English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Bu rehberi çevirin!
Sistem Tasarımı Primer

Motivasyon
Büyük ölçekli sistemlerin nasıl tasarlanacağını öğrenin.>
Sistem tasarımı mülakatına hazırlanın.
Büyük ölçekli sistemlerin nasıl tasarlanacağını öğrenin
Ölçeklenebilir sistemlerin nasıl tasarlanacağını öğrenmek daha iyi bir mühendis olmanıza yardımcı olur.
Sistem tasarımı geniş bir konudur. Web üzerinde sistem tasarımı prensipleriyle ilgili çok fazla dağınık kaynak bulunmaktadır.
Bu repo, ölçekli sistemler inşa etmeyi öğrenmenize yardımcı olacak organize bir kaynak koleksiyonudur.
Açık kaynak topluluğundan öğrenin
Bu sürekli güncellenen, açık kaynaklı bir projedir.
Katkılar memnuniyetle karşılanır!
Sistem tasarımı mülakatına hazırlanın
Kodlama mülakatlarına ek olarak, sistem tasarımı birçok teknoloji şirketinde teknik mülakat sürecinin zorunlu bir bileşenidir.
Yaygın sistem tasarımı mülakat sorularını çözerek ve örnek çözümlerle: tartışmalar, kod ve diyagramlarla karşılaştırarak pratik yapın.
Mülakat hazırlığı için ek başlıklar:
- Çalışma rehberi
- Bir sistem tasarımı mülakat sorusuna nasıl yaklaşılır
- Sistem tasarımı mülakat soruları, çözümleriyle birlikte
- Nesne yönelimli tasarım mülakat soruları, çözümleriyle birlikte
- Ek sistem tasarımı mülakat soruları
Anki flash kartları
Sunulan Anki flash kart desteleri anahtar sistem tasarımı kavramlarını akılda tutmanıza yardımcı olmak için aralıklı tekrar kullanır.
- Sistem tasarımı destesi
- Sistem tasarımı alıştırmaları destesi
- Nesne yönelimli tasarım alıştırmaları destesi
Kodlama Kaynağı: Etkileşimli Kodlama Zorlukları
Kodlama Mülakatına hazırlanmanıza yardımcı olacak kaynaklar mı arıyorsunuz?
Kız kardeş repoya göz atın Etkileşimli Kodlama Zorlukları, ek bir Anki destesi içerir:
Katkıda Bulunma
Topluluktan öğrenin.
Şunlara yardımcı olmak için pull request göndermekten çekinmeyin:
- Hataları düzeltin
- Bölümleri geliştirin
- Yeni bölümler ekle
- Çevir
Katkı Sağlama Yönergelerini inceleyin.
Sistem tasarımı konuları indeksi
Çeşitli sistem tasarımı konularının özetleri, artıları ve eksileri dahil. Her şey bir ödünleşmedir.>
Her bölümde daha derinlemesine kaynaklara bağlantılar bulunur.
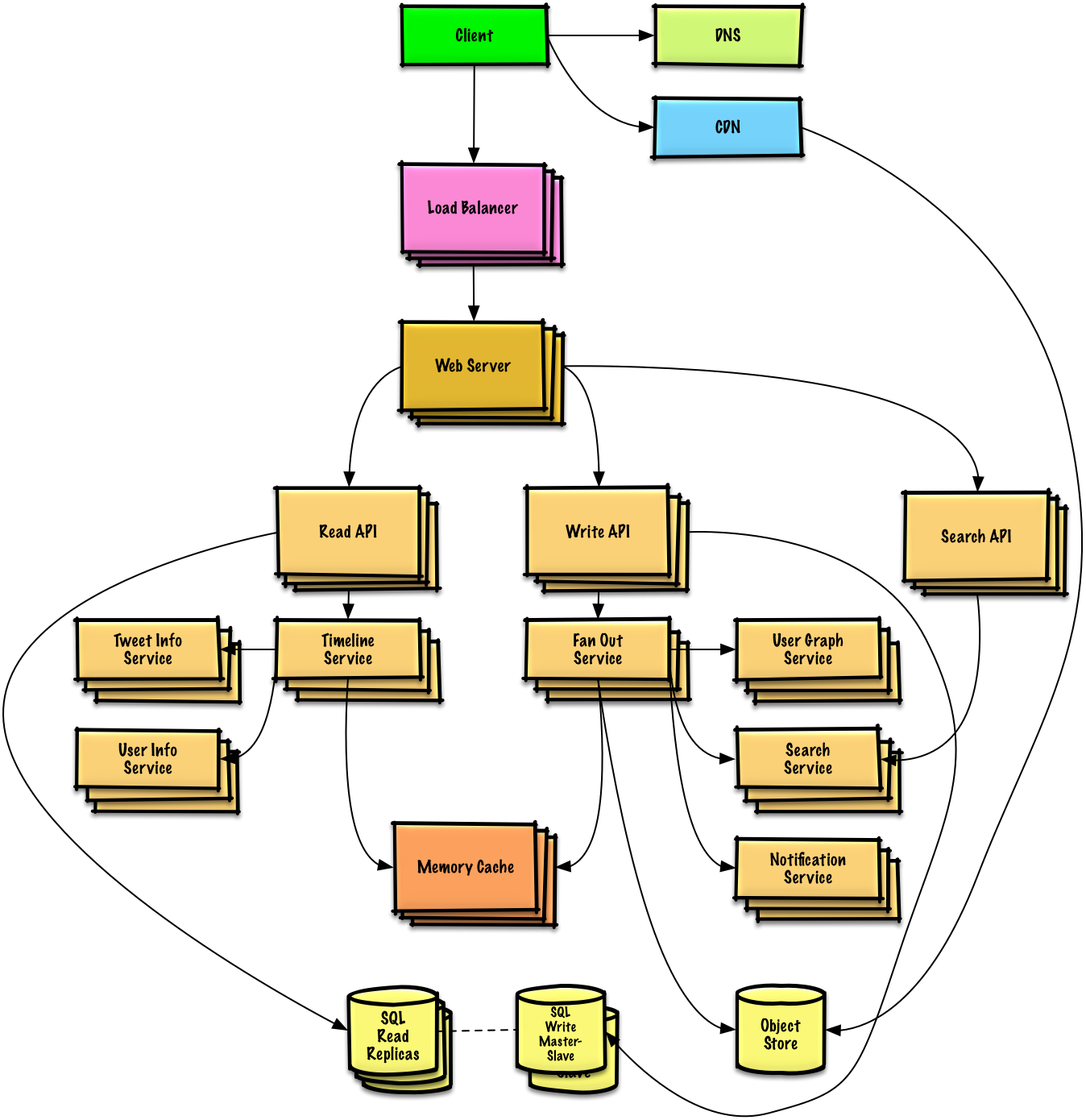
- Sistem tasarımı konuları: buradan başlayın
- Adım 1: Ölçeklenebilirlik video dersini inceleyin
- Adım 2: Ölçeklenebilirlik makalesini inceleyin
- Sonraki adımlar
- Performans vs ölçeklenebilirlik
- Gecikme vs verimlilik
- Kullanılabilirlik vs tutarlılık
- CAP teoremi
- CP - tutarlılık ve bölüm toleransı
- AP - kullanılabilirlik ve bölüm toleransı
- Tutarlılık desenleri
- Zayıf tutarlılık
- Sonunda tutarlılık
- Güçlü tutarlılık
- Kullanılabilirlik desenleri
- Fail-over (hata toleransı)
- Çoğaltma
- Sayılarla kullanılabilirlik
- Alan adı sistemi
- İçerik dağıtım ağı
- Push CDN'ler
- Pull CDN'ler
- Yük dengeleyici
- Aktif-pasif
- Aktif-aktif
- Katman 4 yük dengeleme
- Katman 7 yük dengeleme
- Yatay ölçekleme
- Ters proxy (web sunucusu)
- Yük dengeleyici vs ters proxy
- Uygulama katmanı
- Mikroservisler
- Servis keşfi
- Veritabanı
- İlişkisel veritabanı yönetim sistemi (RDBMS)
- Ana-yedek çoğaltma
- Ana-ana çoğaltma
- Federasyon
- Parçalama (Sharding)
- Denormalizasyon
- SQL ayarlama
- NoSQL
- Anahtar-değer deposu
- Doküman deposu
- Geniş sütun deposu
- Graf Veritabanı
- SQL veya NoSQL
- Önbellek
- İstemci önbelleklemesi
- CDN önbelleklemesi
- Web sunucu önbelleklemesi
- Veritabanı önbelleklemesi
- Uygulama önbelleklemesi
- Veritabanı sorgu seviyesinde önbellekleme
- Nesne seviyesinde önbellekleme
- Önbellek ne zaman güncellenmeli
- Önbellek-yanında
- Yaz-geçişli
- Yaz-geriden (yaz-dönüş)
- Önden-yenileme
- Asenkronluk
- Mesaj kuyrukları
- Görev kuyrukları
- Geri basınç
- İletişim
- Aktarım kontrol protokolü (TCP)
- Kullanıcı veri iletişim protokolü (UDP)
- Uzaktan prosedür çağrısı (RPC)
- Temsili durum aktarımı (REST)
- Güvenlik
- Ekler
- İki tabanı kuvvetler tablosu
- Her programcının bilmesi gereken gecikme değerleri
- Ek sistem tasarımı mülakat soruları
- Gerçek dünya mimarileri
- Şirket mimarileri
- Şirket mühendislik blogları
- Geliştirilmekte
- Katkıda Bulunanlar
- İletişim bilgisi
- Lisans
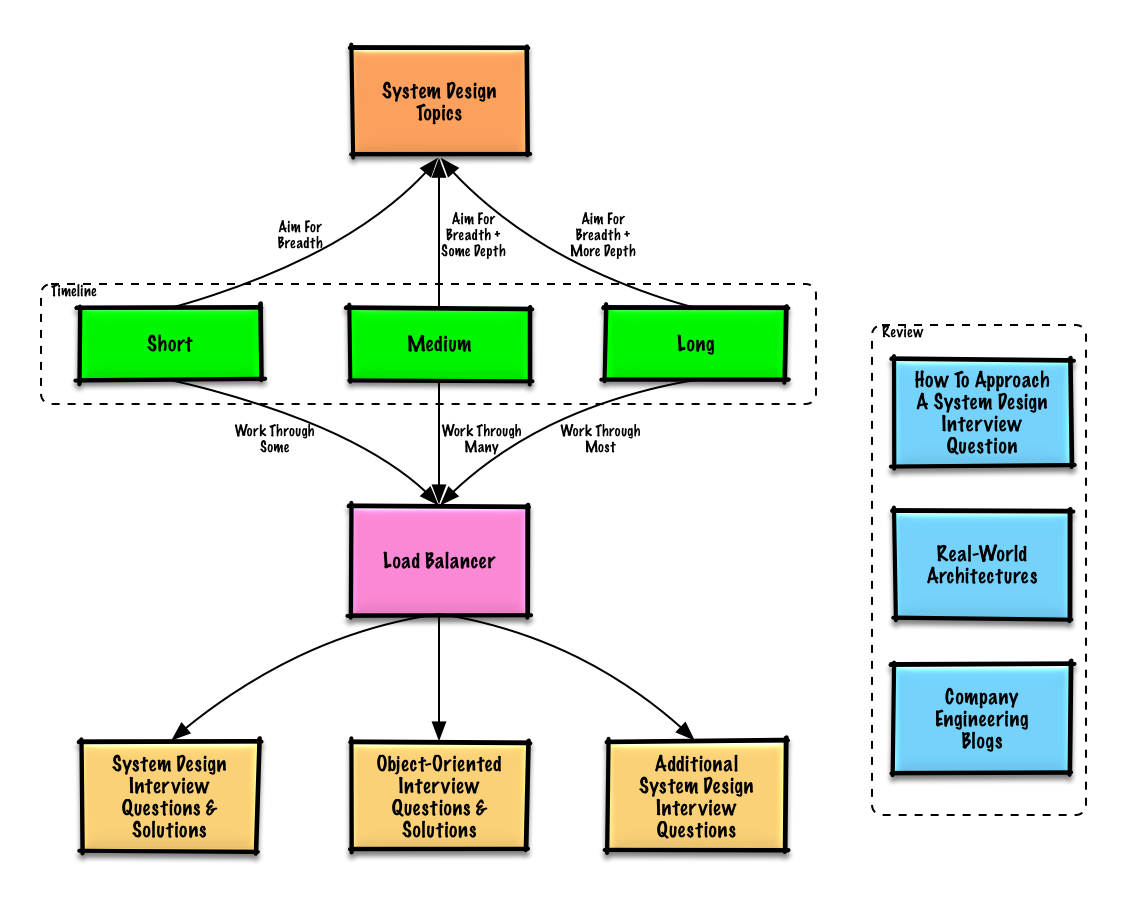
Çalışma rehberi
Mülakat zaman çizelgenize göre incelenmesi önerilen konular (kısa, orta, uzun).
S: Mülakatlar için burada her şeyi bilmem gerekiyor mu?
C: Hayır, mülakat için hazırlıkta burada her şeyi bilmenize gerek yok.
Bir mülakatta size sorulanlar şu değişkenlere bağlıdır:
- Ne kadar deneyiminiz olduğu
- Teknik geçmişinizin ne olduğu
- Hangi pozisyonlar için görüşme yaptığınız
- Hangi şirketlerle görüştüğünüz
- Şans
Geniş başlayın ve birkaç alanda derinleşin. Farklı anahtar sistem tasarımı konuları hakkında biraz bilgi sahibi olmak faydalıdır. Aşağıdaki rehberi zaman çizelgenize, deneyiminize, başvurduğunuz pozisyonlara ve görüşme yaptığınız şirketlere göre uyarlayın.
- Kısa zaman çizelgesi - Sistem tasarım konularında genişlik hedefleyin. Bazı mülakat sorularını çözerek pratik yapın.
- Orta zaman çizelgesi - Sistem tasarım konularında genişlik ve biraz derinlik hedefleyin. Birçok mülakat sorusunu çözerek pratik yapın.
- Uzun zaman çizelgesi - Sistem tasarım konularında genişlik ve daha fazla derinlik hedefleyin. Çoğu mülakat sorusunu çözerek pratik yapın.
Sistem tasarımı mülakat sorusuna nasıl yaklaşılır
Bir sistem tasarımı mülakat sorusu nasıl ele alınır.
Sistem tasarımı mülakatı açık uçlu bir konuşmadır. Bunu yönlendiren kişi olmanız beklenir.
Aşağıdaki adımları tartışmayı yönlendirmek için kullanabilirsiniz. Bu süreci pekiştirmek için, Çözümlü sistem tasarımı mülakat soruları bölümünü aşağıdaki adımları kullanarak inceleyin.
Adım 1: Kullanım senaryolarını, kısıtlamaları ve varsayımları ana hatlarıyla belirtin
Gereksinimleri toplayın ve problemi kapsamlandırın. Kullanım senaryoları ve kısıtlamaları netleştirmek için sorular sorun. Varsayımları tartışın.
- Kim kullanacak?
- Nasıl kullanacaklar?
- Kaç kullanıcı var?
- Sistem ne yapıyor?
- Sistemin girdileri ve çıktıları nelerdir?
- Ne kadar veriyle ilgileneceğiz?
- Saniyede kaç istek bekliyoruz?
- Beklenen okuma/yazma oranı nedir?
Adım 2: Yüksek seviyeli bir tasarım oluşturun
Tüm önemli bileşenlerle yüksek seviyeli bir tasarım ana hatlarını çizin.
- Ana bileşenleri ve bağlantıları taslağını çıkarın
- Fikirlerinizi gerekçelendirin
Adım 3: Temel bileşenleri tasarlayın
Her temel bileşenin ayrıntılarına inin. Örneğin, bir url kısaltma servisi tasarlamanız istenirse, şunları tartışın:
- Tam url'nin bir hash'inin oluşturulması ve saklanması
- MD5 ve Base62
- Hash çakışmaları
- SQL veya NoSQL
- Veritabanı şeması
- Hashlenmiş url'nin tam url'ye çevrilmesi
- Veritabanı sorgusu
- API ve nesne tabanlı tasarım
Adım 4: Tasarımı ölçeklendirin
Kısıtlamalar dikkate alındığında darboğazları belirleyin ve ele alın. Örneğin, ölçeklenebilirlik sorunlarını çözmek için aşağıdakilere ihtiyacınız var mı?
- Yük dengeleyici
- Yatay ölçeklendirme
- Önbellekleme
- Veritabanı bölümlendirme
Kabaca hesaplamalar
Bazı tahminleri elle yapmanız istenebilir. Ek bölümünde aşağıdaki kaynaklara başvurun:
- Kabaca hesaplamalar kullanın
- İki'nin kuvvetleri tablosu
- Her programcının bilmesi gereken gecikme rakamları
Kaynak(lar) ve ileri okuma
Beklentilerinizi daha iyi anlamak için aşağıdaki bağlantılara göz atın:
- Bir sistem tasarımı mülakatını nasıl başarıyla geçersiniz
- Sistem tasarımı mülakatı
- Mimariye ve Sistem Tasarımı Mülakatlarına Giriş
- Sistem tasarımı şablonu
Çözümleriyle sistem tasarımı mülakat soruları
Yaygın sistem tasarımı mülakat soruları örnek tartışmalar, kod ve diyagramlarla birlikte.>
Çözümler solutions/ klasöründeki içeriklere bağlantılıdır.| Soru | | |---|---| | Pastebin.com (veya Bit.ly) tasarlayın | Çözüm | | Twitter zaman akışı ve arama (veya Facebook akışı ve arama) tasarlayın | Çözüm | | Bir web gezgini tasarlayın | Çözüm | | Mint.com’u tasarlayın | Çözüm | | Bir sosyal ağ için veri yapılarını tasarlayın | Çözüm | | Bir arama motoru için anahtar-değer deposu tasarlayın | Çözüm | | Amazon’un kategoriye göre satış sıralama özelliğini tasarlayın | Çözüm | | AWS üzerinde milyonlarca kullanıcıya ölçeklenebilen bir sistem tasarlayın | Çözüm | | Bir sistem tasarımı sorusu ekleyin | Katkıda Bulunun |
Pastebin.com’u (veya Bit.ly) tasarlayın
Alıştırmayı ve çözümü görüntüle
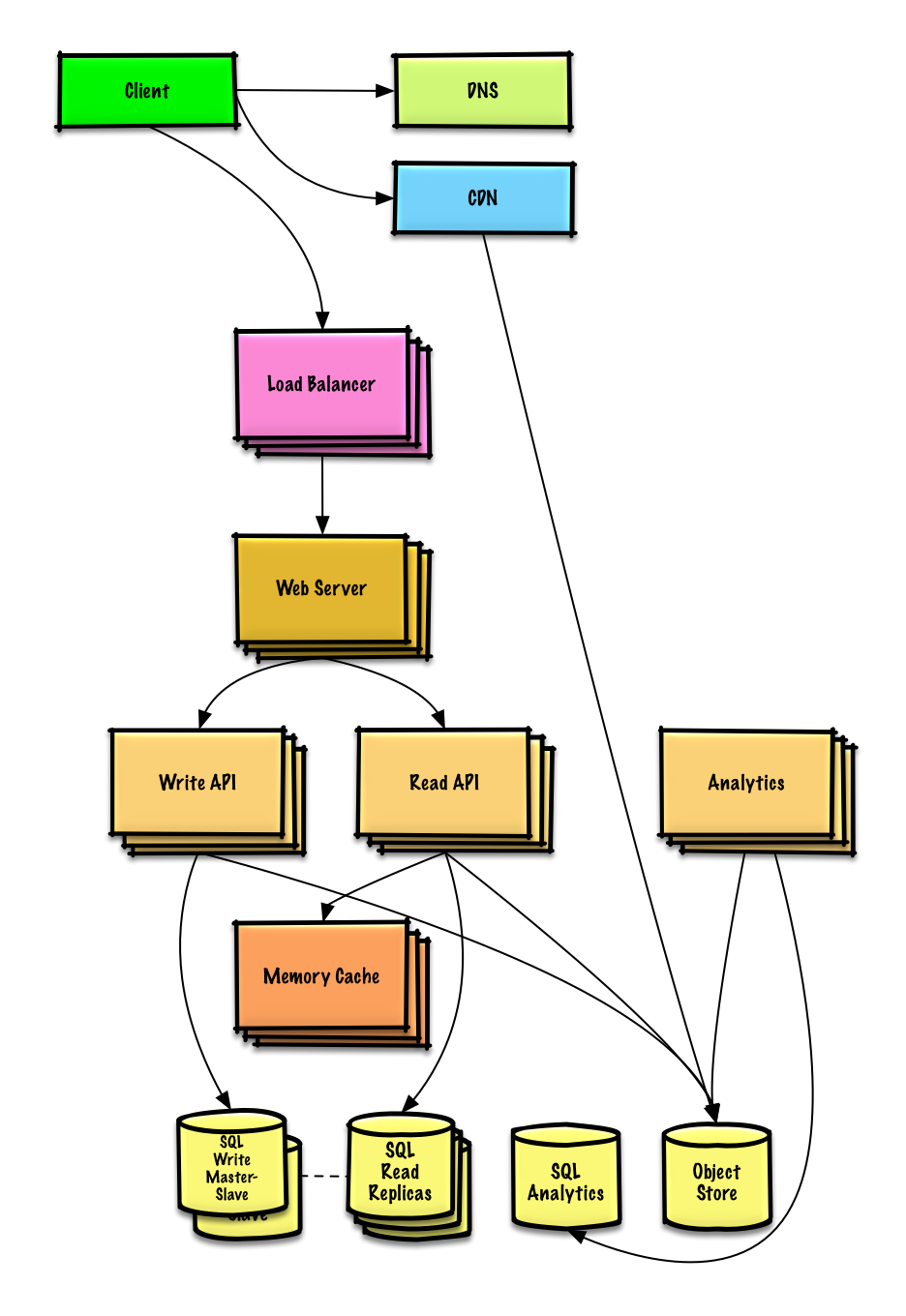
Twitter zaman akışı ve aramayı (veya Facebook akışı ve arama) tasarlayın
Alıştırmayı ve çözümü görüntüle
Bir web gezgini tasarlayın
Alıştırmayı ve çözümü görüntüle
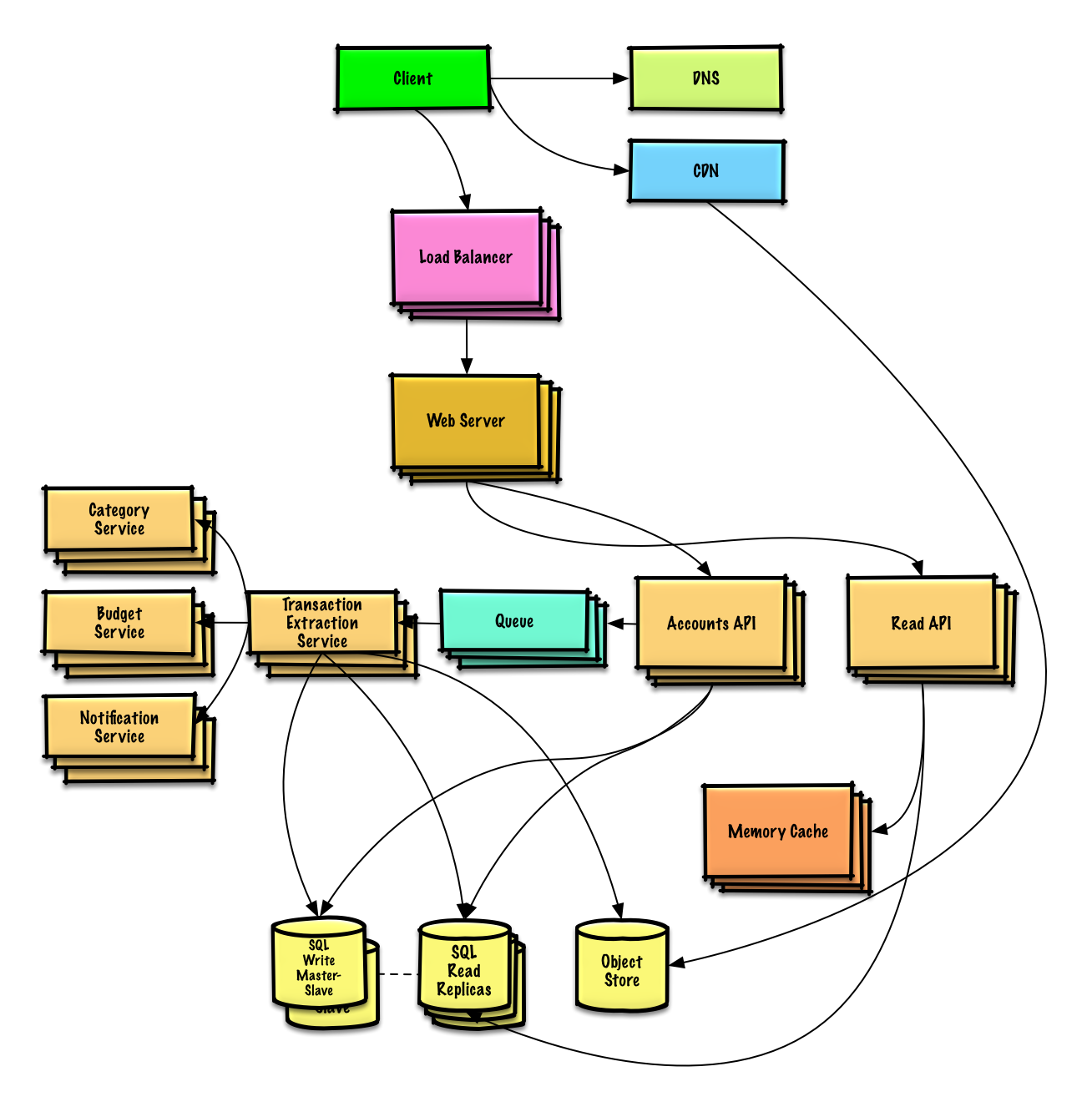
Design Mint.com
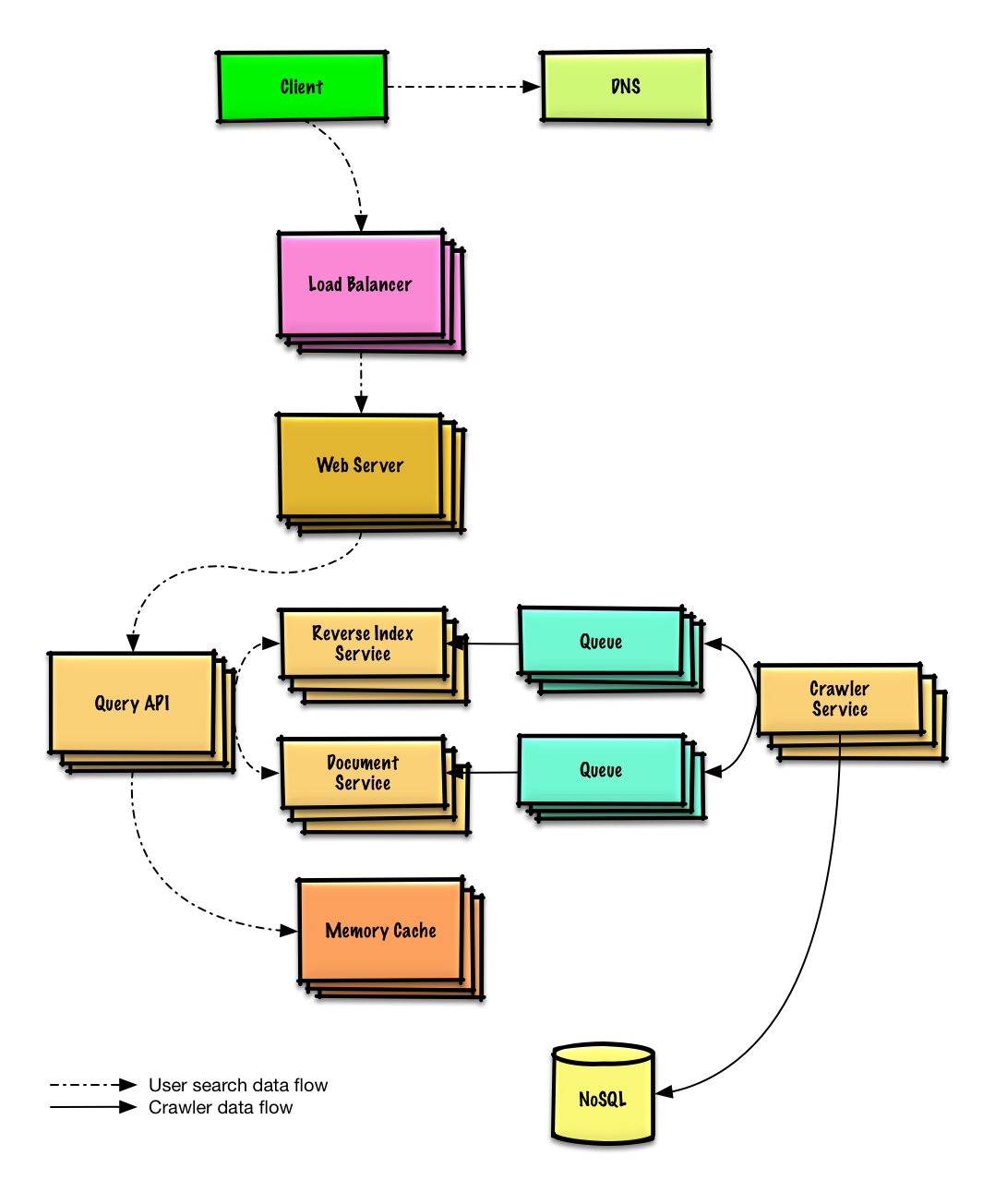
Design the data structures for a social network
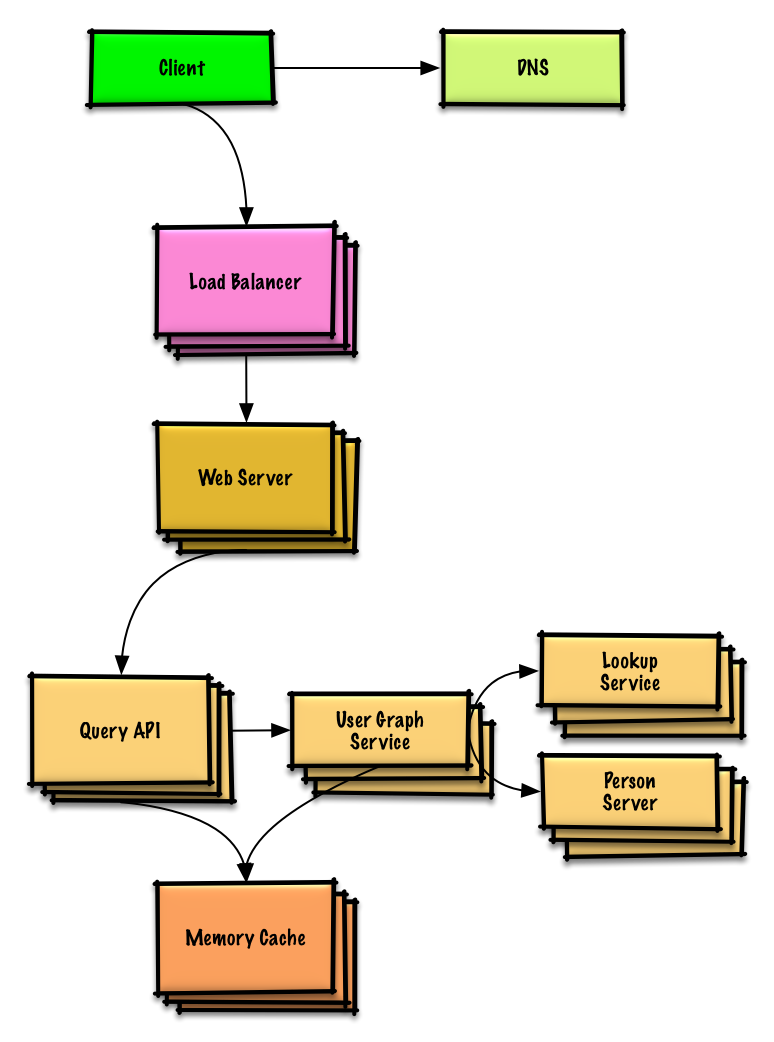
Design a key-value store for a search engine
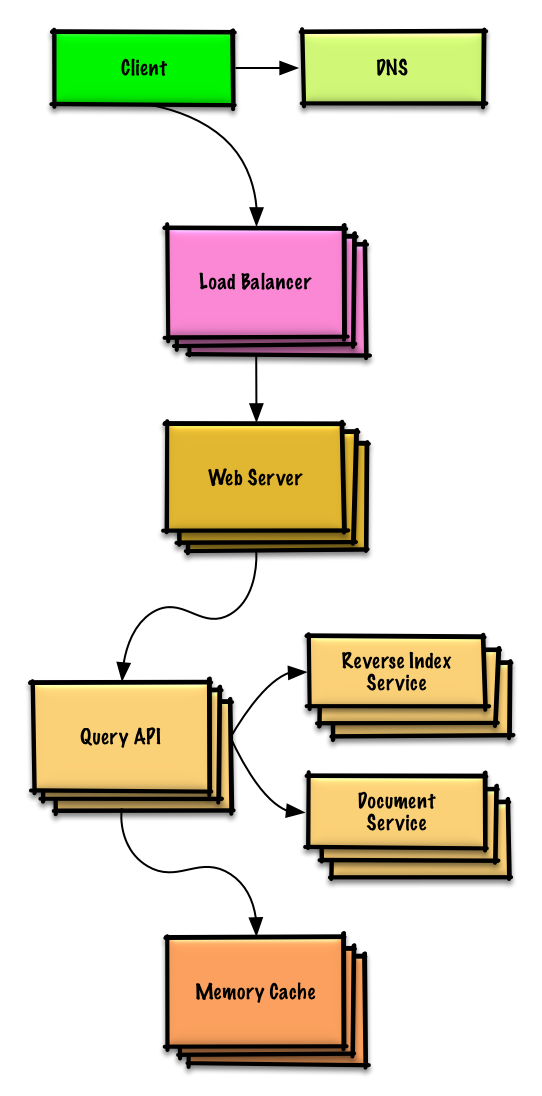
Design Amazon's sales ranking by category feature
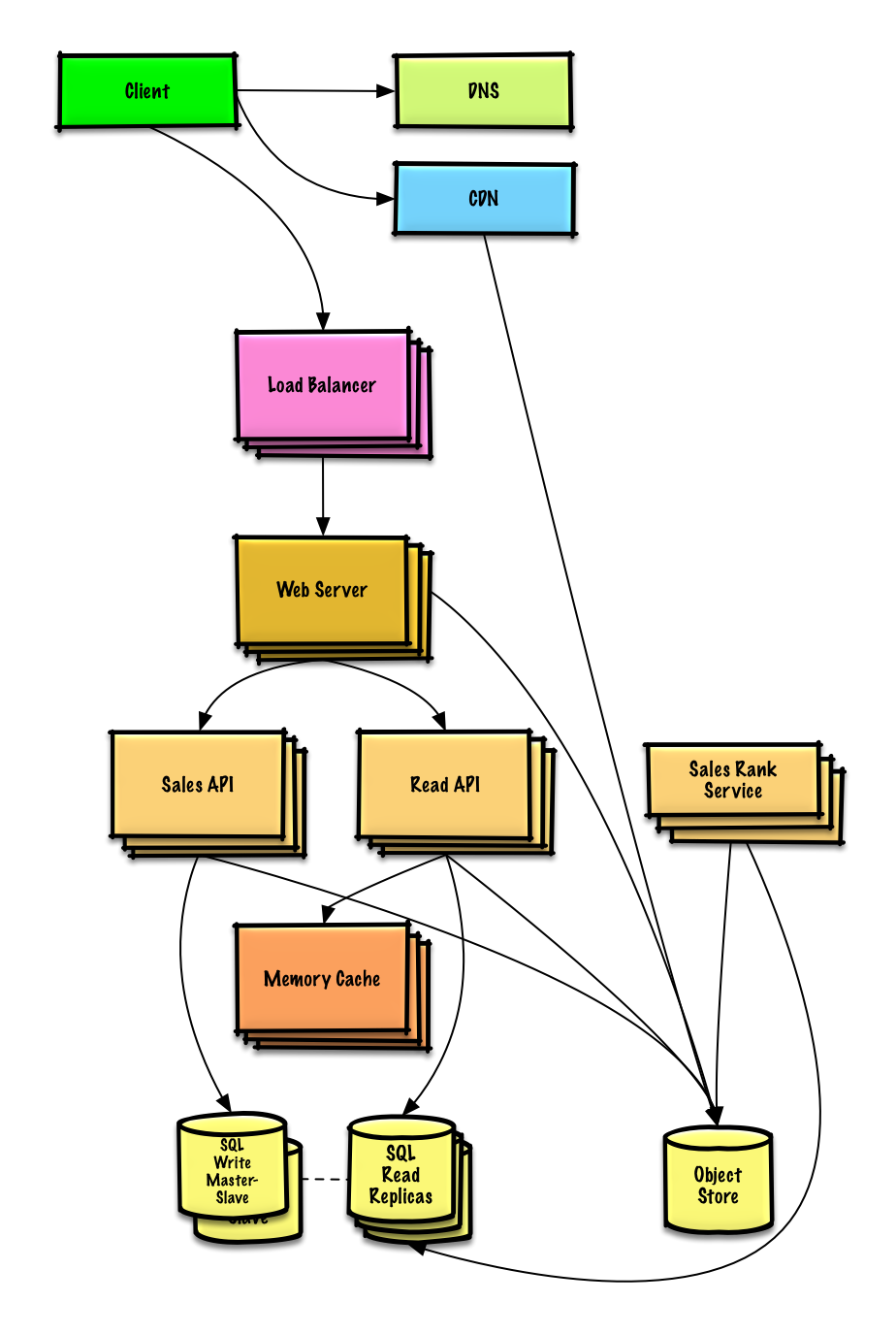
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Bir hash haritası tasarlayın | Çözüm | | En son kullanılmayan önbellek tasarlayın | Çözüm | | Bir çağrı merkezi tasarlayın | Çözüm | | Bir kart destesini tasarlayın | Çözüm | | Bir otopark tasarlayın | Çözüm | | Bir sohbet sunucusu tasarlayın | Çözüm | | Dairesel bir dizi tasarlayın | Katkıda Bulunun | | Nesne tabanlı bir tasarım sorusu ekleyin | Katkıda Bulunun |
Sistem tasarımı konuları: buradan başlayın
Sistem tasarımına yeni misiniz?
Öncelikle, yaygın prensipleri temel olarak anlamanız gerekecek, bunların ne olduklarını, nasıl kullanıldıklarını ve avantaj-dezavantajlarını öğrenmeniz gerekir.
Adım 1: Ölçeklenebilirlik video dersini inceleyin
Harvard'da Ölçeklenebilirlik Dersi
- Kapsanan konular:
- Dikey ölçeklendirme
- Yatay ölçeklendirme
- Önbellekleme
- Yük dengeleme
- Veritabanı çoğaltması
- Veritabanı bölümlendirmesi
Adım 2: Ölçeklenebilirlik makalesini inceleyin
- Kapsanan konular:
- Klonlar
- Veritabanları
- Önbellekler
- Asenkronluk
Sonraki adımlar
Şimdi, üst düzey değiş-tokuşlara bakacağız:
- Performans ve ölçeklenebilirlik
- Gecikme ve verim
- Kullanılabilirlik ve tutarlılık
Daha sonra DNS, CDN'ler ve yük dengeleyicileri gibi daha spesifik konulara ineceğiz.
Performans ve ölçeklenebilirlik
Bir hizmet, eklenen kaynaklarla orantılı şekilde artan performans sağlıyorsa ölçeklenebilirdir. Genellikle, performansı artırmak daha fazla iş birimi sunmak anlamına gelir, ancak büyüyen veri kümeleri gibi daha büyük iş birimlerini işlemek için de olabilir.1
Performans ve ölçeklenebilirliğe başka bir bakış açısı:
- Eğer bir performans sorununuz varsa, sisteminiz tek bir kullanıcı için yavaştır.
- Eğer bir ölçeklenebilirlik sorununuz varsa, sisteminiz tek bir kullanıcı için hızlıdır ancak yoğun yük altında yavaştır.
Kaynak(lar) ve daha fazla okuma
Gecikme ve verim
Gecikme, bir işlemi gerçekleştirmek veya bir sonuç üretmek için geçen süredir.
Verim, birim zamanda gerçekleştirilen bu tür eylemlerin veya sonuçların sayısıdır.
Genel olarak, maksimum verim ile kabul edilebilir gecikme hedeflemelisiniz.
Kaynak(lar) ve daha fazla okuma
Kullanılabilirlik ve tutarlılık
CAP teoremi
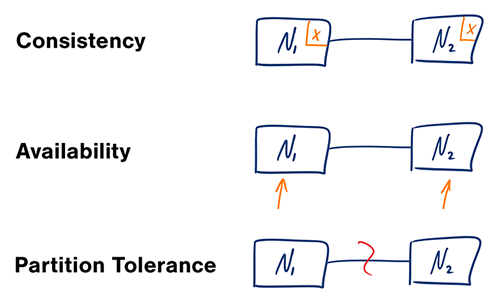
Kaynak: CAP teoremi yeniden gözden geçirildi
Dağıtık bir bilgisayar sisteminde, aşağıdaki garantilerden yalnızca ikisini destekleyebilirsiniz:
- Tutarlılık (Consistency) - Her okuma en güncel yazımı veya bir hata alır
- Kullanılabilirlik (Availability) - Her istek bir yanıt alır, fakat yanıtın en güncel bilgi versiyonunu içerdiği garanti edilmez
- Bölüm Toleransı (Partition Tolerance) - Sistem, ağ hataları nedeniyle oluşan keyfi bölümlere rağmen çalışmaya devam eder
#### CP - tutarlılık ve bölüm toleransı
Bölünmüş düğümden yanıt beklemek, zaman aşımı hatasına yol açabilir. İşletme ihtiyaçlarınız atomik okuma ve yazmalar gerektiriyorsa CP iyi bir seçimdir.
#### AP - kullanılabilirlik ve bölüm toleransı
Yanıtlar, herhangi bir düğümde en kolay erişilebilir veri versiyonunu döndürür; bu veri en güncel olmayabilir. Bölünme çözüldüğünde yazıların yayılması biraz zaman alabilir.
AP, işletme ihtiyaçlarının sonunda tutarlılık gerektirdiği durumlarda veya sistemin dışsal hatalara rağmen çalışmaya devam etmesi gerektiğinde iyi bir seçimdir.
Kaynak(lar) ve daha fazla okuma
Tutarlılık desenleri
Aynı verinin birden fazla kopyası olduğunda, bunları nasıl senkronize edeceğimize dair seçeneklerle karşılaşırız ki istemciler verinin tutarlı bir görünümüne sahip olsun. CAP teoremi tanımını hatırlayın - Her okuma en güncel yazımı veya bir hata alır.
Zayıf tutarlılık
Bir yazımdan sonra, okumalar bu yazımı görebilir veya görmeyebilir. En iyi çaba yaklaşımı kullanılır.
Bu yaklaşım memcached gibi sistemlerde görülür. Zayıf tutarlılık, VoIP, video sohbet ve gerçek zamanlı çok oyunculu oyunlar gibi gerçek zamanlı kullanım senaryolarında iyi çalışır. Örneğin, bir telefon görüşmesindeyken birkaç saniye bağlantıyı kaybederseniz, yeniden bağlantı sağladığınızda bağlantı kaybı sırasında konuşulanları duymazsınız.
Sonunda tutarlılık (Eventual consistency)
Bir yazma işleminden sonra, okuma işlemleri sonunda bunu görecektir (genellikle milisaniyeler içinde). Veriler eşzamansız olarak çoğaltılır.
Bu yaklaşım DNS ve e-posta gibi sistemlerde görülür. Sonunda tutarlılık, yüksek erişilebilirliğe sahip sistemlerde iyi çalışır.
Güçlü tutarlılık (Strong consistency)
Bir yazma işleminden sonra, okuma işlemleri bunu görecektir. Veriler eşzamanlı olarak çoğaltılır.
Bu yaklaşım dosya sistemlerinde ve İlişkisel Veritabanı Yönetim Sistemlerinde (RDBMS) görülür. Güçlü tutarlılık, işlemlere ihtiyaç duyan sistemlerde iyi çalışır.
Kaynak(lar) ve daha fazla okuma
Erişilebilirlik kalıpları
Yüksek erişilebilirliği desteklemek için iki tamamlayıcı kalıp vardır: fail-over ve çoğaltma.
Fail-over (Hata geçişi)
#### Aktif-pasif
Aktif-pasif hata geçişinde, aktif ve yedek beklemedeki pasif sunucu arasında kalp atışları gönderilir. Kalp atışı kesilirse, pasif sunucu aktifin IP adresini alır ve hizmete devam eder.
Kesinti süresi, pasif sunucunun 'sıcak' beklemede olup olmadığına veya 'soğuk' beklemeden başlatılması gerekip gerekmediğine bağlı olarak belirlenir. Sadece aktif sunucu trafiği yönetir.
Aktif-pasif hata geçişi, ana-yedek (master-slave) hata geçişi olarak da adlandırılabilir.
#### Aktif-aktif
Aktif-aktif modelde, her iki sunucu da trafiği yönetir ve yükü aralarında paylaşır.
Sunucular genel erişime açıksa, DNS'nin her iki sunucunun genel IP'lerini bilmesi gerekir. Sunucular iç erişime açıksa, uygulama mantığının her iki sunucuyu da bilmesi gerekir.
Aktif-aktif hata geçişi, ana-ana (master-master) hata geçişi olarak da adlandırılabilir.
Dezavantaj(lar): hata geçişi
- Fail-over daha fazla donanım ve ek karmaşıklık getirir.
- Aktif sistem, yeni yazılmış verilerin pasife çoğaltılmasından önce başarısız olursa veri kaybı riski vardır.
Replikasyon
#### Master-slave ve master-master
Bu konu Veritabanı bölümünde daha ayrıntılı olarak ele alınmıştır:
Sayısal olarak erişilebilirlik
Erişilebilirlik genellikle hizmetin kullanılabilir olduğu sürenin yüzdesi olarak çalışma süresi (veya kesinti süresi) ile nicel olarak belirtilir. Erişilebilirlik genellikle dokuz sayısıyla ölçülür--%99.99 erişilebilirliğe sahip bir hizmet dört dokuzlu olarak tanımlanır.
#### %99.9 erişilebilirlik - üç dokuz
| Süre | Kabul edilebilir kesinti süresi| |---------------------|-------------------------------| | Yıllık kesinti | 8s 45dk 57sn | | Aylık kesinti | 43dk 49.7sn | | Haftalık kesinti | 10dk 4.8sn | | Günlük kesinti | 1dk 26.4sn |
#### %99.99 erişilebilirlik - dört dokuz
| Süre | Kabul edilebilir kesinti süresi| |---------------------|-------------------------------| | Yıllık kesinti | 52dk 35.7sn | | Aylık kesinti | 4dk 23sn | | Haftalık kesinti | 1dk 5sn | | Günlük kesinti | 8.6sn |
#### Paralel ve ardışık erişilebilirlik
Bir hizmet birden fazla arızaya yatkın bileşenden oluşuyorsa, hizmetin genel erişilebilirliği bileşenlerin ardışık mı yoksa paralel mi olduğuna bağlıdır.
###### Ardışık Genel kullanılabilirlik, %100'den az kullanılabilirliğe sahip iki bileşen ardışık olarak bağlandığında azalır:
Availability (Total) = Availability (Foo) * Availability (Bar)Eğer hem Foo hem de Bar ayrı ayrı %99,9 erişilebilirliğe sahipse, ardışık olarak toplam erişilebilirlikleri %99,8 olur.
###### Paralel durumda
İki bileşen %100'den düşük erişilebilirliğe sahip olduğunda paralel çalıştıklarında genel erişilebilirlik artar:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo hem de Bar %99,9 kullanılabilirliğe sahip olsaydı, paralel toplam kullanılabilirlikleri %99,9999 olurdu.Alan adı sistemi
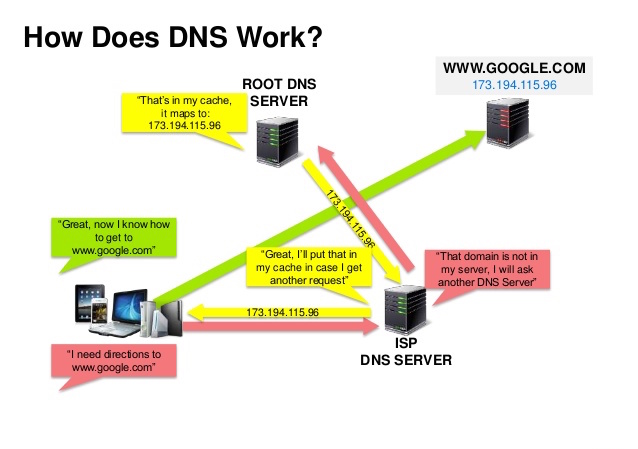
Bir Alan Adı Sistemi (DNS), www.example.com gibi bir alan adını bir IP adresine dönüştürür.
DNS hiyerarşiktir ve en üst düzeyde birkaç yetkili sunucu bulunur. Yönlendiriciniz veya ISS’niz, sorgulama yaparken hangi DNS sunucusuna(larına) başvurulacağını belirten bilgileri sağlar. Alt düzey DNS sunucuları eşlemeleri önbelleğe alır; bu önbellekler, DNS yayılım gecikmeleri nedeniyle güncelliğini yitirebilir. DNS sonuçları ayrıca tarayıcınız veya işletim sisteminiz tarafından, yaşam süresi (TTL) ile belirlenen bir süre boyunca önbelleğe alınabilir.
- NS kaydı (ad sunucusu) - Alan adınız/alt alan adınız için DNS sunucularını belirtir.
- MX kaydı (mail exchange) - Mesajları kabul edecek posta sunucularını belirtir.
- A kaydı (adres) - Bir adı bir IP adresine yönlendirir.
- CNAME (kanonik) - Bir adı başka bir ada veya
CNAME’e (example.com’dan www.example.com’a) ya da birAkaydına yönlendirir.
- Ağırlıklı döngüsel dağıtım
- Bakımda olan sunuculara trafiğin gitmesini engellemek
- Farklı boyutlardaki kümeler arasında denge sağlamak
- A/B testi
- Gecikme tabanlı
- Coğrafi konum tabanlı
Dezavantaj(lar): DNS
- DNS sunucusuna erişmek hafif bir gecikme ekler, ancak yukarıda açıklanan önbellekleme ile azaltılır.
- DNS sunucu yönetimi karmaşık olabilir ve genellikle hükümetler, ISS’ler ve büyük şirketler tarafından yürütülür.
- DNS servisleri yakın zamanda DDoS saldırısına uğramış, kullanıcıların Twitter gibi sitelere Twitter’ın IP adresini bilmeden erişmesini engellemiştir.
Kaynak(lar) ve ileri okuma
İçerik dağıtım ağı
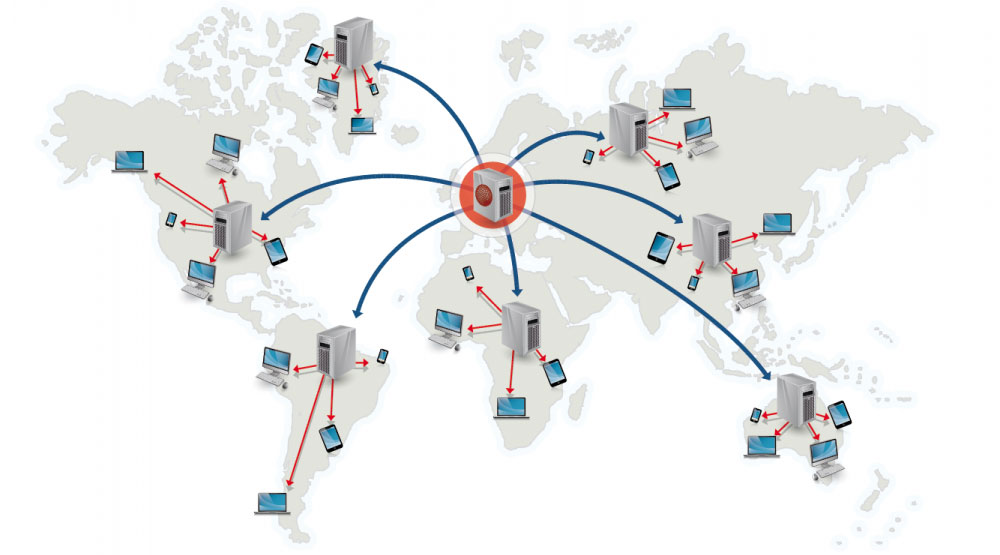
Kaynak: Neden bir CDN kullanılır
Bir içerik dağıtım ağı (CDN), içeriği kullanıcıya daha yakın konumlardan sunan, küresel olarak dağıtılmış bir proxy sunucular ağıdır. Genellikle, HTML/CSS/JS, fotoğraflar ve videolar gibi statik dosyalar CDN üzerinden sunulur, ancak Amazon'un CloudFront'u gibi bazı CDN'ler dinamik içeriği de destekler. Sitenin DNS çözümlemesi, istemcilere hangi sunucuya bağlanacaklarını bildirir.
CDN'lerden içerik sunmak, performansı iki şekilde önemli ölçüde artırabilir:
- Kullanıcılar, kendilerine yakın veri merkezlerinden içerik alır
- Sunucularınız, CDN'nin karşıladığı istekleri sunmak zorunda kalmaz
Push CDN’ler
Push CDN’ler, sunucunuzda değişiklikler olduğunda yeni içeriği alır. İçeriği sağlama sorumluluğu tamamen sizdedir, doğrudan CDN’ye yükleme yapar ve URL’leri CDN’ye işaret edecek şekilde yeniden yazarsınız. İçeriğin ne zaman sona ereceğini ve güncelleneceğini yapılandırabilirsiniz. İçerik yalnızca yeni olduğunda veya değiştiğinde yüklenir, bu da trafiği en aza indirirken depolamayı en üst düzeye çıkarır.
Az trafik alan veya içeriği sık güncellenmeyen siteler push CDN’lerle iyi çalışır. İçerik CDN’lere bir kez yerleştirilir, düzenli aralıklarla tekrar çekilmez.
Pull CDN’ler
Pull CDN’ler, ilk kullanıcı içeriği istediğinde yeni içeriği sunucunuzdan çeker. İçeriği sunucunuzda bırakır ve URL’leri CDN’ye işaret edecek şekilde yeniden yazarsınız. Bu, içerik CDN’de önbelleğe alınana kadar daha yavaş bir isteğe yol açar.
Bir time-to-live (TTL), içeriğin ne kadar süreyle önbellekte tutulacağını belirler. Pull CDN’ler CDN üzerindeki depolama alanını en aza indirir, ancak dosyalar sona ererse ve gerçekten değişmeden önce çekilirse gereksiz trafik oluşturabilir.
Yoğun trafiğe sahip siteler pull CDN’lerle iyi çalışır, çünkü trafik daha dengeli yayılır ve sadece son zamanlarda istenen içerik CDN’de kalır.
Dezavantaj(lar): CDN
- CDN maliyetleri, trafiğe bağlı olarak önemli olabilir, ancak bu, CDN kullanmadığınızda karşılaşacağınız ek maliyetlerle kıyaslanmalıdır.
- İçerik, TTL süresi dolmadan güncellenirse eski kalabilir.
- CDN’ler için statik içerik URL’lerinin CDN’yi işaret edecek şekilde değiştirilmesi gerekir.
Kaynak(lar) ve daha fazla okuma
Yük dengeleyici
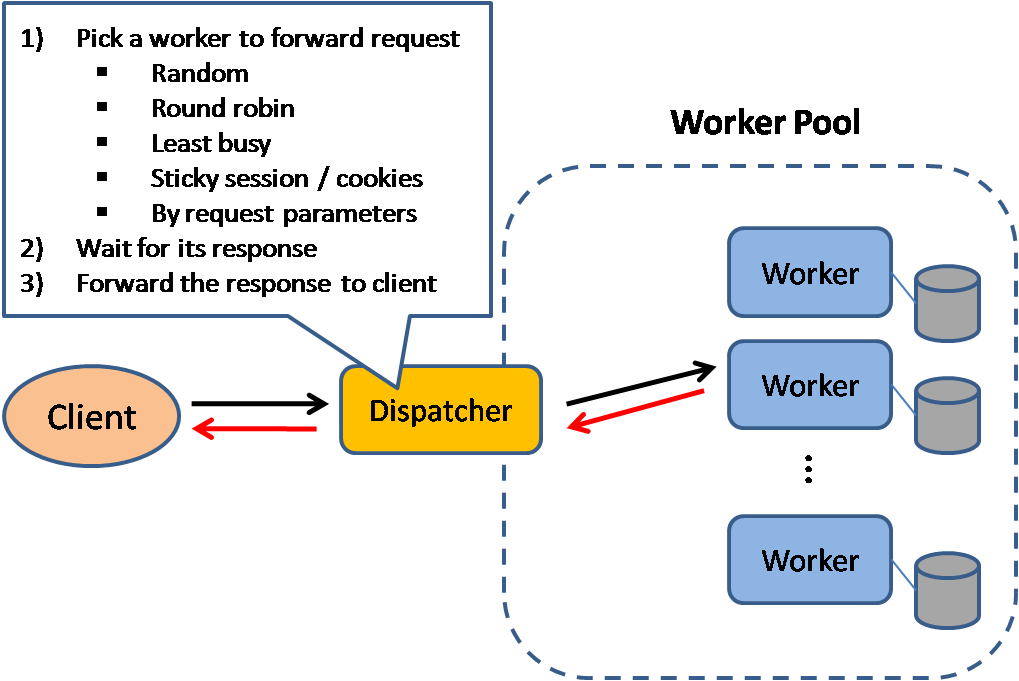
Kaynak: Ölçeklenebilir sistem tasarım desenleri
Yük dengeleyiciler, gelen istemci isteklerini uygulama sunucuları ve veritabanları gibi bilişim kaynaklarına dağıtır. Her durumda, yük dengeleyici yanıtı bilişim kaynağından alıp ilgili istemciye iletir. Yük dengeleyiciler aşağıdaki konularda etkilidir:
- Sağlıksız sunuculara isteklerin gitmesini önlemek
- Kaynakların aşırı yüklenmesini önlemek
- Tek bir hata noktasını ortadan kaldırmaya yardımcı olmak
Ek faydalar arasında şunlar bulunur:
- SSL sonlandırma - Gelen istekleri şifreler ve sunucu yanıtlarını şifreler, böylece arka uç sunucuların bu potansiyel olarak pahalı işlemleri yapmasına gerek kalmaz
- Her sunucuya X.509 sertifikaları yükleme ihtiyacını ortadan kaldırır
- Oturum kalıcılığı - Çerezler vererek ve belirli bir istemcinin isteklerini aynı instance'a yönlendirerek, web uygulamaları oturumları takip etmiyorsa bile oturum devamlılığı sağlar
Yük dengeleyiciler trafiği çeşitli metriklere göre yönlendirebilir, örneğin:
- Rastgele
- En az yükte olan
- Oturum/çerezler
- Round robin veya ağırlıklı round robin
- Layer 4
- Layer 7
Katman 4 yük dengeleme
Katman 4 yük dengeleyiciler, isteklerin nasıl dağıtılacağına karar vermek için iletişim katmanı bilgisini inceler. Genellikle bu, başlıktaki kaynak ve hedef IP adreslerini ve portlarını içerir, ancak paketin içeriğini içermez. Katman 4 yük dengeleyiciler ağ paketlerini yukarıdaki sunucuya iletir ve Ağ Adresi Çevirisi (NAT) uygular.
Katman 7 yük dengeleme
Katman 7 yük dengeleyiciler, isteklerin nasıl dağıtılacağına karar vermek için uygulama katmanına bakar. Bu, başlık, mesaj ve çerezlerin içeriğini içerebilir. Katman 7 yük dengeleyiciler ağ trafiğini sonlandırır, mesajı okur, yük dengeleme kararını verir, ardından seçilen sunucuya bir bağlantı açar. Örneğin, bir katman 7 yük dengeleyici, video trafiğini videoları barındıran sunuculara yönlendirirken, daha hassas kullanıcı fatura trafiğini güvenliği artırılmış sunuculara yönlendirebilir.Esneklik pahasına, katman 4 yük dengeleme, Katman 7'ye göre daha az zaman ve bilgi işlem kaynağı gerektirir, ancak modern donanımlarda performans etkisi minimum olabilir.
Yatay ölçekleme
Yük dengeleyiciler ayrıca yatay ölçeklemeye yardımcı olarak performans ve kullanılabilirliği artırabilir. Ucuz donanım kullanarak ölçeklemek, daha pahalı donanımda tek bir sunucuyu ölçeklemekten (Dikey Ölçekleme olarak adlandırılır) daha maliyet etkin ve daha yüksek kullanılabilirlik sağlar. Ayrıca, ucuz donanımda çalışan yetenekleri işe almak, özel kurumsal sistemler için yetenek bulmaktan daha kolaydır.
#### Dezavantaj(lar): yatay ölçekleme
- Yatay ölçekleme karmaşıklık getirir ve sunucuları klonlamayı gerektirir
- Sunucular durumsuz olmalıdır: oturumlar veya profil resimleri gibi kullanıcıya ait veriler içermemelidir
- Oturumlar merkezi bir veri deposunda, örneğin bir veritabanı (SQL, NoSQL) veya kalıcı bir önbellek (Redis, Memcached) içinde saklanabilir
- Önbellekler ve veritabanları gibi alt sunucular, üst sunucular ölçeklendikçe daha fazla eşzamanlı bağlantıyı yönetmelidir
Dezavantaj(lar): yük dengeleyici
- Yük dengeleyici, yeterli kaynağa sahip değilse veya düzgün yapılandırılmamışsa bir performans darboğazı haline gelebilir.
- Tek hata noktalarını ortadan kaldırmak için yük dengeleyici eklemek, karmaşıklığı artırır.
- Tek bir yük dengeleyici tek hata noktasıdır, birden fazla yük dengeleyici yapılandırmak ise daha fazla karmaşıklık getirir.
Kaynak(lar) ve daha fazla okuma
- NGINX mimarisi
- HAProxy mimari rehberi
- Ölçeklenebilirlik
- Vikipedi)
- Katman 4 yük dengeleme
- Katman 7 yük dengeleme
- ELB dinleyici yapılandırması
Ters proxy (web sunucusu)
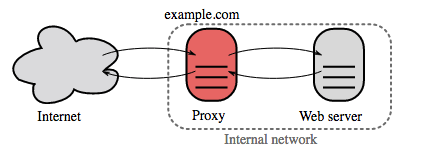
Ters proxy, dahili hizmetleri merkezileştiren ve kamuya birleşik arayüzler sağlayan bir web sunucusudur. İstemcilerden gelen talepler, yerine getirebilecek bir sunucuya iletilir ve ters proxy, sunucunun yanıtını istemciye döndürür.
Ek avantajlar şunlardır:
- Artan güvenlik - Arka uç sunucular hakkındaki bilgileri gizler, IP'leri kara listeye alır, istemci başına bağlantı sayısını sınırlar
- Artan ölçeklenebilirlik ve esneklik - İstemciler yalnızca ters proxy'nin IP'sini görür, böylece sunucuları ölçeklendirebilir veya yapılandırmalarını değiştirebilirsiniz
- SSL sonlandırma - Gelen talepleri çözer ve sunucu yanıtlarını şifreler, böylece arka uç sunucular bu potansiyel olarak maliyetli işlemleri yapmak zorunda kalmaz
- Her sunucuya X.509 sertifikası yükleme gerekliliğini ortadan kaldırır
- Sıkıştırma - Sunucu yanıtlarını sıkıştırır
- Önbellekleme - Önbelleğe alınmış talepler için yanıtı döndürür
- Statik içerik - Statik içerikleri doğrudan sunar
- HTML/CSS/JS
- Fotoğraflar
- Videolar
- vb.
Yük dengeleyici vs ters proxy
- Birden fazla sunucunuz olduğunda yük dengeleyici dağıtmak faydalıdır. Genellikle yük dengeleyiciler, aynı işlevi yerine getiren bir sunucu grubuna trafiği yönlendirir.
- Ters proxyler, yalnızca bir web sunucusu veya uygulama sunucusu olsa bile, önceki bölümde açıklanan avantajları sağlar.
- NGINX ve HAProxy gibi çözümler hem katman 7 ters proxy hem de yük dengeleme desteği sunabilir.
Dezavantaj(lar): ters proxy
- Ters proxy eklemek, daha fazla karmaşıklık getirir.
- Tek bir ters proxy, tek hata noktasıdır; birden fazla ters proxy (örn. failover) yapılandırmak karmaşıklığı daha da artırır.
Kaynak(lar) ve daha fazla okuma
Uygulama katmanı
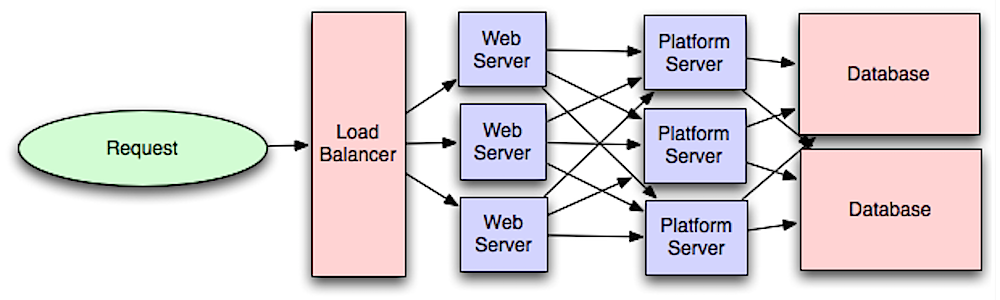
Kaynak: Ölçeklenebilir sistem mimarisi için giriş
Web katmanını uygulama katmanından (diğer adıyla platform katmanı) ayırmak, her iki katmanı da bağımsız olarak ölçeklendirmeye ve yapılandırmaya olanak tanır. Yeni bir API eklemek, mutlaka ek web sunucuları eklemeden uygulama sunucuları eklenmesiyle sonuçlanır. Tek sorumluluk ilkesi, birlikte çalışan küçük ve özerk servisleri savunur. Küçük ekipler ve küçük servisler, hızlı büyümeye daha agresif bir şekilde plan yapabilir.
Uygulama katmanındaki çalışanlar asenkronizmi etkinleştirmeye de yardımcı olur.
Mikroservisler
Bu tartışmayla ilgili olan mikroservisler, bağımsız olarak dağıtılabilen, küçük, modüler servisler paketi olarak tanımlanabilir. Her servis benzersiz bir süreçte çalışır ve iş hedefini gerçekleştirmek için iyi tanımlanmış, hafif bir mekanizma ile iletişim kurar. 1
Örneğin Pinterest, şu mikroservislere sahip olabilir: kullanıcı profili, takipçi, akış, arama, fotoğraf yükleme vb.
Servis Keşfi
Consul, Etcd ve Zookeeper gibi sistemler, kayıtlı isimleri, adresleri ve portları takip ederek servislerin birbirini bulmasına yardımcı olabilir. Sağlık kontrolleri servis bütünlüğünü doğrulamada yardımcı olur ve genellikle bir HTTP uç noktası kullanılarak yapılır. Hem Consul hem de Etcd, yapılandırma değerleri ve diğer paylaşılan verileri depolamak için kullanılabilen yerleşik bir anahtar-değer deposu içerir.
Dezavantaj(lar): uygulama katmanı
- Gevşek bağlı servislerle bir uygulama katmanı eklemek, mimari, operasyon ve süreç açısından (monolitik sisteme kıyasla) farklı bir yaklaşım gerektirir.
- Mikroservisler, dağıtımlar ve operasyonlar açısından karmaşıklık ekleyebilir.
Kaynak(lar) ve daha fazla okuma
- Ölçeklenebilir sistem mimarisi için giriş
- Sistem tasarımı mülakatını aşmak
- Servis odaklı mimari
- Zookeeper’a giriş
- Mikroservisler inşa etmek hakkında bilmeniz gerekenler
Veritabanı
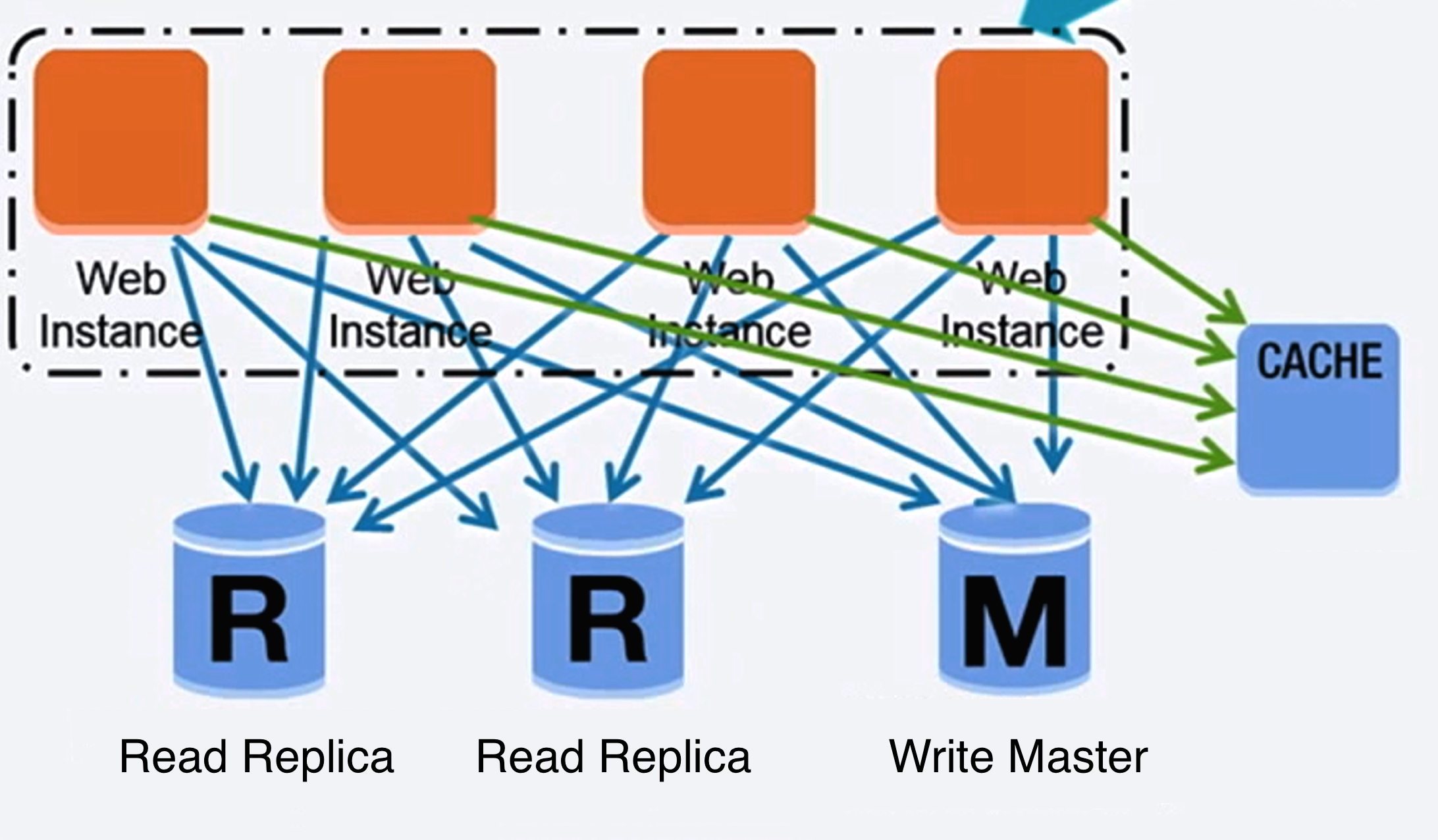
Kaynak: İlk 10 milyon kullanıcınıza ölçeklenmek
İlişkisel veritabanı yönetim sistemi (RDBMS)
SQL gibi ilişkisel bir veritabanı, tablolar halinde düzenlenmiş veri öğelerinin bir koleksiyonudur.
ACID, ilişkisel veritabanı işlemlerinin bir dizi özelliğidir.
- Atomiklik - Her işlem ya tamamen gerçekleşir ya hiç gerçekleşmez
- Tutarlılık - Herhangi bir işlem, veritabanını bir geçerli durumdan başka bir geçerli duruma getirir
- Yalıtım - İşlemlerin eşzamanlı olarak yürütülmesi, işlemlerin ardışık olarak yürütülmesiyle aynı sonuçları verir
- Dayanıklılık - Bir işlem taahhüt edildikten sonra, kalıcı olarak öyle kalır
#### Ana-yedek çoğaltma
Ana sunucu, okuma ve yazma işlemlerini yapar, yazmaları bir veya daha fazla yedeğe çoğaltır; yedekler yalnızca okuma işlemleri yapar. Yedekler ayrıca ağaç yapısında başka yedeklere de çoğaltılabilir. Ana sunucu çevrimdışı olursa, bir yedeğin ana olarak yükseltilmesine veya yeni bir ana sağlanmasına kadar sistem salt okunur modda çalışmaya devam edebilir.
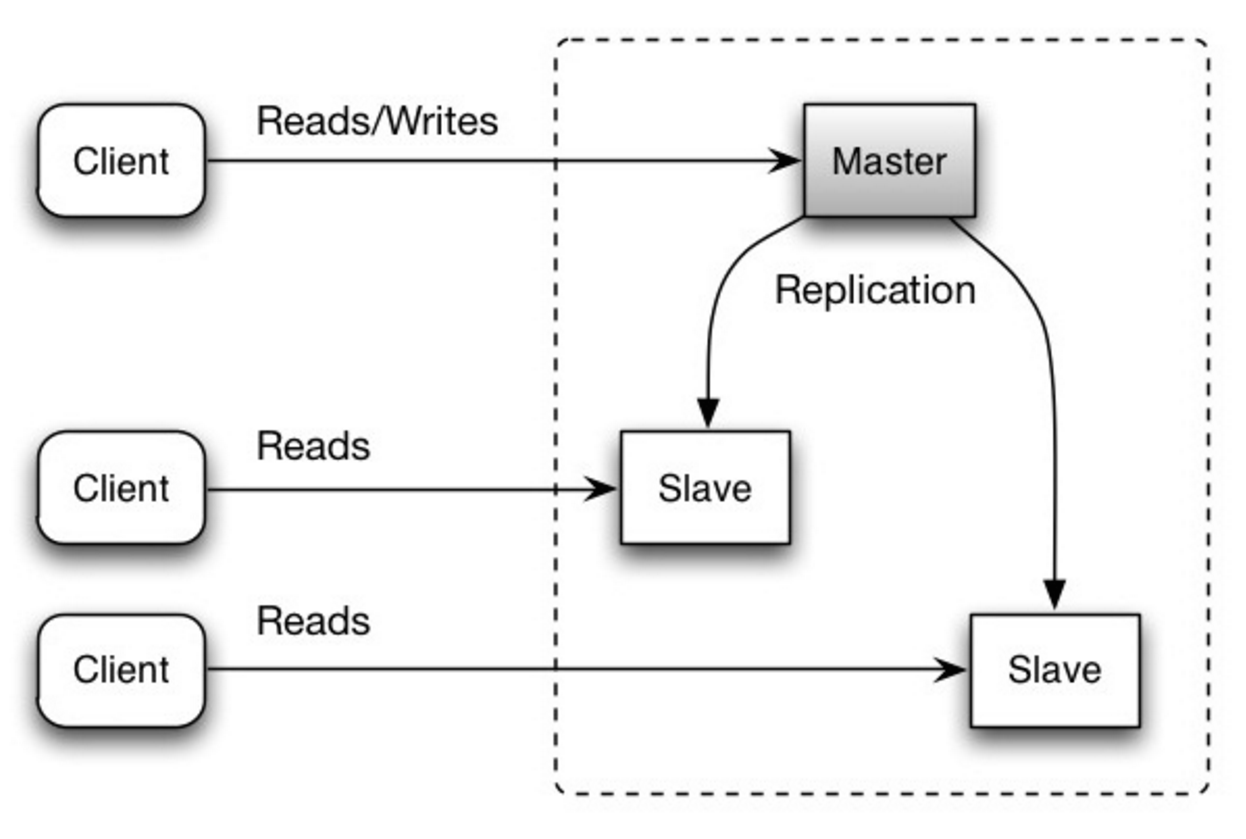
Kaynak: Ölçeklenebilirlik, erişilebilirlik, stabilite, desenler
##### Dezavantaj(lar): ana-yedek çoğaltma
- Bir yedeğin ana olarak yükseltilmesi için ek mantık gerekir.
- Her iki ana-yedek ve ana-ana için ilgili noktalar için Dezavantaj(lar): çoğaltma bölümüne bakınız.
Her iki ana sunucu da okuma ve yazma işlemlerini yapar ve yazma işlemlerinde birbirleriyle koordine olurlar. Ana sunuculardan biri kapanırsa, sistem okuma ve yazma işlemleriyle çalışmaya devam edebilir.
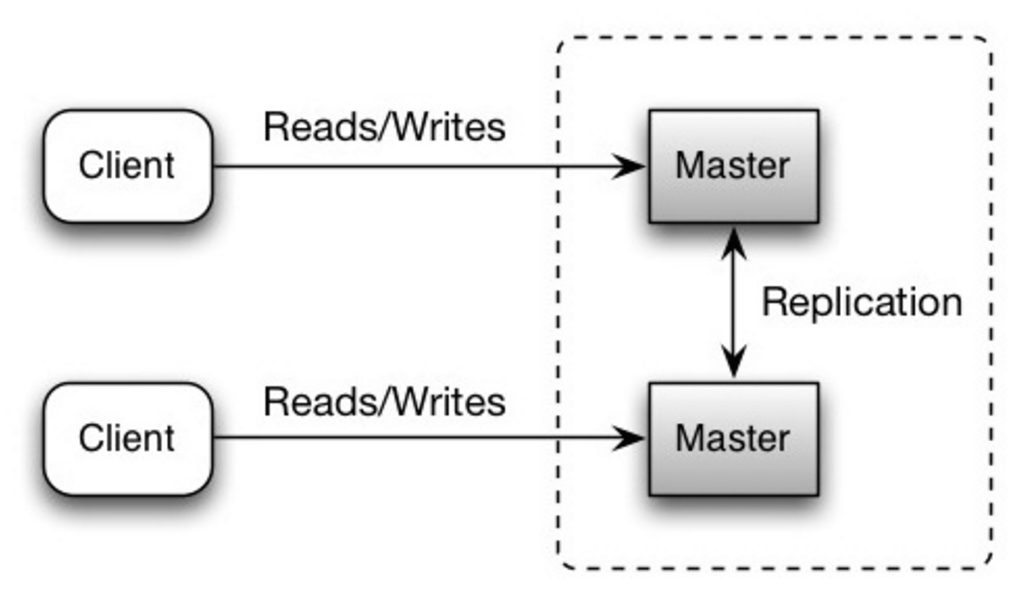
Kaynak: Ölçeklenebilirlik, erişilebilirlik, stabilite, desenler
##### Dezavantaj(lar): ana-ana çoğaltma
- Bir yük dengeleyiciye ihtiyacınız olacak veya uygulama mantığınızda yazmanın nereye yapılacağını belirlemek için değişiklikler yapmanız gerekecek.
- Çoğu ana-ana sistemi ya gevşek tutarlıdır (ACID'i ihlal eder) ya da senkronizasyondan dolayı artan yazma gecikmesine sahiptir.
- Çatışma çözümü, daha fazla yazma düğümü eklendikçe ve gecikme arttıkça daha fazla gündeme gelir.
- Hem master-slave hem de master-master ile ilgili noktalar için Dezavantaj(lar): replikasyon bölümüne bakın.
- Master, yeni yazılmış veriler diğer düğümlere çoğaltılmadan önce arızalanırsa veri kaybı potansiyeli vardır.
- Yazmalar, okuma replikalarına tekrar oynatılır. Eğer çok fazla yazma varsa, okuma replikaları tekrar oynatılan yazmalardan dolayı tıkanabilir ve daha az okuma yapabilirler.
- Ne kadar çok okuma kölesi varsa, o kadar çok çoğaltma yapılır, bu da daha fazla replikasyon gecikmesine yol açar.
- Bazı sistemlerde, master'a yazma işlemi paralel olarak birden fazla iş parçacığı ile başlatılabilirken, okuma replikaları yalnızca tek bir iş parçacığı ile sıralı yazmayı destekler.
- Replikasyon, daha fazla donanım ve ek karmaşıklık getirir.
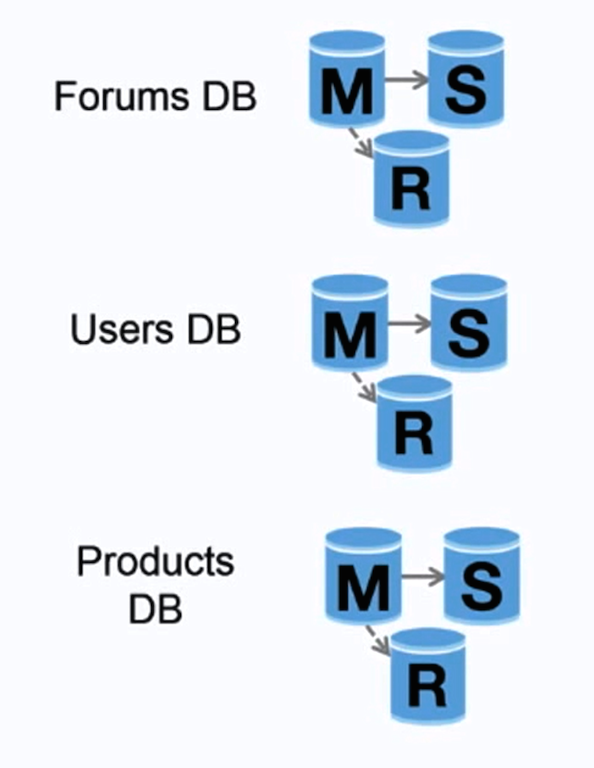
Kaynak: İlk 10 milyon kullanıcınıza ölçeklenme
Federasyon (veya fonksiyonel bölümlendirme), veritabanlarını işlevlerine göre böler. Örneğin, tek ve bütünleşik bir veritabanı yerine, üç farklı veritabanınız olabilir: forumlar, kullanıcılar ve ürünler; bu sayede her bir veritabanına daha az okuma ve yazma trafiği olur ve bu da daha az replikasyon gecikmesi demektir. Küçük veritabanları, belleğe daha fazla veri sığmasını sağlar; bu da geliştirilmiş önbellek lokalliği sayesinde daha fazla önbellek vuruşu elde edilmesine yol açar. Merkezi bir master'ın yazmaları sıralamasının olmaması sayesinde paralel yazma işlemleri yapılabilir ve bu da verimi artırır.
##### Dezavantaj(lar): federasyon
- Şemanız büyük işlevler veya tablolar gerektiriyorsa federasyon etkili değildir.
- Hangi veritabanına okuma/yazma yapılacağını belirlemek için uygulama mantığınızı güncellemeniz gerekir.
- İki veritabanından veri birleştirmek, bir sunucu bağlantısı ile daha karmaşıktır.
- Federasyon, daha fazla donanım ve ek karmaşıklık ekler.
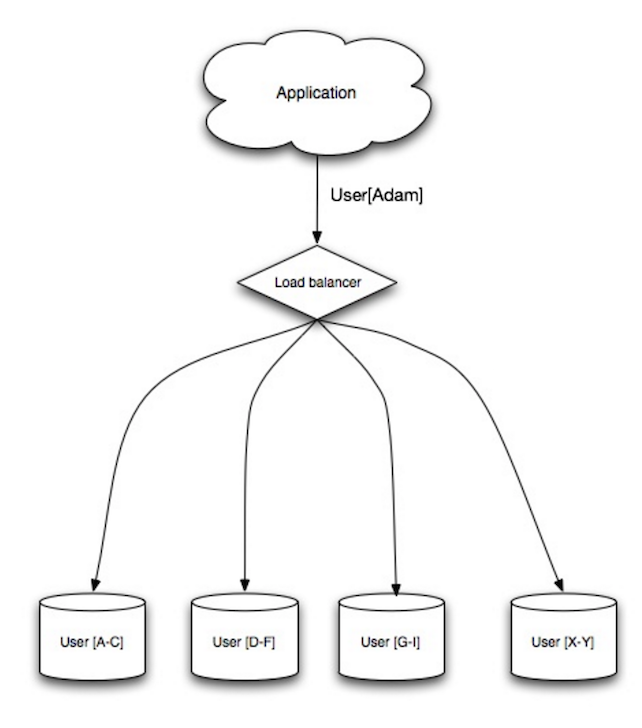
Kaynak: Ölçeklenebilirlik, kullanılabilirlik, stabilite, desenler
Sharding, veriyi farklı veritabanlarına dağıtarak her veritabanının yalnızca verinin bir alt kümesini yönetebilmesini sağlar. Bir kullanıcılar veritabanı örneği üzerinden, kullanıcı sayısı arttıkça kümeye daha fazla parça (shard) eklenir.
Federasyon avantajlarına benzer şekilde, sharding daha az okuma ve yazma trafiği, daha az replikasyon ve daha fazla önbellek vuruşu sağlar. İndeks boyutu da azalır, bu da genellikle daha hızlı sorgular ile performansı arttırır. Bir parça (shard) kapanırsa, diğer parçalar hala çalışır durumda olur, ancak veri kaybını önlemek için bir tür replikasyon eklemek istersiniz. Federasyonda olduğu gibi, yazmaları sıralayan merkezi bir ana sunucu olmadığı için, paralel şekilde daha yüksek verimlilikle yazma yapabilirsiniz.
Bir kullanıcılar tablosunu parçalamanın yaygın yolları, kullanıcının soyadının ilk harfi veya kullanıcının coğrafi konumu üzerinden yapılır.
##### Dezavantaj(lar): sharding
- Uygulama mantığınızı parçalara uyacak şekilde güncellemeniz gerekir, bu da karmaşık SQL sorgularına yol açabilir.
- Bir parçadaki veri dağılımı dengesizleşebilir. Örneğin, bir parçadaki yoğun kullanıcılar diğerlerine göre daha fazla yük oluşturabilir.
- Yeniden dengeleme ek karmaşıklık getirir. Tutarlı karma tabanlı bir parçalara ayırma fonksiyonu taşınan veri miktarını azaltabilir.
- Birden fazla parçadan veri birleştirmek daha karmaşıktır.
- Sharding daha fazla donanım ve ek karmaşıklık getirir.
Denormalizasyon, okuma performansını arttırmaya çalışırken bazı yazma performansından feragat eder. Pahalı birleşimlerden kaçınmak için verinin fazladan kopyaları birden fazla tabloda tutulur. PostgreSQL ve Oracle gibi bazı İlişkisel Veritabanı Yönetim Sistemleri maddileştirilmiş görünümler destekler; bu yapılar fazladan bilginin saklanmasını ve tutarlı kalmasını sağlar.
Veri federasyon ve sharding gibi tekniklerle dağıtıldığında, veri merkezleri arasında birleşim (join) yönetmek karmaşıklığı daha da arttırır. Denormalizasyon, bu tür karmaşık birleşimlere olan ihtiyacı ortadan kaldırabilir.
Çoğu sistemde, okuma işlemleri yazma işlemlerine kıyasla çok daha fazla olabilir; 100:1 hatta 1000:1 oranında. Karmaşık bir veritabanı birleşimiyle sonuçlanan bir okuma, disk işlemlerinde ciddi zaman harcayarak çok pahalı olabilir.
##### Dezavantaj(lar): denormalizasyon
- Veri çoğaltılır.
- Kısıtlar, fazladan kopyaların tutarlı kalmasına yardımcı olabilir, bu da veritabanı tasarımının karmaşıklığını arttırır.
- Yoğun yazma yükü altında denormalize bir veritabanı, normalize edilmiş muadilinden daha kötü performans gösterebilir.
SQL ayarlama geniş bir konudur ve birçok kitap referans olarak yazılmıştır.
Benchmark ve profilleme yapmak, darboğazları simüle etmek ve ortaya çıkarmak için önemlidir.
- Benchmark - ab gibi araçlarla yüksek yük durumlarını simüle edin.
- Profil - Performans sorunlarını izlemeye yardımcı olmak için yavaş sorgu günlüğü gibi araçları etkinleştirin.
##### Şemayı sıkılaştırın
- MySQL, hızlı erişim için verileri disk üzerinde bitişik bloklara döker.
- Sabit uzunluklu alanlar için
CHARkullanın,VARCHARyerine tercih edin. CHAR, hızlı ve rastgele erişime olanak tanırken,VARCHARile bir sonraki stringe geçmeden önce sonunu bulmanız gerekir.- Blog yazıları gibi büyük metin blokları için
TEXTkullanın.TEXTayrıca boolean aramalara olanak tanır. BirTEXTalanı kullanmak, disk üzerinde metin bloğunu bulmak için kullanılan bir işaretçi saklanmasına neden olur. - 2^32 veya 4 milyara kadar olan büyük sayılar için
INTkullanın. - Ondalık gösterim hatalarını önlemek için para birimi için
DECIMALkullanın. - Büyük
BLOB'ları saklamaktan kaçının, bunun yerine nesnenin alınacağı konumu saklayın. VARCHAR(255), 8 bitlik bir sayıda sayılabilecek en fazla karakter sayısıdır ve bazı RDBMS'lerde bir baytın maksimum kullanımını sağlar.- Uygun olan yerlerde
NOT NULLkısıtlamasını ayarlayın, arama performansını artırmak için.
- Sorguladığınız sütunlar (
SELECT,GROUP BY,ORDER BY,JOIN) indekslerle daha hızlı olabilir. - İndeksler genellikle verileri sıralı tutan ve aramaları, ardışık erişimi, eklemeleri ve silmeleri logaritmik zamanda sağlayan kendi kendini dengeleyen B-tree olarak temsil edilir.
- Bir indeks eklemek verileri bellekte tutabilir, bu da daha fazla alan gerektirir.
- Yazma işlemleri daha yavaş olabilir çünkü indeksin de güncellenmesi gerekir.
- Büyük miktarda veri yüklerken, indeksleri devre dışı bırakmak, veriyi yüklemek ve ardından indeksleri yeniden oluşturmak daha hızlı olabilir.
- Performans gerektirdiğinde Denormalizasyon uygulayın.
- Bir tabloyu bölmek için sıcak noktaları ayrı bir tabloda tutarak bellekte kalmasına yardımcı olun.
- Bazı durumlarda, sorgu önbelleği performans sorunlarına yol açabilir.
- MySQL sorgularını optimize etmek için ipuçları
- VARCHAR(255) neden bu kadar sık kullanılıyor?
- Null değerler performansı nasıl etkiler?
- Yavaş sorgu günlüğü
NoSQL
NoSQL, verilerin anahtar-değer deposu, belge deposu, geniş sütun deposu veya graf veritabanı şeklinde temsil edildiği bir veri öğeleri koleksiyonudur. Veriler denormalize edilir ve genellikle birleştirmeler uygulama kodunda yapılır. Çoğu NoSQL deposu gerçek ACID işlemlerinden yoksundur ve sonunda tutarlılık ilkesini benimser.
BASE terimi genellikle NoSQL veritabanlarının özelliklerini tanımlamak için kullanılır. CAP Teoremi ile karşılaştırıldığında, BASE tutarlılık yerine erişilebilirliği seçer.
- Temelde erişilebilir - sistem erişilebilirliği garanti eder.
- Yumuşak durum - sistemin durumu zamanla, girdi olmadan bile değişebilir.
- Sonunda tutarlılık - sistem, belirli bir süre boyunca girdi almazsa zamanla tutarlı hale gelir.
#### Anahtar-değer deposu
Soyutlama: karma tablo
Bir anahtar-değer deposu genellikle O(1) okuma ve yazma olanağı sağlar ve çoğunlukla bellek veya SSD ile desteklenir. Veri depoları anahtarları leksikografik sırada tutabilir, bu da anahtar aralıklarının verimli şekilde alınmasına olanak sağlar. Anahtar-değer depoları bir değere meta veri eklemeye izin verebilir.
Anahtar-değer depoları yüksek performans sağlar ve genellikle basit veri modelleri veya hızlı değişen veriler için, örneğin bellek içi önbellek katmanı olarak kullanılır. Sadece sınırlı bir işlem kümesi sunduklarından, ek işlemler gerektiğinde karmaşıklık uygulama katmanına kayar.
Bir anahtar-değer deposu, belge deposu gibi daha karmaşık sistemlerin ve bazı durumlarda graf veritabanının temelini oluşturur.
##### Kaynak(lar) ve ileri okuma: anahtar-değer deposu
#### Doküman deposuSoyutlama: Anahtar-değer deposu, belgeler değer olarak saklanır
Bir doküman deposu, belgeler (XML, JSON, ikili, vb.) etrafında merkezlenir; bir belge, belirli bir nesneye ait tüm bilgileri saklar. Doküman depoları, belgenin iç yapısına göre sorgulama yapmak için API'ler veya bir sorgu dili sağlar. Not: Birçok anahtar-değer deposu, bir değerin meta verisiyle çalışmak için özellikler sunar ve bu iki depolama türü arasındaki çizgileri bulanıklaştırır.
Altta yatan uygulamaya bağlı olarak, belgeler koleksiyonlar, etiketler, meta veriler veya dizinler aracılığıyla düzenlenir. Belgeler organize edilebilse veya gruplanabilse de, belgeler birbirinden tamamen farklı alanlara sahip olabilir.
Bazı doküman depoları, MongoDB ve CouchDB gibi, karmaşık sorgular gerçekleştirmek için SQL benzeri bir dil sağlar. DynamoDB hem anahtar-değerleri hem de belgeleri destekler.
Doküman depoları yüksek esneklik sağlar ve genellikle ara sıra değişen verilerle çalışmak için kullanılır.
##### Kaynak(lar) ve daha fazla okuma: doküman deposu
#### Geniş sütun deposu
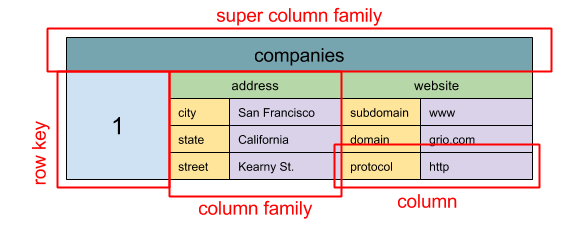
Kaynak: SQL & NoSQL, kısa bir tarihçe
Soyutlama: iç içe harita ColumnFamily> Bir geniş sütun deposunun temel veri birimi bir sütundur (isim/değer çifti). Bir sütun, sütun ailelerinde (SQL tablosuna benzer) gruplanabilir. Süper sütun aileleri ise sütun ailelerini daha da gruplar. Her bir sütuna bir satır anahtarı ile bağımsız olarak erişebilirsiniz ve aynı satır anahtarına sahip sütunlar bir satırı oluşturur. Her değer, sürümleme ve çakışma çözümü için bir zaman damgası içerir.
Google, ilk geniş sütun deposu olarak Bigtable'ı tanıttı; bu, Hadoop ekosisteminde sıkça kullanılan açık kaynak HBase ve Facebook'tan Cassandra'yı etkiledi. BigTable, HBase ve Cassandra gibi depolar anahtarları leksikografik sırada tutar, böylece seçici anahtar aralıklarının verimli bir şekilde alınmasını sağlar.
Geniş sütun depoları yüksek kullanılabilirlik ve yüksek ölçeklenebilirlik sunar. Genellikle çok büyük veri kümeleri için kullanılırlar.
##### Kaynak(lar) ve daha fazla okuma: geniş sütun deposu
#### Grafik veritabanı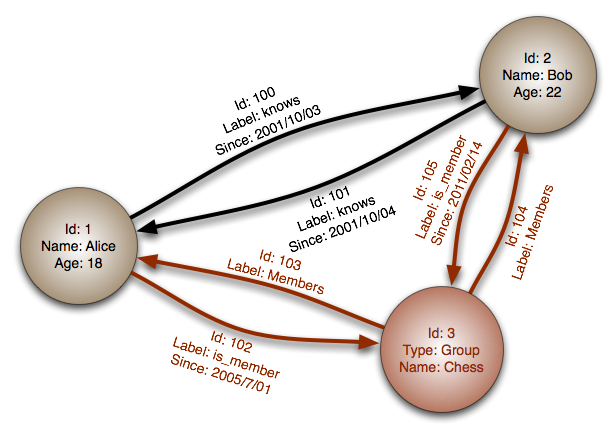
Soyutlama: grafik
Bir grafik veritabanında, her düğüm bir kayıttır ve her yay iki düğüm arasındaki ilişkidir. Grafik veritabanları, çok sayıda yabancı anahtar veya çoktan çoğa ilişkileri olan karmaşık ilişkileri temsil etmek için optimize edilmiştir.
Grafik veritabanları, sosyal ağ gibi karmaşık ilişkilere sahip veri modelleri için yüksek performans sunar. Görece yenidirler ve henüz yaygın olarak kullanılmazlar; geliştirme araçları ve kaynaklarını bulmak daha zor olabilir. Birçok grafiğe yalnızca REST API'leri ile erişilebilir.
##### Kaynak(lar) ve daha fazla okuma: grafik
#### Kaynak(lar) ve daha fazla okuma: NoSQL- Temel terminolojinin açıklaması
- NoSQL veritabanları: bir inceleme ve karar rehberi
- Ölçeklenebilirlik
- NoSQL'e giriş
- NoSQL desenleri
SQL veya NoSQL
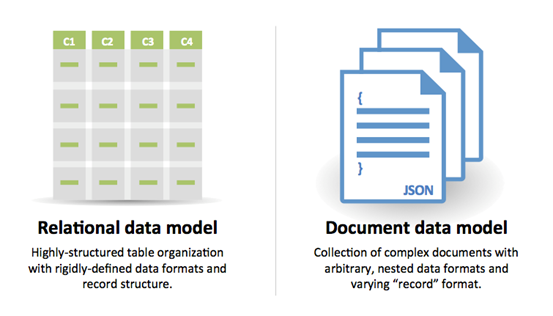
Kaynak: RDBMS'den NoSQL'e Geçiş
SQL için nedenler:
- Yapılandırılmış veri
- Katı şema
- İlişkisel veri
- Karmaşık birleştirmelere ihtiyaç
- İşlemler
- Ölçeklendirme için net desenler
- Daha köklü: geliştiriciler, topluluk, kod, araçlar, vb.
- İndeksle aramalar çok hızlıdır
- Yarı yapılandırılmış veri
- Dinamik veya esnek şema
- İlişkisel olmayan veri
- Karmaşık birleştirmelere ihtiyaç yok
- Birçok TB (veya PB) veri depolama
- Çok veri yoğun iş yükü
- IOPS için çok yüksek verim
- Tıklama akışı ve log verisinin hızlı alınması
- Lider tablosu veya skor verisi
- Geçici veri, örneğin alışveriş sepeti
- Sık erişilen ('sıcak') tablolar
- Meta veri/bakış tabloları
Önbellek
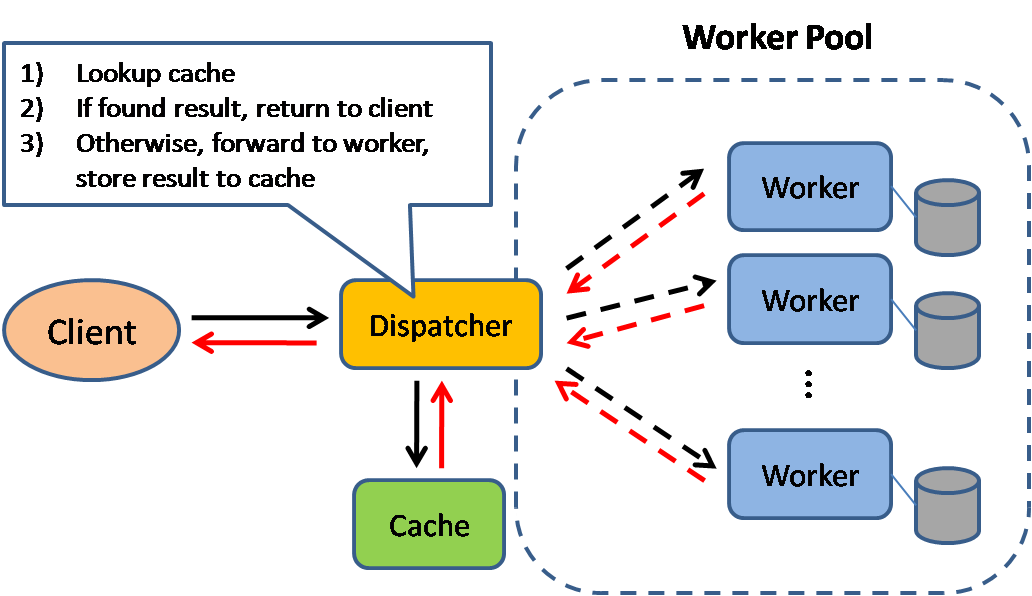
Kaynak: Ölçeklenebilir sistem tasarım desenleri
Önbellekleme, sayfa yükleme sürelerini iyileştirir ve sunucularınız ile veritabanlarınızdaki yükü azaltabilir. Bu modelde, yönlendirici önce isteğin daha önce yapılıp yapılmadığını kontrol eder ve önceki sonucu bulup döndürmeye çalışır, böylece gerçek yürütmeden tasarruf edilir.
Veritabanları genellikle okuma ve yazmaların bölümler arasında eşit dağılımından fayda sağlar. Popüler öğeler dağılımı bozabilir ve darboğazlara neden olabilir. Bir veritabanının önüne bir önbellek koymak, düzensiz yükleri ve trafik artışlarını absorbe edebilir.
İstemci önbelleklemesi
Önbellekler istemci tarafında (İşletim Sistemi veya tarayıcıda), sunucu tarafında veya ayrı bir önbellek katmanında bulunabilir.
CDN önbelleklemesi
CDN'ler bir tür önbellek olarak kabul edilir.
Web sunucusu önbelleklemesi
Ters proxyler ve Varnish gibi önbellekler statik ve dinamik içeriği doğrudan sunabilir. Web sunucuları ayrıca isteklere önbellek uygulayabilir, yanıtları uygulama sunucularına başvurmadan döndürebilir.
Veritabanı önbelleklemesi
Veritabanınız genellikle varsayılan yapılandırmasında, genel bir kullanım senaryosu için optimize edilmiş bir önbellekleme düzeyi içerir. Bu ayarları belirli kullanım desenleri için özelleştirmek performansı daha da artırabilir.
Uygulama önbelleklemesi
Memcached ve Redis gibi bellek içi önbellekler, uygulamanız ile veri depolamanız arasında anahtar-değer depolarıdır. Veriler RAM'de tutulduğundan, verilerin diskte saklandığı tipik veritabanlarından çok daha hızlıdır. RAM, diske göre daha sınırlıdır, bu nedenle önbellek geçersiz kılma algoritmaları, örneğin en son kullanılan (LRU)), 'soğuk' girdileri geçersiz kılmaya ve 'sıcak' verileri RAM'de tutmaya yardımcı olabilir.
Redis aşağıdaki ek özelliklere sahiptir:
- Kalıcılık seçeneği
- Sıralı setler ve listeler gibi yerleşik veri yapıları
- Satır düzeyi
- Sorgu düzeyi
- Tamamlanmış serileştirilebilir nesneler
- Tam olarak işlenmiş HTML
Veritabanı sorgu seviyesinde önbellekleme
Veritabanını her sorguladığınızda, sorguyu bir anahtar olarak hashleyin ve sonucu önbelleğe kaydedin. Bu yaklaşım, süre sonu (expiration) sorunlarından muzdariptir:
- Karmaşık sorgularda önbellekteki bir sonucu silmek zordur
- Bir veri parçası değiştiğinde (örneğin bir tablo hücresi), değişen hücreyi içerebilecek tüm önbellekteki sorguları silmeniz gerekir
Nesne seviyesinde önbellekleme
Verinizi, uygulama kodunuzda yaptığınız gibi bir nesne olarak görün. Uygulamanız, veritabanından veri kümesini bir sınıf örneği veya veri yapısına toplar:
- Nesnenin altındaki veri değiştiyse, nesneyi önbellekten kaldırın
- Eşzamanlı olmayan işleme imkanı sağlar: çalışanlar, en güncel önbellekteki nesneyi tüketerek nesneleri oluşturur
- Kullanıcı oturumları
- Tamamen işlenmiş web sayfaları
- Aktivite akışları
- Kullanıcı grafik verisi
Önbelleği ne zaman güncellemeli
Önbellekte yalnızca sınırlı miktarda veri saklayabileceğiniz için, hangi önbellek güncelleme stratejisinin sizin kullanım senaryonuza en uygun olduğuna karar vermeniz gerekir.
#### Cache-aside (Yan önbellek)
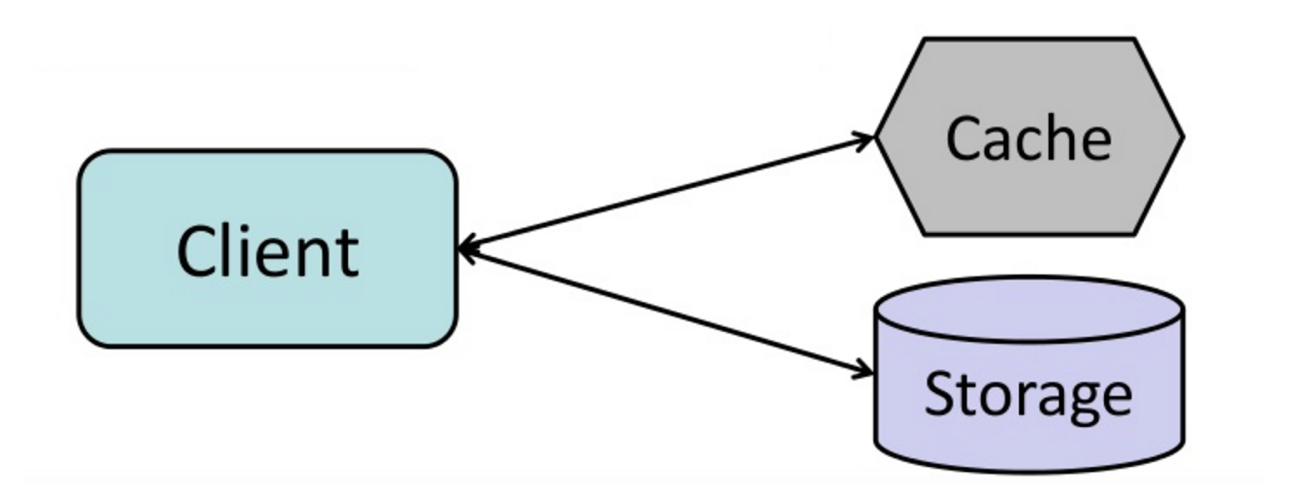
Kaynak: Önbellekten bellek içi veri ızgarasına
Uygulama, depolamadan okuma ve yazmadan sorumludur. Önbellek, doğrudan depolama ile etkileşime girmez. Uygulama aşağıdakileri yapar:
- Önbellekte girdi arar, önbellek kaçırma ile sonuçlanır
- Girdiyi veritabanından yükler
- Girdiyi önbelleğe ekler
- Girdiyi döndürür
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached genellikle bu şekilde kullanılır.
Önbelleğe eklenen verilerin sonraki okumaları hızlıdır. Cache-aside aynı zamanda tembel yükleme olarak da adlandırılır. Yalnızca istenen veriler önbelleğe alınır, böylece istenmeyen verilerle önbelleğin dolması önlenir.
##### Dezavantaj(lar): cache-aside
- Her önbellek kaçırması üç yolculuğa neden olur, bu da fark edilir bir gecikmeye yol açabilir.
- Veriler veritabanında güncellenirse bayatlayabilir. Bu sorun, önbellek kaydının güncellenmesini zorunlu kılan bir yaşam süresi (TTL) ayarlanarak veya write-through kullanılarak hafifletilir.
- Bir düğüm arızalandığında, yeni ve boş bir düğümle değiştirilir, bu da gecikmeyi artırır.
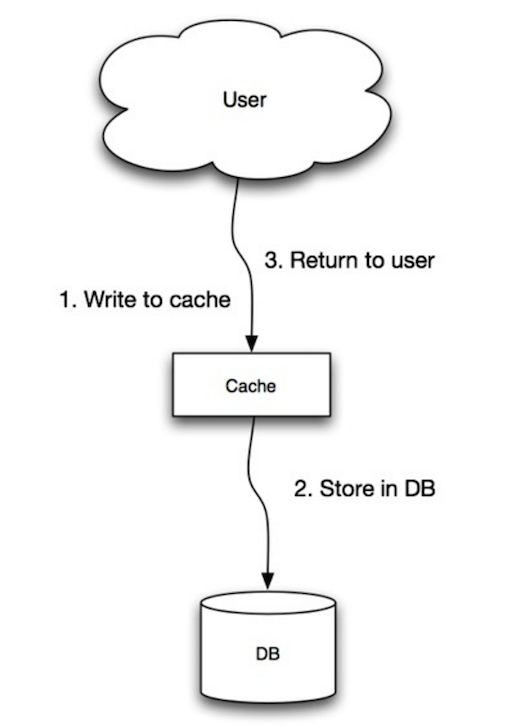
Kaynak: Ölçeklenebilirlik, erişilebilirlik, stabilite, desenler
Uygulama, önbelleği ana veri deposu olarak kullanır, verileri okur ve yazar, önbellek ise veritabanına okuma ve yazma işlemlerinden sorumludur:
- Uygulama önbelleğe kayıt ekler/günceller
- Önbellek kaydı veri deposuna eşzamanlı olarak yazar
- Dönüş
set_user(12345, {"foo":"bar"})Önbellek kodu:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Dezavantaj(lar): write through
- Bir arıza veya ölçeklendirme nedeniyle yeni bir düğüm oluşturulduğunda, yeni düğüm veritabanındaki giriş güncellenene kadar girişleri önbelleğe almaz. Cache-aside ile write through birlikte kullanılarak bu sorun hafifletilebilir.
- Yazılan verilerin çoğu hiçbir zaman okunmayabilir, bu TTL ile en aza indirilebilir.
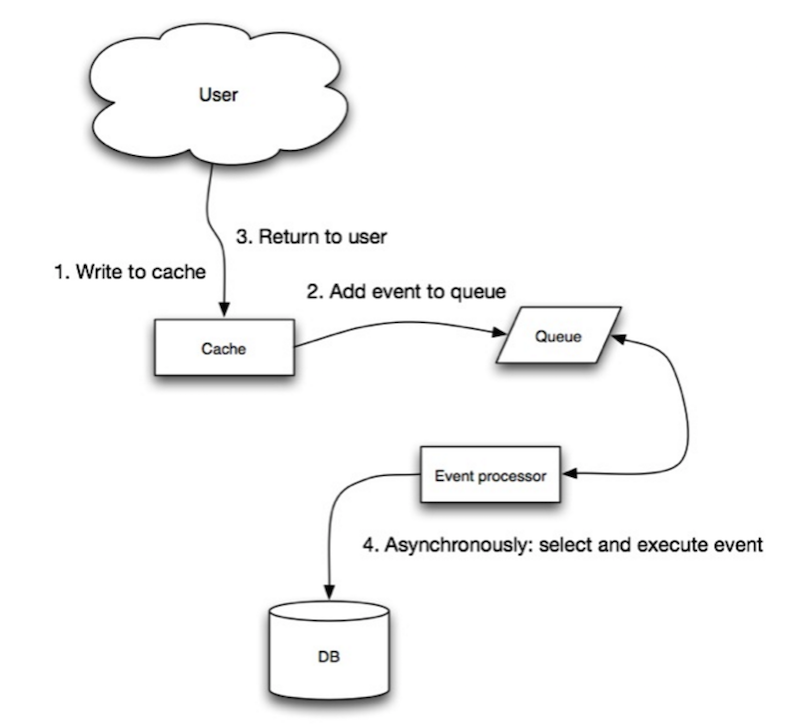
Kaynak: Ölçeklenebilirlik, kullanılabilirlik, stabilite, desenler
Write-behind'da uygulama aşağıdaki işlemleri yapar:
- Önbellekte giriş ekle/güncelle
- Girişi veri deposuna asenkron olarak yazar, yazma performansını artırır
- Önbellek içeriği veri deposuna ulaşmadan önce önbellek kapanırsa veri kaybı olabilir.
- Write-behind uygulamak, cache-aside veya write-through uygulamaktan daha karmaşıktır.
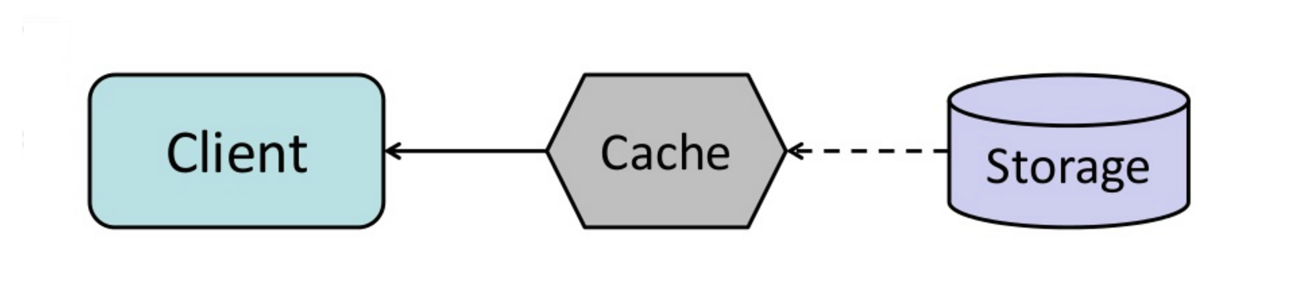
Kaynak: Önbellekten bellek içi veri ızgarasına
Önbelleği, yakın zamanda erişilen herhangi bir önbellek girişini süresi dolmadan önce otomatik olarak yenileyecek şekilde yapılandırabilirsiniz.
Refresh-ahead, önbellek gelecekte hangi öğelerin gerekebileceğini doğru tahmin edebilirse, read-through'a göre gecikmeyi azaltabilir.
##### Dezavantaj(lar): refresh-ahead
- Gelecekte hangi öğelere ihtiyaç duyulacağının doğru tahmin edilememesi, refresh-ahead olmadan olduğundan daha düşük performansa yol açabilir.
Dezavantaj(lar): önbellek
- Önbellekler ile veritabanı gibi gerçek kaynak arasında önbellek geçersizleştirme ile tutarlılık sağlanmalıdır.
- Önbellek geçersizleştirme zor bir problemdir, önbelleğin ne zaman güncelleneceği ile ilgili ek karmaşıklık vardır.
- Redis veya memcached eklemek gibi uygulama değişiklikleri yapmak gerekir.
Kaynak(lar) ve ileri okuma
- Önbellekten bellek içi veri ızgarasına
- Ölçeklenebilir sistem tasarım desenleri
- Ölçek için sistem mimarisine giriş
- Ölçeklenebilirlik, erişilebilirlik, stabilite, desenler
- Ölçeklenebilirlik
- AWS ElastiCache stratejileri
- Vikipedi)
Asenkronluk
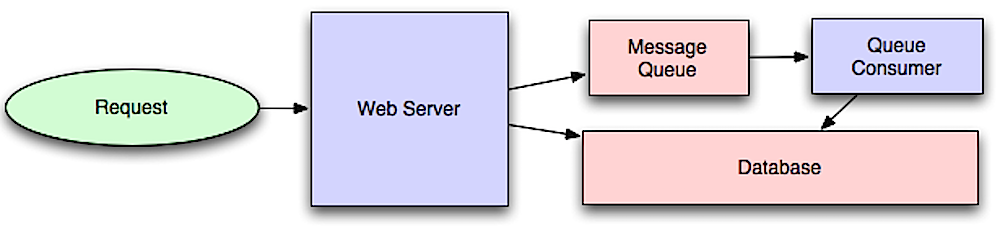
Kaynak: Ölçek için sistem mimarisine giriş
Asenkron iş akışları, satır içi gerçekleştirilecek pahalı işlemler için istek sürelerini azaltmaya yardımcı olur. Ayrıca, veri toplamanın periyodik olarak önceden yapılması gibi zaman alan işleri önceden gerçekleştirerek de fayda sağlar.
Mesaj kuyrukları
Mesaj kuyrukları mesajları alır, tutar ve teslim eder. Bir işlemin satır içi gerçekleştirilmesi çok yavaşsa, aşağıdaki iş akışıyla bir mesaj kuyruğu kullanılabilir:
- Bir uygulama kuyruğa bir işi gönderir, ardından kullanıcıya iş durumu bildirir
- Bir çalışan kuyruğundan işi alır, işler ve işin tamamlandığını bildirir
Redis basit bir mesaj aracısı olarak kullanışlıdır, ancak mesajlar kaybolabilir.
RabbitMQ popülerdir ancak 'AMQP' protokolüne uyum sağlamanızı ve kendi sunucularınızı yönetmenizi gerektirir.
Amazon SQS barındırılır ancak yüksek gecikmeye sahip olabilir ve mesajların iki kez teslim edilme olasılığı vardır.
Görev kuyrukları
Görev kuyrukları görevleri ve ilgili verilerini alır, çalıştırır ve ardından sonuçlarını iletir. Zamanlama desteği sunabilirler ve arka planda hesaplama açısından yoğun işleri çalıştırmak için kullanılabilirler.
Celery zamanlama desteğine sahiptir ve esas olarak python desteği bulunur.
Geri basınç
Kuyruklar önemli ölçüde büyümeye başlarsa, kuyruk boyutu belleği aşabilir ve bu durum önbellek kaçırmaları, disk okuma işlemleri ve daha yavaş performansa yol açabilir. Geri basınç kuyruk boyutunu sınırlandırarak yüksek iş hacmi oranı ve kuyrukta bulunan işler için iyi yanıt sürelerinin korunmasına yardımcı olur. Kuyruk dolduğunda, istemciler sunucu meşgul veya HTTP 503 durum kodu alır ve daha sonra tekrar denemeleri istenir. İstemciler isteği daha sonraki bir zamanda, örneğin üstel geri çekilme ile yeniden deneyebilir.
Dezavantaj(lar): asenkronluk
- Ucuz hesaplamalar ve gerçek zamanlı iş akışları gibi kullanım durumları senkron işlemler için daha uygun olabilir, çünkü kuyrukların eklenmesi gecikme ve karmaşıklık yaratabilir.
Kaynak(lar) ve daha fazla okuma
- Hepsi bir sayı oyunudur
- Aşırı yüklenmede geri basınç uygulama
- Little'ın yasası
- Mesaj kuyruğu ile görev kuyruğu arasındaki fark nedir?
İletişim
{kind=link}
{kind=link}
Hiper metin aktarım protokolü (HTTP)
HTTP, bir istemci ile bir sunucu arasında veri kodlamak ve taşımak için kullanılan bir yöntemdir. İstek/yanıt protokolüdür: istemciler istek gönderir ve sunucular istekle ilgili içerik ve tamamlanma durumu bilgisiyle yanıt verir. HTTP kendi başına çalışır, bu sayede istek ve yanıtlar yük dengeleme, önbellekleme, şifreleme ve sıkıştırma yapan birçok ara yönlendirici ve sunucudan geçebilir.
Temel bir HTTP isteği bir fiil (metot) ve bir kaynak (uç nokta) içerir. Aşağıda yaygın HTTP fiilleri verilmiştir:
| Fiil | Açıklama | Idempotent* | Güvenli | Önbelleklenebilir |
| GET | Bir kaynağı okur | Evet | Evet | Evet | | POST | Bir kaynak oluşturur veya verileri işleyen bir süreci tetikler | Hayır | Hayır | Yanıt tazelik bilgisi içeriyorsa Evet | | PUT | Bir kaynağı oluşturur veya değiştirir | Evet | Hayır | Hayır | | PATCH | Bir kaynağı kısmen günceller | Hayır | Hayır | Yanıt tazelik bilgisi içeriyorsa Evet | | DELETE | Bir kaynağı siler | Evet | Hayır | Hayır |
*Farklı sonuçlar olmadan birçok kez çağrılabilir.
HTTP, TCP ve UDP gibi alt seviye protokollere bağlı bir uygulama katmanı protokolüdür.
#### Kaynak(lar) ve daha fazla okuma: HTTP
İletim Kontrol Protokolü (TCP)
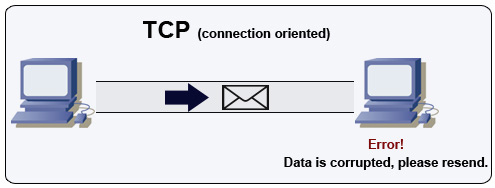
Kaynak: Çok oyunculu bir oyun nasıl yapılır
TCP, IP ağı üzerinden bağlantı odaklı bir protokoldür. Bağlantı, bir el sıkışma ile kurulur ve sonlandırılır. Gönderilen tüm paketlerin orijinal sırada ve bozulmadan hedefe ulaşması şu yollarla garanti edilir:
- Her paket için sıra numaraları ve checksum alanları
- Onay) paketleri ve otomatik yeniden iletim
Yüksek veri aktarımını sağlamak için web sunucuları çok sayıda TCP bağlantısını açık tutabilir, bu da yüksek bellek kullanımıyla sonuçlanır. Web sunucu iş parçacıkları ile örneğin bir memcached sunucusu arasında çok sayıda açık bağlantı olması maliyetli olabilir. Bağlantı havuzu yardımcı olabilir ve uygun olduğunda UDP'ye geçiş yapılabilir.
TCP, yüksek güvenilirlik gerektiren ancak zaman açısından kritik olmayan uygulamalar için uygundur. Bazı örnekler arasında web sunucuları, veritabanı bilgisi, SMTP, FTP ve SSH bulunur.
TCP’yi UDP yerine kullanın, eğer:
- Tüm verilerin sağlam bir şekilde ulaşmasını istiyorsanız
- Ağ bant genişliğinin en iyi şekilde otomatik tahmin edilerek kullanılmasını istiyorsanız
Kullanıcı veri gramı protokolü (UDP)
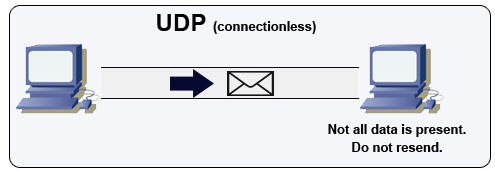
Kaynak: Çok oyunculu oyun nasıl yapılır
UDP bağlantısızdır. Veri grupları (paketlere benzer) sadece veri grubu seviyesinde garanti edilir. Veri grupları hedeflerine sırasız veya hiç ulaşmayabilir. UDP, tıkanıklık kontrolünü desteklemez. TCP'nin sağladığı garantiler olmadan UDP genellikle daha verimlidir.
UDP yayın yapabilir, veri gruplarını alt ağdaki tüm cihazlara gönderebilir. Bu, DHCP ile kullanışlıdır çünkü istemci henüz bir IP adresi almamıştır ve bu nedenle IP adresi olmadan TCP akışı için bir yol engellenir.
UDP daha az güvenilirdir ancak VoIP, video sohbet, yayın akışı ve gerçek zamanlı çok oyunculu oyunlar gibi gerçek zamanlı kullanım senaryolarında iyi çalışır.
Aşağıdaki durumlarda TCP yerine UDP kullanın:
- En düşük gecikmeye ihtiyacınız varsa
- Geç veri, veri kaybından daha kötüyse
- Kendi hata düzeltmenizi uygulamak istiyorsanız
- Oyun programlama için ağ
- TCP ve UDP protokolleri arasındaki temel farklar
- TCP ve UDP arasındaki fark
- Aktarım kontrol protokolü
- Kullanıcı veri gramı protokolü
- Facebook'ta memcache ölçeklendirme
Uzaktan prosedür çağrısı (RPC)
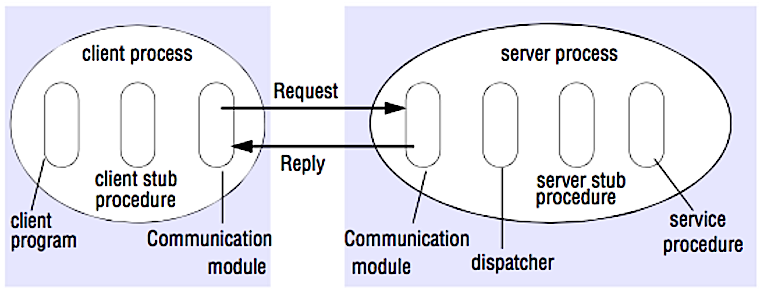
Kaynak: Sistem tasarımı mülakatını çöz
Bir RPC'de, bir istemci genellikle uzak bir sunucuda farklı bir adres alanında bir prosedürün çalışmasını sağlar. Prosedür, yerel bir prosedür çağrısı gibi kodlanır; istemci programından sunucu ile nasıl iletişim kurulacağı ayrıntıları soyutlanır. Uzaktaki çağrılar genellikle yerel çağrılardan daha yavaş ve daha az güvenilirdir, bu nedenle RPC çağrılarını yerel çağrılardan ayırmak faydalıdır. Popüler RPC çerçeveleri arasında Protobuf, Thrift ve Avro bulunur.
RPC bir istek-yanıt protokolüdür:
- İstemci programı - İstemci ara birimi prosedürünü çağırır. Parametreler, yerel prosedür çağrısındaki gibi yığına eklenir.
- İstemci ara birimi prosedürü - Prosedür kimliği ve argümanları bir istek mesajına paketler (marshalling).
- İstemci iletişim modülü - İşletim sistemi, mesajı istemciden sunucuya gönderir.
- Sunucu iletişim modülü - İşletim sistemi, gelen paketleri sunucu ara birimi prosedürüne iletir.
- Sunucu ara birimi prosedürü - Sonuçları açar (unmarshalling), prosedür kimliğiyle eşleşen sunucu prosedürünü çağırır ve verilen argümanları iletir.
- Sunucu yanıtı, yukarıdaki adımların ters sırasıyla tekrar edilir.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC, davranışları ortaya çıkarmaya odaklanır. RPC'ler genellikle iç iletişimlerde performans nedenleriyle kullanılır, çünkü yerel çağrıları el ile oluşturarak kullanım senaryolarınıza daha iyi uyum sağlayabilirsiniz.
Yerel bir kütüphaneyi (SDK olarak da bilinir) şu durumlarda seçin:
- Hedef platformunuzu biliyorsanız.
- "Mantığınızın" nasıl erişileceğini kontrol etmek istiyorsanız.
- Hata kontrolünün kütüphaneniz dışında nasıl gerçekleşeceğini kontrol etmek istiyorsanız.
- Performans ve son kullanıcı deneyimi birincil önceliğiniz ise.
#### Dezavantaj(lar): RPC
- RPC istemcileri, hizmet uygulamasına sıkı şekilde bağımlı hale gelir.
- Her yeni işlem veya kullanım senaryosu için yeni bir API tanımlanmalıdır.
- RPC'yi hata ayıklamak zor olabilir.
- Var olan teknolojilerden kutudan çıktığı gibi faydalanamayabilirsiniz. Örneğin, RPC çağrılarının önbellekleme sunucularında (ör. Squid) düzgün şekilde önbelleklendiğinden emin olmak ek çaba gerektirebilir.
Temsili durum aktarımı (REST)
REST, istemcinin sunucu tarafından yönetilen bir kaynak kümesi üzerinde işlem yaptığı istemci/sunucu modelini zorunlu kılan bir mimari tarzdır. Sunucu, kaynakların bir temsilini ve bu kaynakların temsilini değiştiren veya yeni bir temsilini alan işlemleri sağlar. Tüm iletişimler durumsuz ve önbelleğe alınabilir olmalıdır.
RESTful bir arayüzün dört özelliği vardır:
- Kaynakları tanımla (HTTP'de URI) - herhangi bir işlemden bağımsız olarak aynı URI'yi kullanın.
- Temsillerle değiştir (HTTP'de Fiiller) - fiilleri, başlıkları ve gövdeyi kullanın.
- Kendi kendini açıklayan hata mesajı (HTTP'de durum yanıtı) - Durum kodlarını kullanın, tekerleği yeniden icat etmeyin.
- HATEOAS (HTTP için HTML arayüzü) - web servisiniz tamamen bir tarayıcıda erişilebilir olmalıdır.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
REST, verilerin sunulmasına odaklanır. İstemci/sunucu arasındaki bağı en aza indirir ve genellikle halka açık HTTP API'lerinde kullanılır. REST, kaynakları URI’ler aracılığıyla, başlıklar üzerinden temsili ile ve GET, POST, PUT, DELETE ve PATCH gibi fiillerle daha genel ve uniform bir şekilde sunar. Durumsuz olması sayesinde REST, yatay ölçeklendirme ve bölümlendirme için idealdir.
#### Dezavantaj(lar): REST
- REST, verilerin sunulmasına odaklandığı için, kaynaklar doğal olarak basit bir hiyerarşide düzenlenmemiş veya erişilmiyorsa iyi bir seçenek olmayabilir. Örneğin, belirli bir olay kümesiyle eşleşen son bir saat içindeki tüm güncellenmiş kayıtları döndürmek, bir yol olarak kolayca ifade edilemez. REST ile bu, büyük olasılıkla URI yolu, sorgu parametreleri ve muhtemelen istek gövdesinin birleşimiyle uygulanır.
- REST genellikle birkaç fiile (GET, POST, PUT, DELETE ve PATCH) dayanır, bu da bazen kullanım senaryonuza uymayabilir. Örneğin, süresi dolmuş belgeleri arşiv klasörüne taşımak bu fiillerle tam olarak örtüşmeyebilir.
- İç içe geçmiş hiyerarşilere sahip karmaşık kaynakların alınması, tek bir görünümü işlemek için istemci ile sunucu arasında birden fazla tur gerektirir; örneğin, bir blog girdisinin içeriği ve o girdiye yapılan yorumları almak. Değişken ağ koşullarında çalışan mobil uygulamalar için bu çoklu turlar oldukça istenmeyen bir durumdur.
- Zamanla, bir API yanıtına daha fazla alan eklenebilir ve eski istemciler, ihtiyaç duymadıkları tüm yeni veri alanlarını alır; bu da yük boyutunu artırır ve daha büyük gecikmelere yol açar.
RPC ve REST çağrıları karşılaştırması
| İşlem | RPC | REST |
|---|---|---|
| Kayıt Ol | POST /signup | POST /persons |
| İstifa Et | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Bir kişiyi oku | GET /readPerson?personid=1234 | GET /persons/1234 |
| Bir kişinin ürünler listesini oku | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Bir kişinin ürünler listesine ürün ekle | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Bir ürünü güncelle | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Bir ürünü sil | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Kaynak: Gerçekten REST’i RPC’ye neden tercih ettiğinizi biliyor musunuz?
#### Kaynak(lar) ve daha fazla okuma: REST ve RPC
- Gerçekten REST’i RPC’ye neden tercih ettiğinizi biliyor musunuz?
- Ne zaman RPC-benzeri yaklaşımlar REST’ten daha uygundur?
- REST vs JSON-RPC
- RPC ve REST’in efsanelerini çürütmek
- RESTful API’lerin dezavantajları nelerdir?
- Sistem tasarım mülakatını çözün
- Thrift
- Neden iç kullanımda REST, RPC değil?
Güvenlik
Bu bölümün güncellenmeye ihtiyacı var. Katkıda bulunmayı düşünün!
Güvenlik geniş bir konudur. Önemli bir deneyiminiz, güvenlik geçmişiniz yoksa veya güvenlik bilgisi gerektiren bir pozisyona başvurmuyorsanız, muhtemelen temellerden fazlasını bilmenize gerek yoktur:
- Aktarım sırasında ve depolamada şifreleme yapın.
- XSS ve SQL enjeksiyonu önlemek için tüm kullanıcı girdilerini veya kullanıcıya açık herhangi bir girdi parametresini temizleyin.
- SQL enjeksiyonunu önlemek için parametreli sorgular kullanın.
- En az ayrıcalık ilkesini kullanın.
Kaynak(lar) ve ileri okuma
Ek
Bazen sizden 'kabataslak' tahminler yapmanız istenecektir. Örneğin, diskteki 100 görüntü küçük resminin oluşturulmasının ne kadar süreceğini veya bir veri yapısının ne kadar bellek kullanacağını belirlemeniz gerekebilir. İki tablosunun kuvvetleri ve Her programcının bilmesi gereken gecikme sayıları faydalı başvuru kaynaklarıdır.
İki tablosunun kuvvetleri
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Kaynak(lar) ve daha fazla okuma
Her programcının bilmesi gereken gecikme rakamları
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- HDD'den ardışık okuma 30 MB/sn
- 1 Gbps Ethernet üzerinden ardışık okuma 100 MB/sn
- SSD'den ardışık okuma 1 GB/sn
- Ana bellekten ardışık okuma 4 GB/sn
- Dünya çapında saniyede 6-7 gidiş-dönüş
- Bir veri merkezinde saniyede 2.000 gidiş-dönüş
#### Kaynak(lar) ve daha fazla okuma
- Her programcının bilmesi gereken gecikme sayıları - 1
- Her programcının bilmesi gereken gecikme sayıları - 2
- Büyük dağıtık sistemler inşa ederken edinilen tasarımlar, dersler ve tavsiyeler
- Büyük ölçekli dağıtık sistemler inşa ederken yazılım mühendisliği tavsiyeleri
Ek sistem tasarımı mülakat soruları
Yaygın sistem tasarımı mülakat soruları ve her birini çözmek için kaynak bağlantıları.
| Soru | Kaynak(lar) |
|---|---|
| Dropbox gibi bir dosya senkronizasyon servisi tasarla | youtube.com |
| Google gibi bir arama motoru tasarla | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Google gibi ölçeklenebilir bir web tarayıcı tasarla | quora.com |
| Google docs tasarla | code.google.com
neil.fraser.name |
| Redis gibi bir anahtar-değer deposu tasarla | slideshare.net |
| Memcached gibi bir önbellek sistemi tasarla | slideshare.net |
| Amazon'unki gibi bir öneri sistemi tasarla | hulu.com
ijcai13.org |
| Bitly gibi bir tinyurl sistemi tasarla | n00tc0d3r.blogspot.com |
| WhatsApp gibi bir sohbet uygulaması tasarla | highscalability.com
| Instagram gibi bir resim paylaşım sistemi tasarla | highscalability.com
highscalability.com |
| Facebook haber kaynağı fonksiyonunu tasarla | quora.com
quora.com
slideshare.net |
| Facebook zaman tüneli fonksiyonunu tasarla | facebook.com
highscalability.com |
| Facebook sohbet fonksiyonunu tasarla | erlang-factory.com
facebook.com |
| Facebook gibi bir grafik arama fonksiyonu tasarlayın | facebook.com
facebook.com
facebook.com |
| CloudFlare gibi bir içerik dağıtım ağı tasarlayın | figshare.com |
| Twitter gibi bir gündem belirleme sistemi tasarlayın | michael-noll.com
snikolov .wordpress.com |
| Rastgele ID üretim sistemi tasarlayın | blog.twitter.com
github.com |
| Bir zaman aralığında en çok yapılan k istekleri döndürün | cs.ucsb.edu
wpi.edu |
| Birden fazla veri merkezinden veri sunan bir sistem tasarlayın | highscalability.com |
| Çevrimiçi çok oyunculu bir kart oyunu tasarlayın | indieflashblog.com
buildnewgames.com |
| Çöp toplama sistemi tasarlayın | stuffwithstuff.com
washington.edu |
| API hız sınırlayıcı tasarlayın | https://stripe.com/blog/ |
| Bir Borsa (NASDAQ veya Binance gibi) tasarlayın | Jane Street
Golang Implementation
Go Implementation |
| Bir sistem tasarım sorusu ekleyin | Katkıda Bulunun |
Gerçek dünya mimarileri
Gerçek dünya sistemlerinin nasıl tasarlandığına dair makaleler.
Kaynak: Twitter zaman akışları ölçeklenebilirliği
Aşağıdaki makalelerde teknik detaylara çok takılmayın, bunun yerine:
- Ortak prensipleri, kullanılan teknolojileri ve desenleri belirleyin
- Her bileşenin çözdüğü problemleri, nerede işe yaradığını, nerede yaramadığını inceleyin
- Edinilen dersleri gözden geçirin
Şirket mimarileri
| Şirket | Referans(lar) |
|---|---|
| Amazon | Amazon mimarisi |
| Cinchcast | Her gün 1.500 saat ses üretimi |
| DataSift | Saniyede 120.000 tweet ile gerçek zamanlı veri madenciliği |
| Dropbox | Dropbox'u nasıl ölçeklendirdik |
| ESPN | Saniyede 100.000 duh nuh nuh işlemi |
| Google | Google mimarisi |
| Instagram | 14 milyon kullanıcı, terabaytlarca fotoğraf
Instagram’ı ne güçlendiriyor |
| Justin.tv | Justin.Tv'nin canlı video yayın mimarisi |
| Facebook | Facebook'ta memcached ölçeklendirme
TAO: Facebook’un sosyal grafik için dağıtık veri deposu
Facebook’un fotoğraf depolama sistemi
Facebook Live’ın 800.000 eşzamanlı izleyiciye nasıl yayın yaptığı |
| Flickr | Flickr mimarisi |
| Mailbox | 6 haftada sıfırdan 1 milyon kullanıcıya ölçeklendirme |
| Netflix | Tüm Netflix yığınına 360 derece bakış
Netflix: Play tuşuna bastığınızda ne olur? |
| Pinterest | Aylık 0'dan on milyarlarca sayfa görüntülemeye
18 milyon ziyaretçi, 10x büyüme, 12 çalışan |
| Playfish | 50 milyon aylık kullanıcı ve büyüyor |
| PlentyOfFish | PlentyOfFish mimarisi |
| Salesforce | Günde 1,3 milyar işlemi nasıl yönetiyorlar? |
| Stack Overflow | Stack Overflow mimarisi |
| TripAdvisor | 40M ziyaretçi, 200M dinamik sayfa görüntüleme, 30TB veri |
| Tumblr | Aylık 15 milyar sayfa görüntüleme |
| Twitter | Twitter’ı %10000 daha hızlı hale getirmek
MySQL kullanarak günde 250 milyon tweet depolama
150M aktif kullanıcı, 300K QPS, 22 MB/S ateş hortumu
Zaman çizelgeleri ölçekli olarak
Twitter'da büyük ve küçük veri
Twitter’da operasyonlar: 100 milyon kullanıcıyı aşan ölçekleme
Twitter saniyede 3.000 görseli nasıl işler? |
| Uber | Uber gerçek zamanlı pazar platformunu nasıl ölçeklendiriyor
Uber’i 2000 mühendise, 1000 servise ve 8000 Git deposuna ölçeklendirirken öğrenilen dersler |
| WhatsApp | Facebook’un 19 milyar dolara satın aldığı WhatsApp mimarisi |
| YouTube | YouTube ölçeklenebilirliği
YouTube mimarisi |
Şirket mühendislik blogları
Görüştüğünüz şirketlerin mimarileri.>
Karşılaştığınız sorular aynı alandan olabilir.
- Airbnb Mühendislik
- Atlassian Geliştiriciler
- AWS Blog
- Bitly Mühendislik Blogu
- Box Blogları
- Cloudera Geliştirici Blogu
- Dropbox Teknoloji Blogu
- Quora’da Mühendislik
- Ebay Teknoloji Blogu
- Evernote Teknoloji Blogu
- Etsy Code as Craft
- Facebook Mühendislik
- Flickr Code
- Foursquare Mühendislik Blogu
- GitHub Mühendislik Blogu
- Google Araştırma Blogu
- Groupon Mühendislik Blogu
- Heroku Mühendislik Blogu
- Hubspot Mühendislik Blogu
- High Scalability
- Instagram Mühendislik
- Intel Yazılım Blogu
- Jane Street Teknoloji Blogu
- LinkedIn Mühendislik
- Microsoft Mühendislik
- Microsoft Python Mühendislik
- Netflix Teknoloji Blogu
- Paypal Geliştirici Blogu
- Pinterest Mühendislik Blogu
- Reddit Blogu
- Salesforce Mühendislik Blogu
- Slack Mühendislik Blogu
- Spotify Labs
- Stripe Mühendislik Blogu
- Twilio Mühendislik Blogu
- Twitter Mühendislik
- Uber Mühendislik Blogu
- Yahoo Mühendislik Blogu
- Yelp Mühendislik Blogu
- Zynga Mühendislik Blogu
Bir blog eklemek mi istiyorsunuz? Çakışan işleri önlemek için şirket blogunuzu aşağıdaki repoya eklemeyi düşünün:
Geliştirme aşamasında
Bir bölüm eklemek veya devam eden bir bölümü tamamlamaya yardımcı olmak ister misiniz? Katkıda bulunun!
- MapReduce ile dağıtık hesaplama
- Tutarlı karma
- Dağıtma-toplama (scatter gather)
- Katkıda bulunun
Katkılar
Katkılar ve kaynaklar bu repoda boyunca sağlanmıştır.
Özel teşekkürler:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- Sistem tasarımı hile sayfası
- Dağıtık sistemler okuma listesi
- Sistem tasarımı mülakatını çözme
İletişim bilgileri
Herhangi bir sorun, soru veya yorumunuzu görüşmek için benimle iletişime geçmekten çekinmeyin.
İletişim bilgilerime GitHub sayfamdan ulaşabilirsiniz.
Lisans
Bu depoda size kod ve kaynakları açık kaynak lisansı altında sunuyorum. Bu benim kişisel depom olduğu için, kod ve kaynaklarım için aldığınız lisans bana aittir, işverenim (Facebook) değil.
Telif Hakkı 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---