s3 - تدريب وكيل البحث بكفاءة وفعالية عبر التعلم المعزز
لست بحاجة إلى الكثير من البيانات لتدريب وكيل بحث
![]()
نظرة عامة على الأداء:
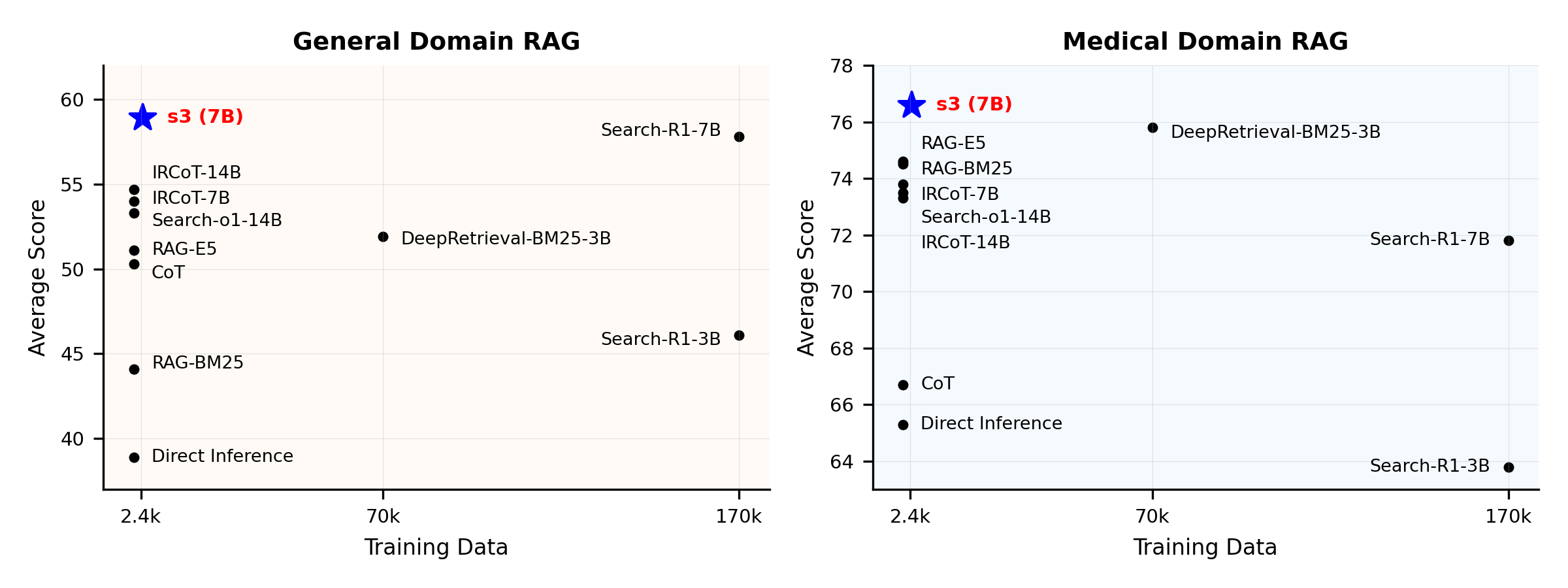
ما هو s3؟
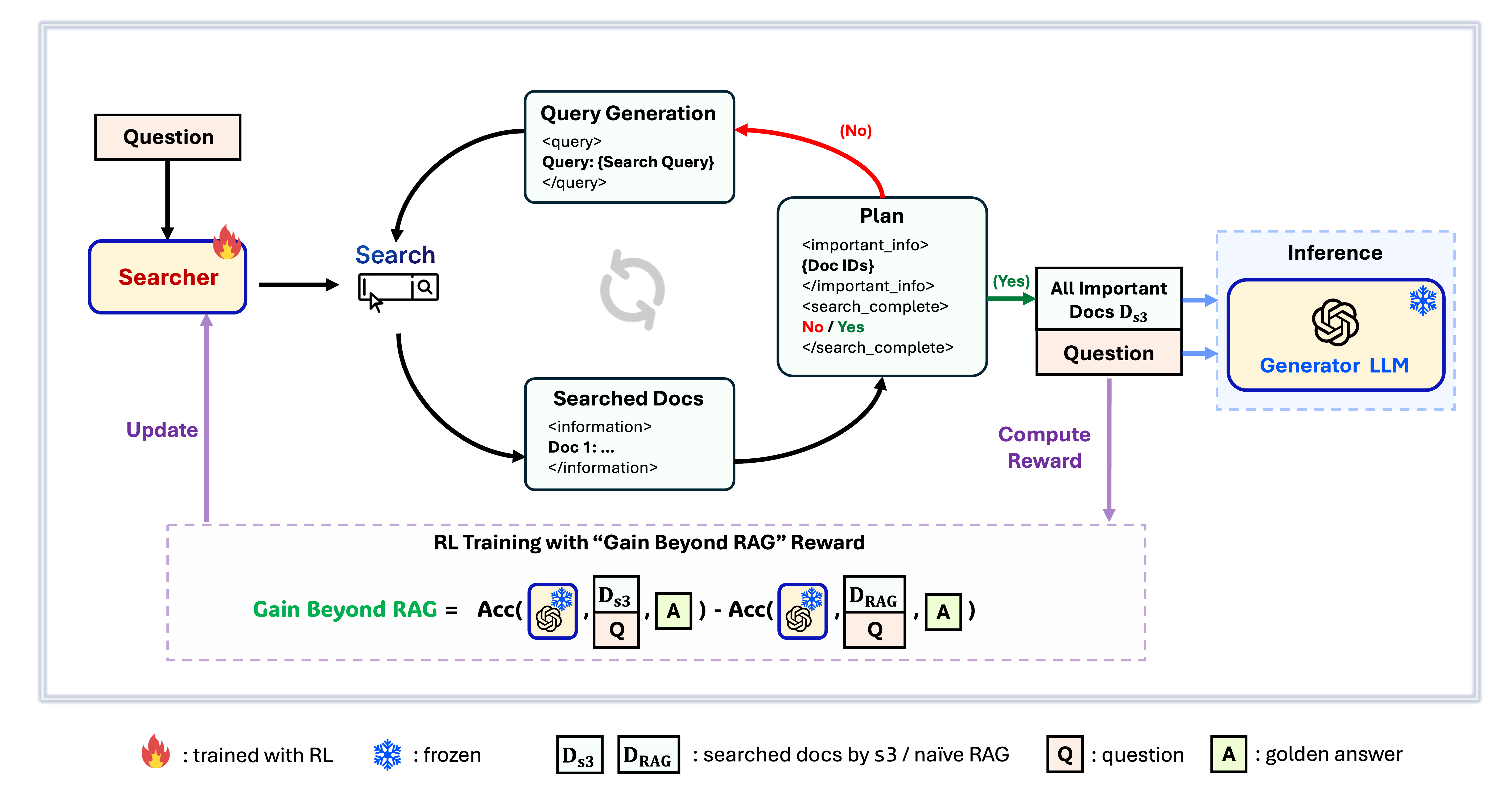
إطار عمل s3
s3 هو إطار عمل بسيط ولكنه قوي لتدريب وكلاء البحث في توليد المعلومات المدعومة بالاسترجاع (RAG). يعلم نماذج اللغة كيفية البحث بشكل أكثر فعالية - دون تغيير وحدة التوليد نفسها. من خلال التركيز فقط على عنصر البحث، يحقق s3 أداءً قويًا عبر مهام الأسئلة والأجوبة باستخدام جزء بسيط فقط من البيانات المستخدمة في الطرق السابقة. إنه معياري، فعال، ومصمم للعمل بسلاسة مع أي نموذج لغة كبير مغلق المصدر.
جدول المحتويات
📦 التثبيت
بيئة الباحث والمُولّد
conda create -n s3 python=3.9
install torch [or you can skip this step and let vllm to install the correct version for you]
pip install torch==2.4.0 --index-url https://download.pytorch.org/whl/cu121
install vllm
pip3 install vllm==0.6.3 # or you can install 0.5.4, 0.4.2 and 0.3.1
pip3 install rayverl
cd code
pip install -e .flash attention 2
pip3 install flash-attn --no-build-isolationwe use pyserini for efficient retrieval and evaluation
pip install pyserini # the version we used is 0.22.1quality of life
pip install wandb IPython matplotlib huggingface_hubconda create -n ret python=3.10
conda activate retconda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia
pip install transformers datasets pyserini
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
pip install uvicorn fastapi
💡 التحضير
تنزيل الفهرس والمجموعةpython scripts/download.py --save_path $save_path
cat $save_path/part_* > $save_path/e5_Flat.index
gzip -d $save_path/wiki-18.jsonl.gzتهيئة RAG البسيطة مسبقة الحساب (أو يمكنك تنزيل بياناتنا المعالجة من هنا: huggingface)
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh # or scripts/deploy_retriever/retrieval_launch_mirage.sh for MedCorp corpus.
deploy generator
bash generator_llms/host.sh # modify tensor-parallel-size to the number of GPUs you use
run precompute
bash scripts/precompute.sh # this step will take a while, as it will precompute the naïve RAG Cache for training🏋️ تشغيل التدريب
هذه الخطوة مخصصة لتدريب S3# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
deploy generator
bash generator_llms/host.sh
run training
bash scripts/train/train_s3.sh🔍 تنفيذ البحث/الاسترجاع
هذه الخطوة مخصصة لجمع السياق لـ s3 / القيم الأساسيةs3
# deploy retriever
bash scripts/deploy_retriever/retrieval_launch.sh
run s3 inference
bash scripts/s3_inference/evaluate-8-3-3.shخطوط الأساس
RAG
bash scripts/deploy_retriever/retrieval_launch.sh # or retrieval_launch_bm25.sh # deploy retriever
bash scripts/baselines/rag.sh # run RAG bash retrieval_launch_bm25.sh # deploy BM25 Model
bash generator_llms/deepretrieval.sh # deploy DeepRetrieval Model
bash scripts/baselines/deepretrieval.sh # run DeepRetrieval Query Rewriting + Retrievalbash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_r1.sh # run Search-R1bash retrieval_launch.sh # deploy e5 retriever
python scripts/baselines/ircot.pybash retrieval_launch.sh # deploy e5 retriever
bash scripts/baselines/search_o1.sh # run Search-o1📈 تشغيل التقييم
هذه الخطوة مخصصة لتقييم s3 / الخطوط الأساسيةbash scripts/evaluation/run.shالأسئلة الشائعة
بيانات مخصصة؟
إذا كنت ترغب في اختبار s3 على بياناتك أو مجموعتك الخاصة، يمكنك الرجوع إلى هذا الالتزام لمعرفة ما يجب عليك فعله لبناء خط أنابيبك الخاص: commit 8420538إعادة إنتاج النتائج؟
لقد قام عدة مطورين بالفعل بإعادة إنتاج نتائجنا بنجاح. إذا كانت لديك أسئلة أو واجهت مشاكل، لا تتردد في فتح تذكرة — يسعدنا تقديم إرشاد عملي (انظر هذا المثال).على الرغم من أن إعادة إنتاج النموذج بنفسك أمر مباشر — ونوصي فعليًا بالتدريب من البداية، حيث أن التقييم غالبًا ما يكون أكثر استهلاكًا للوقت من التدريب — إلا أننا نوفر أيضًا نقطة تحقق مرجعية: s3-8-3-3-20steps، تم تدريبها في حوالي ساعة واحدة.
الاقتباس
@article{jiang2025s3,
title={s3: You Don't Need That Much Data to Train a Search Agent via RL},
author={Jiang, Pengcheng and Xu, Xueqiang and Lin, Jiacheng and Xiao, Jinfeng and Wang, Zifeng and Sun, Jimeng and Han, Jiawei},
journal={arXiv preprint arXiv:2505.14146},
year={2025}
}--- Tranlated By Open Ai Tx | Last indexed: 2025-12-30 ---