🧠 Motor de búsqueda web LLM sin proxy
Una herramienta de recuperación web LLM multibuscador sin necesidad de proxy, compatible con el análisis de contenido de URL y rastreo web, combinando LangGraph y LangGraph-MCP para lograr una cadena de agentes modular. Diseñada para escenarios de acceso a conocimiento externo por modelos de lenguaje grande, soporta obtención y análisis de páginas web con Playwright + Crawl4AI, así como concurrencia asíncrona, segmentación de contenido y reordenamiento filtrado.
🚀 Registro de actualizaciones
- 🔥 2025-09-05: Soporte para langgraph-mcp
- 🔥 2025-09-03: Nuevo despliegue con Docker, reordenador inteligente integrado, soporte para segmentadores y reordenadores de texto personalizados
✨ Vista rápida de características
- 🌐 Sin necesidad de proxy: Configuración de navegador nacional mediante Playwright, permite realizar búsquedas en la web sin requerir proxy.
- 🔍 Soporte para múltiples motores de búsqueda: Compatible con Bing, Quark, Baidu, Sogou y otros motores principales, aumentando la diversidad de fuentes de información.
- 🤖 Reconocimiento de intención: El sistema puede determinar automáticamente si debe realizar una búsqueda web o analizar una URL según el contenido ingresado por el usuario.
- 🔄 Descomposición de consultas: Según la intención de búsqueda del usuario, divide automáticamente la consulta en varias subtareas y las ejecuta secuencialmente, mejorando la relevancia y eficiencia de la búsqueda.
- ⚙️ Arquitectura de agentes inteligentes: Basada en LangGraph, encapsula 「web_search」 y 「link_parser」.
- 🏃♂️ Procesamiento de tareas concurrentes asíncronas: Admite procesamiento asíncrono y concurrente de tareas, permitiendo manejar eficientemente múltiples búsquedas.
- 📝 Optimización del procesamiento de contenido:
- ✂️ Segmentación de contenido: Divide el contenido extenso de las páginas web en secciones.
- 🔄 Reordenamiento de contenido: Reordena inteligentemente para aumentar la relevancia de la información.
- 🚫 Filtrado de contenido: Elimina automáticamente contenido irrelevante o duplicado.
- 🌐 Soporte multiplataforma:
- 🐳 Soporta despliegue en Docker: Inicio con un solo clic, construcción rápida de servicios backend.
- 🖥️ Proporciona interfaz backend con FastAPI, integrable en cualquier sistema.
- 🌍 Ofrece Gradio Web UI, permitiendo rápida implementación como aplicación visual.
- 🧩 Soporte para extensiones de navegador: Compatible con Edge, proporciona extensión inteligente para análisis de URL, permite iniciar solicitudes de análisis y extracción de contenido directamente desde el navegador.

⚡ Comienzo rápido
Clonar el repositorio
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchInstalar dependencias
pip install -r requirements.txt
python -m playwright installConfiguración de variables de entorno
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### DEMO
python agent/demo.py#### SERVICIO API
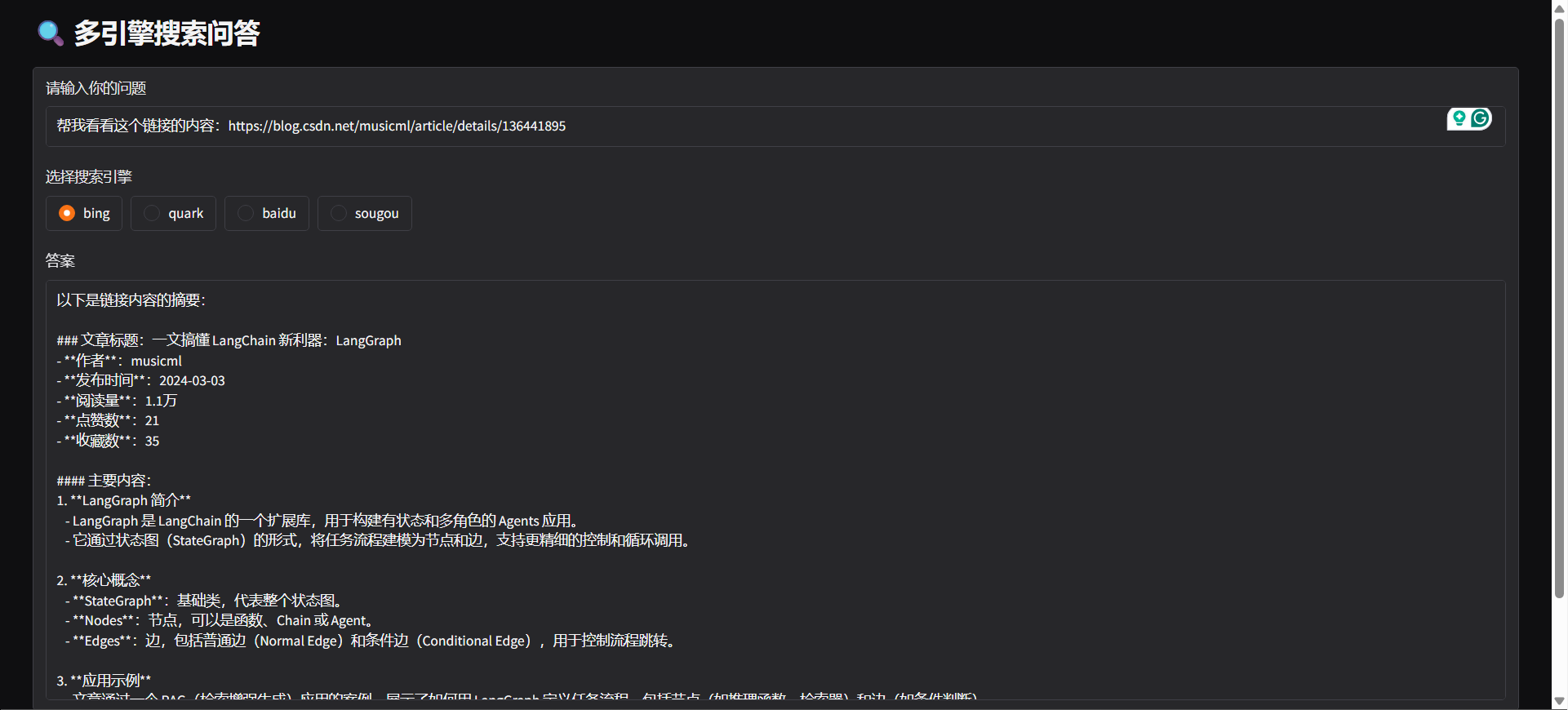
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py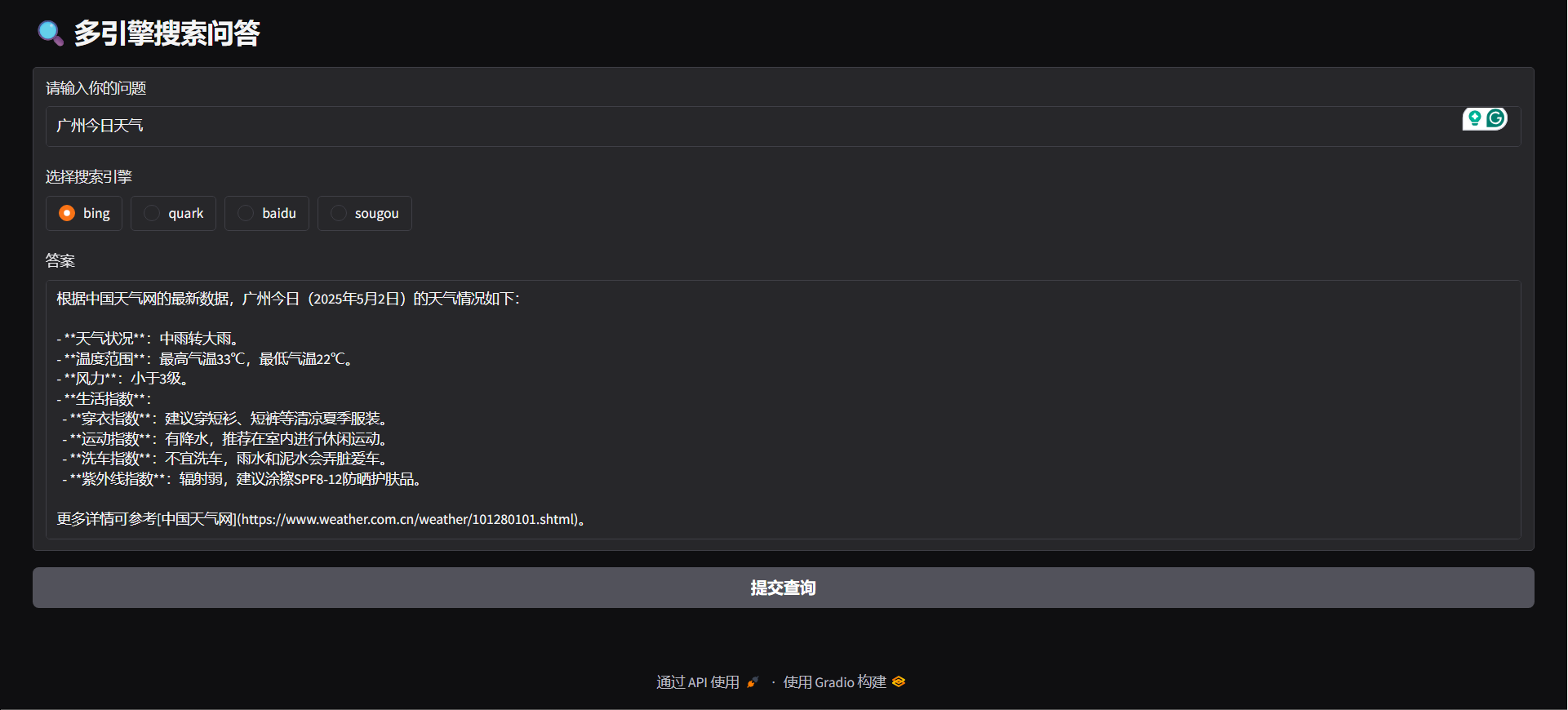
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Iniciar el servicio MCP
python mcp/websearch.py#### DEMOSTRACIÓN
python mcp/demo.py#### SERVICIO API
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildMódulos personalizados
#### Segmentación personalizada
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Reordenación personalizada
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 Comparación con pruebas de búsqueda en línea
Comparamos el proyecto con algunas API en línea populares y evaluamos su desempeño en problemas complejos.
🔥 Conjunto de datos
- El conjunto de datos proviene de WebWalkerQA publicado por Alibaba, contiene 680 preguntas de alta dificultad y abarca educación, conferencias académicas, juegos y otros campos.
- El conjunto de datos incluye preguntas en chino e inglés.
🧑🏫 Resultados comparativos
| Motor de búsqueda/Sistema | ✅ Correcto | ❌ Incorrecto | ⚠️ Parcialmente correcto | | ------------------------ | ---------- | ------------ | ----------------------- | | Volcano Ark | 5.00% | 72.21% | 22.79% | | Bailian | 9.85% | 62.79% | 27.35% | | Nuestro | 19.85% | 47.94% | 32.06% |
🙏 Agradecimientos
Algunas funciones de este proyecto se benefician del apoyo e inspiración de los siguientes proyectos de código abierto, por lo que expresamos nuestro agradecimiento:
- 🧠 LangGraph: Utilizado para construir el marco de agentes modulares, facilita el desarrollo rápido de sistemas de agentes complejos.
- 🕷 Crawl4AI: Potente herramienta de análisis de contenido web, ayuda en la extracción eficiente de datos y el scraping de páginas.
- 🌐 Playwright: Herramienta moderna de automatización de navegadores, soporta scraping y pruebas automatizadas en varios navegadores.
- 🔌 Langchain MCP Adapters: Utilizado para la construcción de MCP de procesamiento multichain.