s3 - Pelatihan Agen Pencarian Efisien dan Efektif melalui RL
Anda Tidak Membutuhkan Begitu Banyak Data untuk Melatih Agen Pencarian
![]()
Ikhtisar Kinerja:
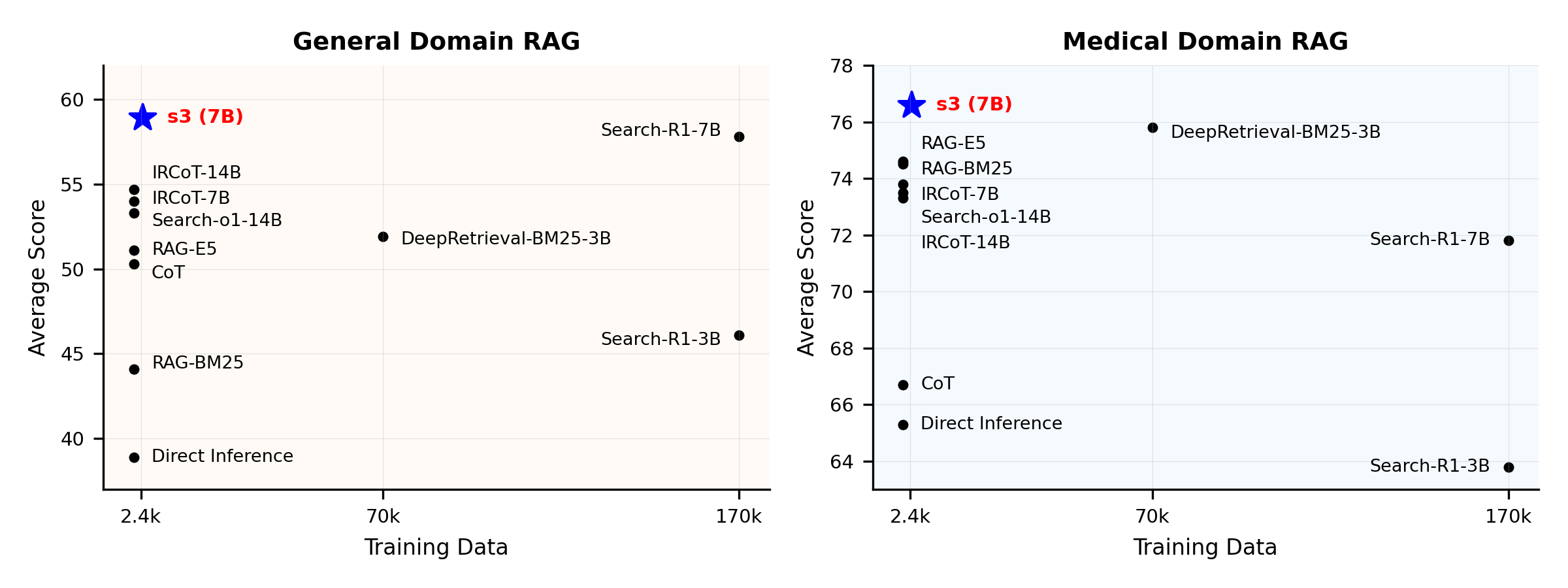
Apa itu s3?
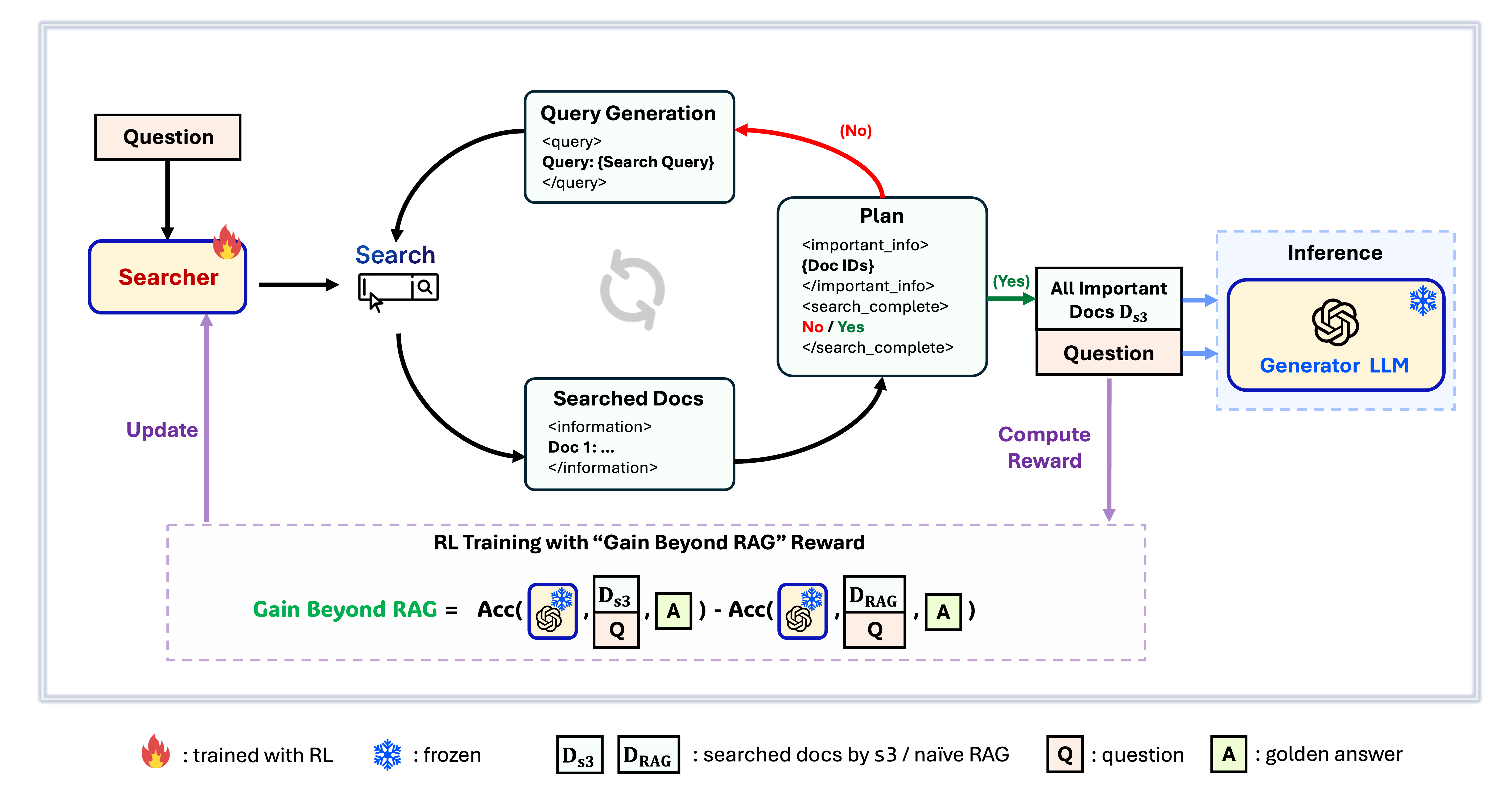
Kerangka Kerja s3
s3 adalah kerangka kerja yang sederhana namun kuat untuk melatih agen pencarian dalam retrieval-augmented generation (RAG). Kerangka ini mengajarkan model bahasa cara mencari dengan lebih efektif—tanpa mengubah generator itu sendiri. Dengan hanya berfokus pada komponen pencarian, s3 mencapai performa yang kuat di berbagai tugas QA dengan hanya sebagian kecil dari data yang digunakan oleh metode sebelumnya. Kerangka ini modular, efisien, dan dirancang untuk bekerja secara mulus dengan LLM black-box apa pun.
Daftar Isi
📦 Instalasi
Lingkungan Searcher & Generator
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Persiapan
Unduh Indeks & Korpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPra-komputasi Inisialisasi RAG Naïf (atau Anda dapat mengunduh data yang telah kami proses di sini: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Jalankan Pelatihan
Langkah ini untuk pelatihan S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Jalankan Pencarian/Pengambilan
Langkah ini untuk pengumpulan konteks s3 / baselines3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shBaselines
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Jalankan Evaluasi
Langkah ini untuk evaluasi s3 / baselinebash scripts/evaluation/run.shTanya Jawab
Data yang Disesuaikan?
Jika Anda ingin menguji s3 pada korpus/dataset Anda sendiri, Anda dapat merujuk pada commit ini untuk melihat apa yang perlu dilakukan untuk membangun pipeline Anda sendiri: commit 8420538Mereproduksi Hasil?
Beberapa pengembang telah berhasil mereproduksi hasil kami. Jika Anda memiliki pertanyaan atau mengalami masalah, silakan buka isu — kami dengan senang hati akan memberikan panduan langsung (lihat contoh ini).Meskipun mereproduksi model sendiri cukup mudah — dan kami sebenarnya merekomendasikan pelatihan dari awal, karena evaluasi seringkali jauh lebih memakan waktu daripada pelatihan — kami juga menyediakan checkpoint referensi: s3-8-3-3-20steps, yang dilatih sekitar satu jam.
Sitasi
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---