s3 - Wydajne, a jednak skuteczne szkolenie agenta wyszukiwania poprzez RL
Nie potrzebujesz aż tyle danych, aby wyszkolić agenta wyszukiwania
![]()
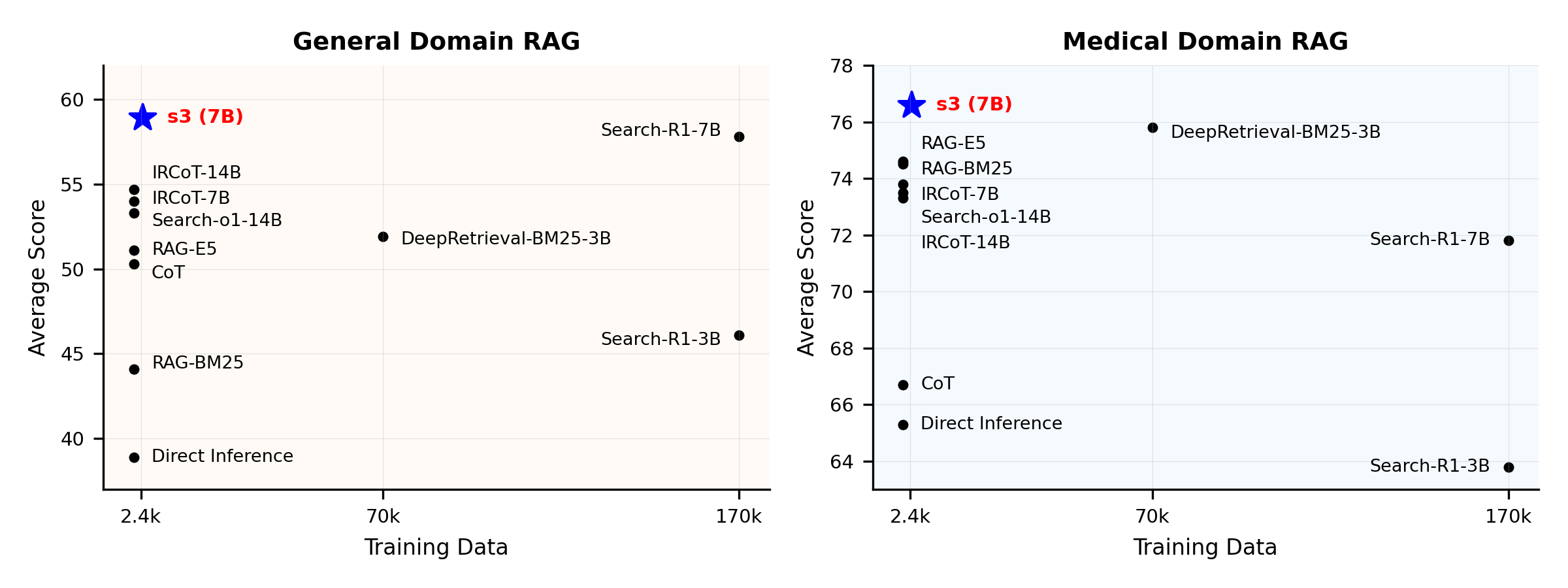
Przegląd wydajności:
Czym jest s3?
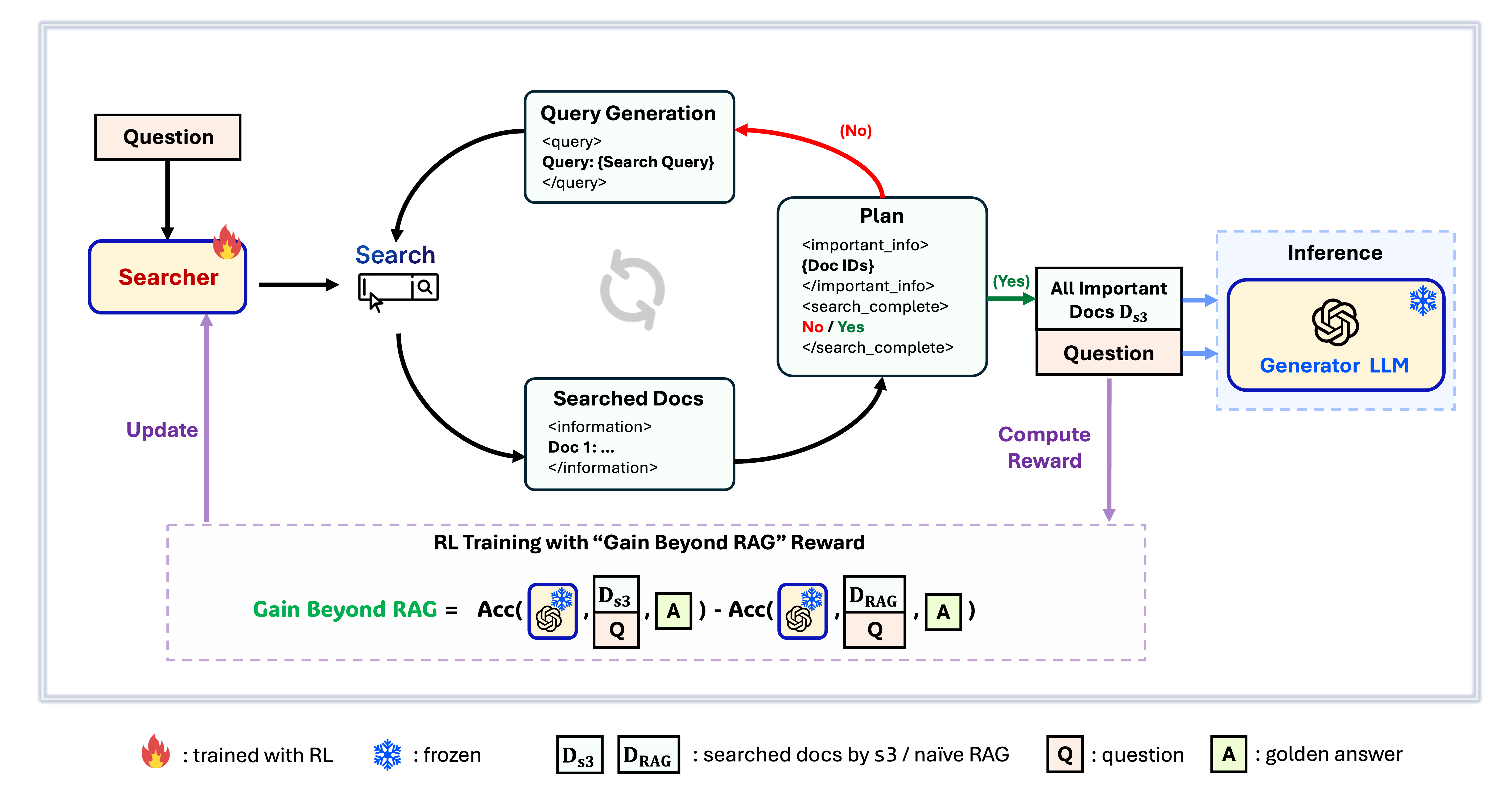
Framework s3
s3 to prosty, ale potężny framework do trenowania agentów wyszukiwania w generowaniu wspieranym przez wyszukiwanie (RAG). Uczy modele językowe skuteczniejszego wyszukiwania—bez zmiany samego generatora. Skupiając się wyłącznie na komponencie wyszukiwania, s3 osiąga wysoką wydajność w zadaniach QA, używając tylko ułamka danych wykorzystywanych przez wcześniejsze metody. Jest modułowy, wydajny i zaprojektowany do bezproblemowej współpracy z dowolnym czarnym pudełkiem LLM.
Spis treści
- 📦 Instalacja
- 💡 Przygotowanie
- 🏋️ Uruchom trenowanie
- 🔍 Uruchom wyszukiwanie/pobieranie
- 📈 Uruchom ewaluację
📦 Instalacja
Środowisko Searcher & Generator
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Przygotowanie
Pobierz Indeks i Korpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzWstępna inicjalizacja Naïve RAG (lub możesz pobrać nasze przetworzone dane tutaj: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Uruchom trening
Ten krok dotyczy trenowania S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Uruchom wyszukiwanie/pobieranie
Ten krok służy do zbierania kontekstu dla s3 / bazowych linii odniesienias3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shLinie bazowe
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Uruchom ocenę
Ten krok służy do oceny s3 / baseline'ówbash scripts/evaluation/run.shPytania i Odpowiedzi
Dostosowane dane?
Jeśli chcesz przetestować s3 na własnym korpusie/danych, możesz odnieść się do tego commita, aby zobaczyć, co musisz zrobić, aby zbudować własny pipeline: commit 8420538Odwzorowanie wyników?
Kilku deweloperów już pomyślnie odtworzyło nasze wyniki. Jeśli masz pytania lub napotkasz problemy, śmiało otwórz zgłoszenie — z przyjemnością udzielimy praktycznej pomocy (zobacz ten przykład).Chociaż samodzielne odtworzenie modelu jest proste — i faktycznie zalecamy trenowanie od zera, ponieważ ocena często zajmuje znacznie więcej czasu niż trening — udostępniamy również punkt referencyjny: s3-8-3-3-20steps, wytrenowany w około godzinę.
Cytowanie
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---