🌐 Language
🧠 Proxyless LLM Web Search Engine
A proxyless multi-search-engine LLM web retrieval tool supporting URL content parsing and web crawling, integrating LangGraph and LangGraph-MCP for modular agent chaining. Specifically designed for external knowledge invocation scenarios for large language models, supporting Playwright + Crawl4AI for web fetching and parsing, as well as asynchronous concurrency, content chunking and re-ranking/filtering.
🚀 Changelog
- 🔥 2025-09-05: Support for langgraph-mcp
- 🔥 2025-09-03: Added Docker deployment, built-in intelligent re-ranker, support for custom text chunkers and re-rankers
✨ Feature Overview
- 🌐 No Proxy Needed: Configure domestic browser support via Playwright, allowing web searches without a proxy.
- 🔍 Multi-Search Engine Support: Supports mainstream search engines such as Bing, Quark, Baidu, Sogou, enhancing diversity of information sources.
- 🤖 Intent Recognition: The system automatically determines whether to perform a web search or parse a URL based on user input.
- 🔄 Query Decomposition: Automatically breaks down queries into multiple subtasks according to search intent and executes them sequentially, improving relevance and efficiency.
- ⚙️ Agent Architecture: Encapsulates "web_search" and "link_parser" based on LangGraph.
- 🏃♂️ Asynchronous Concurrent Task Processing: Supports asynchronous concurrent task handling for efficient processing of multiple search tasks.
- 📝 Content Processing Optimization:
- ✂️ Content Slicing: Splits long webpage content into segments.
- 🔄 Content Reordering: Intelligently reorders to enhance information relevance.
- 🚫 Content Filtering: Automatically removes irrelevant or duplicate content.
- 🌐 Multi-platform Support:
- 🐳 Docker Deployment Support: One-click startup for fast backend service construction.
- 🖥️ Provides FastAPI backend interface, which can be integrated into any system.
- 🌍 Offers Gradio Web UI for rapid deployment as a visual application.
- 🧩 Browser Extension Support: Supports Edge, providing an intelligent URL parsing extension for initiating webpage parsing and content extraction requests directly in the browser.

⚡ Quick Start
Clone the repository
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchInstall dependencies
pip install -r requirements.txt
python -m playwright installEnvironment Variable Configuration
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2Langgraph-Agent
#### DEMO
python agent/demo.py#### API SERVE
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### Gradio
python agent/gradio_demo.py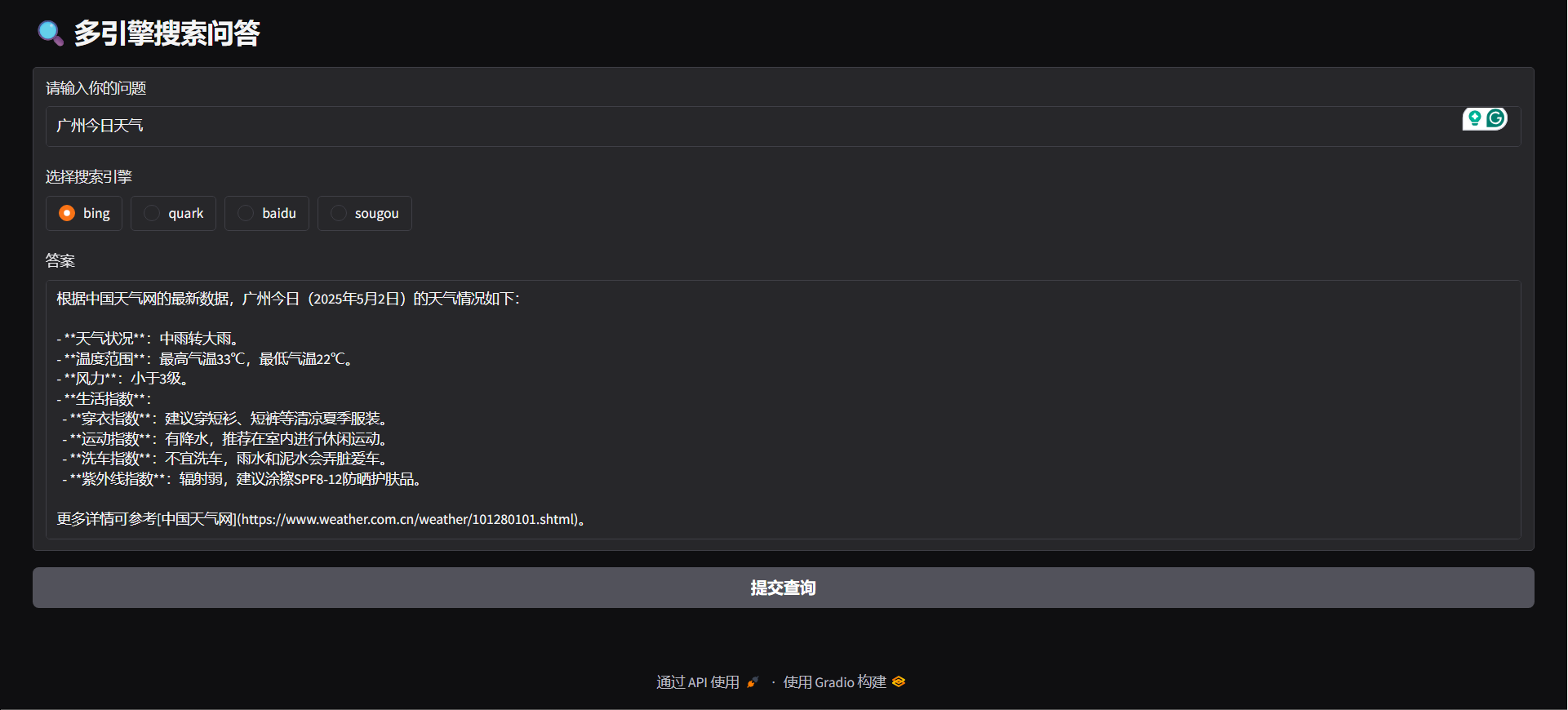
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### Start MCP Service
python mcp/websearch.py#### DEMO
python mcp/demo.py#### API SERVE
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### docker
docker-compose -f docker-compose-mcp.yml up -d --buildCustom Modules
#### Custom Partitioning
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### Custom Rearrangement
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 Comparison with Online Web Search Tests
We compared the project with several mainstream online APIs to evaluate their performance on complex problems.
🔥 Dataset
- The dataset comes from Ali's WebWalkerQA, containing 680 high-difficulty questions covering education, academic conferences, games, and various other fields.
- The dataset includes both Chinese and English questions.
🧑🏫 Comparison Results
| Search Engine/System | ✅ Correct | ❌ Incorrect | ⚠️ Partially Correct | | -------------------- | --------- | ----------- | ------------------- | | Volcano Ark | 5.00% | 72.21% | 22.79% | | Bailian | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 Acknowledgements
Some features of this project benefited from the support and inspiration of the following open-source projects. Special thanks to:
- 🧠 LangGraph: Used for building modular agent link frameworks, helping to quickly set up complex agent systems.
- 🕷 Crawl4AI: Powerful web content parsing tool for efficient web scraping and data extraction.
- 🌐 Playwright: Modern browser automation tool supporting cross-browser web scraping and test automation.
- 🔌 Langchain MCP Adapters: Used for building multi-chain MCP processing.