English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Помогите перевести этот гид!
Системное проектирование: Основы

Мотивация
Научитесь проектировать крупномасштабные системы.>
Подготовьтесь к собеседованию по системному проектированию.
Научитесь проектировать крупномасштабные системы
Изучение принципов масштабирования систем поможет вам стать лучшим инженером.
Системное проектирование — это обширная тема. Огромное количество ресурсов разбросано по всему интернету и посвящено принципам проектирования систем.
Этот репозиторий — организованная коллекция материалов, которые помогут вам научиться строить масштабируемые системы.
Учитесь у сообщества open source
Это постоянно обновляемый проект с открытым исходным кодом.
Вклад приветствуется!
Подготовка к собеседованию по системному проектированию
В дополнение к собеседованиям по программированию системное проектирование является обязательной частью технического интервью во многих IT-компаниях.
Тренируйтесь на популярных вопросах по системному проектированию и сравнивайте свои решения с примерами: обсуждениями, кодом и схемами.
Дополнительные темы для подготовки к собеседованию:
- Путеводитель по изучению
- Как решать вопросы по системному проектированию на собеседовании
- Вопросы по системному дизайну для интервью, с решениями
- Вопросы по объектно-ориентированному дизайну для интервью, с решениями
- Дополнительные вопросы по системному дизайну для интервью
Anki карточки
Предоставленные колоды карточек Anki используют интервальное повторение для закрепления ключевых концепций системного дизайна.
- Колода по системному дизайну
- Колода упражнений по системному дизайну
- Колода упражнений по объектно-ориентированному дизайну
Ресурс по программированию: Интерактивные задачи по программированию
Ищете ресурсы для подготовки к интервью по программированию?
Ознакомьтесь с сестринским репозиторием Interactive Coding Challenges, который содержит дополнительную колоду Anki:
Участие
Учитесь у сообщества.
Не стесняйтесь отправлять pull-запросы, чтобы помочь:
- Исправить ошибки
- Улучшить разделы
- Добавьте новые разделы
- Перевести
Ознакомьтесь с Руководством по внесению изменений.
Индекс тем по проектированию систем
Краткие обзоры различных тем по проектированию систем, включая плюсы и минусы. Всё — компромисс.>
Каждый раздел содержит ссылки на более подробные ресурсы.
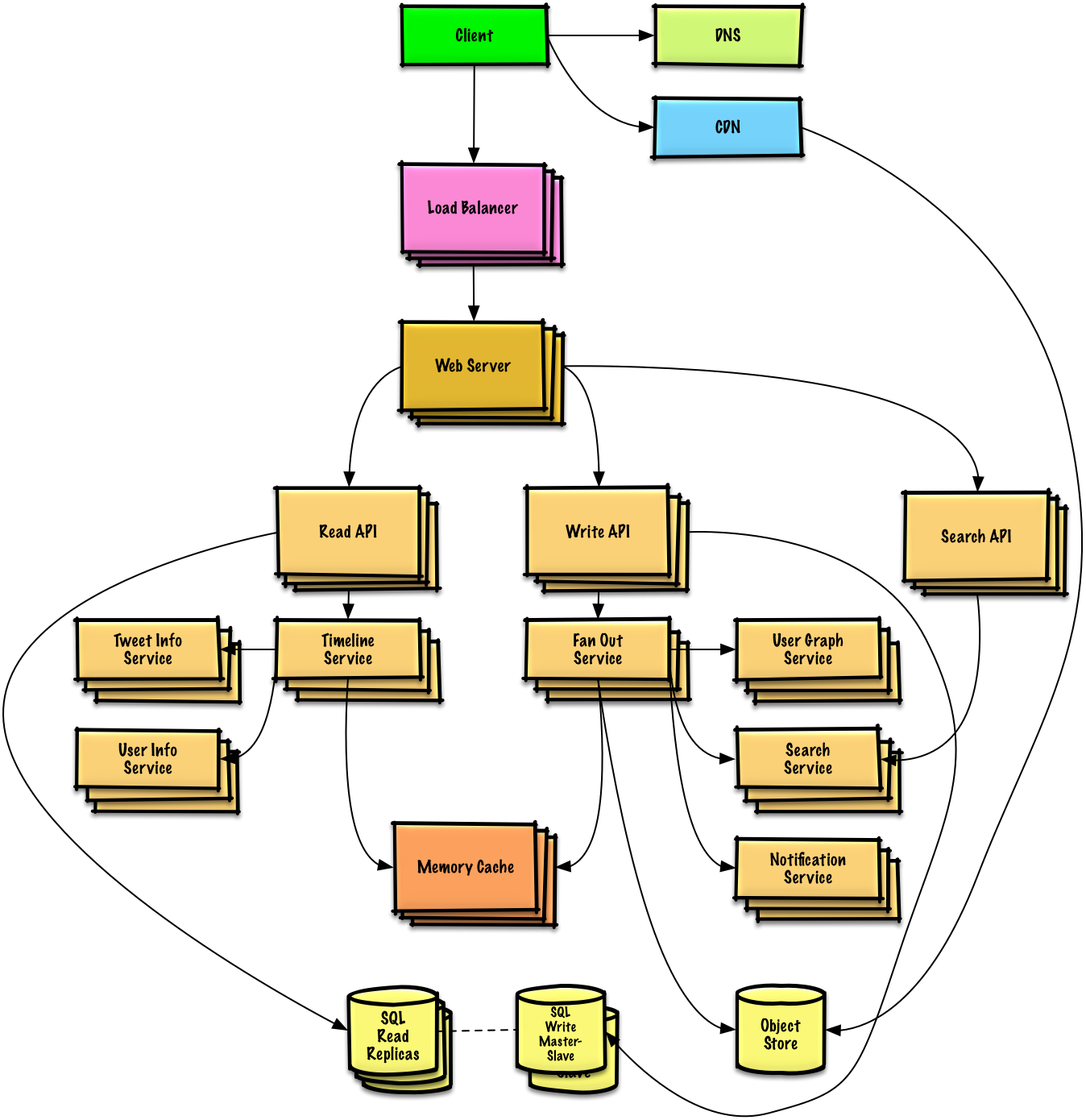
- Темы по проектированию систем: начните здесь
- Шаг 1: Просмотрите видео-лекцию о масштабируемости
- Шаг 2: Ознакомьтесь со статьёй о масштабируемости
- Следующие шаги
- Производительность vs масштабируемость
- Задержка vs пропускная способность
- Доступность vs согласованность
- Теорема CAP
- CP — согласованность и устойчивость к разделению
- AP — доступность и устойчивость к разделению
- Паттерны согласованности
- Слабая согласованность
- В конечном итоге согласованность
- Сильная согласованность
- Паттерны доступности
- Автоматическое переключение
- Репликация
- Доступность в числах
- Система доменных имён
- Сеть доставки контента
- Push CDN
- Pull CDN
- Балансировщик нагрузки
- Активный-пассивный
- Активный-активный
- Балансировка нагрузки на уровне 4
- Балансировка нагрузки на уровне 7
- Горизонтальное масштабирование
- Обратный прокси (веб-сервер)
- Балансировщик нагрузки vs обратный прокси
- Прикладной уровень
- Микросервисы
- Обнаружение сервисов
- База данных
- Система управления реляционными базами данных (СУБД)
- Репликация мастер-слейв
- Репликация мастер-мастер
- Федерация
- Шардинг
- Денормализация
- Оптимизация SQL
- NoSQL
- Ключ-значение хранилище
- Документное хранилище
- Широкостолбцовое хранилище
- Графовая база данных
- SQL или NoSQL
- Кэш
- Кэширование на стороне клиента
- Кэширование на CDN
- Кэширование на веб-сервере
- Кэширование базы данных
- Кэширование на уровне приложения
- Кэширование на уровне запросов к базе данных
- Кэширование на уровне объектов
- Когда обновлять кэш
- Cache-aside (кэш в стороне)
- Write-through (прямое обновление)
- Write-behind (отложенная запись)
- Refresh-ahead (опережающее обновление)
- Асинхронность
- Очереди сообщений
- Очереди задач
- Обратное давление (Back pressure)
- Связь
- Протокол управления передачей (TCP)
- Протокол пользовательских дейтаграмм (UDP)
- Удалённый вызов процедур (RPC)
- Передача представления состояния (REST)
- Безопасность
- Приложение
- Таблица степеней двойки
- Задержки, которые должен знать каждый программист
- Дополнительные вопросы по проектированию систем для интервью
- Архитектуры из реального мира
- Архитектуры компаний
- Инженерные блоги компаний
- В разработке
- Благодарности
- Контактная информация
- Лицензия
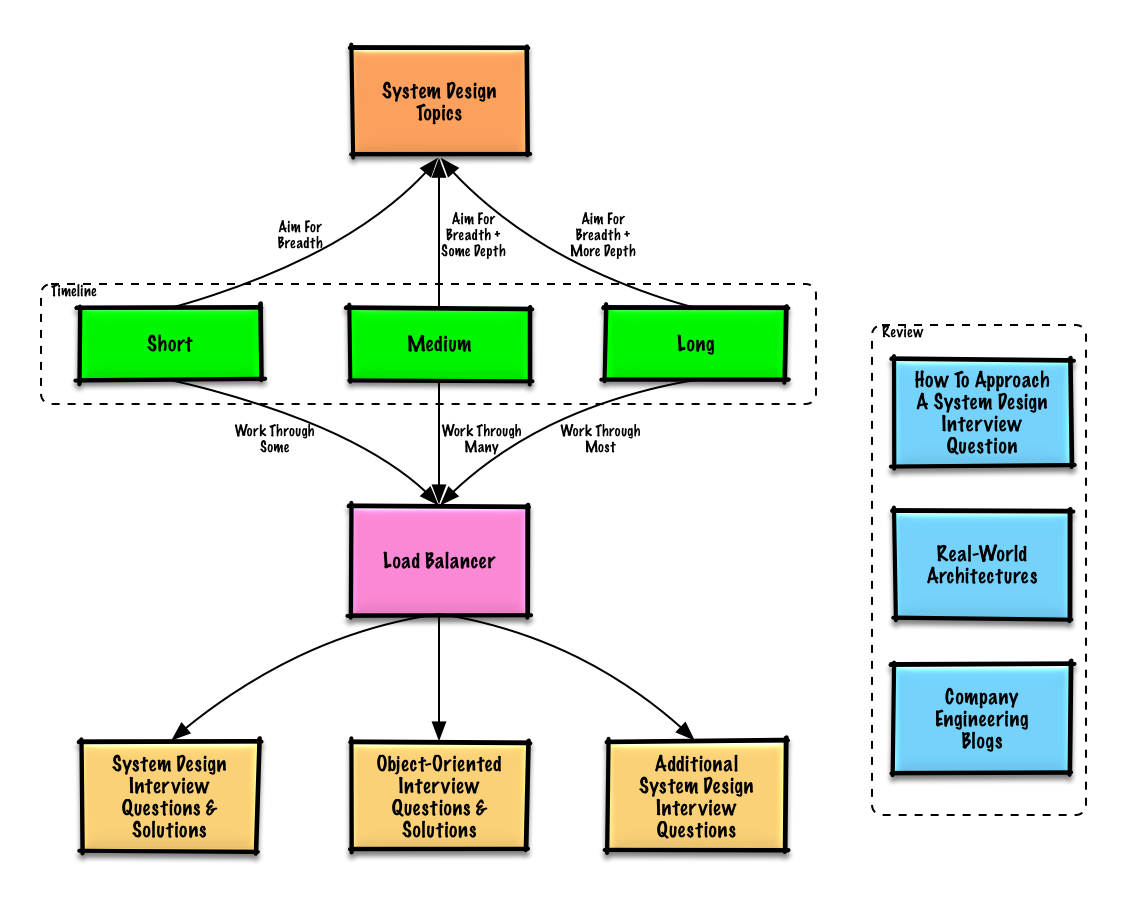
Гайд по обучению
Рекомендуемые темы для изучения в зависимости от вашего графика подготовки к интервью (короткий, средний, длинный).
Вопрос: Для интервью мне нужно знать всё, что здесь указано?
Ответ: Нет, вам не обязательно знать всё это для подготовки к интервью.
Что вас спросят на интервью, зависит от таких факторов, как:
- Ваш опыт работы
- Ваш технический бэкграунд
- Должности, на которые вы проходите собеседование
- Компании, в которых вы проходите собеседование
- Удача
Начните с общего обзора и углубляйтесь в некоторые области. Полезно знать хотя бы немного о различных ключевых темах проектирования систем. Корректируйте следующий гид исходя из вашего графика, опыта, позиций, на которые вы проходите собеседование, и компаний, в которых вы проходите собеседование.
- Короткий срок — ориентируйтесь на широту тем по проектированию систем. Практикуйтесь, решая некоторые вопросы из собеседований.
- Средний срок — ориентируйтесь на широту и некоторую глубину тем по проектированию систем. Практикуйтесь, решая многие вопросы из собеседований.
- Длинный срок — ориентируйтесь на широту и большую глубину тем по проектированию систем. Практикуйтесь, решая большинство вопросов из собеседований.
Как подходить к вопросам по проектированию систем на собеседовании
Как решать вопросы по проектированию систем на собеседовании.
Собеседование по проектированию систем — это открытая беседа. Ожидается, что вы будете ее вести.
Вы можете воспользоваться следующими шагами для ведения дискуссии. Для закрепления этого процесса проработайте раздел Вопросы по проектированию систем с решениями, используя эти шаги.
Шаг 1: Определите варианты использования, ограничения и предположения
Соберите требования и определите рамки задачи. Задавайте вопросы для уточнения вариантов использования и ограничений. Обсуждайте предположения.
- Кто будет этим пользоваться?
- Как они будут этим пользоваться?
- Сколько пользователей будет?
- Что делает система?
- Каковы входные и выходные данные системы?
- Сколько данных мы ожидаем обработать?
- Сколько запросов в секунду мы ожидаем?
- Каково ожидаемое соотношение чтения к записи?
Шаг 2: Создайте высокоуровневый дизайн
Опишите высокоуровневый дизайн с указанием всех важных компонентов.
- Нарисуйте основные компоненты и их соединения
- Обоснуйте свои идеи
Шаг 3: Проектирование основных компонентов
Разберите детали каждого основного компонента. Например, если вам предложено спроектировать сервис сокращения URL, обсудите:
- Генерация и хранение хэша полного URL
- MD5 и Base62
- Коллизии хэшей
- SQL или NoSQL
- Схема базы данных
- Преобразование хэшированного URL обратно в полный URL
- Поиск в базе данных
- API и объектно-ориентированное проектирование
Шаг 4: Масштабирование архитектуры
Определите и устраните узкие места с учетом ограничений. Например, потребуется ли следующее для решения проблем масштабируемости?
- Балансировщик нагрузки
- Горизонтальное масштабирование
- Кэширование
- Шардирование базы данных
Оценки «на коленке»
Вас могут попросить сделать некоторые оценки вручную. Обратитесь к Приложению для следующих ресурсов:
- Используйте оценки «на коленке»
- Таблица степеней двойки
- Числа задержек, которые должен знать каждый программист
Источники и дополнительная литература
Ознакомьтесь со следующими ссылками, чтобы лучше понять, чего ожидать:
- Как пройти собеседование по системному дизайну
- Собеседование по системному дизайну
- Введение в архитектуру и собеседования по системному дизайну
- Шаблон для системного дизайна
Вопросы по системному дизайну с решениями
Типовые вопросы на собеседовании по системному дизайну с примерами обсуждений, кода и схем.>
Решения связаны с содержимым в папке solutions/.| Вопрос | | |---|---| | Спроектируйте Pastebin.com (или Bit.ly) | Решение | | Спроектируйте таймлайн и поиск в Twitter (или ленту и поиск в Facebook) | Решение | | Спроектируйте веб-краулер | Решение | | Спроектируйте Mint.com | Решение | | Спроектируйте структуры данных для социальной сети | Решение | | Спроектируйте key-value хранилище для поисковой системы | Решение | | Спроектируйте функцию ранжирования продаж по категориям в Amazon | Решение | | Спроектируйте систему, масштабируемую до миллионов пользователей на AWS | Решение | | Добавьте вопрос по системному дизайну | Внести вклад |
Спроектируйте Pastebin.com (или Bit.ly)
Просмотреть упражнение и решение
Спроектируйте таймлайн и поиск в Twitter (или ленту и поиск в Facebook)
Просмотреть упражнение и решение
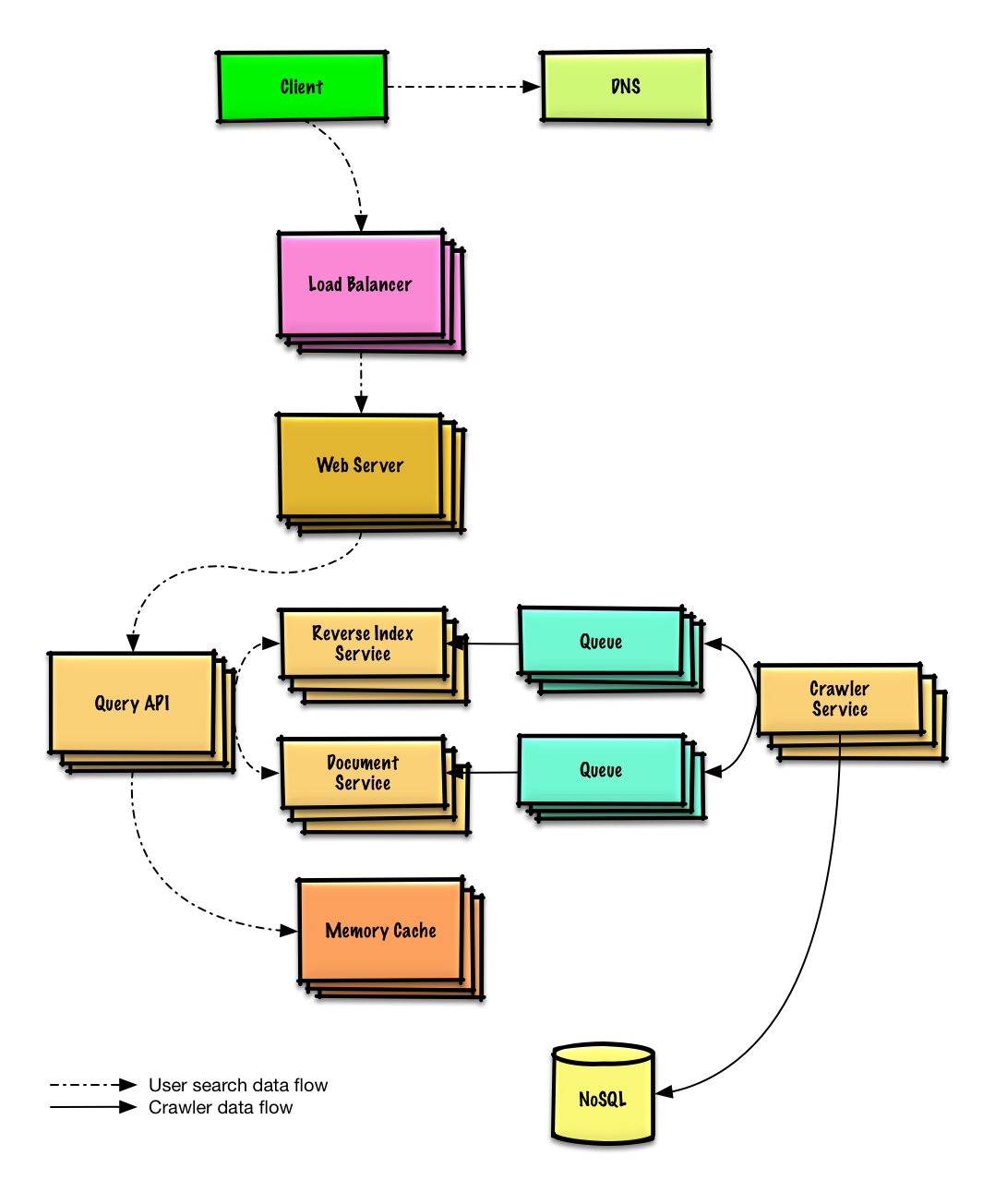
Спроектируйте веб-краулер
Просмотреть упражнение и решение
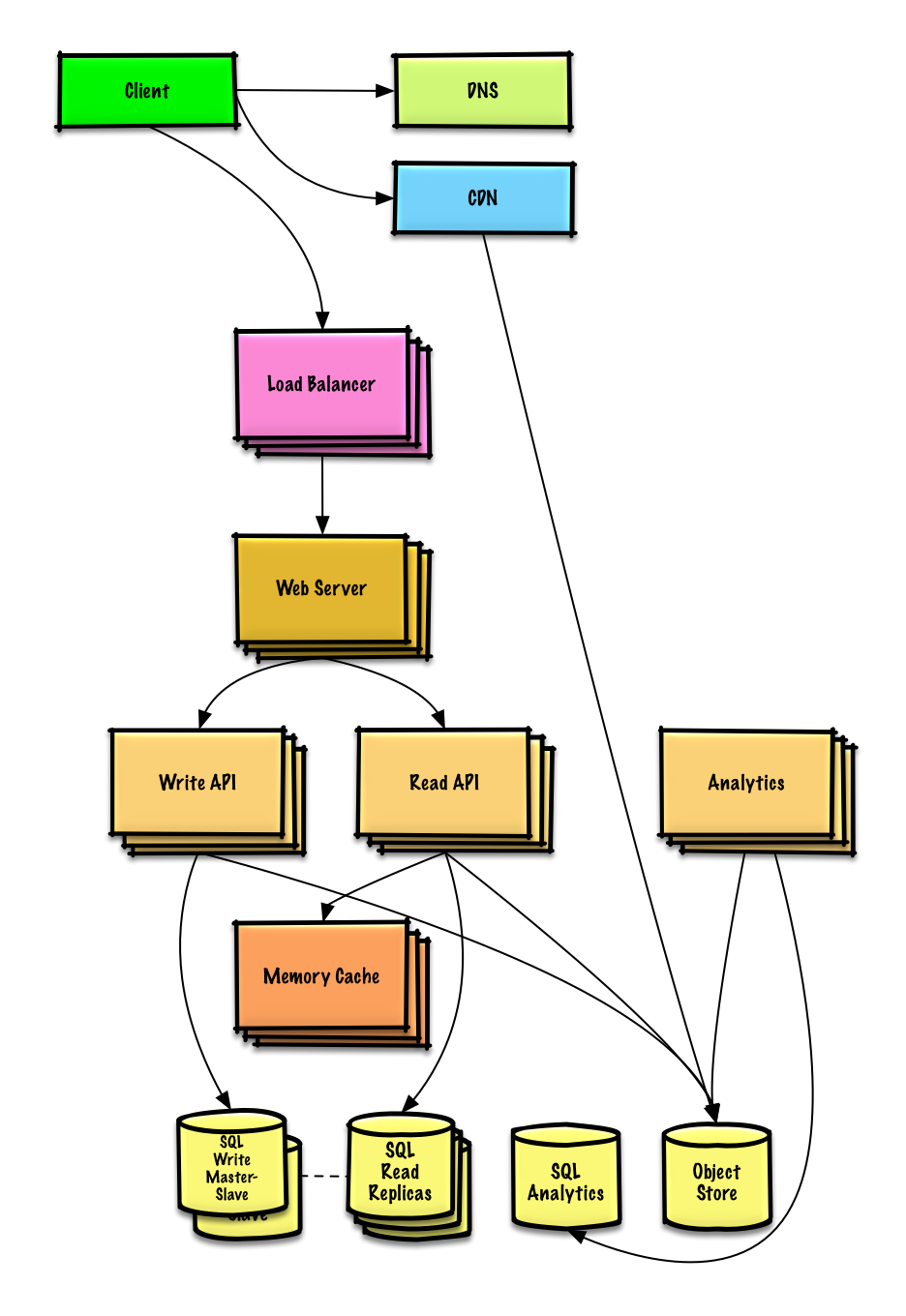
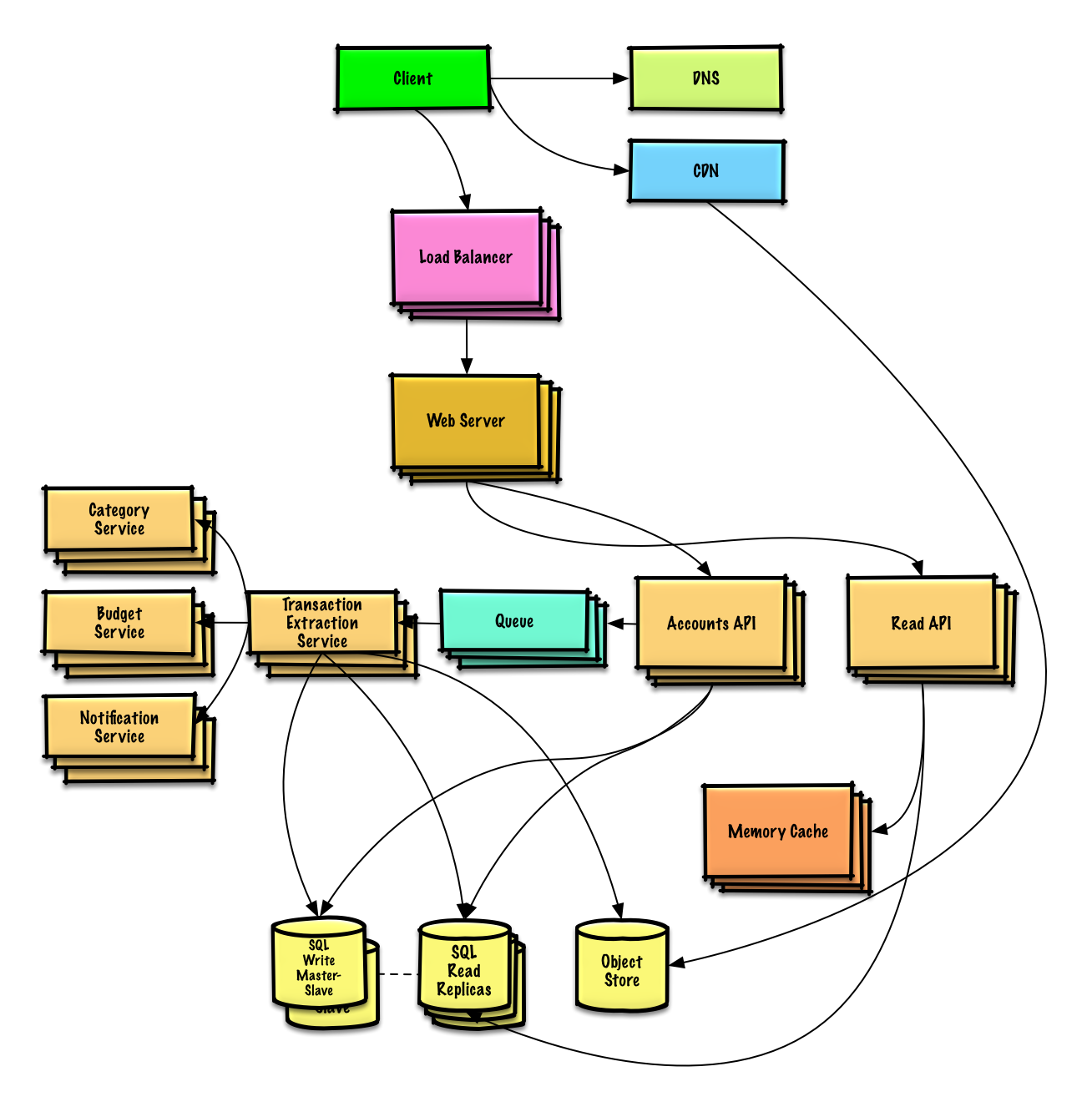
Design Mint.com
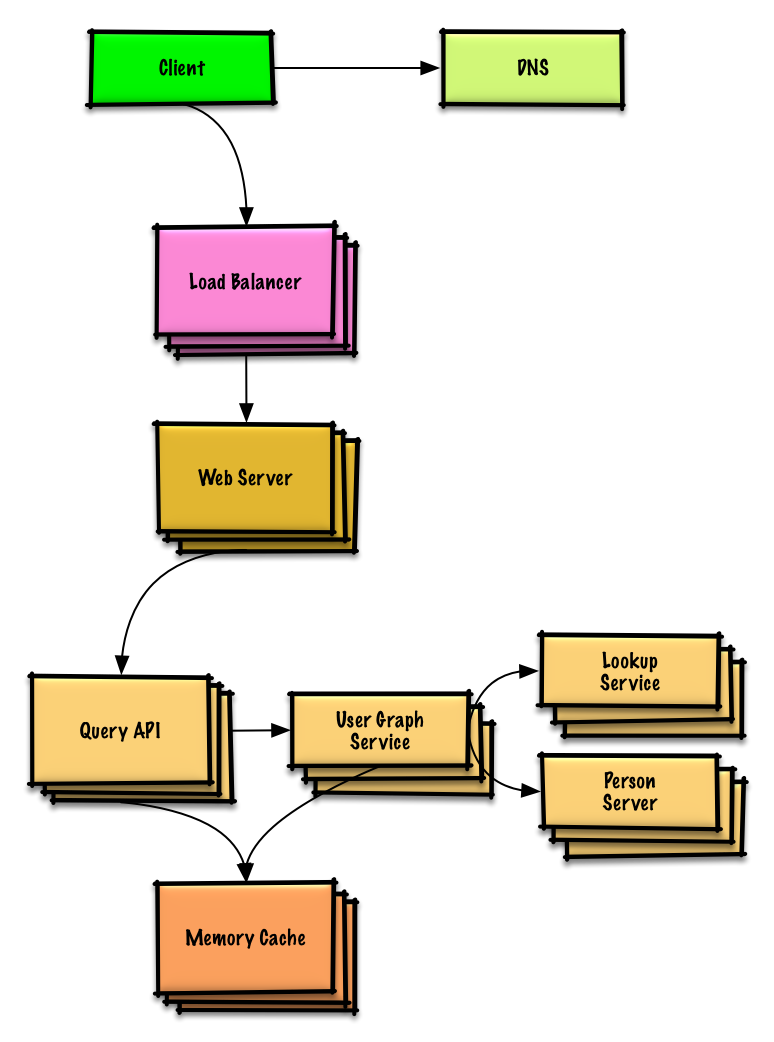
Design the data structures for a social network
Design a key-value store for a search engine
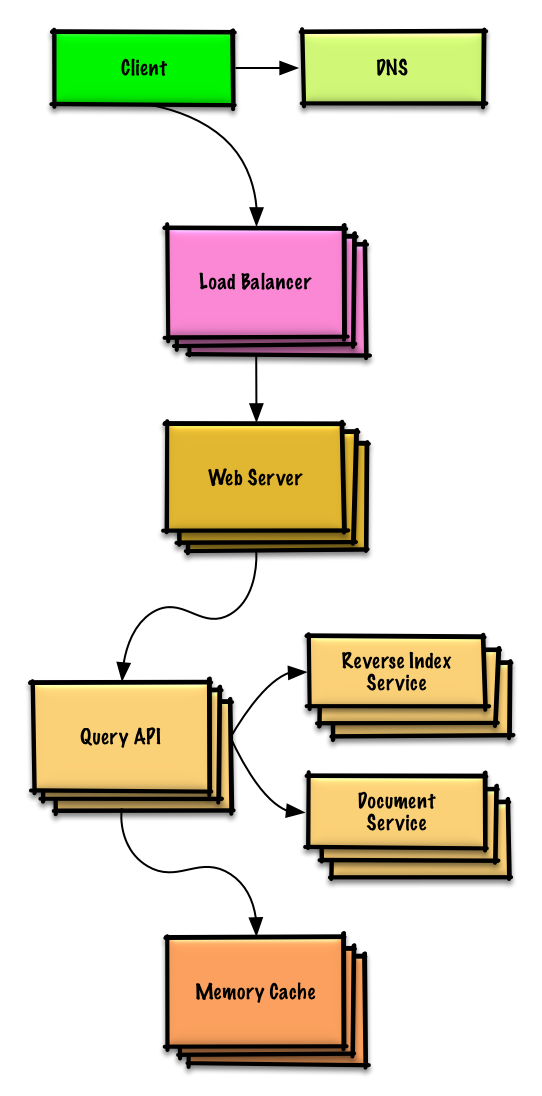
Design Amazon's sales ranking by category feature
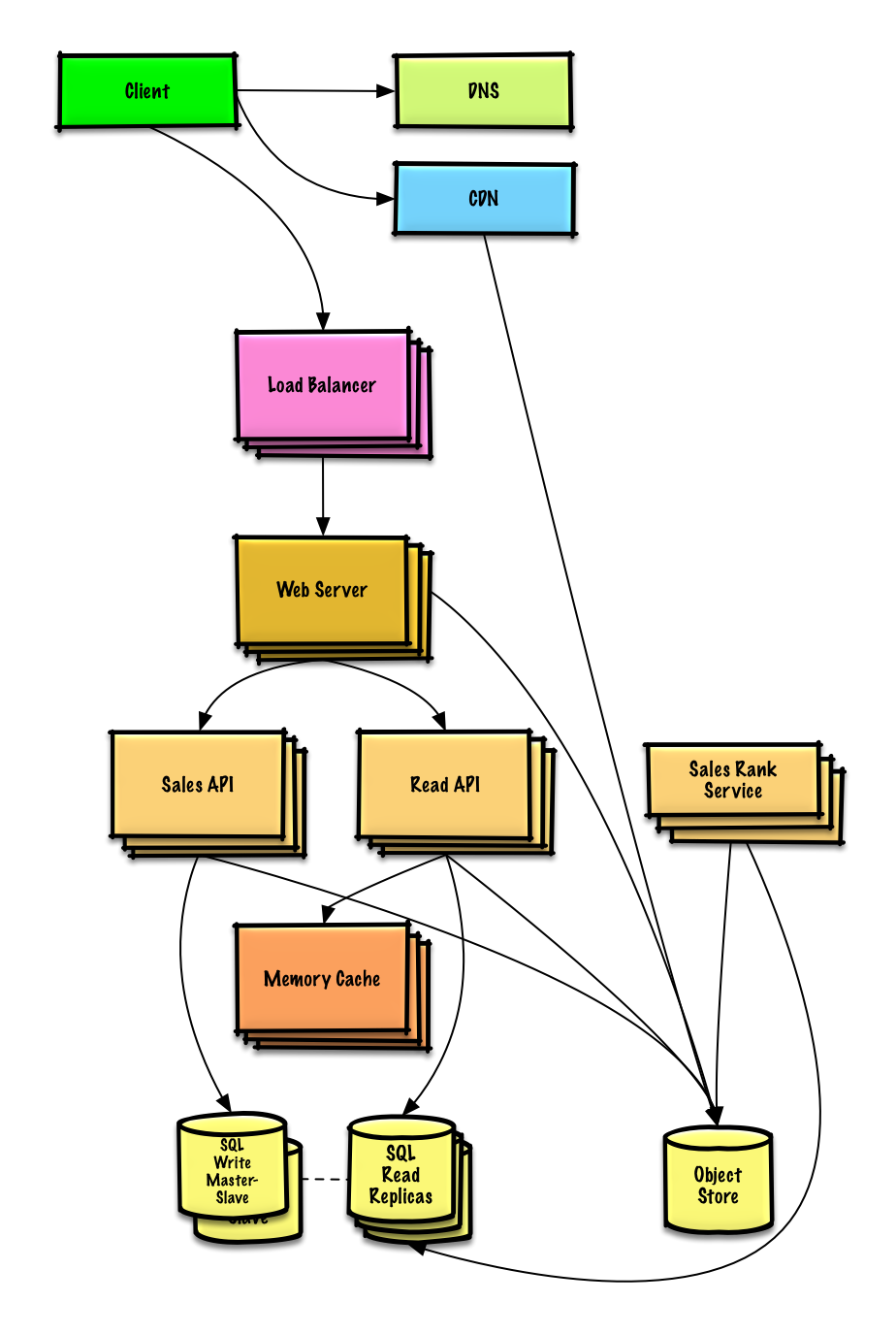
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Спроектировать хеш-таблицу | Решение | | Спроектировать кэш с удалением наименее используемых данных (LRU) | Решение | | Спроектировать колл-центр | Решение | | Спроектировать колоду карт | Решение | | Спроектировать парковку | Решение | | Спроектировать чат-сервер | Решение | | Спроектировать кольцевой массив | Внести вклад | | Добавить вопрос по объектно-ориентированному проектированию | Внести вклад |
Темы системного проектирования: начните здесь
Впервые сталкиваетесь с системным проектированием?
Сначала вам нужно базовое понимание общих принципов: узнать, что это такое, как они применяются, их плюсы и минусы.
Шаг 1: Посмотрите видеолекцию по масштабируемости
Лекция по масштабируемости в Гарварде
- Рассматриваемые темы:
- Вертикальное масштабирование
- Горизонтальное масштабирование
- Кэширование
- Балансировка нагрузки
- Репликация баз данных
- Партиционирование баз данных
Шаг 2: Ознакомьтесь со статьей о масштабируемости
- Рассматриваемые темы:
- Клоны
- Базы данных
- Кэши
- Асинхронность
Следующие шаги
Далее мы рассмотрим компромиссы на высоком уровне:
- Производительность vs масштабируемость
- Задержка vs пропускная способность
- Доступность vs согласованность
Затем мы углубимся в более конкретные темы, такие как DNS, CDN и балансировщики нагрузки.
Производительность vs масштабируемость
Сервис считается масштабируемым, если увеличение ресурсов приводит к пропорциональному росту производительности. Обычно под увеличением производительности понимается возможность обслуживать больше единиц работы, но это также может означать обработку более крупных единиц работы, например, при росте объёмов данных.1
Другой способ взглянуть на производительность и масштабируемость:
- Если у вас проблема с производительностью, ваша система медленно работает для одного пользователя.
- Если у вас проблема с масштабируемостью, ваша система быстро работает для одного пользователя, но медленно под высокой нагрузкой.
Источники и дополнительное чтение
Задержка vs пропускная способность
Задержка — это время, необходимое для выполнения действия или получения результата.
Пропускная способность — это количество таких действий или результатов в единицу времени.
Обычно следует стремиться к максимальной пропускной способности при приемлемой задержке.
Источники и дополнительное чтение
Доступность vs согласованность
Теорема CAP
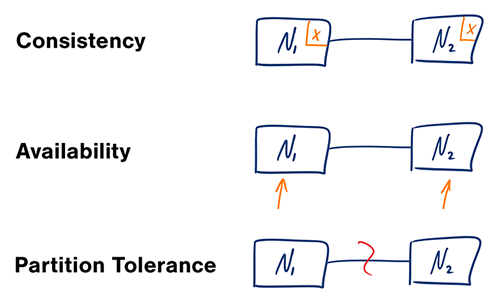
Источник: CAP theorem revisited
В распределённой компьютерной системе можно поддерживать только две из следующих гарантий:
- Согласованность - Каждый запрос на чтение получает либо самое последнее записанное значение, либо ошибку
- Доступность - Каждый запрос получает ответ, но без гарантии, что ответ содержит самую свежую версию информации
- Устойчивость к разделению - Система продолжает работать, несмотря на произвольное разделение из-за сетевых сбоев
#### CP - согласованность и устойчивость к разделению
Ожидание ответа от разделённого узла может привести к ошибке тайм-аута. CP — хороший выбор, если бизнес-требования требуют атомарных операций чтения и записи.
#### AP - доступность и устойчивость к разделению
Ответы возвращают наиболее доступную версию данных на любом узле, которая может быть не самой свежей. Записи могут распространяться с задержкой после восстановления разделения.
AP — хороший выбор, если бизнес допускает постепенную согласованность или если системе требуется продолжать работу несмотря на внешние ошибки.
Источники и дополнительная литература
Шаблоны согласованности
При наличии нескольких копий одних и тех же данных мы сталкиваемся с выбором способа их синхронизации, чтобы клиенты имели согласованный взгляд на данные. Напомним определение согласованности из теоремы CAP — Каждый запрос на чтение получает самое последнее записанное значение или ошибку.
Слабая согласованность
После записи запросы на чтение могут как увидеть, так и не увидеть её. Применяется принцип наилучших усилий.
Этот подход используется в системах типа memcached. Слабая согласованность хорошо работает для случаев реального времени, таких как VoIP, видеочат и онлайн-игры в реальном времени. Например, если во время телефонного разговора вы на несколько секунд теряете связь, то, когда соединение восстанавливается, вы не услышите, что было сказано во время потери связи.
Конечная согласованность
После записи данные будут видны при чтении со временем (обычно в течение миллисекунд). Данные реплицируются асинхронно.
Такой подход используется в системах, таких как DNS и электронная почта. Конечная согласованность хорошо работает в системах с высокой доступностью.
Сильная согласованность
После записи данные будут видны при чтении. Данные реплицируются синхронно.
Такой подход используется в файловых системах и реляционных СУБД. Сильная согласованность хорошо подходит для систем, которым нужны транзакции.
Источники и дополнительная литература
Паттерны обеспечения доступности
Существует два взаимодополняющих паттерна для поддержки высокой доступности: фейловер и репликация.
Фейловер
#### Активный-пассивный
При активном-пассивном фейловере между активным и пассивным сервером на резерве отправляются сигналы "heartbeat". Если сигнал прерывается, пассивный сервер принимает IP-адрес активного и продолжает обслуживание.
Длительность простоя определяется тем, запущен ли пассивный сервер уже в режиме "горячего" резерва, либо ему нужно стартовать из "холодного" резерва. Только активный сервер обрабатывает трафик.
Активно-пассивный фейловер также называют мастер-слейв фейловером.
#### Активный-активный
При активном-активном оба сервера обрабатывают трафик, распределяя нагрузку между собой.
Если серверы доступны из Интернета, DNS должен знать о публичных IP-адресах обоих серверов. Если серверы внутренние, логика приложения должна знать о них.
Активно-активный фейловер также называют мастер-мастер фейловером.
Недостатки: фейловер
- Резервирование требует дополнительного оборудования и увеличивает сложность системы.
- Существует риск потери данных, если активная система выйдет из строя до того, как новые записанные данные будут реплицированы на пассивную.
Репликация
#### Мастер-слейв и мастер-мастер
Эта тема более подробно рассматривается в разделе База данных:
Доступность в числах
Доступность часто выражается временем безотказной работы (или простоя) как процент времени, в течение которого сервис доступен. Обычно доступность измеряется количеством девяток -- сервис с 99,99% доступностью называют сервисом "четыре девятки".
#### 99,9% доступности — три девятки
| Период | Допустимое время простоя| |---------------------|------------------------| | Простой в год | 8ч 45мин 57с | | Простой в месяц | 43мин 49,7с | | Простой в неделю | 10мин 4,8с | | Простой в день | 1мин 26,4с |
#### 99,99% доступности — четыре девятки
| Период | Допустимое время простоя| |---------------------|------------------------| | Простой в год | 52мин 35,7с | | Простой в месяц | 4мин 23с | | Простой в неделю | 1мин 5с | | Простой в день | 8,6с |
#### Доступность при параллельной и последовательной работе
Если сервис состоит из нескольких компонентов, подверженных сбоям, общая доступность сервиса зависит от того, работают ли компоненты последовательно или параллельно.
###### Последовательно
Общая доступность снижается, когда два компонента с доступностью < 100% идут последовательно:
Availability (Total) = Availability (Foo) * Availability (Bar)Если и Foo, и Bar имеют доступность 99,9%, их общая доступность при последовательном соединении будет 99,8%.
###### В параллели
Общая доступность увеличивается, когда два компонента с доступностью < 100% работают параллельно:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo, и Bar имеют доступность 99,9%, их общая доступность в параллельной работе будет 99,9999%.Система доменных имен
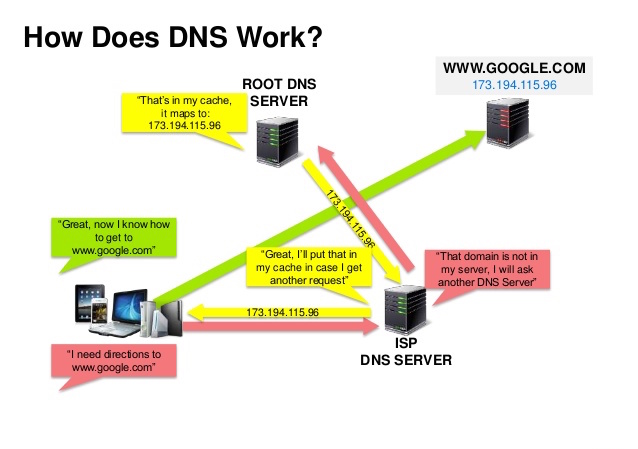
Источник: Презентация по безопасности DNS
Система доменных имен (DNS) переводит доменное имя, такое как www.example.com, в IP-адрес.
DNS иерархична, с несколькими авторитетными серверами на верхнем уровне. Ваш маршрутизатор или интернет-провайдер предоставляет информацию о том, с какими DNS-серверами связываться при поиске. DNS-серверы нижнего уровня кэшируют соответствия, которые могут устаревать из-за задержек распространения DNS. Результаты DNS также могут кэшироваться вашим браузером или ОС в течение определенного периода времени, определяемого временем жизни (TTL).
- NS-запись (сервер имен) – Указывает DNS-серверы для вашего домена/поддомена.
- MX-запись (почтовый обменник) – Указывает почтовые серверы для приема сообщений.
- A-запись (адрес) – Привязывает имя к IP-адресу.
- CNAME (каноническое имя) – Привязывает имя к другому имени или
CNAME(example.com к www.example.com) или кA-записи.
- Взвешенное круговое распределение
- Предотвращение направления трафика на серверы, находящиеся на обслуживании
- Балансировка между кластерами разного размера
- A/B тестирование
- На основе задержки
- На основе геолокации
Недостатки: DNS
- Обращение к DNS-серверу вызывает небольшую задержку, которая, однако, смягчается описанным выше кэшированием.
- Управление DNS-серверами может быть сложным и обычно осуществляется государствами, интернет-провайдерами и крупными компаниями.
- Недавно службы DNS подвергались DDoS-атакам, что не позволяло пользователям заходить на сайты, такие как Twitter, без знания IP-адреса(-ов) Twitter.
Источники и дополнительная литература
Сеть доставки контента
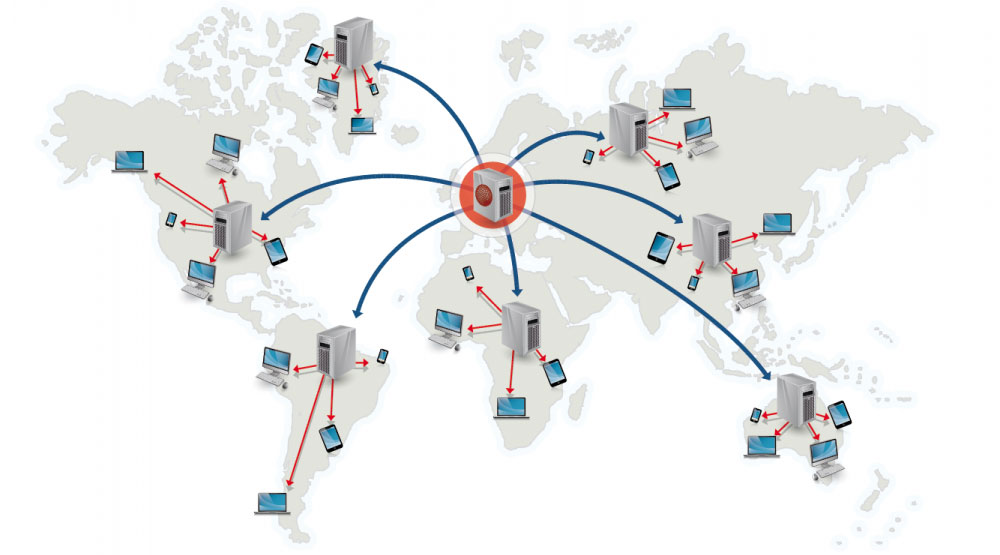
Источник: Почему использовать CDN
Сеть доставки контента (CDN) — это глобально распределённая сеть прокси-серверов, обслуживающая контент из локаций, более близких к пользователю. Как правило, статические файлы, такие как HTML/CSS/JS, фотографии и видео, обслуживаются через CDN, хотя некоторые CDN, например CloudFront от Amazon, поддерживают динамический контент. Разрешение DNS сайта указывает клиентам, к какому серверу обращаться.
Обслуживание контента через CDN может значительно повысить производительность двумя способами:
- Пользователи получают контент из дата-центров, расположенных ближе к ним
- Ваши серверы не обслуживают запросы, которые выполняет CDN
Push CDN
Push CDN получают новый контент всякий раз, когда на вашем сервере происходят изменения. Вы полностью отвечаете за предоставление контента, загружая его напрямую на CDN и переписывая URL на CDN. Вы можете настроить срок хранения контента и время его обновления. Контент загружается только когда он новый или изменён, минимизируя трафик, но увеличивая использование хранилища.
Сайты с небольшим количеством трафика или сайты с редко обновляемым контентом хорошо работают с Push CDN. Контент размещается на CDN один раз, вместо повторной загрузки через регулярные интервалы.
Pull CDN
Pull CDN получают новый контент с вашего сервера, когда первый пользователь запрашивает этот контент. Вы оставляете контент на сервере и переписываете URL на CDN. Это приводит к более медленному запросу, пока контент не будет закэширован на CDN.
Время жизни (TTL) определяет, как долго контент хранится в кеше. Pull CDN минимизируют занимаемое место на CDN, но могут создавать избыточный трафик, если файлы истекают и загружаются повторно до фактических изменений.
Сайты с высоким трафиком хорошо работают с Pull CDN, так как трафик распределяется равномернее, и только недавно запрошенный контент остаётся на CDN.
Недостатки CDN
- Затраты на CDN могут быть значительными в зависимости от трафика, однако их следует сравнивать с дополнительными расходами при отказе от CDN.
- Контент может устареть, если он обновится до истечения TTL.
- Для использования CDN требуется изменение URL-адресов статического контента на адреса CDN.
Источники и дополнительная литература
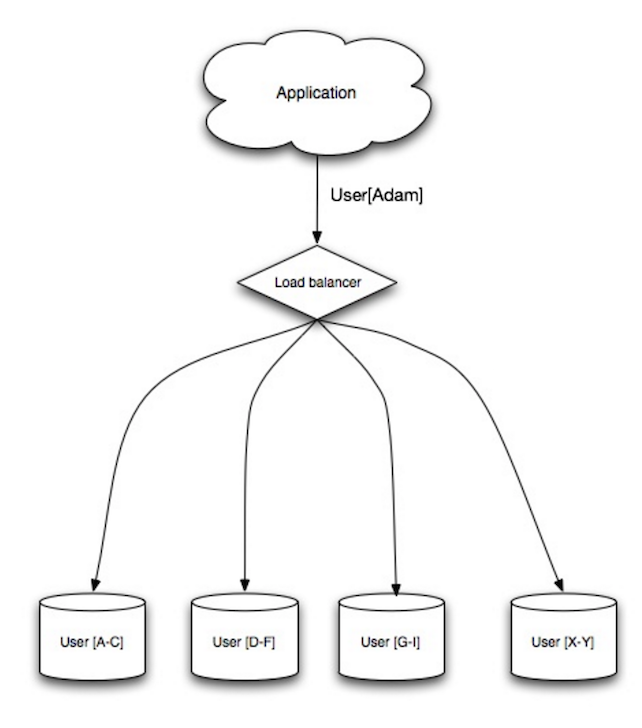
Балансировщик нагрузки
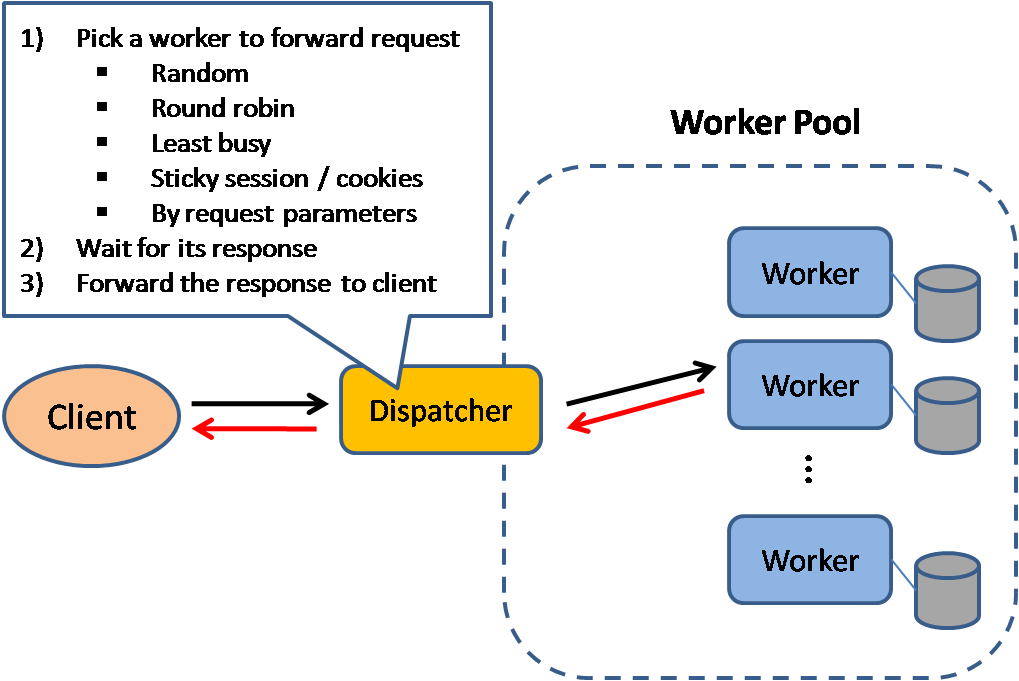
Источник: Шаблоны проектирования масштабируемых систем
Балансировщики нагрузки распределяют входящие клиентские запросы на вычислительные ресурсы, такие как серверы приложений и базы данных. В каждом случае балансировщик возвращает ответ вычислительного ресурса соответствующему клиенту. Балансировщики нагрузки эффективны для:
- Предотвращения отправки запросов на неработоспособные серверы
- Предотвращения перегрузки ресурсов
- Помощи в устранении единой точки отказа
Дополнительные преимущества включают:
- SSL-терминация — Расшифровка входящих запросов и шифрование ответов сервера, чтобы серверы не выполняли эти потенциально дорогие операции
- Устраняет необходимость установки X.509 сертификатов на каждом сервере
- Сохранение сессии — Выпуск cookie и маршрутизация запросов конкретного клиента к одной и той же инстанции, если веб-приложения не отслеживают сессии
Балансировщики нагрузки могут маршрутизировать трафик на основе различных метрик, включая:
- Случайный выбор
- Наименее загруженный
- Сессии/cookie
- Кольцевой или взвешенный кольцевой алгоритм
- Уровень 4
- Уровень 7
Балансировка нагрузки на уровне 4
Балансировщики нагрузки уровня 4 анализируют информацию на транспортном уровне для принятия решения о распределении запросов. Обычно это включает исходные и целевые IP-адреса и порты в заголовке, но не содержимое пакета. Балансировщики уровня 4 пересылают сетевые пакеты на вышестоящий сервер и обратно, выполняя сетевой адресный перевод (NAT).
Балансировка нагрузки на уровне 7
Балансировщики нагрузки уровня 7 анализируют уровень приложения, чтобы решить, как распределять запросы. Это может включать содержимое заголовков, сообщений и cookies. Балансировщик нагрузки уровня 7 завершает сетевой трафик, читает сообщение, принимает решение о балансировке нагрузки, затем открывает соединение с выбранным сервером. Например, балансировщик уровня 7 может направлять видеотрафик на серверы с видео, а более чувствительный трафик, связанный с оплатой, — на защищённые серверы.В ущерб гибкости балансировка нагрузки уровня 4 требует меньше времени и вычислительных ресурсов, чем уровень 7, хотя влияние на производительность может быть минимальным на современном массовом оборудовании.
Горизонтальное масштабирование
Балансировщики нагрузки также помогают с горизонтальным масштабированием, повышая производительность и доступность. Масштабирование с использованием массовых машин более экономично и приводит к большей доступности, чем масштабирование одного сервера на более дорогом оборудовании, называемом вертикальным масштабированием. Также проще нанимать специалистов, работающих с массовым оборудованием, чем с специализированными корпоративными системами.
#### Недостатки: горизонтальное масштабирование
- Горизонтальное масштабирование увеличивает сложность и требует клонирования серверов
- Сервера должны быть без состояния: не должны содержать пользовательские данные, такие как сессии или фотографии профиля
- Сессии можно хранить в централизованном хранилище данных, таком как база данных (SQL, NoSQL) или постоянный кэш (Redis, Memcached)
- Нижестоящие серверы, такие как кэши и базы данных, должны обрабатывать больше одновременных соединений по мере масштабирования верхних серверов
Недостатки: балансировщик нагрузки
- Балансировщик нагрузки может стать узким местом по производительности, если у него недостаточно ресурсов или он неправильно настроен.
- Внедрение балансировщика нагрузки для устранения единой точки отказа увеличивает сложность.
- Один балансировщик нагрузки — это единая точка отказа, настройка нескольких балансировщиков дополнительно усложняет систему.
Источники и дополнительная литература
- Архитектура NGINX
- Руководство по архитектуре HAProxy
- Масштабируемость
- Википедия)
- Балансировка нагрузки уровня 4
- Балансировка нагрузки уровня 7
- Конфигурация ELB listener
Реверс-прокси (веб-сервер)
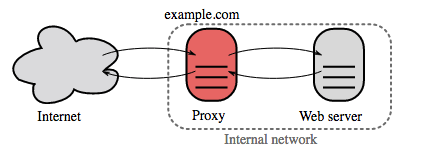
{kind=link}
Реверсивный прокси — это веб-сервер, который централизует внутренние сервисы и предоставляет унифицированные интерфейсы для внешних пользователей. Запросы от клиентов перенаправляются на сервер, который может их обработать, после чего реверсивный прокси возвращает ответ сервера клиенту.
Дополнительные преимущества включают:
- Повышенная безопасность — скрытие информации о сервере бэкенда, черные списки IP, ограничение количества соединений на клиента
- Повышенная масштабируемость и гибкость — клиенты видят только IP-адрес реверсивного прокси, что позволяет масштабировать серверы или менять их конфигурацию
- SSL-терминация — дешифрование входящих запросов и шифрование ответов сервера, чтобы серверы бэкенда не выполняли эти ресурсоемкие операции
- Устраняет необходимость установки X.509 сертификатов на каждом сервере
- Сжатие — сжатие ответов сервера
- Кэширование — возврат ответа для кэшированных запросов
- Статический контент — обслуживание статического контента напрямую
- HTML/CSS/JS
- Фотографии
- Видео
- и др.
Балансировщик нагрузки vs реверсивный прокси
- Использование балансировщика нагрузки полезно, когда у вас несколько серверов. Часто балансировщики маршрутизируют трафик на набор серверов, выполняющих одну функцию.
- Реверсивные прокси могут быть полезны даже при наличии только одного веб-сервера или сервере приложений, открывая преимущества, описанные в предыдущем разделе.
- Решения такие, как NGINX и HAProxy, поддерживают как проксирование на уровне 7, так и балансировку нагрузки.
Недостатки: реверсивный прокси
- Внедрение реверсивного прокси увеличивает сложность инфраструктуры.
- Один реверсивный прокси становится единой точкой отказа, а настройка нескольких прокси (например, аварийное переключение) еще больше усложняет систему.
Источники и дополнительная литература
Прикладной уровень
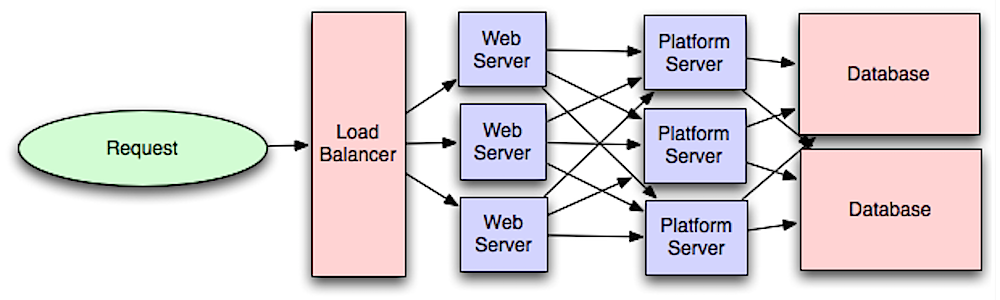
Источник: Введение в архитектурирование систем для масштабирования
Разделение веб-слоя и слоя приложения (также известного как платформенный слой) позволяет масштабировать и конфигурировать оба слоя независимо. Добавление нового API приводит к добавлению серверов приложений без необходимости увеличения количества веб-серверов. Принцип единственной ответственности призывает к созданию небольших и автономных сервисов, которые работают совместно. Маленькие команды с небольшими сервисами могут более агрессивно планировать быстрый рост.
Рабочие процессы в слое приложения также способствуют асинхронности.
Микросервисы
К данной теме относятся микросервисы, которые можно описать как набор автономно разворачиваемых, небольших, модульных сервисов. Каждый сервис запускает уникальный процесс и общается через хорошо определённый, легковесный механизм для достижения бизнес-цели. 1
Например, у Pinterest могут быть следующие микросервисы: профиль пользователя, подписчики, лента, поиск, загрузка фотографий и др.
Обнаружение сервисов
Системы, такие как Consul, Etcd, и Zookeeper помогают сервисам находить друг друга, отслеживая зарегистрированные имена, адреса и порты. Проверки состояния помогают убедиться в целостности сервиса и часто выполняются с помощью HTTP эндпоинта. И Consul, и Etcd имеют встроенное хранилище ключ-значение, полезное для хранения конфигураций и других общих данных.
Недостатки: слой приложения
- Добавление слоя приложения с слабо связанными сервисами требует другого подхода с архитектурной, операционной и процессной точек зрения (в отличие от монолитной системы).
- Микросервисы могут усложнить процесс деплоя и эксплуатации.
Источники и дополнительная литература
- Введение в архитектурирование систем для масштабирования
- Crack the system design interview
- Сервис-ориентированная архитектура
- Введение в Zookeeper
- Что нужно знать о построении микросервисов
База данных
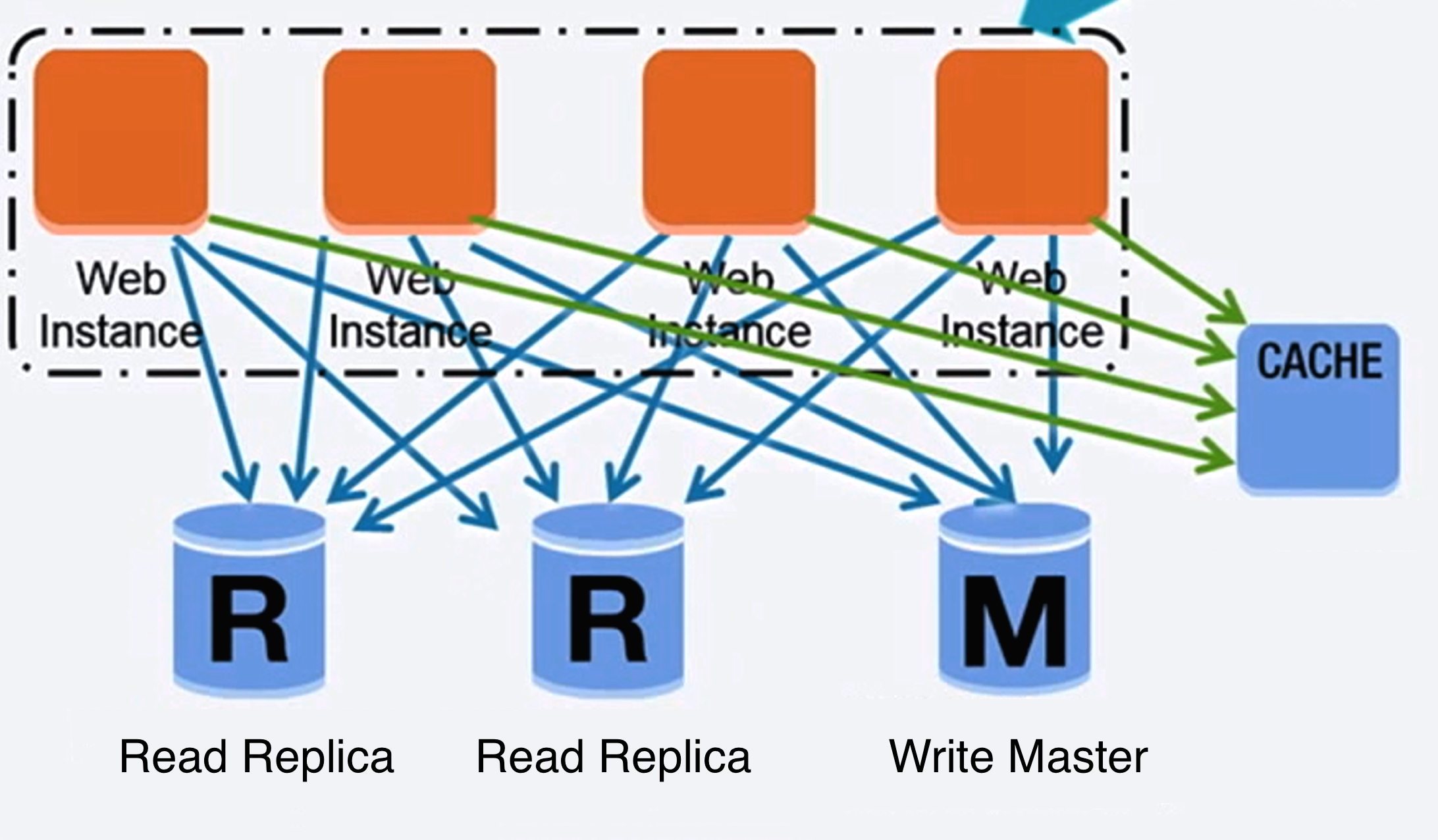
Источник: Масштабирование до первых 10 миллионов пользователей
Реляционная система управления базами данных (RDBMS)
Реляционная база данных, такая как SQL, представляет собой коллекцию элементов данных, организованных в таблицы.
ACID — это набор свойств транзакций реляционной базы данных.
- Атомарность — каждая транзакция выполняется полностью или не выполняется вовсе
- Согласованность — любая транзакция переводит базу данных из одного корректного состояния в другое
- Изолированность — выполнение транзакций параллельно приводит к тем же результатам, что и последовательное выполнение
- Долговечность — после фиксации транзакции она остается сохраненной
#### Мастер-слейв репликация
Мастер обслуживает операции чтения и записи, реплицируя записи на одного или нескольких слейвов, которые обслуживают только чтение. Слейвы также могут реплицироваться на других слейвов в виде дерева. Если мастер выходит из строя, система может продолжать работать в режиме только для чтения до тех пор, пока слейв не будет повышен до мастера или не будет создан новый мастер.
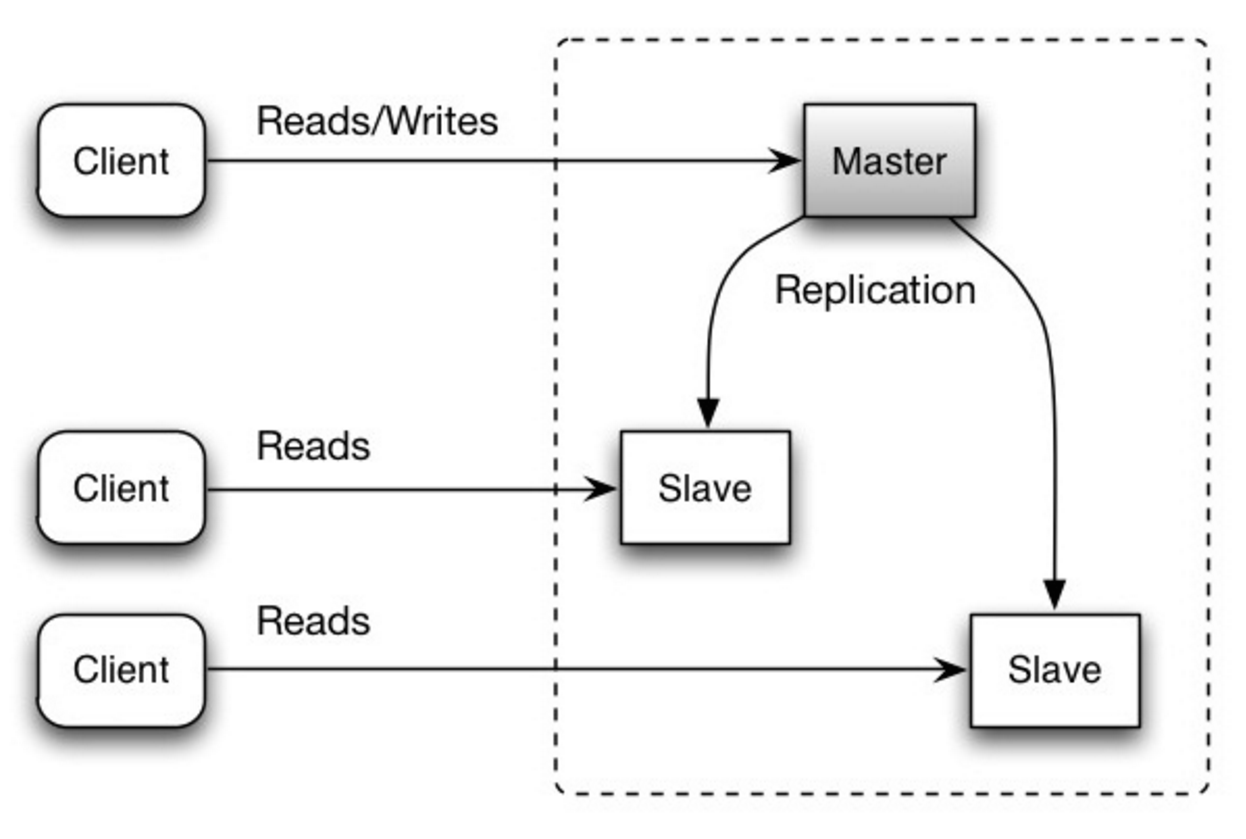
Источник: Масштабируемость, доступность, стабильность, паттерны
##### Недостаток(и): мастер-слейв репликация
- Требуется дополнительная логика для повышения слейва до мастера.
- См. Недостаток(и): репликация для пунктов, относящихся к обеим схемам мастер-слейв и мастер-мастер.
Оба мастера обслуживают операции чтения и записи и согласовывают между собой операции записи. Если один из мастеров выходит из строя, система может продолжать обслуживать как чтение, так и запись.
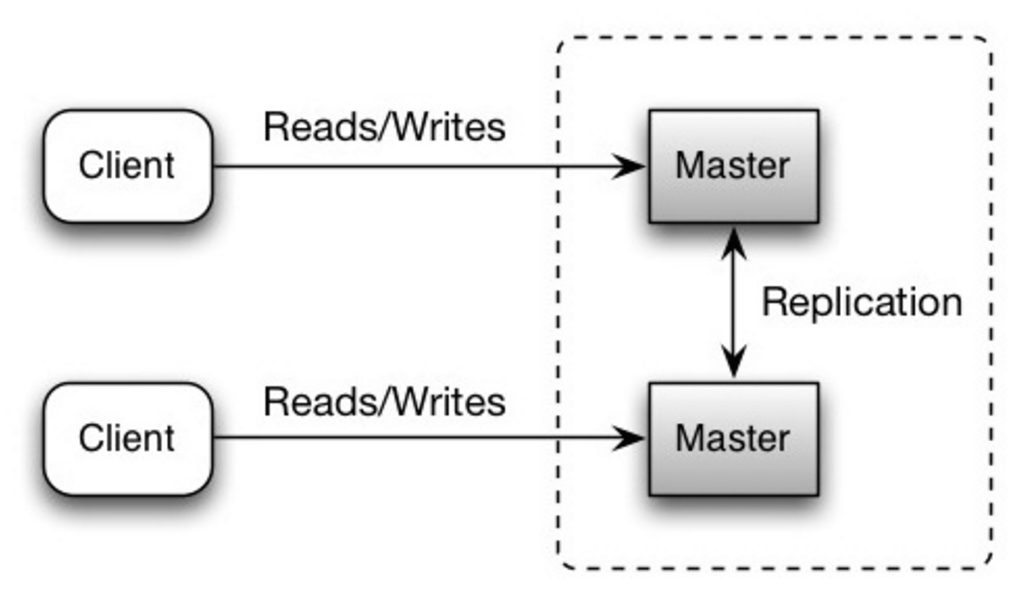
Источник: Масштабируемость, доступность, стабильность, паттерны
##### Недостаток(и): мастер-мастер репликация
- Понадобится балансировщик нагрузки или потребуется внести изменения в логику приложения для определения места записи.
- Большинство мастер-мастер систем либо слабо согласованы (нарушая ACID), либо имеют увеличенную задержку записи из-за синхронизации.
- Разрешение конфликтов становится более актуальным по мере добавления большего количества узлов записи и увеличения задержки.
- См. Недостатки: репликация для моментов, относящихся к мастер-слейв и мастер-мастер.
- Существует вероятность потери данных, если мастер выйдет из строя до того, как вновь записанные данные будут реплицированы на другие узлы.
- Записи воспроизводятся на репликах для чтения. Если записей много, реплики для чтения могут быть перегружены воспроизведением записей и не смогут выполнять столько операций чтения.
- Чем больше реплик для чтения, тем больше требуется реплицировать, что приводит к увеличению задержки репликации.
- В некоторых системах запись на мастер может запускать несколько потоков для параллельной записи, тогда как реплики для чтения поддерживают только последовательную запись одним потоком.
- Репликация требует больше оборудования и увеличивает сложность.
Источник: Масштабирование до первых 10 миллионов пользователей
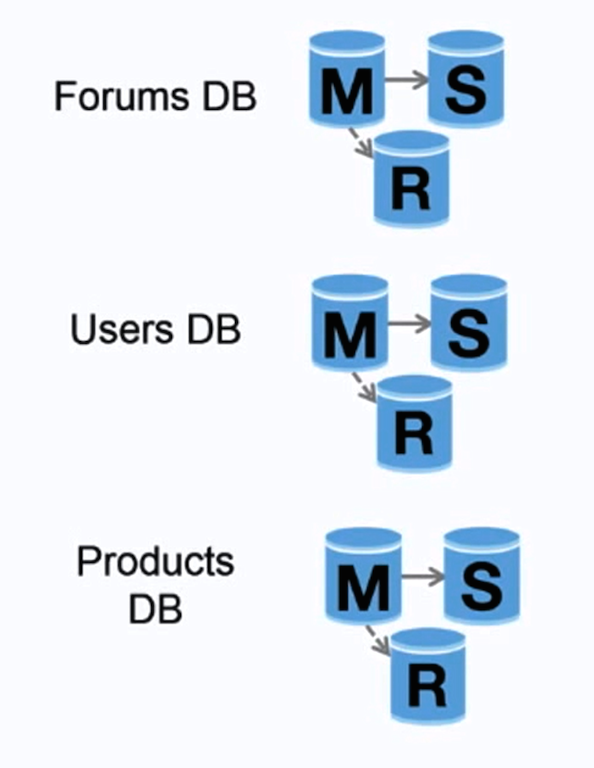
Федерация (или функциональное разделение) разделяет базы данных по функциям. Например, вместо одной монолитной базы данных можно иметь три базы: форумы, пользователи и товары, что приводит к меньшему количеству операций чтения и записи в каждой базе и, соответственно, меньшей задержке репликации. Меньшие базы позволяют большему объему данных помещаться в памяти, что увеличивает количество попаданий в кэш благодаря улучшенной локальности кэша. При отсутствии единого центрального мастера, сериализующего записи, вы можете писать параллельно, увеличивая пропускную способность.
##### Недостатки: федерация
- Федерация неэффективна, если ваша схема требует огромных функций или таблиц.
- Понадобится обновить логику приложения для определения, из какой базы читать и писать.
- Объединение данных из двух баз становится сложнее с использованием server link.
- Федерация требует больше оборудования и увеличивает сложность.
Источник: Масштабируемость, доступность, стабильность, паттерны
Шардинг распределяет данные между различными базами данных таким образом, что каждая база может управлять только частью данных. Например, если рассматривать базу данных пользователей, то с увеличением числа пользователей в кластер добавляются новые шарды.
Подобно преимуществам федерации, шардинг приводит к меньшему количеству операций чтения и записи, меньшему количеству репликаций и большему количеству попаданий в кеш. Размер индекса также уменьшается, что обычно улучшает производительность и ускоряет запросы. Если один шард выходит из строя, остальные продолжают работать, хотя желательно добавить какую-либо форму репликации, чтобы избежать потери данных. Как и при федерации, отсутствует единый центральный мастер, сериализующий записи, что позволяет писать параллельно с увеличенной пропускной способностью.
Распространенные способы шардинга таблицы пользователей — по первой букве фамилии или по географическому расположению пользователя.
##### Недостатки: шардинг
- Необходимо обновлять логику приложения для работы с шардами, что может привести к сложным SQL-запросам.
- Распределение данных может оказаться неравномерным. Например, наличие группы активных пользователей на одном шарде может привести к повышенной нагрузке на этот шард по сравнению с другими.
- Перебалансировка добавляет дополнительную сложность. Функция шардинга на основе консистентного хеширования может уменьшить объем передаваемых данных.
- Объединение данных из нескольких шардов становится более сложным.
- Шардинг требует больше аппаратных ресурсов и увеличивает сложность.
Денормализация пытается повысить производительность чтения за счет некоторого ухудшения производительности записи. Избыточные копии данных записываются в несколько таблиц, чтобы избежать затратных объединений. Некоторые СУБД, такие как PostgreSQL и Oracle, поддерживают материализованные представления, которые берут на себя задачу хранения избыточной информации и поддержания согласованности копий.
Когда данные распределяются с помощью таких техник, как федерация и шардинг, управление объединениями между дата-центрами становится еще сложнее. Денормализация может помочь избежать необходимости в таких сложных объединениях.
В большинстве систем количество чтений значительно превышает количество записей — в соотношении 100:1 или даже 1000:1. Операция чтения, приводящая к сложному объединению в базе данных, может быть очень затратной, тратя значительное время на операции с диском.
##### Недостатки: денормализация
- Данные дублируются.
- Ограничения могут помочь синхронизировать избыточные копии информации, что увеличивает сложность проектирования базы данных.
- Денормализованная база данных под высокой нагрузкой на запись может работать хуже, чем нормализованная.
Настройка SQL — это обширная тема, и написано много книг в качестве справочников.
Важно проводить бенчмаркинг и профилирование для моделирования и выявления узких мест.
- Бенчмаркинг — моделируйте ситуации высокой нагрузки с помощью таких инструментов, как ab.
- Профилирование — используйте такие инструменты, как журнал медленных запросов, чтобы отслеживать проблемы с производительностью.
##### Уточните схему
- MySQL записывает данные на диск в смежных блоках для быстрого доступа.
- Используйте
CHARвместоVARCHARдля полей фиксированной длины. CHARобеспечивает быстрый случайный доступ, тогда как сVARCHARнеобходимо найти конец строки перед переходом к следующей.- Используйте
TEXTдля больших блоков текста, таких как посты блога.TEXTтакже позволяет выполнять булевы поиски. Использование поляTEXTприводит к хранению указателя на диске, который используется для поиска текстового блока. - Используйте
INTдля больших чисел до 2^32 или 4 миллиардов. - Используйте
DECIMALдля хранения валюты, чтобы избежать ошибок представления с плавающей точкой. - Избегайте хранения больших
BLOB, храните только местоположение объекта. VARCHAR(255)— это максимальное количество символов, которое можно посчитать в 8-битном числе, часто позволяя максимально использовать байт в некоторых СУБД.- Устанавливайте ограничение
NOT NULLтам, где это возможно, чтобы улучшить производительность поиска.
- Столбцы, по которым выполняются запросы (
SELECT,GROUP BY,ORDER BY,JOIN), могут работать быстрее с индексами. - Индексы обычно реализованы как самобалансирующееся B-дерево, которое хранит данные в отсортированном виде и позволяет выполнять поиск, последовательный доступ, вставку и удаление за логарифмическое время.
- Размещение индекса может держать данные в памяти, что требует больше пространства.
- Запись может быть медленнее, так как индекс также нужно обновлять.
- При загрузке большого объема данных может быть быстрее отключить индексы, загрузить данные, а затем перестроить индексы.
- Денормализуйте, если этого требует производительность.
- Разделите таблицу, поместив горячие точки в отдельную таблицу, чтобы облегчить её хранение в памяти.
- В некоторых случаях кэш запросов может привести к проблемам с производительностью.
- Советы по оптимизации MySQL-запросов
- Почему так часто используется VARCHAR(255)?
- Как значения NULL влияют на производительность?
- Журнал медленных запросов
NoSQL
NoSQL — это набор элементов данных, представленных в виде хранилища ключ-значение, документного хранилища, широкого столбцового хранилища или графовой базы данных. Данные денормализованы, а соединения обычно выполняются в коде приложения. Большинство NoSQL-хранилищ не поддерживают настоящие транзакции ACID и предпочитают конечную согласованность.
BASE часто используется для описания свойств NoSQL-баз данных. В сравнении с теоремой CAP, BASE выбирает доступность вместо согласованности.
- В основном доступная — система гарантирует доступность.
- Мягкое состояние — состояние системы может изменяться со временем, даже без внешнего воздействия.
- Конечная согласованность — система станет согласованной спустя некоторое время, если за этот период не поступит новых данных.
#### Хранилище ключ-значение
Абстракция: хеш-таблица
Хранилище ключ-значение обычно обеспечивает операции чтения и записи за O(1) и часто работает на основе памяти или SSD. Хранилища могут поддерживать ключи в лексикографическом порядке, что позволяет эффективно извлекать диапазоны ключей. В хранилищах ключ-значение можно хранить метаданные вместе со значением.
Хранилища ключ-значение обеспечивают высокую производительность и часто используются для простых моделей данных или быстро изменяющихся данных, например, для слоя кэша в памяти. Поскольку они предлагают ограниченный набор операций, дополнительная сложность переносится на уровень приложения, если необходимы дополнительные операции.
Хранилище ключ-значение является основой для более сложных систем, таких как документные хранилища, а в некоторых случаях — графовые базы данных.
##### Источники и дополнительная литература: хранилище ключ-значение
#### Документное хранилищеАбстракция: хранилище ключ-значение, где документы сохраняются как значения
Документное хранилище строится вокруг документов (XML, JSON, бинарные файлы и др.), где документ хранит всю информацию об объекте. Документные хранилища предоставляют API или язык запросов для получения данных на основе внутренней структуры самого документа. Заметьте, многие хранилища ключ-значение содержат функции для работы с метаданными значения, размывая границы между этими двумя типами хранения.
В зависимости от реализации документы организованы по коллекциям, тегам, метаданным или директориям. Хотя документы могут быть сгруппированы, поля документов могут сильно отличаться друг от друга.
Некоторые документные хранилища, такие как MongoDB и CouchDB, также предоставляют язык запросов, похожий на SQL, для выполнения сложных запросов. DynamoDB поддерживает работу как с ключ-значениями, так и с документами.
Документные хранилища обеспечивают высокую гибкость и часто используются для работы с редко изменяющимися данными.
##### Источники и дополнительная литература: документное хранилище
- Документно-ориентированная база данных
- Архитектура MongoDB
- Архитектура CouchDB
- Архитектура Elasticsearch
Источник: SQL & NoSQL, краткая история
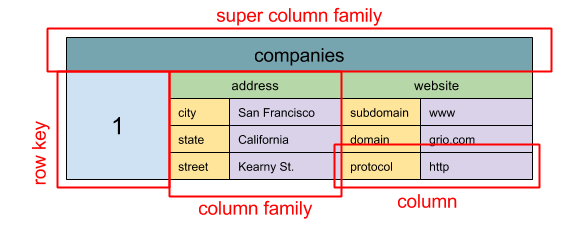
Абстракция: вложенная карта ColumnFamily> Базовой единицей данных в хранилище широких столбцов является столбец (пара имя/значение). Столбцы могут быть сгруппированы в семейства столбцов (аналог таблицы SQL). Суперсемейства столбцов объединяют семейства столбцов. Доступ к каждому столбцу осуществляется независимо по ключу строки, а столбцы с одинаковым ключом строки формируют строку. Каждое значение содержит временную метку для версионирования и разрешения конфликтов.
Google представила Bigtable как первое хранилище широких столбцов, которое повлияло на открытый проект HBase, часто используемый в экосистеме Hadoop, и Cassandra от Facebook. Хранилища типа BigTable, HBase и Cassandra поддерживают ключи в лексикографическом порядке, что позволяет эффективно извлекать диапазоны ключей.
Хранилища широких столбцов обеспечивают высокую доступность и масштабируемость. Они часто применяются для работы с очень большими наборами данных.
##### Источники и дополнительная литература: хранилище широких столбцов
#### Графовые базы данных
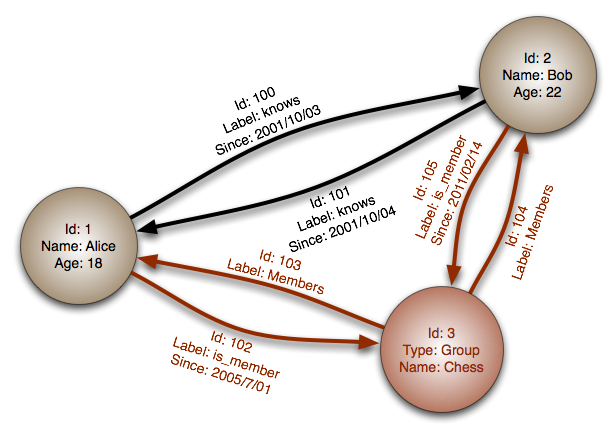
Источник: Графовая база данных
{kind=link}
Абстракция: граф
В графовой базе данных каждая вершина — это запись, а каждое ребро — это связь между двумя вершинами. Графовые базы данных оптимизированы для представления сложных отношений с множеством внешних ключей или отношений многие-ко-многим.
Графовые базы данных обеспечивают высокую производительность для моделей данных со сложными взаимосвязями, таких как социальные сети. Они относительно новые и пока не получили широкого распространения; может быть сложнее найти инструменты и ресурсы для разработки. Многие графы доступны только через REST API.
##### Источники и дополнительная литература: граф
#### Источники и дополнительная литература: NoSQL- Объяснение базовой терминологии
- NoSQL базы данных: обзор и рекомендации по выбору
- Масштабируемость
- Введение в NoSQL
- NoSQL паттерны
SQL или NoSQL
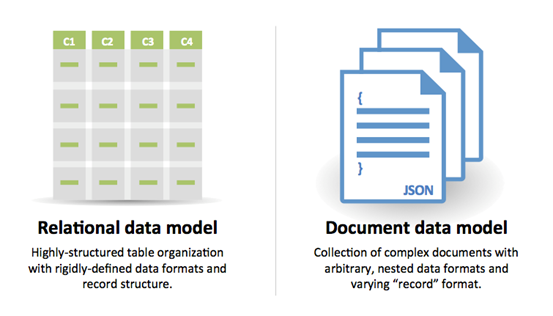
Источник: Переход от RDBMS к NoSQL
Причины выбрать SQL:
- Структурированные данные
- Строгая схема
- Реляционные данные
- Необходимость сложных соединений
- Транзакции
- Четкие паттерны масштабирования
- Более устоявшаяся технология: разработчики, сообщество, код, инструменты и др.
- Поиск по индексу очень быстрый
- Полуструктурированные данные
- Динамическая или гибкая схема
- Нереляционные данные
- Нет необходимости в сложных соединениях
- Хранение многих ТБ (или ПБ) данных
- Очень интенсивная нагрузка на данные
- Очень высокая производительность по IOPS
- Быстрый прием потоковых данных и логов
- Лидеры или данные по очкам
- Временные данные, такие как корзина покупок
- Часто запрашиваемые ("горячие") таблицы
- Таблицы метаданных/поиска
Кэш
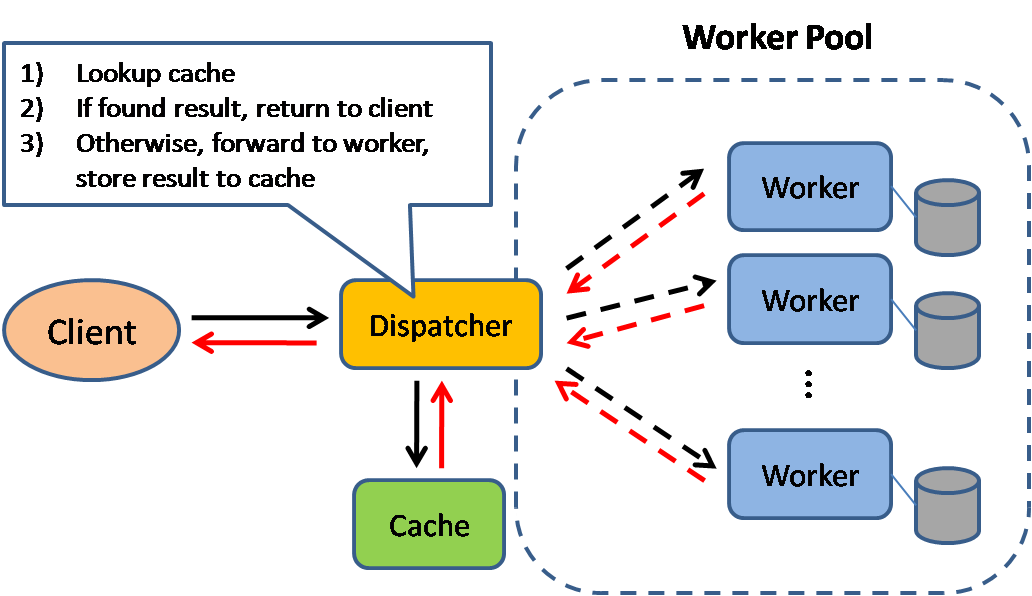
Источник: Шаблоны проектирования масштабируемых систем
Кэширование улучшает время загрузки страниц и может снизить нагрузку на ваши серверы и базы данных. В этой модели диспетчер сначала проверяет, был ли сделан такой запрос ранее, и пытается найти предыдущий результат для возврата, чтобы избежать фактического выполнения.
Базы данных часто выигрывают от равномерного распределения чтений и записей по своим разделам. Популярные элементы могут искажать распределение, вызывая узкие места. Размещение кэша перед базой данных помогает сглаживать неравномерную нагрузку и всплески трафика.
Кэширование на стороне клиента
Кэш может располагаться на стороне клиента (ОС или браузер), на стороне сервера или в отдельном уровне кэширования.
Кэширование CDN
CDN считаются одним из видов кэша.
Кэширование веб-сервера
Обратные прокси и кэши, такие как Varnish, могут обслуживать статический и динамический контент напрямую. Веб-серверы также могут кэшировать запросы, возвращая ответы без обращения к серверу приложений.
Кэширование базы данных
Ваша база данных обычно включает некоторый уровень кэширования в стандартной конфигурации, оптимизированной для общего случая. Настройка этих параметров для конкретных сценариев использования может еще больше повысить производительность.
Кэширование приложения
Кэши в оперативной памяти, такие как Memcached и Redis, являются хранилищами "ключ-значение" между вашим приложением и хранилищем данных. Поскольку данные хранятся в ОЗУ, они намного быстрее, чем в типичных базах данных, где данные записываются на диск. ОЗУ более ограничено, чем диск, поэтому алгоритмы инвалидации кэша, такие как наименее недавно использованные (LRU)), помогают удалять "холодные" записи и держать "горячие" данные в ОЗУ.
У Redis есть следующие дополнительные возможности:
- Опция персистентности
- Встроенные структуры данных, такие как отсортированные множества и списки
- На уровне строки
- На уровне запроса
- Полностью сформированные сериализуемые объекты
- Полностью отрендеренный HTML
Кэширование на уровне запросов к базе данных
Всякий раз, когда вы выполняете запрос к базе данных, хэшируйте запрос как ключ и сохраняйте результат в кэше. Такой подход страдает от проблем с истечением срока действия:
- Сложно удалить закэшированный результат для сложных запросов
- Если одна часть данных изменяется, например ячейка таблицы, необходимо удалить все закэшированные запросы, которые могут содержать измененную ячейку
Кэширование на уровне объекта
Рассматривайте ваши данные как объект, аналогично тому, как вы работаете с кодом приложения. Пусть приложение собирает набор данных из базы в экземпляр класса или структуру данных:
- Удалите объект из кэша, если его исходные данные изменились
- Позволяет асинхронную обработку: воркеры собирают объекты, используя последние закэшированные объекты
- Сессии пользователей
- Полностью отрендеренные веб-страницы
- Потоки активности
- Данные графа пользователя
Когда обновлять кэш
Поскольку вы можете хранить в кэше только ограниченное количество данных, необходимо определить стратегию обновления кэша, которая лучше всего подходит для вашего случая.
#### Cache-aside
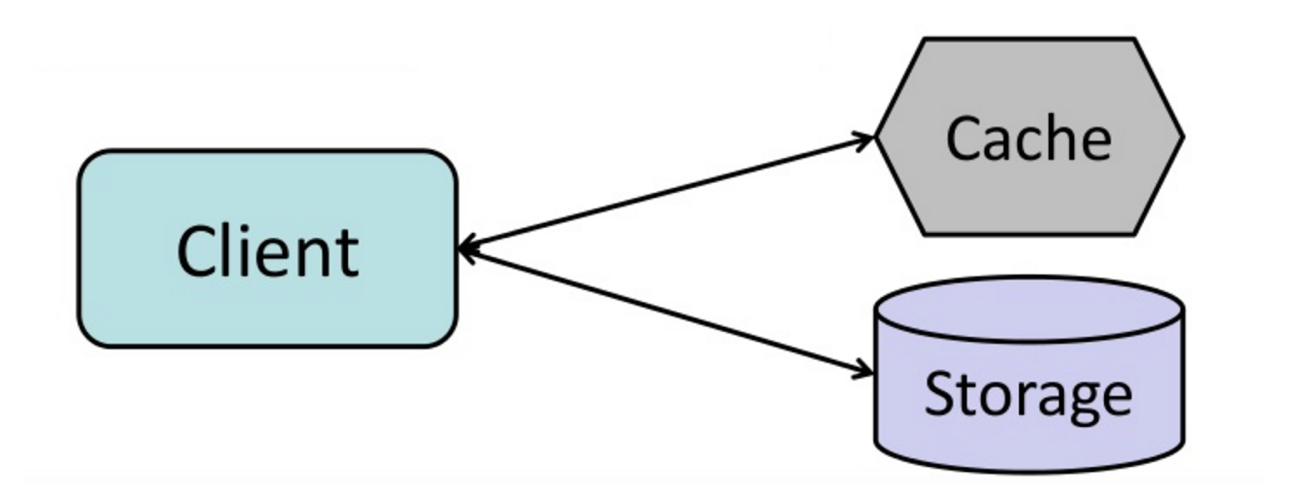
Источник: From cache to in-memory data grid
Приложение отвечает за чтение и запись из хранилища. Кэш не взаимодействует с хранилищем напрямую. Приложение выполняет следующие действия:
- Поиск записи в кэше, приводящий к промаху по кэшу
- Загрузка записи из базы данных
- Добавление записи в кэш
- Возврат записи
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached обычно используется таким образом.
Последующие чтения данных, добавленных в кэш, происходят быстро. Cache-aside также называется ленивой загрузкой (lazy loading). В кэш помещаются только запрошенные данные, что предотвращает заполнение кэша неиспользуемыми данными.
##### Недостаток(и): cache-aside
- Каждый промах кэша приводит к трем обращениям, что может вызвать заметную задержку.
- Данные могут устаревать, если они были обновлены в базе данных. Эта проблема решается установкой времени жизни (TTL), которое принудительно обновляет запись в кэше, или использованием write-through.
- При отказе узла он заменяется новым, пустым узлом, что увеличивает задержку.
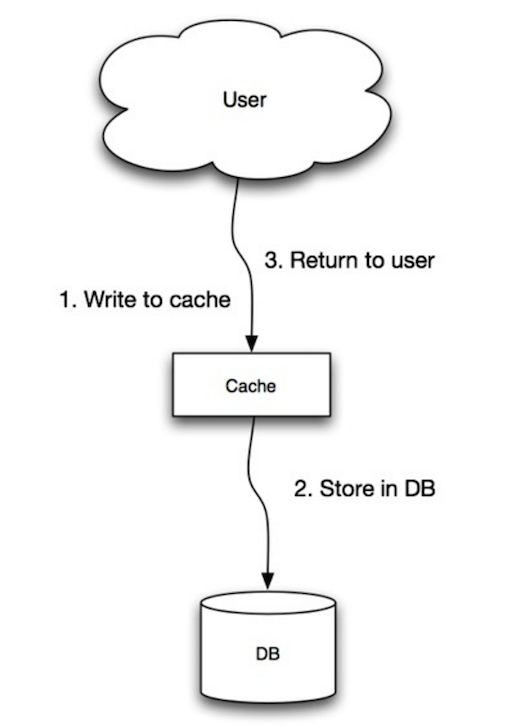
Источник: Масштабируемость, доступность, стабильность, паттерны
Приложение использует кэш как основное хранилище данных, читая и записывая данные в него, при этом кэш отвечает за чтение и запись в базу данных:
- Приложение добавляет/обновляет запись в кэше
- Кэш синхронно записывает запись в хранилище данных
- Возврат
set_user(12345, {"foo":"bar"})Код кэша:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Недостатки: запись с немедленным сохранением
- Когда создается новый узел из-за сбоя или масштабирования, новый узел не будет кэшировать записи до тех пор, пока запись не будет обновлена в базе данных. Использование кэширования по запросу вместе с записью с немедленным сохранением может снизить этот недостаток.
- Большинство записанных данных могут никогда не быть считаны, что можно минимизировать с помощью TTL.
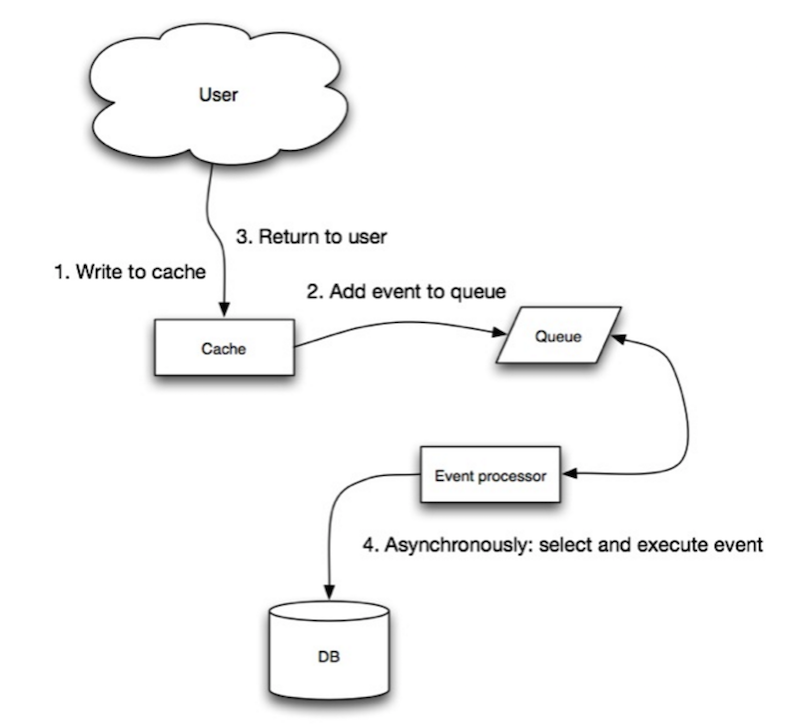
Источник: Масштабируемость, доступность, стабильность, паттерны
При записи с отложенным сохранением приложение выполняет следующие действия:
- Добавляет/обновляет запись в кэше
- Асинхронно записывает запись в хранилище данных, улучшая производительность записи
- Может произойти потеря данных, если кэш выйдет из строя до того, как его содержимое попадет в хранилище данных.
- Реализация записи с отложенным сохранением сложнее, чем реализация кэширования по запросу или записи с немедленным сохранением.
Источник: От кэша к распределенному хранилищу данных в памяти
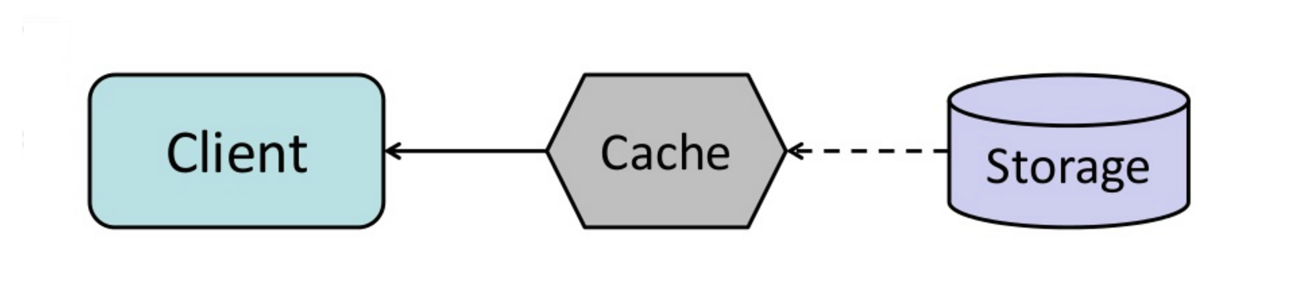
Можно настроить кэш так, чтобы он автоматически обновлял недавно запрошенные записи кэша до их истечения срока действия.
Предварительное обновление может привести к снижению задержки по сравнению с чтением через кэш, если кэш способен точно предсказать, какие элементы могут понадобиться в будущем.
##### Недостатки: предварительное обновление
- Неточной прогнозирование того, какие элементы могут понадобиться в будущем, может привести к снижению производительности по сравнению с отсутствием предварительного обновления.
Недостаток(и): кэш
- Необходимо поддерживать согласованность между кэшами и источником истины, таким как база данных, через инвалидацию кэша.
- Инвалидация кэша — сложная задача, существует дополнительная сложность, связанная с определением момента обновления кэша.
- Требуется внесение изменений в приложение, например добавление Redis или memcached.
Источники и дополнительная литература
- От кэша к распределённой памяти
- Шаблоны проектирования масштабируемых систем
- Введение в архитектуру систем для масштабирования
- Масштабируемость, доступность, стабильность, шаблоны
- Масштабируемость
- Стратегии AWS ElastiCache
- Википедия)
Асинхронность
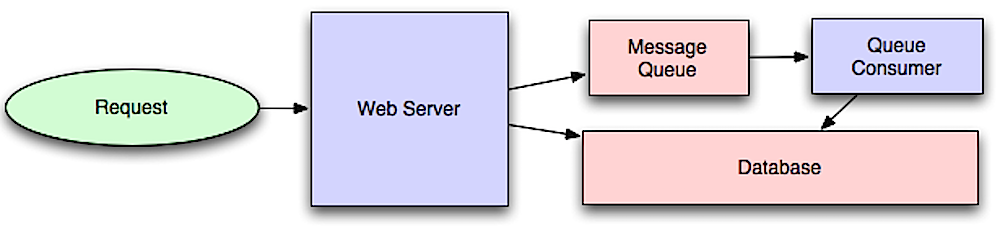
Источник: Введение в архитектуру систем для масштабирования
Асинхронные процессы помогают сократить время ответа для ресурсоёмких операций, которые в противном случае выполнялись бы в реальном времени. Они также полезны для предварительного выполнения трудоёмких задач, например периодической агрегации данных.
Очереди сообщений
Очереди сообщений принимают, хранят и доставляют сообщения. Если операция слишком медленная для выполнения в реальном времени, можно использовать очередь сообщений с следующим процессом:
- Приложение публикует задачу в очередь, затем уведомляет пользователя о статусе задачи
- Рабочий процесс извлекает задачу из очереди, обрабатывает её и сигнализирует о завершении
Redis полезен как простой брокер сообщений, но сообщения могут быть потеряны.
RabbitMQ популярен, но требует адаптации к протоколу 'AMQP' и самостоятельного управления узлами.
Amazon SQS размещается на сервере, но может иметь высокую задержку и возможность повторной доставки сообщений.
Очереди задач
Очереди задач принимают задачи и связанные с ними данные, выполняют их, а затем доставляют результаты. Они поддерживают планирование и могут использоваться для выполнения ресурсоёмких задач в фоновом режиме.
Celery поддерживает планирование и в основном работает с python.
Обратное давление
Если очереди начинают значительно расти, их размер может превысить доступную память, что приведёт к промахам кэша, чтению с диска и ещё большему снижению производительности. Обратное давление помогает, ограничивая размер очереди, что позволяет поддерживать высокую пропускную способность и хорошее время отклика для уже находящихся в очереди задач. Когда очередь переполняется, клиентам возвращается статус "сервер занят" или HTTP 503 с предложением повторить попытку позже. Клиенты могут повторить запрос позднее, возможно, с использованием экспоненциальной задержки.
Недостаток(и): асинхронность
- Для таких случаев, как недорогие вычисления и рабочие процессы в реальном времени, синхронные операции могут быть более подходящими, поскольку внедрение очередей увеличивает задержки и сложность.
Источники и дополнительная литература
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
Связь
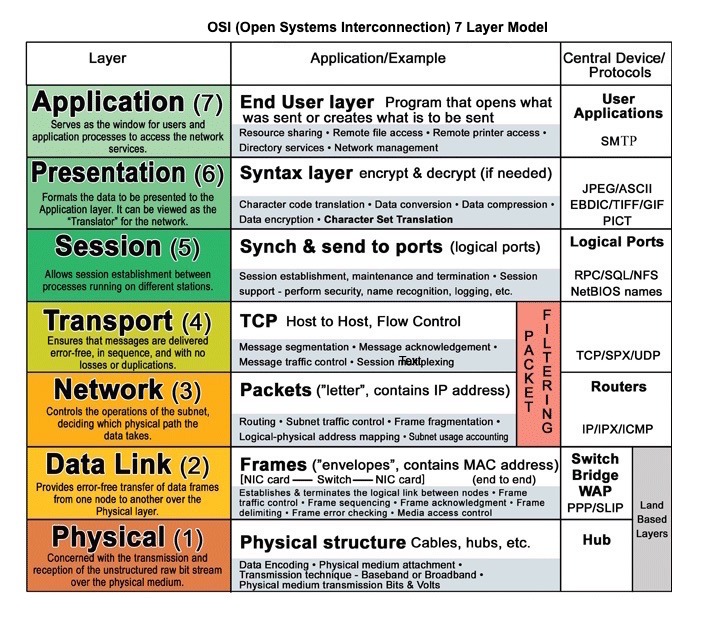
Источник: модель OSI 7 уровней
Протокол передачи гипертекста (HTTP)
HTTP — это способ кодирования и передачи данных между клиентом и сервером. Это протокол запрос/ответ: клиенты отправляют запросы, а серверы возвращают ответы с соответствующим содержимым и статусом завершения запроса. HTTP самодостаточен, позволяя передавать запросы и ответы через множество промежуточных маршрутизаторов и серверов, осуществляющих балансировку нагрузки, кэширование, шифрование и сжатие.
Базовый HTTP-запрос состоит из глагола (метода) и ресурса (конечной точки). Ниже приведены распространённые HTTP-глаголы:
| Глагол | Описание | Идемпотентность* | Безопасность | Кэшируемость | |---|---|---|---|---| | GET | Читает ресурс | Да | Да | Да | | POST | Создает ресурс или запускает процесс обработки данных | Нет | Нет | Да, если ответ содержит информацию о свежести | | PUT | Создает или заменяет ресурс | Да | Нет | Нет | | PATCH | Частично обновляет ресурс | Нет | Нет | Да, если ответ содержит информацию о свежести | | DELETE | Удаляет ресурс | Да | Нет | Нет |
*Может вызываться много раз без разных результатов.
HTTP — это протокол прикладного уровня, основанный на протоколах более низкого уровня, таких как TCP и UDP.
#### Источники и дополнительная литература: HTTP
Протокол управления передачей (TCP)
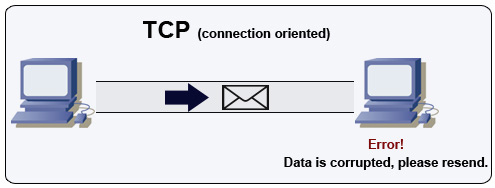
Источник: Как создать многопользовательскую игру
TCP — это ориентированный на соединение протокол поверх IP-сети. Соединение устанавливается и завершается с помощью рукопожатия. Все отправленные пакеты гарантированно достигают назначения в исходном порядке и без повреждений благодаря:
- Номерам последовательности и контрольным суммам для каждого пакета
- Пакетам подтверждения) и автоматической повторной передаче
Для обеспечения высокой пропускной способности веб-серверы могут держать большое количество открытых TCP-соединений, что приводит к высокому расходу памяти. Держать много открытых соединений между потоками веб-сервера и, например, сервером memcached может быть дорого. Пул соединений может помочь, также стоит рассмотреть переход на UDP, где это возможно.
TCP полезен для приложений, которым требуется высокая надежность, но они менее критичны к времени. Примеры: веб-серверы, информация баз данных, SMTP, FTP и SSH.
Используйте TCP вместо UDP, когда:
- Вам нужно, чтобы все данные пришли без потерь
- Вы хотите автоматически оптимально использовать пропускную способность сети
Протокол пользовательских дейтаграмм (UDP)
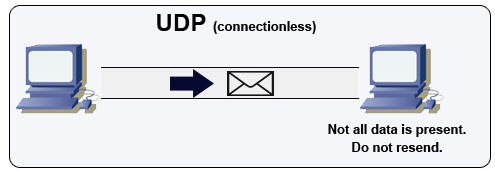
Источник: Как сделать многопользовательскую игру
UDP является протоколом без установления соединения. Дейтаграммы (аналогично пакетам) гарантируются только на уровне дейтаграмм. Дейтаграммы могут прибывать в пункт назначения не по порядку или не прибывать вообще. UDP не поддерживает управление перегрузкой. Без гарантий, которые предоставляет TCP, UDP, как правило, более эффективен.
UDP может осуществлять широковещательную передачу, отправляя дейтаграммы всем устройствам в подсети. Это полезно при DHCP, поскольку клиент еще не получил IP-адрес, что предотвращает возможность потоковой передачи по TCP без IP-адреса.
UDP менее надежен, но хорошо работает в случаях использования в реальном времени, таких как VoIP, видеочат, стриминг и многопользовательские игры в реальном времени.
Используйте UDP вместо TCP, когда:
- Вам нужна минимальная задержка
- Просроченные данные хуже, чем потеря данных
- Вы хотите реализовать собственную коррекцию ошибок
- Сетевые технологии для программирования игр
- Ключевые различия между протоколами TCP и UDP
- Различие между TCP и UDP
- Протокол управления передачей
- Протокол пользовательских дейтаграмм
- Масштабирование memcache в Facebook
Удалённый вызов процедур (RPC)
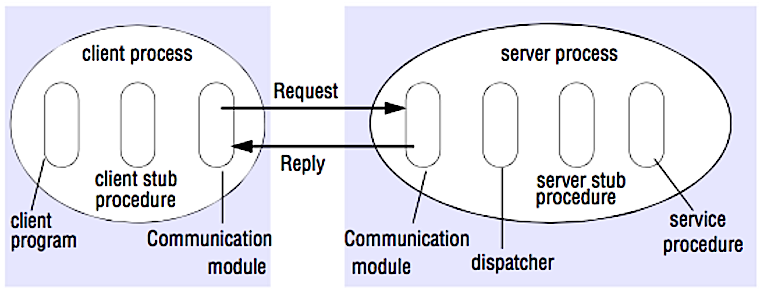
Источник: Crack the system design interview
В RPC клиент инициирует выполнение процедуры в другом адресном пространстве, обычно на удалённом сервере. Процедура кодируется так, как если бы это был локальный вызов процедуры, абстрагируя детали взаимодействия с сервером от клиентской программы. Удалённые вызовы обычно медленнее и менее надёжны, чем локальные, поэтому полезно различать вызовы RPC и локальные вызовы. Популярные фреймворки RPC включают Protobuf, Thrift и Avro.
RPC — это протокол типа запрос-ответ:
- Клиентская программа - Вызывает процедуру клиентского заглушки. Параметры помещаются в стек, как при локальном вызове процедуры.
- Процедура клиентского заглушки - Сериализует (упаковывает) идентификатор процедуры и аргументы в сообщение запроса.
- Модуль связи клиента - ОС отправляет сообщение от клиента на сервер.
- Модуль связи сервера - ОС передает входящие пакеты процедуре серверского заглушки.
- Процедура серверского заглушки - Десериализует результаты, вызывает серверную процедуру, соответствующую идентификатору процедуры, и передает заданные аргументы.
- Ответ сервера повторяет вышеуказанные шаги в обратном порядке.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC ориентирован на предоставление поведения. RPC часто используется для повышения производительности при внутренней коммуникации, поскольку вы можете вручную создавать нативные вызовы, чтобы лучше соответствовать вашим случаям использования.
Выберите нативную библиотеку (также известную как SDK), когда:
- Вы знаете свою целевую платформу.
- Вы хотите контролировать, как ваш "логика" доступна.
- Вы хотите контролировать обработку ошибок вне вашей библиотеки.
- Производительность и опыт конечного пользователя — ваш главный приоритет.
#### Недостатки: RPC
- RPC-клиенты становятся тесно связанными с реализацией сервиса.
- Для каждой новой операции или случая использования необходимо определять новый API.
- Отладка RPC может быть затруднена.
- Возможно, вы не сможете использовать существующие технологии из коробки. Например, может потребоваться дополнительная работа, чтобы RPC-вызовы корректно кэшировались на серверах кэширования, таких как Squid.
Передача состояния представления (REST)
REST — это архитектурный стиль, реализующий модель клиент/сервер, где клиент работает с набором ресурсов, управляемых сервером. Сервер предоставляет представление ресурсов и действия, которые могут либо изменить, либо получить новое представление ресурсов. Вся коммуникация должна быть без состояния и кэшируемой.
У RESTful-интерфейса есть четыре качества:
- Идентификация ресурсов (URI в HTTP) — используйте один и тот же URI независимо от операции.
- Изменение с представлениями (глаголы в HTTP) — используйте глаголы, заголовки и тело.
- Самоописывающее сообщение об ошибке (статус ответа в HTTP) — используйте статус-коды, не изобретайте велосипед.
- HATEOAS (HTML-интерфейс для HTTP) — ваш веб-сервис должен быть полностью доступен через браузер.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Недостатки: REST
- Поскольку REST ориентирован на предоставление данных, он может не подойти, если ресурсы не организованы или не доступны в простой иерархии. Например, возврат всех обновленных записей за последний час, соответствующих определенному набору событий, сложно выразить в виде пути. В REST это, скорее всего, реализуется с помощью комбинации пути URI, параметров запроса и, возможно, тела запроса.
- REST обычно опирается на несколько глаголов (GET, POST, PUT, DELETE и PATCH), которые иногда не соответствуют вашему случаю использования. Например, перемещение просроченных документов в архивную папку может не вписываться в эти глаголы.
- Получение сложных ресурсов с вложенными иерархиями требует нескольких обменов между клиентом и сервером для отображения одного представления, например, получение содержимого записи блога и комментариев к ней. Для мобильных приложений, работающих в переменных сетевых условиях, эти многократные обмены крайне нежелательны.
- Со временем в ответе API могут появляться новые поля, и старые клиенты будут получать все новые поля данных, даже те, которые им не нужны, что приводит к увеличению размера полезной нагрузки и большему времени задержки.
Сравнение вызовов RPC и REST
| Операция | RPC | REST |
|---|---|---|
| Регистрация | POST /signup | POST /persons |
| Увольнение | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Прочитать пользователя | GET /readPerson?personid=1234 | GET /persons/1234 |
| Прочитать список предметов пользователя | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Добавить предмет к списку пользователя | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Обновить предмет | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Удалить предмет | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Источник: Do you really know why you prefer REST over RPC
#### Источники и дополнительная литература: REST и RPC
- Do you really know why you prefer REST over RPC
- Когда подходы, похожие на RPC, более уместны, чем REST?
- REST vs JSON-RPC
- Развенчание мифов о RPC и REST
- Каковы недостатки использования REST
- Crack the system design interview
- Thrift
- Почему REST для внутреннего использования, а не RPC
Безопасность
Этот раздел нуждается в обновлении. Подумайте о вкладе!
Безопасность — это обширная тема. Если у вас нет значительного опыта, образования в области безопасности или вы не претендуете на должность, требующую знаний в области безопасности, вам, вероятно, не потребуется знать больше, чем основы:
- Шифруйте данные при передаче и в состоянии покоя.
- Очищайте все пользовательские вводы или любые параметры, доступные пользователю, чтобы предотвратить XSS и SQL-инъекции.
- Используйте параметризованные запросы для предотвращения SQL-инъекций.
- Применяйте принцип минимальных привилегий.
Источники и дополнительная литература
Приложение
Иногда вас попросят сделать приблизительные оценки «на коленке». Например, вам может понадобиться определить, сколько времени потребуется для генерации 100 миниатюр изображений с диска или сколько памяти займет определённая структура данных. Таблицы Степени двойки и Задержки, которые должен знать каждый программист — полезные справочные материалы.
Таблица степеней двойки
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Источники и дополнительная литература
Числа задержек, которые должен знать каждый программист
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Последовательное чтение с HDD на скорости 30 МБ/с
- Последовательное чтение по 1 Гбит/с Ethernet на скорости 100 МБ/с
- Последовательное чтение с SSD на скорости 1 ГБ/с
- Последовательное чтение из оперативной памяти на скорости 4 ГБ/с
- 6-7 круговых путешествий по всему миру в секунду
- 2 000 круговых путешествий в секунду внутри дата-центра
#### Источники и дополнительное чтение
- Latency numbers every programmer should know - 1
- Latency numbers every programmer should know - 2
- Designs, lessons, and advice from building large distributed systems
- Software Engineering Advice from Building Large-Scale Distributed Systems
Дополнительные вопросы для собеседования по системному дизайну
Популярные вопросы на собеседовании по системному дизайну с ссылками на ресурсы по их решению.
| Вопрос | Ссылка(и) |
|---|---|
| Спроектировать сервис синхронизации файлов как Dropbox | youtube.com |
| Спроектировать поисковую систему как Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Спроектировать масштабируемого веб-краулера как Google | quora.com |
| Спроектировать Google Docs | code.google.com
neil.fraser.name |
| Спроектировать key-value хранилище как Redis | slideshare.net |
| Спроектировать систему кеширования как Memcached | slideshare.net |
| Спроектировать рекомендательную систему как у Amazon | hulu.com
ijcai13.org |
| Спроектировать систему tinyurl как Bitly | n00tc0d3r.blogspot.com |
| Спроектировать чат-приложение как WhatsApp | highscalability.com
| Спроектировать систему обмена фотографиями как Instagram | highscalability.com
highscalability.com |
| Спроектировать функцию новостной ленты Facebook | quora.com
quora.com
slideshare.net |
| Спроектировать функцию хроники Facebook | facebook.com
highscalability.com |
| Спроектировать функцию чата Facebook | erlang-factory.com
facebook.com |
| Разработайте функцию поиска по графу, как у Facebook | facebook.com
facebook.com
facebook.com |
| Разработайте сеть доставки контента, как CloudFlare | figshare.com |
| Разработайте систему трендовых тем, как у Twitter | michael-noll.com
snikolov.wordpress.com |
| Разработайте систему генерации случайных идентификаторов | blog.twitter.com
github.com |
| Возвращайте топ k запросов за интервал времени | cs.ucsb.edu
wpi.edu |
| Разработайте систему, обслуживающую данные из нескольких дата-центров | highscalability.com |
| Разработайте онлайн-многопользовательскую карточную игру | indieflashblog.com
buildnewgames.com |
| Разработайте систему сборки мусора | stuffwithstuff.com
washington.edu |
| Разработайте ограничитель частоты запросов API | https://stripe.com/blog/ |
| Разработайте фондовую биржу (например, NASDAQ или Binance) | Jane Street
Golang Implementation
Go Implementation |
| Добавьте вопрос по проектированию системы | Contribute |
Архитектуры из реального мира
Статьи о том, как устроены реальные системы.
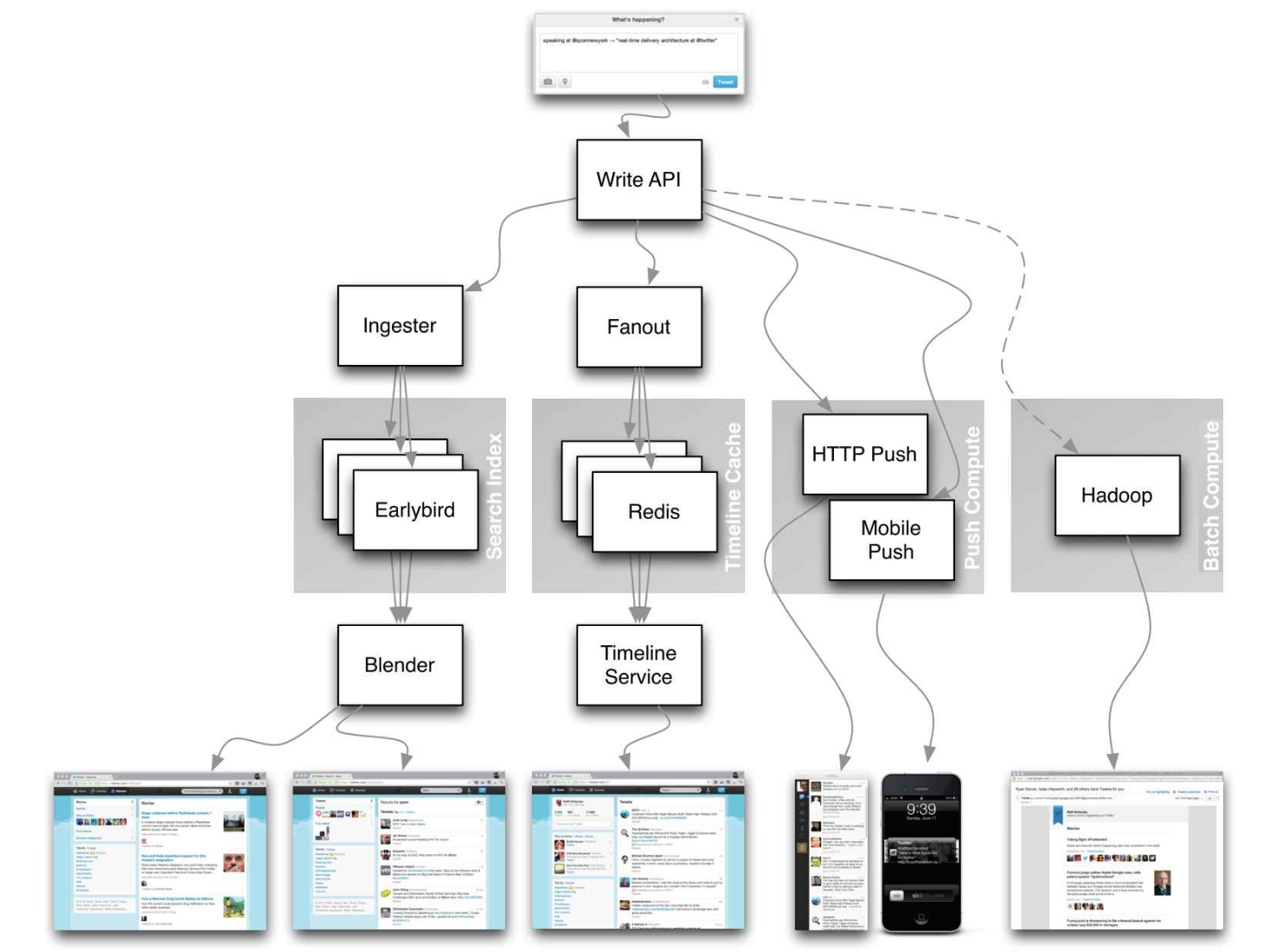
Источник: Масштабируемость таймлайнов Twitter
Не зацикливайтесь на мельчайших деталях из следующих статей, вместо этого:
- Выделяйте общие принципы, технологии и паттерны, встречающиеся в этих статьях
- Изучайте, какие задачи решает каждый компонент, где он работает, а где нет
- Анализируйте полученные уроки
Архитектуры компаний
| Компания | Ссылка(и) |
|---|---|
| Amazon | Архитектура Amazon |
| Cinchcast | Производство 1500 часов аудио в день |
| DataSift | Анализ данных в реальном времени на 120 000 твитов в секунду |
| Dropbox | Как мы масштабировали Dropbox |
| ESPN | Работа на 100 000 duh nuh nuhs в секунду |
| Google | Архитектура Google |
| Instagram | 14 миллионов пользователей, терабайты фото
Что обеспечивает работу Instagram |
| Justin.tv | Архитектура потокового видео Justin.tv |
| Facebook | Масштабирование memcached в Facebook
TAO: распределенное хранилище данных для социальной графа Facebook
Хранение фотографий в Facebook
Как Facebook транслирует Live для 800 000 одновременных зрителей |
| Flickr | Архитектура Flickr |
| Mailbox | С 0 до миллиона пользователей за 6 недель |
| Netflix | 360-градусный взгляд на стек Netflix
Netflix: что происходит, когда вы нажимаете Play? |
| Pinterest | С 0 до десятков миллиардов просмотров страниц в месяц
18 миллионов посетителей, рост в 10 раз, 12 сотрудников |
| Playfish | 50 миллионов пользователей в месяц и рост |
| PlentyOfFish | Архитектура PlentyOfFish |
| Salesforce | Как они обрабатывают 1,3 миллиарда транзакций в день |
| Stack Overflow | Архитектура Stack Overflow |
| TripAdvisor | 40 млн посетителей, 200 млн динамических просмотров, 30 ТБ данных |
| Tumblr | 15 миллиардов просмотров страниц в месяц |
| Twitter | Ускорение Twitter на 10000 процентов
Хранение 250 миллионов твитов в день на MySQL
150 млн активных пользователей, 300K QPS, поток 22 МБ/с
Таймлайны в масштабе
Большие и малые данные в Twitter
Операции в Twitter: масштабирование за 100 миллионов пользователей
Как Twitter обрабатывает 3 000 изображений в секунду |
| Uber | Как Uber масштабирует свою платформу реального времени
Уроки масштабирования Uber до 2000 инженеров, 1000 сервисов и 8000 репозиториев |
| WhatsApp | Архитектура WhatsApp, купленная Facebook за $19 миллиардов |
| YouTube | Масштабируемость YouTube
Архитектура YouTube |
Инженерные блоги компаний
Архитектуры компаний, в которых вы проходите собеседование.>
Вопросы, с которыми вы сталкиваетесь, могут быть из той же области.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Хотите добавить блог? Чтобы избежать дублирования работы, рассмотрите возможность добавления блога вашей компании в следующий репозиторий:
В разработке
Хотите добавить раздел или помочь завершить текущий? Внесите вклад!
- Распределённые вычисления с MapReduce
- Консистентное хеширование
- Scatter gather
- Внесите вклад
Благодарности
Благодарности и источники указаны по всему этому репозиторию.
Особая благодарность:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Контактная информация
Не стесняйтесь обращаться ко мне для обсуждения любых проблем, вопросов или комментариев.
Мои контактные данные можно найти на моей странице GitHub.
Лицензия
Я предоставляю код и ресурсы в этом репозитории вам по открытой лицензии. Поскольку это мой личный репозиторий, лицензию на мой код и ресурсы вы получаете от меня, а не от моего работодателя (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---