🧠 बिना प्रॉक्सी के LLM वेब खोज इंजन
एक बिना प्रॉक्सी के मल्टी-सर्च इंजन LLM वेब रिट्रीवल टूल, जो URL सामग्री विश्लेषण और वेब क्रॉलिंग को सपोर्ट करता है, LangGraph और LangGraph-MCP को जोड़कर मॉड्यूलर एजेंट लिंक बनाता है। यह बड़े भाषा मॉडल के बाहरी ज्ञान कॉलिंग के लिए डिज़ाइन किया गया है, Playwright + Crawl4AI वेब प्राप्ति और विश्लेषण को सपोर्ट करता है, असिंक क्रॉनकरेंसी, कंटेंट स्लाइसिंग और री-रैंकिंग फ़िल्टरिंग को सपोर्ट करता है।
🚀 अद्यतन लॉग
- 🔥 2025-09-05: langgraph-mcp का समर्थन
- 🔥 2025-09-03: नया Docker डिप्लॉयमेंट, इनबिल्ट इंटेलिजेंट री-रैंकर, कस्टम टेक्स्ट स्लाइसर और री-रैंकर का समर्थन
✨ फीचर झलक
- 🌐 प्रॉक्सी की आवश्यकता नहीं: Playwright के माध्यम से घरेलू ब्राउज़र समर्थन कॉन्फ़िगर करें, बिना प्रॉक्सी के भी वेब खोज संभव।
- 🔍 कई सर्च इंजन सपोर्ट: Bing, Quark, Baidu, Sogou जैसे प्रमुख सर्च इंजनों का समर्थन, सूचना स्रोतों की विविधता बढ़ाता है।
- 🤖 इरादे की पहचान: सिस्टम उपयोगकर्ता की इनपुट सामग्री के आधार पर स्वतः निर्धारित करता है कि वेब खोज करनी है या URL को पार्स करना है।
- 🔄 क्वेरी विभाजन: उपयोगकर्ता की खोज की मंशा के अनुसार, क्वेरी को स्वतः कई उप-कार्यों में विभाजित कर क्रमशः निष्पादित किया जाता है, जिससे प्रासंगिकता और दक्षता बढ़ती है।
- ⚙️ इंटेलिजेंट एजेंट संरचना: LangGraph आधारित "web_search" और "link_parser" को समाहित किया गया है।
- 🏃♂️ असिंक्रोनस कनकरंट टास्क प्रोसेसिंग: असिंक्रोनस कनकरंट टास्क प्रोसेसिंग का समर्थन करता है, जिससे कई सर्च टास्क कुशलता से संभाले जा सकते हैं।
- 📝 सामग्री प्रसंस्करण अनुकूलन:
- ✂️ सामग्री खंडन: लंबे वेबपेज कंटेंट को अनुच्छेद अनुसार विभाजित करें।
- 🔄 सामग्री पुन: क्रमबद्धता: स्मार्ट रीऑर्डरिंग द्वारा सूचना की प्रासंगिकता बढ़ाएं।
- 🚫 सामग्री फ़िल्टरिंग: अप्रासंगिक या डुप्लिकेट कंटेंट को स्वतः हटाएं।
- 🌐 मल्टीप्लेटफॉर्म सपोर्ट:
- 🐳 Docker डिप्लॉयमेंट सपोर्ट: वन-क्लिक स्टार्ट, बैकएंड सेवा का त्वरित निर्माण।
- 🖥️ FastAPI बैकएंड इंटरफ़ेस प्रदान करता है, जिसे किसी भी सिस्टम में इंटीग्रेट किया जा सकता है।
- 🌍 Gradio Web UI प्रदान करता है, जिसे आसानी से विज़ुअल एप्लिकेशन के रूप में डिप्लॉय किया जा सकता है।
- 🧩 ब्राउज़र प्लगइन सपोर्ट: Edge सपोर्ट करता है, स्मार्ट URL पार्सिंग प्लगइन प्रदान करता है, जिससे ब्राउज़र में ही वेबपेज विश्लेषण व कंटेंट एक्सट्रैक्शन अनुरोध किए जा सकते हैं।
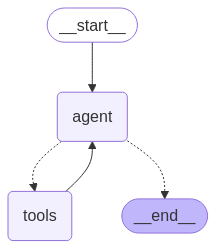

⚡ तेज़ शुरुआत
रिपॉजिटरी क्लोन करें
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchनिर्भरता स्थापित करें
pip install -r requirements.txt
python -m playwright installपर्यावरण वेरिएबल कॉन्फ़िगरेशन
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2लैंगग्राफ-एजेंट
#### डेमो
python agent/demo.py#### एपीआई सेवा
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### ग्रैडियो
python agent/gradio_demo.py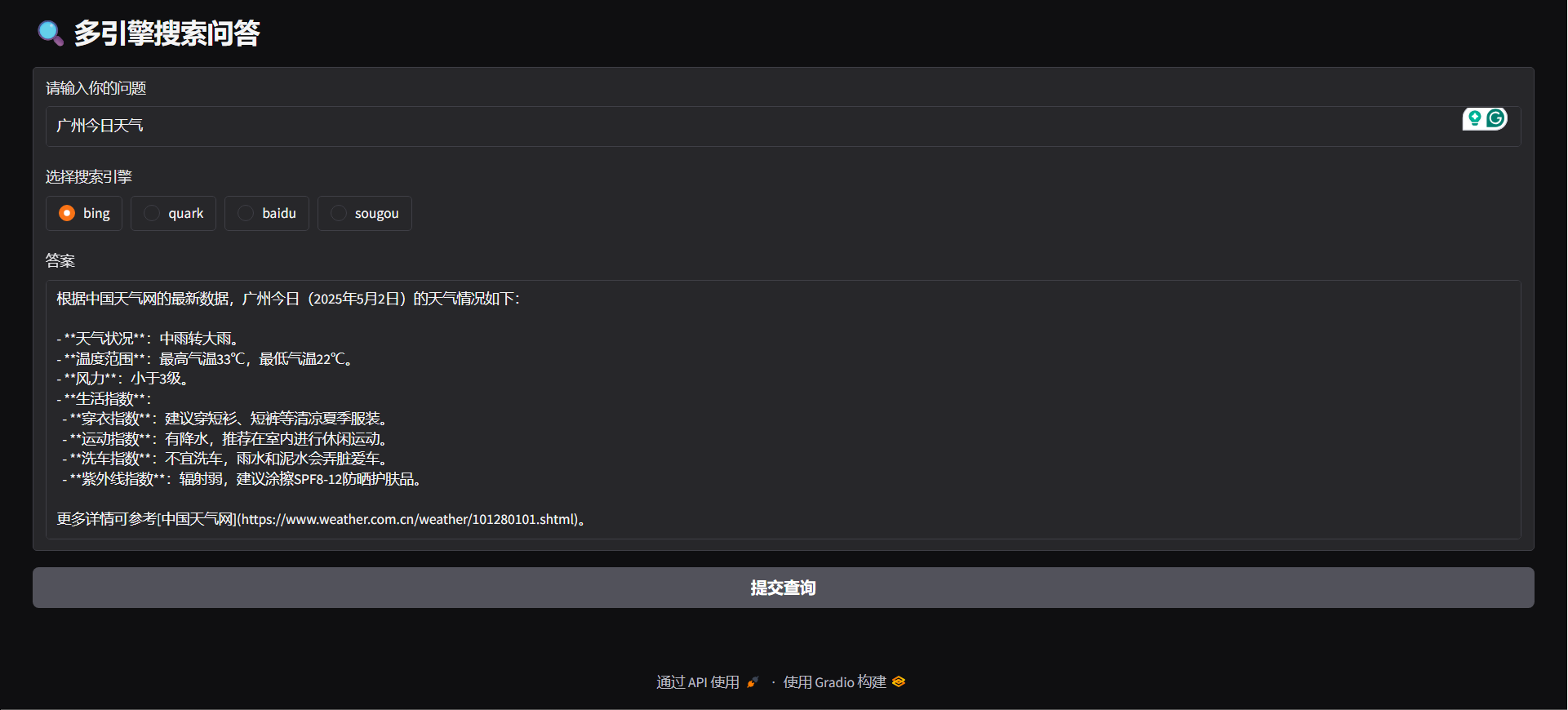
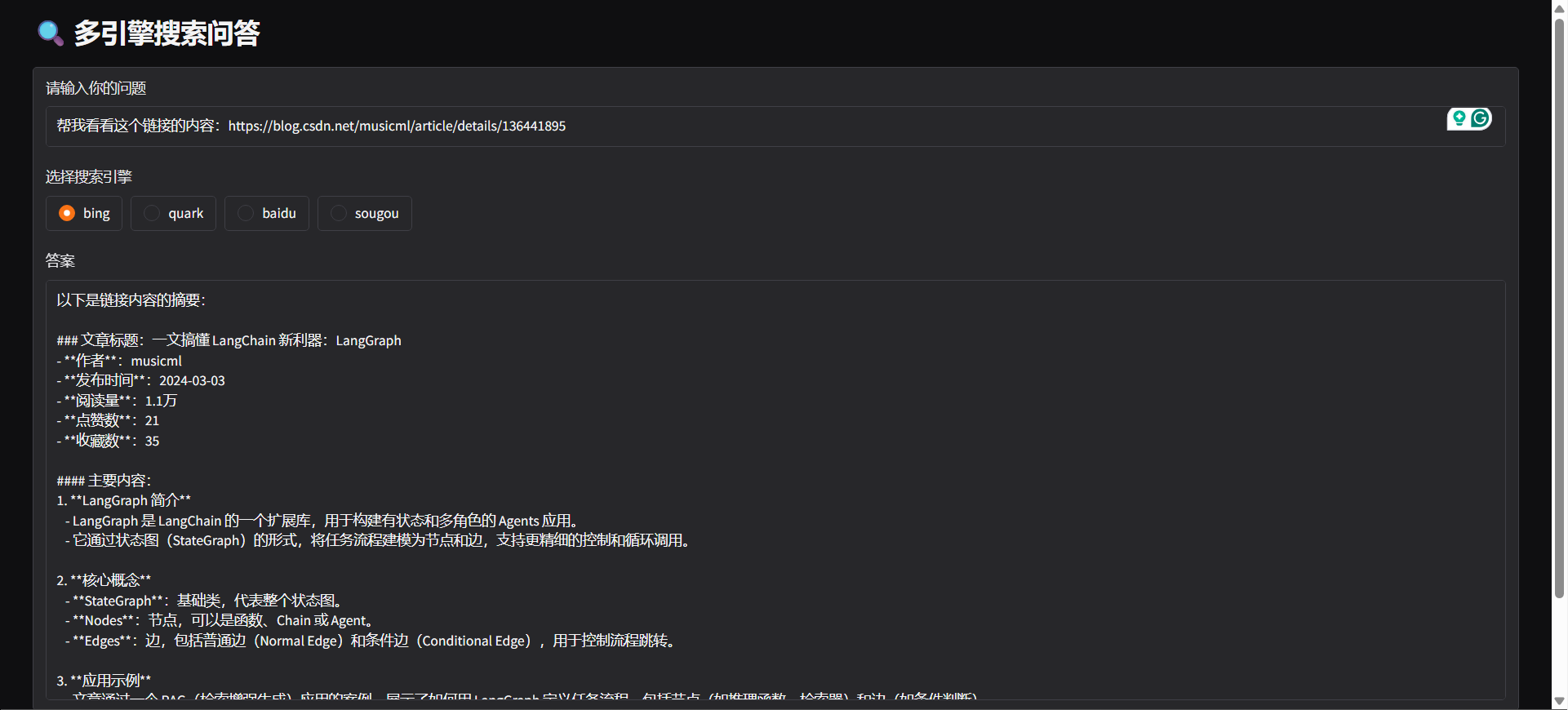
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### MCP सेवा प्रारंभ करें
python mcp/websearch.py#### डेमो
python mcp/demo.py#### एपीआई सेवा
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### डॉकर
docker-compose -f docker-compose-mcp.yml up -d --buildकस्टम मॉड्यूल
#### कस्टम ब्लॉकिंग
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### कस्टम पुनः क्रमबद्धीकरण
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 ऑनलाइन नेटवर्क खोज परीक्षण की तुलना
हमने परियोजना की तुलना कुछ प्रमुख ऑनलाइन API से की, और जटिल समस्याओं पर इसके प्रदर्शन का मूल्यांकन किया।
🔥 डेटा सेट
- डेटा सेट अली द्वारा जारी WebWalkerQA से लिया गया है, जिसमें 680 उच्च कठिनाई वाले प्रश्न शामिल हैं, जो शिक्षा, अकादमिक सम्मेलन, गेमिंग आदि कई क्षेत्रों को कवर करता है।
- डेटा सेट में चीनी और अंग्रेज़ी दोनों भाषाओं के प्रश्न शामिल हैं।
🧑🏫 तुलना परिणाम
| खोज इंजन/सिस्टम | ✅ सही | ❌ गलत | ⚠️ आंशिक रूप से सही | | -------------- | --------- | ----------- | ------------------- | | हुओशान फांगझोउ | 5.00% | 72.21% | 22.79% | | बाईलियन | 9.85% | 62.79% | 27.35% | | हमारा | 19.85% | 47.94% | 32.06% |
🙏 आभार
इस परियोजना की कुछ कार्यक्षमताएँ निम्नलिखित ओपन सोर्स परियोजनाओं के समर्थन और प्रेरणा से मिली हैं, इसके लिए विशेष धन्यवाद:
- 🧠 LangGraph: मॉड्यूलर एजेंट लिंक फ्रेमवर्क के निर्माण के लिए, जो जटिल एजेंट सिस्टम को तेजी से तैयार करने में मदद करता है।
- 🕷 Crawl4AI: शक्तिशाली वेब सामग्री विश्लेषण उपकरण, कुशल वेब क्रॉलिंग और डेटा निष्कर्षण में सहायक।
- 🌐 Playwright: आधुनिक ब्राउज़र ऑटोमेशन टूल, क्रॉस-ब्राउज़र वेब क्रॉलिंग और परीक्षण ऑटोमेशन को सपोर्ट करता है।
- 🔌 Langchain MCP Adapters: मल्टी-चेन प्रोसेसिंग MCP के निर्माण के लिए।