English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation このガイドの翻訳にご協力ください!
システム設計入門

動機
大規模システムの設計方法を学ぶ。>
システム設計面接の準備をする。
大規模システムの設計方法を学ぶ
スケーラブルなシステムの設計方法を学ぶことは、より良いエンジニアになる助けとなります。
システム設計は広範なトピックです。システム設計の原則に関する膨大な量のリソースがウェブ上に散在しています。
このリポジトリは、スケールするシステムの構築方法を学ぶのに役立つ体系的に整理されたリソースのコレクションです。
オープンソースコミュニティから学ぶ
これは継続的に更新されるオープンソースプロジェクトです。
貢献を歓迎します!
システム設計面接の準備
コーディング面接に加えて、多くの技術系企業の技術面接プロセスにはシステム設計が必須の要素となっています。
一般的なシステム設計面接の質問を練習し、議論、コード、図解を含むサンプル解答と比較しましょう。
面接準備のための追加トピック:
Ankiフラッシュカード
提供されているAnkiフラッシュカードデッキは、間隔反復を利用して主要なシステム設計の概念を記憶するのに役立ちます。
外出先での利用に最適です。コーディングリソース: インタラクティブコーディングチャレンジ
コーディング面接の準備に役立つリソースをお探しですか?
姉妹リポジトリのInteractive Coding Challengesもぜひご覧ください。追加のAnkiデッキが含まれています:
貢献について
コミュニティから学びましょう。
以下のためにプルリクエストを自由に送ってください:
- 誤りの修正
- セクションの改善
- 新しいセクションを追加
- 翻訳
貢献ガイドラインを確認してください。
システム設計トピックの索引
さまざまなシステム設計トピックの概要、利点と欠点を含む。 すべてはトレードオフです。>
各セクションには、より詳細なリソースへのリンクが含まれています。
- システム設計トピック:ここから始める
- ステップ1:スケーラビリティのビデオ講義を確認
- ステップ2:スケーラビリティの記事を確認
- 次のステップ
- パフォーマンス対スケーラビリティ
- レイテンシ対スループット
- 可用性対整合性
- CAP定理
- CP - 整合性と分割耐性
- AP - 可用性と分割耐性
- 整合性パターン
- 弱い整合性
- 最終的整合性
- 強い整合性
- 可用性パターン
- フェイルオーバー
- レプリケーション
- 可用性の数値
- ドメインネームシステム
- コンテンツ配信ネットワーク
- プッシュCDN
- プルCDN
- ロードバランサー
- アクティブ-パッシブ
- アクティブ-アクティブ
- レイヤー4ロードバランシング
- レイヤー7ロードバランシング
- 水平スケーリング
- リバースプロキシ(ウェブサーバー)
- ロードバランサーとリバースプロキシの違い
- アプリケーション層
- マイクロサービス
- サービスディスカバリー
- データベース
- リレーショナルデータベース管理システム(RDBMS)
- マスター-スレーブレプリケーション
- マスター-マスターレプリケーション
- フェデレーション
- シャーディング
- 非正規化
- SQLチューニング
- NoSQL
- キー・バリューストア
- ドキュメントストア
- ワイドカラムストア
- グラフデータベース
- SQLまたはNoSQL
- キャッシュ
- クライアントキャッシュ
- CDNキャッシュ
- ウェブサーバーキャッシュ
- データベースキャッシュ
- アプリケーションキャッシュ
- データベースクエリレベルでのキャッシュ
- オブジェクトレベルでのキャッシュ
- キャッシュ更新のタイミング
- キャッシュアサイド
- ライトスルー
- ライトビハインド(ライトバック)
- リフレッシュアヘッド
- 非同期処理
- メッセージキュー
- タスクキュー
- バックプレッシャー
- 通信
- トランスミッションコントロールプロトコル (TCP)
- ユーザーデータグラムプロトコル (UDP)
- リモートプロシージャコール (RPC)
- 表現状態転送 (REST)
- セキュリティ
- 付録
- 2のべき乗表
- すべてのプログラマーが知るべきレイテンシ数値
- 追加のシステム設計面接質問
- 実際のアーキテクチャ
- 企業のアーキテクチャ
- 企業のエンジニアリングブログ
- 開発中
- クレジット
- 連絡先情報
- ライセンス
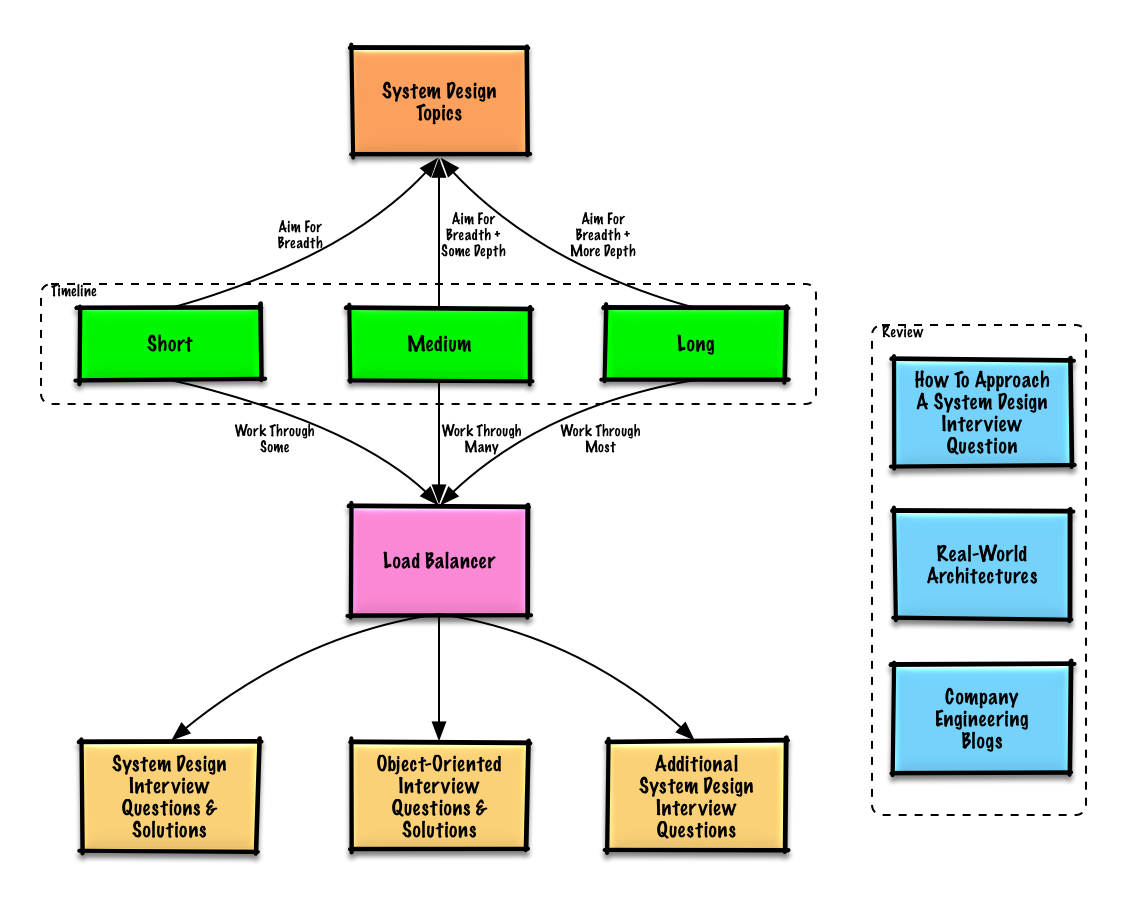
学習ガイド
面接のスケジュールに基づく推奨トピック(短期、中期、長期)。
Q: 面接のためにここにあるすべてを知る必要がありますか?
A: いいえ、面接準備のためにここにあるすべてを知る必要はありません。
面接で問われる内容は以下のような変数によって異なります:
- あなたの経験の量
- あなたの技術的な背景
- 面接を受けるポジション
- 面接を受ける企業
- 運
幅広く学び、いくつかの分野で深掘りしましょう。システム設計の主要なトピックについて少し知っておくと役立ちます。以下のガイドは、あなたのスケジュール、経験、面接するポジションや企業に応じて調整してください。
- 短期間 - システム設計トピックの広範囲を目指しましょう。いくつかの面接問題を解いて練習します。
- 中期間 - システム設計トピックの広範囲と一部の深掘りを目指しましょう。多くの面接問題を解いて練習します。
- 長期間 - システム設計トピックの広範囲とより深い理解を目指しましょう。ほとんどの面接問題を解いて練習します。
システム設計面接質問への取り組み方
システム設計面接質問にどう取り組むか。
システム設計面接はオープンエンドな対話です。あなたが主導することが期待されます。
以下のステップを使って議論を進めることができます。このプロセスを確実にするために、システム設計面接質問と解答のセクションを以下のステップに従って取り組みましょう。
ステップ1: ユースケース、制約、仮定の概要を示す
要件を集めて問題の範囲を定めます。ユースケースや制約を明確にするために質問し、仮定を議論します。
- 誰が使うのか?
- どのように使うのか?
- ユーザー数は?
- システムは何をするのか?
- システムの入力と出力は何か?
- どれくらいのデータを扱うことを想定しているか?
- 1秒あたりのリクエスト数はどれくらいか?
- 読み込みと書き込みの比率はどの程度か?
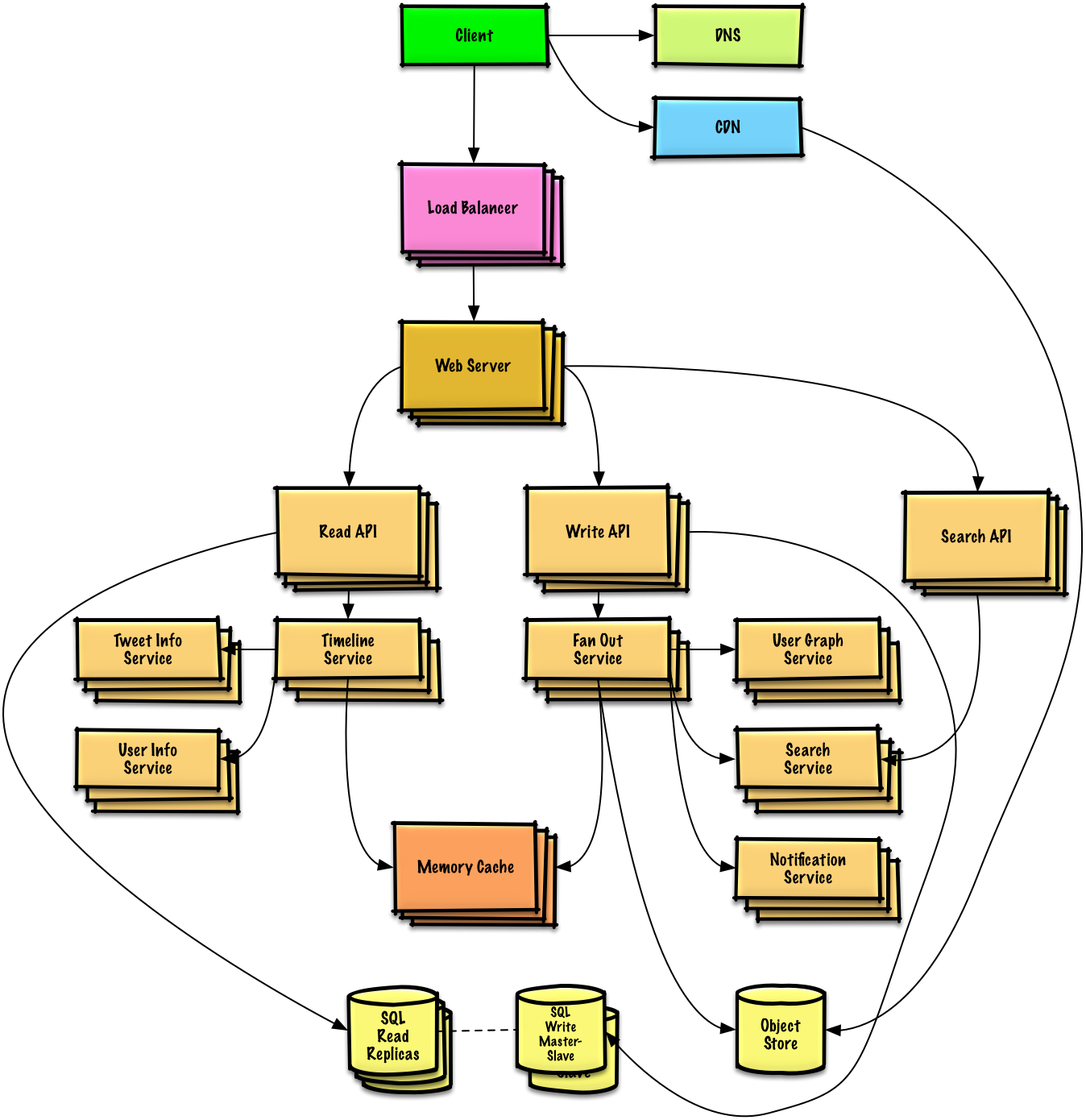
ステップ2: 高レベル設計を作成する
すべての重要なコンポーネントを含む高レベル設計の概要を示します。
- 主なコンポーネントと接続をスケッチする
- アイデアの正当性を説明する
ステップ3: コアコンポーネントの設計
各コアコンポーネントの詳細に入り込む。たとえば、もしURL短縮サービスを設計するように求められた場合、以下を議論する:
- フルURLのハッシュを生成し保存する
- MD5とBase62
- ハッシュの衝突
- SQLかNoSQLか
- データベーススキーマ
- ハッシュ化されたURLをフルURLに変換する
- データベース検索
- APIとオブジェクト指向設計
ステップ4: 設計のスケールアップ
制約条件を踏まえてボトルネックを特定し対処する。たとえば、スケーラビリティの問題に対処するために以下が必要か?
- ロードバランサー
- 水平スケーリング
- キャッシュ
- データベースシャーディング
おおまかな計算
手計算での見積もりを求められることがある。付録の以下のリソースを参照せよ:
参考文献およびさらなる読書
以下のリンクを確認し、何を期待すべきかの理解を深めよう:
システム設計面接の質問と解答例
一般的なシステム設計面接の質問とサンプルディスカッション、コード、図解。>
解答は solutions/ フォルダ内の内容にリンク。| 質問 | | |---|---| | Pastebin.com(または Bit.ly)の設計 | 解答 | | Twitterのタイムラインと検索の設計(またはFacebookのフィードと検索) | 解答 | | ウェブクローラーの設計 | 解答 | | Mint.comの設計 | 解答 | | ソーシャルネットワークのデータ構造の設計 | 解答 | | 検索エンジン用のキー・バリューストアの設計 | 解答 | | Amazonのカテゴリー別売上ランキング機能の設計 | 解答 | | AWSで数百万ユーザーにスケール可能なシステムの設計 | 解答 | | システム設計の質問を追加する | 貢献する |
Pastebin.com(または Bit.ly)の設計
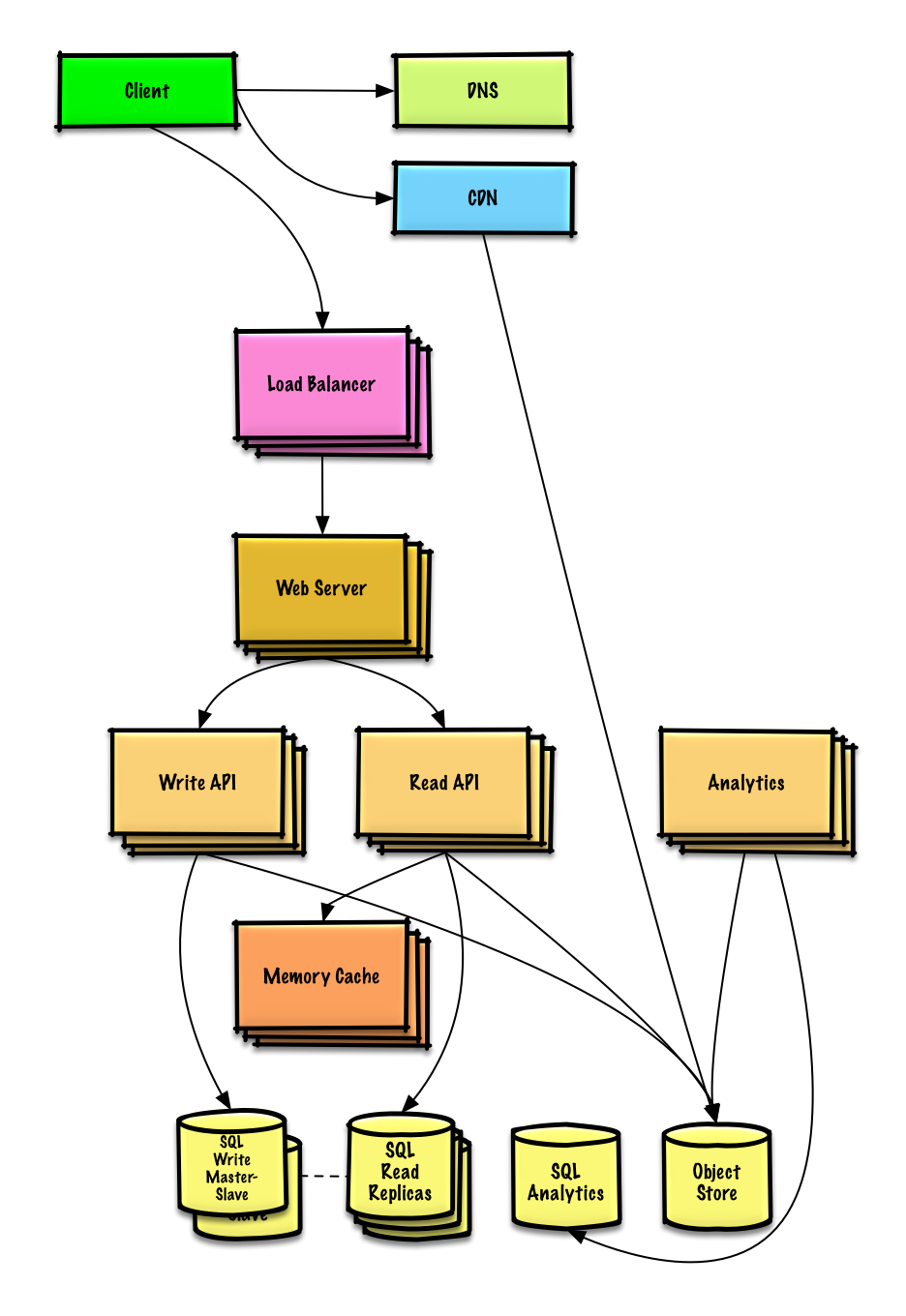
Twitterのタイムラインと検索の設計(またはFacebookのフィードと検索)
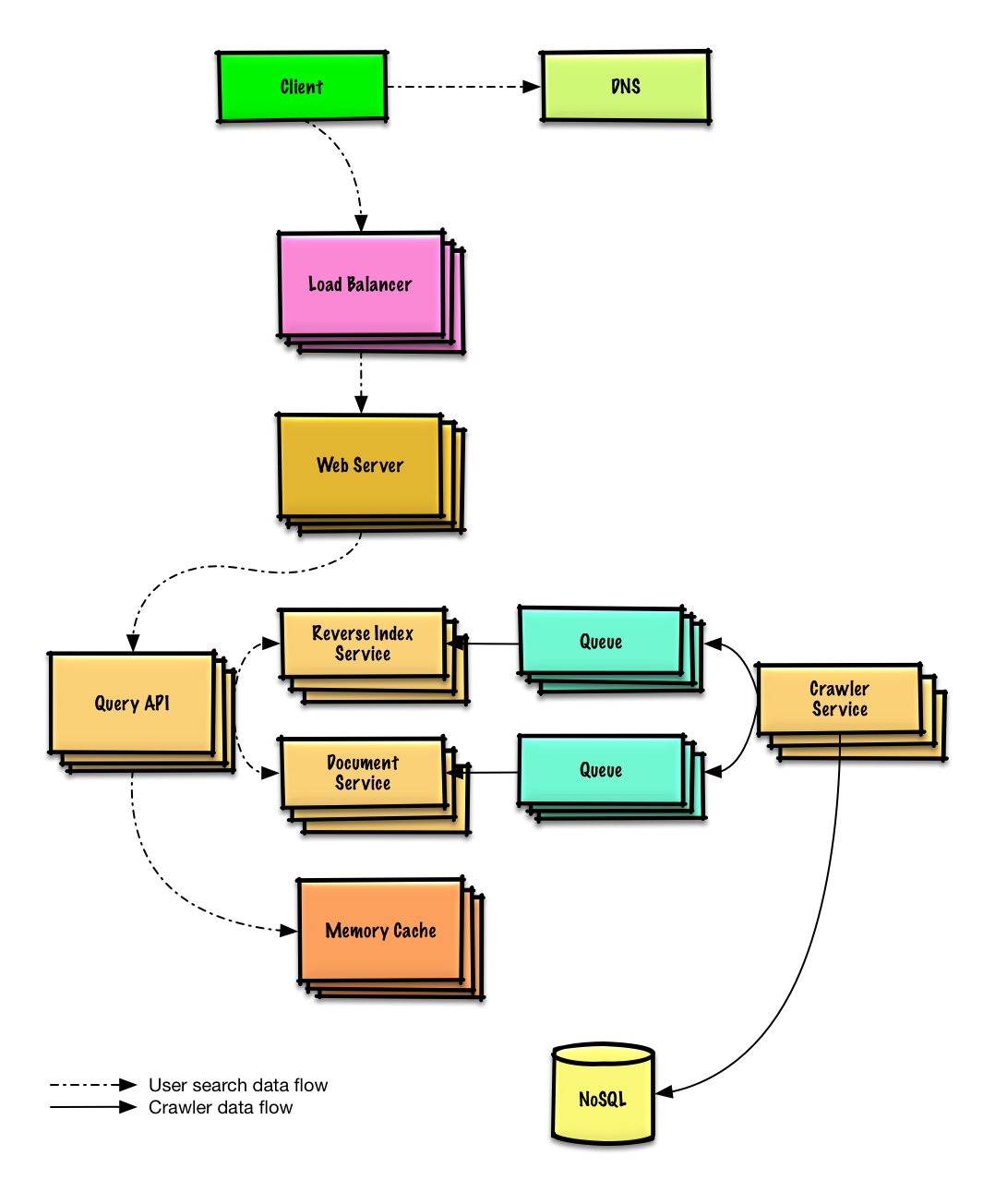
ウェブクローラーの設計
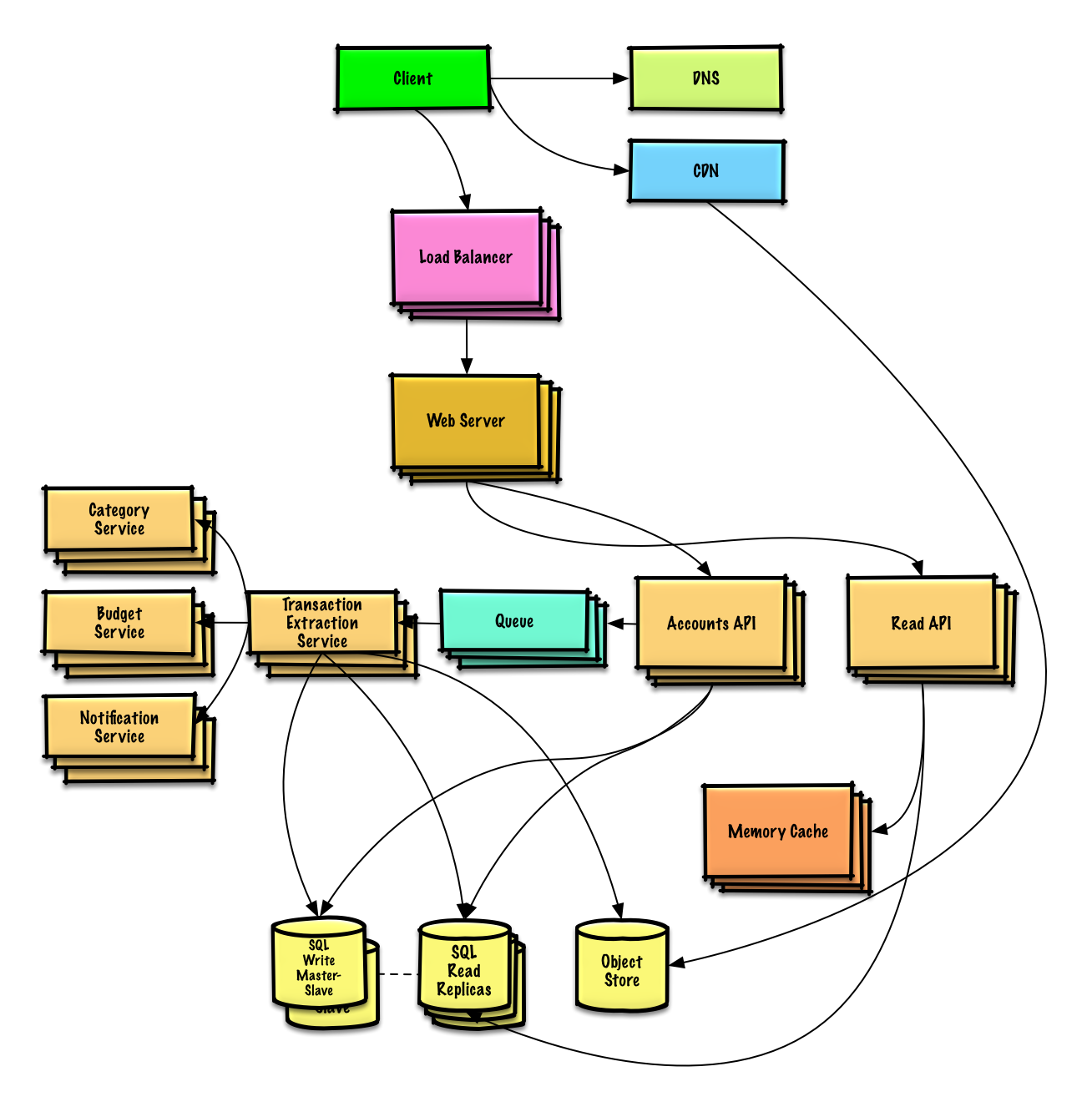
Design Mint.com
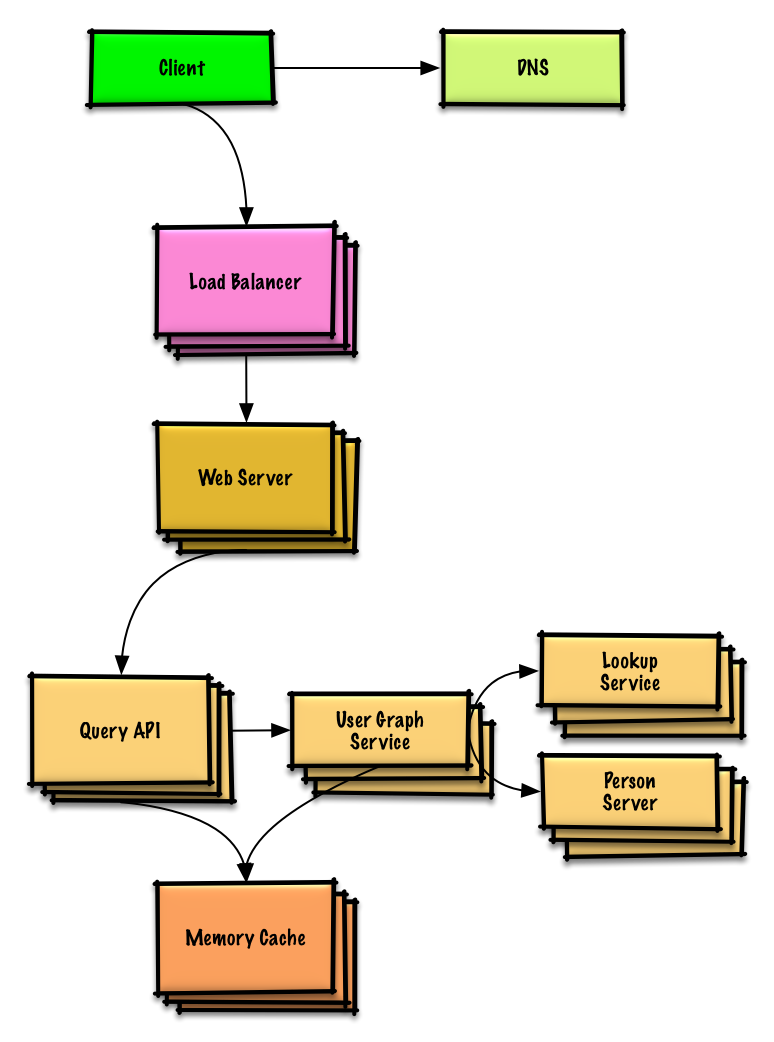
Design the data structures for a social network
Design a key-value store for a search engine
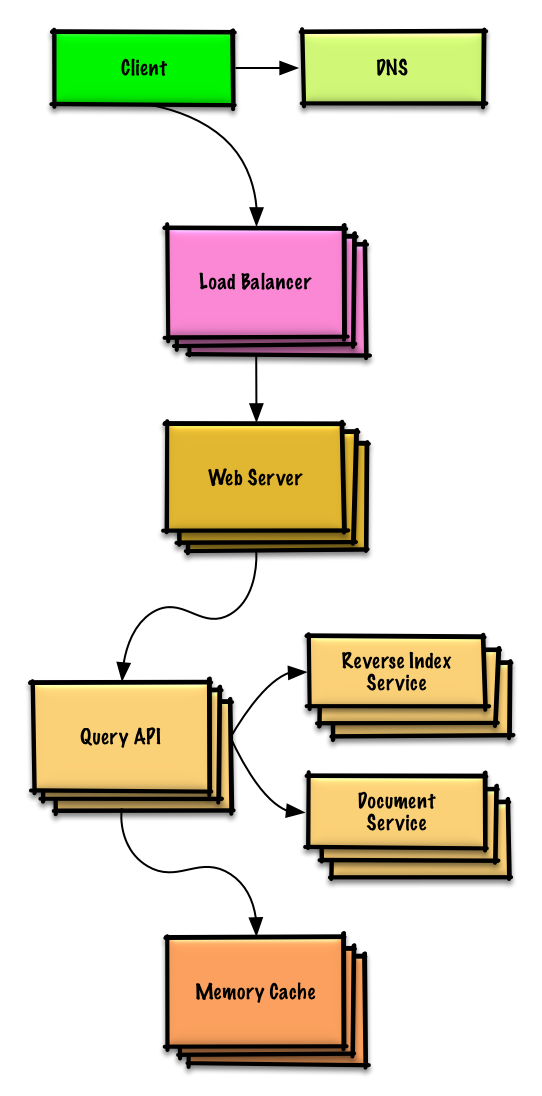
Design Amazon's sales ranking by category feature
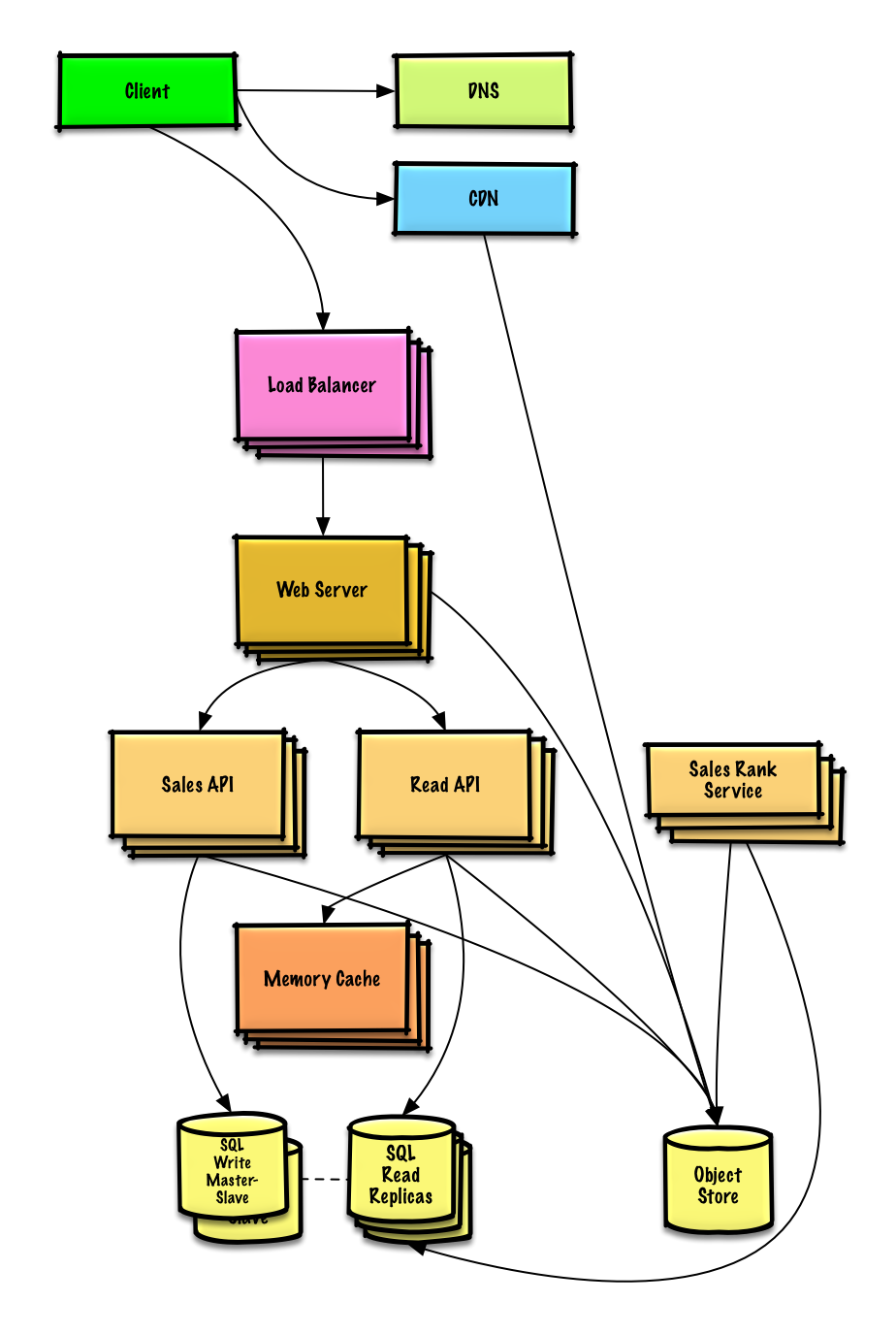
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | ハッシュマップを設計する | 解答 | | LRUキャッシュを設計する | 解答 | | コールセンターを設計する | 解答 | | トランプの山札を設計する | 解答 | | 駐車場を設計する | 解答 | | チャットサーバーを設計する | 解答 | | 循環配列を設計する | 貢献する | | オブジェクト指向設計の質問を追加する | 貢献する |
システム設計トピック:ここから始めよう
システム設計は初めてですか?
まず、基本的な共通原則の理解が必要です。これらが何であるか、どのように使われるか、その利点と欠点について学びましょう。
ステップ1:スケーラビリティのビデオ講義を視聴する
- カバーするトピック:
- 垂直スケーリング
- 水平スケーリング
- キャッシュ
- ロードバランシング
- データベースのレプリケーション
- データベースのパーティショニング
ステップ2:スケーラビリティの記事を読む
次のステップ
次に、高レベルのトレードオフについて見ていきます:
- パフォーマンス vs スケーラビリティ
- レイテンシ vs スループット
- 可用性 vs 一貫性
その後、DNS、CDN、ロードバランサーなど、より具体的なトピックに踏み込んでいきます。
パフォーマンス vs スケーラビリティ
サービスがスケーラブルであるとは、追加したリソースに比例してパフォーマンスが向上する場合を指します。一般的に、パフォーマンスの向上とはより多くの作業単位を処理することを意味しますが、データセットが増大する場合のように、より大きな作業単位を扱うことも含まれます。1
パフォーマンスとスケーラビリティの別の見方:
- パフォーマンスの問題がある場合、単一ユーザーに対してシステムが遅い。
- スケーラビリティの問題がある場合、単一ユーザーには速いが、負荷が高いときに遅くなる。
参考文献とさらなる読み物
レイテンシ vs スループット
レイテンシは、ある操作を実行するか結果を出すまでの時間です。
スループットは、単位時間あたりのそのような操作や結果の数です。
一般的には、許容可能なレイテンシで最大スループットを目指すべきです。
参考文献とさらなる読み物
可用性 vs 一貫性
CAP定理
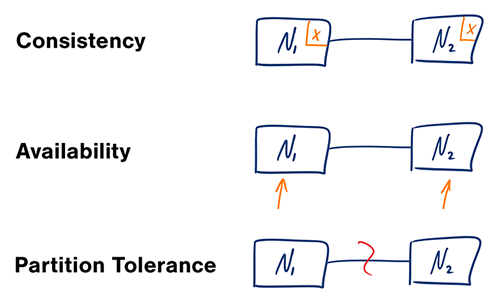
分散コンピュータシステムでは、次の3つの保証のうち2つだけをサポートできます:
- 一貫性(Consistency) - すべての読み取りは最新の書き込みを受け取るか、エラーになる
- 可用性(Availability) - すべてのリクエストは応答を受け取るが、最新の情報が含まれている保証はない
- 分割耐性(Partition Tolerance) - ネットワーク障害による任意の分割があってもシステムは動作し続ける
#### CP - 一貫性と分割耐性
分割されたノードからの応答を待つとタイムアウトエラーになる可能性があります。ビジネス上の要件が原子性のある読み書きを必要とする場合、CPは良い選択です。
#### AP - 可用性と分割耐性
応答は任意のノードで最も利用可能なバージョンのデータを返しますが、最新ではない場合があります。分割が解消されると書き込みの伝播に時間がかかることがあります。
APは最終的な一貫性を許容する必要がある場合や、外部のエラーがあってもシステムを継続動作させる必要がある場合に適しています。
出典とさらなる参考資料
一貫性パターン
同じデータの複数のコピーが存在する場合、クライアントが一貫したデータビューを持つようにそれらをどのように同期させるかの選択肢があります。CAP定理の一貫性の定義を思い出してください - すべての読み取りは最新の書き込みを受け取るか、エラーになる。
弱い一貫性
書き込み後に読み取りがそれを見える場合も見えない場合もあります。ベストエフォートのアプローチです。
このアプローチはmemcachedのようなシステムで見られます。弱い一貫性はVoIP、ビデオチャット、リアルタイムマルチプレイヤーゲームなどのリアルタイムユースケースでよく機能します。例えば、電話中に数秒間通信が途切れた場合、接続が回復してもその間に話された内容は聞こえません。
最終的整合性
書き込み後、読み取りは最終的にそれを参照します(通常は数ミリ秒以内)。データは非同期に複製されます。
このアプローチはDNSやメールのようなシステムで見られます。最終的整合性は高可用性システムでうまく機能します。
強い整合性
書き込み後、読み取りはそれを参照します。データは同期的に複製されます。
このアプローチはファイルシステムやRDBMSで見られます。強い整合性はトランザクションを必要とするシステムでうまく機能します。
出典およびさらなる読み物
可用性パターン
高可用性をサポートするための相補的なパターンが二つあります:フェイルオーバーとレプリケーション。
フェイルオーバー
#### アクティブ-パッシブ
アクティブ-パッシブフェイルオーバーでは、アクティブサーバーと待機中のパッシブサーバー間でハートビートが送信されます。ハートビートが中断された場合、パッシブサーバーがアクティブのIPアドレスを引き継ぎサービスを再開します。
ダウンタイムの長さは、パッシブサーバーがすでに「ホット」スタンバイで稼働しているか、「コールド」スタンバイから起動する必要があるかで決まります。トラフィックを処理するのはアクティブサーバーのみです。
アクティブ-パッシブフェイルオーバーはマスター-スレーブフェイルオーバーとも呼ばれます。
#### アクティブ-アクティブ
アクティブ-アクティブでは、両方のサーバーがトラフィックを管理し、負荷を分散しています。
サーバーが公開向けの場合、DNSは両方のサーバーのパブリックIPを認識する必要があります。サーバーが内部向けの場合、アプリケーションロジックが両方のサーバーを認識する必要があります。
アクティブ-アクティブフェイルオーバーはマスター-マスターフェイルオーバーとも呼ばれます。
欠点:フェイルオーバー
- フェイルオーバーは、より多くのハードウェアと追加の複雑さをもたらします。
- アクティブシステムが、新たに書き込まれたデータがパッシブに複製される前に障害が発生した場合、データの損失の可能性があります。
複製
#### マスター・スレーブおよびマスター・マスター
このトピックはデータベースセクションでさらに詳しく説明されています:
可用性の数値
可用性はしばしばサービスが利用可能な時間の割合としてアップタイム(またはダウンタイム)で定量化されます。可用性は一般的に「9の数」で測定され、99.99%の可用性を持つサービスは「4つの9」と表現されます。
#### 99.9%の可用性 - 3つの9
| 期間 | 許容ダウンタイム | |---------------------|--------------------| | 年間ダウンタイム | 8時間45分57秒 | | 月間ダウンタイム | 43分49.7秒 | | 週間ダウンタイム | 10分4.8秒 | | 1日あたりのダウンタイム | 1分26.4秒 |
#### 99.99%の可用性 - 4つの9
| 期間 | 許容ダウンタイム | |---------------------|--------------------| | 年間ダウンタイム | 52分35.7秒 | | 月間ダウンタイム | 4分23秒 | | 週間ダウンタイム | 1分5秒 | | 1日あたりのダウンタイム | 8.6秒 |
#### 並列可用性と直列可用性
サービスが障害を起こしやすい複数のコンポーネントで構成されている場合、サービス全体の可用性はコンポーネントが直列か並列かによって異なります。
###### 直列の場合
全体の可用性は、可用性が100%未満の2つのコンポーネントが直列に接続されている場合に低下します:
Availability (Total) = Availability (Foo) * Availability (Bar)もし Foo と Bar の両方がそれぞれ99.9%の可用性を持っている場合、それらが直列に接続されると合計の可用性は99.8%になります。
###### 並列の場合
可用性が100%未満の2つのコンポーネントを並列に配置すると、全体の可用性は向上します:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo と Bar の両方がそれぞれ99.9%の可用性を持っている場合、並列での総可用性は99.9999%になります。ドメインネームシステム
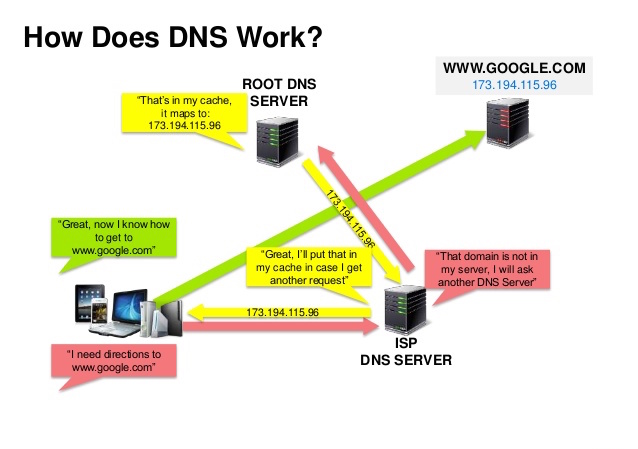
ドメインネームシステム(DNS)は、www.example.comのようなドメイン名をIPアドレスに変換します。
DNSは階層構造を持ち、最上位にいくつかの権威サーバーがあります。ルーターやISPは、名前解決時にどのDNSサーバーに連絡すべきかの情報を提供します。下位のDNSサーバーはマッピングをキャッシュしますが、DNS伝播遅延により古くなることがあります。DNSの結果はブラウザやOSによっても一定期間キャッシュされ、その期間はTTL(Time to Live)によって決まります。
- NSレコード(ネームサーバー) - ドメイン/サブドメインのDNSサーバーを指定します。
- MXレコード(メール交換) - メッセージ受信のためのメールサーバーを指定します。
- Aレコード(アドレス) - 名前をIPアドレスに紐づけます。
- CNAME(カノニカル) - 名前を別の名前や
CNAME(例: example.com を www.example.com に)またはAレコードに紐づけます。
- 重み付きラウンドロビン
- メンテナンス中のサーバーへのトラフィックを防ぐ
- 異なるクラスタサイズ間のバランス調整
- A/Bテスト
- レイテンシベース
- 地理位置ベース
DNSの欠点
- DNSサーバーにアクセスすることで若干の遅延が発生しますが、前述のキャッシュにより軽減されます。
- DNSサーバーの管理は複雑であり、一般的に政府、ISP、大企業によって管理されています。
- 最近DNSサービスはDDoS攻撃を受けており、ユーザーがTwitterなどのウェブサイトにアクセスする際にTwitterのIPアドレスを知らないとアクセスできない状況が発生しています。
参考文献とさらなる情報
- DNSアーキテクチャ.aspx)
- Wikipedia
- DNS関連記事
コンテンツ配信ネットワーク
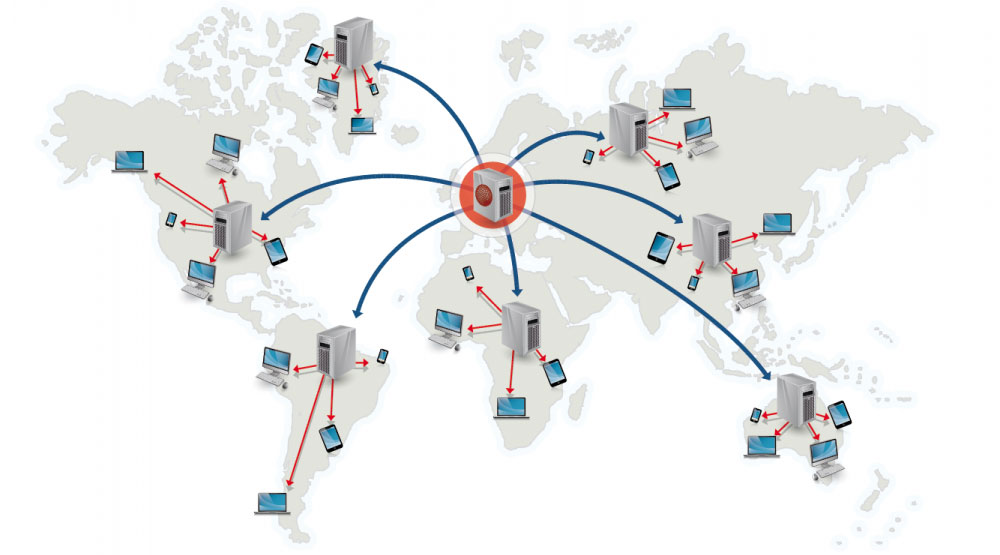
コンテンツ配信ネットワーク(CDN)は、ユーザーに近い場所からコンテンツを配信する、世界中に分散したプロキシサーバーのネットワークです。一般的に、HTML/CSS/JS、写真、動画などの静的ファイルはCDNから配信されますが、AmazonのCloudFrontのように動的コンテンツをサポートするCDNもあります。サイトのDNS解決はクライアントにどのサーバーに接続すべきかを伝えます。
CDNからコンテンツを配信することで、次の2つの方法でパフォーマンスが大幅に向上します:
- ユーザーは自分に近いデータセンターからコンテンツを受け取る
- サーバーはCDNが対応するリクエストを処理する必要がなくなる
プッシュCDN
プッシュCDNはサーバーで変更があるたびに新しいコンテンツを受け取ります。コンテンツ提供の全責任はあなたにあり、直接CDNにアップロードし、URLを書き換えてCDNを指すようにします。コンテンツの有効期限や更新タイミングを設定できます。コンテンツは新規または変更時のみアップロードされるため、トラフィックを最小限に抑えつつ、ストレージを最大限に活用します。
トラフィックが少ないサイトや更新頻度の低いコンテンツのサイトではプッシュCDNが適しています。コンテンツは一度CDNに配置され、定期的に再取得されることはありません。
プルCDN
プルCDNは最初のユーザーがコンテンツをリクエストした際にあなたのサーバーから新しいコンテンツを取得します。コンテンツはサーバー上に残し、URLを書き換えてCDNを指すようにします。そのため、コンテンツがCDNにキャッシュされるまではリクエストが遅くなります。
TTL(Time-to-Live)はコンテンツがキャッシュされる期間を決定します。プルCDNはCDN上のストレージ使用を最小限に抑えますが、ファイルの期限切れ後に実際には変更されていない場合でも再取得されることで冗長なトラフィックが発生する可能性があります。
トラフィックが多いサイトではプルCDNが適しており、最近リクエストされたコンテンツのみがCDNに残り、トラフィックがより均等に分散されます。
デメリット:CDN
- トラフィックによってはCDNコストが大きくなる可能性がありますが、CDNを使わなかった場合の追加コストと比較する必要があります。
- TTLが切れる前に更新された場合、コンテンツが古いままになる可能性があります。
- 静的コンテンツのURLをCDNを指すように変更する必要があります。
出典および参考文献
ロードバランサー
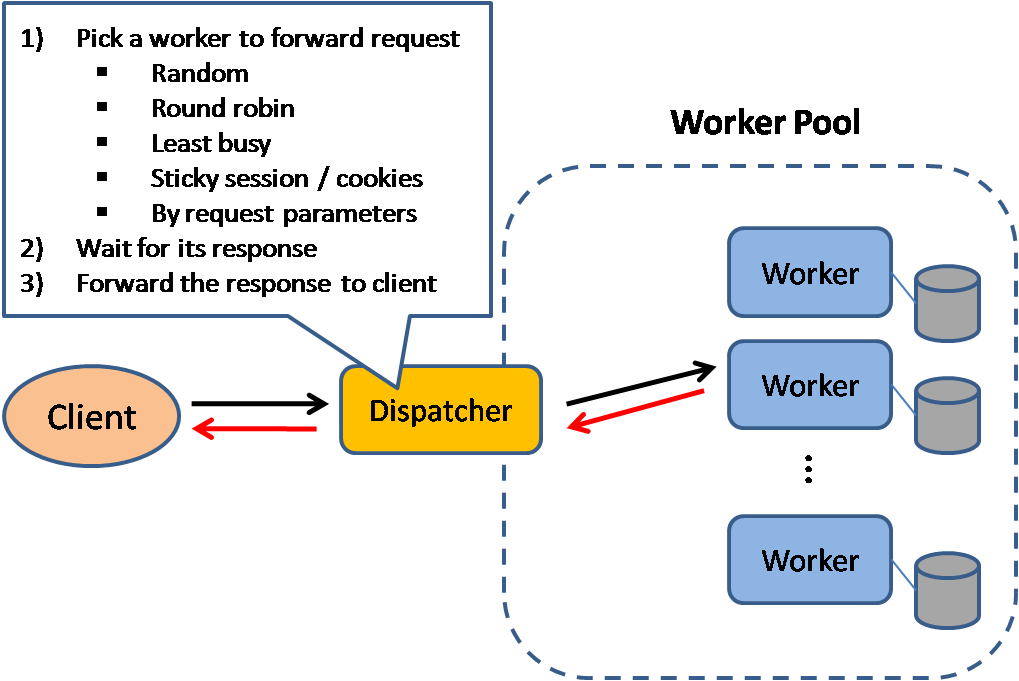
ロードバランサーは、アプリケーションサーバーやデータベースなどのコンピューティングリソースに対するクライアントからのリクエストを分散します。 各ケースで、ロードバランサーはコンピューティングリソースからのレスポンスを適切なクライアントに返します。 ロードバランサーは以下に効果的です:
- 不健康なサーバーへのリクエストを防ぐ
- リソースの過負荷を防ぐ
- 単一障害点の排除に役立つ
追加の利点には以下があります:
- SSL終端 - 受信リクエストの復号化とサーバーレスポンスの暗号化を行い、バックエンドサーバーがこれらの高コストな処理を行わずに済むようにする
- 各サーバーにX.509証明書をインストールする必要がなくなる
- セッション持続性 - クッキーを発行し、ウェブアプリがセッションを追跡しない場合に特定クライアントのリクエストを同一インスタンスにルーティングする
ロードバランサーは以下のような様々な指標に基づいてトラフィックをルーティングできます:
- ランダム
- 最も負荷の低い
- セッション/クッキー
- ラウンドロビンまたは加重ラウンドロビン
- レイヤー4
- レイヤー7
レイヤー4ロードバランシング
レイヤー4ロードバランサーはリクエスト分散のためにトランスポート層の情報を参照します。 一般的には、ヘッダー内の送信元・宛先IPアドレスとポートを使いますが、パケットの内容は見ません。 レイヤー4ロードバランサーはアップストリームサーバーへのネットワークパケットを転送し、ネットワークアドレス変換(NAT)を行います。
レイヤー7ロードバランシング
レイヤー7のロードバランサーは、リクエストをどのように分配するかを決定するためにアプリケーション層を参照します。これはヘッダー、メッセージ、クッキーの内容を含む場合があります。レイヤー7のロードバランサーはネットワークトラフィックを終端し、メッセージを読み込み、負荷分散の決定を行い、選択されたサーバーへの接続を開きます。例えば、レイヤー7のロードバランサーは動画トラフィックを動画をホストするサーバーに、より機密性の高いユーザー請求トラフィックをセキュリティ強化されたサーバーに振り分けることができます。柔軟性の代償として、レイヤー4のロードバランシングはレイヤー7よりも少ない時間と計算資源を必要としますが、最新の汎用ハードウェアではパフォーマンスへの影響は最小限です。
水平スケーリング
ロードバランサーは水平スケーリングにも役立ち、パフォーマンスと可用性を向上させます。汎用マシンを使用してスケールアウトすることは、より高価なハードウェア上で単一のサーバーをスケールアップする(垂直スケーリングと呼ばれる)よりもコスト効率が高く、可用性も向上します。また、専門的な企業システムよりも汎用ハードウェアで働く人材を採用する方が容易です。
#### 欠点:水平スケーリング
- 水平スケーリングは複雑さを導入し、サーバーの複製を伴います
- サーバーはステートレスであるべきです:セッションやプロフィール画像などのユーザー関連データを含まないこと
- セッションはデータベース(SQL、NoSQL)や永続的なキャッシュ(Redis、Memcached)などの集中管理されたデータストアに保存できます
- キャッシュやデータベースなどの下流サーバーは、上流サーバーのスケールアウトに伴い同時接続数の増加を処理する必要があります
欠点:ロードバランサー
- ロードバランサーが十分なリソースを持たない場合や適切に設定されていない場合、パフォーマンスのボトルネックになる可能性があります。
- 単一障害点を排除するためにロードバランサーを導入すると、複雑さが増します。
- 単一のロードバランサーは単一障害点であり、複数のロードバランサーを設定するとさらに複雑さが増します。
参考文献およびさらなる読み物
リバースプロキシ(ウェブサーバー)
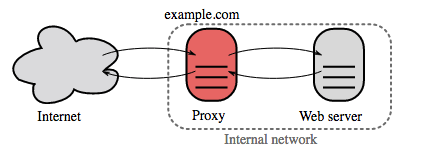
リバースプロキシは、内部サービスを集中管理し、一般向けに統一されたインターフェースを提供するウェブサーバーです。 クライアントからのリクエストは、それを満たすことができるサーバーに転送され、リバースプロキシはそのサーバーの応答をクライアントに返します。
追加の利点には以下が含まれます:
- セキュリティの向上 - バックエンドサーバーの情報を隠し、IPをブラックリスト化し、クライアントごとの接続数を制限
- スケーラビリティと柔軟性の向上 - クライアントはリバースプロキシのIPのみを認識し、サーバーのスケールや設定変更が可能
- SSL終了処理 - 受信リクエストを復号し、サーバー応答を暗号化することで、バックエンドサーバーがこれらの高コストな処理を行わなくて済む
- 各サーバーにX.509証明書をインストールする必要がなくなる
- 圧縮 - サーバー応答の圧縮
- キャッシュ - キャッシュされたリクエストに対して応答を返す
- 静的コンテンツ - 静的コンテンツを直接配信
- HTML/CSS/JS
- 写真
- 動画
- その他
ロードバランサーとリバースプロキシの違い
- 複数のサーバーがある場合、ロードバランサーの導入は有用です。多くの場合、ロードバランサーは同一機能を提供するサーバー群へトラフィックを振り分けます。
- リバースプロキシは、単一のウェブサーバーやアプリケーションサーバーでも有用であり、前述の利点を享受できます。
- NGINXやHAProxyなどのソリューションは、レイヤ7のリバースプロキシとロードバランシングの両方をサポートします。
リバースプロキシの欠点
- リバースプロキシを導入すると複雑さが増します。
- 単一のリバースプロキシは単一障害点となり、複数のリバースプロキシ(例:フェイルオーバー)を設定するとさらに複雑になります。
参考文献とさらなる読み物
アプリケーション層
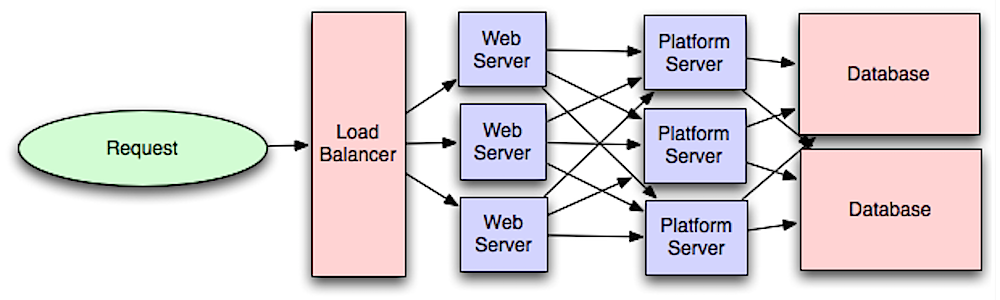
ウェブ層をアプリケーション層(プラットフォーム層とも呼ばれる)から分離することで、両層を独立してスケールおよび構成できます。新しいAPIを追加する場合、必ずしも追加のウェブサーバーを増やすことなくアプリケーションサーバーを追加できます。単一責任の原則は、小さく自律的なサービスが連携して動作することを推奨します。小さなチームと小さなサービスは、急速な成長に対してより積極的な計画が可能です。
アプリケーション層のワーカーは、非同期処理の実現も支援します。
マイクロサービス
この議論に関連するのがマイクロサービスであり、独立してデプロイ可能な小さくモジュール化されたサービス群として説明できます。各サービスは独自のプロセスを実行し、ビジネス目標を達成するために定義された軽量の通信手段を通じて連携します。1
例えばPinterestでは、ユーザープロファイル、フォロワー、フィード、検索、写真アップロードなどのマイクロサービスが存在する可能性があります。
サービスディスカバリ
Consul、Etcd、およびZookeeperなどのシステムは、登録された名前、アドレス、ポートを追跡することでサービス同士の検出を支援します。ヘルスチェックはサービスの健全性を検証し、多くの場合HTTPエンドポイントを使用して行われます。ConsulとEtcdは共に構成値やその他の共有データを保存するのに便利な組み込みのkey-valueストアを備えています。
欠点:アプリケーション層
- ゆるく結合されたサービスを持つアプリケーション層の追加は、モノリシックシステムとは異なるアーキテクチャ、運用、プロセスのアプローチを必要とします。
- マイクロサービスはデプロイや運用の面で複雑さを増す可能性があります。
出典および参考資料
データベース
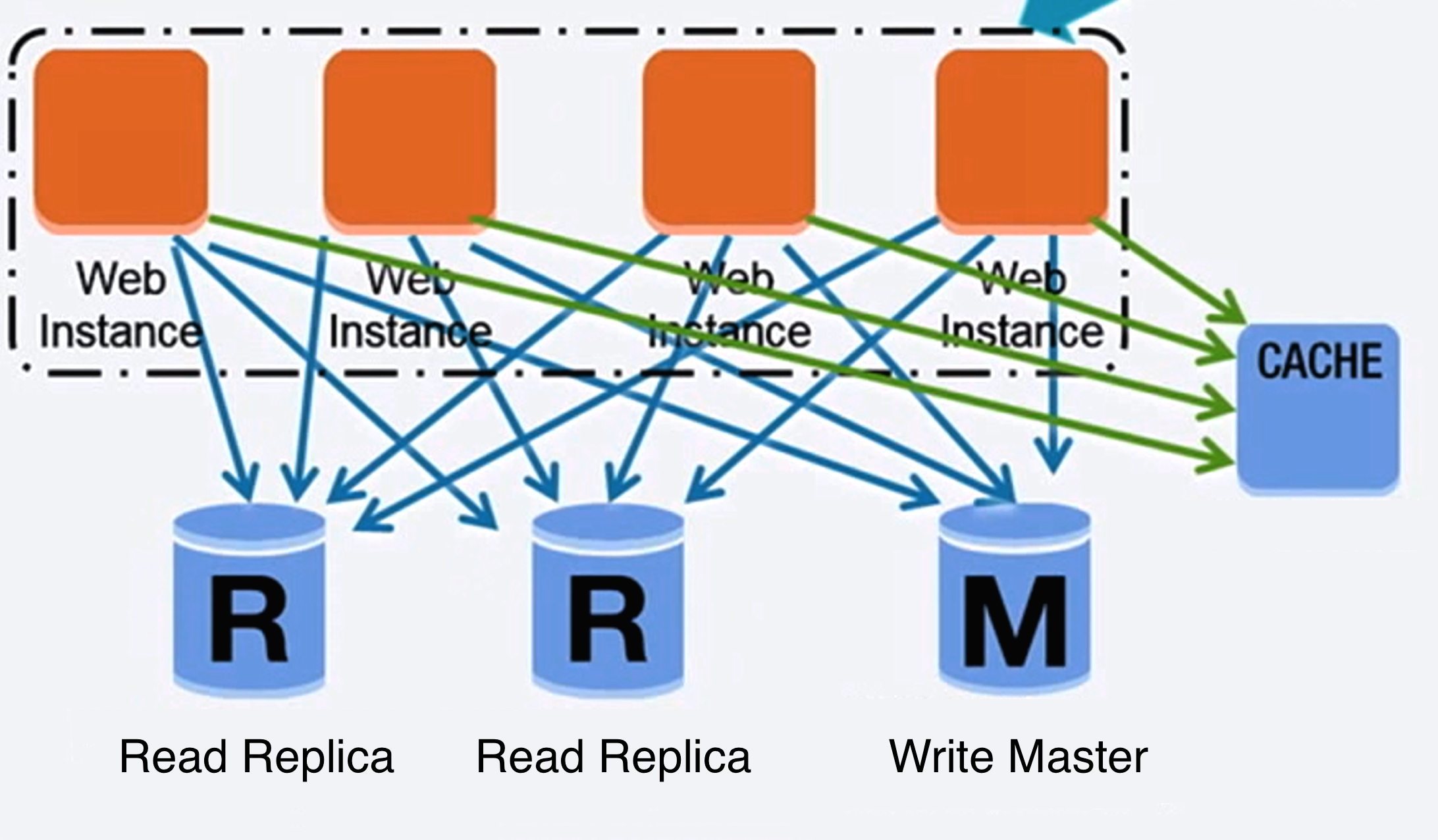
リレーショナルデータベース管理システム(RDBMS)
リレーショナルデータベース(SQLのようなもの)は、テーブルに整理されたデータ項目の集合です。
ACID はリレーショナルデータベースのトランザクションの特性のセットです。
- Atomicity(原子性) - 各トランザクションは全か無かである
- Consistency(一貫性) - いかなるトランザクションもデータベースを有効な状態から別の有効な状態へと変える
- Isolation(独立性) - トランザクションを同時に実行しても、直列に実行した場合と同じ結果になる
- Durability(永続性) - 一度コミットされたトランザクションは保持され続ける
#### マスター・スレーブレプリケーション
マスターは読み書きを提供し、書き込みを一つ以上のスレーブにレプリケートします。スレーブは読み込みのみを提供します。スレーブはさらに木構造のように別のスレーブにレプリケートすることもできます。マスターがオフラインになった場合、スレーブがマスターに昇格されるか新しいマスターが用意されるまで、システムは読み取り専用モードで動作を続けられます。
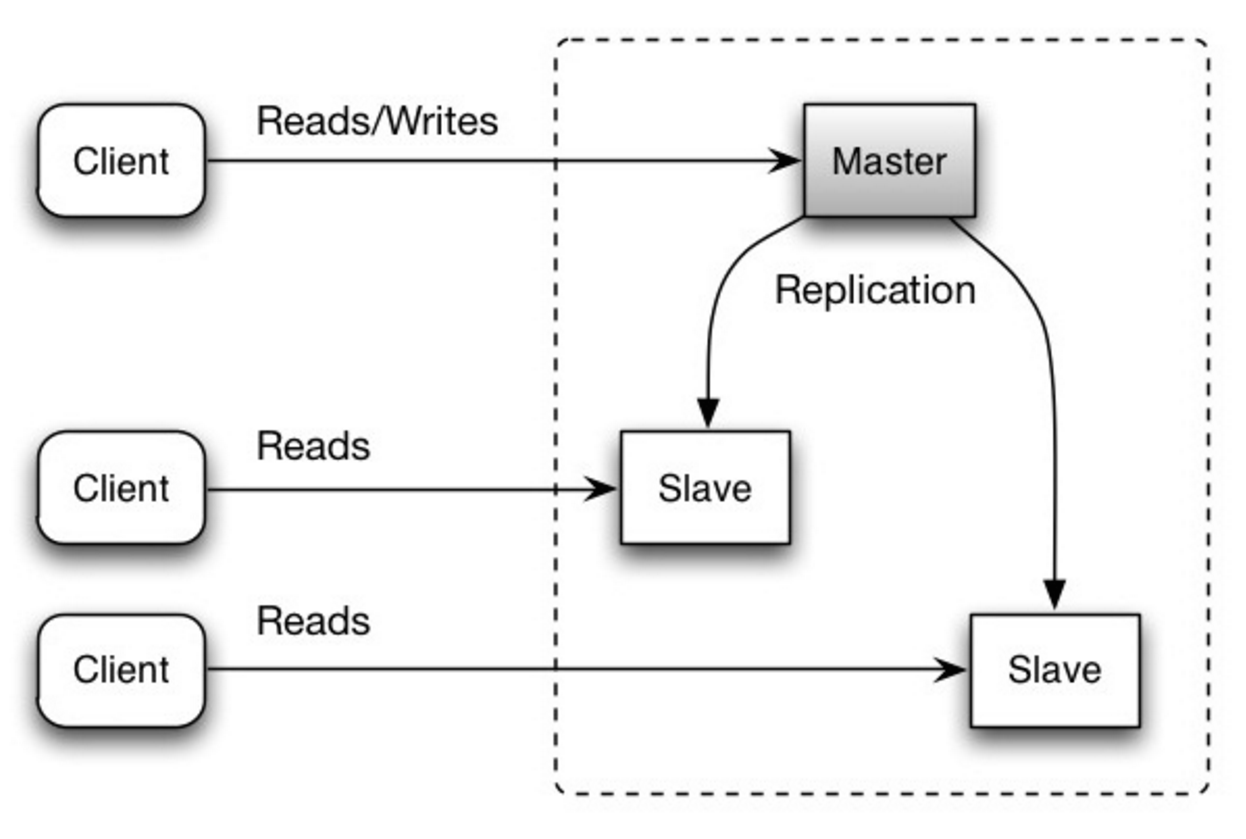
出典: Scalability, availability, stability, patterns
##### 欠点:マスター・スレーブレプリケーション
- スレーブをマスターに昇格させるための追加のロジックが必要です。
- マスター・スレーブ と マスター・マスター の両方に関係する点は 欠点:レプリケーション を参照してください。
両方のマスターが読み書きを提供し、書き込みに関しては互いに調整します。どちらかのマスターがダウンしても、システムは読み書きの両方を継続して動作できます。
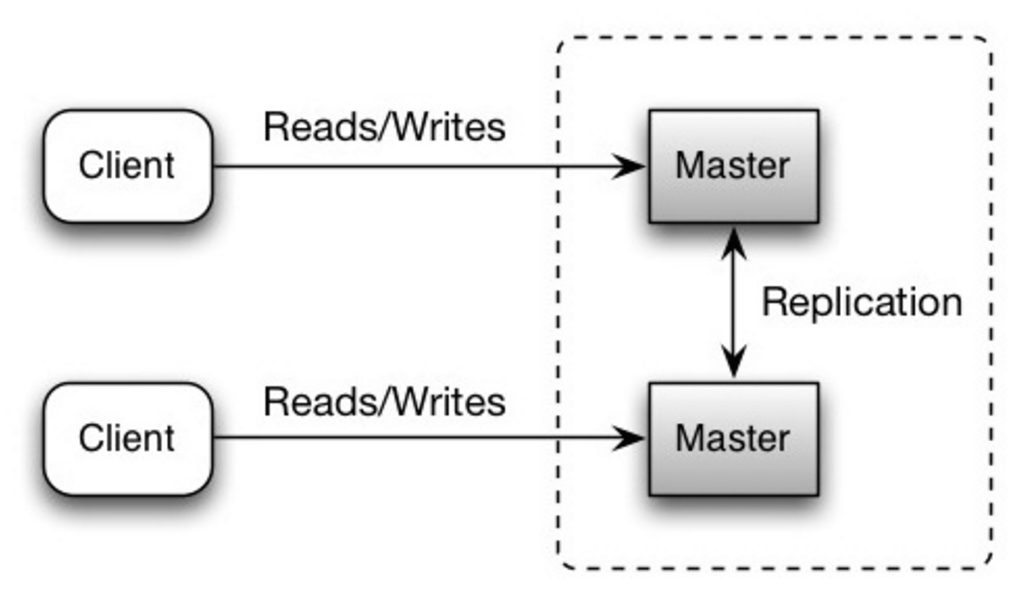
出典: Scalability, availability, stability, patterns
##### 欠点:マスター・マスターレプリケーション
- ロードバランサーが必要になるか、書き込み先を決定するためにアプリケーションロジックを変更する必要があります。
- ほとんどのマスター・マスターシステムは緩やかに整合性が保たれている(ACIDを破る)か、同期による書き込み遅延が増加します。
- コンフリクト解決は、書き込みノードが増え、レイテンシが増加するにつれてより重要になります。
- マスター・スレーブおよびマスター・マスターの両方に関連するポイントについては、欠点:レプリケーションを参照してください。
- マスターが新たに書き込まれたデータを他のノードにレプリケートする前に障害が発生した場合、データが失われる可能性があります。
- 書き込みはリードレプリカにリプレイされます。書き込みが多いと、リードレプリカは書き込みのリプレイで遅くなり、読み込み処理が減少します。
- リードスレーブが多いほど、レプリケーションする量が増え、レプリケーション遅延が大きくなります。
- 一部のシステムでは、マスターへの書き込みは複数のスレッドで並列に行われますが、リードレプリカは単一スレッドで順次書き込みのみサポートします。
- レプリケーションはハードウェアの追加と複雑さを増加させます。
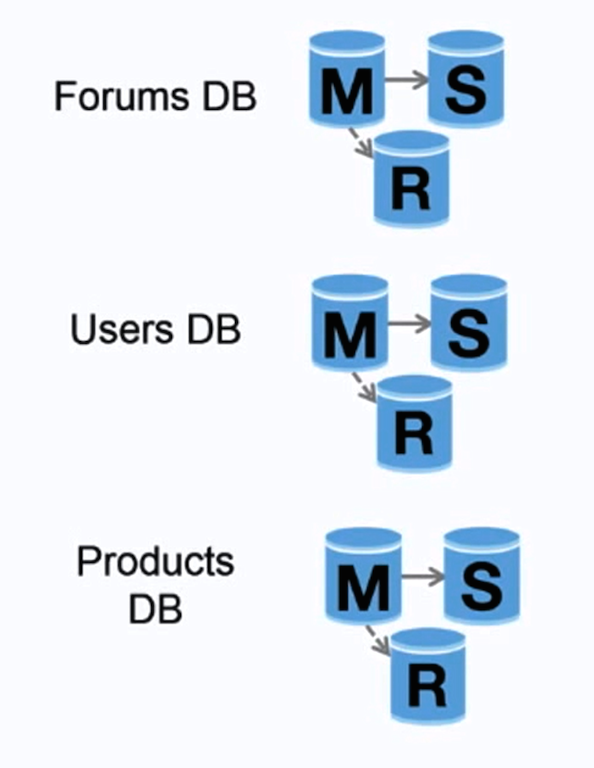
フェデレーション(または機能的パーティショニング)は、データベースを機能ごとに分割します。例えば、単一のモノリシックなデータベースの代わりに、フォーラム、ユーザー、製品の3つのデータベースを持つことで、各データベースへの読み書きトラフィックが減り、その結果レプリケーション遅延が少なくなります。小さいデータベースはメモリに収まるデータが増え、キャッシュの局所性が向上するためキャッシュヒット率が上がります。単一の中央マスターが書き込みを直列化しないため、並列に書き込むことができ、スループットが向上します。
##### 欠点:フェデレーション
- スキーマが巨大な関数やテーブルを必要とする場合、フェデレーションは効果的ではありません。
- どのデータベースを読み書きするかを判断するためにアプリケーションロジックを更新する必要があります。
- 2つのデータベースからのデータ結合は、サーバーリンクを使うためより複雑です。
- フェデレーションはハードウェアの追加と複雑さを増加させます。
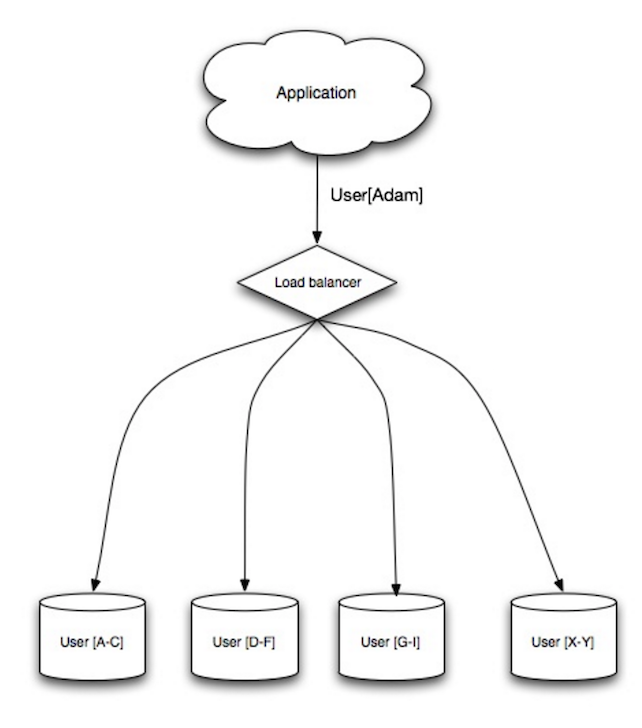
シャーディングはデータを異なるデータベースに分散させ、各データベースがデータのサブセットのみを管理できるようにします。ユーザーデータベースを例に取ると、ユーザー数が増えるにつれて、クラスターにシャードが追加されます。
federationの利点と同様に、シャーディングは読み書きトラフィックの減少、レプリケーションの減少、キャッシュヒットの増加をもたらします。インデックスサイズも減少し、一般的にクエリの高速化によってパフォーマンスが向上します。1つのシャードがダウンしても他のシャードは稼働し続けますが、データ損失を防ぐために何らかのレプリケーションを追加する必要があります。federationと同様に、書き込みを直列化する単一の中央マスターがないため、スループットを増加させて並列書き込みが可能です。
ユーザーテーブルをシャーディングする一般的な方法は、ユーザーの姓のイニシャルや地理的位置によるものです。
##### 欠点:シャーディング
- シャードに対応するためにアプリケーションロジックを更新する必要があり、複雑なSQLクエリになる可能性があります。
- データの分布がシャード内で偏ることがあります。例えば、特定のシャードにパワーユーザーが集中すると、そのシャードの負荷が他より増加します。
- リバランスはさらなる複雑さを加えます。一貫性ハッシュに基づくシャーディング関数は転送データ量を減らせます。
- 複数シャードのデータを結合するのはより複雑です。
- シャーディングはハードウェアと複雑さを増やします。
非正規化は書き込み性能を一部犠牲にして読み取り性能を向上させることを試みます。高価な結合を避けるために、冗長なデータコピーを複数のテーブルに書き込みます。PostgreSQLやOracleなど一部のRDBMSは、冗長情報の保持とコピーの一貫性維持を処理するマテリアライズドビューをサポートしています。
federationやshardingのような技術でデータが分散されると、データセンター間の結合管理はさらに複雑になります。非正規化はそのような複雑な結合の必要性を回避するかもしれません。
ほとんどのシステムでは、読み取りが書き込みを100:1または1000:1で大幅に上回ることがあります。複雑なデータベース結合を伴う読み取りは非常にコストがかかり、多くの時間をディスク操作に費やします。
##### 欠点:非正規化
- データが重複します。
- 制約は冗長な情報コピーの同期を助けますが、データベース設計の複雑さを増します。
- 非正規化データベースは書き込み負荷が高いと、正規化されたものより性能が悪化することがあります。
SQL チューニングは広範なトピックであり、多くの書籍が参考資料として書かれています。
ベンチマークおよびプロファイリングを行い、ボトルネックをシミュレートして発見することが重要です。
ベンチマークとプロファイリングによって、次の最適化が示唆されることがあります。##### スキーマを厳密にする
- MySQLは高速アクセスのためにディスクに連続したブロックでダンプします。
- 固定長フィールドには
CHARを使用します。 CHARは高速なランダムアクセスを可能にしますが、VARCHARは次の文字列に移動する前に文字列の終端を見つける必要があります。- ブログ投稿などの大きなテキストブロックには
TEXTを使います。TEXTはブール検索も可能です。TEXTフィールドを使用すると、テキストブロックを特定するためのポインタがディスクに保存されます。 - 2^32(約40億)までの大きな数値には
INTを使います。 - 浮動小数点の表現誤差を避けるために通貨には
DECIMALを使います。 - 大きな
BLOBを保存するのは避け、代わりにオブジェクトの取得場所を保存します。 VARCHAR(255)は8ビット数でカウントできる最大の文字数であり、多くのRDBMSでバイトの使用を最大化します。- 適用可能な場合は
NOT NULL制約を設定して検索性能を改善します。
- クエリで使用するカラム(
SELECT、GROUP BY、ORDER BY、JOIN)はインデックスで高速化できます。 - インデックスは通常、データをソートし、探索、順次アクセス、挿入、削除を対数時間で行う自己平衡型のB木として表されます。
- インデックスを配置するとデータをメモリに保持でき、より多くのスペースを要します。
- インデックスも更新する必要があるため、書き込みは遅くなることがあります。
- 大量データのロード時はインデックスを無効化し、ロード後に再構築する方が速い場合があります。
- パフォーマンスが求められる場合は非正規化を行います。
- ホットスポットを別のテーブルに分割してメモリに保持しやすくする。
- 場合によっては、クエリキャッシュがパフォーマンスの問題を引き起こすことがある。
NoSQL
NoSQLはキー・バリュー・ストア、ドキュメントストア、ワイドカラムストア、またはグラフデータベースで表現されるデータ項目の集合である。 データは非正規化されており、結合は一般的にアプリケーションコード内で行われる。 多くのNoSQLストアは真のACIDトランザクションを欠き、最終的整合性を重視する。
BASEはNoSQLデータベースの特性を表すために使われることが多い。 CAP定理と比較すると、BASEは一貫性よりも可用性を優先する。
- 基本的に利用可能 - システムは可用性を保証する。
- ソフトステート - システムの状態は入力がなくても時間とともに変化する可能性がある。
- 最終的整合性 - システムは一定期間入力がなければ整合性が取れる状態になる。
#### キー・バリュー・ストア
抽象化:ハッシュテーブル
キー・バリュー・ストアは一般的にO(1)の読み書きを可能にし、メモリまたはSSDでバックアップされることが多い。 データストアは辞書式順序でキーを保持でき、キー範囲の効率的な取得を可能にする。 キー・バリュー・ストアは値にメタデータを格納することもできる。
キー・バリュー・ストアは高いパフォーマンスを提供し、シンプルなデータモデルやインメモリキャッシュ層のような急速に変化するデータによく使われる。 限られた操作セットのみを提供するため、追加の操作が必要な場合は複雑さがアプリケーション層に移る。
キー・バリュー・ストアはドキュメントストアや場合によってはグラフデータベースのようなより複雑なシステムの基礎となる。
##### 出典および参考文献:キー・バリュー・ストア
#### ドキュメントストア抽象化: ドキュメントを値として格納するキー・バリュー・ストア
ドキュメントストアはドキュメント(XML、JSON、バイナリなど)を中心に設計されており、ドキュメントは特定のオブジェクトに関するすべての情報を格納します。ドキュメントストアは、ドキュメント内部の構造に基づいてクエリを実行するためのAPIやクエリ言語を提供します。注:多くのキー・バリュー・ストアは値のメタデータを扱う機能を含んでおり、これら二つのストレージタイプの境界を曖昧にしています。
基盤となる実装により、ドキュメントはコレクション、タグ、メタデータ、またはディレクトリによって組織化されます。ドキュメントはグループ化されることもありますが、ドキュメント同士が全く異なるフィールドを持つ場合もあります。
MongoDBやCouchDBのような一部のドキュメントストアは、複雑なクエリを実行するためのSQLに似た言語も提供しています。DynamoDBはキー・バリューとドキュメントの両方をサポートしています。
ドキュメントストアは高い柔軟性を持ち、時折変更されるデータを扱う場合によく使われます。
##### 参考文献およびさらなる学習: ドキュメントストア
#### ワイドカラムストア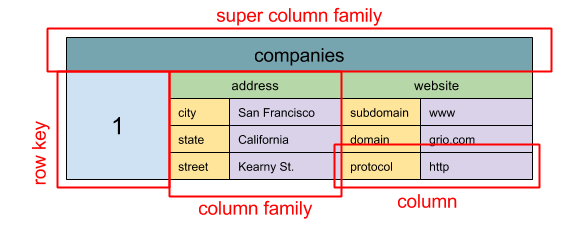
抽象化: ネストされたマップ ColumnFamily> ワイドカラムストアの基本データ単位はカラム(名前/値のペア)です。カラムはカラムファミリー(SQLのテーブルに類似)にグループ化されます。スーパーカラムファミリーはさらにカラムファミリーをグループ化します。行キーで各カラムに独立してアクセスでき、同じ行キーのカラムが行を形成します。各値にはバージョニングや競合解決のためのタイムスタンプが含まれます。
Googleは最初のワイドカラムストアとしてBigtableを導入し、これがHadoopエコシステムでよく使われるオープンソースのHBaseやFacebookのCassandraに影響を与えました。BigTable、HBase、Cassandraなどのストアはキーを辞書順で保持し、選択的なキー範囲の効率的な取得を可能にしています。
ワイドカラムストアは高い可用性と高いスケーラビリティを提供し、非常に大規模なデータセットによく使用されます。
##### 参考文献およびさらなる学習: ワイドカラムストア
#### グラフデータベース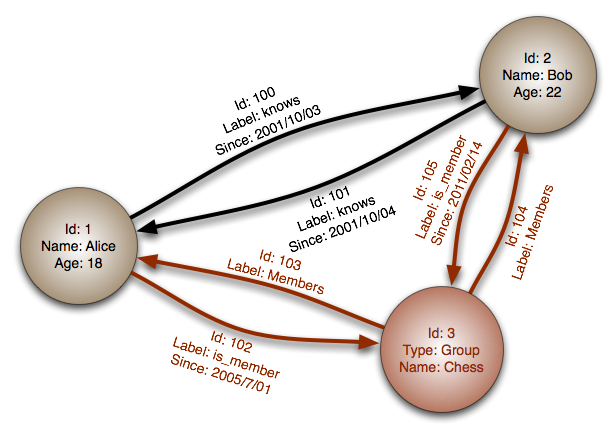
抽象化:グラフ
グラフデータベースでは、各ノードがレコードであり、各アークが2つのノード間の関係を表します。グラフデータベースは、多数の外部キーや多対多の関係を持つ複雑な関係を表現するように最適化されています。
グラフデータベースは、ソーシャルネットワークのような複雑な関係を持つデータモデルに対して高いパフォーマンスを提供します。比較的新しい技術であり、まだ広く使われていないため、開発ツールやリソースを見つけるのが難しい場合があります。多くのグラフはREST APIでのみアクセス可能です。
##### 出典および追加資料:グラフ
#### 出典および追加資料:NoSQLSQLまたはNoSQL
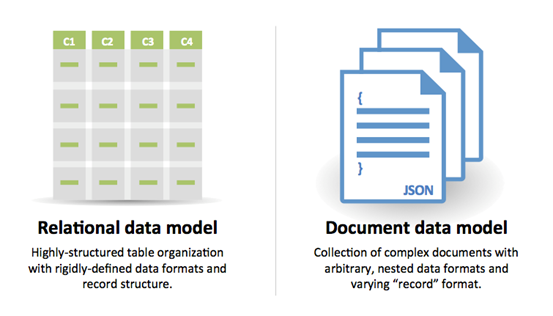
SQLを選ぶ理由:
- 構造化データ
- 厳密なスキーマ
- リレーショナルデータ
- 複雑な結合が必要
- トランザクション
- スケーリングのための明確なパターン
- より確立されている:開発者、コミュニティ、コード、ツールなど
- インデックスによるルックアップが非常に高速
- 半構造化データ
- 動的または柔軟なスキーマ
- 非リレーショナルデータ
- 複雑な結合が不要
- 多数のTB(またはPB)のデータを保存
- 非常にデータ集約型のワークロード
- 非常に高いIOPSスループット
- クリックストリームやログデータの迅速な取り込み
- リーダーボードやスコアリングデータ
- ショッピングカートのような一時データ
- 頻繁にアクセスされる(「ホット」)テーブル
- メタデータ/ルックアップテーブル
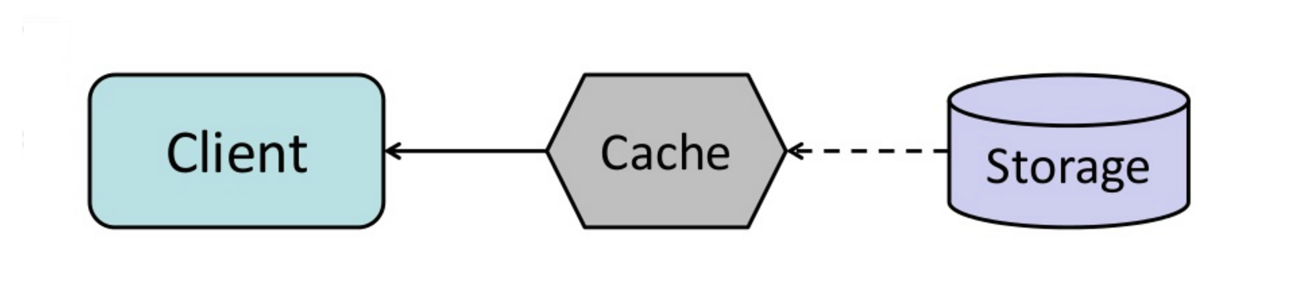
キャッシュ
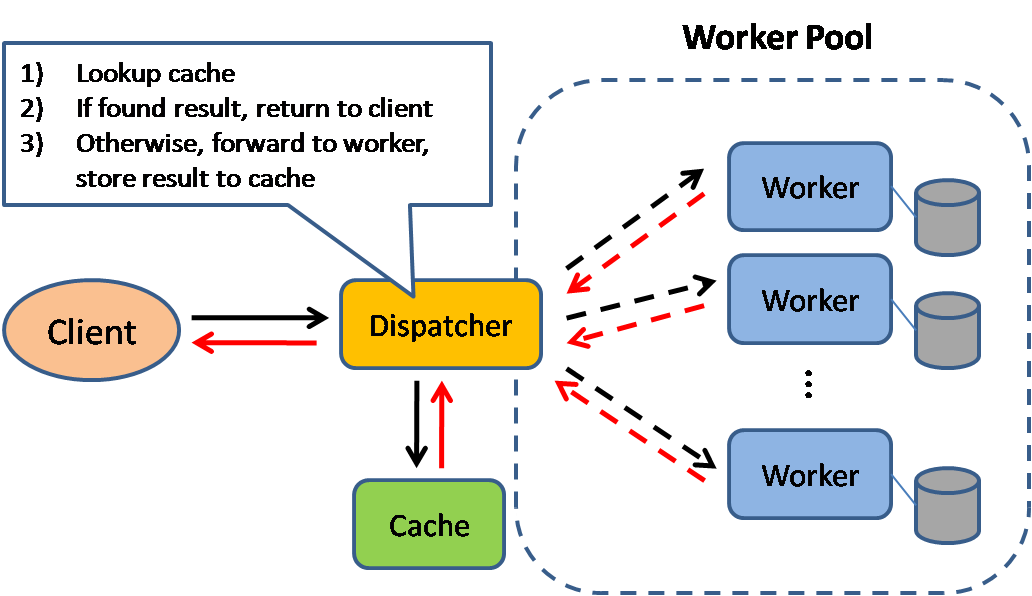
キャッシュはページの読み込み時間を改善し、サーバーやデータベースの負荷を軽減できます。このモデルでは、ディスパッチャーがまずリクエストが以前に行われたかどうかを確認し、実際の実行を省くために以前の結果を返そうとします。
データベースは通常、パーティション全体で読み書きが均等に分布することで恩恵を受けます。人気のあるアイテムは分布を偏らせ、ボトルネックを引き起こす可能性があります。データベースの前にキャッシュを置くことで、不均等な負荷やトラフィックの急増を吸収できます。
クライアントキャッシュ
キャッシュはクライアント側(OSやブラウザ)、サーバー側、または独立したキャッシュ層に配置できます。
CDNキャッシュ
CDNはキャッシュの一種と見なされます。
ウェブサーバーキャッシュ
リバースプロキシやVarnishのようなキャッシュは静的および動的コンテンツを直接提供できます。ウェブサーバーもリクエストをキャッシュし、アプリケーションサーバーに連絡せずにレスポンスを返せます。
データベースキャッシュ
データベースは通常、デフォルト設定で何らかのキャッシュレベルを含み、汎用的なユースケースに最適化されています。特定の使用パターンに合わせてこれらの設定を調整すると、さらにパフォーマンスを向上させることができます。
アプリケーションキャッシュ
MemcachedやRedisのようなインメモリキャッシュは、アプリケーションとデータストレージの間にあるキー・バリューストアです。データがRAMに保持されるため、通常ディスクに保存されるデータベースよりもはるかに高速です。RAMはディスクよりも容量が限られているため、キャッシュ無効化アルゴリズム(例えば最も最近使われていない(LRU)))が「冷たい」エントリを無効化し、「熱い」データをRAMに保持するのに役立ちます。
Redisには以下の追加機能があります:
- 永続化オプション
- ソート済みセットやリストなどの組み込みデータ構造
- 行レベル
- クエリレベル
- 完全に形成されたシリアライズ可能なオブジェクト
- 完全にレンダリングされたHTML
データベースクエリレベルでのキャッシュ
データベースをクエリするたびに、クエリをキーとしてハッシュ化し、その結果をキャッシュに保存します。この方法は有効期限の問題があります:
- 複雑なクエリのキャッシュ結果を削除するのが難しい
- テーブルのセルなど一部のデータが変更された場合、変更されたセルを含む可能性のあるすべてのキャッシュクエリを削除する必要がある
オブジェクトレベルでのキャッシュ
データをアプリケーションコードと同様にオブジェクトとして見なします。アプリケーションがデータベースからのデータセットをクラスインスタンスやデータ構造に組み立てます:
- 基盤となるデータが変更された場合、オブジェクトをキャッシュから削除する
- 非同期処理を可能にする:ワーカーは最新のキャッシュされたオブジェクトを利用してオブジェクトを組み立てる
- ユーザーセッション
- 完全にレンダリングされたウェブページ
- アクティビティストリーム
- ユーザーグラフデータ
キャッシュを更新するタイミング
キャッシュに保存できるデータ量は限られているため、ユースケースに最適なキャッシュ更新戦略を決定する必要があります。
#### Cache-aside
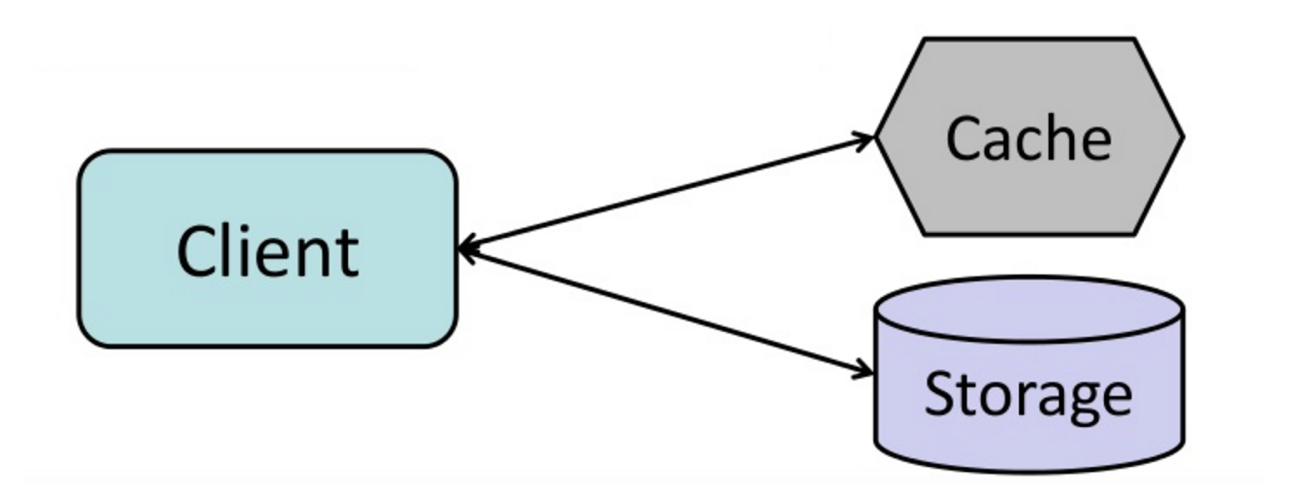
出典: From cache to in-memory data grid
アプリケーションがストレージからの読み書きを担当します。キャッシュはストレージと直接やり取りしません。アプリケーションの動作は以下の通りです:
- キャッシュ内のエントリを探すが、キャッシュミスとなる
- データベースからエントリを読み込む
- エントリをキャッシュに追加する
- エントリを返す
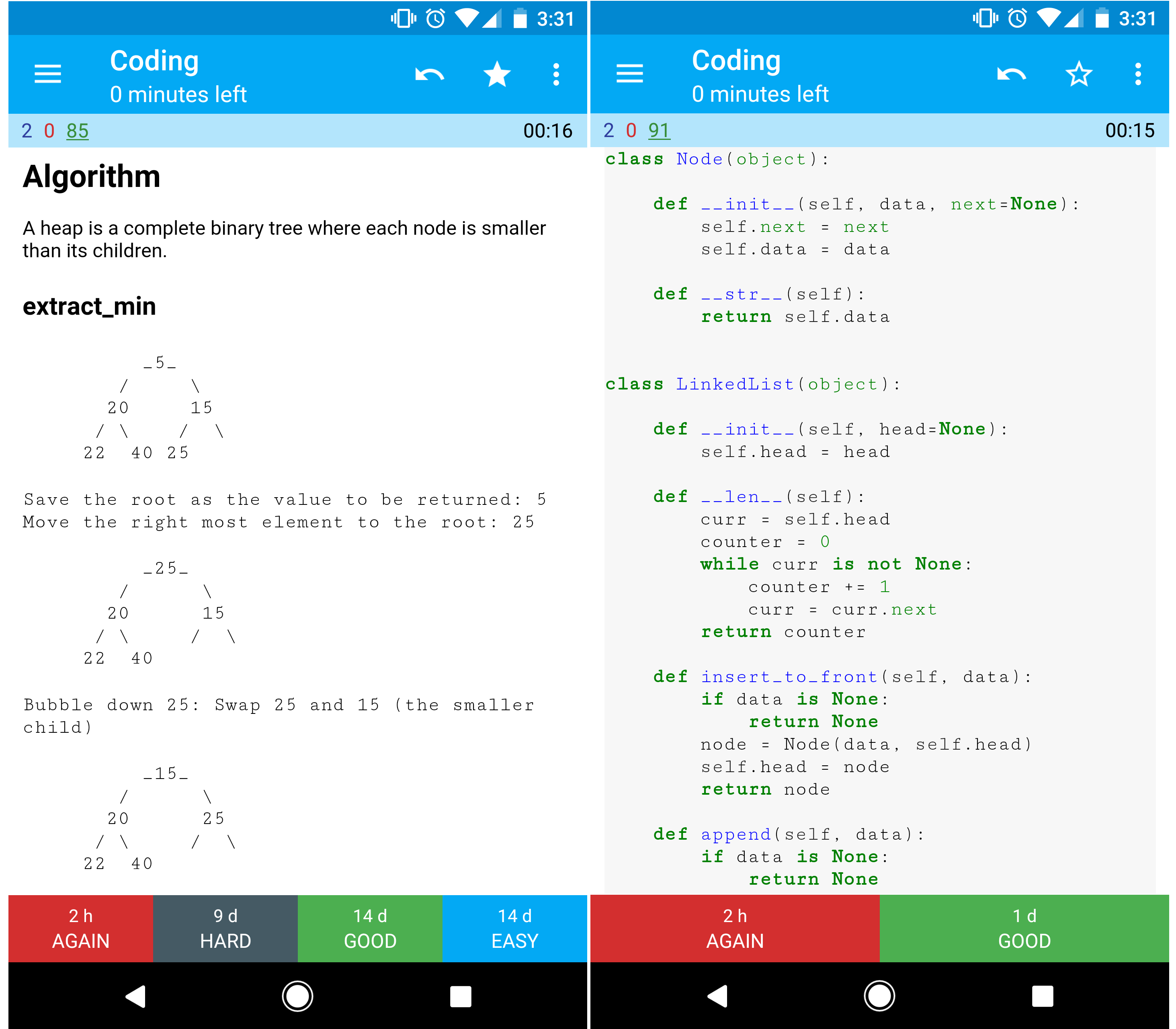
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userキャッシュに追加されたデータの後続の読み取りは高速です。Cache-asideはレイジーローディングとも呼ばれます。要求されたデータのみがキャッシュされ、要求されていないデータでキャッシュが埋まるのを防ぎます。
##### 欠点: cache-aside
- キャッシュミスごとに3回の往復が発生し、目に見える遅延を引き起こす可能性があります。
- データベースで更新された場合、データが古くなる可能性があります。この問題は、キャッシュエントリの更新を強制するTTL(有効期限)を設定するか、ライトスルーを使用することで緩和されます。
- ノードが故障した場合、新しい空のノードに置き換えられ、レイテンシが増加します。
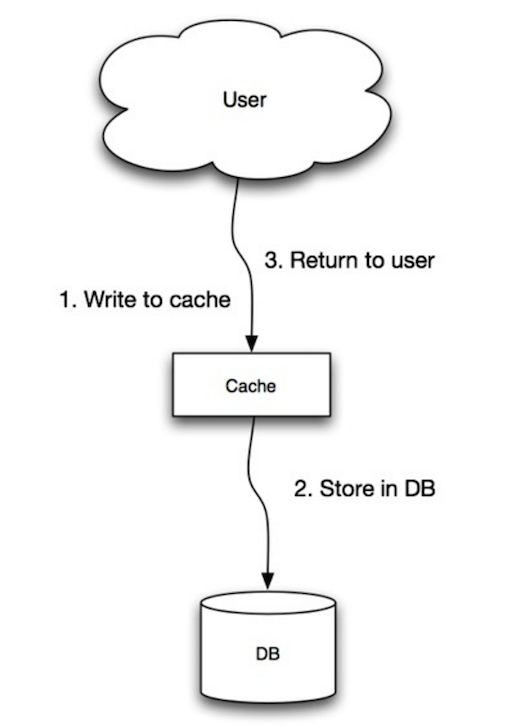
出典: Scalability, availability, stability, patterns
アプリケーションはキャッシュを主要なデータストアとして使用し、読み書きを行い、キャッシュはデータベースへの読み書きを担当します:
- アプリケーションがキャッシュにエントリを追加/更新
- キャッシュが同期的にデータストアにエントリを書き込み
- 戻り値を返す
set_user(12345, {"foo":"bar"})def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)ライトスルーは書き込み操作のため全体的に遅いですが、直後に書き込まれたデータの読み取りは高速です。ユーザーはデータの更新よりも読み取り時の遅延を一般的により許容します。キャッシュ内のデータは古くありません。
##### デメリット:ライトスルー
- 障害やスケーリングにより新しいノードが作成された場合、そのノードはデータベースでエントリが更新されるまでエントリをキャッシュしません。キャッシュアサイドとライトスルーを組み合わせることでこの問題を軽減できます。
- 書き込まれたデータの多くは一度も読み取られない可能性があり、TTLでこれを最小化できます。
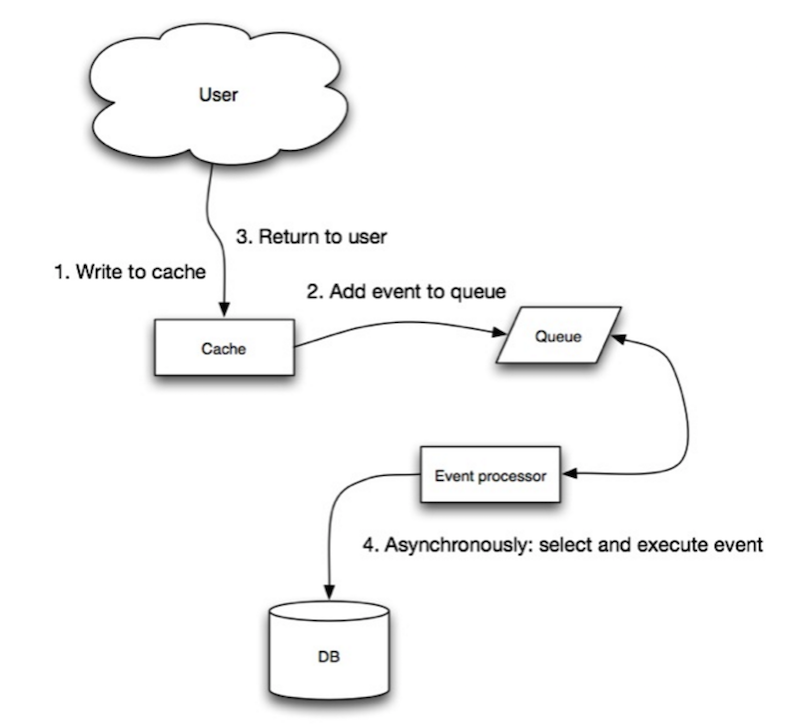
ライトビハインドでは、アプリケーションは以下を行います:
- キャッシュにエントリを追加/更新
- 非同期でデータストアにエントリを書き込み、書き込み性能を向上させる
- キャッシュの内容がデータストアに反映される前にキャッシュがダウンするとデータ損失が発生する可能性があります。
- ライトビハインドはキャッシュアサイドやライトスルーよりも実装が複雑です。
キャッシュは自動的に最近アクセスされたキャッシュエントリを期限切れ前にリフレッシュするよう設定できます。
リフレッシュアヘッドは、キャッシュが将来必要とされる可能性のあるアイテムを正確に予測できれば、リードスルーよりもレイテンシを低減できます。
##### デメリット:リフレッシュアヘッド
- 将来必要になる可能性が高いアイテムを正確に予測できないと、リフレッシュアヘッドなしの場合よりもパフォーマンスが低下することがある。
欠点: キャッシュ
- キャッシュとデータベースなどの真実のソースとの一貫性をキャッシュ無効化を通じて維持する必要がある。
- キャッシュ無効化は難しい問題であり、いつキャッシュを更新するかに関する追加の複雑さがある。
- Redisやmemcachedの追加など、アプリケーションの変更が必要になる。
参考文献およびさらなる読み物
- キャッシュからインメモリデータグリッドへ
- スケーラブルシステム設計パターン
- スケールのためのシステム設計入門
- スケーラビリティ、可用性、安定性のパターン
- スケーラビリティ
- AWS ElastiCache戦略
- ウィキペディア)
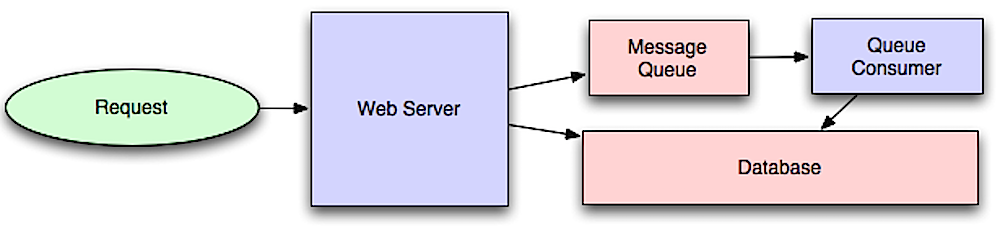
非同期処理
非同期ワークフローは、インラインで実行すると高コストな操作のリクエスト時間を短縮するのに役立つ。また、定期的なデータ集約など、時間のかかる作業を事前に行うことにも役立つ。
メッセージキュー
メッセージキューはメッセージの受信、保持、配信を行う。操作がインラインで行うには遅すぎる場合、以下のワークフローでメッセージキューを利用できる。
- アプリケーションがジョブをキューに公開し、ユーザーにジョブの状態を通知する。
- ワーカーがキューからジョブを取得して処理し、ジョブの完了を通知する。
Redis はシンプルなメッセージブローカーとして有用だが、メッセージが失われる可能性がある。
RabbitMQ は人気があるが、'AMQP'プロトコルに適応し、自分でノードを管理する必要がある。 Amazon SQS はホスト型ですが、高遅延が発生する可能性があり、メッセージが二重に配信される可能性があります。
タスクキュー
タスクキューはタスクと関連データを受け取り、それを実行し、結果を届けます。スケジューリングをサポートでき、計算負荷の高いジョブをバックグラウンドで実行するのに利用可能です。
Celery はスケジューリングをサポートし、主にPythonでのサポートがあります。
バックプレッシャー
キューのサイズが大幅に増加すると、キューサイズがメモリ容量を超え、キャッシュミスやディスク読み込みが発生し、さらにパフォーマンスが低下します。バックプレッシャー はキューサイズを制限することで、スループット率を維持し、キュー内のジョブに対して良好な応答時間を保つのに役立ちます。キューが満杯になると、クライアントはサーバービジーやHTTP 503ステータスコードを受け取り、後で再試行を促されます。クライアントは後でリクエストを再試行でき、指数バックオフを用いることもあります。
デメリット:非同期性
- 安価な計算やリアルタイムワークフローのようなユースケースには、キューを導入すると遅延や複雑さが増すため、同期処理の方が適している場合があります。
出典および参考文献
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
通信
ハイパーテキスト転送プロトコル(HTTP)
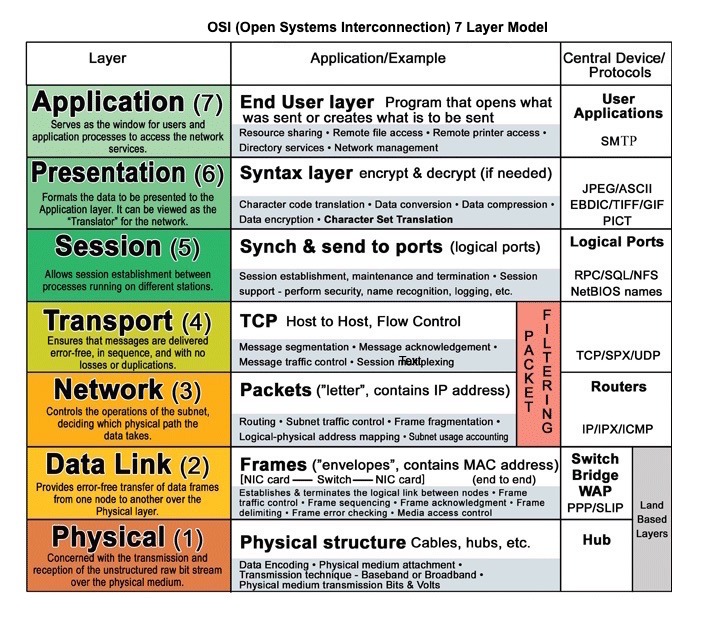
HTTPはクライアントとサーバー間でデータをエンコードし転送する方法です。リクエスト/レスポンス型のプロトコルであり、クライアントはリクエストを発行し、サーバーは関連コンテンツとリクエストの完了状態情報を含むレスポンスを返します。HTTPは自己完結型であり、多くの中間ルーターやサーバーを経由してロードバランシング、キャッシュ、暗号化、圧縮を行いながらリクエストとレスポンスが流れます。
基本的なHTTPリクエストは動詞(メソッド)とリソース(エンドポイント)で構成されます。以下は一般的なHTTP動詞です:
| 動詞 | 説明 | 冪等* | 安全 | キャッシュ可能 | |---|---|---|---|---|
| GET | リソースを読み取る | はい | はい | はい | | POST | リソースを作成するか、データを処理するプロセスをトリガーする | いいえ | いいえ | レスポンスに新鮮さ情報が含まれる場合ははい | | PUT | リソースを作成または置き換える | はい | いいえ | いいえ | | PATCH | リソースを部分的に更新する | いいえ | いいえ | レスポンスに新鮮さ情報が含まれる場合ははい | | DELETE | リソースを削除する | はい | いいえ | いいえ |
- 結果が変わらない場合、何度でも呼び出せます。
#### 出典およびさらなる読み物: HTTP
トランスミッションコントロールプロトコル(TCP)
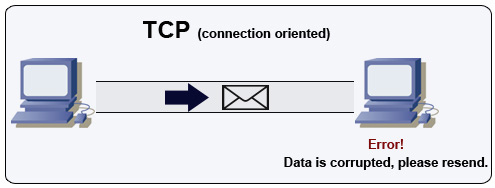
TCPはIPネットワーク上のコネクション指向プロトコルです。接続はハンドシェイクを使って確立および終了されます。送信されるすべてのパケットは、次の方法で元の順序で破損なく宛先に届くことが保証されます:
- 各パケットに対するシーケンス番号とチェックサムフィールド
- 確認応答パケットと自動再送信
高スループットを確保するために、ウェブサーバーは多数のTCP接続を開いたままにでき、その結果メモリ使用量が増加します。ウェブサーバースレッドと例えばmemcachedサーバー間で多数の開いた接続を持つことはコストがかかります。コネクションプーリングは、適用可能な場合はUDPへの切り替えに加えて役立ちます。
TCPは高い信頼性が必要で時間的制約が比較的少ないアプリケーションに有用です。例としてウェブサーバー、データベース情報、SMTP、FTP、SSHなどがあります。
UDPよりTCPを使う場合:
- すべてのデータが完全に届く必要がある場合
- ネットワークスループットの最善推定を自動的に行いたい場合
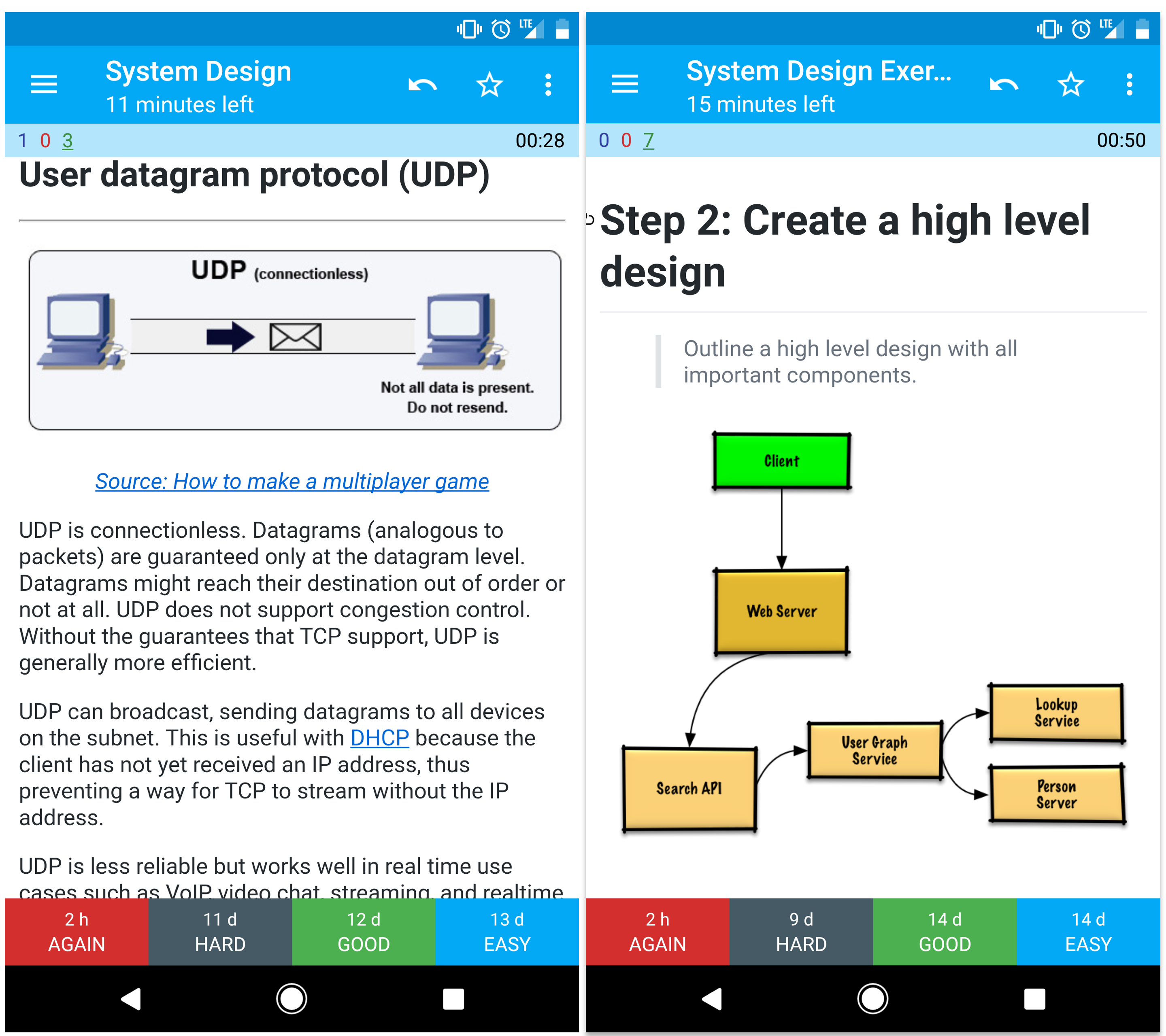
ユーザーデータグラムプロトコル(UDP)
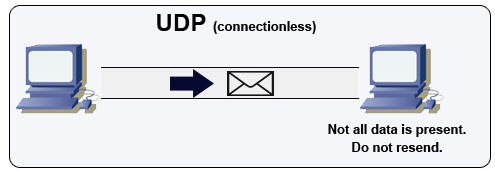
UDPはコネクションレスです。データグラム(パケットに類似)はデータグラムレベルでのみ保証されます。データグラムは順序が入れ替わって届くことや、全く届かないこともあります。UDPは輻輳制御をサポートしません。TCPがサポートする保証がないため、UDPは一般的により効率的です。
UDPはブロードキャストが可能で、サブネット上の全デバイスにデータグラムを送信します。これはクライアントがまだIPアドレスを受け取っていないため、TCPがIPアドレスなしでストリームを送る方法を妨げるDHCPで有用です。
UDPは信頼性は低いですが、VoIP、ビデオチャット、ストリーミング、リアルタイムマルチプレイヤーゲームなどのリアルタイム用途に適しています。
UDPをTCPの代わりに使うのは以下の場合です:
- 最低の遅延が必要なとき
- 遅延したデータはデータ損失より悪いとき
- 独自の誤り訂正を実装したいとき
- ゲームプログラミングのためのネットワーキング
- TCPとUDPプロトコルの主な違い
- TCPとUDPの違い
- 伝送制御プロトコル
- ユーザーデータグラムプロトコル
- Facebookのmemcacheスケーリング
リモートプロシージャコール(RPC)
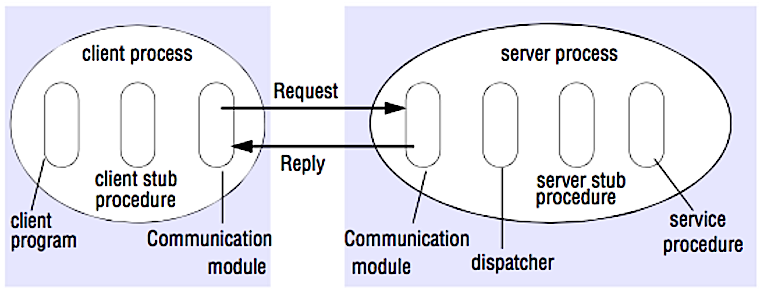
RPCでは、クライアントが通常リモートサーバーの異なるアドレス空間でプロシージャを実行させます。プロシージャはローカルプロシージャコールのようにコード化されており、クライアントプログラムからサーバーとの通信方法の詳細を抽象化しています。リモートコールは通常ローカルコールより遅く信頼性が低いため、RPCコールとローカルコールを区別することが有用です。代表的なRPCフレームワークにはProtobuf、Thrift、Avroがあります。
RPCはリクエスト-レスポンスプロトコルです:
- クライアントプログラム - クライアントスタブ手続きを呼び出します。パラメータはローカル手続き呼び出しのようにスタックにプッシュされます。
- クライアントスタブ手続き - 手続きIDと引数をリクエストメッセージにマーシャリング(パック)します。
- クライアント通信モジュール - OSがクライアントからサーバへメッセージを送信します。
- サーバ通信モジュール - OSが受信パケットをサーバスタブ手続きに渡します。
- サーバスタブ手続き - 結果をアンマーシャルし、手続きIDに対応するサーバ手続きを呼び出し、引数を渡します。
- サーバの応答は上記の手順を逆順で繰り返します。
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
ネイティブライブラリ(別名SDK)を選択する場合:
- 対象プラットフォームが明確である。
- 「ロジック」へのアクセス方法を制御したい。
- ライブラリ外でのエラー制御の方法を制御したい。
- パフォーマンスとエンドユーザーの体験が最優先である。
#### 欠点:RPC
- RPCクライアントはサービス実装に強く結合される。
- 新しい操作やユースケースごとに新しいAPIを定義する必要がある。
- RPCのデバッグは困難な場合がある。
- 既存の技術をすぐに活用できないかもしれない。例えば、RPC呼び出しがキャッシュサーバー(例:[Squid)で正しくキャッシュされるようにする](https://web.archive.org/web/20170608193645/http://etherealbits.com/2012/12/debunking-the-myths-of-rpc-rest/)には追加の労力が必要なことがある。
表現状態転送(REST)
RESTはクライアント/サーバーモデルを強制するアーキテクチャスタイルで、クライアントはサーバーが管理するリソースの集合に対して動作します。サーバーはリソースの表現と、リソースを操作したり新しい表現を取得したりするためのアクションを提供します。全ての通信はステートレスでキャッシュ可能でなければなりません。
RESTfulインターフェースには4つの特徴があります:
- リソースの識別(HTTPのURI) - 操作に関わらず同じURIを使用する。
- 表現による変更(HTTPの動詞) - 動詞、ヘッダー、ボディを使用する。
- 自己記述的なエラーメッセージ(HTTPのステータス応答) - ステータスコードを使い、再発明しない。
- HATEOAS(HTTPのHTMLインターフェース) - ウェブサービスはブラウザで完全にアクセス可能であるべき。
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### 欠点: REST
- RESTはデータ公開に焦点を当てているため、リソースが自然に単純な階層構造で整理またはアクセスされない場合には適さないことがあります。例えば、過去1時間に特定のイベントに一致するすべての更新レコードを返すことは、パスとして簡単に表現できません。RESTでは、URIパス、クエリパラメータ、および場合によってはリクエストボディの組み合わせで実装される可能性が高いです。
- RESTは通常、いくつかの動詞(GET、POST、PUT、DELETE、PATCH)に依存しますが、これらが必ずしもユースケースに合わないことがあります。例えば、期限切れのドキュメントをアーカイブフォルダに移動する処理は、これらの動詞のどれにもきれいに収まらないかもしれません。
- 入れ子構造を持つ複雑なリソースを取得するには、クライアントとサーバー間で複数回の往復が必要となり、単一ビューのレンダリングに時間がかかります。例えば、ブログエントリの内容とそのエントリに対するコメントを取得する場合です。変動するネットワーク環境で動作するモバイルアプリケーションでは、これらの複数の往復は非常に望ましくありません。
- 時間が経つにつれてAPIレスポンスにより多くのフィールドが追加されることがあり、古いクライアントは必要のない新しいデータフィールドもすべて受け取ってしまいます。その結果、ペイロードサイズが膨れ上がり、レイテンシが大きくなります。
RPCとREST呼び出しの比較
| 操作 | RPC | REST |
|---|---|---|
| サインアップ | POST /signup | POST /persons |
| 退会 | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| 人物情報取得 | GET /readPerson?personid=1234 | GET /persons/1234 |
| 人物のアイテムリスト取得 | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| 人物のアイテムに追加 | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| アイテム更新 | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| アイテム削除 | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
#### 出典およびさらなる参考資料: RESTとRPC
- RESTをRPCより好む理由を本当に知っていますか
- RPC的アプローチがRESTより適切な場合とは?
- REST vs JSON-RPC
- RPCとRESTの神話を覆す
- RESTの欠点とは?
- システム設計面接を攻略する
- Thrift
- なぜ内部利用にはRESTでRPCではないのか
セキュリティ
このセクションは更新が必要です。貢献をご検討ください!
セキュリティは広範なテーマです。 かなりの経験やセキュリティの背景があるか、セキュリティ知識が必要な職に応募していない限り、おそらく基本的なこと以上を知る必要はありません:
- 転送中および保存時に暗号化する。
- XSSやSQLインジェクションを防ぐために、すべてのユーザー入力やユーザーに公開されている入力パラメータをサニタイズする。
- SQLインジェクションを防ぐためにパラメータ化クエリを使用する。
- 最小特権の原則を利用する。
参考資料およびさらなる読み物
付録
時折「ざっとした」見積もりを求められることがあります。 例えば、ディスクから100枚の画像サムネイルを生成するのにどれくらい時間がかかるか、またはデータ構造がどれほどのメモリを必要とするかを見積もる場合です。 2のべき乗表 と すべてのプログラマーが知っておくべきレイテンシ数値 は便利な参考資料です。
2のべき乗表
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### 参照元およびさらなる読書資料
すべてのプログラマーが知っておくべきレイテンシーの数値
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- HDDからの順次読み取り速度は30 MB/s
- 1 Gbpsイーサネットからの順次読み取り速度は100 MB/s
- SSDからの順次読み取り速度は1 GB/s
- メインメモリからの順次読み取り速度は4 GB/s
- 世界中で6〜7回の往復通信が1秒間に可能
- データセンター内では1秒間に2,000回の往復通信が可能
#### 出典およびさらなる参考資料
- Latency numbers every programmer should know - 1
- Latency numbers every programmer should know - 2
- 大規模分散システム構築からの設計・教訓・アドバイス
- 大規模分散システム構築からのソフトウェア工学アドバイス
追加のシステム設計面接質問
一般的なシステム設計の面接質問と、それぞれの解決方法へのリンク集。
| 質問 | 参考リンク |
|---|---|
| Dropboxのようなファイル同期サービスを設計せよ | youtube.com |
| Googleのような検索エンジンを設計せよ | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Googleのようなスケーラブルなウェブクローラーを設計せよ | quora.com |
| Googleドキュメントを設計せよ | code.google.com
neil.fraser.name |
| Redisのようなキー・バリューストアを設計せよ | slideshare.net |
| Memcachedのようなキャッシュシステムを設計せよ | slideshare.net |
| Amazonのようなレコメンデーションシステムを設計せよ | hulu.com
ijcai13.org |
| BitlyのようなTinyURLシステムを設計せよ | n00tc0d3r.blogspot.com |
| WhatsAppのようなチャットアプリを設計せよ | highscalability.com
| Instagramのような写真共有システムを設計せよ | highscalability.com
highscalability.com |
| Facebookのニュースフィード機能を設計せよ | quora.com
quora.com
slideshare.net |
| Facebookのタイムライン機能を設計せよ | facebook.com
highscalability.com |
| Facebookのチャット機能を設計せよ | erlang-factory.com
facebook.com |
| Facebookのようなグラフ検索機能を設計する | facebook.com
facebook.com
facebook.com |
| CloudFlareのようなコンテンツ配信ネットワークを設計する | figshare.com |
| Twitterのようなトレンドトピックシステムを設計する | michael-noll.com
snikolov .wordpress.com |
| ランダムID生成システムを設計する | blog.twitter.com
github.com |
| 一定時間内のトップkリクエストを返す | cs.ucsb.edu
wpi.edu |
| 複数のデータセンターからデータを提供するシステムを設計する | highscalability.com |
| オンラインマルチプレイヤーカードゲームを設計する | indieflashblog.com
buildnewgames.com |
| ガベージコレクションシステムを設計する | stuffwithstuff.com
washington.edu |
| APIレートリミッターを設計する | https://stripe.com/blog/ |
| 株式取引所(NASDAQやBinanceのような)を設計する | Jane Street
Golang Implementation
Go Implementation |
| システム設計の質問を追加する | Contribute |
実世界のアーキテクチャ
実際のシステムがどのように設計されているかに関する記事。
{kind=link}
{kind=link}
以下の記事では細かい詳細にこだわらず、代わりに:
- これらの記事に共通する原則、一般的な技術、パターンを特定する
- 各コンポーネントが解決する問題、機能する箇所、機能しない箇所を学ぶ
- 得られた教訓を振り返る
企業アーキテクチャ
| 企業 | 参照 |
|---|---|
| Amazon | Amazonアーキテクチャ |
| Cinchcast | 毎日1,500時間のオーディオ制作 |
| DataSift | 毎秒120,000ツイートのリアルタイムデータマイニング |
| Dropbox | Dropboxのスケーリング方法 |
| ESPN | 毎秒100,000回の操作 |
| Google | Googleアーキテクチャ |
| Instagram | 1400万人のユーザー、テラバイトの写真
Instagramの動力源 |
| Justin.tv | Justin.Tvのライブビデオ放送アーキテクチャ |
| Facebook | Facebookでのmemcachedのスケーリング
TAO: Facebookのソーシャルグラフ用分散データストア
Facebookの写真ストレージ
Facebookが80万人の同時視聴者にライブ配信する方法 |
| Flickr | Flickrアーキテクチャ |
| Mailbox | 6週間で0から100万人のユーザーへ |
| Netflix | Netflixスタックの360度ビュー
Netflix:再生ボタンを押すと何が起こるか |
| Pinterest | 月間数百億ページビューへのスケーリング
1800万人の訪問者、10倍の成長、従業員12名 |
| Playfish | 月間5,000万人のユーザー数と成長 |
| PlentyOfFish | PlentyOfFishアーキテクチャ |
| Salesforce | 1日13億件のトランザクションを処理する方法 |
| Stack Overflow | Stack Overflowアーキテクチャ |
| TripAdvisor | 4,000万人の訪問者、2億の動的ページビュー、30TBのデータ |
| Tumblr | 月間150億ページビュー |
| Twitter | Twitterを1万倍高速化
MySQLで1日2.5億ツイートを保存
1億5,000万人のアクティブユーザー、30万QPS、22MB/sのファイアホース
大規模なタイムライン
Twitterのビッグ&スモールデータ
Twitterの運用:1億ユーザー超のスケーリング
Twitterが毎秒3,000枚の画像を処理する方法 |
| Uber | Uberのリアルタイムマーケットプラットフォームのスケーリング方法
Uberのスケーリング教訓:2000エンジニア、1000サービス、8000 Gitリポジトリ |
| WhatsApp | Facebookが190億ドルで買収したWhatsAppのアーキテクチャ |
| YouTube | YouTubeのスケーラビリティ
YouTubeアーキテクチャ |
企業のエンジニアリングブログ
面接を受ける企業のアーキテクチャ。>
出題される質問は同じドメインから来ることがあります。
- Airbnb エンジニアリング
- Atlassian デベロッパー
- AWS ブログ
- Bitly エンジニアリングブログ
- Box ブログ
- Cloudera デベロッパーブログ
- Dropbox テックブログ
- Quora のエンジニアリング
- Ebay テックブログ
- Evernote テックブログ
- Etsy Code as Craft
- Facebook エンジニアリング
- Flickr Code
- Foursquare エンジニアリングブログ
- GitHub エンジニアリングブログ
- Google リサーチブログ
- Groupon エンジニアリングブログ
- Heroku エンジニアリングブログ
- Hubspot エンジニアリングブログ
- High Scalability
- Instagram エンジニアリング
- Intel ソフトウェアブログ
- Jane Street テックブログ
- LinkedIn エンジニアリング
- Microsoft エンジニアリング
- Microsoft Python エンジニアリング
- Netflix テックブログ
- Paypal デベロッパーブログ
- Pinterest エンジニアリングブログ
- Reddit ブログ
- Salesforce エンジニアリングブログ
- Slack エンジニアリングブログ
- Spotify ラボ
- Stripe エンジニアリングブログ
- Twilio エンジニアリングブログ
- Twitter エンジニアリング
- Uber エンジニアリングブログ
- Yahoo エンジニアリングブログ
- Yelp エンジニアリングブログ
- Zynga エンジニアリングブログ
ブログを追加したいですか? 重複作業を避けるために、以下のリポジトリにあなたの会社のブログを追加することを検討してください:
開発中
セクションを追加したり、進行中のものを完成させるのを手伝いたいですか? 貢献する!
- MapReduceを用いた分散コンピューティング
- 一貫性のあるハッシュ
- スキャッター・ギャザー
- 貢献する
クレジット
クレジットと出典はこのリポジトリ全体にわたって提供されています。
特別な感謝:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
連絡先情報
ご質問やご意見、ご不明な点がございましたら、お気軽にご連絡ください。
私の連絡先情報はGitHubページに記載されています。
ライセンス
このリポジトリのコードおよびリソースはオープンソースライセンスのもとで提供しています。これは私個人のリポジトリであるため、コードおよびリソースに対するライセンスは私から直接提供されており、私の勤務先(Facebook)からではありません。
著作権 2017 Donne Martin
クリエイティブ・コモンズ 表示 4.0 国際 ライセンス (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---