🌐 Language
s3 - Efficient Yet Effective Search Agent Training via RL
You Don't Need That Much Data to Train a Search Agent
![]()
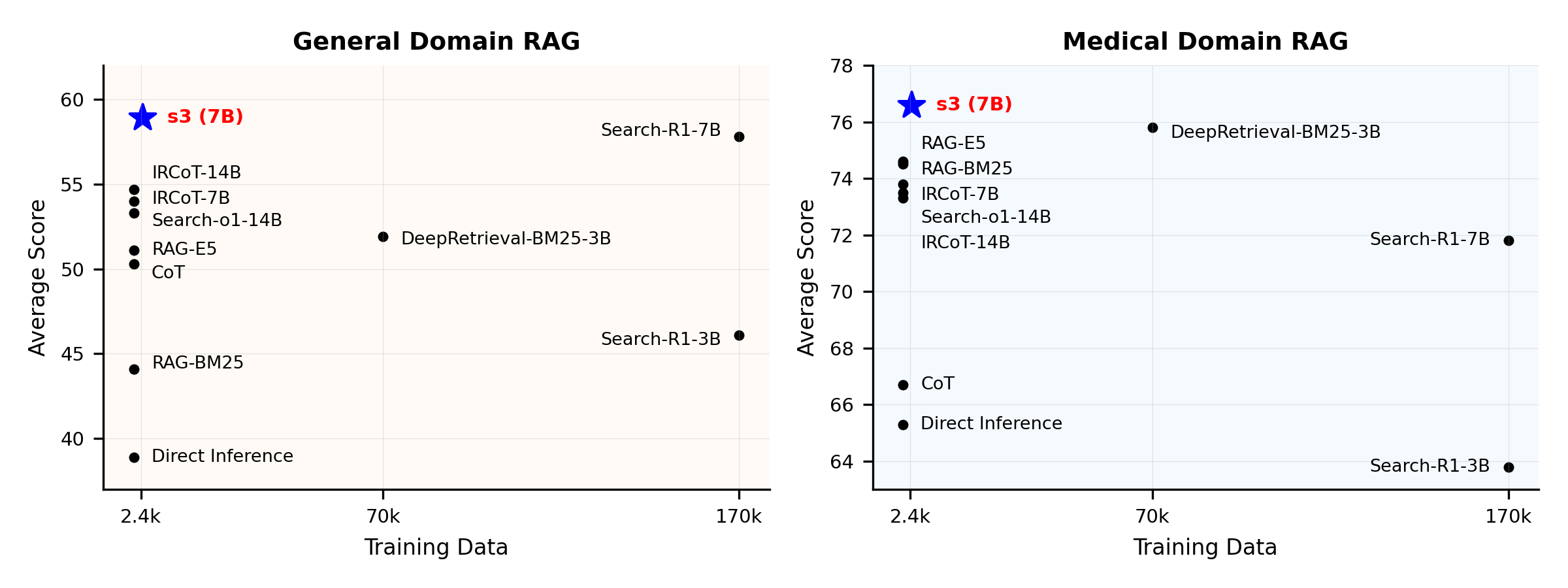
Performance Overview:
What is s3?
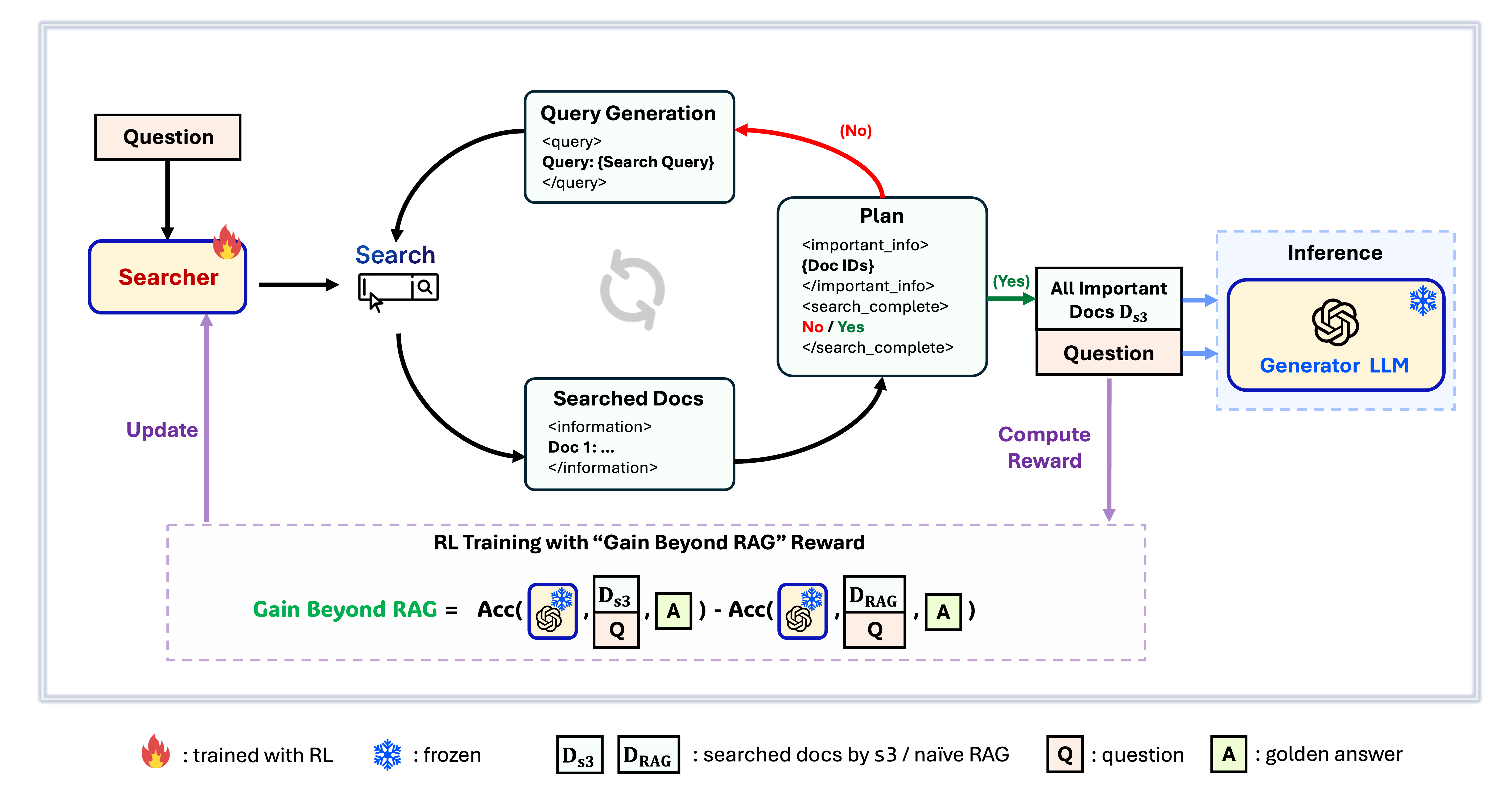
s3 Framework
s3 is a simple yet powerful framework for training search agents in retrieval-augmented generation (RAG). It teaches language models how to search more effectively—without changing the generator itself. By focusing solely on the search component, s3 achieves strong performance across QA tasks with just a fraction of the data used by prior methods. It's modular, efficient, and designed to work seamlessly with any black-box LLM.
Table of Contents
📦 Installation
Searcher & Generator Environment
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Preparation
Download Index & Corpuspython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzPrecompute Naïve RAG Initialization (or you can download our processed data here: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Run Training
This step is for the training of S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Run Search/Retrieval
This step is for the context gathering of s3 / baseliness3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shBaselines
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Run Evaluation
This step is for the evaluation of s3 / baselinesbash scripts/evaluation/run.shQ&A
Customized Data?
If you want to test s3 on your own corpus/dataset, you can refer to this commit to see what you need to do to build your own pipeline: commit 8420538Reproducing Results?
Several developers have already reproduced our results successfully. If you have questions or run into issues, feel free to open an issue — we’re happy to provide hands-on guidance (see this example).Although reproducing the model yourself is straightforward — and we actually recommend training from scratch, since evaluation is often much more time-consuming than training — we also provide a reference checkpoint: s3-8-3-3-20steps, trained in about one hour.
Citation
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---