🧠 Motor de Busca de Rede LLM Sem Necessidade de Proxy
Uma ferramenta de recuperação de rede LLM multi-motor sem necessidade de proxy, com suporte à análise de conteúdo de URL e rastreamento de páginas da web, integrando LangGraph e LangGraph-MCP para uma cadeia de agentes modularizada. Projetado para cenários de chamada de conhecimento externo em grandes modelos de linguagem, com suporte para aquisição e análise de páginas via Playwright + Crawl4AI, além de suporte para concorrência assíncrona, fragmentação de conteúdo e reordenamento/filtragem.
🚀 Registro de Atualizações
- 🔥 2025-09-05: Suporte para langgraph-mcp
- 🔥 2025-09-03: Adicionado implantação via Docker, reranqueador inteligente embutido, suporte para divisor e reranqueador de texto personalizado
✨ Visão Geral dos Recursos
- 🌐 Sem necessidade de proxy: Configuração do navegador nacional via Playwright, permitindo buscas online sem proxy.
- 🔍 Suporte a múltiplos motores de busca: Compatível com Bing, Quark, Baidu, Sogou e outros principais motores, ampliando a diversidade de fontes de informação.
- 🤖 Reconhecimento de intenção: O sistema identifica automaticamente, com base na entrada do usuário, se deve realizar uma busca online ou analisar uma URL.
- 🔄 Decomposição de consulta: De acordo com a intenção de busca do usuário, a consulta é automaticamente dividida em várias subtarefas executadas sequencialmente, melhorando a relevância e eficiência da busca.
- ⚙️ Arquitetura de agentes: Baseado no LangGraph, encapsula "web_search" e "link_parser".
- 🏃♂️ Processamento assíncrono e concorrente de tarefas: Suporta processamento assíncrono e paralelo, permitindo lidar eficientemente com múltiplas buscas.
- 📝 Otimização do processamento de conteúdo:
- ✂️ Segmentação de conteúdo: Divide conteúdos extensos de páginas em segmentos.
- 🔄 Reordenação de conteúdo: Reordena inteligentemente para aumentar a relevância da informação.
- 🚫 Filtragem de conteúdo: Remove automaticamente informações irrelevantes ou duplicadas.
- 🌐 Suporte multiplataforma:
- 🐳 Suporte a implantação via Docker: Inicialização com um clique, construção rápida de serviços backend.
- 🖥️ Disponibiliza API backend com FastAPI, podendo ser integrado a qualquer sistema.
- 🌍 Disponibiliza Web UI com Gradio, permitindo implantação rápida como aplicação visual.
- 🧩 Suporte a extensão de navegador: Compatível com Edge, oferece extensão para análise inteligente de URL, permitindo requisições de análise e extração de conteúdo diretamente no navegador.

⚡ Início rápido
Clonar o repositório
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchInstalar dependências
pip install -r requirements.txt
python -m playwright installConfiguração de variáveis de ambiente
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agente
#### DEMONSTRAÇÃO
python agent/demo.py#### API SERVE
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py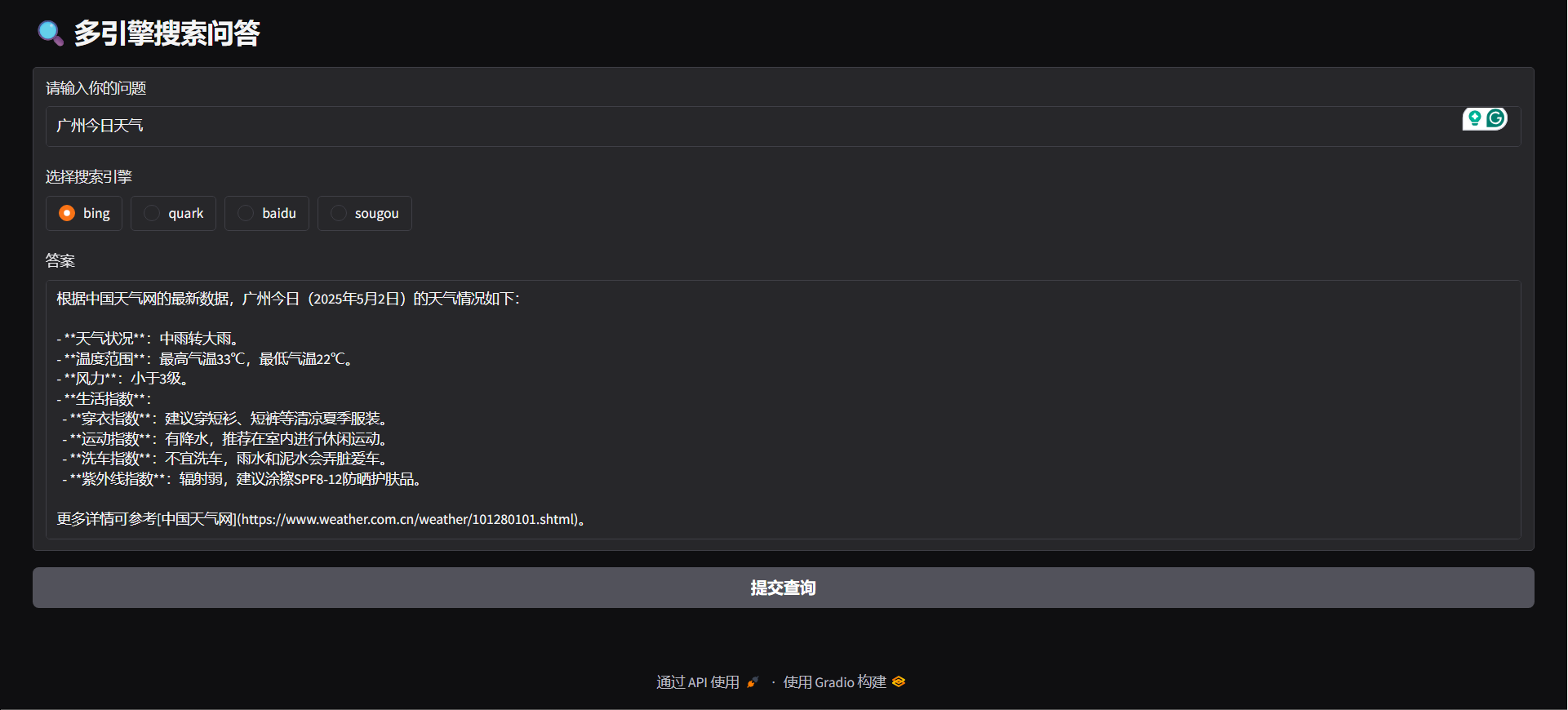
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Iniciar o serviço MCP
python mcp/websearch.py#### DEMONSTRAÇÃO
python mcp/demo.py#### API SERVE
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildMódulos Personalizados
#### Divisão Personalizada
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Reordenação personalizada
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 Comparação com Testes de Busca Online
Comparamos o projeto com algumas APIs online populares, avaliando seu desempenho em questões complexas.
🔥 Conjunto de Dados
- O conjunto de dados é proveniente do WebWalkerQA divulgado pela Alibaba, contendo 680 questões de alta dificuldade, cobrindo áreas como educação, conferências acadêmicas, jogos e outros.
- O conjunto de dados inclui perguntas em chinês e inglês.
🧑🏫 Resultados Comparativos
| Motor de Busca/Sistema | ✅ Correto | ❌ Incorreto | ⚠️ Parcialmente Correto | | ---------------------- | ----------| ------------| ----------------------- | | Volcano Ark | 5,00% | 72,21% | 22,79% | | Bailian | 9,85% | 62,79% | 27,35% | | Nosso | 19,85% | 47,94% | 32,06% |
🙏 Agradecimentos
Algumas funcionalidades do projeto foram beneficiadas pelo suporte e inspiração dos seguintes projetos open source, aos quais agradecemos:
- 🧠 LangGraph: Utilizado para construir o framework modular de agentes, facilitando a rápida montagem de sistemas de agentes complexos.
- 🕷 Crawl4AI: Ferramenta poderosa de análise de conteúdo web, auxiliando na captura e extração eficiente de dados de páginas.
- 🌐 Playwright: Ferramenta moderna de automação de navegadores, com suporte para captura de páginas e automação de testes entre diversos navegadores.
- 🔌 Langchain MCP Adapters: Utilizado para construção de MCP em processamento de múltiplas cadeias.