🧠 Công cụ tìm kiếm LLM không cần proxy
Một công cụ truy xuất thông tin web đa công cụ tìm kiếm LLM không cần proxy, hỗ trợ phân tích nội dung URL và thu thập dữ liệu trang web, kết hợp LangGraph và LangGraph-MCP để xây dựng chuỗi tác tử mô-đun. Được thiết kế dành riêng cho các tình huống LLM cần truy xuất kiến thức bên ngoài, hỗ trợ Playwright + Crawl4AI để lấy và phân tích nội dung web, hỗ trợ bất đồng bộ, cắt nhỏ nội dung, lọc và xếp lại thứ tự.
🚀 Nhật ký cập nhật
- 🔥 2025-09-05: Hỗ trợ langgraph-mcp
- 🔥 2025-09-03: Thêm triển khai Docker, bộ xếp lại thông minh tích hợp, hỗ trợ tùy chỉnh bộ phân đoạn văn bản và bộ xếp lại
✨ Tổng quan tính năng
- 🌐 Không cần proxy: Thông qua cấu hình Playwright hỗ trợ trình duyệt trong nước, có thể tìm kiếm web mà không cần proxy.
- 🔍 Hỗ trợ nhiều công cụ tìm kiếm: Hỗ trợ các công cụ tìm kiếm phổ biến như Bing, Quark, Baidu, Sogou, tăng sự đa dạng nguồn thông tin.
- 🤖 Nhận diện ý định: Hệ thống có thể tự động nhận biết dựa trên nội dung nhập của người dùng, xác định là tìm kiếm web hay phân tích URL.
- 🔄 Phân tách truy vấn: Tùy theo ý định tìm kiếm của người dùng, tự động phân tách truy vấn thành nhiều nhiệm vụ con và thực hiện lần lượt, nâng cao độ liên quan và hiệu quả tìm kiếm.
- ⚙️ Kiến trúc tác tử: Dựa trên LangGraph đóng gói 「web_search」 và 「link_parser」.
- 🏃♂️ Xử lý nhiệm vụ bất đồng bộ song song: Hỗ trợ xử lý nhiệm vụ bất đồng bộ song song, xử lý hiệu quả nhiều tác vụ tìm kiếm cùng lúc.
- 📝 Tối ưu hóa xử lý nội dung:
- ✂️ Cắt lát nội dung: Chia nhỏ nội dung trang web dài theo đoạn.
- 🔄 Sắp xếp lại nội dung: Sắp xếp thông minh, tăng mức độ liên quan thông tin.
- 🚫 Lọc nội dung: Tự động loại bỏ nội dung không liên quan hoặc trùng lặp.
- 🌐 Hỗ trợ đa nền tảng:
- 🐳 Hỗ trợ triển khai Docker: Khởi động một lần, nhanh chóng xây dựng dịch vụ backend.
- 🖥️ Cung cấp API backend FastAPI, có thể tích hợp vào mọi hệ thống.
- 🌍 Cung cấp Gradio Web UI, nhanh chóng triển khai thành ứng dụng trực quan.
- 🧩 Hỗ trợ plugin trình duyệt: Hỗ trợ Edge, cung cấp plugin phân tích URL thông minh, gửi yêu cầu phân tích trang web và trích xuất nội dung trực tiếp trên trình duyệt.

⚡ Bắt đầu nhanh
Clone kho lưu trữ
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchCài đặt các phụ thuộc
pip install -r requirements.txt
python -m playwright installCấu hình biến môi trường
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### TRÌNH DIỄN
python agent/demo.py#### API PHỤC VỤ
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py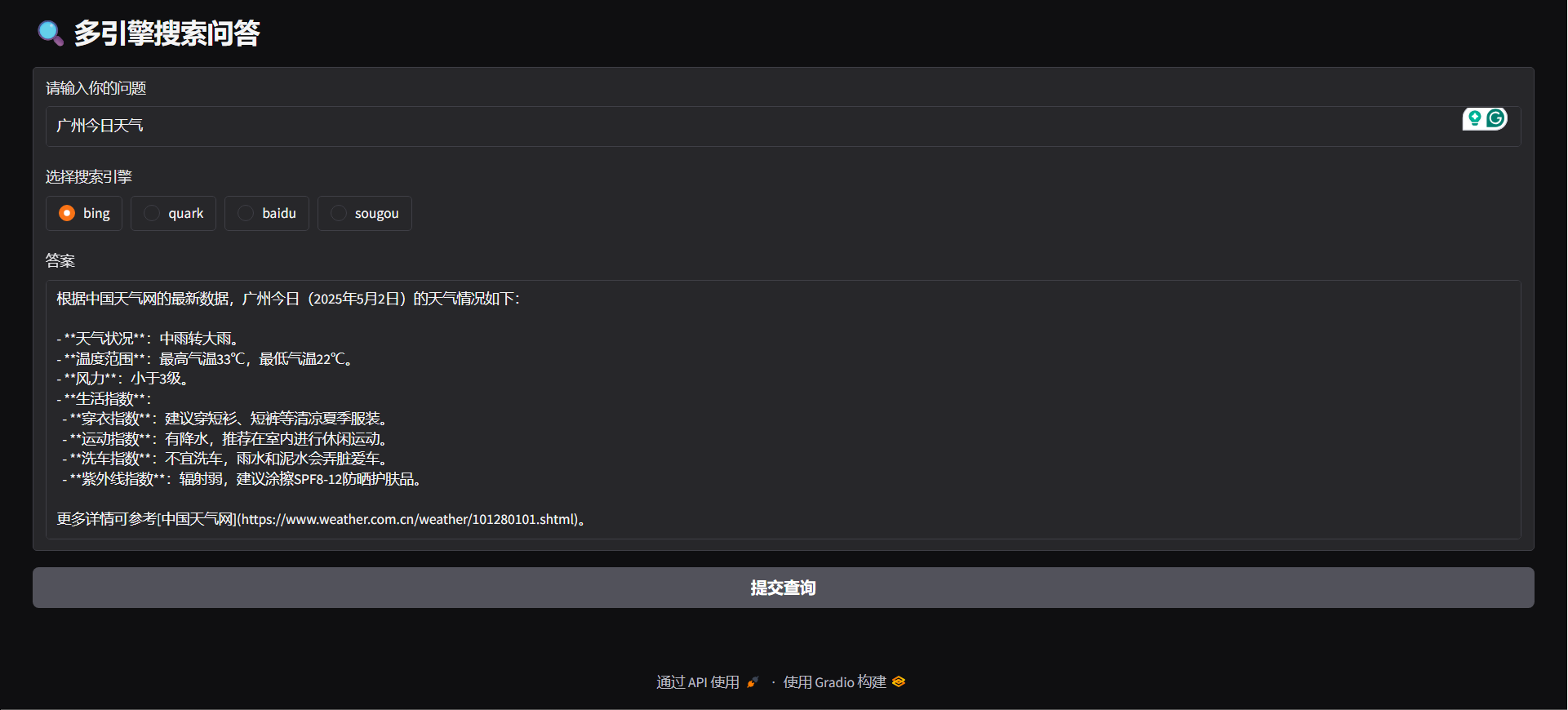
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Khởi động dịch vụ MCP
python mcp/websearch.py#### TRÌNH DIỄN
python mcp/demo.py#### API PHỤC VỤ
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildMô-đun tùy chỉnh
#### Phân khối tùy chỉnh
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Tùy chỉnh sắp xếp lại
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 So sánh với kiểm thử truy vấn mạng trực tuyến
Chúng tôi so sánh dự án với một số API trực tuyến chủ đạo, đánh giá hiệu suất của chúng với các câu hỏi phức tạp.
🔥 Bộ dữ liệu
- Bộ dữ liệu được lấy từ WebWalkerQA do Alibaba phát hành, bao gồm 680 câu hỏi khó, bao phủ các lĩnh vực như giáo dục, hội nghị học thuật, trò chơi v.v.
- Bộ dữ liệu bao gồm các câu hỏi bằng tiếng Trung và tiếng Anh.
🧑🏫 Kết quả so sánh
| Công cụ tìm kiếm/Hệ thống | ✅ Đúng | ❌ Sai | ⚠️ Đúng một phần | | ------------------------ | ------ | ------ | --------------- | | Volcano Ark | 5.00% | 72.21% | 22.79% | | BaiLian | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 Lời cảm ơn
Một số chức năng của dự án này được hưởng lợi từ sự hỗ trợ và truyền cảm hứng của các dự án mã nguồn mở sau, xin trân trọng cảm ơn:
- 🧠 LangGraph: Dùng để xây dựng khung chuỗi tác nhân mô-đun, giúp triển khai nhanh hệ thống tác nhân phức tạp.
- 🕷 Crawl4AI: Công cụ phân tích nội dung web mạnh mẽ, hỗ trợ thu thập và trích xuất dữ liệu web hiệu quả.
- 🌐 Playwright: Công cụ tự động hóa trình duyệt hiện đại, hỗ trợ thu thập và kiểm thử web đa trình duyệt.
- 🔌 Langchain MCP Adapters: Dùng để xây dựng MCP xử lý đa chuỗi.