s3 - आरएल के माध्यम से कुशल लेकिन प्रभावी खोज एजेंट प्रशिक्षण
खोज एजेंट को प्रशिक्षित करने के लिए आपको इतनी अधिक डेटा की आवश्यकता नहीं है
![]()
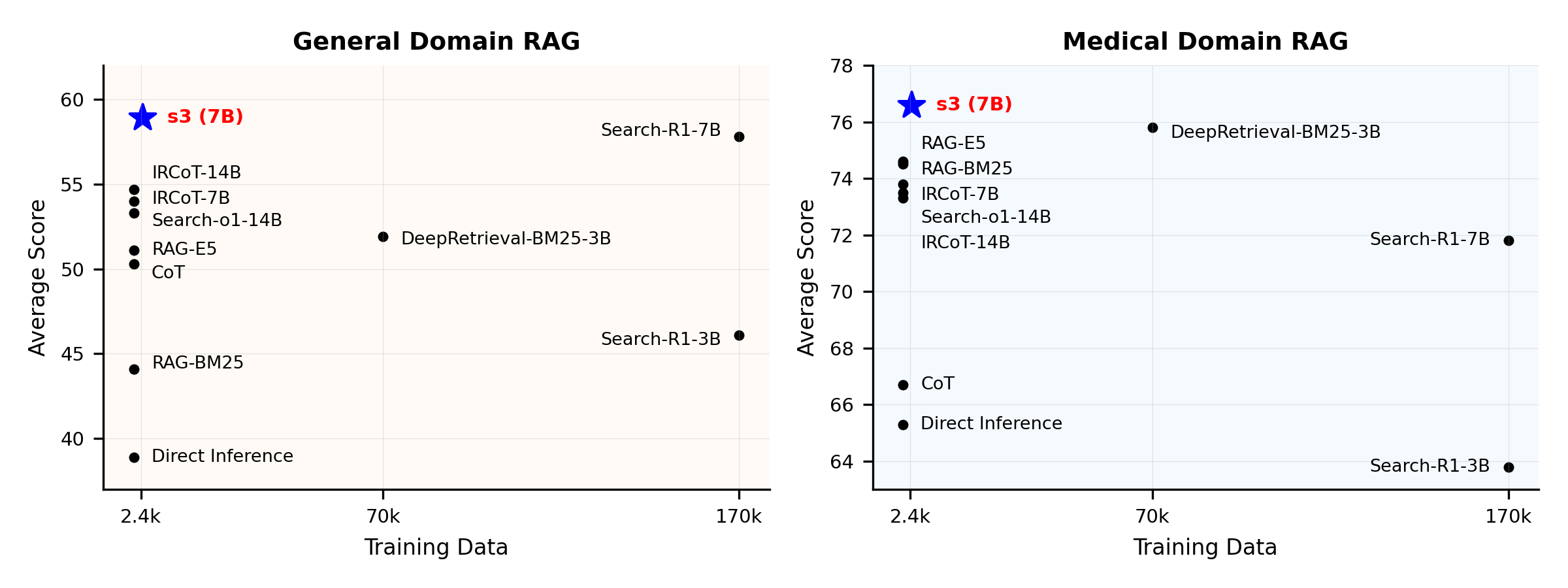
प्रदर्शन अवलोकन:
s3 क्या है?
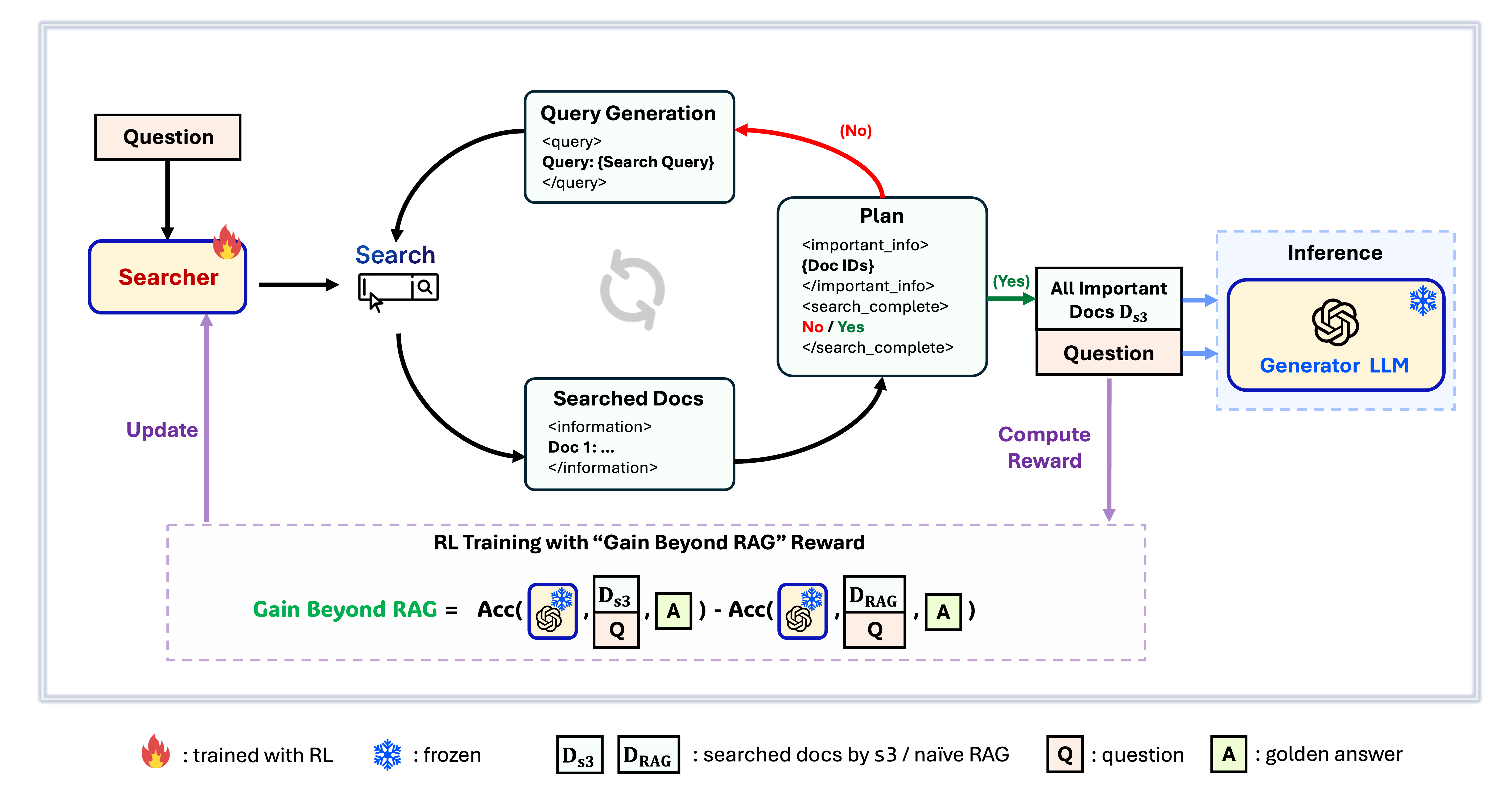
s3 फ्रेमवर्क
s3 एक सरल लेकिन शक्तिशाली फ्रेमवर्क है जो रिट्रीवल-ऑगमेंटेड जेनरेशन (RAG) में खोज एजेंट्स को ट्रेन करने के लिए बनाया गया है। यह भाषा मॉडल्स को अधिक प्रभावी ढंग से खोज करना सिखाता है—बिना जनरेटर को बदले। केवल खोज घटक पर ध्यान केंद्रित करके, s3 कम डेटा में भी पिछले तरीकों की तुलना में QA कार्यों में मजबूत प्रदर्शन प्राप्त करता है। यह मॉड्यूलर, कुशल और किसी भी ब्लैक-बॉक्स LLM के साथ सहजता से काम करने के लिए डिज़ाइन किया गया है।
विषय सूची
📦 इंस्टॉलेशन
सर्चर और जनरेटर वातावरण
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 तैयारी
इंडेक्स और कॉर्पस डाउनलोड करेंpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzपूर्वगणना सामान्य RAG प्रारंभिकरण (या आप हमारा संसाधित डेटा यहाँ डाउनलोड कर सकते हैं: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ प्रशिक्षण चलाएँ
यह चरण S3 के प्रशिक्षण के लिए है# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 खोज/पुनः प्राप्ति चलाएँ
यह चरण s3 / बेसलाइन की संदर्भ संग्रहण के लिए हैs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shमूल रेखाएँ
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 मूल्यांकन चलाएँ
यह चरण s3 / बेसलाइन के मूल्यांकन के लिए हैbash scripts/evaluation/run.shप्रश्नोत्तर
अनुकूलित डेटा?
यदि आप अपने स्वयं के कॉर्पस/डेटासेट पर s3 का परीक्षण करना चाहते हैं, तो आप इस कमिट का संदर्भ ले सकते हैं यह देखने के लिए कि अपनी स्वयं की पाइपलाइन बनाने के लिए आपको क्या करना होगा: commit 8420538परिणामों की पुनरुत्पत्ति?
कई डेवलपर्स ने पहले ही हमारे परिणामों को सफलतापूर्वक पुनरुत्पादित किया है। यदि आपके कोई प्रश्न हैं या किसी समस्या का सामना कर रहे हैं, तो बेझिझक issue खोलें — हम व्यावहारिक मार्गदर्शन देने में खुश हैं (देखें यह उदाहरण)।हालांकि स्वयं मॉडल को पुनरुत्पादित करना सीधा है — और हम वास्तव में शुरुआत से प्रशिक्षण की सलाह देते हैं, क्योंकि मूल्यांकन अक्सर प्रशिक्षण की तुलना में अधिक समय लेता है — हम एक संदर्भ चेकपॉइंट भी प्रदान करते हैं: s3-8-3-3-20steps, जिसे लगभग एक घंटे में प्रशिक्षित किया गया था।
संदर्भ
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---