English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
ช่วย แปล คู่มือนี้!
The System Design Primer

แรงจูงใจ
เรียนรู้วิธีออกแบบระบบขนาดใหญ่>
เตรียมตัวสำหรับสัมภาษณ์การออกแบบระบบ
เรียนรู้วิธีออกแบบระบบขนาดใหญ่
การเรียนรู้วิธีออกแบบระบบที่สามารถขยายขนาดได้จะช่วยให้คุณเป็นวิศวกรที่ดีขึ้น
การออกแบบระบบเป็นหัวข้อที่กว้าง มี แหล่งข้อมูลจำนวนมากกระจายอยู่ทั่วอินเทอร์เน็ต เกี่ยวกับหลักการออกแบบระบบ
repo นี้คือ การรวบรวมแหล่งข้อมูลอย่างเป็นระเบียบ เพื่อช่วยให้คุณเรียนรู้วิธีสร้างระบบขนาดใหญ่
เรียนรู้จากชุมชนโอเพ่นซอร์ส
นี่คือโปรเจกต์โอเพ่นซอร์สที่มีการอัปเดตอย่างต่อเนื่อง
เตรียมตัวสำหรับสัมภาษณ์การออกแบบระบบ
นอกเหนือจากการสัมภาษณ์เขียนโค้ดแล้ว การออกแบบระบบยังเป็น องค์ประกอบสำคัญ ของ กระบวนการสัมภาษณ์ทางเทคนิค ในหลายบริษัทเทคโนโลยี
ฝึกตอบคำถามสัมภาษณ์การออกแบบระบบที่พบบ่อย และ เปรียบเทียบ ผลลัพธ์ของคุณกับ ตัวอย่างคำตอบ: การอภิปราย โค้ด และไดอะแกรม
หัวข้อเพิ่มเติมเพื่อเตรียมสัมภาษณ์:
- คู่มือการศึกษา
- วิธีเข้าหาคำถามสัมภาษณ์การออกแบบระบบ
- คำถามสัมภาษณ์การออกแบบระบบ, พร้อมคำตอบ
- คำถามสัมภาษณ์การออกแบบเชิงวัตถุ, พร้อมคำตอบ
- คำถามสัมภาษณ์การออกแบบระบบเพิ่มเติม
บัตรคำ Anki
ชุด บัตรคำ Anki ที่ให้มาใช้เทคนิคการทบทวนแบบเว้นระยะ เพื่อช่วยให้จดจำแนวคิดสำคัญในการออกแบบระบบ
เหมาะสำหรับใช้ขณะเดินทางแหล่งข้อมูลการเขียนโค้ด: แบบฝึกหัดโค้ดเชิงโต้ตอบ
กำลังมองหาแหล่งข้อมูลเพื่อเตรียมตัวสำหรับ การสัมภาษณ์โค้ดดิ้ง?
ลองดูรีโปซิทอรีที่เกี่ยวข้อง Interactive Coding Challenges ซึ่งมีชุดบัตรคำ Anki เพิ่มเติม:
การมีส่วนร่วม
เรียนรู้จากชุมชน
สามารถส่ง pull request เพื่อช่วยได้อย่างอิสระ:
- แก้ไขข้อผิดพลาด
- ปรับปรุงเนื้อหา
- เพิ่มส่วนใหม่
- แปล
ตรวจสอบ แนวทางการมีส่วนร่วม
ดัชนีหัวข้อการออกแบบระบบ
สรุปหัวข้อต่างๆเกี่ยวกับการออกแบบระบบ รวมถึงข้อดีข้อเสีย ทุกสิ่งล้วนเป็นการแลกเปลี่ยนข้อดีข้อเสีย.>
แต่ละส่วนมีลิงก์ไปยังแหล่งข้อมูลเชิงลึกเพิ่มเติม
- หัวข้อการออกแบบระบบ: เริ่มต้นที่นี่
- ขั้นตอนที่ 1: ดูวิดีโอบรรยายเกี่ยวกับความสามารถในการขยายตัว
- ขั้นตอนที่ 2: อ่านบทความเกี่ยวกับความสามารถในการขยายตัว
- ขั้นตอนถัดไป
- ประสิทธิภาพเทียบกับความสามารถในการขยายตัว
- ความหน่วงเทียบกับปริมาณงาน
- ความพร้อมใช้งานเทียบกับความสอดคล้อง
- ทฤษฎี CAP
- CP - ความสอดคล้องและการทนต่อการแบ่งส่วน
- AP - ความพร้อมใช้งานและการทนต่อการแบ่งส่วน
- รูปแบบความสอดคล้อง
- ความสอดคล้องแบบอ่อน
- ความสอดคล้องในที่สุด
- ความสอดคล้องแบบแข็งแกร่ง
- รูปแบบความพร้อมใช้งาน
- การสลับการทำงานเมื่อเกิดข้อผิดพลาด
- การจำลองข้อมูล
- ความพร้อมใช้งานในเชิงตัวเลข
- ระบบชื่อโดเมน
- เครือข่ายจัดส่งเนื้อหา
- Push CDN
- Pull CDN
- ตัวจัดสมดุลโหลด (Load balancer)
- แอคทีฟ-พาสซีฟ (Active-passive)
- แอคทีฟ-แอคทีฟ (Active-active)
- การจัดสมดุลโหลดระดับชั้นที่ 4
- การจัดสมดุลโหลดระดับชั้นที่ 7
- การปรับขยายในแนวนอน (Horizontal scaling)
- พร็อกซีแบบย้อนกลับ (Reverse proxy) (เว็บเซิร์ฟเวอร์)
- ตัวจัดสมดุลโหลด vs พร็อกซีแบบย้อนกลับ
- เลเยอร์แอปพลิเคชัน
- ไมโครเซอร์วิส (Microservices)
- การค้นหาบริการ (Service discovery)
- ฐานข้อมูล
- ระบบจัดการฐานข้อมูลเชิงสัมพันธ์ (RDBMS)
- การจำลองข้อมูลแบบต้นทาง-ปลายทาง (Master-slave replication)
- การจำลองข้อมูลแบบต้นทาง-ต้นทาง (Master-master replication)
- เฟเดอเรชัน (Federation)
- การแบ่งชิ้นส่วนข้อมูล (Sharding)
- การทำข้อมูลให้ไม่ปกติ (Denormalization)
- การปรับจูน SQL (SQL tuning)
- NoSQL
- ที่เก็บคีย์-ค่า (Key-value store)
- ที่เก็บเอกสาร (Document store)
- ที่เก็บคอลัมน์แบบกว้าง (Wide column store)
- ฐานข้อมูลกราฟ (Graph Database)
- SQL หรือ NoSQL
- แคช (Cache)
- การแคชฝั่งไคลเอนต์
- การแคช CDN
- การแคชเว็บเซิร์ฟเวอร์
- การแคชฐานข้อมูล
- การแคชแอปพลิเคชัน
- การแคชในระดับคิวรีฐานข้อมูล
- การแคชในระดับอ็อบเจ็กต์
- เมื่อใดควรอัปเดตแคช
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- การทำงานแบบอะซิงโครนัส (Asynchronism)
- คิวข้อความ (Message queues)
- คิวงาน (Task queues)
- แรงดันย้อนกลับ (Back pressure)
- การสื่อสาร (Communication)
- โปรโตคอลควบคุมการส่งข้อมูล (TCP)
- โปรโตคอลดาตาแกรมของผู้ใช้ (UDP)
- การเรียกใช้ฟังก์ชันระยะไกล (RPC)
- การถ่ายโอนสถานะที่แทนด้วยตัวแทน (REST)
- ความปลอดภัย (Security)
- ภาคผนวก (Appendix)
- ตารางเลขยกกำลังสอง (Powers of two table)
- ตัวเลขความหน่วงที่โปรแกรมเมอร์ทุกคนควรรู้
- คำถามการออกแบบระบบเพิ่มเติมสำหรับสัมภาษณ์
- สถาปัตยกรรมในโลกจริง
- สถาปัตยกรรมบริษัท
- บล็อกวิศวกรรมของบริษัท
- อยู่ระหว่างการพัฒนา
- เครดิต
- ข้อมูลติดต่อ
- ใบอนุญาต
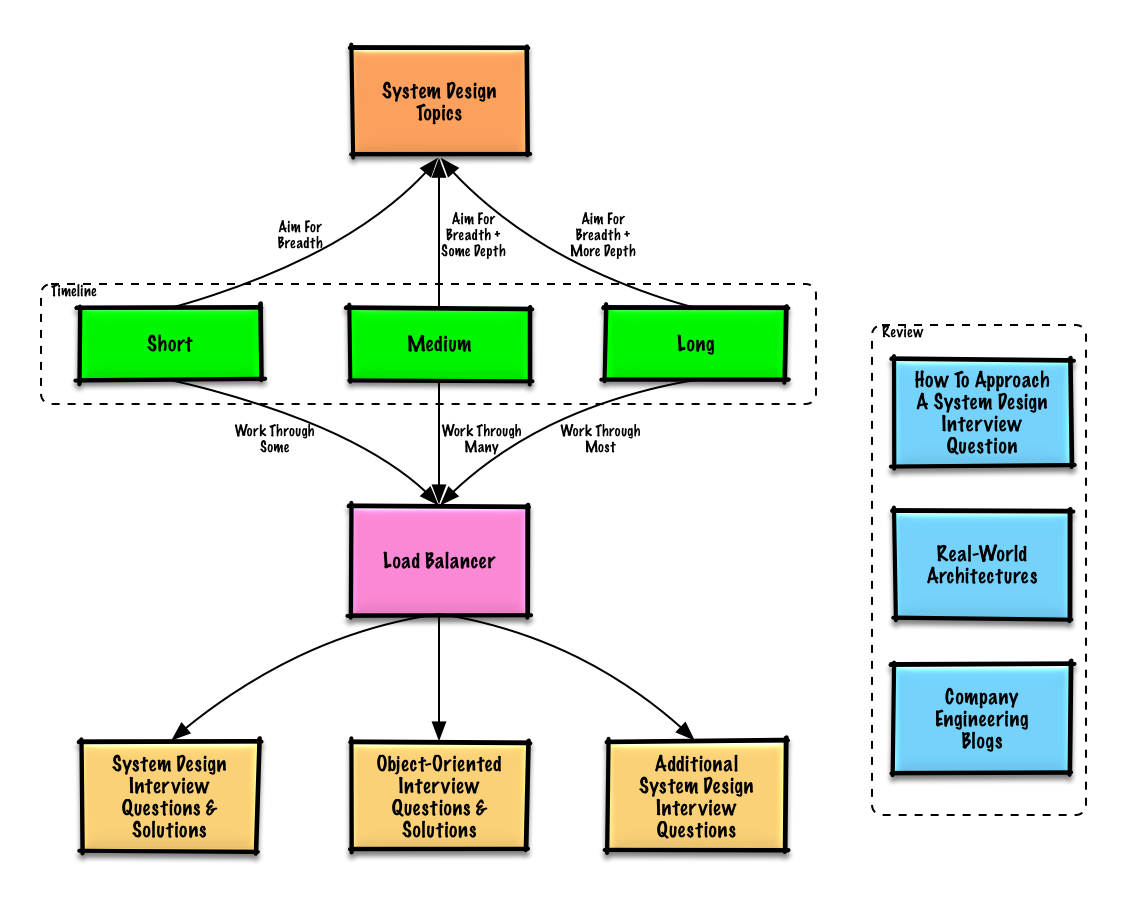
คู่มือการศึกษา
หัวข้อที่แนะนำให้ทบทวนตามระยะเวลาสัมภาษณ์ของคุณ (สั้น, กลาง, ยาว)
ถาม: สำหรับการสัมภาษณ์ ฉันจำเป็นต้องรู้ทุกอย่างที่นี่หรือไม่?
ตอบ: ไม่ คุณไม่จำเป็นต้องรู้ทุกอย่างที่นี่เพื่อเตรียมตัวสำหรับสัมภาษณ์
สิ่งที่คุณจะถูกถามในการสัมภาษณ์ขึ้นอยู่กับตัวแปรต่างๆ เช่น:
- คุณมีประสบการณ์มากแค่ไหน
- คุณมีพื้นฐานทางเทคนิคอย่างไร
- คุณสมัครตำแหน่งอะไร
- คุณสัมภาษณ์กับบริษัทไหน
- โชค
เริ่มต้นจากภาพรวมและค่อยๆ เจาะลึกในบางส่วน การรู้พื้นฐานในหัวข้อการออกแบบระบบที่สำคัญหลายๆ ด้านจะช่วยได้ ปรับแต่งคู่มือด้านล่างนี้ตามระยะเวลาที่คุณมี ประสบการณ์ของคุณ ตำแหน่งงานที่คุณสมัคร และบริษัทที่คุณสมัคร
- ระยะเวลาสั้น - เน้นที่ ความกว้าง ของหัวข้อการออกแบบระบบ ฝึกฝนด้วยการแก้ไข บาง คำถามสัมภาษณ์
- ระยะเวลาปานกลาง - เน้นที่ ความกว้าง และ ลึกบางส่วน ของหัวข้อการออกแบบระบบ ฝึกฝนด้วยการแก้ไข หลาย คำถามสัมภาษณ์
- ระยะเวลานาน - เน้นที่ ความกว้าง และ ความลึกมากขึ้น ของหัวข้อการออกแบบระบบ ฝึกฝนด้วยการแก้ไข ส่วนใหญ่ ของคำถามสัมภาษณ์
วิธีรับมือกับคำถามสัมภาษณ์การออกแบบระบบ
วิธีจัดการกับคำถามสัมภาษณ์การออกแบบระบบ
การสัมภาษณ์ออกแบบระบบเป็น การสนทนาแบบเปิด โดยคุณควรเป็นผู้นำการสนทนา
คุณสามารถใช้ขั้นตอนต่อไปนี้เพื่อช่วยนำการพูดคุย เพื่อช่วยให้เข้าใจขั้นตอนนี้ ฝึกทำส่วน คำถามสัมภาษณ์การออกแบบระบบพร้อมคำตอบ โดยใช้ขั้นตอนดังต่อไปนี้
ขั้นตอนที่ 1: สรุปกรณีใช้งาน ข้อจำกัด และสมมติฐาน
รวบรวมความต้องการและขอบเขตของปัญหา ตั้งคำถามเพื่อชี้แจงกรณีใช้งานและข้อจำกัด พูดคุยเกี่ยวกับสมมติฐาน
- ใครจะเป็นผู้ใช้ระบบ?
- ผู้ใช้จะใช้ระบบอย่างไร?
- มีผู้ใช้จำนวนเท่าไร?
- ระบบทำหน้าที่อะไร?
- ระบบรับและส่งข้อมูลอะไรบ้าง?
- คาดว่าจะต้องจัดการข้อมูลมากแค่ไหน?
- คาดว่าจะมีจำนวนคำขอต่อวินาทีเท่าไร?
- อัตราส่วนการอ่านต่อการเขียนที่คาดหวังคือเท่าไร?
ขั้นตอนที่ 2: สร้างการออกแบบระดับสูง
สรุปภาพรวมการออกแบบระดับสูงโดยระบุองค์ประกอบสำคัญทั้งหมด
- ร่างส่วนประกอบหลักและการเชื่อมต่อ
- อธิบายเหตุผลของแนวคิดของคุณ
ขั้นตอนที่ 3: ออกแบบส่วนประกอบหลัก
ลงรายละเอียดสำหรับแต่ละส่วนประกอบหลัก ตัวอย่างเช่น หากคุณถูกขอให้ ออกแบบบริการย่อ URL ให้พูดถึง:
- การสร้างและจัดเก็บแฮชของ URL เต็ม
- MD5 และ Base62
- การชนกันของแฮช
- SQL หรือ NoSQL
- โครงสร้างฐานข้อมูล
- การแปลง URL ที่ถูกแฮชกลับเป็น URL เต็ม
- การค้นหาในฐานข้อมูล
- การออกแบบ API และเชิงวัตถุ
ขั้นตอนที่ 4: ขยายการออกแบบ
ระบุและแก้ไขจุดคอขวดโดยพิจารณาจากข้อจำกัด ตัวอย่างเช่น คุณต้องการสิ่งเหล่านี้เพื่อแก้ปัญหาความสามารถในการปรับขนาดหรือไม่?
- ตัวกระจายโหลด
- การขยายแนวนอน
- การแคช
- การแบ่งฐานข้อมูล
การคำนวณแบบหยาบๆ
คุณอาจถูกขอให้ประมาณค่าด้วยมือ ดู ภาคผนวก สำหรับแหล่งข้อมูลต่อไปนี้:
แหล่งข้อมูลและการอ่านเพิ่มเติม
ดูที่ลิงก์ต่อไปนี้เพื่อให้เข้าใจมากขึ้นว่าควรคาดหวังอะไรบ้าง:
- วิธีพิชิตการสัมภาษณ์ออกแบบระบบ
- การสัมภาษณ์ออกแบบระบบ
- แนะนำสถาปัตยกรรมและการสัมภาษณ์ออกแบบระบบ
- เทมเพลตออกแบบระบบ
คำถามสัมภาษณ์ออกแบบระบบพร้อมคำตอบ
คำถามสัมภาษณ์ออกแบบระบบที่พบบ่อย พร้อมตัวอย่างการอภิปราย โค้ด และไดอะแกรม>
คำตอบเชื่อมโยงไปยังเนื้อหาในโฟลเดอร์ solutions/| คำถาม | | |---|---| | ออกแบบ Pastebin.com (หรือ Bit.ly) | คำตอบ | | ออกแบบไทม์ไลน์และค้นหา Twitter (หรือฟีดและค้นหา Facebook) | คำตอบ | | ออกแบบเว็บครอว์เลอร์ | คำตอบ | | ออกแบบ Mint.com | คำตอบ | | ออกแบบโครงสร้างข้อมูลสำหรับโซเชียลเน็ตเวิร์ก | คำตอบ | | ออกแบบ key-value store สำหรับ search engine | คำตอบ | | ออกแบบฟีเจอร์จัดอันดับยอดขายตามหมวดหมู่ของ Amazon | คำตอบ | | ออกแบบระบบที่ขยายรองรับผู้ใช้หลักล้านบน AWS | คำตอบ | | เพิ่มคำถามออกแบบระบบ | ร่วมสมทบ |
ออกแบบ Pastebin.com (หรือ Bit.ly)
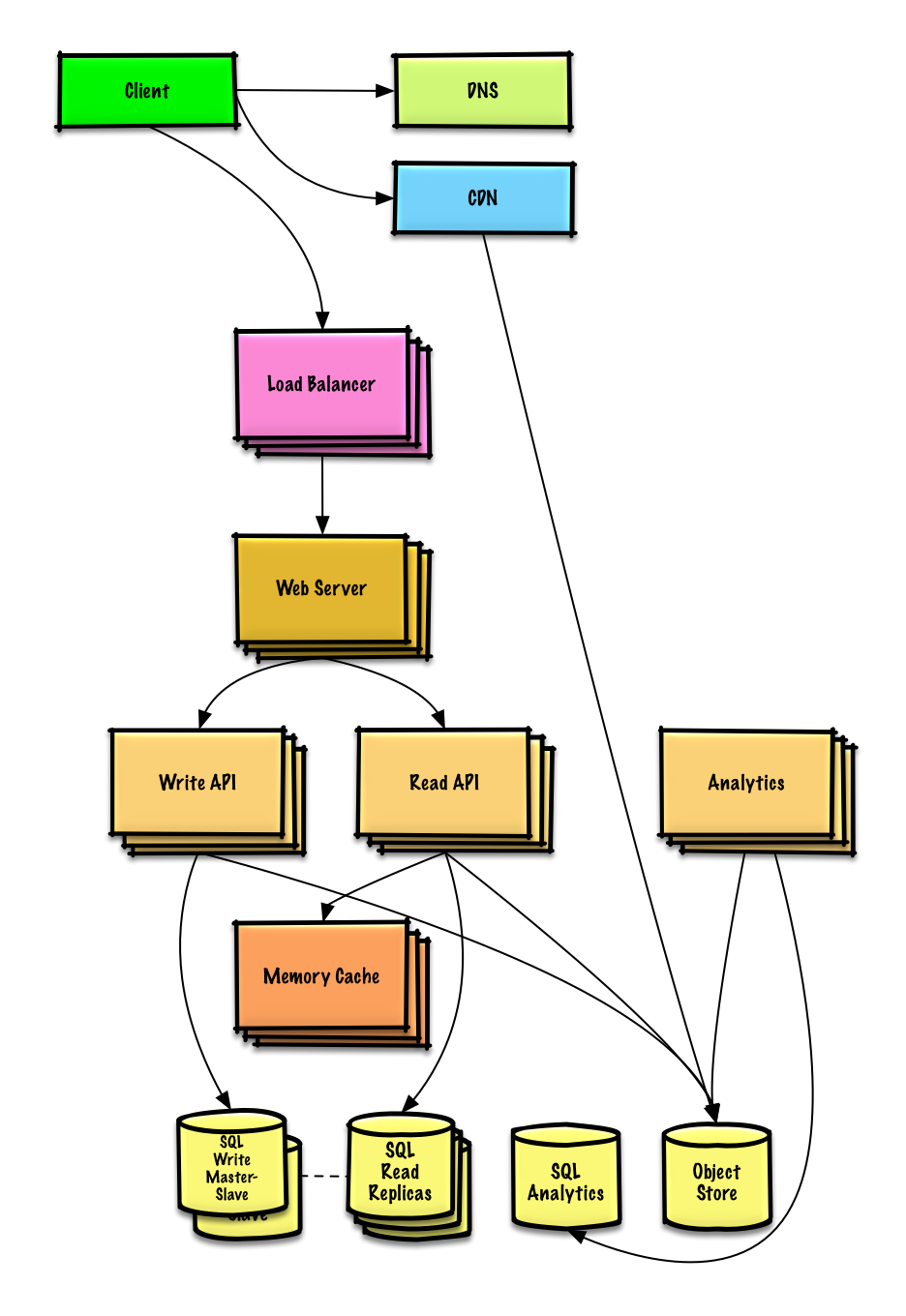
ออกแบบไทม์ไลน์และค้นหา Twitter (หรือฟีดและค้นหา Facebook)
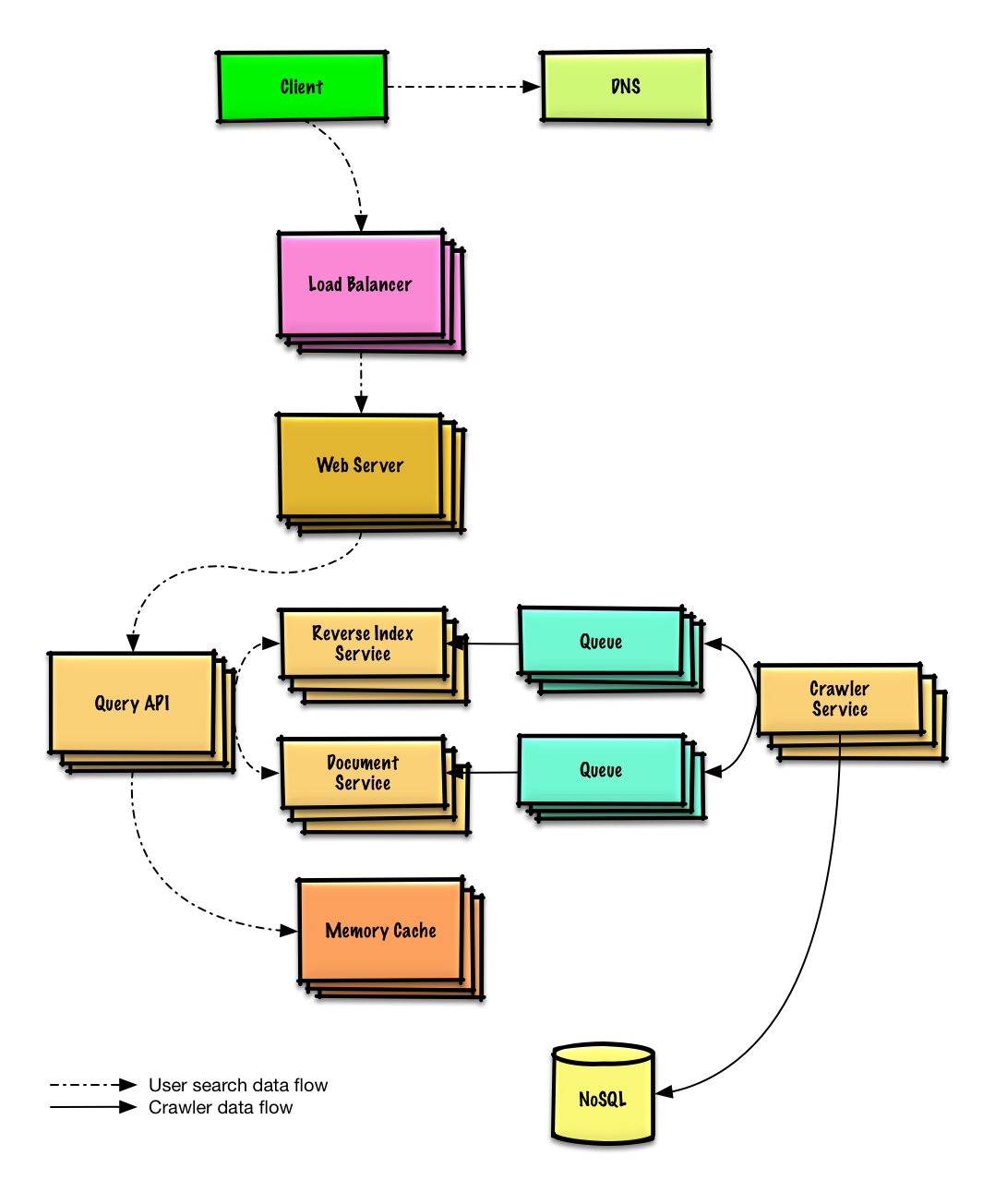
ออกแบบเว็บครอว์เลอร์
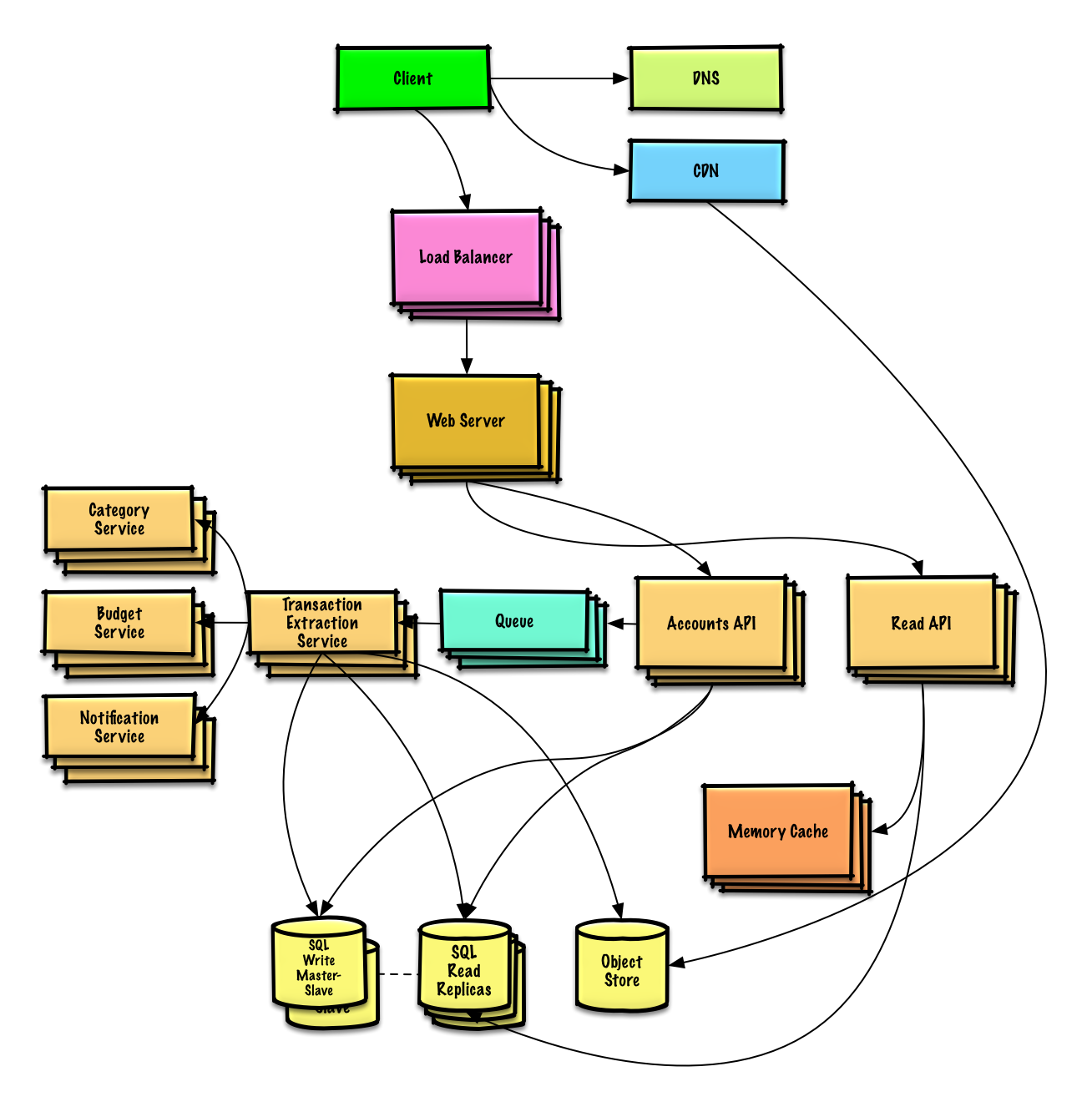
Design Mint.com
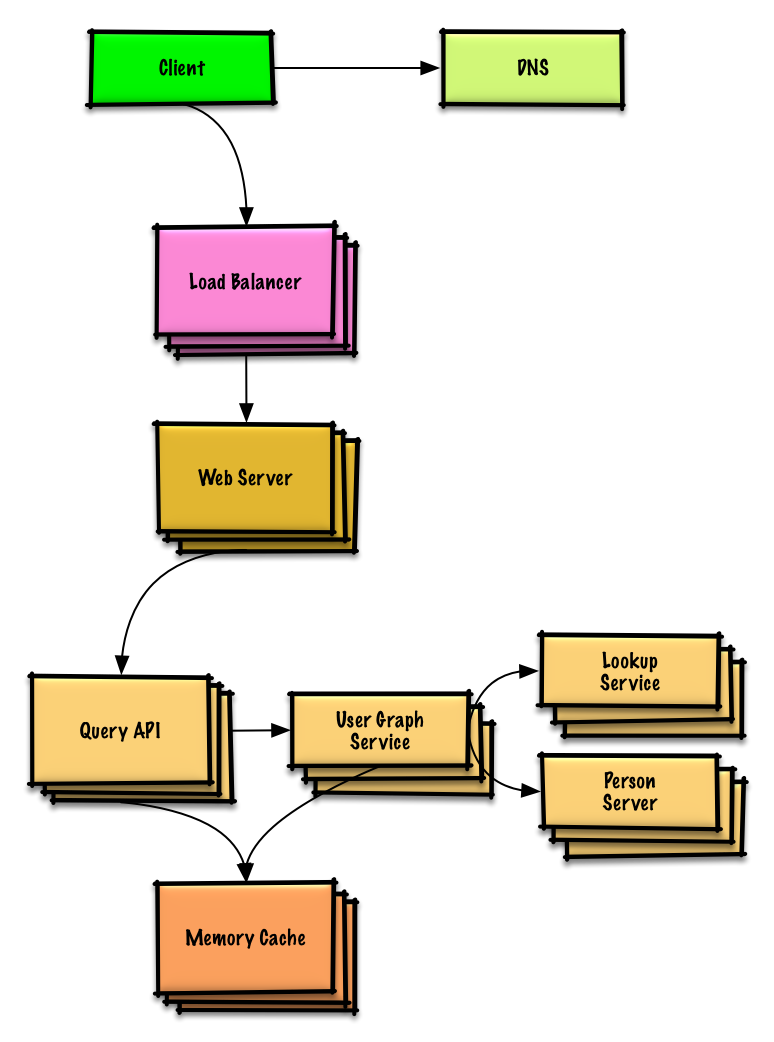
Design the data structures for a social network
Design a key-value store for a search engine
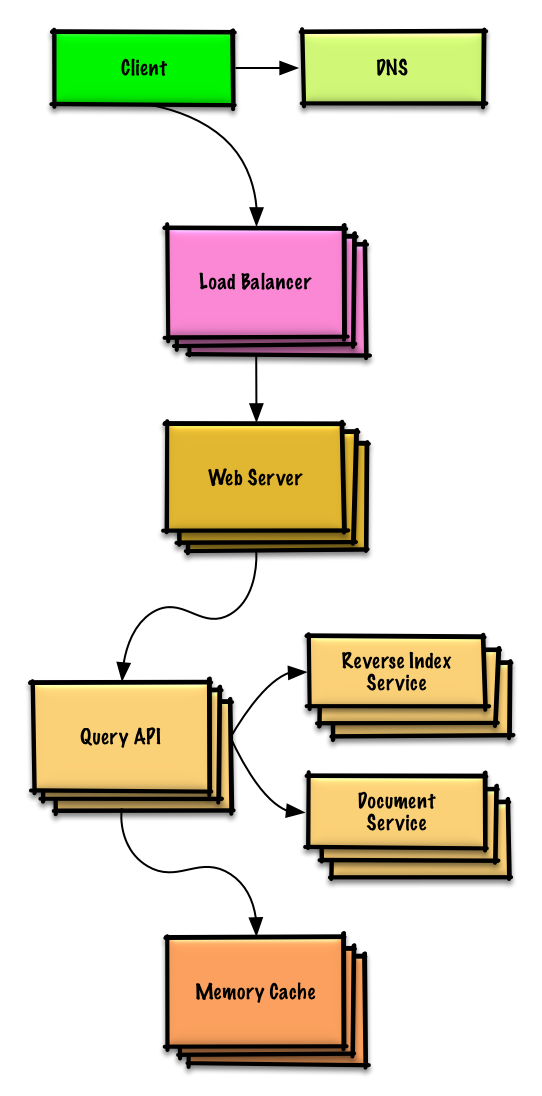
Design Amazon's sales ranking by category feature
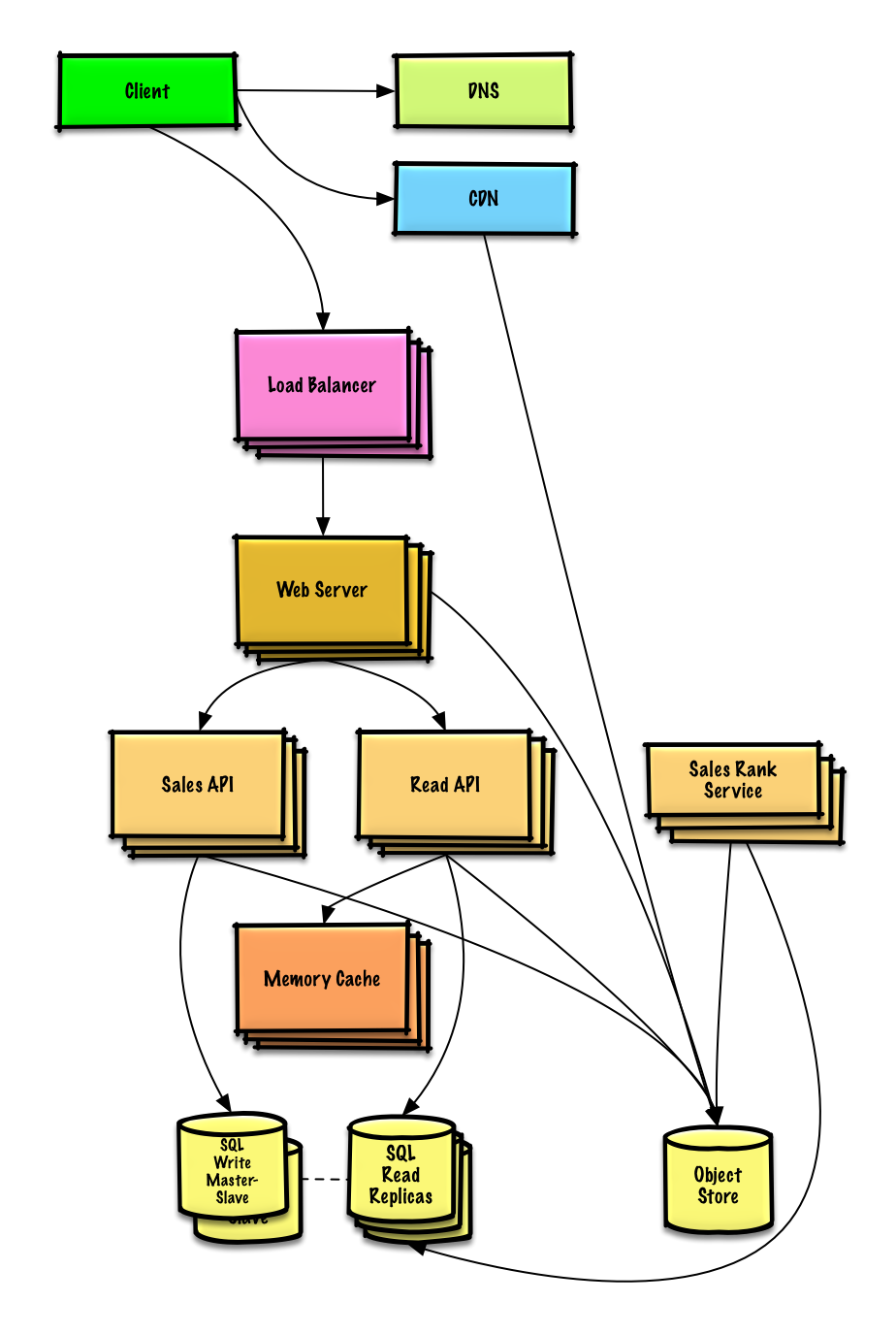
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | ออกแบบแฮชแมป | คำตอบ | | ออกแบบแคชแบบ least recently used | คำตอบ | | ออกแบบศูนย์บริการลูกค้า | คำตอบ | | ออกแบบสำรับไพ่ | คำตอบ | | ออกแบบที่จอดรถ | คำตอบ | | ออกแบบเซิร์ฟเวอร์แชท | คำตอบ | | ออกแบบอาร์เรย์วงกลม | ร่วมสมทบ | | เพิ่มคำถามการออกแบบเชิงวัตถุ | ร่วมสมทบ |
หัวข้อการออกแบบระบบ: เริ่มต้นที่นี่
ใหม่กับการออกแบบระบบ?
ก่อนอื่น คุณต้องเข้าใจหลักการทั่วไปเกี่ยวกับสิ่งเหล่านี้ การใช้งาน และข้อดีข้อเสีย
ขั้นตอนที่ 1: ทบทวนวิดีโอบรรยายเรื่องการขยายระบบ
บรรยาย Scalability ที่ Harvard
- หัวข้อที่ครอบคลุม:
- การขยายแนวตั้ง
- การขยายแนวนอน
- การแคช
- การบาลานซ์โหลด
- การจำลองฐานข้อมูล
- การแบ่งส่วนฐานข้อมูล
ขั้นตอนที่ 2: ทบทวนบทความเกี่ยวกับการขยายระบบ
- หัวข้อที่ครอบคลุม:
- โคลน
- ฐานข้อมูล
- แคช
- การทำงานแบบอะซิงโครนัส
ขั้นตอนถัดไป
ต่อไป เราจะมาดูการชั่งน้ำหนักในระดับสูง:
- ประสิทธิภาพ เทียบกับ ความสามารถในการขยายตัว
- ความหน่วง เทียบกับ อัตราการส่งผ่านข้อมูล
- ความพร้อมใช้งาน เทียบกับ ความสอดคล้อง
จากนั้นเราจะเจาะลึกในหัวข้อเฉพาะ เช่น DNS, CDN และโหลดบาลานเซอร์
ประสิทธิภาพเทียบกับความสามารถในการขยายตัว
บริการจะ ขยายตัวได้ ถ้าผลลัพธ์คือการเพิ่มขึ้นของ ประสิทธิภาพ ในสัดส่วนที่เหมาะสมกับทรัพยากรที่เพิ่มขึ้น โดยทั่วไป การเพิ่มประสิทธิภาพหมายถึงการให้บริการหน่วยงานมากขึ้น แต่ก็อาจรวมถึงการรองรับหน่วยงานที่ใหญ่ขึ้นด้วย เช่น เมื่อชุดข้อมูลเติบโตขึ้น1
อีกวิธีหนึ่งในการมองประสิทธิภาพเทียบกับความสามารถในการขยายตัว:
- หากคุณมีปัญหา ประสิทธิภาพ ระบบของคุณจะช้าสำหรับผู้ใช้เพียงคนเดียว
- หากคุณมีปัญหา การขยายตัว ระบบของคุณจะเร็วสำหรับผู้ใช้คนเดียวแต่ช้าภายใต้ภาระงานหนัก
แหล่งข้อมูลและอ่านเพิ่มเติม
ความหน่วงเทียบกับอัตราการส่งผ่านข้อมูล
ความหน่วง คือเวลาที่ใช้ในการดำเนินการบางอย่างหรือเพื่อสร้างผลลัพธ์บางอย่าง
อัตราการส่งผ่านข้อมูล คือจำนวนของการกระทำหรือผลลัพธ์ดังกล่าวต่อหน่วยเวลา
โดยทั่วไป คุณควรมุ่งเน้นไปที่ อัตราการส่งผ่านข้อมูลสูงสุด พร้อม ความหน่วงที่ยอมรับได้
แหล่งข้อมูลและอ่านเพิ่มเติม
ความพร้อมใช้งานเทียบกับความสอดคล้อง
ทฤษฎี CAP
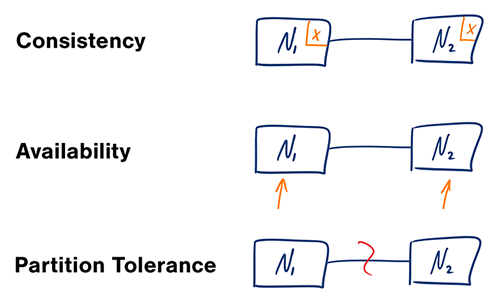
ในระบบคอมพิวเตอร์แบบกระจาย คุณสามารถรองรับได้เพียงสองในสามของการรับประกันดังต่อไปนี้:
- ความสอดคล้อง (Consistency) - ทุกการอ่านจะได้รับการเขียนล่าสุดหรือเกิดข้อผิดพลาด
- ความพร้อมใช้งาน (Availability) - ทุกคำขอจะได้รับการตอบกลับ โดยไม่รับประกันว่าข้อมูลนั้นเป็นเวอร์ชันล่าสุด
- ความทนทานต่อการแบ่งเครือข่าย (Partition Tolerance) - ระบบยังคงทำงานต่อไปได้ แม้เกิดการแบ่งเครือข่ายอันเนื่องมาจากความล้มเหลวของเครือข่าย
#### CP - ความสอดคล้องและความทนทานต่อการแบ่งเครือข่าย
การรอคำตอบจากโหนดที่ถูกแบ่งอาจทำให้เกิดข้อผิดพลาดแบบหมดเวลา CP เป็นตัวเลือกที่ดีหากธุรกิจของคุณต้องการการอ่านและเขียนแบบอะตอมิก
#### AP - ความพร้อมใช้งานและความทนทานต่อการแบ่งเครือข่าย
การตอบกลับจะส่งเวอร์ชันที่พร้อมใช้งานมากที่สุดของข้อมูลในโหนดใดๆ ซึ่งอาจไม่ใช่ข้อมูลล่าสุด การเขียนอาจใช้เวลาบางส่วนในการเผยแพร่เมื่อแบ่งเครือข่ายถูกแก้ไข
AP เป็นตัวเลือกที่ดีหากธุรกิจต้องการ ความสอดคล้องในที่สุด หรือเมื่อระบบจำเป็นต้องทำงานต่อไปแม้เกิดข้อผิดพลาดภายนอก
แหล่งข้อมูลและอ่านเพิ่มเติม
รูปแบบความสอดคล้อง
เมื่อมีการสำเนาข้อมูลเดียวกันหลายชุด เราต้องตัดสินใจว่าจะซิงโครไนซ์ข้อมูลเหล่านั้นอย่างไร เพื่อให้ลูกค้ามีมุมมองข้อมูลที่สอดคล้องกัน จำคำนิยามของความสอดคล้องจาก ทฤษฎี CAP - ทุกการอ่านจะได้รับการเขียนล่าสุดหรือเกิดข้อผิดพลาด
ความสอดคล้องแบบอ่อน (Weak consistency)
หลังจากการเขียน การอ่านอาจเห็นหรือไม่เห็นข้อมูลนั้นก็ได้ โดยใช้วิธีที่ดีที่สุดเท่าที่จะทำได้
แนวทางนี้พบในระบบเช่น memcached ความสอดคล้องแบบอ่อนเหมาะกับกรณีใช้งานเรียลไทม์ เช่น VoIP, วิดีโอแชท, และเกมผู้เล่นหลายคนแบบเรียลไทม์ ตัวอย่างเช่น หากคุณกำลังโทรศัพท์แล้วสัญญาณขาดหายไปสองสามวินาที เมื่อสัญญาณกลับมา คุณจะไม่ได้ยินสิ่งที่พูดในช่วงที่ขาดการเชื่อมต่อ
ความสอดคล้องแบบสุดท้าย (Eventual consistency)
หลังจากการเขียน ข้อมูลที่อ่านจะสามารถเห็นการเปลี่ยนแปลงได้ในที่สุด (โดยปกติภายในไม่กี่มิลลิวินาที) ข้อมูลจะถูกจำลองแบบแบบอะซิงโครนัส
แนวทางนี้พบได้ในระบบเช่น DNS และอีเมล ความสอดคล้องแบบสุดท้ายเหมาะกับระบบที่ต้องการความพร้อมใช้งานสูง
ความสอดคล้องแบบเข้มงวด (Strong consistency)
หลังจากการเขียน ข้อมูลที่อ่านจะสามารถเห็นการเปลี่ยนแปลงทันที ข้อมูลจะถูกจำลองแบบแบบซิงโครนัส
แนวทางนี้พบได้ในระบบไฟล์และ RDBMS ความสอดคล้องแบบเข้มงวดเหมาะกับระบบที่ต้องการธุรกรรม
แหล่งข้อมูลและอ่านเพิ่มเติม
รูปแบบความพร้อมใช้งาน
มีรูปแบบเสริมสองแบบเพื่อรองรับความพร้อมใช้งานสูง: การสลับไปยังตัวสำรอง (fail-over) และ การจำลองแบบ (replication)
การสลับไปยังตัวสำรอง (Fail-over)
#### แอคทีฟ-พาสซีฟ (Active-passive)
ในการสลับแบบแอคทีฟ-พาสซีฟ จะมีการส่งสัญญาณหัวใจระหว่างเซิร์ฟเวอร์ที่ทำงาน (active) และเซิร์ฟเวอร์สำรอง (passive) ที่อยู่ในโหมด standby หากสัญญาณหัวใจขาดหาย เซิร์ฟเวอร์สำรองจะรับที่อยู่ IP ของเซิร์ฟเวอร์ active และเริ่มให้บริการต่อ
ระยะเวลาการหยุดทำงานขึ้นอยู่กับว่าเซิร์ฟเวอร์สำรองอยู่ในโหมด 'hot' standby หรือจะต้องเริ่มต้นจาก 'cold' standby เซิร์ฟเวอร์ active เท่านั้นที่รับส่งข้อมูล
การสลับแบบแอคทีฟ-พาสซีฟนี้ยังเรียกว่า master-slave failover
#### แอคทีฟ-แอคทีฟ (Active-active)
ในการสลับแบบแอคทีฟ-แอคทีฟ เซิร์ฟเวอร์ทั้งสองจะจัดการทราฟฟิกและแบ่งโหลดร่วมกัน
หากเซิร์ฟเวอร์เปิดเผยต่อสาธารณะ DNS จะต้องทราบที่อยู่ IP สาธารณะของทั้งสองเซิร์ฟเวอร์ หากเป็นเซิร์ฟเวอร์ภายในตรรกะของแอปพลิเคชันจะต้องทราบถึงทั้งสองเซิร์ฟเวอร์
การสลับแบบแอคทีฟ-แอคทีฟนี้ยังเรียกว่า master-master failover
ข้อเสีย: การสลับไปยังตัวสำรอง (failover)
- การทำงานแบบ Fail-over ต้องเพิ่มฮาร์ดแวร์และความซับซ้อนเพิ่มเติม
- มีโอกาสสูญเสียข้อมูลหากระบบที่กำลังทำงานล้มเหลวก่อนที่ข้อมูลใหม่จะถูกจำลองไปยังระบบสำรอง
การจำลองข้อมูล
#### แบบ Master-slave และ Master-master
หัวข้อนี้มีการพูดถึงเพิ่มเติมในส่วน ฐานข้อมูล:
ความพร้อมใช้งานในตัวเลข
ความพร้อมใช้งานมักถูกระบุด้วยเวลาที่ระบบทำงาน (หรือเวลาที่ไม่ทำงาน) เป็นเปอร์เซ็นต์ของเวลาที่ให้บริการ โดยทั่วไปจะวัดเป็นจำนวนเลข 9--บริการที่มีความพร้อมใช้งาน 99.99% จะถูกเรียกว่า "สี่ 9"
#### ความพร้อมใช้งาน 99.9% - สาม 9
| ระยะเวลา | เวลาหยุดทำงานที่ยอมรับได้ | |---------------------|--------------------| | หยุดทำงานต่อปี | 8ชั่วโมง 45นาที 57วินาที | | หยุดทำงานต่อเดือน | 43นาที 49.7วินาที | | หยุดทำงานต่อสัปดาห์ | 10นาที 4.8วินาที | | หยุดทำงานต่อวัน | 1นาที 26.4วินาที |
#### ความพร้อมใช้งาน 99.99% - สี่ 9
| ระยะเวลา | เวลาหยุดทำงานที่ยอมรับได้ | |---------------------|--------------------| | หยุดทำงานต่อปี | 52นาที 35.7วินาที | | หยุดทำงานต่อเดือน | 4นาที 23วินาที | | หยุดทำงานต่อสัปดาห์ | 1นาที 5วินาที | | หยุดทำงานต่อวัน | 8.6วินาที |
#### ความพร้อมใช้งานแบบขนาน vs แบบเรียงลำดับ
หากบริการประกอบด้วยหลายองค์ประกอบที่มีโอกาสล้มเหลว ความพร้อมใช้งานโดยรวมของบริการขึ้นอยู่กับว่าองค์ประกอบเหล่านั้นอยู่ในลำดับหรือขนานกัน
###### แบบเรียงลำดับ
ความพร้อมใช้งานโดยรวมจะลดลงเมื่อมีสององค์ประกอบที่มีความพร้อมใช้งานน้อยกว่า 100% ต่อเนื่องกัน:
Availability (Total) = Availability (Foo) * Availability (Bar)หากทั้ง Foo และ Bar มีความพร้อมใช้งานอยู่ที่ 99.9% แต่ละตัว ความพร้อมใช้งานรวมกันในลำดับจะเหลือ 99.8%
###### แบบขนาน
ความพร้อมใช้งานโดยรวมจะเพิ่มขึ้นเมื่อมีสององค์ประกอบที่มีความพร้อมใช้งาน < 100% ทำงานแบบขนานกัน:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo และ Bar มีความพร้อมใช้งาน 99.9% แต่ละตัว ความพร้อมใช้งานรวมกันแบบขนานจะเป็น 99.9999%ระบบชื่อโดเมน
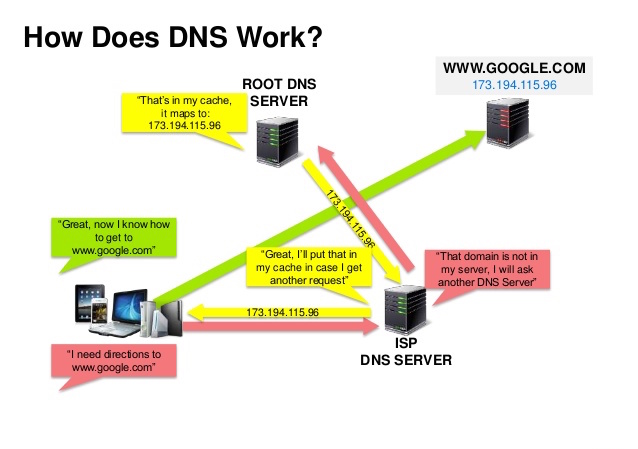
ที่มา: การนำเสนอความปลอดภัยของ DNS
ระบบชื่อโดเมน (DNS) ทำหน้าที่แปลงชื่อโดเมน เช่น www.example.com เป็นที่อยู่ IP
DNS มีลำดับชั้น โดยมีเซิร์ฟเวอร์ที่เชื่อถือได้ไม่กี่ตัวอยู่ระดับบนสุด เราเตอร์หรือ ISP จะให้ข้อมูลเกี่ยวกับเซิร์ฟเวอร์ DNS ที่จะติดต่อเมื่อทำการค้นหา เซิร์ฟเวอร์ DNS ระดับล่างจะเก็บแคชการจับคู่ซึ่งอาจล้าสมัยได้เนื่องจากการเผยแพร่ DNS ที่ล่าช้า ผลลัพธ์ DNS ยังสามารถถูกแคชโดยเบราว์เซอร์หรือระบบปฏิบัติการของคุณในระยะเวลาหนึ่ง โดยกำหนดจาก time to live (TTL)
- NS record (name server) - กำหนดเซิร์ฟเวอร์ DNS สำหรับโดเมน/ซับโดเมนของคุณ
- MX record (mail exchange) - กำหนดเซิร์ฟเวอร์เมลสำหรับรับข้อความ
- A record (address) - ชี้ชื่อไปยังที่อยู่ IP
- CNAME (canonical) - ชี้ชื่อไปยังอีกชื่อหนึ่งหรือ
CNAME(example.com ไป www.example.com) หรือไปยังArecord
- Weighted round robin
- ป้องกันทราฟฟิกไปยังเซิร์ฟเวอร์ที่อยู่ระหว่างการบำรุงรักษา
- สมดุลระหว่างขนาดคลัสเตอร์ที่แตกต่างกัน
- ทดสอบแบบ A/B
- Latency-based
- Geolocation-based
ข้อเสีย: DNS
- การเข้าถึงเซิร์ฟเวอร์ DNS จะมีความล่าช้าเล็กน้อย แม้จะถูกลดผลกระทบด้วยการแคชที่กล่าวถึงข้างต้น
- การบริหารจัดการเซิร์ฟเวอร์ DNS อาจซับซ้อนและโดยทั่วไปจะถูกดูแลโดย รัฐบาล, ISP และบริษัทขนาดใหญ่
- บริการ DNS เมื่อเร็วๆ นี้ถูกโจมตีด้วย DDoS ทำให้ผู้ใช้ไม่สามารถเข้าเว็บไซต์เช่น Twitter ได้หากไม่ทราบที่อยู่ IP ของ Twitter
แหล่งข้อมูลและอ่านเพิ่มเติม
เครือข่ายการส่งมอบเนื้อหา (Content delivery network)
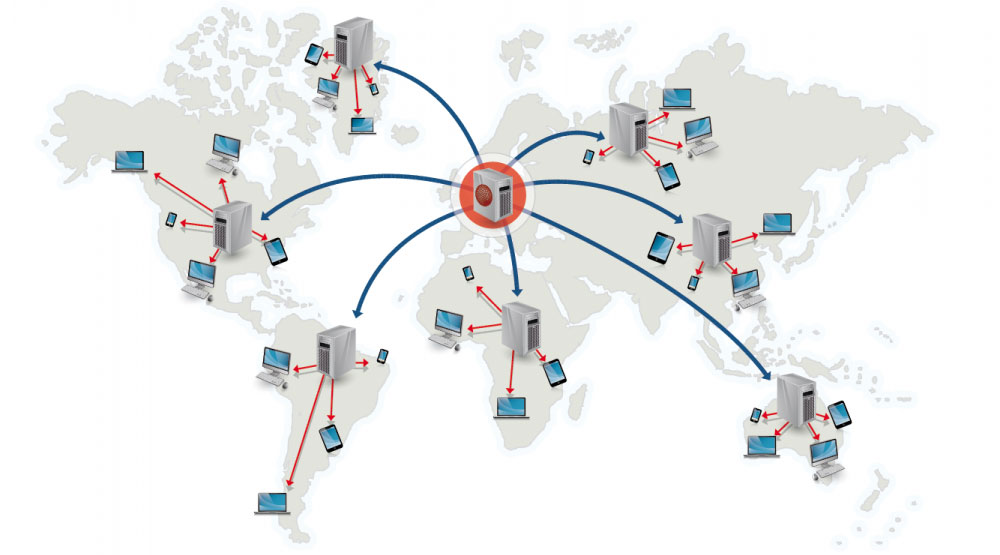
เครือข่ายการส่งมอบเนื้อหา (CDN) คือเครือข่ายพร็อกซีเซิร์ฟเวอร์ที่กระจายอยู่ทั่วโลก มีหน้าที่ให้บริการเนื้อหาจากตำแหน่งที่ใกล้กับผู้ใช้มากที่สุด โดยทั่วไปไฟล์แบบสถาติก เช่น HTML/CSS/JS, รูปภาพ และวิดีโอ จะถูกให้บริการผ่าน CDN แม้ว่า CDN บางตัว เช่น CloudFront ของ Amazon จะรองรับเนื้อหาแบบไดนามิกด้วย การแก้ไข DNS ของเว็บไซต์จะบอกลูกค้าว่าควรติดต่อเซิร์ฟเวอร์ใด
การให้บริการเนื้อหาจาก CDN สามารถปรับปรุงประสิทธิภาพได้อย่างมากในสองลักษณะ:
- ผู้ใช้จะได้รับเนื้อหาจากศูนย์ข้อมูลที่อยู่ใกล้กับตนเอง
- เซิร์ฟเวอร์ของคุณไม่จำเป็นต้องตอบสนองคำขอที่ CDN ได้รับแทนแล้ว
Push CDN
Push CDN จะได้รับเนื้อหาใหม่เมื่อมีการเปลี่ยนแปลงบนเซิร์ฟเวอร์ของคุณ คุณจะรับผิดชอบในการจัดเตรียมเนื้อหา อัปโหลดโดยตรงไปยัง CDN และแก้ไข URL เพื่อชี้ไปยัง CDN คุณสามารถกำหนดเวลาหมดอายุและการอัปเดตเนื้อหาได้ เนื้อหาจะถูกอัปโหลดก็ต่อเมื่อมีการเปลี่ยนแปลงหรือเป็นเนื้อหาใหม่เท่านั้น ซึ่งช่วยลดปริมาณการรับส่งข้อมูลแต่เพิ่มพื้นที่จัดเก็บ
เว็บไซต์ที่มีปริมาณการใช้งานน้อยหรือเนื้อหาที่ไม่ค่อยมีการอัปเดตเหมาะกับ Push CDN เนื้อหาจะถูกนำขึ้น CDN เพียงครั้งเดียวแทนที่จะดึงใหม่ตามช่วงเวลา
Pull CDN
Pull CDN จะดึงเนื้อหาใหม่จากเซิร์ฟเวอร์ของคุณเมื่อผู้ใช้คนแรกขอเนื้อหานั้น คุณจะปล่อยให้เนื้อหาอยู่บนเซิร์ฟเวอร์และแก้ไข URL เพื่อชี้ไปที่ CDN ส่งผลให้การร้องขอครั้งแรกช้ากว่าจนกว่าเนื้อหาจะถูกแคชบน CDN
ค่า time-to-live (TTL) จะกำหนดระยะเวลาการแคชเนื้อหา Pull CDN ช่วยลดพื้นที่จัดเก็บบน CDN แต่สามารถเกิดการรับส่งข้อมูลซ้ำซ้อนหากไฟล์หมดอายุก่อนที่เนื้อหาจะมีการเปลี่ยนแปลงจริง
เว็บไซต์ที่มีปริมาณการใช้งานสูงเหมาะกับ Pull CDN เพราะปริมาณการรับส่งข้อมูลจะแบ่งกระจายอย่างเหมาะสม โดยเนื้อหาที่มีการร้องขอล่าสุดเท่านั้นจะอยู่บน CDN
ข้อเสีย: CDN
- ค่าใช้จ่ายของ CDN อาจสูงมากขึ้นอยู่กับปริมาณการใช้งาน แม้ว่าควรเปรียบเทียบกับค่าใช้จ่ายเพิ่มเติมหากไม่ใช้ CDN
- เนื้อหาอาจล้าสมัยหากมีการอัปเดตก่อนที่ TTL จะหมดอายุ
- การใช้ CDN จำเป็นต้องเปลี่ยน URL ของเนื้อหาสถาติกให้ชี้ไปยัง CDN
แหล่งข้อมูลและการอ่านเพิ่มเติม
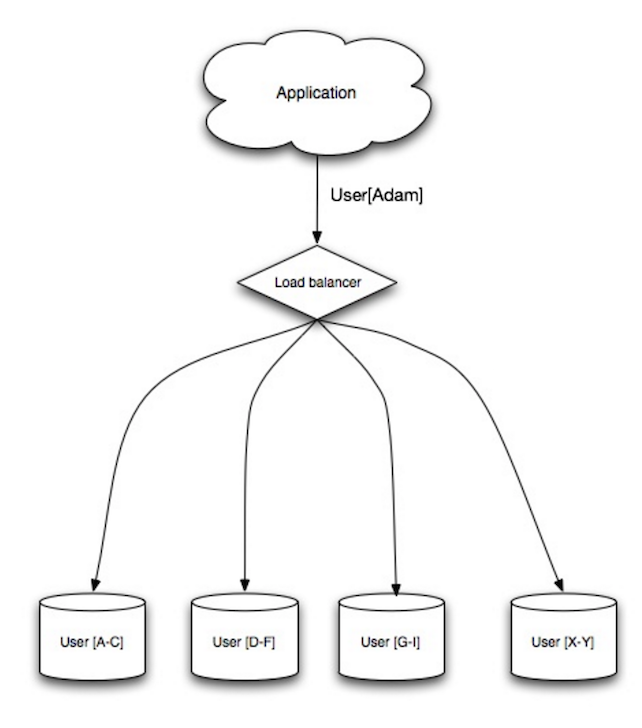
ตัวกระจายโหลด (Load balancer)
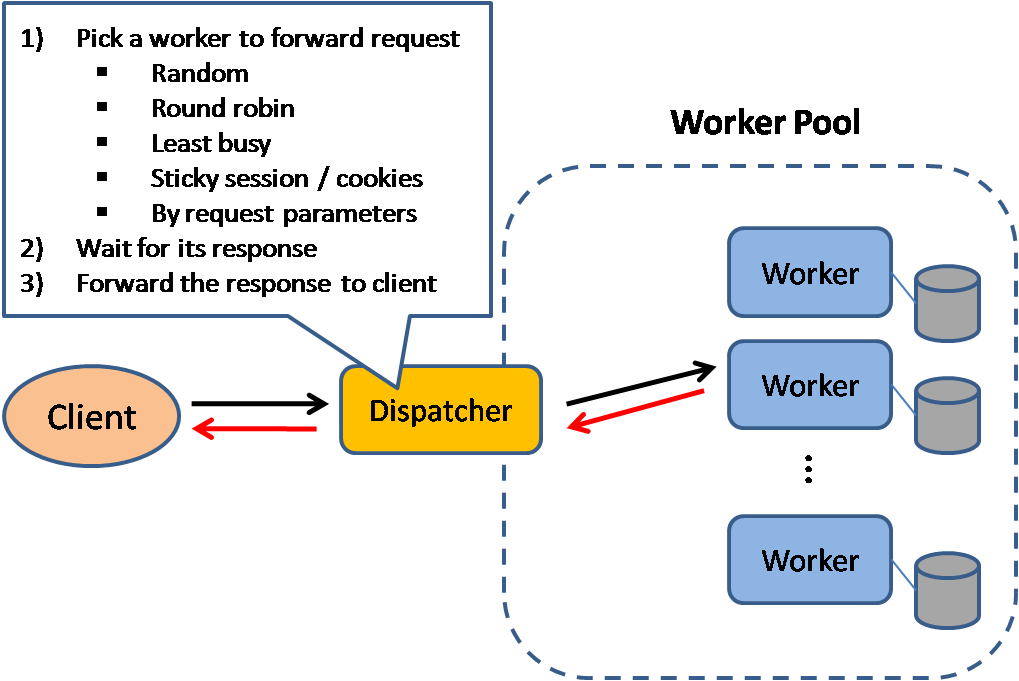
ที่มา: รูปแบบการออกแบบระบบที่ปรับขยายได้
ตัวกระจายโหลดจะกระจายคำขอจากลูกค้าที่เข้ามายังทรัพยากรคอมพิวเตอร์ เช่น เซิร์ฟเวอร์แอปพลิเคชันและฐานข้อมูล ในแต่ละกรณี ตัวกระจายโหลดจะส่งคืนการตอบกลับจากทรัพยากรคอมพิวเตอร์ไปยังลูกค้าที่เหมาะสม ตัวกระจายโหลดมีประสิทธิภาพในการ:
- ป้องกันไม่ให้คำขอถูกส่งไปยังเซิร์ฟเวอร์ที่ไม่พร้อมใช้งาน
- ป้องกันการใช้งานทรัพยากรเกินขีดจำกัด
- ช่วยขจัดจุดล้มเหลวเดียว
ประโยชน์เพิ่มเติม ได้แก่:
- SSL termination - ถอดรหัสคำขอที่เข้ามาและเข้ารหัสการตอบกลับของเซิร์ฟเวอร์เพื่อให้เซิร์ฟเวอร์เบื้องหลังไม่ต้องดำเนินการที่มีต้นทุนสูงเหล่านี้
- ไม่จำเป็นต้องติดตั้ง ใบรับรอง X.509 บนแต่ละเซิร์ฟเวอร์
- Session persistence - ออกคุกกี้และกำหนดเส้นทางคำขอของลูกค้ารายเดิมไปยังอินสแตนซ์เดียวกัน หากเว็บแอปไม่ได้ติดตามเซสชัน
ตัวกระจายโหลดสามารถกำหนดเส้นทางการรับส่งข้อมูลตามตัวชี้วัดต่างๆ ได้แก่:
- สุ่ม
- โหลดน้อยที่สุด
- เซสชัน/คุกกี้
- รอบโรบินหรือรอบโรบินแบบถ่วงน้ำหนัก
- Layer 4
- Layer 7
การกระจายโหลดชั้นที่ 4
ตัวกระจายโหลดชั้นที่ 4 จะพิจารณาข้อมูลใน เลเยอร์ขนส่ง เพื่อใช้ตัดสินใจว่าจะกระจายคำขออย่างไร โดยทั่วไปจะเกี่ยวข้องกับที่อยู่ IP ต้นทางและปลายทาง และพอร์ตในส่วนหัว แต่จะไม่ดูเนื้อหาของแพ็กเก็ต ตัวกระจายโหลดชั้นที่ 4 จะส่งต่อแพ็กเก็ตเครือข่ายไปและกลับจากเซิร์ฟเวอร์ต้นทาง โดยดำเนินการ Network Address Translation (NAT)
การกระจายโหลดชั้นที่ 7
ตัวบาลานซ์โหลดเลเยอร์ 7 จะดูที่ ชั้นแอปพลิเคชัน เพื่อช่วยตัดสินใจว่าจะกระจายคำขออย่างไร ซึ่งอาจเกี่ยวข้องกับเนื้อหาของส่วนหัว ข้อความ และคุกกี้ ตัวบาลานซ์โหลดเลเยอร์ 7 จะยุติทราฟฟิกเครือข่าย อ่านข้อความ ตัดสินใจในการบาลานซ์โหลด แล้วเปิดการเชื่อมต่อกับเซิร์ฟเวอร์ที่เลือก ตัวอย่างเช่น ตัวบาลานซ์โหลดเลเยอร์ 7 สามารถนำทราฟฟิกวิดีโอไปยังเซิร์ฟเวอร์ที่โฮสต์วิดีโอ ในขณะที่นำทราฟฟิกที่เกี่ยวกับการเรียกเก็บเงินของผู้ใช้ที่มีความละเอียดอ่อนไปยังเซิร์ฟเวอร์ที่มีการเสริมความปลอดภัยด้วยต้นทุนด้านความยืดหยุ่น การบาลานซ์โหลดเลเยอร์ 4 ต้องการเวลาน้อยกว่าและทรัพยากรคอมพิวเตอร์น้อยกว่าเลเยอร์ 7 แม้ว่าผลกระทบต่อประสิทธิภาพจะน้อยมากในฮาร์ดแวร์ทั่วไปยุคใหม่
การขยายแนวนอน
ตัวบาลานซ์โหลดยังช่วยในการขยายแนวนอน เพื่อปรับปรุงประสิทธิภาพและความพร้อมใช้งาน การขยายออกโดยใช้เครื่องราคาถูกจะมีประสิทธิภาพด้านต้นทุนมากกว่าและให้ความพร้อมใช้งานที่สูงกว่าการขยายเซิร์ฟเวอร์เดียวด้วยฮาร์ดแวร์ราคาแพง ซึ่งเรียกว่า การขยายแนวตั้ง นอกจากนี้ยังง่ายกว่าที่จะหาบุคลากรที่มีความสามารถทำงานกับฮาร์ดแวร์ทั่วไปมากกว่าระบบองค์กรเฉพาะทาง
#### ข้อเสีย: การขยายแนวนอน
- การขยายแนวนอนเพิ่มความซับซ้อนและเกี่ยวข้องกับการโคลนเซิร์ฟเวอร์
- เซิร์ฟเวอร์ควรเป็นแบบไร้สถานะ: ไม่ควรมีข้อมูลที่เกี่ยวข้องกับผู้ใช้ เช่น เซสชันหรือรูปโปรไฟล์
- เซสชันสามารถจัดเก็บไว้ในคลังข้อมูลแบบรวมศูนย์ เช่น ฐานข้อมูล (SQL, NoSQL) หรือ แคช แบบถาวร (Redis, Memcached)
- เซิร์ฟเวอร์ปลายทาง เช่น แคชและฐานข้อมูล ต้องรองรับการเชื่อมต่อพร้อมกันมากขึ้นเมื่อเซิร์ฟเวอร์ต้นทางขยายตัว
ข้อเสีย: ตัวบาลานซ์โหลด
- ตัวบาลานซ์โหลดอาจกลายเป็นคอขวดด้านประสิทธิภาพหากไม่มีทรัพยากรเพียงพอหรือไม่ได้รับการกำหนดค่าอย่างถูกต้อง
- การนำตัวบาลานซ์โหลดมาใช้เพื่อขจัดจุดล้มเหลวเพียงจุดเดียวจะเพิ่มความซับซ้อน
- ตัวบาลานซ์โหลดเดียวเป็นจุดล้มเหลวเพียงจุดเดียว การกำหนดค่าตัวบาลานซ์โหลดหลายตัวจะเพิ่มความซับซ้อนอีก
แหล่งข้อมูลและอ่านเพิ่มเติม
- โครงสร้างสถาปัตยกรรม NGINX
- คู่มือโครงสร้างสถาปัตยกรรม HAProxy
- ความสามารถในการขยายตัว
- วิกิพีเดีย)
- การบาลานซ์โหลดเลเยอร์ 4
- การบาลานซ์โหลดเลเยอร์ 7
- การตั้งค่า ELB listener
รีเวิร์สพร็อกซี (เว็บเซิร์ฟเวอร์)
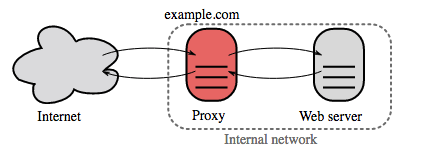
รีเวิร์สพร็อกซี่คือเว็บเซิร์ฟเวอร์ที่รวมบริการภายในและให้บริการอินเตอร์เฟซแบบรวมถึงสาธารณะ คำขอจากไคลเอนต์จะถูกส่งต่อไปยังเซิร์ฟเวอร์ที่สามารถตอบสนองได้ก่อนที่รีเวิร์สพร็อกซี่จะส่งคืนการตอบสนองของเซิร์ฟเวอร์ไปยังไคลเอนต์
ประโยชน์เพิ่มเติมประกอบด้วย:
- เพิ่มความปลอดภัย - ซ่อนข้อมูลเกี่ยวกับแบ็กเอนด์เซิร์ฟเวอร์, แบล็กลิสต์ IP, จำกัดจำนวนการเชื่อมต่อต่อไคลเอนต์
- เพิ่มความสามารถในการขยายและความยืดหยุ่น - ไคลเอนต์จะเห็นแค่ IP ของรีเวิร์สพร็อกซี่ ทำให้สามารถขยายเซิร์ฟเวอร์หรือเปลี่ยนการตั้งค่าได้
- SSL termination - ถอดรหัสคำขอขาเข้าและเข้ารหัสการตอบสนองเซิร์ฟเวอร์เพื่อให้แบ็กเอนด์เซิร์ฟเวอร์ไม่ต้องดำเนินการเหล่านี้ซึ่งอาจมีค่าใช้จ่ายสูง
- ไม่จำเป็นต้องติดตั้ง ใบรับรอง X.509 บนแต่ละเซิร์ฟเวอร์
- การบีบอัด - บีบอัดการตอบสนองของเซิร์ฟเวอร์
- การแคช - ส่งคืนการตอบสนองสำหรับคำขอที่ถูกแคชไว้
- เนื้อหาสถิต - ให้บริการเนื้อหาสถิตโดยตรง
- HTML/CSS/JS
- รูปภาพ
- วิดีโอ
- ฯลฯ
ตัวโหลดบาลานเซอร์ vs รีเวิร์สพร็อกซี่
- การติดตั้งโหลดบาลานเซอร์จะมีประโยชน์เมื่อคุณมีหลายเซิร์ฟเวอร์ โดยปกติโหลดบาลานเซอร์จะส่งทราฟฟิกไปยังชุดเซิร์ฟเวอร์ที่ให้บริการฟังก์ชันเดียวกัน
- รีเวิร์สพร็อกซี่มีประโยชน์แม้จะมีเว็บเซิร์ฟเวอร์หรือแอปพลิเคชันเซิร์ฟเวอร์เพียงตัวเดียว โดยเปิดใช้ประโยชน์ตามที่กล่าวไว้ในส่วนก่อนหน้า
- โซลูชันเช่น NGINX และ HAProxy รองรับทั้งการรีเวิร์สพร็อกซี่เลเยอร์ 7 และโหลดบาลานซิ่ง
ข้อเสีย: รีเวิร์สพร็อกซี่
- การเพิ่มรีเวิร์สพร็อกซี่ทำให้เกิดความซับซ้อนเพิ่มขึ้น
- การมีรีเวิร์สพร็อกซี่เพียงตัวเดียวเป็นจุดล้มเหลวเดียว การตั้งค่าหลายรีเวิร์สพร็อกซี่ (เช่น failover) จะเพิ่มความซับซ้อนเข้าไปอีก
แหล่งข้อมูลและอ่านเพิ่มเติม
เลเยอร์แอปพลิเคชัน
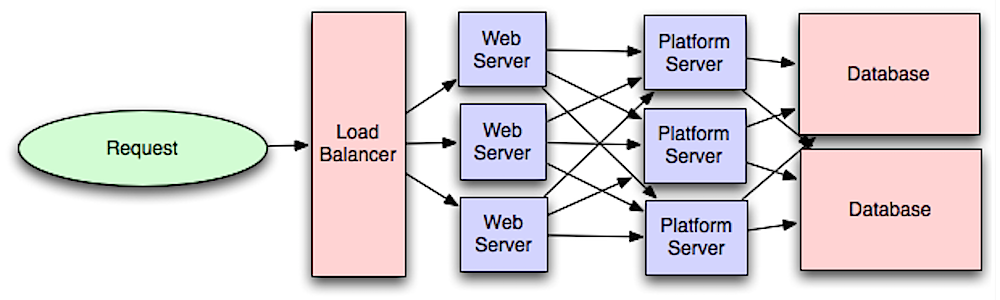
ที่มา: แนะนำการออกแบบสถาปัตยกรรมระบบสำหรับการขยายขนาด
การแยกชั้นเว็บออกจากชั้นแอปพลิเคชัน (หรือที่เรียกว่าชั้นแพลตฟอร์ม) ทำให้สามารถขยายและปรับแต่งแต่ละชั้นได้อย่างอิสระ การเพิ่ม API ใหม่จะนำไปสู่การเพิ่มเซิร์ฟเวอร์แอปพลิเคชันโดยไม่จำเป็นต้องเพิ่มเซิร์ฟเวอร์เว็บเพิ่มเติม หลักการความรับผิดชอบเดียวสนับสนุนบริการขนาดเล็กและอิสระที่ทำงานร่วมกัน ทีมขนาดเล็กที่มีบริการขนาดเล็กสามารถวางแผนการเติบโตอย่างรวดเร็วได้อย่างจริงจัง
Worker ในชั้นแอปพลิเคชันยังช่วยเปิดใช้งาน การทำงานแบบอะซิงโครนัส ได้อีกด้วย
ไมโครเซอร์วิส
ที่เกี่ยวข้องกับการอภิปรายนี้คือ ไมโครเซอร์วิส ซึ่งสามารถอธิบายได้ว่าเป็นชุดของบริการขนาดเล็กแบบแยกติดตั้งได้แต่ละบริการทำงานเป็นกระบวนการเฉพาะและสื่อสารกันผ่านกลไกที่นิยามไว้อย่างชัดเจนและเบาเพื่อบรรลุเป้าหมายทางธุรกิจ 1
ตัวอย่างเช่น Pinterest อาจมีไมโครเซอร์วิสดังนี้: โปรไฟล์ผู้ใช้, ผู้ติดตาม, ฟีด, การค้นหา, อัปโหลดรูปภาพ ฯลฯ
การค้นหาบริการ
ระบบอย่าง Consul, Etcd, และ Zookeeper สามารถช่วยให้บริการค้นหาซึ่งกันและกันโดยติดตามชื่อ, ที่อยู่, และพอร์ตที่ลงทะเบียน Health checks ใช้ตรวจสอบความสมบูรณ์ของบริการและมักดำเนินการโดยใช้ HTTP endpoint ทั้ง Consul และ Etcd มี key-value store ในตัวซึ่งมีประโยชน์สำหรับจัดเก็บค่าคอนฟิกและข้อมูลที่ใช้ร่วมกันอื่น ๆ
ข้อเสีย: ชั้นแอปพลิเคชัน
- การเพิ่มชั้นแอปพลิเคชันที่มีบริการเชื่อมโยงกันอย่างหลวมต้องการแนวทางที่แตกต่างในแง่สถาปัตยกรรม, การปฏิบัติการ, และกระบวนการ (เมื่อเทียบกับระบบแบบโมโนลิทิก)
- ไมโครเซอร์วิสอาจเพิ่มความซับซ้อนในด้านการติดตั้งและการปฏิบัติการ
แหล่งข้อมูลและอ่านเพิ่มเติม
- แนะนำการออกแบบสถาปัตยกรรมระบบสำหรับการขยายขนาด
- เตรียมตัวสัมภาษณ์ออกแบบระบบ
- สถาปัตยกรรมแบบบริการเป็นศูนย์กลาง
- แนะนำ Zookeeper
- สิ่งที่ควรรู้เกี่ยวกับการสร้างไมโครเซอร์วิส
ฐานข้อมูล
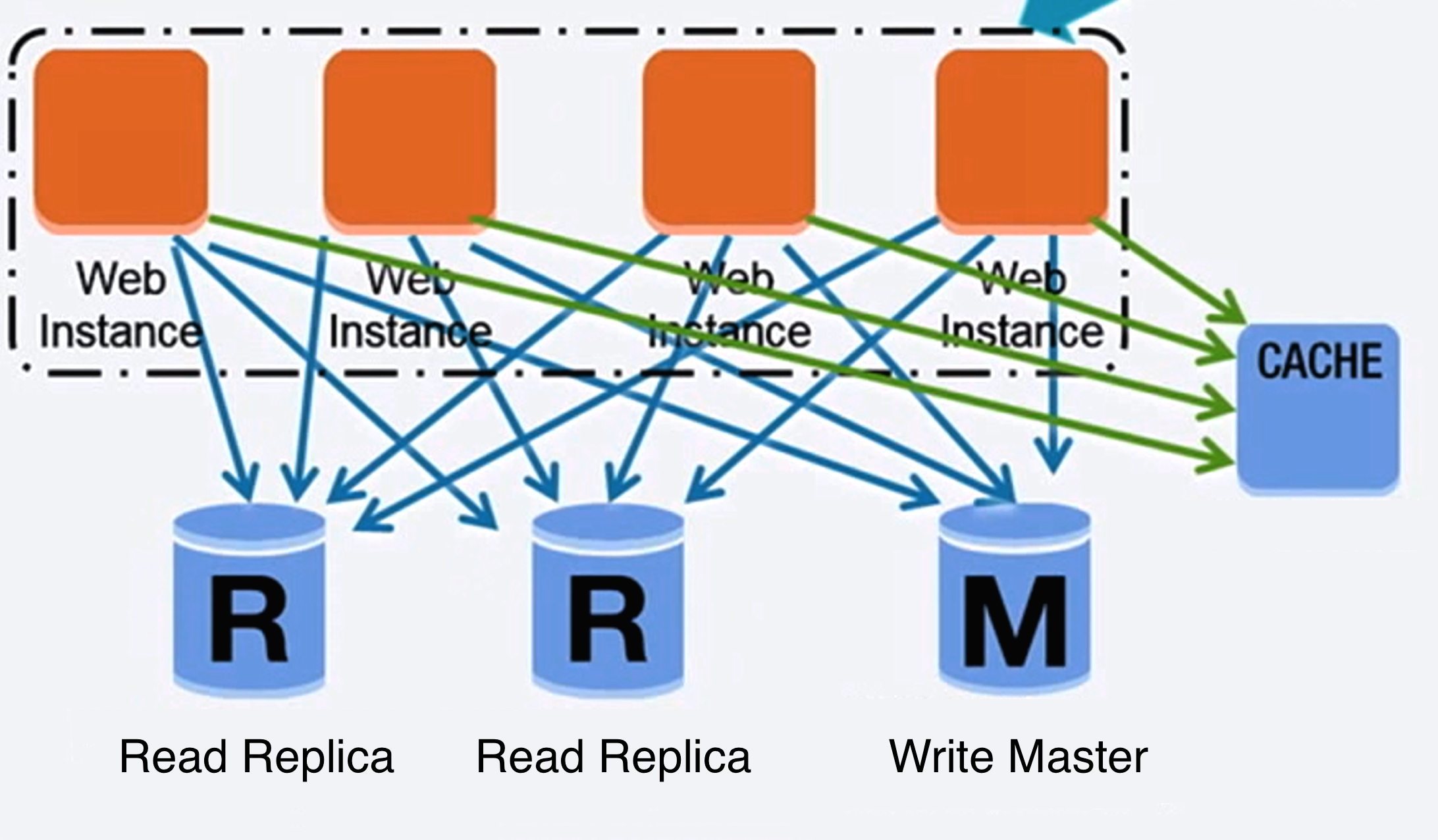
ที่มา: การขยายระบบรองรับผู้ใช้ 10 ล้านคนแรก
ระบบจัดการฐานข้อมูลเชิงสัมพันธ์ (RDBMS)
ฐานข้อมูลเชิงสัมพันธ์เช่น SQL คือการรวบรวมรายการข้อมูลที่ถูกจัดระเบียบในรูปแบบตาราง
ACID คือชุดคุณสมบัติของ ธุรกรรม ฐานข้อมูลเชิงสัมพันธ์
- Atomicity - แต่ละธุรกรรมต้องสำเร็จทั้งหมดหรือไม่สำเร็จเลย
- Consistency - ทุกธุรกรรมจะเปลี่ยนฐานข้อมูลจากสถานะที่ถูกต้องหนึ่งไปยังอีกสถานะที่ถูกต้อง
- Isolation - การดำเนินการธุรกรรมพร้อมกันจะให้ผลลัพธ์เหมือนกับการดำเนินการแบบเรียงลำดับทีละธุรกรรม
- Durability - เมื่อธุรกรรมถูกยืนยันแล้ว จะคงอยู่ถาวร
#### การจำลองแบบมาสเตอร์-สเลฟ
มาสเตอร์ให้บริการการอ่านและเขียน โดยจำลองข้อมูลที่เขียนไปยังหนึ่งหรือหลายสเลฟ ซึ่งให้บริการอ่านเท่านั้น สเลฟยังสามารถจำลองข้อมูลไปยังสเลฟเพิ่มเติมในลักษณะเป็นต้นไม้ หากมาสเตอร์ออฟไลน์ ระบบยังคงให้บริการในโหมดอ่านอย่างเดียวจนกว่าสเลฟจะถูกยกระดับเป็นมาสเตอร์หรือมีการจัดเตรียมมาสเตอร์ใหม่
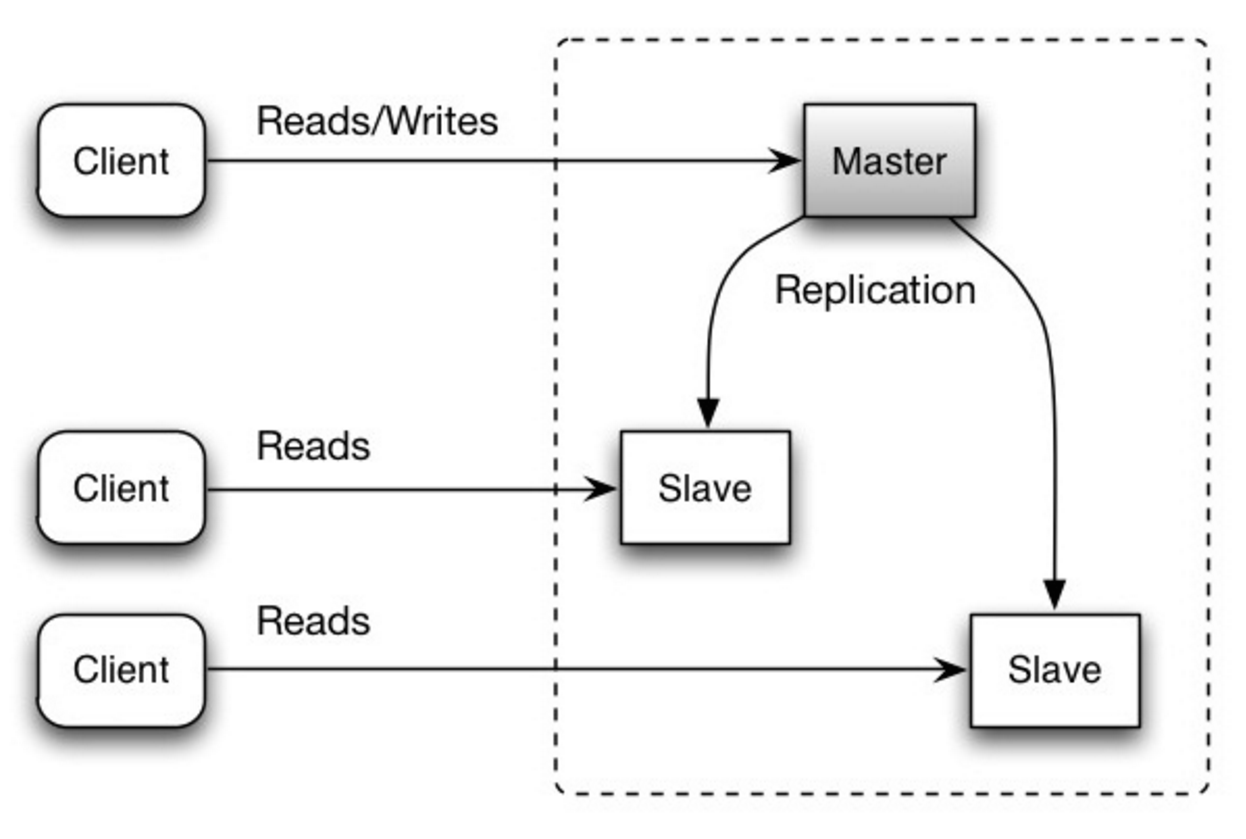
ที่มา: Scalability, availability, stability, patterns
##### ข้อเสีย: การจำลองแบบมาสเตอร์-สเลฟ
- ต้องมีตรรกะเพิ่มเติมเพื่อยกระดับสเลฟเป็นมาสเตอร์
- ดู ข้อเสีย: การจำลองแบบ สำหรับประเด็นที่เกี่ยวข้องกับทั้งมาสเตอร์-สเลฟและมาสเตอร์-มาสเตอร์
ทั้งสองมาสเตอร์ให้บริการการอ่านและเขียน และประสานงานกันในการเขียน หากมาสเตอร์ใดมาสเตอร์หนึ่งล่ม ระบบยังคงให้บริการทั้งอ่านและเขียนได้
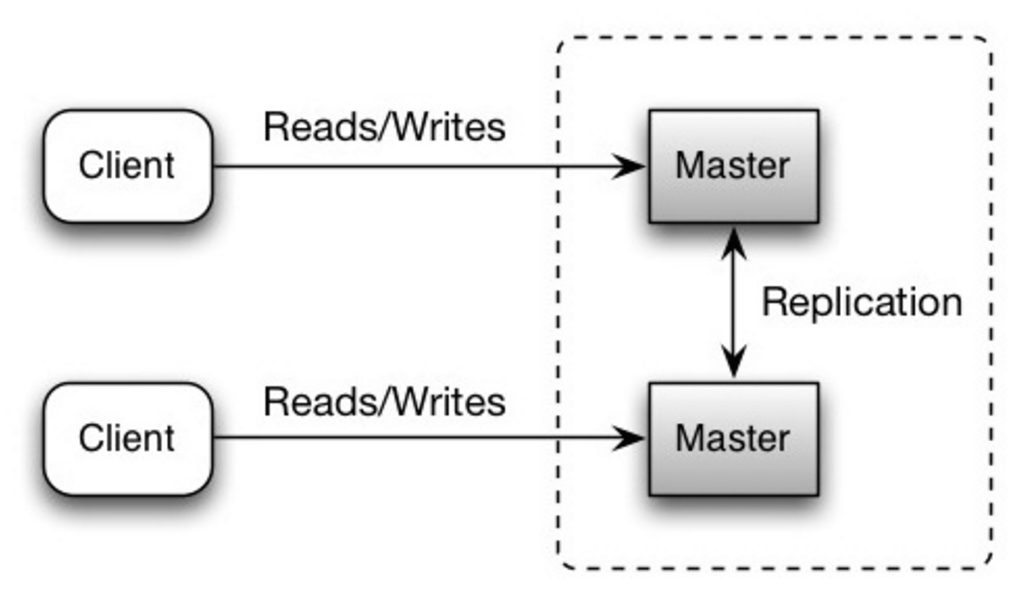
ที่มา: Scalability, availability, stability, patterns
##### ข้อเสีย: การจำลองแบบมาสเตอร์-มาสเตอร์
- คุณต้องมีตัวจัดสมดุลโหลด หรือคุณต้องปรับเปลี่ยนตรรกะของแอปพลิเคชันเพื่อกำหนดว่าจะเขียนที่ใด
- ระบบมาสเตอร์-มาสเตอร์ส่วนใหญ่จะมีความสอดคล้องหลวม (ละเมิด ACID) หรือมีความหน่วงในการเขียนเพิ่มขึ้นเนื่องจากต้องประสานข้อมูล
- การแก้ไขข้อขัดแย้งจะมีบทบาทมากขึ้นเมื่อมีการเพิ่มโหนดที่สามารถเขียนข้อมูลได้มากขึ้นและเมื่อความหน่วงเพิ่มสูงขึ้น
- ดู ข้อเสีย: การทำสำเนา (replication) สำหรับจุดที่เกี่ยวข้องกับ ทั้ง ระบบ master-slave และ master-master
- มีความเสี่ยงที่จะสูญเสียข้อมูลหากเครื่อง master ล้มเหลวก่อนที่ข้อมูลที่เขียนใหม่จะถูกส่งต่อไปยังโหนดอื่นๆ
- การเขียนข้อมูลจะถูกเล่นซ้ำไปยัง read replica หากมีการเขียนมาก read replica อาจประสบปัญหาเนื่องจากต้องเล่นซ้ำการเขียนและอาจอ่านข้อมูลได้ลดลง
- ยิ่งมี read slave มากเท่าไร ก็ยิ่งต้องทำสำเนามากขึ้น ส่งผลให้เกิดความล่าช้าในการทำสำเนามากขึ้น
- บางระบบสามารถเขียนไปยัง master ได้โดยสร้าง thread หลายตัวเพื่อเขียนแบบขนาน ขณะที่ read replica รองรับการเขียนแบบต่อเนื่องด้วย thread เดียวเท่านั้น
- การทำสำเนาเพิ่มฮาร์ดแวร์และความซับซ้อนมากขึ้น
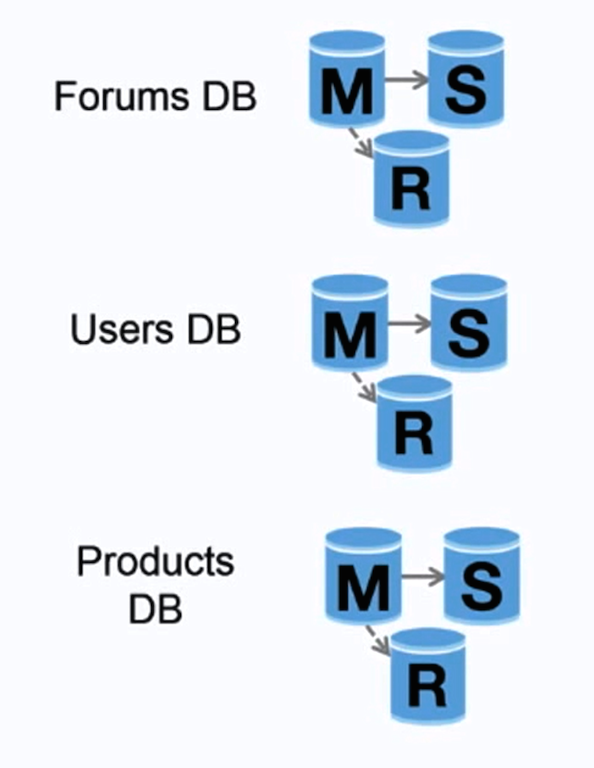
ที่มา: Scaling up to your first 10 million users
Federation (หรือการแบ่งกลุ่มตามหน้าที่) คือการแยกฐานข้อมูลตามฟังก์ชัน เช่น แทนที่จะใช้ฐานข้อมูลเดียวแบบ monolithic คุณอาจมีฐานข้อมูลสามส่วน: forums, users และ products ส่งผลให้การอ่านและเขียนข้อมูลแต่ละฐานข้อมูลลดลง และลดความล่าช้าในการทำสำเนา ฐานข้อมูลขนาดเล็กทำให้ข้อมูลจำนวนมากถูกเก็บในหน่วยความจำได้มากขึ้น ส่งผลให้ cache hit เพิ่มขึ้นเนื่องจาก locality ของ cache ดีขึ้น เมื่อไม่มี master กลางที่คอย serialize การเขียน คุณสามารถเขียนแบบขนานได้ ส่งผลให้ throughput เพิ่มขึ้น
##### ข้อเสีย: Federation
- Federation ไม่ได้ผลหาก schema ของคุณต้องการฟังก์ชันหรือ table ขนาดใหญ่
- คุณต้องปรับปรุงตรรกะของแอปพลิเคชันเพื่อกำหนดว่าจะอ่านหรือเขียนฐานข้อมูลใด
- การ join ข้อมูลจากสองฐานข้อมูลจะซับซ้อนมากขึ้นเมื่อใช้ server link
- Federation เพิ่มฮาร์ดแวร์และความซับซ้อนมากขึ้น
ที่มา: Scalability, availability, stability, patterns
Sharding คือการกระจายข้อมูลไปยังฐานข้อมูลต่าง ๆ โดยแต่ละฐานข้อมูลจะจัดการข้อมูลเพียงบางส่วนเท่านั้น ตัวอย่างเช่นฐานข้อมูลผู้ใช้ เมื่อจำนวนผู้ใช้เพิ่มขึ้น ก็จะมีการเพิ่ม shard ในคลัสเตอร์
เช่นเดียวกับข้อดีของ federation การ sharding จะช่วยลดปริมาณการอ่านและเขียน ลดการทำซ้ำข้อมูล และเพิ่มโอกาสในการ cache hit ขนาดของดัชนีก็ลดลง ซึ่งโดยทั่วไปจะช่วยให้ประสิทธิภาพดีขึ้นด้วยการ query ที่เร็วขึ้น หาก shard ใดล่ม shard อื่น ๆ ยังสามารถทำงานได้ตามปกติ แม้ว่าคุณจะต้องเพิ่มการทำ replication เพื่อป้องกันการสูญหายของข้อมูลก็ตาม เช่นเดียวกับ federation ไม่มี master กลางที่เป็นศูนย์กลางในการ serialize การเขียน ทำให้สามารถเขียนข้อมูลแบบขนานและ throughput เพิ่มขึ้น
วิธีการ sharding ฐานข้อมูลผู้ใช้ที่พบบ่อย คือการใช้ตัวอักษรแรกของนามสกุลผู้ใช้ หรือใช้ตำแหน่งทางภูมิศาสตร์ของผู้ใช้
##### ข้อเสีย: sharding
- คุณจะต้องปรับตรรกะของแอปพลิเคชันให้รองรับ shard ซึ่งอาจทำให้ query SQL ซับซ้อนมากขึ้น
- การกระจายข้อมูลใน shard อาจไม่สมดุล เช่น หากมีผู้ใช้ที่ใช้ระบบหนักมากอยู่ใน shard เดียวกัน อาจทำให้ shard นั้นรับโหลดมากกว่าชุดอื่น ๆ
- การปรับสมดุล (rebalancing) เพิ่มความซับซ้อน ฟังก์ชัน sharding ที่ใช้ consistent hashing สามารถลดปริมาณข้อมูลที่ต้องโอนย้าย
- การ join ข้อมูลจากหลาย shard จะซับซ้อนมากขึ้น
- การ sharding เพิ่มความต้องการฮาร์ดแวร์และความซับซ้อนโดยรวม
Denormalization คือการปรับปรุงประสิทธิภาพการอ่านโดยแลกกับประสิทธิภาพการเขียนในบางกรณี โดยเขียนข้อมูลสำรองซ้ำในหลายตารางเพื่อลดความจำเป็นในการ join ที่มีต้นทุนสูง RDBMS บางตัวเช่น PostgreSQL และ Oracle รองรับ materialized views ที่ช่วยจัดการข้อมูลสำรองและทำให้ข้อมูลคัดลอกซ้ำกันมีความสอดคล้องกัน
เมื่อข้อมูลถูกกระจายด้วยเทคนิคอย่าง federation และ sharding การจัดการ join ข้าม data center จะมีความซับซ้อนมากขึ้น การ denormalization อาจช่วยหลีกเลี่ยงความจำเป็นในการ join ที่ซับซ้อนเหล่านี้
ในระบบส่วนใหญ่ การอ่านมักจะมากกว่าการเขียน 100:1 หรือถึง 1000:1 การอ่านที่ต้อง join ฐานข้อมูลซับซ้อนอาจมีต้นทุนสูงมาก ใช้เวลาทำงานกับดิสก์นาน
##### ข้อเสีย: denormalization
- ข้อมูลถูกคัดลอกซ้ำ
- Constraint สามารถช่วยให้ข้อมูลซ้ำกันมีความสอดคล้องกัน ซึ่งเพิ่มความซับซ้อนของการออกแบบฐานข้อมูล
- ฐานข้อมูลที่ denormalized ภายใต้โหลดการเขียนหนัก อาจมีประสิทธิภาพแย่กว่าฐานข้อมูลที่ normalized
การปรับแต่ง SQL เป็นหัวข้อที่กว้างและมี หนังสือ จำนวนมากที่เขียนไว้เป็นข้อมูลอ้างอิง
สิ่งสำคัญคือการ ทดสอบสมรรถนะ และ วิเคราะห์ประสิทธิภาพ เพื่อจำลองและค้นหาคอขวด
- ทดสอบสมรรถนะ - จำลองสถานการณ์โหลดสูงด้วยเครื่องมือเช่น ab
- วิเคราะห์ประสิทธิภาพ - เปิดใช้งานเครื่องมือเช่น slow query log เพื่อช่วยติดตามปัญหาด้านประสิทธิภาพ
##### ปรับแต่ง schema ให้เหมาะสม
- MySQL จะ dump ข้อมูลลงดิสก์เป็นบล็อกที่ต่อเนื่องกันเพื่อการเข้าถึงที่รวดเร็ว
- ใช้
CHARแทนVARCHARสำหรับฟิลด์ที่มีความยาวคงที่ CHARให้การเข้าถึงแบบสุ่มที่รวดเร็ว ในขณะที่VARCHARต้องค้นหาจุดสิ้นสุดของสตริงก่อนจึงจะไปยังรายการถัดไปได้- ใช้
TEXTสำหรับบล็อกข้อความขนาดใหญ่เช่นโพสต์บล็อกTEXTยังรองรับการค้นหาแบบ boolean ด้วย การใช้ฟิลด์TEXTจะจัดเก็บพอยน์เตอร์บนดิสก์ที่ใช้ค้นหาบล็อกข้อความ - ใช้
INTสำหรับตัวเลขขนาดใหญ่ถึง 2^32 หรือ 4 พันล้าน - ใช้
DECIMALสำหรับสกุลเงินเพื่อหลีกเลี่ยงข้อผิดพลาดในการแทนค่าตัวเลขทศนิยมแบบ floating point - หลีกเลี่ยงการจัดเก็บ
BLOBขนาดใหญ่ ให้จัดเก็บตำแหน่งที่สามารถเรียกใช้อ็อบเจ็กต์แทน VARCHAR(255)คือจำนวนตัวอักษรมากที่สุดที่สามารถนับในตัวเลข 8 บิต มักใช้เพื่อให้เกิดการใช้ไบต์สูงสุดในบาง RDBMS- กำหนด
NOT NULLconstraint เมื่อเหมาะสมเพื่อ ปรับปรุงประสิทธิภาพการค้นหา
- คอลัมน์ที่ใช้ในการ query (
SELECT,GROUP BY,ORDER BY,JOIN) จะทำงานได้เร็วขึ้นเมื่อมีอินเด็กซ์ - อินเด็กซ์มักจะแทนด้วย B-tree ที่ปรับสมดุลตัวเองและจัดเรียงข้อมูลรวมถึงช่วยในการค้นหา การเข้าถึงแบบลำดับ การแทรก และการลบในเวลาเชิงลอการิทึม
- การสร้างอินเด็กซ์จะทำให้ข้อมูลอยู่ในหน่วยความจำซึ่งต้องการพื้นที่มากขึ้น
- การเขียนข้อมูลอาจช้าลงเนื่องจากต้องอัปเดตอินเด็กซ์ด้วย
- เมื่อโหลดข้อมูลปริมาณมาก อาจเร็วกว่าถ้าปิดอินเด็กซ์ โหลดข้อมูล แล้วสร้างอินเด็กซ์ใหม่
- Denormalize เมื่อประสิทธิภาพเป็นสิ่งจำเป็น
- แยกตารางโดยนำจุดสำคัญไปไว้ในตารางแยกเพื่อช่วยให้ข้อมูลอยู่ในหน่วยความจำ
- ในบางกรณี query cache อาจทำให้เกิด ปัญหาด้านประสิทธิภาพ
- เคล็ดลับการปรับแต่ง MySQL queries
- เหตุผลที่ใช้ VARCHAR(255) บ่อย ๆ คืออะไร?
- ค่า null มีผลต่อประสิทธิภาพอย่างไร?
- บันทึกคำสั่งค้นหาช้า (Slow query log)
NoSQL
NoSQL คือการจัดเก็บข้อมูลในรูปแบบ key-value store, document store, wide column store หรือ graph database ข้อมูลจะถูกทำให้ไม่เป็นปกติ (denormalized) และโดยทั่วไปการ join จะทำในโค้ดแอปพลิเคชัน ฐานข้อมูล NoSQL ส่วนมากจะไม่มีธุรกรรม ACID ที่แท้จริงและเน้นที่ eventual consistency
BASE มักถูกใช้เพื่ออธิบายคุณสมบัติของฐานข้อมูล NoSQL เมื่อเปรียบเทียบกับ ทฤษฎี CAP ฐานข้อมูล BASE เลือกความพร้อมใช้งานมากกว่าความถูกต้อง
- Basically available - ระบบรับประกันความพร้อมใช้งาน
- Soft state - สถานะของระบบอาจเปลี่ยนแปลงได้ตลอดเวลา แม้ไม่มีอินพุต
- Eventual consistency - ระบบจะกลับมาสอดคล้องกันในช่วงเวลาหนึ่ง หากไม่มีอินพุตเข้ามาในช่วงเวลานั้น
#### Key-value store
นามธรรม: hash table
Key-value store โดยทั่วไปจะรองรับการอ่านและเขียนแบบ O(1) และมักจัดเก็บข้อมูลในหน่วยความจำหรือ SSD ฐานข้อมูลแบบนี้สามารถจัดเรียงคีย์ตาม ลำดับตัวอักษร เพื่อให้ดึงข้อมูลช่วงคีย์ได้อย่างมีประสิทธิภาพ Key-value store สามารถจัดเก็บข้อมูลเมตากับค่าได้
Key-value store ให้ประสิทธิภาพสูงและมักใช้กับโมเดลข้อมูลที่ง่ายหรือข้อมูลที่เปลี่ยนแปลงเร็ว เช่น cache ที่อยู่ในหน่วยความจำ เนื่องจากมีชุดคำสั่งจำกัด ความซับซ้อนจึงถูกผลักไปที่ชั้นแอปพลิเคชันหากต้องการคำสั่งเพิ่มเติม
Key-value store เป็นพื้นฐานของระบบที่ซับซ้อนกว่า เช่น document store และในบางกรณีคือ graph database
##### แหล่งข้อมูลและอ่านเพิ่มเติม: key-value store
#### Document storeนามธรรม: คีย์-แวลูสโตร์ที่จัดเก็บเอกสารเป็นค่า
Document store จะเน้นที่เอกสาร (XML, JSON, ไบนารี ฯลฯ) ซึ่งเอกสารจะเก็บข้อมูลทั้งหมดสำหรับอ็อบเจกต์หนึ่ง ๆ Document store จะมี API หรือภาษาคิวรีสำหรับการค้นหาตามโครงสร้างภายในของเอกสารเอง หมายเหตุ หลาย key-value store มีฟีเจอร์ในการทำงานกับ metadata ของค่า ทำให้เส้นแบ่งระหว่าง storage ทั้งสองประเภทนี้ไม่ชัดเจน
ขึ้นอยู่กับการนำไปใช้ที่อยู่เบื้องหลัง เอกสารอาจถูกจัดกลุ่มโดย collections, tags, metadata หรือ directories แม้ว่าเอกสารจะถูกจัดหรือกลุ่มเข้าด้วยกันได้ แต่เอกสารแต่ละฉบับก็อาจมีฟิลด์ที่แตกต่างกันโดยสิ้นเชิง
Document store บางตัวเช่น MongoDB และ CouchDB มีภาษาคิวรีที่คล้าย SQL สำหรับคิวรีที่ซับซ้อน DynamoDB รองรับทั้งคีย์-แวลูและเอกสาร
Document store มีความยืดหยุ่นสูงและมักใช้กับข้อมูลที่เปลี่ยนแปลงเป็นครั้งคราว
##### แหล่งข้อมูลและอ่านเพิ่มเติม: document store
#### Wide column store
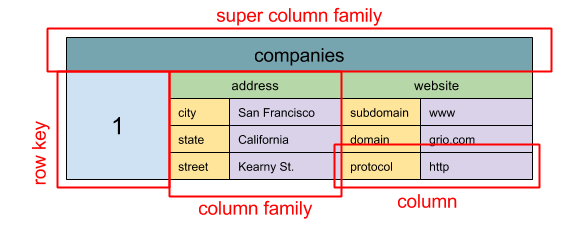
ที่มา: SQL & NoSQL, ประวัติย่อ
นามธรรม: แมพซ้อน ColumnFamily> Wide column store มีหน่วยข้อมูลพื้นฐานเป็น column (คู่ชื่อ/ค่า) column สามารถจัดกลุ่มใน column families (คล้ายกับตาราง SQL) super column families จะกลุ่ม column families เพิ่มขึ้น คุณสามารถเข้าถึงแต่ละ column โดยใช้ row key และ column ที่มี row key เดียวกันจะรวมกันเป็นแถว แต่ละค่าสามารถมี timestamp สำหรับการจัดเวอร์ชันและแก้ไขข้อขัดแย้ง
Google ได้เปิดตัว Bigtable เป็น wide column store ตัวแรก ซึ่งมีอิทธิพลต่อ HBase ที่ใช้ในระบบ Hadoop และ Cassandra จาก Facebook สโตร์อย่าง BigTable, HBase และ Cassandra จะจัดคีย์ตามลำดับพจนานุกรม ทำให้สามารถดึงข้อมูลช่วงคีย์ที่ต้องการได้อย่างมีประสิทธิภาพ
Wide column store มีความพร้อมใช้งานสูงและขยายขนาดได้ดี มักใช้กับชุดข้อมูลขนาดใหญ่มาก
##### แหล่งข้อมูลและอ่านเพิ่มเติม: wide column store
#### ฐานข้อมูลแบบกราฟ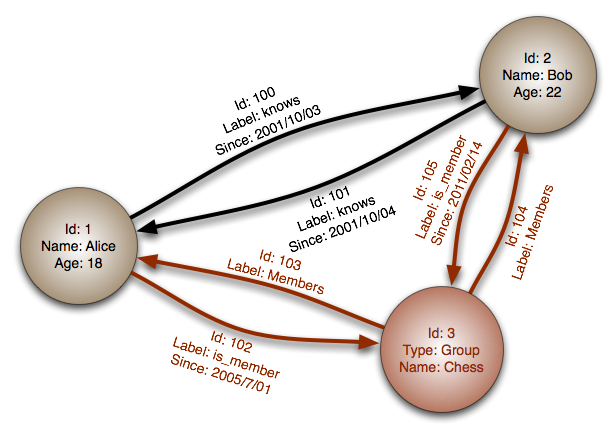
นามธรรม: กราฟ
ในฐานข้อมูลแบบกราฟ แต่ละโหนดคือเรคคอร์ดและแต่ละเส้นเชื่อมคือความสัมพันธ์ระหว่างสองโหนด ฐานข้อมูลกราฟถูกปรับแต่งเพื่อแสดงความสัมพันธ์ที่ซับซ้อน เช่น มีคีย์ต่างประเทศจำนวนมากหรือความสัมพันธ์แบบ many-to-many
ฐานข้อมูลกราฟให้ประสิทธิภาพสูงสำหรับโมเดลข้อมูลที่มีความสัมพันธ์ซับซ้อน เช่น เครือข่ายสังคม โดยยังค่อนข้างใหม่และยังไม่แพร่หลาย อาจจะหาทูลหรือทรัพยากรสำหรับพัฒนาได้ยาก หลายกราฟสามารถเข้าถึงได้แค่ REST APIs
##### แหล่งข้อมูลและอ่านเพิ่มเติม: กราฟ
#### แหล่งข้อมูลและอ่านเพิ่มเติม: NoSQL- คำอธิบายคำศัพท์พื้นฐาน
- สำรวจและแนวทางตัดสินใจฐานข้อมูล NoSQL
- ความสามารถในการขยาย
- แนะนำ NoSQL
- รูปแบบ NoSQL
SQL หรือ NoSQL
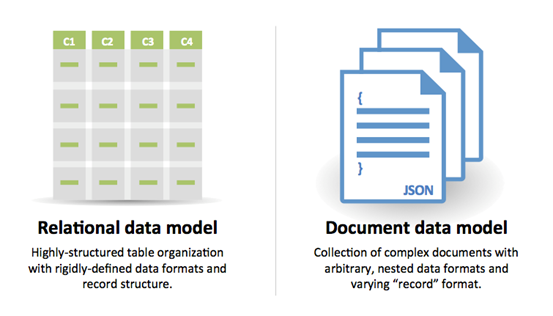
ที่มา: การเปลี่ยนผ่านจาก RDBMS ไป NoSQL
เหตุผลสำหรับ SQL:
- ข้อมูลที่มีโครงสร้าง
- สคีมาที่เข้มงวด
- ข้อมูลเชิงสัมพันธ์
- ต้องการการ join ที่ซับซ้อน
- ธุรกรรม (Transactions)
- รูปแบบที่ชัดเจนสำหรับการขยายขนาด
- เป็นที่ยอมรับมากกว่า: นักพัฒนา, ชุมชน, โค้ด, เครื่องมือ ฯลฯ
- การค้นหาด้วยดัชนีทำได้รวดเร็วมาก
- ข้อมูลกึ่งโครงสร้าง
- สคีมาที่ยืดหยุ่นหรือเปลี่ยนแปลงได้
- ข้อมูลที่ไม่ใช่เชิงสัมพันธ์
- ไม่ต้องการ join ที่ซับซ้อน
- จัดเก็บข้อมูลขนาดหลาย TB (หรือ PB)
- งานที่ใช้ข้อมูลเข้มข้นมาก
- มี throughput สูงมากสำหรับ IOPS
- รับข้อมูล clickstream และ log อย่างรวดเร็ว
- ข้อมูลกระดานผู้นำหรือคะแนน
- ข้อมูลชั่วคราว เช่น ตะกร้าสินค้า
- ตารางที่ถูกเข้าถึงบ่อย ('hot' tables)
- ตาราง metadata/lookup
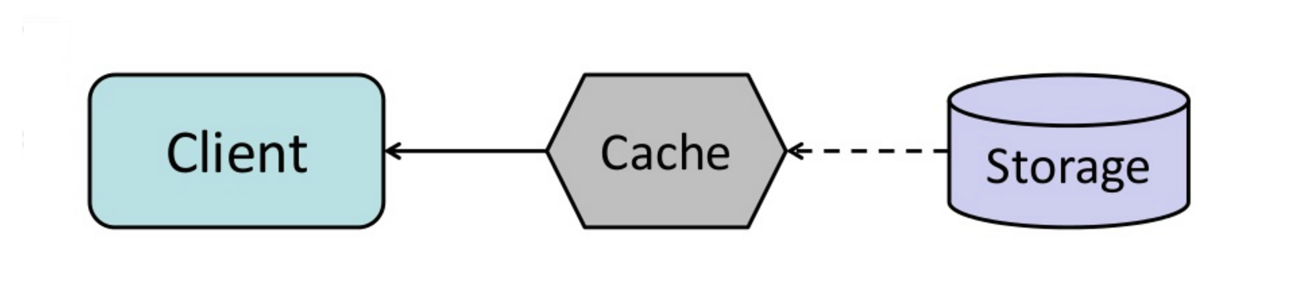
แคช
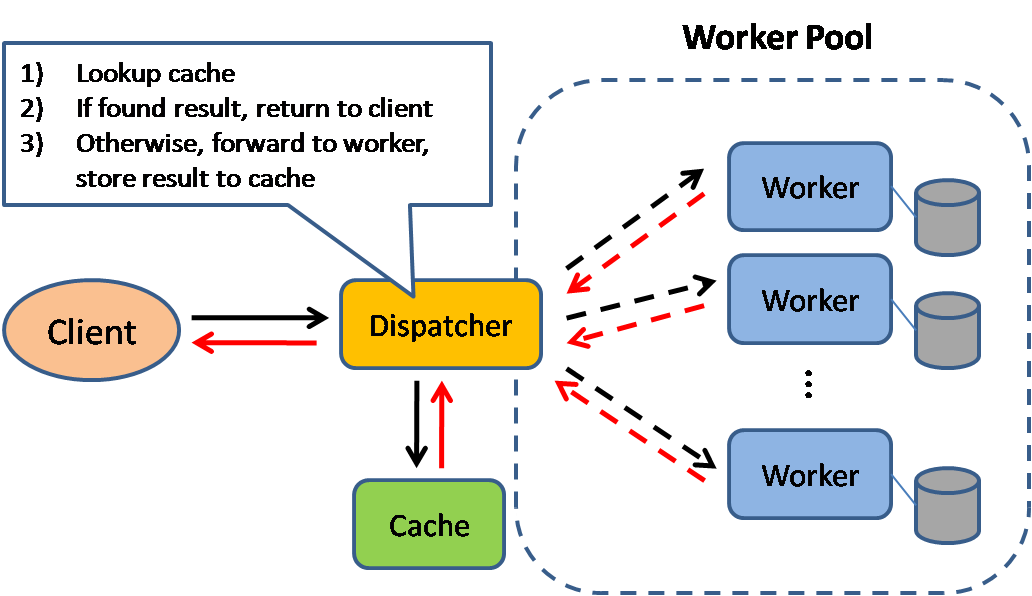
ที่มา: รูปแบบการออกแบบระบบที่ขยายขนาดได้
การแคชช่วยปรับปรุงเวลาในการโหลดหน้าเว็บและสามารถลดภาระบนเซิร์ฟเวอร์และฐานข้อมูลของคุณได้ ในโมเดลนี้ dispatcher จะตรวจสอบก่อนว่ามีการร้องขอในลักษณะเดียวกันมาก่อนหรือไม่ และพยายามค้นหาผลลัพธ์เดิมเพื่อนำกลับมาใช้ เพื่อลดการประมวลผลที่แท้จริง
ฐานข้อมูลมักจะได้รับประโยชน์จากการกระจายการอ่านและเขียนอย่างสม่ำเสมอในแต่ละพาร์ติชัน รายการยอดนิยมสามารถทำให้การกระจายไม่เท่ากันและเกิดคอขวด การวางแคชไว้หน้าฐานข้อมูลสามารถช่วยดูดซับภาระที่ไม่สมดุลและการพุ่งขึ้นของทราฟฟิก
การแคชฝั่งลูกข่าย
แคชสามารถอยู่ฝั่งลูกข่าย (OS หรือเบราว์เซอร์), ฝั่งเซิร์ฟเวอร์ หรืออยู่ในชั้นแคชโดยเฉพาะ
การแคช CDN
CDN ถือว่าเป็นประเภทหนึ่งของแคช
การแคชเว็บเซิร์ฟเวอร์
Reverse proxy และแคชอย่างเช่น Varnish สามารถให้บริการคอนเทนต์แบบสถิตและไดนามิกโดยตรง เว็บเซิร์ฟเวอร์ยังสามารถแคชคำร้องขอและคืนผลลัพธ์โดยไม่ต้องติดต่อกับแอปพลิเคชันเซิร์ฟเวอร์
การแคชฐานข้อมูล
ฐานข้อมูลของคุณมักจะมีการตั้งค่าแคชในระดับหนึ่งในค่าคอนฟิกเริ่มต้นที่ปรับให้เหมาะกับการใช้งานทั่วไป การปรับแต่งค่าเหล่านี้ให้เหมาะกับรูปแบบการใช้งานเฉพาะสามารถช่วยเพิ่มประสิทธิภาพได้อีก
การแคชแอปพลิเคชัน
แคชในหน่วยความจำเช่น Memcached และ Redis เป็น key-value store ที่อยู่ระหว่างแอปพลิเคชันของคุณกับที่เก็บข้อมูล เนื่องจากข้อมูลอยู่ใน RAM จึงเร็วกว่าฐานข้อมูลทั่วไปที่ข้อมูลอยู่บนดิสก์ RAM มีข้อจำกัดมากกว่าดิสก์ ดังนั้น อัลกอริทึมการลบแคช เช่น least recently used (LRU)) จะช่วยลบข้อมูลที่ไม่ได้ใช้งานและเก็บข้อมูลที่ถูกใช้งานบ่อยไว้ใน RAM
Redis มีคุณสมบัติเพิ่มเติมดังนี้:
- ตัวเลือกการเก็บข้อมูลถาวร
- โครงสร้างข้อมูลในตัว เช่น sorted sets และ lists
- ระดับแถว
- ระดับคำสั่งค้นหา
- อ็อบเจกต์ที่จัดรูปแบบพร้อมทำการ serialize
- HTML ที่เรนเดอร์เสร็จสมบูรณ์
การแคชในระดับการคิวรีฐานข้อมูล
เมื่อใดก็ตามที่คุณคิวรีฐานข้อมูล ให้แฮชคิวรีเป็นคีย์และเก็บผลลัพธ์ไว้ในแคช วิธีนี้มีปัญหาเกี่ยวกับการหมดอายุ:
- ลบผลลัพธ์ที่แคชไว้ได้ยากในกรณีที่เป็นคิวรีซับซ้อน
- หากข้อมูลส่วนหนึ่งเปลี่ยนแปลง เช่น เซลล์ในตาราง คุณต้องลบคิวรีที่แคชไว้ทั้งหมดซึ่งอาจมีเซลล์ที่เปลี่ยนแปลงนั้น
การแคชในระดับอ็อบเจกต์
มองข้อมูลของคุณเป็นอ็อบเจกต์ คล้ายกับที่คุณทำกับโค้ดแอปพลิเคชัน ให้แอปพลิเคชันของคุณประกอบชุดข้อมูลจากฐานข้อมูลเป็นอินสแตนซ์คลาสหรือโครงสร้างข้อมูล:
- ลบอ็อบเจกต์ออกจากแคชหากข้อมูลพื้นฐานของมันเปลี่ยนแปลง
- รองรับการประมวลผลแบบอะซิงโครนัส: worker ประกอบอ็อบเจกต์โดยใช้ข้อมูลแคชล่าสุด
- เซสชันผู้ใช้
- หน้าเว็บที่แสดงผลเรียบร้อยแล้ว
- สตรีมกิจกรรม
- ข้อมูลกราฟผู้ใช้
เมื่อใดควรอัปเดตแคช
เนื่องจากคุณสามารถเก็บข้อมูลในแคชได้จำนวนจำกัด คุณจะต้องกำหนดกลยุทธ์ในการอัปเดตแคชที่เหมาะสมกับการใช้งานของคุณ
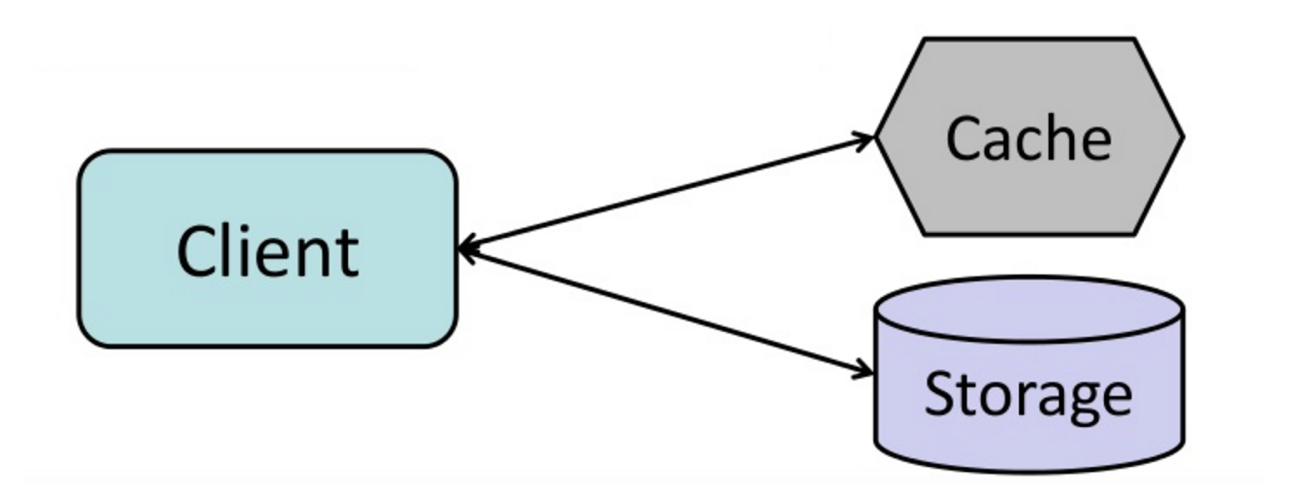
#### Cache-aside
ที่มา: From cache to in-memory data grid
แอปพลิเคชันรับผิดชอบในการอ่านและเขียนข้อมูลจากสตอเรจ แคชจะไม่ติดต่อกับสตอเรจโดยตรง แอปพลิเคชันจะดำเนินการดังนี้:
- ค้นหารายการในแคช หากไม่พบจะเกิด cache miss
- โหลดรายการจากฐานข้อมูล
- เพิ่มรายการลงในแคช
- ส่งคืนรายการ
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached มักจะถูกใช้งานในลักษณะนี้
การอ่านข้อมูลซ้ำที่ถูกเพิ่มเข้าไปในแคชจะมีความรวดเร็ว Cache-aside หรือที่เรียกอีกชื่อว่า lazy loading จะมีการแคชเฉพาะข้อมูลที่ถูกเรียกใช้งาน ซึ่งช่วยหลีกเลี่ยงการเติมข้อมูลที่ไม่ถูกเรียกใช้เข้าไปในแคช
##### ข้อเสีย: cache-aside
- ทุกครั้งที่แคชไม่พบข้อมูลจะต้องเดินทางสามครั้ง ซึ่งอาจทำให้เกิดความล่าช้าอย่างเห็นได้ชัด
- ข้อมูลอาจเก่าได้หากมีการอัปเดตในฐานข้อมูล ปัญหานี้สามารถลดลงได้ด้วยการตั้งค่า time-to-live (TTL) เพื่อบังคับให้อัปเดต entry ในแคช หรือโดยใช้ write-through
- เมื่อโหนดล้มเหลว จะถูกแทนที่ด้วยโหนดใหม่ที่ว่างเปล่า ซึ่งเพิ่มค่า latency
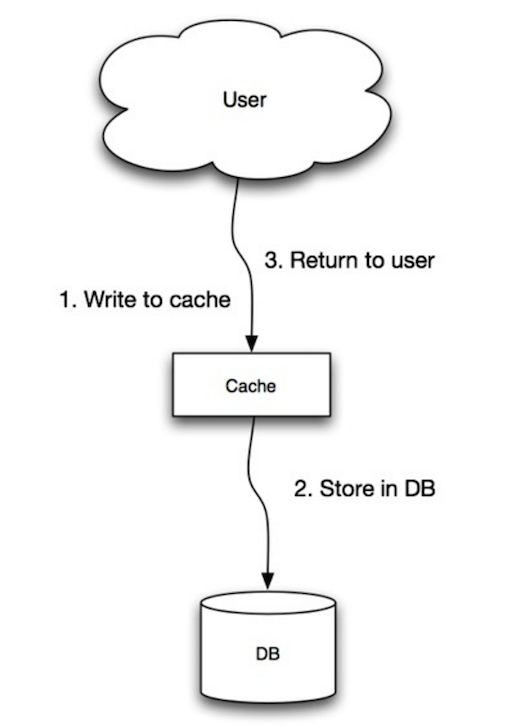
ที่มา: Scalability, availability, stability, patterns
แอปพลิเคชันจะใช้แคชเป็นแหล่งจัดเก็บข้อมูลหลัก โดยอ่านและเขียนข้อมูลกับแคช ในขณะที่แคชรับผิดชอบการอ่านและเขียนกับฐานข้อมูล:
- แอปพลิเคชันเพิ่ม/อัปเดต entry ในแคช
- แคชเขียน entry ไปยัง data store แบบ synchronous
- ส่งกลับ
set_user(12345, {"foo":"bar"})โค้ดแคช:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### ข้อเสีย: write through
- เมื่อมีการสร้างโหนดใหม่เนื่องจากความล้มเหลวหรือการขยายขนาด โหนดใหม่จะไม่แคชข้อมูลจนกว่าข้อมูลนั้นจะถูกอัปเดตในฐานข้อมูล การใช้ cache-aside ร่วมกับ write through สามารถช่วยลดปัญหานี้ได้
- ข้อมูลส่วนใหญ่ที่ถูกเขียนอาจไม่เคยถูกอ่าน ซึ่งสามารถลดได้ด้วยการกำหนด TTL
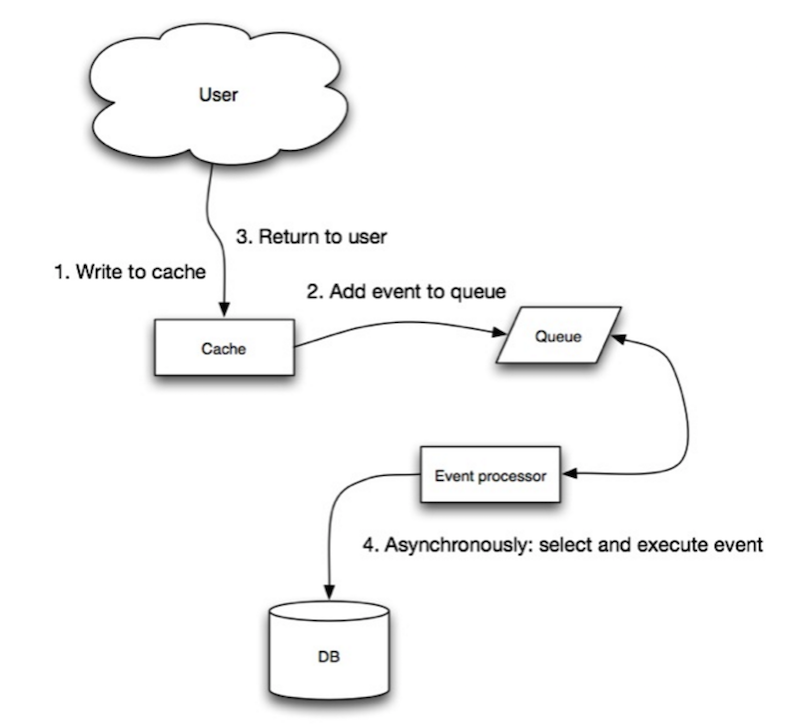
ที่มา: Scalability, availability, stability, patterns
ในการเขียนแบบ Write-behind แอปพลิเคชันจะดำเนินการดังนี้:
- เพิ่ม/อัปเดตรายการในแคช
- เขียนข้อมูลไปยัง data store แบบ asynchronous เพื่อเพิ่มประสิทธิภาพการเขียน
- อาจเกิดการสูญหายของข้อมูลหากแคชหยุดทำงานก่อนที่ข้อมูลจะถูกส่งไปยัง data store
- การเขียนแบบ write-behind มีความซับซ้อนมากกว่าการทำ cache-aside หรือ write-through
ที่มา: From cache to in-memory data grid
คุณสามารถกำหนดค่าแคชให้รีเฟรชรายการที่เข้าถึงล่าสุดโดยอัตโนมัติก่อนหมดอายุ
Refresh-ahead สามารถลด latency ได้มากกว่า read-through หากแคชสามารถทำนายได้อย่างแม่นยำว่ารายการใดจะถูกใช้งานในอนาคต
##### ข้อเสีย: refresh-ahead
- การไม่สามารถคาดการณ์ได้อย่างถูกต้องว่าสินค้าใดจะถูกต้องการในอนาคต อาจทำให้ประสิทธิภาพลดลงมากกว่าการไม่ใช้ refresh-ahead
ข้อเสีย: แคช
- จำเป็นต้องรักษาความสอดคล้องระหว่างแคชและแหล่งข้อมูลหลัก เช่น ฐานข้อมูล ผ่าน การทำให้แคชไม่ถูกต้อง
- การทำให้แคชไม่ถูกต้องเป็นปัญหาที่ยาก มีความซับซ้อนเพิ่มเติมเกี่ยวกับเวลาที่จะอัปเดตแคช
- จำเป็นต้องเปลี่ยนแปลงแอปพลิเคชัน เช่น การเพิ่ม Redis หรือ memcached
แหล่งข้อมูลและการอ่านเพิ่มเติม
- จากแคชสู่ in-memory data grid
- รูปแบบการออกแบบระบบที่ปรับขยายได้
- บทนำสู่การออกแบบสถาปัตยกรรมระบบเพื่อรองรับการขยายตัว
- รูปแบบความสามารถในการขยาย, ความพร้อมใช้งาน, เสถียรภาพ
- ความสามารถในการขยาย
- กลยุทธ์ AWS ElastiCache
- วิกิพีเดีย)
ความไม่ประสานกัน (Asynchronism)
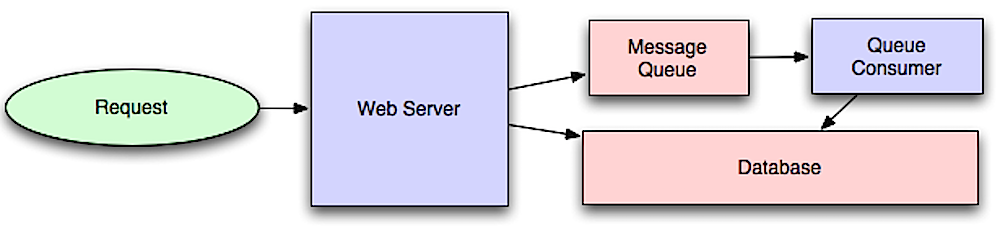
ที่มา: Intro to architecting systems for scale
เวิร์กโฟลว์แบบอะซิงโครนัสช่วยลดเวลาการร้องขอสำหรับการดำเนินการที่มีค่าใช้จ่ายสูงซึ่งปกติจะดำเนินการแบบอินไลน์ นอกจากนี้ยังช่วยโดยการทำงานที่ใช้เวลานานล่วงหน้า เช่น การรวมข้อมูลเป็นระยะ
คิวข้อความ (Message queues)
คิวข้อความรับ, ถือ และส่งต่อข้อความ หากการดำเนินการใดช้าเกินไปที่จะทำแบบอินไลน์ คุณสามารถใช้คิวข้อความกับเวิร์กโฟลว์ดังนี้:
- แอปพลิเคชันเผยแพ่งานไปยังคิว จากนั้นแจ้งสถานะงานแก่ผู้ใช้
- พนักงาน (worker) จะรับงานจากคิว ประมวลผลงาน แล้วส่งสัญญาณว่างานเสร็จสิ้น
Redis มีประโยชน์ในฐานะ message broker ที่เรียบง่ายแต่ข้อความอาจสูญหายได้
RabbitMQ เป็นที่นิยมแต่คุณต้องปรับตัวเข้ากับโปรโตคอล 'AMQP' และจัดการโหนดของคุณเอง Amazon SQS เป็นบริการที่โฮสต์อยู่แต่สามารถมีความหน่วงสูงและมีโอกาสที่ข้อความจะถูกส่งซ้ำสองครั้ง
คิวงาน (Task queues)
คิวงานจะรับงานและข้อมูลที่เกี่ยวข้อง, ดำเนินการงานเหล่านั้น, แล้วส่งผลลัพธ์กลับ พวกมันสามารถรองรับการตั้งเวลาและใช้สำหรับประมวลผลงานที่ต้องใช้คำนวณหนักในเบื้องหลังได้
Celery รองรับการตั้งเวลาและสนับสนุนภาษา python เป็นหลัก
Back pressure
หากคิวเริ่มมีขนาดใหญ่ขึ้นอย่างมาก ขนาดของคิวอาจใหญ่กว่าหน่วยความจำ ส่งผลให้เกิดการพลาดแคช, อ่านข้อมูลจากดิสก์, และประสิทธิภาพที่ช้าลง Back pressure สามารถช่วยโดยการจำกัดขนาดของคิว, ซึ่งจะช่วยรักษาอัตราผ่านงานสูงและเวลาในการตอบสนองที่ดีสำหรับงานที่อยู่ในคิว เมื่อคิวเต็มแล้ว ลูกค้าจะได้รับสถานะเซิร์ฟเวอร์ไม่ว่างหรือ HTTP 503 ให้ลองใหม่ในภายหลัง ลูกค้าสามารถลองส่งคำขอใหม่อีกครั้งในภายหลัง, อาจใช้วิธี exponential backoff
ข้อเสีย: ความไม่ซิงโครนัส (asynchronism)
- กรณีการใช้งานเช่นการคำนวณต้นทุนต่ำและเวิร์กโฟลว์แบบเรียลไทม์อาจเหมาะกับการทำงานแบบซิงโครนัสมากกว่า เพราะการเพิ่มคิวอาจทำให้เกิดความล่าช้าและความซับซ้อน
แหล่งข้อมูลและอ่านเพิ่มเติม
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
การสื่อสาร (Communication)
{kind=link}
{kind=link}
โปรโตคอลการรับส่งข้อมูลแบบไฮเปอร์เท็กซ์ (HTTP)
HTTP เป็นวิธีสำหรับเข้ารหัสและขนส่งข้อมูลระหว่างไคลเอนต์และเซิร์ฟเวอร์ เป็นโปรโตคอลแบบ request/response: ไคลเอนต์จะส่งคำขอและเซิร์ฟเวอร์จะตอบกลับด้วยเนื้อหาที่เกี่ยวข้องและข้อมูลสถานะการดำเนินการของคำขอ HTTP เป็นระบบปิดในตัวเอง ช่วยให้คำขอและการตอบกลับไหลผ่านตัวกลางหลายตัว เช่น ตัวกระจายโหลด, แคช, การเข้ารหัส, และการบีบอัดข้อมูล
คำขอ HTTP พื้นฐานจะประกอบด้วยคำกริยา (method) และทรัพยากร (endpoint) ด้านล่างคือตัวอย่างคำกริยา HTTP ที่ใช้บ่อย:
| Verb | คำอธิบาย | Idempotent* | Safe | Cacheable |
| GET | อ่านทรัพยากร | ใช่ | ใช่ | ใช่ | | POST | สร้างทรัพยากรหรือกระตุ้นกระบวนการที่จัดการข้อมูล | ไม่ | ไม่ | ใช่ถ้าการตอบกลับมีข้อมูลความสดใหม่ | | PUT | สร้างหรือแทนที่ทรัพยากร | ใช่ | ไม่ | ไม่ | | PATCH | อัปเดตทรัพยากรบางส่วน | ไม่ | ไม่ | ใช่ถ้าการตอบกลับมีข้อมูลความสดใหม่ | | DELETE | ลบทรัพยากร | ใช่ | ไม่ | ไม่ |
*สามารถเรียกซ้ำหลายครั้งโดยไม่มีผลลัพธ์ที่ต่างกัน
HTTP เป็นโปรโตคอลชั้นแอปพลิเคชันที่อาศัยโปรโตคอลระดับล่างเช่น TCP และ UDP.
#### แหล่งข้อมูลและอ่านเพิ่มเติม: HTTP
โปรโตคอลควบคุมการส่งข้อมูล (TCP)
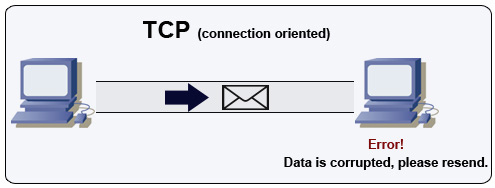
ที่มา: วิธีสร้างเกมผู้เล่นหลายคน
TCP เป็นโปรโตคอลแบบเชื่อมต่อบนเครือข่าย IP การเชื่อมต่อถูกสร้างและสิ้นสุดโดยใช้ แฮนด์เชค แพ็กเก็ตที่ถูกส่งจะถูกรับประกันว่าถึงปลายทางตามลำดับเดิมและไม่เสียหายด้วย:
- หมายเลขลำดับและ ช่องตรวจสอบค่าถูกต้อง สำหรับแต่ละแพ็กเก็ต
- แพ็กเก็ต การตอบรับ) และการส่งซ้ำอัตโนมัติ
เพื่อให้เกิดปริมาณข้อมูลสูง เซิร์ฟเวอร์เว็บสามารถเปิดการเชื่อมต่อ TCP จำนวนมาก ส่งผลให้ใช้หน่วยความจำสูง การมีการเชื่อมต่อจำนวนมากระหว่างเธรดของเซิร์ฟเวอร์เว็บกับเซิร์ฟเวอร์ memcached อาจมีค่าใช้จ่ายสูง การรวมการเชื่อมต่อ สามารถช่วยได้ รวมถึงการเปลี่ยนไปใช้ UDP เมื่อเหมาะสม
TCP เหมาะสำหรับแอปพลิเคชันที่ต้องการความน่าเชื่อถือสูงแต่ไม่เร่งด่วนด้านเวลา ตัวอย่างเช่น เซิร์ฟเวอร์เว็บ ข้อมูลฐานข้อมูล SMTP FTP และ SSH
ใช้ TCP แทน UDP เมื่อ:
- คุณต้องการให้ข้อมูลทั้งหมดมาถึงอย่างครบถ้วน
- คุณต้องการให้ระบบประมาณการใช้งานความเร็วเครือข่ายอัตโนมัติ
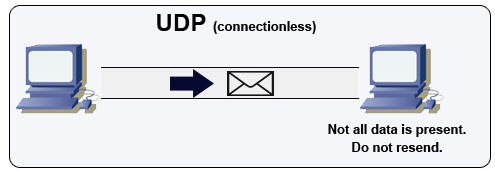
โปรโตคอล User datagram (UDP)
ที่มา: วิธีสร้างเกมผู้เล่นหลายคน
UDP เป็นโปรโตคอลแบบไม่มีการเชื่อมต่อ ข้อมูล datagram (คล้ายกับแพ็กเก็ต) จะได้รับประกันเฉพาะในระดับ datagram เท่านั้น ข้อมูล datagram อาจไปถึงปลายทางแบบไม่เรียงลำดับหรืออาจไม่ถึงเลย UDP ไม่รองรับการควบคุมความแออัด เนื่องจากไม่มีการรับประกันเหมือน TCP UDP จึงมีประสิทธิภาพมากกว่าโดยทั่วไป
UDP สามารถกระจายข้อมูล (broadcast) ส่ง datagram ไปยังทุกอุปกรณ์ในเครือข่ายย่อย ซึ่งมีประโยชน์กับ DHCP เพราะไคลเอนต์ยังไม่ได้รับที่อยู่ IP ทำให้ไม่สามารถใช้ TCP สตรีมข้อมูลโดยไม่มี IP address ได้
UDP มีความน่าเชื่อถือน้อยกว่าแต่ทำงานได้ดีในกรณีใช้งานแบบเรียลไทม์ เช่น VoIP, วิดีโอแชท, สตรีมมิ่ง และเกมผู้เล่นหลายคนแบบเรียลไทม์
ใช้ UDP แทน TCP เมื่อ:
- คุณต้องการความหน่วงต่ำที่สุด
- ข้อมูลที่ล่าช้าแย่กว่าการสูญเสียข้อมูล
- คุณต้องการพัฒนาแก้ไขข้อผิดพลาดเอง
- Networking for game programming
- ความแตกต่างหลักระหว่างโปรโตคอล TCP และ UDP
- ความแตกต่างระหว่าง TCP และ UDP
- โปรโตคอลควบคุมการส่งข้อมูล
- โปรโตคอล User datagram
- การปรับขนาด memcache ที่ Facebook
การเรียกใช้ฟังก์ชันระยะไกล (RPC)
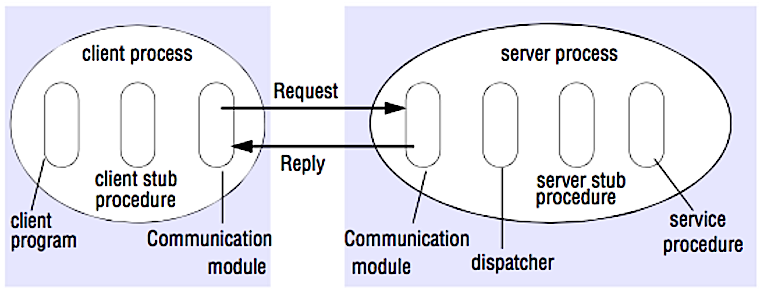
ที่มา: Crack the system design interview
ในการเรียกใช้ RPC ไคลเอนต์จะสั่งให้ฟังก์ชันทำงานใน address space อื่น โดยปกติจะเป็นเซิร์ฟเวอร์ระยะไกล ฟังก์ชันจะถูกเขียนเหมือนเป็นการเรียกใช้ฟังก์ชันในเครื่อง โดยซ่อนรายละเอียดการสื่อสารกับเซิร์ฟเวอร์จากโปรแกรมไคลเอนต์ การเรียกใช้ระยะไกลจะช้ากว่าและเชื่อถือน้อยกว่าการเรียกใช้ในเครื่อง จึงควรแยกความแตกต่างระหว่าง RPC กับการเรียกใช้ในเครื่อง Framework RPC ที่นิยม ได้แก่ Protobuf, Thrift, และ Avro
RPC เป็นโปรโตคอลแบบ request-response:
- โปรแกรมไคลเอนต์ - เรียกใช้งานขั้นตอนไคลเอนต์สตับ พารามิเตอร์จะถูกผลักลงบนสแต็กเหมือนการเรียกใช้งานขั้นตอนภายในเครื่อง
- ขั้นตอนไคลเอนต์สตับ - จัดเก็บ (แพ็ค) ไอดีของขั้นตอนและอาร์กิวเมนต์ลงในข้อความคำขอ
- โมดูลการสื่อสารของไคลเอนต์ - ระบบปฏิบัติการส่งข้อความจากไคลเอนต์ไปยังเซิร์ฟเวอร์
- โมดูลการสื่อสารของเซิร์ฟเวอร์ - ระบบปฏิบัติการส่งแพ็กเก็ตที่เข้ามาไปยังขั้นตอนเซิร์ฟเวอร์สตับ
- ขั้นตอนเซิร์ฟเวอร์สตับ - แกะผลลัพธ์ เรียกใช้งานขั้นตอนเซิร์ฟเวอร์ที่ตรงกับไอดีขั้นตอน และส่งผ่านอาร์กิวเมนต์ที่ได้รับ
- การตอบกลับของเซิร์ฟเวอร์จะทำตามขั้นตอนข้างต้นในลำดับย้อนกลับ
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
เลือกใช้ native library (หรือ SDK) เมื่อ:
- คุณทราบแพลตฟอร์มเป้าหมายของคุณ
- คุณต้องการควบคุมวิธีการเข้าถึง "ตรรกะ" ของคุณ
- คุณต้องการควบคุมการจัดการข้อผิดพลาดที่เกิดขึ้นจากไลบรารีของคุณ
- ประสิทธิภาพและประสบการณ์ผู้ใช้เป็นสิ่งสำคัญสูงสุดของคุณ
#### ข้อเสีย: RPC
- RPC client จะผูกติดกับการทำงานของ service มากเกินไป
- ต้องกำหนด API ใหม่สำหรับทุกการดำเนินการหรือกรณีการใช้งานใหม่
- อาจเป็นเรื่องยากในการ debug RPC
- คุณอาจไม่สามารถใช้เทคโนโลยีที่มีอยู่ได้ทันที ตัวอย่างเช่น อาจต้องใช้ความพยายามเพิ่มเติมเพื่อให้แน่ใจว่า RPC calls ได้รับการแคชอย่างถูกต้อง บนเซิร์ฟเวอร์แคช เช่น Squid
Representational state transfer (REST)
REST เป็นรูปแบบสถาปัตยกรรมที่บังคับใช้โมเดล client/server โดยที่ client ทำงานกับชุดของ resource ที่ถูกจัดการโดย server server จะให้การแสดงผลของ resource และการกระทำที่สามารถเปลี่ยนแปลงหรือรับการแสดงผลใหม่ของ resource ได้ การสื่อสารทั้งหมดต้องเป็นแบบไร้สถานะและสามารถแคชได้
RESTful interface มีคุณสมบัติ 4 ประการ:
- ระบุ resource (URI ใน HTTP) - ใช้ URI เดียวกันไม่ว่าจะเป็นการดำเนินการใด
- เปลี่ยนด้วย representations (Verbs ใน HTTP) - ใช้ verb, header และ body
- ข้อความแสดงข้อผิดพลาดที่อธิบายตัวเอง (status response ใน HTTP) - ใช้ status code ไม่ต้องสร้างใหม่เอง
- HATEOAS (HTML interface สำหรับ HTTP) - web service ของคุณควรเข้าถึงได้เต็มรูปแบบผ่าน browser
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### ข้อเสีย: REST
- เนื่องจาก REST เน้นการเปิดเผยข้อมูล อาจไม่เหมาะหาก resource ไม่ถูกจัดระเบียบหรือเข้าถึงในลำดับชั้นที่ง่าย ตัวอย่างเช่น การคืนข้อมูลทั้งหมดที่ถูกอัปเดตในชั่วโมงที่ผ่านมาโดยตรงกับชุด event เฉพาะ ไม่สามารถแสดงเป็น path ได้ง่ายนัก ใน REST มักต้องใช้การรวมกันของ URI path, query parameters และอาจรวมถึง request body
- REST โดยทั่วไปจะใช้ verb เพียงไม่กี่ตัว (GET, POST, PUT, DELETE และ PATCH) ซึ่งบางครั้งอาจไม่ตรงกับ use case ของคุณ เช่น การย้ายเอกสารที่หมดอายุไปยังโฟลเดอร์ archive อาจไม่ตรงกับ verb เหล่านี้อย่างชัดเจน
- การดึง resource ที่ซับซ้อนและมีลำดับชั้นซ้อนกันต้องใช้การรับ-ส่งข้อมูลระหว่าง client และ server หลายรอบ เพื่อแสดงผลในมุมมองเดียว เช่น การดึงเนื้อหาของบล็อกและคอมเมนต์ สำหรับแอปมือถือที่ทำงานในเครือข่ายที่ไม่แน่นอน การรับ-ส่งข้อมูลหลายรอบเหล่านี้ไม่พึงประสงค์อย่างยิ่ง
- เมื่อเวลาผ่านไป อาจมีการเพิ่ม field ใหม่ใน API response และ client รุ่นเก่าจะได้รับข้อมูล field ใหม่ทั้งหมด แม้จะไม่ได้ต้องการ ส่งผลให้ payload ใหญ่ขึ้นและ latency สูงขึ้น
การเปรียบเทียบ RPC และ REST
| Operation | RPC | REST |
|---|---|---|
| สมัครสมาชิก | POST /signup | POST /persons |
| ลาออก | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| อ่านข้อมูลบุคคล | GET /readPerson?personid=1234 | GET /persons/1234 |
| อ่านรายการสิ่งของของบุคคล | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| เพิ่มสิ่งของให้บุคคล | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| อัปเดตสิ่งของ | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| ลบสิ่งของ | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
ที่มา: คุณรู้จริงหรือไม่ว่าทำไมคุณถึงชอบ REST มากกว่า RPC
#### แหล่งข้อมูลและอ่านเพิ่มเติม: REST และ RPC
- คุณรู้จริงหรือไม่ว่าทำไมคุณถึงชอบ REST มากกว่า RPC
- เมื่อไรที่แนวทาง RPC-ish เหมาะสมกว่า REST?
- REST vs JSON-RPC
- หักล้างความเชื่อผิด ๆ เกี่ยวกับ RPC และ REST
- ข้อเสียของการใช้ REST คืออะไร
- Crack the system design interview
- Thrift
- ทำไม REST สำหรับการใช้งานภายในจึงดีกว่า RPC
ความปลอดภัย
ส่วนนี้อาจต้องการการอัปเดต กรุณา ร่วมแก้ไข!
ความปลอดภัยเป็นหัวข้อที่กว้างใหญ่ หากคุณไม่มีประสบการณ์มาก หรือไม่มีพื้นฐานด้านความปลอดภัย หรือไม่ได้สมัครงานที่ต้องการความรู้ด้านความปลอดภัย คุณอาจไม่จำเป็นต้องรู้มากไปกว่าข้อมูลพื้นฐาน:
- เข้ารหัสข้อมูลทั้งขณะส่งผ่านและขณะเก็บรักษา
- กำจัดข้อมูลอินพุตจากผู้ใช้ หรือพารามิเตอร์อินพุตใด ๆ ที่ผู้ใช้สามารถเข้าถึงได้ เพื่อป้องกัน XSS และ SQL injection
- ใช้การ query แบบมีการกำหนดพารามิเตอร์เพื่อป้องกัน SQL injection
- ใช้หลักการ least privilege
แหล่งข้อมูลและบทความเพิ่มเติม
ภาคผนวก
บางครั้งคุณอาจถูกขอให้ทำการประเมินโดยประมาณคร่าว ๆ เช่น คุณอาจต้องคำนวณว่าต้องใช้เวลากี่นาทีในการสร้างรูปย่อขนาด 100 ภาพจากดิสก์ หรือโครงสร้างข้อมูลหนึ่ง ๆ จะใช้หน่วยความจำเท่าใด ตาราง กำลังสอง และ ตัวเลขความหน่วงที่โปรแกรมเมอร์ควรรู้ เป็นข้อมูลอ้างอิงที่มีประโยชน์
ตารางกำลังสอง
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### แหล่งข้อมูลและอ่านเพิ่มเติม
ตัวเลขค่า Latency ที่โปรแกรมเมอร์ทุกคนควรรู้
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
ข้อมูลเมตริกที่เป็นประโยชน์จากตัวเลขข้างต้น:
- อ่านข้อมูลแบบลำดับจาก HDD ที่ 30 MB/s
- อ่านข้อมูลแบบลำดับจาก Ethernet 1 Gbps ที่ 100 MB/s
- อ่านข้อมูลแบบลำดับจาก SSD ที่ 1 GB/s
- อ่านข้อมูลแบบลำดับจากหน่วยความจำหลักที่ 4 GB/s
- เดินทางรอบโลก 6-7 ครั้งต่อวินาที
- เดินทางรอบในดาต้าเซ็นเตอร์ 2,000 ครั้งต่อวินาที
#### แหล่งข้อมูลและอ่านเพิ่มเติม
- ตัวเลขความหน่วงที่โปรแกรมเมอร์ควรรู้ - 1
- ตัวเลขความหน่วงที่โปรแกรมเมอร์ควรรู้ - 2
- การออกแบบ, บทเรียน, และคำแนะนำจากการสร้างระบบกระจายขนาดใหญ่
- คำแนะนำด้านวิศวกรรมซอฟต์แวร์จากการสร้างระบบกระจายขนาดใหญ่
คำถามสัมภาษณ์ออกแบบระบบเพิ่มเติม
คำถามสัมภาษณ์ออกแบบระบบที่พบบ่อย พร้อมลิงก์แหล่งข้อมูลวิธีแก้แต่ละข้อ
| คำถาม | แหล่งอ้างอิง |
|---|---|
| ออกแบบบริการซิงค์ไฟล์แบบ Dropbox | youtube.com |
| ออกแบบเครื่องมือค้นหาเช่น Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| ออกแบบเว็บครอเลอร์ที่ปรับขนาดได้เช่น Google | quora.com |
| ออกแบบ Google docs | code.google.com
neil.fraser.name |
| ออกแบบระบบ key-value store เช่น Redis | slideshare.net |
| ออกแบบระบบแคชเช่น Memcached | slideshare.net |
| ออกแบบระบบแนะนำสินค้าแบบ Amazon | hulu.com
ijcai13.org |
| ออกแบบระบบ tinyurl เช่น Bitly | n00tc0d3r.blogspot.com |
| ออกแบบแอพแชทเช่น WhatsApp | highscalability.com
| ออกแบบระบบแชร์รูปภาพเช่น Instagram | highscalability.com
highscalability.com |
| ออกแบบฟังก์ชันฟีดข่าว Facebook | quora.com
quora.com
slideshare.net |
| ออกแบบฟังก์ชันไทม์ไลน์ Facebook | facebook.com
highscalability.com |
| ออกแบบฟังก์ชันแชท Facebook | erlang-factory.com
facebook.com |
| ออกแบบฟังก์ชันค้นหาแบบกราฟเหมือน Facebook | facebook.com
facebook.com
facebook.com |
| ออกแบบระบบ Content Delivery Network เหมือน CloudFlare | figshare.com |
| ออกแบบระบบหัวข้อยอดนิยมเหมือน Twitter | michael-noll.com
snikolov .wordpress.com |
| ออกแบบระบบสร้างรหัสสุ่ม | blog.twitter.com
github.com |
| ส่งคืนคำขอสูงสุด k ในช่วงเวลาหนึ่ง | cs.ucsb.edu
wpi.edu |
| ออกแบบระบบให้บริการข้อมูลจากหลายดาต้าเซ็นเตอร์ | highscalability.com |
| ออกแบบเกมไพ่ผู้เล่นหลายคนออนไลน์ | indieflashblog.com
buildnewgames.com |
| ออกแบบระบบจัดการขยะ (Garbage Collection) | stuffwithstuff.com
washington.edu |
| ออกแบบ API rate limiter | https://stripe.com/blog/ |
| ออกแบบตลาดหลักทรัพย์ (เช่น NASDAQ หรือ Binance) | Jane Street
Golang Implementation
Go Implementation |
| เพิ่มคำถามออกแบบระบบ | ร่วมสมทบ |
สถาปัตยกรรมในโลกจริง
บทความเกี่ยวกับการออกแบบระบบในโลกจริง
ที่มา: Twitter timelines at scale
ไม่ต้องเน้นรายละเอียดปลีกย่อยสำหรับบทความเหล่านี้ แต่ให้:
- ระบุหลักการที่ใช้ร่วมกัน เทคโนโลยีทั่วไป และรูปแบบที่พบในบทความเหล่านี้
- ศึกษาว่าแต่ละองค์ประกอบแก้ไขปัญหาอะไร ตรงจุดไหนที่เหมาะสม และจุดไหนที่ไม่เหมาะสม
- ทบทวนบทเรียนที่ได้รับ
สถาปัตยกรรมของบริษัท
| บริษัท | แหล่งอ้างอิง |
|---|---|
| Amazon | สถาปัตยกรรม Amazon |
| Cinchcast | การผลิตไฟล์เสียง 1,500 ชั่วโมงต่อวัน |
| DataSift | การทำเหมืองข้อมูลแบบเรียลไทม์ที่ 120,000 ทวีตต่อวินาที |
| Dropbox | วิธีที่ Dropbox ขยายตัว |
| ESPN | การดำเนินงานที่ 100,000 duh nuh nuhs ต่อวินาที |
| Google | สถาปัตยกรรม Google |
| Instagram | 14 ล้านผู้ใช้, เทราไบต์ของรูปภาพ
สิ่งที่ขับเคลื่อน Instagram |
| Justin.tv | สถาปัตยกรรมถ่ายทอดสดของ Justin.tv |
| Facebook | การขยาย memcached ที่ Facebook
TAO: ที่เก็บข้อมูลแบบกระจายสำหรับ social graph ของ Facebook
การจัดเก็บรูปภาพของ Facebook
วิธีที่ Facebook ถ่ายทอดสดไปยัง 800,000 ผู้ชมพร้อมกัน |
| Flickr | สถาปัตยกรรม Flickr |
| Mailbox | จาก 0 ถึงหนึ่งล้านผู้ใช้ใน 6 สัปดาห์ |
| Netflix | มุมมอง 360 องศาต่อสแต็กทั้งหมดของ Netflix
Netflix: เกิดอะไรขึ้นเมื่อคุณกดเล่น? |
| Pinterest | จาก 0 ถึงหลายสิบพันล้าน page views ต่อเดือน
18 ล้านผู้เข้าชม, เติบโต 10 เท่า, พนักงาน 12 คน |
| Playfish | 50 ล้านผู้ใช้ต่อเดือนและยังคงเพิ่มขึ้น |
| PlentyOfFish | สถาปัตยกรรม PlentyOfFish |
| Salesforce | วิธีจัดการธุรกรรม 1.3 พันล้านรายการต่อวัน |
| Stack Overflow | สถาปัตยกรรม Stack Overflow |
| TripAdvisor | 40 ล้านผู้เข้าชม, 200 ล้าน page views แบบไดนามิก, ข้อมูล 30TB |
| Tumblr | 15 พันล้าน page views ต่อเดือน |
| Twitter | ทำให้ Twitter เร็วขึ้น 10000 เปอร์เซ็นต์
การจัดเก็บ 250 ล้านทวีตต่อวันด้วย MySQL
150 ล้านผู้ใช้, 300K QPS, ข้อมูล 22 MB/S
ไทม์ไลน์ที่ขยายได้
ข้อมูลใหญ่และเล็กที่ Twitter
การดำเนินงานที่ Twitter: ขยายเกิน 100 ล้านผู้ใช้
Twitter รับมือกับ 3,000 รูปภาพต่อวินาทีอย่างไร |
| Uber | Uber ขยายแพลตฟอร์มตลาดแบบเรียลไทม์อย่างไร
บทเรียนจากการขยาย Uber ไปยัง 2000 วิศวกร, 1000 บริการ, และ 8000 Git repositories |
| WhatsApp | สถาปัตยกรรม WhatsApp ที่ Facebook ซื้อไปในราคา 19 พันล้านเหรียญ |
| YouTube | การปรับขนาดของ YouTube
สถาปัตยกรรม YouTube |
บล็อกวิศวกรรมของบริษัท
สถาปัตยกรรมสำหรับบริษัทที่คุณกำลังสัมภาษณ์งานด้วย>
คำถามที่คุณพบอาจมาจากโดเมนเดียวกัน
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
กำลังมองหาบล็อกที่จะเพิ่ม? เพื่อหลีกเลี่ยงการทำงานซ้ำ โปรดพิจารณาเพิ่มบล็อกบริษัทของคุณลงใน repo ต่อไปนี้:
กำลังอยู่ระหว่างการพัฒนา
สนใจจะเพิ่มหัวข้อหรือช่วยเติมเต็มส่วนที่กำลังดำเนินการอยู่หรือไม่? ร่วมสมทบ!
- การประมวลผลแบบกระจายด้วย MapReduce
- Consistent hashing
- Scatter gather
- ร่วมสมทบ
เครดิต
เครดิตและแหล่งข้อมูลมีให้ตลอดทั้ง repo นี้
ขอขอบคุณเป็นพิเศษแก่:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
ข้อมูลติดต่อ
สามารถติดต่อฉันได้หากต้องการพูดคุยเกี่ยวกับปัญหา คำถาม หรือข้อเสนอแนะใด ๆ
ข้อมูลการติดต่อของฉันสามารถพบได้ที่ GitHub page
ใบอนุญาต
ฉันให้โค้ดและทรัพยากรในรีโพซิทอรีนี้แก่คุณภายใต้สัญญาอนุญาตแบบโอเพนซอร์ส เนื่องจากนี่คือรีโพซิทอรีส่วนตัวของฉัน สัญญาอนุญาตที่คุณได้รับสำหรับโค้ดและทรัพยากรจึงเป็นจากฉัน ไม่ใช่นายจ้างของฉัน (Facebook)
Copyright 2017 Donne Martin
ใบอนุญาต Creative Commons Attribution 4.0 International (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---