s3 - Treinamento Eficiente e Eficaz de Agentes de Busca via RL
Você não precisa de tantos dados para treinar um agente de busca
![]()
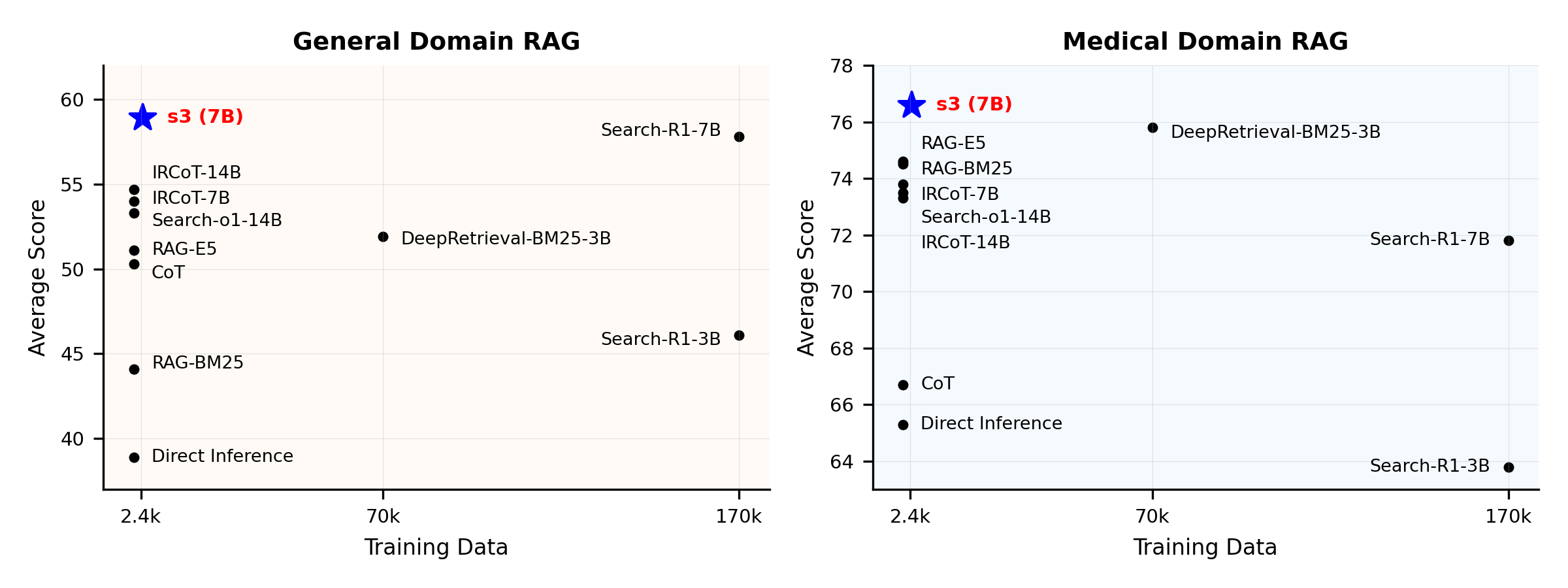
Visão Geral de Performance:
O que é s3?
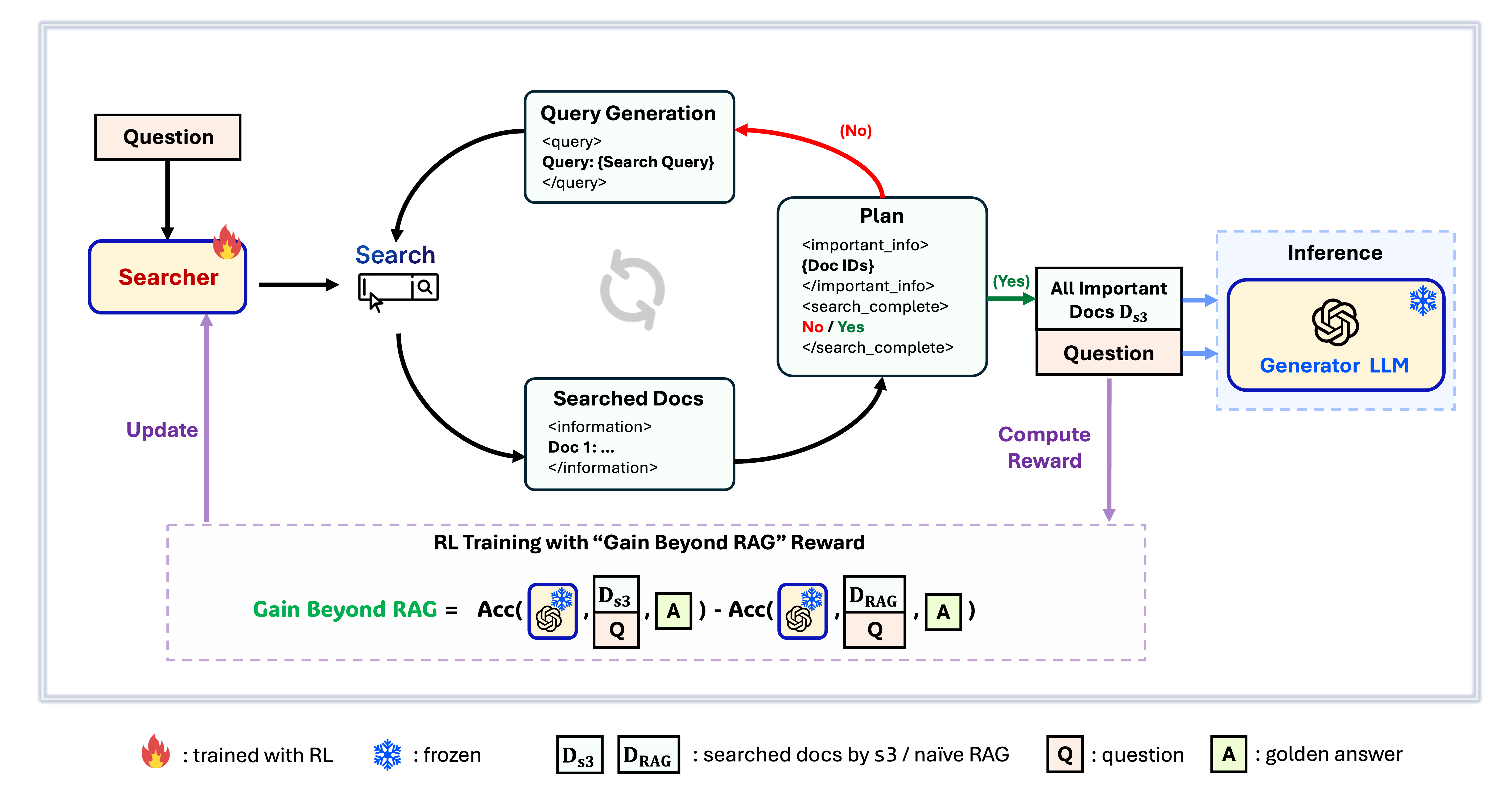
Framework s3
s3 é um framework simples, porém poderoso, para treinar agentes de busca em geração aumentada por recuperação (RAG). Ele ensina modelos de linguagem a buscar de forma mais eficiente—sem alterar o próprio gerador. Ao focar exclusivamente no componente de busca, s3 alcança alto desempenho em tarefas de QA usando apenas uma fração dos dados empregados por métodos anteriores. É modular, eficiente e projetado para funcionar perfeitamente com qualquer LLM de caixa-preta.
Índice
📦 Instalação
Ambiente do Buscador & Gerador
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Preparação
Baixar Índice & Corpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPré-computar Inicialização Ingênua do RAG (ou você pode baixar nossos dados processados aqui: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Executar Treinamento
Esta etapa é para o treinamento do S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Executar Busca/Recuperação
Esta etapa é para a coleta de contexto do s3 / linhas de bases3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shReferências
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Executar Avaliação
Esta etapa é para a avaliação de s3 / baselinesbash scripts/evaluation/run.shPerguntas e Respostas
Dados Personalizados?
Se você deseja testar o s3 em seu próprio corpus/conjunto de dados, pode consultar este commit para ver o que precisa fazer para construir seu próprio pipeline: commit 8420538Reproduzindo Resultados?
Vários desenvolvedores já reproduziram nossos resultados com sucesso. Se você tiver dúvidas ou encontrar problemas, fique à vontade para abrir uma issue — teremos prazer em fornecer orientação prática (veja este exemplo).Embora reproduzir o modelo você mesmo seja simples — e na verdade recomendamos treinar do zero, já que a avaliação costuma ser muito mais demorada do que o treinamento — também fornecemos um checkpoint de referência: s3-8-3-3-20steps, treinado em cerca de uma hora.
Citação
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---