🧠 موتور جستجوی وب LLM بدون نیاز به پراکسی
یک ابزار جستجوی وب LLM چندموتوره بدون نیاز به پراکسی، با قابلیت تحلیل محتوای URL و خزش صفحات وب، مبتنی بر LangGraph و LangGraph-MCP برای پیادهسازی زنجیرههای عامل ماژولار. ویژه فراخوانی دانش خارجی توسط مدلهای زبانی بزرگ، پشتیبانی از بازیابی و تحلیل صفحات با Playwright + Crawl4AI، پشتیبانی از همزمانی غیرهمزمان، قطعهبندی و بازچینی/فیلتر محتوا.
🚀 گزارش بروزرسانیها
- 🔥 2025-09-05: پشتیبانی از langgraph-mcp
- 🔥 2025-09-03: افزودن دیپلوی داکر، بازچین هوشمند داخلی، پشتیبانی از تقسیمکننده و بازچین متن سفارشی
✨ مرور ویژگیها
- 🌐 بدون نیاز به پراکسی: با پیکربندی مرورگر داخلی از طریق Playwright، بدون نیاز به پراکسی میتوانید جستجوی اینترنتی انجام دهید.
- 🔍 پشتیبانی از چندین موتور جستجو: از موتورهای جستجوی مطرحی مانند Bing، Quark، Baidu، Sogou و غیره پشتیبانی میشود تا تنوع منابع اطلاعاتی افزایش یابد.
- 🤖 تشخیص نیت: سیستم بر اساس محتوای ورودی کاربر، به صورت خودکار تشخیص میدهد که جستجوی اینترنتی انجام شود یا آدرس URL تحلیل گردد.
- 🔄 تقسیمبندی پرسشها: با توجه به نیت جستجوی کاربر، به طور خودکار پرسشها به چندین زیر وظیفه تقسیم و به ترتیب اجرا میشوند تا ارتباط و کارایی جستجو افزایش یابد.
- ⚙️ معماری عامل هوشمند: مبتنی بر LangGraph، شامل بستهبندی "web_search" و "link_parser" است.
- 🏃♂️ پردازش وظایف همزمان و غیرهمزمان: از پردازش وظایف همزمان و غیرهمزمان پشتیبانی میکند و قادر به مدیریت مؤثر چندین وظیفه جستجو است.
- 📝 بهینهسازی پردازش محتوا:
- ✂️ برش محتوا: بخشبندی محتوای طولانی صفحات وب به پاراگرافهای جداگانه.
- 🔄 بازآرایی محتوا: مرتبسازی هوشمند برای افزایش ارتباط اطلاعات.
- 🚫 فیلتر محتوا: حذف خودکار محتوای نامرتبط یا تکراری.
- 🌐 پشتیبانی از چندین پلتفرم:
- 🐳 پشتیبانی از استقرار Docker: شروع با یک کلیک و ساخت سریع سرویس بکاند.
- 🖥️ ارائه رابط بکاند FastAPI، قابل ادغام با هر سیستم دلخواه.
- 🌍 ارائه رابط کاربری Gradio Web UI، قابل استقرار سریع به عنوان اپلیکیشن تصویری.
- 🧩 پشتیبانی از افزونه مرورگر: پشتیبانی از Edge و ارائه افزونه هوشمند تحلیل URL، ارسال درخواست تحلیل صفحه و استخراج محتوا مستقیماً در مرورگر.
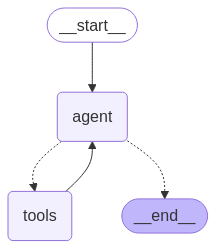

⚡ شروع سریع
کلون کردن مخزن
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchنصب وابستگیها
pip install -r requirements.txt
python -m playwright installپیکربندی متغیرهای محیطی
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### دمو
python agent/demo.py#### سرویسدهی API
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### گریدیو
python agent/gradio_demo.py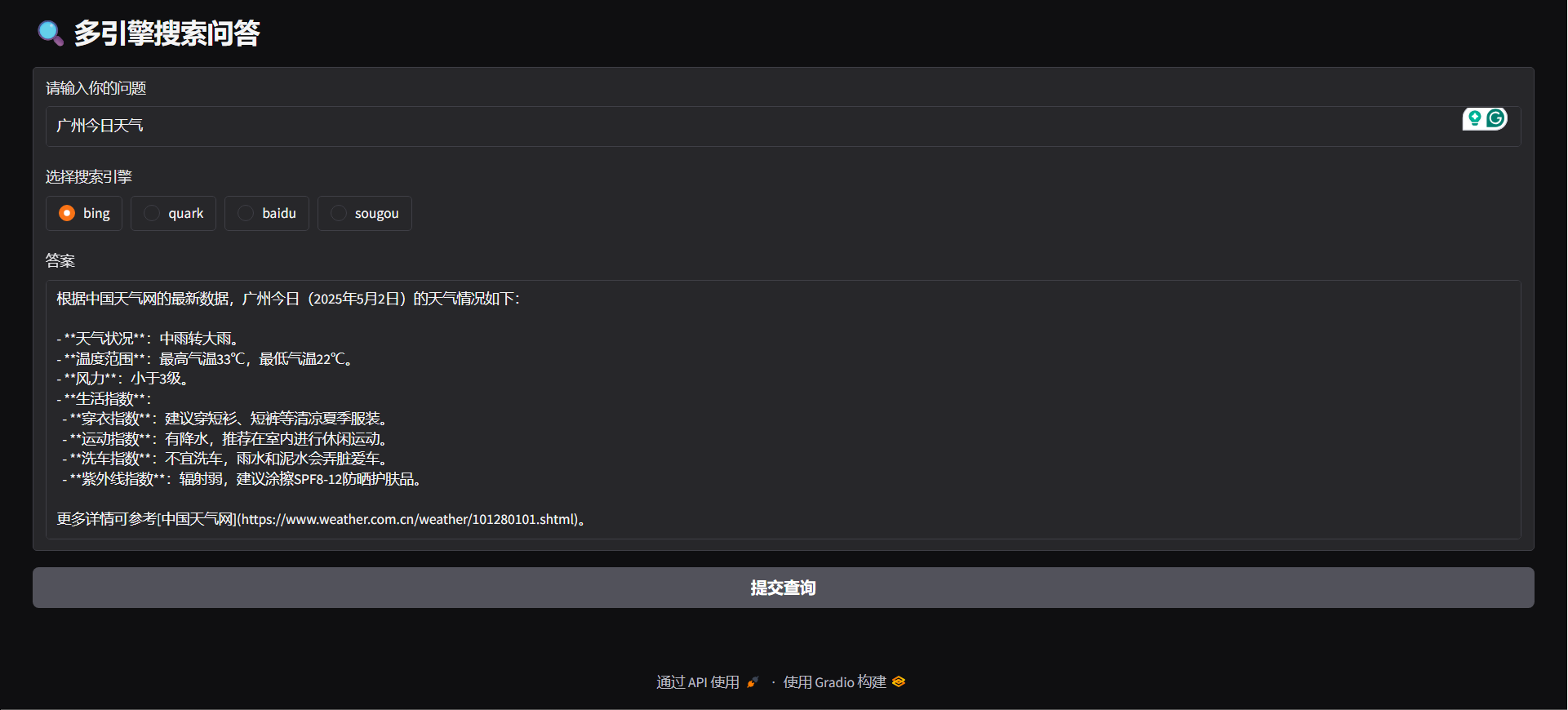
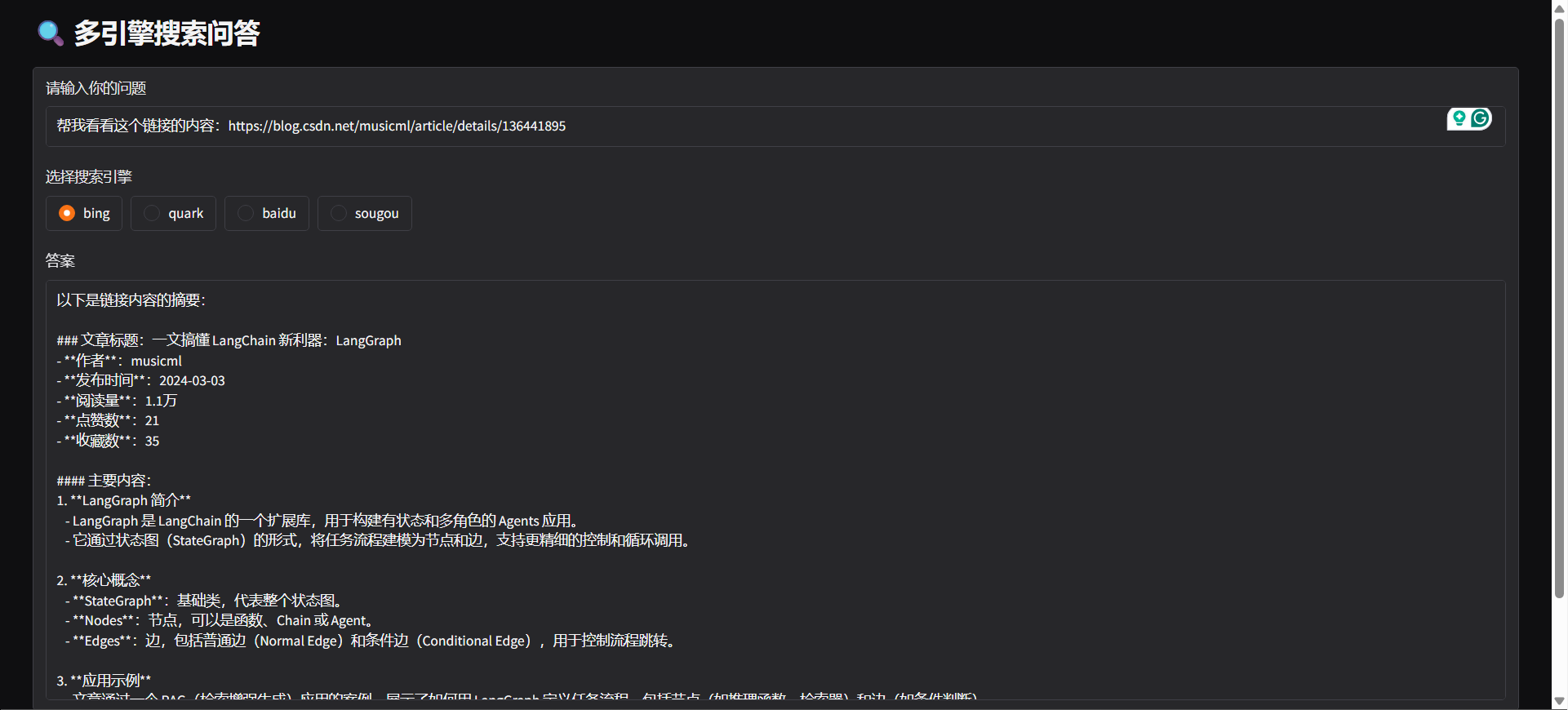
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### راهاندازی سرویس MCP
python mcp/websearch.py#### دمو
python mcp/demo.py#### سرویسدهی API
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### داکر
docker-compose -f docker-compose-mcp.yml up -d --buildماژول سفارشی
#### تقسیمبندی سفارشی
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### بازچینش سفارشی
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 مقایسه با آزمونهای جستجوی آنلاین
ما پروژه را با برخی از APIهای آنلاین رایج مقایسه کردیم و عملکرد آن را در مسائل پیچیده ارزیابی نمودیم.
🔥 مجموعه داده
- مجموعه داده از WebWalkerQA منتشر شده توسط علی گرفته شده است که شامل ۶۸۰ پرسش دشوار و حوزههای مختلفی مانند آموزش، کنفرانسهای علمی، بازیها و غیره را پوشش میدهد.
- مجموعه داده شامل پرسشهای چینی و انگلیسی است.
🧑🏫 نتایج مقایسه
| موتور جستجو/سیستم | ✅ درست | ❌ نادرست | ⚠️ تا حدی درست | | ------------------ | ------- | -------- | -------------- | | آتشفشان فانژو | ۵.۰۰٪ | ۷۲.۲۱٪ | ۲۲.۷۹٪ | | بایلین | ۹.۸۵٪ | ۶۲.۷۹٪ | ۲۷.۳۵٪ | | ما | ۱۹.۸۵٪ | ۴۷.۹۴٪ | ۳۲.۰۶٪ |
🙏 سپاسگزاری
برخی قابلیتهای این پروژه با حمایت و الهام از پروژههای متنباز زیر فراهم شده است، بدین وسیله تقدیر مینماییم:
- 🧠 LangGraph: برای ساخت چارچوب زنجیرهای عاملهای ماژولار، کمک به راهاندازی سریع سیستمهای عامل پیچیده.
- 🕷 Crawl4AI: ابزار قدرتمند تجزیه محتوای صفحات وب، کمک به استخراج داده و وبکراولینگ کارآمد.
- 🌐 Playwright: ابزار اتوماسیون مرورگرهای مدرن، پشتیبانی از کراس-مرورگر برای وبکراولینگ و تست اتوماتیک.
- 🔌 Langchain MCP Adapters: برای ساخت چندزنجیرهای MCP.