🧠 프록시 없는 LLM 웹 검색 엔진
프록시 없이 다중 검색 엔진을 지원하는 LLM 기반 웹 검색 도구로, URL 내용 분석과 웹 크롤링을 지원합니다. LangGraph와 LangGraph-MCP를 결합하여 모듈형 에이전트 체인을 구현합니다. 대형 언어 모델의 외부 지식 호출 시나리오에 특화되어 있으며, Playwright + Crawl4AI를 통한 웹 데이터 획득 및 분석, 비동기 동시 처리, 컨텐츠 슬라이싱과 재정렬 필터링을 지원합니다.
🚀 업데이트 로그
- 🔥 2025-09-05: langgraph-mcp 지원 추가
- 🔥 2025-09-03: Docker 배포, 내장형 스마트 재정렬기, 사용자 정의 텍스트 슬라이서 및 재정렬기 지원
✨ 주요 기능 요약
- 🌐 프록시 불필요: Playwright로 국내 브라우저를 지원하여 프록시 없이도 네트워크 검색이 가능합니다.
- 🔍 다양한 검색 엔진 지원: Bing, Quark, Baidu, Sogou 등 주요 검색 엔진을 지원하여 정보 출처의 다양성을 높입니다.
- 🤖 의도 인식: 시스템이 사용자의 입력 내용을 기반으로 웹 검색 또는 URL 분석을 자동 판단합니다.
- 🔄 쿼리 분해: 사용자의 검색 의도에 따라 쿼리를 여러 하위 작업으로 자동 분해하여 순차적으로 실행, 검색 관련성과 효율성 향상.
- ⚙️ 에이전트 아키텍처: LangGraph 기반으로 「web_search」와 「link_parser」를 패키징.
- 🏃♂️ 비동기 병렬 작업 처리: 비동기 병렬 작업 처리를 지원하여 여러 검색 작업을 효율적으로 처리합니다.
- 📝 콘텐츠 처리 최적화:
- ✂️ 콘텐츠 슬라이싱: 웹페이지의 긴 내용을 단락별로 분할합니다.
- 🔄 콘텐츠 재배열: 스마트 재정렬로 정보의 관련성을 높입니다.
- 🚫 콘텐츠 필터링: 불필요하거나 중복된 콘텐츠를 자동으로 제거합니다.
- 🌐 멀티플랫폼 지원:
- 🐳 Docker 배포 지원: 원클릭 실행, 빠르게 백엔드 서비스를 구축할 수 있습니다.
- 🖥️ FastAPI 백엔드 인터페이스 제공, 어떤 시스템에도 통합 가능.
- 🌍 Gradio Web UI 제공, 시각화 앱으로 빠르게 배포 가능.
- 🧩 브라우저 플러그인 지원: Edge 지원, 스마트 URL 분석 플러그인 제공으로 브라우저에서 직접 웹페이지 분석 및 콘텐츠 추출 요청 가능.

⚡ 빠른 시작
저장소 클론
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearch의존성 설치
pip install -r requirements.txt
python -m playwright install환경 변수 구성
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### 데모
python agent/demo.py#### API 제공
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
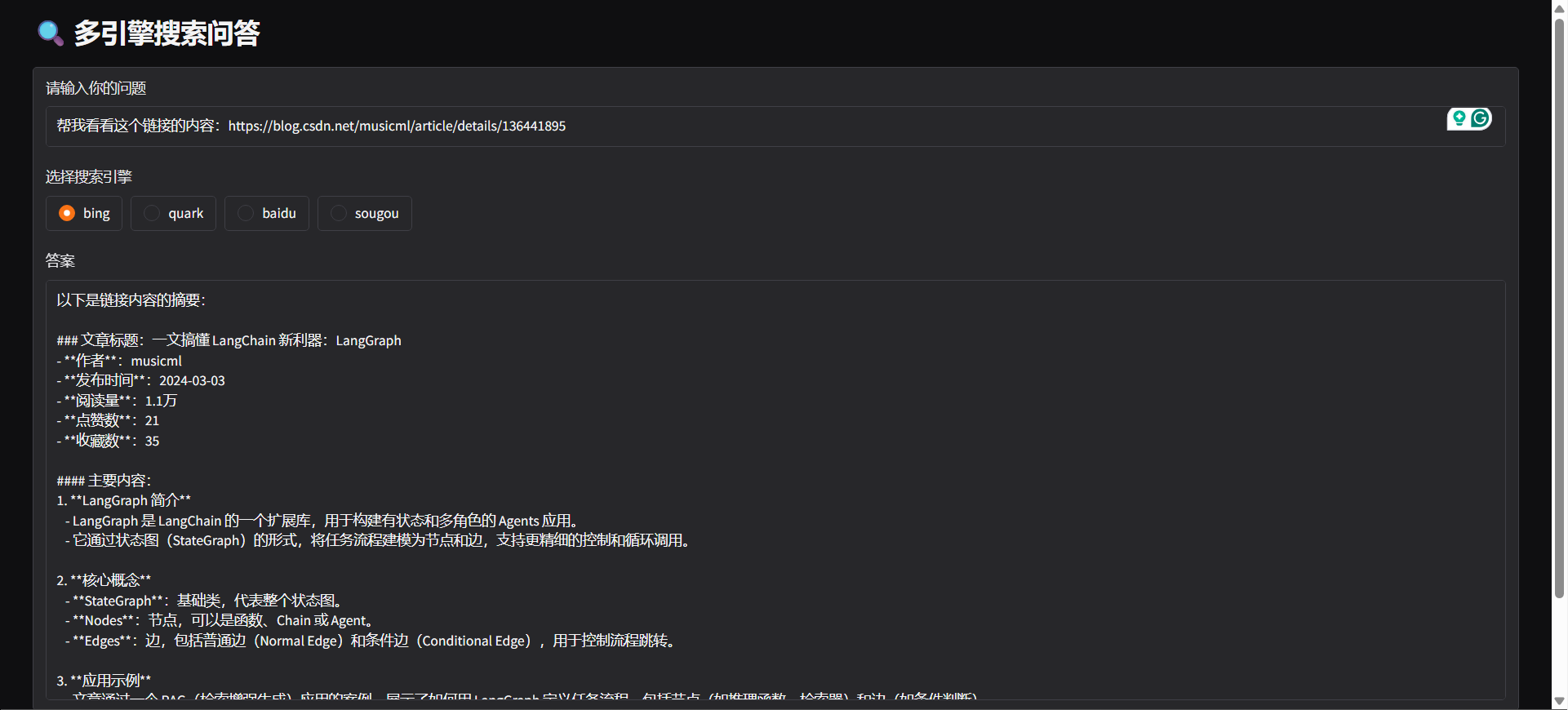
#### 그라디오
python agent/gradio_demo.py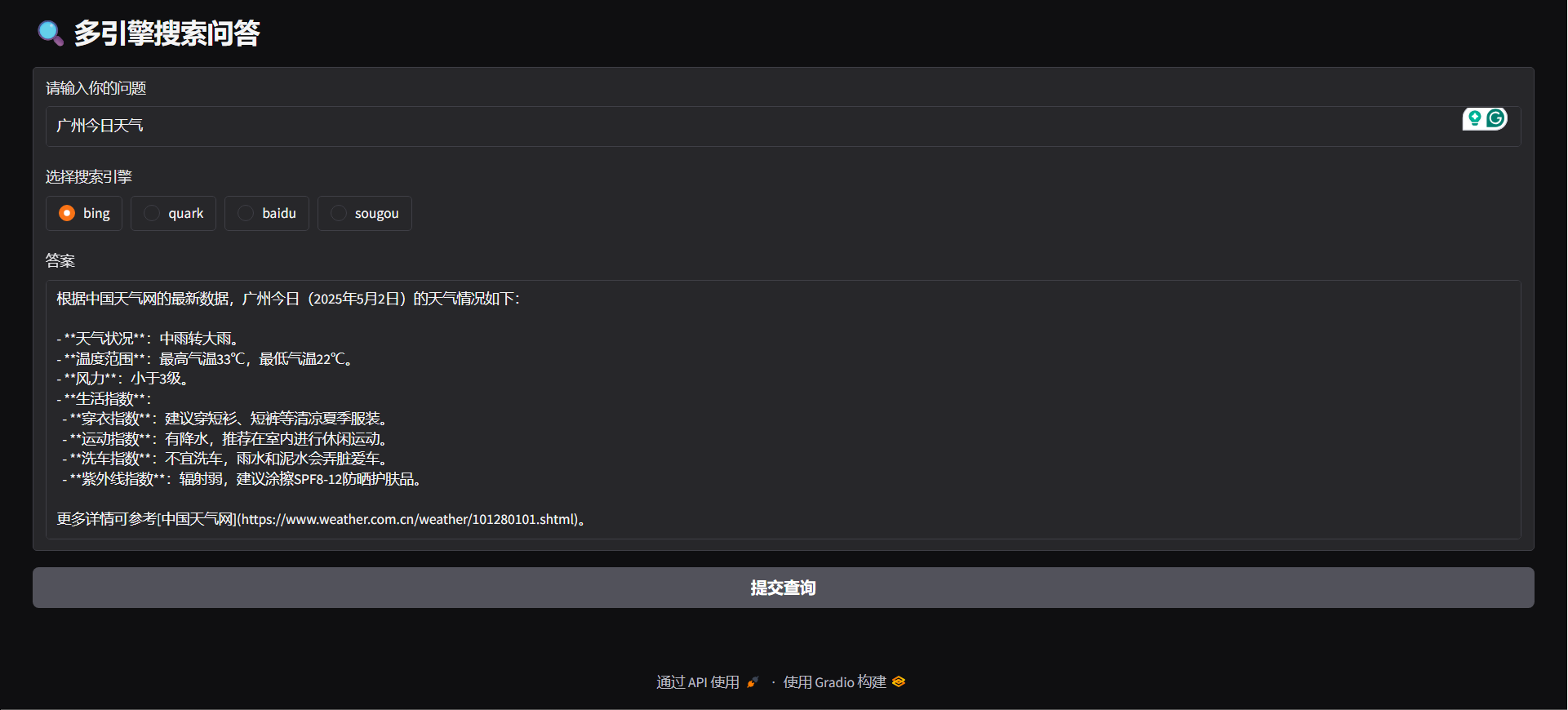
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### MCP 서비스 시작
python mcp/websearch.py#### 데모
python mcp/demo.py#### API 제공
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### 도커
docker-compose -f docker-compose-mcp.yml up -d --build사용자 정의 모듈
#### 사용자 정의 블록
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### 사용자 지정 재배열
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 온라인 네트워크 검색 테스트와의 비교
우리는 프로젝트를 일부 주요 온라인 API와 비교하여 복잡한 문제에 대한 성능을 평가했습니다.
🔥 데이터셋
- 데이터셋은 알리에서 공개한 WebWalkerQA에서 가져왔으며, 680개의 고난도 문제를 포함하고 교육, 학술회의, 게임 등 다양한 분야를 아우릅니다.
- 데이터셋은 중영문 문제를 포함합니다.
🧑🏫 비교 결과
| 검색엔진/시스템 | ✅ 정답 | ❌ 오답 | ⚠️ 부분 정답 | | -------------- | --------- | ----------- | ------------------- | | 화산방주 | 5.00% | 72.21% | 22.79% | | 백련 | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 감사의 말씀
본 프로젝트의 일부 기능은 다음 오픈소스 프로젝트의 지원과 영감에 힘입은 바가 있어, 깊이 감사드립니다:
- 🧠 LangGraph: 모듈화된 에이전트 체인 프레임워크 구축에 사용되었으며, 복잡한 에이전트 시스템을 빠르게 구축하는 데 도움을 주었습니다.
- 🕷 Crawl4AI: 강력한 웹 콘텐츠 파싱 도구로, 효율적인 웹 크롤링과 데이터 추출을 지원합니다.
- 🌐 Playwright: 현대적인 브라우저 자동화 도구로, 크로스 브라우저 웹 크롤링과 테스트 자동화를 지원합니다.
- 🔌 Langchain MCP Adapters: 다중 체인 처리 MCP 구축에 사용됩니다.