s3 - Entrenamiento Eficiente pero Efectivo de Agentes de Búsqueda mediante RL
No necesitas tantos datos para entrenar un agente de búsqueda
![]()
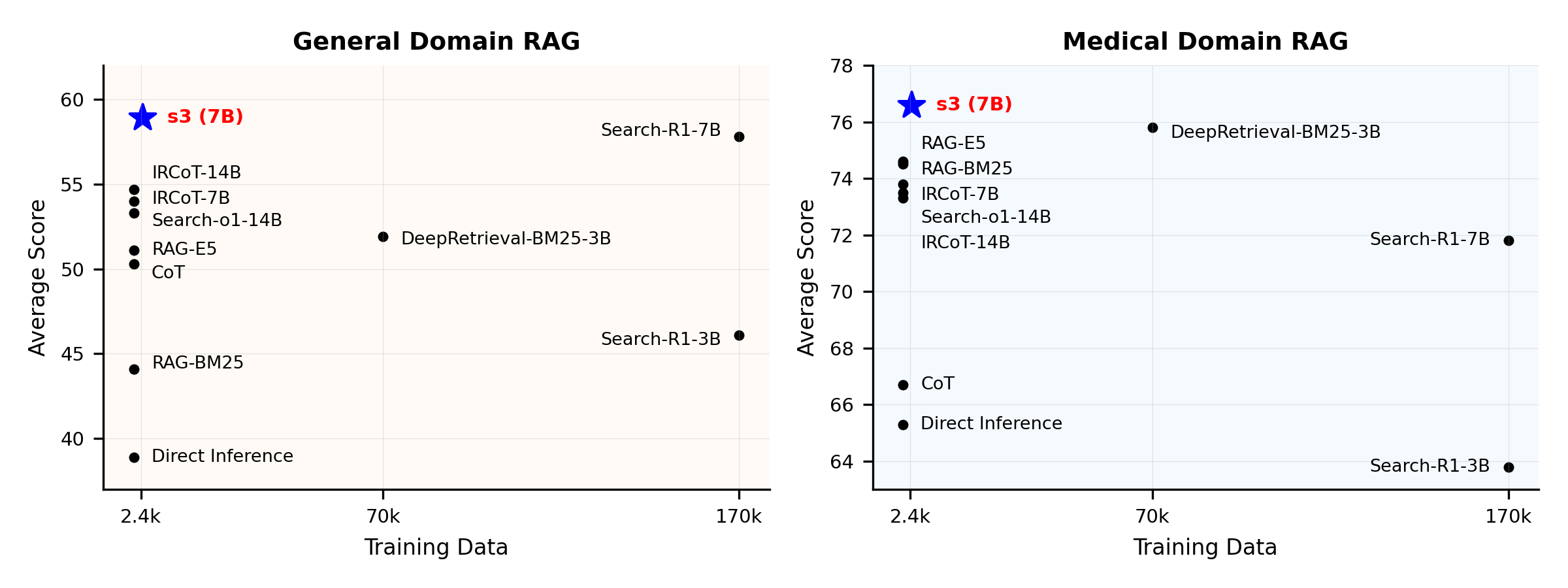
Resumen de Rendimiento:
¿Qué es s3?
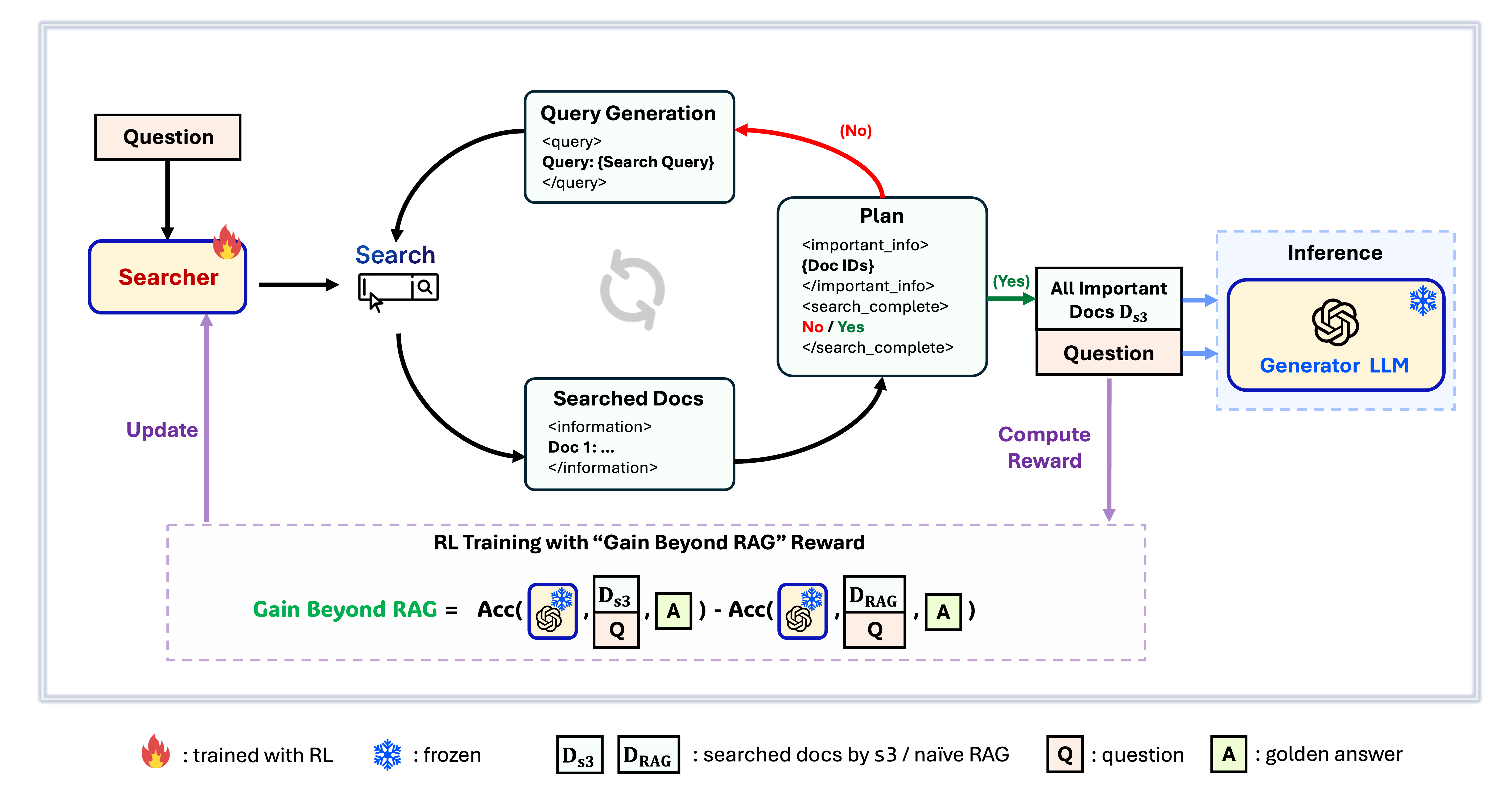
Framework s3
s3 es un framework simple pero potente para entrenar agentes de búsqueda en generación aumentada por recuperación (RAG). Enseña a los modelos de lenguaje cómo buscar de manera más efectiva, sin modificar el generador en sí. Al centrarse únicamente en el componente de búsqueda, s3 logra un alto rendimiento en tareas de preguntas y respuestas utilizando solo una fracción de los datos requeridos por métodos previos. Es modular, eficiente y está diseñado para funcionar perfectamente con cualquier LLM de caja negra.
Tabla de Contenidos
- 📦 Instalación
- 💡 Preparación
- 🏋️ Ejecutar Entrenamiento
- 🔍 Ejecutar Búsqueda/Recuperación
- 📈 Ejecutar Evaluación
📦 Instalación
Entorno de Buscador & Generador
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Preparación
Descargar Índice y Corpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPrecalcular la Inicialización Ingenua de RAG (o puedes descargar nuestros datos procesados aquí: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Ejecutar Entrenamiento
Este paso es para el entrenamiento de S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Ejecutar Búsqueda/Recuperación
Este paso es para la recopilación de contexto de s3 / líneas bases3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shLíneas base
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Ejecutar Evaluación
Este paso es para la evaluación de s3 / líneas basebash scripts/evaluation/run.shPreguntas y Respuestas
¿Datos Personalizados?
Si deseas probar s3 en tu propio corpus/conjunto de datos, puedes consultar este commit para ver qué necesitas hacer para construir tu propio pipeline: commit 8420538¿Reproducción de Resultados?
Varios desarrolladores ya han reproducido nuestros resultados exitosamente. Si tienes preguntas o encuentras problemas, no dudes en abrir un issue — estaremos encantados de ofrecerte orientación práctica (ver este ejemplo).Aunque reproducir el modelo tú mismo es sencillo — y de hecho recomendamos entrenar desde cero, ya que la evaluación suele ser mucho más lenta que el entrenamiento — también proporcionamos un checkpoint de referencia: s3-8-3-3-20steps, entrenado en aproximadamente una hora.
Citación
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---