


[!IMPORTANT]
Aviso de Licencia
Este repositorio de código se publica bajo la Licencia Apache y todos los pesos de los modelos se publican bajo la Licencia CC-BY-NC-SA-4.0. Por favor, consulte LICENSE para más detalles.
[!WARNING]
Descargo de Responsabilidad Legal
No asumimos ninguna responsabilidad por el uso ilegal de este repositorio. Por favor, consulte las leyes locales sobre DMCA y otras leyes relacionadas.
🎉 Anuncio
Nos complace anunciar que nos hemos renovado como OpenAudio — presentando una nueva serie revolucionaria de avanzados modelos de Texto a Voz que se basa en la fundación de Fish-Speech.
Nos enorgullece lanzar OpenAudio-S1 como el primer modelo de esta serie, ofreciendo mejoras significativas en calidad, rendimiento y capacidades.
OpenAudio-S1 está disponible en dos versiones: OpenAudio-S1 y OpenAudio-S1-mini. Ambos modelos están disponibles en Fish Audio Playground (para OpenAudio-S1) y en Hugging Face (para OpenAudio-S1-mini).
Visita el sitio web de OpenAudio para el blog e informe técnico.
Destacados ✨
Excelente calidad TTS
Utilizamos las métricas de evaluación Seed TTS Eval Metrics para evaluar el rendimiento del modelo, y los resultados muestran que OpenAudio S1 alcanza 0.008 WER y 0.004 CER en texto en inglés, lo que es significativamente mejor que modelos anteriores. (Inglés, evaluación automática, basada en OpenAI gpt-4o-transcribe, distancia del hablante usando Revai/pyannote-wespeaker-voxceleb-resnet34-LM)
| Modelo | Tasa de Error de Palabras (WER) | Tasa de Error de Caracteres (CER) | Distancia del Hablante | |--------|-------------------------------|-------------------------------|------------------------| | S1 | 0.008 | 0.004 | 0.332 | | S1-mini | 0.011 | 0.005 | 0.380 |
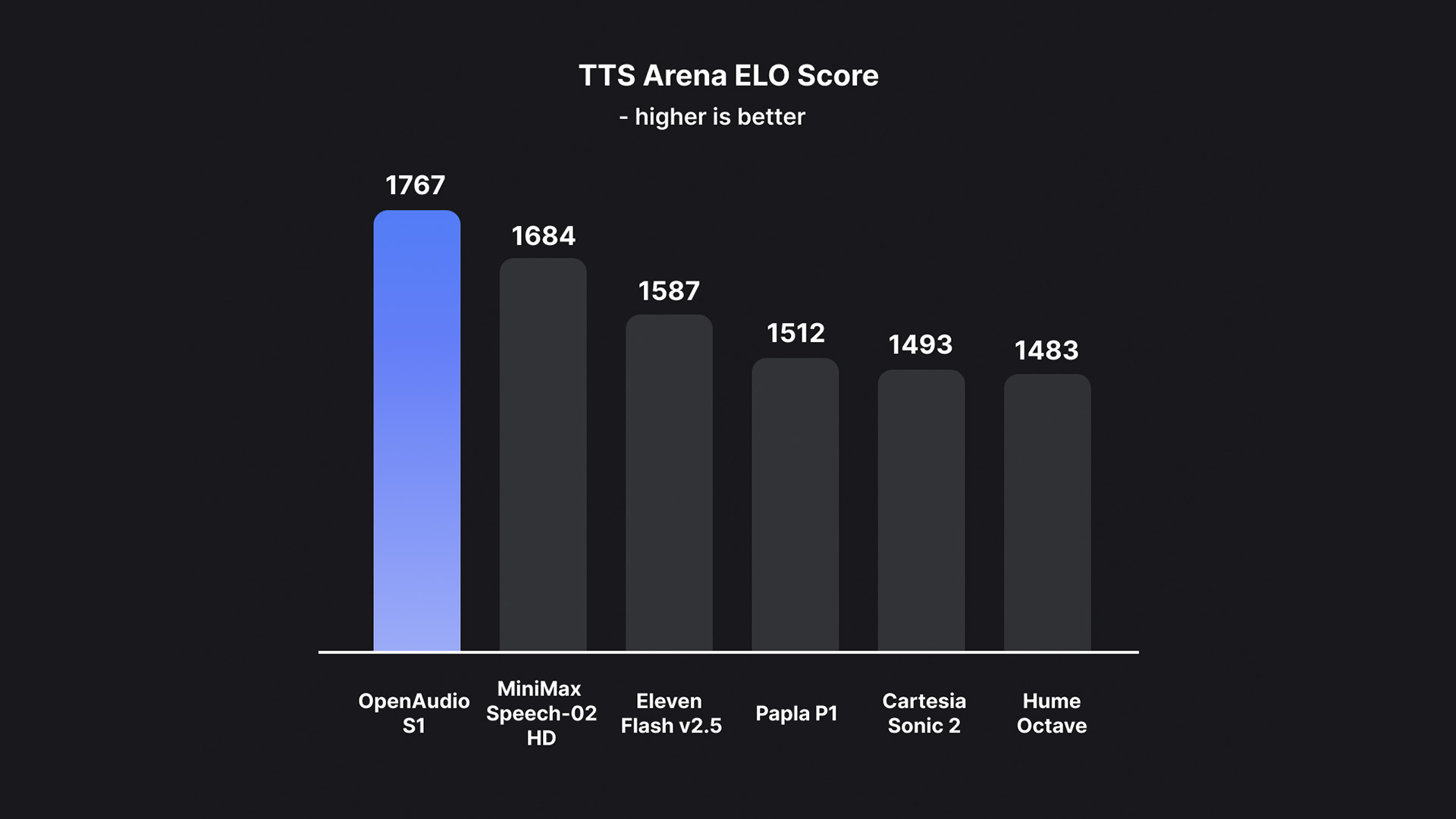
Mejor Modelo en TTS-Arena2 🏆
OpenAudio S1 ha logrado el puesto #1 en TTS-Arena2, el benchmark para la evaluación de texto a voz:
Control de Voz
OpenAudio S1 soporta una variedad de emociones, tonos y marcadores especiales para mejorar la síntesis de voz:
- Emociones básicas:
(angry) (sad) (excited) (surprised) (satisfied) (delighted)
(scared) (worried) (upset) (nervous) (frustrated) (depressed)
(empathetic) (embarrassed) (disgusted) (moved) (proud) (relaxed)
(grateful) (confident) (interested) (curious) (confused) (joyful)- Emociones avanzadas:
(disdainful) (unhappy) (anxious) (hysterical) (indifferent)
(impatient) (guilty) (scornful) (panicked) (furious) (reluctant)
(keen) (disapproving) (negative) (denying) (astonished) (serious)
(sarcastic) (conciliative) (comforting) (sincere) (sneering)
(hesitating) (yielding) (painful) (awkward) (amused)- Marcadores de tono:
(in a hurry tone) (shouting) (screaming) (whispering) (soft tone)- Efectos de audio especiales:
(laughing) (chuckling) (sobbing) (crying loudly) (sighing) (panting)
(groaning) (crowd laughing) (background laughter) (audience laughing)También puedes usar Ha,ha,ha para controlar, hay muchos otros casos esperando ser explorados por ti mismo.
(¡Actualmente soporta inglés, chino y japonés, y pronto habrá más idiomas!)
Dos Tipos de Modelos
| Modelo | Tamaño | Disponibilidad | Características | |--------|--------|----------------|-----------------| | S1 | 4B parámetros | Disponible en fish.audio | Modelo insignia con todas las funciones | | S1-mini | 0.5B parámetros | Disponible en huggingface hf space | Versión destilada con capacidades principales |
Tanto S1 como S1-mini incorporan aprendizaje por refuerzo en línea a partir de retroalimentación humana (RLHF).
Características
- TTS Zero-shot & Few-shot: Ingresa una muestra vocal de 10 a 30 segundos para generar una salida TTS de alta calidad. Para pautas detalladas, consulta Mejores Prácticas de Clonado de Voz.
- Soporte multilingüe y cruzado: Simplemente copia y pega texto multilingüe en el cuadro de entrada—no te preocupes por el idioma. Actualmente soporta inglés, japonés, coreano, chino, francés, alemán, árabe y español.
- Sin dependencia de fonemas: El modelo tiene fuertes capacidades de generalización y no depende de fonemas para TTS. Puede manejar texto en cualquier sistema de escritura de idioma.
- Alta precisión: Alcanza un CER (Tasa de Error de Caracteres) bajo, alrededor del 0.4% y un WER (Tasa de Error de Palabras) de alrededor del 0.8% para Seed-TTS Eval.
- Rápido: Con aceleración fish-tech, el factor de tiempo real es aproximadamente 1:5 en una laptop Nvidia RTX 4060 y 1:15 en una Nvidia RTX 4090.
- Inferencia WebUI: Cuenta con una interfaz web fácil de usar basada en Gradio, compatible con Chrome, Firefox, Edge y otros navegadores.
- Inferencia GUI: Ofrece una interfaz gráfica PyQt6 que funciona perfectamente con el servidor API. Soporta Linux, Windows y macOS. Ver GUI.
- Amigable para despliegue: Configura fácilmente un servidor de inferencia con soporte nativo para Linux, Windows (MacOS próximamente), minimizando la pérdida de velocidad.
Medios y Demos
Redes Sociales
Demos Interactivas
Demostraciones en Video

Muestras de Audio
Documentos
Créditos
Informe Técnico (V1.4)
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}