🧠 Moteur de recherche Web LLM sans proxy
Un outil de recherche Web LLM multi-moteurs sans proxy, prenant en charge l'analyse du contenu des URL et l'exploration de pages web, combinant LangGraph et LangGraph-MCP pour réaliser une chaîne d'agents modulaires. Conçu pour les scénarios d'appel à des connaissances externes par les grands modèles de langage, il prend en charge l'acquisition et l'analyse de pages web via Playwright + Crawl4AI, la concurrence asynchrone, le découpage du contenu et le filtrage/réorganisation.
🚀 Journal des mises à jour
- 🔥 2025-09-05 : Prise en charge de langgraph-mcp
- 🔥 2025-09-03 : Ajout du déploiement Docker, réorganisateur intelligent intégré, support des découpeurs de texte et réorganisateurs personnalisés
✨ Aperçu des fonctionnalités
- 🌐 Sans proxy : Configuration du navigateur national via Playwright, permettant la recherche en ligne sans proxy.
- 🔍 Prise en charge de plusieurs moteurs de recherche : Prise en charge de Bing, Quark, Baidu, Sogou et autres principaux moteurs, pour une diversité des sources d'information.
- 🤖 Reconnaissance d’intention : Le système peut automatiquement déterminer, selon la saisie de l'utilisateur, s’il s'agit d’une recherche web ou d’une analyse d'URL.
- 🔄 Décomposition des requêtes : Selon l’intention de recherche de l’utilisateur, les requêtes sont automatiquement divisées en sous-tâches exécutées successivement, optimisant la pertinence et l'efficacité des recherches.
- ⚙️ Architecture intelligente : Basée sur LangGraph, encapsulant « web_search » et « link_parser ».
- 🏃♂️ Gestion asynchrone et concurrente des tâches : Prise en charge du traitement asynchrone et concurrent des tâches pour une gestion efficace de multiples recherches.
- 📝 Optimisation du traitement du contenu :
- ✂️ Découpage du contenu : Fractionnement du contenu long des pages web en segments.
- 🔄 Réorganisation du contenu : Reclassement intelligent pour améliorer la pertinence des informations.
- 🚫 Filtrage du contenu : Suppression automatique du contenu non pertinent ou dupliqué.
- 🌐 Prise en charge multi-plateforme :
- 🐳 Déploiement Docker pris en charge : Démarrage en un clic, création rapide de services backend.
- 🖥️ Interface backend FastAPI fournie, intégrable à tout système.
- 🌍 Interface Web Gradio fournie, pour un déploiement rapide en application visuelle.
- 🧩 Prise en charge des extensions de navigateur : Prise en charge d’Edge, extension intelligente d'analyse d’URL pour lancer des requêtes d’analyse et d’extraction directement depuis le navigateur.
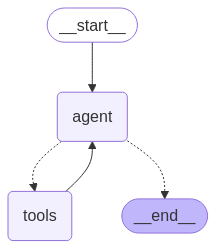

⚡ Démarrage rapide
Cloner le dépôt
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchInstallation des dépendances
pip install -r requirements.txt
python -m playwright installConfiguration des variables d'environnement
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### DÉMONSTRATION
python agent/demo.py#### SERVEUR API
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py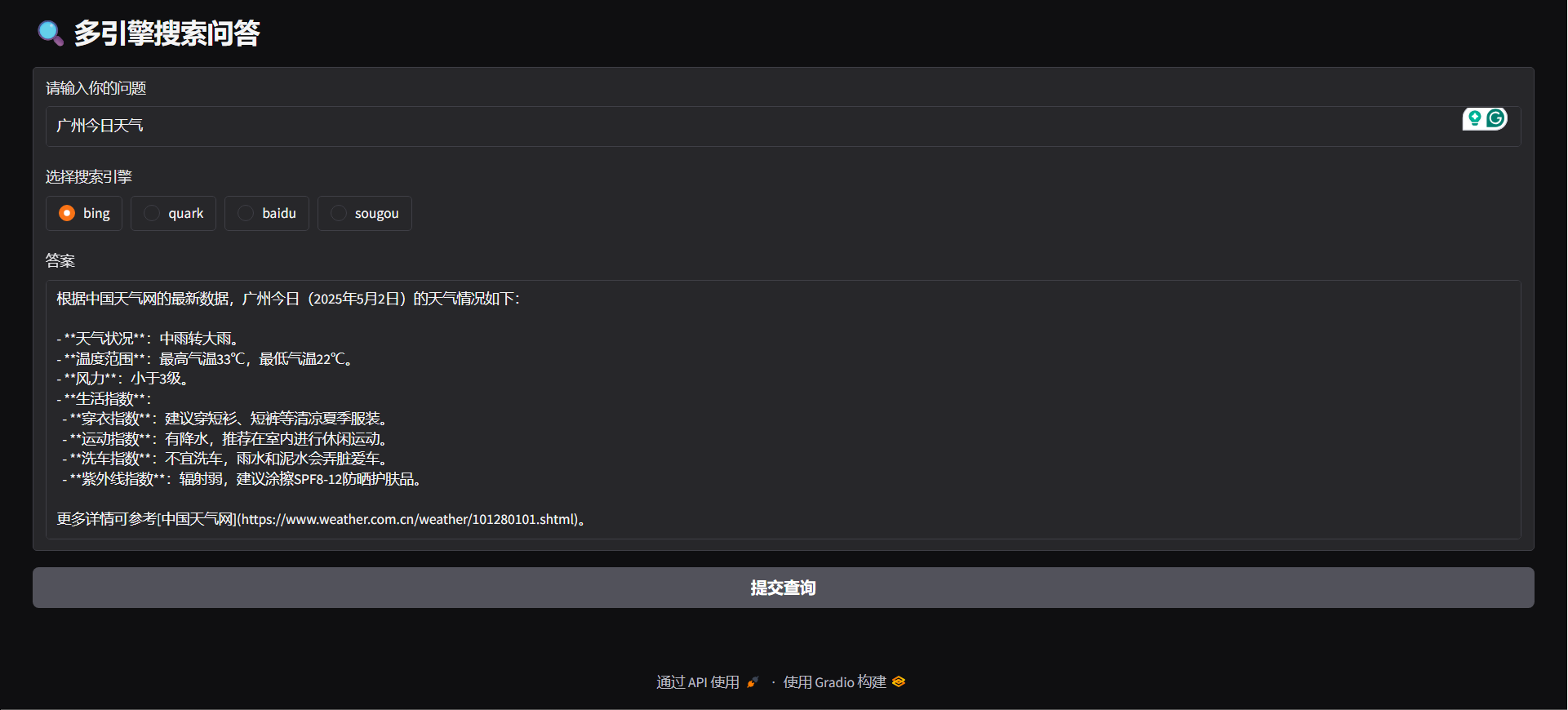
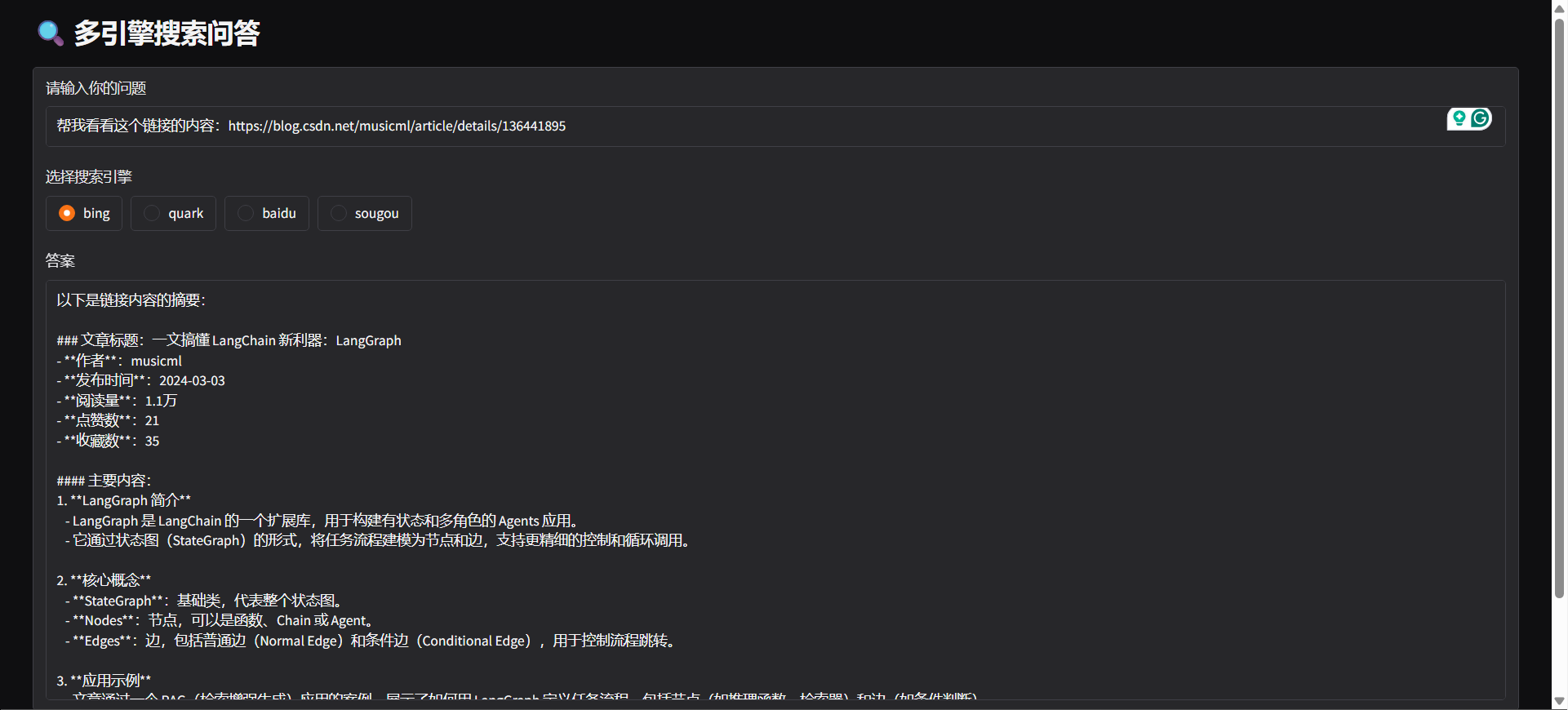
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Démarrer le service MCP
python mcp/websearch.py#### DÉMO
python mcp/demo.py#### SERVEUR API
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildModule personnalisé
#### Partitionnement personnalisé
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Réorganisation personnalisée
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 Comparaison avec les tests de recherche en ligne
Nous avons comparé le projet avec certaines API en ligne populaires, en évaluant leurs performances sur des questions complexes.
🔥 Jeu de données
- Le jeu de données provient du WebWalkerQA publié par Alibaba, contenant 680 questions de haut niveau de difficulté, couvrant l’éducation, les conférences académiques, les jeux et d’autres domaines.
- Le jeu de données inclut des questions en chinois et en anglais.
🧑🏫 Résultats de la comparaison
| Moteur de recherche/système | ✅ Correct | ❌ Incorrect | ⚠️ Partiellement correct | | -------------------------- | --------- | ----------- | ----------------------- | | Volcano Ark | 5.00% | 72.21% | 22.79% | | Bailian | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 Remerciements
Certaines fonctionnalités du projet bénéficient du soutien et de l’inspiration des projets open source suivants, que nous remercions tout particulièrement :
- 🧠 LangGraph : utilisé pour construire un cadre modulaire de chaînes d’agents intelligents, aidant à mettre en place rapidement des systèmes d’agents complexes.
- 🕷 Crawl4AI : puissant outil d’analyse de contenu web, facilitant l’extraction de données et le crawling efficace de pages.
- 🌐 Playwright : outil moderne d’automatisation de navigateurs, supportant le crawling et les tests automatisés multiplateformes.
- 🔌 Langchain MCP Adapters : utilisé pour la construction MCP multi-chaînes.