English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Help vertaal deze gids!
De System Design Primer

Motivatie
Leer hoe je grootschalige systemen ontwerpt.>
Bereid je voor op het system design interview.
Leer hoe je grootschalige systemen ontwerpt
Leren hoe je schaalbare systemen ontwerpt helpt je om een betere engineer te worden.
Systeemontwerp is een breed onderwerp. Er zijn een enorme hoeveelheid bronnen verspreid over het web over principes van systeemontwerp.
Deze repo is een georganiseerde verzameling van bronnen om je te helpen leren hoe je systemen op schaal bouwt.
Leer van de open source community
Dit is een voortdurend geüpdatet, open source project.
Bijdragen zijn welkom!
Bereid je voor op het system design interview
Naast codeer-interviews is systeemontwerp een verplicht onderdeel van het technisch sollicitatieproces bij veel techbedrijven.
Oefen veel voorkomende systeemontwerp interviewvragen en vergelijk je resultaten met voorbeeldoplossingen: discussies, code en diagrammen.
Extra onderwerpen voor interviewvoorbereiding:
- Studiemateriaal
- Hoe een systeemontwerp interviewvraag aan te pakken
- Systeemontwerp interviewvragen, met oplossingen
- Object-georiënteerd ontwerp interviewvragen, met oplossingen
- Aanvullende systeemontwerp interviewvragen
Anki-flashcards
De aangeboden Anki-flashcarddecks gebruiken gespreide herhaling om je te helpen belangrijke systeemontwerpconcepten te onthouden.
Ideaal om onderweg te gebruiken.Codering Resource: Interactieve programmeeruitdagingen
Op zoek naar bronnen om je voor te bereiden op het Programmeergesprek?
Bekijk de zusterrepo Interactieve programmeeruitdagingen, die een extra Anki-deck bevat:
Bijdragen
Leer van de community.
Voel je vrij om pull requests in te dienen om te helpen:
- Fouten te corrigeren
- Secties te verbeteren
- Nieuwe secties toevoegen
- Vertalen
Bekijk de Richtlijnen voor bijdragen.
Index van systeemontwerponderwerpen
Samenvattingen van verschillende systeemontwerponderwerpen, inclusief voor- en nadelen. Alles is een afweging.>
Elke sectie bevat links naar meer diepgaande bronnen.
- Systeemontwerponderwerpen: begin hier
- Stap 1: Bekijk de videolezing over schaalbaarheid
- Stap 2: Lees het artikel over schaalbaarheid
- Volgende stappen
- Prestaties vs schaalbaarheid
- Latentie vs doorvoer
- Beschikbaarheid vs consistentie
- CAP-theorema
- CP - consistentie en partitie-tolerantie
- AP - beschikbaarheid en partitie-tolerantie
- Consistentiepatronen
- Zwakke consistentie
- Eventuele consistentie
- Sterke consistentie
- Beschikbaarheidspatronen
- Fail-over
- Replicatie
- Beschikbaarheid in cijfers
- Domeinnaamsysteem
- Content delivery network
- Push-CDNs
- Pull-CDNs
- Load balancer
- Actief-passief
- Actief-actief
- Laag 4 load balancing
- Laag 7 load balancing
- Horizontale schaalvergroting
- Reverse proxy (webserver)
- Load balancer vs reverse proxy
- Applicatielaag
- Microservices
- Service discovery
- Database
- Relationeel databasemanagementsysteem (RDBMS)
- Master-slave replicatie
- Master-master replicatie
- Federatie
- Sharding
- Denormalisatie
- SQL tuning
- NoSQL
- Key-value store
- Document store
- Wide column store
- Graph Database
- SQL of NoSQL
- Cache
- Client caching
- CDN caching
- Webserver caching
- Database caching
- Applicatie caching
- Caching op het niveau van databasequery's
- Caching op objectniveau
- Wanneer de cache bijwerken
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- Asynchronisme
- Message queues
- Taakwachtrijen
- Terugdruk
- Communicatie
- Transmission Control Protocol (TCP)
- User Datagram Protocol (UDP)
- Remote Procedure Call (RPC)
- Representational State Transfer (REST)
- Beveiliging
- Appendix
- Tabel machten van twee
- Latentiecijfers die elke programmeur zou moeten kennen
- Extra systeemontwerp interviewvragen
- Architecturen uit de echte wereld
- Architecturen van bedrijven
- Engineeringblogs van bedrijven
- In ontwikkeling
- Credits
- Contactinformatie
- Licentie
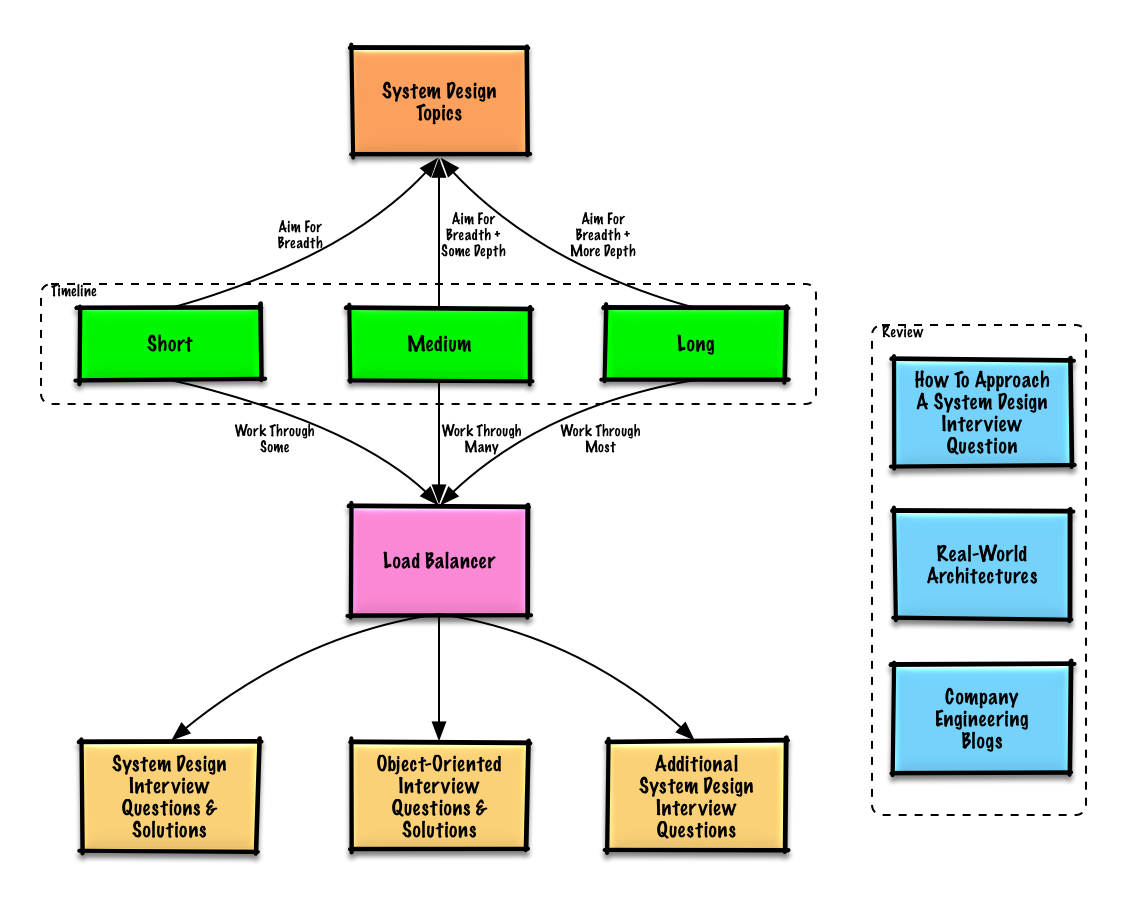
Studiegids
Voorgestelde onderwerpen om te herzien op basis van je interviewplanning (kort, middellang, lang).
V: Moet ik alles hier weten voor interviews?
A: Nee, je hoeft niet alles hier te weten om je voor te bereiden op het interview.
Wat je gevraagd wordt in een interview hangt af van variabelen zoals:
- Hoeveel ervaring je hebt
- Wat je technische achtergrond is
- Voor welke functies je solliciteert
- Bij welke bedrijven je solliciteert
- Geluk
Begin breed en ga dieper in op enkele gebieden. Het is nuttig om een beetje te weten over verschillende belangrijke onderwerpen in systeemontwerp. Pas de volgende gids aan op basis van je tijdlijn, ervaring, voor welke functies je solliciteert, en bij welke bedrijven je solliciteert.
- Korte tijdlijn - Richt je op breedte bij systeemontwerp onderwerpen. Oefen door enkele interviewvragen op te lossen.
- Middel lange tijdlijn - Richt je op breedte en enige diepte bij systeemontwerp onderwerpen. Oefen door veel interviewvragen op te lossen.
- Lange tijdlijn - Richt je op breedte en meer diepte bij systeemontwerp onderwerpen. Oefen door de meeste interviewvragen op te lossen.
Hoe een systeemontwerp interviewvraag aan te pakken
Hoe je een systeemontwerp interviewvraag aanpakt.
Het systeemontwerp interview is een open gesprek. Je wordt verwacht het gesprek te leiden.
Je kunt de volgende stappen gebruiken om het gesprek te sturen. Om dit proces te versterken, werk door de sectie Systeemontwerp interviewvragen met oplossingen met de volgende stappen.
Stap 1: Schets gebruiksscenario's, beperkingen en aannames
Verzamel eisen en bepaal de omvang van het probleem. Stel vragen om gebruiksscenario's en beperkingen te verduidelijken. Bespreek aannames.
- Wie gaat het gebruiken?
- Hoe gaan ze het gebruiken?
- Hoeveel gebruikers zijn er?
- Wat doet het systeem?
- Wat zijn de inputs en outputs van het systeem?
- Hoeveel data verwachten we te verwerken?
- Hoeveel verzoeken per seconde verwachten we?
- Wat is de verwachte lees-schrijf verhouding?
Stap 2: Maak een hoog-niveau ontwerp
Schets een hoog-niveau ontwerp met alle belangrijke componenten.
- Schets de hoofdcomponenten en verbindingen
- Motiveer je ideeën
Stap 3: Ontwerp kerncomponenten
Ga in op details voor elke kerncomponent. Bijvoorbeeld, als je gevraagd werd om een url-verkortingsdienst te ontwerpen, bespreek dan:
- Het genereren en opslaan van een hash van de volledige url
- MD5 en Base62
- Hash-botsingen
- SQL of NoSQL
- Databaseschema
- Het vertalen van een gehashte url naar de volledige url
- Database-opzoeking
- API- en objectgeoriënteerd ontwerp
Stap 4: Schaal het ontwerp op
Identificeer en pak knelpunten aan, gegeven de beperkingen. Heb je bijvoorbeeld het volgende nodig om schaalbaarheidsproblemen aan te pakken?
- Load balancer
- Horizontaal schalen
- Caching
- Database sharding
Berekeningen op de achterkant van een envelop
Het kan zijn dat je enkele schattingen met de hand moet maken. Raadpleeg de Appendix voor de volgende bronnen:
- Gebruik berekeningen op de achterkant van een envelop
- Tabel machten van twee
- Latentiecijfers die elke programmeur moet weten
Bron(nen) en verdere literatuur
Bekijk de volgende links om een beter idee te krijgen van wat je kunt verwachten:
- Hoe je een systems design interview kunt halen
- Het system design interview
- Introductie tot architectuur en systems design interviews
- System design sjabloon
System design interview vragen met oplossingen
Veelvoorkomende system design interviewvragen met voorbeeldbesprekingen, code en diagrammen.>
Oplossingen gekoppeld aan inhoud in de map solutions/.| Vraag | | |---|---| | Ontwerp Pastebin.com (of Bit.ly) | Oplossing | | Ontwerp de Twitter-tijdlijn en zoekfunctie (of Facebook-feed en zoekfunctie) | Oplossing | | Ontwerp een webcrawler | Oplossing | | Ontwerp Mint.com | Oplossing | | Ontwerp de datastructuren voor een sociaal netwerk | Oplossing | | Ontwerp een key-value store voor een zoekmachine | Oplossing | | Ontwerp Amazons verkoopranking per categorie | Oplossing | | Ontwerp een systeem dat schaalt naar miljoenen gebruikers op AWS | Oplossing | | Voeg een system design vraag toe | Bijdragen |
Ontwerp Pastebin.com (of Bit.ly)
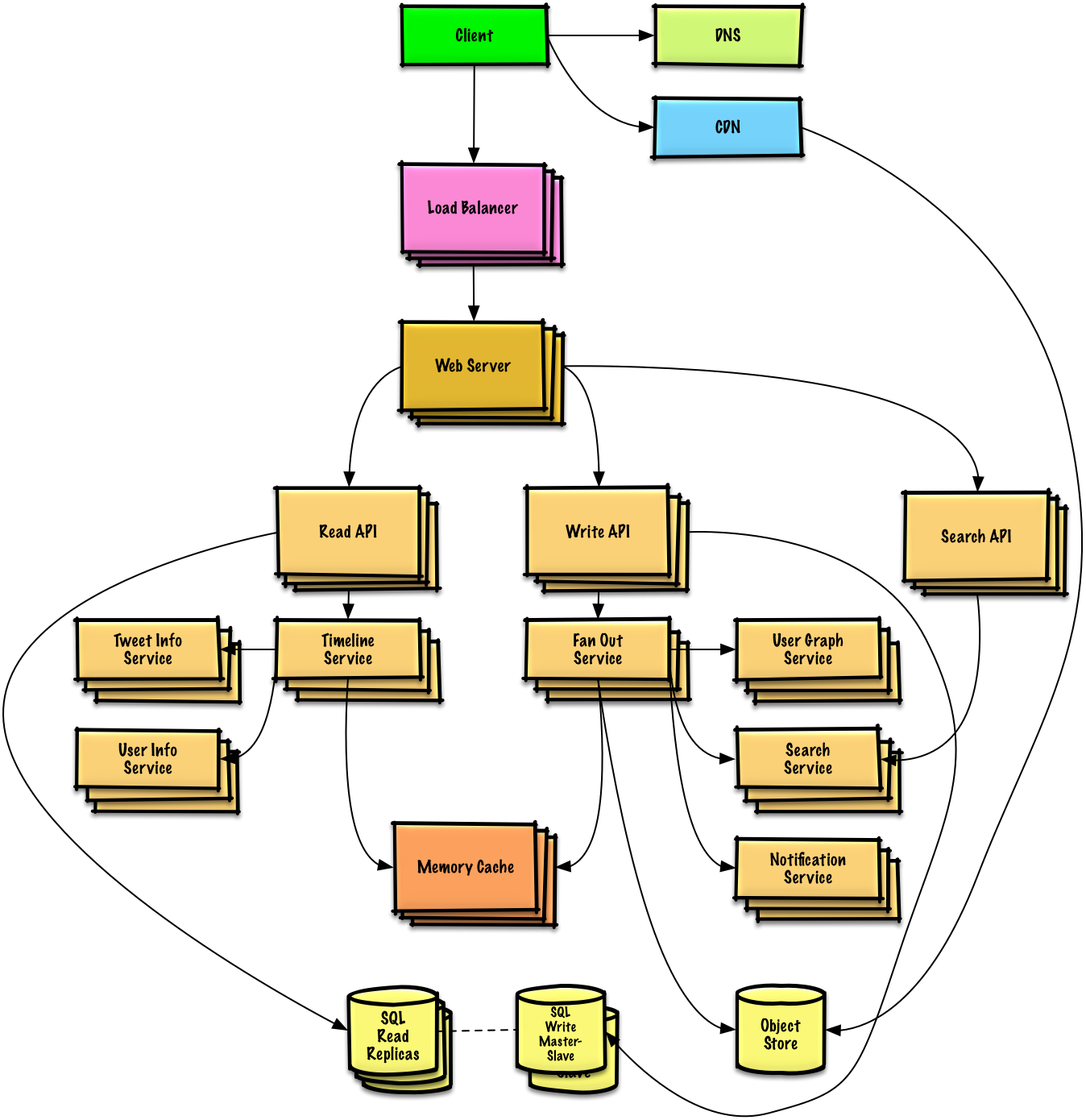
Ontwerp de Twitter-tijdlijn en zoekfunctie (of Facebook-feed en zoekfunctie)
Ontwerp een webcrawler
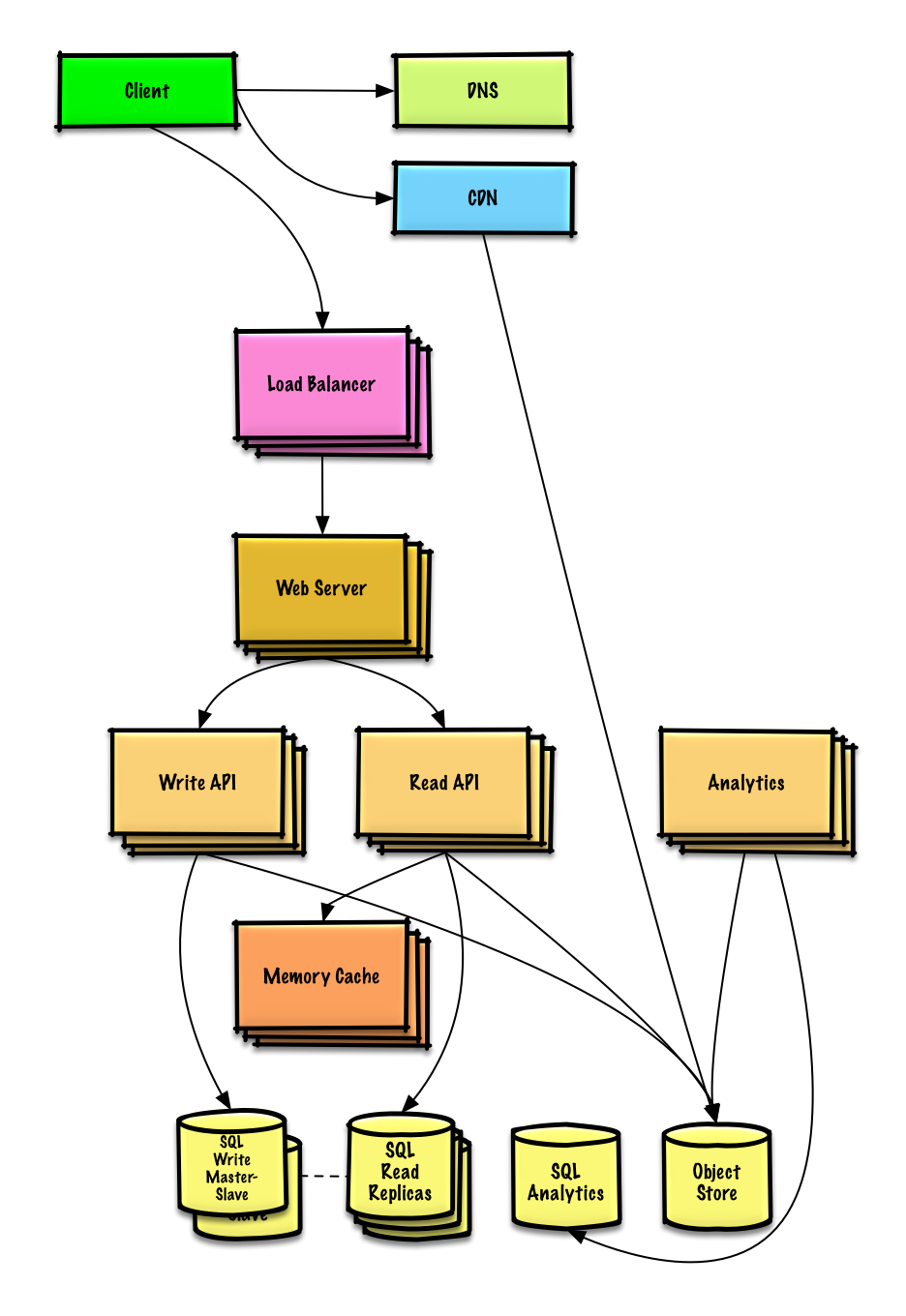
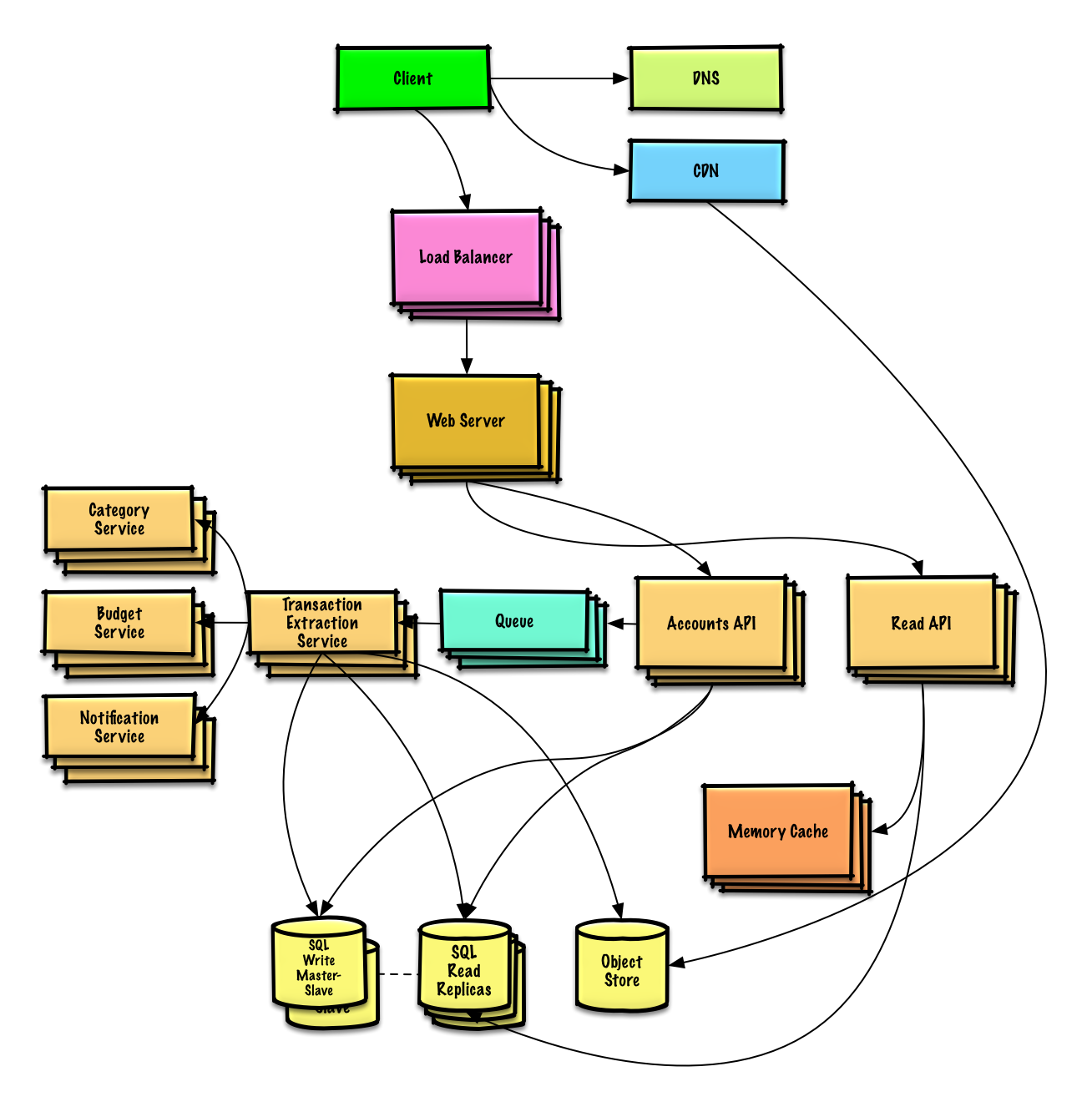
Design Mint.com
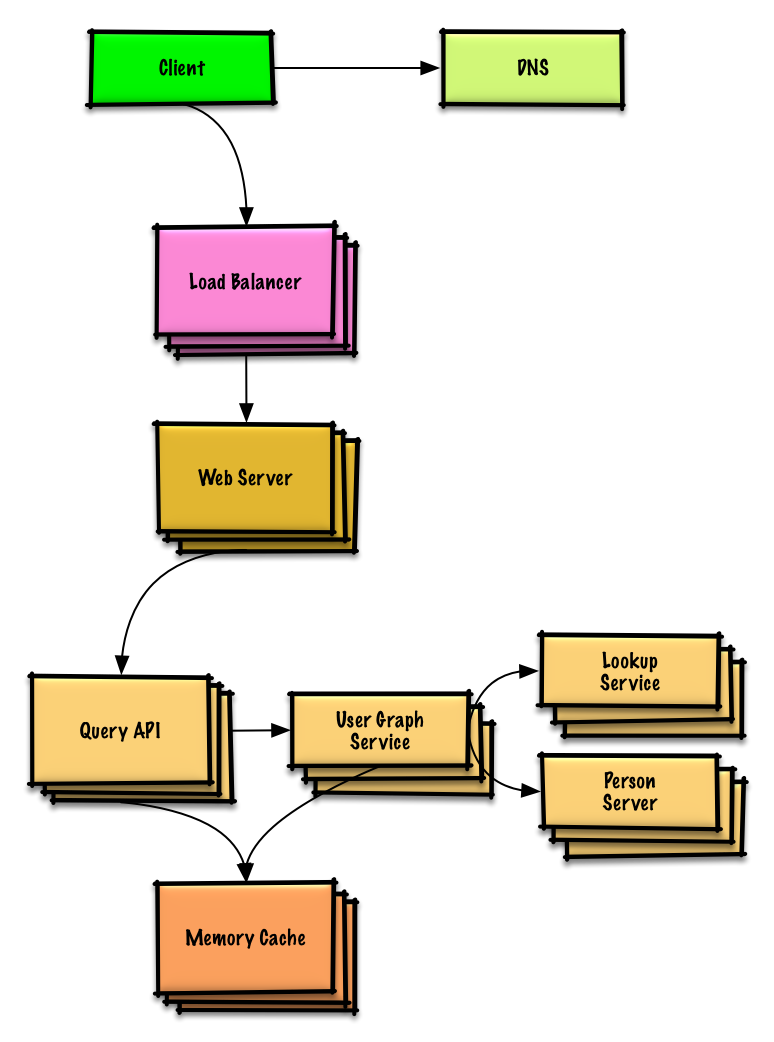
Design the data structures for a social network
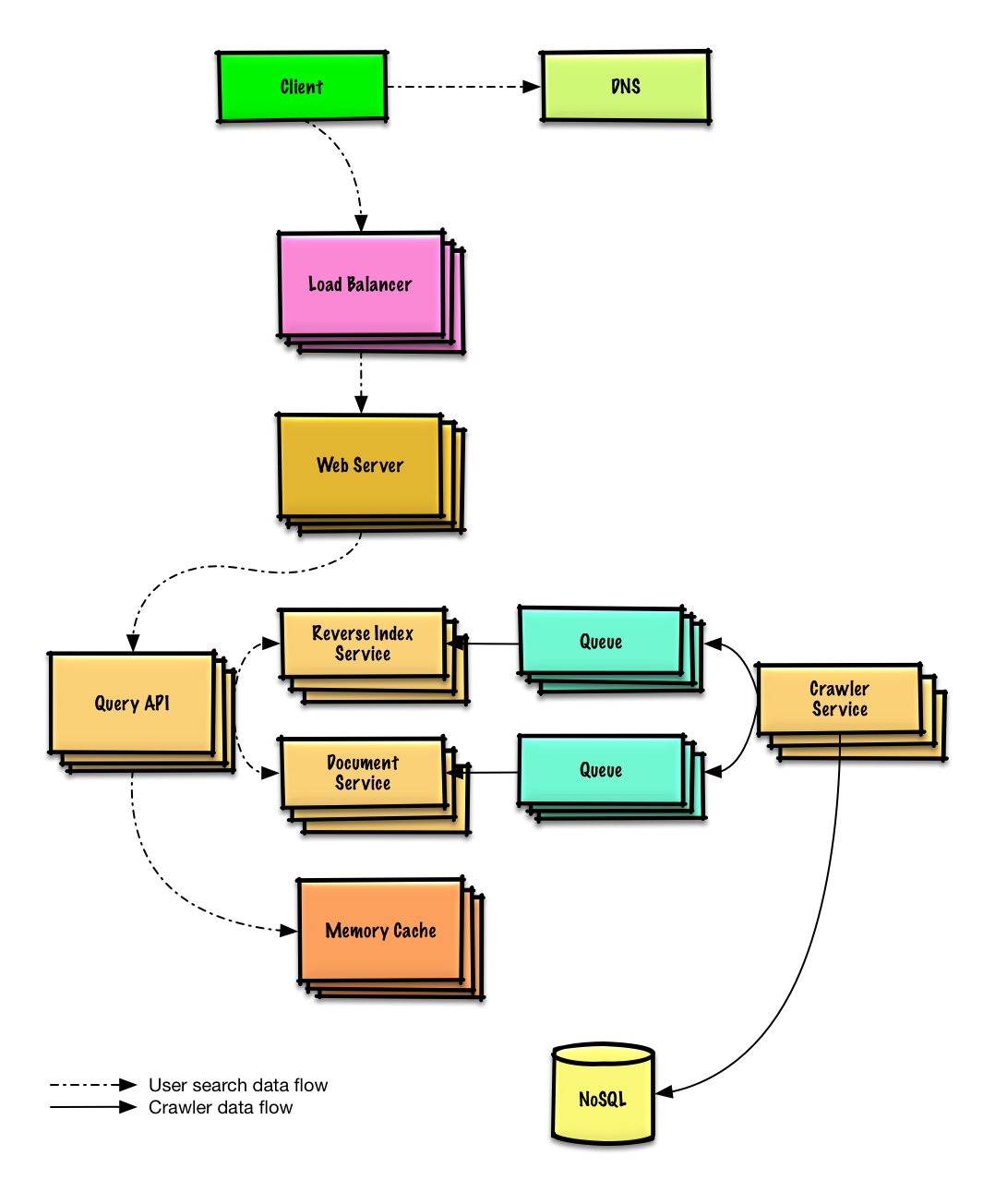
Design a key-value store for a search engine
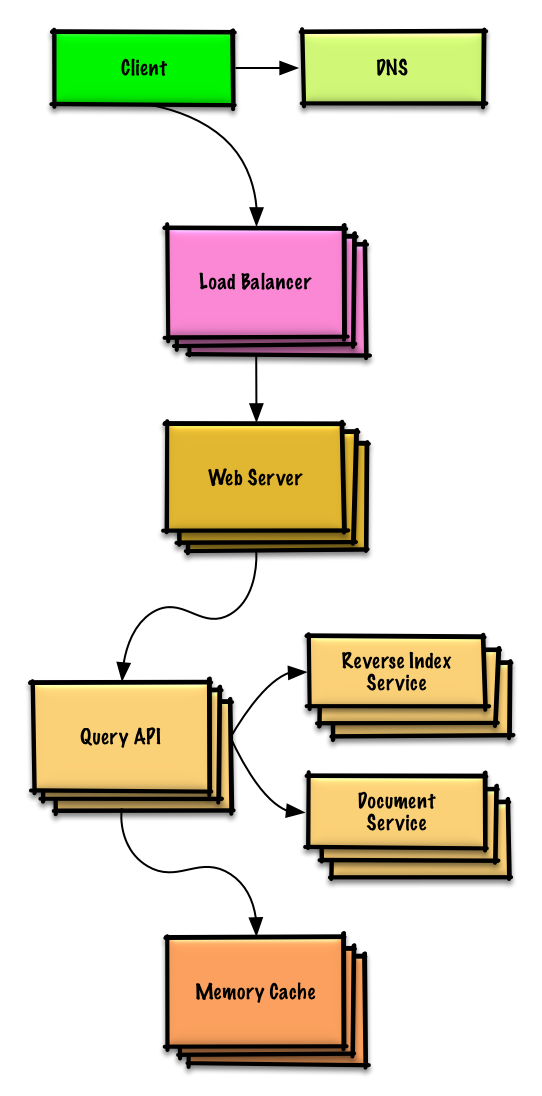
Design Amazon's sales ranking by category feature
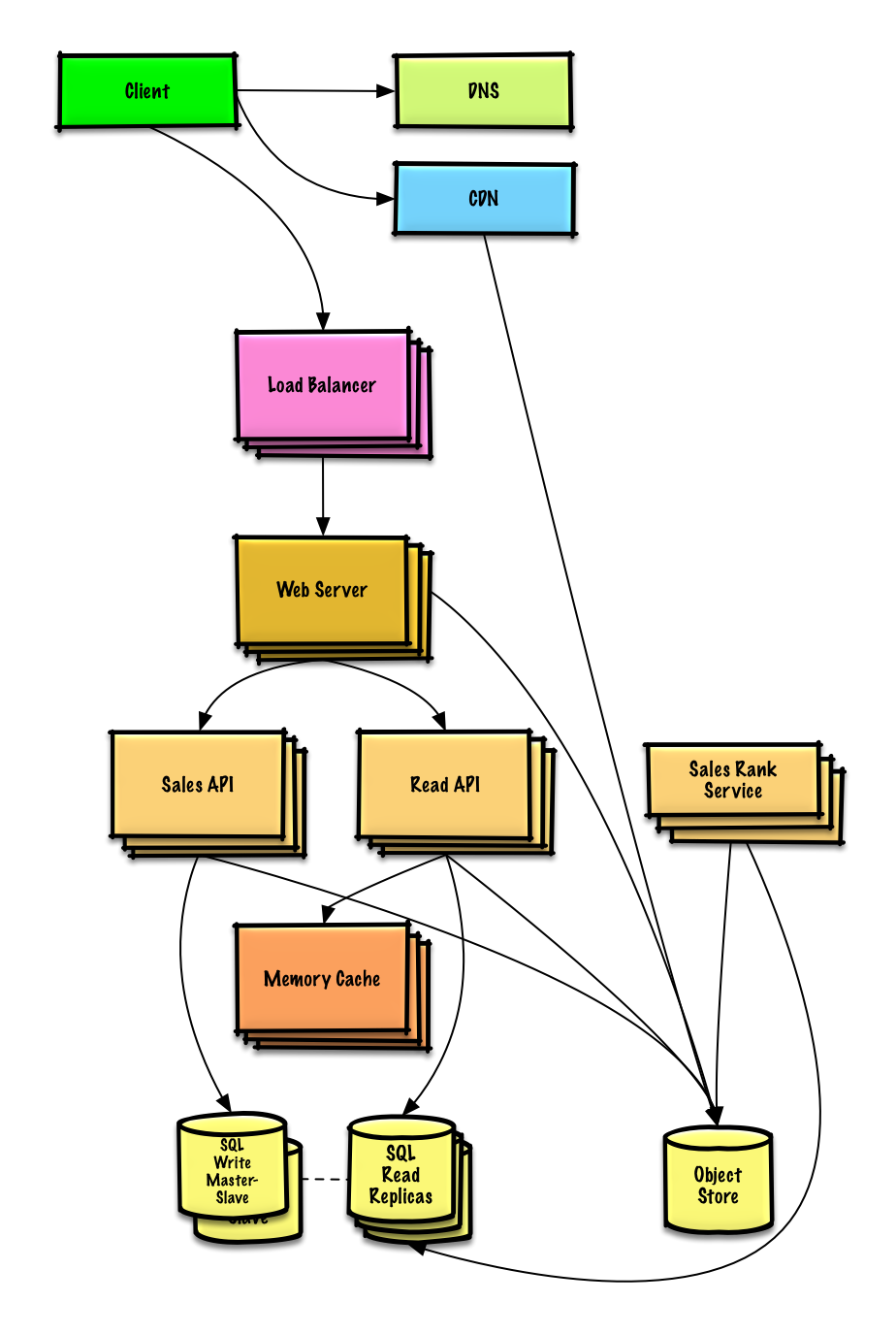
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Ontwerp een hash map | Oplossing | | Ontwerp een least recently used cache | Oplossing | | Ontwerp een callcenter | Oplossing | | Ontwerp een kaartspel | Oplossing | | Ontwerp een parkeerplaats | Oplossing | | Ontwerp een chatserver | Oplossing | | Ontwerp een circulaire array | Bijdragen | | Voeg een objectgeoriënteerde ontwerpopgave toe | Bijdragen |
Systeemontwerp onderwerpen: begin hier
Nieuw met systeemontwerp?
Ten eerste heb je een basisbegrip nodig van algemene principes, leren wat ze zijn, hoe ze worden gebruikt, en hun voor- en nadelen.
Stap 1: Bekijk de schaalbaarheidsvideolezing
Schaalbaarheidslezing aan Harvard
- Onderwerpen:
- Verticaal schalen
- Horizontaal schalen
- Caching
- Load balancing
- Database replicatie
- Database partitionering
Stap 2: Bekijk het schaalbaarheidsartikel
- Onderwerpen:
- Clones
- Databases
- Caches
- Asynchronisme
Volgende stappen
Vervolgens bekijken we trade-offs op hoog niveau:
- Performance versus schaalbaarheid
- Latentie versus doorvoer
- Beschikbaarheid versus consistentie
Daarna duiken we in meer specifieke onderwerpen zoals DNS, CDN's en load balancers.
Performance versus schaalbaarheid
Een dienst is schaalbaar als deze leidt tot een verhoogde performance op een manier die proportioneel is aan de toegevoegde resources. Over het algemeen betekent het verhogen van de performance dat er meer eenheden werk worden bediend, maar het kan ook betekenen dat grotere eenheden werk worden verwerkt, bijvoorbeeld wanneer datasets groeien.1
Een andere manier om naar performance versus schaalbaarheid te kijken:
- Als je een performance probleem hebt, is je systeem traag voor één gebruiker.
- Als je een schaalbaarheidsprobleem hebt, is je systeem snel voor één gebruiker maar traag bij zware belasting.
Bron(nen) en verdere literatuur
Latentie versus doorvoer
Latentie is de tijd die nodig is om een bepaalde actie uit te voeren of een resultaat te produceren.
Doorvoer is het aantal van dergelijke acties of resultaten per tijdseenheid.
Over het algemeen moet je streven naar maximale doorvoer met acceptabele latentie.
Bron(nen) en verdere literatuur
Beschikbaarheid versus consistentie
CAP-theorema
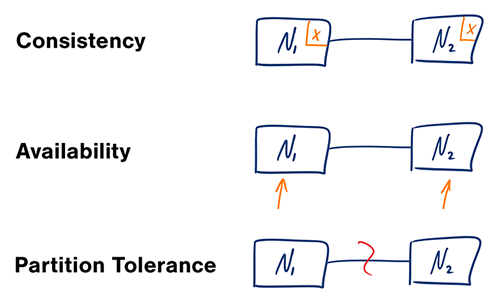
In een gedistribueerd computersysteem kun je slechts twee van de volgende garanties ondersteunen:
- Consistentie - Elke leesactie ontvangt de meest recente schrijfbeurt of een foutmelding
- Beschikbaarheid - Elke aanvraag ontvangt een reactie, zonder garantie dat deze de meest recente versie van de informatie bevat
- Partitioneringstolerantie - Het systeem blijft functioneren ondanks willekeurige partitionering door netwerkstoringen
#### CP - consistentie en partitioneringstolerantie
Wachten op een reactie van het gescheiden knooppunt kan resulteren in een timeout-fout. CP is een goede keuze als je zakelijke behoeften atomische lees- en schrijfbeurten vereisen.
#### AP - beschikbaarheid en partitioneringstolerantie
Reacties leveren de meest direct beschikbare versie van de gegevens op elk knooppunt, wat mogelijk niet de nieuwste is. Schrijfacties kunnen enige tijd duren om te propagateren wanneer de partitionering is opgelost.
AP is een goede keuze als de zakelijke behoeften eventuele consistentie toestaan of wanneer het systeem moet blijven werken ondanks externe fouten.
Bron(nen) en verdere lectuur
- CAP theorem revisited
- Een eenvoudig Engelse introductie tot de CAP-theorema
- CAP FAQ
- Het CAP-theorema
Consistentiepatronen
Met meerdere kopieën van dezelfde gegevens staan we voor keuzes over hoe we ze synchroniseren zodat cliënten een consistent beeld van de gegevens hebben. Herinner je de definitie van consistentie uit het CAP-theorema - Elke leesactie ontvangt de meest recente schrijfbeurt of een fout.
Zwakke consistentie
Na een schrijfbeurt kunnen leesacties deze wel of niet zien. Er wordt een best effort benadering genomen.
Deze aanpak zie je in systemen zoals memcached. Zwakke consistentie werkt goed in realtime use cases zoals VoIP, videochat en realtime multiplayer games. Bijvoorbeeld, als je aan het bellen bent en enkele seconden geen verbinding hebt, hoor je bij het terugkrijgen van de verbinding niet wat er gezegd is tijdens het verlies van de verbinding.
Eventuele consistentie
Na een schrijfoperatie zullen lezers deze uiteindelijk zien (meestal binnen milliseconden). Gegevens worden asynchroon gerepliceerd.
Deze aanpak wordt gebruikt in systemen zoals DNS en e-mail. Eventuele consistentie werkt goed in systemen met hoge beschikbaarheid.
Sterke consistentie
Na een schrijfoperatie zullen lezers deze direct zien. Gegevens worden synchroon gerepliceerd.
Deze aanpak wordt gebruikt in bestandssystemen en relationele databases. Sterke consistentie werkt goed in systemen die transacties vereisen.
Bron(nen) en verdere literatuur
Beschikbaarheidspatronen
Er zijn twee complementaire patronen om hoge beschikbaarheid te ondersteunen: failover en replicatie.
Failover
#### Actief-passief
Bij actief-passief failover worden hartslagen verstuurd tussen de actieve en passieve server in standby. Als de hartslag wordt onderbroken, neemt de passieve server het IP-adres van de actieve over en hervat de dienst.
De lengte van de downtime wordt bepaald door of de passieve server al draait in 'hot' standby of nog moet opstarten vanuit 'cold' standby. Alleen de actieve server verwerkt verkeer.
Actief-passief failover wordt ook wel master-slave failover genoemd.
#### Actief-actief
Bij actief-actief beheren beide servers het verkeer en verdelen ze de belasting.
Als de servers publiek toegankelijk zijn, moet de DNS op de hoogte zijn van de publieke IP-adressen van beide servers. Als de servers intern zijn, moet de applicatielogica beide servers kennen.
Actief-actief failover wordt ook wel master-master failover genoemd.
Nadeel/Nadelen: failover
- Failover voegt meer hardware en extra complexiteit toe.
- Er is een potentieel voor dataverlies als het actieve systeem faalt voordat nieuw geschreven data naar het passieve systeem gerepliceerd kan worden.
Reproductie
#### Master-slave en master-master
Dit onderwerp wordt verder besproken in de Database sectie:
Beschikbaarheid in cijfers
Beschikbaarheid wordt vaak gekwantificeerd door uptime (of downtime) als een percentage van de tijd dat de dienst beschikbaar is. Beschikbaarheid wordt meestal gemeten in aantal negens—een dienst met 99,99% beschikbaarheid wordt aangeduid als vier negens.
#### 99,9% beschikbaarheid - drie negens
| Duur | Acceptabele uitvaltijd| |---------------------|----------------------| | Uitvaltijd per jaar | 8u 45min 57s | | Uitvaltijd per maand| 43m 49,7s | | Uitvaltijd per week | 10m 4,8s | | Uitvaltijd per dag | 1m 26,4s |
#### 99,99% beschikbaarheid - vier negens
| Duur | Acceptabele uitvaltijd| |---------------------|----------------------| | Uitvaltijd per jaar | 52min 35,7s | | Uitvaltijd per maand| 4m 23s | | Uitvaltijd per week | 1m 5s | | Uitvaltijd per dag | 8,6s |
#### Beschikbaarheid in parallel versus in serie
Als een dienst bestaat uit meerdere componenten die kunnen falen, hangt de totale beschikbaarheid van de dienst af van of de componenten in serie of parallel staan.
###### In serie
De algehele beschikbaarheid neemt af wanneer twee componenten met een beschikbaarheid < 100% in serie staan:
Availability (Total) = Availability (Foo) * Availability (Bar)Als zowel Foo als Bar elk 99,9% beschikbaarheid hadden, zou hun totale beschikbaarheid in serie 99,8% zijn.
###### Parallel
De totale beschikbaarheid neemt toe wanneer twee componenten met een beschikbaarheid < 100% parallel staan:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Als zowel Foo als Bar elk 99,9% beschikbaarheid hadden, zou hun totale beschikbaarheid in parallel 99,9999% zijn.
Domain Name System
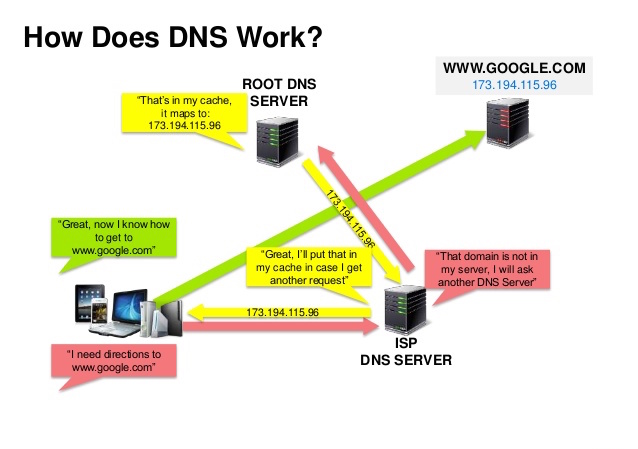
Bron: DNS beveiligingspresentatie
Een Domain Name System (DNS) vertaalt een domeinnaam zoals www.example.com naar een IP-adres.
DNS is hiërarchisch, met enkele gezaghebbende servers op het hoogste niveau. Je router of ISP geeft informatie over welke DNS-server(s) je moet contacteren bij een opzoeking. Lagere DNS-servers cachen koppelingen, die verouderd kunnen raken door DNS-propagatievertragingen. DNS-resultaten kunnen ook worden gecachet door je browser of besturingssysteem voor een bepaalde periode, bepaald door de time to live (TTL).
- NS-record (name server) - Specificeert de DNS-servers voor je domein/subdomein.
- MX-record (mail exchange) - Specificeert de mailservers voor het accepteren van berichten.
- A-record (address) - Verwijst een naam naar een IP-adres.
- CNAME (canonical) - Verwijst een naam naar een andere naam of
CNAME(example.com naar www.example.com) of naar eenA-record.
- Weighted round robin
- Voorkom dat verkeer naar servers gaat die in onderhoud zijn
- Balans tussen verschillende cluster-groottes
- A/B-testen
- Latency-based
- Geolocatie-gebaseerd
Nadeel(en): DNS
- Toegang tot een DNS-server veroorzaakt een kleine vertraging, hoewel dit wordt verminderd door caching zoals hierboven beschreven.
- DNS-serverbeheer kan complex zijn en wordt doorgaans beheerd door overheden, ISP's en grote bedrijven.
- DNS-diensten zijn onlangs doelwit geweest van DDoS-aanvallen, waardoor gebruikers geen toegang hadden tot websites zoals Twitter zonder het IP-adres(sen) van Twitter te kennen.
Bron(nen) en verdere literatuur
Content delivery network
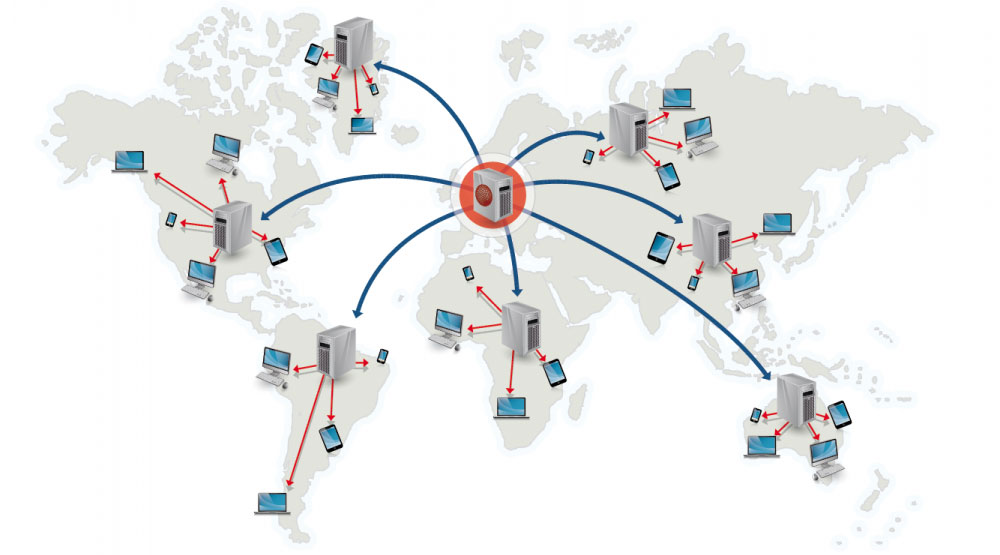
Bron: Waarom een CDN gebruiken
Een content delivery network (CDN) is een wereldwijd verspreid netwerk van proxyservers die content leveren vanaf locaties dichter bij de gebruiker. Over het algemeen worden statische bestanden zoals HTML/CSS/JS, foto's en video's via CDN geleverd, hoewel sommige CDNs zoals Amazon's CloudFront ook dynamische content ondersteunen. De DNS-resolutie van de site vertelt cliënten welke server ze moeten benaderen.
Het leveren van content via CDNs kan de prestaties aanzienlijk verbeteren op twee manieren:
- Gebruikers ontvangen content van datacenters in hun nabijheid
- Je servers hoeven geen verzoeken te verwerken die door de CDN worden afgehandeld
Push CDNs
Push CDNs ontvangen nieuwe content wanneer er wijzigingen plaatsvinden op je server. Je bent volledig verantwoordelijk voor het aanleveren van de content, uploadt deze direct naar de CDN en herschrijft URLs zodat ze naar de CDN verwijzen. Je kunt instellen wanneer content verloopt en wanneer deze wordt geüpdatet. Content wordt alleen geüpload als deze nieuw of gewijzigd is, wat het verkeer minimaliseert maar de opslag maximaliseert.
Sites met weinig verkeer of sites waarvan de content niet vaak wordt bijgewerkt, werken goed met push CDNs. Content wordt één keer naar de CDN gebracht, in plaats van op vaste tijdstippen opnieuw te worden opgehaald.
Pull CDNs
Pull CDNs halen nieuwe content van je server wanneer de eerste gebruiker erom vraagt. Je laat de content op je eigen server staan en herschrijft URLs zodat ze naar de CDN verwijzen. Dit resulteert in een trager verzoek totdat de content op de CDN is gecached.
Een time-to-live (TTL) bepaalt hoe lang content wordt gecached. Pull CDNs minimaliseren de opslagruimte op de CDN, maar kunnen voor overbodig verkeer zorgen als bestanden verlopen en opnieuw worden opgehaald voordat ze daadwerkelijk zijn gewijzigd.
Sites met veel verkeer werken goed met pull CDNs, omdat het verkeer gelijkmatiger wordt verdeeld en alleen recent opgevraagde content op de CDN blijft.
Nadelen: CDN
- CDN-kosten kunnen aanzienlijk zijn afhankelijk van het verkeer, hoewel dit moet worden afgewogen tegen extra kosten die je zou maken als je geen CDN gebruikt.
- Content kan verouderd zijn als het wordt bijgewerkt voordat de TTL verloopt.
- CDNs vereisen het wijzigen van URLs voor statische content zodat ze naar de CDN verwijzen.
Bron(nen) en verdere literatuur
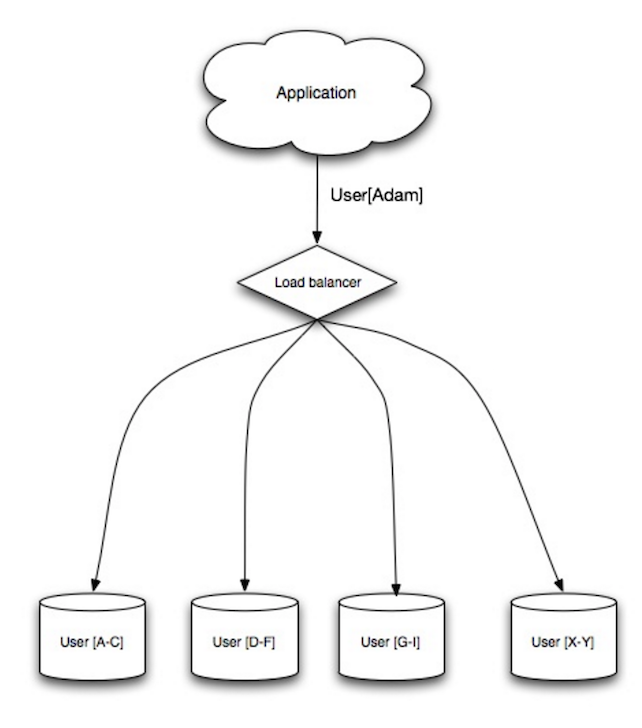
Load balancer
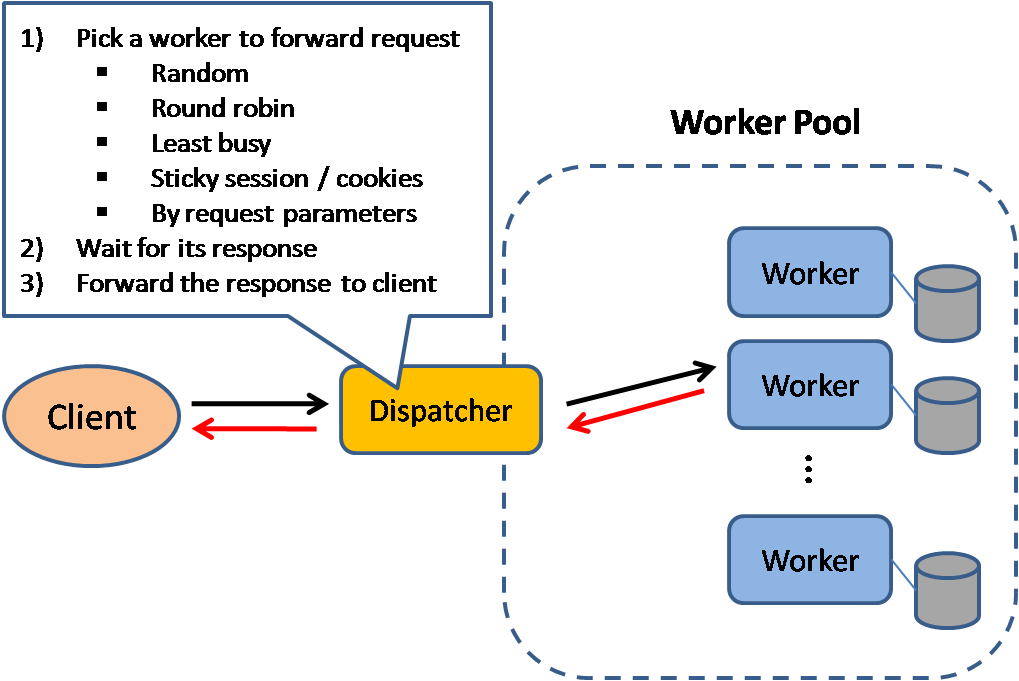
Bron: Schaalbare systeemontwerp patronen
Load balancers verdelen binnenkomende clientverzoeken over computerbronnen zoals applicatieservers en databases. In elk geval stuurt de load balancer het antwoord van de computerbron terug naar de juiste client. Load balancers zijn effectief bij:
- Voorkomen dat verzoeken naar ongezonde servers gaan
- Voorkomen van overbelasting van bronnen
- Helpen om een enkelvoudig faalpunt te elimineren
Extra voordelen zijn onder andere:
- SSL-terminatie - Ontsleutelt binnenkomende verzoeken en versleutelt serverantwoorden zodat backendservers deze mogelijk dure bewerkingen niet hoeven uit te voeren
- Verwijdert de noodzaak om X.509 certificaten op elke server te installeren
- Sessie persistentie - Geeft cookies uit en leidt de verzoeken van een specifieke client naar dezelfde instantie indien de webapplicaties geen sessies bijhouden
Load balancers kunnen verkeer routeren op basis van verschillende criteria, waaronder:
- Willekeurig
- Minst belast
- Sessie/cookies
- Round robin of gewogen round robin
- Laag 4
- Laag 7
Laag 4 load balancing
Laag 4 load balancers kijken naar informatie op de transportlaag om te beslissen hoe verzoeken te verdelen. Dit betreft doorgaans de bron-, bestemming-IP-adressen en poorten in de header, maar niet de inhoud van het pakket. Laag 4 load balancers sturen netwerkpakketten door naar en van de upstream-server en voeren Network Address Translation (NAT) uit.
Laag 7 load balancing
Laag 7 load balancers kijken naar de applicatielaag om te bepalen hoe aanvragen worden verdeeld. Dit kan betrekking hebben op de inhoud van de header, het bericht en cookies. Laag 7 load balancers beëindigen netwerkverkeer, lezen het bericht, nemen een load-balancing beslissing en openen vervolgens een verbinding met de geselecteerde server. Een laag 7 load balancer kan bijvoorbeeld videoverkeer naar servers sturen die video's hosten, terwijl gevoeliger betalingsverkeer van gebruikers naar extra beveiligde servers wordt geleid.Ten koste van flexibiliteit vereist load balancing op laag 4 minder tijd en rekenkracht dan op laag 7, hoewel de prestatie-impact op moderne standaardhardware minimaal kan zijn.
Horizontaal schalen
Load balancers kunnen ook helpen met horizontaal schalen, wat prestaties en beschikbaarheid verbetert. Uitbreiden met standaardmachines is kostenefficiënter en resulteert in een hogere beschikbaarheid dan het opschalen van één enkele server op duurdere hardware, ook wel Verticale Schaling genoemd. Het is ook makkelijker om personeel te vinden voor standaardhardware dan voor gespecialiseerde bedrijfsystemen.
#### Nadeel(en): horizontaal schalen
- Horizontaal schalen introduceert complexiteit en omvat het klonen van servers
- Servers moeten stateless zijn: ze mogen geen gebruikersgegevens bevatten zoals sessies of profielfoto's
- Sessies kunnen worden opgeslagen in een gecentraliseerde opslag zoals een database (SQL, NoSQL) of een persistente cache (Redis, Memcached)
- Downstream servers zoals caches en databases moeten meer gelijktijdige verbindingen aankunnen naarmate upstream servers worden uitgebreid
Nadeel(en): load balancer
- De load balancer kan een prestatiedrempel worden als deze niet genoeg middelen heeft of niet goed geconfigureerd is.
- Het introduceren van een load balancer om een single point of failure te elimineren, zorgt voor meer complexiteit.
- Een enkele load balancer is een single point of failure; het configureren van meerdere load balancers verhoogt de complexiteit verder.
Bron(nen) en verdere lectuur
- NGINX architectuur
- HAProxy architectuurgids
- Schaalbaarheid
- Wikipedia)
- Laag 4 load balancing
- Laag 7 load balancing
- ELB listener config
Reverse proxy (webserver)
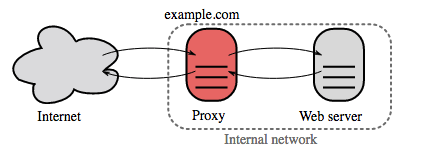
Een reverse proxy is een webserver die interne diensten centraliseert en uniforme interfaces aan het publiek aanbiedt. Verzoeken van clients worden doorgestuurd naar een server die het kan afhandelen, waarna de reverse proxy het antwoord van de server terugstuurt naar de client.
Aanvullende voordelen zijn onder andere:
- Verhoogde veiligheid - Verberg informatie over backend-servers, blokkeer IP-adressen, beperk het aantal verbindingen per client
- Grotere schaalbaarheid en flexibiliteit - Clients zien alleen het IP-adres van de reverse proxy, waardoor je servers kunt schalen of hun configuratie kunt wijzigen
- SSL-terminatie - Ontcijfer inkomende verzoeken en versleutel serverantwoorden zodat backend-servers deze mogelijk dure operaties niet hoeven uit te voeren
- Verwijdert de noodzaak om X.509-certificaten op elke server te installeren
- Compressie - Comprimeer serverantwoorden
- Caching - Geef het antwoord op gecachte verzoeken terug
- Statische content - Bedien statische content direct
- HTML/CSS/JS
- Foto's
- Video's
- Etc
Load balancer versus reverse proxy
- Het inzetten van een load balancer is nuttig wanneer je meerdere servers hebt. Vaak sturen load balancers verkeer naar een set servers met dezelfde functie.
- Reverse proxies kunnen ook nuttig zijn met slechts één webserver of applicatieserver, waardoor je de hierboven beschreven voordelen krijgt.
- Oplossingen zoals NGINX en HAProxy ondersteunen zowel layer 7 reverse proxying als load balancing.
Nadeel/nadelen: reverse proxy
- Het introduceren van een reverse proxy zorgt voor verhoogde complexiteit.
- Een enkele reverse proxy is een single point of failure; het configureren van meerdere reverse proxies (bijvoorbeeld een failover) vergroot de complexiteit verder.
Bron(nen) en verder lezen
Applicatielaag
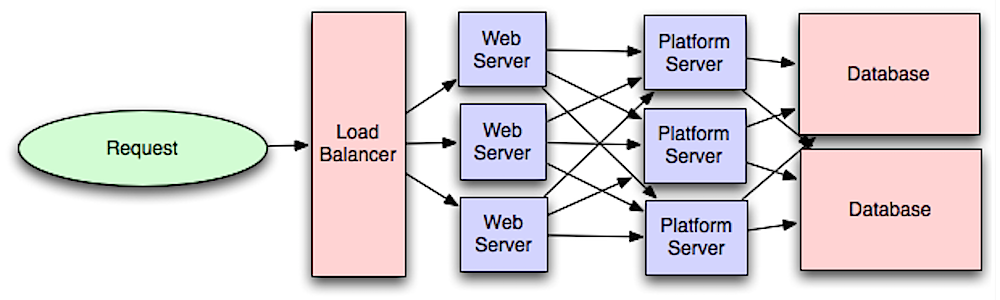
Bron: Introductie tot het ontwerpen van systemen voor schaalbaarheid
Het scheiden van de weblaag van de applicatielaag (ook bekend als platformlaag) stelt je in staat beide lagen onafhankelijk te schalen en te configureren. Het toevoegen van een nieuwe API leidt tot het toevoegen van applicatieservers zonder noodzakelijkerwijs extra webservers toe te voegen. Het single responsibility principle pleit voor kleine en autonome services die samenwerken. Kleine teams met kleine services kunnen agressiever plannen voor snelle groei.
Workers in de applicatielaag helpen ook bij het mogelijk maken van asynchroniteit.
Microservices
Hieraan gerelateerd zijn microservices, die omschreven kunnen worden als een verzameling onafhankelijk uitrolbare, kleine, modulaire services. Elke service draait een uniek proces en communiceert via een goed gedefinieerd, lichtgewicht mechanisme om een zakelijk doel te dienen. 1
Pinterest zou bijvoorbeeld de volgende microservices kunnen hebben: gebruikersprofiel, volger, feed, zoekfunctie, foto uploaden, enzovoort.
Service Discovery
Systemen zoals Consul, Etcd, en Zookeeper kunnen services helpen elkaar te vinden door geregistreerde namen, adressen en poorten bij te houden. Health checks helpen bij het verifiëren van de integriteit van services en worden vaak uitgevoerd via een HTTP endpoint. Zowel Consul als Etcd hebben een ingebouwde key-value store die nuttig kan zijn voor het opslaan van configuratiewaarden en andere gedeelde data.
Nadelen: applicatielaag
- Het toevoegen van een applicatielaag met losjes gekoppelde services vereist een andere benadering vanuit architectuur-, operations- en procesperspectief (vs een monolithisch systeem).
- Microservices kunnen complexiteit toevoegen op het gebied van deployment en beheer.
Bronnen en verdere literatuur
- Introductie tot het ontwerpen van systemen voor schaalbaarheid
- Crack the system design interview
- Service oriented architecture
- Introductie tot Zookeeper
- Dit is wat je moet weten over het bouwen van microservices
Database
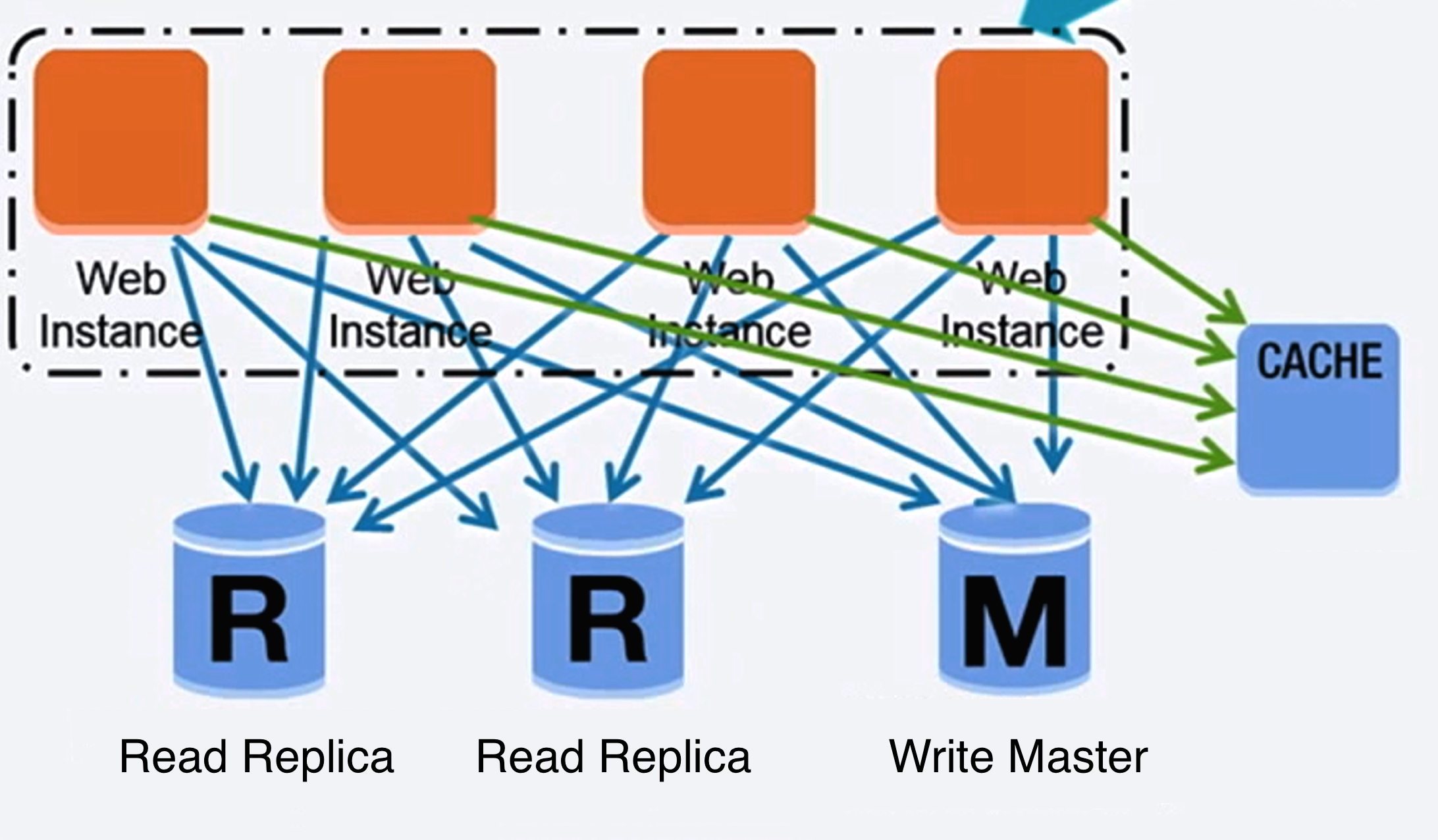
Bron: Opschalen tot je eerste 10 miljoen gebruikers
Relationeel databasemanagementsysteem (RDBMS)
Een relationele database zoals SQL is een verzameling gegevens die in tabellen zijn georganiseerd.
ACID is een reeks eigenschappen van relationele database-transacties.
- Atomiciteit - Elke transactie is alles of niets
- Consistentie - Elke transactie brengt de database van één geldige toestand naar een andere
- Isolatie - Het gelijktijdig uitvoeren van transacties levert dezelfde resultaten op als wanneer de transacties serieel werden uitgevoerd
- Duurzaamheid - Zodra een transactie is bevestigd, blijft deze zo
#### Master-slave replicatie
De master verzorgt lees- en schrijfbewerkingen en replikeert schrijfbewerkingen naar één of meer slaves, die alleen leesbewerkingen uitvoeren. Slaves kunnen ook naar extra slaves repliceren in een boomstructuur. Als de master offline gaat, kan het systeem in alleen-lezen modus blijven werken totdat een slave tot master wordt gepromoveerd of een nieuwe master wordt voorzien.
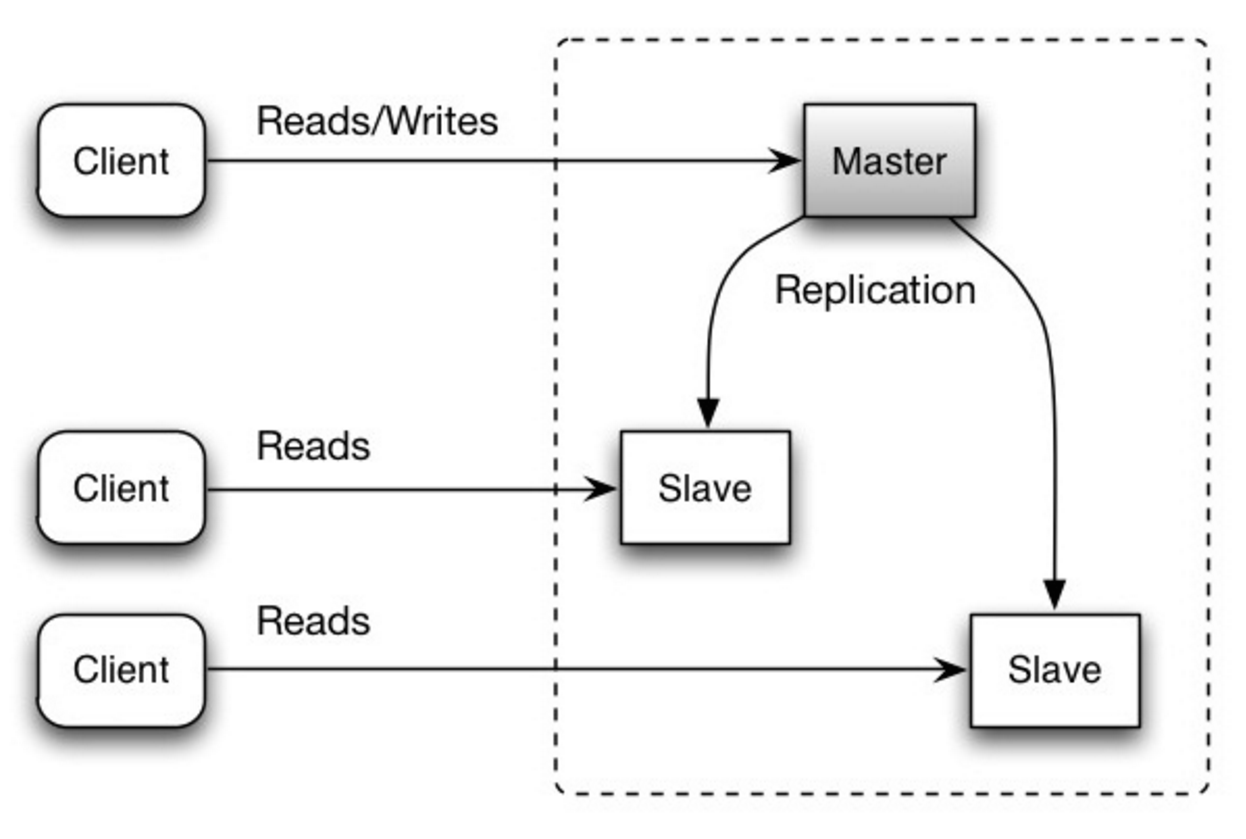
Bron: Scalability, availability, stability, patterns
##### Nadeel/nadelen: master-slave replicatie
- Extra logica is nodig om een slave tot master te promoveren.
- Zie Nadeel/nadelen: replicatie voor punten die betrekking hebben op zowel master-slave als master-master.
Beide masters verzorgen lees- en schrijfbewerkingen en coördineren onderling bij schrijven. Als één van de masters uitvalt, kan het systeem blijven werken met zowel lezen als schrijven.
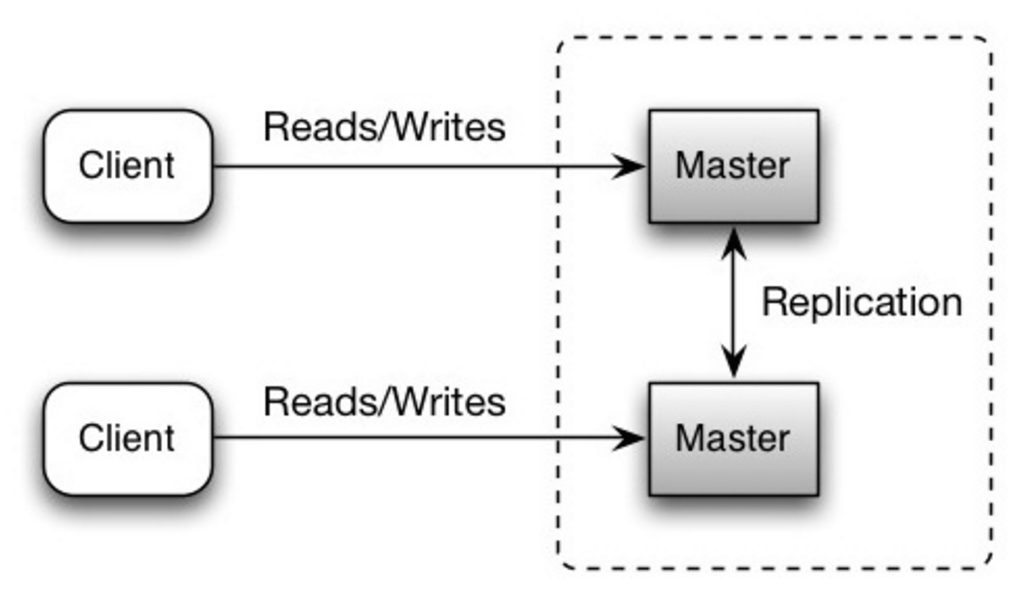
Bron: Scalability, availability, stability, patterns
##### Nadeel/nadelen: master-master replicatie
- Je hebt een load balancer nodig of je moet wijzigingen aanbrengen in de applicatielogica om te bepalen waar te schrijven.
- De meeste master-master systemen zijn ofwel losjes consistent (ACID wordt geschonden) of hebben verhoogde schrijflatentie door synchronisatie.
- Conflictoplossing speelt een grotere rol naarmate er meer schrijfnodes worden toegevoegd en de latentie toeneemt.
- Zie Nadeel(en): replicatie voor punten die betrekking hebben op zowel master-slave als master-master.
- Er is een potentieel voor dataverlies als de master faalt voordat nieuw geschreven data naar andere nodes kan worden gerepliceerd.
- Schrijfacties worden opnieuw afgespeeld op de leesreplica's. Als er veel schrijfacties zijn, kunnen de leesreplica's vertraging oplopen door het herhalen van schrijfacties en minder leesacties uitvoeren.
- Hoe meer lees-slaves, hoe meer je moet repliceren, wat leidt tot grotere replicatielag.
- Op sommige systemen kan schrijven naar de master meerdere threads starten om parallel te schrijven, terwijl leesreplica's alleen sequentieel schrijven met één thread ondersteunen.
- Replicatie vereist meer hardware en extra complexiteit.
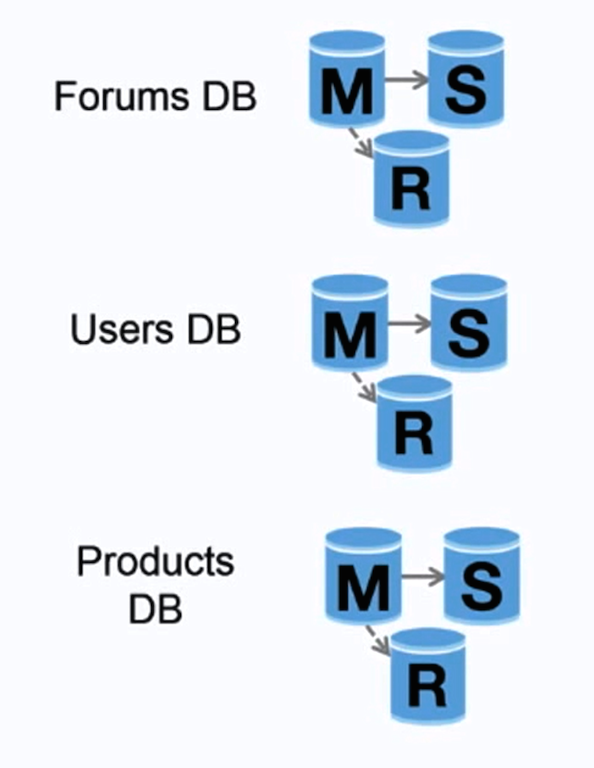
Bron: Opschalen naar je eerste 10 miljoen gebruikers
Federatie (of functionele partitionering) splitst databases op basis van functie. Bijvoorbeeld, in plaats van een enkele, monolithische database, kun je drie databases hebben: forums, gebruikers en producten, wat resulteert in minder lees- en schrijverkeer naar elke database en daardoor minder replicatielag. Kleinere databases zorgen ervoor dat meer data in het geheugen past, wat op zijn beurt leidt tot meer cache hits door verbeterde cache-lokaliteit. Omdat er geen centrale master is die schrijfacties serialiseert, kun je parallel schrijven, waardoor de throughput toeneemt.
##### Nadeel(en): federatie
- Federatie is niet effectief als je schema enorme functies of tabellen vereist.
- Je moet je applicatielogica aanpassen om te bepalen uit welke database je leest en schrijft.
- Het joinen van data uit twee databases is complexer met een serverlink.
- Federatie vereist meer hardware en extra complexiteit.
Bron: Scalability, availability, stability, patterns
Sharding verdeelt data over verschillende databases zodat elke database slechts een subset van de data beheert. Neem bijvoorbeeld een gebruikersdatabase: naarmate het aantal gebruikers toeneemt, worden er meer shards aan de cluster toegevoegd.
Net als bij de voordelen van federatie, resulteert sharding in minder lees- en schrijverkeer, minder replicatie en meer cache-hits. Ook de indexgrootte wordt verkleind, wat over het algemeen de prestaties verbetert door snellere queries. Als één shard uitvalt, blijven de andere shards operationeel, hoewel je een vorm van replicatie wilt toevoegen om dataverlies te voorkomen. Net als bij federatie is er geen centrale master die schrijfacties serialiseert, waardoor je parallel kunt schrijven met een hogere throughput.
Veelgebruikte manieren om een tabel met gebruikers te sharden zijn op basis van de beginletter van de achternaam van de gebruiker of de geografische locatie van de gebruiker.
##### Nadeel/nadelen: sharding
- Je moet je applicatielogica aanpassen om met shards te werken, wat kan resulteren in complexe SQL-query's.
- De dataverdeling kan scheefgroeien binnen een shard. Bijvoorbeeld, een groep power users op een shard kan leiden tot een hogere belasting voor die shard ten opzichte van andere shards.
- Herverdelen voegt extra complexiteit toe. Een shardingfunctie gebaseerd op consistent hashing kan de hoeveelheid overgedragen data verminderen.
- Het samenvoegen van data uit meerdere shards is complexer.
- Sharding vereist meer hardware en extra complexiteit.
Denormalisatie probeert de leesprestaties te verbeteren ten koste van wat schrijfprestaties. Redundante kopieën van de data worden in meerdere tabellen geschreven om dure joins te vermijden. Sommige RDBMS zoals PostgreSQL en Oracle ondersteunen materialized views, die het werk doen van het opslaan van redundante informatie en het consistent houden van kopieën.
Zodra data wordt gedistribueerd met technieken zoals federatie en sharding, maakt het beheren van joins over datacenters de complexiteit nog groter. Denormalisatie kan de noodzaak voor zulke complexe joins omzeilen.
In de meeste systemen zijn lezingen veel talrijker dan schrijfacties, bijvoorbeeld 100:1 of zelfs 1000:1. Een lezing die resulteert in een complexe database-join kan erg duur zijn, doordat er veel tijd aan schijfoperaties wordt besteed.
##### Nadeel/nadelen: denormalisatie
- Data wordt gedupliceerd.
- Constraints kunnen helpen om redundante kopieën van informatie synchroon te houden, maar verhogen de complexiteit van het databaseontwerp.
- Een gedennormaliseerde database onder zware schrijfbelasting kan slechter presteren dan een genormaliseerde variant.
SQL-optimalisatie is een breed onderwerp en er zijn veel boeken als referentie geschreven.
Het is belangrijk om te benchmarken en profileren om knelpunten te simuleren en te ontdekken.
- Benchmark - Simuleer situaties met hoge belasting met tools zoals ab.
- Profileren - Schakel tools in zoals het slow query log om prestatieproblemen te traceren.
##### Schema optimaliseren
- MySQL dumpt naar disk in aaneengesloten blokken voor snelle toegang.
- Gebruik
CHARin plaats vanVARCHARvoor velden met vaste lengte. CHARmaakt snelle, willekeurige toegang mogelijk, terwijl bijVARCHAReerst het einde van een string gevonden moet worden voordat je naar de volgende gaat.- Gebruik
TEXTvoor grote tekstblokken zoals blogposts.TEXTmaakt ook booleaanse zoekopdrachten mogelijk. Het gebruik van eenTEXT-veld zorgt ervoor dat er een pointer op de schijf wordt opgeslagen die wordt gebruikt om het tekstblok te vinden. - Gebruik
INTvoor grotere getallen tot 2^32 of 4 miljard. - Gebruik
DECIMALvoor valuta om fouten in drijvende-kommagetallen te voorkomen. - Vermijd het opslaan van grote
BLOBS, sla in plaats daarvan de locatie op waar het object te vinden is. VARCHAR(255)is het grootste aantal tekens dat kan worden geteld in een 8-bits getal, wat vaak het gebruik van een byte in sommige RDBMS maximaliseert.- Stel waar mogelijk de
NOT NULL-beperking in om zoekprestaties te verbeteren.
- Kolommen waarop je queryt (
SELECT,GROUP BY,ORDER BY,JOIN) kunnen sneller zijn met indexen. - Indexen worden meestal weergegeven als zelf-balancerende B-boom die data sorteert en zoeken, sequentiële toegang, invoegingen en verwijderingen in logaritmische tijd mogelijk maakt.
- Het plaatsen van een index kan ervoor zorgen dat de data in het geheugen blijft, wat meer ruimte vereist.
- Schrijfbewerkingen kunnen ook trager zijn omdat de index ook geüpdatet moet worden.
- Bij het laden van grote hoeveelheden data kan het sneller zijn om indexen uit te schakelen, de data te laden en daarna de indexen opnieuw op te bouwen.
- Denormaliseer waar de prestaties dit vereisen.
- Splits een tabel op door hot spots in een aparte tabel te plaatsen om te helpen het in het geheugen te houden.
- In sommige gevallen kan de querycache leiden tot prestatieproblemen.
- Tips voor het optimaliseren van MySQL-query's
- Is er een goede reden waarom ik VARCHAR(255) zo vaak zie?
- Hoe beïnvloeden null-waarden de prestaties?
- Slow query log
NoSQL
NoSQL is een verzameling gegevensitems weergegeven in een key-value store, document store, wide column store of een grafendatabase. Gegevens zijn gedenormaliseerd en joins worden doorgaans in de applicatiecode uitgevoerd. De meeste NoSQL-stores missen echte ACID-transacties en geven de voorkeur aan eventual consistency.
BASE wordt vaak gebruikt om de eigenschappen van NoSQL-databases te beschrijven. In vergelijking met de CAP Theorema, kiest BASE voor beschikbaarheid boven consistentie.
- Basically available - het systeem garandeert beschikbaarheid.
- Soft state - de toestand van het systeem kan in de loop van de tijd veranderen, zelfs zonder invoer.
- Eventual consistency - het systeem zal consistent worden over een bepaalde periode, mits het systeem in die periode geen invoer ontvangt.
#### Key-value store
Abstractie: hashtabel
Een key-value store staat doorgaans O(1) lezen en schrijven toe en wordt vaak ondersteund door geheugen of SSD. Datastores kunnen sleutels in lexicografische volgorde bewaren, waardoor efficiënte retrieval van sleutelbereiken mogelijk is. Key-value stores kunnen het opslaan van metadata bij een waarde toestaan.
Key-value stores bieden hoge prestaties en worden vaak gebruikt voor eenvoudige datamodellen of voor snel veranderende data, zoals een in-memory cachelaag. Omdat ze slechts een beperkte set aan bewerkingen bieden, verschuift de complexiteit naar de applicatielaag als er extra operaties nodig zijn.
Een key-value store vormt de basis voor complexere systemen zoals een document store, en in sommige gevallen een grafendatabase.
##### Bron(nen) en verdere literatuur: key-value store
#### Document storeAbstractie: key-value store met documenten opgeslagen als waarden
Een document store is gericht op documenten (XML, JSON, binair, enz.), waarbij een document alle informatie voor een bepaald object opslaat. Document stores bieden API's of een querytaal om te zoeken op basis van de interne structuur van het document zelf. Let op, veel key-value stores bevatten functies om met de metadata van een waarde te werken, waardoor de grenzen tussen deze twee opslagtypen vervagen.
Afhankelijk van de onderliggende implementatie worden documenten georganiseerd via collecties, tags, metadata of mappen. Hoewel documenten georganiseerd of gegroepeerd kunnen worden, kunnen documenten velden bevatten die volledig verschillend zijn van elkaar.
Sommige document stores zoals MongoDB en CouchDB bieden ook een SQL-achtige taal om complexe queries uit te voeren. DynamoDB ondersteunt zowel key-values als documenten.
Document stores bieden hoge flexibiliteit en worden vaak gebruikt voor het werken met af en toe veranderende data.
##### Bron(nen) en verdere literatuur: document store
#### Wide column store
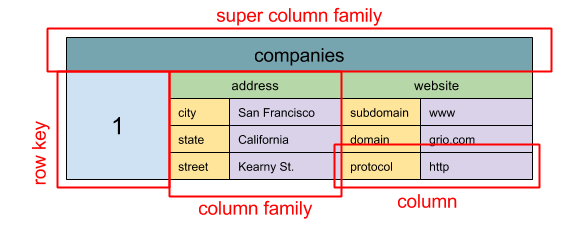
Bron: SQL & NoSQL, een korte geschiedenis
Abstractie: geneste map ColumnFamily> De basis eenheid van data in een wide column store is een kolom (naam/waarde-paar). Een kolom kan worden gegroepeerd in kolomfamilies (vergelijkbaar met een SQL-tabel). Super column families groeperen kolomfamilies verder. Je kunt elke kolom onafhankelijk benaderen met een rij-sleutel, en kolommen met dezelfde rij-sleutel vormen een rij. Elke waarde bevat een timestamp voor versiebeheer en conflictoplossing.
Google introduceerde Bigtable als de eerste wide column store, wat invloed had op de open-source HBase die vaak gebruikt wordt in het Hadoop-ecosysteem, en Cassandra van Facebook. Stores zoals BigTable, HBase en Cassandra houden sleutels in lexicografische volgorde bij, waardoor efficiënte opvraging van selectieve sleutelbereiken mogelijk is.
Wide column stores bieden hoge beschikbaarheid en hoge schaalbaarheid. Ze worden vaak gebruikt voor zeer grote datasets.
##### Bron(nen) en verdere literatuur: wide column store
#### Grafendatabase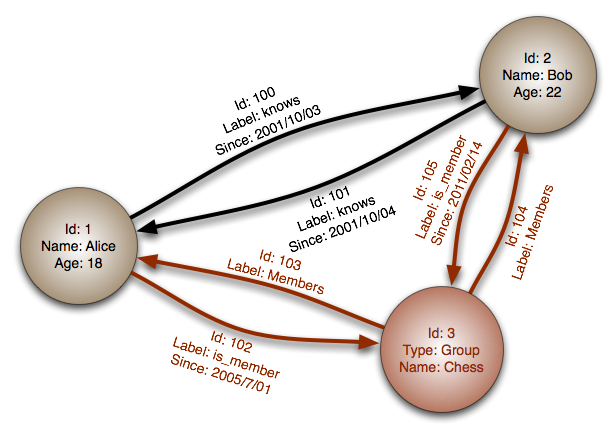
Abstractie: graaf
In een grafendatabase is elke knoop een record en elke boog een relatie tussen twee knopen. Grafendatabases zijn geoptimaliseerd om complexe relaties met veel vreemde sleutels of veel-naar-veel-relaties weer te geven.
Grafendatabases bieden hoge prestaties voor datamodellen met complexe relaties, zoals een sociaal netwerk. Ze zijn relatief nieuw en nog niet wijdverspreid gebruikt; het kan moeilijker zijn om ontwikkeltools en bronnen te vinden. Veel grafen zijn alleen toegankelijk via REST API's.
##### Bron(nen) en verdere literatuur: graaf
#### Bron(nen) en verdere literatuur: NoSQL- Uitleg van base terminologie
- NoSQL-databases: een overzicht en beslissingshulp
- Schaalbaarheid
- Introductie tot NoSQL
- NoSQL-patronen
SQL of NoSQL
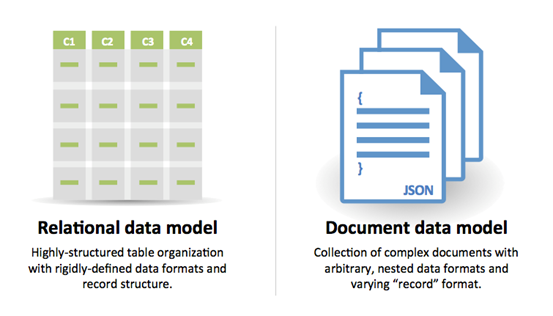
Bron: Overgang van RDBMS naar NoSQL
Redenen voor SQL:
- Gestructureerde data
- Strikt schema
- Relationele data
- Behoefte aan complexe joins
- Transacties
- Duidelijke patronen voor schaalbaarheid
- Meer gevestigd: ontwikkelaars, community, code, tools, enz.
- Opzoeken via index is erg snel
- Semi-gestructureerde data
- Dynamisch of flexibel schema
- Niet-relationele data
- Geen behoefte aan complexe joins
- Opslaan van vele TB (of PB) aan data
- Zeer data-intensieve workload
- Zeer hoge doorvoer voor IOPS
- Snelle opname van clickstream- en logdata
- Leaderboard- of scoringsdata
- Tijdelijke data, zoals een winkelwagen
- Vaak geraadpleegde ('hot') tabellen
- Metadata/lookup-tabellen
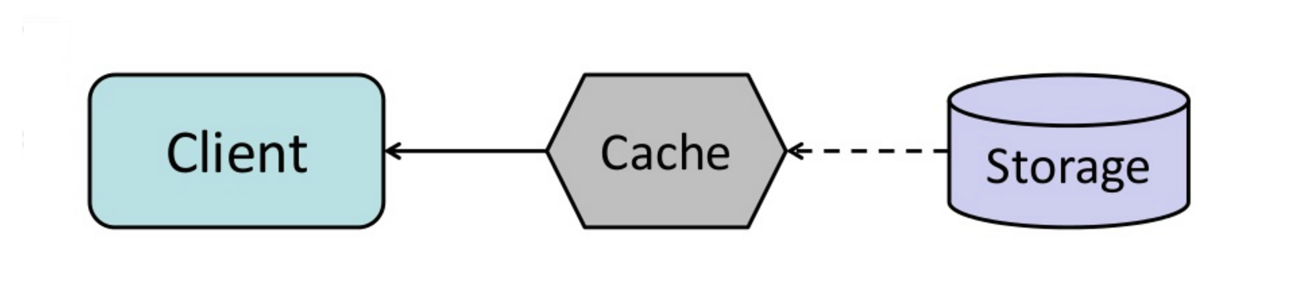
Cache
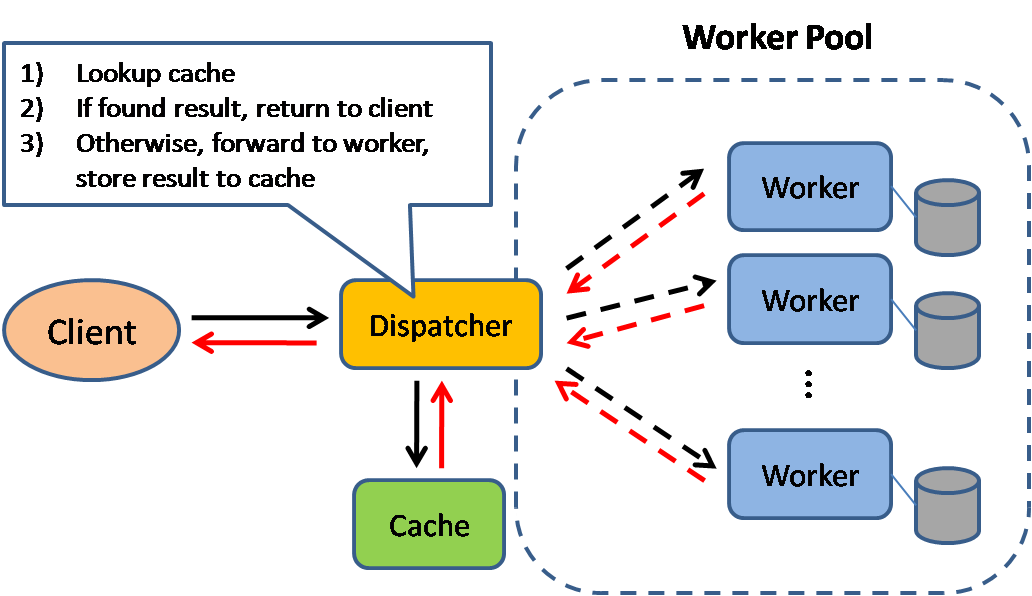
Bron: Schaalbare systeemontwerppatronen
Caching verbetert de laadtijden van pagina's en kan de belasting van uw servers en databases verminderen. In dit model zal de dispatcher eerst controleren of het verzoek eerder is gedaan en proberen het eerdere resultaat te vinden om terug te geven, om zo de daadwerkelijke uitvoering te besparen.
Databases profiteren vaak van een uniforme verdeling van lees- en schrijfbewerkingen over hun partities. Populaire items kunnen de verdeling verstoren, wat knelpunten veroorzaakt. Een cache voor een database kan helpen om onevenwichtige belasting en pieken in verkeer op te vangen.
Client-caching
Caches kunnen zich bevinden aan de clientzijde (OS of browser), serverzijde, of in een aparte cachelaag.
CDN-caching
CDN's worden beschouwd als een type cache.
Webserver-caching
Reverse proxies en caches zoals Varnish kunnen statische en dynamische inhoud direct serveren. Webservers kunnen ook verzoeken cachen, waardoor ze antwoorden kunnen geven zonder applicatieservers te hoeven raadplegen.
Database-caching
Uw database bevat meestal een bepaald niveau van caching in de standaardconfiguratie, geoptimaliseerd voor een generiek gebruiksscenario. Het aanpassen van deze instellingen voor specifieke gebruikspatronen kan de prestaties verder verbeteren.
Applicatie-caching
In-memory caches zoals Memcached en Redis zijn key-value stores tussen uw applicatie en uw gegevensopslag. Omdat de gegevens in RAM worden gehouden, is het veel sneller dan typische databases waar gegevens op schijf worden opgeslagen. RAM is beperkter dan schijf, dus cache-invalidatie algoritmes zoals least recently used (LRU)) kunnen helpen om 'koude' items te verwijderen en 'hete' data in RAM te houden.
Redis heeft de volgende extra functies:
- Optie voor persistentie
- Ingebouwde datastructuren zoals gesorteerde sets en lijsten
- Rij-niveau
- Query-niveau
- Volledig gevormde serialiseerbare objecten
- Volledig gerenderde HTML
Caching op het niveau van databasequery's
Wanneer je de database bevraagt, hash je de query als een sleutel en sla je het resultaat op in de cache. Deze aanpak heeft te maken met problemen rondom verlopen:
- Moeilijk om een gecachet resultaat met complexe queries te verwijderen
- Als één stukje data verandert, zoals een tabelcel, moet je alle gecachete queries verwijderen die de gewijzigde cel kunnen bevatten
Caching op objectniveau
Zie je data als een object, vergelijkbaar met wat je doet met je applicatiecode. Laat je applicatie de dataset uit de database samenstellen tot een klasse-instantie of een datastructuur(en):
- Verwijder het object uit de cache als de onderliggende data is gewijzigd
- Staat asynchrone verwerking toe: workers stellen objecten samen door het meest recente gecachete object te gebruiken
- Gebruikerssessies
- Volledig gerenderde webpagina's
- Activiteitenstromen
- Gebruikersgrafiekdata
Wanneer de cache bijwerken
Aangezien je maar een beperkte hoeveelheid data in de cache kunt opslaan, moet je bepalen welke cache-update strategie het beste werkt voor jouw use case.
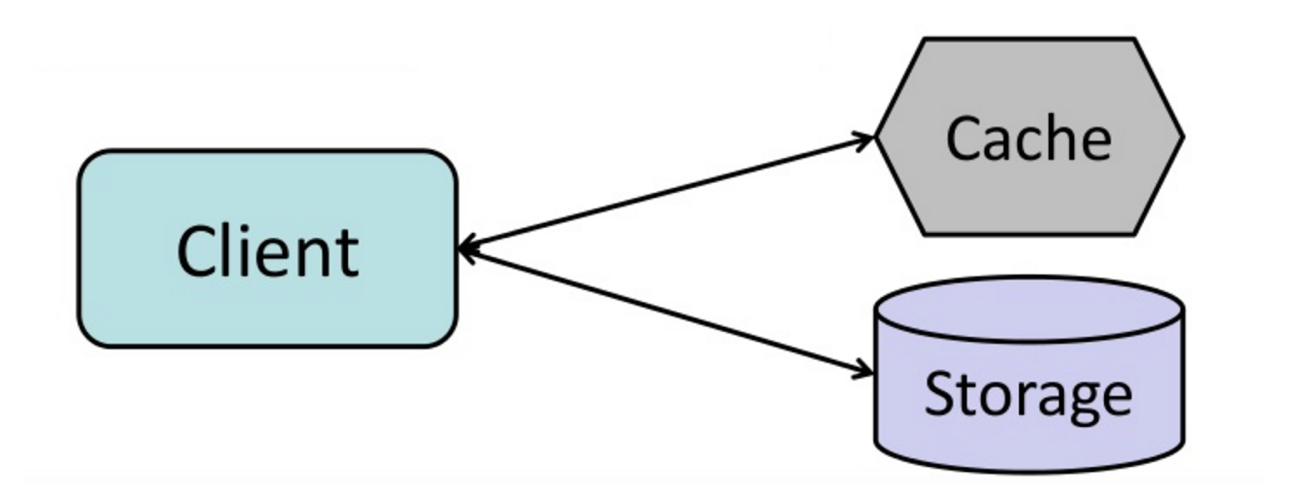
#### Cache-aside
Bron: From cache to in-memory data grid
De applicatie is verantwoordelijk voor het lezen en schrijven vanuit de opslag. De cache werkt niet direct samen met de opslag. De applicatie doet het volgende:
- Zoek naar een item in de cache, wat resulteert in een cache-miss
- Laad item uit de database
- Voeg item toe aan de cache
- Geef item terug
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached wordt doorgaans op deze manier gebruikt.
Latere uitlezingen van gegevens die aan de cache zijn toegevoegd, zijn snel. Cache-aside wordt ook wel lazy loading genoemd. Alleen opgevraagde gegevens worden gecachet, waardoor wordt voorkomen dat de cache vol raakt met niet-opgevraagde gegevens.
##### Nadeel(en): cache-aside
- Elke cache miss resulteert in drie bewerkingen, wat een merkbare vertraging kan veroorzaken.
- Gegevens kunnen verouderd raken als ze worden bijgewerkt in de database. Dit probleem wordt verminderd door een time-to-live (TTL) in te stellen, waardoor een update van het cache-item wordt afgedwongen, of door write-through te gebruiken.
- Wanneer een node faalt, wordt deze vervangen door een nieuwe, lege node, wat de latentie verhoogt.
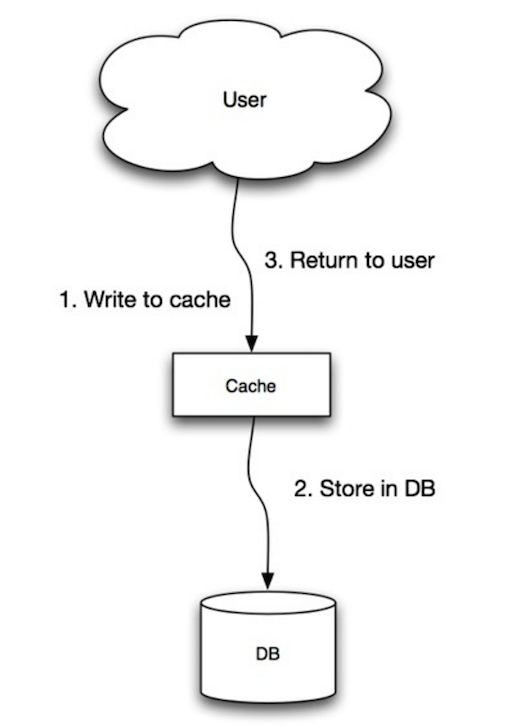
Bron: Scalability, availability, stability, patterns
De applicatie gebruikt de cache als hoofdgegevensopslag, waarbij het lezen en schrijven van gegevens via de cache verloopt, terwijl de cache verantwoordelijk is voor het lezen en schrijven naar de database:
- Applicatie voegt een item toe aan de cache of werkt deze bij
- Cache schrijft het item synchroon naar de datastore
- Retourneer
set_user(12345, {"foo":"bar"})Cachecode:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Nadeel/nadelen: write through
- Wanneer er een nieuwe node wordt aangemaakt door een storing of opschaling, zal de nieuwe node geen items cachen totdat het item is bijgewerkt in de database. Cache-aside in combinatie met write through kan dit probleem verminderen.
- De meeste geschreven data wordt mogelijk nooit gelezen, wat kan worden geminimaliseerd met een TTL.
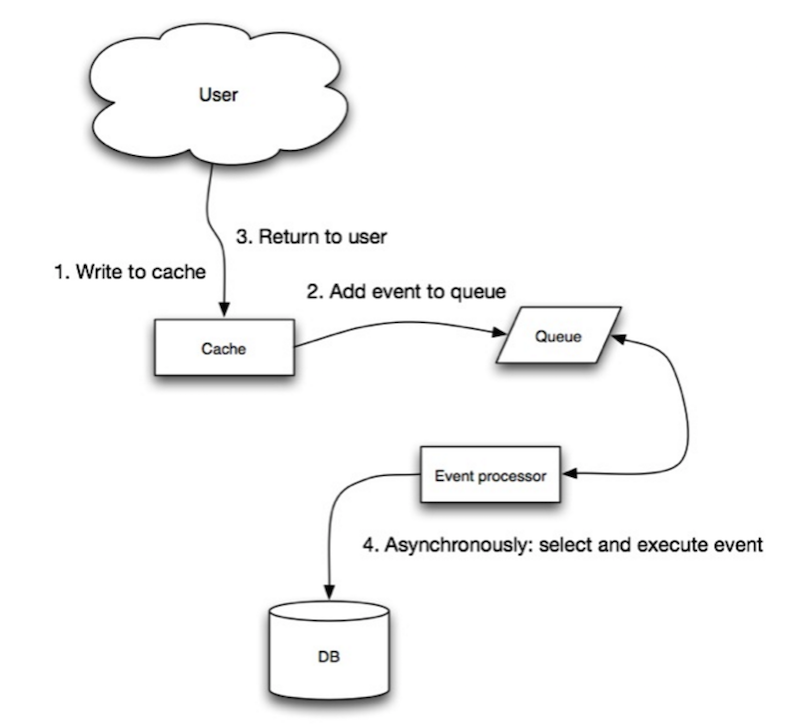
Bron: Scalability, availability, stability, patterns
Bij write-behind voert de applicatie het volgende uit:
- Item toevoegen/bijwerken in de cache
- Item asynchroon schrijven naar de datastore, wat de schrijfprestaties verbetert
- Er kan dataverlies optreden als de cache uitvalt voordat de inhoud naar de datastore is weggeschreven.
- Het is complexer om write-behind te implementeren dan cache-aside of write-through.
Bron: From cache to in-memory data grid
Je kunt de cache zo configureren dat deze automatisch elke recent geraadpleegde cache-entry ververst voordat deze verloopt.
Refresh-ahead kan resulteren in lagere latentie t.o.v. read-through als de cache nauwkeurig kan voorspellen welke items waarschijnlijk in de toekomst nodig zijn.
##### Nadeel/nadelen: refresh-ahead
- Het niet nauwkeurig voorspellen welke items waarschijnlijk in de toekomst nodig zullen zijn, kan leiden tot een lagere prestatie dan zonder refresh-ahead.
Nadeel/nadelen: cache
- Consistentie moet worden behouden tussen caches en de bron van waarheid, zoals de database, door middel van cache-invalidatie.
- Cache-invalidatie is een lastig probleem, er is extra complexiteit verbonden aan het moment waarop de cache moet worden bijgewerkt.
- Er moeten applicatiewijzigingen worden doorgevoerd, zoals het toevoegen van Redis of memcached.
Bron(nen) en verdere literatuur
- Van cache naar in-memory data grid
- Schaalbare systeemontwerp-patronen
- Introductie tot het ontwerpen van systemen voor schaalbaarheid
- Schaalbaarheid, beschikbaarheid, stabiliteit, patronen
- Schaalbaarheid
- AWS ElastiCache strategieën
- Wikipedia)
Asynchronisme
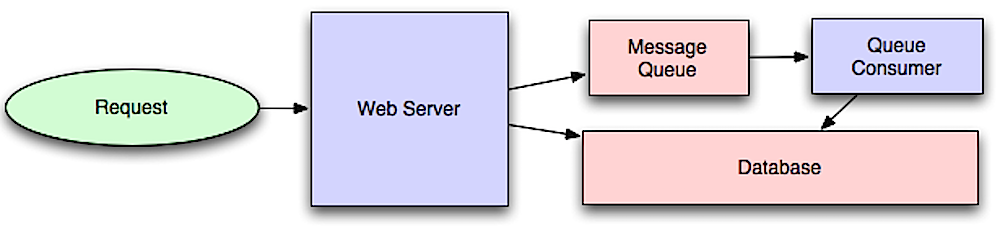
Bron: Introductie tot het ontwerpen van systemen voor schaalbaarheid
Asynchrone workflows helpen om verzoektijden te verkorten voor dure operaties die anders in-line zouden worden uitgevoerd. Ze kunnen ook helpen door tijdrovend werk vooraf uit te voeren, zoals periodieke aggregatie van data.
Message queues
Message queues ontvangen, bewaren en leveren berichten. Als een operatie te traag is om in-line uit te voeren, kun je een message queue gebruiken met de volgende workflow:
- Een applicatie publiceert een taak naar de queue en meldt vervolgens de status aan de gebruiker
- Een worker haalt de taak uit de queue, verwerkt deze, en geeft daarna aan dat de taak voltooid is
Redis is bruikbaar als eenvoudige message broker, maar berichten kunnen verloren gaan.
RabbitMQ is populair maar vereist dat je je aanpast aan het 'AMQP'-protocol en je eigen nodes beheert. Amazon SQS is gehost maar kan hoge latentie hebben en berichten kunnen mogelijk dubbel worden afgeleverd.
Taakwachtrijen
Taakwachtrijen ontvangen taken en de bijbehorende data, voeren deze uit en leveren vervolgens de resultaten af. Ze kunnen planning ondersteunen en worden gebruikt voor het uitvoeren van rekenintensieve taken op de achtergrond.
Celery ondersteunt planning en heeft voornamelijk ondersteuning voor Python.
Terugdruk (Back pressure)
Als wachtrijen aanzienlijk beginnen te groeien, kan de wachtrij groter worden dan het geheugen, wat leidt tot cache-misses, schijflezingen en zelfs tragere prestaties. Terugdruk kan helpen door de wachtrijgrootte te beperken, waardoor een hoge doorvoersnelheid en goede responstijden voor reeds aanwezige taken in de wachtrij behouden blijven. Zodra de wachtrij vol is, krijgen clients een 'server busy' of HTTP 503 statuscode om het later opnieuw te proberen. Clients kunnen het verzoek op een later tijdstip opnieuw proberen, eventueel met exponentiële back-off.
Nadeel/nadelen: asynchronisme
- Gebruiksscenario's zoals goedkope berekeningen en realtime workflows zijn mogelijk beter geschikt voor synchrone operaties, omdat het introduceren van wachtrijen vertragingen en complexiteit kan toevoegen.
Bron(nen) en verdere lectuur
- Het is allemaal een kwestie van cijfers
- Terugdruk toepassen bij overbelasting
- Wet van Little
- Wat is het verschil tussen een berichtwachtrij en een taakwachtrij?
Communicatie
{kind=link}
{kind=link}
Hypertext transfer protocol (HTTP)
HTTP is een methode voor het coderen en transporteren van data tussen een client en een server. Het is een request/response-protocol: clients sturen verzoeken en servers sturen antwoorden met relevante inhoud en statusinformatie over het verzoek. HTTP is zelfvoorzienend, waardoor verzoeken en antwoorden door veel tussenliggende routers en servers kunnen stromen die load balancing, caching, encryptie en compressie uitvoeren.
Een basale HTTP-aanvraag bestaat uit een werkwoord (methode) en een bron (endpoint). Hieronder staan gangbare HTTP-werkwoorden:
| Werkwoord | Beschrijving | Idempotent* | Veilig | Cachebaar | |---|---|---|---|---|
| GET | Leest een resource | Ja | Ja | Ja | | POST | Creëert een resource of start een proces dat gegevens verwerkt | Nee | Nee | Ja, als de reactie versheidsinformatie bevat | | PUT | Creëert of vervangt een resource | Ja | Nee | Nee | | PATCH | Past een resource gedeeltelijk aan | Nee | Nee | Ja, als de reactie versheidsinformatie bevat | | DELETE | Verwijdert een resource | Ja | Nee | Nee |
*Kan meerdere keren worden aangeroepen zonder verschillende uitkomsten.
HTTP is een applicatielaagprotocol dat afhankelijk is van onderliggende protocollen zoals TCP en UDP.
#### Bron(nen) en verder lezen: HTTP
Transmission Control Protocol (TCP)
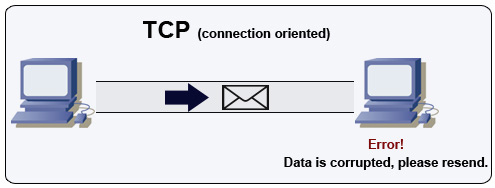
Bron: How to make a multiplayer game
TCP is een verbindingsgericht protocol via een IP-netwerk. Verbinding wordt opgezet en beëindigd met een handshake. Alle verzonden pakketten worden gegarandeerd in de originele volgorde en zonder fouten afgeleverd door:
- Sequentienummers en checksumvelden voor elk pakket
- Bevestigings)pakketten en automatische hertransmissie
Om een hoge doorvoersnelheid te garanderen, kunnen webservers een groot aantal TCP-verbindingen open houden, wat leidt tot hoog geheugengebruik. Het kan kostbaar zijn om veel open verbindingen te hebben tussen webserverthreads en bijvoorbeeld een memcached server. Connection pooling kan helpen, naast overschakelen op UDP waar mogelijk.
TCP is nuttig voor toepassingen die hoge betrouwbaarheid vereisen, maar minder tijdkritisch zijn. Enkele voorbeelden zijn webservers, database-informatie, SMTP, FTP en SSH.
Gebruik TCP boven UDP wanneer:
- Je wilt dat alle gegevens intact aankomen
- Je automatisch het beste gebruik van de netwerkdoorvoer wilt maken
User datagram protocol (UDP)
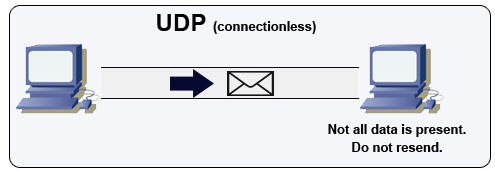
Bron: Hoe maak je een multiplayer spel
UDP is verbindingloos. Datagrammen (vergelijkbaar met pakketten) zijn alleen gegarandeerd op het niveau van het datagram. Datagrammen kunnen hun bestemming in verkeerde volgorde bereiken of helemaal niet. UDP ondersteunt geen congestiecontrole. Zonder de garanties die TCP biedt, is UDP over het algemeen efficiënter.
UDP kan broadcasten, datagrammen versturen naar alle apparaten op het subnet. Dit is handig bij DHCP omdat de client nog geen IP-adres heeft ontvangen, waardoor TCP niet kan streamen zonder het IP-adres.
UDP is minder betrouwbaar maar werkt goed in real-time toepassingen zoals VoIP, videochat, streaming en realtime multiplayer games.
Gebruik UDP boven TCP wanneer:
- Je de laagste latency nodig hebt
- Late gegevens zijn erger dan verlies van gegevens
- Je je eigen foutcorrectie wilt implementeren
- Netwerken voor game-programmering
- Belangrijkste verschillen tussen TCP- en UDP-protocollen
- Verschil tussen TCP en UDP
- Transmission control protocol
- User datagram protocol
- Memcache schalen bij Facebook
Remote procedure call (RPC)
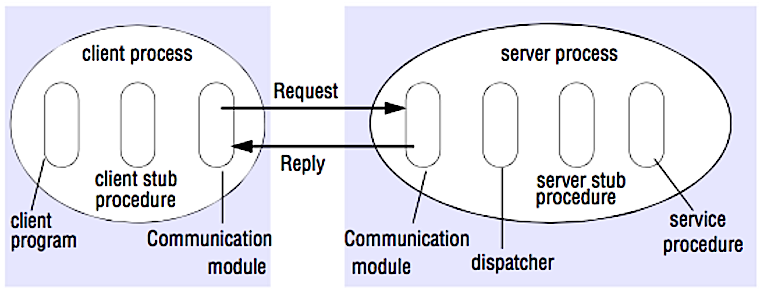
Bron: Crack the system design interview
Bij een RPC zorgt een client ervoor dat een procedure wordt uitgevoerd op een ander adresruimte, meestal een externe server. De procedure wordt gecodeerd alsof het een lokale procedure-aanroep is, waarbij de details van de communicatie met de server voor het clientprogramma worden geabstraheerd. Externe aanroepen zijn meestal trager en minder betrouwbaar dan lokale aanroepen, dus het is nuttig om RPC-aanroepen te onderscheiden van lokale aanroepen. Populaire RPC-frameworks zijn onder andere Protobuf, Thrift en Avro.
RPC is een request-response protocol:
- Clientprogramma - Roept de client-stubprocedure aan. De parameters worden op de stack geplaatst zoals bij een lokale procedureaanroep.
- Client-stubprocedure - Verpakt (marshalt) het procedure-ID en de argumenten in een verzoekbericht.
- Communicatiemodule cliënt - Het besturingssysteem verzendt het bericht van de cliënt naar de server.
- Communicatiemodule server - Het besturingssysteem geeft de binnenkomende pakketten door aan de server-stubprocedure.
- Server-stubprocedure - Haalt de resultaten uit elkaar (unmarshalt), roept de serverprocedure aan die overeenkomt met het procedure-ID en geeft de meegegeven argumenten door.
- De serverreactie herhaalt bovenstaande stappen in omgekeerde volgorde.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC is gericht op het blootleggen van gedragingen. RPC's worden vaak gebruikt om prestatie-redenen bij interne communicatie, omdat je native aanroepen handmatig kunt aanpassen aan je use-cases.
Kies een native bibliotheek (ook wel SDK) wanneer:
- Je weet wat je doelsysteem is.
- Je wilt controleren hoe je "logica" toegankelijk is.
- Je wilt controleren hoe foutafhandeling buiten je bibliotheek gebeurt.
- Prestaties en gebruikerservaring zijn je primaire zorg.
#### Nadelen: RPC
- RPC-clients worden sterk gekoppeld aan de implementatie van de service.
- Voor elke nieuwe operatie of use-case moet een nieuwe API worden gedefinieerd.
- Het kan lastig zijn om RPC te debuggen.
- Mogelijk kun je bestaande technologieën niet direct gebruiken. Bijvoorbeeld, het kan extra inspanning kosten om te zorgen dat RPC-aanroepen correct worden gecached op caching servers zoals Squid.
Representational state transfer (REST)
REST is een architecturale stijl die een client/server-model afdwingt waarbij de client werkt op een set resources beheerd door de server. De server biedt een representatie van resources en acties die resources kunnen manipuleren of een nieuwe representatie kunnen ophalen. Alle communicatie moet stateless en cachebaar zijn.
Er zijn vier kwaliteiten van een RESTful interface:
- Identificeer resources (URI in HTTP) - gebruik dezelfde URI ongeacht de operatie.
- Wijzig met representaties (Werkwoorden in HTTP) - gebruik werkwoorden, headers en body.
- Zelfbeschrijvende foutmelding (statusrespons in HTTP) - Gebruik statuscodes, bedenk het wiel niet opnieuw.
- HATEOAS (HTML-interface voor HTTP) - je webservice moet volledig toegankelijk zijn in een browser.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Nadeel/nadelen: REST
- Omdat REST zich richt op het beschikbaar stellen van data, is het misschien niet geschikt als resources niet op natuurlijke wijze georganiseerd zijn of niet eenvoudig via een hiërarchie benaderd kunnen worden. Bijvoorbeeld, het teruggeven van alle bijgewerkte records van het afgelopen uur die overeenkomen met een bepaalde set gebeurtenissen is niet eenvoudig uit te drukken als een pad. Bij REST wordt dit waarschijnlijk geïmplementeerd met een combinatie van URI-pad, queryparameters en mogelijk de request body.
- REST vertrouwt doorgaans op een paar werkwoorden (GET, POST, PUT, DELETE en PATCH) die soms niet bij je use case passen. Bijvoorbeeld, het verplaatsen van verlopen documenten naar de archiefmap past misschien niet goed binnen deze werkwoorden.
- Het ophalen van ingewikkelde resources met geneste hiërarchieën vereist meerdere roundtrips tussen client en server om één enkele view weer te geven, bijvoorbeeld het ophalen van de inhoud van een blogbericht en de reacties op dat bericht. Voor mobiele applicaties die werken onder wisselende netwerkcondities zijn deze meerdere roundtrips zeer ongewenst.
- Na verloop van tijd kunnen er meer velden worden toegevoegd aan een API-respons en oudere clients ontvangen dan alle nieuwe datavelden, zelfs diegene die ze niet nodig hebben, wat leidt tot een opgeblazen payload en grotere latenties.
Vergelijking RPC- en REST-aanroepen
| Operatie | RPC | REST |
|---|---|---|
| Aanmelden | POST /signup | POST /persons |
| Afmelden | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Lees een persoon | GET /readPerson?personid=1234 | GET /persons/1234 |
| Lees de itemlijst van een persoon | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Voeg een item toe aan de items van een persoon | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Update een item | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Verwijder een item | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Bron: Weet je echt waarom je REST verkiest boven RPC?
#### Bron(nen) en verder lezen: REST en RPC
- Weet je echt waarom je REST verkiest boven RPC
- Wanneer zijn RPC-achtige benaderingen geschikter dan REST?
- REST vs JSON-RPC
- Mythes over RPC en REST ontkracht
- Wat zijn de nadelen van het gebruik van REST
- Kraak het system design interview
- Thrift
- Waarom REST voor intern gebruik en niet RPC
Beveiliging
Deze sectie kan wel wat updates gebruiken. Overweeg om bij te dragen!
Beveiliging is een breed onderwerp. Tenzij je aanzienlijke ervaring hebt, een achtergrond in beveiliging, of solliciteert naar een functie die kennis van beveiliging vereist, hoef je waarschijnlijk niet meer te weten dan de basis:
- Versleutel tijdens transport en opslag.
- Sanitize alle gebruikersinvoer of elke invoerparameter die aan de gebruiker wordt blootgesteld om XSS en SQL-injectie te voorkomen.
- Gebruik geparameteriseerde queries om SQL-injectie te voorkomen.
- Gebruik het principe van least privilege.
Bron(nen) en verdere literatuur
Appendix
Je zult soms worden gevraagd om 'back-of-the-envelope' schattingen te maken. Bijvoorbeeld, je moet misschien bepalen hoe lang het duurt om 100 afbeeldingsminiaturen van schijf te genereren of hoeveel geheugen een datastructuur zal innemen. De Twee machten-tabel en Latentiecijfers die elke programmeur zou moeten kennen zijn handige referenties.
Twee machten-tabel
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Bron(nen) en verdere literatuur
Latency-cijfers die elke programmeur zou moeten kennen
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Sequentieel lezen van HDD met 30 MB/s
- Sequentieel lezen via 1 Gbps Ethernet met 100 MB/s
- Sequentieel lezen van SSD met 1 GB/s
- Sequentieel lezen uit hoofdgeheugen met 4 GB/s
- 6-7 wereldwijde roundtrips per seconde
- 2.000 roundtrips per seconde binnen een datacenter
#### Bron(nen) en verdere literatuur
- Latentiegetallen die elke programmeur zou moeten weten - 1
- Latentiegetallen die elke programmeur zou moeten weten - 2
- Ontwerpen, lessen en advies uit het bouwen van grote gedistribueerde systemen
- Advies software engineering uit het bouwen van grootschalige gedistribueerde systemen
Extra systeemontwerp interviewvragen
Veelvoorkomende systeemontwerp interviewvragen, met links naar bronnen over hoe je ze oplost.
| Vraag | Referentie(s) |
|---|---|
| Ontwerp een bestandsynchronisatieservice zoals Dropbox | youtube.com |
| Ontwerp een zoekmachine zoals Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Ontwerp een schaalbare webcrawler zoals Google | quora.com |
| Ontwerp Google docs | code.google.com
neil.fraser.name |
| Ontwerp een key-value store zoals Redis | slideshare.net |
| Ontwerp een cachesysteem zoals Memcached | slideshare.net |
| Ontwerp een aanbevelingssysteem zoals dat van Amazon | hulu.com
ijcai13.org |
| Ontwerp een tinyurl systeem zoals Bitly | n00tc0d3r.blogspot.com |
| Ontwerp een chatapp zoals WhatsApp | highscalability.com
| Ontwerp een fotosharing systeem zoals Instagram | highscalability.com
highscalability.com |
| Ontwerp de Facebook nieuwsfeed functie | quora.com
quora.com
slideshare.net |
| Ontwerp de Facebook tijdlijnfunctie | facebook.com
highscalability.com |
| Ontwerp de Facebook chatfunctie | erlang-factory.com
facebook.com |
| Ontwerp een grafzoekfunctie zoals die van Facebook | facebook.com
facebook.com
facebook.com |
| Ontwerp een content delivery network zoals CloudFlare | figshare.com |
| Ontwerp een trending topic systeem zoals dat van Twitter | michael-noll.com
snikolov .wordpress.com |
| Ontwerp een willekeurig ID-generatiesysteem | blog.twitter.com
github.com |
| Geef de top k verzoeken terug binnen een tijdsinterval | cs.ucsb.edu
wpi.edu |
| Ontwerp een systeem dat data uit meerdere datacenters serveert | highscalability.com |
| Ontwerp een online multiplayer kaartspel | indieflashblog.com
buildnewgames.com |
| Ontwerp een garbage collection systeem | stuffwithstuff.com
washington.edu |
| Ontwerp een API rate limiter | https://stripe.com/blog/ |
| Ontwerp een effectenbeurs (zoals NASDAQ of Binance) | Jane Street
Golang Implementation
Go Implementation |
| Voeg een systeemontwerpvraag toe | Bijdragen |
Architecturen uit de echte wereld
Artikelen over hoe systemen uit de echte wereld zijn ontworpen.
Bron: Twitter tijdlijnen op schaal
Focus niet op de kleine details in de volgende artikelen, maar:
- Identificeer gedeelde principes, gemeenschappelijke technologieën en patronen binnen deze artikelen
- Bestudeer welke problemen door elk component worden opgelost, waar het werkt en waar niet
- Bekijk de geleerde lessen
Bedrijfsarchitecturen
| Bedrijf | Referentie(s) |
|---|---|
| Amazon | Amazon architectuur |
| Cinchcast | Dagelijks 1.500 uur audio produceren |
| DataSift | Realtime datamining bij 120.000 tweets per seconde |
| Dropbox | Hoe we Dropbox hebben opgeschaald |
| ESPN | Werken op 100.000 duh nuh nuhs per seconde |
| Google | Google architectuur |
| Instagram | 14 miljoen gebruikers, terabytes aan foto's
Wat Instagram aandrijft |
| Justin.tv | Live video-uitzendarchitectuur van Justin.tv |
| Facebook | Memcached opschalen bij Facebook
TAO: Facebook’s gedistribueerde datastore voor het sociale netwerk
Facebook’s foto-opslag
Hoe Facebook Live streams naar 800.000 gelijktijdige kijkers |
| Flickr | Flickr architectuur |
| Mailbox | Van 0 naar een miljoen gebruikers in 6 weken |
| Netflix | Een 360 graden blik op de volledige Netflix stack
Netflix: Wat gebeurt er als je op Play drukt? |
| Pinterest | Van 0 naar tientallen miljarden pageviews per maand
18 miljoen bezoekers, 10x groei, 12 werknemers |
| Playfish | 50 miljoen maandelijkse gebruikers en groeiend |
| PlentyOfFish | PlentyOfFish architectuur |
| Salesforce | Hoe ze 1,3 miljard transacties per dag verwerken |
| Stack Overflow | Stack Overflow architectuur |
| TripAdvisor | 40M bezoekers, 200M dynamische pageviews, 30TB data |
| Tumblr | 15 miljard pageviews per maand |
| Twitter | Twitter 10.000 procent sneller maken
250 miljoen tweets per dag opslaan met MySQL
150M actieve gebruikers, 300K QPS, een 22 MB/S firehose
Tijdlijnen op schaal
Big en small data bij Twitter
Operaties bij Twitter: opschalen tot boven de 100 miljoen gebruikers
Hoe Twitter 3.000 afbeeldingen per seconde verwerkt |
| Uber | Hoe Uber hun realtime marktplaats platform opschaalt
Lessen van het opschalen van Uber naar 2000 engineers, 1000 services, en 8000 Git repositories |
| WhatsApp | De WhatsApp architectuur die Facebook kocht voor $19 miljard |
| YouTube | YouTube schaalbaarheid
YouTube architectuur |
Engineering blogs van bedrijven
Architecturen voor bedrijven waar je solliciteert.>
Vragen die je tegenkomt kunnen uit hetzelfde domein komen.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Wil je een blog toevoegen? Om dubbel werk te voorkomen, overweeg dan om de blog van jouw bedrijf toe te voegen aan de volgende repo:
In ontwikkeling
Geïnteresseerd om een sectie toe te voegen of te helpen met het afronden van een sectie die nog in ontwikkeling is? Draag bij!
- Gedistribueerd rekenen met MapReduce
- Consistente hashing
- Scatter gather
- Draag bij
Dankbetuigingen
Dankbetuigingen en bronnen zijn door deze repo heen vermeld.
Speciale dank aan:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Contactinformatie
Neem gerust contact met mij op om eventuele problemen, vragen of opmerkingen te bespreken.
Mijn contactgegevens zijn te vinden op mijn GitHub-pagina.
Licentie
Ik stel code en bronnen in deze repository aan u beschikbaar onder een open source-licentie. Omdat dit mijn persoonlijke repository is, ontvangt u de licentie voor mijn code en bronnen van mij en niet van mijn werkgever (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---