s3 - Effiziente und dennoch effektive Ausbildung von Suchagenten mittels RL
Man braucht gar nicht so viele Daten, um einen Suchagenten zu trainieren
![]()
Leistungsübersicht:
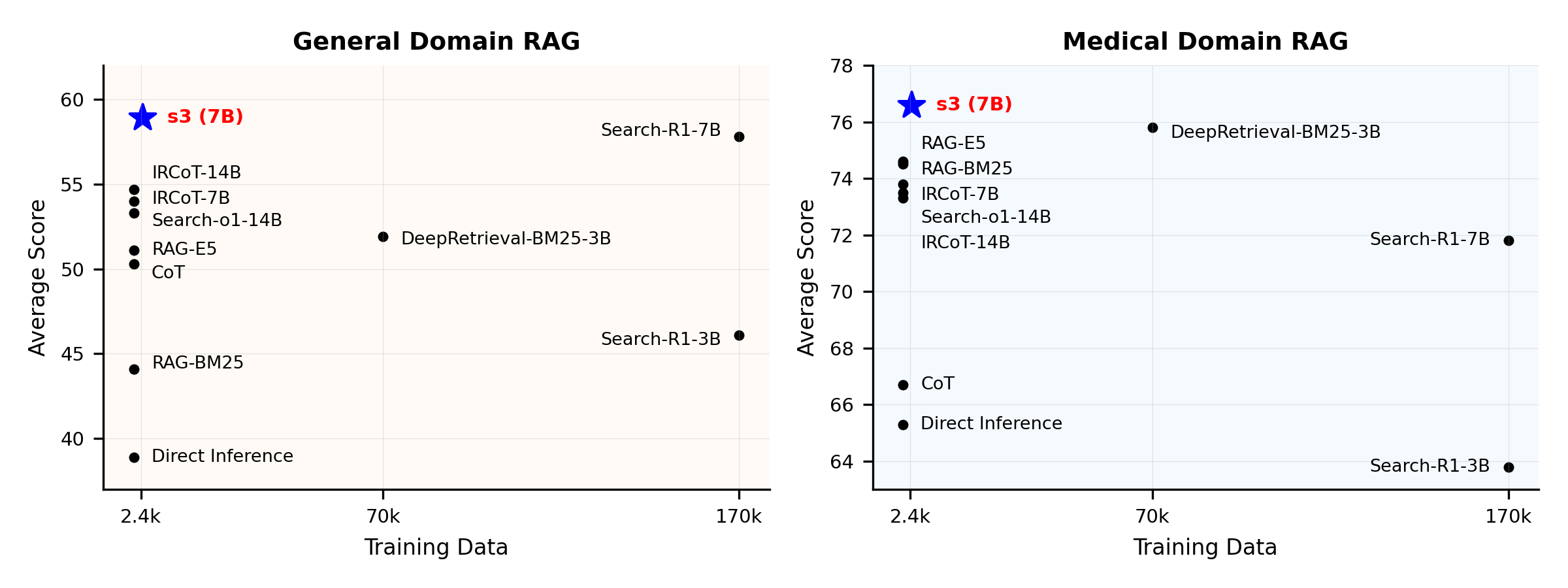
Was ist s3?
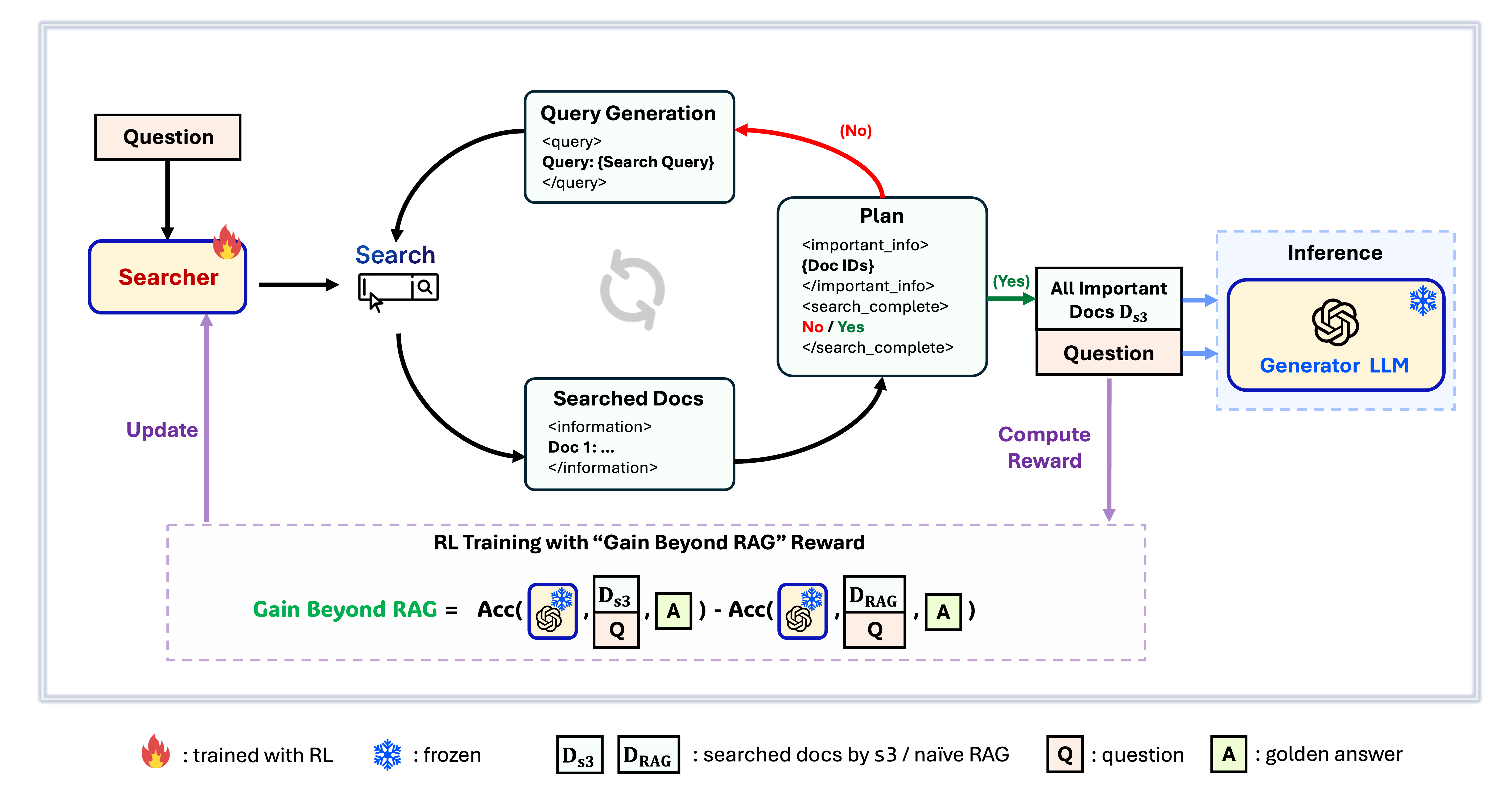
s3 Framework
s3 ist ein einfaches, aber leistungsstarkes Framework zum Trainieren von Suchagenten für Retrieval-Augmented Generation (RAG). Es bringt Sprachmodellen bei, effektiver zu suchen – ohne den Generator selbst zu verändern. Durch den Fokus ausschließlich auf die Suchkomponente erzielt s3 starke Leistungen bei QA-Aufgaben mit nur einem Bruchteil der Daten, die frühere Methoden benötigen. Es ist modular, effizient und darauf ausgelegt, nahtlos mit jedem Black-Box-LLM zusammenzuarbeiten.
Inhaltsverzeichnis
📦 Installation
Sucher- & Generator-Umgebung
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 Vorbereitung
Index & Korpus herunterladenpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzNaive RAG-Initialisierung vorab berechnen (oder Sie können unsere verarbeiteten Daten hier herunterladen: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ Training ausführen
Dieser Schritt ist für das Training von S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 Suche/Abruf ausführen
Dieser Schritt dient dem Sammeln von Kontext für s3 / Baseliness3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shBaselines
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 Auswertung ausführen
Dieser Schritt dient der Bewertung von s3 / Baselinesbash scripts/evaluation/run.shQ&A
Benutzerdefinierte Daten?
Wenn Sie s3 mit Ihrem eigenen Korpus/Datensatz testen möchten, können Sie sich auf diesen Commit beziehen, um zu sehen, was Sie tun müssen, um Ihre eigene Pipeline zu erstellen: commit 8420538Ergebnisse reproduzieren?
Mehrere Entwickler haben unsere Ergebnisse bereits erfolgreich reproduziert. Wenn Sie Fragen haben oder auf Probleme stoßen, können Sie gerne ein Issue eröffnen — wir helfen Ihnen gerne praktisch weiter (siehe dieses Beispiel).Obwohl die eigenständige Reproduktion des Modells unkompliziert ist — und wir tatsächlich empfehlen, von Grund auf neu zu trainieren, da die Auswertung oft viel zeitaufwändiger ist als das Training — stellen wir auch einen Referenz-Checkpoint bereit: s3-8-3-3-20steps, in etwa einer Stunde trainiert.
Zitation
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---