s3 - আৰএল দ্বাৰা দক্ষ আৰু ফলপ্ৰসূ সন্ধান এজেন্ট প্ৰশিক্ষণ
এটা সন্ধান এজেন্ট প্ৰশিক্ষণৰ বাবে আপুনি ইমান ডাটা লাগিব নালাগে
![]()
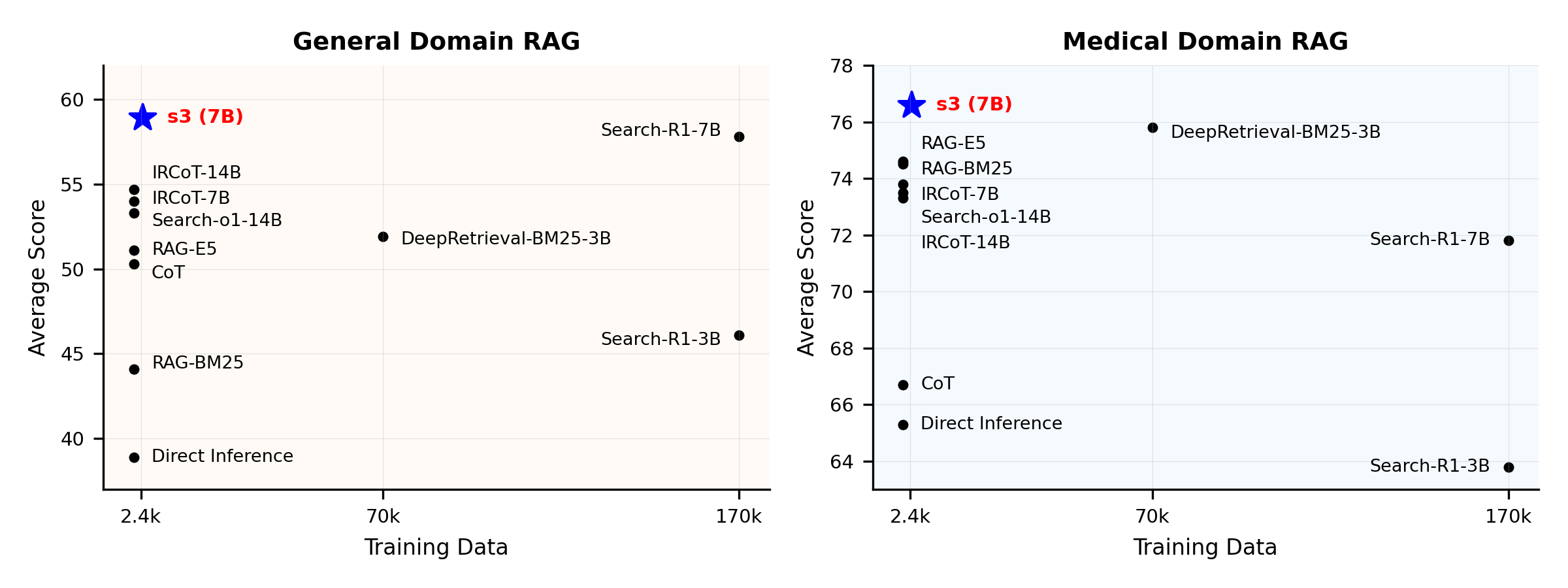
কাৰ্যক্ষমতাৰ সামগ্ৰিক পৰ্যালোচনা:
s3 কি?
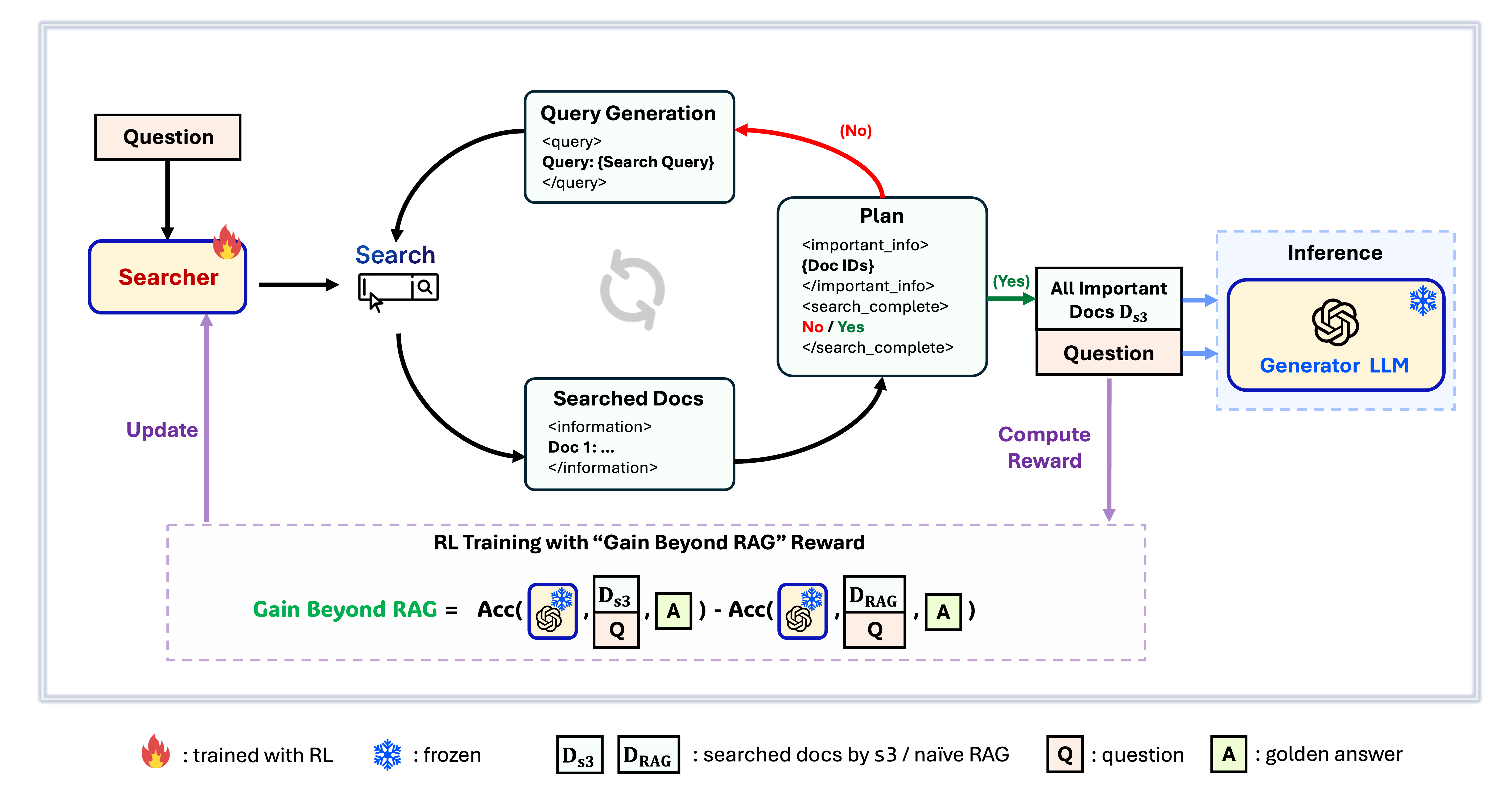
s3 ফ্ৰেমৱৰ্ক
s3 হৈছে অনুসন্ধান এজেন্ট প্ৰশিক্ষণৰ বাবে এটা সহজ কিন্তু শক্তিশালী ফ্ৰেমৱৰ্ক, যি retrieval-augmented generation (RAG)ত ব্যৱহাৰ হয়। ই ভাষা মডেলসমূহক অধিক কার্যকৰীভাৱে সন্ধান কৰিবলৈ শিকায়—উৎপাদকক পৰিবৰ্তন নকৰাকৈ। কেৱল অনুসন্ধান অংশত কেন্দ্ৰিত হৈ, s3 আগৰ পদ্ধতিত ব্যৱহৃত তথ্যৰ অতি কম অংশ ব্যৱহাৰ কৰি QA কামত শক্তিশালী কাৰ্যক্ষমতা দেখুৱাই। ই মডুলাৰ, দক্ষ, আৰু যিকোনো ব্লেক-বক্স LLMৰ সৈতে নিৰৱিচ্ছিন্নভাৱে কাম কৰাৰ বাবে ডিজাইন কৰা।
বিষয়বস্তু সূচী
📦 ইনষ্টলেশ্বন
সাৰ্চাৰ & জেনাৰেটৰ পৰিৱেশ
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubৰিট্ৰিভাৰ পৰিৱেশ
conda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 প্রস্তুতি
সূচী আৰু কোৰ্পাছ ডাউনলোড কৰকpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzপ্ৰাক-গণনা কৰা Naïve RAG Initialization (অথবা আপুনি আমাৰ প্ৰক্ৰিয়াকৃত ডাটা ইয়াত ডাউনলোড কৰিব পাৰে: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ প্ৰশিক্ষণ চলাও
এই খোজটো S3-ৰ প্ৰশিক্ষণৰ বাবে# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 সন্ধান/পুনঃপ্ৰাপ্তি চলাও
এই পদক্ষেপটো s3 / বেছলাইনসমূহৰ প্ৰসংগ সংগ্ৰহৰ বাবেs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shবেছলাইনসমূহ
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG DeepRetrieval
bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalসন্ধান-R1
bash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1IRCoT
bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pyসন্ধান-o1
bash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 মূল্যায়ন চলাও
এই পদক্ষেপটো s3 / মূল মানদণ্ডৰ মূল্যায়নৰ বাবেbash scripts/evaluation/run.shপ্ৰশ্ন আৰু উত্তৰ
ব্যক্তিগত ডাটা?
যদি আপুনি আপোনাৰ নিজৰ কোৰ্পাছ/ডেটাচেটত s3 পৰীক্ষা কৰিব বিচাৰে, তেন্তে এই কমিটটো চাব পাৰে যাতে আপোনাৰ নিজৰ পাইপলাইন বনাবলৈ কি কৰিব লাগিব সেই বিষয়ে জানিব: commit 8420538ফলাফল পুনৰ উৎপাদন?
কেইজনমান বিকাশকাৰীয়ে আমাৰ ফলাফল ইতিমধ্যে সফলভাৱে পুনৰ উৎপাদন কৰিছে। যদি আপোনাৰ প্ৰশ্ন থাকে বা সমস্যা হয়, নিশ্চিন্তে open an issue কৰক — আমি সহায় কৰিবলৈ সদায় সাজু (চাওক এই উদাহৰণ)।যদিও মডেলটো নিজে উৎপাদন কৰা সহজ — আৰু আমি আসলে শূন্যৰ পৰা প্ৰশিক্ষণ কৰিবলৈ পৰামৰ্শ দিছোঁ, কাৰণ মূল্যায়ন সাধাৰণতে প্ৰশিক্ষণতকৈ বহু অধিক সময় লাগে — আমি এক ৰেফাৰেন্স চেকপইণ্টো দিছোঁ: s3-8-3-3-20steps, প্ৰায় এক ঘণ্টাত প্ৰশিক্ষিত।
উদ্ধৃতি
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}Thanks for your interest in our work!
--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---