🧠 Motore di ricerca LLM senza proxy
Uno strumento di recupero web multi-motore LLM che non richiede proxy, supporta l'analisi dei contenuti degli URL e il crawling delle pagine web, integra LangGraph e LangGraph-MCP per realizzare una catena modulare di agenti. Progettato per scenari di accesso a conoscenza esterna per grandi modelli linguistici, supporta l'acquisizione e l'analisi delle pagine tramite Playwright + Crawl4AI, con supporto per asincronia, slicing e riordino dei contenuti.
🚀 Registro degli aggiornamenti
- 🔥 2025-09-05: Supporto a langgraph-mcp
- 🔥 2025-09-03: Nuovo deploy Docker, riordinatore intelligente integrato, supporto per splitter e riordinatore di testo personalizzati
✨ Panoramica delle funzionalità
- 🌐 Nessun bisogno di proxy: Tramite la configurazione di Playwright per il supporto ai browser nazionali, è possibile effettuare ricerche online senza necessità di proxy.
- 🔍 Supporto a più motori di ricerca: Supporta i principali motori come Bing, Quark, Baidu, Sogou, aumentando la varietà delle fonti informative.
- 🤖 Riconoscimento dell’intento: Il sistema è in grado di determinare automaticamente, in base all’input utente, se effettuare una ricerca web o analizzare un URL.
- 🔄 Scomposizione delle query: In base all’intento di ricerca, suddivide automaticamente la richiesta in più sotto-attività eseguite in sequenza, migliorando la pertinenza ed efficienza della ricerca.
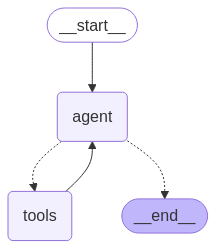
- ⚙️ Architettura degli agenti: Basata su LangGraph, racchiude “web_search” e “link_parser”.
- 🏃♂️ Gestione asincrona e concorrente delle attività: Supporta la gestione asincrona e concorrente, permettendo di processare più ricerche in modo efficiente.
- 📝 Ottimizzazione del trattamento dei contenuti:
- ✂️ Suddivisione dei contenuti: Suddivide i contenuti lunghi delle pagine web in sezioni.
- 🔄 Riordino dei contenuti: Riordino intelligente per incrementare la pertinenza delle informazioni.
- 🚫 Filtraggio dei contenuti: Elimina automaticamente contenuti irrilevanti o duplicati.
- 🌐 Supporto multipiattaforma:
- 🐳 Supporto per il deploy su Docker: Avvio con un click, costruzione rapida dei servizi backend.
- 🖥️ Interfaccia backend FastAPI, integrabile in qualsiasi sistema.
- 🌍 Interfaccia Gradio Web UI, per un deploy rapido come applicazione visuale.
- 🧩 Supporto ai plugin per browser: Supporta Edge, offre plugin per l’analisi intelligente degli URL, per avviare richieste di parsing e estrazione contenuti direttamente dal browser.

⚡ Avvio rapido
Clona il repository
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchInstallazione delle dipendenze
pip install -r requirements.txt
python -m playwright installConfigurazione delle variabili d'ambiente
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### DEMO
python agent/demo.py#### API SERVE
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py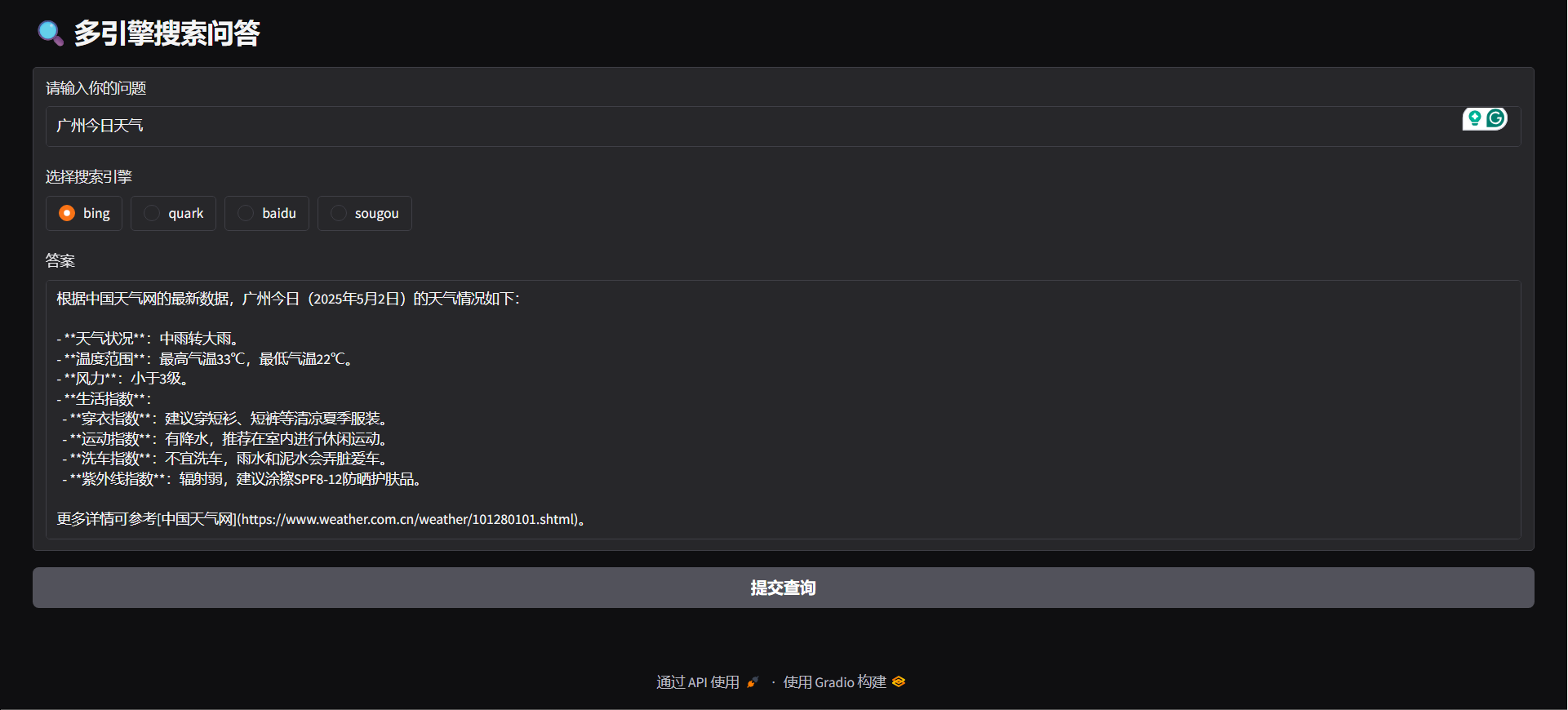
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Avvio del servizio MCP
python mcp/websearch.py#### DEMO
python mcp/demo.py#### API SERVE
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildModuli personalizzati
#### Suddivisione personalizzata
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Riordinamento personalizzato
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 Confronto con i test di ricerca online
Abbiamo confrontato il progetto con alcune delle principali API online, valutando le loro prestazioni su problemi complessi.
🔥 Dataset
- Il dataset proviene da WebWalkerQA rilasciato da Alibaba, contiene 680 domande ad alta difficoltà, coprendo diversi ambiti come istruzione, conferenze accademiche, giochi, ecc.
- Il dataset include domande sia in cinese che in inglese.
🧑🏫 Risultati del confronto
| Motore di ricerca/sistema | ✅ Corretto | ❌ Errato | ⚠️ Parzialmente corretto | | ------------------------ | ---------- | -------- | ----------------------- | | Volcano Ark | 5,00% | 72,21% | 22,79% | | Bailian | 9,85% | 62,79% | 27,35% | | Our | 19,85% | 47,94% | 32,06% |
🙏 Ringraziamenti
Alcune funzionalità di questo progetto sono state rese possibili grazie al supporto e all’ispirazione dei seguenti progetti open source, che ringraziamo:
- 🧠 LangGraph: utilizzato per costruire una struttura modulare di agenti, aiutando a creare rapidamente sistemi di agenti complessi.
- 🕷 Crawl4AI: potente strumento di parsing dei contenuti web, fondamentale per il web scraping efficiente e l’estrazione dati.
- 🌐 Playwright: moderno strumento di automazione browser, supporta scraping e test automatizzati cross-browser.
- 🔌 Langchain MCP Adapters: utilizzato per la creazione MCP multi-chain.