🌐 Język
Dopasowywanie przepływu w PyTorch
To repozytorium zawiera prostą implementację w PyTorch artykułu Flow Matching for Generative Modeling.
Przykład dopasowywania przepływu w 2D
Poniższy gif demonstruje mapowanie pojedynczego rozkładu normalnego na rozkład szachownicowy, z wizualizacją pola wektorowego.
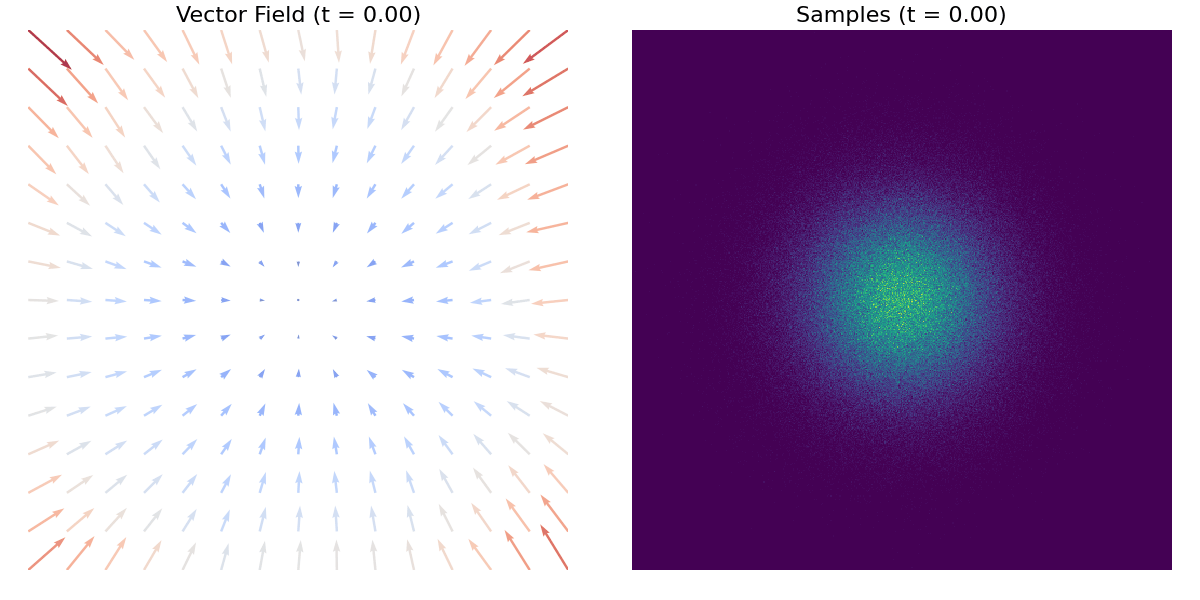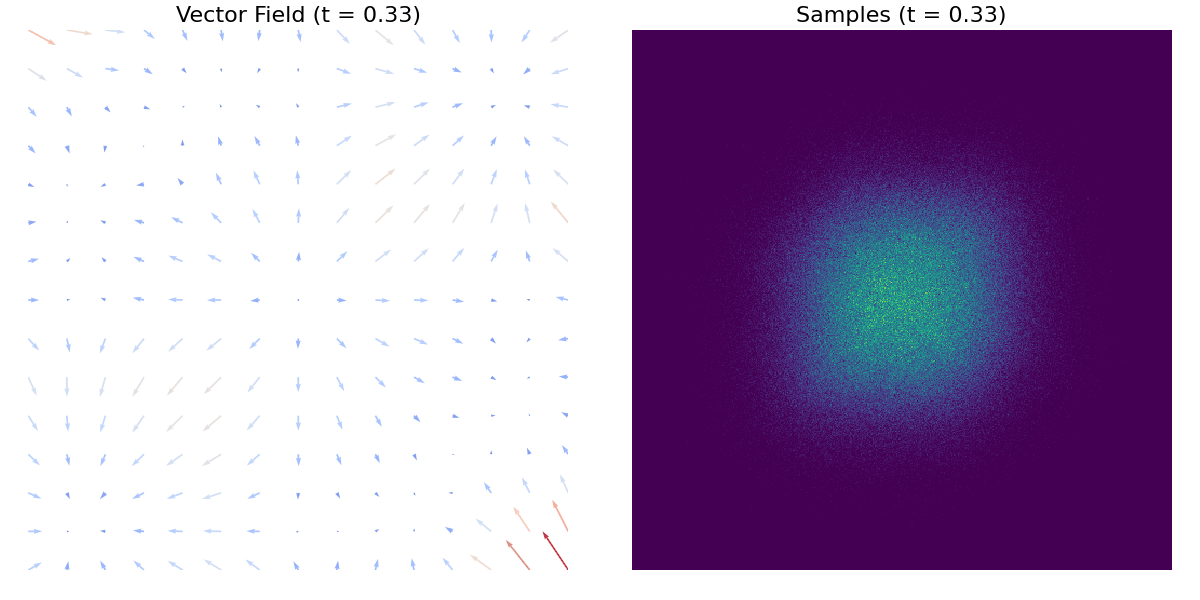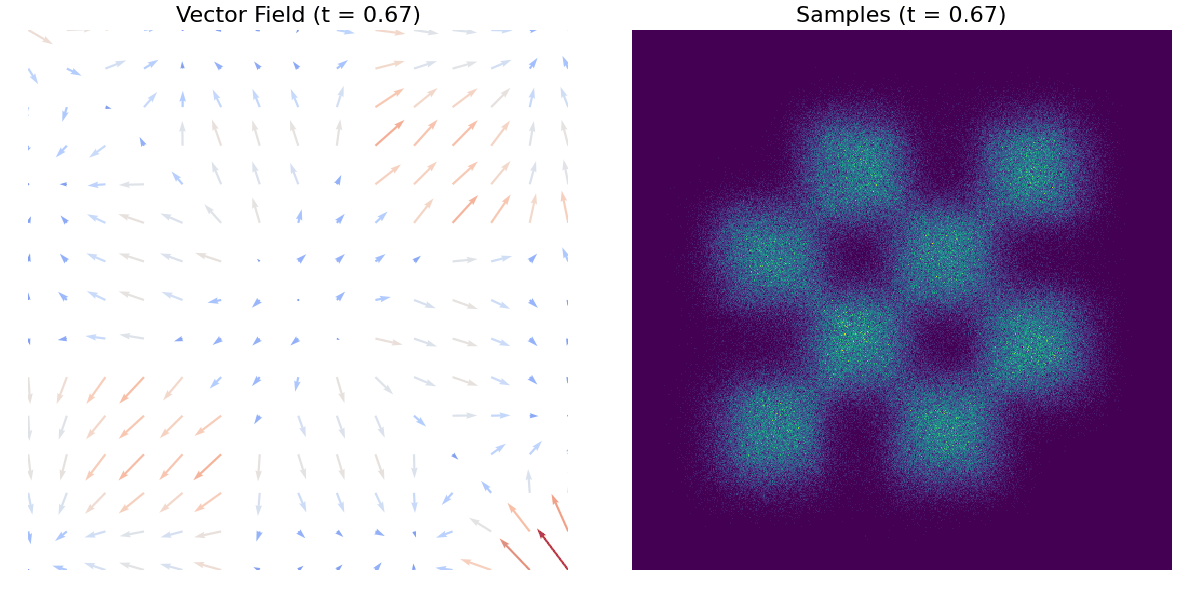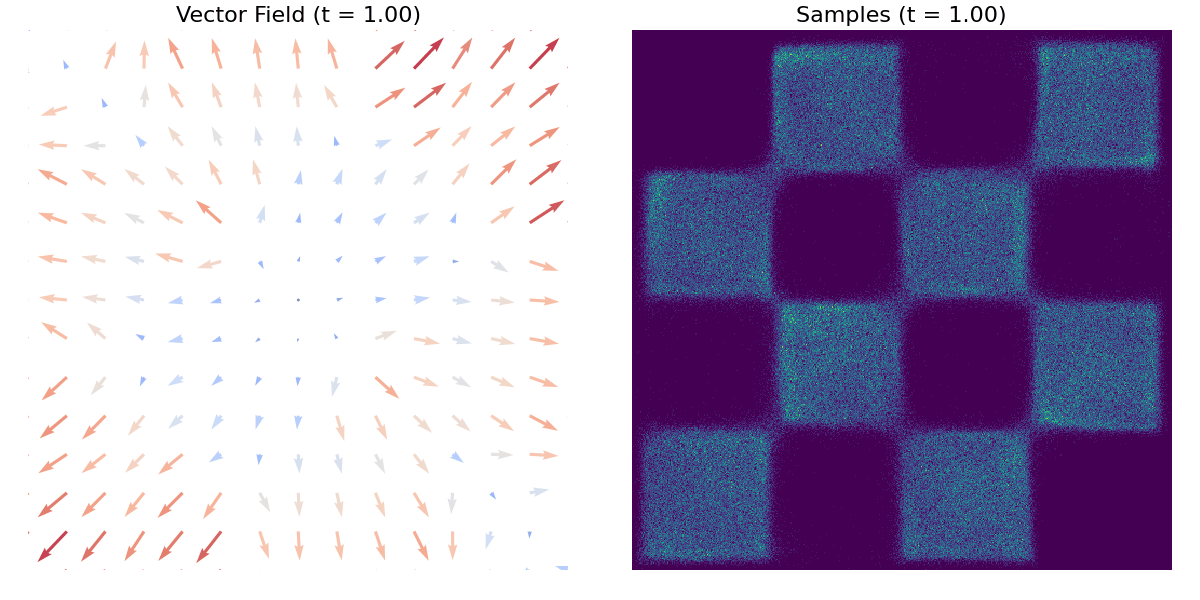
A tutaj znajduje się inny przykład z użyciem zbioru danych moons.
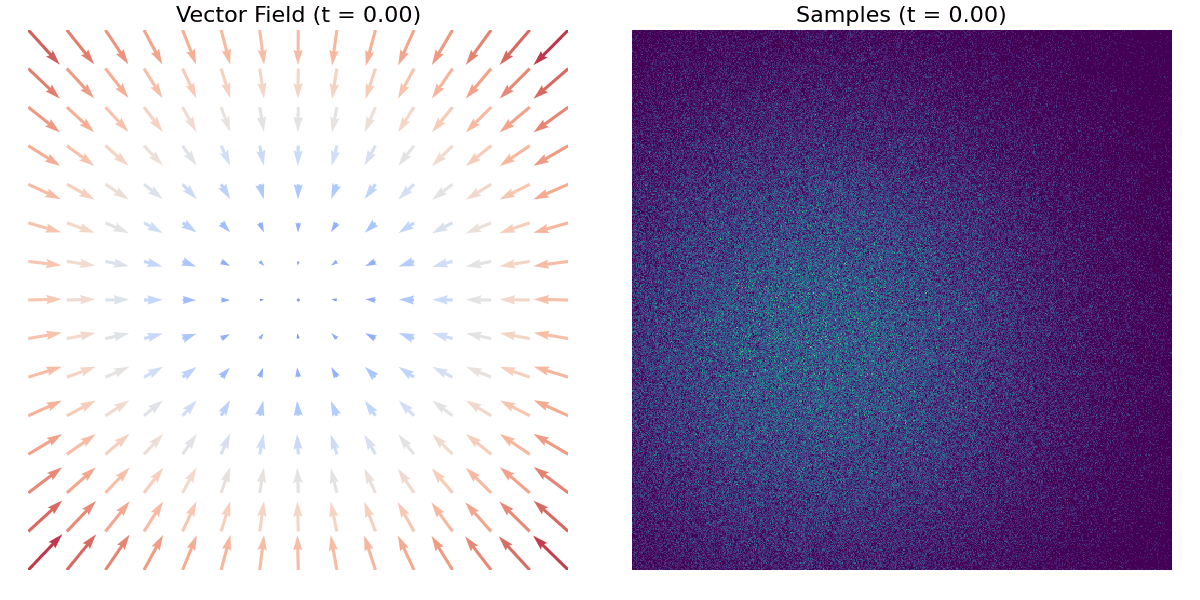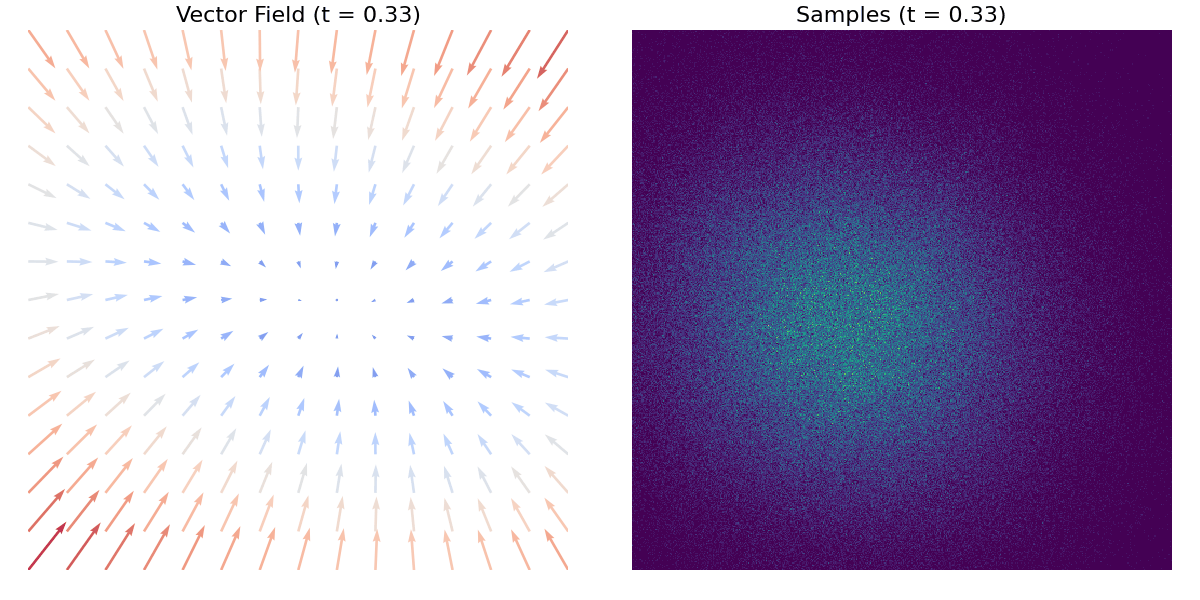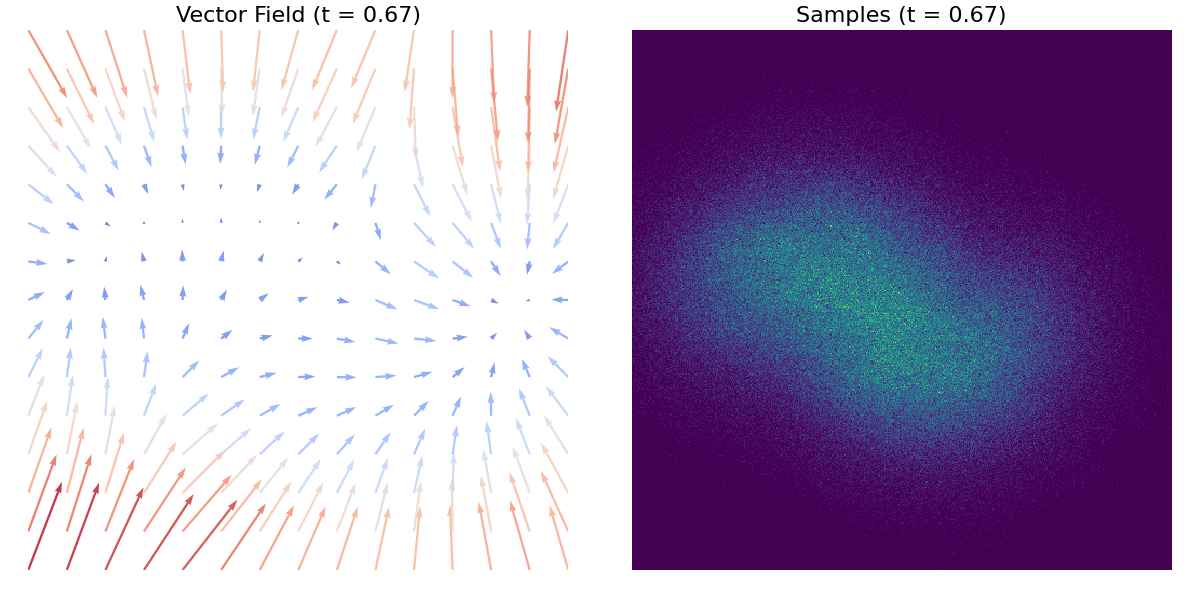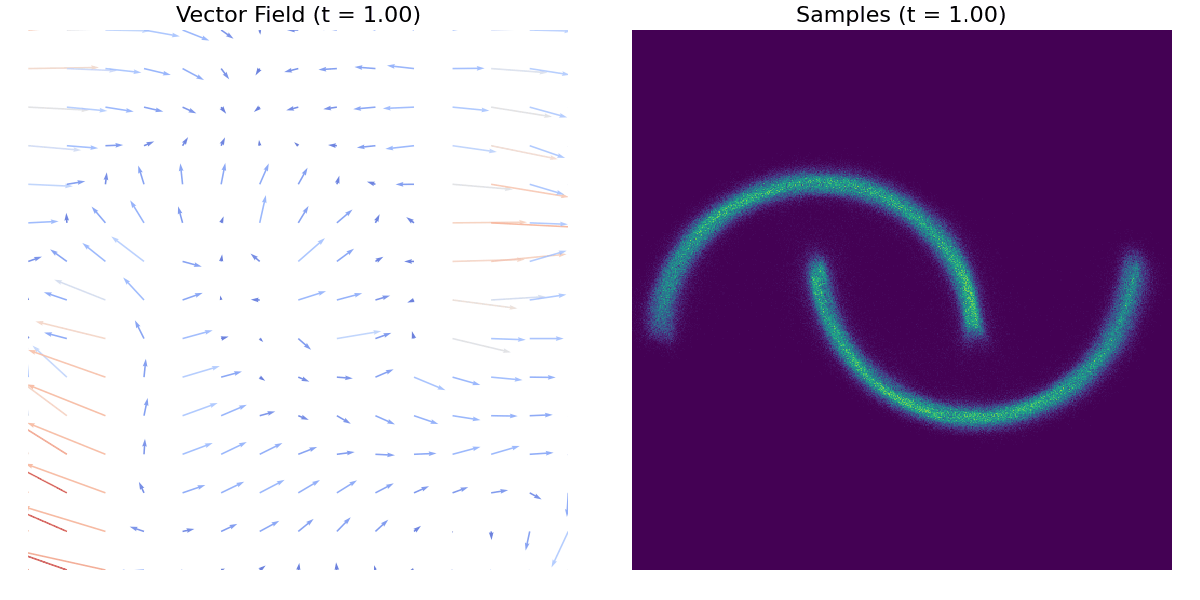
Pierwsze kroki
Sklonuj repozytorium i skonfiguruj środowisko Pythona.
git clone https://github.com/keishihara/flow-matching.git
cd flow-matchingUpewnij się, że masz zainstalowanego Pythona w wersji 3.12+.
Zainstaluj uv:
curl -LsSf https://astral.sh/uv/install.sh | shuv syncConditional Flow Matching [Lipman+ 2023]
To jest oryginalna implementacja artykułu CFM [1]. Niektóre komponenty kodu zostały zaadaptowane z [2] oraz [3].
Dwuwymiarowe zabawkowe zbiory danych
Modele CFM można trenować na dwuwymiarowych syntetycznych zbiorach danych takich jak checkerboard oraz moons. Nazwę zbioru danych należy określić za pomocą opcji --dataset. Parametry treningu są zdefiniowane w skrypcie, a wizualizacje wyników treningu są zapisywane w katalogu outputs/. Punkty kontrolne modeli nie są dołączone, ponieważ można je łatwo odtworzyć przy domyślnych ustawieniach.
uv run scripts/train_flow_matching_2d.py --dataset checkerboardPola wektorowe i wygenerowane próbki, takie jak te wyświetlane jako GIF-y na górze tego pliku README, można teraz znaleźć w katalogu outputs/cfm/.
Zbiory danych obrazów
Możesz także trenować modele CFM warunkowane klasami na popularnych zbiorach danych do klasyfikacji obrazów. Zarówno wygenerowane próbki, jak i punkty kontrolne modeli będą przechowywane w katalogu outputs/cfm. Aby uzyskać szczegółową listę parametrów treningowych, uruchom uv run scripts/train_flow_matching_on_image.py --help.
Aby wytrenować model CFM warunkowany klasami na zbiorze danych MNIST, uruchom:
uv run scripts/train_flow_matching_on_image.py --do_train --dataset mnistPo zakończeniu treningu możesz teraz generować próbki za pomocą:
uv run scripts/train_flow_matching_on_image.py --do_sample --dataset mnistTeraz powinieneś zobaczyć wygenerowane próbki w katalogu outputs/cfm/mnist/.

Rectified Flow [Liu+ 2023]
Jest to implementacja modelu Reflow (dokładniej 2-Rectified Flow) z artykułu Rectified Flow [2].
Dane syntetyczne 2D
Zaimplementowaliśmy Reflow na syntetycznych zbiorach danych 2D, tak samo jak CFM. Aby wytrenować reflow, musisz podać wstępnie wytrenowane punkty kontrolne CFM, ponieważ reflow jest modelem destylacji.
Na przykład, aby trenować na zbiorze danych checkerboard z wstępnie wytrenowanym punktem kontrolnym CFM:
uv run scripts/train_reflow_2d.py --dataset checkerboardWyniki treningu, w tym wizualizacje pól wektorowych oraz wygenerowane próbki, są zapisywane w folderze outputs/reflow/.
Porównanie procesu próbkowania między CFM a Reflow
Aby porównać CFM i Reflow na zbiorach danych 2D, uruchom:
uv run scripts/plot_comparison_2d.py --dataset checkerboardoutputs/comparisons/. Poniżej znajduje się przykładowe porównanie dwóch metod w zbiorze danych checkerboard:
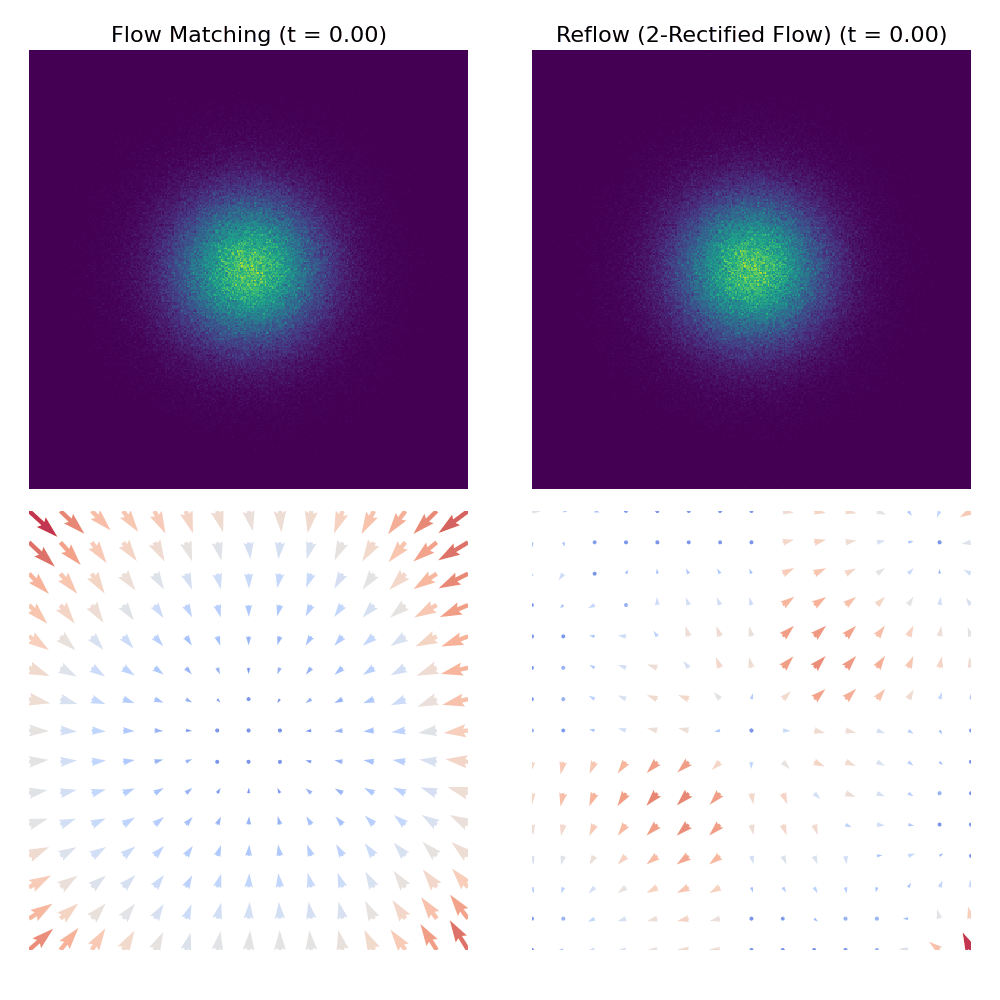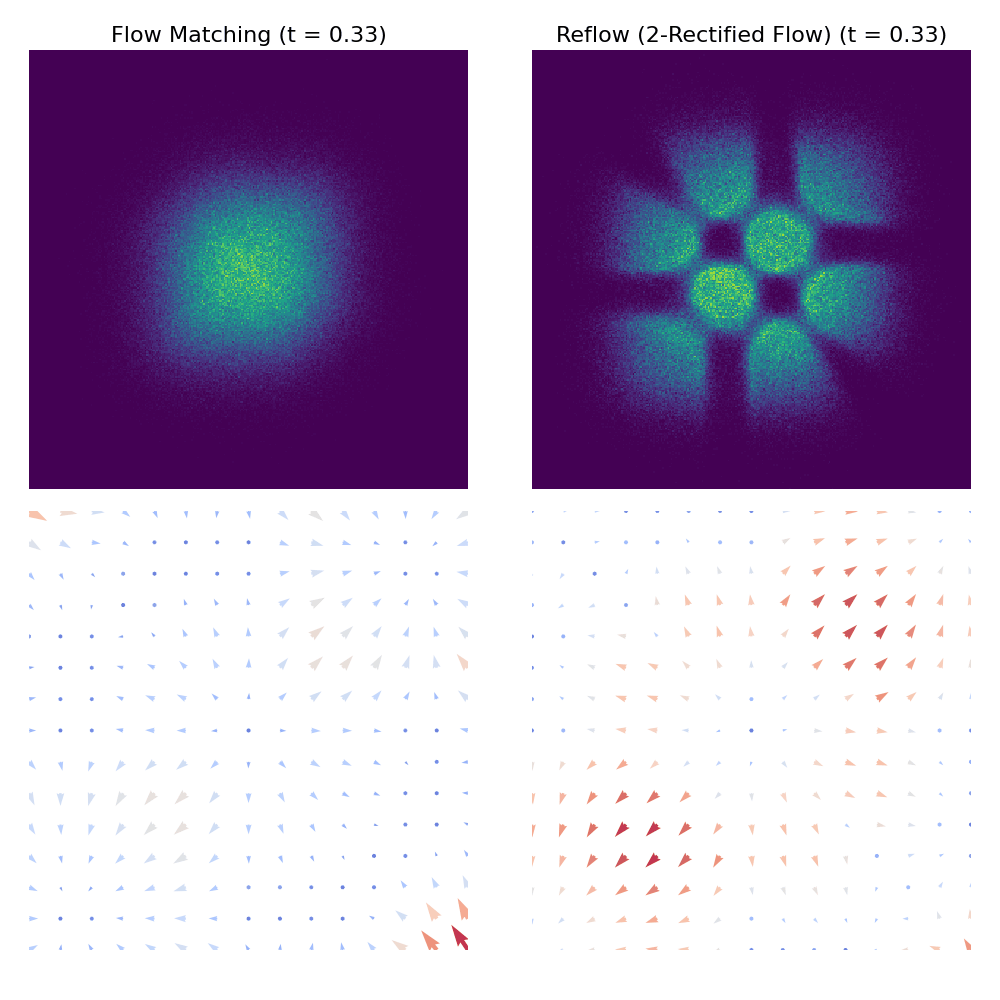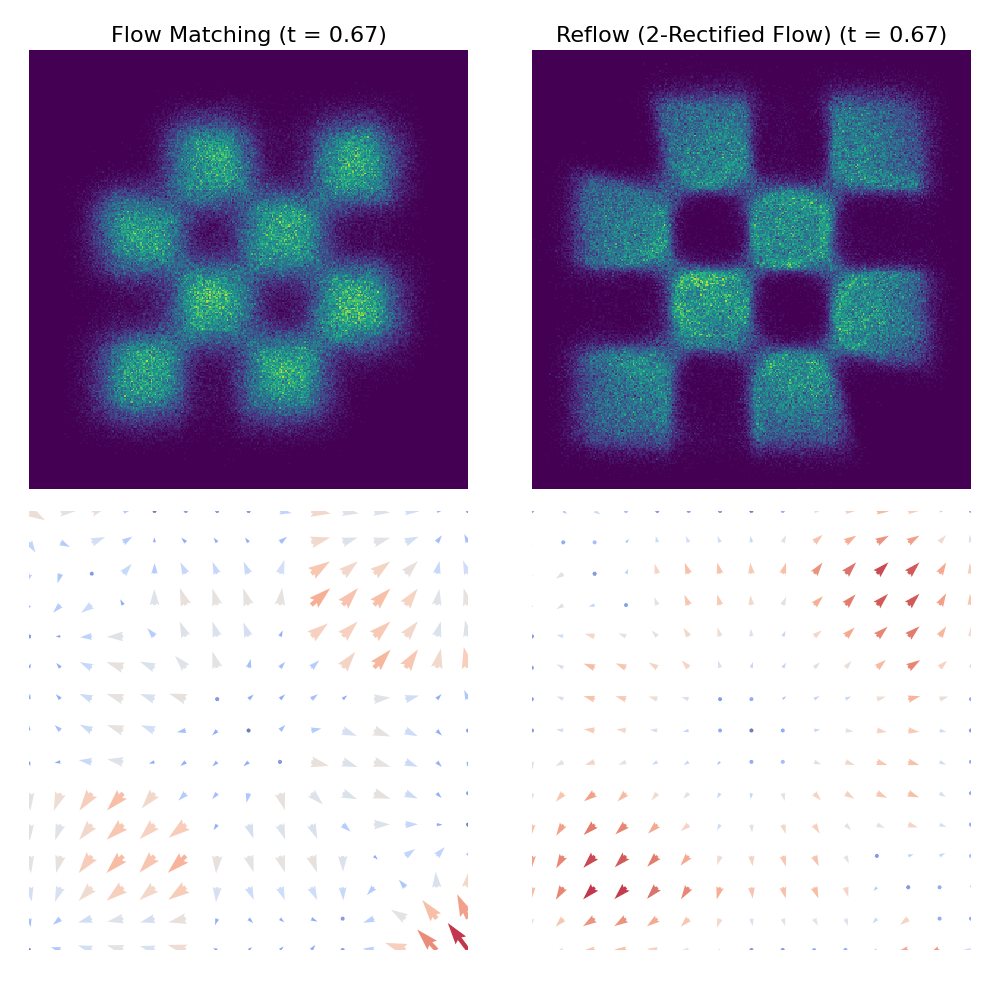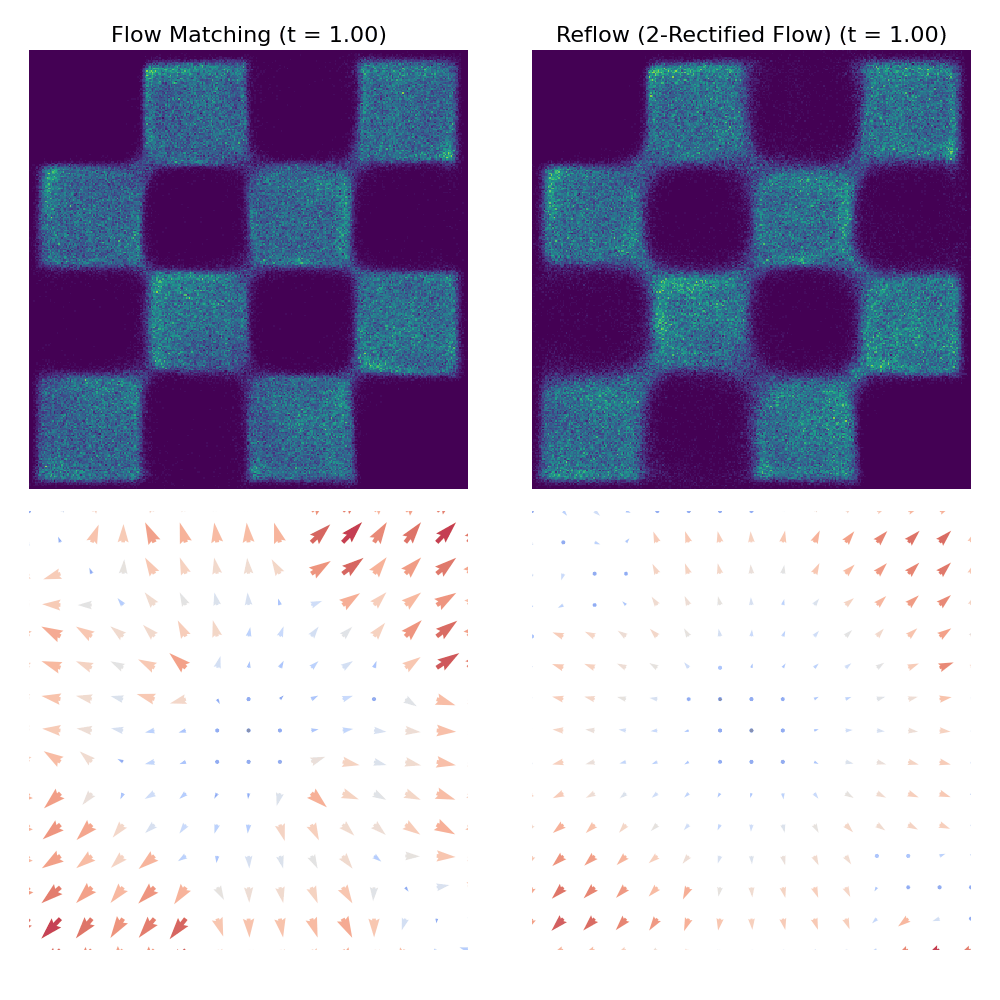
Odniesienia
- [1] Lipman, Yaron, i in. "Flow Matching for Generative Modeling." arXiv:2210.02747
- [2] Liu, Xingchao, i in. "Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow." arXiv:2209.03003
- [3] facebookresearch/flow_matching
- [4] atong01/conditional-flow-matching