English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Ajude a traduzir este guia!
O Guia de Projeto de Sistemas

Motivação
Aprenda como projetar sistemas em larga escala.>
Prepare-se para a entrevista de design de sistemas.
Aprenda como projetar sistemas em larga escala
Aprender a projetar sistemas escaláveis vai ajudar você a se tornar um engenheiro melhor.
Projeto de sistemas é um tópico amplo. Existe uma quantidade enorme de recursos espalhados pela web sobre princípios de design de sistemas.
Este repositório é uma coleção organizada de recursos para ajudar você a aprender como construir sistemas em escala.
Aprenda com a comunidade open source
Este é um projeto open source continuamente atualizado.
Contribuições são bem-vindas!
Prepare-se para a entrevista de design de sistemas
Além das entrevistas de programação, o design de sistemas é um componente obrigatório do processo de entrevista técnica em muitas empresas de tecnologia.
Pratique perguntas comuns de entrevista de design de sistemas e compare seus resultados com soluções de exemplo: discussões, código e diagramas.
Tópicos adicionais para preparação para entrevistas:
- Guia de estudos
- Como abordar uma pergunta de entrevista de design de sistemas
- Perguntas de entrevista de design de sistemas, com soluções
- Perguntas de entrevista de design orientado a objetos, com soluções
- Perguntas adicionais de entrevista de design de sistemas
Flashcards Anki
Os decks de flashcards Anki fornecidos usam repetição espaçada para ajudar você a reter conceitos-chave de design de sistemas.
- Deck de design de sistemas
- Deck de exercícios de design de sistemas
- Deck de exercícios de design orientado a objetos
Recurso de Codificação: Desafios Interativos de Programação
Procurando recursos para ajudar você a se preparar para a Entrevista de Programação?
Confira o repositório irmão Interactive Coding Challenges, que contém um deck Anki adicional:
Contribuindo
Aprenda com a comunidade.
Sinta-se à vontade para enviar pull requests para ajudar:
- Corrigir erros
- Melhorar seções
- Adicione novas seções
- Traduzir
Revise as Diretrizes de Contribuição.
Índice de tópicos de design de sistemas
Resumos de vários tópicos de design de sistemas, incluindo prós e contras. Tudo é uma troca.>
Cada seção contém links para recursos mais aprofundados.
- Tópicos de design de sistemas: comece aqui
- Passo 1: Revise a videoaula sobre escalabilidade
- Passo 2: Revise o artigo sobre escalabilidade
- Próximos passos
- Desempenho vs escalabilidade
- Latência vs vazão
- Disponibilidade vs consistência
- Teorema CAP
- CP - consistência e tolerância à partição
- AP - disponibilidade e tolerância à partição
- Padrões de consistência
- Consistência fraca
- Consistência eventual
- Consistência forte
- Padrões de disponibilidade
- Fail-over
- Replicação
- Disponibilidade em números
- Sistema de nomes de domínio
- Rede de entrega de conteúdo
- CDNs Push
- CDNs Pull
- Balanceador de carga
- Ativo-passivo
- Ativo-ativo
- Balanceamento de carga na Camada 4
- Balanceamento de carga na Camada 7
- Escalonamento horizontal
- Proxy reverso (servidor web)
- Balanceador de carga vs proxy reverso
- Camada de aplicação
- Microsserviços
- Descoberta de serviços
- Banco de dados
- Sistema de gerenciamento de banco de dados relacional (SGBDR)
- Replicação mestre-escravo
- Replicação mestre-mestre
- Federação
- Fragmentação (Sharding)
- Desnormalização
- Otimização de SQL
- NoSQL
- Armazenamento chave-valor
- Armazenamento de documentos
- Armazenamento em colunas largas
- Banco de dados de grafos
- SQL ou NoSQL
- Cache
- Cache do cliente
- Cache de CDN
- Cache do servidor web
- Cache de banco de dados
- Cache da aplicação
- Cache no nível de consulta ao banco de dados
- Cache no nível de objeto
- Quando atualizar o cache
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- Assincronismo
- Filas de mensagens
- Filas de tarefas
- Pressão reversa (Back pressure)
- Comunicação
- Protocolo de controle de transmissão (TCP)
- Protocolo de datagrama do usuário (UDP)
- Chamada de procedimento remoto (RPC)
- Transferência de estado representacional (REST)
- Segurança
- Apêndice
- Tabela de potências de dois
- Números de latência que todo programador deveria saber
- Perguntas adicionais de entrevista de design de sistemas
- Arquiteturas do mundo real
- Arquiteturas de empresas
- Blogs de engenharia de empresas
- Em desenvolvimento
- Créditos
- Informações de contato
- Licença
Guia de estudos
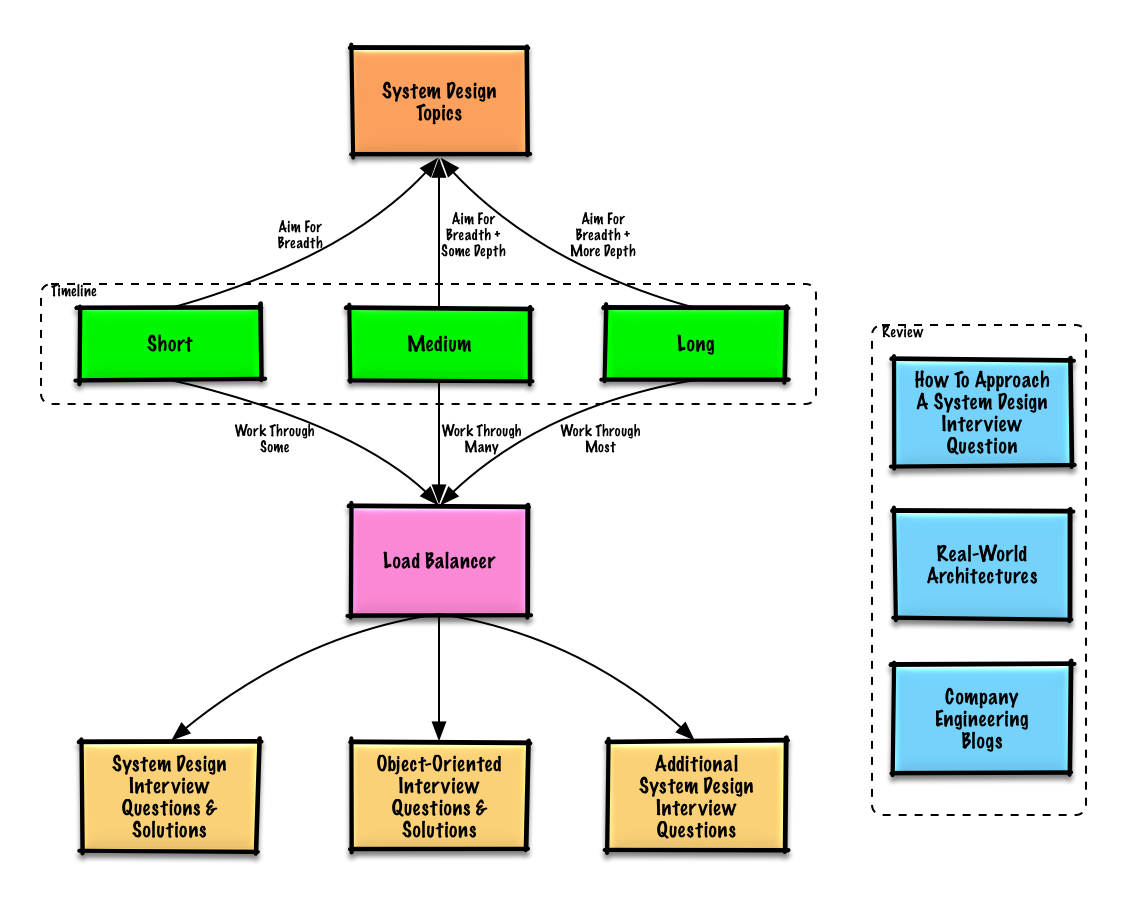
Tópicos sugeridos para revisar com base na sua linha do tempo para entrevistas (curto, médio, longo).
P: Para entrevistas, eu preciso saber tudo aqui?
R: Não, você não precisa saber tudo aqui para se preparar para a entrevista.
O que será perguntado em uma entrevista depende de variáveis como:
- Quanto de experiência você tem
- Qual é o seu histórico técnico
- Para quais cargos você está entrevistando
- Com quais empresas você está entrevistando
- Sorte
Comece amplo e aprofunde-se em algumas áreas. Ajuda conhecer um pouco sobre diversos tópicos-chave de design de sistemas. Ajuste o guia abaixo conforme seu cronograma, experiência, os cargos para os quais está se candidatando e as empresas onde irá entrevistar.
- Cronograma curto - Foque em amplitude nos tópicos de design de sistemas. Pratique resolvendo algumas questões de entrevista.
- Cronograma médio - Foque em amplitude e alguma profundidade nos tópicos de design de sistemas. Pratique resolvendo muitas questões de entrevista.
- Cronograma longo - Foque em amplitude e maior profundidade nos tópicos de design de sistemas. Pratique resolvendo a maioria das questões de entrevista.
Como abordar uma questão de entrevista de design de sistemas
Como lidar com uma questão de entrevista de design de sistemas.
A entrevista de design de sistemas é uma conversa aberta. Espera-se que você a conduza.
Você pode usar os seguintes passos para guiar a discussão. Para ajudar a solidificar esse processo, trabalhe com as Questões de entrevista de design de sistemas com soluções usando os passos abaixo.
Passo 1: Delimite casos de uso, restrições e suposições
Recolha requisitos e defina o escopo do problema. Faça perguntas para esclarecer casos de uso e restrições. Discuta suposições.
- Quem vai usar?
- Como irão usar?
- Quantos usuários existem?
- O que o sistema faz?
- Quais são as entradas e saídas do sistema?
- Qual o volume de dados esperado?
- Quantas requisições por segundo esperamos?
- Qual a proporção esperada de leitura para escrita?
Passo 2: Crie um design de alto nível
Descreva um design de alto nível com todos os componentes importantes.
- Esboce os principais componentes e conexões
- Justifique suas ideias
Etapa 3: Projetar componentes principais
Aprofunde-se nos detalhes de cada componente principal. Por exemplo, se você fosse solicitado a projetar um serviço de encurtamento de URL, discuta:
- Gerar e armazenar um hash da URL completa
- MD5 e Base62
- Colisões de hash
- SQL ou NoSQL
- Esquema de banco de dados
- Traduzir uma URL hasheada para a URL completa
- Consulta ao banco de dados
- API e design orientado a objetos
Etapa 4: Escalar o projeto
Identifique e resolva gargalos, dadas as restrições. Por exemplo, você precisa dos seguintes itens para resolver questões de escalabilidade?
- Balanceador de carga
- Escalabilidade horizontal
- Cache
- Sharding de banco de dados
Cálculos rápidos
Você pode ser solicitado a fazer algumas estimativas à mão. Consulte o Apêndice para os seguintes recursos:
- Use cálculos rápidos
- Tabela de potências de dois
- Números de latência que todo programador deve saber
Fonte(s) e leitura adicional
Confira os links abaixo para ter uma ideia melhor do que esperar:
- Como se sair bem em uma entrevista de design de sistemas
- A entrevista de design de sistemas
- Introdução à Arquitetura e Entrevistas de Design de Sistemas
- Template de design de sistemas
Perguntas de entrevista de design de sistemas com soluções
Perguntas comuns de entrevistas de design de sistemas com discussões de exemplo, código e diagramas.>
Soluções vinculadas ao conteúdo na pasta solutions/.| Pergunta | | |---|---| | Como projetar o Pastebin.com (ou Bit.ly) | Solução | | Como projetar a timeline e busca do Twitter (ou feed e busca do Facebook) | Solução | | Como projetar um web crawler | Solução | | Como projetar o Mint.com | Solução | | Como projetar as estruturas de dados para uma rede social | Solução | | Como projetar um armazenamento chave-valor para um mecanismo de busca | Solução | | Como projetar o recurso de ranking de vendas por categoria da Amazon | Solução | | Como projetar um sistema que escale para milhões de usuários na AWS | Solução | | Adicione uma questão de design de sistema | Contribua |
Como projetar o Pastebin.com (ou Bit.ly)
Como projetar a timeline e busca do Twitter (ou feed e busca do Facebook)
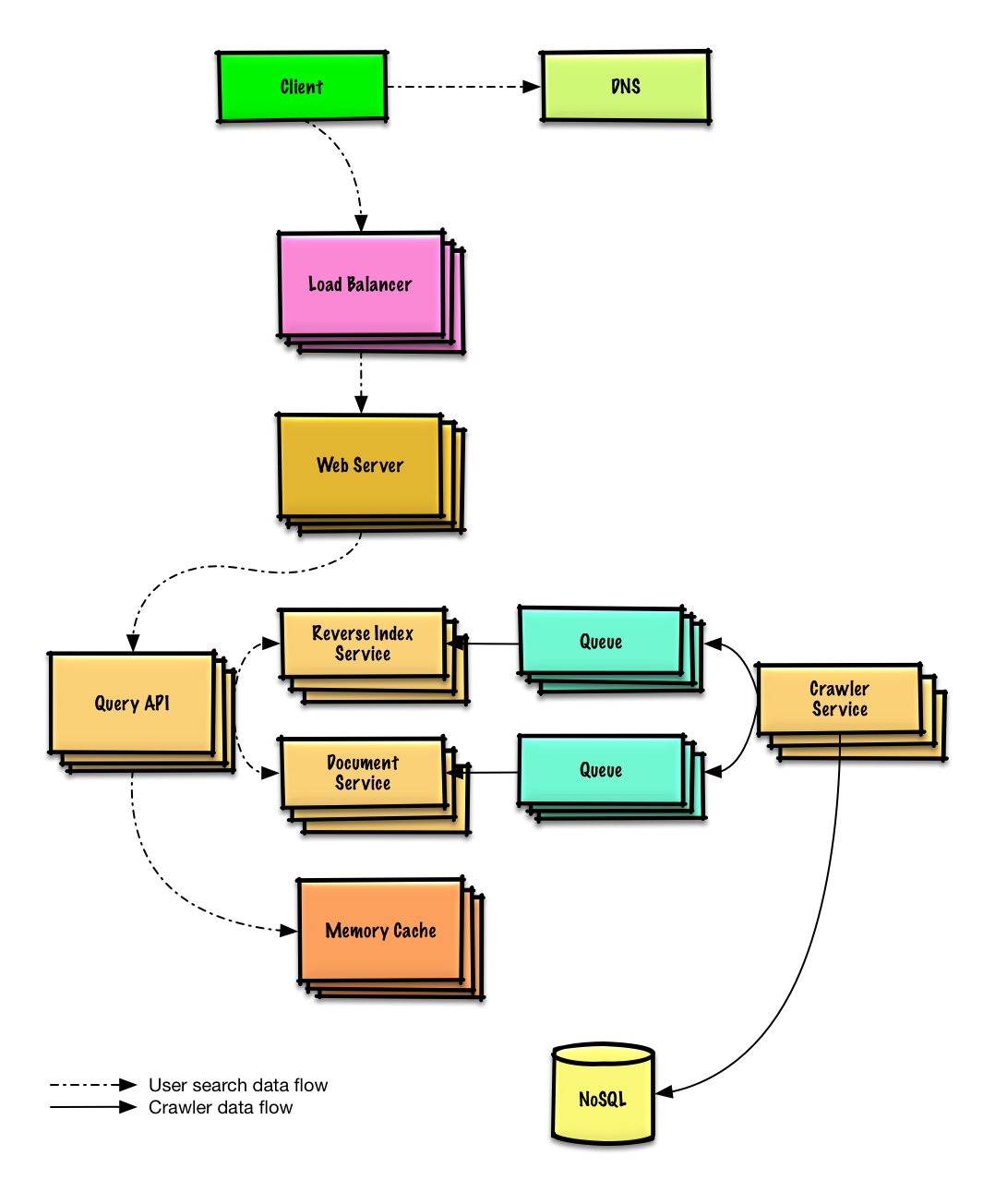
Como projetar um web crawler
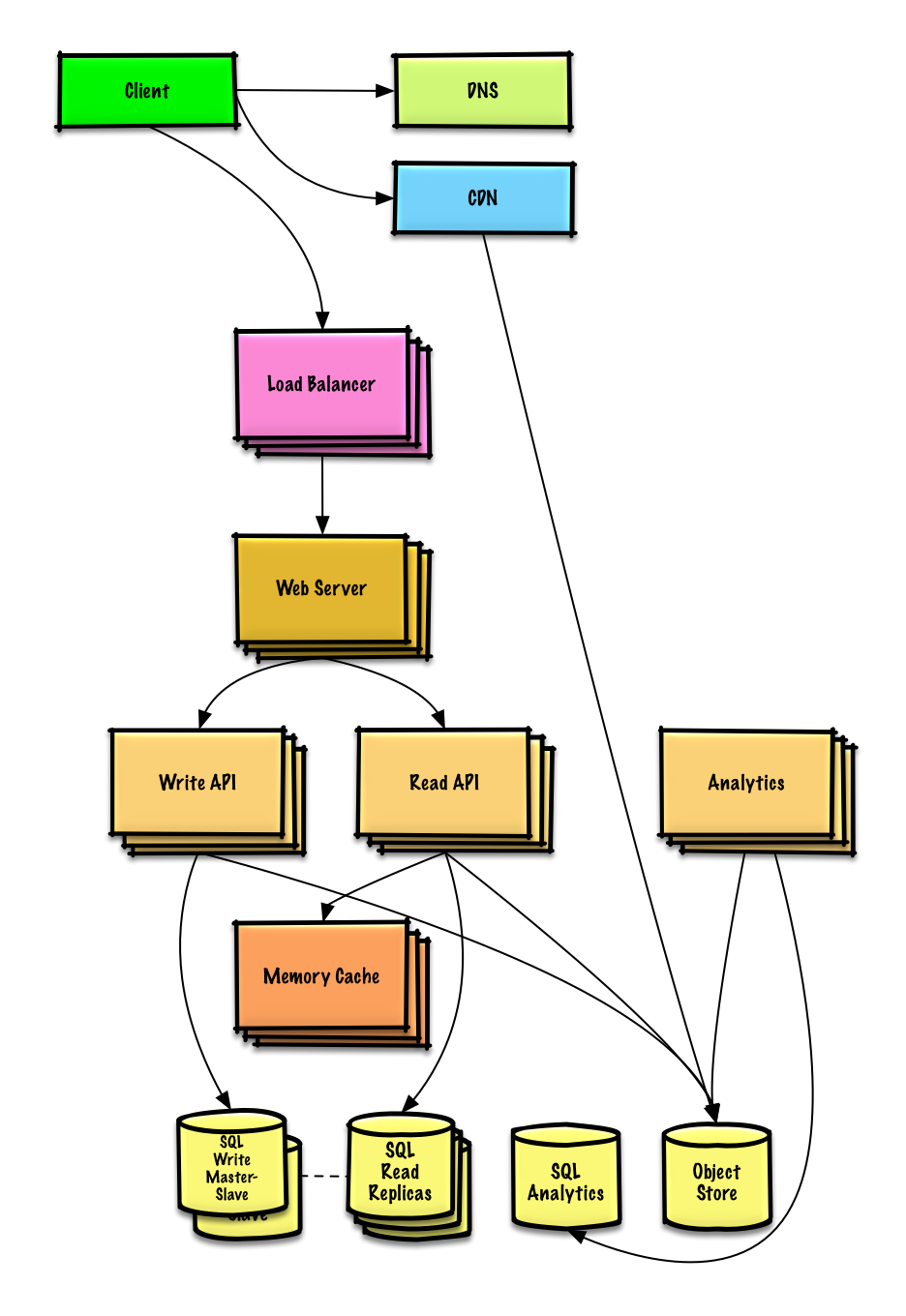
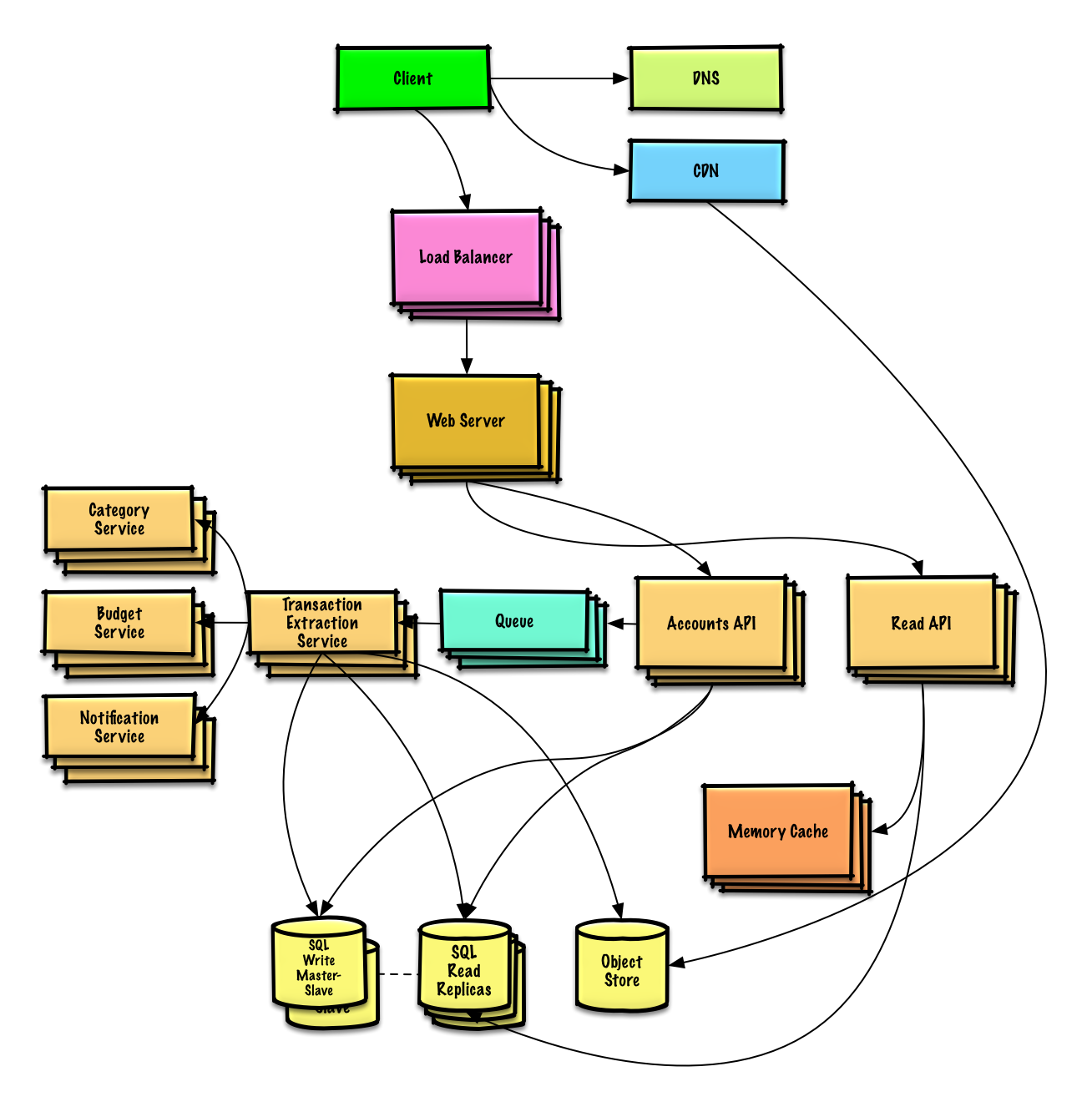
Design Mint.com
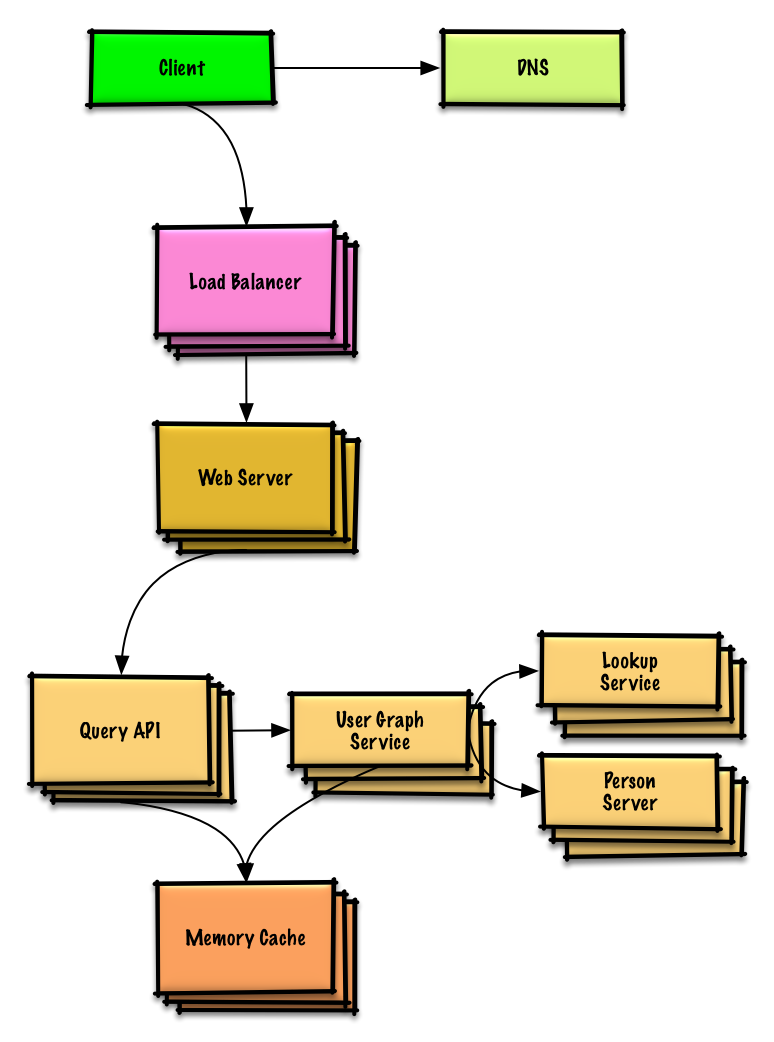
Design the data structures for a social network
Design a key-value store for a search engine
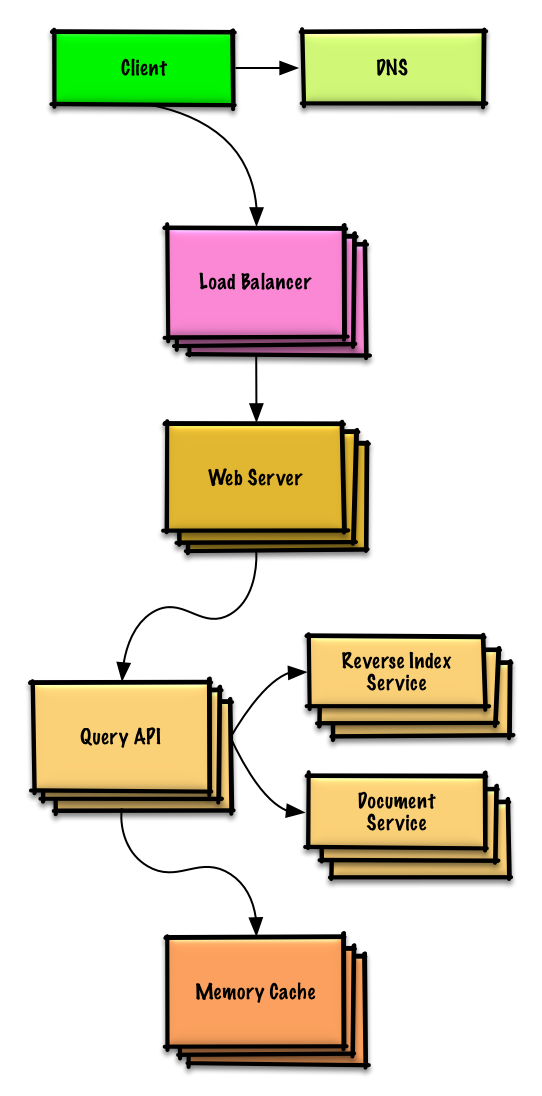
Design Amazon's sales ranking by category feature
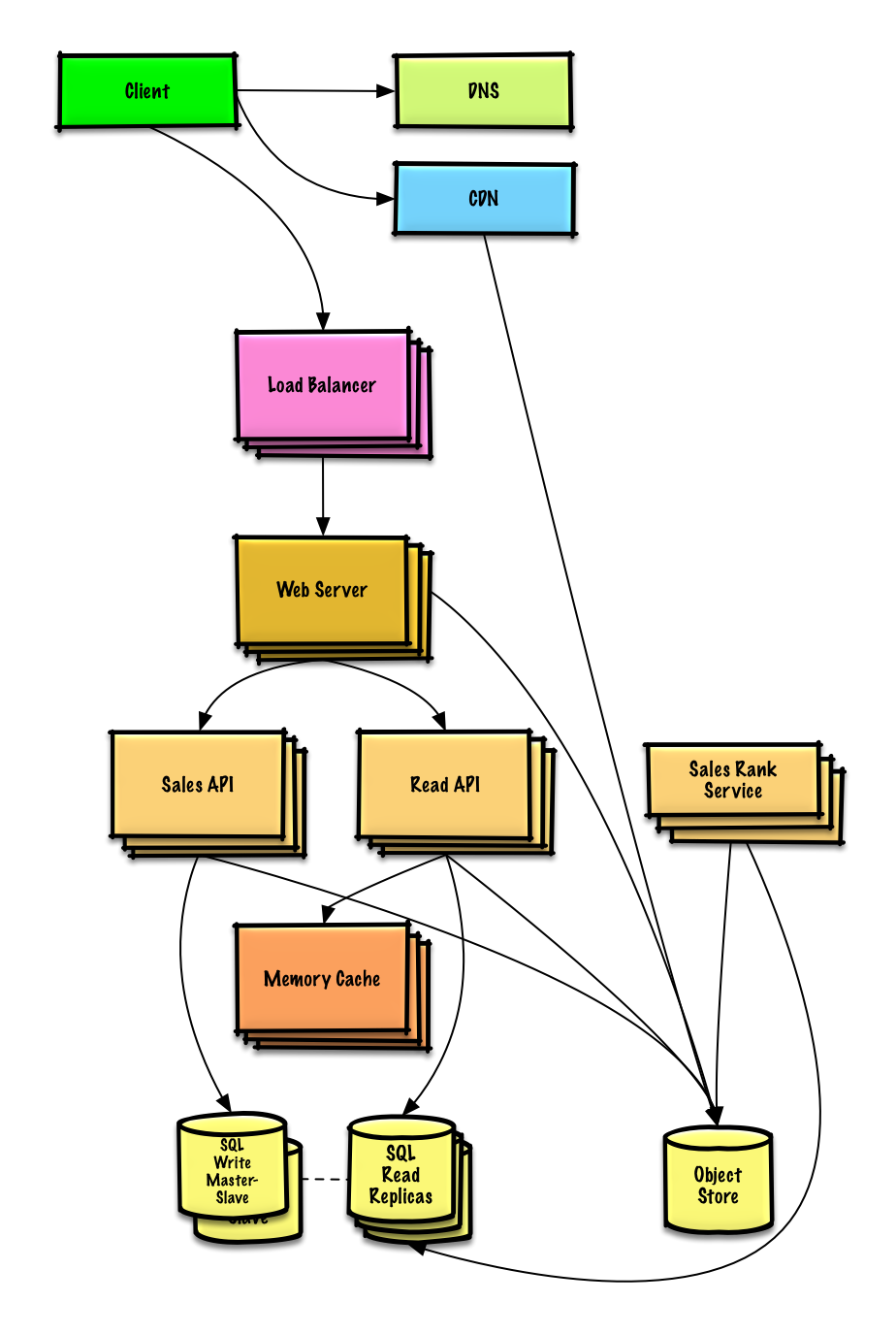
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Desenvolva um mapa de hash | Solução | | Desenvolva um cache menos recentemente usado | Solução | | Desenvolva uma central de atendimento | Solução | | Desenvolva um baralho de cartas | Solução | | Desenvolva um estacionamento | Solução | | Desenvolva um servidor de chat | Solução | | Desenvolva um array circular | Contribua | | Adicione uma questão de design orientado a objetos | Contribua |
Tópicos de design de sistemas: comece aqui
Novo em design de sistemas?
Primeiro, você precisará de um entendimento básico dos princípios comuns, aprendendo o que são, como são usados e seus prós e contras.
Passo 1: Revise a videoaula sobre escalabilidade
Palestra sobre Escalabilidade em Harvard
- Tópicos abordados:
- Escalabilidade vertical
- Escalabilidade horizontal
- Cache
- Balanceamento de carga
- Replicação de banco de dados
- Particionamento de banco de dados
Passo 2: Revise o artigo sobre escalabilidade
- Tópicos abordados:
- Clones
- Bancos de dados
- Caches
- Assincronismo
Próximos passos
A seguir, veremos os trade-offs de alto nível:
- Desempenho vs escalabilidade
- Latência vs taxa de transferência
- Disponibilidade vs consistência
Depois, vamos abordar tópicos mais específicos como DNS, CDNs e balanceadores de carga.
Desempenho vs escalabilidade
Um serviço é escalável se resulta em aumento de desempenho de forma proporcional aos recursos adicionados. Geralmente, aumentar o desempenho significa atender mais unidades de trabalho, mas também pode ser para lidar com unidades maiores, como quando os conjuntos de dados crescem.1
Outra maneira de analisar desempenho vs escalabilidade:
- Se você tem um problema de desempenho, seu sistema é lento para um único usuário.
- Se você tem um problema de escalabilidade, seu sistema é rápido para um único usuário, mas lento sob carga pesada.
Fonte(s) e leitura adicional
Latência vs taxa de transferência
Latência é o tempo para realizar uma ação ou produzir um resultado.
Taxa de transferência é o número dessas ações ou resultados por unidade de tempo.
Geralmente, você deve buscar taxa de transferência máxima com latência aceitável.
Fonte(s) e leitura adicional
Disponibilidade vs consistência
Teorema CAP
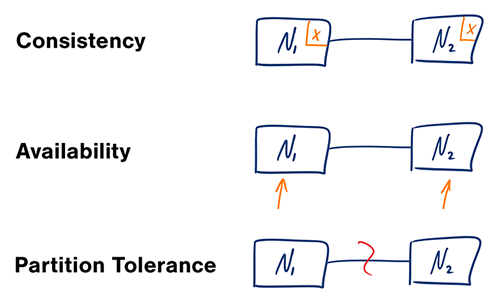
Em um sistema distribuído de computadores, você só pode suportar duas das seguintes garantias:
- Consistência - Toda leitura recebe a escrita mais recente ou um erro
- Disponibilidade - Toda requisição recebe uma resposta, sem garantia de que contém a versão mais recente da informação
- Tolerância a Partição - O sistema continua a operar apesar de partições arbitrárias devido a falhas de rede
#### CP - consistência e tolerância a partição
Aguardar uma resposta do nó particionado pode resultar em um erro de timeout. CP é uma boa escolha se as necessidades do negócio exigem leituras e escritas atômicas.
#### AP - disponibilidade e tolerância a partição
Respostas retornam a versão mais prontamente disponível dos dados em qualquer nó, que pode não ser a mais recente. Escritas podem levar algum tempo para se propagar quando a partição é resolvida.
AP é uma boa escolha se as necessidades do negócio permitem consistência eventual ou quando o sistema precisa continuar funcionando apesar de erros externos.
Fonte(s) e leitura adicional
Padrões de consistência
Com múltiplas cópias dos mesmos dados, enfrentamos opções sobre como sincronizá-las para que os clientes tenham uma visão consistente dos dados. Relembre a definição de consistência do teorema CAP - Toda leitura recebe a escrita mais recente ou um erro.
Consistência fraca
Após uma escrita, leituras podem ou não vê-la. Uma abordagem de melhor esforço é utilizada.
Esta abordagem é vista em sistemas como memcached. Consistência fraca funciona bem em casos de uso em tempo real como VoIP, chat de vídeo e jogos multiplayer em tempo real. Por exemplo, se você está em uma ligação e perde o sinal por alguns segundos, ao recuperar a conexão você não ouve o que foi dito durante a perda da conexão.
Consistência eventual
Após uma escrita, as leituras eventualmente a verão (normalmente dentro de milissegundos). Os dados são replicados de forma assíncrona.
Essa abordagem é vista em sistemas como DNS e email. A consistência eventual funciona bem em sistemas altamente disponíveis.
Consistência forte
Após uma escrita, as leituras a verão. Os dados são replicados de forma síncrona.
Essa abordagem é vista em sistemas de arquivos e SGBDRs. Consistência forte funciona bem em sistemas que precisam de transações.
Fonte(s) e leitura adicional
Padrões de disponibilidade
Existem dois padrões complementares para suportar alta disponibilidade: fail-over e replicação.
Fail-over
#### Ativo-passivo
Com fail-over ativo-passivo, sinais de vida são enviados entre o servidor ativo e o passivo em espera. Se o sinal de vida for interrompido, o servidor passivo assume o endereço IP do ativo e retoma o serviço.
O tempo de inatividade é determinado por o servidor passivo já estar executando em standby 'quente' ou se precisa iniciar em standby 'frio'. Apenas o servidor ativo lida com o tráfego.
Fail-over ativo-passivo também pode ser chamado de fail-over mestre-escravo.
#### Ativo-ativo
No ativo-ativo, ambos os servidores gerenciam o tráfego, distribuindo a carga entre eles.
Se os servidores forem voltados ao público, o DNS precisaria saber sobre os IPs públicos de ambos os servidores. Se forem voltados para uso interno, a lógica da aplicação precisaria saber sobre ambos os servidores.
Fail-over ativo-ativo também pode ser chamado de fail-over mestre-mestre.
Desvantagem(ns): failover
- O fail-over adiciona mais hardware e complexidade adicional.
- Há um potencial de perda de dados se o sistema ativo falhar antes que qualquer dado recém-escrito seja replicado para o passivo.
Replicação
#### Master-slave e master-master
Este tópico é discutido mais detalhadamente na seção Banco de Dados:
Disponibilidade em números
A disponibilidade é frequentemente quantificada pelo tempo de funcionamento (ou tempo de inatividade) como uma porcentagem do tempo em que o serviço está disponível. A disponibilidade é geralmente medida em número de 9s--um serviço com 99,99% de disponibilidade é descrito como tendo quatro noves.
#### 99,9% de disponibilidade - três noves
| Duração | Tempo de inatividade aceitável| |---------------------|------------------------------| | Inatividade por ano | 8h 45min 57s | | Inatividade por mês | 43m 49,7s | | Inatividade por semana | 10m 4,8s | | Inatividade por dia | 1m 26,4s |
#### 99,99% de disponibilidade - quatro noves
| Duração | Tempo de inatividade aceitável| |---------------------|------------------------------| | Inatividade por ano | 52min 35,7s | | Inatividade por mês | 4m 23s | | Inatividade por semana | 1m 5s | | Inatividade por dia | 8,6s |
#### Disponibilidade em paralelo vs em sequência
Se um serviço consiste em múltiplos componentes propensos a falhas, a disponibilidade geral do serviço depende se os componentes estão em sequência ou em paralelo.
###### Em sequência
A disponibilidade geral diminui quando dois componentes com disponibilidade < 100% estão em sequência:
Availability (Total) = Availability (Foo) * Availability (Bar)Se tanto Foo quanto Bar tivessem 99,9% de disponibilidade cada um, a disponibilidade total em sequência seria de 99,8%.
###### Em paralelo
A disponibilidade geral aumenta quando dois componentes com disponibilidade < 100% estão em paralelo:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo quanto Bar tivessem 99,9% de disponibilidade cada, a disponibilidade total em paralelo seria de 99,9999%.Sistema de nomes de domínio
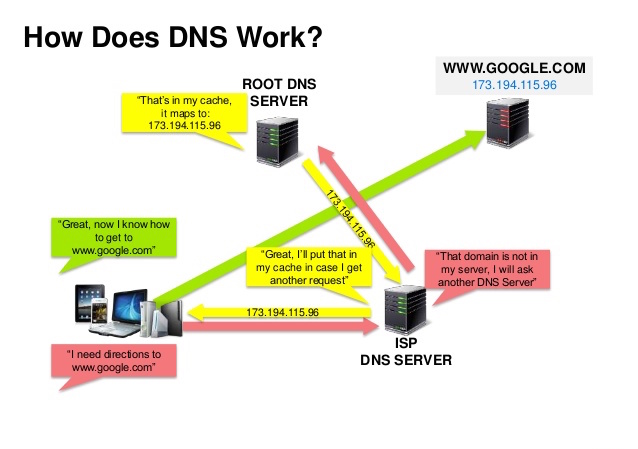
Fonte: Apresentação sobre segurança de DNS
Um Sistema de Nomes de Domínio (DNS) traduz um nome de domínio como www.example.com para um endereço IP.
O DNS é hierárquico, com alguns servidores autorizados no topo. Seu roteador ou ISP fornece informações sobre quais servidores DNS contatar ao fazer uma consulta. Servidores DNS de níveis inferiores armazenam em cache mapeamentos, que podem ficar desatualizados devido a atrasos na propagação do DNS. Os resultados do DNS também podem ser armazenados em cache pelo seu navegador ou sistema operacional por um determinado período, determinado pelo time to live (TTL).
- Registro NS (name server) - Especifica os servidores DNS para seu domínio/subdomínio.
- Registro MX (mail exchange) - Especifica os servidores de e-mail para receber mensagens.
- Registro A (address) - Aponta um nome para um endereço IP.
- CNAME (canônico) - Aponta um nome para outro nome ou
CNAME(example.com para www.example.com) ou para um registroA.
- Round robin ponderado
- Impede que o tráfego vá para servidores em manutenção
- Equilibra entre tamanhos de cluster variados
- Teste A/B
- Baseado em latência
- Baseado em geolocalização
Desvantagem(ns): DNS
- O acesso a um servidor DNS introduz um pequeno atraso, embora mitigado pelo cache descrito acima.
- O gerenciamento de servidores DNS pode ser complexo e geralmente é feito por governos, ISPs e grandes empresas.
- Serviços DNS têm sido alvo de ataques DDoS, impedindo usuários de acessarem sites como o Twitter sem conhecer os endereços IP do Twitter.
Fonte(s) e leitura adicional
Rede de entrega de conteúdo
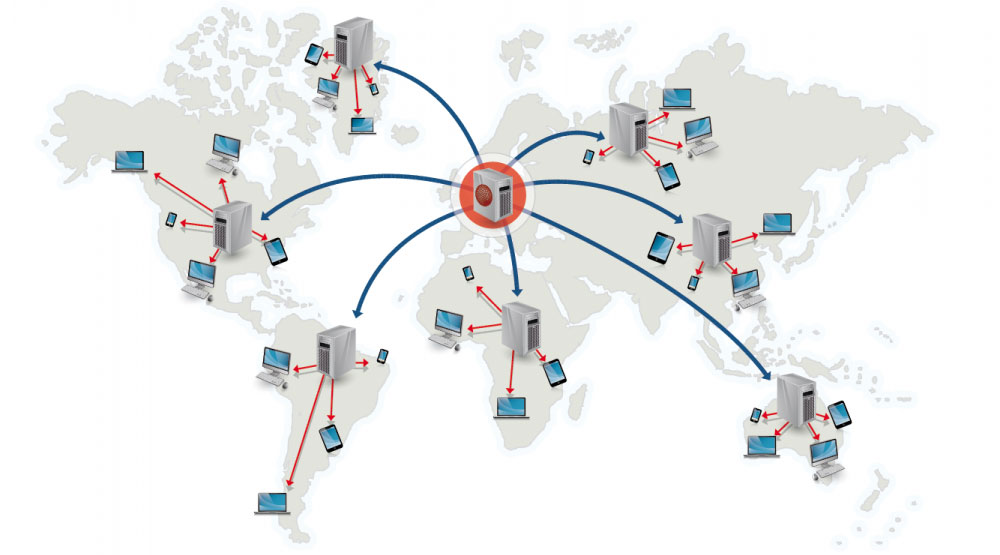
Uma rede de entrega de conteúdo (CDN) é uma rede globalmente distribuída de servidores proxy, que servem conteúdo de locais mais próximos ao usuário. Geralmente, arquivos estáticos como HTML/CSS/JS, fotos e vídeos são servidos pela CDN, embora algumas CDNs como a CloudFront da Amazon suportem conteúdo dinâmico. A resolução de DNS do site indicará aos clientes qual servidor contatar.
Servir conteúdo por meio de CDNs pode melhorar significativamente o desempenho de duas maneiras:
- Os usuários recebem conteúdo de data centers próximos a eles
- Seus servidores não precisam atender às solicitações que a CDN cumpre
CDNs Push
CDNs Push recebem novo conteúdo sempre que alterações ocorrem em seu servidor. Você assume total responsabilidade por fornecer o conteúdo, fazendo upload direto para a CDN e reescrevendo URLs para apontar para a CDN. Você pode configurar quando o conteúdo expira e quando é atualizado. O conteúdo é enviado somente quando é novo ou alterado, minimizando o tráfego, mas maximizando o armazenamento.
Sites com baixo tráfego ou sites cujo conteúdo não é atualizado com frequência funcionam bem com CDNs Push. O conteúdo é colocado nas CDNs uma vez, em vez de ser repuxado em intervalos regulares.
CDNs Pull
CDNs Pull buscam novo conteúdo do seu servidor quando o primeiro usuário solicita o conteúdo. Você mantém o conteúdo em seu servidor e reescreve as URLs para apontar para a CDN. Isso resulta em uma requisição mais lenta até que o conteúdo seja armazenado em cache na CDN.
Um time-to-live (TTL) determina por quanto tempo o conteúdo fica em cache. CDNs Pull minimizam o espaço de armazenamento na CDN, mas podem criar tráfego redundante se os arquivos expirarem e forem buscados antes de realmente terem mudado.
Sites com alto tráfego funcionam bem com CDNs Pull, pois o tráfego é distribuído mais uniformemente, com apenas o conteúdo recentemente solicitado permanecendo na CDN.
Desvantagem(ns): CDN
- Os custos de CDN podem ser significativos dependendo do tráfego, embora isso deva ser ponderado com os custos adicionais que você teria sem usar uma CDN.
- O conteúdo pode ficar desatualizado se for atualizado antes do TTL expirar.
- CDNs exigem alteração de URLs para conteúdo estático a fim de apontar para a CDN.
Fonte(s) e leitura adicional
Balanceador de carga
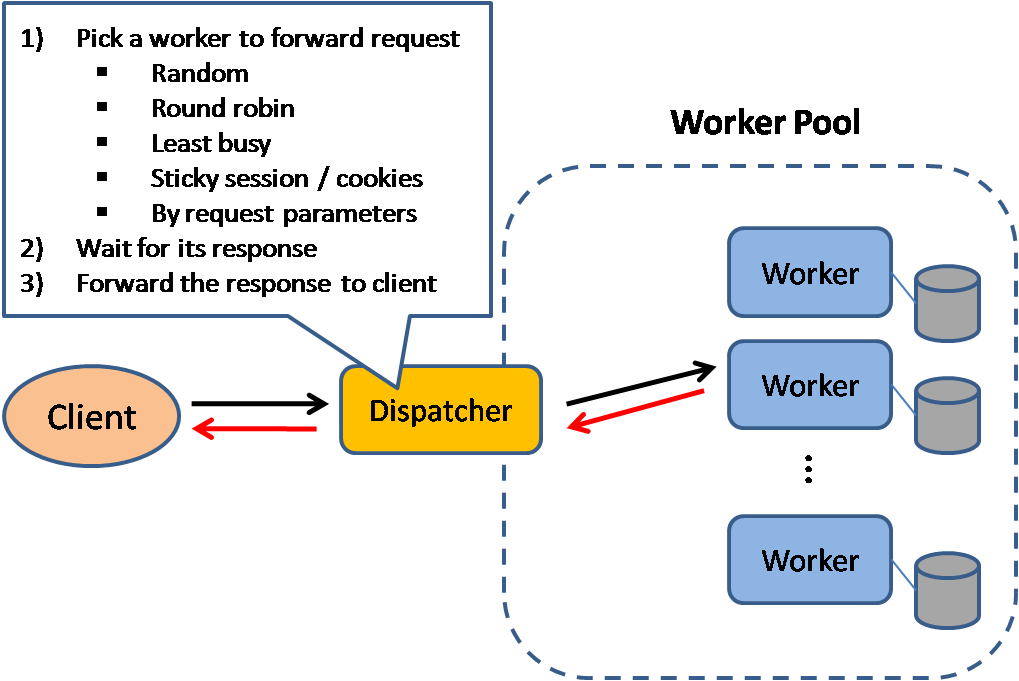
Fonte: Padrões de design de sistemas escaláveis
Balanceadores de carga distribuem as requisições dos clientes para recursos computacionais como servidores de aplicação e bancos de dados. Em cada caso, o balanceador de carga retorna a resposta do recurso computacional para o cliente apropriado. Os balanceadores de carga são eficazes para:
- Evitar que requisições sejam encaminhadas para servidores com problemas
- Prevenir sobrecarga de recursos
- Ajudar a eliminar um único ponto de falha
Benefícios adicionais incluem:
- Terminação SSL - Descriptografa as requisições recebidas e criptografa as respostas do servidor para que os servidores backend não precisem realizar essas operações potencialmente custosas
- Elimina a necessidade de instalar certificados X.509 em cada servidor
- Persistência de sessão - Emite cookies e direciona as requisições de um cliente específico para a mesma instância caso os aplicativos web não mantenham o controle das sessões
Balanceadores de carga podem rotear o tráfego com base em várias métricas, incluindo:
- Aleatório
- Menor carga
- Sessão/cookies
- Round robin ou round robin ponderado
- Camada 4
- Camada 7
Balanceamento de carga na Camada 4
Balanceadores de carga na Camada 4 analisam informações na camada de transporte para decidir como distribuir as requisições. Geralmente, isso envolve os endereços IP de origem e destino e as portas no cabeçalho, mas não o conteúdo do pacote. Balanceadores de carga da Camada 4 encaminham pacotes de rede para e do servidor upstream, realizando Tradução de Endereço de Rede (NAT).
Balanceamento de carga na Camada 7
Balanceadores de carga de Camada 7 analisam a camada de aplicação para decidir como distribuir as requisições. Isso pode envolver o conteúdo do cabeçalho, mensagem e cookies. Balanceadores de carga de Camada 7 encerram o tráfego de rede, leem a mensagem, tomam uma decisão de balanceamento de carga e então abrem uma conexão com o servidor selecionado. Por exemplo, um balanceador de carga de camada 7 pode direcionar tráfego de vídeo para servidores que hospedam vídeos enquanto direciona tráfego de cobrança de usuários para servidores reforçados em segurança.À custa de flexibilidade, o balanceamento de carga na camada 4 requer menos tempo e recursos computacionais do que na Camada 7, embora o impacto no desempenho possa ser mínimo em hardware comum moderno.
Escalabilidade horizontal
Balanceadores de carga também podem ajudar com a escalabilidade horizontal, melhorando o desempenho e a disponibilidade. Escalar horizontalmente usando máquinas comuns é mais eficiente em termos de custo e resulta em maior disponibilidade do que escalar verticalmente um único servidor em hardware mais caro, chamado de Escalabilidade Vertical. Também é mais fácil contratar profissionais para trabalhar com hardware comum do que para sistemas corporativos especializados.
#### Desvantagem(ns): escalabilidade horizontal
- Escalar horizontalmente introduz complexidade e envolve a clonagem de servidores
- Servidores devem ser stateless: não devem conter dados relacionados ao usuário como sessões ou fotos de perfil
- Sessões podem ser armazenadas em um armazenamento de dados centralizado como um banco de dados (SQL, NoSQL) ou um cache persistente (Redis, Memcached)
- Servidores downstream como caches e bancos de dados precisam lidar com mais conexões simultâneas à medida que servidores upstream escalam horizontalmente
Desvantagem(ns): balanceador de carga
- O balanceador de carga pode se tornar um gargalo de desempenho se não tiver recursos suficientes ou se não estiver configurado corretamente.
- Introduzir um balanceador de carga para ajudar a eliminar um ponto único de falha resulta em aumento de complexidade.
- Um único balanceador de carga é um ponto único de falha; configurar múltiplos balanceadores de carga aumenta ainda mais a complexidade.
Fonte(s) e leituras adicionais
- Arquitetura NGINX
- Guia de arquitetura HAProxy
- Escalabilidade
- Wikipedia)
- Balanceamento de carga na camada 4
- Balanceamento de carga na camada 7
- Configuração de listener do ELB
Proxy reverso (servidor web)
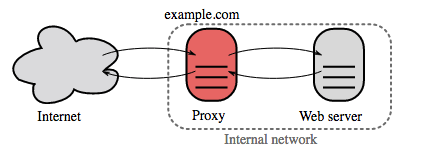
{kind=link}
Um proxy reverso é um servidor web que centraliza serviços internos e fornece interfaces unificadas ao público. As solicitações dos clientes são encaminhadas para um servidor que pode atendê-las antes que o proxy reverso retorne a resposta do servidor ao cliente.
Benefícios adicionais incluem:
- Aumento da segurança - Oculta informações sobre servidores backend, bloqueia IPs, limita o número de conexões por cliente
- Maior escalabilidade e flexibilidade - Os clientes veem apenas o IP do proxy reverso, permitindo escalar servidores ou alterar sua configuração
- Terminação SSL - Descriptografa solicitações recebidas e criptografa respostas do servidor para que os servidores backend não precisem realizar essas operações potencialmente caras
- Elimina a necessidade de instalar certificados X.509 em cada servidor
- Compressão - Comprime as respostas dos servidores
- Cache - Retorna a resposta para solicitações em cache
- Conteúdo estático - Serve conteúdo estático diretamente
- HTML/CSS/JS
- Fotos
- Vídeos
- Etc
Balanceador de carga vs proxy reverso
- Implantar um balanceador de carga é útil quando você tem vários servidores. Frequentemente, balanceadores de carga direcionam o tráfego para um conjunto de servidores que servem à mesma função.
- Proxies reversos podem ser úteis mesmo com apenas um servidor web ou de aplicação, permitindo os benefícios descritos na seção anterior.
- Soluções como NGINX e HAProxy podem suportar tanto proxy reverso na camada 7 quanto balanceamento de carga.
Desvantagem(ns): proxy reverso
- A introdução de um proxy reverso resulta em aumento de complexidade.
- Um único proxy reverso é um ponto único de falha, configurar múltiplos proxies reversos (ou seja, um failover) aumenta ainda mais a complexidade.
Fonte(s) e leitura adicional
Camada de aplicação
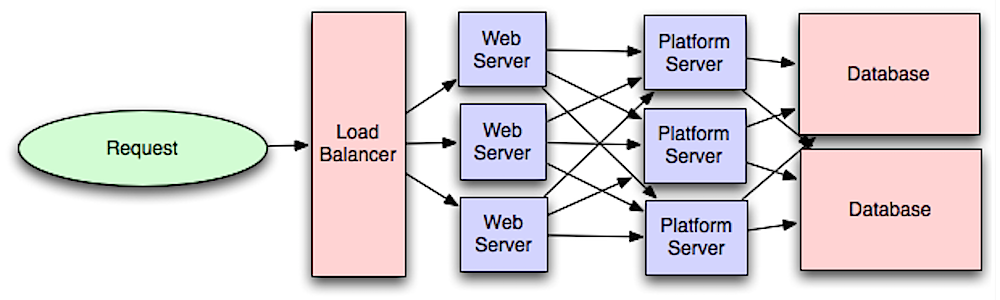
Fonte: Introdução à arquitetura de sistemas para escala
Separar a camada web da camada de aplicação (também conhecida como camada de plataforma) permite escalar e configurar ambas as camadas de forma independente. Adicionar uma nova API resulta na adição de servidores de aplicação sem necessariamente adicionar servidores web adicionais. O princípio da responsabilidade única defende serviços pequenos e autônomos que trabalham juntos. Pequenas equipes com pequenos serviços podem planejar de forma mais agressiva para um crescimento rápido.
Trabalhadores na camada de aplicação também ajudam a habilitar assincronismo.
Microsserviços
Relacionado a essa discussão estão os microsserviços, que podem ser descritos como um conjunto de serviços pequenos, modulares e implantáveis de forma independente. Cada serviço executa um processo único e se comunica através de um mecanismo leve e bem definido para atender a um objetivo de negócio. 1
O Pinterest, por exemplo, poderia ter os seguintes microsserviços: perfil de usuário, seguidores, feed, busca, upload de fotos, etc.
Descoberta de Serviços
Sistemas como Consul, Etcd, e Zookeeper podem ajudar os serviços a se encontrarem, rastreando nomes, endereços e portas registrados. Health checks ajudam a verificar a integridade dos serviços e geralmente são feitos usando um endpoint HTTP. Tanto o Consul quanto o Etcd possuem um armazenamento de chave-valor integrado que pode ser útil para armazenar valores de configuração e outros dados compartilhados.
Desvantagem(ns): camada de aplicação
- Adicionar uma camada de aplicação com serviços fracamente acoplados requer uma abordagem diferente do ponto de vista arquitetural, operacional e de processos (em comparação a um sistema monolítico).
- Microsserviços podem adicionar complexidade em termos de implantação e operações.
Fonte(s) e leituras adicionais
- Introdução à arquitetura de sistemas para escala
- Crack the system design interview
- Arquitetura orientada a serviços
- Introdução ao Zookeeper
- Aqui está o que você precisa saber sobre construção de microsserviços
Banco de Dados
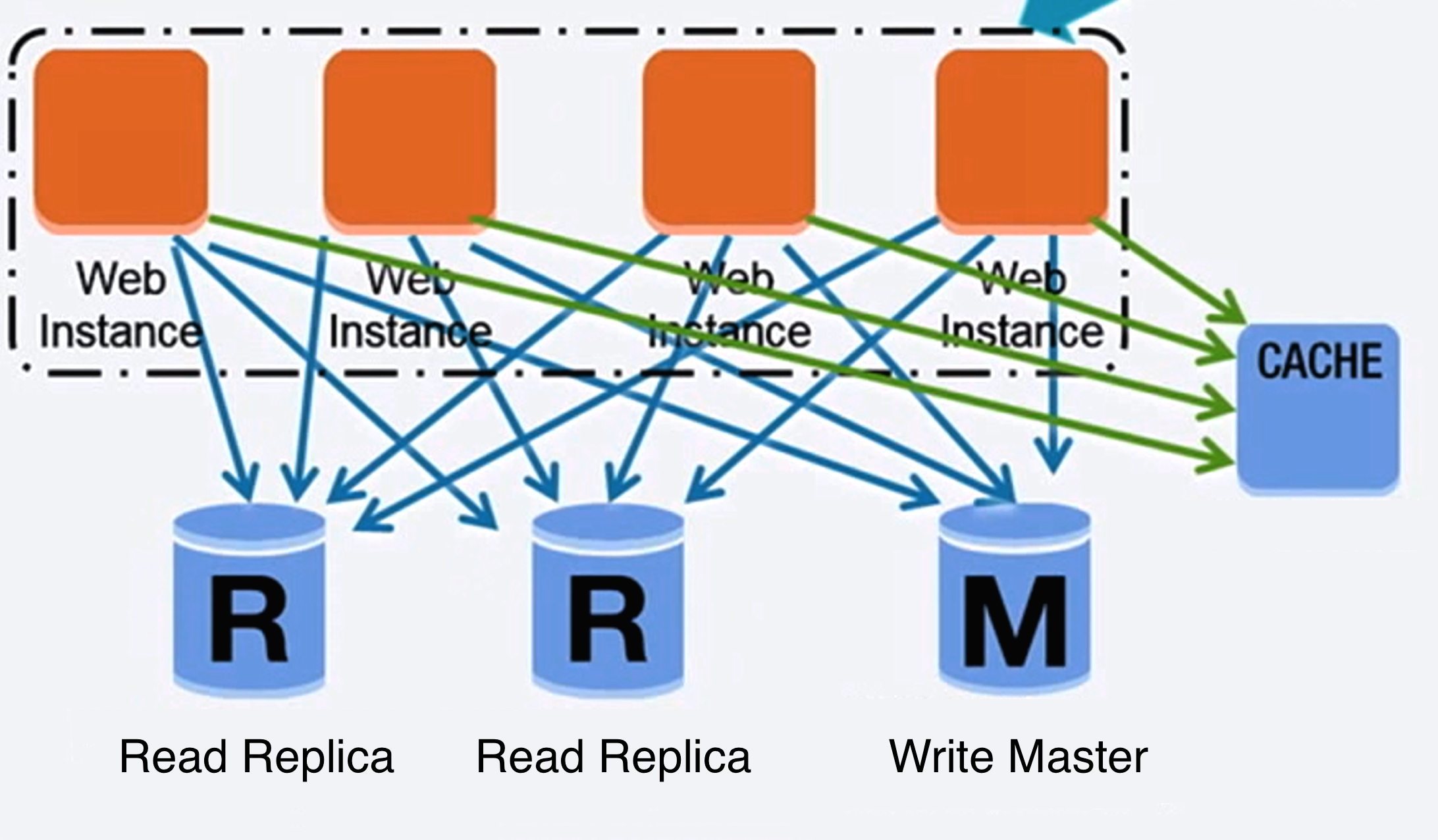
Fonte: Escalando para seus primeiros 10 milhões de usuários
Sistema de gerenciamento de banco de dados relacional (RDBMS)
Um banco de dados relacional como SQL é uma coleção de itens de dados organizados em tabelas.
ACID é um conjunto de propriedades de transações de banco de dados relacional.
- Atomicidade - Cada transação é tudo ou nada
- Consistência - Qualquer transação levará o banco de dados de um estado válido a outro
- Isolamento - Executar transações simultaneamente tem os mesmos resultados que se as transações fossem executadas em série
- Durabilidade - Uma vez que uma transação foi confirmada, ela permanecerá assim
#### Replicação mestre-escravo
O mestre atende leituras e escritas, replicando as escritas para um ou mais escravos, que servem apenas leituras. Escravos também podem replicar para escravos adicionais em uma estrutura semelhante a uma árvore. Se o mestre ficar offline, o sistema pode continuar operando em modo somente leitura até que um escravo seja promovido a mestre ou um novo mestre seja provisionado.
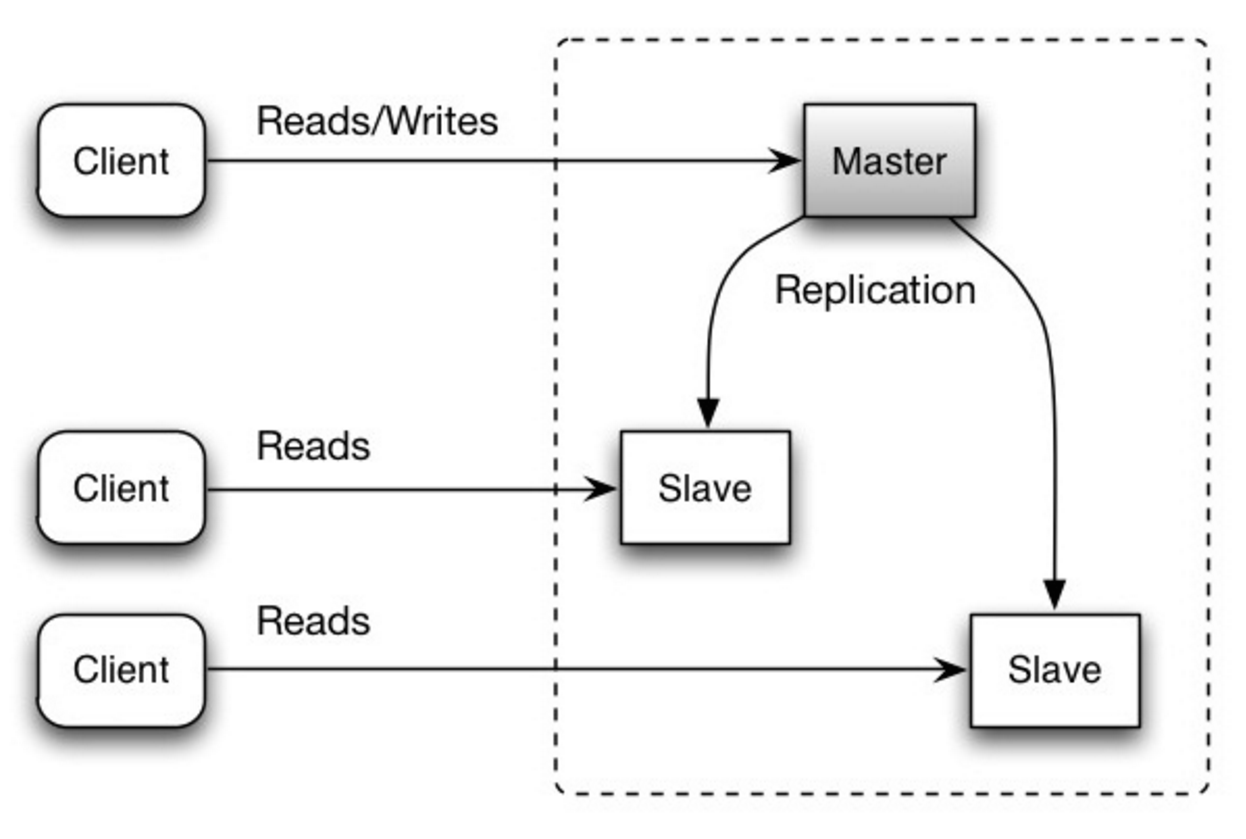
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
##### Desvantagem(ns): replicação mestre-escravo
- Lógica adicional é necessária para promover um escravo a mestre.
- Veja Desvantagem(ns): replicação para pontos relacionados a ambos mestre-escravo e mestre-mestre.
Ambos os mestres atendem leituras e escritas e coordenam entre si nas escritas. Se qualquer mestre cair, o sistema pode continuar operando com leituras e escritas.
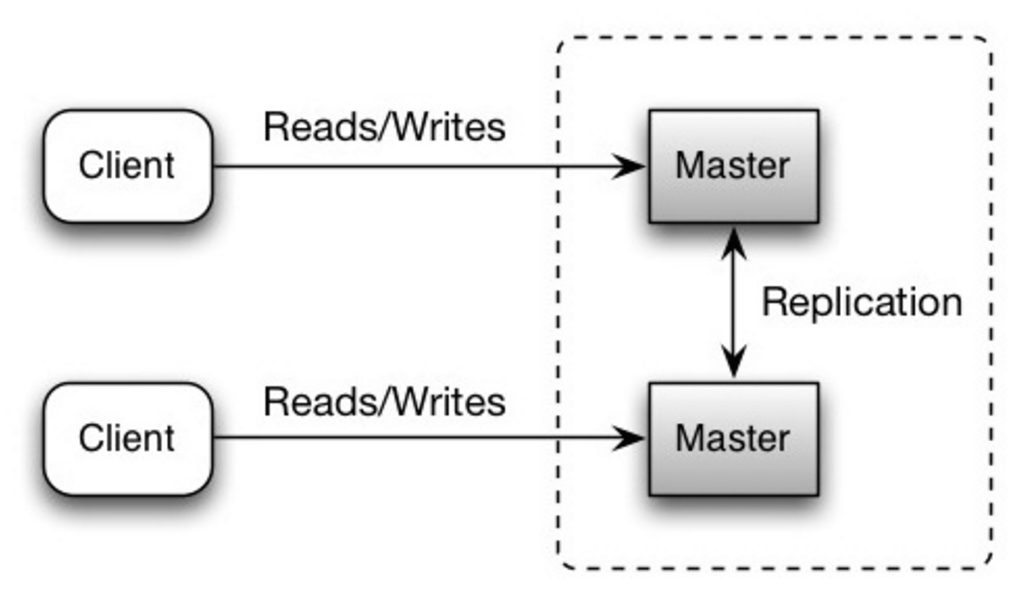
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
##### Desvantagem(ns): replicação mestre-mestre
- Você precisará de um balanceador de carga ou precisará fazer alterações na lógica da sua aplicação para determinar onde gravar.
- A maioria dos sistemas mestre-mestre é ou fracamente consistente (violando ACID) ou tem latência de escrita aumentada devido à sincronização.
- A resolução de conflitos torna-se mais relevante à medida que mais nós de escrita são adicionados e à medida que a latência aumenta.
- Veja Desvantagem(ns): replicação para pontos relacionados a ambos master-slave e master-master.
- Existe potencial para perda de dados se o master falhar antes que qualquer dado recém-escrito seja replicado para outros nós.
- As escritas são reproduzidas para os réplicas de leitura. Se houver muitas escritas, os réplicas de leitura podem ficar sobrecarregados ao reproduzir escritas e não conseguem realizar tantas leituras.
- Quanto mais slaves de leitura, mais você precisa replicar, o que leva a maior latência de replicação.
- Em alguns sistemas, escrever no master pode gerar múltiplas threads para escrita em paralelo, enquanto réplicas de leitura só suportam escrita sequencial com uma única thread.
- A replicação adiciona mais hardware e complexidade adicional.
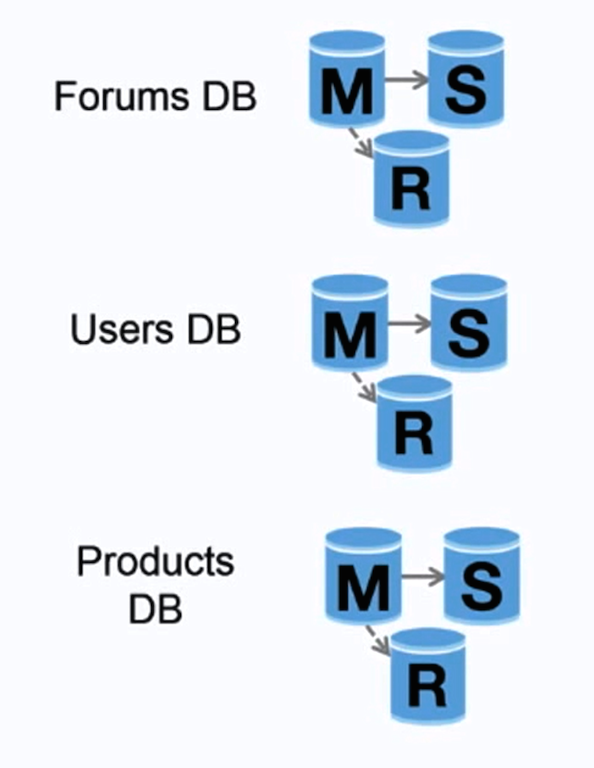
Fonte: Escalando para seus primeiros 10 milhões de usuários
Federação (ou particionamento funcional) divide bancos de dados por função. Por exemplo, ao invés de um único banco de dados monolítico, você pode ter três bancos: fóruns, usuários e produtos, resultando em menos tráfego de leitura e escrita para cada banco e, portanto, menor latência de replicação. Bancos menores permitem que mais dados caibam na memória, o que resulta em mais acertos de cache devido à melhoria da localidade de cache. Sem um master central único serializando escritas, você pode escrever em paralelo, aumentando o throughput.
##### Desvantagem(ns): federação
- Federação não é eficaz se seu esquema exigir funções ou tabelas gigantes.
- Será necessário atualizar a lógica da aplicação para determinar de qual banco ler e escrever.
- Realizar junção de dados entre dois bancos é mais complexo com um server link.
- Federação adiciona mais hardware e complexidade adicional.
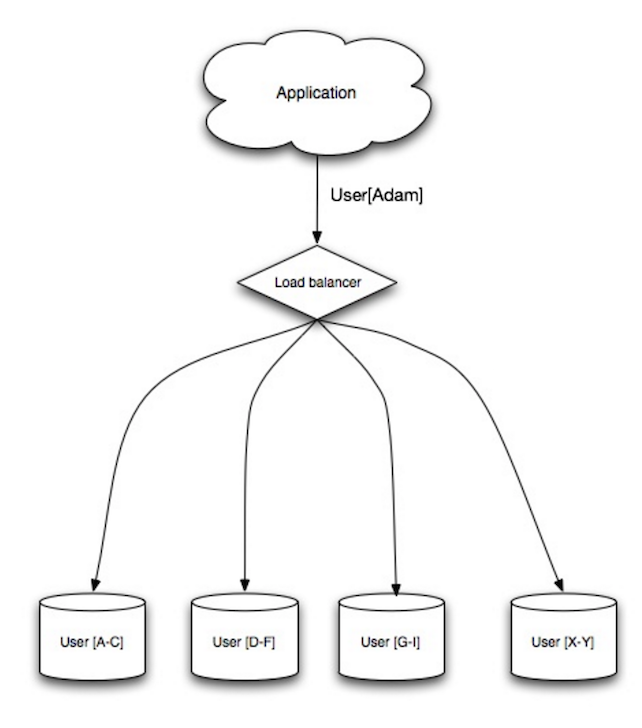
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
Sharding distribui os dados entre diferentes bancos de dados, de modo que cada banco só gerencia um subconjunto dos dados. Tomando como exemplo um banco de usuários, à medida que o número de usuários aumenta, mais shards são adicionados ao cluster.
Similar às vantagens da federação, o sharding resulta em menos tráfego de leitura e escrita, menos replicação e mais acertos de cache. O tamanho do índice também é reduzido, o que geralmente melhora o desempenho com consultas mais rápidas. Se um shard falhar, os outros shards continuam operacionais, embora seja recomendável adicionar algum tipo de replicação para evitar perda de dados. Como na federação, não há um único mestre central serializando escritas, permitindo escritas em paralelo com maior throughput.
As formas comuns de particionar uma tabela de usuários são pelo inicial do sobrenome do usuário ou pela localização geográfica do usuário.
##### Desvantagem(ns): sharding
- Será necessário atualizar a lógica da aplicação para trabalhar com shards, o que pode resultar em consultas SQL complexas.
- A distribuição dos dados pode ficar desequilibrada em um shard. Por exemplo, um conjunto de usuários intensivos em um shard pode gerar maior carga nesse shard em relação aos outros.
- O reequilíbrio adiciona complexidade extra. Uma função de sharding baseada em hashing consistente pode reduzir a quantidade de dados transferidos.
- Realizar joins entre dados de múltiplos shards é mais complexo.
- Sharding adiciona mais hardware e complexidade extra.
A desnormalização tenta melhorar o desempenho de leitura ao custo de algum desempenho de escrita. Cópias redundantes dos dados são escritas em múltiplas tabelas para evitar joins caros. Alguns SGBDRs como PostgreSQL e Oracle suportam views materializadas, que fazem o trabalho de armazenar informações redundantes e manter cópias redundantes consistentes.
Quando os dados passam a ser distribuídos por técnicas como federação e sharding, gerenciar joins entre data centers aumenta ainda mais a complexidade. A desnormalização pode contornar a necessidade desses joins complexos.
Na maioria dos sistemas, leituras podem superar escritas em 100:1 ou até 1000:1. Uma leitura que resulta em um join complexo pode ser muito cara, gastando muito tempo em operações de disco.
##### Desvantagem(ns): desnormalização
- Os dados são duplicados.
- Restrições podem ajudar cópias redundantes de informações a se manterem sincronizadas, o que aumenta a complexidade do design do banco de dados.
- Um banco de dados desnormalizado sob alta carga de escrita pode ter desempenho pior do que um banco normalizado.
A otimização de SQL é um tema amplo e muitos livros foram escritos como referência.
É importante fazer benchmark e perfilamento para simular e identificar gargalos.
- Benchmark - Simule situações de alta carga com ferramentas como ab.
- Perfilamento - Ative ferramentas como o slow query log para ajudar a rastrear problemas de desempenho.
##### Aperfeiçoe o esquema
- O MySQL grava em disco em blocos contíguos para acesso rápido.
- Use
CHARao invés deVARCHARpara campos de tamanho fixo. CHARpermite acesso rápido e aleatório, enquanto comVARCHARé necessário encontrar o final da string antes de passar para a próxima.- Use
TEXTpara grandes blocos de texto, como posts de blog.TEXTtambém permite buscas booleanas. Utilizar um campoTEXTresulta em armazenar um ponteiro em disco que é usado para localizar o bloco de texto. - Use
INTpara números maiores até 2^32 ou 4 bilhões. - Use
DECIMALpara valores monetários para evitar erros de representação de ponto flutuante. - Evite armazenar grandes
BLOBS, armazene o local de onde obter o objeto. VARCHAR(255)é o maior número de caracteres que pode ser contado em um número de 8 bits, muitas vezes maximizando o uso de um byte em alguns SGBDs.- Defina a restrição
NOT NULLonde aplicável para melhorar o desempenho da busca.
- Colunas consultadas (
SELECT,GROUP BY,ORDER BY,JOIN) podem ser mais rápidas com índices. - Índices geralmente são representados como B-tree auto-balanceadas que mantêm os dados ordenados e permitem buscas, acessos sequenciais, inserções e deleções em tempo logarítmico.
- Colocar um índice pode manter os dados na memória, exigindo mais espaço.
- Escritas também podem ser mais lentas, já que o índice precisa ser atualizado.
- Ao carregar grandes volumes de dados, pode ser mais rápido desabilitar os índices, carregar os dados e então reconstruir os índices.
- Desnormalize onde o desempenho exigir.
- Divida uma tabela colocando os pontos críticos em uma tabela separada para ajudar a mantê-los na memória.
- Em alguns casos, o cache de consultas pode levar a problemas de desempenho.
- Dicas para otimizar consultas MySQL
- Existe uma boa razão para o uso frequente de VARCHAR(255)?
- Como valores nulos afetam o desempenho?
- Log de consultas lentas
NoSQL
NoSQL é uma coleção de itens de dados representados em um armazenamento chave-valor, armazenamento de documentos, armazenamento de colunas largas ou banco de dados de grafos. Os dados são desnormalizados e os joins geralmente são realizados no código da aplicação. A maioria dos bancos NoSQL não possui transações ACID verdadeiras e favorece a consistência eventual.
BASE é frequentemente usado para descrever as propriedades dos bancos de dados NoSQL. Em comparação com o Teorema CAP, BASE escolhe disponibilidade em vez de consistência.
- Basicamente disponível - o sistema garante disponibilidade.
- Estado suave - o estado do sistema pode mudar ao longo do tempo, mesmo sem entrada.
- Consistência eventual - o sistema se tornará consistente ao longo do tempo, desde que não receba entrada durante esse período.
#### Armazenamento chave-valor
Abstração: tabela hash
Um armazenamento chave-valor geralmente permite leituras e gravações O(1) e costuma ser suportado por memória ou SSD. Armazenamentos de dados podem manter chaves em ordem lexicográfica, permitindo recuperação eficiente de intervalos de chaves. Armazenamentos chave-valor podem permitir o armazenamento de metadados junto com um valor.
Armazenamentos chave-valor oferecem alto desempenho e são frequentemente usados para modelos de dados simples ou para dados que mudam rapidamente, como uma camada de cache em memória. Como oferecem apenas um conjunto limitado de operações, a complexidade é transferida para a camada da aplicação caso operações adicionais sejam necessárias.
Um armazenamento chave-valor é a base para sistemas mais complexos, como um armazenamento de documentos e, em alguns casos, um banco de dados de grafos.
##### Fonte(s) e leituras adicionais: armazenamento chave-valor
- Banco de dados chave-valor
- Desvantagens de armazenamentos chave-valor
- Arquitetura do Redis
- Arquitetura do Memcached
Abstração: armazenamento de chave-valor com documentos armazenados como valores
Um armazenamento de documentos é centrado em documentos (XML, JSON, binário, etc), onde um documento armazena todas as informações para um determinado objeto. Os armazenamentos de documentos fornecem APIs ou uma linguagem de consulta para consultas baseadas na estrutura interna do próprio documento. Observe que muitos armazenamentos de chave-valor incluem recursos para trabalhar com os metadados de um valor, tornando a linha entre esses dois tipos de armazenamento menos clara.
Com base na implementação subjacente, os documentos são organizados por coleções, tags, metadados ou diretórios. Embora os documentos possam ser organizados ou agrupados, eles podem possuir campos completamente diferentes uns dos outros.
Alguns armazenamentos de documentos como MongoDB e CouchDB também fornecem uma linguagem semelhante ao SQL para realizar consultas complexas. DynamoDB suporta tanto chave-valor quanto documentos.
Os armazenamentos de documentos oferecem alta flexibilidade e são frequentemente usados para trabalhar com dados que mudam ocasionalmente.
##### Fonte(s) e leitura adicional: armazenamento de documentos
- Banco de dados orientado a documentos
- Arquitetura do MongoDB
- Arquitetura do CouchDB
- Arquitetura do Elasticsearch
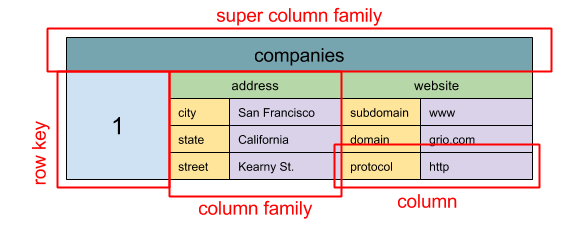
Fonte: SQL & NoSQL, uma breve história
Abstração: mapa aninhado ColumnFamily> A unidade básica de dados de um armazenamento de colunas largas é uma coluna (par nome/valor). Uma coluna pode ser agrupada em famílias de colunas (análogo a uma tabela SQL). Famílias supercolunas agrupam ainda mais famílias de colunas. Você pode acessar cada coluna independentemente com uma chave de linha, e colunas com a mesma chave de linha formam uma linha. Cada valor contém um timestamp para versionamento e resolução de conflitos.
O Google introduziu o Bigtable como o primeiro armazenamento de colunas largas, que influenciou o open-source HBase muito utilizado no ecossistema Hadoop, e o Cassandra do Facebook. Armazenamentos como BigTable, HBase e Cassandra mantêm as chaves em ordem lexicográfica, permitindo recuperação eficiente de intervalos seletivos de chaves.
Armazenamentos de colunas largas oferecem alta disponibilidade e escalabilidade. Eles são frequentemente usados para conjuntos de dados muito grandes.
##### Fonte(s) e leitura adicional: armazenamento de colunas largas
- SQL & NoSQL, uma breve história
- Arquitetura do Bigtable
- Arquitetura do HBase
- Arquitetura do Cassandra
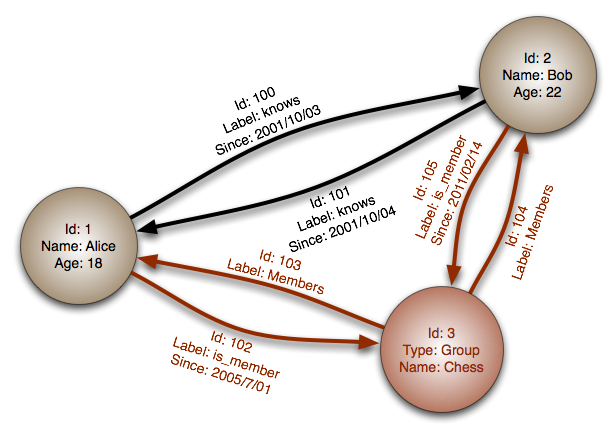
Fonte: Banco de dados de grafos
{kind=link}
Abstração: grafo
Em um banco de dados de grafos, cada nó é um registro e cada arco é um relacionamento entre dois nós. Bancos de dados de grafos são otimizados para representar relacionamentos complexos com muitas chaves estrangeiras ou muitos relacionamentos muitos-para-muitos.
Bancos de dados de grafos oferecem alto desempenho para modelos de dados com relacionamentos complexos, como uma rede social. Eles são relativamente novos e ainda não são amplamente utilizados; pode ser mais difícil encontrar ferramentas de desenvolvimento e recursos. Muitos grafos só podem ser acessados por APIs REST.
##### Fonte(s) e leituras adicionais: grafo
#### Fonte(s) e leituras adicionais: NoSQL- Explicação da terminologia BASE
- Bancos de dados NoSQL: um levantamento e orientação de decisão
- Escalabilidade
- Introdução ao NoSQL
- Padrões NoSQL
SQL ou NoSQL
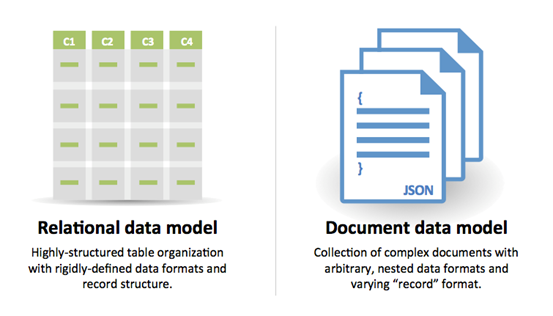
Fonte: Transição de RDBMS para NoSQL
Razões para SQL:
- Dados estruturados
- Esquema rígido
- Dados relacionais
- Necessidade de joins complexos
- Transações
- Padrões claros para escalabilidade
- Mais estabelecido: desenvolvedores, comunidade, código, ferramentas, etc.
- Buscas por índice são muito rápidas
- Dados semiestruturados
- Esquema dinâmico ou flexível
- Dados não relacionais
- Não há necessidade de joins complexos
- Armazenar muitos TB (ou PB) de dados
- Carga de trabalho muito intensiva em dados
- Altíssima taxa de IOPS
- Ingestão rápida de dados de clickstream e logs
- Dados de placares ou pontuação
- Dados temporários, como um carrinho de compras
- Tabelas frequentemente acessadas ('quentes')
- Tabelas de metadados/consulta
Cache
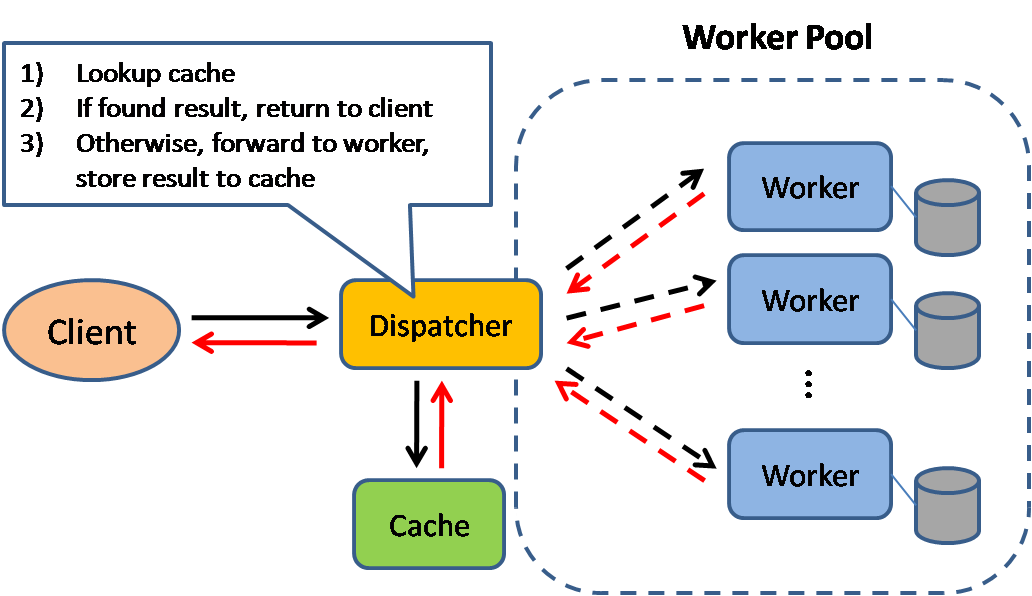
Fonte: Padrões de design de sistemas escaláveis
O cache melhora o tempo de carregamento das páginas e pode reduzir a carga nos seus servidores e bancos de dados. Neste modelo, o despachante primeiro verifica se a requisição já foi feita anteriormente e tenta encontrar o resultado anterior para retornar, a fim de poupar a execução real.
Os bancos de dados frequentemente se beneficiam de uma distribuição uniforme de leituras e escritas entre suas partições. Itens populares podem distorcer essa distribuição, causando gargalos. Colocar um cache na frente do banco de dados pode ajudar a absorver cargas desiguais e picos de tráfego.
Cache do cliente
Os caches podem estar localizados no lado do cliente (SO ou navegador), lado do servidor, ou em uma camada de cache distinta.
Cache de CDN
CDNs são consideradas um tipo de cache.
Cache do servidor web
Proxies reversos e caches como Varnish podem servir conteúdo estático e dinâmico diretamente. Servidores web também podem armazenar requisições em cache, retornando respostas sem precisar contatar servidores de aplicação.
Cache de banco de dados
Seu banco de dados geralmente inclui algum nível de cache em uma configuração padrão, otimizada para um caso de uso genérico. Ajustar essas configurações para padrões de uso específicos pode aumentar ainda mais o desempenho.
Cache de aplicação
Caches em memória como Memcached e Redis são armazenamentos chave-valor entre sua aplicação e o armazenamento de dados. Como os dados são mantidos na RAM, é muito mais rápido que bancos de dados típicos, onde os dados são armazenados em disco. A RAM é mais limitada que o disco, então algoritmos de invalidação de cache como least recently used (LRU)) podem ajudar a invalidar entradas "frias" e manter dados "quentes" na RAM.
O Redis possui os seguintes recursos adicionais:
- Opção de persistência
- Estruturas de dados embutidas, como conjuntos ordenados e listas
- Nível de linha
- Nível de consulta
- Objetos totalmente formados e serializáveis
- HTML totalmente renderizado
Cacheamento no nível da consulta ao banco de dados
Sempre que você consulta o banco de dados, faça o hash da consulta como uma chave e armazene o resultado no cache. Esta abordagem sofre com problemas de expiração:
- Difícil excluir um resultado em cache com consultas complexas
- Se um dado mudar, como uma célula de tabela, você precisa excluir todas as consultas em cache que possam incluir a célula alterada
Cacheamento no nível do objeto
Veja seus dados como um objeto, semelhante ao que você faz com o código da sua aplicação. Faça sua aplicação montar o conjunto de dados do banco de dados em uma instância de classe ou estrutura(s) de dados:
- Remova o objeto do cache se seus dados subjacentes mudarem
- Permite processamento assíncrono: trabalhadores montam objetos consumindo o último objeto em cache
- Sessões de usuário
- Páginas web totalmente renderizadas
- Fluxos de atividade
- Dados de grafo de usuário
Quando atualizar o cache
Como você só pode armazenar uma quantidade limitada de dados em cache, será necessário determinar qual estratégia de atualização de cache funciona melhor para seu caso de uso.
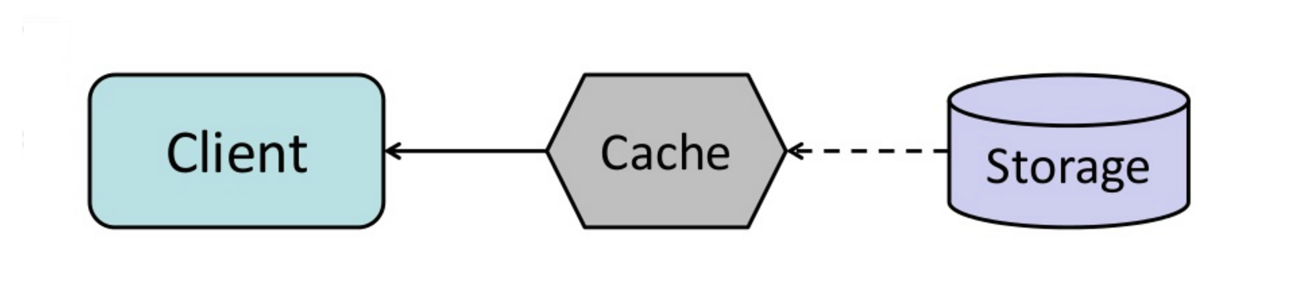
#### Cache-aside
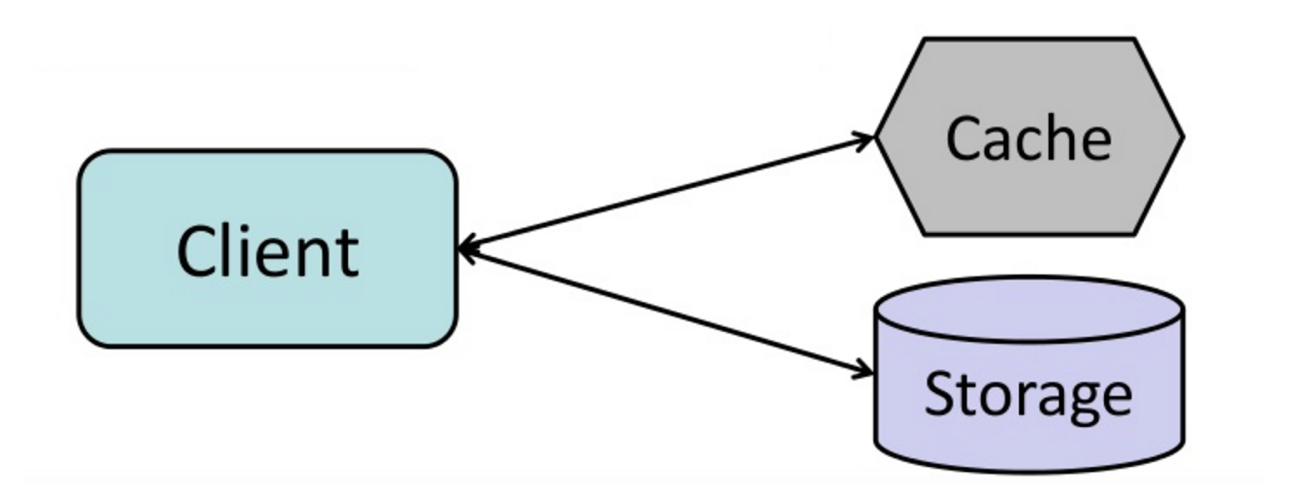
Fonte: Do cache ao grid de dados em memória
A aplicação é responsável por ler e escrever do armazenamento. O cache não interage diretamente com o armazenamento. A aplicação faz o seguinte:
- Procura a entrada no cache, resultando em falta de cache
- Carrega a entrada do banco de dados
- Adiciona a entrada ao cache
- Retorna a entrada
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached é geralmente usado desta maneira.
Leituras subsequentes dos dados adicionados ao cache são rápidas. Cache-aside também é chamado de lazy loading. Apenas os dados solicitados são armazenados em cache, o que evita encher o cache com dados que não são requisitados.
##### Desvantagem(ns): cache-aside
- Cada falta no cache resulta em três viagens, o que pode causar um atraso perceptível.
- Os dados podem ficar desatualizados se forem atualizados no banco de dados. Este problema é mitigado definindo um time-to-live (TTL), que força uma atualização da entrada no cache, ou usando write-through.
- Quando um nó falha, ele é substituído por um novo nó vazio, aumentando a latência.
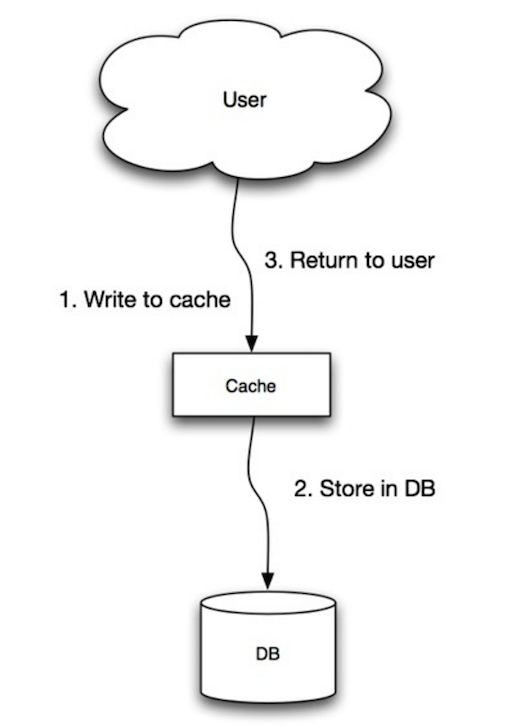
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
A aplicação utiliza o cache como o principal repositório de dados, lendo e escrevendo dados nele, enquanto o cache é responsável por ler e escrever no banco de dados:
- Aplicação adiciona/atualiza entrada no cache
- Cache grava a entrada de forma síncrona no repositório de dados
- Retorno
set_user(12345, {"foo":"bar"})Código de cache:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Desvantagem(ns): write-through
- Quando um novo nó é criado devido a falha ou escalonamento, o novo nó não irá armazenar entradas em cache até que a entrada seja atualizada no banco de dados. Cache-aside em conjunto com write-through pode mitigar esse problema.
- A maioria dos dados escritos pode nunca ser lida, o que pode ser minimizado com um TTL.
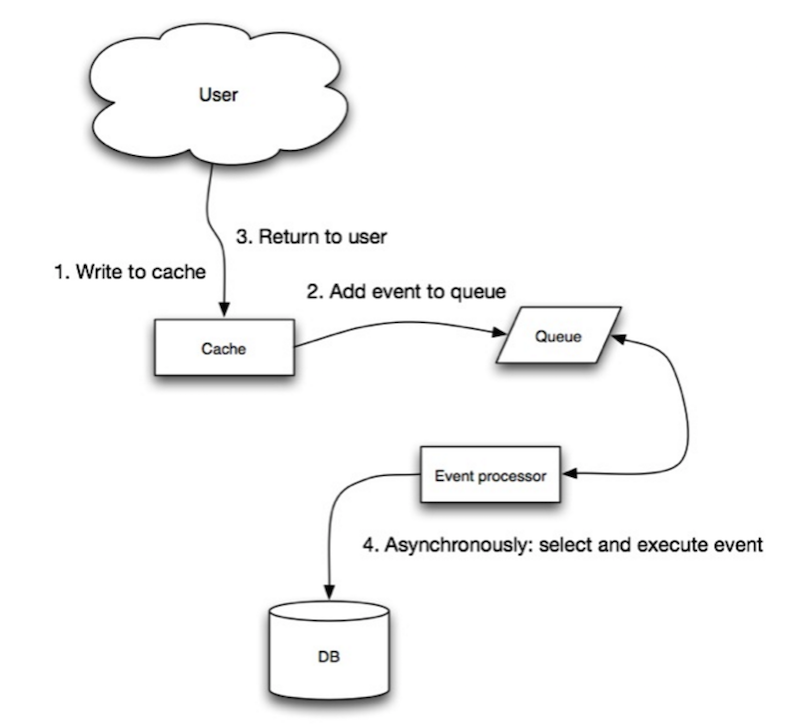
Fonte: Escalabilidade, disponibilidade, estabilidade, padrões
No write-behind, a aplicação faz o seguinte:
- Adiciona/atualiza a entrada no cache
- Escreve a entrada de forma assíncrona no armazenamento de dados, melhorando o desempenho de escrita
- Pode ocorrer perda de dados se o cache cair antes que seu conteúdo seja gravado no armazenamento de dados.
- É mais complexo implementar write-behind do que implementar cache-aside ou write-through.
Fonte: Do cache ao data grid em memória
Você pode configurar o cache para atualizar automaticamente qualquer entrada acessada recentemente antes de sua expiração.
Refresh-ahead pode resultar em menor latência em relação ao read-through se o cache conseguir prever com precisão quais itens provavelmente serão necessários no futuro.
##### Desvantagem(ns): refresh-ahead
- Não prever com precisão quais itens provavelmente serão necessários no futuro pode resultar em desempenho reduzido em comparação a não utilizar refresh-ahead.
Desvantagem(ns): cache
- É necessário manter a consistência entre os caches e a fonte de verdade, como o banco de dados, através da invalidação de cache.
- A invalidação de cache é um problema difícil, há uma complexidade adicional associada ao momento de atualizar o cache.
- É preciso realizar alterações na aplicação, como adicionar Redis ou memcached.
Fonte(s) e leituras adicionais
- Do cache ao data grid em memória
- Padrões de design de sistemas escaláveis
- Introdução à arquitetura de sistemas para escala
- Escalabilidade, disponibilidade, estabilidade, padrões
- Escalabilidade
- Estratégias do AWS ElastiCache
- Wikipédia)
Assincronismo
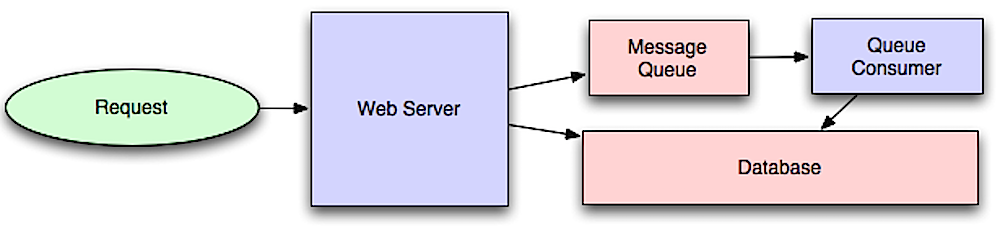
Fonte: Introdução à arquitetura de sistemas para escala
Fluxos de trabalho assíncronos ajudam a reduzir os tempos de requisição para operações caras que, de outra forma, seriam realizadas em linha. Eles também podem ajudar ao executar trabalhos demorados de forma antecipada, como agregações periódicas de dados.
Filas de mensagens
Filas de mensagens recebem, armazenam e entregam mensagens. Se uma operação é muito lenta para ser feita em linha, você pode usar uma fila de mensagens com o seguinte fluxo de trabalho:
- Uma aplicação publica um trabalho na fila e, em seguida, notifica o usuário sobre o status do trabalho
- Um worker retira o trabalho da fila, processa e sinaliza que o trabalho está concluído
Redis é útil como um broker de mensagens simples, mas mensagens podem ser perdidas.
RabbitMQ é popular, mas requer adaptação ao protocolo 'AMQP' e gerenciamento dos seus próprios nodes.
Amazon SQS é hospedado, mas pode apresentar alta latência e possibilidade de entrega duplicada de mensagens.
Filas de tarefas
Filas de tarefas recebem tarefas e seus dados relacionados, executam-nas e entregam seus resultados. Elas podem suportar agendamento e ser usadas para rodar trabalhos computacionalmente intensivos em segundo plano.
Celery tem suporte para agendamento e oferece principalmente suporte para Python.
Contrapressão
Se as filas começarem a crescer significativamente, o tamanho da fila pode superar a memória, resultando em falhas de cache, leituras de disco e desempenho ainda mais lento. Contrapressão pode ajudar limitando o tamanho da fila, mantendo assim uma alta taxa de processamento e bons tempos de resposta para tarefas já na fila. Quando a fila está cheia, os clientes recebem o código de status "servidor ocupado" ou HTTP 503 para tentar novamente mais tarde. Os clientes podem tentar novamente mais tarde, talvez com backoff exponencial.
Desvantagem(ns): assincronismo
- Casos de uso como cálculos baratos e fluxos de trabalho em tempo real podem ser mais adequados para operações síncronas, pois a introdução de filas pode adicionar atrasos e complexidade.
Fonte(s) e leituras adicionais
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- Qual a diferença entre uma fila de mensagens e uma fila de tarefas?
Comunicação
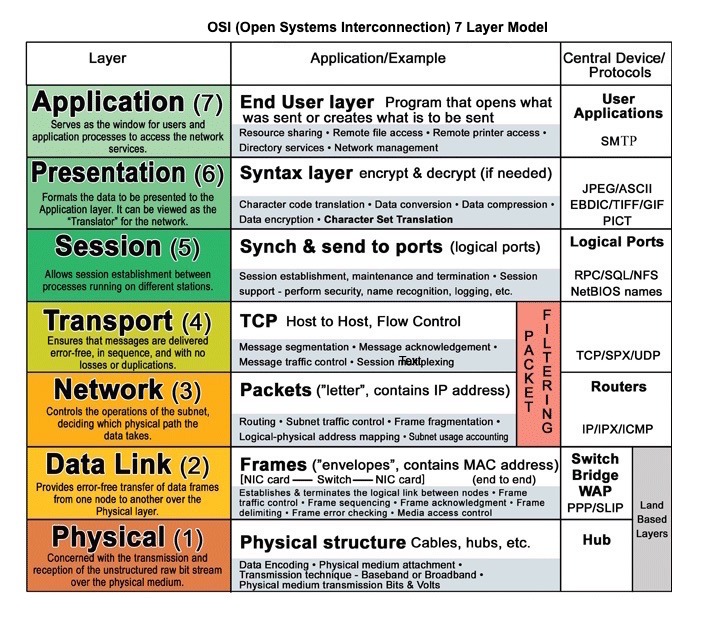
Fonte: Modelo OSI de 7 camadas
Protocolo de transferência de hipertexto (HTTP)
HTTP é um método para codificar e transportar dados entre um cliente e um servidor. É um protocolo de requisição/resposta: clientes enviam requisições e servidores enviam respostas com conteúdo relevante e informações de status de conclusão sobre a requisição. HTTP é auto-suficiente, permitindo que requisições e respostas passem por muitos roteadores e servidores intermediários que realizam balanceamento de carga, cache, criptografia e compressão.
Uma requisição HTTP básica consiste em um verbo (método) e um recurso (endpoint). Abaixo estão verbos HTTP comuns:
| Verbo | Descrição | Idempotente* | Seguro | Cacheável | |---|---|---|---|---| | GET | Lê um recurso | Sim | Sim | Sim | | POST | Cria um recurso ou aciona um processo que manipula dados | Não | Não | Sim, se a resposta contiver informações de atualidade | | PUT | Cria ou substitui um recurso | Sim | Não | Não | | PATCH | Atualiza parcialmente um recurso | Não | Não | Sim, se a resposta contiver informações de atualidade | | DELETE | Exclui um recurso | Sim | Não | Não |
*Pode ser chamado várias vezes sem resultados diferentes.
HTTP é um protocolo de camada de aplicação que depende de protocolos de camadas inferiores como TCP e UDP.
#### Fonte(s) e leituras adicionais: HTTP
Protocolo de controle de transmissão (TCP)
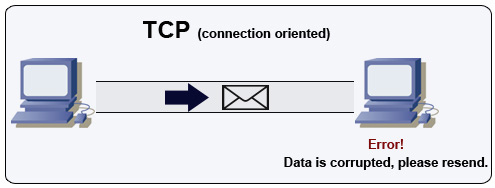
Fonte: Como criar um jogo multiplayer
TCP é um protocolo orientado à conexão sobre uma rede IP. A conexão é estabelecida e finalizada usando um handshake. Todos os pacotes enviados são garantidos de chegar ao destino na ordem original e sem corrupção através de:
- Números de sequência e campos de checksum para cada pacote
- Pacotes de confirmação) e retransmissão automática
Para garantir alta taxa de transferência, servidores web podem manter um grande número de conexões TCP abertas, resultando em alto uso de memória. Pode ser caro manter muitas conexões abertas entre threads do servidor web e, por exemplo, um servidor memcached. Pool de conexões pode ajudar, além de alternar para UDP onde aplicável.
TCP é útil para aplicações que exigem alta confiabilidade, mas são menos críticas quanto ao tempo. Alguns exemplos incluem servidores web, informações de banco de dados, SMTP, FTP e SSH.
Use TCP ao invés de UDP quando:
- Você precisa que todos os dados cheguem intactos
- Você deseja estimar automaticamente o melhor uso da largura de banda da rede
Protocolo de datagrama de usuário (UDP)
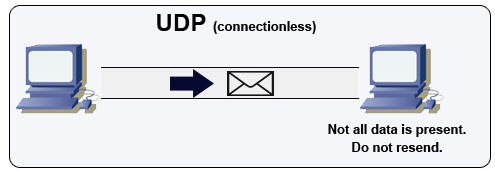
Fonte: Como criar um jogo multiplayer
UDP é sem conexão. Datagramas (análogos a pacotes) são garantidos apenas no nível do datagrama. Os datagramas podem chegar ao destino fora de ordem ou não chegar. O UDP não suporta controle de congestionamento. Sem as garantias que o TCP oferece, o UDP geralmente é mais eficiente.
UDP pode fazer broadcast, enviando datagramas para todos os dispositivos na sub-rede. Isso é útil com DHCP porque o cliente ainda não recebeu um endereço IP, impedindo uma forma do TCP transmitir sem o endereço IP.
UDP é menos confiável, mas funciona bem em casos de uso em tempo real, como VoIP, vídeo chamada, streaming e jogos multiplayer em tempo real.
Use UDP em vez de TCP quando:
- Você precisa da menor latência possível
- Dados atrasados são piores do que perda de dados
- Você deseja implementar sua própria correção de erros
- Redes para programação de jogos
- Principais diferenças entre os protocolos TCP e UDP
- Diferença entre TCP e UDP
- Protocolo de controle de transmissão
- Protocolo de datagrama de usuário
- Escalando o memcache no Facebook
Chamada de procedimento remoto (RPC)
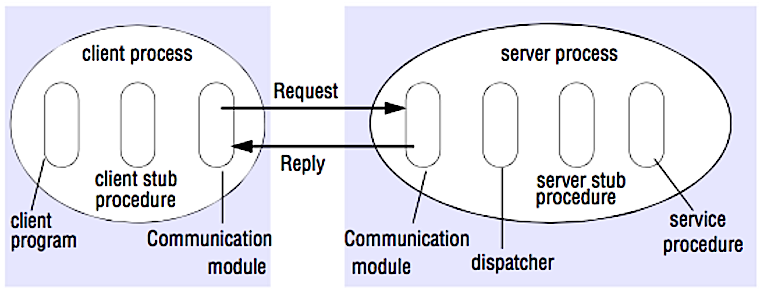
Fonte: Crack the system design interview
Em um RPC, um cliente faz com que um procedimento seja executado em um espaço de endereço diferente, geralmente em um servidor remoto. O procedimento é codificado como se fosse uma chamada de procedimento local, abstraindo os detalhes de como comunicar com o servidor a partir do programa cliente. Chamadas remotas geralmente são mais lentas e menos confiáveis do que chamadas locais, por isso é útil distinguir chamadas RPC de chamadas locais. Frameworks RPC populares incluem Protobuf, Thrift, e Avro.
RPC é um protocolo de requisição-resposta:
- Programa cliente - Chama o procedimento stub do cliente. Os parâmetros são empilhados como em uma chamada de procedimento local.
- Procedimento stub do cliente - Empacota (marshals) o id do procedimento e os argumentos em uma mensagem de requisição.
- Módulo de comunicação do cliente - O sistema operacional envia a mensagem do cliente para o servidor.
- Módulo de comunicação do servidor - O sistema operacional passa os pacotes recebidos para o procedimento stub do servidor.
- Procedimento stub do servidor - Desempacota (unmarshalls) os resultados, chama o procedimento do servidor correspondente ao id do procedimento e passa os argumentos fornecidos.
- A resposta do servidor repete os passos acima na ordem inversa.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC está focado em expor comportamentos. RPCs são frequentemente usados por motivos de desempenho em comunicações internas, pois você pode criar chamadas nativas sob medida para melhor atender aos seus casos de uso.
Escolha uma biblioteca nativa (também conhecida como SDK) quando:
- Você conhece sua plataforma alvo.
- Você quer controlar como sua "lógica" é acessada.
- Você quer controlar como o controle de erros ocorre fora da sua biblioteca.
- Desempenho e experiência do usuário final são sua principal preocupação.
#### Desvantagem(ns): RPC
- Clientes RPC tornam-se fortemente acoplados à implementação do serviço.
- Uma nova API deve ser definida para cada nova operação ou caso de uso.
- Pode ser difícil depurar RPC.
- Você pode não conseguir aproveitar tecnologias existentes imediatamente. Por exemplo, pode exigir esforço adicional para garantir que as chamadas RPC sejam devidamente cacheadas em servidores de cache como o Squid.
Transferência de estado representacional (REST)
REST é um estilo arquitetural que impõe um modelo cliente/servidor onde o cliente atua sobre um conjunto de recursos gerenciados pelo servidor. O servidor fornece uma representação dos recursos e ações que podem manipular ou obter uma nova representação dos recursos. Toda comunicação deve ser sem estado e cacheável.
Existem quatro qualidades de uma interface RESTful:
- Identificar recursos (URI no HTTP) - use o mesmo URI independentemente da operação.
- Alterar com representações (Verbos no HTTP) - use verbos, cabeçalhos e corpo.
- Mensagem de erro auto-descritiva (resposta de status no HTTP) - Use códigos de status, não reinvente a roda.
- HATEOAS (interface HTML para HTTP) - seu serviço web deve ser totalmente acessível em um navegador.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
REST é focado na exposição de dados. Minimiza o acoplamento entre cliente/servidor e é frequentemente usado para APIs HTTP públicas. REST utiliza um método mais genérico e uniforme de expor recursos através de URIs, representação por meio de cabeçalhos, e ações por meio de verbos como GET, POST, PUT, DELETE e PATCH. Por ser stateless, REST é excelente para escalabilidade horizontal e particionamento.
#### Desvantagem(ns): REST
- Com REST sendo focado em expor dados, pode não ser ideal se os recursos não são naturalmente organizados ou acessados em uma hierarquia simples. Por exemplo, retornar todos os registros atualizados na última hora que correspondam a um conjunto específico de eventos não é facilmente expresso como um caminho. Com REST, isso provavelmente será implementado com uma combinação de caminho URI, parâmetros de consulta e possivelmente o corpo da requisição.
- REST normalmente depende de poucos verbos (GET, POST, PUT, DELETE e PATCH), o que às vezes não se encaixa no seu caso de uso. Por exemplo, mover documentos expirados para a pasta de arquivo pode não se encaixar adequadamente nesses verbos.
- Buscar recursos complexos com hierarquias aninhadas requer múltiplas idas e vindas entre o cliente e servidor para renderizar uma única visualização, por exemplo, buscar o conteúdo de uma postagem de blog e os comentários dessa postagem. Para aplicativos móveis operando em condições de rede variáveis, essas múltiplas idas e vindas são altamente indesejáveis.
- Com o tempo, mais campos podem ser adicionados à resposta da API e clientes mais antigos receberão todos os novos campos de dados, mesmo aqueles que não precisam, o que aumenta o tamanho do payload e resulta em maiores latências.
Comparação de chamadas RPC e REST
| Operação | RPC | REST |
|---|---|---|
| Cadastro | POST /signup | POST /persons |
| Demissão | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Ler uma pessoa | GET /readPerson?personid=1234 | GET /persons/1234 |
| Ler lista de itens de uma pessoa | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Adicionar um item à lista de itens de uma pessoa | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Atualizar um item | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Excluir um item | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Fonte: Você realmente sabe por que prefere REST ao invés de RPC
#### Fonte(s) e leituras adicionais: REST e RPC
- Você realmente sabe por que prefere REST ao invés de RPC
- Quando abordagens RPC-ish são mais apropriadas que REST?
- REST vs JSON-RPC
- Desmistificando os mitos de RPC e REST
- Quais são as desvantagens de usar REST
- Crack the system design interview
- Thrift
- Por que REST para uso interno e não RPC
Segurança
Esta seção poderia ser atualizada. Considere contribuir! Segurança é um tópico amplo. A menos que você tenha experiência considerável, formação em segurança ou esteja se candidatando a uma vaga que exija conhecimento em segurança, provavelmente não precisará saber mais do que o básico:
- Criptografe dados em trânsito e em repouso.
- Sanitizar todas as entradas do usuário ou quaisquer parâmetros de entrada expostos ao usuário para prevenir XSS e injeção de SQL.
- Use consultas parametrizadas para evitar injeção de SQL.
- Use o princípio do menor privilégio.
Fonte(s) e leituras adicionais
Apêndice
Às vezes, você será solicitado a fazer estimativas rápidas. Por exemplo, pode ser necessário determinar quanto tempo levará para gerar 100 miniaturas de imagens a partir do disco ou quanta memória uma estrutura de dados ocupará. A tabela de potências de dois e números de latência que todo programador deve saber são referências úteis.
Tabela de potências de dois
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Fonte(s) e leitura adicional
Números de latência que todo programador deve conhecer
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Métricas úteis com base nos números acima:
- Leitura sequencial de HDD a 30 MB/s
- Leitura sequencial de Ethernet de 1 Gbps a 100 MB/s
- Leitura sequencial de SSD a 1 GB/s
- Leitura sequencial de memória principal a 4 GB/s
- 6-7 viagens de ida e volta mundial por segundo
- 2.000 viagens de ida e volta por segundo dentro de um data center
#### Fonte(s) e leitura adicional
- Números de latência que todo programador deve saber - 1
- Números de latência que todo programador deve saber - 2
- Projetos, lições e conselhos de construção de grandes sistemas distribuídos
- Conselhos de Engenharia de Software de Grandes Sistemas Distribuídos
Questões adicionais de entrevistas de design de sistemas
Questões comuns de entrevistas de design de sistemas, com links para recursos sobre como resolver cada uma.
| Pergunta | Referência(s) |
|---|---|
| Projetar um serviço de sincronização de arquivos como Dropbox | youtube.com |
| Projetar um mecanismo de busca como Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Projetar um web crawler escalável como o Google | quora.com |
| Projetar Google Docs | code.google.com
neil.fraser.name |
| Projetar um armazenamento chave-valor como Redis | slideshare.net |
| Projetar um sistema de cache como Memcached | slideshare.net |
| Projetar um sistema de recomendação como o da Amazon | hulu.com
ijcai13.org |
| Projetar um sistema tinyurl como Bitly | n00tc0d3r.blogspot.com |
| Projetar um aplicativo de chat como WhatsApp | highscalability.com
| Projetar um sistema de compartilhamento de fotos como Instagram | highscalability.com
highscalability.com |
| Projetar a função de feed de notícias do Facebook | quora.com
quora.com
slideshare.net |
| Projetar a função de linha do tempo do Facebook | facebook.com
highscalability.com |
| Projetar a função de chat do Facebook | erlang-factory.com
facebook.com |
| Projete uma função de busca em grafos como a do Facebook | facebook.com
facebook.com
facebook.com |
| Projete uma rede de entrega de conteúdo como a CloudFlare | figshare.com |
| Projete um sistema de tópicos em tendência como o do Twitter | michael-noll.com
snikolov .wordpress.com |
| Projete um sistema de geração de ID aleatório | blog.twitter.com
github.com |
| Retorne os top k pedidos durante um intervalo de tempo | cs.ucsb.edu
wpi.edu |
| Projete um sistema que serve dados de múltiplos data centers | highscalability.com |
| Projete um jogo de cartas multiplayer online | indieflashblog.com
buildnewgames.com |
| Projete um sistema de coleta de lixo | stuffwithstuff.com
washington.edu |
| Projete um limitador de taxa de API | https://stripe.com/blog/ |
| Projete uma Bolsa de Valores (como NASDAQ ou Binance) | Jane Street
Implementação em Golang
Implementação em Go |
| Adicione uma questão de design de sistema | Contribua |
Arquiteturas do mundo real
Artigos sobre como sistemas do mundo real são projetados.
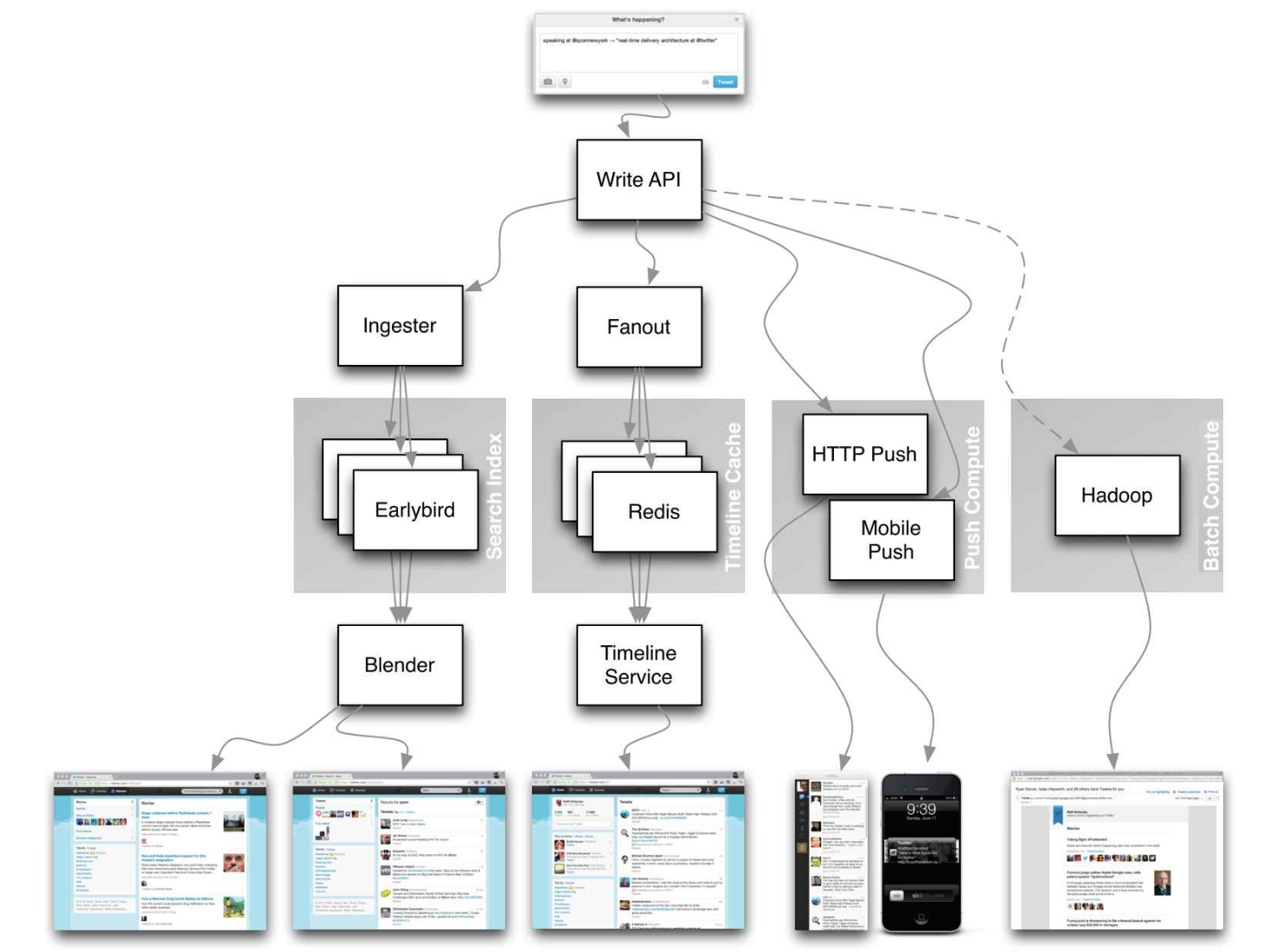
Fonte: Linhas do tempo do Twitter em escala
Não foque em detalhes minuciosos nos artigos a seguir, em vez disso:
- Identifique princípios compartilhados, tecnologias comuns e padrões nesses artigos
- Estude quais problemas são resolvidos por cada componente, onde funciona, onde não funciona
- Revise os aprendizados obtidos
Arquiteturas de empresas
| Empresa | Referência(s) |
|---|---|
| Amazon | Arquitetura da Amazon |
| Cinchcast | Produzindo 1.500 horas de áudio por dia |
| DataSift | Mineração de dados em tempo real a 120.000 tweets por segundo |
| Dropbox | Como escalamos o Dropbox |
| ESPN | Operando a 100.000 duh nuh nuhs por segundo |
| Google | Arquitetura do Google |
| Instagram | 14 milhões de usuários, terabytes de fotos
O que move o Instagram |
| Justin.tv | Arquitetura de transmissão de vídeo ao vivo do Justin.tv |
| Facebook | Escalando o memcached no Facebook
TAO: Data store distribuído do Facebook para o grafo social
Armazenamento de fotos do Facebook
Como o Facebook Live transmite para 800.000 espectadores simultâneos |
| Flickr | Arquitetura do Flickr |
| Mailbox | De 0 a um milhão de usuários em 6 semanas |
| Netflix | Uma visão 360 graus de toda a stack do Netflix
Netflix: O que acontece quando você aperta play? |
| Pinterest | De 0 a dezenas de bilhões de page views por mês
18 milhões de visitantes, crescimento de 10x, 12 funcionários |
| Playfish | 50 milhões de usuários mensais e crescendo |
| PlentyOfFish | Arquitetura do PlentyOfFish |
| Salesforce | Como eles processam 1,3 bilhão de transações por dia |
| Stack Overflow | Arquitetura do Stack Overflow |
| TripAdvisor | 40M visitantes, 200M page views dinâmicas, 30TB de dados |
| Tumblr | 15 bilhões de page views por mês |
| Twitter | Deixando o Twitter 10.000% mais rápido
Armazenando 250 milhões de tweets por dia usando MySQL
150M usuários ativos, 300K QPS, um firehose de 22 MB/S
Timelines em escala
Big e small data no Twitter
Operações no Twitter: escalando além de 100 milhões de usuários
Como o Twitter processa 3.000 imagens por segundo |
| Uber | Como o Uber escala sua plataforma de mercado em tempo real
Lições aprendidas ao escalar o Uber para 2000 engenheiros, 1000 serviços e 8000 repositórios Git |
| WhatsApp | A arquitetura do WhatsApp que o Facebook comprou por US$19 bilhões |
| YouTube | Escalabilidade do YouTube
Arquitetura do YouTube |
Blogs de engenharia de empresas
Arquiteturas das empresas com as quais você está entrevistando.>
As perguntas que você encontrar podem ser do mesmo domínio.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Quer adicionar um blog? Para evitar trabalho duplicado, considere adicionar o blog da sua empresa ao seguinte repositório:
Em desenvolvimento
Interessado em adicionar uma seção ou ajudar a completar uma em andamento? Contribua!
- Computação distribuída com MapReduce
- Hashing consistente
- Scatter gather
- Contribua
Créditos
Créditos e fontes são fornecidos ao longo deste repositório.
Agradecimentos especiais a:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Informações de contato
Sinta-se à vontade para entrar em contato comigo para discutir quaisquer problemas, dúvidas ou comentários.
Minhas informações de contato podem ser encontradas na minha página do GitHub.
Licença
Estou fornecendo código e recursos neste repositório sob uma licença de código aberto. Como este é meu repositório pessoal, a licença que você recebe do meu código e recursos é minha e não do meu empregador (Facebook).
Copyright 2017 Donne Martin
Licença Creative Commons Attribution 4.0 International (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---