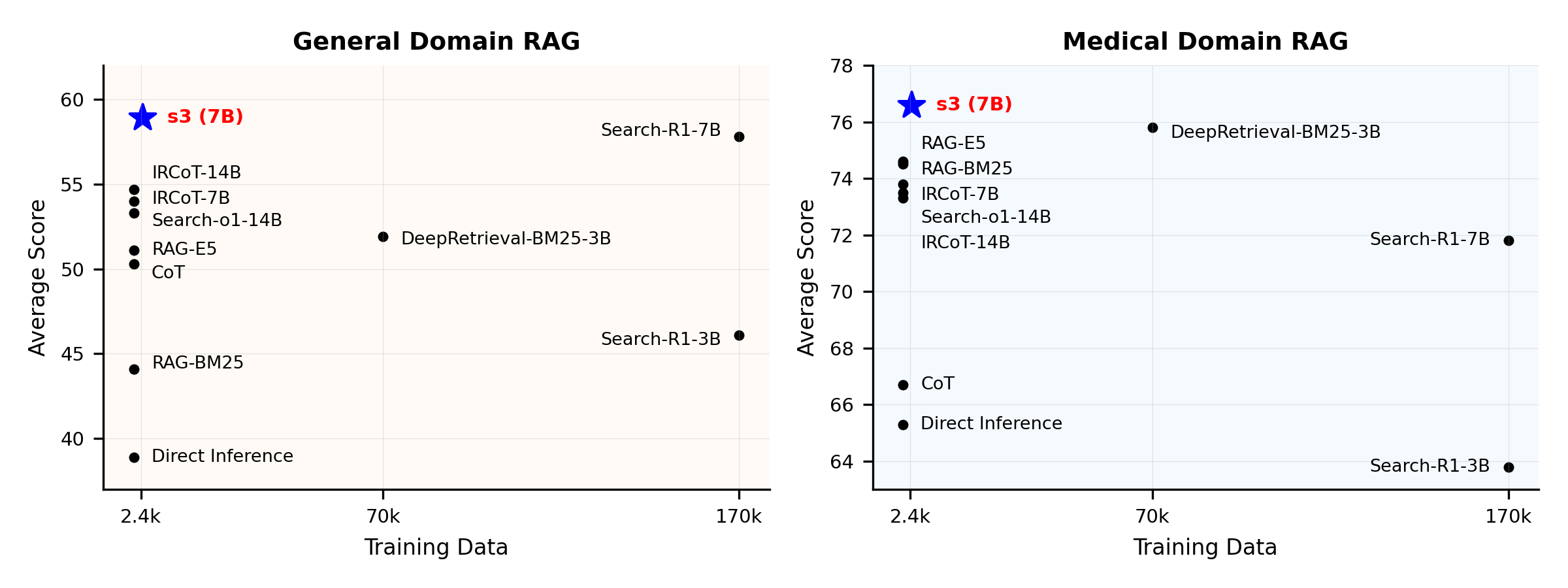
S3 là gì?
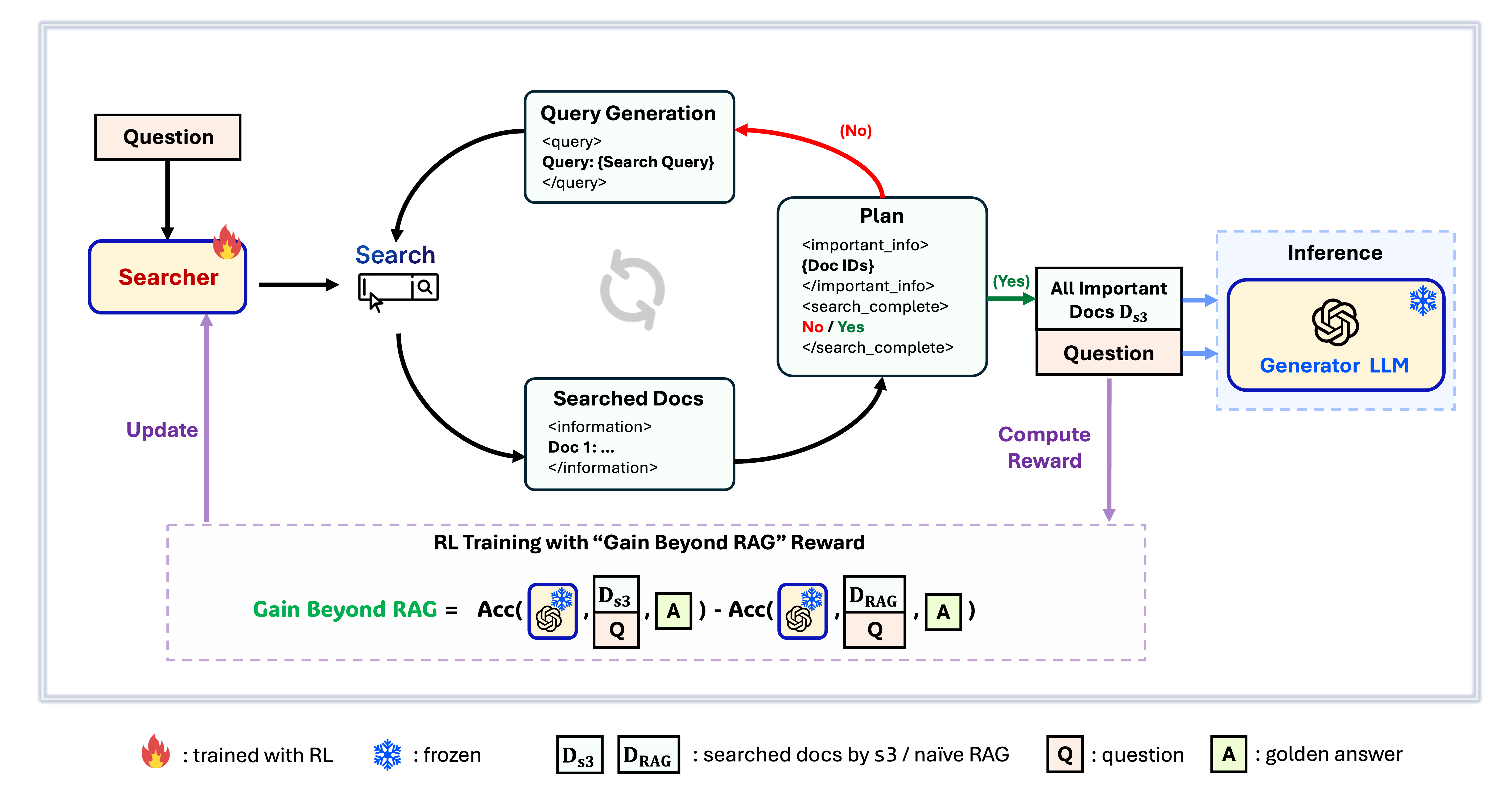
Khung s3
s3 là một khung đơn giản nhưng mạnh mẽ để huấn luyện các tác nhân tìm kiếm trong hệ thống tạo nội dung có hỗ trợ truy xuất thông tin (RAG). Nó dạy các mô hình ngôn ngữ cách tìm kiếm hiệu quả hơn—mà không cần thay đổi bộ tạo nội dung. Bằng cách chỉ tập trung vào thành phần tìm kiếm, s3 đạt hiệu suất cao trong các tác vụ hỏi đáp với chỉ một phần nhỏ dữ liệu so với các phương pháp trước đó. Khung này có tính mô-đun, hiệu quả, và được thiết kế để tích hợp mượt mà với bất kỳ LLM hộp đen nào.
Mục lục
📦 Cài đặt
Môi trường Searcher & Generator
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Chuẩn bị
Tải xuống Chỉ mục & Tập dữ liệupython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzTiền xử lý Khởi tạo RAG Đơn giản (hoặc bạn có thể tải xuống dữ liệu đã xử lý của chúng tôi tại đây: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Chạy Huấn Luyện
Bước này dành cho việc huấn luyện S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Chạy Tìm kiếm/Truy xuất
Bước này dùng để thu thập ngữ cảnh của s3 / các đường cơ sởs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shCác đường cơ sở
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Chạy Đánh Giá
Bước này dành cho việc đánh giá s3 / các đường cơ sởbash scripts/evaluation/run.shHỏi & Đáp
Dữ liệu Tùy chỉnh?
Nếu bạn muốn thử nghiệm s3 trên tập dữ liệu/corpus của riêng mình, bạn có thể tham khảo commit này để xem bạn cần làm gì để xây dựng pipeline riêng: commit 8420538Tái tạo Kết quả?
Một số nhà phát triển đã tái tạo thành công kết quả của chúng tôi. Nếu bạn có câu hỏi hoặc gặp sự cố, cứ thoải mái mở một issue — chúng tôi sẵn sàng hướng dẫn thực tế (xem ví dụ này).Mặc dù việc tự mình tái tạo mô hình khá đơn giản — và thực ra chúng tôi khuyên bạn nên huấn luyện từ đầu, vì đánh giá thường tốn nhiều thời gian hơn huấn luyện — chúng tôi cũng cung cấp một checkpoint tham khảo: s3-8-3-3-20steps, được huấn luyện trong khoảng một giờ.
Trích dẫn
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---