


[!IMPORTANT]
许可证说明
本代码库以 Apache License 许可证发布,所有模型权重以 CC-BY-NC-SA-4.0 License 许可证发布。详情请参见 LICENSE。
[!WARNING]
法律免责声明
对于本代码库的任何非法使用我们不承担任何责任。请遵守您当地关于 DMCA 及相关法律法规。
🎉 公告
我们很高兴地宣布,Fish-Speech 正式更名为 OpenAudio —— 这是一个全新的革命性高级文本转语音模型系列,基于 Fish-Speech 的技术基础上全新打造。
我们自豪地发布该系列的首个模型 OpenAudio-S1,在质量、性能和功能上带来了重大提升。
OpenAudio-S1 提供两个版本:OpenAudio-S1 和 OpenAudio-S1-mini。两个模型现已分别在 Fish Audio Playground(OpenAudio-S1)和 Hugging Face(OpenAudio-S1-mini)上线。
访问 OpenAudio 官网 获取博客与技术报告。
亮点 ✨
卓越的 TTS 质量
我们使用 Seed TTS 评测指标对模型性能进行评估,结果显示 OpenAudio S1 在英文文本上达到 0.008 WER 和 0.004 CER,远优于以往模型。(英文,自动评测,基于 OpenAI gpt-4o-transcribe,发音人距离使用 Revai/pyannote-wespeaker-voxceleb-resnet34-LM)
| 模型 | 词错误率 (WER) | 字符错误率 (CER) | 发音人距离 | |-------|----------------------|---------------------------|------------------| | S1 | 0.008 | 0.004 | 0.332 | | S1-mini | 0.011 | 0.005 | 0.380 |
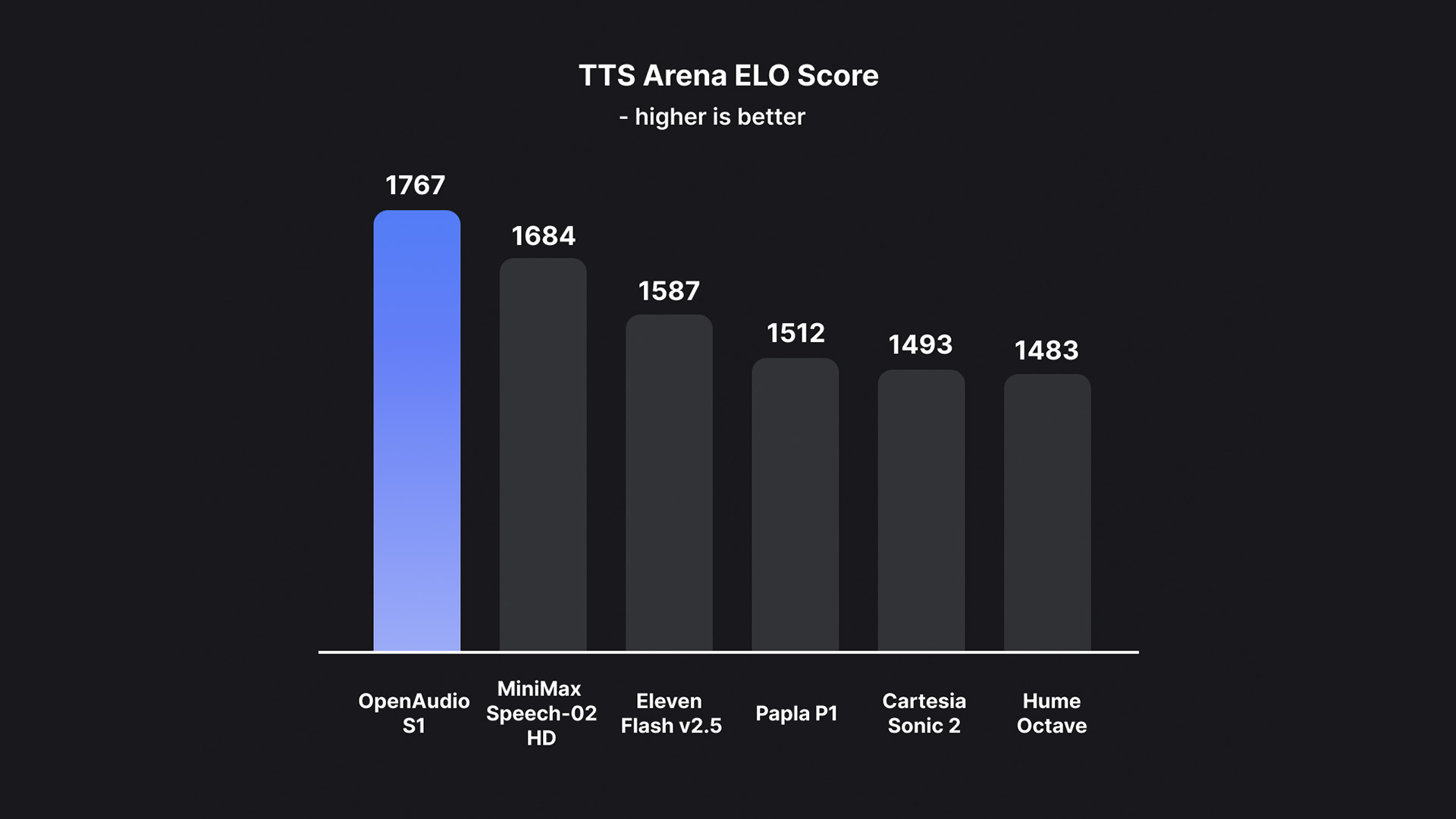
TTS-Arena2 最佳模型 🏆
OpenAudio S1 在文本转语音评测基准 TTS-Arena2 上取得了 第一名 的成绩:
语音可控性
OpenAudio S1 支持多种情感、语气和特殊标记,进一步提升语音合成的表现力:
- 基础情感:
(angry) (sad) (excited) (surprised) (satisfied) (delighted)
(scared) (worried) (upset) (nervous) (frustrated) (depressed)
(empathetic) (embarrassed) (disgusted) (moved) (proud) (relaxed)
(grateful) (confident) (interested) (curious) (confused) (joyful)- 高级情感:
(disdainful) (unhappy) (anxious) (hysterical) (indifferent)
(impatient) (guilty) (scornful) (panicked) (furious) (reluctant)
(keen) (disapproving) (negative) (denying) (astonished) (serious)
(sarcastic) (conciliative) (comforting) (sincere) (sneering)
(hesitating) (yielding) (painful) (awkward) (amused)- 语气标记:
(in a hurry tone) (shouting) (screaming) (whispering) (soft tone)- 特殊音效:
(laughing) (chuckling) (sobbing) (crying loudly) (sighing) (panting)
(groaning) (crowd laughing) (background laughter) (audience laughing)你还可以使用 Ha,ha,ha 进行控制,更多用法等你自行探索。
(目前支持英文、中文和日语,更多语言即将上线!)
两种模型类型
| 模型 | 参数量 | 可用性 | 特性 | |-------|------|--------------|----------| | S1 | 40亿参数 | 可在 fish.audio 获取 | 全功能旗舰版 | | S1-mini | 5亿参数 | 可在 huggingface hf space 获取 | 精简核心功能版 |
S1 与 S1-mini 均集成了在线人类反馈强化学习(RLHF)。
功能特性
- 零样本 & 少样本 TTS: 输入 10-30 秒的人声样本,即可生成高质量 TTS 结果。详见 声音克隆最佳实践。
- 多语言 & 跨语言支持: 直接复制粘贴多语言文本到输入框,无需担心语种。目前支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语。
- 无需音素依赖: 模型具备强泛化能力,无需依赖音素即可实现 TTS,支持任意语言文本输入。
- 高准确率: Seed-TTS 评测中,CER(字符错误率)约为 0.4%,WER(词错误率)约为 0.8%。
- 推理速度快: 采用 fish-tech 加速,Nvidia RTX 4060 笔记本实测实时因子约为 1:5,Nvidia RTX 4090 为 1:15。
- WebUI 推理: 提供基于 Gradio 的易用网页界面,兼容 Chrome、Firefox、Edge 等主流浏览器。
- GUI 推理: 提供 PyQt6 图形界面,与 API 服务器无缝协作。支持 Linux、Windows、macOS。查看 GUI。
- 易于部署: 可轻松搭建推理服务器,原生支持 Linux、Windows(MacOS 即将支持),速度损耗极小。
媒体与演示
社交媒体
在线演示
视频展示

音频样例
文档
致谢
技术报告 (V1.4)
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},