English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Pomóż przetłumaczyć ten przewodnik!
The System Design Primer

Motywacja
Naucz się projektować systemy na dużą skalę.>
Przygotuj się do rozmowy rekrutacyjnej z zakresu projektowania systemów.
Naucz się projektować systemy na dużą skalę
Nauka projektowania skalowalnych systemów pomoże Ci stać się lepszym inżynierem.
Projektowanie systemów to szeroki temat. Istnieje ogromna ilość zasobów rozproszonych po całym internecie na temat zasad projektowania systemów.
To repozytorium to zorganizowana kolekcja zasobów, które pomogą Ci nauczyć się budować systemy na dużą skalę.
Ucz się od społeczności open source
To jest stale aktualizowany projekt open source.
Wkłady są mile widziane!
Przygotuj się do rozmowy rekrutacyjnej z zakresu projektowania systemów
Oprócz rozmów technicznych z zakresu kodowania, projektowanie systemów jest wymaganym elementem procesu rekrutacyjnego w wielu firmach technologicznych.
Ćwicz popularne pytania rekrutacyjne z projektowania systemów i porównuj swoje odpowiedzi z przykładowymi rozwiązaniami: dyskusje, kod oraz diagramy.
Dodatkowe tematy do przygotowania do rozmowy rekrutacyjnej:
- Przewodnik do nauki
- Jak podejść do pytania z projektowania systemów na rozmowie
- Pytania z zakresu projektowania systemów, z rozwiązaniami
- Pytania z zakresu projektowania obiektowego, z rozwiązaniami
- Dodatkowe pytania z zakresu projektowania systemów
Fiszki Anki
Dostarczone talii fiszek Anki używają powtarzania rozłożonego w czasie, aby pomóc Ci zapamiętać kluczowe pojęcia z projektowania systemów.
- Talia projektowania systemów
- Talia ćwiczeń z projektowania systemów
- Talia ćwiczeń z projektowania obiektowego
Zasób programistyczny: Interaktywne wyzwania programistyczne
Szukasz zasobów, które pomogą Ci przygotować się do rozmowy rekrutacyjnej z kodowania?
Zobacz repozytorium siostrzane Interaktywne wyzwania programistyczne, które zawiera dodatkową talię Anki:
Współtworzenie
Ucz się od społeczności.
Zachęcamy do zgłaszania pull requestów, aby pomóc:
- Poprawić błędy
- Ulepszyć sekcje
- Dodaj nowe sekcje
- Tłumacz
Przejrzyj Wytyczne dotyczące współtworzenia.
Indeks tematów dotyczących projektowania systemów
Podsumowania różnych tematów związanych z projektowaniem systemów, w tym zalety i wady. Wszystko jest kompromisem.>
Każda sekcja zawiera linki do bardziej szczegółowych materiałów.
- Tematy projektowania systemów: zacznij tutaj
- Krok 1: Przejrzyj wykład wideo o skalowalności
- Krok 2: Przejrzyj artykuł o skalowalności
- Następne kroki
- Wydajność vs skalowalność
- Opóźnienie vs przepustowość
- Dostępność vs spójność
- Teoria CAP
- CP - spójność i tolerancja podziału
- AP - dostępność i tolerancja podziału
- Wzorce spójności
- Słaba spójność
- Ostateczna spójność
- Silna spójność
- Wzorce dostępności
- Fail-over
- Replikacja
- Dostępność w liczbach
- System nazw domenowych
- Sieć dostarczania treści
- Push CDN-y
- Pull CDN-y
- Load balancer
- Aktywny-pasywny
- Aktywny-aktywny
- Równoważenie obciążenia warstwy 4
- Równoważenie obciążenia warstwy 7
- Skalowanie horyzontalne
- Reverse proxy (serwer WWW)
- Load balancer vs reverse proxy
- Warstwa aplikacji
- Mikrousługi
- Odkrywanie usług
- Baza danych
- Relacyjny system zarządzania bazą danych (RDBMS)
- Replikacja master-slave
- Replikacja master-master
- Federacja
- Sharding (dzielenie danych)
- Denormalizacja
- Optymalizacja SQL
- NoSQL
- Magazyn klucz-wartość
- Magazyn dokumentów
- Magazyn szerokokolumnowy
- Baza danych grafowa
- SQL czy NoSQL
- Cache
- Cache po stronie klienta
- Cache CDN
- Cache serwera WWW
- Cache bazy danych
- Cache aplikacji
- Cache na poziomie zapytań do bazy
- Cache na poziomie obiektów
- Kiedy aktualizować cache
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- Asynchroniczność
- Kolejki wiadomości
- Kolejki zadań
- Ciśnienie zwrotne
- Komunikacja
- Protokół sterowania transmisją (TCP)
- Protokół datagramów użytkownika (UDP)
- Zdalne wywołanie procedury (RPC)
- Reprezentacyjny transfer stanu (REST)
- Bezpieczeństwo
- Aneks
- Tabela potęg dwójki
- Liczby opóźnień, które każdy programista powinien znać
- Dodatkowe pytania do rozmów o projektowaniu systemów
- Architektury rzeczywiste
- Architektury firm
- Firmowe blogi inżynierskie
- W trakcie rozwoju
- Podziękowania
- Informacje kontaktowe
- Licencja
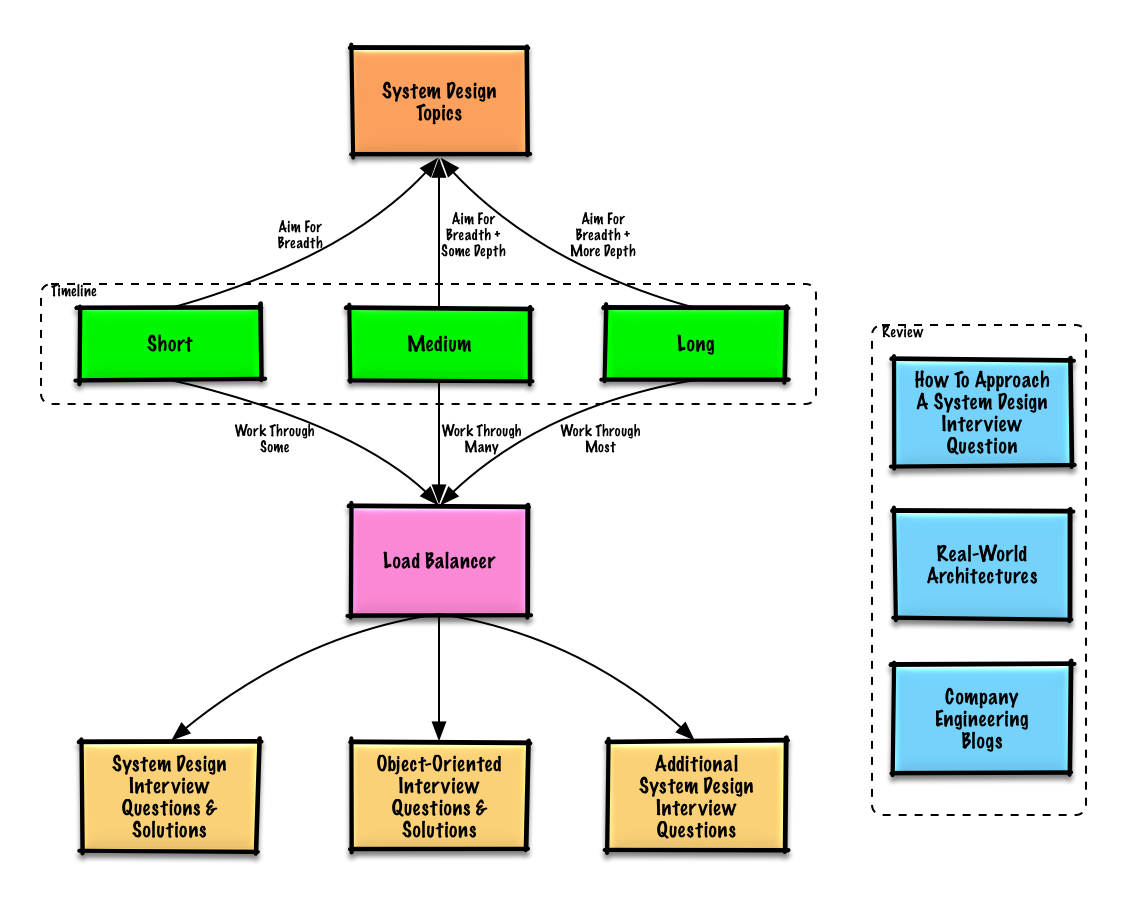
Przewodnik do nauki
Zalecane tematy do przeglądu w zależności od terminu rozmowy kwalifikacyjnej (krótki, średni, długi).
P: Czy na rozmowę kwalifikacyjną muszę znać wszystko z tej listy?
O: Nie, nie musisz znać wszystkiego, aby przygotować się do rozmowy kwalifikacyjnej.
O co zostaniesz zapytany na rozmowie zależy od takich czynników jak:
- Jakie masz doświadczenie
- Jakie masz techniczne przygotowanie
- Na jakie stanowiska aplikujesz
- Do jakich firm aplikujesz
- Szczęście
Zacznij szeroko i pogłęb się w kilku obszarach. Pomaga znać podstawy różnych kluczowych zagadnień z zakresu projektowania systemów. Dostosuj poniższy przewodnik do swojego harmonogramu, doświadczenia, stanowisk na które aplikujesz oraz firm, z którymi masz rozmowy.
- Krótki harmonogram – Skup się na szerokości zagadnień związanych z projektowaniem systemów. Ćwicz rozwiązując kilka pytań z rozmów kwalifikacyjnych.
- Średni harmonogram – Skup się na szerokości i pewnej głębokości zagadnień z projektowania systemów. Ćwicz rozwiązując wiele pytań z rozmów kwalifikacyjnych.
- Długi harmonogram – Skup się na szerokości i większej głębokości zagadnień z projektowania systemów. Ćwicz rozwiązując większość pytań z rozmów kwalifikacyjnych.
Jak podejść do pytania z projektowania systemu
Jak zmierzyć się z pytaniem na rozmowie o projektowaniu systemu.
Rozmowa z projektowania systemu to otwarta dyskusja. Oczekuje się, że to Ty ją poprowadzisz.
Możesz skorzystać z poniższych kroków, aby poprowadzić rozmowę. Aby utrwalić ten proces, przejdź sekcję Pytania z rozmów z projektowania systemów wraz z rozwiązaniami korzystając z tych kroków.
Krok 1: Określ przypadki użycia, ograniczenia i założenia
Zbierz wymagania i określ zakres problemu. Zadawaj pytania, aby wyjaśnić przypadki użycia i ograniczenia. Omów założenia.
- Kto będzie z tego korzystał?
- Jak będą z tego korzystać?
- Ilu będzie użytkowników?
- Co robi system?
- Jakie są wejścia i wyjścia systemu?
- Ile danych spodziewamy się obsłużyć?
- Ilu żądań na sekundę się spodziewamy?
- Jaki jest oczekiwany stosunek odczytów do zapisów?
Krok 2: Stwórz projekt na wysokim poziomie
Przedstaw projekt na wysokim poziomie ze wszystkimi istotnymi komponentami.
- Naszkicuj główne komponenty i połączenia
- Uzasadnij swoje pomysły
Krok 3: Zaprojektuj główne komponenty
Przejdź do szczegółów każdego kluczowego komponentu. Na przykład, jeśli poproszono Cię o zaprojektowanie usługi skracania URL, omów:
- Generowanie i przechowywanie skrótu pełnego adresu URL
- MD5 oraz Base62
- Kolizje skrótów
- SQL czy NoSQL
- Schemat bazy danych
- Tłumaczenie skróconego URL na pełny adres URL
- Wyszukiwanie w bazie danych
- Projektowanie API i obiektowe
Krok 4: Skalowanie projektu
Zidentyfikuj i rozwiąż wąskie gardła, biorąc pod uwagę ograniczenia. Na przykład, czy potrzebujesz poniższych rozwiązań, aby rozwiązać problemy ze skalowalnością?
- Load balancer
- Skalowanie horyzontalne
- Cache'owanie
- Sharding bazy danych
Szacowania „na szybko”
Możesz zostać poproszony o wykonanie szacowań ręcznych. Zajrzyj do Aneksu, gdzie znajdziesz następujące materiały:
- Używaj szacowań „na szybko”
- Tabela potęg dwójki
- Liczby opóźnień, które każdy programista powinien znać
Źródła i dalsza lektura
Zapoznaj się z poniższymi linkami, aby lepiej zrozumieć, czego się spodziewać:
- Jak zdać rozmowę kwalifikacyjną z projektowania systemów
- Rozmowa kwalifikacyjna z projektowania systemów
- Wprowadzenie do architektury i rozmów kwalifikacyjnych z projektowania systemów
- Szablon projektowania systemu
Pytania z rozmów kwalifikacyjnych z projektowania systemów wraz z rozwiązaniami
Typowe pytania z rozmów kwalifikacyjnych z projektowania systemów wraz z przykładami dyskusji, kodem i diagramami.>
Rozwiązania powiązane z zawartością w folderze solutions/.| Pytanie | | |---|---| | Zaprojektuj Pastebin.com (lub Bit.ly) | Rozwiązanie | | Zaprojektuj linię czasu i wyszukiwanie na Twitterze (lub Facebook feed i wyszukiwanie) | Rozwiązanie | | Zaprojektuj crawler internetowy | Rozwiązanie | | Zaprojektuj Mint.com | Rozwiązanie | | Zaprojektuj struktury danych dla sieci społecznościowej | Rozwiązanie | | Zaprojektuj magazyn klucz-wartość dla wyszukiwarki | Rozwiązanie | | Zaprojektuj funkcję rankingów sprzedaży według kategorii Amazon | Rozwiązanie | | Zaprojektuj system skalujący się do milionów użytkowników na AWS | Rozwiązanie | | Dodaj pytanie z projektowania systemu | Współtwórz |
Zaprojektuj Pastebin.com (lub Bit.ly)
Zobacz ćwiczenie i rozwiązanie
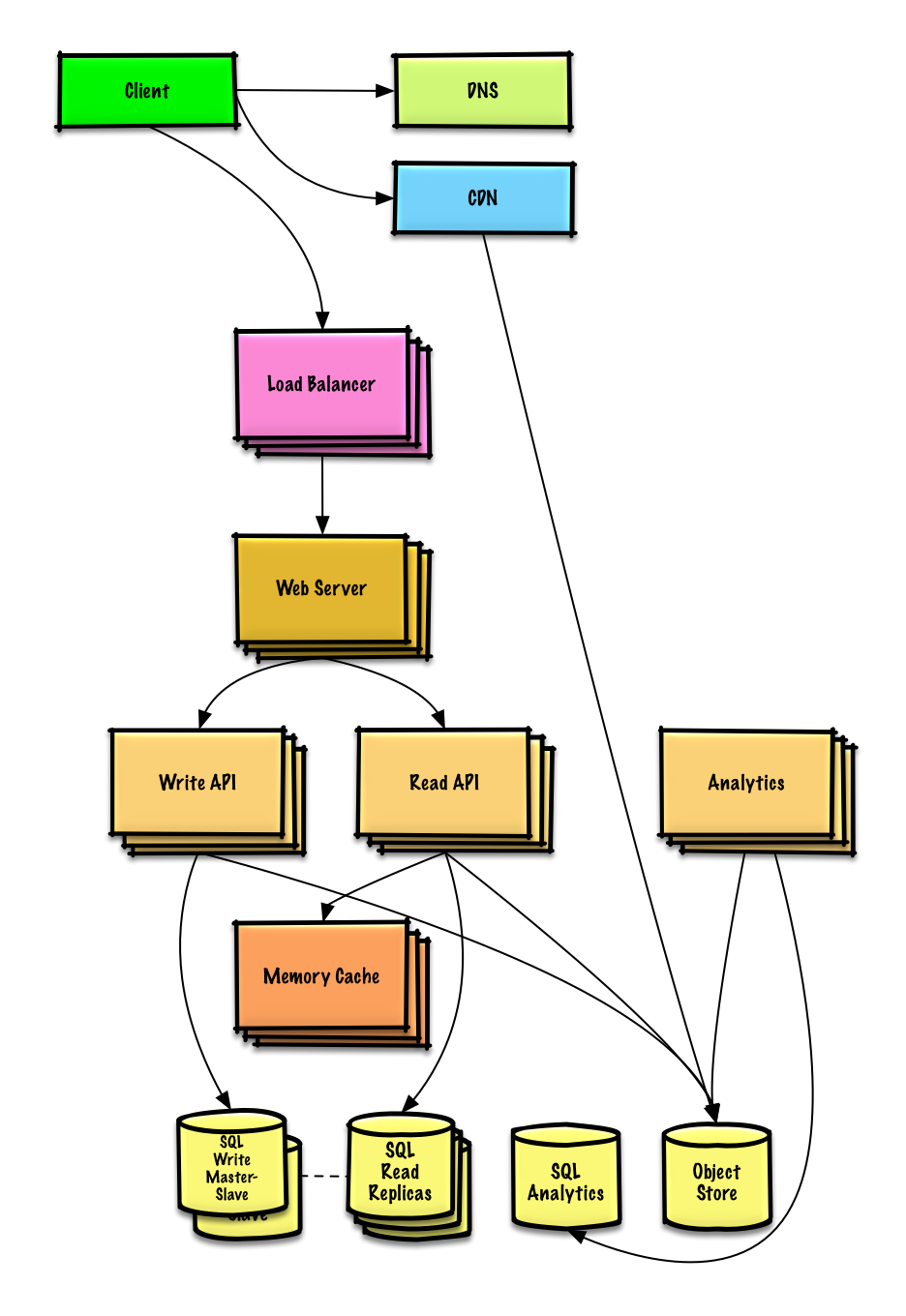
Zaprojektuj linię czasu i wyszukiwanie na Twitterze (lub Facebook feed i wyszukiwanie)
Zobacz ćwiczenie i rozwiązanie
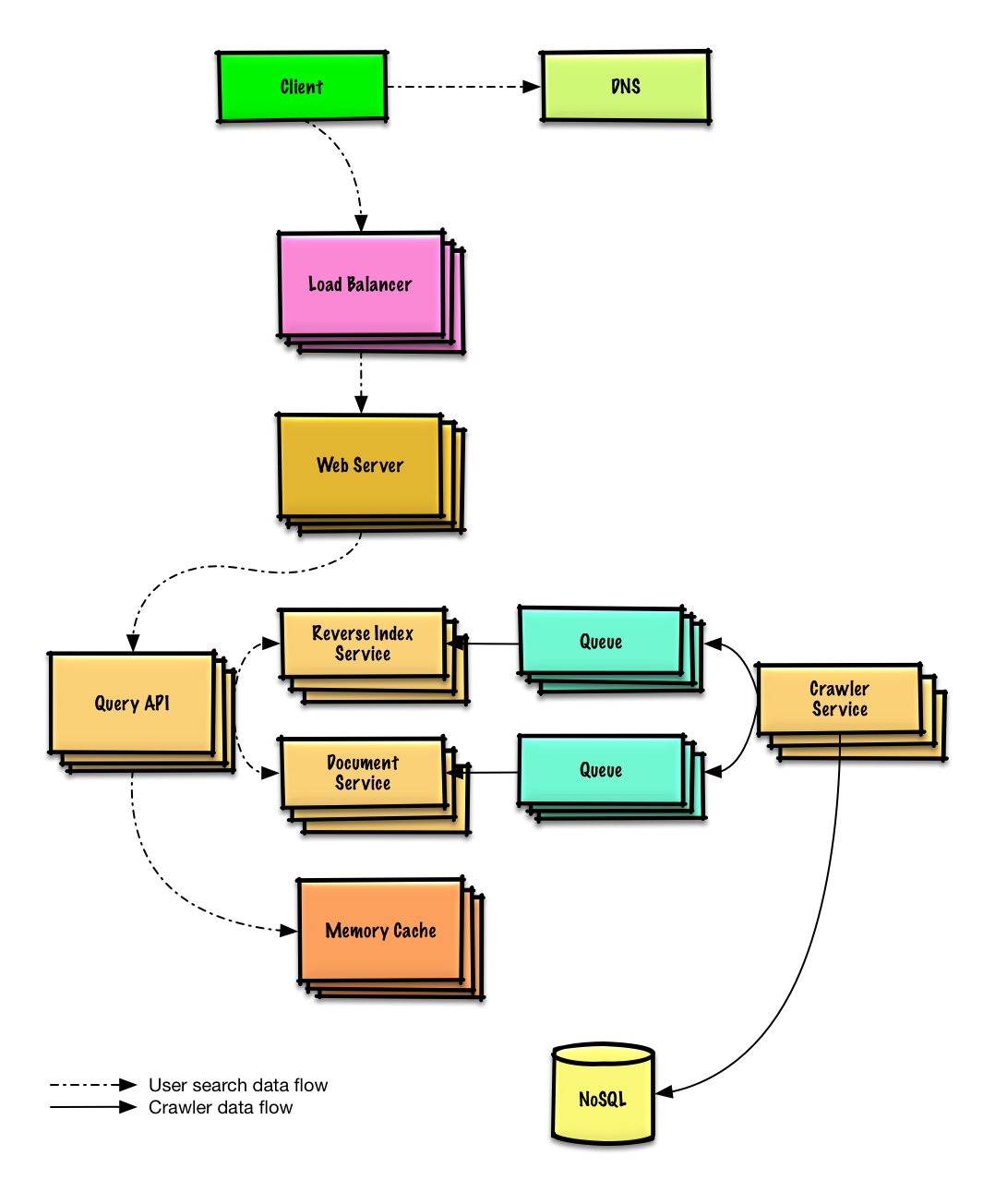
Zaprojektuj crawler internetowy
Zobacz ćwiczenie i rozwiązanie
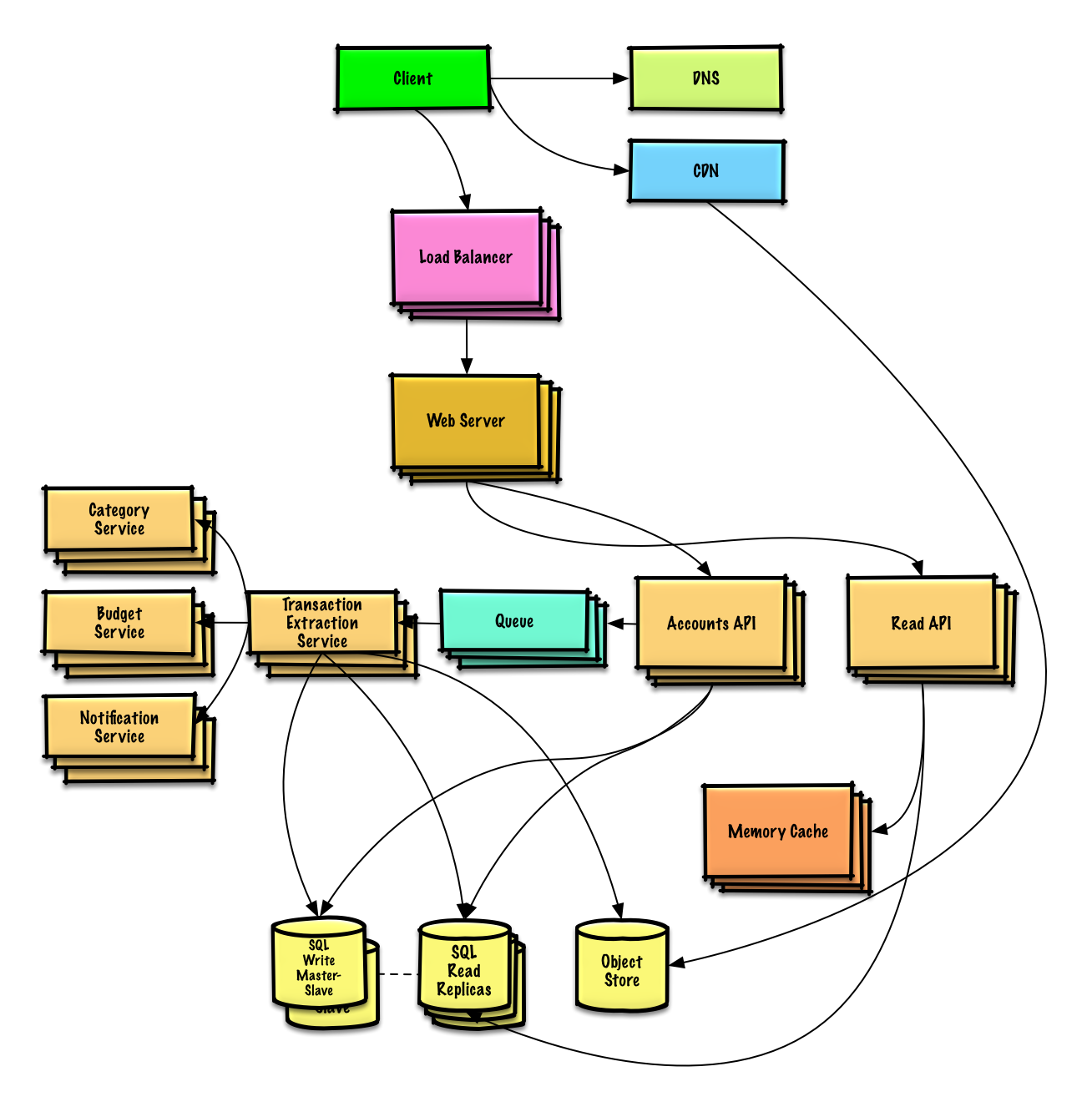
Design Mint.com
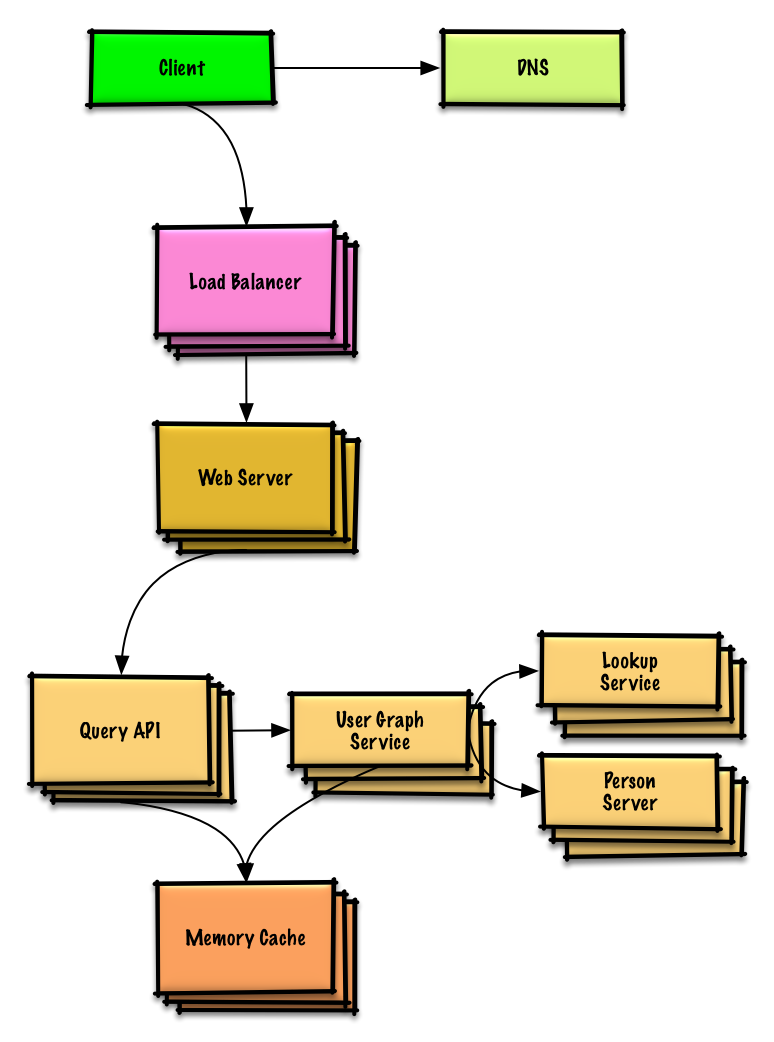
Design the data structures for a social network
Design a key-value store for a search engine
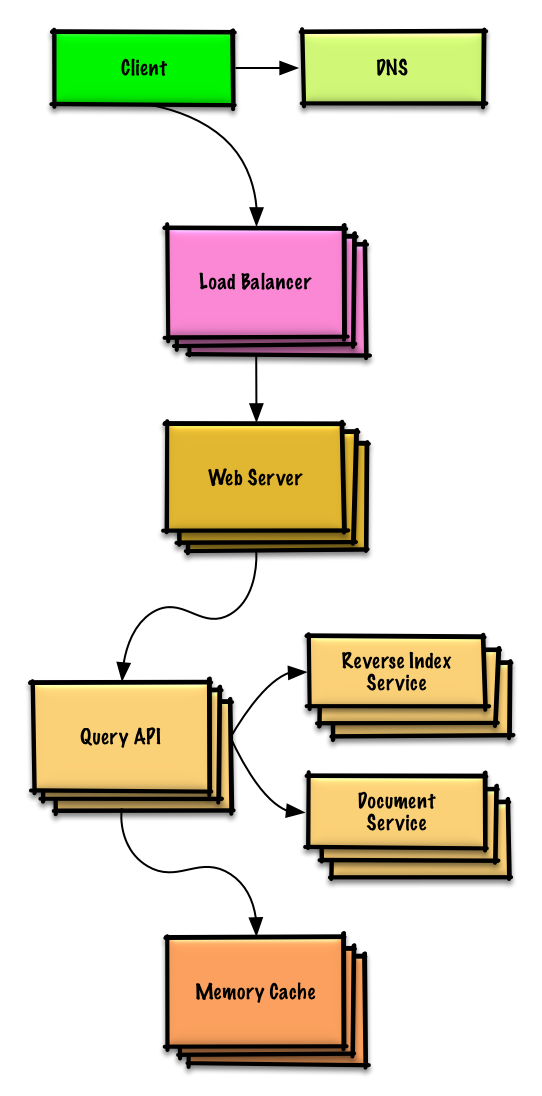
Design Amazon's sales ranking by category feature
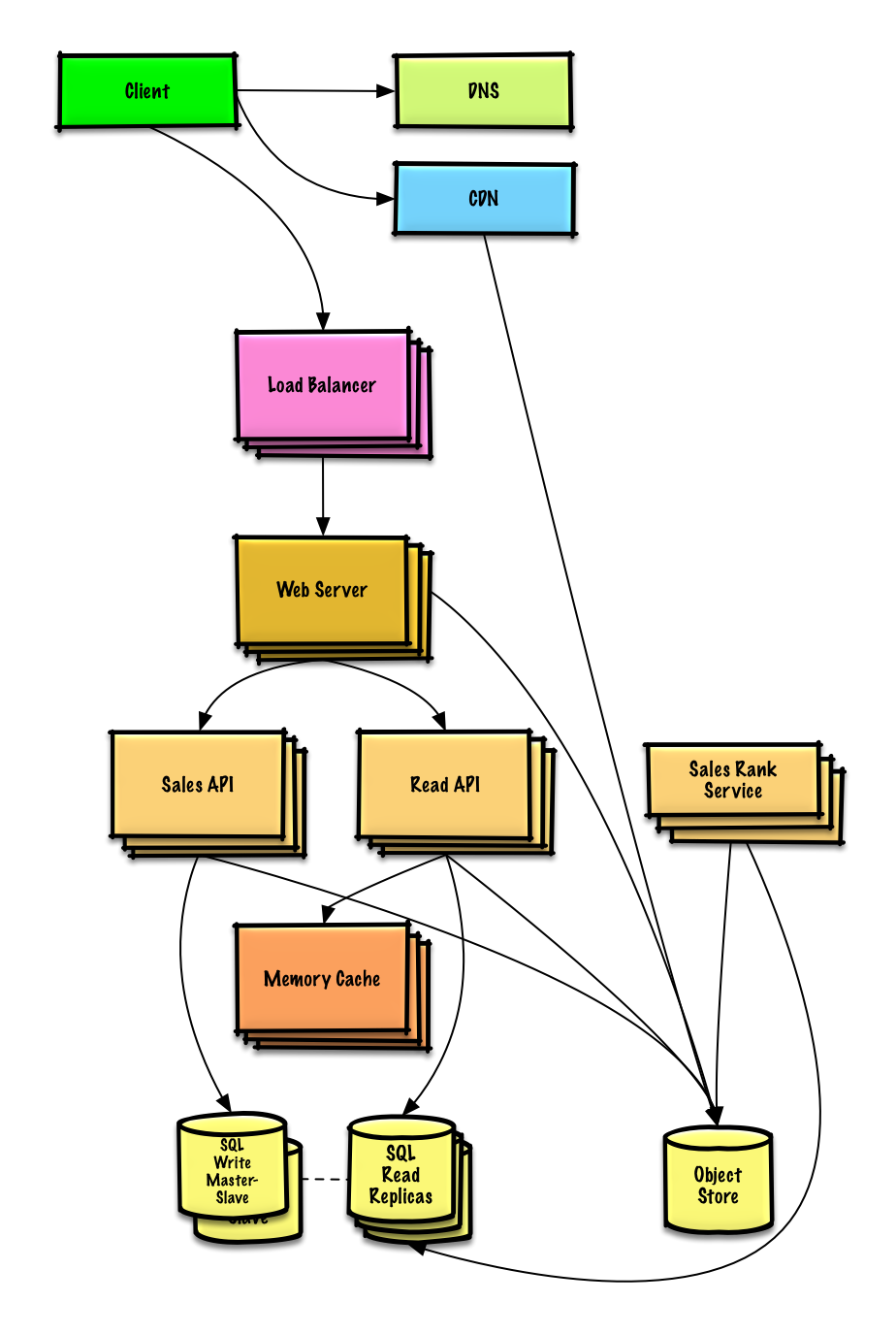
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Zaprojektuj tablicę mieszającą (hash map) | Rozwiązanie | | Zaprojektuj pamięć podręczną najmniej używanych danych (LRU cache) | Rozwiązanie | | Zaprojektuj centrum obsługi połączeń | Rozwiązanie | | Zaprojektuj talię kart | Rozwiązanie | | Zaprojektuj parking | Rozwiązanie | | Zaprojektuj serwer czatu | Rozwiązanie | | Zaprojektuj tablicę cykliczną | Wnieś swój wkład | | Dodaj pytanie z zakresu projektowania obiektowego | Wnieś swój wkład |
Tematy projektowania systemów: zacznij tutaj
Nowy w projektowaniu systemów?
Najpierw musisz mieć podstawową wiedzę na temat powszechnych zasad, dowiedzieć się czym są, jak się ich używa oraz poznać ich zalety i wady.
Krok 1: Zapoznaj się z wykładem wideo o skalowalności
Wykład o skalowalności na Harvardzie
- Poruszane tematy:
- Skalowanie wertykalne
- Skalowanie horyzontalne
- Buforowanie (Caching)
- Równoważenie obciążenia (Load balancing)
- Replikacja bazy danych
- Partycjonowanie bazy danych
Krok 2: Zapoznaj się z artykułem o skalowalności
- Poruszane tematy:
- Klonowanie
- Bazy danych
- Bufory
- Asynchroniczność
Kolejne kroki
Następnie przyjrzymy się kompromisom na wysokim poziomie:
- Wydajność vs skalowalność
- Opóźnienie vs przepustowość
- Dostępność vs spójność
Potem przejdziemy do bardziej szczegółowych tematów, takich jak DNS, CDN i load balancery.
Wydajność vs skalowalność
Usługa jest skalowalna, jeśli powoduje wzrost wydajności proporcjonalny do dodanych zasobów. Zazwyczaj zwiększenie wydajności oznacza obsługę większej liczby jednostek pracy, ale może też oznaczać obsługę większych jednostek pracy, np. gdy rosną zbiory danych.1
Inny sposób spojrzenia na wydajność vs skalowalność:
- Jeśli masz problem z wydajnością, Twój system jest wolny dla pojedynczego użytkownika.
- Jeśli masz problem ze skalowalnością, Twój system jest szybki dla pojedynczego użytkownika, ale wolny przy dużym obciążeniu.
Źródła i dalsza lektura
Opóźnienie vs przepustowość
Opóźnienie to czas potrzebny na wykonanie jakiejś akcji lub uzyskanie wyniku.
Przepustowość to liczba takich akcji lub wyników w jednostce czasu.
Zasadniczo należy dążyć do maksymalnej przepustowości przy akceptowalnym opóźnieniu.
Źródła i dalsza lektura
Dostępność vs spójność
Twierdzenie CAP
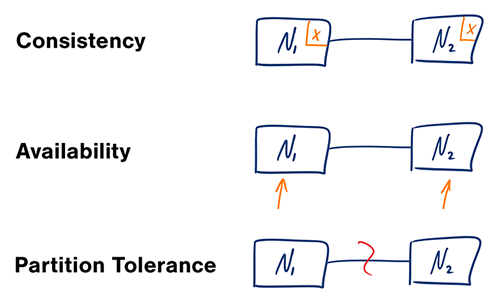
W rozproszonym systemie komputerowym można zapewnić tylko dwie z poniższych gwarancji:
- Spójność (Consistency) – Każdy odczyt otrzymuje najnowszy zapis lub błąd
- Dostępność (Availability) – Każde żądanie otrzymuje odpowiedź, bez gwarancji, że zawiera najnowszą wersję informacji
- Odporność na podziały (Partition Tolerance) – System działa mimo dowolnych podziałów spowodowanych awariami sieci
#### CP – spójność i odporność na podziały
Oczekiwanie na odpowiedź od podzielonego węzła może skutkować błędem przekroczenia czasu oczekiwania. CP jest dobrym wyborem, jeśli wymagania biznesowe wymagają atomowych odczytów i zapisów.
#### AP – dostępność i odporność na podziały
Odpowiedzi zwracają najłatwiej dostępną wersję danych na dowolnym węźle, która może nie być najnowsza. Zapisy mogą wymagać czasu na propagację po rozwiązaniu podziału.
AP jest dobrym wyborem, jeśli wymagania biznesowe dopuszczają ostateczną spójność lub gdy system musi działać mimo błędów zewnętrznych.
Źródła i dalsza lektura
Wzorce spójności
Przy wielu kopiach tych samych danych musimy zdecydować, jak je synchronizować, aby klienci mieli spójny widok danych. Przypomnijmy definicję spójności z twierdzenia CAP – Każdy odczyt otrzymuje najnowszy zapis lub błąd.
Słaba spójność (Weak consistency)
Po zapisie odczyty mogą go widzieć lub nie. Stosuje się podejście „najlepszych starań”.
To podejście występuje w systemach takich jak memcached. Słaba spójność sprawdza się w zastosowaniach czasu rzeczywistego, takich jak VoIP, czat wideo i gry wieloosobowe w czasie rzeczywistym. Na przykład, jeśli podczas rozmowy telefonicznej utracisz zasięg na kilka sekund, po odzyskaniu połączenia nie usłyszysz tego, co zostało powiedziane podczas utraty połączenia.
Spójność ostateczna
Po zapisie, odczyty ostatecznie go zobaczą (zazwyczaj w ciągu milisekund). Dane są replikowane asynchronicznie.
To podejście jest stosowane w systemach takich jak DNS i poczta elektroniczna. Spójność ostateczna dobrze sprawdza się w systemach o wysokiej dostępności.
Spójność silna
Po zapisie, odczyty go zobaczą. Dane są replikowane synchronicznie.
To podejście jest stosowane w systemach plików i relacyjnych bazach danych (RDBMS). Spójność silna dobrze sprawdza się w systemach wymagających transakcji.
Źródło(ła) i dalsza lektura
Wzorce dostępności
Istnieją dwa komplementarne wzorce wspierające wysoką dostępność: przełączanie awaryjne i replikacja.
Przełączanie awaryjne
#### Aktywny-pasywny
W przełączaniu awaryjnym aktywny-pasywny, między serwerem aktywnym a pasywnym (w trybie gotowości) są wysyłane sygnały kontrolne (heartbeat). Jeśli sygnał zostanie przerwany, serwer pasywny przejmuje adres IP aktywnego i wznawia usługę.
Długość przestoju zależy od tego, czy serwer pasywny działa już w trybie „gorącej” gotowości, czy musi uruchomić się z „zimnej” gotowości. Tylko serwer aktywny obsługuje ruch.
Przełączanie awaryjne aktywny-pasywny może być również nazywane przełączaniem awaryjnym master-slave.
#### Aktywny-aktywny
W przełączaniu aktywny-aktywny oba serwery obsługują ruch, rozkładając obciążenie między sobą.
Jeśli serwery są dostępne publicznie, DNS musi znać publiczne adresy IP obu serwerów. Jeśli serwery są dostępne wewnętrznie, logika aplikacji musi znać oba serwery.
Przełączanie awaryjne aktywny-aktywny może być również nazywane przełączaniem awaryjnym master-master.
Wada(y): przełączanie awaryjne
- Fail-over wymaga dodatkowego sprzętu oraz zwiększa złożoność systemu.
- Istnieje ryzyko utraty danych, jeśli aktywny system ulegnie awarii zanim nowo zapisane dane zostaną zreplikowane do pasywnego.
Replikacja
#### Master-slave i master-master
Ten temat jest szczegółowo omówiony w sekcji Baza danych:
Dostępność w liczbach
Dostępność jest często wyrażana jako procent czasu działania (lub przestoju), w którym usługa jest dostępna. Dostępność zwykle mierzy się liczbą dziewiątek--usługa o dostępności 99,99% jest określana jako mająca cztery dziewiątki.
#### 99,9% dostępności - trzy dziewiątki
| Okres | Akceptowalny czas przestoju| |----------------------|----------------------------| | Przestój rocznie | 8h 45min 57s | | Przestój miesięcznie | 43m 49,7s | | Przestój tygodniowo | 10m 4,8s | | Przestój dziennie | 1m 26,4s |
#### 99,99% dostępności - cztery dziewiątki
| Okres | Akceptowalny czas przestoju| |----------------------|----------------------------| | Przestój rocznie | 52min 35,7s | | Przestój miesięcznie | 4m 23s | | Przestój tygodniowo | 1m 5s | | Przestój dziennie | 8,6s |
#### Dostępność równoległa vs sekwencyjna
Jeśli usługa składa się z kilku komponentów podatnych na awarie, całkowita dostępność zależy od tego, czy komponenty są połączone sekwencyjnie czy równolegle.
###### Sekwencyjnie Ogólna dostępność maleje, gdy dwa komponenty o dostępności < 100% są połączone szeregowo:
Availability (Total) = Availability (Foo) * Availability (Bar)Jeśli zarówno Foo, jak i Bar miałyby dostępność na poziomie 99,9%, ich łączna dostępność w sekwencji wynosiłaby 99,8%.
###### Równolegle
Całkowita dostępność wzrasta, gdy dwa komponenty o dostępności < 100% są połączone równolegle:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo, jak i Bar miałyby dostępność na poziomie 99,9%, ich łączna dostępność w trybie równoległym wynosiłaby 99,9999%.System nazw domenowych
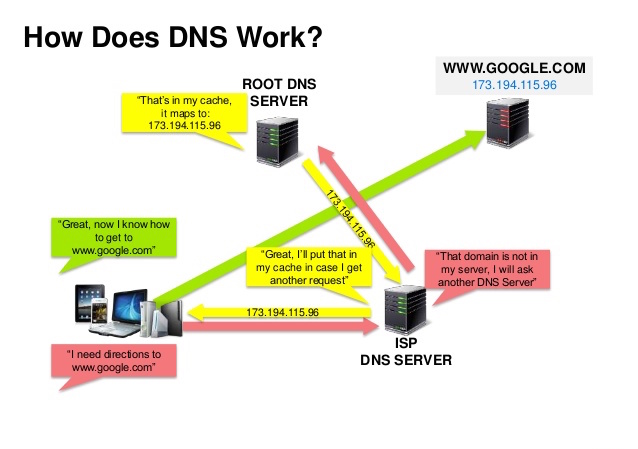
Źródło: Prezentacja o bezpieczeństwie DNS
System nazw domenowych (DNS) tłumaczy nazwę domeny, taką jak www.example.com, na adres IP.
DNS jest hierarchiczny, z kilkoma autorytatywnymi serwerami na najwyższym poziomie. Twój router lub dostawca internetu (ISP) dostarcza informacje o tym, z jakim(i) serwerem(i) DNS się łączyć podczas wyszukiwania. Niższe poziomy serwerów DNS przechowują w pamięci podręcznej mapowania, które mogą się zdezaktualizować z powodu opóźnień propagacji DNS. Wyniki DNS mogą być również buforowane przez Twoją przeglądarkę lub system operacyjny przez określony czas, ustalany przez parametr time to live (TTL).
- Rekord NS (name server) - Określa serwery DNS dla Twojej domeny/poddomeny.
- Rekord MX (mail exchange) - Określa serwery pocztowe do odbierania wiadomości.
- Rekord A (address) - Wskazuje nazwę na adres IP.
- CNAME (canonical) - Wskazuje nazwę na inną nazwę lub
CNAME(example.com na www.example.com) lub na rekordA.
- Ważony round robin
- Zapobiega kierowaniu ruchu na serwery będące w konserwacji
- Równoważy pomiędzy różnymi rozmiarami klastrów
- Testy A/B
- Na podstawie opóźnienia (latency-based)
- Na podstawie geolokalizacji (geolocation-based)
Wada(-y): DNS
- Dostęp do serwera DNS wprowadza niewielkie opóźnienie, choć łagodzone przez opisane powyżej buforowanie.
- Zarządzanie serwerem DNS może być skomplikowane i jest zwykle prowadzone przez rządy, dostawców internetu i duże firmy.
- Usługi DNS były ostatnio celem ataku DDoS, uniemożliwiając użytkownikom dostęp do stron takich jak Twitter bez znajomości adresu(-ów) IP Twittera.
Źródła i dalsza lektura
Sieć dostarczania treści
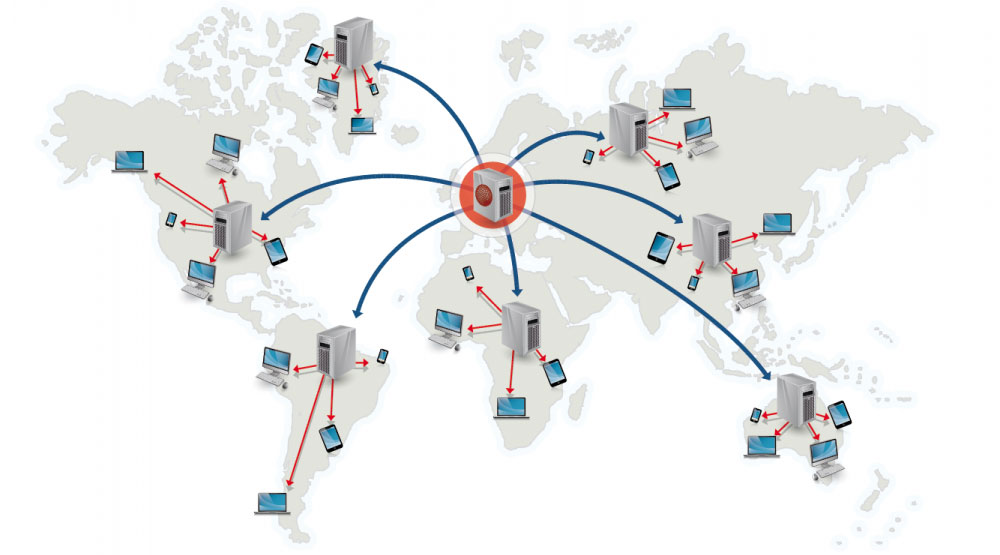
Źródło: Dlaczego warto używać CDN
Sieć dostarczania treści (CDN) to globalnie rozproszona sieć serwerów proxy, która udostępnia treści z lokalizacji bliższych użytkownikowi. Zazwyczaj z CDN serwowane są pliki statyczne, takie jak HTML/CSS/JS, zdjęcia i filmy, chociaż niektóre CDN-y, jak Amazon CloudFront, obsługują także treści dynamiczne. Rozwiązanie DNS strony wskaże klientom, z którym serwerem się połączyć.
Serwowanie treści z CDN znacząco poprawia wydajność na dwa sposoby:
- Użytkownicy otrzymują treści z centrów danych bliższych sobie
- Twoje serwery nie muszą obsługiwać żądań spełnianych przez CDN
Push CDN
Push CDN otrzymuje nowe treści za każdym razem, gdy nastąpią zmiany na Twoim serwerze. Bierzesz pełną odpowiedzialność za dostarczanie treści, przesyłając je bezpośrednio do CDN i przepisując adresy URL tak, aby wskazywały na CDN. Możesz skonfigurować, kiedy treść wygasa i kiedy jest aktualizowana. Treść jest przesyłana tylko gdy jest nowa lub zmieniona, minimalizując ruch, ale maksymalizując zużycie miejsca.
Strony z niewielkim ruchem lub takie, których treść rzadko się zmienia, dobrze współpracują z Push CDN. Treść jest umieszczana na CDN tylko raz, zamiast być ponownie pobieraną w regularnych odstępach czasu.
Pull CDN
Pull CDN pobiera nowe treści z Twojego serwera, gdy pierwszy użytkownik zażąda tej treści. Pozostawiasz treść na swoim serwerze i przepisujesz adresy URL, aby wskazywały na CDN. Powoduje to wolniejsze żądanie, dopóki treść nie zostanie zapisana w pamięci podręcznej CDN.
Parametr time-to-live (TTL) określa, jak długo treść jest przechowywana w pamięci podręcznej. Pull CDN minimalizuje wykorzystanie przestrzeni na CDN, ale może generować zbędny ruch, jeśli pliki wygasną i zostaną pobrane, zanim rzeczywiście się zmienią.
Strony z dużym ruchem dobrze współpracują z Pull CDN, ponieważ ruch jest równomierniej rozłożony, a na CDN pozostaje tylko niedawno żądana treść.
Wady: CDN
- Koszty CDN mogą być znaczące w zależności od ruchu, chociaż należy je porównać z dodatkowymi kosztami, które poniósłbyś nie używając CDN.
- Treść może być nieaktualna, jeśli zostanie zaktualizowana przed wygaśnięciem TTL.
- CDN wymaga zmiany adresów URL dla treści statycznych, aby wskazywały na CDN.
Źródła i dalsza lektura
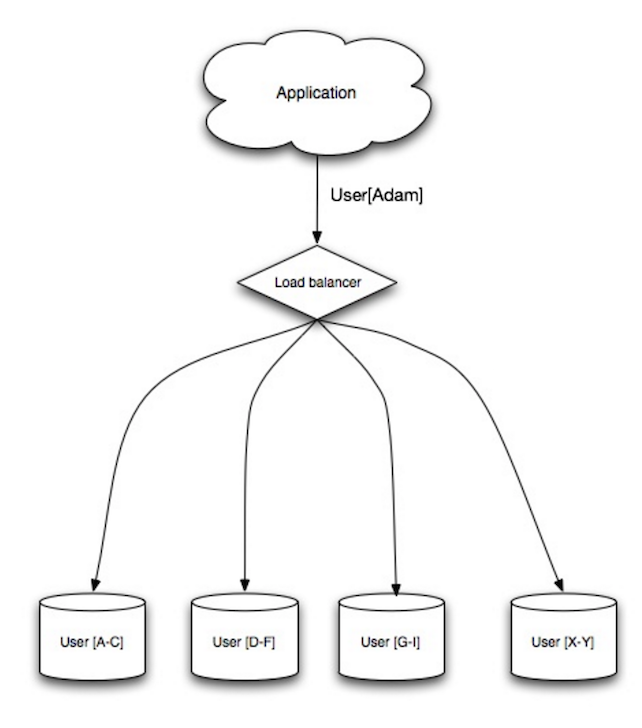
Load balancer
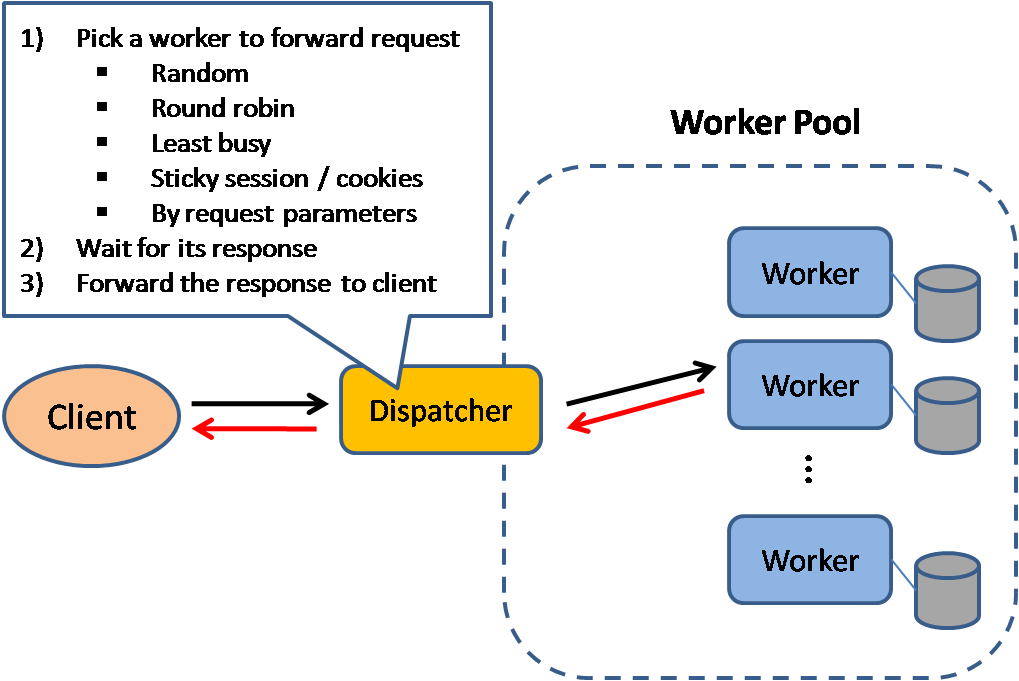
Źródło: Wzorce projektowe skalowalnych systemów
Load balancery rozdzielają przychodzące żądania klientów na zasoby obliczeniowe, takie jak serwery aplikacyjne i bazy danych. W każdym przypadku load balancer zwraca odpowiedź z zasobu obliczeniowego do odpowiedniego klienta. Load balancery są skuteczne w:
- Zapobieganiu kierowania żądań do niezdrowych serwerów
- Zapobieganiu przeciążaniu zasobów
- Pomaganiu w eliminacji pojedynczego punktu awarii
Dodatkowe korzyści obejmują:
- Zakończenie SSL – Odszyfrowywanie przychodzących żądań i szyfrowanie odpowiedzi serwera, aby serwery backendowe nie musiały wykonywać tych potencjalnie kosztownych operacji
- Usuwa konieczność instalowania certyfikatów X.509 na każdym serwerze
- Utrzymanie sesji – Wystawianie ciasteczek i kierowanie żądań konkretnego klienta do tej samej instancji, jeśli aplikacje webowe nie śledzą sesji
Load balancery mogą kierować ruch na podstawie różnych metryk, w tym:
- Losowo
- Najmniej obciążony
- Sesja/ciasteczka
- Round robin lub weighted round robin
- Warstwa 4
- Warstwa 7
Load balancing warstwy 4
Load balancery warstwy 4 analizują informacje na warstwie transportowej, aby zdecydować, jak rozdzielić żądania. Zazwyczaj obejmuje to źródłowe i docelowe adresy IP oraz porty w nagłówku, ale nie zawartość pakietu. Load balancery warstwy 4 przekazują pakiety sieciowe do i z serwera nadrzędnego, wykonując Translację Adresów Sieciowych (NAT).
Load balancing warstwy 7
Load balancery warstwy 7 analizują warstwę aplikacji, aby zdecydować, jak rozdzielić żądania. Może to obejmować zawartość nagłówka, wiadomości i ciasteczek. Load balancery warstwy 7 kończą ruch sieciowy, odczytują wiadomość, podejmują decyzję o rozkładzie obciążenia, a następnie otwierają połączenie z wybranym serwerem. Na przykład, load balancer warstwy 7 może kierować ruch wideo do serwerów hostujących filmy, podczas gdy bardziej wrażliwy ruch związany z rozliczeniami użytkowników przekierowywać na serwery wzmocnione pod względem bezpieczeństwa.
Kosztem elastyczności, load balancing warstwy 4 wymaga mniej czasu i zasobów obliczeniowych niż warstwy 7, chociaż wpływ na wydajność może być minimalny na współczesnym sprzęcie klasy konsumenckiej.
Skalowanie horyzontalne
Load balancery mogą również pomagać w skalowaniu horyzontalnym, poprawiając wydajność i dostępność. Skalowanie za pomocą maszyn klasy konsumenckiej jest bardziej opłacalne i skutkuje wyższą dostępnością niż rozbudowa pojedynczego serwera na droższym sprzęcie, nazywana skalowaniem wertykalnym. Łatwiej jest również zatrudnić specjalistów pracujących na sprzęcie konsumenckim niż do systemów korporacyjnych wymagających specjalizacji.
#### Wada(y): skalowanie horyzontalne
- Skalowanie horyzontalne wprowadza złożoność i wymaga klonowania serwerów
- Serwery powinny być bezstanowe: nie powinny zawierać żadnych danych użytkowników, takich jak sesje czy zdjęcia profilowe
- Sesje mogą być przechowywane w centralnym magazynie danych takim jak baza danych (SQL, NoSQL) lub trwała pamięć podręczna (Redis, Memcached)
- Serwery niższego szczebla, takie jak cache i bazy danych, muszą obsłużyć więcej jednoczesnych połączeń, gdy serwery wyższego szczebla się skalują
Wada(y): load balancer
- Load balancer może stać się wąskim gardłem wydajności, jeśli nie ma wystarczających zasobów lub nie jest właściwie skonfigurowany.
- Wprowadzenie load balancera w celu eliminacji pojedynczego punktu awarii powoduje wzrost złożoności.
- Pojedynczy load balancer to pojedynczy punkt awarii, skonfigurowanie wielu load balancerów jeszcze bardziej zwiększa złożoność.
Źródła i dalsza lektura
- Architektura NGINX
- Przewodnik po architekturze HAProxy
- Skalowalność
- Wikipedia)
- Load balancing warstwy 4
- Load balancing warstwy 7
- Konfiguracja listenera ELB
Reverse proxy (serwer WWW)
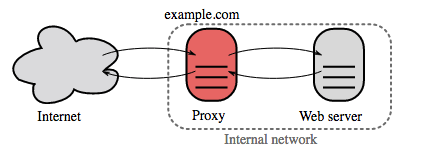
Reverse proxy to serwer WWW, który centralizuje usługi wewnętrzne i zapewnia jednolite interfejsy dla użytkowników zewnętrznych. Żądania od klientów są przekazywane do serwera, który może je obsłużyć, zanim reverse proxy zwróci odpowiedź serwera do klienta.
Dodatkowe korzyści obejmują:
- Zwiększone bezpieczeństwo – Ukrywanie informacji o serwerach zaplecza, czarna lista IP, ograniczenie liczby połączeń na klienta
- Zwiększona skalowalność i elastyczność – Klienci widzą tylko adres IP reverse proxy, co pozwala skalować serwery lub zmieniać ich konfigurację
- Terminacja SSL – Odszyfrowywanie przychodzących żądań i szyfrowanie odpowiedzi serwera, dzięki czemu serwery zaplecza nie muszą wykonywać tych kosztownych operacji
- Usuwa potrzebę instalowania certyfikatów X.509 na każdym serwerze
- Kompresja – Kompresowanie odpowiedzi serwera
- Buforowanie – Zwracanie odpowiedzi dla buforowanych żądań
- Treści statyczne – Bezpośrednie serwowanie treści statycznych
- HTML/CSS/JS
- Zdjęcia
- Filmy
- Itd.
Load balancer vs reverse proxy
- Wdrożenie load balancera jest użyteczne, gdy masz wiele serwerów. Często load balancery kierują ruch do zbioru serwerów pełniących tę samą funkcję.
- Reverse proxy mogą być przydatne nawet przy jednym serwerze WWW lub aplikacyjnym, zapewniając opisane wcześniej korzyści.
- Rozwiązania takie jak NGINX i HAProxy mogą obsługiwać zarówno reverse proxy na warstwie 7, jak i load balancing.
Wady: reverse proxy
- Wprowadzenie reverse proxy powoduje wzrost złożoności.
- Jeden reverse proxy to pojedynczy punkt awarii, a konfiguracja wielu reverse proxy (np. failover) jeszcze bardziej zwiększa złożoność.
Źródła i dalsza lektura
Warstwa aplikacji
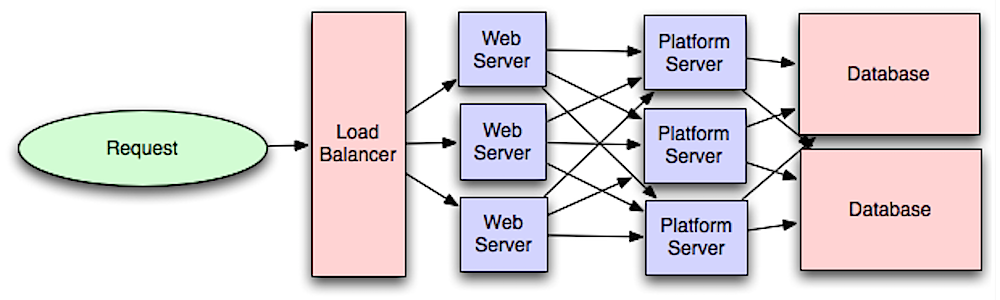
Źródło: Wprowadzenie do architektury systemów dla skalowalności
Oddzielenie warstwy webowej od warstwy aplikacyjnej (znanej również jako warstwa platformowa) umożliwia skalowanie i konfigurowanie obu warstw niezależnie. Dodanie nowego API powoduje dodanie serwerów aplikacyjnych bez konieczności dodawania dodatkowych serwerów webowych. Zasada pojedynczej odpowiedzialności opowiada się za małymi i autonomicznymi usługami współpracującymi ze sobą. Małe zespoły z małymi usługami mogą agresywniej planować szybki wzrost.
Pracownicy w warstwie aplikacyjnej pomagają również umożliwić asynchroniczność.
Mikrousługi
Powiązane z tą dyskusją są mikrousługi, które można opisać jako zestaw niezależnie wdrażalnych, małych, modułowych usług. Każda usługa działa jako unikalny proces i komunikuje się przez dobrze zdefiniowany, lekki mechanizm, aby realizować cel biznesowy. 1
Pinterest, na przykład, może posiadać następujące mikrousługi: profil użytkownika, obserwujący, kanał, wyszukiwarka, przesyłanie zdjęć itd.
Odkrywanie usług
Systemy takie jak Consul, Etcd, oraz Zookeeper mogą pomagać usługom odnajdywać się nawzajem poprzez śledzenie zarejestrowanych nazw, adresów i portów. Kontrole zdrowia pomagają weryfikować integralność usług i często są wykonywane przy użyciu punktu końcowego HTTP. Zarówno Consul jak i Etcd posiadają wbudowany magazyn klucz-wartość, który może być użyteczny do przechowywania wartości konfiguracyjnych i innych współdzielonych danych.
Wady: warstwa aplikacyjna
- Dodanie warstwy aplikacyjnej z luźno powiązanymi usługami wymaga innego podejścia pod względem architektury, operacji i procesu (w porównaniu do systemu monolitycznego).
- Mikrousługi mogą zwiększyć złożoność wdrożeń i operacji.
Źródła i dalsza lektura
- Wprowadzenie do architektury systemów dla skalowalności
- Rozwiązanie rozmowy kwalifikacyjnej z projektowania systemów
- Architektura zorientowana na usługi
- Wprowadzenie do Zookeeper
- Co musisz wiedzieć o budowaniu mikrousług
Baza danych
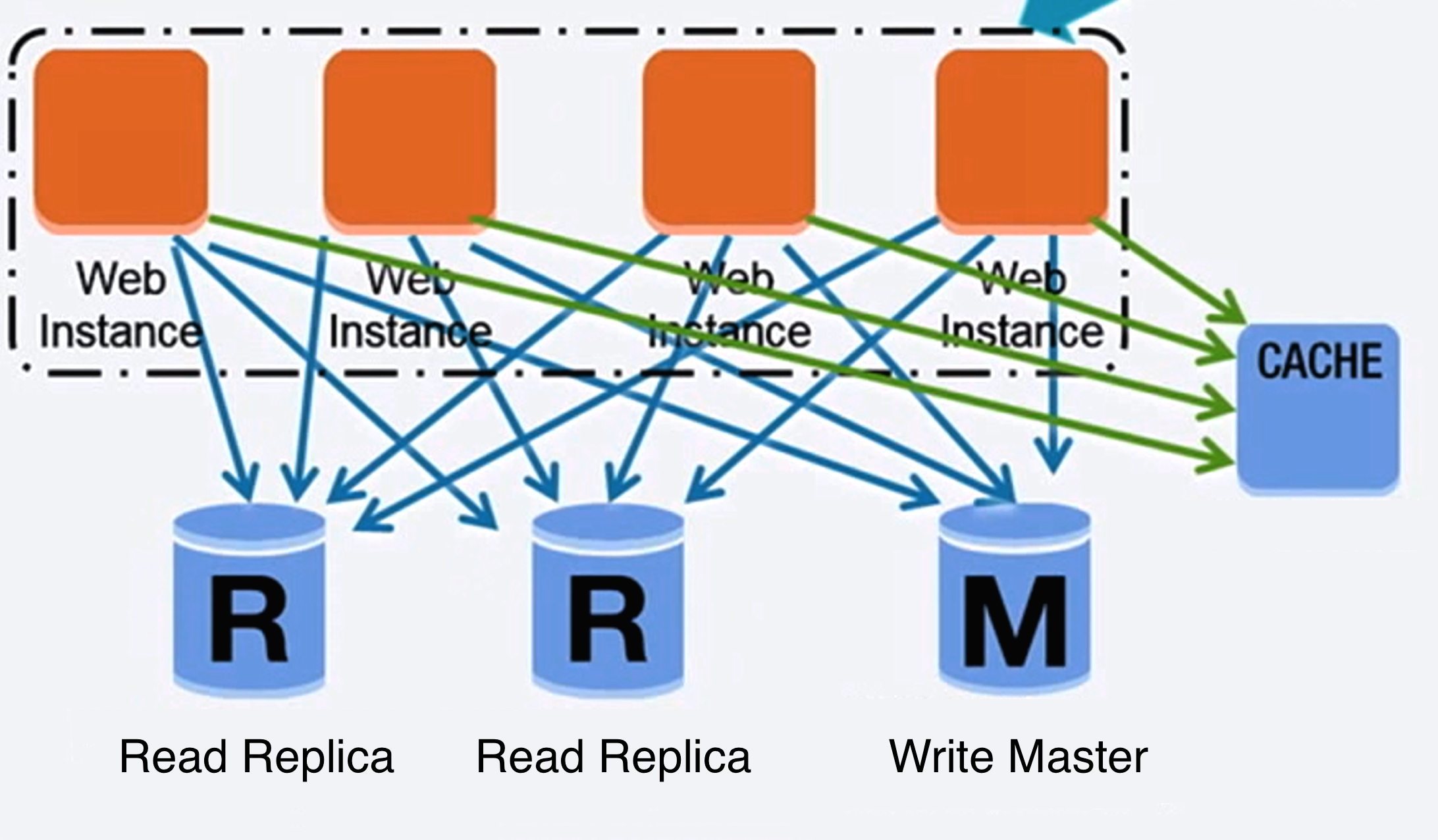
Źródło: Skalowanie do pierwszych 10 milionów użytkowników
Relacyjny system zarządzania bazą danych (RDBMS)
Relacyjna baza danych, taka jak SQL, to zbiór danych zorganizowanych w tabelach.
ACID to zbiór właściwości transakcji relacyjnych baz danych.
- Atomowość - Każda transakcja jest wykonywana w całości lub wcale
- Spójność - Każda transakcja przenosi bazę danych ze stanu prawidłowego do innego stanu prawidłowego
- Izolacja - Wykonywanie transakcji równolegle daje taki sam rezultat jak ich wykonywanie pojedynczo
- Trwałość - Po zatwierdzeniu transakcji pozostaje ona trwała
#### Replikacja master-slave
Master obsługuje operacje odczytu i zapisu, replikując zapisy do jednego lub więcej slave’ów, które obsługują tylko odczyty. Slave’y mogą replikować się do kolejnych slave’ów w strukturze drzewiastej. Jeśli master przestanie działać, system może nadal działać w trybie tylko do odczytu, aż slave zostanie awansowany na mastera lub zostanie utworzony nowy master.
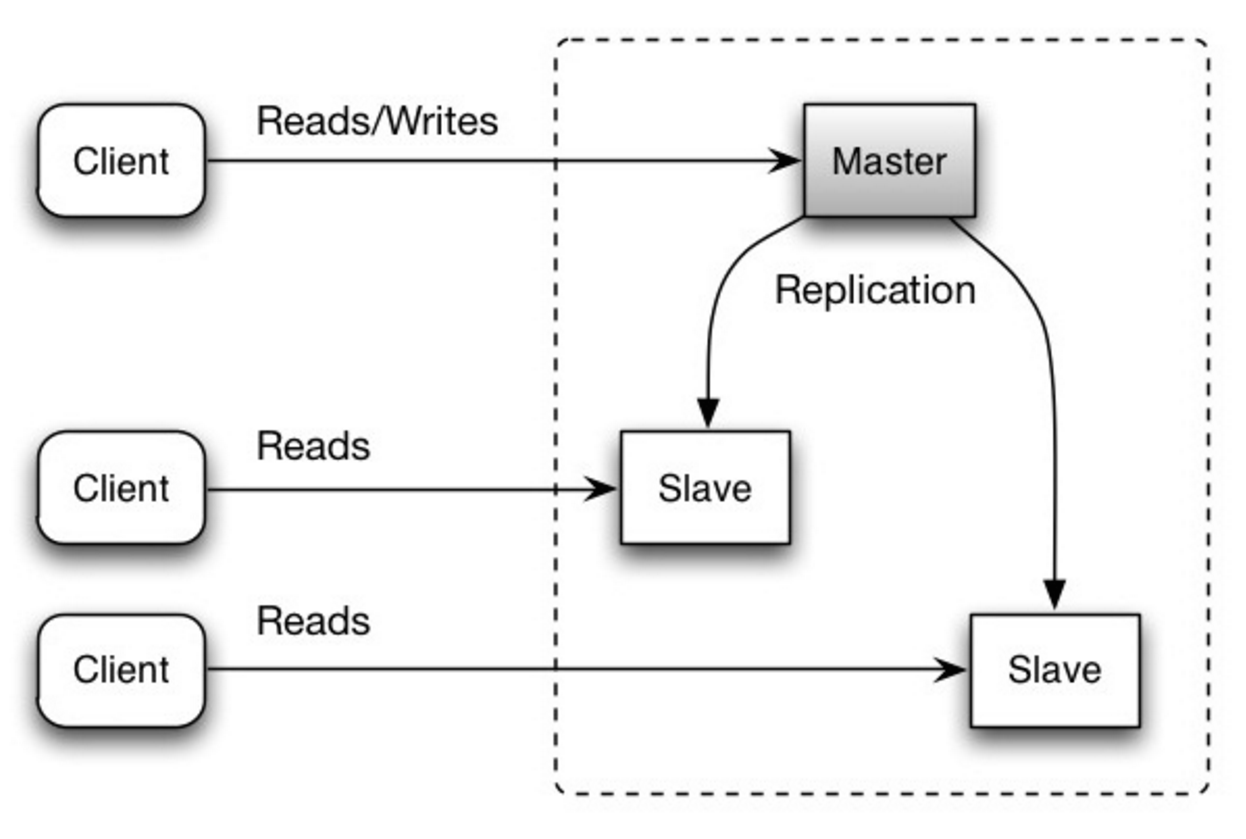
Źródło: Skalowalność, dostępność, stabilność, wzorce
##### Wada(y): replikacja master-slave
- Potrzebna jest dodatkowa logika do awansowania slave’a na mastera.
- Zobacz Wada(y): replikacja dla punktów dotyczących zarówno master-slave, jak i master-master.
Oba master’y obsługują odczyty i zapisy oraz koordynują się nawzajem przy zapisach. Jeśli którykolwiek z master’ów przestanie działać, system może nadal obsługiwać zarówno odczyty, jak i zapisy.
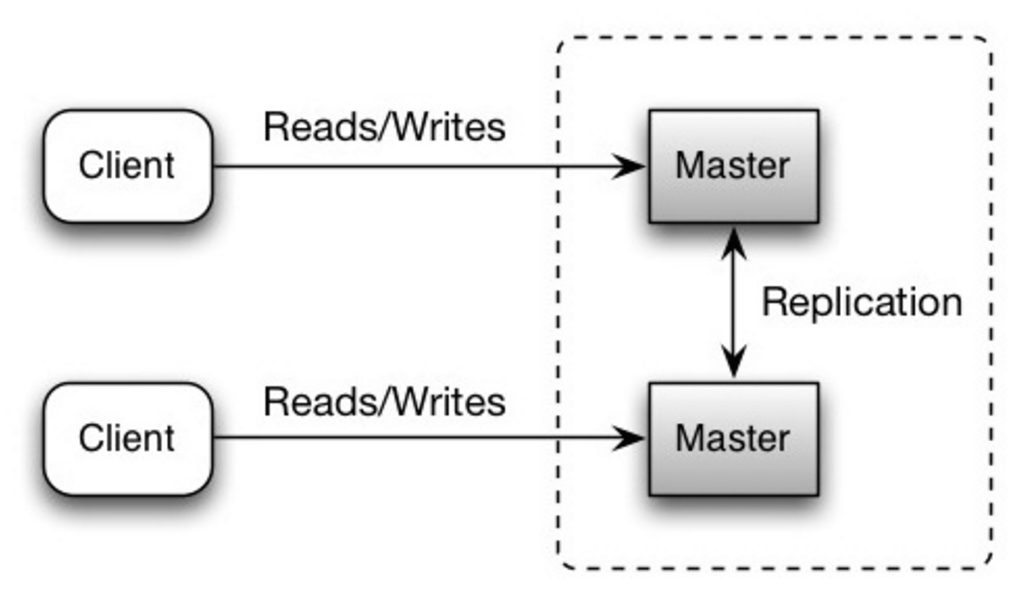
Źródło: Skalowalność, dostępność, stabilność, wzorce
##### Wada(y): replikacja master-master
- Potrzebny będzie load balancer lub konieczne będą zmiany w logice aplikacji, aby określić gdzie zapisywać.
- Większość systemów master-master jest albo luźno spójna (naruszając ACID), albo charakteryzuje się zwiększoną latencją zapisu z powodu synchronizacji.
- Rozwiązywanie konfliktów staje się coraz ważniejsze wraz ze wzrostem liczby węzłów zapisujących oraz zwiększającymi się opóźnieniami.
- Zobacz Wady: replikacja dla punktów dotyczących zarówno master-slave, jak i master-master.
- Istnieje ryzyko utraty danych, jeśli master ulegnie awarii zanim nowe dane zostaną zreplikowane na inne węzły.
- Zapisy są odtwarzane na replikach do odczytu. Jeśli występuje dużo zapisów, repliki do odczytu mogą zostać przeciążone odtwarzaniem zapisów i nie będą w stanie realizować tylu odczytów.
- Im więcej replik do odczytu, tym więcej trzeba replikować, co prowadzi do większych opóźnień replikacji.
- W niektórych systemach zapis na masterze może uruchamiać wiele wątków zapisujących równolegle, podczas gdy repliki do odczytu obsługują tylko zapisy sekwencyjne przy użyciu pojedynczego wątku.
- Replikacja wymaga dodatkowego sprzętu i wprowadza dodatkową złożoność.
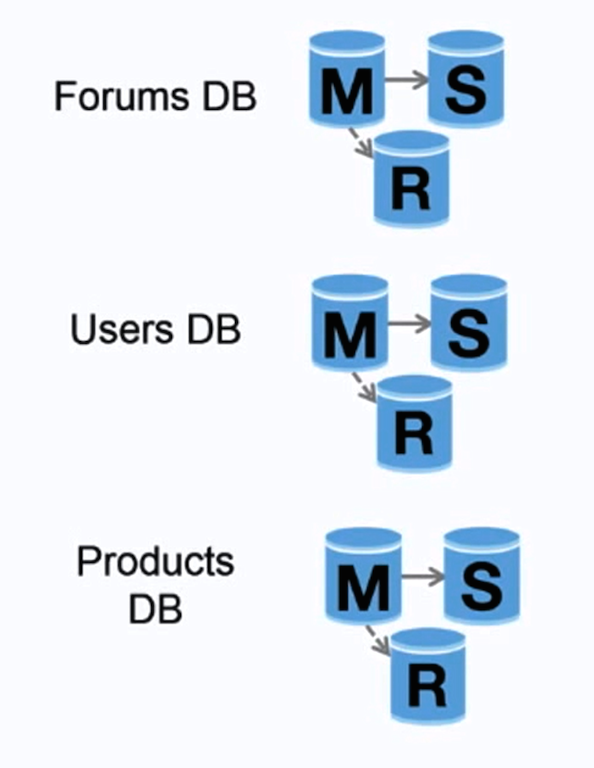
Źródło: Skalowanie do pierwszych 10 milionów użytkowników
Federacja (lub partycjonowanie funkcjonalne) dzieli bazy danych według funkcji. Na przykład zamiast pojedynczej, monolitycznej bazy danych, możesz mieć trzy bazy: fora, użytkownicy i produkty, co skutkuje mniejszym ruchem odczytu i zapisu dla każdej bazy, a tym samym mniejszym opóźnieniem replikacji. Mniejsze bazy danych pozwalają na przechowywanie większej ilości danych w pamięci, co z kolei prowadzi do większej liczby trafień w cache dzięki poprawionej lokalności. Brak centralnego mastera serializującego zapisy umożliwia wykonywanie zapisów równolegle, zwiększając przepustowość.
##### Wady: federacja
- Federacja nie jest skuteczna, jeśli Twój schemat wymaga ogromnych funkcji lub tabel.
- Należy zaktualizować logikę aplikacji, aby określić, z której bazy odczytywać i do której zapisywać.
- Łączenie danych z dwóch baz danych jest bardziej złożone przy użyciu linku serwera.
- Federacja wymaga dodatkowego sprzętu i wprowadza dodatkową złożoność.
Źródło: Skalowalność, dostępność, stabilność, wzorce
Sharding (dzielenie na fragmenty) rozprowadza dane pomiędzy różne bazy danych, tak że każda baza może zarządzać tylko podzbiorem danych. Na przykładzie bazy użytkowników, gdy liczba użytkowników rośnie, do klastra dodawane są kolejne shard'y.
Podobnie jak zalety federacji, sharding powoduje mniejszy ruch odczytu i zapisu, mniej replikacji i więcej trafień do cache. Zmniejsza się również rozmiar indeksu, co generalnie poprawia wydajność przez szybsze zapytania. Jeśli jeden shard przestanie działać, pozostałe nadal funkcjonują, choć warto wdrożyć jakąś formę replikacji, by uniknąć utraty danych. Podobnie jak w federacji, nie ma jednego centralnego mastera serializującego zapisy, co pozwala na równoległe zapisy i większą przepustowość.
Typowe metody dzielenia tabeli użytkowników to np. według pierwszej litery nazwiska lub lokalizacji geograficznej użytkownika.
##### Wady: sharding
- Trzeba zaktualizować logikę aplikacji, by działała z shardami, co może skutkować złożonymi zapytaniami SQL.
- Rozkład danych w shardzie może być nierównomierny. Przykładowo, grupa aktywnych użytkowników na jednym shardzie może generować większe obciążenie niż na innych.
- Równoważenie obciążenia dodaje dodatkową złożoność. Funkcja shardingowa oparta na spójnym haszowaniu może zmniejszyć ilość przesyłanych danych.
- Łączenie danych z wielu shardów jest bardziej skomplikowane.
- Sharding wymaga więcej sprzętu i większej złożoności.
Denormalizacja stara się poprawić wydajność odczytu kosztem wydajności zapisu. Redundantne kopie danych zapisywane są w wielu tabelach, by uniknąć kosztownych połączeń (joinów). Niektóre systemy RDBMS, jak PostgreSQL czy Oracle wspierają widoki materializowane, które zajmują się przechowywaniem redundantnych informacji i utrzymywaniem ich spójności.
Gdy dane zostaną rozproszone za pomocą takich technik jak federacja i sharding, zarządzanie joinami pomiędzy centrami danych staje się jeszcze bardziej złożone. Denormalizacja może obejść potrzebę takich skomplikowanych joinów.
W większości systemów odczyty znacznie przewyższają zapisy, nawet w stosunku 100:1 czy 1000:1. Odczyt wymagający złożonego połączenia bazodanowego może być bardzo kosztowny, zajmując znaczną część czasu na operacje dyskowe.
##### Wady: denormalizacja
- Dane są duplikowane.
- Ograniczenia mogą pomóc utrzymać redundantne kopie informacji w synchronizacji, co zwiększa złożoność projektu bazy danych.
- Denormalizowana baza danych pod dużym obciążeniem zapisu może działać gorzej niż jej znormalizowany odpowiednik.
Optymalizacja SQL to szeroki temat, do którego powstało wiele książek jako źródło referencyjne.
Ważne jest, aby przeprowadzać benchmarking i profilowanie, aby symulować oraz wykrywać wąskie gardła.
- Benchmark - Symulacja sytuacji wysokiego obciążenia za pomocą narzędzi takich jak ab.
- Profilowanie - Włączenie narzędzi takich jak slow query log, aby śledzić problemy z wydajnością.
##### Uściślij schemat
- MySQL zapisuje dane na dysku w blokach sąsiadujących dla szybkiego dostępu.
- Używaj
CHARzamiastVARCHARdla pól o stałej długości. CHARpozwala na szybki, losowy dostęp, podczas gdy przyVARCHARtrzeba odnaleźć koniec ciągu przed przejściem do następnego.- Używaj
TEXTdla dużych bloków tekstu, np. postów na blogu.TEXTpozwala także na wyszukiwania logiczne. Użycie polaTEXTskutkuje zapisaniem wskaźnika na dysku, który wskazuje lokalizację bloku tekstowego. - Używaj
INTdla większych liczb do 2^32 czyli 4 miliardów. - Używaj
DECIMALdla wartości walutowych, aby uniknąć błędów reprezentacji zmiennoprzecinkowej. - Unikaj przechowywania dużych
BLOBS, przechowuj raczej lokalizację obiektu. VARCHAR(255)to największa liczba znaków, którą można policzyć w liczbie 8-bitowej, często maksymalizując wykorzystanie bajtu w niektórych RDBMS.- Ustawiaj ograniczenie
NOT NULL, gdzie to możliwe, aby poprawić wydajność wyszukiwania.
- Kolumny, po których wykonujesz zapytania (
SELECT,GROUP BY,ORDER BY,JOIN), mogą działać szybciej z indeksami. - Indeksy są zwykle reprezentowane jako samobalansujące drzewa B, które utrzymują dane posortowane i umożliwiają wyszukiwania, dostęp sekwencyjny, wstawianie i usuwanie w czasie logarytmicznym.
- Założenie indeksu może sprawić, że dane będą przechowywane w pamięci, wymagając więcej miejsca.
- Operacje zapisu mogą być wolniejsze, ponieważ indeks też musi być aktualizowany.
- Przy ładowaniu dużych ilości danych czasem szybciej jest wyłączyć indeksy, załadować dane, a następnie odbudować indeksy.
- Denormalizuj, gdy wymaga tego wydajność.
- Podziel tabelę, umieszczając gorące punkty w osobnej tabeli, aby ułatwić jej przechowywanie w pamięci.
- W niektórych przypadkach pamięć podręczna zapytań może prowadzić do problemów z wydajnością.
- Porady dotyczące optymalizacji zapytań MySQL
- Dlaczego VARCHAR(255) jest tak często używany?
- Jak wartości null wpływają na wydajność?
- Log wolnych zapytań
NoSQL
NoSQL to zbiór elementów danych reprezentowanych jako magazyn klucz-wartość, magazyn dokumentów, magazyn szerokich kolumn lub baza danych grafowa. Dane są zdenormalizowane, a łączenia zwykle wykonywane są w kodzie aplikacji. Większość baz NoSQL nie oferuje prawdziwych transakcji ACID i preferuje spójność ostateczną.
BASE jest często używany do opisu właściwości baz danych NoSQL. W porównaniu z Teorią CAP, BASE wybiera dostępność ponad spójność.
- Podstawowo dostępny – system gwarantuje dostępność.
- Stan miękki – stan systemu może zmieniać się z czasem, nawet bez wejścia.
- Spójność ostateczna – system stanie się spójny w pewnym okresie, pod warunkiem że nie otrzyma nowych danych w tym czasie.
#### Magazyn klucz-wartość
Abstrakcja: tablica mieszająca
Magazyn klucz-wartość zazwyczaj umożliwia odczyty i zapisy w czasie O(1) i często jest oparty na pamięci RAM lub SSD. Magazyny danych mogą utrzymywać klucze w porządku leksykograficznym, co pozwala na efektywne pobieranie zakresów kluczy. Magazyny klucz-wartość mogą pozwalać na przechowywanie metadanych wraz z wartością.
Magazyny klucz-wartość zapewniają wysoką wydajność i są często używane dla prostych modeli danych lub szybko zmieniających się danych, takich jak warstwa pamięci podręcznej w pamięci operacyjnej. Ponieważ oferują tylko ograniczony zestaw operacji, złożoność jest przenoszona do warstwy aplikacji, jeśli wymagane są dodatkowe operacje.
Magazyn klucz-wartość jest podstawą dla bardziej złożonych systemów, takich jak magazyn dokumentów, a w niektórych przypadkach baza danych grafowa.
##### Źródła i dalsza lektura: magazyn klucz-wartość
#### Magazyn dokumentówAbstrakcja: magazyn klucz-wartość z dokumentami przechowywanymi jako wartości
Magazyn dokumentów koncentruje się wokół dokumentów (XML, JSON, binarne itd.), gdzie dokument przechowuje wszystkie informacje dotyczące danego obiektu. Magazyny dokumentów udostępniają API lub język zapytań do wyszukiwania na podstawie wewnętrznej struktury samego dokumentu. Uwaga, wiele magazynów klucz-wartość zawiera funkcje do pracy z metadanymi wartości, co zaciera granice między tymi dwoma typami magazynowania.
W zależności od implementacji dokumenty są organizowane według kolekcji, tagów, metadanych lub katalogów. Chociaż dokumenty mogą być organizowane lub grupowane razem, pola w dokumentach mogą się całkowicie różnić od siebie.
Niektóre magazyny dokumentów, takie jak MongoDB oraz CouchDB, udostępniają język zbliżony do SQL umożliwiający wykonywanie złożonych zapytań. DynamoDB obsługuje zarówno klucz-wartość, jak i dokumenty.
Magazyny dokumentów oferują wysoką elastyczność i są często używane do pracy z danymi zmieniającymi się okazjonalnie.
##### Źródła i dalsza lektura: magazyn dokumentów
#### Magazyn szerokokolumnowy
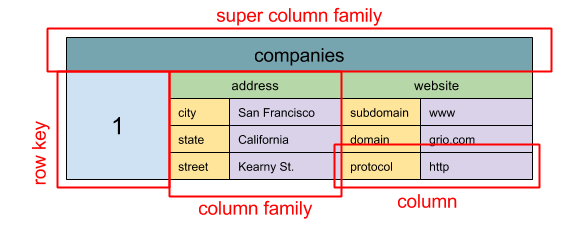
Źródło: SQL & NoSQL, krótka historia
Abstrakcja: zagnieżdżona mapa ColumnFamily> Podstawową jednostką danych magazynu szerokokolumnowego jest kolumna (para nazwa/wartość). Kolumny mogą być grupowane w rodziny kolumn (analogicznie do tabeli SQL). Super-rodziny kolumn dodatkowo grupują rodziny kolumn. Dostęp do każdej kolumny można uzyskać niezależnie za pomocą klucza wiersza, a kolumny o tym samym kluczu wiersza tworzą wiersz. Każda wartość zawiera znacznik czasu do wersjonowania i rozwiązywania konfliktów.
Google wprowadziło Bigtable jako pierwszy magazyn szerokokolumnowy, który wpłynął na otwartoźródłowe HBase często używane w ekosystemie Hadoop oraz Cassandra od Facebooka. Magazyny takie jak BigTable, HBase i Cassandra utrzymują klucze w porządku leksykograficznym, co pozwala na efektywne pobieranie wybranych zakresów kluczy.
Magazyny szerokokolumnowe oferują wysoką dostępność i skalowalność. Często używane są do bardzo dużych zbiorów danych.
##### Źródła i dalsza lektura: magazyn szerokokolumnowy
#### Baza danych grafowa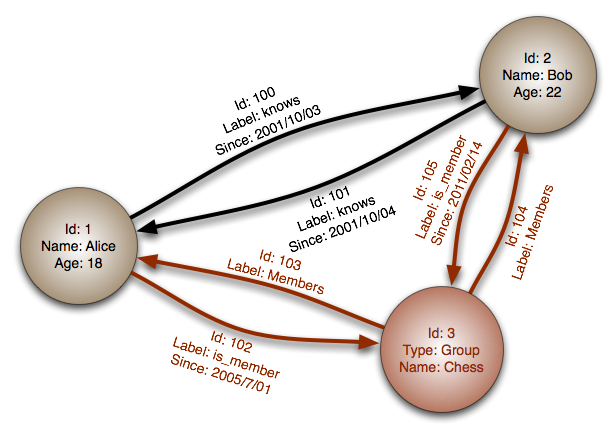
Abstrakcja: graf
W bazie danych grafowej każdy węzeł to rekord, a każda krawędź to relacja między dwoma węzłami. Bazy danych grafowe są zoptymalizowane do reprezentowania złożonych zależności z wieloma kluczami obcymi lub relacjami wiele-do-wielu.
Bazy grafowe oferują wysoką wydajność dla modeli danych z rozbudowanymi relacjami, jak w sieciach społecznościowych. Są stosunkowo nowe i nie są jeszcze szeroko stosowane; może być trudniej znaleźć narzędzia programistyczne i zasoby. Wiele grafów można uzyskać tylko przez REST API.
##### Źródła i dalsza lektura: graf
#### Źródła i dalsza lektura: NoSQL- Wyjaśnienie podstawowej terminologii
- Bazy NoSQL - przegląd i wskazówki decyzyjne
- Skalowalność
- Wprowadzenie do NoSQL
- Wzorce NoSQL
SQL czy NoSQL
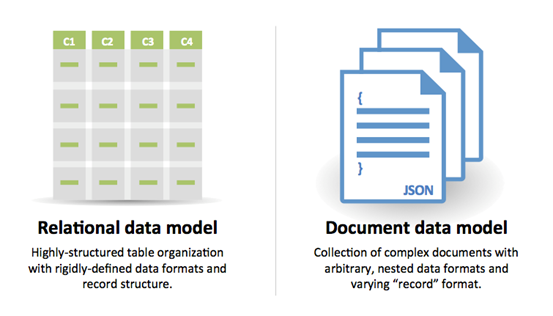
Źródło: Przechodzenie z RDBMS na NoSQL
Powody wyboru SQL:
- Dane strukturalne
- Ścisła struktura (schema)
- Dane relacyjne
- Potrzeba złożonych połączeń (joinów)
- Transakcje
- Jasne wzorce skalowania
- Bardziej ugruntowane: deweloperzy, społeczność, kod, narzędzia itd.
- Wyszukiwanie po indeksie jest bardzo szybkie
- Dane półstrukturalne
- Dynamiczna lub elastyczna struktura
- Dane nierelacyjne
- Brak potrzeby złożonych połączeń
- Przechowywanie wielu TB (lub PB) danych
- Bardzo intensywne obciążenie danych
- Bardzo wysoka przepustowość operacji IOPS
- Szybkie zbieranie danych clickstream oraz logów
- Dane z rankingów lub punktacji
- Tymczasowe dane, np. koszyk zakupowy
- Często odwiedzane ('gorące') tabele
- Tabele z metadanymi lub do wyszukiwania
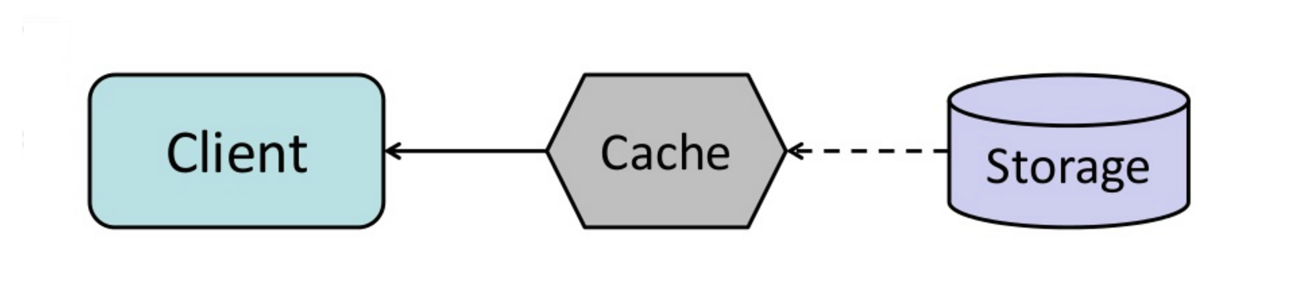
Cache
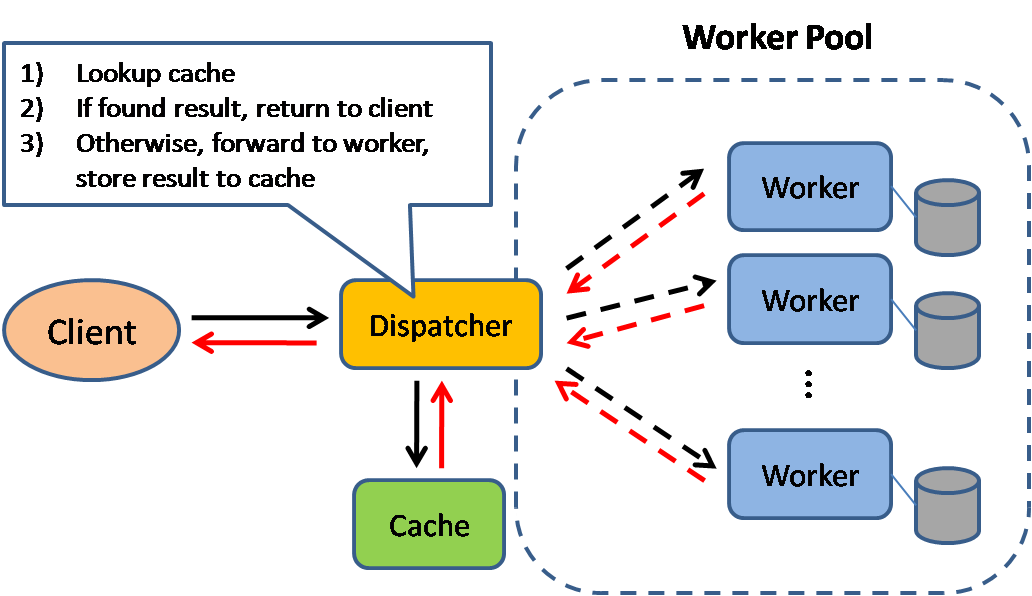
Źródło: Wzorce projektowe skalowalnych systemów
Buforowanie poprawia czas ładowania strony i może zmniejszyć obciążenie serwerów oraz baz danych. W tym modelu dispatcher najpierw sprawdza, czy żądanie zostało już wcześniej wykonane i próbuje znaleźć poprzedni wynik do zwrotu, aby zaoszczędzić faktyczne wykonanie.
Bazy danych często korzystają z równomiernego rozkładu odczytów i zapisów między partycjami. Popularne elementy mogą zaburzać ten rozkład, powodując wąskie gardła. Umieszczenie bufora przed bazą danych może pomóc w absorbowaniu nierównomiernych obciążeń i skoków ruchu.
Buforowanie po stronie klienta
Bufory mogą być zlokalizowane po stronie klienta (system operacyjny lub przeglądarka), po stronie serwera lub w oddzielnej warstwie bufora.
Buforowanie CDN
CDN-y są uznawane za rodzaj bufora.
Buforowanie serwera WWW
Reverse proxy oraz bufory takie jak Varnish mogą obsługiwać bezpośrednio treści statyczne i dynamiczne. Serwery WWW mogą także buforować żądania, zwracając odpowiedzi bez kontaktu z serwerami aplikacji.
Buforowanie bazy danych
Twoja baza danych zazwyczaj zawiera pewien poziom buforowania w domyślnej konfiguracji, zoptymalizowanej dla ogólnego przypadku użycia. Dostosowanie tych ustawień do konkretnych wzorców użytkowania może dodatkowo zwiększyć wydajność.
Buforowanie aplikacji
Bufory w pamięci RAM, takie jak Memcached i Redis, to magazyny klucz-wartość pomiędzy aplikacją a magazynem danych. Ponieważ dane przechowywane są w RAM, dostęp do nich jest znacznie szybszy niż w typowych bazach, gdzie dane znajdują się na dysku. RAM jest bardziej ograniczony niż dysk, dlatego algorytmy inwalidacji bufora takie jak najrzadziej używane (LRU)) pomagają usuwać „zimne” wpisy i trzymać „gorące” dane w RAM.
Redis oferuje następujące dodatkowe funkcje:
- Opcja trwałości
- Wbudowane struktury danych, takie jak uporządkowane zbiory i listy
- Poziom wiersza
- Poziom zapytania
- W pełni utworzone obiekty serializowalne
- W pełni wyrenderowany HTML
Buforowanie na poziomie zapytań do bazy danych
Za każdym razem, gdy wykonujesz zapytanie do bazy danych, zhashuj zapytanie jako klucz i zapisz wynik w pamięci podręcznej. To podejście ma problemy z wygasaniem:
- Trudno usunąć zapisany wynik przy złożonych zapytaniach
- Jeśli zmieni się jedna część danych, np. komórka tabeli, trzeba usunąć wszystkie zapytania z bufora, które mogą zawierać zmienioną komórkę
Buforowanie na poziomie obiektów
Traktuj swoje dane jako obiekt, podobnie jak robisz to w kodzie aplikacji. Niech aplikacja złoży zestaw danych z bazy do instancji klasy lub struktury danych:
- Usuń obiekt z pamięci podręcznej, jeśli jego dane źródłowe się zmieniły
- Pozwala na asynchroniczne przetwarzanie: workerzy składają obiekty, korzystając z najnowszych danych z bufora
- Sesje użytkowników
- W pełni wyrenderowane strony internetowe
- Strumienie aktywności
- Dane grafu użytkownika
Kiedy aktualizować bufor
Ponieważ można przechowywać ograniczoną ilość danych w pamięci podręcznej, trzeba określić, która strategia aktualizacji bufora najlepiej pasuje do Twojego przypadku użycia.
#### Cache-aside (bufor pośredni)
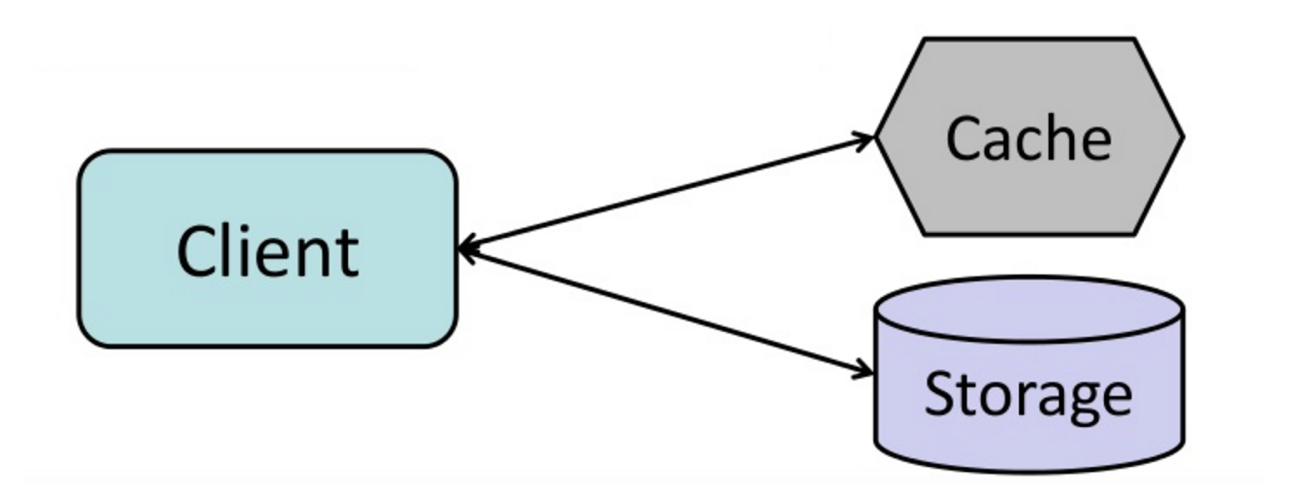
Źródło: From cache to in-memory data grid
Aplikacja odpowiada za odczyt i zapis z/do magazynu. Bufor nie komunikuje się bezpośrednio z magazynem. Aplikacja wykonuje następujące kroki:
- Szuka wpisu w buforze, skutkuje to brakiem w buforze
- Ładuje wpis z bazy danych
- Dodaje wpis do bufora
- Zwraca wpis
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached jest zazwyczaj używany w ten sposób.
Kolejne odczyty danych dodanych do pamięci podręcznej są szybkie. Cache-aside nazywane jest również leniwym ładowaniem. Do pamięci podręcznej trafiają tylko żądane dane, co zapobiega zapełnieniu jej niepotrzebnymi informacjami.
##### Wada(-y): cache-aside
- Każde nietrafienie w pamięć podręczną skutkuje trzema operacjami, co może powodować zauważalne opóźnienie.
- Dane mogą stać się nieaktualne, jeśli zostaną zaktualizowane w bazie danych. Problem ten można ograniczyć, ustawiając czas życia (TTL), który wymusza aktualizację wpisu w pamięci podręcznej, lub stosując write-through.
- Gdy węzeł ulegnie awarii, zostaje zastąpiony nowym, pustym węzłem, co zwiększa opóźnienie.
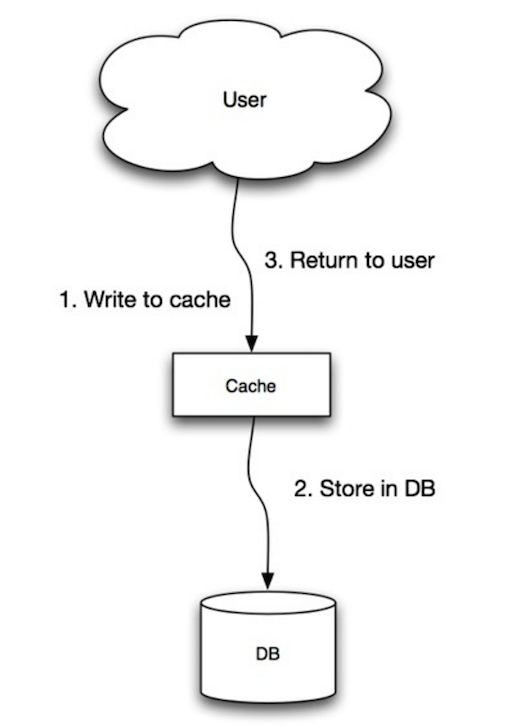
Źródło: Skalowalność, dostępność, stabilność, wzorce
Aplikacja wykorzystuje pamięć podręczną jako główny magazyn danych, odczytując i zapisując w niej dane, podczas gdy pamięć podręczna odpowiada za odczyt i zapis do bazy danych:
- Aplikacja dodaje/aktualizuje wpis w pamięci podręcznej
- Pamięć podręczna synchronicznie zapisuje wpis do magazynu danych
- Zwraca
set_user(12345, {"foo":"bar"})Kod pamięci podręcznej:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Wada(y): write-through
- Gdy nowy węzeł zostaje utworzony z powodu awarii lub skalowania, nowy węzeł nie będzie buforować wpisów, dopóki wpis nie zostanie zaktualizowany w bazie danych. Połączenie cache-aside i write-through może złagodzić ten problem.
- Większość zapisanych danych może nigdy nie zostać odczytana, co można zminimalizować poprzez ustawienie TTL.
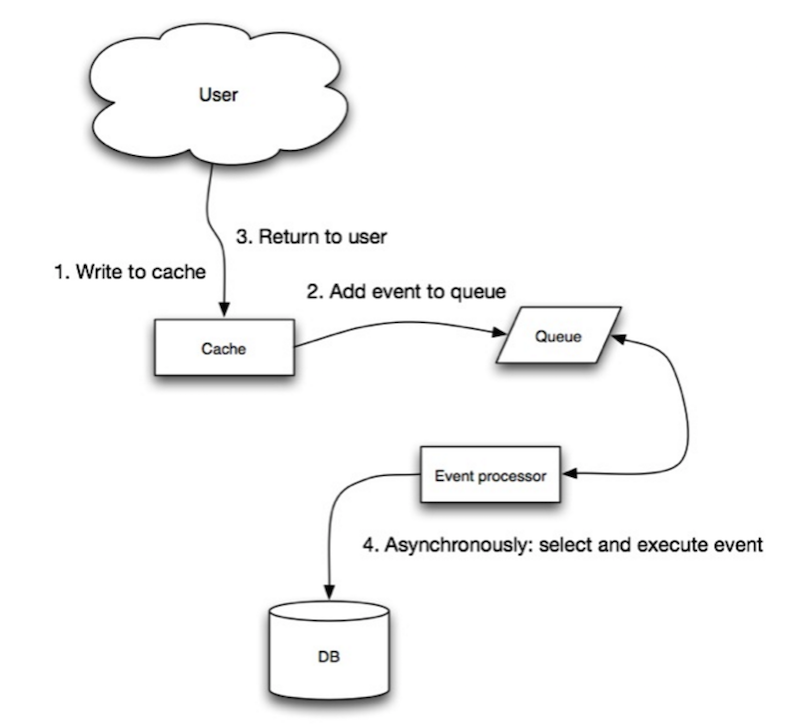
Źródło: Scalability, availability, stability, patterns
W write-behind aplikacja wykonuje następujące czynności:
- Dodaje/aktualizuje wpis w pamięci podręcznej
- Asynchronicznie zapisuje wpis do magazynu danych, poprawiając wydajność zapisu
- Może dojść do utraty danych, jeśli pamięć podręczna ulegnie awarii, zanim jej zawartość trafi do magazynu danych.
- Implementacja write-behind jest bardziej złożona niż cache-aside czy write-through.
Źródło: From cache to in-memory data grid
Możesz skonfigurować pamięć podręczną, aby automatycznie odświeżała każdy ostatnio używany wpis przed jego wygaśnięciem.
Refresh-ahead może skutkować niższą latencją w porównaniu do read-through, jeśli pamięć podręczna potrafi dokładnie przewidzieć, które elementy będą potrzebne w przyszłości.
##### Wada(y): refresh-ahead
- Nieprawidłowe przewidywanie, które elementy będą potrzebne w przyszłości, może skutkować gorszą wydajnością niż bez mechanizmu odświeżania z wyprzedzeniem.
Wada(y): cache
- Konieczność utrzymania spójności pomiędzy cache a źródłem prawdy, takim jak baza danych, poprzez unieważnianie cache.
- Unieważnianie cache to trudny problem, istnieje dodatkowa złożoność związana z określeniem, kiedy zaktualizować cache.
- Konieczność wprowadzenia zmian w aplikacji, takich jak dodanie Redis lub memcached.
Źródło(a) i dalsza lektura
- Od cache do in-memory data grid
- Wzorce projektowe systemów skalowalnych
- Wprowadzenie do architektury systemów na skalę
- Skalowalność, dostępność, stabilność, wzorce
- Skalowalność
- Strategie AWS ElastiCache
- Wikipedia)
Asynchroniczność
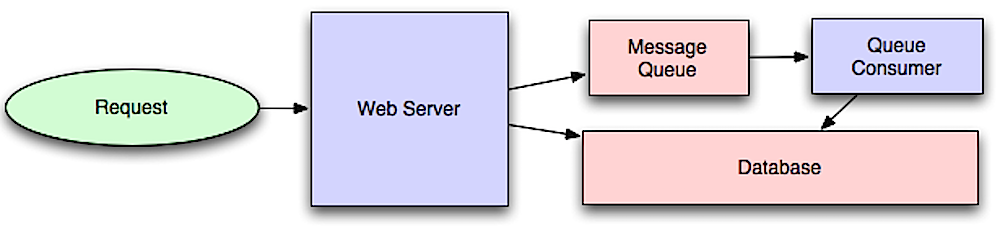
Źródło: Wprowadzenie do architektury systemów na skalę
Asynchroniczne przepływy pracy pomagają skrócić czas odpowiedzi na kosztowne operacje, które w przeciwnym razie byłyby wykonywane synchronicznie. Mogą również pomóc wykonując czasochłonne zadania z wyprzedzeniem, takie jak okresowa agregacja danych.
Kolejki wiadomości
Kolejki wiadomości odbierają, przechowują i dostarczają wiadomości. Jeśli operacja jest zbyt wolna, by wykonać ją synchronicznie, można użyć kolejki wiadomości zgodnie z poniższym schematem:
- Aplikacja publikuje zadanie do kolejki, następnie informuje użytkownika o statusie zadania
- Worker odbiera zadanie z kolejki, przetwarza je, a następnie sygnalizuje zakończenie zadania
Redis jest przydatny jako prosty broker wiadomości, ale wiadomości mogą zostać utracone.
RabbitMQ jest popularny, ale wymaga dostosowania się do protokołu 'AMQP' i samodzielnego zarządzania węzłami. Amazon SQS jest usługą hostowaną, ale może charakteryzować się dużym opóźnieniem oraz możliwością dwukrotnego dostarczenia wiadomości.
Kolejki zadań
Kolejki zadań odbierają zadania wraz z powiązanymi danymi, wykonują je, a następnie dostarczają wyniki. Mogą wspierać harmonogramowanie i są używane do uruchamiania zasobożernych obliczeń w tle.
Celery posiada wsparcie dla harmonogramowania i przede wszystkim obsługuje język Python.
Presja zwrotna
Jeśli kolejki zaczną znacząco rosnąć, ich rozmiar może przekroczyć pojemność pamięci, skutkując nietrafieniami do pamięci podręcznej, odczytami z dysku oraz jeszcze wolniejszym działaniem. Presja zwrotna pomaga poprzez ograniczenie rozmiaru kolejki, utrzymując wysoką przepustowość i dobre czasy odpowiedzi dla już oczekujących zadań. Po zapełnieniu kolejki klient otrzymuje informację o zajętości serwera lub kod HTTP 503, by spróbować ponownie później. Klient może powtórzyć żądanie później, na przykład stosując eksponencjalne opóźnienie.
Wada(-y): asynchroniczność
- Przypadki użycia takie jak tanie obliczenia i przepływy danych w czasie rzeczywistym mogą być lepiej obsługiwane przez operacje synchroniczne, gdyż wprowadzenie kolejek dodaje opóźnienia i złożoność.
Źródła i dalsza lektura
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
Komunikacja
{kind=link}
{kind=link}
Protokół przesyłania hipertekstu (HTTP)
HTTP to metoda kodowania i przesyłania danych między klientem a serwerem. Jest to protokół żądanie/odpowiedź: klient wysyła żądania, a serwer odpowiada odpowiednimi danymi oraz informacją o statusie realizacji żądania. HTTP jest niezależny, pozwala na przekazywanie żądań i odpowiedzi przez wiele pośrednich routerów i serwerów realizujących równoważenie obciążenia, buforowanie, szyfrowanie i kompresję.
Podstawowe żądanie HTTP składa się z czasownika (metody) i zasobu (endpointu). Poniżej przedstawiono typowe czasowniki HTTP:
| Czasownik | Opis | Idempotentny* | Bezpieczny | Buforowalny |
| GET | Odczytuje zasób | Tak | Tak | Tak | | POST | Tworzy zasób lub uruchamia proces obsługujący dane | Nie | Nie | Tak, jeśli odpowiedź zawiera informację o świeżości | | PUT | Tworzy lub zastępuje zasób | Tak | Nie | Nie | | PATCH | Częściowo aktualizuje zasób | Nie | Nie | Tak, jeśli odpowiedź zawiera informację o świeżości | | DELETE | Usuwa zasób | Tak | Nie | Nie |
*Można wywołać wiele razy bez różnych rezultatów.
HTTP to protokół warstwy aplikacji opierający się na niższych protokołach takich jak TCP i UDP.
#### Źródło(-a) i dalsza lektura: HTTP
Protokół kontroli transmisji (TCP)
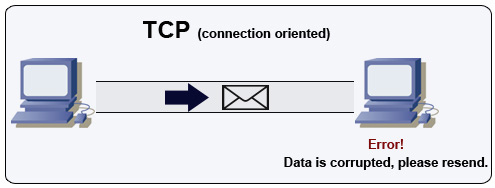
Źródło: How to make a multiplayer game
TCP to protokół połączeniowy działający na sieci IP. Połączenie jest ustanawiane i kończone za pomocą handshake. Wszystkie wysłane pakiety mają gwarancję dotarcia do celu w oryginalnej kolejności i bez uszkodzeń dzięki:
- Numerom sekwencyjnym i polom sumy kontrolnej dla każdego pakietu
- Pakietom potwierdzenia) i automatycznemu retransmitowaniu
Aby zapewnić wysoką przepustowość, serwery WWW mogą utrzymywać dużą liczbę otwartych połączeń TCP, co skutkuje dużym zużyciem pamięci. Utrzymywanie wielu otwartych połączeń między wątkami serwera WWW a np. serwerem memcached może być kosztowne. Pule połączeń mogą pomóc, podobnie jak przejście na UDP tam, gdzie to możliwe.
TCP jest przydatny dla aplikacji wymagających wysokiej niezawodności, ale mniej krytycznych czasowo. Przykłady to serwery WWW, informacje z baz danych, SMTP, FTP i SSH.
Użyj TCP zamiast UDP, gdy:
- Potrzebujesz, by wszystkie dane dotarły w całości
- Chcesz automatycznie jak najlepiej wykorzystać przepustowość sieci
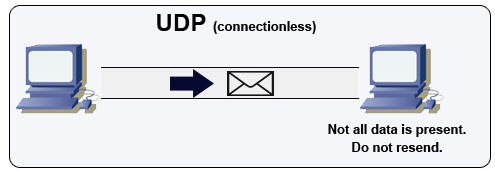
Protokół datagramów użytkownika (UDP)
Źródło: Jak stworzyć grę wieloosobową
UDP jest bezpołączeniowy. Datagramy (analogiczne do pakietów) są gwarantowane tylko na poziomie pojedynczego datagramu. Datagramy mogą dotrzeć do celu w niewłaściwej kolejności lub wcale. UDP nie obsługuje kontroli przeciążenia. Bez gwarancji oferowanych przez TCP, UDP jest na ogół bardziej wydajny.
UDP umożliwia rozgłaszanie, wysyłając datagramy do wszystkich urządzeń w podsieci. Jest to użyteczne przy DHCP, ponieważ klient nie otrzymał jeszcze adresu IP, co uniemożliwia TCP przesyłanie strumieniowe bez adresu IP.
UDP jest mniej niezawodny, ale sprawdza się w zastosowaniach czasu rzeczywistego, takich jak VoIP, czat wideo, streaming i gry wieloosobowe w czasie rzeczywistym.
Użyj UDP zamiast TCP gdy:
- Potrzebujesz najniższych opóźnień
- Późne dane są gorsze niż utrata danych
- Chcesz zaimplementować własną korekcję błędów
- Sieciowanie dla programowania gier
- Kluczowe różnice między protokołami TCP i UDP
- Różnica między TCP a UDP
- Protokół kontroli transmisji
- Protokół datagramów użytkownika
- Skalowanie memcache w Facebooku
Zdalne wywołanie procedury (RPC)
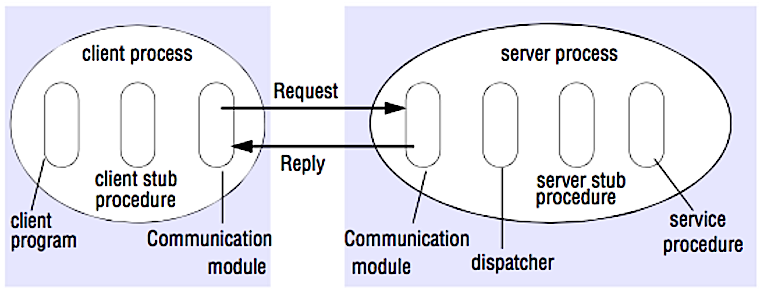
Źródło: Crack the system design interview
W RPC klient powoduje wykonanie procedury w innym obszarze adresowym, zwykle na zdalnym serwerze. Procedura jest kodowana tak, jakby była lokalnym wywołaniem procedury, ukrywając szczegóły komunikacji z serwerem przed programem klienckim. Zdalne wywołania są zwykle wolniejsze i mniej niezawodne niż lokalne wywołania, dlatego warto odróżniać wywołania RPC od lokalnych. Popularne frameworki RPC to Protobuf, Thrift oraz Avro.
RPC jest protokołem żądanie-odpowiedź:
- Program klienta - Wywołuje procedurę stub klienta. Parametry są umieszczane na stosie tak jak w przypadku wywołania lokalnej procedury.
- Procedura stub klienta - Pakietuje (marshaluje) identyfikator procedury i argumenty do wiadomości żądania.
- Moduł komunikacji klienta - System operacyjny przesyła wiadomość od klienta do serwera.
- Moduł komunikacji serwera - System operacyjny przekazuje przychodzące pakiety do procedury stub serwera.
- Procedura stub serwera - Odpakowuje (unmarshaluje) wyniki, wywołuje procedurę serwera odpowiadającą identyfikatorowi procedury i przekazuje podane argumenty.
- Odpowiedź serwera powtarza powyższe kroki w odwrotnej kolejności.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC koncentruje się na udostępnianiu zachowań. RPC są często używane ze względów wydajnościowych w komunikacji wewnętrznej, ponieważ można ręcznie dostosować natywne wywołania do własnych przypadków użycia.
Wybierz natywną bibliotekę (czyli SDK), gdy:
- Znasz swoją docelową platformę.
- Chcesz kontrolować dostęp do swojej "logiki".
- Chcesz kontrolować, jak obsługa błędów odbywa się poza twoją biblioteką.
- Wydajność i doświadczenie użytkownika końcowego są twoim głównym priorytetem.
#### Wada(y): RPC
- Klienci RPC są silnie powiązani z implementacją usługi.
- Nowe API musi być zdefiniowane dla każdej nowej operacji lub przypadku użycia.
- Debugowanie RPC może być trudne.
- Możesz nie być w stanie wykorzystać istniejących technologii "z pudełka". Na przykład, może być wymagany dodatkowy wysiłek, by zapewnić poprawne buforowanie wywołań RPC na serwerach cache, takich jak Squid.
Representational state transfer (REST)
REST to styl architektoniczny wymuszający model klient/serwer, w którym klient operuje na zestawie zasobów zarządzanych przez serwer. Serwer dostarcza reprezentację zasobów i akcje, które mogą manipulować lub pobierać nową reprezentację zasobów. Cała komunikacja musi być bezstanowa i możliwa do buforowania.
RESTful interfejs ma cztery cechy:
- Identyfikacja zasobów (URI w HTTP) - używaj tego samego URI niezależnie od operacji.
- Zmiana przez reprezentacje (czasowniki w HTTP) - używaj czasowników, nagłówków i ciała żądania.
- Samoopisujące komunikaty błędów (status response w HTTP) - używaj kodów statusu, nie wymyślaj koła na nowo.
- HATEOAS (interfejs HTML dla HTTP) - twoja usługa webowa powinna być w pełni dostępna w przeglądarce.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Wada(y): REST
- Ponieważ REST koncentruje się na udostępnianiu danych, może nie być odpowiedni, jeśli zasoby nie są naturalnie zorganizowane lub dostępne w prostej hierarchii. Na przykład zwrócenie wszystkich zaktualizowanych rekordów z ostatniej godziny pasujących do określonego zestawu zdarzeń nie jest łatwo wyrażalne jako ścieżka. W REST prawdopodobnie zostanie to zaimplementowane jako kombinacja ścieżki URI, parametrów zapytania i możliwie ciała żądania.
- REST zazwyczaj opiera się na kilku czasownikach (GET, POST, PUT, DELETE i PATCH), które czasami nie pasują do Twojego przypadku użycia. Na przykład przeniesienie wygasłych dokumentów do folderu archiwum może nie pasować czysto do tych czasowników.
- Pobieranie skomplikowanych zasobów z zagnieżdżonymi hierarchiami wymaga wielu rund pomiędzy klientem a serwerem, aby wyrenderować pojedynczy widok, np. pobranie zawartości wpisu na blogu i komentarzy do tego wpisu. Dla aplikacji mobilnych działających w zmiennych warunkach sieciowych te wielokrotne rundy są bardzo niepożądane.
- Z czasem do odpowiedzi API mogą być dodawane kolejne pola, a starsze klienty będą otrzymywać wszystkie nowe pola danych, nawet te, których nie potrzebują, co prowadzi do zwiększenia rozmiaru ładunku i większych opóźnień.
Porównanie wywołań RPC i REST
| Operacja | RPC | REST |
|---|---|---|
| Rejestracja | POST /signup | POST /persons |
| Rezygnacja | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Odczyt osoby | GET /readPerson?personid=1234 | GET /persons/1234 |
| Odczyt listy przedmiotów osoby | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Dodanie przedmiotu do listy osoby | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Aktualizacja przedmiotu | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Usunięcie przedmiotu | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Źródło: Czy naprawdę wiesz, dlaczego preferujesz REST nad RPC
#### Źródło(a) i dalsza lektura: REST i RPC
- Czy naprawdę wiesz, dlaczego preferujesz REST nad RPC
- Kiedy podejścia podobne do RPC są bardziej odpowiednie niż REST?
- REST vs JSON-RPC
- Obalanie mitów RPC i REST
- Jakie są wady korzystania z REST
- Crack the system design interview
- Thrift
- Dlaczego REST do użytku wewnętrznego, a nie RPC
Bezpieczeństwo
Ta sekcja wymaga aktualizacji. Rozważ wniesienie wkładu!
Bezpieczeństwo to szeroki temat. Jeśli nie masz dużego doświadczenia, wykształcenia w zakresie bezpieczeństwa lub nie aplikujesz na stanowisko wymagające wiedzy z zakresu bezpieczeństwa, prawdopodobnie wystarczy Ci znajomość podstaw:
- Szyfruj dane w tranzycie oraz podczas przechowywania.
- Sanityzuj wszystkie dane wejściowe użytkownika lub dowolne parametry wejściowe udostępnione użytkownikowi, aby zapobiec XSS oraz SQL injection.
- Używaj zapytań parametryzowanych, aby zapobiec SQL injection.
- Stosuj zasadę najmniejszych uprawnień.
Źródła i dalsza lektura
Dodatek
Czasem zostaniesz poproszony o wykonanie szacunków „na szybko”. Na przykład możesz potrzebować określić, ile czasu zajmie wygenerowanie 100 miniatur obrazów z dysku lub ile pamięci zajmie struktura danych. Tabela potęg dwójki oraz Liczby opóźnień, które każdy programista powinien znać to przydatne odniesienia.
Tabela potęg dwójki
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Źródła i dalsza lektura
Liczby opóźnień, które powinien znać każdy programista
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Odczyt sekwencyjny z HDD z prędkością 30 MB/s
- Odczyt sekwencyjny z Ethernetu 1 Gbps z prędkością 100 MB/s
- Odczyt sekwencyjny z SSD z prędkością 1 GB/s
- Odczyt sekwencyjny z pamięci głównej z prędkością 4 GB/s
- 6-7 podróży dookoła świata na sekundę
- 2 000 podróży w obrębie centrum danych na sekundę
#### Źródło(-a) i dalsza lektura
- Liczby dotyczące opóźnień, które powinien znać każdy programista - 1
- Liczby dotyczące opóźnień, które powinien znać każdy programista - 2
- Projekty, lekcje i rady z budowy dużych systemów rozproszonych
- Porady inżynierii oprogramowania z budowy dużych systemów rozproszonych
Dodatkowe pytania na rozmowę o projektowaniu systemów
Typowe pytania na rozmowach o projektowaniu systemów, wraz z odnośnikami do zasobów, jak je rozwiązać.
| Pytanie | Odnośnik(i) |
|---|---|
| Zaprojektuj usługę synchronizacji plików jak Dropbox | youtube.com |
| Zaprojektuj wyszukiwarkę jak Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Zaprojektuj skalowalnego web crawlera jak Google | quora.com |
| Zaprojektuj Google docs | code.google.com
neil.fraser.name |
| Zaprojektuj sklep klucz-wartość jak Redis | slideshare.net |
| Zaprojektuj system cache jak Memcached | slideshare.net |
| Zaprojektuj system rekomendacji jak Amazon | hulu.com
ijcai13.org |
| Zaprojektuj system tinyurl jak Bitly | n00tc0d3r.blogspot.com |
| Zaprojektuj aplikację czatu jak WhatsApp | highscalability.com
| Zaprojektuj system udostępniania zdjęć jak Instagram | highscalability.com
highscalability.com |
| Zaprojektuj funkcję news feed Facebooka | quora.com
quora.com
slideshare.net |
| Zaprojektuj funkcję timeline Facebooka | facebook.com
highscalability.com |
| Zaprojektuj funkcję czatu Facebooka | erlang-factory.com
facebook.com |
| Zaprojektuj funkcję wyszukiwania grafu jak na Facebooku | facebook.com
facebook.com
facebook.com |
| Zaprojektuj sieć dostarczania treści jak CloudFlare | figshare.com |
| Zaprojektuj system trendujących tematów jak na Twitterze | michael-noll.com
snikolov .wordpress.com |
| Zaprojektuj system generowania losowych identyfikatorów | blog.twitter.com
github.com |
| Zwróć k najczęściej żądanych zapytań w określonym przedziale czasu | cs.ucsb.edu
wpi.edu |
| Zaprojektuj system obsługujący dane z wielu centrów danych | highscalability.com |
| Zaprojektuj internetową grę karcianą multiplayer | indieflashblog.com
buildnewgames.com |
| Zaprojektuj system garbage collection | stuffwithstuff.com
washington.edu |
| Zaprojektuj ogranicznik zapytań API | https://stripe.com/blog/ |
| Zaprojektuj giełdę (np. NASDAQ lub Binance) | Jane Street
Golang Implementation
Go Implementation |
| Dodaj pytanie dotyczące projektowania systemu | Contribute |
Architektury rzeczywiste
Artykuły o tym, jak projektowane są rzeczywiste systemy.
Źródło: Twitter timelines at scale
Nie skupiaj się na drobnych szczegółach w poniższych artykułach, zamiast tego:
- Zidentyfikuj wspólne zasady, technologie i wzorce w tych artykułach
- Przeanalizuj jakie problemy rozwiązuje każdy komponent, gdzie działa, a gdzie nie
- Przejrzyj zdobyte doświadczenia
Architektury firm
| Firma | Referencje |
|---|---|
| Amazon | Amazon architecture |
| Cinchcast | Produkcja 1 500 godzin audio każdego dnia |
| DataSift | Analiza danych w czasie rzeczywistym przy 120 000 tweetów na sekundę |
| Dropbox | Jak skalowaliśmy Dropbox |
| ESPN | Przetwarzanie 100 000 duh nuh nuhs na sekundę |
| Google | Architektura Google |
| Instagram | 14 milionów użytkowników, terabajty zdjęć
Co napędza Instagram |
| Justin.tv | Architektura transmisji wideo na żywo Justin.TV |
| Facebook | Skalowanie Memcached w Facebooku
TAO: rozproszony magazyn danych Facebooka dla grafu społecznościowego
Przechowywanie zdjęć w Facebooku
Jak Facebook transmituje na żywo do 800 000 jednoczesnych widzów |
| Flickr | Architektura Flickr |
| Mailbox | Od 0 do miliona użytkowników w 6 tygodni |
| Netflix | 360-stopniowy widok całego stosu Netflix
Netflix: Co się dzieje po naciśnięciu „Play”? |
| Pinterest | Od 0 do dziesiątek miliardów odsłon miesięcznie
18 milionów odwiedzających, 10x wzrost, 12 pracowników |
| Playfish | 50 milionów użytkowników miesięcznie i rośnie |
| PlentyOfFish | Architektura PlentyOfFish |
| Salesforce | Jak obsługują 1,3 miliarda transakcji dziennie |
| Stack Overflow | Architektura Stack Overflow |
| TripAdvisor | 40 mln odwiedzających, 200 mln dynamicznych odsłon, 30 TB danych |
| Tumblr | 15 miliardów odsłon miesięcznie |
| Twitter | Przyspieszenie Twittera o 10 000 procent
Przechowywanie 250 milionów tweetów dziennie za pomocą MySQL
150 mln aktywnych użytkowników, 300 tys. QPS, 22 MB/s firehose
Oś czasu w skali
Duże i małe dane w Twitterze
Operacje w Twitterze: skalowanie ponad 100 milionów użytkowników
Jak Twitter obsługuje 3 000 obrazów na sekundę |
| Uber | Jak Uber skaluje swój platformę rynku czasu rzeczywistego
Wnioski z skalowania Ubera do 2000 inżynierów, 1000 usług i 8000 repozytoriów Git |
| WhatsApp | Architektura WhatsApp, którą Facebook kupił za 19 miliardów dolarów |
| YouTube | Skalowalność YouTube
Architektura YouTube |
Firmowe blogi inżynierskie
Architektury firm, z którymi prowadzisz rozmowy kwalifikacyjne.>
Pytania, z którymi się spotkasz, mogą pochodzić z tej samej dziedziny.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Chcesz dodać bloga? Aby uniknąć powielania pracy, rozważ dodanie bloga swojej firmy do następującego repozytorium:
W trakcie rozwoju
Chcesz dodać sekcję lub pomóc ukończyć jedną z rozpoczętych? Wnieś swój wkład!
- Przetwarzanie rozproszone z MapReduce
- Haszowanie konsystentne
- Scatter gather
- Wnieś swój wkład
Podziękowania
Podziękowania i źródła są podane w całym repozytorium.
Szczególne podziękowania dla:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Informacje kontaktowe
Zapraszam do kontaktu w celu omówienia wszelkich problemów, pytań lub uwag.
Moje dane kontaktowe znajdziesz na mojej stronie GitHub.
Licencja
Kod i zasoby w tym repozytorium udostępniam na licencji open source. Ponieważ jest to moje osobiste repozytorium, licencja na mój kod i zasoby jest udzielana przeze mnie, a nie przez mojego pracodawcę (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---