s3 - آموزش عامل جستجوی کارآمد اما مؤثر با استفاده از یادگیری تقویتی
برای آموزش یک عامل جستجو به این مقدار داده نیاز ندارید
![]()
نمای کلی عملکرد:
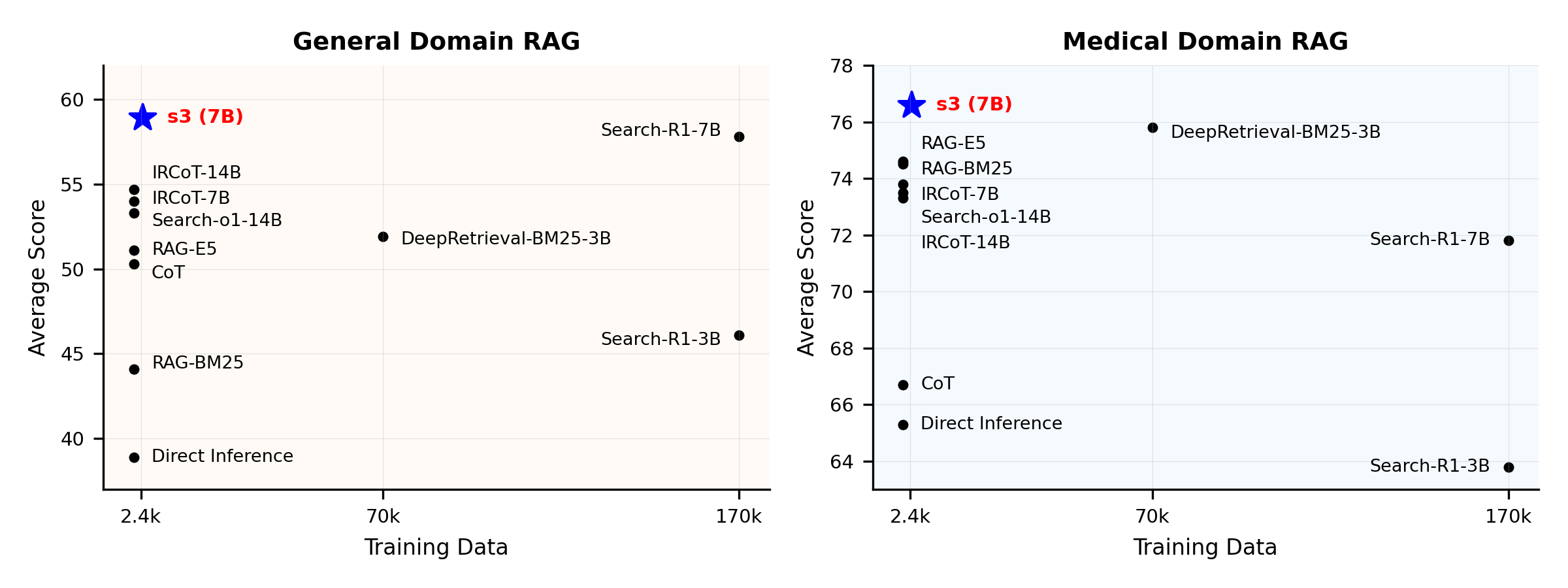
s3 چیست؟
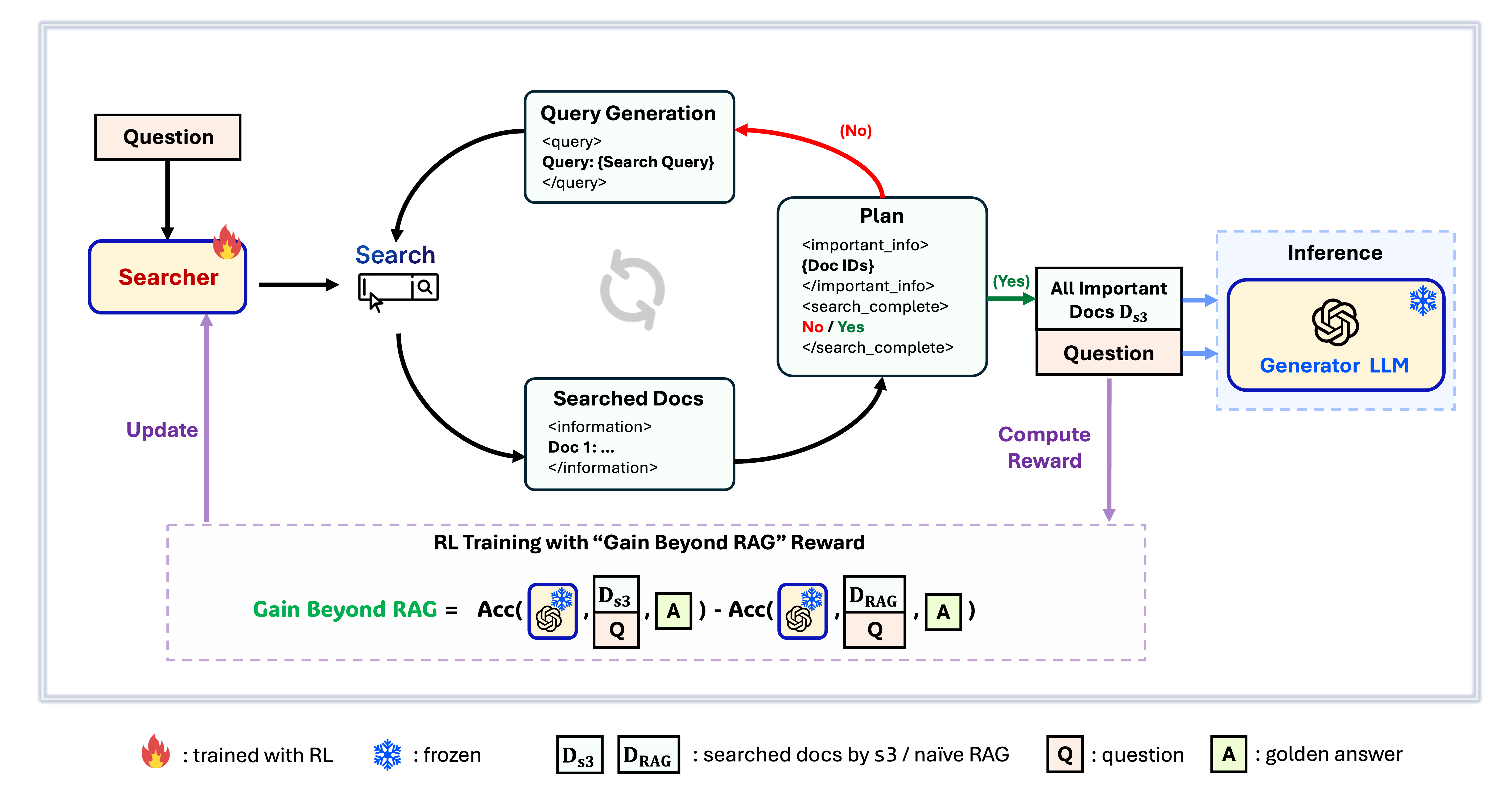
چارچوب s3
s3 یک چارچوب ساده اما قدرتمند برای آموزش عاملهای جستجو در تولید تقویتشده با بازیابی (RAG) است. این چارچوب به مدلهای زبانی آموزش میدهد تا مؤثرتر جستجو کنند—بدون تغییر در خود مولد. با تمرکز صرفاً بر مؤلفه جستجو، s3 با تنها کسری از دادههای مورد استفاده روشهای قبلی، عملکرد قوی در وظایف پرسش و پاسخ ارائه میدهد. این چارچوب ماژولار، کارآمد و برای کار بینقص با هر LLM جعبهسیاه طراحی شده است.
فهرست مطالب
📦 نصب
محیط جستجوگر و مولد
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 آمادهسازی
دانلود ایندکس و پایگاه دادهpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzپیشپردازش اولیه RAG به روش ساده (یا میتوانید دادههای پردازششده ما را از اینجا دانلود کنید: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ اجرای آموزش
این مرحله برای آموزش S3 است# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 اجرای جستجو/بازیابی
این مرحله برای گردآوری زمینه s3 / خطوط پایه استs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shمبانی
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 اجرای ارزیابی
این مرحله برای ارزیابی s3 / خطوط پایه استbash scripts/evaluation/run.shپرسش و پاسخ
دادههای سفارشی؟
اگر میخواهید s3 را روی کورپوس/داده خودتان تست کنید، میتوانید به این کامیت مراجعه کنید تا ببینید برای ساختن پایپلاین خودتان چه کارهایی باید انجام دهید: commit 8420538بازتولید نتایج؟
چندین توسعهدهنده قبلاً نتایج ما را با موفقیت بازتولید کردهاند. اگر سوالی داشتید یا با مشکلی مواجه شدید، میتوانید یک ایشو باز کنید — با خوشحالی راهنمایی عملی ارائه میدهیم (به این مثال مراجعه کنید).اگرچه بازتولید مدل توسط خودتان ساده است — و در واقع پیشنهاد میکنیم مدل را از ابتدا آموزش دهید، زیرا ارزیابی اغلب بسیار زمانبرتر از آموزش است — ما همچنین یک چکپوینت مرجع ارائه دادهایم: s3-8-3-3-20steps، که در حدود یک ساعت آموزش دیده است.
ارجاع
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---