English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation 이 가이드를 번역하는 데 도움을 주세요!
시스템 설계 기초

동기
대규모 시스템을 설계하는 방법을 배우세요.>
시스템 설계 인터뷰 준비.
대규모 시스템 설계 방법 배우기
확장 가능한 시스템 설계 방법을 배우면 더 나은 엔지니어가 될 수 있습니다.
시스템 설계는 광범위한 주제입니다. 시스템 설계 원칙에 관한 방대한 양의 자료가 웹 곳곳에 흩어져 있습니다.
이 저장소는 대규모 시스템 구축 방법을 배우는 데 도움이 되는 체계적으로 정리된 자료 모음입니다.
오픈 소스 커뮤니티에서 배우기
이 프로젝트는 지속적으로 업데이트되는 오픈 소스 프로젝트입니다.
기여를 환영합니다!
시스템 설계 인터뷰 준비
코딩 인터뷰 외에도 시스템 설계는 많은 기술 회사의 기술 인터뷰 과정에서 필수 구성 요소입니다.
일반적인 시스템 설계 인터뷰 질문을 연습하고 토론, 코드, 다이어그램으로 구성된 샘플 솔루션과 비교하세요.
인터뷰 준비를 위한 추가 주제:
Anki 플래시카드
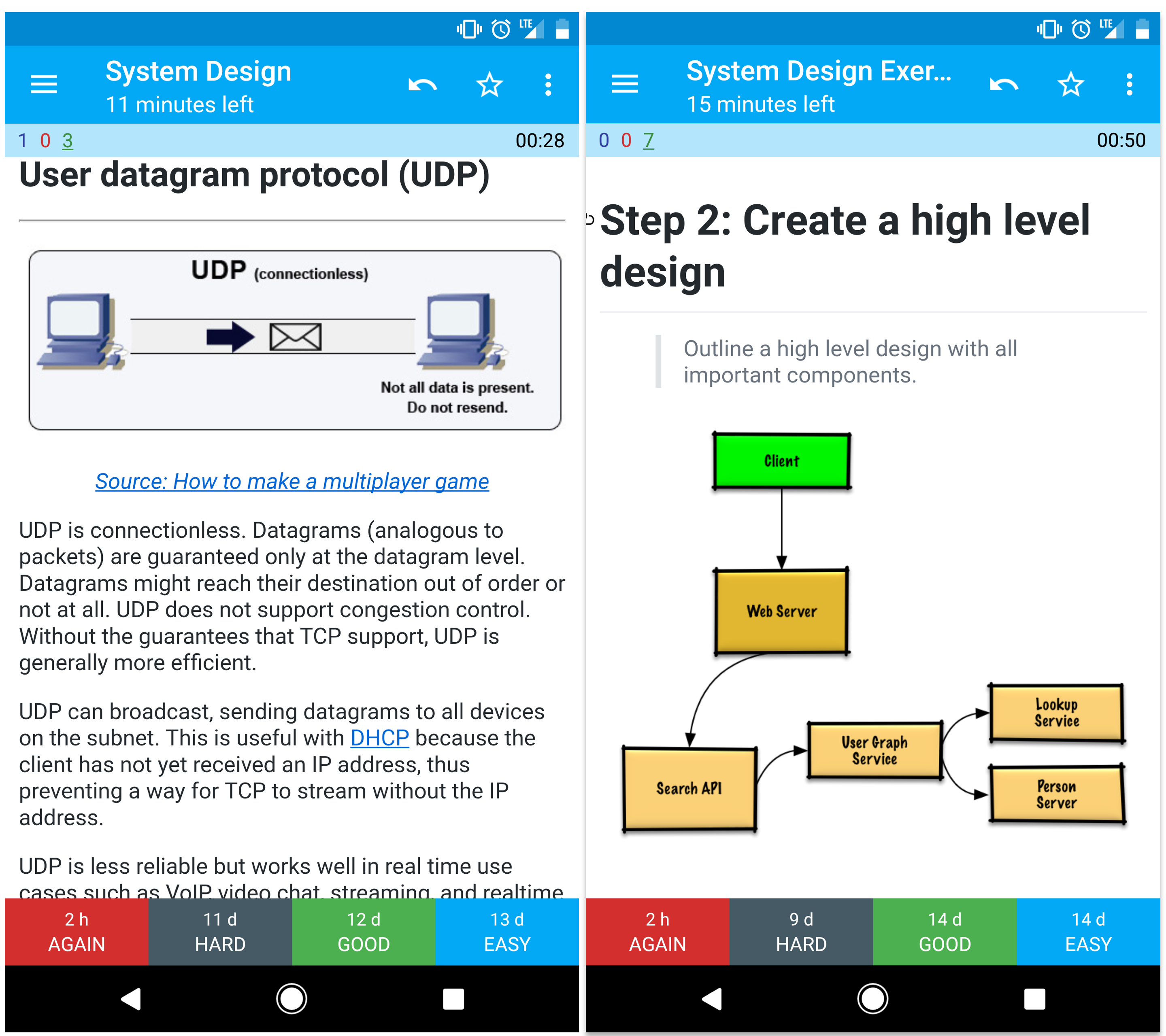
제공된 Anki 플래시카드 덱은 간격 반복법을 이용해 핵심 시스템 설계 개념을 기억하는 데 도움을 줍니다.
외출 중에도 사용하기 좋습니다.코딩 자료: 인터랙티브 코딩 챌린지
코딩 인터뷰 준비에 도움이 될 자료를 찾고 있나요?
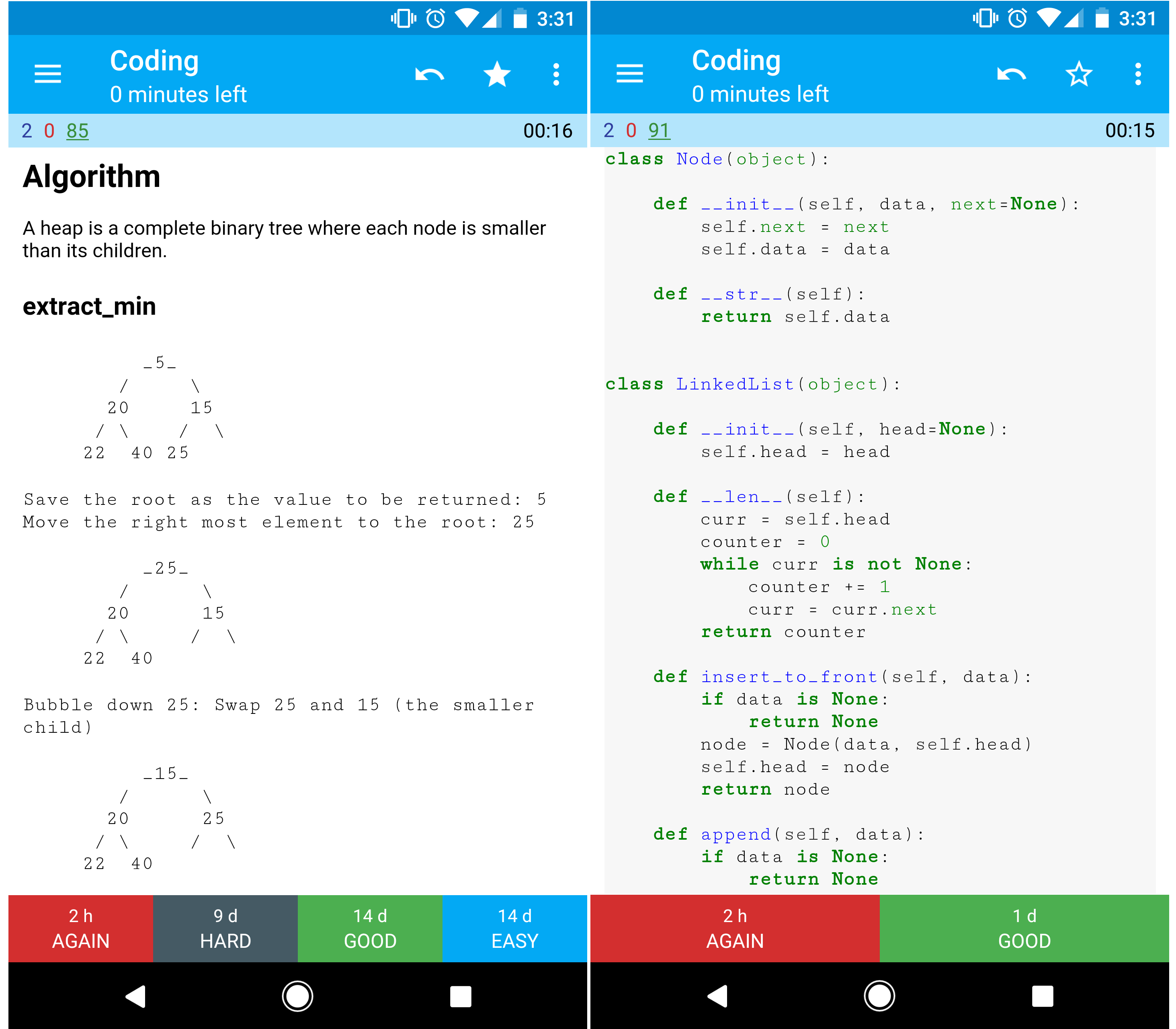
자매 저장소 인터랙티브 코딩 챌린지에서 추가 Anki 덱을 확인해 보세요:
기여하기
커뮤니티로부터 배우세요.
다음 사항에 기여할 수 있는 풀 리퀘스트를 자유롭게 제출하세요:
- 오류 수정
- 섹션 개선
- 새 섹션 추가
- 번역하기
기여 지침을 검토하세요.
시스템 설계 주제 색인
장단점을 포함한 다양한 시스템 설계 주제 요약입니다. 모든 것은 트레이드오프입니다.>
각 섹션에는 더 심도 있는 자료로 연결되는 링크가 포함되어 있습니다.
- 시스템 설계 주제: 여기서 시작하세요
- 1단계: 확장성 비디오 강의 검토
- 2단계: 확장성 기사 검토
- 다음 단계
- 성능 대 확장성
- 지연 시간 대 처리량
- 가용성 대 일관성
- CAP 정리
- CP - 일관성과 분할 허용
- AP - 가용성과 분할 허용
- 일관성 패턴
- 약한 일관성
- 최종 일관성
- 강한 일관성
- 가용성 패턴
- 장애 조치
- 복제
- 숫자로 보는 가용성
- 도메인 이름 시스템
- 콘텐츠 전송 네트워크
- 푸시 CDN
- 풀 CDN
- 로드 밸런서
- 액티브-패시브
- 액티브-액티브
- 레이어 4 로드 밸런싱
- 레이어 7 로드 밸런싱
- 수평 확장
- 리버스 프록시 (웹 서버)
- 로드 밸런서 vs 리버스 프록시
- 애플리케이션 계층
- 마이크로서비스
- 서비스 디스커버리
- 데이터베이스
- 관계형 데이터베이스 관리 시스템 (RDBMS)
- 마스터-슬레이브 복제
- 마스터-마스터 복제
- 페더레이션
- 샤딩
- 비정규화
- SQL 튜닝
- NoSQL
- 키-값 저장소
- 문서 저장소
- 와이드 컬럼 저장소
- 그래프 데이터베이스
- SQL 또는 NoSQL
- 캐시
- 클라이언트 캐싱
- CDN 캐싱
- 웹 서버 캐싱
- 데이터베이스 캐싱
- 애플리케이션 캐싱
- 데이터베이스 쿼리 레벨에서의 캐싱
- 객체 레벨에서의 캐싱
- 캐시 업데이트 시기
- 캐시-어사이드
- 쓰기-스루
- 쓰기-비하인드 (쓰기-백)
- 리프레시-어헤드
- 비동기 처리
- 메시지 큐
- 작업 큐
- 백프레셔
- 통신
- 전송 제어 프로토콜 (TCP)
- 사용자 데이터그램 프로토콜 (UDP)
- 원격 프로시저 호출 (RPC)
- 표현 상태 전송 (REST)
- 보안
- 부록
- 2의 거듭제곱 표
- 모든 프로그래머가 알아야 할 지연 시간 숫자
- 추가 시스템 설계 인터뷰 질문
- 실제 아키텍처
- 회사 아키텍처
- 회사 엔지니어링 블로그
- 개발 중
- 크레딧
- 연락처 정보
- 라이선스
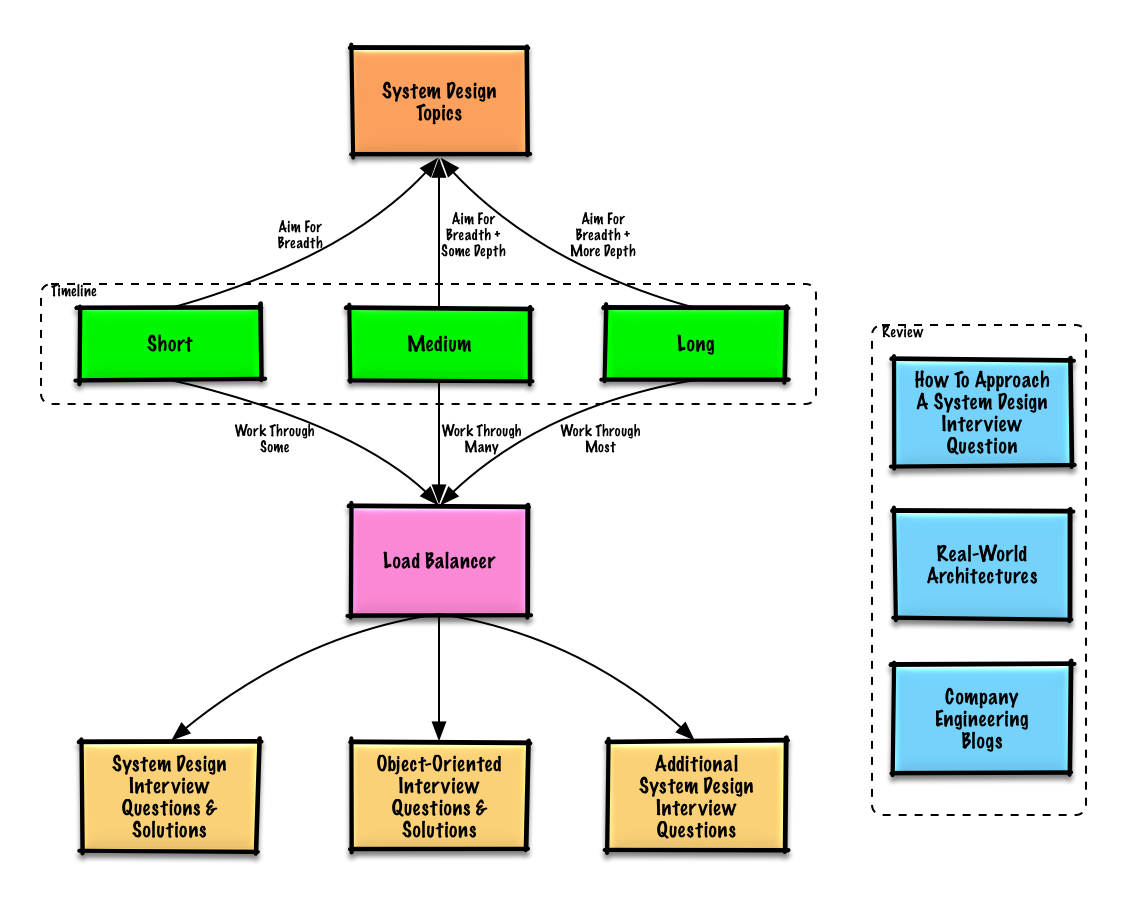
학습 가이드
인터뷰 일정(단기, 중기, 장기)을 기준으로 검토할 추천 주제입니다.
Q: 인터뷰를 위해 여기 있는 모든 내용을 알아야 하나요?
A: 아니요, 인터뷰 준비를 위해 여기 있는 모든 내용을 알 필요는 없습니다.
인터뷰에서 질문받는 내용은 다음과 같은 변수에 따라 달라집니다:
- 경력 수준
- 기술 배경
- 지원하는 직무
- 인터뷰하는 회사
- 운
넓게 시작해서 몇몇 영역에서 깊게 들어가세요. 다양한 핵심 시스템 설계 주제에 대해 조금 아는 것이 도움이 됩니다. 일정, 경험, 지원하는 포지션, 면접 보는 회사에 따라 다음 가이드를 조정하세요.
- 짧은 일정 - 시스템 설계 주제의 폭넓은 이해를 목표로 하세요. 몇 개의 면접 질문을 풀면서 연습하세요.
- 중간 일정 - 시스템 설계 주제의 폭넓은 이해와 일부 깊이를 목표로 하세요. 많은 면접 질문을 풀면서 연습하세요.
- 긴 일정 - 시스템 설계 주제의 폭넓은 이해와 더 깊은 이해를 목표로 하세요. 대부분의 면접 질문을 풀면서 연습하세요.
시스템 설계 면접 질문에 접근하는 방법
시스템 설계 면접 질문을 해결하는 방법.
시스템 설계 면접은 개방형 대화입니다. 당신이 주도해야 합니다.
다음 단계를 사용해 토론을 이끌 수 있습니다. 이 과정을 확실히 익히려면, 시스템 설계 면접 질문과 해답 섹션을 다음 단계를 따라 풀어보세요.
1단계: 사용 사례, 제약 조건, 가정 개요 작성
요구 사항을 수집하고 문제 범위를 설정하세요. 사용 사례와 제약 조건을 명확히 하기 위해 질문하세요. 가정을 논의하세요.
- 누가 사용할 것인가?
- 어떻게 사용할 것인가?
- 사용자 수는 얼마인가?
- 시스템이 하는 일은 무엇인가?
- 시스템의 입력과 출력은 무엇인가?
- 처리할 데이터 양은 얼마나 예상하는가?
- 초당 요청 수는 얼마나 예상하는가?
- 예상 읽기 대 쓰기 비율은 얼마인가?
2단계: 상위 수준 설계 작성
모든 주요 구성 요소를 포함한 상위 수준 설계 개요를 작성하세요.
- 주요 구성 요소 및 연결 스케치
- 아이디어에 대한 근거 제시
3단계: 핵심 구성 요소 설계
각 핵심 구성 요소에 대해 자세히 살펴보세요. 예를 들어, URL 단축 서비스 설계를 요청받았다면 다음을 논의하세요:
- 전체 URL의 해시 생성 및 저장
- MD5 및 Base62
- 해시 충돌
- SQL 또는 NoSQL
- 데이터베이스 스키마
- 해시된 URL을 전체 URL로 변환
- 데이터베이스 조회
- API 및 객체 지향 설계
4단계: 설계 확장
제약 조건을 고려하여 병목 현상을 식별하고 해결하세요. 예를 들어, 확장성 문제를 해결하기 위해 다음이 필요한가요?
- 로드 밸런서
- 수평 확장
- 캐싱
- 데이터베이스 샤딩
대략적 계산
손으로 일부 추정을 하라는 요청을 받을 수 있습니다. 다음 리소스를 참조하세요:
출처 및 추가 자료
다음 링크들을 확인하여 무엇을 기대할 수 있는지 더 잘 이해하세요:
솔루션이 포함된 시스템 설계 인터뷰 질문
일반적인 시스템 설계 인터뷰 질문과 예시 토론, 코드, 다이어그램.>
솔루션은 solutions/ 폴더 내의 내용과 연결되어 있습니다.| 질문 | | |---|---| | Pastebin.com (또는 Bit.ly) 설계하기 | 솔루션 | | 트위터 타임라인 및 검색 설계하기 (또는 페이스북 피드 및 검색) | 솔루션 | | 웹 크롤러 설계하기 | 솔루션 | | Mint.com 설계하기 | 솔루션 | | 소셜 네트워크용 데이터 구조 설계하기 | 솔루션 | | 검색 엔진용 키-값 저장소 설계하기 | 솔루션 | | 아마존 카테고리별 판매 순위 기능 설계하기 | 솔루션 | | AWS에서 수백만 사용자로 확장 가능한 시스템 설계하기 | 솔루션 | | 시스템 설계 질문 추가하기 | 기여하기 |
Pastebin.com (또는 Bit.ly) 설계하기
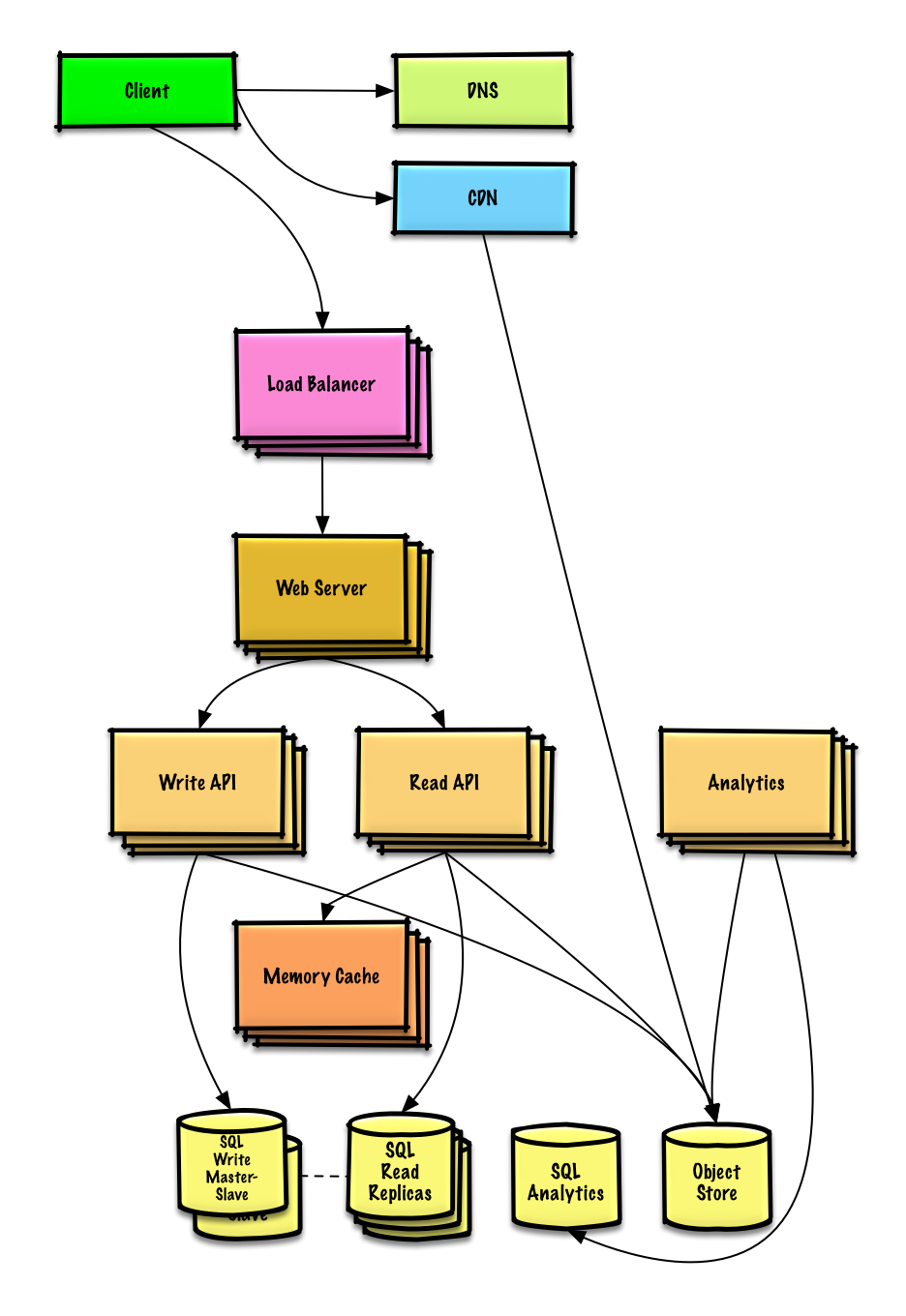
트위터 타임라인 및 검색 설계하기 (또는 페이스북 피드 및 검색)
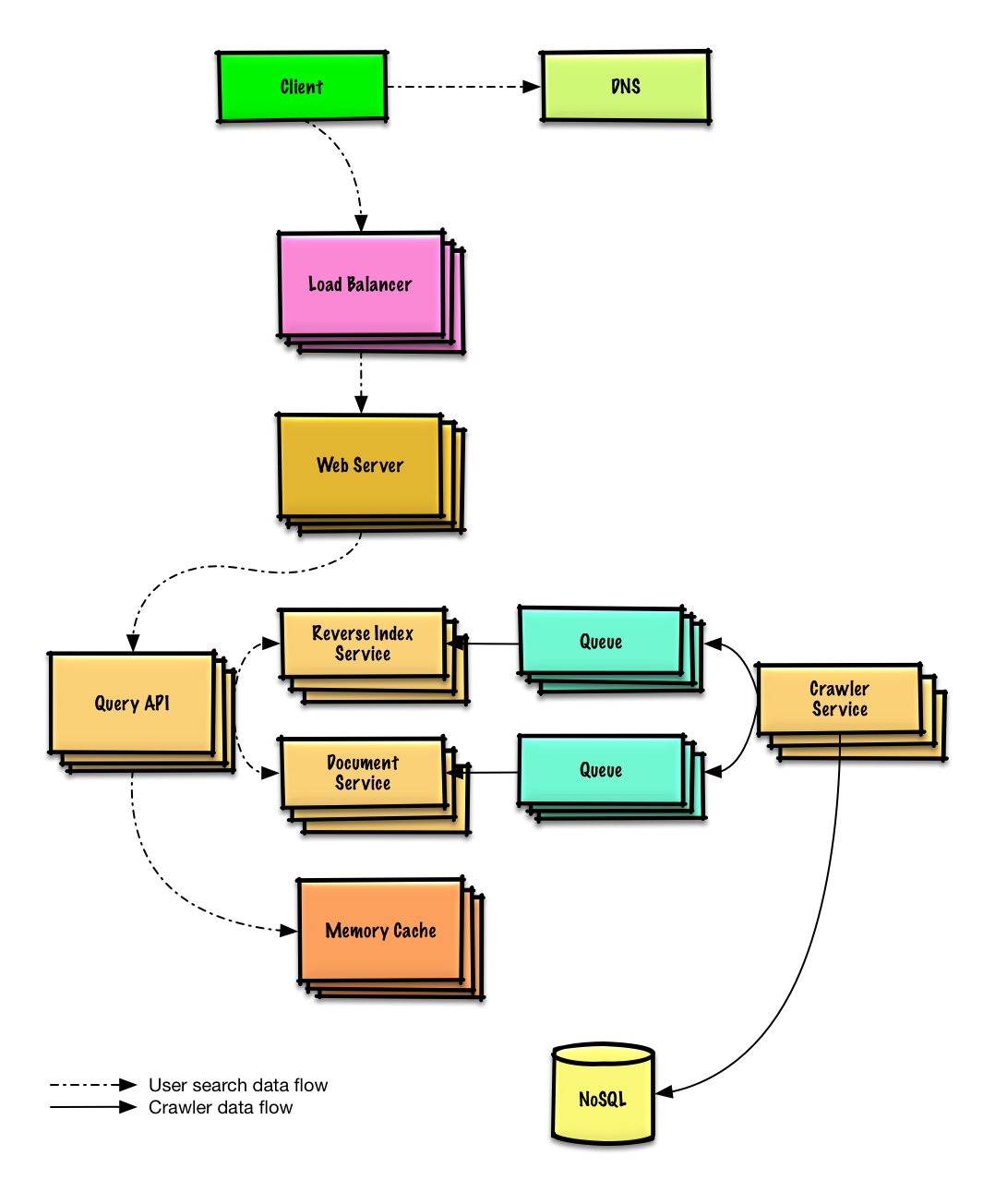
웹 크롤러 설계하기
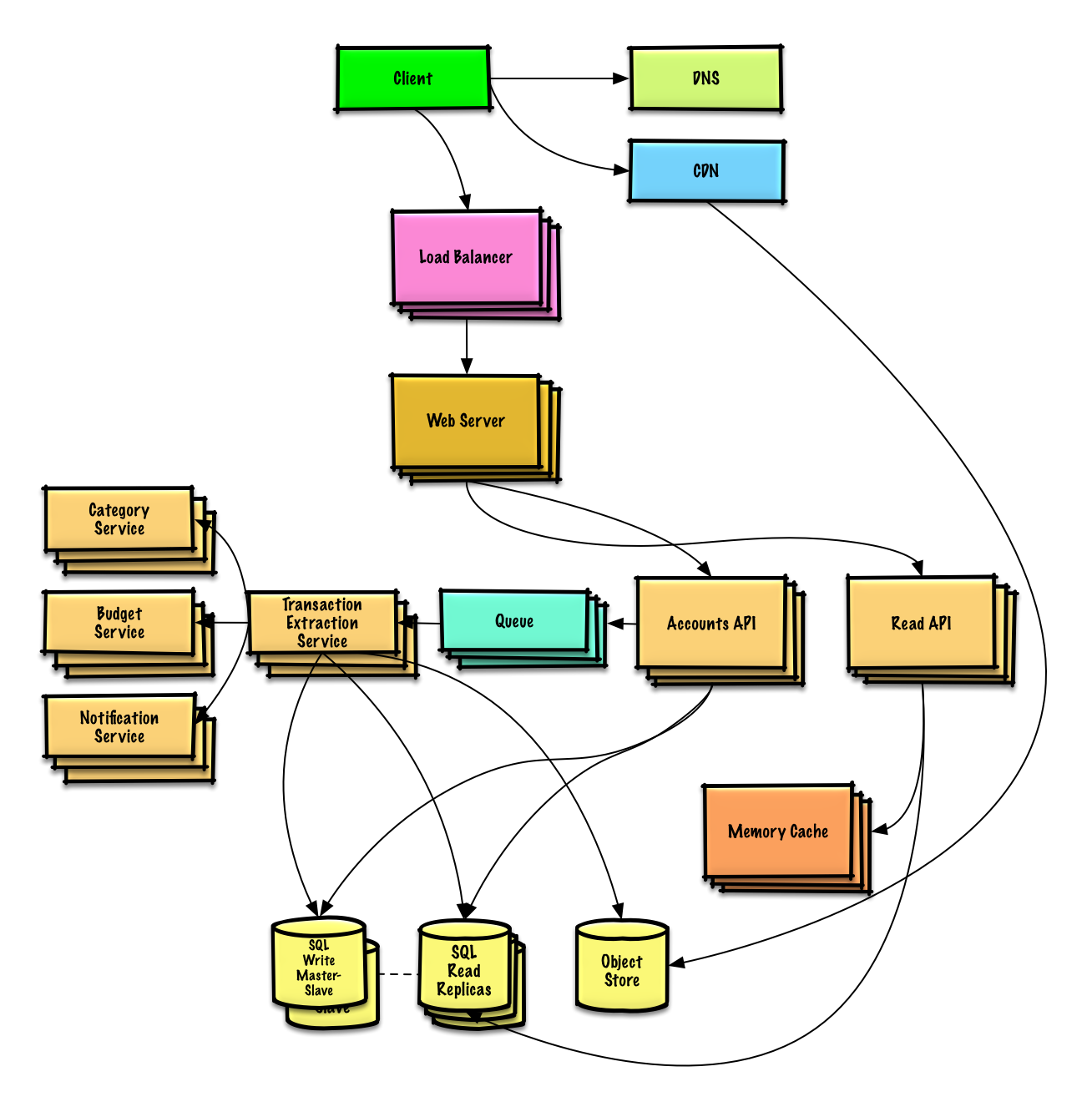
Design Mint.com
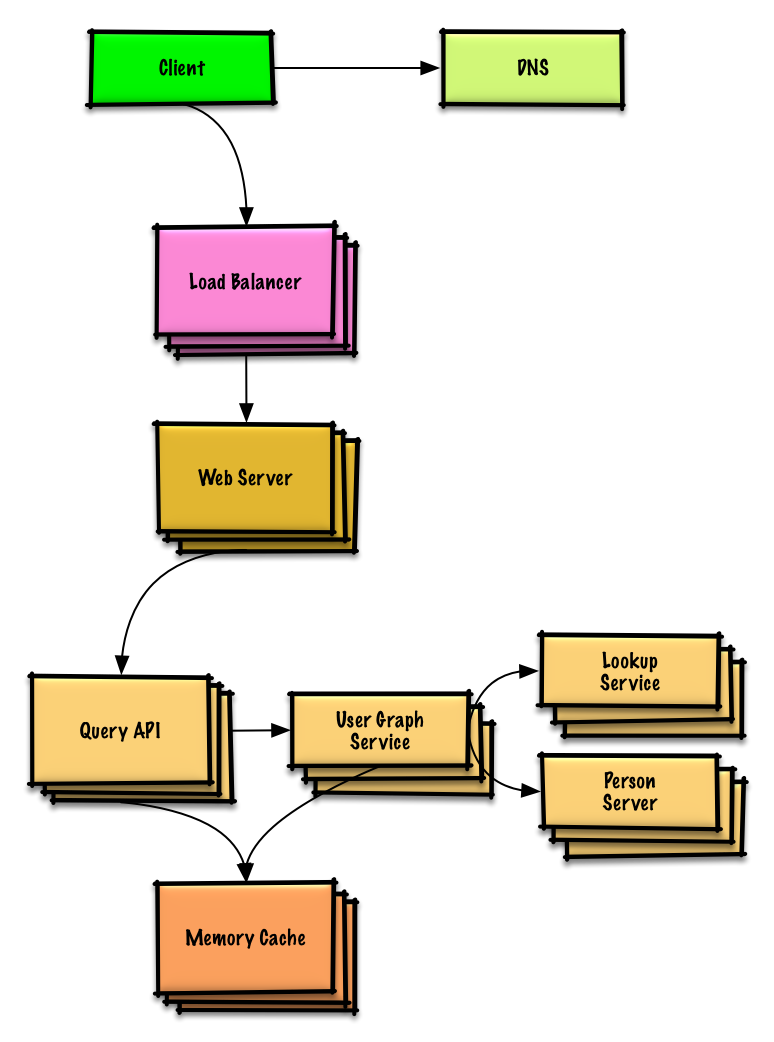
Design the data structures for a social network
Design a key-value store for a search engine
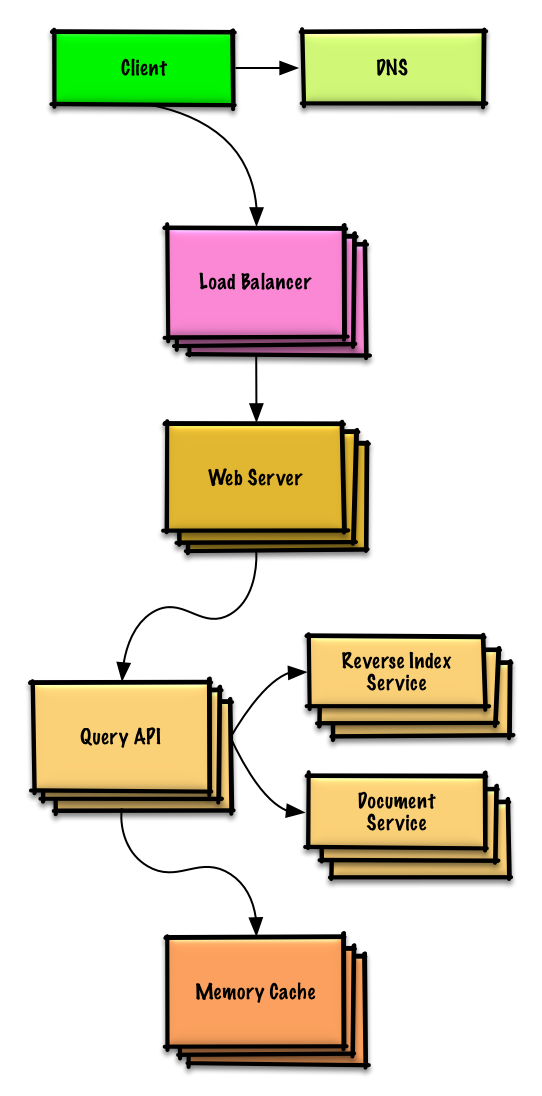
Design Amazon's sales ranking by category feature
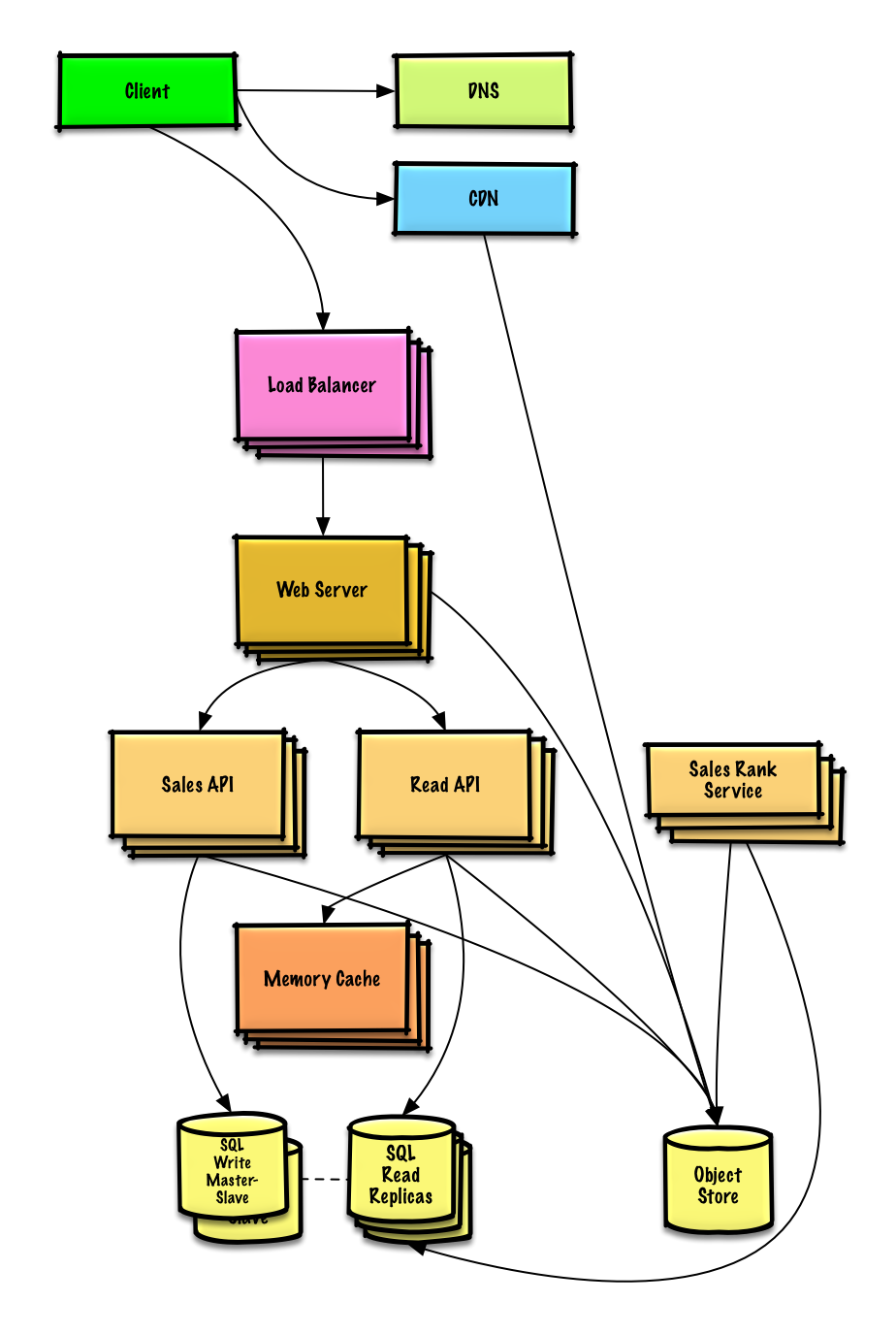
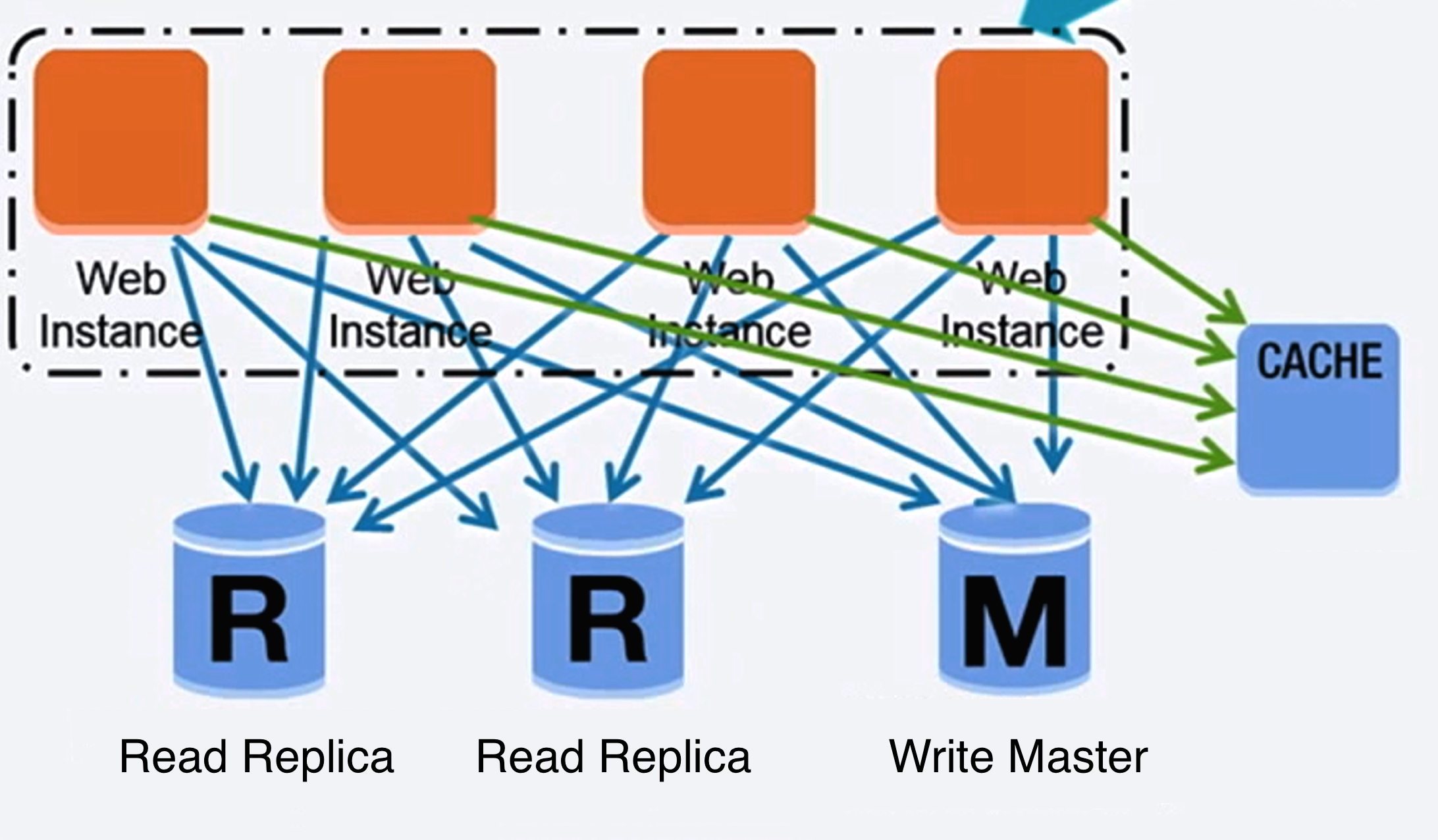
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | 해시 맵 설계 | 솔루션 | | 최근에 가장 적게 사용된 캐시 설계 | 솔루션 | | 콜 센터 설계 | 솔루션 | | 카드 덱 설계 | 솔루션 | | 주차장 설계 | 솔루션 | | 채팅 서버 설계 | 솔루션 | | 원형 배열 설계 | 기여하기 | | 객체지향 설계 질문 추가 | 기여하기 |
시스템 설계 주제: 여기서 시작하세요
시스템 설계가 처음인가요?
먼저, 일반적인 원리에 대한 기본 이해가 필요합니다. 그것들이 무엇인지, 어떻게 사용되는지, 그리고 장단점에 대해 배우세요.
1단계: 확장성 비디오 강의 검토
- 다루는 주제:
- 수직 확장
- 수평 확장
- 캐싱
- 부하 분산
- 데이터베이스 복제
- 데이터베이스 파티셔닝
2단계: 확장성 기사 검토
다음 단계
다음으로 고수준의 트레이드오프를 살펴보겠습니다:
- 성능 대 확장성
- 지연 시간 대 처리량
- 가용성 대 일관성
그 다음에는 DNS, CDN, 로드 밸런서와 같은 더 구체적인 주제로 들어가겠습니다.
성능 대 확장성
서비스가 추가된 자원에 비례하여 성능이 증가한다면 그 서비스는 확장 가능하다고 합니다. 일반적으로 성능 증가란 더 많은 작업 단위를 처리하는 것을 의미하지만, 데이터셋이 커질 때처럼 더 큰 작업 단위를 처리하는 것도 포함됩니다.1
성능과 확장성을 바라보는 또 다른 관점:
- 성능 문제가 있다면, 단일 사용자에 대해 시스템이 느립니다.
- 확장성 문제가 있다면, 단일 사용자에 대해서는 시스템이 빠르지만, 부하가 많을 때 느립니다.
출처 및 추가 읽기 자료
지연 시간 대 처리량
지연 시간은 어떤 작업을 수행하거나 결과를 생성하는 데 걸리는 시간입니다.
처리량은 단위 시간당 그러한 작업이나 결과의 수입니다.
일반적으로 허용 가능한 지연 시간을 유지하면서 최대 처리량을 목표로 해야 합니다.
출처 및 추가 읽기 자료
가용성 대 일관성
CAP 정리
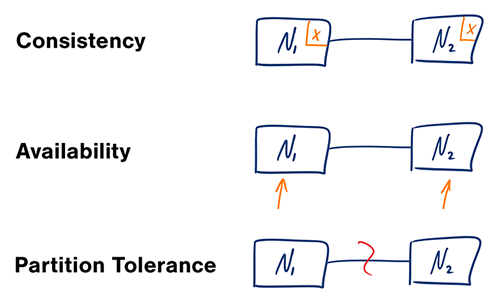
분산 컴퓨터 시스템에서는 다음 보장 중 두 가지만 지원할 수 있습니다:
- 일관성 (Consistency) - 모든 읽기 요청이 가장 최근의 쓰기 작업을 받거나 오류를 반환함
- 가용성 (Availability) - 모든 요청이 응답을 받지만, 최신 버전의 정보를 포함한다는 보장은 없음
- 분할 허용성 (Partition Tolerance) - 네트워크 장애로 인한 임의의 분할에도 시스템이 계속 작동함
#### CP - 일관성과 분할 허용성
분할된 노드로부터 응답을 기다리면 타임아웃 오류가 발생할 수 있습니다. CP는 비즈니스 요구가 원자적 읽기와 쓰기를 필요로 할 때 좋은 선택입니다.
#### AP - 가용성과 분할 허용성
응답은 가장 쉽게 사용할 수 있는 노드의 데이터 버전을 반환하며, 최신 버전이 아닐 수 있습니다. 분할이 해제되면 쓰기가 전파되는 데 시간이 걸릴 수 있습니다.
AP는 비즈니스가 최종 일관성을 허용해야 하거나 시스템이 외부 오류에도 계속 작동해야 할 때 좋은 선택입니다.
출처 및 추가 자료
일관성 패턴
같은 데이터의 여러 복사본이 있을 때, 클라이언트가 데이터에 대해 일관된 뷰를 갖도록 동기화하는 방법을 선택해야 합니다. CAP 정리에서 정의한 일관성은 모든 읽기가 가장 최근의 쓰기 작업을 받거나 오류를 반환하는 것을 의미합니다.
약한 일관성
쓰기 후 읽기가 해당 쓰기를 볼 수도 있고 보지 못할 수도 있습니다. 최선의 노력 방식이 사용됩니다.
이 방식은 memcached와 같은 시스템에서 볼 수 있습니다. 약한 일관성은 VoIP, 비디오 채팅, 실시간 멀티플레이어 게임과 같은 실시간 사용 사례에 적합합니다. 예를 들어, 전화 통화 중 몇 초간 수신이 끊기면 연결이 복구되었을 때 그 사이에 오간 대화는 들리지 않습니다.
최종 일관성
쓰기 작업 후, 읽기는 결국 이를 보게 됩니다(일반적으로 밀리초 내에). 데이터는 비동기적으로 복제됩니다.
이 접근 방식은 DNS 및 이메일과 같은 시스템에서 볼 수 있습니다. 최종 일관성은 고가용성 시스템에서 잘 작동합니다.
강력한 일관성
쓰기 작업 후, 읽기는 이를 즉시 보게 됩니다. 데이터는 동기적으로 복제됩니다.
이 접근 방식은 파일 시스템 및 RDBMS에서 볼 수 있습니다. 강력한 일관성은 트랜잭션이 필요한 시스템에서 잘 작동합니다.
출처 및 추가 읽을거리
가용성 패턴
고가용성을 지원하는 두 가지 상호 보완적인 패턴이 있습니다: 페일오버와 복제.
페일오버
#### 액티브-패시브
액티브-패시브 페일오버에서는, 활성 서버와 대기 중인 수동 서버 간에 하트비트가 전송됩니다. 하트비트가 끊기면, 수동 서버가 활성 서버의 IP 주소를 인계받아 서비스를 재개합니다.
다운타임 길이는 수동 서버가 이미 '핫' 대기 상태인지 아니면 '콜드' 대기 상태에서 시작해야 하는지에 따라 결정됩니다. 오직 활성 서버만 트래픽을 처리합니다.
액티브-패시브 페일오버는 마스터-슬레이브 페일오버라고도 불릴 수 있습니다.
#### 액티브-액티브
액티브-액티브에서는 두 서버가 모두 트래픽을 관리하며 부하를 분산합니다.
서버가 공개용이라면, DNS는 두 서버의 공용 IP를 알아야 합니다. 서버가 내부용이라면, 애플리케이션 로직이 두 서버를 알아야 합니다.
액티브-액티브 페일오버는 마스터-마스터 페일오버라고도 불릴 수 있습니다.
단점: 페일오버
- 장애 조치(fail-over)는 더 많은 하드웨어와 추가적인 복잡성을 더한다.
- 활성 시스템이 새로 작성된 데이터를 수동 시스템으로 복제하기 전에 실패할 경우 데이터 손실 가능성이 있다.
복제
#### 마스터-슬레이브와 마스터-마스터
이 주제는 데이터베이스 섹션에서 더 자세히 다룬다:
가용성 수치
가용성은 서비스가 사용 가능한 시간의 백분율로 가동 시간(또는 다운타임)으로 자주 정량화된다. 가용성은 일반적으로 9의 개수로 측정되며, 99.99% 가용성은 네 개의 9를 가진 것으로 표현된다.
#### 99.9% 가용성 - 세 개의 9
| 기간 | 허용 가능한 다운타임 | |--------------------|---------------------| | 연간 다운타임 | 8시간 45분 57초 | | 월간 다운타임 | 43분 49.7초 | | 주간 다운타임 | 10분 4.8초 | | 일간 다운타임 | 1분 26.4초 |
#### 99.99% 가용성 - 네 개의 9
| 기간 | 허용 가능한 다운타임 | |--------------------|---------------------| | 연간 다운타임 | 52분 35.7초 | | 월간 다운타임 | 4분 23초 | | 주간 다운타임 | 1분 5초 | | 일간 다운타임 | 8.6초 |
#### 병렬 가용성 대 순차 가용성
서비스가 고장에 취약한 여러 구성 요소로 이루어져 있다면, 서비스의 전체 가용성은 구성 요소들이 순차적(sequence)인지 병렬(parallel)인지에 따라 달라진다.
###### 순차적 구성
전체 가용성은 가용성이 100% 미만인 두 구성 요소가 순차적으로 연결될 때 감소합니다:
Availability (Total) = Availability (Foo) * Availability (Bar)만약 Foo와 Bar가 각각 99.9%의 가용성을 가진다면, 순차적으로 연결되었을 때 전체 가용성은 99.8%가 됩니다.
###### 병렬로
두 개의 가용성이 100% 미만인 구성 요소가 병렬로 연결되면 전체 가용성이 증가합니다:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))만약 Foo와 Bar가 각각 99.9% 가용성을 가진다면, 병렬로 연결된 전체 가용성은 99.9999%가 됩니다.
도메인 이름 시스템
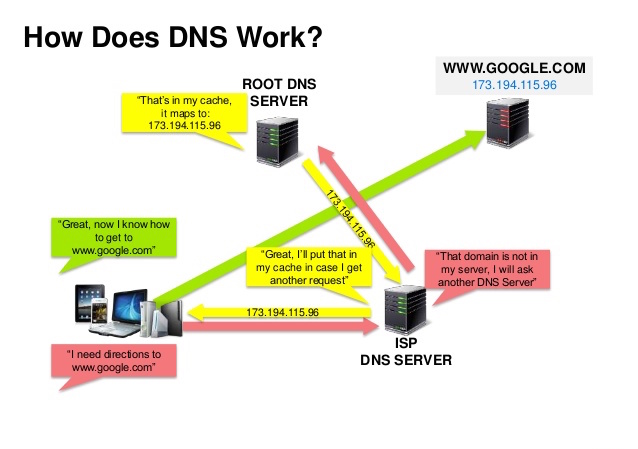
도메인 이름 시스템(DNS)은 www.example.com과 같은 도메인 이름을 IP 주소로 변환합니다.
DNS는 계층적 구조이며, 최상위에는 몇 개의 권위 있는 서버가 있습니다. 라우터나 ISP는 조회 시 어떤 DNS 서버에 접속할지 정보를 제공합니다. 하위 DNS 서버들은 매핑 정보를 캐시하는데, 이는 DNS 전파 지연으로 인해 오래될 수 있습니다. DNS 결과는 브라우저나 OS에 의해 일정 기간 동안 캐시될 수 있으며, 이 기간은 TTL(수명, time to live)에 의해 결정됩니다.
- NS 레코드 (네임 서버) - 도메인/서브도메인에 대한 DNS 서버를 지정합니다.
- MX 레코드 (메일 교환) - 메시지를 수신할 메일 서버를 지정합니다.
- A 레코드 (주소) - 이름을 IP 주소에 연결합니다.
- CNAME (정식 이름) - 이름을 다른 이름이나
CNAME(예: example.com을 www.example.com으로) 또는A레코드에 연결합니다.
단점: DNS
- DNS 서버에 접근하는 것은 약간의 지연을 유발하지만, 위에서 설명한 캐싱으로 완화됩니다.
- DNS 서버 관리는 복잡할 수 있으며 일반적으로 정부, ISP, 대기업에서 관리합니다.
- 최근 DNS 서비스는 DDoS 공격을 받아, 사용자들이 Twitter의 IP 주소를 모르면 웹사이트에 접속하지 못하는 상황이 발생했습니다.
출처 및 추가 읽을거리
콘텐츠 전송 네트워크
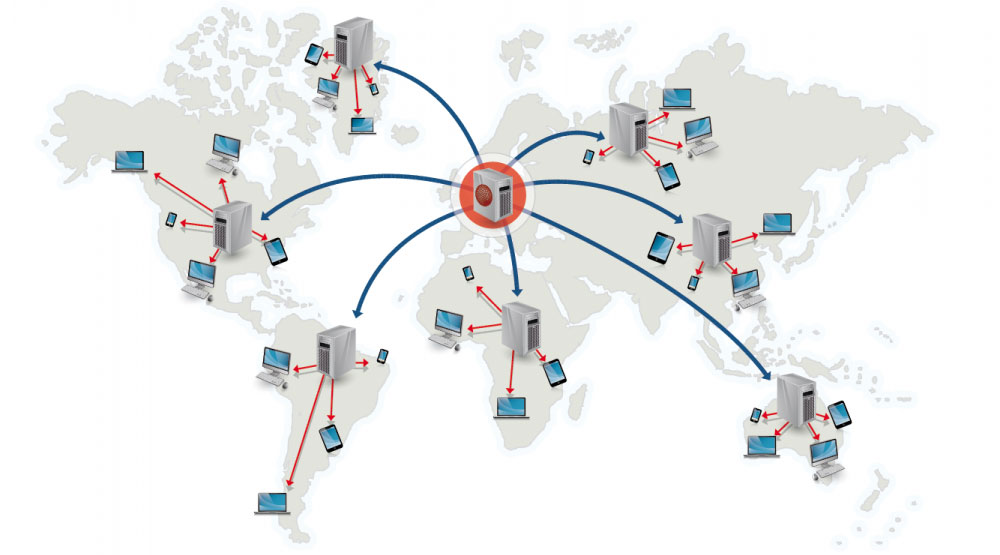
콘텐츠 전송 네트워크(CDN)는 전 세계에 분산된 프록시 서버 네트워크로, 사용자와 더 가까운 위치에서 콘텐츠를 제공합니다. 일반적으로 HTML/CSS/JS, 사진, 비디오와 같은 정적 파일이 CDN에서 제공되지만, Amazon의 CloudFront와 같은 일부 CDN은 동적 콘텐츠도 지원합니다. 사이트의 DNS 해석은 클라이언트가 어떤 서버에 접속할지 알려줍니다.
CDN에서 콘텐츠를 제공하면 두 가지 방식으로 성능을 크게 향상시킬 수 있습니다:
- 사용자는 자신과 가까운 데이터 센터에서 콘텐츠를 받습니다.
- 귀하의 서버는 CDN이 처리하는 요청을 직접 처리할 필요가 없습니다.
푸시 CDN
푸시 CDN은 서버에서 변경이 발생할 때마다 새 콘텐츠를 받습니다. 콘텐츠 제공에 대한 전적인 책임을 지며, CDN에 직접 업로드하고 URL을 CDN을 가리키도록 재작성합니다. 콘텐츠 만료 시점과 업데이트 시점을 설정할 수 있습니다. 콘텐츠는 새롭거나 변경된 경우에만 업로드되어 트래픽을 최소화하고 저장 공간을 최대한 활용합니다.
트래픽이 적거나 자주 업데이트되지 않는 콘텐츠를 가진 사이트는 푸시 CDN과 잘 맞습니다. 콘텐츠가 정기적으로 다시 가져오는 것이 아니라 한 번 CDN에 배치됩니다.
풀 CDN
풀 CDN은 첫 번째 사용자가 콘텐츠를 요청할 때 서버에서 새 콘텐츠를 가져옵니다. 콘텐츠는 서버에 남겨두고 URL을 CDN을 가리키도록 재작성합니다. 이로 인해 콘텐츠가 CDN에 캐시될 때까지 요청이 느려질 수 있습니다.
TTL(수명, Time-to-live)은 콘텐츠가 얼마나 오래 캐시되는지 결정합니다. 풀 CDN은 CDN에서 저장 공간을 최소화하지만, 파일이 변경되지 않았음에도 만료되어 다시 가져오는 경우 중복 트래픽이 발생할 수 있습니다.
트래픽이 많은 사이트는 요청된 최신 콘텐츠만 CDN에 남아 트래픽이 더 고르게 분산되므로 풀 CDN과 잘 맞습니다.
단점: CDN
- 트래픽에 따라 CDN 비용이 상당할 수 있지만, CDN을 사용하지 않을 경우 발생할 추가 비용과 비교해야 합니다.
- TTL 만료 전에 업데이트된 콘텐츠는 오래된 상태일 수 있습니다.
- 정적 콘텐츠의 URL을 CDN을 가리키도록 변경해야 합니다.
출처 및 추가 자료
로드 밸런서
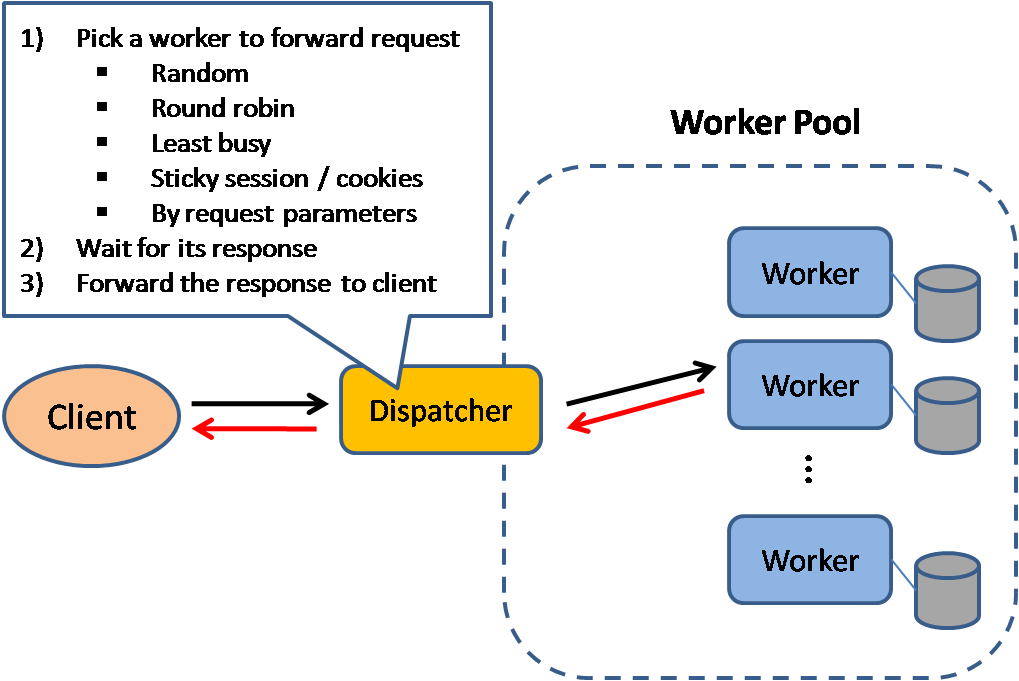
로드 밸런서는 애플리케이션 서버 및 데이터베이스와 같은 컴퓨팅 자원에 들어오는 클라이언트 요청을 분배합니다. 각 경우에 로드 밸런서는 컴퓨팅 자원으로부터의 응답을 적절한 클라이언트에게 반환합니다. 로드 밸런서는 다음과 같은 점에서 효과적입니다:
- 상태가 좋지 않은 서버로 요청이 가지 않도록 방지
- 자원의 과부하 방지
- 단일 장애점 제거에 도움
추가 이점은 다음과 같습니다:
- SSL 종료 - 들어오는 요청을 복호화하고 서버 응답을 암호화하여 백엔드 서버가 비용이 많이 드는 작업을 수행하지 않아도 됨
- 각 서버에 X.509 인증서를 설치할 필요 제거
- 세션 지속성 - 쿠키를 발급하고 웹 앱이 세션을 추적하지 않는 경우 특정 클라이언트 요청을 동일 인스턴스로 라우팅
로드 밸런서는 다음을 포함한 다양한 지표를 기반으로 트래픽을 라우팅할 수 있습니다:
- 랜덤
- 가장 적게 로드된 서버
- 세션/쿠키
- 라운드 로빈 또는 가중 라운드 로빈
- 레이어 4
- 레이어 7
레이어 4 로드 밸런싱
레이어 4 로드 밸런서는 요청 분배를 결정하기 위해 전송 계층의 정보를 봅니다. 일반적으로 소스, 목적지 IP 주소와 헤더의 포트를 포함하지만 패킷 내용은 포함하지 않습니다. 레이어 4 로드 밸런서는 네트워크 패킷을 업스트림 서버로 포워딩하며, 네트워크 주소 변환 (NAT)을 수행합니다.
레이어 7 로드 밸런싱
Layer 7 로드 밸런서는 요청을 어떻게 분배할지 결정하기 위해 애플리케이션 계층을 살펴봅니다. 이는 헤더, 메시지 및 쿠키의 내용을 포함할 수 있습니다. Layer 7 로드 밸런서는 네트워크 트래픽을 종료하고, 메시지를 읽고, 로드 밸런싱 결정을 내린 후 선택된 서버에 연결을 엽니다. 예를 들어, Layer 7 로드 밸런서는 비디오 트래픽을 비디오를 호스팅하는 서버로, 더 민감한 사용자 청구 트래픽을 보안이 강화된 서버로 안내할 수 있습니다.유연성의 대가로, Layer 4 로드 밸런싱은 Layer 7보다 적은 시간과 컴퓨팅 자원을 필요로 하지만, 최신 일반 하드웨어에서는 성능 영향이 미미할 수 있습니다.
수평 확장
로드 밸런서는 수평 확장에도 도움을 주어 성능과 가용성을 향상시킵니다. 일반 하드웨어를 사용한 수평 확장은 더 비싼 하드웨어에서 단일 서버를 확장하는 수직 확장보다 비용 효율적이며 더 높은 가용성을 제공합니다. 또한 일반 하드웨어에서 일하는 인재를 고용하는 것이 전문 기업 시스템보다 더 쉽습니다.
#### 단점: 수평 확장
- 수평 확장은 복잡성을 도입하며 서버 복제를 포함합니다
- 서버는 상태 비저장(stateless)이어야 합니다: 세션이나 프로필 사진 같은 사용자 관련 데이터를 포함하지 않아야 합니다
- 세션은 중앙 집중식 데이터 저장소(예: 데이터베이스(SQL, NoSQL) 또는 영속적인 캐시(Redis, Memcached))에 저장할 수 있습니다
- 캐시 및 데이터베이스와 같은 다운스트림 서버는 업스트림 서버가 확장됨에 따라 더 많은 동시 연결을 처리해야 합니다
단점: 로드 밸런서
- 로드 밸런서가 충분한 자원을 갖추지 못했거나 제대로 구성되지 않은 경우 성능 병목 현상이 발생할 수 있습니다.
- 단일 실패 지점을 제거하기 위해 로드 밸런서를 도입하면 복잡성이 증가합니다.
- 단일 로드 밸런서는 단일 실패 지점이며, 여러 로드 밸런서를 구성하면 복잡성이 더욱 증가합니다.
출처 및 추가 읽기 자료
리버스 프록시 (웹 서버)
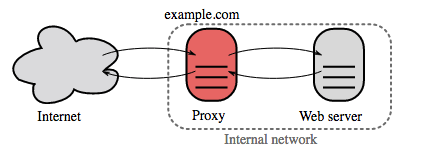
리버스 프록시는 내부 서비스를 중앙 집중화하고 대중에게 통합된 인터페이스를 제공하는 웹 서버입니다. 클라이언트의 요청은 리버스 프록시가 서버로 전달하여 서버가 요청을 처리한 후, 서버의 응답을 클라이언트에게 반환합니다.
추가적인 이점은 다음과 같습니다:
- 보안 강화 - 백엔드 서버에 대한 정보 숨기기, IP 차단, 클라이언트별 연결 수 제한
- 확장성 및 유연성 향상 - 클라이언트는 리버스 프록시의 IP만 보므로 서버를 확장하거나 구성 변경 가능
- SSL 종료 - 들어오는 요청을 복호화하고 서버 응답을 암호화하여 백엔드 서버가 비용이 많이 드는 작업을 수행하지 않아도 됨
- 각 서버에 X.509 인증서 설치 필요성 제거
- 압축 - 서버 응답 압축
- 캐싱 - 캐시된 요청에 대해 응답 반환
- 정적 콘텐츠 - 정적 콘텐츠 직접 제공
- HTML/CSS/JS
- 사진
- 비디오
- 기타
로드 밸런서 vs 리버스 프록시
- 여러 서버가 있을 때 로드 밸런서를 배포하는 것이 유용합니다. 로드 밸런서는 종종 동일한 기능을 제공하는 서버 집합으로 트래픽을 라우팅합니다.
- 리버스 프록시는 웹 서버나 애플리케이션 서버가 하나만 있어도 유용하며, 이전 섹션에서 설명한 이점을 제공합니다.
- NGINX와 HAProxy 같은 솔루션은 레이어 7 리버스 프록시 및 로드 밸런싱을 모두 지원할 수 있습니다.
단점: 리버스 프록시
- 리버스 프록시 도입으로 복잡성이 증가합니다.
- 단일 리버스 프록시는 단일 실패 지점이 되며, 여러 리버스 프록시를 구성하는 것(예: 페일오버)은 복잡성을 더욱 증가시킵니다.
출처 및 추가 읽을거리
애플리케이션 레이어
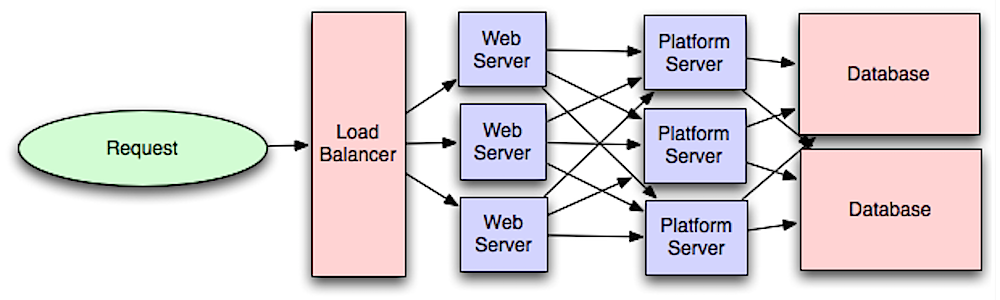
웹 계층을 애플리케이션 계층(플랫폼 계층이라고도 함)과 분리하면 두 계층을 독립적으로 확장하고 구성할 수 있습니다. 새로운 API를 추가하면 반드시 추가 웹 서버를 추가하지 않고도 애플리케이션 서버를 추가할 수 있습니다. 단일 책임 원칙은 함께 작동하는 작고 자율적인 서비스를 권장합니다. 작은 팀이 작은 서비스를 관리하면 빠른 성장을 보다 적극적으로 계획할 수 있습니다.
애플리케이션 계층의 워커는 또한 비동기성을 가능하게 하는 데 도움을 줍니다.
마이크로서비스
이와 관련된 개념으로는 마이크로서비스가 있으며, 이는 독립적으로 배포 가능한 작고 모듈화된 서비스 모음으로 설명할 수 있습니다. 각 서비스는 고유한 프로세스를 실행하고 잘 정의된 경량 메커니즘을 통해 통신하여 비즈니스 목표를 달성합니다. 1
예를 들어 Pinterest는 사용자 프로필, 팔로워, 피드, 검색, 사진 업로드 등의 마이크로서비스를 가질 수 있습니다.
서비스 디스커버리
Consul, Etcd, Zookeeper와 같은 시스템은 등록된 이름, 주소 및 포트를 추적하여 서비스들이 서로를 찾을 수 있도록 도와줍니다. 헬스 체크는 서비스 무결성을 검증하는 데 도움을 주며 종종 HTTP 엔드포인트를 사용해 수행됩니다. Consul과 Etcd 모두 구성 값 및 기타 공유 데이터를 저장하는 데 유용한 내장 키-값 저장소를 가지고 있습니다.
단점: 애플리케이션 계층
- 느슨하게 결합된 서비스로 애플리케이션 계층을 추가하면 아키텍처, 운영 및 프로세스 관점에서 다른 접근 방식이 필요합니다(모놀리식 시스템과 대비).
- 마이크로서비스는 배포 및 운영 측면에서 복잡성을 더할 수 있습니다.
출처 및 추가 읽기 자료
데이터베이스
관계형 데이터베이스 관리 시스템 (RDBMS)
관계형 데이터베이스인 SQL은 테이블에 조직된 데이터 항목들의 모음입니다.
ACID는 관계형 데이터베이스 트랜잭션의 속성 집합입니다.
- 원자성(Atomicity) - 각 트랜잭션은 전부 수행되거나 전혀 수행되지 않아야 합니다.
- 일관성(Consistency) - 모든 트랜잭션은 데이터베이스를 한 유효한 상태에서 다른 유효한 상태로 전환합니다.
- 격리성(Isolation) - 트랜잭션을 동시에 실행해도 트랜잭션을 순차적으로 실행한 것과 동일한 결과를 가져옵니다.
- 지속성(Durability) - 트랜잭션이 커밋되면 그 상태가 유지됩니다.
#### 마스터-슬레이브 복제
마스터는 읽기와 쓰기를 처리하며, 쓰기를 하나 이상의 슬레이브에게 복제합니다. 슬레이브는 읽기만 처리합니다. 슬레이브는 트리 형태로 추가 슬레이브에게도 복제할 수 있습니다. 마스터가 오프라인이 되면, 슬레이브가 마스터로 승격되거나 새 마스터가 준비될 때까지 시스템은 읽기 전용 모드로 계속 동작할 수 있습니다.
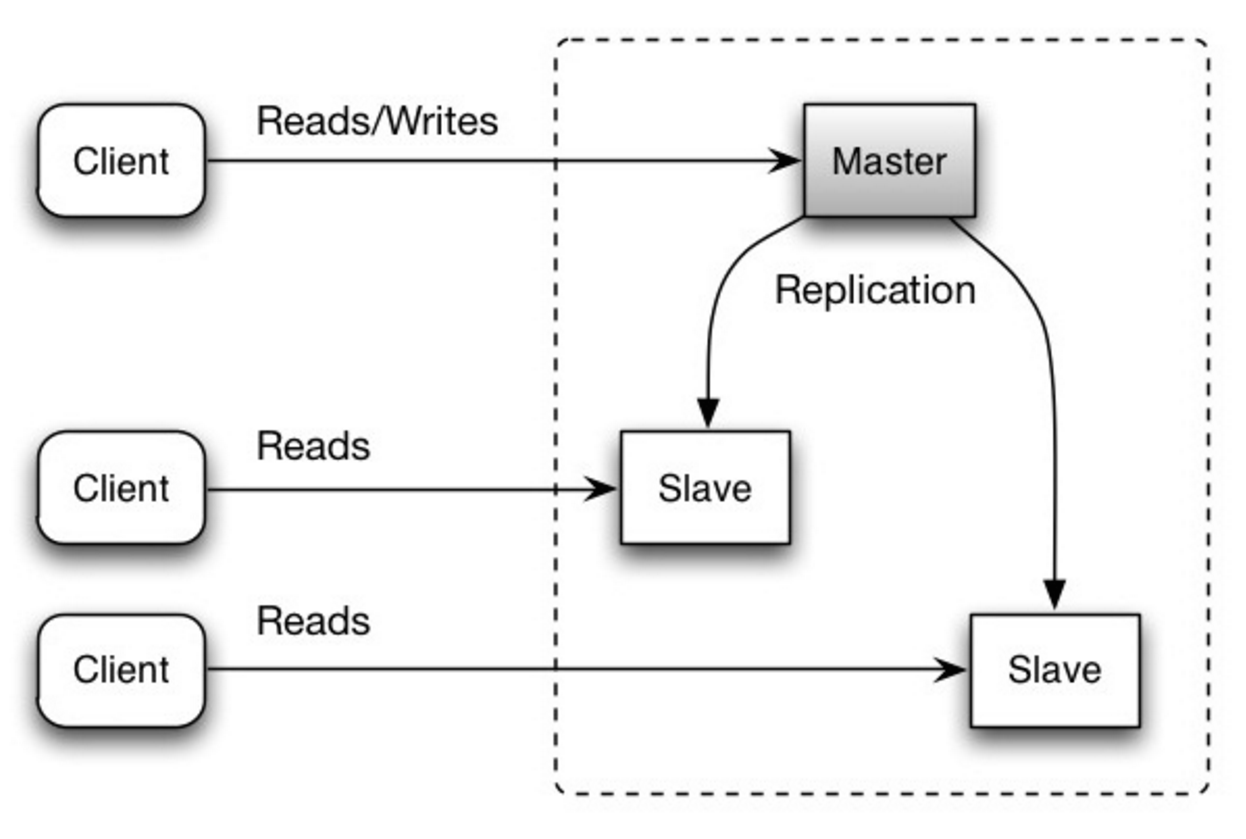
##### 단점: 마스터-슬레이브 복제
- 슬레이브를 마스터로 승격시키기 위한 추가 로직이 필요합니다.
- 마스터-슬레이브와 마스터-마스터 모두에 관련된 사항은 단점: 복제를 참조하세요.
두 마스터 모두 읽기와 쓰기를 처리하며, 쓰기 작업에 대해 서로 조정합니다. 어느 한 쪽 마스터가 다운되더라도 시스템은 읽기와 쓰기를 계속 수행할 수 있습니다.
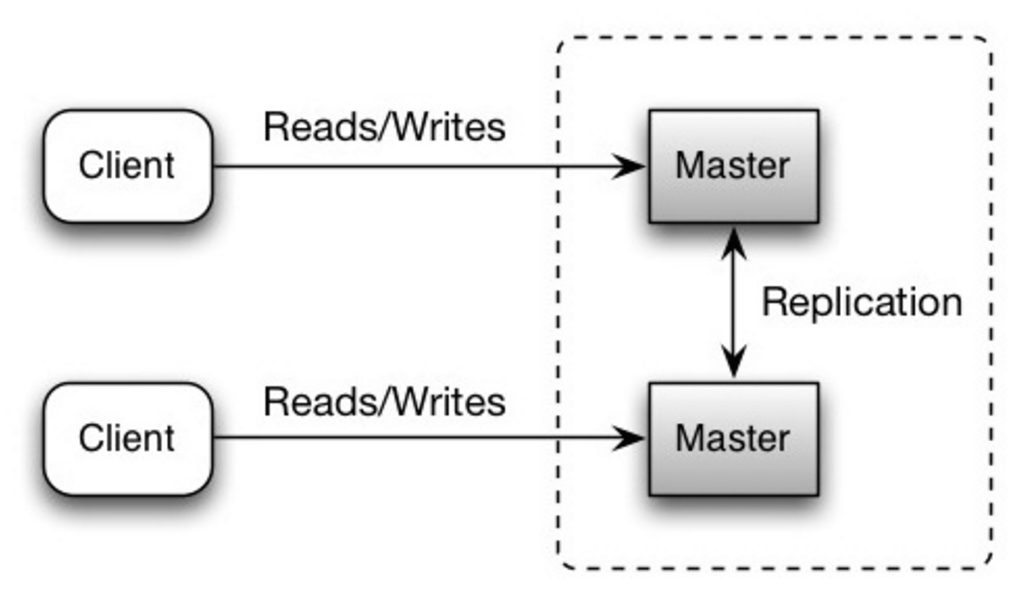
##### 단점: 마스터-마스터 복제
- 로드 밸런서가 필요하거나, 어디에 쓸지 결정하기 위해 애플리케이션 로직을 변경해야 합니다.
- 대부분의 마스터-마스터 시스템은 느슨한 일관성(ACID 위반) 또는 동기화로 인한 쓰기 지연 증가 문제를 가집니다.
- 더 많은 쓰기 노드가 추가되고 지연 시간이 증가함에 따라 충돌 해결이 더 중요해집니다.
- 마스터-슬레이브 및 마스터-마스터 모두와 관련된 내용은 단점: 복제를 참조하세요.
- 마스터가 새로 쓴 데이터를 다른 노드에 복제하기 전에 실패하면 데이터 손실 가능성이 있습니다.
- 쓰기 작업은 읽기 복제본에 재생됩니다. 쓰기가 많으면 읽기 복제본이 쓰기 재생에 부담을 느껴 읽기 성능이 저하될 수 있습니다.
- 읽기 슬레이브가 많을수록 복제해야 할 양이 많아져 복제 지연이 커집니다.
- 일부 시스템에서는 마스터에 쓰기 시 여러 스레드가 병렬로 쓰기를 수행하지만, 읽기 복제본은 단일 스레드로 순차적 쓰기만 지원합니다.
- 복제는 더 많은 하드웨어와 추가적인 복잡성을 초래합니다.
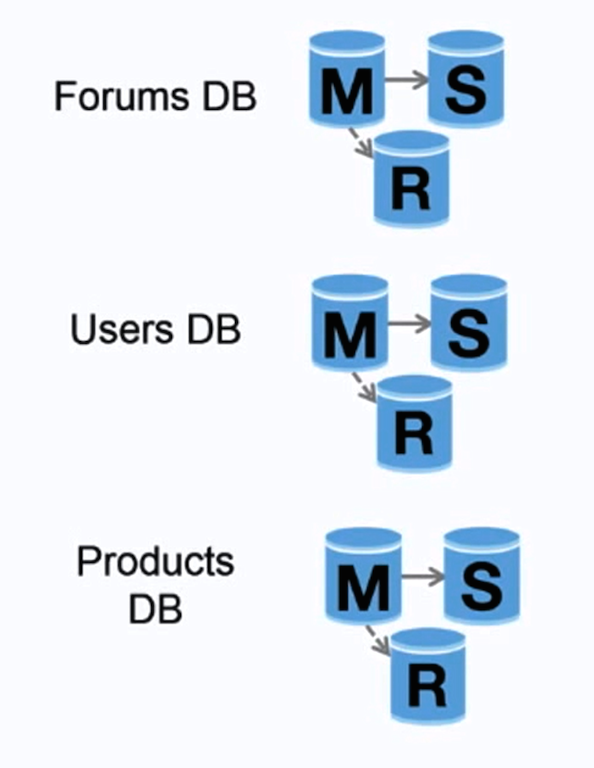
페더레이션(또는 기능 분할)은 데이터베이스를 기능별로 분리합니다. 예를 들어, 단일 모놀리식 데이터베이스 대신에 포럼, 사용자, 제품이라는 세 개의 데이터베이스로 나누어 각 데이터베이스에 대한 읽기 및 쓰기 트래픽을 줄이고 복제 지연을 감소시킵니다. 작은 데이터베이스는 메모리에 더 많은 데이터를 적재할 수 있어 캐시 국소성이 향상되어 캐시 적중률이 높아집니다. 단일 중앙 마스터가 쓰기를 직렬화하지 않으므로 병렬로 쓸 수 있어 처리량이 증가합니다.
##### 단점: 페더레이션
- 스키마가 거대한 기능이나 테이블을 요구하는 경우 페더레이션은 효과적이지 않습니다.
- 어느 데이터베이스를 읽고 쓸지 결정하기 위해 애플리케이션 로직을 업데이트해야 합니다.
- 두 개의 데이터베이스에서 데이터를 조인하는 것은 서버 링크를 사용해도 더 복잡합니다.
- 페더레이션은 더 많은 하드웨어와 추가적인 복잡성을 초래합니다.
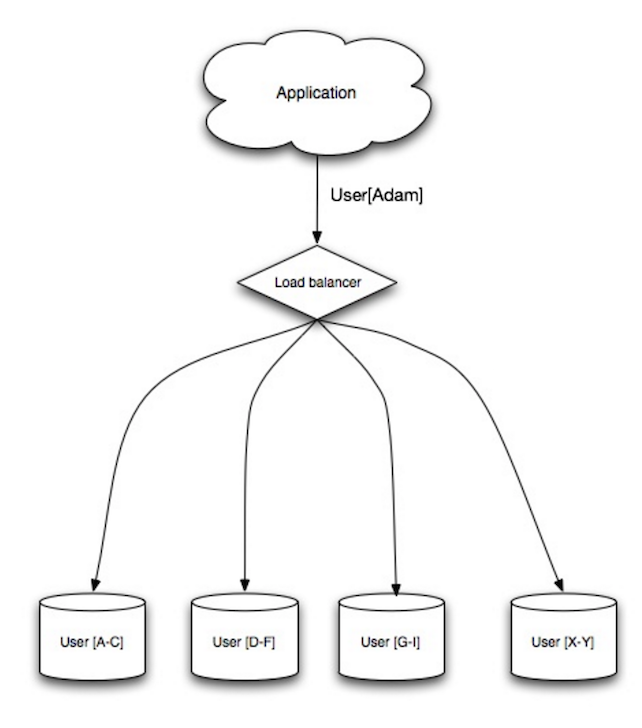
샤딩은 데이터를 서로 다른 데이터베이스에 분산시켜 각 데이터베이스가 데이터의 일부만 관리하도록 합니다. 사용자 데이터베이스를 예로 들면, 사용자가 증가함에 따라 클러스터에 더 많은 샤드가 추가됩니다.
federation의 장점과 유사하게, 샤딩은 읽기 및 쓰기 트래픽 감소, 복제 감소, 캐시 적중률 증가를 가져옵니다. 인덱스 크기도 줄어들어 일반적으로 더 빠른 쿼리로 성능이 향상됩니다. 하나의 샤드가 다운되더라도 다른 샤드는 여전히 작동하지만, 데이터 손실을 방지하기 위해 복제 형태를 추가하는 것이 좋습니다. federation과 마찬가지로, 단일 중앙 마스터가 쓰기를 직렬화하지 않아 병렬로 쓰기가 가능하며 처리량이 증가합니다.
사용자 테이블을 샤딩하는 일반적인 방법은 사용자의 성(last name) 이니셜이나 사용자의 지리적 위치를 기준으로 하는 것입니다.
##### 단점: 샤딩
- 샤드와 작동하도록 애플리케이션 로직을 업데이트해야 하며, 이는 복잡한 SQL 쿼리를 초래할 수 있습니다.
- 데이터 분포가 샤드 내에서 불균형해질 수 있습니다. 예를 들어, 특정 샤드에 파워 유저 집단이 몰리면 해당 샤드에 부하가 증가할 수 있습니다.
- 리밸런싱은 추가적인 복잡성을 더합니다. 일관 해싱(consistent hashing)을 기반으로 한 샤딩 함수는 전송되는 데이터 양을 줄일 수 있습니다.
- 여러 샤드의 데이터를 조인하는 것이 더 복잡합니다.
- 샤딩은 더 많은 하드웨어와 추가적인 복잡성을 수반합니다.
비정규화는 일부 쓰기 성능을 희생하는 대신 읽기 성능을 향상시키려 시도합니다. 비용이 많이 드는 조인을 피하기 위해 여러 테이블에 중복된 데이터 복사본을 작성합니다. PostgreSQL과 Oracle 같은 일부 RDBMS는 중복 정보를 저장하고 중복 복사본을 일관되게 유지하는 작업을 처리하는 물리화 뷰(materialized views)를 지원합니다.
federation과 sharding 같은 기술로 데이터가 분산되면 데이터 센터 간 조인 관리가 더욱 복잡해집니다. 비정규화는 이러한 복잡한 조인 필요성을 우회할 수 있습니다.
대부분 시스템에서 읽기 작업이 쓰기 작업보다 100:1 또는 심지어 1000:1로 훨씬 많을 수 있습니다. 복잡한 데이터베이스 조인으로 인한 읽기는 매우 비용이 많이 들며 디스크 작업에 상당한 시간이 소요될 수 있습니다.
##### 단점: 비정규화
- 데이터가 중복됩니다.
- 중복 정보의 동기화를 돕는 제약 조건은 데이터베이스 설계의 복잡성을 증가시킵니다.
- 무거운 쓰기 부하가 걸린 비정규화 데이터베이스는 정규화된 데이터베이스보다 성능이 더 나쁠 수 있습니다.
SQL 튜닝은 광범위한 주제로 많은 서적이 참고서로 출판되었습니다.
병목 현상을 시뮬레이션하고 발견하기 위해 벤치마크와 프로파일링이 중요합니다.
벤치마킹과 프로파일링을 통해 다음과 같은 최적화를 할 수 있습니다.##### 스키마를 강화하세요
- MySQL은 빠른 접근을 위해 디스크에 연속된 블록으로 덤프합니다.
- 고정 길이 필드에는
VARCHAR대신CHAR를 사용하세요. CHAR는 빠르고 임의 접근이 가능하지만,VARCHAR는 다음 문자열로 넘어가기 전에 문자열 끝을 찾아야 합니다.- 블로그 게시물 같은 큰 텍스트 블록에는
TEXT를 사용하세요.TEXT는 불리언 검색도 허용합니다.TEXT필드를 사용하면 디스크에 텍스트 블록 위치를 찾는 포인터를 저장합니다. - 2^32 또는 40억까지 큰 숫자에는
INT를 사용하세요. - 부동 소수점 표현 오류를 피하기 위해 화폐에는
DECIMAL을 사용하세요. - 큰
BLOB저장은 피하고 객체를 가져올 위치를 저장하세요. VARCHAR(255)는 8비트 숫자로 셀 수 있는 최대 문자 수로, 일부 RDBMS에서 바이트 사용을 극대화합니다.- 적용 가능한 경우
NOT NULL제약 조건을 설정하여 검색 성능 향상을 도모하세요.
- 쿼리하는 열(
SELECT,GROUP BY,ORDER BY,JOIN)에는 인덱스가 더 빠를 수 있습니다. - 인덱스는 데이터를 정렬 상태로 유지하고 로그 시간에 검색, 순차 접근, 삽입 및 삭제를 허용하는 자기 균형 B-트리로 보통 구현됩니다.
- 인덱스 배치는 데이터를 메모리에 유지할 수 있어 더 많은 공간이 필요합니다.
- 인덱스도 업데이트되어야 하므로 쓰기 작업이 느려질 수 있습니다.
- 대량 데이터를 로드할 때는 인덱스를 비활성화한 후 데이터를 로드하고 인덱스를 다시 구축하는 것이 더 빠를 수 있습니다.
- 성능이 필요할 때는 비정규화를 적용하세요.
- 핫스팟을 별도의 테이블로 분리하여 테이블을 나누면 메모리 유지에 도움이 됩니다.
NoSQL
NoSQL은 키-값 저장소, 문서 저장소, 와이드 컬럼 저장소, 또는 그래프 데이터베이스로 표현되는 데이터 항목들의 집합입니다. 데이터가 비정규화되어 있으며, 조인은 일반적으로 애플리케이션 코드에서 수행됩니다. 대부분의 NoSQL 저장소는 진정한 ACID 트랜잭션이 부족하며 최종 일관성을 선호합니다.
BASE는 종종 NoSQL 데이터베이스의 속성을 설명하는 데 사용됩니다. CAP 정리와 비교할 때, BASE는 일관성보다 가용성을 선택합니다.
- 기본적으로 가용함 - 시스템은 가용성을 보장합니다.
- 소프트 상태 - 입력이 없더라도 시스템 상태가 시간에 따라 변할 수 있습니다.
- 최종 일관성 - 시스템이 일정 기간 동안 입력을 받지 않으면 그 기간 후에 일관성을 갖게 됩니다.
#### 키-값 저장소
추상화: 해시 테이블
키-값 저장소는 일반적으로 O(1) 읽기 및 쓰기를 허용하며, 메모리 또는 SSD로 백업되는 경우가 많습니다. 데이터 저장소는 사전식 순서로 키를 유지할 수 있어 키 범위의 효율적인 검색이 가능합니다. 키-값 저장소는 값과 함께 메타데이터 저장도 허용할 수 있습니다.
키-값 저장소는 높은 성능을 제공하며 단순 데이터 모델이나 빠르게 변하는 데이터, 예를 들어 인메모리 캐시 계층에 자주 사용됩니다. 제한된 연산만 제공하기 때문에 추가 연산이 필요할 경우 복잡성이 애플리케이션 계층으로 전가됩니다.
키-값 저장소는 문서 저장소나 경우에 따라 그래프 데이터베이스와 같은 더 복잡한 시스템의 기반입니다.
##### 출처 및 추가 읽기: 키-값 저장소
#### 문서 저장소추상화: 문서가 값으로 저장된 키-값 저장소
문서 저장소는 문서(XML, JSON, 바이너리 등)를 중심으로 하며, 문서는 주어진 객체에 대한 모든 정보를 저장합니다. 문서 저장소는 문서 자체의 내부 구조를 기반으로 쿼리할 수 있는 API 또는 쿼리 언어를 제공합니다. 참고로, 많은 키-값 저장소는 값의 메타데이터를 다루는 기능을 포함하여 이 두 저장 유형의 경계를 모호하게 만듭니다.
기본 구현 방식에 따라 문서는 컬렉션, 태그, 메타데이터 또는 디렉터리로 조직됩니다. 문서들은 함께 조직되거나 그룹화될 수 있지만, 문서 간에 완전히 다른 필드를 가질 수도 있습니다.
MongoDB와 CouchDB와 같은 일부 문서 저장소는 복잡한 쿼리를 수행하기 위해 SQL과 유사한 언어도 제공합니다. DynamoDB는 키-값과 문서 모두를 지원합니다.
문서 저장소는 높은 유연성을 제공하며 가끔 변경되는 데이터 작업에 자주 사용됩니다.
##### 출처 및 추가 읽을거리: 문서 저장소
#### 와이드 컬럼 저장소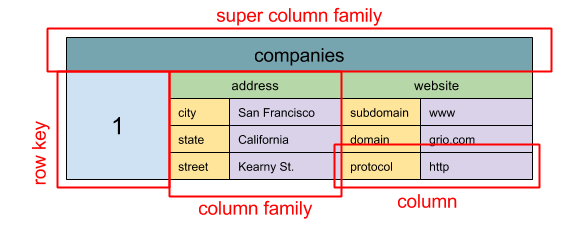
추상화: 중첩된 맵 ColumnFamily> 와이드 컬럼 저장소의 기본 데이터 단위는 컬럼(이름/값 쌍)입니다. 컬럼은 컬럼 패밀리( SQL 테이블에 상응)로 그룹화될 수 있습니다. 슈퍼 컬럼 패밀리는 컬럼 패밀리를 더 그룹화합니다. 각 컬럼은 행 키로 독립적으로 접근할 수 있고, 동일한 행 키를 가진 컬럼들이 행을 형성합니다. 각 값은 버전 관리 및 충돌 해결을 위한 타임스탬프를 포함합니다.
구글은 최초의 와이드 컬럼 저장소인 Bigtable을 도입했으며, 이는 하둡 생태계에서 자주 사용되는 오픈소스 HBase와 페이스북의 Cassandra에 영향을 주었습니다. BigTable, HBase, Cassandra와 같은 저장소는 키를 사전식 순서로 유지하여 선택적 키 범위의 효율적 검색을 가능하게 합니다.
와이드 컬럼 저장소는 높은 가용성과 높은 확장성을 제공합니다. 매우 큰 데이터 세트에 자주 사용됩니다.
##### 출처 및 추가 읽을거리: 와이드 컬럼 저장소
#### 그래프 데이터베이스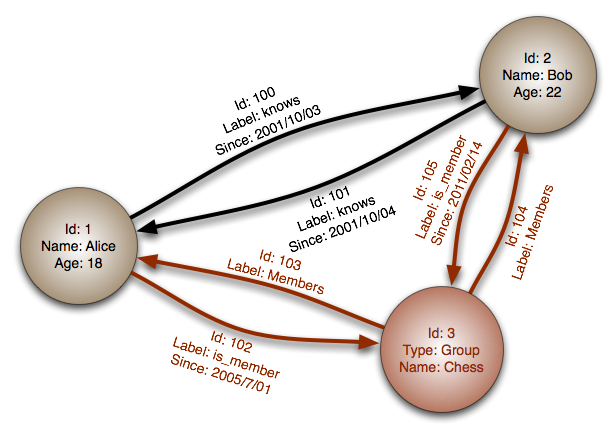
추상화: 그래프
그래프 데이터베이스에서 각 노드는 레코드이고 각 호(arc)는 두 노드 간의 관계입니다. 그래프 데이터베이스는 많은 외래 키 또는 다대다 관계가 있는 복잡한 관계를 표현하는 데 최적화되어 있습니다.
그래프 데이터베이스는 소셜 네트워크와 같은 복잡한 관계를 가진 데이터 모델에 대해 높은 성능을 제공합니다. 비교적 새롭고 아직 널리 사용되지 않았으며 개발 도구와 리소스를 찾기가 더 어려울 수 있습니다. 많은 그래프는 REST API를 통해서만 접근할 수 있습니다.
##### 출처 및 추가 읽을거리: 그래프
#### 출처 및 추가 읽을거리: NoSQLSQL 또는 NoSQL
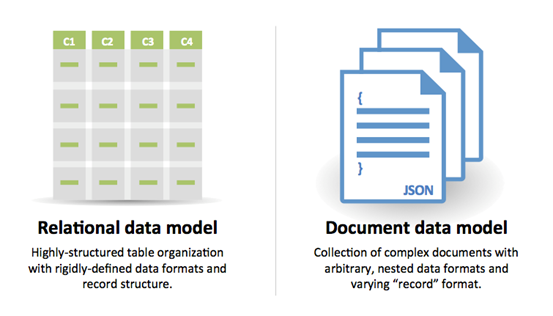
SQL의 이유:
- 구조화된 데이터
- 엄격한 스키마
- 관계형 데이터
- 복잡한 조인 필요
- 트랜잭션
- 명확한 확장 패턴
- 더 확립됨: 개발자, 커뮤니티, 코드, 도구 등
- 인덱스 조회가 매우 빠름
- 반구조화된 데이터
- 동적 또는 유연한 스키마
- 비관계형 데이터
- 복잡한 조인 불필요
- 수 TB(또는 PB) 데이터 저장
- 매우 데이터 집약적인 작업 부하
- 매우 높은 IOPS 처리량
- 클릭스트림 및 로그 데이터의 빠른 수집
- 리더보드 또는 점수 데이터
- 쇼핑카트와 같은 임시 데이터
- 자주 접근하는('핫') 테이블
- 메타데이터/조회 테이블
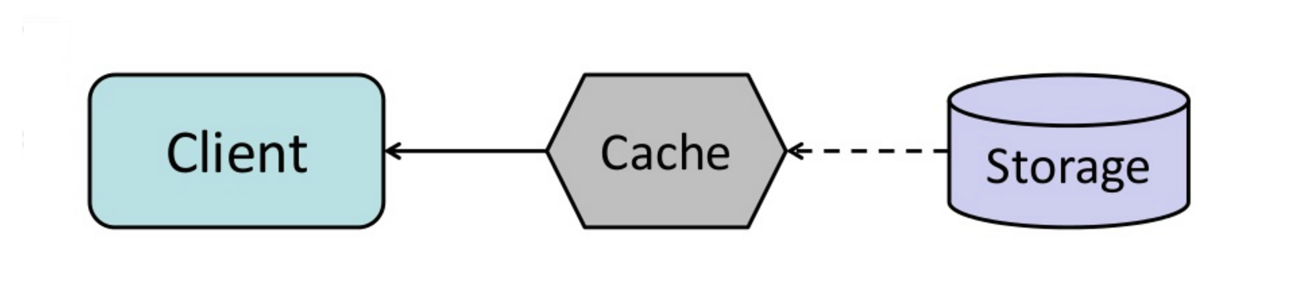
캐시
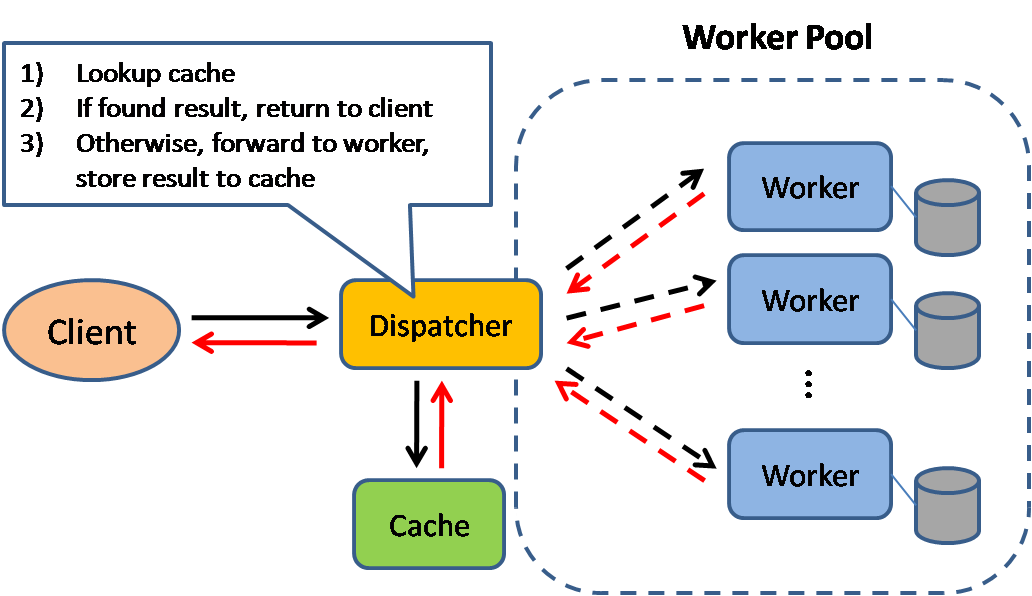
캐싱은 페이지 로드 시간을 개선하고 서버 및 데이터베이스의 부하를 줄일 수 있습니다. 이 모델에서 디스패처는 먼저 요청이 이전에 이루어졌는지 확인하고, 이전 결과를 찾아 반환하여 실제 실행을 절약하려고 합니다.
데이터베이스는 종종 파티션 전반에 걸쳐 읽기와 쓰기의 균일한 분포에서 이점을 얻습니다. 인기 있는 항목은 분포를 왜곡시켜 병목 현상을 초래할 수 있습니다. 데이터베이스 앞에 캐시를 두면 불균형한 부하와 트래픽 급증을 흡수하는 데 도움이 됩니다.
클라이언트 캐싱
캐시는 클라이언트 측(OS 또는 브라우저), 서버 측 또는 별도의 캐시 계층에 위치할 수 있습니다.
CDN 캐싱
CDN은 캐시의 한 종류로 간주됩니다.
웹 서버 캐싱
리버스 프록시 및 Varnish와 같은 캐시는 정적 및 동적 콘텐츠를 직접 제공할 수 있습니다. 웹 서버는 요청을 캐시하여 애플리케이션 서버에 연락하지 않고도 응답을 반환할 수 있습니다.
데이터베이스 캐싱
데이터베이스는 일반적으로 기본 구성에서 어느 정도의 캐싱을 포함하며, 일반적인 사용 사례에 최적화되어 있습니다. 특정 사용 패턴에 맞게 이러한 설정을 조정하면 성능을 더욱 향상시킬 수 있습니다.
애플리케이션 캐싱
Memcached 및 Redis와 같은 메모리 내 캐시는 애플리케이션과 데이터 저장소 사이의 키-값 저장소입니다. 데이터가 RAM에 저장되기 때문에, 디스크에 데이터를 저장하는 일반 데이터베이스보다 훨씬 빠릅니다. RAM은 디스크보다 제한적이므로, 캐시 무효화 알고리즘인 최소 최근 사용(LRU)) 등이 '차가운' 항목을 무효화하고 '뜨거운' 데이터를 RAM에 유지하는 데 도움이 됩니다.
Redis는 다음과 같은 추가 기능을 제공합니다:
- 지속성 옵션
- 정렬된 집합과 리스트 같은 내장 데이터 구조
- 행 수준
- 쿼리 수준
- 완전히 형성된 직렬화 가능한 객체
- 완전히 렌더링된 HTML
데이터베이스 쿼리 레벨에서의 캐싱
데이터베이스를 쿼리할 때마다 쿼리를 키로 해싱하고 결과를 캐시에 저장합니다. 이 접근법은 만료 문제를 겪습니다:
- 복잡한 쿼리로 캐시된 결과를 삭제하기 어려움
- 테이블 셀과 같은 데이터 한 조각이 변경되면, 변경된 셀을 포함할 수 있는 모든 캐시된 쿼리를 삭제해야 함
객체 레벨에서의 캐싱
데이터를 애플리케이션 코드에서 하는 것처럼 객체로 봅니다. 애플리케이션이 데이터베이스에서 데이터셋을 클래스 인스턴스나 데이터 구조로 조립하도록 합니다:
- 기본 데이터가 변경되면 객체를 캐시에서 제거
- 비동기 처리 가능: 작업자가 최신 캐시된 객체를 소비하여 객체를 조립함
- 사용자 세션
- 완전히 렌더링된 웹 페이지
- 활동 스트림
- 사용자 그래프 데이터
캐시를 언제 업데이트할지
캐시에 저장할 수 있는 데이터가 제한적이므로, 어떤 캐시 업데이트 전략이 귀하의 사용 사례에 가장 적합한지 결정해야 합니다.
#### 캐시-어사이드
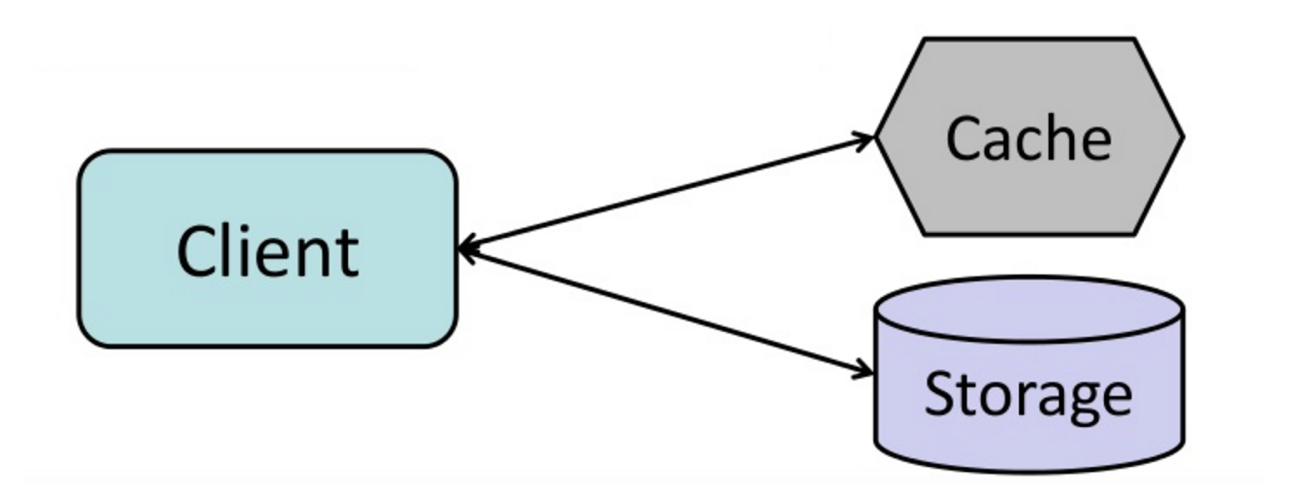
애플리케이션이 저장소에서 읽기 및 쓰기를 담당합니다. 캐시는 저장소와 직접 상호작용하지 않습니다. 애플리케이션은 다음을 수행합니다:
- 캐시에서 항목을 찾으나 캐시 미스 발생
- 데이터베이스에서 항목을 로드
- 항목을 캐시에 추가
- 항목을 반환
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return user캐시에 추가된 데이터의 후속 읽기는 빠릅니다. 캐시 어사이드는 지연 로딩(lazy loading)이라고도 합니다. 요청된 데이터만 캐시에 저장되므로 요청되지 않은 데이터로 캐시가 가득 차는 것을 방지합니다.
##### 단점: 캐시 어사이드
- 각 캐시 미스는 세 번의 왕복을 발생시켜 눈에 띄는 지연을 초래할 수 있습니다.
- 데이터가 데이터베이스에서 업데이트되면 오래된 데이터가 될 수 있습니다. 이 문제는 TTL(time-to-live)을 설정하여 캐시 항목의 업데이트를 강제하거나 쓰기 쓰루(write-through)를 사용하여 완화됩니다.
- 노드가 실패하면 새롭고 빈 노드로 교체되어 지연 시간이 증가합니다.
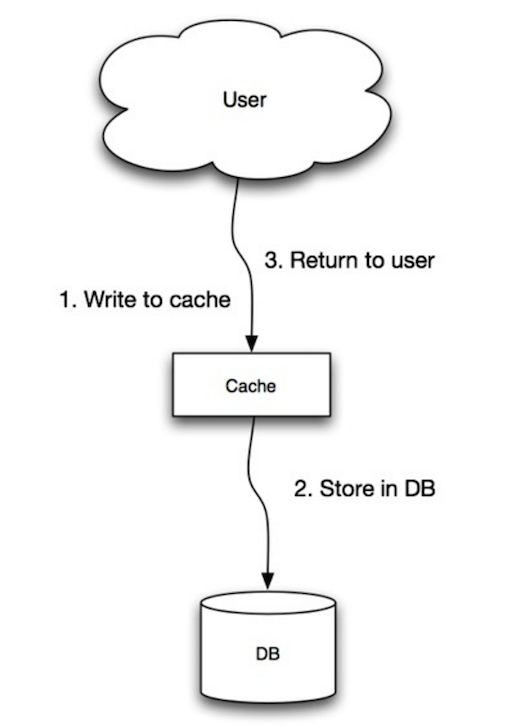
출처: Scalability, availability, stability, patterns
애플리케이션은 캐시를 주요 데이터 저장소로 사용하며, 캐시가 데이터베이스에 대해 읽기 및 쓰기를 담당하는 동안 데이터를 읽고 씁니다:
- 애플리케이션이 캐시에 항목을 추가/업데이트합니다.
- 캐시는 동기적으로 데이터 저장소에 항목을 씁니다.
- 반환
set_user(12345, {"foo":"bar"})def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### 단점: write through
- 장애나 확장으로 인해 새 노드가 생성되면, 데이터베이스에서 항목이 업데이트될 때까지 새 노드는 항목을 캐시하지 않습니다. write through와 함께 cache-aside를 사용하면 이 문제를 완화할 수 있습니다.
- 대부분의 쓰여진 데이터는 읽히지 않을 수 있으며, 이는 TTL로 최소화할 수 있습니다.
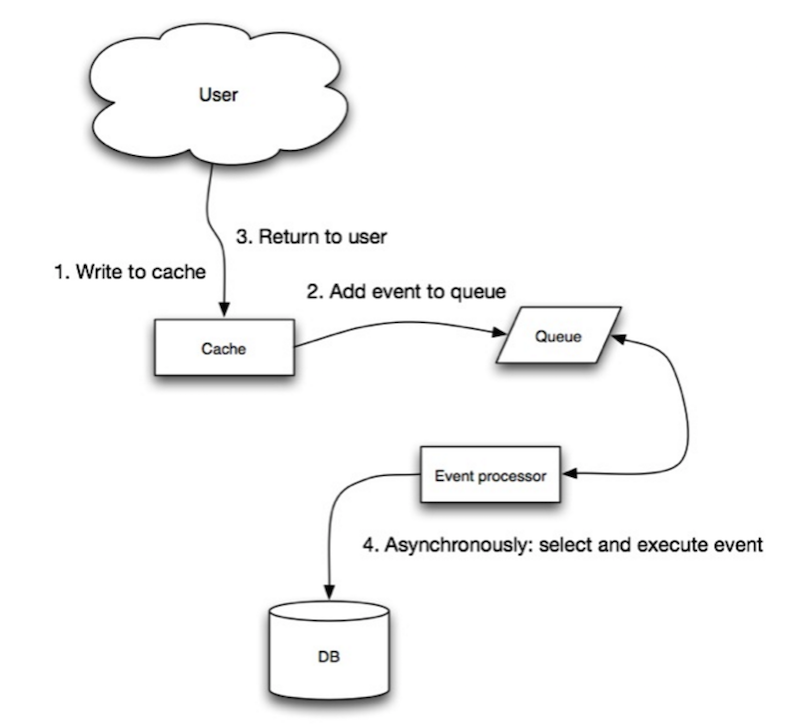
write-behind에서 애플리케이션은 다음을 수행합니다:
- 캐시에 항목 추가/업데이트
- 비동기적으로 항목을 데이터 저장소에 기록하여 쓰기 성능 향상
- 캐시가 데이터 저장소에 내용이 기록되기 전에 다운되면 데이터 손실이 발생할 수 있습니다.
- write-behind 구현은 cache-aside나 write-through 구현보다 더 복잡합니다.
캐시가 만료되기 전에 최근에 액세스한 캐시 항목을 자동으로 갱신하도록 구성할 수 있습니다.
Refresh-ahead는 캐시가 앞으로 필요할 가능성이 높은 항목을 정확히 예측할 수 있으면 read-through 대비 지연 시간을 줄일 수 있습니다.
##### 단점: refresh-ahead
- 미래에 필요할 가능성이 높은 항목을 정확하게 예측하지 못하면 리프레시 어헤드 없이 사용하는 것보다 성능이 저하될 수 있습니다.
단점: 캐시
- 캐시와 데이터베이스와 같은 진실의 원천(source of truth) 간의 일관성을 캐시 무효화를 통해 유지해야 합니다.
- 캐시 무효화는 어려운 문제이며, 캐시를 언제 업데이트할지에 대한 추가적인 복잡성이 있습니다.
- Redis나 memcached 추가와 같은 애플리케이션 변경이 필요합니다.
출처 및 추가 읽을거리
비동기 처리
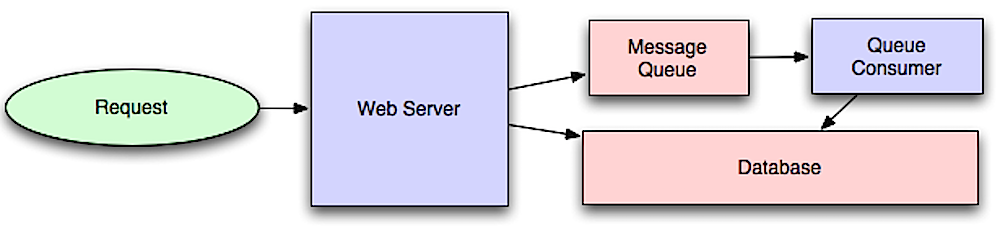
비동기 워크플로우는 인라인으로 수행하면 시간이 많이 걸리는 작업에 대한 요청 시간을 줄이는 데 도움이 됩니다. 또한 데이터의 주기적 집계와 같이 시간이 많이 걸리는 작업을 미리 수행하는 데도 도움이 됩니다.
메시지 큐
메시지 큐는 메시지를 수신, 보관, 전달합니다. 작업이 인라인으로 수행하기에 너무 느리면 다음과 같은 워크플로우로 메시지 큐를 사용할 수 있습니다:
- 애플리케이션이 작업을 큐에 게시한 후 사용자에게 작업 상태를 알립니다.
- 워커가 큐에서 작업을 가져와 처리한 후 작업이 완료되었음을 알립니다.
Redis 는 간단한 메시지 브로커로 유용하지만 메시지가 손실될 수 있습니다.
RabbitMQ 는 인기가 있지만 'AMQP' 프로토콜에 적응하고 자체 노드를 관리해야 합니다. Amazon SQS는 호스팅되는 서비스이지만 지연 시간이 높을 수 있으며 메시지가 두 번 전달될 가능성이 있습니다.
작업 큐
작업 큐는 작업과 관련 데이터를 받아 실행한 후 결과를 전달합니다. 스케줄링을 지원할 수 있으며, 백그라운드에서 계산 집약적인 작업을 실행하는 데 사용할 수 있습니다.
Celery는 스케줄링을 지원하며 주로 파이썬을 지원합니다.
역압(Back pressure)
큐가 크게 증가하기 시작하면 큐 크기가 메모리보다 커져 캐시 미스, 디스크 읽기 및 더 느린 성능이 발생할 수 있습니다. 역압은 큐 크기를 제한하여 이미 큐에 있는 작업의 높은 처리량과 좋은 응답 시간을 유지하는 데 도움을 줄 수 있습니다. 큐가 가득 차면 클라이언트는 서버 바쁨 또는 HTTP 503 상태 코드를 받아 나중에 다시 시도합니다. 클라이언트는 나중에 요청을 재시도할 수 있으며, 지수 백오프를 사용할 수도 있습니다.
단점: 비동기성
- 저렴한 계산이나 실시간 워크플로우 같은 사용 사례는 큐 도입으로 인해 지연과 복잡성이 증가할 수 있으므로 동기식 작업에 더 적합할 수 있습니다.
출처 및 추가 읽을거리
통신
하이퍼텍스트 전송 프로토콜(HTTP)
HTTP는 클라이언트와 서버 간에 데이터를 인코딩하고 전송하는 방법입니다. 요청/응답 프로토콜로서, 클라이언트가 요청을 보내면 서버가 관련 콘텐츠와 요청 완료 상태 정보를 담은 응답을 보냅니다. HTTP는 자체 포함형으로, 요청과 응답이 부하 분산, 캐싱, 암호화, 압축을 수행하는 여러 중간 라우터와 서버를 통해 흐를 수 있습니다.
기본 HTTP 요청은 동사(메서드)와 자원(엔드포인트)으로 구성됩니다. 아래는 일반적인 HTTP 동사입니다:
| 동사 | 설명 | 멱등성* | 안전성 | 캐시 가능 | |---|---|---|---|---|
| GET | 리소스를 읽음 | 예 | 예 | 예 | | POST | 리소스를 생성하거나 데이터를 처리하는 프로세스를 트리거함 | 아니오 | 아니오 | 응답에 최신 정보가 포함된 경우 예 | | PUT | 리소스를 생성하거나 교체함 | 예 | 아니오 | 아니오 | | PATCH | 리소스를 부분적으로 업데이트함 | 아니오 | 아니오 | 응답에 최신 정보가 포함된 경우 예 | | DELETE | 리소스를 삭제함 | 예 | 아니오 | 아니오 |
*다른 결과 없이 여러 번 호출할 수 있음.
HTTP는 TCP 및 UDP와 같은 하위 계층 프로토콜에 의존하는 애플리케이션 계층 프로토콜임.
#### 출처 및 추가 읽을거리: HTTP
전송 제어 프로토콜 (TCP)
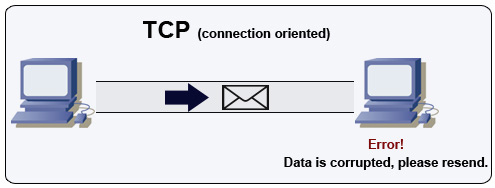
TCP는 IP 네트워크 위의 연결 지향 프로토콜임. 연결은 핸드셰이크를 사용하여 설정되고 종료됨. 모든 전송된 패킷은 다음을 통해 원래 순서대로 손상 없이 목적지에 도달함이 보장됨:
발신자가 올바른 응답을 받지 못하면 패킷을 재전송함. 여러 번 타임아웃이 발생하면 연결이 끊어짐. TCP는 또한 흐름 제어)와 혼잡 제어를 구현함. 이러한 보장은 지연을 초래하며 일반적으로 UDP보다 전송 효율이 낮음.높은 처리량을 보장하기 위해 웹 서버는 많은 수의 TCP 연결을 유지할 수 있으며, 이는 높은 메모리 사용량을 초래함. 웹 서버 스레드와 예를 들어 memcached 서버 간에 많은 수의 열린 연결을 유지하는 것은 비용이 많이 들 수 있음. 연결 풀링은 UDP로 전환하는 것과 더불어 도움이 될 수 있음.
TCP는 높은 신뢰성이 필요하지만 시간에 덜 민감한 애플리케이션에 유용함. 예로는 웹 서버, 데이터베이스 정보, SMTP, FTP 및 SSH 등이 있음.
UDP보다 TCP를 사용해야 하는 경우:
- 모든 데이터가 온전하게 도착해야 할 때
- 네트워크 처리량을 자동으로 최적 추정하여 사용하고자 할 때
사용자 데이터그램 프로토콜 (UDP)
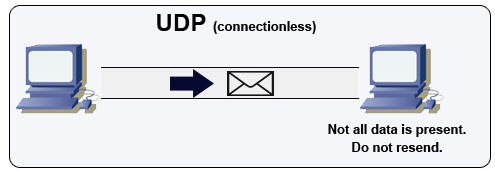
UDP는 연결 지향적이지 않습니다. 데이터그램(패킷에 해당)은 데이터그램 수준에서만 보장됩니다. 데이터그램은 순서가 뒤바뀌어 도착하거나 전혀 도착하지 않을 수 있습니다. UDP는 혼잡 제어를 지원하지 않습니다. TCP가 지원하는 보장 없이, UDP는 일반적으로 더 효율적입니다.
UDP는 서브넷 내 모든 장치에 데이터그램을 브로드캐스트할 수 있습니다. 이는 클라이언트가 아직 IP 주소를 받지 않은 상태이므로 TCP가 IP 주소 없이 스트리밍할 수 없게 하는 DHCP에서 유용합니다.
UDP는 신뢰성은 떨어지지만 VoIP, 영상 통화, 스트리밍, 실시간 멀티플레이어 게임과 같은 실시간 사용 사례에 적합합니다.
TCP 대신 UDP를 사용해야 할 때:
- 가장 낮은 지연 시간이 필요할 때
- 늦은 데이터가 데이터 손실보다 나쁠 때
- 자체 오류 수정 구현을 원할 때
원격 프로시저 호출 (RPC)
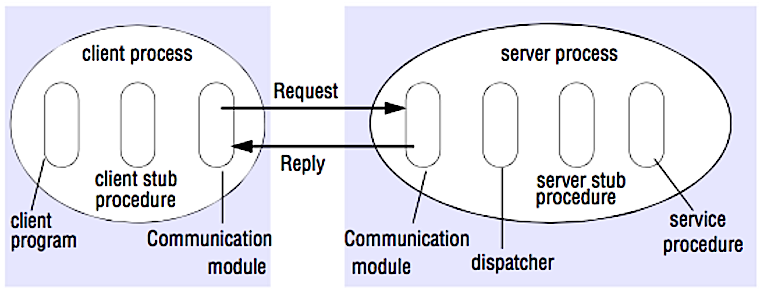
RPC에서는 클라이언트가 다른 주소 공간, 보통 원격 서버에서 프로시저를 실행하도록 합니다. 프로시저는 로컬 프로시저 호출인 것처럼 코딩되어, 클라이언트 프로그램으로부터 서버와 통신하는 세부 사항을 추상화합니다. 원격 호출은 보통 로컬 호출보다 느리고 신뢰성이 떨어지므로 RPC 호출과 로컬 호출을 구분하는 것이 유용합니다. 널리 사용되는 RPC 프레임워크로는 Protobuf, Thrift, Avro가 있습니다.
RPC는 요청-응답 프로토콜입니다:
- 클라이언트 프로그램 - 클라이언트 스텁 프로시저를 호출합니다. 매개변수는 로컬 프로시저 호출처럼 스택에 푸시됩니다.
- 클라이언트 스텁 프로시저 - 프로시저 ID와 인수를 요청 메시지로 마샬링(패킹)합니다.
- 클라이언트 통신 모듈 - OS가 클라이언트에서 서버로 메시지를 전송합니다.
- 서버 통신 모듈 - OS가 들어오는 패킷을 서버 스텁 프로시저로 전달합니다.
- 서버 스텁 프로시저 - 결과를 언마샬링하고, 프로시저 ID에 맞는 서버 프로시저를 호출하며 주어진 인수를 전달합니다.
- 서버 응답은 위 단계를 역순으로 반복합니다.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
네이티브 라이브러리(즉, SDK)를 선택할 때:
- 대상 플랫폼을 알고 있을 때.
- "로직"에 대한 접근 방식을 제어하고 싶을 때.
- 라이브러리 밖에서 오류 제어 방식을 제어하고 싶을 때.
- 성능과 최종 사용자 경험이 주요 관심사일 때.
#### 단점: RPC
- RPC 클라이언트는 서비스 구현에 밀접하게 결합됩니다.
- 새로운 작업이나 사용 사례마다 새로운 API를 정의해야 합니다.
- RPC를 디버깅하기 어려울 수 있습니다.
- 기존 기술을 바로 활용하지 못할 수 있습니다. 예를 들어, RPC 호출이 적절히 캐시되는지 Squid 같은 캐싱 서버에서 추가 노력이 필요할 수 있습니다.
표현 상태 전송 (REST)
REST는 클라이언트가 서버가 관리하는 자원 집합에 작용하는 클라이언트/서버 모델을 강제하는 아키텍처 스타일입니다. 서버는 자원과 자원을 조작하거나 새로운 자원 표현을 얻을 수 있는 동작의 표현을 제공합니다. 모든 통신은 무상태이며 캐시 가능해야 합니다.
RESTful 인터페이스의 네 가지 특성:
- 자원 식별(HTTP의 URI) - 모든 작업에 대해 동일한 URI 사용.
- 표현으로 변경(HTTP의 동사) - 동사, 헤더, 본문 사용.
- 자기 설명적 오류 메시지(HTTP의 상태 응답) - 상태 코드를 사용하며, 새로운 방식 고안 금지.
- HATEOAS (HTTP용 HTML 인터페이스) - 웹 서비스는 브라우저에서 완전히 접근 가능해야 함.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### 단점: REST
- REST는 데이터를 노출하는 데 중점을 두기 때문에, 리소스가 자연스럽게 조직되거나 간단한 계층 구조로 접근되지 않는 경우 적합하지 않을 수 있습니다. 예를 들어, 특정 이벤트 집합과 일치하는 지난 한 시간 동안 업데이트된 모든 기록을 반환하는 것은 경로로 쉽게 표현되지 않습니다. REST에서는 URI 경로, 쿼리 매개변수, 그리고 경우에 따라 요청 본문의 조합으로 구현될 가능성이 큽니다.
- REST는 일반적으로 몇 가지 동사(GET, POST, PUT, DELETE, PATCH)에 의존하는데, 이는 때때로 사용 사례에 맞지 않을 수 있습니다. 예를 들어, 만료된 문서를 보관 폴더로 이동하는 작업은 이러한 동사에 깔끔하게 맞지 않을 수 있습니다.
- 중첩된 계층 구조를 가진 복잡한 리소스를 가져오려면 클라이언트와 서버 간 여러 번 왕복해야 하며, 예를 들어 블로그 항목의 내용과 그 댓글을 가져올 때 단일 뷰를 렌더링하기 위해 여러 번 왕복이 필요합니다. 가변적인 네트워크 조건에서 작동하는 모바일 애플리케이션에는 이러한 다중 왕복이 매우 바람직하지 않습니다.
- 시간이 지남에 따라 API 응답에 더 많은 필드가 추가될 수 있으며, 이전 클라이언트는 필요하지 않은 새로운 데이터 필드까지 모두 수신하게 되어, 페이로드 크기가 증가하고 지연 시간이 길어집니다.
RPC와 REST 호출 비교
| 작업 | RPC | REST |
|---|---|---|
| 가입 | POST /signup | POST /persons |
| 탈퇴 | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| 사람 정보 읽기 | GET /readPerson?personid=1234 | GET /persons/1234 |
| 사람의 아이템 목록 읽기 | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| 사람의 아이템에 추가 | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| 아이템 업데이트 | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| 아이템 삭제 | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
출처: Do you really know why you prefer REST over RPC
#### 출처 및 추가 읽을거리: REST 및 RPC
- Do you really know why you prefer REST over RPC
- 언제 RPC 방식이 REST보다 더 적합한가?
- REST vs JSON-RPC
- RPC와 REST의 신화 깨기
- REST 사용의 단점은 무엇인가?
- 시스템 설계 인터뷰 깨기
- Thrift
- 내부 사용에 REST가 RPC보다 나은 이유
보안
이 섹션은 업데이트가 필요합니다. 기여를 고려해 주세요!
보안은 광범위한 주제입니다. 상당한 경험이나 보안 배경이 없거나 보안 지식을 요구하는 직위에 지원하지 않는 한, 기본 사항만 알아도 충분할 것입니다:
- 전송 중 및 저장 중 데이터 암호화.
- 모든 사용자 입력 또는 사용자에게 노출된 입력 매개변수를 정화하여 XSS 및 SQL 인젝션 방지.
- SQL 인젝션 방지를 위해 매개변수화된 쿼리 사용.
- 최소 권한 원칙 적용.
출처 및 추가 자료
부록
때때로 '간단한 계산' 추정을 요청받을 수 있습니다. 예를 들어, 디스크에서 100개의 이미지 썸네일을 생성하는 데 걸리는 시간이나 데이터 구조가 차지하는 메모리 양을 결정해야 할 수도 있습니다. 2의 거듭제곱 표와 모든 프로그래머가 알아야 할 지연 시간 수치는 유용한 참고 자료입니다.
2의 거듭제곱 표
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB모든 프로그래머가 알아야 할 지연 시간 수치들
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- HDD에서 순차적으로 읽기: 30 MB/s
- 1 Gbps 이더넷에서 순차적으로 읽기: 100 MB/s
- SSD에서 순차적으로 읽기: 1 GB/s
- 메인 메모리에서 순차적으로 읽기: 4 GB/s
- 전 세계 왕복 6-7회/초
- 데이터 센터 내 왕복 2,000회/초
#### 출처 및 추가 읽기 자료
- 프로그래머라면 알아야 할 지연 시간 수치 - 1
- 프로그래머라면 알아야 할 지연 시간 수치 - 2
- 대규모 분산 시스템 구축에서 얻은 설계, 교훈 및 조언
- 대규모 분산 시스템 구축에서 얻은 소프트웨어 공학 조언
추가 시스템 설계 인터뷰 질문
일반적인 시스템 설계 인터뷰 질문과 각 질문 해결 방법에 대한 자료 링크.
| 질문 | 참고자료 |
|---|---|
| Dropbox 같은 파일 동기화 서비스 설계 | youtube.com |
| Google 같은 검색 엔진 설계 | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Google 같은 확장 가능한 웹 크롤러 설계 | quora.com |
| Google Docs 설계 | code.google.com
neil.fraser.name |
| Redis 같은 키-값 저장소 설계 | slideshare.net |
| Memcached 같은 캐시 시스템 설계 | slideshare.net |
| Amazon 같은 추천 시스템 설계 | hulu.com
ijcai13.org |
| Bitly 같은 TinyURL 시스템 설계 | n00tc0d3r.blogspot.com |
| WhatsApp 같은 채팅 앱 설계 | highscalability.com |
| Instagram 같은 사진 공유 시스템 설계 | highscalability.com
highscalability.com |
| Facebook 뉴스 피드 기능 설계 | quora.com
quora.com
slideshare.net |
| Facebook 타임라인 기능 설계 | facebook.com
highscalability.com |
| Facebook 채팅 기능 설계 | erlang-factory.com
facebook.com |
| 페이스북과 같은 그래프 검색 기능 설계 | facebook.com
facebook.com
facebook.com |
| 클라우드플레어와 같은 콘텐츠 전송 네트워크 설계 | figshare.com |
| 트위터의 트렌딩 토픽 시스템 설계 | michael-noll.com
snikolov .wordpress.com |
| 랜덤 ID 생성 시스템 설계 | blog.twitter.com
github.com |
| 특정 시간 구간 내 상위 k 요청 반환 | cs.ucsb.edu
wpi.edu |
| 다중 데이터 센터에서 데이터를 제공하는 시스템 설계 | highscalability.com |
| 온라인 멀티플레이어 카드 게임 설계 | indieflashblog.com
buildnewgames.com |
| 가비지 컬렉션 시스템 설계 | stuffwithstuff.com
washington.edu |
| API 속도 제한기 설계 | https://stripe.com/blog/ |
| 주식 거래소 설계 (NASDAQ 또는 Binance와 같은) | Jane Street
Golang 구현
Go 구현 |
| 시스템 설계 질문 추가 | 기여하기 |
실제 세계 아키텍처
실제 시스템이 어떻게 설계되었는지에 관한 글들입니다.
{kind=link}
{kind=link}
다음 글들에서는 세부사항에 집중하지 말고, 대신에:
- 이 글들에서 공유되는 원칙, 공통 기술, 패턴을 파악하세요
- 각 컴포넌트가 해결하는 문제, 작동하는 상황과 그렇지 않은 상황을 연구하세요
- 배운 교훈들을 복습하세요
기업 아키텍처
| 기업 | 참고 자료 |
|---|---|
| Amazon | Amazon 아키텍처 |
| Cinchcast | 매일 1,500시간의 오디오 생산 |
| DataSift | 초당 120,000 트윗의 실시간 데이터 마이닝 |
| Dropbox | 우리가 Dropbox를 확장한 방법 |
| ESPN | 초당 100,000 duh nuh nuhs 운영 |
| Google | Google 아키텍처 |
| Instagram | 1,400만 사용자, 수 테라바이트의 사진
Instagram의 동력 |
| Justin.tv | Justin.Tv의 라이브 비디오 방송 아키텍처 |
| Facebook | Facebook에서의 memcached 확장
TAO: Facebook의 소셜 그래프를 위한 분산 데이터 저장소
Facebook의 사진 저장소
Facebook이 80만 동시 시청자에게 라이브 스트리밍 하는 방법 |
| Flickr | Flickr 아키텍처 |
| Mailbox | 6주 만에 0에서 100만 사용자로 |
| Netflix | Netflix 전체 스택 360도 보기
Netflix: 재생 버튼을 눌렀을 때 무슨 일이 일어나는가? |
| Pinterest | 0에서 매월 수십억 페이지뷰까지
1,800만 방문자, 10배 성장, 12명 직원 |
| Playfish | 5천만 월간 사용자 및 성장 중 |
| PlentyOfFish | PlentyOfFish 아키텍처 |
| Salesforce | 하루 13억 건의 트랜잭션 처리 방법 |
| Stack Overflow | Stack Overflow 아키텍처 |
| TripAdvisor | 4천만 방문자, 2억 동적 페이지뷰, 30TB 데이터 |
| Tumblr | 매월 150억 페이지뷰 |
| Twitter | Twitter를 10000% 빠르게 만들기
MySQL을 사용해 하루 2억 5천만 트윗 저장하기
1억 5천만 활성 사용자, 30만 QPS, 22MB/s 파이어호스
대규모 타임라인
Twitter의 대용량 및 소규모 데이터
Twitter 운영: 1억 사용자 이상 확장
초당 3,000개 이미지 처리 방법 |
| Uber | Uber의 실시간 시장 플랫폼 확장 방법
2000명 엔지니어, 1000개 서비스, 8000개 Git 저장소로 확장하며 배운 교훈 |
| WhatsApp | Facebook이 190억 달러에 인수한 WhatsApp 아키텍처 |
| YouTube | YouTube 확장성
YouTube 아키텍처 |
회사 엔지니어링 블로그
면접을 보는 회사들의 아키텍처.>
마주칠 수 있는 질문들이 같은 도메인에서 나올 수 있습니다.
- Airbnb 엔지니어링
- Atlassian 개발자 블로그
- AWS 블로그
- Bitly 엔지니어링 블로그
- Box 블로그
- Cloudera 개발자 블로그
- Dropbox 기술 블로그
- Quora 엔지니어링
- Ebay 기술 블로그
- Evernote 기술 블로그
- Etsy Code as Craft
- Facebook 엔지니어링
- Flickr 코드
- Foursquare 엔지니어링 블로그
- GitHub 엔지니어링 블로그
- Google 연구 블로그
- Groupon 엔지니어링 블로그
- Heroku 엔지니어링 블로그
- Hubspot 엔지니어링 블로그
- High Scalability
- Instagram 엔지니어링
- Intel 소프트웨어 블로그
- Jane Street 기술 블로그
- LinkedIn 엔지니어링
- Microsoft 엔지니어링
- Microsoft Python 엔지니어링
- Netflix 기술 블로그
- Paypal 개발자 블로그
- Pinterest 엔지니어링 블로그
- Reddit 블로그
- Salesforce 엔지니어링 블로그
- Slack 엔지니어링 블로그
- Spotify Labs
- Stripe 엔지니어링 블로그
- 트윌리오 엔지니어링 블로그
- 트위터 엔지니어링
- 우버 엔지니어링 블로그
- 야후 엔지니어링 블로그
- 옐프 엔지니어링 블로그
- 징가 엔지니어링 블로그
블로그를 추가하고 싶으신가요? 작업 중복을 피하기 위해 아래 저장소에 회사 블로그를 추가하는 것을 고려해 보세요:
개발 중
섹션을 추가하거나 진행 중인 섹션 완성에 도움을 주고 싶으신가요? 기여하기!
- MapReduce를 이용한 분산 컴퓨팅
- 일관성 해싱
- 스캐터 갤러
- 기여하기
감사의 글
이 저장소 전반에 걸쳐 출처와 감사의 글이 제공됩니다.
특별한 감사의 말씀을 전합니다:
- Hired in tech
- 코딩 인터뷰 완전 정복
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- 시스템 디자인 치트 시트
- 분산 시스템 읽기 목록
- 시스템 디자인 인터뷰 완전 정복
연락처 정보
문제, 질문 또는 의견이 있으시면 언제든지 저에게 연락해 주세요.
제 연락처 정보는 제 GitHub 페이지에서 확인하실 수 있습니다.
라이선스
이 저장소의 코드와 자료는 오픈 소스 라이선스 하에 제공됩니다. 이 저장소는 개인 저장소이므로, 코드와 자료에 대한 라이선스는 제 개인 자격으로 제공되며, 제 고용주(페이스북)와는 무관합니다.
저작권 2017 Donne Martin
크리에이티브 커먼즈 저작자표시 4.0 국제 라이선스 (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---