s3 - Agent de Recherche Efficace et Performant via l’Apprentissage par Renforcement
Vous n’avez pas besoin de tant de données pour entraîner un agent de recherche
![]()
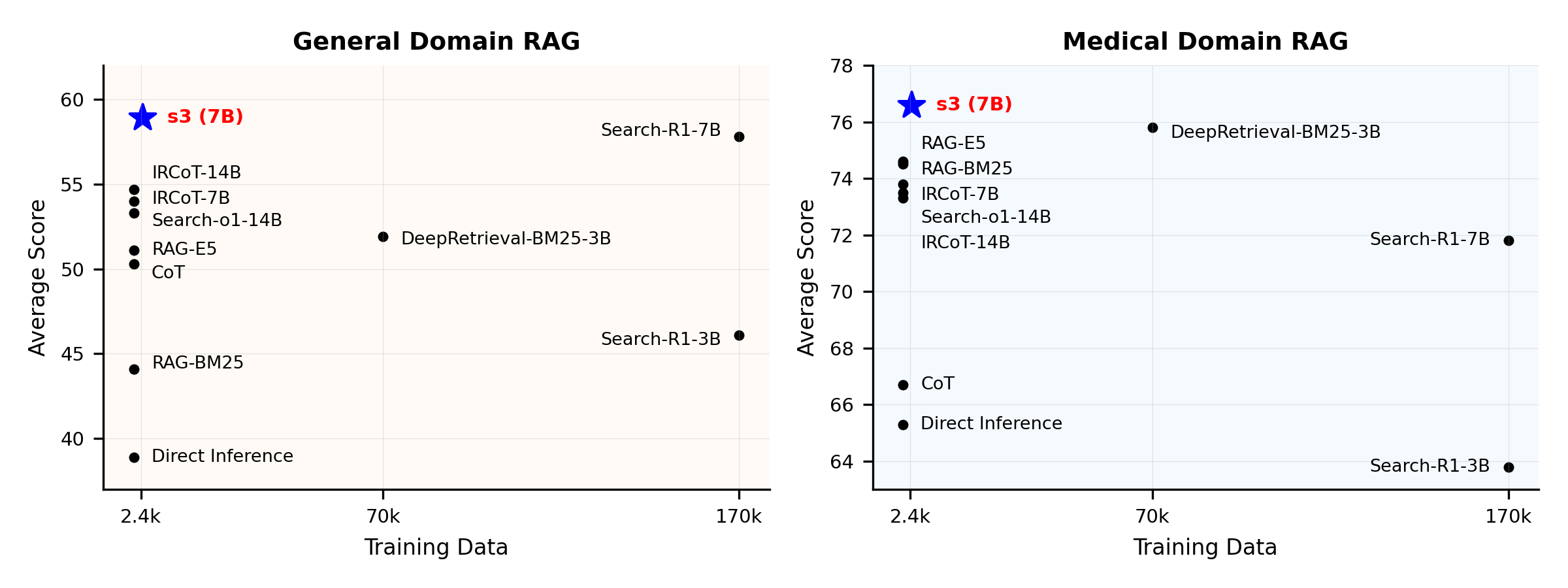
Aperçu des performances :
Qu'est-ce que s3 ?
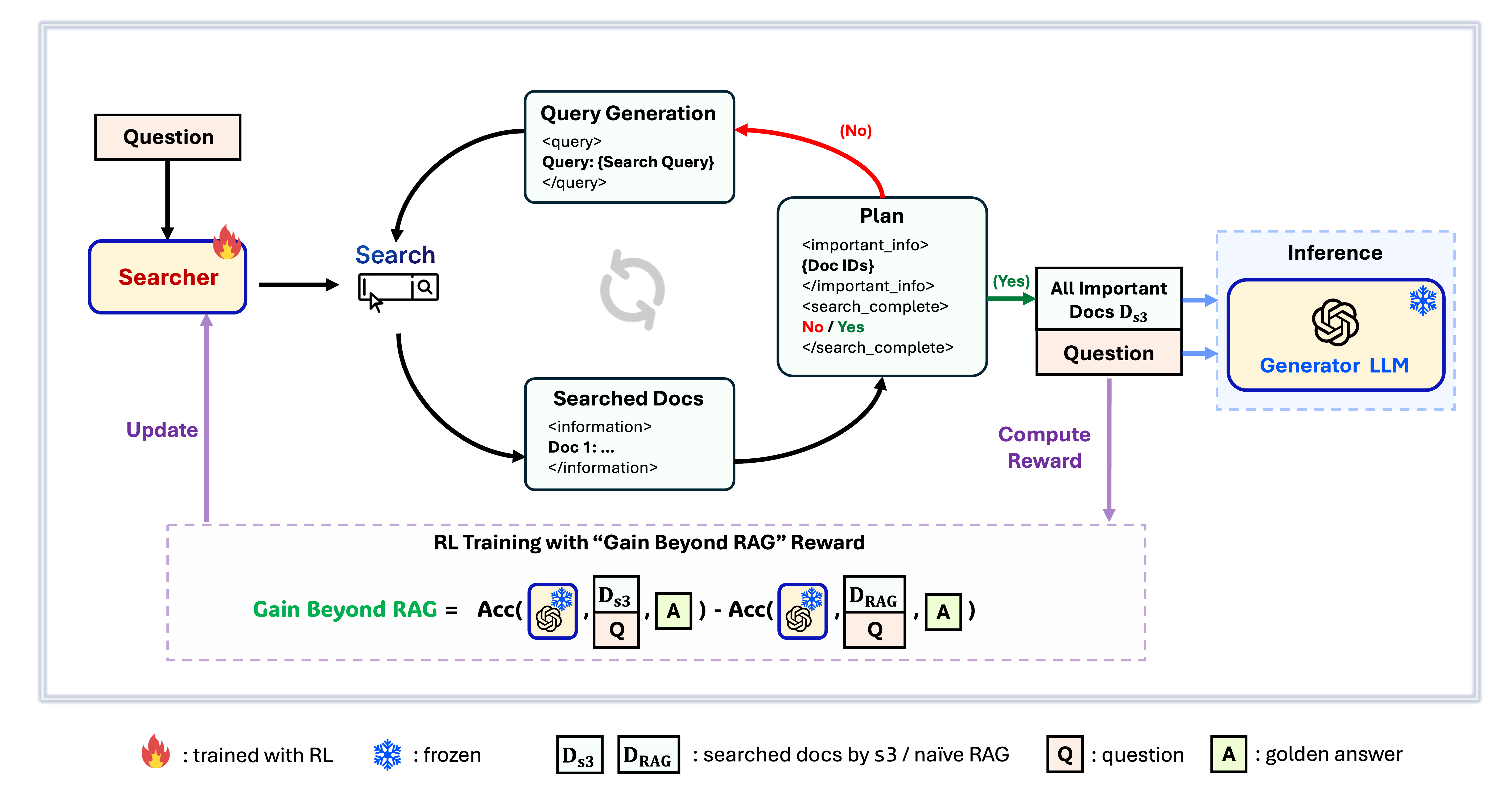
Framework s3
s3 est un framework simple mais puissant pour entraîner des agents de recherche dans la génération augmentée par récupération (RAG). Il apprend aux modèles de langage à rechercher plus efficacement—sans modifier le générateur lui-même. En se concentrant uniquement sur le composant de recherche, s3 obtient d'excellentes performances sur les tâches de QA avec seulement une fraction des données utilisées par les méthodes précédentes. Il est modulaire, efficace et conçu pour fonctionner parfaitement avec n'importe quel LLM boîte noire.
Table des matières
- 📦 Installation
- 💡 Préparation
- 🏋️ Lancer l’entraînement
- 🔍 Lancer la recherche/récupération
- 📈 Lancer l’évaluation
📦 Installation
Environnement du chercheur & générateur
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Préparation
Télécharger l’Index & le Corpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPré-calculer l'initialisation RAG naïve (ou vous pouvez télécharger nos données traitées ici : huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Exécuter l'entraînement
Cette étape concerne l'entraînement de S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Exécuter la recherche/récupération
Cette étape concerne la collecte de contexte de s3 / bases de références3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shRéférences de base
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Exécuter l'évaluation
Cette étape concerne l'évaluation de s3 / des lignes de basebash scripts/evaluation/run.shQ&R
Données personnalisées ?
Si vous souhaitez tester s3 sur votre propre corpus/ensemble de données, vous pouvez vous référer à ce commit pour voir ce qu'il faut faire pour construire votre propre pipeline : commit 8420538Reproduire les résultats ?
Plusieurs développeurs ont déjà reproduit nos résultats avec succès. Si vous avez des questions ou rencontrez des problèmes, n'hésitez pas à ouvrir une issue — nous sommes ravis de fournir une assistance pratique (voir cet exemple).Bien que reproduire le modèle vous-même soit simple — et nous recommandons réellement d'entraîner depuis zéro, car l'évaluation est souvent bien plus chronophage que l'entraînement — nous fournissons aussi un checkpoint de référence : s3-8-3-3-20steps, entraîné en environ une heure.
Citation
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---