s3 - Addestramento Efficiente ed Efficace di Agenti di Ricerca tramite RL
Non serve così tanti dati per addestrare un agente di ricerca
![]()
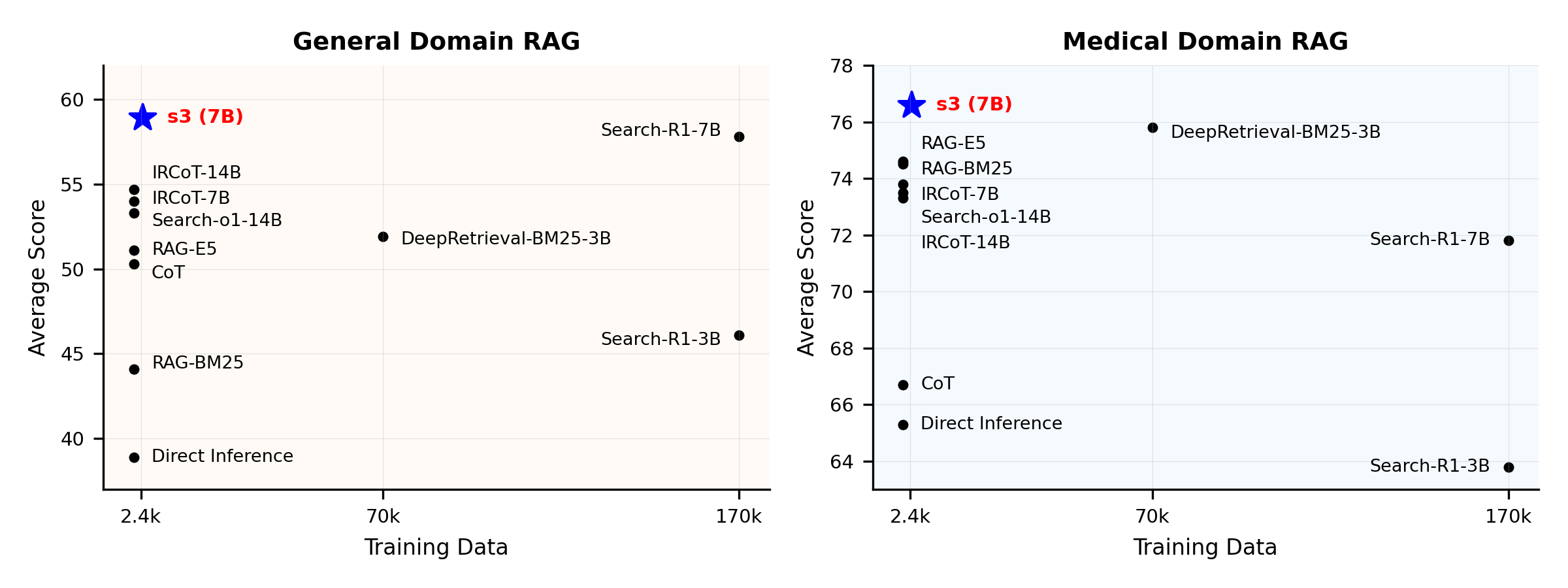
Panoramica delle prestazioni:
Cos'è s3?
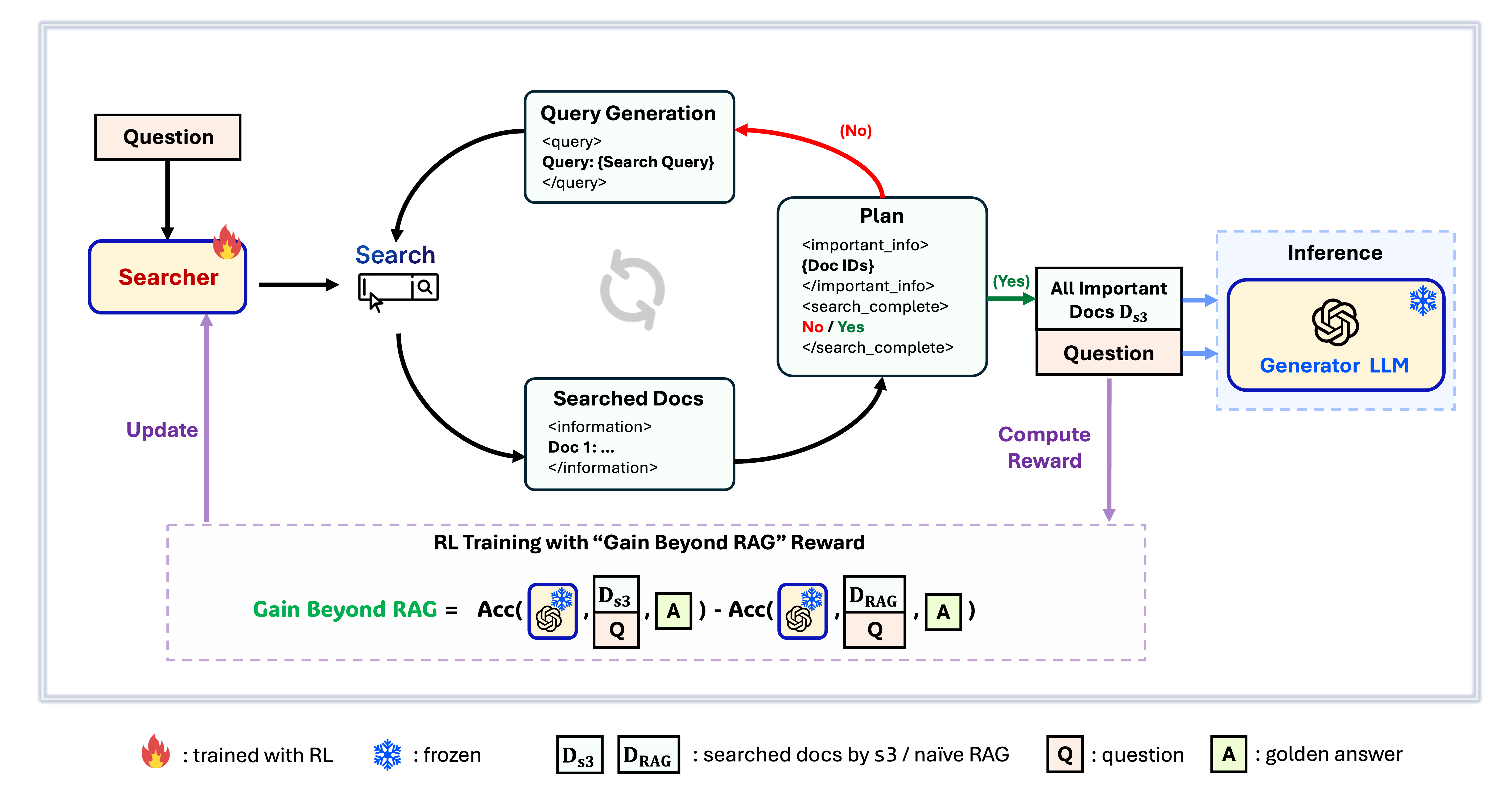
s3 Framework
s3 è un framework semplice ma potente per l’addestramento di agenti di ricerca nella generazione aumentata dal recupero (RAG). Insegna ai modelli linguistici come cercare in modo più efficace—senza modificare il generatore stesso. Concentrandosi esclusivamente sulla componente di ricerca, s3 ottiene prestazioni elevate nei task di QA usando solo una frazione dei dati richiesti dai metodi precedenti. È modulare, efficiente e progettato per funzionare perfettamente con qualsiasi LLM black-box.
Indice
- 📦 Installazione
- 💡 Preparazione
- 🏋️ Avvia l’addestramento
- 🔍 Avvia ricerca/recupero
- 📈 Avvia valutazione
📦 Installazione
Ambiente Searcher & Generator
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Preparazione
Scarica Indice e Corpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPrecomputazione Inizializzazione RAG Naïve (oppure puoi scaricare i nostri dati elaborati qui: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Avvia l'Addestramento
Questo passaggio riguarda l'addestramento di S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Esegui Ricerca/Recupero
Questo passaggio serve per la raccolta del contesto di s3 / baselines3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shBaseline
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Esegui Valutazione
Questo passaggio è per la valutazione di s3 / baselinesbash scripts/evaluation/run.shDomande e Risposte
Dati personalizzati?
Se vuoi testare s3 sul tuo corpus/dataset, puoi fare riferimento a questo commit per vedere cosa devi fare per costruire la tua pipeline: commit 8420538Riproduzione dei risultati?
Diversi sviluppatori hanno già riprodotto con successo i nostri risultati. Se hai domande o riscontri problemi, sentiti libero di aprire una issue — saremo felici di fornire assistenza pratica (vedi questo esempio).Sebbene riprodurre il modello autonomamente sia semplice — e in realtà raccomandiamo di addestrare da zero, poiché la valutazione è spesso molto più lunga rispetto all’addestramento — forniamo anche un checkpoint di riferimento: s3-8-3-3-20steps, addestrato in circa un’ora.
Citazione
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---