s3 - Efficiënte Maar Effectieve Training van Zoekagenten via RL
Je hebt niet zoveel data nodig om een zoekagent te trainen
![]()
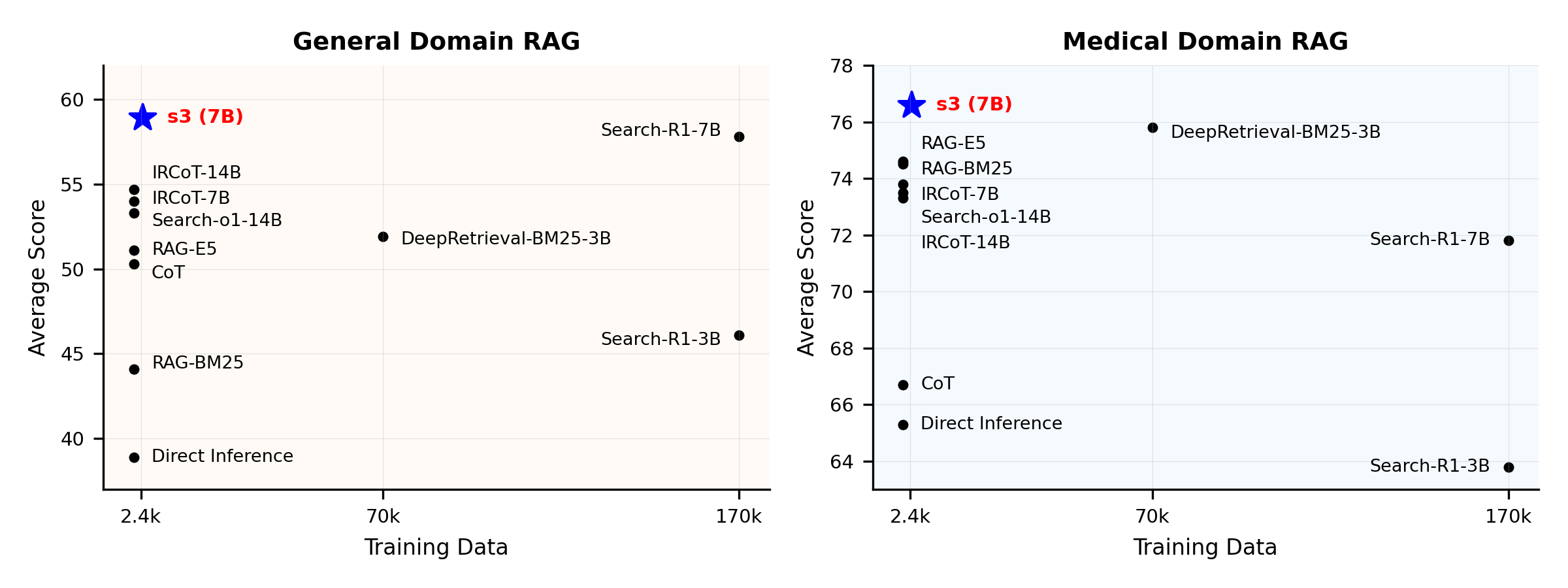
Prestatieoverzicht:
Wat is s3?
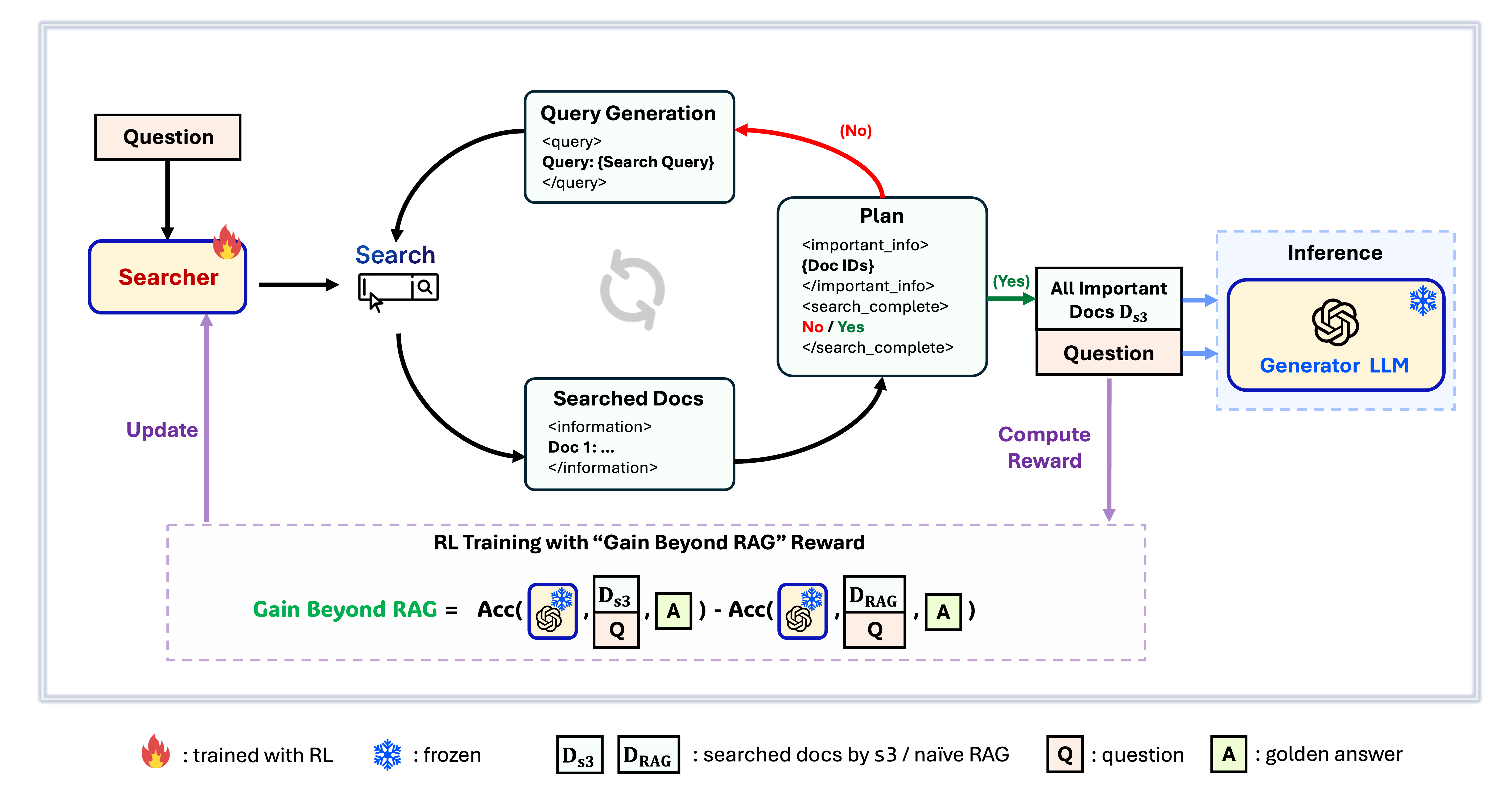
s3 Framework
s3 is een eenvoudig maar krachtig framework voor het trainen van zoekagenten in retrieval-augmented generation (RAG). Het leert taalmodellen om effectiever te zoeken—zonder de generator zelf te veranderen. Door zich uitsluitend te richten op de zoekcomponent, behaalt s3 sterke prestaties bij QA-taken met slechts een fractie van de data die door eerdere methoden werd gebruikt. Het is modulair, efficiënt en ontworpen om naadloos samen te werken met elke black-box LLM.
Inhoudsopgave
- 📦 Installatie
- 💡 Voorbereiding
- 🏋️ Training uitvoeren
- 🔍 Zoeken/Ophalen uitvoeren
- 📈 Evaluatie uitvoeren
📦 Installatie
Zoeker & Generator omgeving
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Voorbereiding
Index & Corpus downloadenpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPrecompute Naïeve RAG-initialisatie (of u kunt onze verwerkte data hier downloaden: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Training uitvoeren
Deze stap is voor de training van S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Zoek-/Ophaalbewerking uitvoeren
Deze stap is bedoeld voor het verzamelen van context voor s3 / baseliness3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shBaselines
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Evaluatie uitvoeren
Deze stap is voor de evaluatie van s3 / baselinesbash scripts/evaluation/run.shV&A
Aangepaste Data?
Als je s3 wilt testen op je eigen corpus/dataset, kun je deze commit raadplegen om te zien wat je moet doen om je eigen pipeline te bouwen: commit 8420538Resultaten Reproduceren?
Verschillende ontwikkelaars hebben onze resultaten al succesvol gereproduceerd. Als je vragen hebt of tegen problemen aanloopt, voel je vrij om een issue te openen — we geven graag praktische begeleiding (zie dit voorbeeld).Hoewel het zelf reproduceren van het model eenvoudig is — en we raden zelfs aan vanaf nul te trainen, omdat evaluatie vaak veel tijdrovender is dan het trainen — bieden we ook een referentie-checkpoint aan: s3-8-3-3-20steps, getraind in ongeveer één uur.
Referentie
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---