s3 - Эффективное и результативное обучение поискового агента с помощью RL
Вам не нужно так много данных для обучения поискового агента
![]()
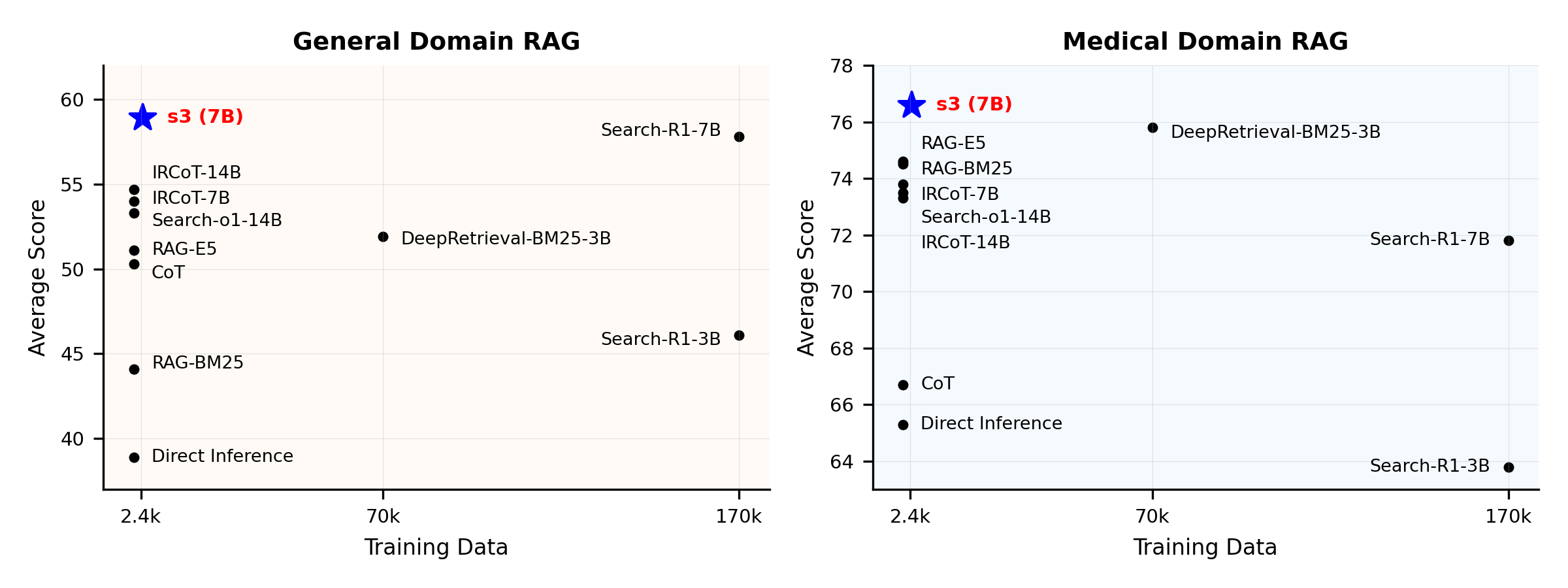
Обзор производительности:
Что такое s3?
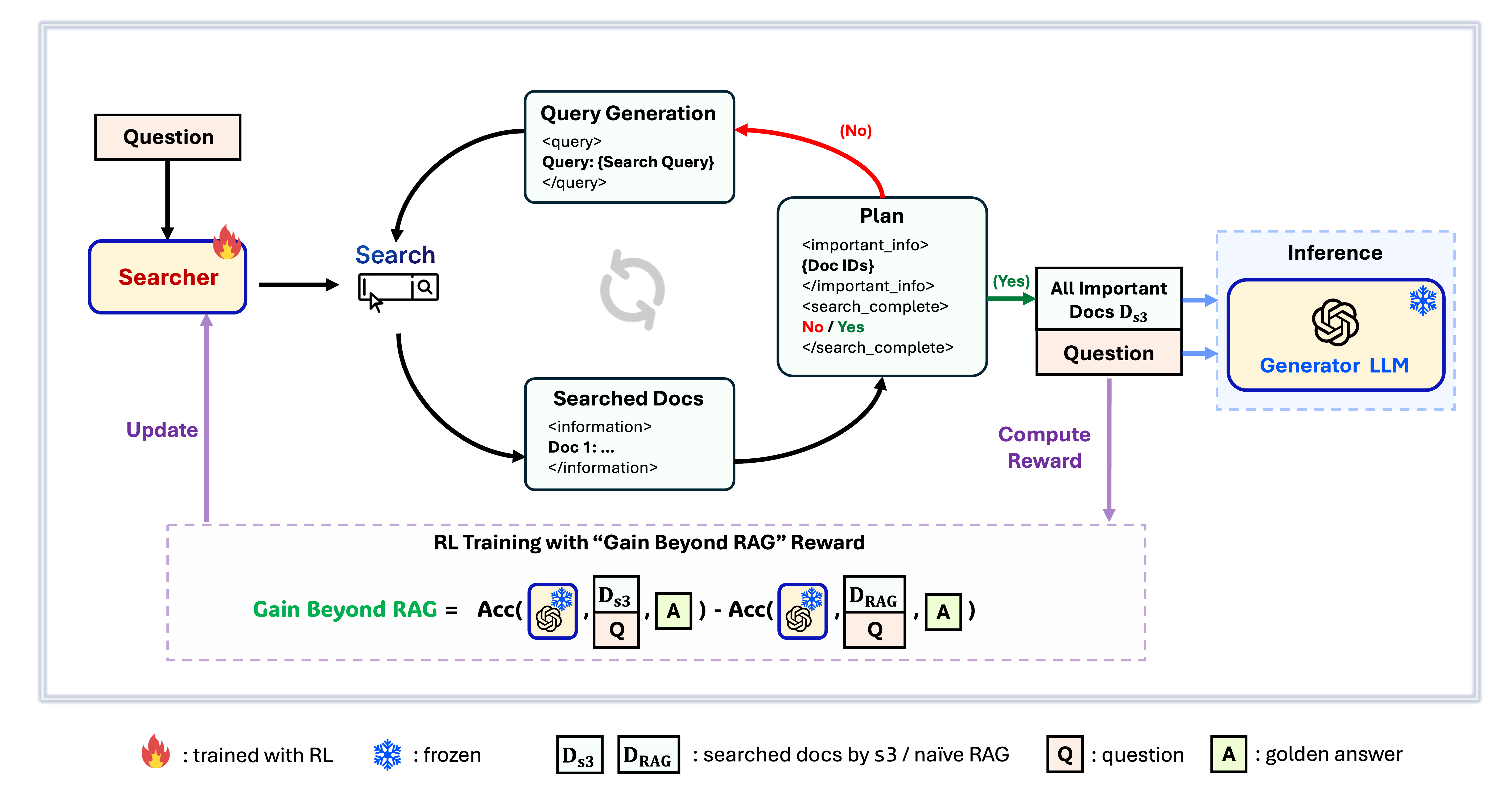
Фреймворк s3
s3 — это простой, но мощный фреймворк для обучения поисковых агентов в retrieval-augmented generation (RAG). Он обучает языковые модели более эффективно осуществлять поиск — без изменений в самом генераторе. Фокусируясь только на поисковой составляющей, s3 достигает высокой производительности в QA-задачах, используя лишь малую часть данных по сравнению с предыдущими подходами. Это модульное, эффективное решение, спроектированное для работы с любым "черным ящиком" LLM.
Содержание
📦 Установка
Окружение для Searcher & Generator
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Подготовка
Скачать индекс и корпусpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzПредварительный расчет наивной инициализации RAG (или вы можете скачать наши обработанные данные здесь: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Запуск обучения
Этот шаг предназначен для обучения S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Запуск поиска/извлечения
Этот шаг предназначен для сбора контекста s3 / базовых линийs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shБазовые показатели
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Запуск оценки
Этот шаг предназначен для оценки s3 / базовых линийbash scripts/evaluation/run.shВопросы и ответы
Пользовательские данные?
Если вы хотите протестировать s3 на собственном корпусе/датасете, вы можете обратиться к этому коммиту, чтобы узнать, что необходимо сделать для построения собственного пайплайна: commit 8420538Воспроизведение результатов?
Несколько разработчиков уже успешно воспроизвели наши результаты. Если у вас возникнут вопросы или проблемы, не стесняйтесь открыть issue — мы рады предоставить практическую поддержку (см. этот пример).Хотя воспроизвести модель самостоятельно довольно просто — и мы на самом деле рекомендуем обучение с нуля, так как оценка зачастую занимает больше времени, чем обучение — мы также предоставляем контрольную точку: s3-8-3-3-20steps, обученную примерно за час.
Цитирование
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---