s3 - 효율적이면서 효과적인 검색 에이전트 RL 기반 학습
검색 에이전트를 학습시키는 데 그렇게 많은 데이터가 필요하지 않습니다
![]()
성능 개요:
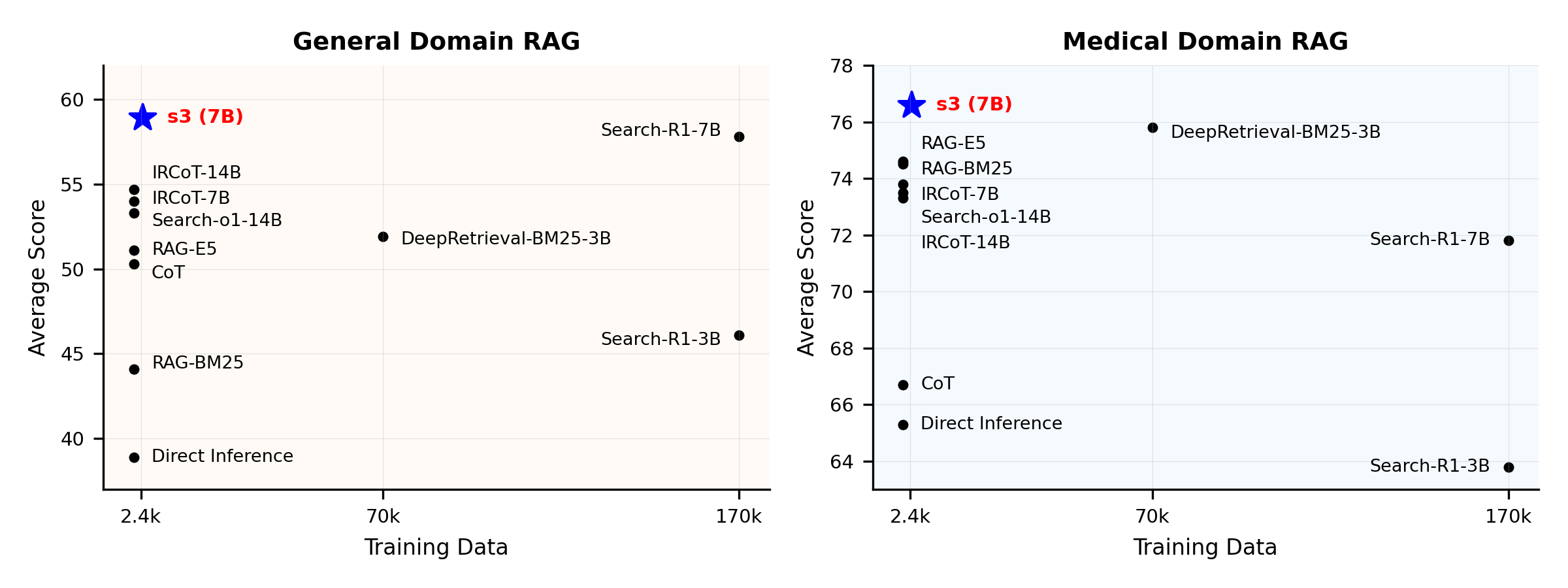
s3란 무엇인가요?
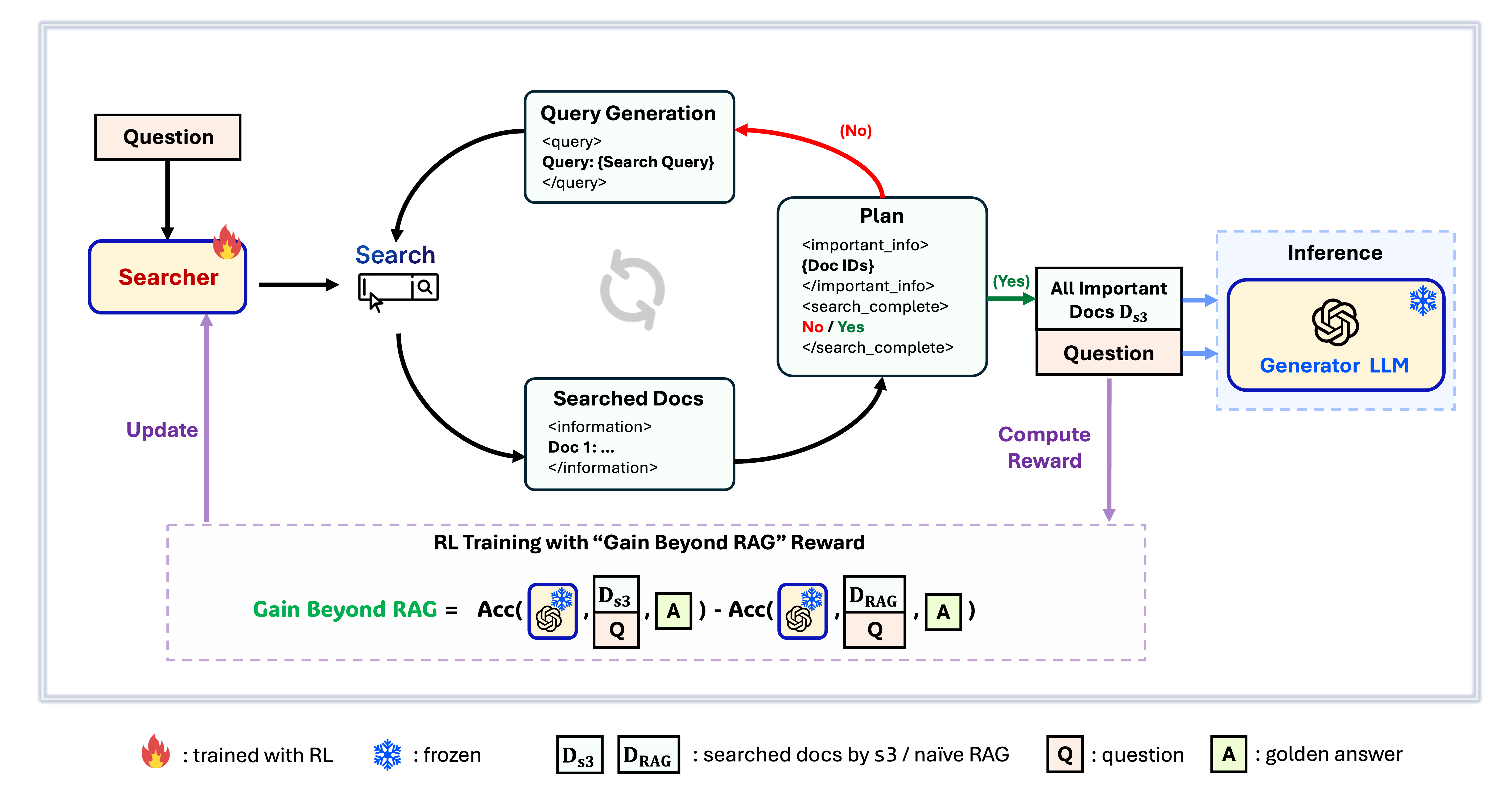
s3 프레임워크
s3는 검색 에이전트를 훈련하기 위한 간단하면서도 강력한 프레임워크로, 검색 기반 생성(RAG)에 사용됩니다. 이 프레임워크는 생성기를 변경하지 않고도 언어 모델이 더 효과적으로 검색하는 방법을 학습할 수 있게 합니다. s3는 검색 컴포넌트에만 집중함으로써, 기존 방법보다 훨씬 적은 데이터만으로도 QA 작업에서 강력한 성능을 달성합니다. 모듈식 구조로 효율적이며, 모든 블랙박스 LLM과 완벽하게 호환되도록 설계되었습니다.
목차
📦 설치
검색기 & 생성기 환경
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 준비하기
색인 및 말뭉치 다운로드python scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzNaïve RAG 초기화 사전 계산 (또는 저희가 처리한 데이터를 여기에서 다운로드할 수 있습니다: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ 훈련 실행
이 단계는 S3 훈련을 위한 것입니다# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 검색/검색 실행
이 단계는 s3 / 기준선의 컨텍스트 수집을 위한 것입니다s3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.sh
기준선
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG 딥리트리벌
bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1
📈 실행 평가
이 단계는 s3 / 기준선 평가를 위한 단계입니다bash scripts/evaluation/run.shQ&A
맞춤형 데이터?
자신만의 말뭉치/데이터셋에서 s3를 테스트하려면, 이 커밋을 참고하여 자체 파이프라인을 구축하기 위해 필요한 작업을 확인할 수 있습니다: commit 8420538결과 재현?
여러 개발자들이 이미 우리의 결과를 성공적으로 재현했습니다. 질문이 있거나 문제가 발생하면 언제든지 이슈를 열어 문의하세요 — 직접적인 안내를 기꺼이 제공해드립니다 (참고: 이 예시).모델을 직접 재현하는 것은 간단하며 — 실제로 우리는 처음부터 학습하는 것을 추천합니다. 평가가 학습보다 시간이 더 많이 걸리는 경우가 많기 때문입니다 — 참고용 체크포인트도 제공합니다: s3-8-3-3-20steps, 약 1시간 동안 학습되었습니다.
인용
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}우리 작업에 관심을 가져 주셔서 감사합니다!
--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---