🧠 محرك بحث LLM للويب بدون وكيل
أداة استرجاع ويب متعددة محركات البحث للـ LLM لا تتطلب وكيلًا، تدعم تحليل محتوى الروابط واستخلاص صفحات الويب، وتدمج LangGraph و LangGraph-MCP لتحقيق سلاسل الوكلاء الذكية المعيارية. مصممة خصيصًا لاستدعاء المعرفة الخارجية لنماذج اللغة الكبيرة، وتدعم Playwright + Crawl4AI لجلب وتحليل صفحات الويب، مع دعم التوازي غير المتزامن، وتقطيع المحتوى وإعادة ترتيبه وتصفيته.
🚀 سجل التحديثات
- 🔥 2025-09-05: دعم langgraph-mcp
- 🔥 2025-09-03: إضافة النشر عبر Docker، إعادة ترتيب ذكية مدمجة، دعم تقسيم النصوص وإعادة ترتيبها بشكل مخصص
✨ نظرة على الميزات
- 🌐 لا حاجة للوكيل: من خلال إعداد Playwright لدعم المتصفحات المحلية، يمكنك إجراء البحث على الإنترنت بدون الحاجة لوكيل.
- 🔍 دعم محركات بحث متعددة: يدعم Bing، Quark، Baidu، Sogou وغيرها من محركات البحث الرئيسية، مما يعزز تنوع مصادر المعلومات.
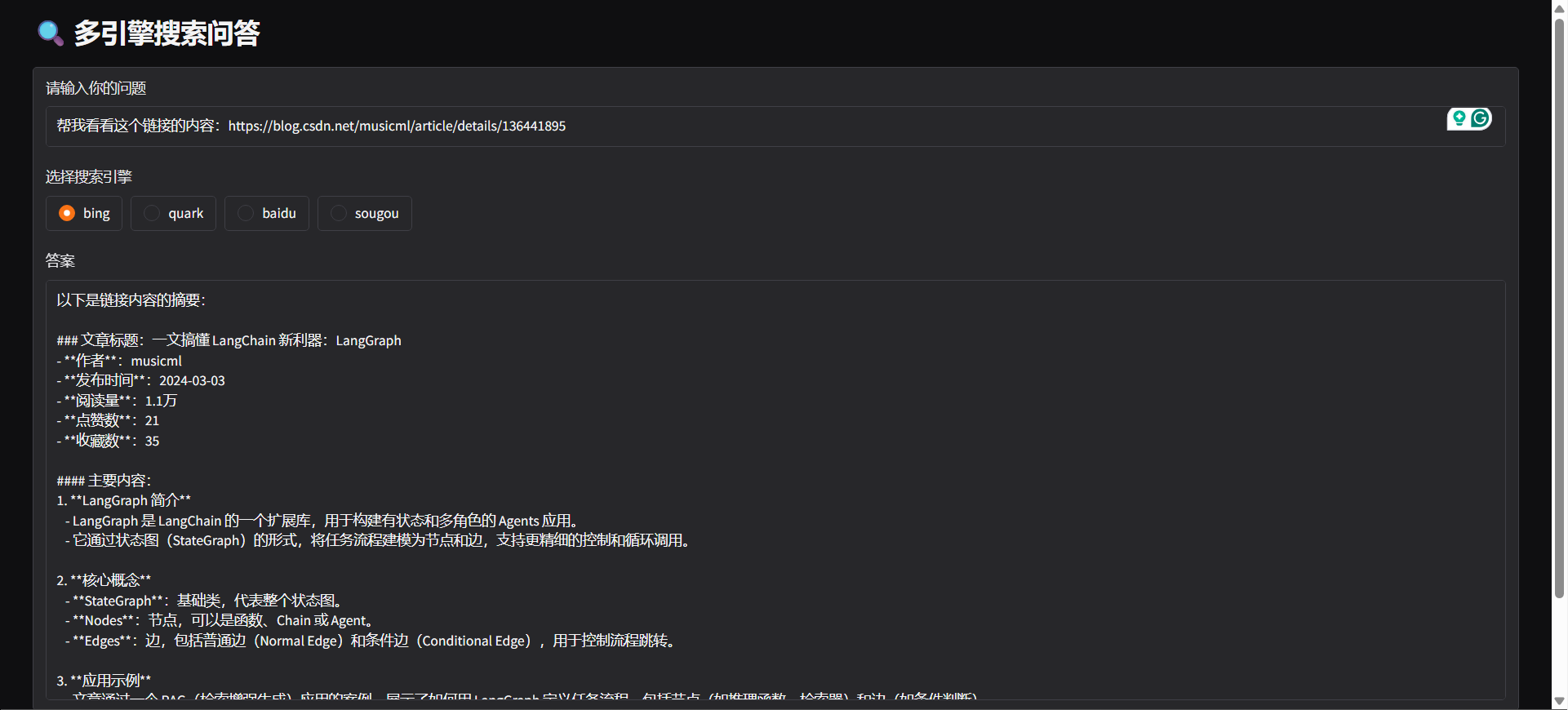
- 🤖 التعرف على النية: يستطيع النظام تلقائيًا تحديد ما إذا كان الإدخال يتطلب بحثًا عبر الإنترنت أو تحليل عنوان URL بناءً على محتوى المستخدم.
- 🔄 تفكيك الاستعلام: يقوم تلقائيًا بتقسيم الاستعلام إلى عدة مهام فرعية وتنفيذها بالتسلسل وفقًا لنية البحث، مما يحسن الصلة والكفاءة.
- ⚙️ بنية الوكيل الذكي: يعتمد على LangGraph لتغليف "web_search" و "link_parser".
- 🏃♂️ معالجة المهام المتزامنة غير المتزامنة: يدعم معالجة المهام بشكل متزامن وغير متزامن بكفاءة عالية للبحث المتعدد.
- 📝 تحسين معالجة المحتوى:
- ✂️ تقطيع المحتوى: تقسيم المحتوى الطويل للصفحات إلى مقاطع.
- 🔄 إعادة ترتيب المحتوى: إعادة ترتيب ذكية لتحسين صلة المعلومات.
- 🚫 تصفية المحتوى: إزالة المحتوى غير ذي الصلة أو المكرر تلقائيًا.
- 🌐 دعم متعدد الأنظمة:
- 🐳 دعم النشر عبر Docker: تشغيل بنقرة واحدة، بناء سريع لخدمات الخلفية.
- 🖥️ يوفر واجهة خلفية FastAPI، يمكن دمجها في أي نظام.
- 🌍 يوفر واجهة Gradio Web UI، يمكن نشرها بسرعة كتطبيق مرئي.
- 🧩 دعم إضافات المتصفح: يدعم Edge، ويوفر إضافة لتحليل عناوين URL الذكية، لإجراء تحليل الصفحات واستخلاص المحتوى مباشرة من المتصفح.

⚡ البدء السريع
استنساخ المستودع
git clone https://github.com/itshyao/proxyless-llm-websearch.git
cd proxyless-llm-websearchتثبيت الاعتمادات
pip install -r requirements.txt
python -m playwright installتكوين متغيرات البيئة
# 百炼llm
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxx
MODEL_NAME=qwen-plus-latest百炼embedding
EMBEDDING_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_API_KEY=sk-xxx
EMBEDDING_MODEL_NAME=text-embedding-v4百炼reranker
RERANK_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
RERANK_API_KEY=sk-xxx
RERANK_MODEL=gte-rerank-v2وكيل Langgraph
#### العرض التوضيحي
python agent/demo.py#### خدمة واجهة برمجة التطبيقات (API SERVE)
python agent/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气",
"engine": "bing",
"split": {
"chunk_size": 512,
"chunk_overlap": 128
},
"rerank": {
"top_k": 5
}
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### جراديو
python agent/gradio_demo.py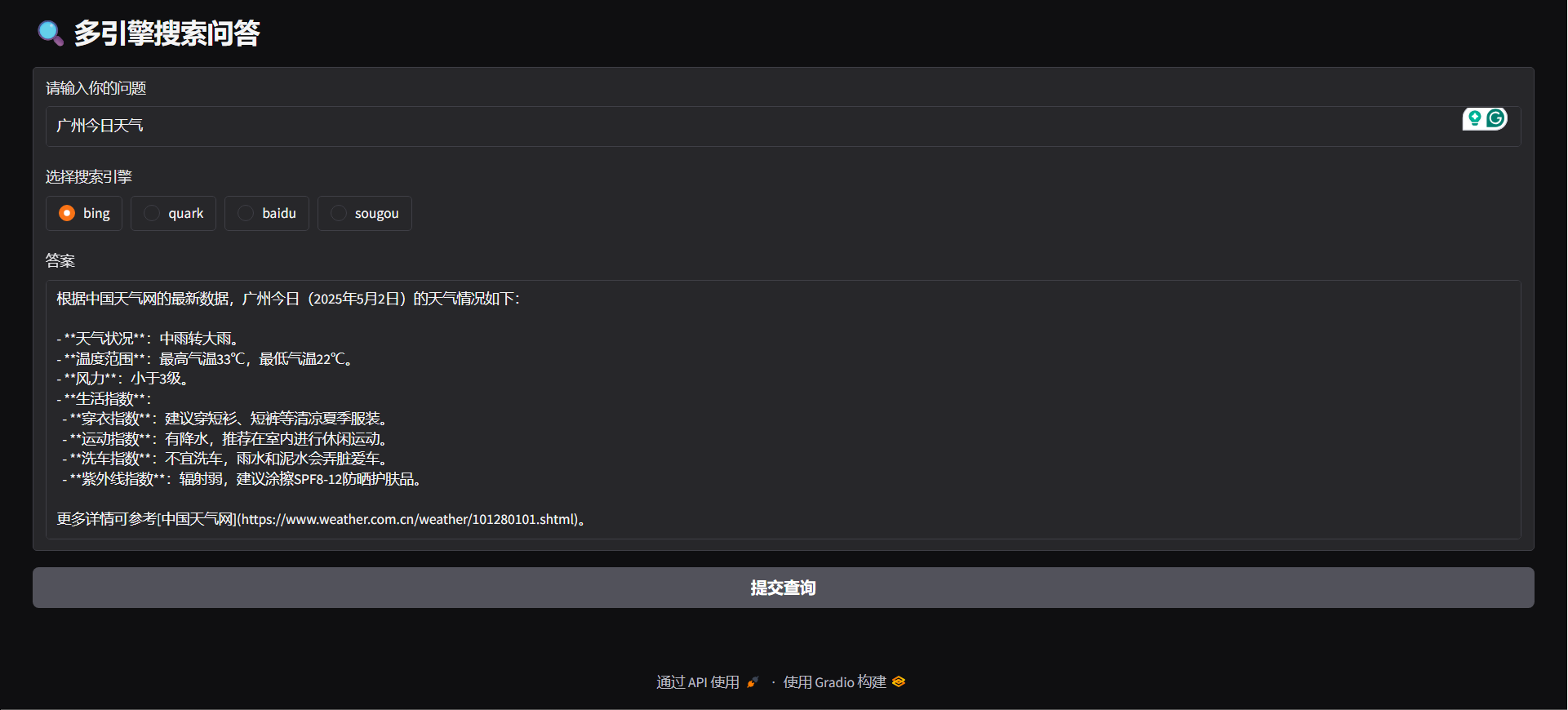
#### docker
docker-compose -f docker-compose-ag.yml up -d --buildLanggrph-MCP
#### بدء خدمة MCP
python mcp/websearch.py#### عرض توضيحي
python mcp/demo.py#### خدمة واجهة برمجة التطبيقات (API SERVE)
python mcp/api_serve.pyimport requestsurl = "http://localhost:8800/search"
data = {
"question": "广州今日天气"
}
try:
response = requests.post(
url,
json=data
)
if response.status_code == 200:
print("✅ 请求成功!")
print("响应内容:", response.json())
else:
print(f"❌ 请求失败,状态码:{response.status_code}")
print("错误信息:", response.text)
except requests.exceptions.RequestException as e:
print(f"⚠️ 请求异常:{str(e)}")
#### دوكر
docker-compose -f docker-compose-mcp.yml up -d --buildالوحدات المخصصة
#### تقسيم مخصص
from typing import Optional, Listclass YourSplitter:
def __init__(self, text: str, chunk_size: int = 512, chunk_overlap: int = 128):
self.text = text
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: Optional[str] = None) -> List:
# TODO: implement splitting logic
return ["your chunk"]
#### إعادة ترتيب مخصص
from typing import List, Union, Tupleclass YourReranker:
async def get_reranked_documents(
self,
query: Union[str, List[str]],
documents: List[str],
) -> Union[
Tuple[List[str]],
Tuple[List[int]],
]:
return ["your chunk"], ["chunk index"]
🔍 مقارنة مع اختبارات البحث عبر الإنترنت
قمنا بمقارنة المشروع مع بعض واجهات برمجة التطبيقات (API) الرئيسية على الإنترنت، وقيمنا أداءها في المسائل المعقدة.
🔥 مجموعة البيانات
- مجموعة البيانات مأخوذة من WebWalkerQA التي نشرتها شركة علي بابا، وتحتوي على 680 سؤالاً عالي الصعوبة، وتغطي مجالات التعليم والمؤتمرات الأكاديمية والألعاب وغيرها.
- مجموعة البيانات تشمل أسئلة باللغتين الصينية والإنجليزية.
🧑🏫 نتائج المقارنة
| محرك البحث/النظام | ✅ صحيح | ❌ غير صحيح | ⚠️ صحيح جزئياً | | ------------------- | ------- | ---------- | -------------- | | 火山方舟 | 5.00% | 72.21% | 22.79% | | 百炼 | 9.85% | 62.79% | 27.35% | | Our | 19.85% | 47.94% | 32.06% |
🙏 الشكر والتقدير
يستفيد بعض وظائف هذا المشروع من دعم وإلهام المشاريع مفتوحة المصدر التالية، ونود أن نشكرها بشكل خاص:
- 🧠 LangGraph: لبناء إطار سلاسل الوكلاء الذكية بطريقة معيارية، مما يساعد على بناء أنظمة وكلاء معقدة بسرعة.
- 🕷 Crawl4AI: أداة قوية لتحليل محتوى صفحات الويب، تسهم في استخراج البيانات وجلب الصفحات بكفاءة عالية.
- 🌐 Playwright: أداة حديثة لأتمتة المتصفحات، تدعم جلب الصفحات واختبار الأتمتة عبر متصفحات مختلفة.
- 🔌 Langchain MCP Adapters: تستخدم لبناء معالجة MCP متعددة السلاسل.