English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Hãy dịch hướng dẫn này!
Hướng Dẫn Thiết Kế Hệ Thống

Động lực
Học cách thiết kế các hệ thống quy mô lớn.>
Chuẩn bị cho phỏng vấn thiết kế hệ thống.
Học cách thiết kế hệ thống quy mô lớn
Học cách thiết kế các hệ thống có khả năng mở rộng sẽ giúp bạn trở thành một kỹ sư giỏi hơn.
Thiết kế hệ thống là một chủ đề rộng. Có rất nhiều tài nguyên phân tán trên web về các nguyên tắc thiết kế hệ thống.
Kho lưu trữ này là một bộ sưu tập tổ chức các tài nguyên để giúp bạn học cách xây dựng hệ thống ở quy mô lớn.
Học hỏi từ cộng đồng mã nguồn mở
Đây là một dự án mã nguồn mở, được cập nhật liên tục.
Đóng góp luôn được hoan nghênh!
Chuẩn bị cho phỏng vấn thiết kế hệ thống
Bên cạnh các cuộc phỏng vấn lập trình, thiết kế hệ thống là một thành phần bắt buộc trong quy trình phỏng vấn kỹ thuật tại nhiều công ty công nghệ.
Thực hành các câu hỏi phỏng vấn thiết kế hệ thống phổ biến và so sánh kết quả của bạn với các giải pháp mẫu: thảo luận, mã nguồn và sơ đồ.
Các chủ đề bổ sung để chuẩn bị phỏng vấn:
- Hướng dẫn học tập
- Cách tiếp cận một câu hỏi phỏng vấn thiết kế hệ thống
- Các câu hỏi phỏng vấn thiết kế hệ thống, có giải pháp
- Các câu hỏi phỏng vấn thiết kế hướng đối tượng, có giải pháp
- Các câu hỏi phỏng vấn thiết kế hệ thống bổ sung
Thẻ ghi nhớ Anki
Bộ thẻ ghi nhớ Anki được cung cấp sử dụng phương pháp lặp lại ngắt quãng giúp bạn ghi nhớ các khái niệm thiết kế hệ thống quan trọng.
Rất tiện lợi khi sử dụng lúc di chuyển.Tài nguyên lập trình: Thử thách Lập trình Tương tác
Bạn đang tìm kiếm tài nguyên để luyện tập cho Phỏng vấn Lập trình?
Hãy xem kho lưu trữ chị em Thử thách Lập trình Tương tác, trong đó có thêm một bộ thẻ Anki:
Đóng góp
Học hỏi từ cộng đồng.
Bạn hoàn toàn có thể gửi pull request để giúp:
- Sửa lỗi
- Cải thiện các phần
- Thêm các mục mới
- Dịch
Xem lại Hướng dẫn đóng góp.
Mục lục các chủ đề thiết kế hệ thống
Tóm tắt các chủ đề thiết kế hệ thống khác nhau, bao gồm ưu và nhược điểm. Mọi thứ đều là sự đánh đổi.>
Mỗi mục đều có liên kết đến các tài liệu chuyên sâu hơn.
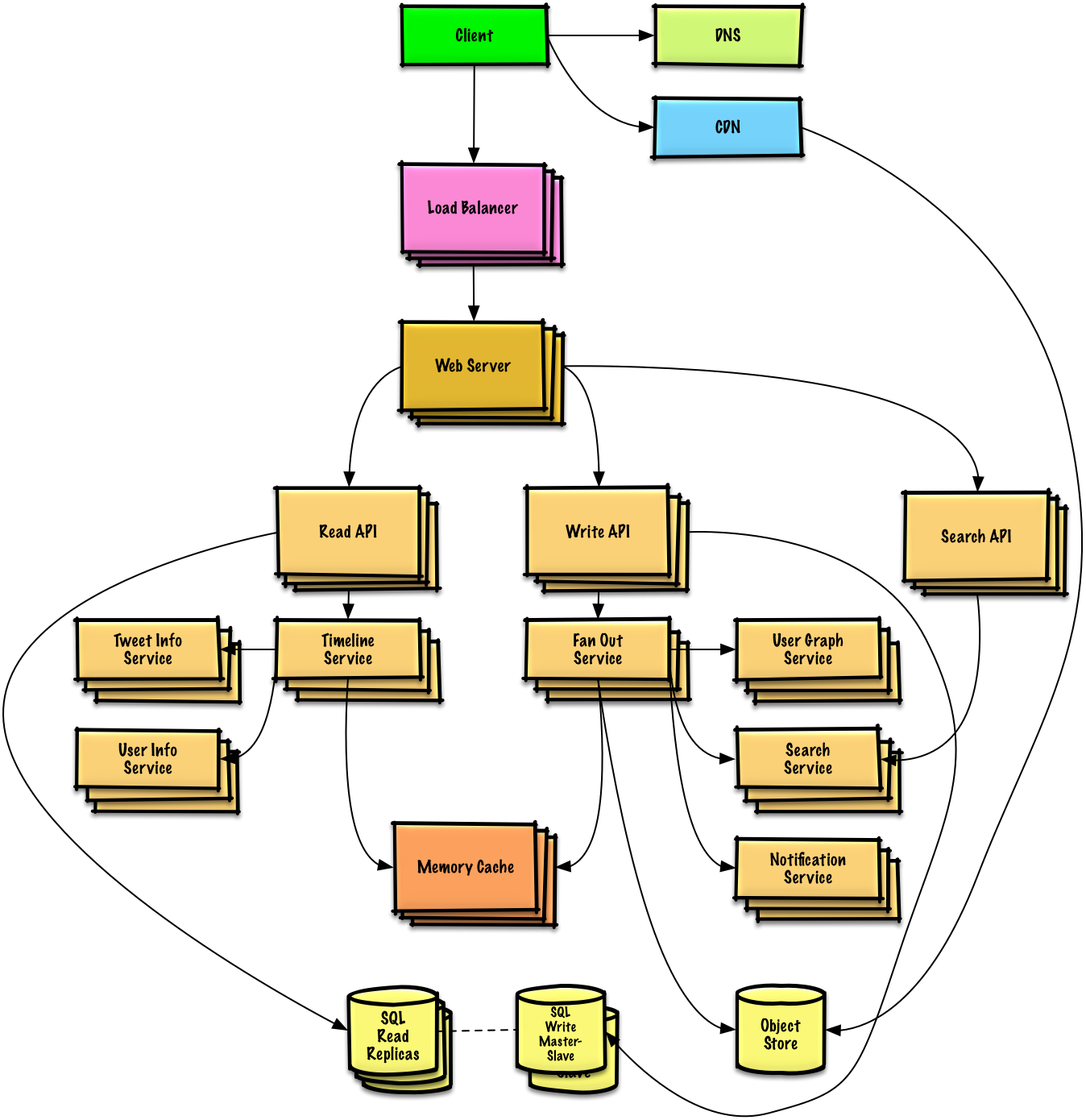
- Chủ đề thiết kế hệ thống: bắt đầu tại đây
- Bước 1: Xem lại bài giảng video về khả năng mở rộng
- Bước 2: Xem lại bài viết về khả năng mở rộng
- Các bước tiếp theo
- Hiệu năng so với khả năng mở rộng
- Độ trễ so với thông lượng
- Khả dụng so với tính nhất quán
- Định lý CAP
- CP - tính nhất quán và chịu phân vùng
- AP - khả dụng và chịu phân vùng
- Các mẫu nhất quán
- Nhất quán yếu
- Nhất quán cuối cùng
- Nhất quán mạnh
- Các mẫu khả dụng
- Chuyển đổi dự phòng
- Sao chép dữ liệu
- Khả dụng theo các con số
- Hệ thống tên miền
- Mạng phân phối nội dung
- Push CDN
- Pull CDN
- Bộ cân bằng tải
- Hoạt động chủ động - bị động
- Hoạt động chủ động - chủ động
- Cân bằng tải tầng 4
- Cân bằng tải tầng 7
- Mở rộng theo chiều ngang
- Proxy đảo chiều (máy chủ web)
- Bộ cân bằng tải vs proxy đảo chiều
- Tầng ứng dụng
- Kiến trúc vi dịch vụ
- Khám phá dịch vụ
- Cơ sở dữ liệu
- Hệ quản trị cơ sở dữ liệu quan hệ (RDBMS)
- Sao chép chủ-tớ
- Sao chép chủ-chủ
- Liên kết liên bang
- Phân mảnh dữ liệu
- Phi chuẩn hóa dữ liệu
- Tối ưu hóa SQL
- NoSQL
- Lưu trữ dạng khóa-giá trị
- Lưu trữ tài liệu
- Lưu trữ cột rộng
- Cơ sở dữ liệu đồ thị
- SQL hay NoSQL
- Bộ nhớ đệm
- Bộ nhớ đệm phía khách hàng
- Bộ nhớ đệm CDN
- Bộ nhớ đệm máy chủ web
- Bộ nhớ đệm cơ sở dữ liệu
- Bộ nhớ đệm ứng dụng
- Bộ nhớ đệm ở mức truy vấn cơ sở dữ liệu
- Bộ nhớ đệm ở mức đối tượng
- Khi nào cập nhật bộ nhớ đệm
- Cache-aside
- Ghi-thẳng
- Ghi-ngầm (ghi-lại)
- Làm mới trước
- Tính phi đồng bộ
- Hàng đợi tin nhắn
- Hàng đợi tác vụ
- Áp lực ngược
- Giao tiếp
- Giao thức điều khiển truyền tải (TCP)
- Giao thức datagram người dùng (UDP)
- Gọi thủ tục từ xa (RPC)
- Chuyển trạng thái đại diện (REST)
- Bảo mật
- Phụ lục
- Bảng lũy thừa của hai
- Các số liệu độ trễ mà mọi lập trình viên nên biết
- Các câu hỏi phỏng vấn thiết kế hệ thống bổ sung
- Kiến trúc thực tế
- Kiến trúc công ty
- Blog kỹ thuật công ty
- Đang phát triển
- Ghi nhận
- Thông tin liên hệ
- Giấy phép
Hướng dẫn học tập
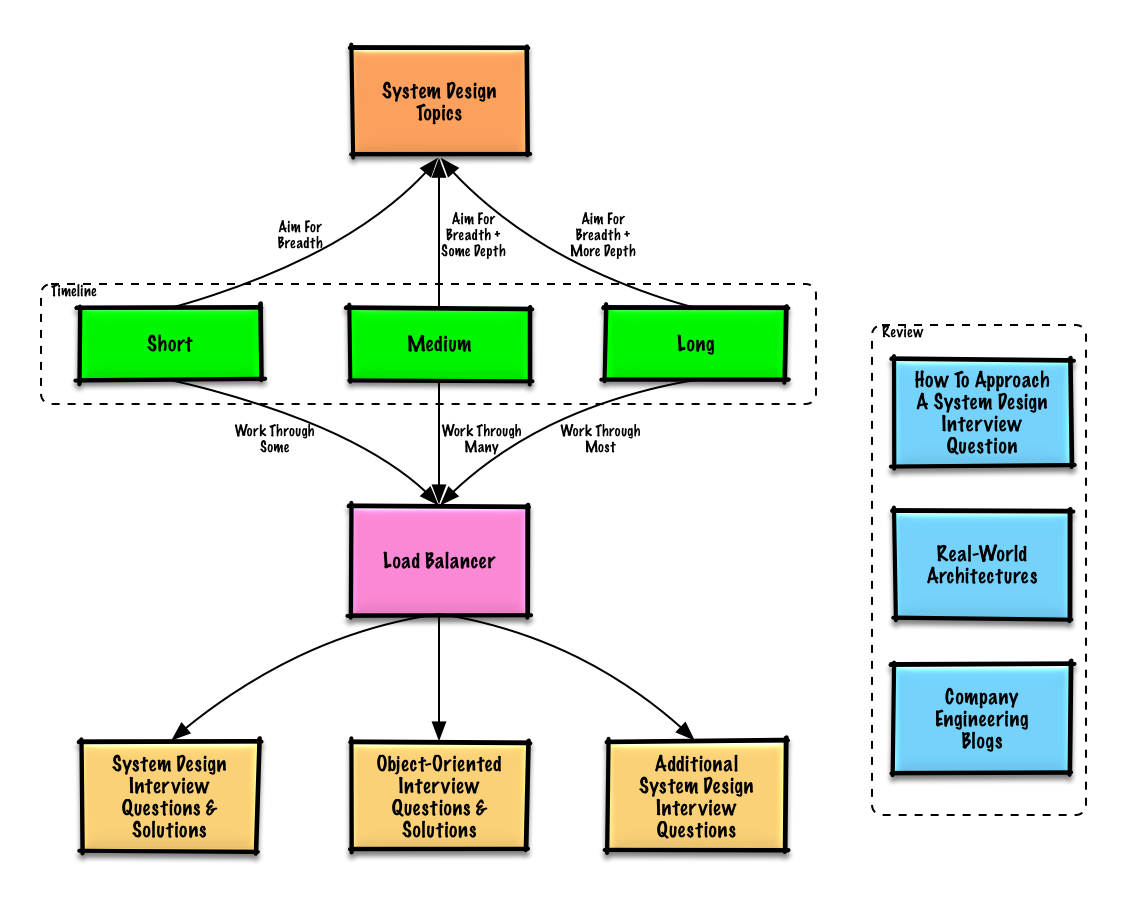
Các chủ đề gợi ý để ôn tập dựa trên thời gian phỏng vấn của bạn (ngắn, trung bình, dài).
Q: Để phỏng vấn, tôi có cần biết tất cả mọi thứ ở đây không?
A: Không, bạn không cần phải biết tất cả mọi thứ ở đây để chuẩn bị cho buổi phỏng vấn.
Những gì bạn được hỏi trong buổi phỏng vấn phụ thuộc vào các biến số như:
- Bạn có bao nhiêu kinh nghiệm
- Nền tảng kỹ thuật của bạn là gì
- Bạn đang phỏng vấn cho vị trí nào
- Bạn đang phỏng vấn với công ty nào
- May mắn
Bắt đầu từ tổng quan và đi sâu vào một vài lĩnh vực nhất định. Việc biết một chút về các chủ đề thiết kế hệ thống quan trọng sẽ rất hữu ích. Điều chỉnh hướng dẫn dưới đây dựa trên thời gian, kinh nghiệm, vị trí bạn đang phỏng vấn và công ty bạn ứng tuyển.
- Thời gian ngắn - Nhắm đến độ rộng với các chủ đề thiết kế hệ thống. Luyện tập bằng cách giải một số câu hỏi phỏng vấn.
- Thời gian trung bình - Nhắm đến độ rộng và một số chiều sâu với các chủ đề thiết kế hệ thống. Luyện tập bằng cách giải nhiều câu hỏi phỏng vấn.
- Thời gian dài - Nhắm đến độ rộng và nhiều chiều sâu hơn với các chủ đề thiết kế hệ thống. Luyện tập bằng cách giải hầu hết các câu hỏi phỏng vấn.
Cách tiếp cận câu hỏi phỏng vấn thiết kế hệ thống
Cách giải quyết một câu hỏi phỏng vấn thiết kế hệ thống.
Phỏng vấn thiết kế hệ thống là một cuộc trò chuyện mở. Bạn được mong đợi sẽ dẫn dắt buổi phỏng vấn.
Bạn có thể sử dụng các bước sau để định hướng cuộc thảo luận. Để củng cố quy trình này, hãy luyện tập với Câu hỏi phỏng vấn thiết kế hệ thống có đáp án sử dụng các bước sau.
Bước 1: Phác thảo các trường hợp sử dụng, ràng buộc, và giả định
Thu thập yêu cầu và xác định phạm vi vấn đề. Đặt câu hỏi để làm rõ trường hợp sử dụng và các ràng buộc. Thảo luận về các giả định.
- Ai sẽ sử dụng nó?
- Họ sẽ sử dụng nó như thế nào?
- Có bao nhiêu người dùng?
- Hệ thống sẽ làm gì?
- Đầu vào và đầu ra của hệ thống là gì?
- Dự kiến sẽ xử lý bao nhiêu dữ liệu?
- Dự kiến có bao nhiêu yêu cầu mỗi giây?
- Tỷ lệ đọc/ghi dự kiến là bao nhiêu?
Bước 2: Tạo thiết kế cấp cao
Phác thảo thiết kế tổng quan với tất cả các thành phần quan trọng.
- Phác thảo các thành phần chính và kết nối
- Giải thích lý do cho các ý tưởng của bạn
Bước 3: Thiết kế các thành phần cốt lõi
Đi sâu vào chi tiết cho từng thành phần cốt lõi. Ví dụ, nếu bạn được yêu cầu thiết kế dịch vụ rút gọn url, hãy thảo luận:
- Tạo và lưu trữ một hash của toàn bộ url
- MD5 và Base62
- Va chạm hash
- SQL hoặc NoSQL
- Lược đồ cơ sở dữ liệu
- Chuyển đổi url đã băm về url đầy đủ
- Truy vấn cơ sở dữ liệu
- Thiết kế API và hướng đối tượng
Bước 4: Mở rộng thiết kế
Xác định và giải quyết các điểm nghẽn, dựa trên các ràng buộc. Ví dụ, bạn có cần các yếu tố sau để xử lý vấn đề mở rộng?
- Bộ cân bằng tải
- Mở rộng ngang
- Bộ nhớ đệm
- Phân mảnh cơ sở dữ liệu
Tính toán sơ bộ
Bạn có thể được yêu cầu thực hiện một số ước tính bằng tay. Tham khảo Phụ lục cho các nguồn sau:
Nguồn và tài liệu đọc thêm
Xem các liên kết sau để có ý tưởng rõ hơn về những gì sẽ gặp phải:
- Cách vượt qua phỏng vấn thiết kế hệ thống
- Phỏng vấn thiết kế hệ thống
- Giới thiệu về phỏng vấn kiến trúc và thiết kế hệ thống
- Mẫu thiết kế hệ thống
Các câu hỏi phỏng vấn thiết kế hệ thống kèm giải pháp
Các câu hỏi phỏng vấn thiết kế hệ thống phổ biến kèm thảo luận mẫu, mã nguồn, và sơ đồ.>
Các giải pháp liên kết đến nội dung trong thư mục solutions/.| Câu hỏi | | |---|---| | Thiết kế Pastebin.com (hoặc Bit.ly) | Giải pháp | | Thiết kế dòng thời gian và tìm kiếm của Twitter (hoặc bảng tin và tìm kiếm của Facebook) | Giải pháp | | Thiết kế trình thu thập dữ liệu web | Giải pháp | | Thiết kế Mint.com | Giải pháp | | Thiết kế cấu trúc dữ liệu cho mạng xã hội | Giải pháp | | Thiết kế khoá-giá trị cho công cụ tìm kiếm | Giải pháp | | Thiết kế tính năng xếp hạng bán hàng theo danh mục của Amazon | Giải pháp | | Thiết kế hệ thống mở rộng cho hàng triệu người dùng trên AWS | Giải pháp | | Thêm câu hỏi thiết kế hệ thống | Đóng góp |
Thiết kế Pastebin.com (hoặc Bit.ly)
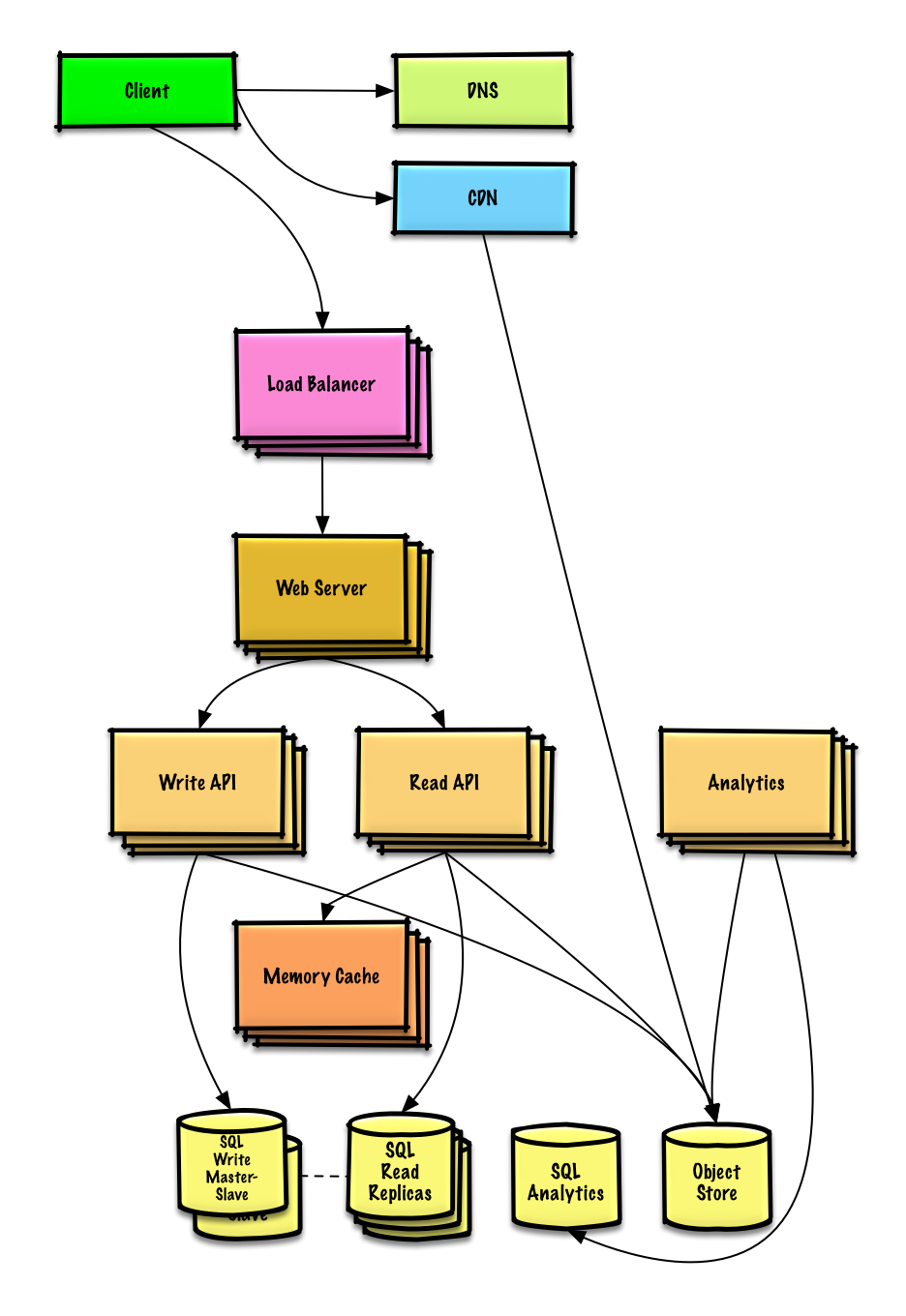
Thiết kế dòng thời gian và tìm kiếm của Twitter (hoặc bảng tin và tìm kiếm của Facebook)
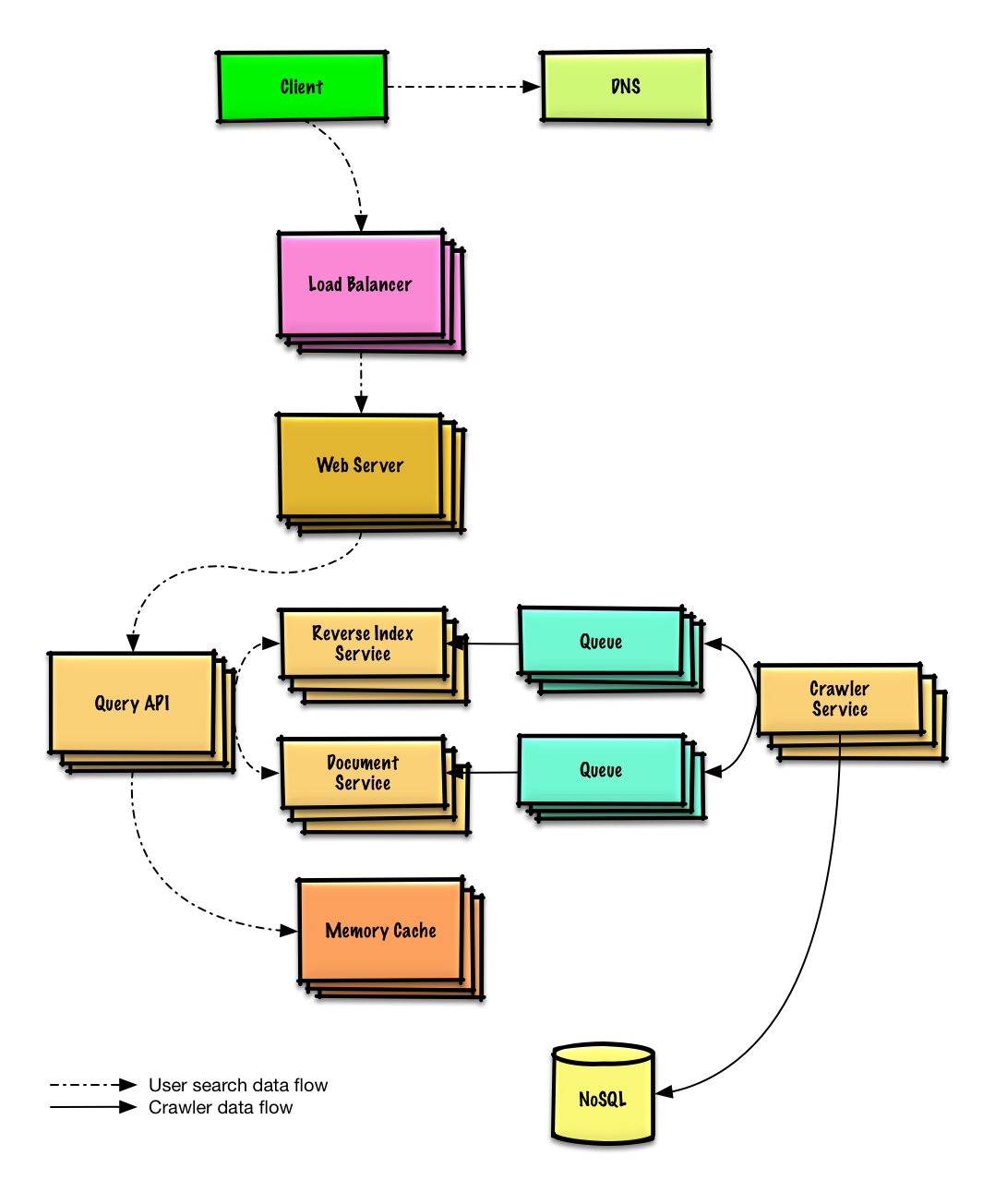
Thiết kế trình thu thập dữ liệu web
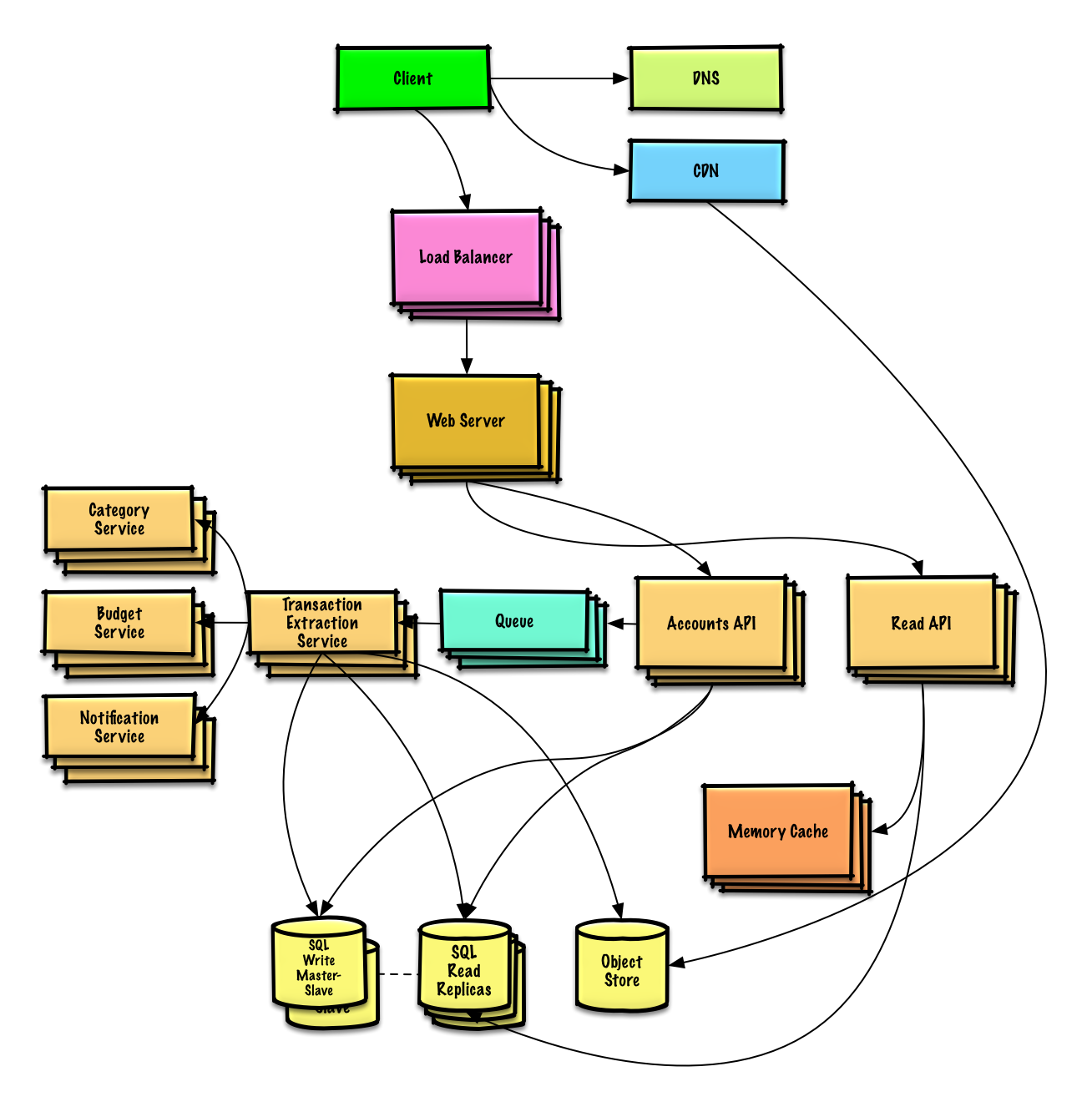
Design Mint.com
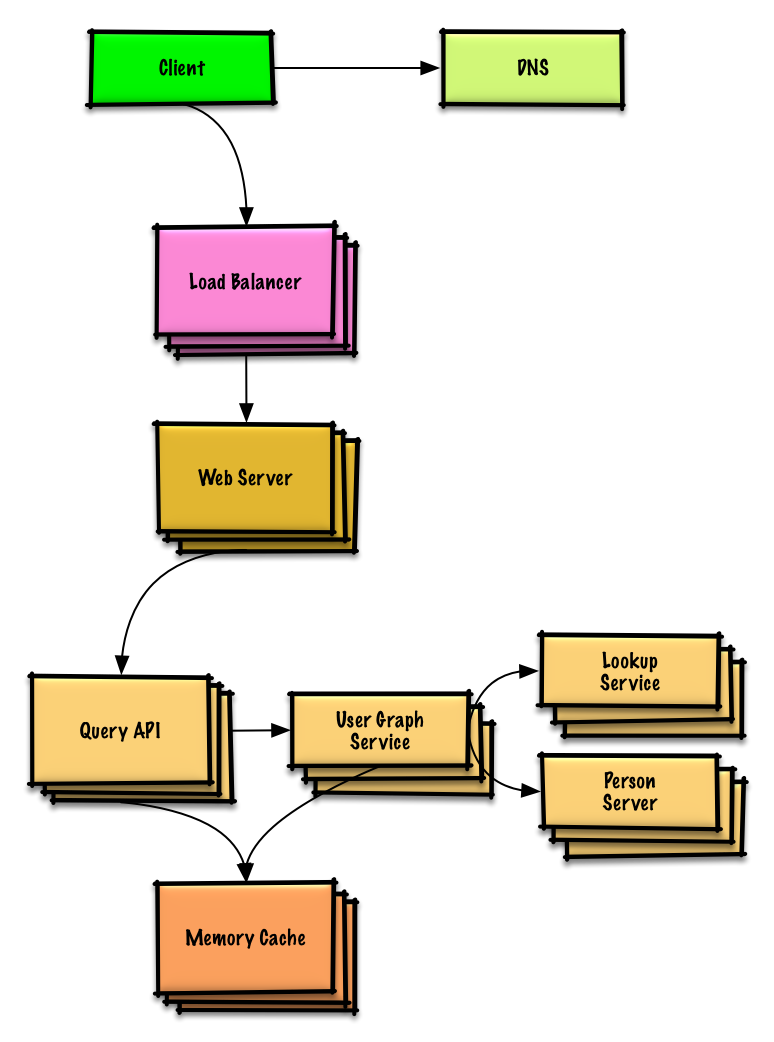
Design the data structures for a social network
Design a key-value store for a search engine
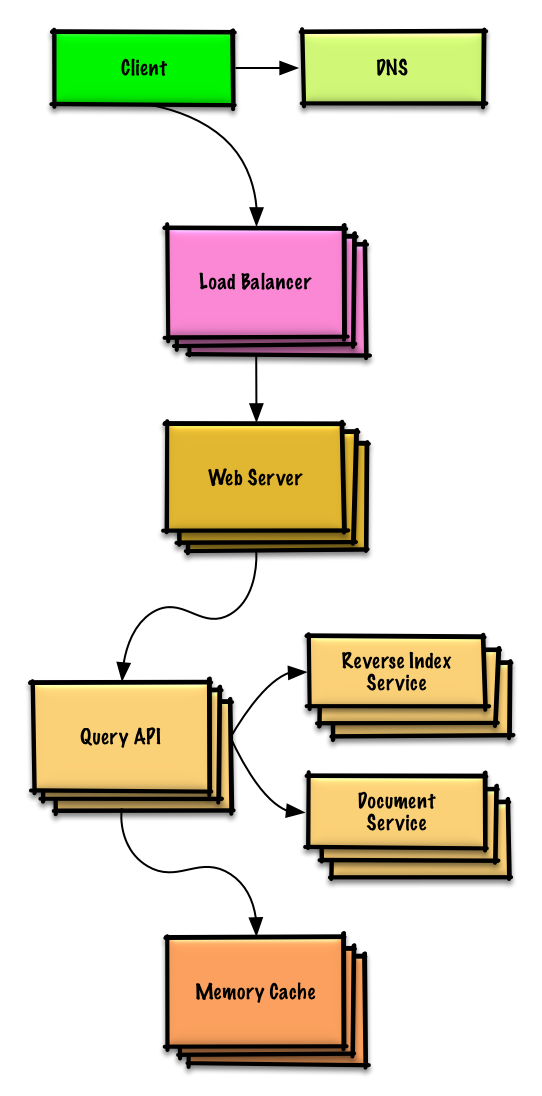
Design Amazon's sales ranking by category feature
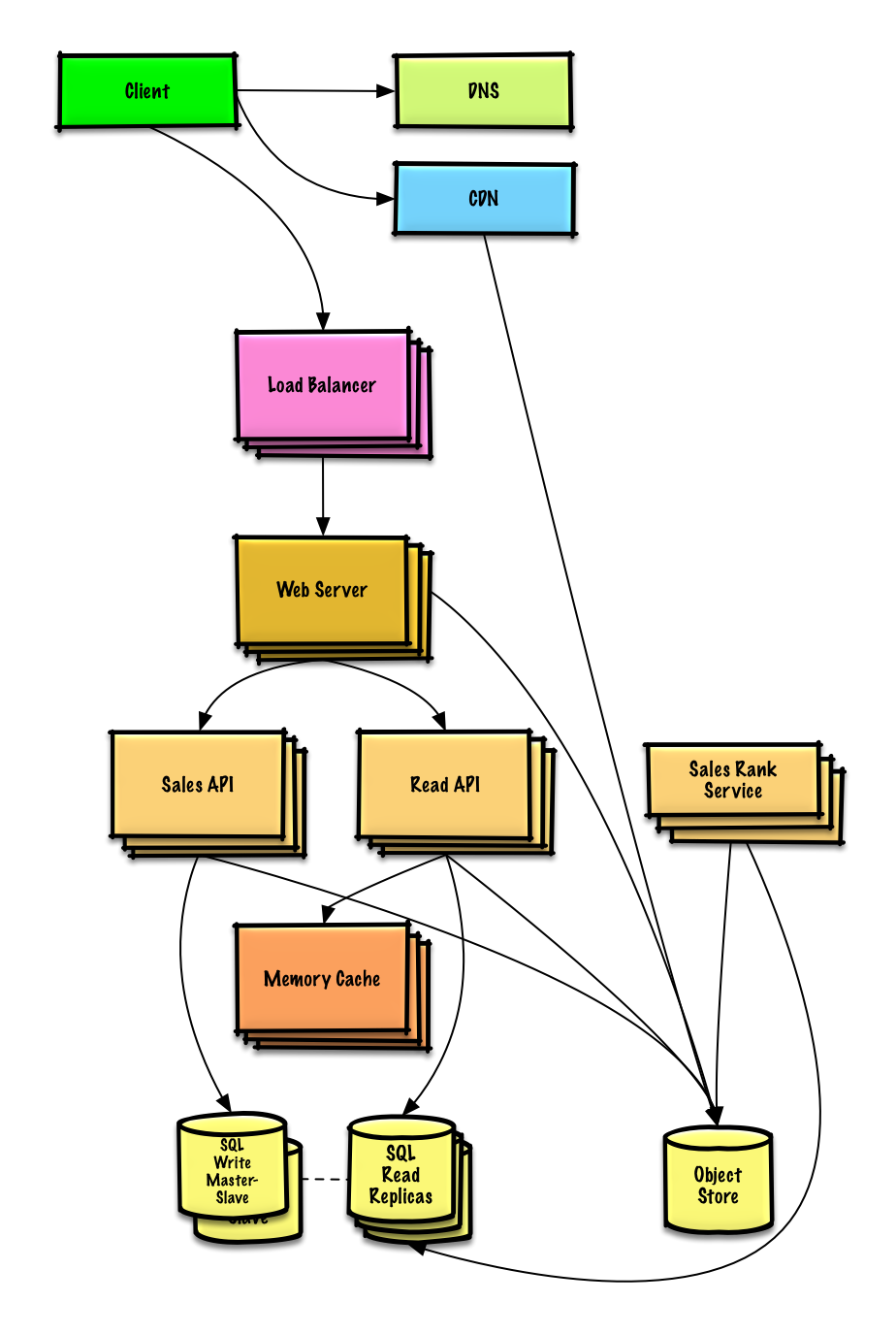
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Thiết kế một bảng băm | Giải pháp | | Thiết kế bộ nhớ đệm truy xuất gần nhất (LRU cache) | Giải pháp | | Thiết kế tổng đài điện thoại | Giải pháp | | Thiết kế bộ bài | Giải pháp | | Thiết kế bãi đậu xe | Giải pháp | | Thiết kế máy chủ chat | Giải pháp | | Thiết kế mảng vòng tròn | Đóng góp | | Thêm một câu hỏi thiết kế hướng đối tượng | Đóng góp |
Chủ đề thiết kế hệ thống: bắt đầu từ đây
Bạn mới làm quen với thiết kế hệ thống?
Trước tiên, bạn cần hiểu cơ bản về các nguyên tắc phổ biến, tìm hiểu chúng là gì, cách sử dụng, và điểm mạnh/yếu của chúng.
Bước 1: Xem bài giảng video về khả năng mở rộng
Bài giảng về khả năng mở rộng tại Harvard
- Các chủ đề bao gồm:
- Mở rộng theo chiều dọc
- Mở rộng theo chiều ngang
- Bộ nhớ đệm
- Cân bằng tải
- Nhân bản cơ sở dữ liệu
- Phân vùng cơ sở dữ liệu
Bước 2: Đọc bài viết về khả năng mở rộng
- Các chủ đề bao gồm:
- Bản sao
- Cơ sở dữ liệu
- Bộ nhớ đệm
- Tính bất đồng bộ
Các bước tiếp theo
Tiếp theo, chúng ta sẽ xem xét các sự đánh đổi ở cấp độ cao:
- Hiệu năng so với khả năng mở rộng
- Độ trễ so với thông lượng
- Khả dụng so với tính nhất quán
Sau đó, chúng ta sẽ đi sâu vào các chủ đề cụ thể hơn như DNS, CDN, và bộ cân bằng tải.
Hiệu năng vs khả năng mở rộng
Một dịch vụ được gọi là có khả năng mở rộng nếu nó có thể tăng hiệu năng theo tỷ lệ với tài nguyên được thêm vào. Thông thường, tăng hiệu năng nghĩa là phục vụ được nhiều đơn vị công việc hơn, nhưng nó cũng có thể là xử lý các đơn vị công việc lớn hơn, ví dụ như khi bộ dữ liệu tăng lên.1
Một cách khác để nhìn nhận về hiệu năng và khả năng mở rộng:
- Nếu bạn có vấn đề về hiệu năng, hệ thống của bạn chậm đối với một người dùng đơn lẻ.
- Nếu bạn có vấn đề về khả năng mở rộng, hệ thống của bạn nhanh với một người dùng đơn lẻ nhưng chậm khi tải lớn.
Nguồn và đọc thêm
Độ trễ vs thông lượng
Độ trễ là thời gian để thực hiện một hành động hoặc tạo ra một kết quả.
Thông lượng là số lượng các hành động hoặc kết quả đó trên mỗi đơn vị thời gian.
Thông thường, bạn nên hướng tới thông lượng tối đa với độ trễ chấp nhận được.
Nguồn và đọc thêm
Khả dụng vs tính nhất quán
Định lý CAP
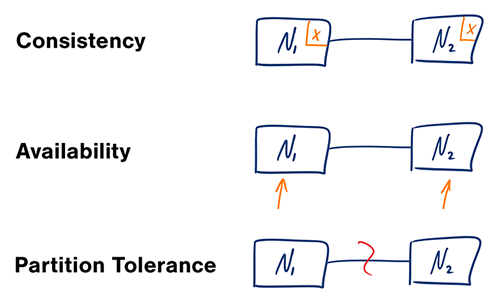
Trong một hệ thống máy tính phân tán, bạn chỉ có thể đảm bảo hai trong ba yếu tố sau:
- Tính nhất quán (Consistency) - Mỗi lần đọc đều nhận được lần ghi mới nhất hoặc báo lỗi
- Tính sẵn sàng (Availability) - Mỗi yêu cầu đều nhận được phản hồi, nhưng không đảm bảo chứa phiên bản mới nhất của thông tin
- Chịu phân vùng (Partition Tolerance) - Hệ thống tiếp tục hoạt động mặc dù bị phân vùng tùy ý do lỗi mạng
#### CP - nhất quán và chịu phân vùng
Chờ phản hồi từ nút bị phân vùng có thể dẫn đến lỗi quá thời gian. CP là lựa chọn tốt nếu yêu cầu kinh doanh của bạn đòi hỏi đọc và ghi nguyên tử.
#### AP - sẵn sàng và chịu phân vùng
Phản hồi trả về phiên bản dữ liệu có sẵn nhất trên bất kỳ nút nào, có thể không phải là phiên bản mới nhất. Các thao tác ghi có thể mất thời gian để lan truyền khi phân vùng được giải quyết.
AP là lựa chọn phù hợp nếu nhu cầu kinh doanh cho phép tính nhất quán cuối cùng hoặc khi hệ thống cần tiếp tục hoạt động dù xảy ra lỗi bên ngoài.
Nguồn và tài liệu tham khảo
Các mẫu nhất quán
Khi có nhiều bản sao của cùng một dữ liệu, chúng ta phải lựa chọn cách đồng bộ để khách hàng có cái nhìn nhất quán về dữ liệu. Hãy nhớ lại định nghĩa về tính nhất quán từ định lý CAP - Mỗi lần đọc nhận được lần ghi mới nhất hoặc báo lỗi.
Nhất quán yếu
Sau một lần ghi, các lần đọc có thể thấy hoặc không thấy kết quả đó. Một cách tiếp cận nỗ lực tốt nhất được áp dụng.
Cách tiếp cận này thường thấy ở các hệ thống như memcached. Tính nhất quán yếu hoạt động tốt trong các trường hợp thời gian thực như VoIP, video chat và trò chơi nhiều người chơi trực tuyến. Ví dụ, nếu bạn đang gọi điện thoại và mất sóng trong vài giây, khi kết nối lại bạn sẽ không nghe được những gì đã nói trong lúc mất kết nối.
Tính nhất quán cuối cùng
Sau một lần ghi, các lần đọc cuối cùng sẽ thấy nó (thường trong vòng mili giây). Dữ liệu được sao chép bất đồng bộ.
Cách tiếp cận này được sử dụng trong các hệ thống như DNS và email. Tính nhất quán cuối cùng hoạt động tốt trong các hệ thống có độ khả dụng cao.
Tính nhất quán mạnh
Sau một lần ghi, các lần đọc sẽ thấy nó. Dữ liệu được sao chép đồng bộ.
Cách tiếp cận này được sử dụng trong hệ thống tệp và các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS). Tính nhất quán mạnh phù hợp với các hệ thống cần giao dịch.
Nguồn và tài liệu đọc thêm
Mô hình khả dụng
Có hai mô hình bổ trợ để hỗ trợ khả dụng cao: chuyển đổi dự phòng và sao chép dữ liệu.
Chuyển đổi dự phòng
#### Chủ động - bị động
Với chuyển đổi dự phòng chủ động - bị động, các tín hiệu nhịp tim được gửi giữa máy chủ chủ động và máy chủ bị động ở chế độ chờ. Nếu tín hiệu nhịp tim bị gián đoạn, máy chủ bị động sẽ tiếp nhận địa chỉ IP của máy chủ chủ động và tiếp tục dịch vụ.
Thời gian ngừng hoạt động phụ thuộc vào việc máy chủ bị động đã chạy ở chế độ chờ 'nóng' hay cần khởi động từ chế độ chờ 'lạnh'. Chỉ máy chủ chủ động xử lý lưu lượng.
Chuyển đổi dự phòng chủ động - bị động còn được gọi là chuyển đổi dự phòng chủ - tớ.
#### Chủ động - chủ động
Trong chuyển đổi dự phòng chủ động - chủ động, cả hai máy chủ đều xử lý lưu lượng, phân chia tải giữa chúng.
Nếu các máy chủ hướng ra công chúng, DNS cần biết về các địa chỉ IP công khai của cả hai máy chủ. Nếu các máy chủ hướng nội bộ, logic ứng dụng cần biết về cả hai máy chủ.
Chuyển đổi dự phòng chủ động - chủ động còn được gọi là chuyển đổi dự phòng chủ - chủ.
Nhược điểm: chuyển đổi dự phòng
- Chuyển đổi dự phòng (fail-over) yêu cầu thêm phần cứng và tăng độ phức tạp.
- Có khả năng mất dữ liệu nếu hệ thống chủ động gặp sự cố trước khi dữ liệu mới được ghi được sao chép sang hệ thống bị động.
Sao chép dữ liệu (Replication)
#### Mô hình chủ-tớ và chủ-chủ
Chủ đề này được thảo luận thêm trong phần Cơ sở dữ liệu:
Tỷ lệ sẵn sàng dưới dạng số liệu
Tỷ lệ sẵn sàng thường được định lượng bằng thời gian hoạt động (hoặc thời gian ngừng hoạt động) dưới dạng phần trăm thời gian dịch vụ có thể truy cập. Tỷ lệ sẵn sàng thường được đo bằng số lượng số 9--một dịch vụ có tỷ lệ sẵn sàng 99,99% được mô tả là có bốn số 9.
#### Tỷ lệ sẵn sàng 99,9% - ba số 9
| Thời lượng | Thời gian ngừng hoạt động chấp nhận được| |------------------------|-----------------------------------------| | Ngừng hoạt động mỗi năm| 8 giờ 45 phút 57 giây | | Ngừng hoạt động mỗi tháng| 43 phút 49,7 giây | | Ngừng hoạt động mỗi tuần| 10 phút 4,8 giây | | Ngừng hoạt động mỗi ngày| 1 phút 26,4 giây |
#### Tỷ lệ sẵn sàng 99,99% - bốn số 9
| Thời lượng | Thời gian ngừng hoạt động chấp nhận được| |------------------------|-----------------------------------------| | Ngừng hoạt động mỗi năm| 52 phút 35,7 giây | | Ngừng hoạt động mỗi tháng| 4 phút 23 giây | | Ngừng hoạt động mỗi tuần| 1 phút 5 giây | | Ngừng hoạt động mỗi ngày| 8,6 giây |
#### Tỷ lệ sẵn sàng song song so với tuần tự
Nếu một dịch vụ bao gồm nhiều thành phần có khả năng gặp sự cố, tỷ lệ sẵn sàng tổng thể của dịch vụ phụ thuộc vào việc các thành phần này được sắp xếp theo tuần tự hay song song.
###### Theo tuần tự
Tổng độ sẵn sàng giảm khi hai thành phần có độ sẵn sàng < 100% được kết nối nối tiếp:
Availability (Total) = Availability (Foo) * Availability (Bar)Nếu cả Foo và Bar đều có độ sẵn sàng 99,9%, tổng độ sẵn sàng của chúng khi nối tiếp sẽ là 99,8%.
###### Song song
Độ sẵn sàng tổng thể tăng lên khi hai thành phần có độ sẵn sàng < 100% được kết nối song song:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo và Bar đều có mức độ sẵn sàng 99,9%, tổng mức độ sẵn sàng khi chạy song song của chúng sẽ là 99,9999%.Hệ thống tên miền (Domain name system)
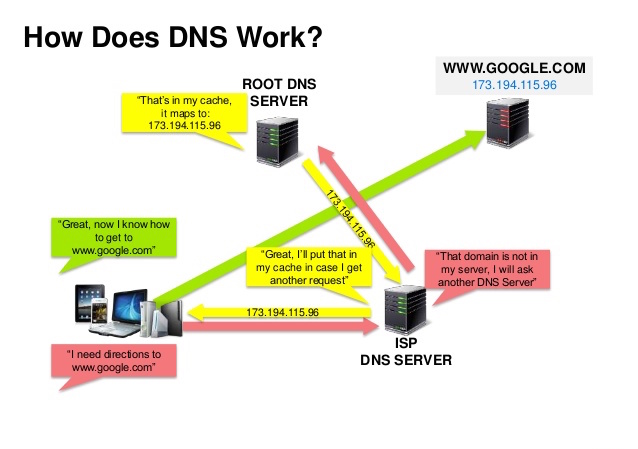
Nguồn: Bài thuyết trình về bảo mật DNS
Hệ thống tên miền (DNS) chuyển đổi một tên miền như www.example.com thành một địa chỉ IP.
DNS có cấu trúc phân cấp, với một vài máy chủ có thẩm quyền ở cấp cao nhất. Bộ định tuyến hoặc nhà cung cấp dịch vụ internet (ISP) của bạn cung cấp thông tin về máy chủ DNS cần liên hệ khi thực hiện truy vấn. Các máy chủ DNS cấp thấp hơn lưu bộ nhớ đệm các ánh xạ, có thể bị lỗi thời do độ trễ truyền bá DNS. Kết quả DNS cũng có thể được trình duyệt hoặc hệ điều hành của bạn lưu vào bộ đệm trong một khoảng thời gian nhất định, được xác định bởi thời gian tồn tại (TTL).
- Bản ghi NS (name server) - Chỉ định các máy chủ DNS cho miền/phụ miền của bạn.
- Bản ghi MX (mail exchange) - Chỉ định các máy chủ thư để nhận tin nhắn.
- Bản ghi A (address) - Trỏ một tên đến một địa chỉ IP.
- CNAME (canonical) - Trỏ một tên đến tên khác hoặc
CNAME(example.com đến www.example.com) hoặc đến bản ghiA.
- Vòng lặp trọng số
- Ngăn lưu lượng truy cập đến các máy chủ đang bảo trì
- Cân bằng giữa các cụm có kích thước khác nhau
- Kiểm thử A/B
- Dựa trên độ trễ
- Dựa trên vị trí địa lý
Nhược điểm: DNS
- Truy cập một máy chủ DNS gây ra độ trễ nhỏ, mặc dù đã được giảm nhẹ bởi cơ chế lưu bộ nhớ đệm như trên.
- Quản lý máy chủ DNS có thể phức tạp và thường được quản lý bởi chính phủ, ISP, và các công ty lớn.
- Các dịch vụ DNS gần đây đã bị tấn công DDoS, ngăn người dùng truy cập các website như Twitter nếu không biết địa chỉ IP của Twitter.
Nguồn và tài liệu đọc thêm
Mạng phân phối nội dung
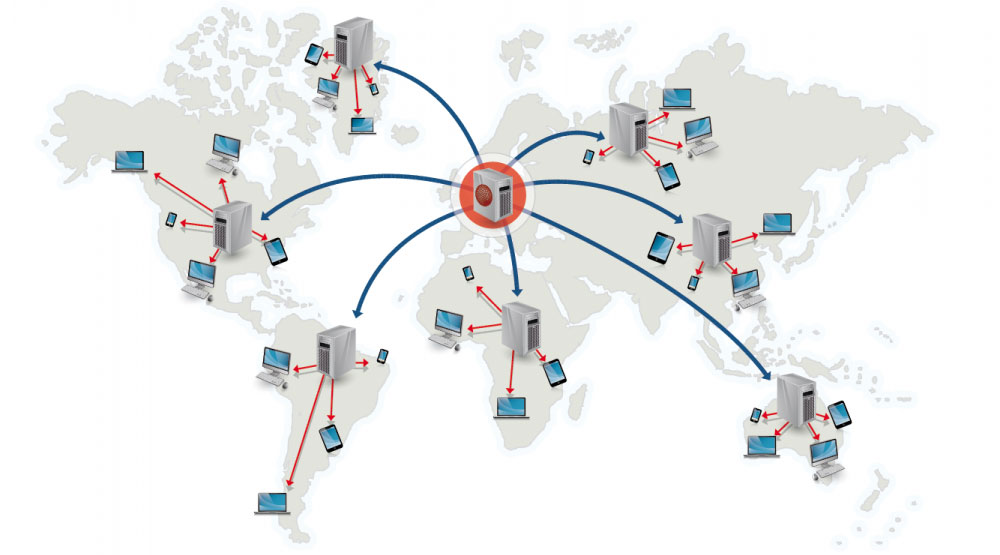
Mạng phân phối nội dung (CDN) là một mạng lưới các máy chủ proxy được phân phối toàn cầu, cung cấp nội dung từ các vị trí gần người dùng hơn. Thông thường, các tệp tĩnh như HTML/CSS/JS, ảnh và video được phục vụ từ CDN, mặc dù một số CDN như CloudFront của Amazon hỗ trợ cả nội dung động. Quá trình phân giải DNS của trang web sẽ cho khách truy cập biết nên liên hệ với máy chủ nào.
Việc cung cấp nội dung từ CDN có thể cải thiện hiệu suất đáng kể theo hai cách:
- Người dùng nhận nội dung từ trung tâm dữ liệu gần họ nhất
- Máy chủ của bạn không phải phục vụ các yêu cầu mà CDN đã đáp ứng
Push CDN
Push CDN nhận nội dung mới mỗi khi có thay đổi trên máy chủ của bạn. Bạn hoàn toàn chịu trách nhiệm cung cấp nội dung, tải trực tiếp lên CDN và viết lại URL để trỏ tới CDN. Bạn có thể cấu hình thời điểm nội dung hết hạn và được cập nhật. Nội dung chỉ được tải lên khi có mới hoặc thay đổi, giảm thiểu lưu lượng nhưng tối đa hóa lưu trữ.
Các trang web có lưu lượng nhỏ hoặc nội dung không thường xuyên thay đổi rất phù hợp với Push CDN. Nội dung được đặt lên CDN một lần, thay vì bị lấy lại định kỳ.
Pull CDN
Pull CDN lấy nội dung mới từ máy chủ của bạn khi người dùng đầu tiên yêu cầu nội dung đó. Bạn để nội dung trên máy chủ và viết lại URL để trỏ đến CDN. Điều này dẫn đến lần truy cập đầu tiên chậm hơn cho đến khi nội dung được cache trên CDN.
Thời gian sống (TTL) xác định thời gian nội dung được cache. Pull CDN giảm thiểu không gian lưu trữ trên CDN, nhưng có thể tạo ra lưu lượng dư thừa nếu các tệp hết hạn và bị lấy lại trước khi chúng thực sự thay đổi.
Các trang web có lưu lượng lớn hoạt động hiệu quả với Pull CDN, vì lưu lượng được phân tán đều hơn và chỉ những nội dung vừa được yêu cầu mới ở lại trên CDN.
Nhược điểm: CDN
- Chi phí CDN có thể đáng kể tùy theo lưu lượng, tuy nhiên nên cân nhắc với chi phí bổ sung nếu không sử dụng CDN.
- Nội dung có thể bị lỗi thời nếu được cập nhật trước khi TTL hết hạn.
- CDN yêu cầu thay đổi URL của nội dung tĩnh để trỏ tới CDN.
Nguồn và đọc thêm
Bộ cân bằng tải
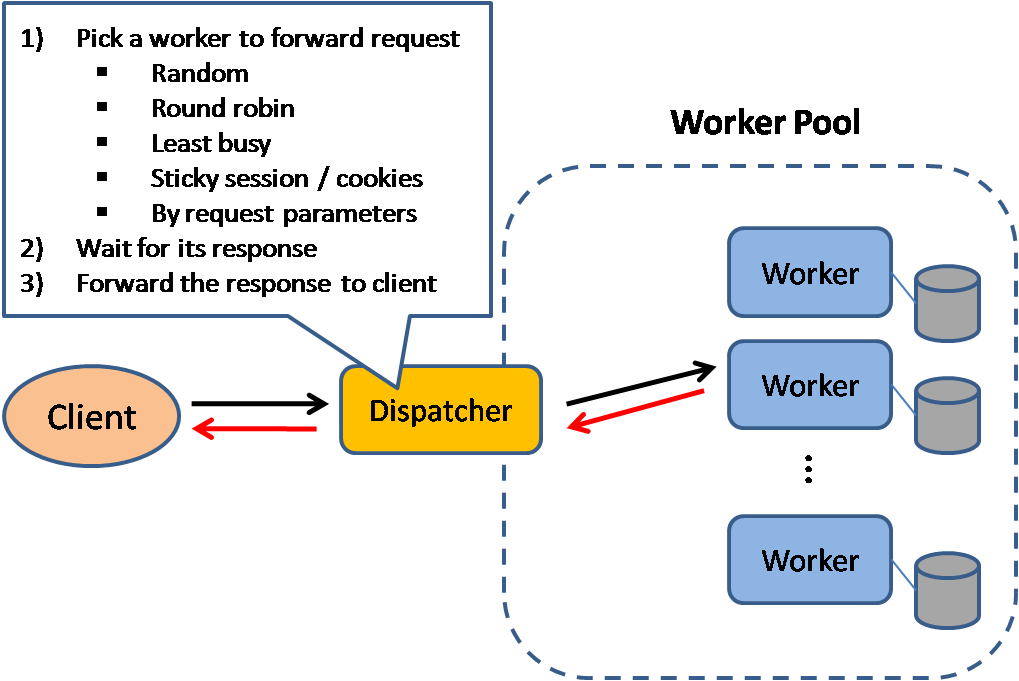
Nguồn: Các mẫu thiết kế hệ thống có khả năng mở rộng
Bộ cân bằng tải phân phối các yêu cầu từ khách hàng đến các tài nguyên tính toán như máy chủ ứng dụng và cơ sở dữ liệu. Trong mỗi trường hợp, bộ cân bằng tải trả về phản hồi từ tài nguyên tính toán đến đúng khách hàng. Bộ cân bằng tải hiệu quả trong việc:
- Ngăn chặn các yêu cầu đến các máy chủ không khỏe mạnh
- Ngăn chặn việc quá tải tài nguyên
- Giúp loại bỏ điểm lỗi đơn lẻ
Các lợi ích bổ sung bao gồm:
- Kết thúc SSL - Giải mã các yêu cầu đến và mã hóa phản hồi từ máy chủ để các máy chủ backend không phải thực hiện những tác vụ tốn kém này
- Loại bỏ nhu cầu cài đặt chứng chỉ X.509 trên mỗi máy chủ
- Duy trì phiên - Phát hành cookie và định tuyến các yêu cầu của một khách hàng cụ thể đến cùng một phiên bản nếu ứng dụng web không lưu trữ phiên
Bộ cân bằng tải có thể định tuyến lưu lượng dựa trên nhiều chỉ số khác nhau, bao gồm:
- Ngẫu nhiên
- Tải ít nhất
- Phiên/cookie
- Vòng luân phiên hoặc vòng luân phiên có trọng số
- Tầng 4
- Tầng 7
Cân bằng tải tầng 4
Bộ cân bằng tải tầng 4 xem xét thông tin tại tầng vận chuyển để quyết định cách phân phối yêu cầu. Thông thường, điều này liên quan đến địa chỉ IP nguồn, đích và các cổng trong phần đầu, nhưng không phải nội dung của gói tin. Bộ cân bằng tải tầng 4 chuyển tiếp các gói mạng đến và từ máy chủ upstream, thực hiện Chuyển đổi địa chỉ mạng (NAT).
Cân bằng tải tầng 7
Bộ cân bằng tải tầng 7 kiểm tra tầng ứng dụng để quyết định cách phân phối các yêu cầu. Điều này có thể liên quan đến nội dung của tiêu đề, thông điệp và cookie. Bộ cân bằng tải tầng 7 sẽ chấm dứt lưu lượng mạng, đọc thông điệp, đưa ra quyết định cân bằng tải, sau đó mở kết nối đến máy chủ đã được chọn. Ví dụ, bộ cân bằng tải tầng 7 có thể chuyển hướng lưu lượng video đến các máy chủ lưu trữ video trong khi chuyển hướng lưu lượng thanh toán người dùng nhạy cảm đến các máy chủ đã được tăng cường bảo mật.Đổi lại cho sự linh hoạt, cân bằng tải tầng 4 yêu cầu ít thời gian và tài nguyên tính toán hơn tầng 7, mặc dù tác động đến hiệu suất có thể không đáng kể trên phần cứng phổ thông hiện đại.
Mở rộng theo chiều ngang
Bộ cân bằng tải cũng giúp mở rộng theo chiều ngang, cải thiện hiệu suất và độ sẵn sàng. Mở rộng bằng các máy phổ thông tiết kiệm chi phí hơn và mang lại độ sẵn sàng cao hơn so với mở rộng một máy chủ duy nhất trên phần cứng đắt tiền, gọi là Mở rộng theo chiều dọc. Việc tuyển dụng nhân sự làm việc với phần cứng phổ thông cũng dễ dàng hơn so với các hệ thống doanh nghiệp chuyên biệt.
#### Nhược điểm: mở rộng theo chiều ngang
- Mở rộng theo chiều ngang làm tăng độ phức tạp và liên quan đến việc nhân bản máy chủ
- Máy chủ nên là không trạng thái: không nên chứa dữ liệu liên quan đến người dùng như phiên hoặc ảnh đại diện
- Phiên có thể được lưu trong kho dữ liệu tập trung như cơ sở dữ liệu (SQL, NoSQL) hoặc bộ nhớ đệm lâu dài (Redis, Memcached)
- Các máy chủ phía dưới như bộ đệm và cơ sở dữ liệu cần xử lý nhiều kết nối đồng thời hơn khi các máy chủ phía trên mở rộng
Nhược điểm: bộ cân bằng tải
- Bộ cân bằng tải có thể trở thành nút thắt về hiệu suất nếu không đủ tài nguyên hoặc cấu hình không đúng.
- Việc thêm bộ cân bằng tải để loại bỏ điểm lỗi đơn lại làm tăng độ phức tạp.
- Một bộ cân bằng tải đơn là một điểm lỗi đơn, cấu hình nhiều bộ cân bằng tải sẽ càng tăng độ phức tạp.
Nguồn và đọc thêm
- Kiến trúc NGINX
- Hướng dẫn kiến trúc HAProxy
- Khả năng mở rộng
- Wikipedia)
- Cân bằng tải tầng 4
- Cân bằng tải tầng 7
- Cấu hình listener ELB
Reverse proxy (máy chủ web)
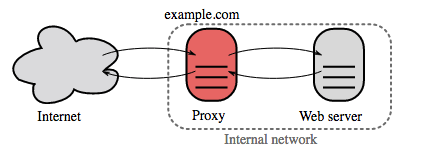
Reverse proxy là một máy chủ web tập trung các dịch vụ nội bộ và cung cấp giao diện thống nhất cho công chúng. Các yêu cầu từ khách hàng sẽ được chuyển tiếp đến máy chủ có thể xử lý trước khi reverse proxy trả về phản hồi của máy chủ cho khách hàng.
Các lợi ích bổ sung bao gồm:
- Tăng cường bảo mật - Ẩn thông tin về các máy chủ backend, chặn danh sách đen IP, giới hạn số lượng kết nối trên mỗi khách hàng
- Tăng khả năng mở rộng và linh hoạt - Khách hàng chỉ nhìn thấy IP của reverse proxy, cho phép bạn mở rộng máy chủ hoặc thay đổi cấu hình của chúng
- Chấm dứt SSL - Giải mã các yêu cầu đến và mã hóa phản hồi của máy chủ để các máy chủ backend không phải thực hiện những thao tác có thể tốn kém này
- Loại bỏ nhu cầu cài đặt chứng chỉ X.509 trên mỗi máy chủ
- Nén - Nén phản hồi của máy chủ
- Bộ nhớ đệm - Trả về phản hồi cho các yêu cầu đã được lưu trong bộ nhớ đệm
- Nội dung tĩnh - Phục vụ trực tiếp nội dung tĩnh
- HTML/CSS/JS
- Ảnh
- Video
- V.v.
Bộ cân bằng tải vs reverse proxy
- Triển khai bộ cân bằng tải rất hữu ích khi bạn có nhiều máy chủ. Thường thì các bộ cân bằng tải sẽ định tuyến lưu lượng đến một tập hợp các máy chủ phục vụ cùng chức năng.
- Reverse proxy có thể hữu ích ngay cả khi chỉ có một máy chủ web hoặc máy chủ ứng dụng, mở ra các lợi ích như đã mô tả ở phần trước.
- Các giải pháp như NGINX và HAProxy có thể hỗ trợ cả reverse proxy tầng 7 và cân bằng tải.
Bất lợi: reverse proxy
- Việc giới thiệu reverse proxy làm tăng độ phức tạp.
- Một reverse proxy duy nhất là điểm lỗi duy nhất, cấu hình nhiều reverse proxy (ví dụ như failover) càng làm tăng độ phức tạp.
Nguồn và đọc thêm
Tầng ứng dụng
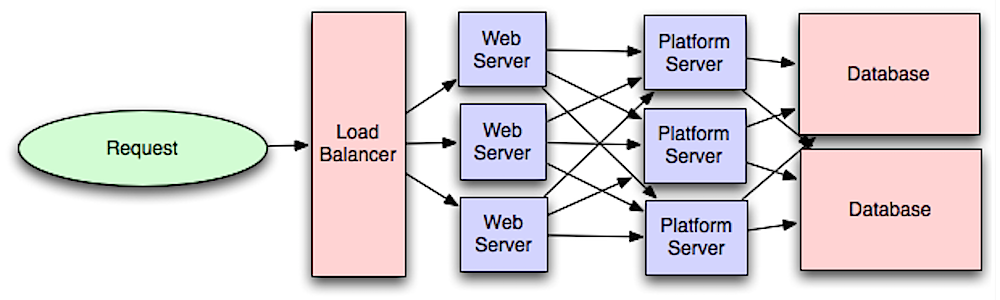
Nguồn: Giới thiệu về kiến trúc hệ thống cho khả năng mở rộng
Tách biệt tầng web khỏi tầng ứng dụng (còn gọi là tầng nền tảng) cho phép bạn mở rộng và cấu hình cả hai tầng một cách độc lập. Việc thêm một API mới dẫn đến việc bổ sung máy chủ ứng dụng mà không nhất thiết phải thêm máy chủ web bổ sung. Nguyên tắc single responsibility khuyến khích các dịch vụ nhỏ và tự động làm việc cùng nhau. Các nhóm nhỏ với các dịch vụ nhỏ có thể lập kế hoạch phát triển nhanh chóng một cách tích cực hơn.
Các worker ở tầng ứng dụng cũng giúp kích hoạt tính bất đồng bộ.
Microservices
Liên quan đến chủ đề này là microservices, có thể được mô tả là một bộ các dịch vụ nhỏ, mô-đun, có thể triển khai độc lập. Mỗi dịch vụ chạy một tiến trình riêng biệt và giao tiếp qua một cơ chế nhẹ, được xác định rõ nhằm phục vụ mục tiêu kinh doanh. 1
Pinterest, ví dụ, có thể có các microservice như: hồ sơ người dùng, theo dõi, nguồn cấp, tìm kiếm, tải ảnh lên, v.v.
Khám phá dịch vụ
Các hệ thống như Consul, Etcd, và Zookeeper có thể giúp các dịch vụ tìm nhau bằng cách theo dõi tên, địa chỉ và cổng đã đăng ký. Kiểm tra sức khỏe giúp xác minh tính toàn vẹn của dịch vụ và thường được thực hiện thông qua một endpoint HTTP. Cả Consul và Etcd đều có kho lưu trữ key-value tích hợp sẵn, hữu ích để lưu giá trị cấu hình và dữ liệu chia sẻ khác.
Nhược điểm: tầng ứng dụng
- Thêm tầng ứng dụng với các dịch vụ liên kết lỏng lẻo đòi hỏi một cách tiếp cận khác về mặt kiến trúc, vận hành và quy trình (so với hệ thống nguyên khối).
- Microservice có thể làm tăng độ phức tạp trong triển khai và vận hành.
Nguồn và tài liệu đọc thêm
- Giới thiệu về kiến trúc hệ thống cho khả năng mở rộng
- Crack the system design interview
- Kiến trúc hướng dịch vụ
- Giới thiệu về Zookeeper
- Những điều bạn cần biết về xây dựng microservice
Cơ sở dữ liệu
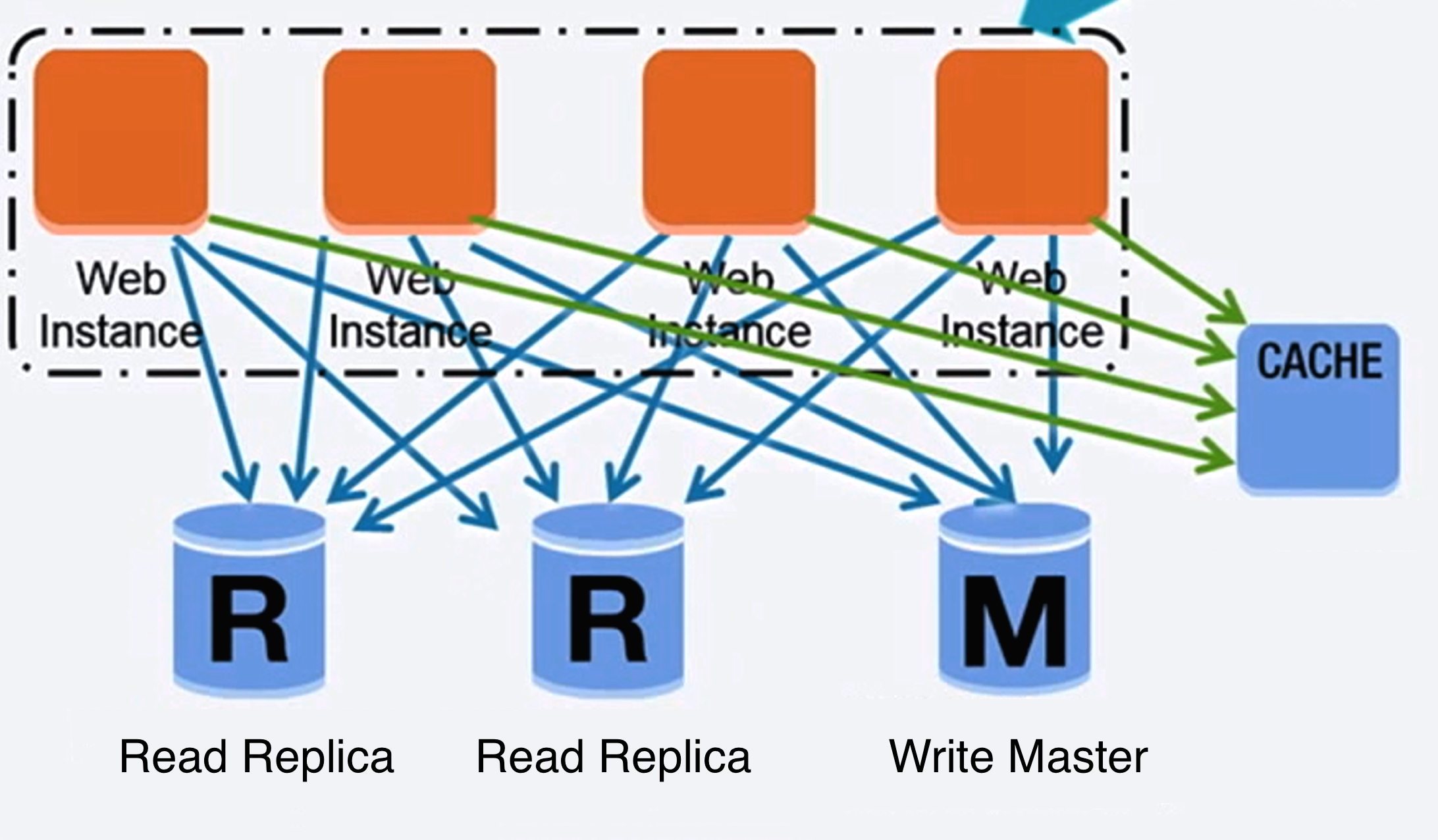
Nguồn: Mở rộng lên 10 triệu người dùng đầu tiên
Hệ quản trị cơ sở dữ liệu quan hệ (RDBMS)
Một cơ sở dữ liệu quan hệ như SQL là một tập hợp các mục dữ liệu được tổ chức trong các bảng.
ACID là một tập hợp các thuộc tính của giao dịch trong cơ sở dữ liệu quan hệ.
- Atomicity - Mỗi giao dịch là tất cả hoặc không có gì
- Consistency - Bất kỳ giao dịch nào cũng sẽ đưa cơ sở dữ liệu từ một trạng thái hợp lệ này sang trạng thái hợp lệ khác
- Isolation - Việc thực thi đồng thời các giao dịch sẽ cho kết quả giống như khi các giao dịch được thực thi tuần tự
- Durability - Một khi giao dịch đã được cam kết, nó sẽ được giữ nguyên
#### Nhân bản chủ-tớ
Chủ phục vụ cả đọc và ghi, nhân bản các thao tác ghi đến một hoặc nhiều tớ, các tớ chỉ phục vụ đọc. Các tớ cũng có thể nhân bản đến các tớ bổ sung theo dạng cây. Nếu chủ bị ngắt kết nối, hệ thống có thể tiếp tục hoạt động ở chế độ chỉ đọc cho đến khi một tớ được nâng cấp thành chủ hoặc một chủ mới được cung cấp.
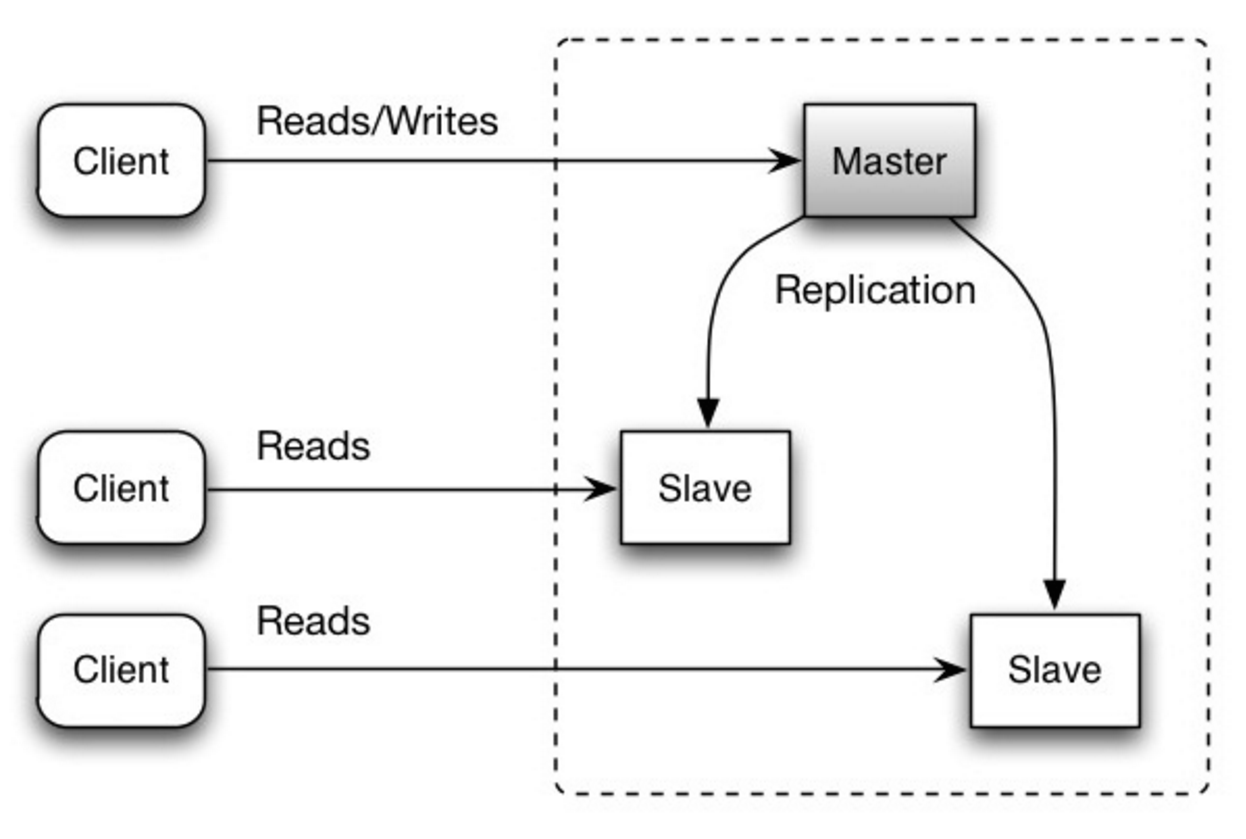
Nguồn: Scalability, availability, stability, patterns
##### Nhược điểm: nhân bản chủ-tớ
- Cần bổ sung logic để nâng cấp một tớ thành chủ.
- Xem Nhược điểm: replication cho các điểm liên quan đến cả nhân bản chủ-tớ và chủ-chủ.
Cả hai chủ đều phục vụ đọc và ghi và phối hợp với nhau về các thao tác ghi. Nếu một trong hai chủ gặp sự cố, hệ thống vẫn có thể tiếp tục hoạt động với cả đọc và ghi.
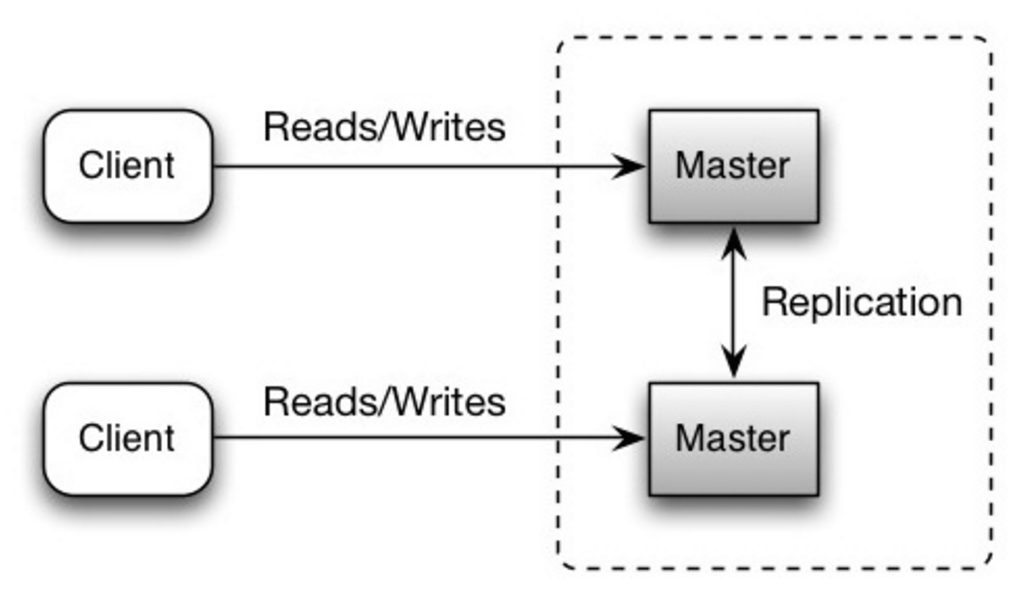
Nguồn: Scalability, availability, stability, patterns
##### Nhược điểm: nhân bản chủ-chủ
- Bạn sẽ cần bộ cân bằng tải hoặc cần sửa đổi logic ứng dụng để xác định vị trí ghi dữ liệu.
- Hầu hết các hệ thống chủ-chủ hoặc là nhất quán lỏng lẻo (vi phạm ACID) hoặc có độ trễ ghi tăng lên do đồng bộ hóa.
- Việc giải quyết xung đột trở nên quan trọng hơn khi có nhiều node ghi hơn và khi độ trễ tăng lên.
- Xem Nhược điểm: nhân bản để biết các điểm liên quan đến cả master-slave và master-master.
- Có khả năng mất dữ liệu nếu master bị lỗi trước khi bất kỳ dữ liệu mới nào được ghi có thể được nhân bản đến các node khác.
- Các ghi lại được phát lại đến các bản sao đọc. Nếu có nhiều ghi, các bản sao đọc có thể bị quá tải bởi việc phát lại ghi và không thể thực hiện nhiều đọc.
- Càng nhiều slave đọc thì càng phải nhân bản nhiều, dẫn đến độ trễ nhân bản lớn hơn.
- Trên một số hệ thống, ghi vào master có thể sinh ra nhiều luồng để ghi song song, trong khi bản sao đọc chỉ hỗ trợ ghi tuần tự với một luồng duy nhất.
- Nhân bản bổ sung thêm phần cứng và sự phức tạp.
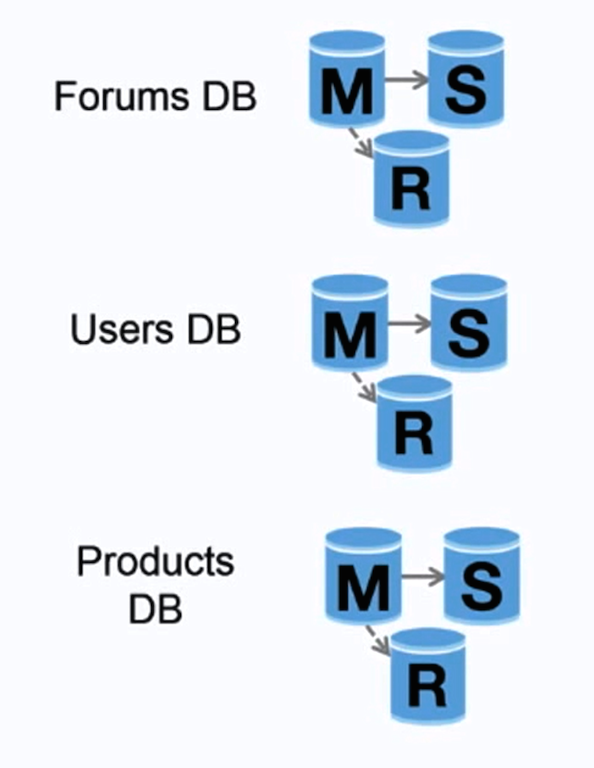
Nguồn: Scaling up to your first 10 million users
Federation (hoặc phân vùng chức năng) chia nhỏ cơ sở dữ liệu theo chức năng. Ví dụ, thay vì một cơ sở dữ liệu đơn lẻ, nguyên khối, bạn có thể có ba cơ sở dữ liệu: forums, users, và products, dẫn đến ít lưu lượng đọc và ghi đến mỗi cơ sở dữ liệu hơn và do đó ít độ trễ nhân bản hơn. Các cơ sở dữ liệu nhỏ hơn giúp nhiều dữ liệu có thể nằm trong bộ nhớ hơn, từ đó tăng số lần truy cập cache nhờ cải thiện tính cục bộ của cache. Không có master trung tâm duy nhất để tuần tự hóa ghi, bạn có thể ghi song song, tăng thông lượng.
##### Nhược điểm: federation
- Federation không hiệu quả nếu lược đồ của bạn yêu cầu các chức năng hoặc bảng quá lớn.
- Bạn sẽ cần cập nhật logic ứng dụng để xác định cơ sở dữ liệu nào cần đọc và ghi.
- Kết hợp dữ liệu từ hai cơ sở dữ liệu sẽ phức tạp hơn với một server link.
- Federation bổ sung thêm phần cứng và sự phức tạp.
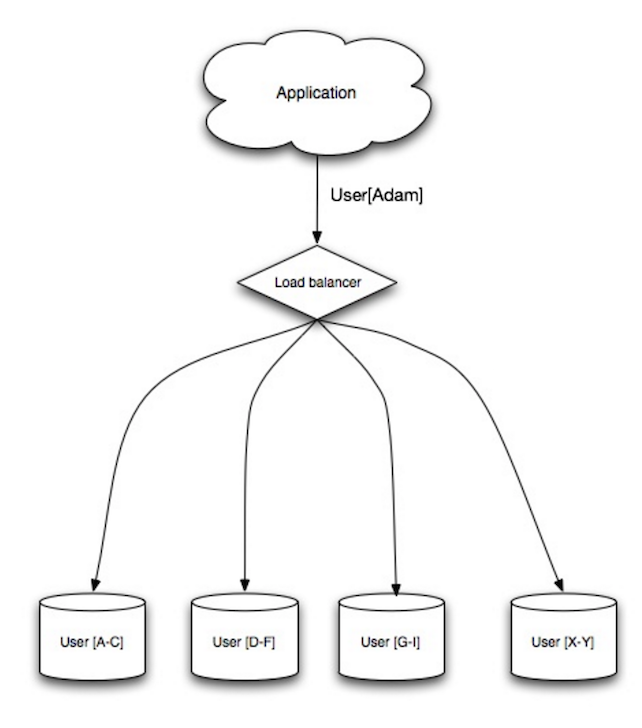
Nguồn: Scalability, availability, stability, patterns
Sharding phân phối dữ liệu qua các cơ sở dữ liệu khác nhau sao cho mỗi cơ sở dữ liệu chỉ quản lý một phần của dữ liệu. Lấy ví dụ với cơ sở dữ liệu người dùng, khi số lượng người dùng tăng lên, nhiều shard hơn sẽ được thêm vào cụm.
Tương tự như lợi ích của federation, sharding giúp giảm lưu lượng đọc và ghi, giảm việc nhân bản dữ liệu, và tăng tỷ lệ cache hit. Kích thước chỉ mục cũng được giảm, thường cải thiện hiệu năng với các truy vấn nhanh hơn. Nếu một shard gặp sự cố, các shard khác vẫn hoạt động, tuy nhiên bạn sẽ muốn thêm một số hình thức nhân bản để tránh mất dữ liệu. Giống như federation, không có một master trung tâm duy nhất serial hóa việc ghi, cho phép bạn ghi song song với thông lượng cao hơn.
Các cách phổ biến để shard bảng người dùng là dựa vào ký tự đầu của họ người dùng hoặc vị trí địa lý của người dùng.
##### Nhược điểm: sharding
- Bạn sẽ cần cập nhật logic ứng dụng để làm việc với các shard, điều này có thể dẫn đến các truy vấn SQL phức tạp.
- Phân phối dữ liệu có thể trở nên mất cân đối trong một shard. Ví dụ, một nhóm người dùng mạnh trên một shard có thể dẫn đến tải tăng lên cho shard đó so với các shard khác.
- Cân bằng lại dữ liệu làm tăng độ phức tạp. Hàm sharding dựa trên consistent hashing có thể giảm lượng dữ liệu cần chuyển.
- Kết nối dữ liệu từ nhiều shard trở nên phức tạp hơn.
- Sharding thêm nhiều phần cứng và độ phức tạp bổ sung.
Denormalization cố gắng cải thiện hiệu năng đọc bằng cách hy sinh một phần hiệu năng ghi. Các bản sao dư thừa của dữ liệu được ghi vào nhiều bảng để tránh các phép nối đắt đỏ. Một số RDBMS như PostgreSQL và Oracle hỗ trợ materialized views giúp lưu trữ thông tin dư thừa và giữ các bản sao dư thừa nhất quán.
Khi dữ liệu được phân phối bằng các kỹ thuật như federation và sharding, việc quản lý các phép nối qua các trung tâm dữ liệu càng làm tăng độ phức tạp. Denormalization có thể giúp tránh được nhu cầu thực hiện các phép nối phức tạp như vậy.
Trong hầu hết các hệ thống, số lần đọc có thể vượt xa số lần ghi với tỷ lệ 100:1 hoặc thậm chí 1000:1. Một lần đọc dẫn đến phép nối dữ liệu phức tạp có thể rất tốn kém, tiêu tốn nhiều thời gian cho các thao tác ổ đĩa.
##### Nhược điểm: denormalization
- Dữ liệu bị trùng lặp.
- Các ràng buộc có thể giúp các bản sao dư thừa của thông tin luôn đồng bộ, làm tăng độ phức tạp của thiết kế cơ sở dữ liệu.
- Cơ sở dữ liệu denormalized dưới tải ghi lớn có thể hoạt động kém hơn so với cơ sở dữ liệu normalized.
Tinh chỉnh SQL là một chủ đề rộng lớn và nhiều sách đã được viết làm tài liệu tham khảo.
Điều quan trọng là phải kiểm thử hiệu năng và phân tích hồ sơ để mô phỏng và phát hiện các nút thắt cổ chai.
- Kiểm thử hiệu năng - Mô phỏng tình huống tải cao với các công cụ như ab.
- Phân tích hồ sơ - Kích hoạt các công cụ như slow query log để giúp theo dõi các vấn đề về hiệu năng.
##### Siết chặt lược đồ
- MySQL ghi ra đĩa thành các khối liên tiếp để truy cập nhanh.
- Dùng
CHARthay vìVARCHARcho các trường có độ dài cố định. CHARthực sự cho phép truy cập ngẫu nhiên nhanh, trong khi vớiVARCHAR, bạn phải tìm điểm kết thúc của chuỗi trước khi chuyển sang chuỗi tiếp theo.- Dùng
TEXTcho các khối văn bản lớn như bài đăng blog.TEXTcũng cho phép tìm kiếm kiểu boolean. Dùng trườngTEXTsẽ lưu một con trỏ trên đĩa để xác định vị trí khối văn bản. - Dùng
INTcho các số lớn lên đến 2^32 hoặc 4 tỷ. - Dùng
DECIMALcho tiền tệ để tránh lỗi biểu diễn số thực. - Tránh lưu trữ các
BLOBlớn, thay vào đó lưu vị trí lấy đối tượng. VARCHAR(255)là số lượng ký tự lớn nhất có thể được đếm trong một số 8 bit, thường tối đa hóa việc sử dụng một byte ở một số Hệ quản trị CSDL.- Đặt ràng buộc
NOT NULLkhi áp dụng để cải thiện hiệu suất tìm kiếm.
- Các cột mà bạn truy vấn (
SELECT,GROUP BY,ORDER BY,JOIN) có thể nhanh hơn với chỉ mục. - Chỉ mục thường được biểu diễn dưới dạng B-tree tự cân bằng giúp dữ liệu được sắp xếp và cho phép tìm kiếm, truy cập tuần tự, chèn, xóa trong thời gian logarit.
- Đặt chỉ mục có thể giữ dữ liệu trong bộ nhớ, yêu cầu thêm không gian lưu trữ.
- Việc ghi dữ liệu cũng có thể chậm hơn vì cần cập nhật chỉ mục.
- Khi tải lượng lớn dữ liệu, có thể nhanh hơn nếu tắt chỉ mục, tải dữ liệu, rồi xây dựng lại chỉ mục.
- Phi chuẩn hóa khi hiệu năng yêu cầu.
- Chia nhỏ một bảng bằng cách đưa các điểm nóng vào một bảng riêng biệt để giúp giữ nó trong bộ nhớ.
- Trong một số trường hợp, bộ nhớ đệm truy vấn có thể dẫn đến vấn đề hiệu năng.
- Mẹo tối ưu hóa truy vấn MySQL
- Có lý do gì để VARCHAR(255) được sử dụng phổ biến như vậy?
- Giá trị null ảnh hưởng đến hiệu suất như thế nào?
- Nhật ký truy vấn chậm
NoSQL
NoSQL là tập hợp các mục dữ liệu được thể hiện bằng key-value store, document store, wide column store, hoặc graph database. Dữ liệu được phi chuẩn hóa và các phép nối thường được thực hiện trong mã ứng dụng. Hầu hết các kho NoSQL không có giao dịch ACID thực sự và ưu tiên tính nhất quán cuối cùng.
BASE thường được dùng để mô tả các đặc tính của cơ sở dữ liệu NoSQL. So với Định lý CAP, BASE chọn tính sẵn sàng thay vì tính nhất quán.
- Basically available - hệ thống đảm bảo tính sẵn sàng.
- Soft state - trạng thái của hệ thống có thể thay đổi theo thời gian, ngay cả khi không có đầu vào.
- Eventual consistency - hệ thống sẽ trở nên nhất quán sau một khoảng thời gian, miễn là hệ thống không nhận thêm đầu vào trong khoảng thời gian đó.
#### Key-value store
Trừu tượng: bảng băm
Một key-value store thường cho phép đọc và ghi với độ phức tạp O(1), thường được hỗ trợ bởi bộ nhớ hoặc SSD. Các kho dữ liệu có thể duy trì khóa theo thứ tự từ điển, cho phép truy xuất phạm vi khóa hiệu quả. Key-value store có thể lưu trữ siêu dữ liệu cùng với giá trị.
Key-value store cung cấp hiệu năng cao và thường được dùng cho các mô hình dữ liệu đơn giản hoặc dữ liệu thay đổi nhanh, như lớp bộ nhớ đệm trong RAM. Vì chúng chỉ cung cấp một tập hợp thao tác hạn chế, độ phức tạp sẽ chuyển sang tầng ứng dụng nếu cần thêm thao tác.
Key-value store là nền tảng cho các hệ thống phức tạp hơn như document store, và trong một số trường hợp, graph database.
##### Nguồn và tài liệu đọc thêm: key-value store
#### Kho lưu trữ tài liệuTrừu tượng: kho lưu trữ key-value với tài liệu được lưu trữ dưới dạng giá trị
Kho lưu trữ tài liệu tập trung vào các tài liệu (XML, JSON, nhị phân, v.v.), trong đó một tài liệu lưu trữ toàn bộ thông tin cho một đối tượng nhất định. Kho lưu trữ tài liệu cung cấp API hoặc ngôn ngữ truy vấn để truy vấn dựa trên cấu trúc nội bộ của chính tài liệu đó. Lưu ý, nhiều kho key-value cũng bao gồm các chức năng làm việc với siêu dữ liệu của giá trị, làm mờ ranh giới giữa hai loại lưu trữ này.
Tùy thuộc vào cách triển khai bên dưới, tài liệu được tổ chức theo bộ sưu tập, thẻ, siêu dữ liệu hoặc thư mục. Mặc dù tài liệu có thể được tổ chức hoặc nhóm lại, các trường của tài liệu có thể hoàn toàn khác nhau giữa các tài liệu.
Một số kho lưu trữ tài liệu như MongoDB và CouchDB còn cung cấp ngôn ngữ giống SQL để thực hiện các truy vấn phức tạp. DynamoDB hỗ trợ cả key-value và tài liệu.
Kho lưu trữ tài liệu mang lại tính linh hoạt cao và thường được sử dụng cho dữ liệu thay đổi không thường xuyên.
##### Nguồn và đọc thêm: kho lưu trữ tài liệu
#### Kho lưu trữ cột rộng
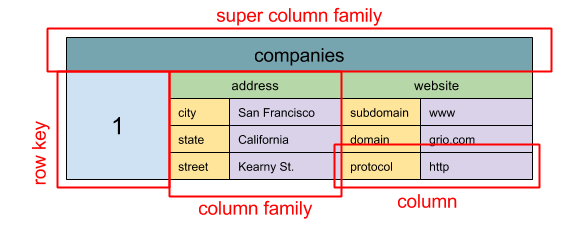
Nguồn: SQL & NoSQL, lịch sử ngắn gọn
Trừu tượng: bản đồ lồng nhau ColumnFamily> Đơn vị dữ liệu cơ bản của kho lưu trữ cột rộng là một cột (cặp tên/giá trị). Một cột có thể được nhóm thành các họ cột (tương tự như bảng trong SQL). Họ siêu cột tiếp tục nhóm các họ cột. Bạn có thể truy cập từng cột độc lập bằng khóa dòng, và các cột có cùng khóa dòng tạo thành một dòng. Mỗi giá trị chứa một dấu thời gian để phân phiên bản và giải quyết xung đột.
Google đã giới thiệu Bigtable là kho lưu trữ cột rộng đầu tiên, ảnh hưởng đến HBase mã nguồn mở thường dùng trong hệ sinh thái Hadoop, và Cassandra của Facebook. Các kho như BigTable, HBase, và Cassandra duy trì các khóa theo thứ tự từ điển, cho phép truy xuất hiệu quả các dải khóa lựa chọn.
Kho lưu trữ cột rộng cung cấp tính sẵn sàng cao và khả năng mở rộng lớn. Chúng thường được sử dụng cho bộ dữ liệu rất lớn.
##### Nguồn và đọc thêm: kho lưu trữ cột rộng
#### Cơ sở dữ liệu đồ thị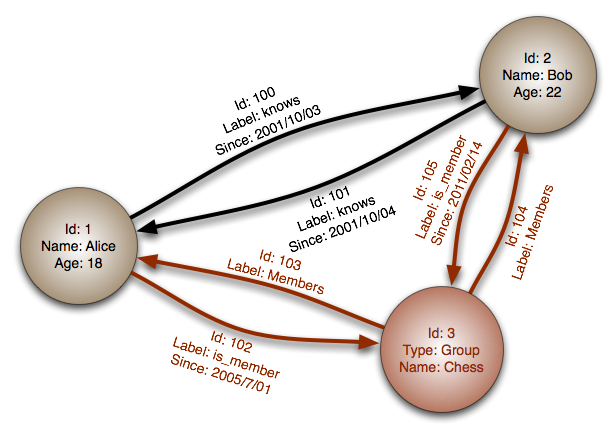
Trừu tượng: đồ thị
Trong cơ sở dữ liệu đồ thị, mỗi nút là một bản ghi và mỗi cung là một mối quan hệ giữa hai nút. Cơ sở dữ liệu đồ thị được tối ưu hóa để biểu diễn các mối quan hệ phức tạp với nhiều khóa ngoại hoặc các quan hệ nhiều-nhiều.
Cơ sở dữ liệu đồ thị cung cấp hiệu năng cao cho các mô hình dữ liệu có mối quan hệ phức tạp, ví dụ như mạng xã hội. Chúng còn khá mới và chưa được sử dụng rộng rãi; có thể sẽ khó tìm công cụ và tài nguyên phát triển. Nhiều cơ sở dữ liệu đồ thị chỉ có thể truy cập qua REST APIs.
##### Nguồn và tài liệu đọc thêm: đồ thị
#### Nguồn và tài liệu đọc thêm: NoSQL- Giải thích các thuật ngữ cơ bản
- Khảo sát và hướng dẫn quyết định về cơ sở dữ liệu NoSQL
- Khả năng mở rộng
- Giới thiệu về NoSQL
- Mẫu NoSQL
SQL hay NoSQL
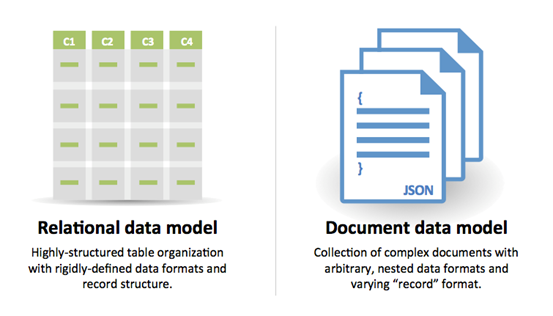
Nguồn: Chuyển đổi từ RDBMS sang NoSQL
Lý do chọn SQL:
- Dữ liệu có cấu trúc
- Lược đồ nghiêm ngặt
- Dữ liệu quan hệ
- Cần kết hợp phức tạp (joins)
- Giao dịch
- Có các mô hình mở rộng rõ ràng
- Được sử dụng lâu đời: nhiều lập trình viên, cộng đồng, mã nguồn, công cụ, v.v.
- Tìm kiếm theo chỉ mục rất nhanh
- Dữ liệu bán cấu trúc
- Lược đồ động hoặc linh hoạt
- Dữ liệu phi quan hệ
- Không cần kết hợp phức tạp (joins)
- Lưu trữ nhiều TB (hoặc PB) dữ liệu
- Khối lượng công việc dữ liệu rất lớn
- Thông lượng IOPS rất cao
- Tiếp nhận nhanh dữ liệu clickstream và log
- Dữ liệu bảng xếp hạng hoặc điểm số
- Dữ liệu tạm thời, như giỏ hàng mua sắm
- Các bảng truy cập thường xuyên ('nóng')
- Bảng metadata/tra cứu
Bộ nhớ đệm (Cache)
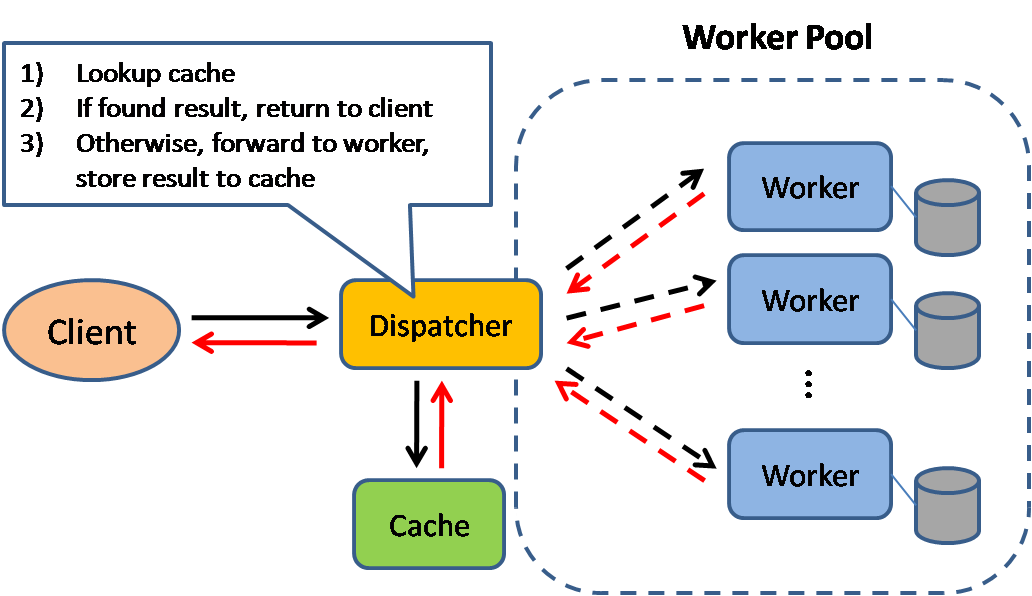
Nguồn: Các mẫu thiết kế hệ thống có khả năng mở rộng
Bộ nhớ đệm giúp cải thiện thời gian tải trang và có thể giảm tải cho máy chủ và cơ sở dữ liệu của bạn. Trong mô hình này, bộ phân phối sẽ kiểm tra xem yêu cầu đã được thực hiện trước đó chưa và cố gắng tìm kết quả trước đó để trả về, nhằm tiết kiệm việc thực thi thực tế.
Cơ sở dữ liệu thường hưởng lợi từ việc phân phối đều các thao tác đọc và ghi trên các phân vùng của nó. Những mục phổ biến có thể làm lệch phân phối, gây ra điểm nghẽn. Đặt bộ nhớ đệm phía trước cơ sở dữ liệu có thể giúp hấp thụ tải không đều và các đợt tăng đột biến lưu lượng truy cập.
Bộ nhớ đệm phía khách
Bộ nhớ đệm có thể được đặt ở phía khách (hệ điều hành hoặc trình duyệt), phía máy chủ, hoặc trong một tầng bộ nhớ đệm riêng biệt.
Bộ nhớ đệm CDN
CDN được xem là một loại bộ nhớ đệm.
Bộ nhớ đệm máy chủ web
Reverse proxy và các bộ nhớ đệm như Varnish có thể phục vụ nội dung tĩnh và động trực tiếp. Máy chủ web cũng có thể lưu bộ nhớ đệm các yêu cầu, trả về phản hồi mà không cần liên hệ với máy chủ ứng dụng.
Bộ nhớ đệm cơ sở dữ liệu
Cơ sở dữ liệu của bạn thường bao gồm một mức bộ nhớ đệm nào đó trong cấu hình mặc định, được tối ưu cho trường hợp sử dụng tổng quát. Tinh chỉnh các thiết lập này cho các mẫu sử dụng cụ thể có thể tăng hiệu suất hơn nữa.
Bộ nhớ đệm ứng dụng
Các bộ nhớ đệm trong RAM như Memcached và Redis là các kho lưu trữ key-value nằm giữa ứng dụng của bạn và bộ lưu trữ dữ liệu. Vì dữ liệu được giữ trong RAM, nó nhanh hơn nhiều so với các cơ sở dữ liệu thông thường nơi dữ liệu được lưu trên ổ đĩa. RAM bị giới hạn hơn so với ổ đĩa, vì vậy các thuật toán hủy bộ nhớ đệm như ít được sử dụng gần đây nhất (LRU)) có thể giúp loại bỏ các mục 'lạnh' và giữ dữ liệu 'nóng' trong RAM.
Redis có các tính năng bổ sung sau:
- Tùy chọn lưu trữ bền vững
- Các cấu trúc dữ liệu tích hợp như tập hợp có thứ tự và danh sách
- Cấp độ dòng
- Cấp độ truy vấn
- Đối tượng đã được tuần tự hóa hoàn chỉnh
- HTML đã được render hoàn chỉnh
Bộ nhớ đệm ở cấp độ truy vấn cơ sở dữ liệu
Bất cứ khi nào bạn truy vấn cơ sở dữ liệu, hãy băm truy vấn thành một khóa và lưu kết quả vào bộ nhớ đệm. Cách tiếp cận này gặp phải các vấn đề về hết hạn:
- Khó xóa một kết quả đã lưu trong bộ nhớ đệm với các truy vấn phức tạp
- Nếu một phần dữ liệu thay đổi như một ô trong bảng, bạn cần xóa tất cả các truy vấn đã lưu trong bộ nhớ đệm có thể chứa ô đã thay đổi
Bộ nhớ đệm ở cấp độ đối tượng
Xem dữ liệu của bạn như một đối tượng, giống như cách bạn làm với mã ứng dụng của mình. Hãy để ứng dụng của bạn tập hợp bộ dữ liệu từ cơ sở dữ liệu thành một thể hiện lớp hoặc một cấu trúc dữ liệu:
- Xóa đối tượng khỏi bộ nhớ đệm nếu dữ liệu cơ bản của nó đã thay đổi
- Cho phép xử lý bất đồng bộ: các worker tập hợp đối tượng bằng cách lấy đối tượng đã lưu trong bộ nhớ đệm mới nhất
- Phiên người dùng
- Các trang web đã được render đầy đủ
- Luồng hoạt động
- Dữ liệu đồ thị người dùng
Khi nào cập nhật bộ nhớ đệm
Vì bạn chỉ có thể lưu một lượng dữ liệu giới hạn trong bộ nhớ đệm, bạn sẽ cần xác định chiến lược cập nhật bộ nhớ đệm nào phù hợp nhất với trường hợp sử dụng của mình.
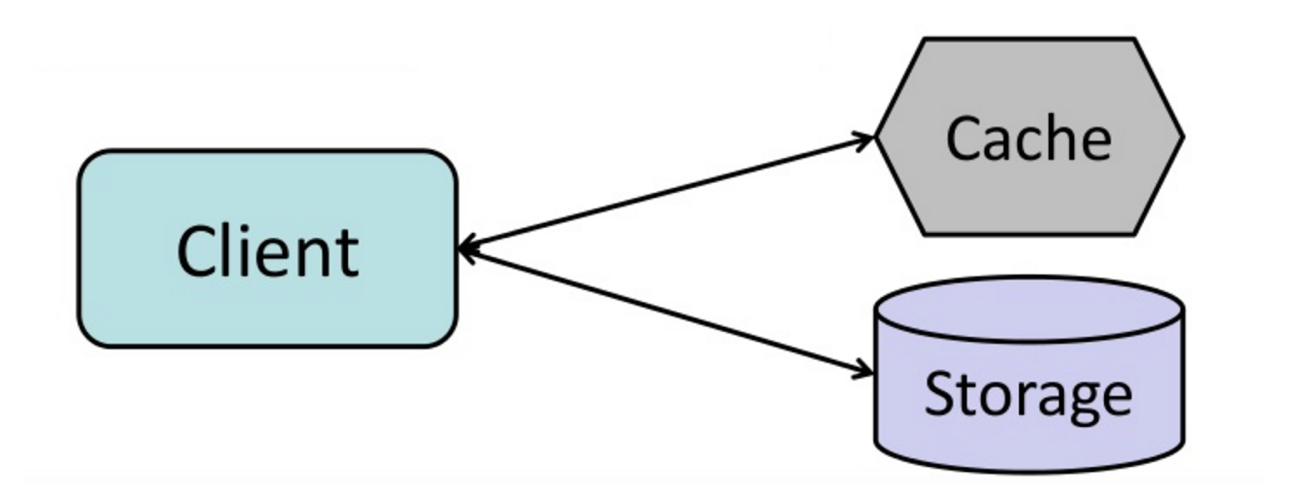
#### Cache-aside
Nguồn: From cache to in-memory data grid
Ứng dụng chịu trách nhiệm đọc và ghi từ bộ lưu trữ. Bộ nhớ đệm không tương tác trực tiếp với bộ lưu trữ. Ứng dụng sẽ thực hiện các bước sau:
- Tìm kiếm mục trong bộ nhớ đệm, dẫn đến cache miss
- Tải mục từ cơ sở dữ liệu
- Thêm mục vào bộ nhớ đệm
- Trả về mục
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached thường được sử dụng theo cách này.
Các lần đọc dữ liệu tiếp theo được thêm vào bộ nhớ đệm sẽ rất nhanh. Cache-aside còn được gọi là lazy loading. Chỉ dữ liệu được yêu cầu mới được lưu vào cache, tránh làm đầy bộ nhớ đệm với dữ liệu không được yêu cầu.
##### Nhược điểm: cache-aside
- Mỗi lần cache miss sẽ tạo ra ba lượt truy cập, có thể gây ra độ trễ rõ rệt.
- Dữ liệu có thể trở nên lỗi thời nếu được cập nhật trong cơ sở dữ liệu. Vấn đề này được giảm nhẹ bằng cách đặt thời gian sống (TTL) để buộc cập nhật lại mục trong cache, hoặc sử dụng write-through.
- Khi một node bị lỗi, nó sẽ được thay thế bằng một node mới, rỗng, làm tăng độ trễ.
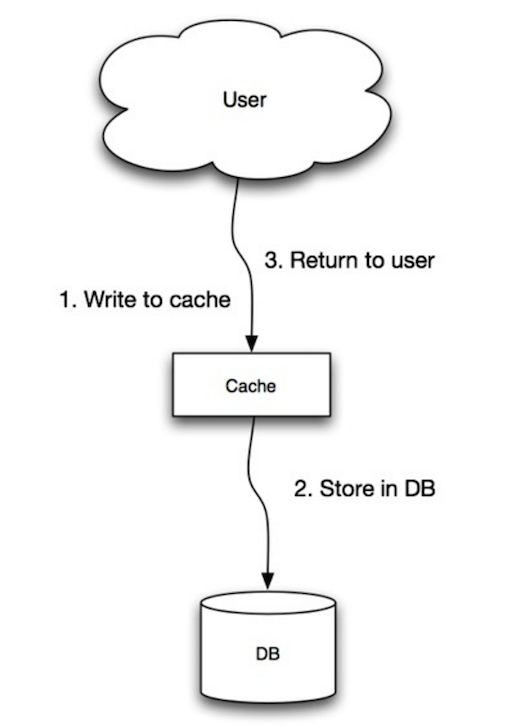
Nguồn: Scalability, availability, stability, patterns
Ứng dụng sử dụng bộ nhớ đệm như kho lưu trữ dữ liệu chính, đọc và ghi dữ liệu vào đó, trong khi bộ nhớ đệm chịu trách nhiệm đọc và ghi vào cơ sở dữ liệu:
- Ứng dụng thêm/cập nhật mục trong bộ nhớ đệm
- Bộ nhớ đệm ghi mục vào kho dữ liệu một cách đồng bộ
- Trả về
set_user(12345, {"foo":"bar"})Mã bộ nhớ đệm:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Bất lợi: ghi trực tiếp
- Khi một node mới được tạo ra do sự cố hoặc mở rộng, node mới sẽ không lưu vào bộ nhớ đệm các mục cho đến khi mục đó được cập nhật trong cơ sở dữ liệu. Kết hợp cache-aside với ghi trực tiếp có thể giảm thiểu vấn đề này.
- Hầu hết dữ liệu được ghi có thể không bao giờ được đọc, điều này có thể được giảm thiểu với TTL.
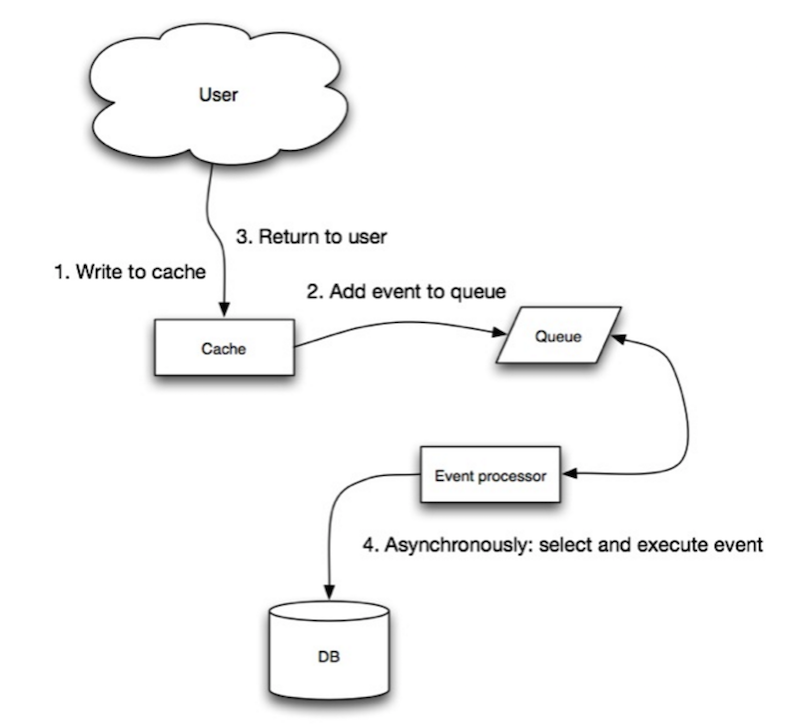
Nguồn: Scalability, availability, stability, patterns
Trong ghi phía sau, ứng dụng thực hiện các bước sau:
- Thêm/cập nhật mục trong bộ nhớ đệm
- Ghi mục vào kho dữ liệu một cách bất đồng bộ, cải thiện hiệu năng ghi
- Có thể mất dữ liệu nếu bộ nhớ đệm bị sập trước khi nội dung của nó được ghi vào kho dữ liệu.
- Việc triển khai ghi phía sau phức tạp hơn so với cache-aside hoặc ghi trực tiếp.
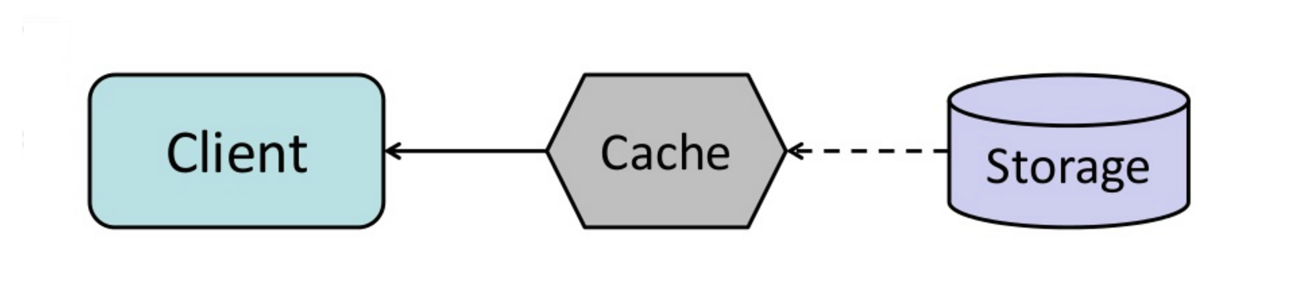
Nguồn: From cache to in-memory data grid
Bạn có thể cấu hình bộ nhớ đệm để tự động làm mới bất kỳ mục bộ nhớ đệm nào vừa được truy cập trước khi nó hết hạn.
Làm mới trước có thể giảm độ trễ so với đọc thông qua nếu bộ nhớ đệm dự đoán chính xác các mục sẽ cần trong tương lai.
##### Bất lợi: làm mới trước
- Việc không dự đoán chính xác các mục nào có khả năng cần thiết trong tương lai có thể dẫn đến hiệu suất giảm hơn so với khi không sử dụng refresh-ahead.
Nhược điểm: bộ nhớ đệm
- Cần duy trì tính nhất quán giữa các bộ nhớ đệm và nguồn dữ liệu gốc như cơ sở dữ liệu thông qua làm mất hiệu lực bộ nhớ đệm.
- Làm mất hiệu lực bộ nhớ đệm là một vấn đề khó, có thêm sự phức tạp liên quan đến việc khi nào cần cập nhật bộ nhớ đệm.
- Cần thay đổi ứng dụng như thêm Redis hoặc memcached.
Nguồn và tài liệu đọc thêm
- Từ cache đến in-memory data grid
- Các mẫu thiết kế hệ thống có thể mở rộng
- Giới thiệu về kiến trúc hệ thống để mở rộng
- Scalability, availability, stability, patterns
- Scalability
- Chiến lược AWS ElastiCache
- Wikipedia)
Bất đồng bộ
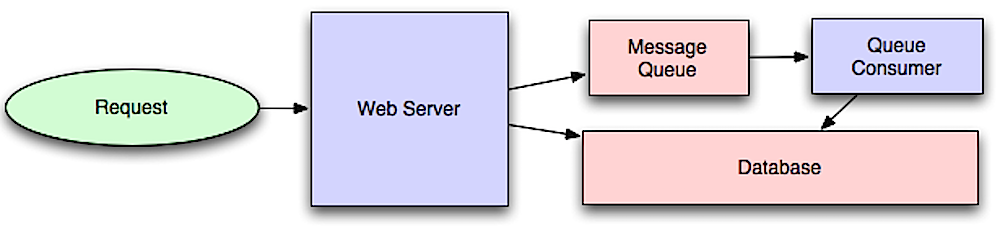
Nguồn: Giới thiệu về kiến trúc hệ thống để mở rộng
Luồng công việc bất đồng bộ giúp giảm thời gian yêu cầu cho các thao tác tốn kém mà bình thường sẽ được thực hiện ngay lập tức. Chúng cũng có thể giúp thực hiện các công việc tốn nhiều thời gian trước, như tổng hợp dữ liệu định kỳ.
Hàng đợi tin nhắn
Hàng đợi tin nhắn nhận, giữ và chuyển phát tin nhắn. Nếu một thao tác quá chậm để thực hiện ngay, bạn có thể sử dụng hàng đợi tin nhắn với quy trình sau:
- Ứng dụng gửi một công việc vào hàng đợi, sau đó thông báo cho người dùng về trạng thái công việc
- Một worker nhận công việc từ hàng đợi, xử lý, rồi báo hiệu công việc đã hoàn thành
Redis hữu ích như một message broker đơn giản nhưng có thể bị mất tin nhắn.
RabbitMQ phổ biến nhưng yêu cầu bạn phải thích nghi với giao thức 'AMQP' và tự quản lý các node.
Amazon SQS là dịch vụ được lưu trữ nhưng có thể có độ trễ cao và có khả năng tin nhắn được gửi hai lần.
Hàng đợi tác vụ
Hàng đợi tác vụ nhận các tác vụ và dữ liệu liên quan, thực hiện chúng, sau đó trả về kết quả. Chúng có thể hỗ trợ lập lịch và được sử dụng để chạy các công việc tính toán nặng ở chế độ nền.
Celery hỗ trợ lập lịch và chủ yếu hỗ trợ python.
Áp lực ngược (Back pressure)
Nếu các hàng đợi bắt đầu tăng lên đáng kể, kích thước hàng đợi có thể lớn hơn bộ nhớ, dẫn đến lỗi bộ nhớ cache, đọc từ đĩa và hiệu suất chậm hơn. Áp lực ngược có thể giúp bằng cách giới hạn kích thước hàng đợi, giữ tốc độ thông lượng cao và thời gian phản hồi tốt cho các công việc đã có trong hàng đợi. Khi hàng đợi đầy, khách hàng sẽ nhận được thông báo máy chủ bận hoặc mã trạng thái HTTP 503 để thử lại sau. Khách hàng có thể thử lại yêu cầu vào thời điểm sau, có thể với phương pháp lùi theo cấp số nhân.
Bất lợi: tính bất đồng bộ
- Các trường hợp sử dụng như tính toán giá rẻ và quy trình thời gian thực có thể phù hợp hơn với hoạt động đồng bộ, vì việc đưa hàng đợi vào có thể gây ra độ trễ và phức tạp.
Nguồn và đọc thêm
- Tất cả là một trò chơi số
- Áp dụng áp lực ngược khi quá tải
- Định luật Little
- Sự khác biệt giữa hàng đợi tin nhắn và hàng đợi tác vụ là gì?
Giao tiếp
{kind=link}
{kind=link}
Giao thức truyền siêu văn bản (HTTP)
HTTP là một phương thức để mã hóa và truyền dữ liệu giữa máy khách và máy chủ. Đây là giao thức yêu cầu/đáp ứng: máy khách gửi yêu cầu và máy chủ phản hồi với nội dung liên quan và thông tin trạng thái hoàn thành về yêu cầu. HTTP là tự chứa, cho phép yêu cầu và phản hồi đi qua nhiều bộ định tuyến và máy chủ trung gian thực hiện cân bằng tải, bộ nhớ đệm, mã hóa và nén.
Một yêu cầu HTTP cơ bản gồm một động từ (phương thức) và một tài nguyên (điểm cuối). Dưới đây là các động từ HTTP phổ biến:
| Động từ | Mô tả | Idempotent* | An toàn | Có thể lưu vào bộ đệm | |---|---|---|---|---| | GET | Đọc một tài nguyên | Có | Có | Có | | POST | Tạo một tài nguyên hoặc kích hoạt một tiến trình xử lý dữ liệu | Không | Không | Có nếu phản hồi chứa thông tin độ tươi mới | | PUT | Tạo hoặc thay thế một tài nguyên | Có | Không | Không | | PATCH | Cập nhật một phần tài nguyên | Không | Không | Có nếu phản hồi chứa thông tin độ tươi mới | | DELETE | Xóa một tài nguyên | Có | Không | Không |
*Có thể gọi nhiều lần mà không có kết quả khác biệt.
HTTP là một giao thức tầng ứng dụng dựa vào các giao thức tầng thấp hơn như TCP và UDP.
#### Nguồn và đọc thêm: HTTP
Giao thức điều khiển truyền tải (TCP)
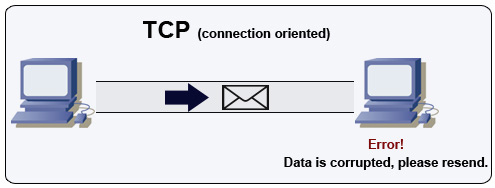
Nguồn: Cách làm game nhiều người chơi
TCP là một giao thức hướng kết nối hoạt động trên mạng IP. Kết nối được thiết lập và kết thúc bằng cách sử dụng bắt tay. Tất cả các gói gửi đi đều được đảm bảo đến đích theo đúng thứ tự ban đầu và không bị lỗi thông qua:
- Số thứ tự và trường kiểm tra tổng cho từng gói
- Gói xác nhận) và tự động truyền lại
Để đảm bảo thông lượng cao, các máy chủ web có thể giữ một số lượng lớn kết nối TCP mở, dẫn đến sử dụng bộ nhớ cao. Việc có nhiều kết nối mở giữa các luồng máy chủ web và ví dụ, một máy chủ memcached có thể tốn kém. Pooling kết nối có thể giúp ngoài việc chuyển sang UDP khi phù hợp.
TCP hữu ích cho các ứng dụng đòi hỏi độ tin cậy cao nhưng không quá nhạy về thời gian. Một số ví dụ bao gồm máy chủ web, dữ liệu cơ sở dữ liệu, SMTP, FTP và SSH.
Sử dụng TCP thay vì UDP khi:
- Bạn cần tất cả dữ liệu phải đến nguyên vẹn
- Bạn muốn tự động ước lượng tối ưu băng thông mạng
Giao thức datagram người dùng (UDP)
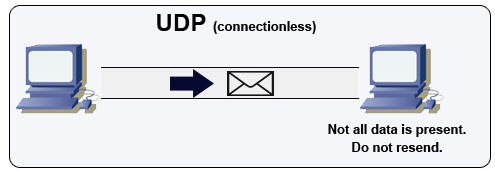
Nguồn: Cách tạo một trò chơi nhiều người chơi
UDP là giao thức không kết nối. Datagram (tương tự như gói tin) chỉ được đảm bảo ở cấp độ datagram. Datagram có thể đến đích không theo thứ tự hoặc có thể không đến được. UDP không hỗ trợ kiểm soát tắc nghẽn. Không có các đảm bảo như TCP, UDP thường hiệu quả hơn.
UDP có thể phát sóng, gửi datagram đến tất cả các thiết bị trong mạng con. Điều này hữu ích với DHCP vì máy khách chưa nhận được địa chỉ IP, do đó ngăn chặn việc TCP truyền dữ liệu mà không có địa chỉ IP.
UDP kém tin cậy hơn nhưng hoạt động tốt trong các trường hợp sử dụng thời gian thực như VoIP, trò chuyện video, streaming và trò chơi nhiều người chơi thời gian thực.
Sử dụng UDP thay cho TCP khi:
- Bạn cần độ trễ thấp nhất
- Dữ liệu đến muộn còn tệ hơn dữ liệu bị mất
- Bạn muốn tự triển khai cơ chế sửa lỗi
- Mạng cho lập trình game
- Sự khác biệt chính giữa các giao thức TCP và UDP
- Sự khác biệt giữa TCP và UDP
- Giao thức điều khiển truyền tải
- Giao thức datagram người dùng
- Scaling memcache tại Facebook
Gọi thủ tục từ xa (RPC)
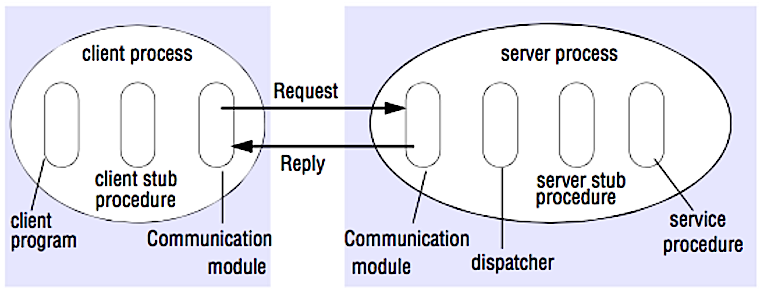
Nguồn: Crack the system design interview
Trong RPC, một máy khách gây ra việc thực thi một thủ tục ở không gian địa chỉ khác, thường là máy chủ từ xa. Thủ tục này được mã hóa như một lời gọi thủ tục cục bộ, trừu tượng hóa chi tiết về cách giao tiếp với máy chủ khỏi chương trình máy khách. Các lời gọi từ xa thường chậm hơn và kém tin cậy hơn các lời gọi cục bộ, vì vậy nên phân biệt các lời gọi RPC với lời gọi cục bộ. Các framework RPC phổ biến bao gồm Protobuf, Thrift, và Avro.
RPC là giao thức yêu cầu-phản hồi:
- Chương trình khách - Gọi thủ tục stub phía khách. Các tham số được đẩy lên stack giống như một lời gọi thủ tục cục bộ.
- Thủ tục stub phía khách - Đóng gói (marshals) id thủ tục và các tham số vào một thông điệp yêu cầu.
- Mô-đun truyền thông phía khách - Hệ điều hành gửi thông điệp từ khách đến máy chủ.
- Mô-đun truyền thông phía máy chủ - Hệ điều hành chuyển các gói tin đến thủ tục stub phía máy chủ.
- Thủ tục stub phía máy chủ - Giải nén kết quả, gọi thủ tục máy chủ tương ứng với id thủ tục và truyền các tham số đã cho.
- Phản hồi từ máy chủ lặp lại các bước trên theo thứ tự ngược lại.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
Chọn thư viện gốc (hay còn gọi là SDK) khi:
- Bạn biết nền tảng mục tiêu của mình.
- Bạn muốn kiểm soát cách "logic" của mình được truy cập.
- Bạn muốn kiểm soát cách kiểm soát lỗi xảy ra bên ngoài thư viện của mình.
- Hiệu năng và trải nghiệm người dùng cuối là mối quan tâm chính của bạn.
#### Nhược điểm: RPC
- Các client RPC trở nên phụ thuộc chặt chẽ vào cách triển khai dịch vụ.
- Một API mới phải được định nghĩa cho mỗi thao tác hoặc trường hợp sử dụng mới.
- Có thể khó gỡ lỗi RPC.
- Bạn có thể không tận dụng được các công nghệ hiện có ngay lập tức. Ví dụ, có thể cần thêm nỗ lực để đảm bảo các lệnh gọi RPC được lưu vào bộ nhớ đệm đúng cách trên các máy chủ cache như Squid.
Representational state transfer (REST)
REST là một kiểu kiến trúc áp đặt mô hình client/server, trong đó client thao tác trên tập hợp các tài nguyên do server quản lý. Server cung cấp đại diện của tài nguyên và các hành động có thể thao tác hoặc lấy đại diện mới của tài nguyên đó. Mọi giao tiếp đều phải không trạng thái và có thể lưu vào bộ nhớ đệm.
Có bốn đặc tính của một giao diện RESTful:
- Định danh tài nguyên (URI trong HTTP) - sử dụng cùng một URI bất kể thao tác nào.
- Thay đổi theo đại diện (Động từ trong HTTP) - sử dụng động từ, header và body.
- Thông điệp lỗi tự mô tả (phản hồi trạng thái trong HTTP) - sử dụng mã trạng thái, không phát minh lại bánh xe.
- HATEOAS (giao diện HTML cho HTTP) - dịch vụ web của bạn nên được truy cập đầy đủ qua trình duyệt.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Nhược điểm: REST
- Vì REST tập trung vào việc cung cấp dữ liệu, nó có thể không phù hợp nếu tài nguyên không được tổ chức hoặc truy cập một cách tự nhiên trong một hệ thống phân cấp đơn giản. Ví dụ, trả về tất cả các bản ghi cập nhật trong giờ qua phù hợp với một tập hợp sự kiện cụ thể không dễ dàng thể hiện dưới dạng một đường dẫn. Với REST, có khả năng phải thực hiện với sự kết hợp của đường dẫn URI, tham số truy vấn và có thể là phần thân yêu cầu.
- REST thường dựa vào một vài động từ (GET, POST, PUT, DELETE và PATCH) mà đôi khi không phù hợp với trường hợp sử dụng của bạn. Ví dụ, di chuyển tài liệu hết hạn vào thư mục lưu trữ có thể không phù hợp một cách rõ ràng với các động từ này.
- Việc lấy các tài nguyên phức tạp với cấu trúc phân cấp lồng nhau cần nhiều lần trao đổi giữa client và server để hiển thị một view duy nhất, ví dụ như lấy nội dung của một bài blog và các bình luận trên bài đó. Đối với các ứng dụng di động hoạt động trong điều kiện mạng thay đổi, nhiều lần trao đổi này là điều rất không mong muốn.
- Theo thời gian, có thể có thêm nhiều trường dữ liệu được bổ sung vào phản hồi API và các client cũ sẽ nhận tất cả các trường dữ liệu mới, kể cả những trường mà chúng không cần, dẫn đến payload bị phình to và độ trễ lớn hơn.
So sánh các gọi RPC và REST
| Hoạt động | RPC | REST |
|---|---|---|
| Đăng ký | POST /signup | POST /persons |
| Nghỉ việc | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Đọc thông tin một người | GET /readPerson?personid=1234 | GET /persons/1234 |
| Đọc danh sách vật phẩm của một người | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Thêm vật phẩm vào danh sách của một người | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Cập nhật vật phẩm | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Xóa vật phẩm | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Nguồn: Bạn có thật sự biết vì sao bạn thích REST hơn RPC không
#### Nguồn và tài liệu đọc thêm: REST và RPC
- Bạn có thật sự biết vì sao bạn thích REST hơn RPC không
- Khi nào cách tiếp cận kiểu RPC phù hợp hơn REST?
- REST vs JSON-RPC
- Phá bỏ các huyền thoại về RPC và REST
- Những bất lợi khi sử dụng REST
- Crack the system design interview
- Thrift
- Tại sao REST dùng cho nội bộ mà không phải RPC
Bảo mật
Phần này có thể cần cập nhật. Hãy cân nhắc đóng góp!
Bảo mật là một chủ đề rộng. Trừ khi bạn có kinh nghiệm đáng kể, có nền tảng về bảo mật, hoặc đang ứng tuyển vào vị trí yêu cầu kiến thức về bảo mật, bạn có lẽ chỉ cần biết những điều cơ bản sau:
- Mã hóa dữ liệu khi truyền và khi lưu trữ.
- Làm sạch tất cả dữ liệu đầu vào từ người dùng hoặc bất kỳ tham số nào được người dùng truy cập để ngăn chặn XSS và SQL injection.
- Sử dụng truy vấn tham số hóa để ngăn SQL injection.
- Áp dụng nguyên tắc quyền hạn tối thiểu.
Nguồn và tài liệu đọc thêm
Phụ lục
Đôi khi bạn sẽ được yêu cầu ước lượng nhanh. Ví dụ, bạn có thể cần xác định mất bao lâu để tạo 100 ảnh thumbnail từ đĩa hoặc một cấu trúc dữ liệu sẽ tiêu tốn bao nhiêu bộ nhớ. Bảng số mũ của hai và Các con số độ trễ mà lập trình viên nên biết là những tài liệu tham khảo hữu ích.
Bảng số mũ của hai
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Nguồn và tài liệu đọc thêm
Những con số độ trễ mà mọi lập trình viên nên biết
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Đọc tuần tự từ HDD ở tốc độ 30 MB/s
- Đọc tuần tự từ Ethernet 1 Gbps ở tốc độ 100 MB/s
- Đọc tuần tự từ SSD ở tốc độ 1 GB/s
- Đọc tuần tự từ bộ nhớ chính ở tốc độ 4 GB/s
- 6-7 lượt đi/về toàn cầu mỗi giây
- 2.000 lượt đi/về mỗi giây trong một trung tâm dữ liệu
#### Nguồn và tài liệu đọc thêm
- Những con số độ trễ mà lập trình viên nên biết - 1
- Những con số độ trễ mà lập trình viên nên biết - 2
- Thiết kế, bài học và lời khuyên khi xây dựng hệ thống phân tán lớn
- Lời khuyên Kỹ thuật phần mềm từ việc xây dựng hệ thống phân tán quy mô lớn
Các câu hỏi phỏng vấn thiết kế hệ thống bổ sung
Các câu hỏi phỏng vấn thiết kế hệ thống phổ biến, kèm liên kết đến tài liệu hướng dẫn cách giải.
| Câu hỏi | Tài liệu tham khảo |
|---|---|
| Thiết kế dịch vụ đồng bộ tập tin như Dropbox | youtube.com |
| Thiết kế công cụ tìm kiếm như Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Thiết kế trình thu thập dữ liệu web có khả năng mở rộng như Google | quora.com |
| Thiết kế Google Docs | code.google.com
neil.fraser.name |
| Thiết kế kho key-value như Redis | slideshare.net |
| Thiết kế hệ thống cache như Memcached | slideshare.net |
| Thiết kế hệ thống đề xuất như Amazon | hulu.com
ijcai13.org |
| Thiết kế hệ thống tinyurl như Bitly | n00tc0d3r.blogspot.com |
| Thiết kế ứng dụng chat như WhatsApp | highscalability.com
| Thiết kế hệ thống chia sẻ ảnh như Instagram | highscalability.com
highscalability.com |
| Thiết kế chức năng news feed của Facebook | quora.com
quora.com
slideshare.net |
| Thiết kế chức năng timeline của Facebook | facebook.com
highscalability.com |
| Thiết kế chức năng chat của Facebook | erlang-factory.com
facebook.com |
| Thiết kế một chức năng tìm kiếm đồ thị giống Facebook | facebook.com
facebook.com
facebook.com |
| Thiết kế một mạng phân phối nội dung giống CloudFlare | figshare.com |
| Thiết kế hệ thống chủ đề thịnh hành giống Twitter | michael-noll.com
snikolov .wordpress.com |
| Thiết kế hệ thống sinh ID ngẫu nhiên | blog.twitter.com
github.com |
| Trả về k yêu cầu hàng đầu trong một khoảng thời gian | cs.ucsb.edu
wpi.edu |
| Thiết kế hệ thống phục vụ dữ liệu từ nhiều trung tâm dữ liệu | highscalability.com |
| Thiết kế trò chơi bài đa người chơi trực tuyến | indieflashblog.com
buildnewgames.com |
| Thiết kế hệ thống thu gom rác | stuffwithstuff.com
washington.edu |
| Thiết kế bộ giới hạn tần suất gọi API | https://stripe.com/blog/ |
| Thiết kế một Sàn giao dịch chứng khoán (như NASDAQ hoặc Binance) | Jane Street
Golang Implementation
Go Implementation |
| Thêm một câu hỏi thiết kế hệ thống | Đóng góp |
Kiến trúc thực tế
Các bài viết về cách hệ thống thực tế được thiết kế.
Nguồn: Twitter timelines at scale
Đừng tập trung vào chi tiết vụn vặt trong các bài viết sau, thay vào đó:
- Xác định các nguyên lý chung, công nghệ phổ biến và mẫu thiết kế trong các bài viết này
- Tìm hiểu các vấn đề được giải quyết bởi từng thành phần, điểm mạnh, điểm yếu
- Xem lại các bài học kinh nghiệm
Kiến trúc của các công ty
| Công ty | Tham khảo |
|---|---|
| Amazon | Kiến trúc Amazon |
| Cinchcast | Sản xuất 1.500 giờ âm thanh mỗi ngày |
| DataSift | Khai thác dữ liệu thời gian thực với 120.000 tweet mỗi giây |
| Dropbox | Cách Dropbox mở rộng quy mô |
| ESPN | Vận hành với 100.000 duh nuh nuhs mỗi giây |
| Google | Kiến trúc Google |
| Instagram | 14 triệu người dùng, hàng terabyte ảnh
Công nghệ phía sau Instagram |
| Justin.tv | Kiến trúc phát video trực tuyến của Justin.tv |
| Facebook | Mở rộng memcached tại Facebook
TAO: Kho dữ liệu phân tán cho social graph của Facebook
Lưu trữ ảnh của Facebook
Cách Facebook Live phát trực tiếp đến 800.000 người xem đồng thời |
| Flickr | Kiến trúc Flickr |
| Mailbox | Từ 0 đến một triệu người dùng trong 6 tuần |
| Netflix | Toàn cảnh hệ thống Netflix
Netflix: Chuyện gì xảy ra khi bạn nhấn Play? |
| Pinterest | Từ 0 đến hàng chục tỷ lượt xem trang mỗi tháng
18 triệu khách truy cập, tăng trưởng 10 lần, 12 nhân viên |
| Playfish | 50 triệu người dùng hàng tháng và tiếp tục tăng trưởng |
| PlentyOfFish | Kiến trúc PlentyOfFish |
| Salesforce | Cách họ xử lý 1,3 tỷ giao dịch mỗi ngày |
| Stack Overflow | Kiến trúc Stack Overflow |
| TripAdvisor | 40 triệu khách truy cập, 200 triệu lượt xem trang động, 30TB dữ liệu |
| Tumblr | 15 tỷ lượt xem trang mỗi tháng |
| Twitter | Làm Twitter nhanh hơn 10.000 lần
Lưu trữ 250 triệu tweet mỗi ngày bằng MySQL
150 triệu người dùng hoạt động, 300K QPS, 22 MB/S dữ liệu lớn
Timeline ở quy mô lớn
Dữ liệu lớn và nhỏ tại Twitter
Vận hành tại Twitter: mở rộng vượt quá 100 triệu người dùng
Cách Twitter xử lý 3.000 ảnh mỗi giây |
| Uber | Cách Uber mở rộng nền tảng thị trường thời gian thực
Bài học từ việc mở rộng Uber lên 2000 kỹ sư, 1000 dịch vụ, và 8000 kho Git |
| WhatsApp | Kiến trúc WhatsApp mà Facebook mua với giá 19 tỷ USD |
| YouTube | Khả năng mở rộng của YouTube
Kiến trúc YouTube |
Blog kỹ thuật của các công ty
Kiến trúc của các công ty mà bạn đang phỏng vấn.>
Những câu hỏi bạn gặp phải có thể đến từ cùng một lĩnh vực.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Muốn thêm blog? Để tránh trùng lặp công việc, hãy cân nhắc thêm blog công ty của bạn vào kho lưu trữ sau:
Đang phát triển
Quan tâm đến việc thêm một mục hoặc giúp hoàn thành một mục đang tiến hành? Đóng góp!
- Điện toán phân tán với MapReduce
- Băm nhất quán
- Scatter gather
- Đóng góp
Ghi công
Ghi công và nguồn được cung cấp xuyên suốt kho lưu trữ này.
Đặc biệt cảm ơn:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Thông tin liên hệ
Hãy liên hệ với tôi để thảo luận về bất kỳ vấn đề, câu hỏi hoặc ý kiến nào.
Thông tin liên hệ của tôi có thể được tìm thấy trên trang GitHub của tôi.
Giấy phép
Tôi cung cấp mã nguồn và tài nguyên trong kho lưu trữ này cho bạn theo giấy phép nguồn mở. Vì đây là kho lưu trữ cá nhân của tôi, giấy phép bạn nhận được đối với mã nguồn và tài nguyên là từ tôi chứ không phải từ công ty tôi (Facebook).
Bản quyền 2017 Donne Martin
Giấy phép Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---