🧠 เครื่องมือค้นหาเว็บ LLM แบบไม่ต้องใช้พร็อกซี
เครื่องมือค้นหาและดึงข้อมูลเว็บ LLM แบบหลายเสิร์ชเอนจิ้นโดยไม่ต้องใช้พร็อกซี รองรับการวิเคราะห์เนื้อหา URL และการรวบรวมข้อมูลเว็บ ผสมผสาน LangGraph กับ LangGraph-MCP เพื่อสร้างสายงานเอเจนต์อัจฉริยะที่เป็นโมดูล ออกแบบมาโดยเฉพาะสำหรับการเรียกใช้ความรู้ภายนอกของโมเดลภาษาขนาดใหญ่ รองรับการดึงข้อมูลเว็บและวิเคราะห์ผ่าน Playwright + Crawl4AI พร้อมการประมวลผลแบบอะซิงโครนัส การแบ่งเนื้อหาและการเรียงลำดับใหม่
🚀 บันทึกการอัปเดต
- 🔥 2025-09-05: รองรับ langgraph-mcp
- 🔥 2025-09-03: เพิ่มการติดตั้งแบบ Docker, ตัวเรียงลำดับอัจฉริยะในตัว, รองรับตัวแบ่งข้อความและตัวเรียงลำดับแบบกำหนดเอง
✨ คุณสมบัติเด่น
- 🌐 ไม่ต้องใช้พร็อกซี: รองรับการใช้งานเบราว์เซอร์ในประเทศผ่านการตั้งค่า Playwright โดยไม่ต้องใช้พร็อกซี ก็สามารถค้นหาข้อมูลทางอินเทอร์เน็ตได้
- 🔍 รองรับหลายเครื่องมือค้นหา: รองรับ Bing, Quark, Baidu, Sogou และเครื่องมือค้นหาหลักอื่น ๆ เพื่อเพิ่มความหลากหลายของแหล่งข้อมูล
- 🤖 การระบุเจตนา: ระบบสามารถวิเคราะห์เนื้อหาที่ผู้ใช้ป้อน เพื่อกำหนดว่าเป็นการค้นหาข้อมูล หรือการวิเคราะห์ URL โดยอัตโนมัติ
- 🔄 การแยกคำค้น: ตามเจตนาการค้นหาของผู้ใช้ ระบบจะทำการแบ่งคำค้นออกเป็นงานย่อยหลายส่วนและดำเนินการตามลำดับ เพื่อเพิ่มความเกี่ยวข้องและประสิทธิภาพ
- ⚙️ สถาปัตยกรรมอัจฉริยะ: ใช้ LangGraph ห่อหุ้ม 「web_search」 และ 「link_parser」
- 🏃♂️ รองรับงานแบบอะซิงโครนัสและหลายงานพร้อมกัน: รองรับการจัดการงานแบบอะซิงโครนัสและหลายงานพร้อมกัน สามารถประมวลผลงานค้นหาได้อย่างมีประสิทธิภาพ
- 📝 การปรับแต่งการจัดการเนื้อหา:
- ✂️ การแบ่งเนื้อหา: แบ่งเนื้อหายาวของหน้าเว็บออกเป็นหลายส่วน
- 🔄 การจัดเรียงใหม่ของเนื้อหา: จัดเรียงเนื้อหาอย่างชาญฉลาดเพื่อเพิ่มความเกี่ยวข้องของข้อมูล
- 🚫 การกรองเนื้อหา: กำจัดเนื้อหาที่ไม่เกี่ยวข้องหรือซ้ำโดยอัตโนมัติ
- 🌐 รองรับหลายแพลตฟอร์ม:
- 🐳 รองรับการติดตั้งผ่าน Docker: เริ่มต้นได้ในคลิกเดียว สร้างบริการ backend ได้อย่างรวดเร็ว
- 🖥️ มี API backend ด้วย FastAPI สามารถนำไปผสานกับระบบใดก็ได้
- 🌍 มี Gradio Web UI สามารถนำไปใช้เป็นแอปพลิเคชันแบบภาพได้อย่างรวดเร็ว
- 🧩 รองรับปลั๊กอินเบราว์เซอร์: รองรับ Edge โดยมีปลั๊กอินวิเคราะห์ URL อัจฉริยะ เรียกใช้งานการวิเคราะห์เว็บและดึงข้อมูลได้โดยตรงจากเบราว์เซอร์
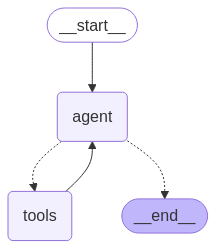

⚡ เริ่มต้นใช้งานอย่างรวดเร็ว
โคลน repository
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchติดตั้ง dependencies
pip install -r requirements.txt
python -m playwright installการกำหนดค่าตัวแปรสภาพแวดล้อม
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### สาธิต
python agent/demo.py#### การให้บริการ API
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py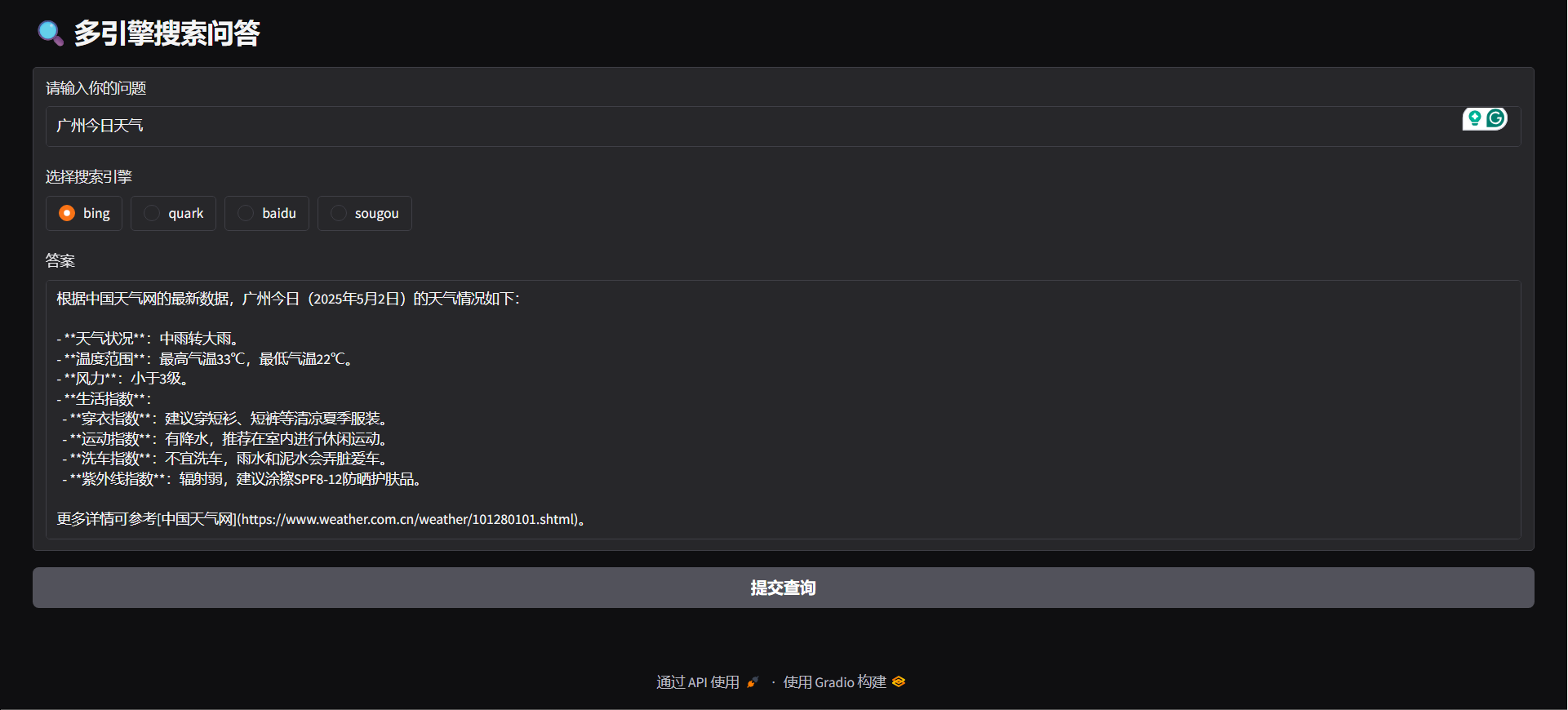
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### เริ่มต้นบริการ MCP
python mcp/websearch.py#### ตัวอย่างสาธิต
python mcp/demo.py#### การให้บริการ API
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildโมดูลที่กำหนดเอง
#### การแบ่งบล็อกแบบกำหนดเอง
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### การจัดเรียงใหม่แบบกำหนดเอง
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 เปรียบเทียบกับการทดสอบค้นหาข้อมูลออนไลน์
เราได้นำโปรเจกต์ไปเปรียบเทียบกับ API ออนไลน์ที่เป็นที่นิยมหลายรายการ เพื่อประเมินประสิทธิภาพในการตอบโจทย์ที่ซับซ้อน
🔥 ชุดข้อมูล
- ชุดข้อมูลมาจาก WebWalkerQA ที่เผยแพร่โดยอาลีบาบา มีคำถามยาก 680 ข้อ ครอบคลุมด้านการศึกษา การประชุมวิชาการ เกม ฯลฯ
- ชุดข้อมูลนี้มีคำถามทั้งภาษาจีนและอังกฤษ
🧑🏫 ผลการเปรียบเทียบ
| เครื่องมือค้นหา/ระบบ | ✅ ถูกต้อง | ❌ ไม่ถูกต้อง | ⚠️ ถูกต้องบางส่วน | | --------------------- | ---------- | ------------- | ----------------- | | Huoshan Ark | 5.00% | 72.21% | 22.79% | | Bailian | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 คำขอบคุณ
ฟีเจอร์บางส่วนของโปรเจกต์นี้ได้รับแรงบันดาลใจและสนับสนุนจากโครงการโอเพ่นซอร์สดังต่อไปนี้ ขอบคุณมา ณ ที่นี้
- 🧠 LangGraph: ใช้สร้างเฟรมเวิร์กเชื่อมต่อโมดูลเอเจนต์ ช่วยให้สร้างระบบเอเจนต์ที่ซับซ้อนได้อย่างรวดเร็ว
- 🕷 Crawl4AI: เครื่องมือแยกวิเคราะห์เนื้อหาเว็บที่ทรงพลัง ช่วยให้การเก็บข้อมูลและดึงข้อมูลจากเว็บมีประสิทธิภาพ
- 🌐 Playwright: เครื่องมืออัตโนมัติสำหรับเบราว์เซอร์ยุคใหม่ รองรับการเก็บข้อมูลและทดสอบอัตโนมัติข้ามเบราว์เซอร์
- 🔌 Langchain MCP Adapters: ใช้สำหรับสร้าง MCP ที่รองรับการประมวลผลแบบหลายสาย