English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Aiuta a tradurre questa guida!
The System Design Primer

Motivazione
Impara a progettare sistemi su larga scala.>
Preparati per il colloquio di system design.
Impara a progettare sistemi su larga scala
Imparare a progettare sistemi scalabili ti aiuterà a diventare un ingegnere migliore.
La progettazione dei sistemi è un argomento ampio. Ci sono numerose risorse sparse sul web riguardanti i principi di progettazione dei sistemi.
Questa repository è una raccolta organizzata di risorse per aiutarti a imparare come costruire sistemi su larga scala.
Impara dalla comunità open source
Questo è un progetto open source continuamente aggiornato.
Contributi sono benvenuti!
Preparati per il colloquio di system design
Oltre ai colloqui di coding, il system design è una componente obbligatoria del processo di colloquio tecnico in molte aziende tecnologiche.
Esercitati con le domande comuni dei colloqui di system design e confronta i tuoi risultati con soluzioni di esempio: discussioni, codice e diagrammi.
Argomenti aggiuntivi per prepararti al colloquio:
- Guida allo studio
- Come affrontare una domanda di colloquio di system design
- Domande di colloquio sulla progettazione di sistemi, con soluzioni
- Domande di colloquio sulla progettazione orientata agli oggetti, con soluzioni
- Domande aggiuntive di colloquio sulla progettazione di sistemi
Flashcard Anki
I mazzi di flashcard Anki forniti utilizzano la ripetizione dilazionata per aiutarti a memorizzare i concetti chiave di progettazione dei sistemi.
- Mazzo progettazione di sistemi
- Mazzo esercizi di progettazione di sistemi
- Mazzo esercizi di progettazione orientata agli oggetti
Risorsa di programmazione: Sfide di programmazione interattive
Cerchi risorse per prepararti al Colloquio di programmazione?
Dai un'occhiata al repository gemello Interactive Coding Challenges, che contiene un ulteriore mazzo Anki:
Contribuire
Impara dalla community.
Sentiti libero di inviare pull request per aiutare a:
- Correggere errori
- Migliorare le sezioni
- Aggiungi nuove sezioni
- Traduci
Consulta le Linee guida per i contributi.
Indice degli argomenti di system design
Sommari di vari argomenti di system design, inclusi pro e contro. Tutto è un compromesso.>
Ogni sezione contiene link a risorse più approfondite.
- Argomenti di system design: inizia qui
- Passo 1: Guarda la lezione video sulla scalabilità
- Passo 2: Leggi l'articolo sulla scalabilità
- Prossimi passi
- Prestazioni vs scalabilità
- Latenza vs throughput
- Disponibilità vs consistenza
- Teorema CAP
- CP - consistenza e tolleranza alle partizioni
- AP - disponibilità e tolleranza alle partizioni
- Pattern di consistenza
- Consistenza debole
- Consistenza eventuale
- Consistenza forte
- Pattern di disponibilità
- Fail-over
- Replica
- Disponibilità in numeri
- Domain name system
- Content delivery network
- Push CDN
- Pull CDN
- Bilanciatore di carico
- Attivo-passivo
- Attivo-attivo
- Bilanciamento del carico Layer 4
- Bilanciamento del carico Layer 7
- Scalabilità orizzontale
- Proxy inverso (server web)
- Bilanciatore di carico vs proxy inverso
- Livello applicativo
- Microservizi
- Service discovery
- Database
- Sistema di gestione di database relazionali (RDBMS)
- Replica master-slave
- Replica master-master
- Federazione
- Sharding
- Denormalizzazione
- Ottimizzazione SQL
- NoSQL
- Archivio chiave-valore
- Archivio di documenti
- Archivio a colonne larghe
- Database a grafo
- SQL o NoSQL
- Cache
- Caching lato client
- Caching CDN
- Caching del server web
- Caching del database
- Caching dell'applicazione
- Caching a livello di query del database
- Caching a livello di oggetto
- Quando aggiornare la cache
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- Asincronismo
- Code di messaggi
- Code di attività
- Contenimento della pressione
- Comunicazione
- Transmission control protocol (TCP)
- User datagram protocol (UDP)
- Remote procedure call (RPC)
- Representational state transfer (REST)
- Sicurezza
- Appendice
- Tabella delle potenze di due
- Numeri di latenza che ogni programmatore dovrebbe conoscere
- Domande aggiuntive per colloqui di progettazione di sistemi
- Architetture reali
- Architetture aziendali
- Blog ingegneristici aziendali
- In fase di sviluppo
- Crediti
- Informazioni di contatto
- Licenza
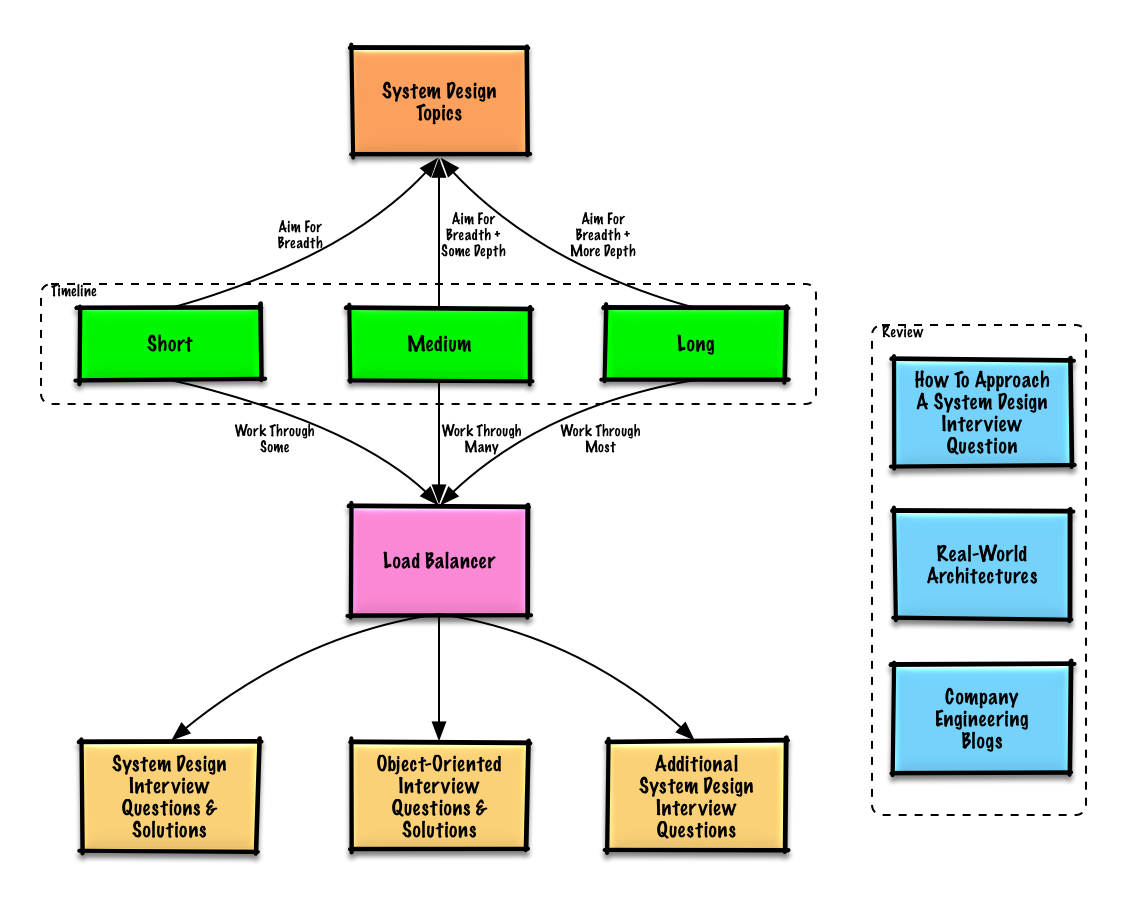
Guida allo studio
Argomenti suggeriti da rivedere in base alla tempistica del tuo colloquio (breve, media, lunga).
D: Per i colloqui, devo conoscere tutto ciò che è qui?
R: No, non è necessario conoscere tutto ciò che è qui per prepararsi al colloquio.
Le domande che ti vengono poste in un colloquio dipendono da variabili come:
- Quanta esperienza hai
- Qual è il tuo background tecnico
- Per quali posizioni stai facendo il colloquio
- Con quali aziende stai facendo il colloquio
- Fortuna
Inizia in modo ampio e approfondisci in alcune aree. È utile conoscere almeno un po’ i vari temi chiave della progettazione dei sistemi. Adatta la guida seguente in base alla tua tempistica, esperienza, alle posizioni per cui stai facendo colloqui e alle aziende con cui ti stai candidando.
- Tempistica breve - Punta alla ampiezza sui temi di progettazione dei sistemi. Allenati risolvendo alcune domande di colloquio.
- Tempistica media - Punta alla ampiezza e un po’ di profondità sui temi di progettazione dei sistemi. Allenati risolvendo molte domande di colloquio.
- Tempistica lunga - Punta alla ampiezza e maggiore profondità sui temi di progettazione dei sistemi. Allenati risolvendo la maggior parte delle domande di colloquio.
Come affrontare una domanda di colloquio di progettazione di sistemi
Come gestire una domanda di colloquio sulla progettazione di sistemi.
Il colloquio di progettazione di sistemi è una conversazione aperta. Ci si aspetta che tu la conduca.
Puoi utilizzare i seguenti passaggi per guidare la discussione. Per aiutarti a consolidare questo processo, lavora sulle Domande di colloquio di progettazione di sistemi con soluzioni seguendo i passaggi seguenti.
Passaggio 1: Definisci casi d’uso, vincoli e assunzioni
Raccogli i requisiti e delimita il problema. Fai domande per chiarire i casi d’uso e i vincoli. Discuti le assunzioni.
- Chi lo userà?
- Come lo useranno?
- Quanti utenti ci sono?
- Cosa fa il sistema?
- Quali sono gli input e gli output del sistema?
- Quanti dati prevediamo di gestire?
- Quante richieste al secondo prevediamo?
- Qual è il rapporto previsto tra letture e scritture?
Passaggio 2: Crea un design ad alto livello
Definisci un design ad alto livello con tutti i componenti importanti.
- Disegna i principali componenti e connessioni
- Giustifica le tue idee
Step 3: Progettazione dei componenti principali
Approfondisci i dettagli di ciascun componente principale. Ad esempio, se ti venisse chiesto di progettare un servizio di abbreviazione URL, discuti:
- Generazione e memorizzazione di un hash dell’URL completo
- MD5 e Base62
- Collisioni di hash
- SQL o NoSQL
- Schema del database
- Traduzione di un URL hashato all’URL completo
- Ricerca nel database
- API e progettazione orientata agli oggetti
Step 4: Scala il design
Identifica e affronta i colli di bottiglia, dati i vincoli. Ad esempio, hai bisogno di quanto segue per affrontare problemi di scalabilità?
- Bilanciatore di carico
- Scalabilità orizzontale
- Caching
- Sharding del database
Calcoli approssimativi
Potresti essere invitato a fare alcune stime manuali. Consulta l’Appendice per le seguenti risorse:
- Usa calcoli approssimativi
- Tabella delle potenze di due
- Numeri di latenza che ogni programmatore dovrebbe conoscere
Fonte/i e ulteriori letture
Consulta i seguenti link per avere un’idea più chiara di cosa aspettarti:
- Come superare un colloquio di progettazione di sistemi
- Il colloquio di progettazione di sistemi
- Introduzione all'architettura e ai colloqui di progettazione di sistemi
- Template per la progettazione di sistemi
Domande di colloquio di progettazione di sistemi con soluzioni
Domande comuni di colloquio di progettazione di sistemi con discussioni, codice e diagrammi di esempio.>
Soluzioni collegate ai contenuti nella cartella solutions/.| Domanda | | |---|---| | Progettare Pastebin.com (o Bit.ly) | Soluzione | | Progettare la timeline e la ricerca di Twitter (o feed e ricerca di Facebook) | Soluzione | | Progettare un web crawler | Soluzione | | Progettare Mint.com | Soluzione | | Progettare le strutture dati per un social network | Soluzione | | Progettare un archivio chiave-valore per un motore di ricerca | Soluzione | | Progettare la funzione di ranking delle vendite per categoria di Amazon | Soluzione | | Progettare un sistema che scala a milioni di utenti su AWS | Soluzione | | Aggiungi una domanda di progettazione di sistemi | Contribuisci |
Progettare Pastebin.com (o Bit.ly)
Visualizza esercizio e soluzione
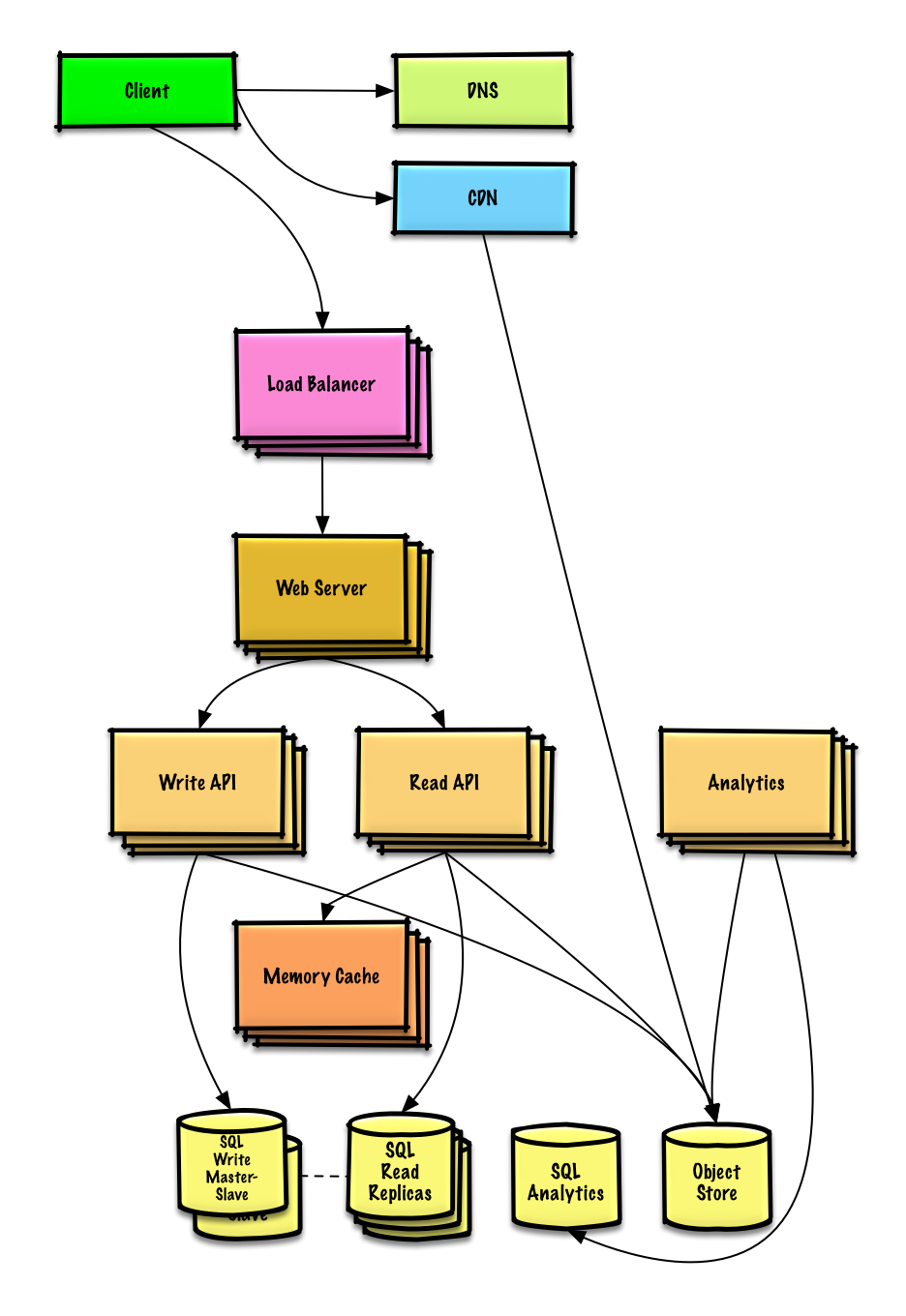
Progettare la timeline e la ricerca di Twitter (o feed e ricerca di Facebook)
Visualizza esercizio e soluzione
Progettare un web crawler
Visualizza esercizio e soluzione
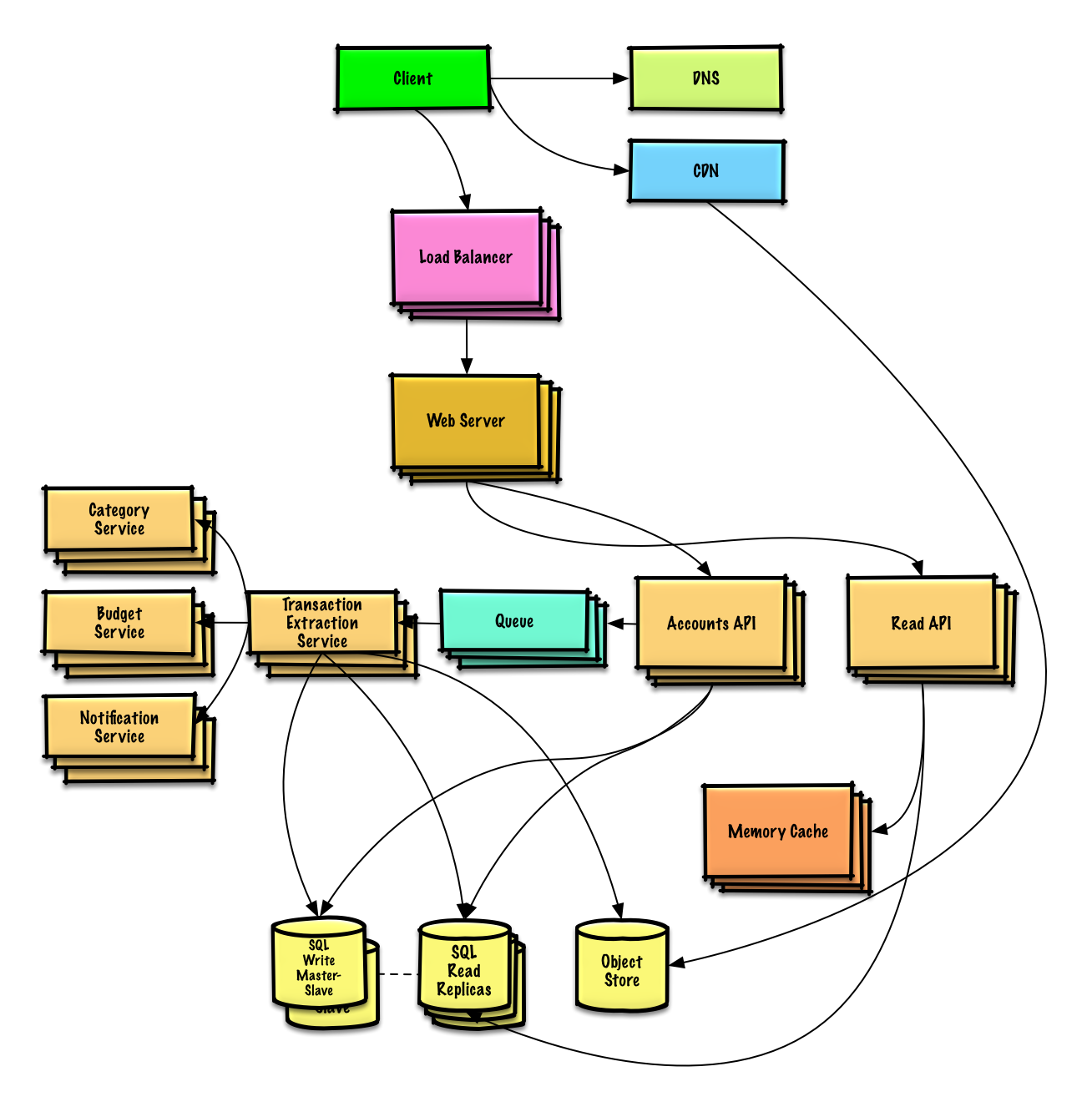
Design Mint.com
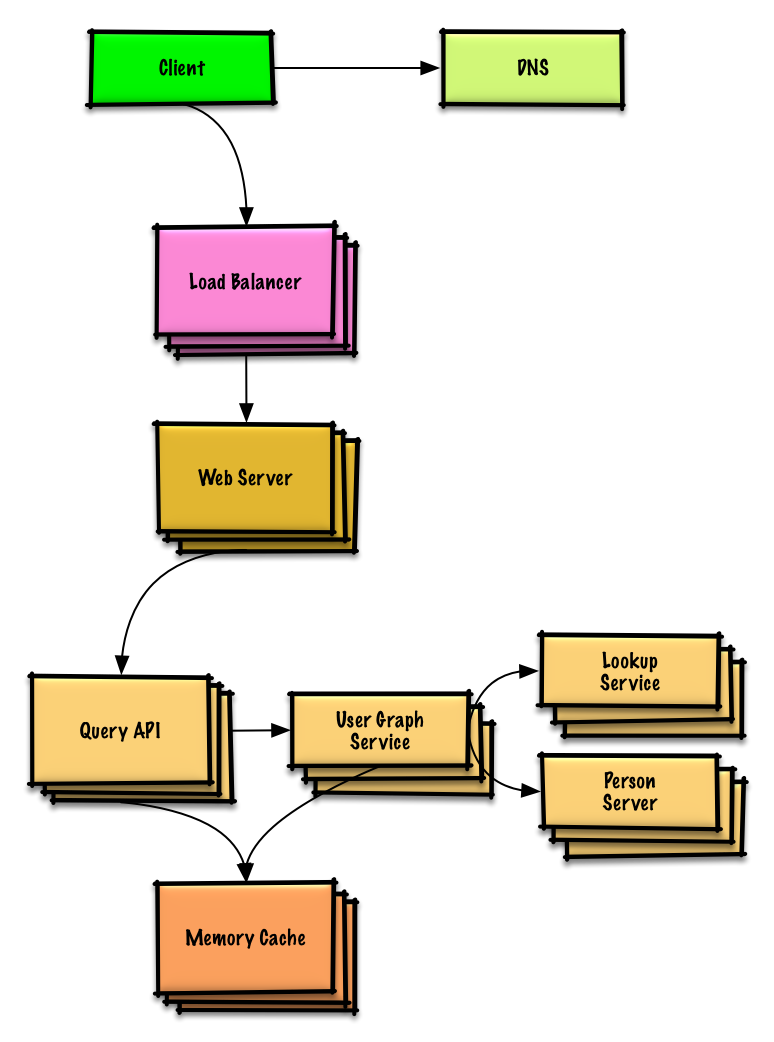
Design the data structures for a social network
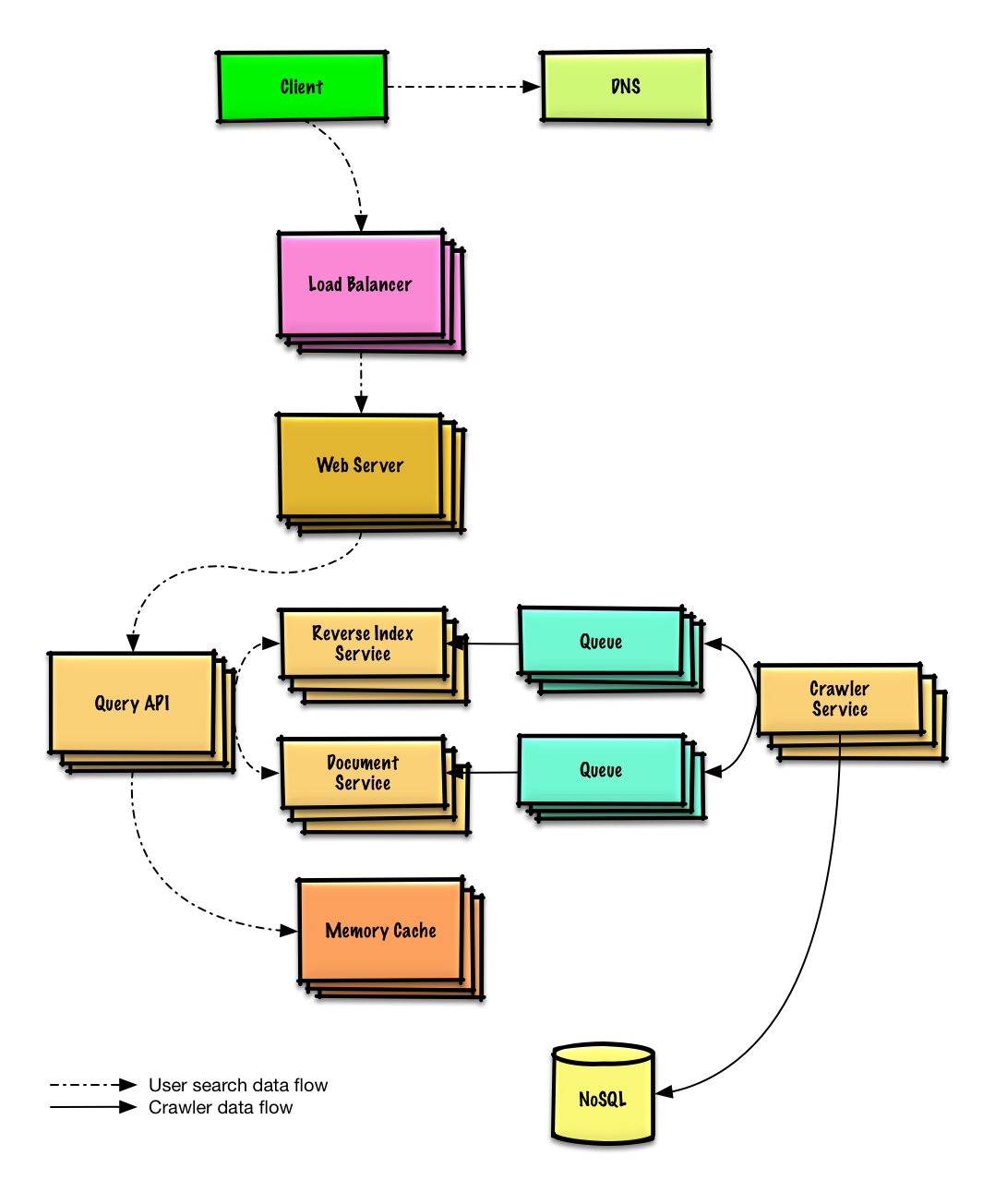
Design a key-value store for a search engine
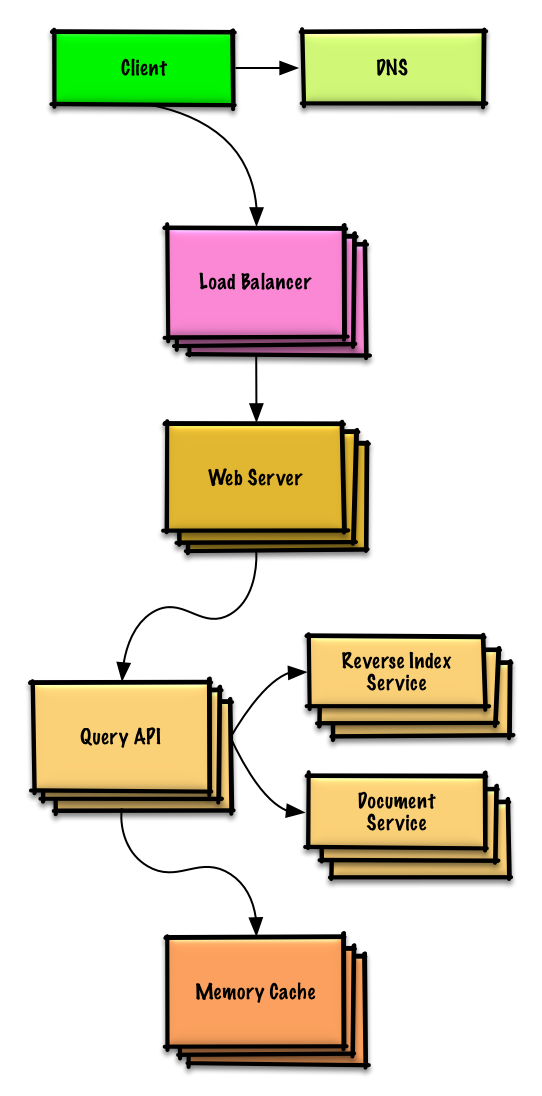
Design Amazon's sales ranking by category feature
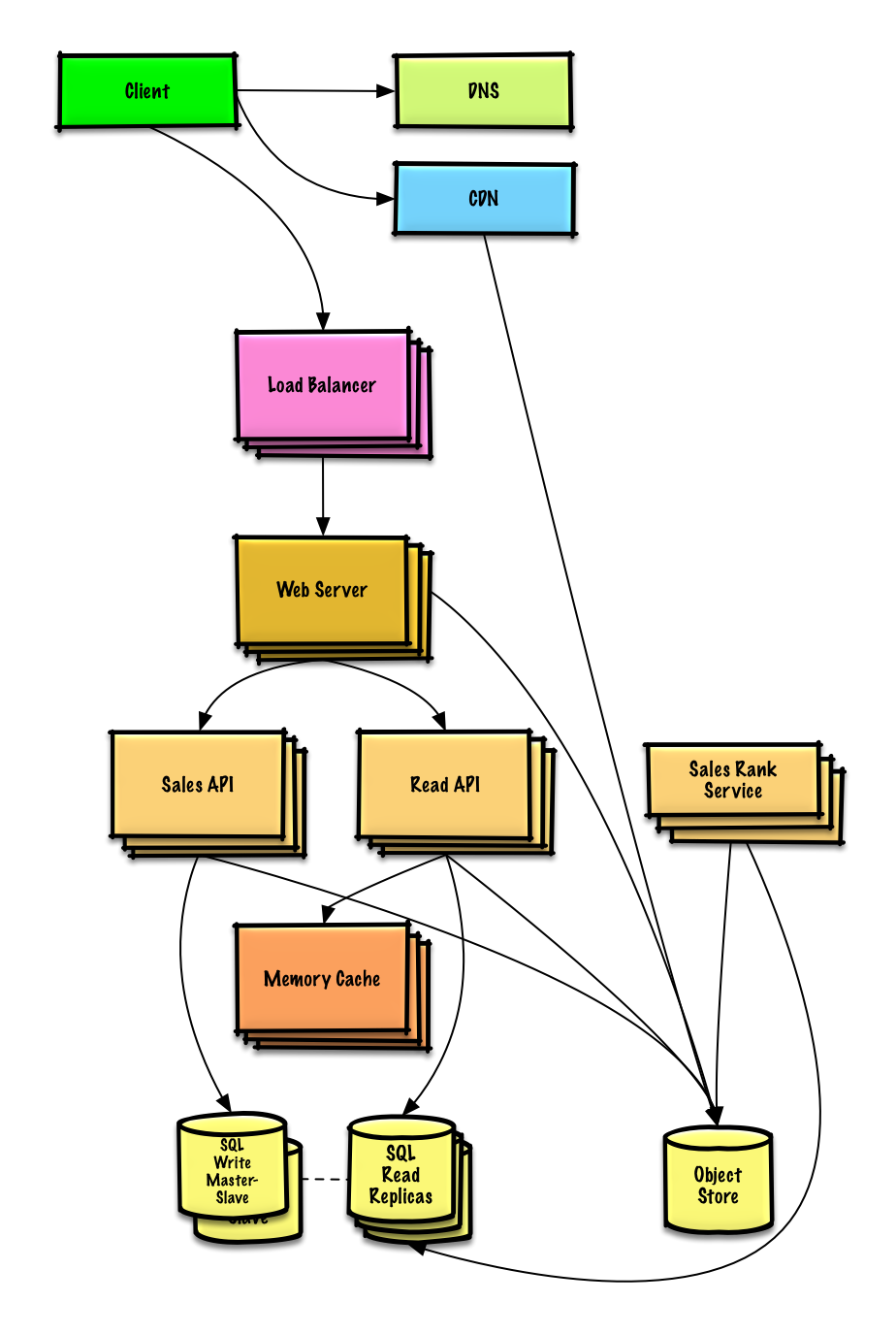
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Progetta una hash map | Soluzione | | Progetta una cache least recently used | Soluzione | | Progetta un call center | Soluzione | | Progetta un mazzo di carte | Soluzione | | Progetta un parcheggio | Soluzione | | Progetta un server di chat | Soluzione | | Progetta un array circolare | Contribuisci | | Aggiungi una domanda di progettazione orientata agli oggetti | Contribuisci |
Argomenti di system design: inizia qui
Nuovo alla progettazione di sistemi?
Per prima cosa, avrai bisogno di una comprensione di base dei principi comuni, imparando cosa sono, come vengono utilizzati e i loro pro e contro.
Passo 1: Rivedi la video-lezione sulla scalabilità
Lezione sulla Scalabilità ad Harvard
- Argomenti trattati:
- Scalabilità verticale
- Scalabilità orizzontale
- Caching
- Bilanciamento del carico
- Replica del database
- Partizionamento del database
Passo 2: Rivedi l'articolo sulla scalabilità
- Argomenti trattati:
- Cloni
- Database
- Cache
- Asincronismo
Prossimi passi
Successivamente, esamineremo i compromessi di alto livello:
- Prestazioni vs scalabilità
- Latenza vs throughput
- Disponibilità vs coerenza
Poi approfondiremo argomenti più specifici come DNS, CDN e bilanciatori di carico.
Prestazioni vs scalabilità
Un servizio è scalabile se porta a un aumento delle prestazioni in modo proporzionale alle risorse aggiunte. In generale, aumentare le prestazioni significa servire più unità di lavoro, ma può anche significare gestire unità di lavoro più grandi, come quando i dataset crescono.1
Un altro modo di vedere prestazioni vs scalabilità:
- Se hai un problema di prestazioni, il tuo sistema è lento per un singolo utente.
- Se hai un problema di scalabilità, il tuo sistema è veloce per un singolo utente ma lento sotto carico elevato.
Fonte(i) e ulteriori letture
Latenza vs throughput
Latenza è il tempo necessario per eseguire un'azione o produrre un risultato.
Throughput è il numero di tali azioni o risultati per unità di tempo.
In generale, dovresti puntare a massimizzare il throughput con latenza accettabile.
Fonte(i) e ulteriori letture
Disponibilità vs coerenza
Teorema CAP
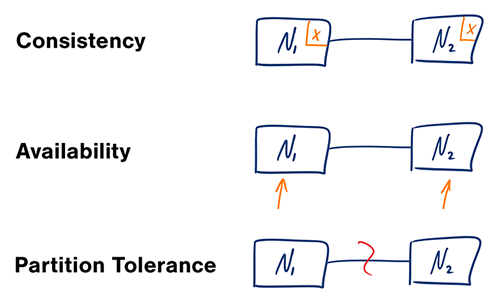
In un sistema informatico distribuito, puoi supportare solo due delle seguenti garanzie:
- Consistenza - Ogni lettura riceve la scrittura più recente o un errore
- Disponibilità - Ogni richiesta riceve una risposta, senza garanzia che contenga la versione più recente dell'informazione
- Tolleranza alle Partizioni - Il sistema continua a funzionare nonostante partizioni arbitrarie dovute a guasti di rete
#### CP - consistenza e tolleranza alle partizioni
Attendere una risposta dal nodo partizionato potrebbe causare un errore di timeout. CP è una buona scelta se le esigenze aziendali richiedono letture e scritture atomiche.
#### AP - disponibilità e tolleranza alle partizioni
Le risposte restituiscono la versione più facilmente disponibile dei dati su qualsiasi nodo, che potrebbe non essere la più recente. Le scritture potrebbero impiegare del tempo per propagarsi quando la partizione viene risolta.
AP è una buona scelta se le esigenze aziendali consentono consistenza eventuale o quando il sistema deve continuare a funzionare nonostante errori esterni.
Fonte/i e ulteriori letture
Pattern di consistenza
Con più copie degli stessi dati, ci troviamo di fronte a diverse opzioni su come sincronizzarle affinché i client abbiano una visione coerente dei dati. Ricorda la definizione di consistenza dal teorema CAP - Ogni lettura riceve la scrittura più recente o un errore.
Consistenza debole
Dopo una scrittura, le letture potrebbero vederla o meno. Si adotta un approccio best effort.
Questo approccio si osserva in sistemi come memcached. La consistenza debole funziona bene in casi d'uso in tempo reale come VoIP, video chat e giochi multiplayer in tempo reale. Ad esempio, se sei al telefono e perdi la ricezione per alcuni secondi, quando riacquisti la connessione non senti ciò che è stato detto durante la perdita di connessione.
Consistenza eventuale
Dopo una scrittura, le letture la vedranno eventualmente (tipicamente entro millisecondi). I dati sono replicati in modo asincrono.
Questo approccio si trova in sistemi come DNS ed email. La consistenza eventuale funziona bene nei sistemi altamente disponibili.
Consistenza forte
Dopo una scrittura, le letture la vedranno. I dati sono replicati in modo sincrono.
Questo approccio si trova nei file system e nei RDBMS. La consistenza forte funziona bene nei sistemi che necessitano di transazioni.
Fonte/i e ulteriori letture
Pattern di disponibilità
Ci sono due pattern complementari per supportare un’elevata disponibilità: fail-over e replicazione.
Fail-over
#### Attivo-passivo
Con il fail-over attivo-passivo, vengono inviati heartbeat tra il server attivo e quello passivo in standby. Se l’heartbeat viene interrotto, il server passivo assume l’indirizzo IP dell’attivo e riprende il servizio.
La durata del downtime è determinata dal fatto che il server passivo sia già in standby “hot” o se debba avviarsi da standby “cold”. Solo il server attivo gestisce il traffico.
Il failover attivo-passivo può essere chiamato anche failover master-slave.
#### Attivo-attivo
Nell’attivo-attivo, entrambi i server gestiscono il traffico, distribuendo il carico tra loro.
Se i server sono pubblici, il DNS deve conoscere gli IP pubblici di entrambi i server. Se i server sono interni, la logica applicativa deve conoscere entrambi i server.
Il failover attivo-attivo può essere chiamato anche failover master-master.
Svantaggio/i: failover
- Il fail-over aggiunge più hardware e ulteriore complessità.
- Esiste la possibilità di perdita di dati se il sistema attivo si guasta prima che i nuovi dati scritti possano essere replicati su quello passivo.
Replicazione
#### Master-slave e master-master
Questo argomento è ulteriormente trattato nella sezione Database:
Disponibilità in numeri
La disponibilità è spesso quantificata dal tempo di attività (o inattività) come percentuale del tempo in cui il servizio è disponibile. La disponibilità viene generalmente misurata in numero di 9--un servizio con il 99,99% di disponibilità viene descritto come avente quattro 9.
#### 99,9% di disponibilità - tre 9
| Durata | Tempo di inattività accettabile| |---------------------|-------------------------------| | Inattività per anno | 8h 45min 57s | | Inattività per mese | 43m 49,7s | | Inattività per settimana | 10m 4,8s | | Inattività per giorno| 1m 26,4s |
#### 99,99% di disponibilità - quattro 9
| Durata | Tempo di inattività accettabile| |---------------------|-------------------------------| | Inattività per anno | 52min 35,7s | | Inattività per mese | 4m 23s | | Inattività per settimana | 1m 5s | | Inattività per giorno| 8,6s |
#### Disponibilità in parallelo vs in sequenza
Se un servizio è composto da più componenti soggetti a guasti, la disponibilità complessiva del servizio dipende dal fatto che i componenti siano in sequenza o in parallelo.
###### In sequenza
La disponibilità complessiva diminuisce quando due componenti con disponibilità < 100% sono in sequenza:
Availability (Total) = Availability (Foo) * Availability (Bar)Se sia Foo che Bar avessero ciascuno una disponibilità del 99,9%, la loro disponibilità totale in sequenza sarebbe del 99,8%.
###### In parallelo
La disponibilità complessiva aumenta quando due componenti con disponibilità < 100% sono in parallelo:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Se sia Foo che Bar avessero ciascuno una disponibilità del 99,9%, la loro disponibilità totale in parallelo sarebbe del 99,9999%.
Sistema dei nomi di dominio
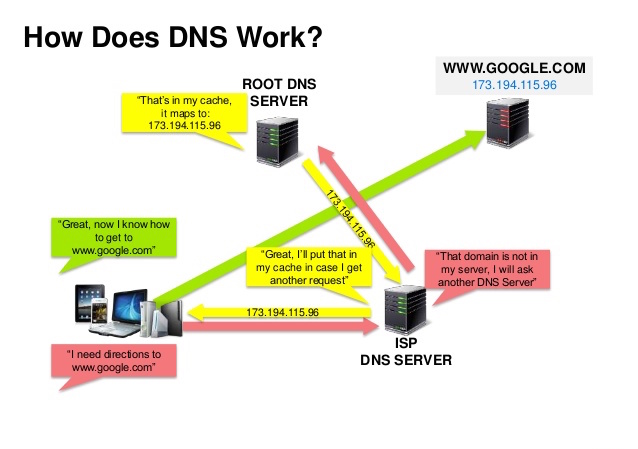
Fonte: Presentazione sulla sicurezza DNS
Un Sistema dei Nomi di Dominio (DNS) traduce un nome di dominio come www.example.com in un indirizzo IP.
Il DNS è gerarchico, con pochi server autorevoli al livello superiore. Il tuo router o ISP fornisce informazioni su quale(i) server DNS contattare durante una ricerca. I server DNS di livello inferiore memorizzano nella cache le mappature, che potrebbero diventare obsolete a causa dei ritardi di propagazione DNS. I risultati DNS possono essere memorizzati nella cache anche dal browser o dal sistema operativo per un certo periodo di tempo, determinato dal time to live (TTL).
- Record NS (name server) - Specifica i server DNS per il tuo dominio/sottodominio.
- Record MX (mail exchange) - Specifica i server di posta per accettare i messaggi.
- Record A (address) - Punta un nome a un indirizzo IP.
- CNAME (canonical) - Punta un nome a un altro nome o
CNAME(example.com a www.example.com) o a un recordA.
- Round robin pesato
- Impedire che il traffico vada ai server in manutenzione
- Bilanciare tra dimensioni del cluster variabili
- Test A/B
- Basato sulla latenza
- Basato sulla geolocalizzazione
Svantaggio(i): DNS
- Accedere a un server DNS introduce un leggero ritardo, sebbene mitigato dalla cache descritta sopra.
- La gestione dei server DNS può essere complessa ed è generalmente gestita da governi, ISP e grandi aziende.
- I servizi DNS sono stati recentemente oggetto di attacchi DDoS, impedendo agli utenti di accedere a siti web come Twitter senza conoscere l'indirizzo/i IP di Twitter.
Fonte(i) e ulteriori letture
Content delivery network
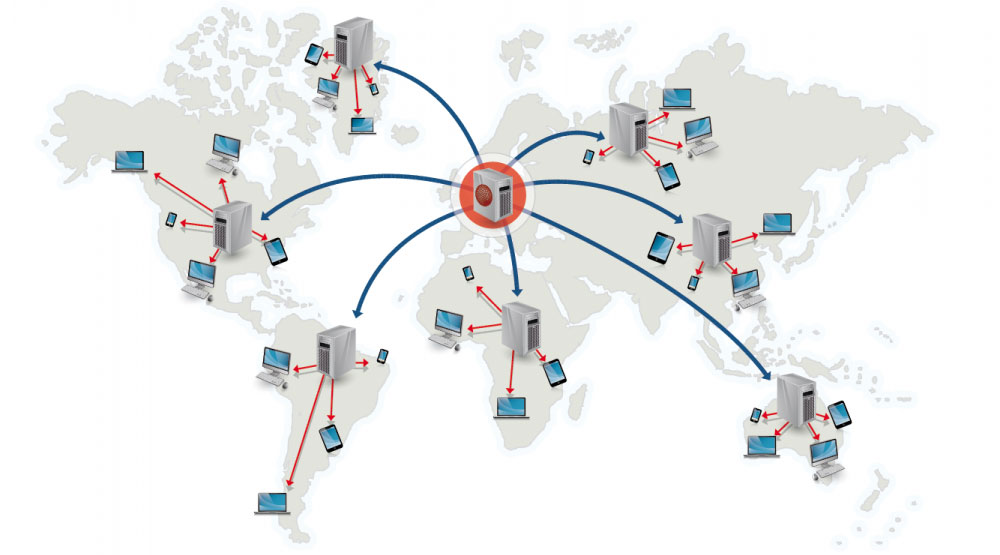
Una content delivery network (CDN) è una rete globale distribuita di server proxy, che fornisce contenuti da posizioni più vicine all'utente. Generalmente, file statici come HTML/CSS/JS, foto e video sono serviti da una CDN, anche se alcune CDN come CloudFront di Amazon supportano contenuti dinamici. La risoluzione DNS del sito indicherà ai client quale server contattare.
Fornire contenuti tramite CDN può migliorare significativamente le prestazioni in due modi:
- Gli utenti ricevono i contenuti da data center a loro vicini
- I tuoi server non devono servire le richieste che la CDN soddisfa
Push CDN
Le push CDN ricevono nuovi contenuti ogni volta che si verificano cambiamenti sul tuo server. Sei completamente responsabile della fornitura dei contenuti, caricandoli direttamente sulla CDN e riscrivendo gli URL per puntare alla CDN. Puoi configurare quando i contenuti scadono e quando vengono aggiornati. I contenuti vengono caricati solo quando sono nuovi o modificati, minimizzando il traffico ma massimizzando lo storage.
I siti con poco traffico o con contenuti che non vengono aggiornati spesso funzionano bene con le push CDN. I contenuti vengono caricati sulle CDN una sola volta, invece di essere ripresi regolarmente.
Pull CDN
Le pull CDN prelevano nuovi contenuti dal tuo server quando il primo utente li richiede. Lasci i contenuti sul tuo server e riscrivi gli URL per puntare alla CDN. Questo comporta una richiesta più lenta fino a quando il contenuto non viene memorizzato nella cache sulla CDN.
Un time-to-live (TTL) determina per quanto tempo i contenuti vengono mantenuti in cache. Le pull CDN minimizzano lo spazio di archiviazione sulla CDN, ma possono creare traffico ridondante se i file scadono e vengono ripresi prima che siano effettivamente cambiati.
I siti con molto traffico funzionano bene con le pull CDN, poiché il traffico viene distribuito più uniformemente e solo i contenuti richiesti di recente rimangono sulla CDN.
Svantaggio(i): CDN
- I costi della CDN possono essere significativi a seconda del traffico, anche se questo va valutato rispetto ai costi aggiuntivi che si sosterrebbero non usando una CDN.
- I contenuti potrebbero essere obsoleti se aggiornati prima che il TTL scada.
- Le CDN richiedono la modifica degli URL dei contenuti statici per puntare alla CDN.
Fonte(i) e approfondimenti
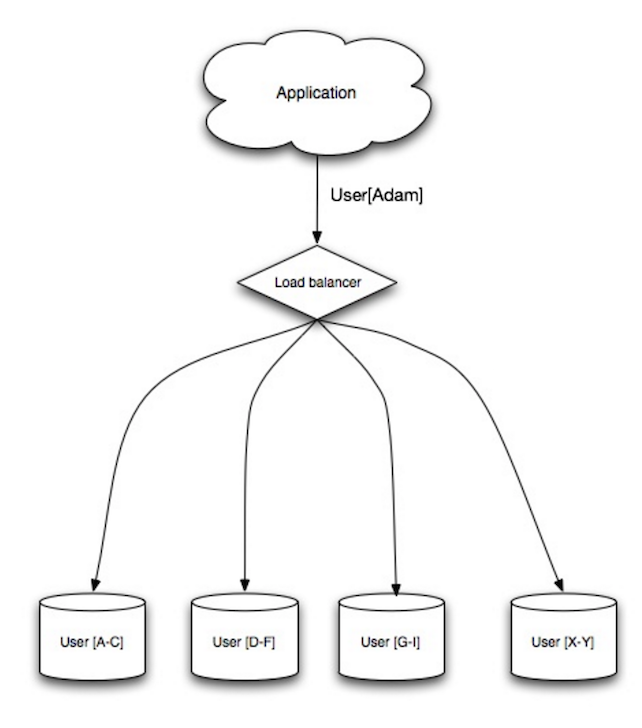
Bilanciatore di carico
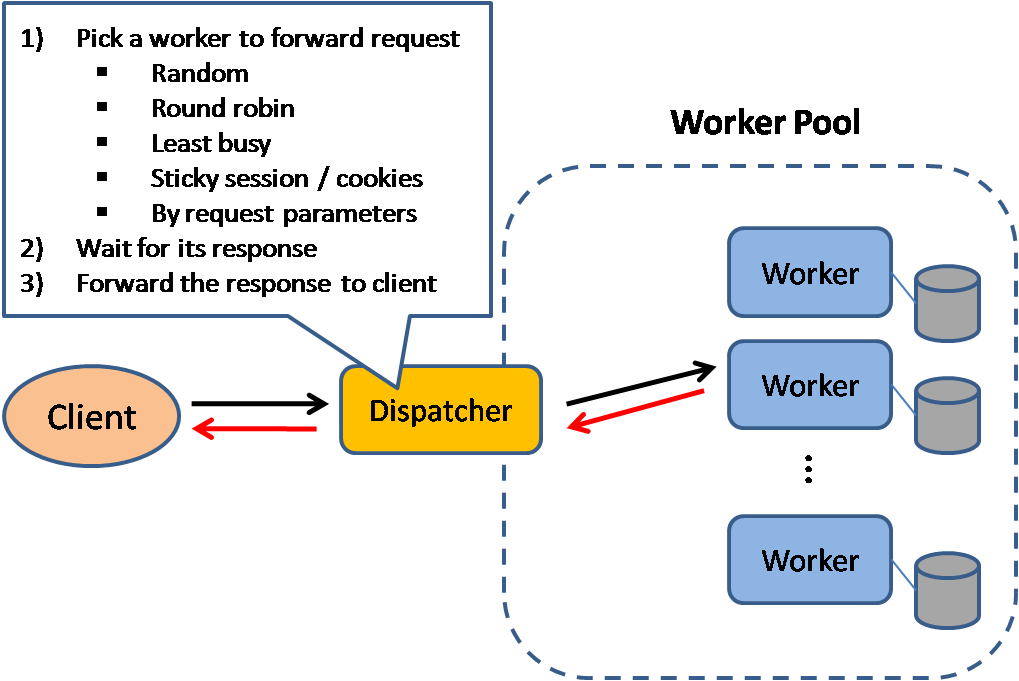
Fonte: Scalable system design patterns
I bilanciatori di carico distribuiscono le richieste dei client in arrivo alle risorse di calcolo come server applicativi e database. In ogni caso, il bilanciatore di carico restituisce la risposta dalla risorsa di calcolo al client appropriato. I bilanciatori di carico sono efficaci per:
- Impedire che le richieste vadano ai server non funzionanti
- Prevenire il sovraccarico delle risorse
- Aiutare ad eliminare un singolo punto di fallimento
Ulteriori vantaggi includono:
- Terminazione SSL - Decifra le richieste in arrivo e cifra le risposte dei server in modo che i server backend non debbano eseguire queste operazioni potenzialmente costose
- Elimina la necessità di installare i certificati X.509 su ogni server
- Persistenza della sessione - Emette cookie e instrada le richieste di uno specifico client alla stessa istanza se le web app non tengono traccia delle sessioni
I bilanciatori di carico possono instradare il traffico in base a vari parametri, tra cui:
- Casuale
- Meno carico
- Sessione/cookie
- Round robin o round robin ponderato
- Layer 4
- Layer 7
Bilanciamento del carico Layer 4
I bilanciatori di carico Layer 4 osservano le informazioni al livello di trasporto per decidere come distribuire le richieste. Generalmente, questo implica gli indirizzi IP di origine e destinazione e le porte nell’intestazione, ma non il contenuto del pacchetto. I bilanciatori di carico Layer 4 inoltrano i pacchetti di rete da e verso il server upstream, effettuando il Network Address Translation (NAT).
Bilanciamento del carico Layer 7
I bilanciatori di carico Layer 7 esaminano il livello applicativo per decidere come distribuire le richieste. Questo può coinvolgere il contenuto dell’header, del messaggio e dei cookie. I bilanciatori di carico Layer 7 terminano il traffico di rete, leggono il messaggio, prendono una decisione di bilanciamento del carico, quindi aprono una connessione al server selezionato. Ad esempio, un bilanciatore di carico Layer 7 può indirizzare il traffico video ai server che ospitano i video mentre indirizza il traffico di fatturazione utente più sensibile a server rinforzati per la sicurezza.Al costo della flessibilità, il bilanciamento del carico Layer 4 richiede meno tempo e risorse di calcolo rispetto al Layer 7, anche se l’impatto sulle prestazioni può essere minimo sull’hardware moderno di tipo commerciale.
Scalabilità orizzontale
I bilanciatori di carico possono anche aiutare con la scalabilità orizzontale, migliorando prestazioni e disponibilità. L’ampliamento tramite macchine commerciali è più conveniente e garantisce una maggiore disponibilità rispetto all’ampliamento di un singolo server su hardware più costoso, chiamato Scalabilità Verticale. È anche più facile assumere personale che lavori su hardware commerciale rispetto a sistemi aziendali specializzati.
#### Svantaggio(i): scalabilità orizzontale
- La scalabilità orizzontale introduce complessità e implica la clonazione dei server
- I server dovrebbero essere stateless: non dovrebbero contenere dati utente come sessioni o foto profilo
- Le sessioni possono essere archiviate in un archivio dati centralizzato come un database (SQL, NoSQL) o una cache persistente (Redis, Memcached)
- I server downstream come cache e database devono gestire più connessioni simultanee man mano che i server upstream si espandono
Svantaggio(i): bilanciatore di carico
- Il bilanciatore di carico può diventare un collo di bottiglia nelle prestazioni se non dispone di risorse sufficienti o se non è configurato correttamente.
- L’introduzione di un bilanciatore di carico per eliminare un singolo punto di errore comporta una complessità maggiore.
- Un singolo bilanciatore di carico è un punto di errore singolo; la configurazione di più bilanciatori di carico aumenta ulteriormente la complessità.
Fonte(i) e approfondimenti
- Architettura NGINX
- Guida all’architettura HAProxy
- Scalabilità
- Wikipedia)
- Bilanciamento del carico Layer 4
- Bilanciamento del carico Layer 7
- Config listener ELB
Reverse proxy (server web)
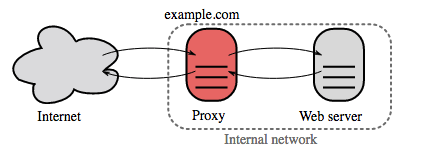
Un reverse proxy è un server web che centralizza i servizi interni e fornisce interfacce unificate al pubblico. Le richieste dei client vengono inoltrate a un server che può soddisfarle, prima che il reverse proxy restituisca la risposta del server al client.
Ulteriori vantaggi includono:
- Maggiore sicurezza - Nasconde le informazioni sui server backend, mette in blacklist gli IP, limita il numero di connessioni per client
- Maggiore scalabilità e flessibilità - I client vedono solo l'IP del reverse proxy, consentendo di scalare i server o modificarne la configurazione
- Terminazione SSL - Decripta le richieste in entrata e cripta le risposte del server così i server backend non devono eseguire queste operazioni potenzialmente costose
- Elimina la necessità di installare certificati X.509 su ogni server
- Compressione - Comprime le risposte del server
- Caching - Restituisce la risposta per richieste già memorizzate in cache
- Contenuti statici - Serve direttamente contenuti statici
- HTML/CSS/JS
- Foto
- Video
- Etc
Bilanciatore di carico vs reverse proxy
- Implementare un bilanciatore di carico è utile quando si hanno più server. Spesso, i bilanciatori di carico instradano il traffico a un gruppo di server che svolgono la stessa funzione.
- I reverse proxy possono essere utili anche con un solo server web o application server, offrendo i vantaggi descritti nella sezione precedente.
- Soluzioni come NGINX e HAProxy possono supportare sia il reverse proxy di livello 7 sia il bilanciamento del carico.
Svantaggio(i): reverse proxy
- L'introduzione di un reverse proxy comporta una maggiore complessità.
- Un singolo reverse proxy rappresenta un single point of failure, configurare più reverse proxy (ad esempio un failover) aumenta ulteriormente la complessità.
Fonte(i) e ulteriori letture
- Reverse proxy vs bilanciatore di carico
- Architettura NGINX
- Guida all'architettura di HAProxy
- Wikipedia
Livello applicazione
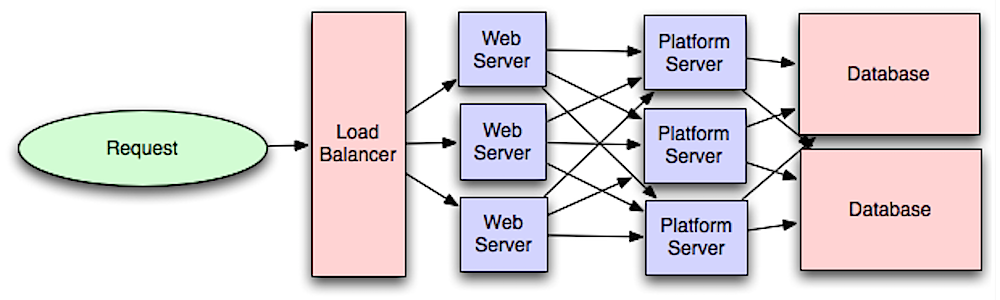
Fonte: Introduzione all'architettura di sistemi scalabili
Separare il livello web dal livello applicativo (noto anche come livello piattaforma) permette di scalare e configurare entrambi i livelli in modo indipendente. Aggiungere una nuova API comporta l'aggiunta di server applicativi senza necessariamente aggiungere ulteriori server web. Il principio della singola responsabilità sostiene servizi piccoli e autonomi che collaborano tra loro. Piccoli team con piccoli servizi possono pianificare più aggressivamente una crescita rapida.
I worker nel livello applicativo aiutano anche ad abilitare l'asincronismo.
Microservizi
Riguardo questa discussione ci sono i microservizi, che possono essere descritti come un insieme di servizi piccoli, modulari e distribuibili in modo indipendente. Ogni servizio esegue un processo unico e comunica tramite un meccanismo ben definito e leggero per raggiungere un obiettivo aziendale. 1
Pinterest, ad esempio, potrebbe avere i seguenti microservizi: profilo utente, follower, feed, ricerca, caricamento foto, ecc.
Service Discovery
Sistemi come Consul, Etcd, e Zookeeper aiutano i servizi a trovarsi tra loro tenendo traccia di nomi registrati, indirizzi e porte. I controlli di integrità aiutano a verificare l'integrità del servizio e sono spesso eseguiti tramite un endpoint HTTP. Sia Consul che Etcd hanno un key-value store integrato che può essere utile per memorizzare valori di configurazione e altri dati condivisi.
Svantaggi: livello applicativo
- Aggiungere un livello applicativo con servizi disaccoppiati richiede un approccio diverso dal punto di vista architetturale, operativo e dei processi (rispetto a un sistema monolitico).
- I microservizi possono aggiungere complessità in termini di deployment e operazioni.
Fonte(e) e approfondimenti
- Introduzione all'architettura di sistemi scalabili
- Crack the system design interview
- Architettura orientata ai servizi
- Introduzione a Zookeeper
- Cosa sapere per costruire microservizi
Database
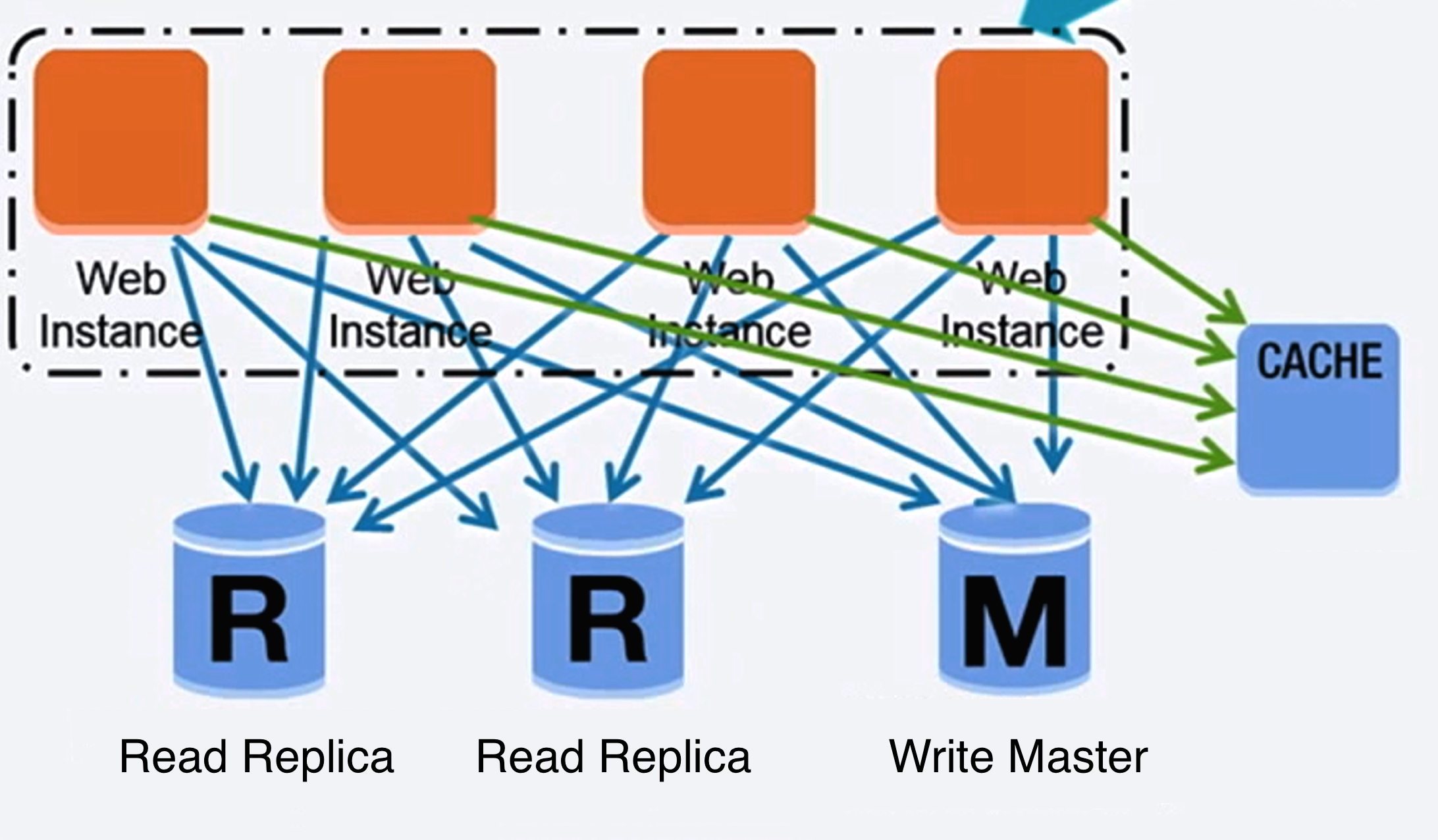
Fonte: Scalare fino ai tuoi primi 10 milioni di utenti
Sistema di gestione di database relazionali (RDBMS)
Un database relazionale come SQL è una raccolta di elementi di dati organizzati in tabelle.
ACID è un insieme di proprietà delle transazioni dei database relazionali.
- Atomicità - Ogni transazione è tutto o niente
- Coerenza - Qualsiasi transazione porterà il database da uno stato valido a un altro
- Isolamento - L'esecuzione concorrente delle transazioni produce gli stessi risultati che se fossero eseguite in serie
- Durabilità - Una volta che una transazione è stata confermata, rimarrà tale
#### Replicazione master-slave
Il master gestisce le letture e le scritture, replicando le scritture su uno o più slave, che gestiscono solo le letture. Gli slave possono anche replicare su altri slave in modo gerarchico. Se il master va offline, il sistema può continuare a funzionare in modalità sola lettura fino a quando uno slave viene promosso a master o viene predisposto un nuovo master.
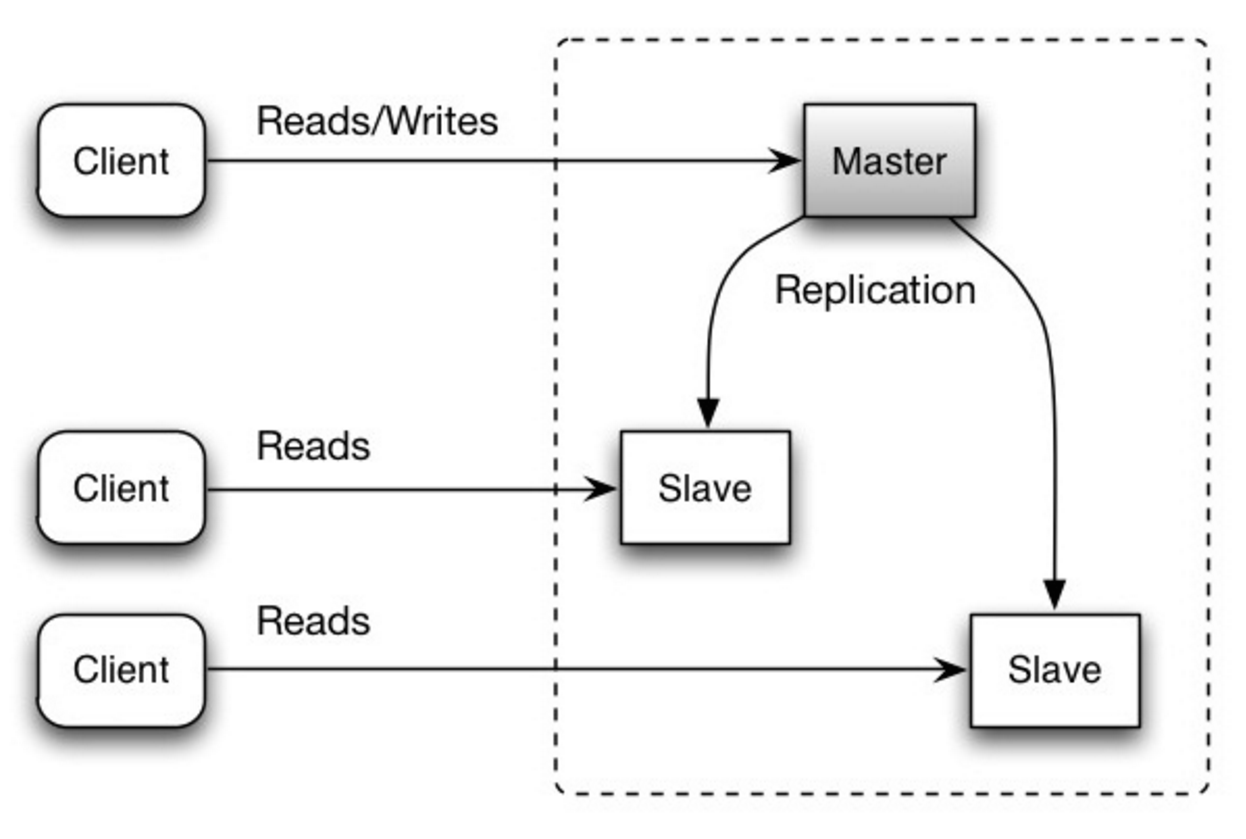
Fonte: Scalabilità, disponibilità, stabilità, pattern
##### Svantaggio/i: replicazione master-slave
- È necessaria logica aggiuntiva per promuovere uno slave a master.
- Vedi Svantaggio/i: replicazione per i punti relativi sia a master-slave che master-master.
Entrambi i master gestiscono letture e scritture e si coordinano tra loro sulle scritture. Se uno dei master si guasta, il sistema può continuare a funzionare sia per le letture che per le scritture.
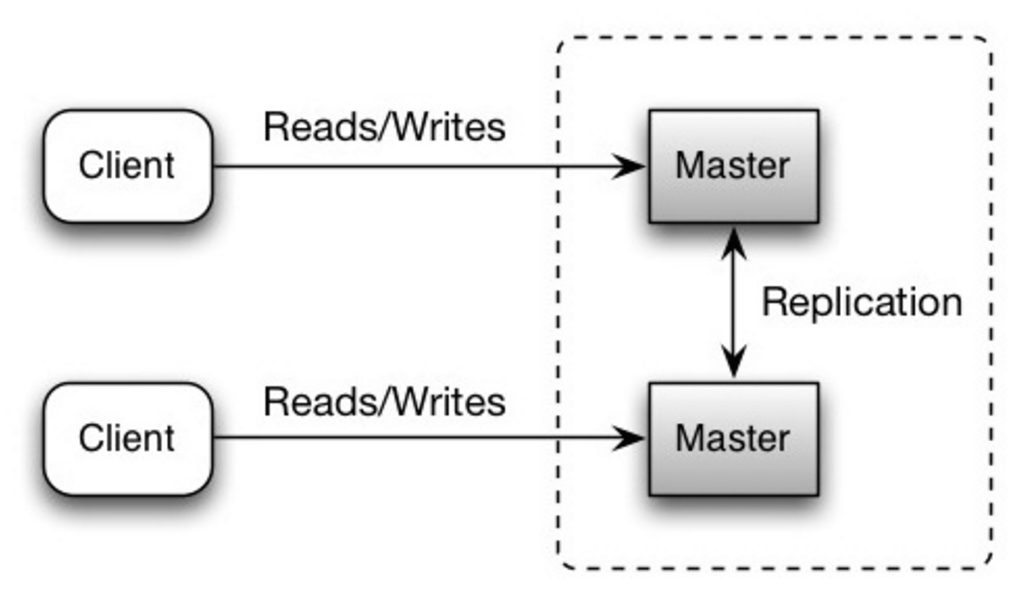
Fonte: Scalabilità, disponibilità, stabilità, pattern
##### Svantaggio/i: replicazione master-master
- Sarà necessario un bilanciatore di carico oppure dovrai modificare la logica dell'applicazione per determinare dove scrivere.
- La maggior parte dei sistemi master-master sono o debolmente consistenti (violando ACID) oppure presentano una maggiore latenza di scrittura dovuta alla sincronizzazione.
- La risoluzione dei conflitti diventa più rilevante man mano che si aggiungono più nodi di scrittura e che la latenza aumenta.
- Vedi Svantaggio(i): replica per punti relativi sia a master-slave che a master-master.
- Esiste il potenziale di perdita di dati se il master fallisce prima che i nuovi dati scritti possano essere replicati sugli altri nodi.
- Le scritture vengono riprodotte sulle repliche di lettura. Se ci sono molte scritture, le repliche di lettura possono essere rallentate dal replay delle scritture e non riescono a gestire altrettante letture.
- Più slave di lettura ci sono, più dati bisogna replicare, il che porta a un maggiore ritardo di replica.
- Su alcuni sistemi, la scrittura sul master può generare più thread per scrivere in parallelo, mentre le repliche di lettura supportano solo la scrittura sequenziale con un singolo thread.
- La replica aggiunge più hardware e ulteriore complessità.
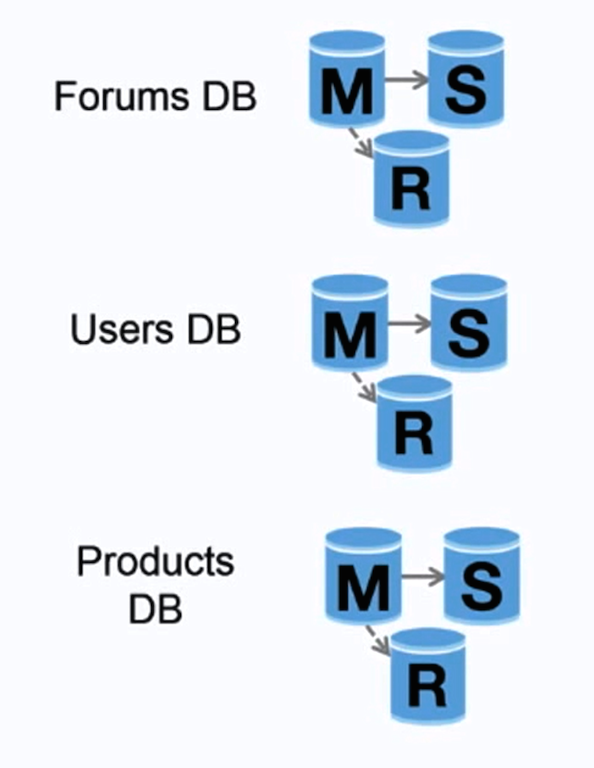
Fonte: Scaling up to your first 10 million users
La federazione (o partizionamento funzionale) suddivide i database in base alla funzione. Ad esempio, invece di un singolo database monolitico, si potrebbero avere tre database: forum, utenti e prodotti, con conseguente minore traffico di lettura e scrittura per ogni database e quindi minore ritardo di replica. Database più piccoli permettono di memorizzare più dati in memoria, il che si traduce in più hit della cache grazie a una migliore località della cache. Non avendo un unico master centrale che serializza le scritture, è possibile scrivere in parallelo, aumentando il throughput.
##### Svantaggio(i): federazione
- La federazione non è efficace se lo schema richiede funzioni o tabelle molto grandi.
- Sarà necessario aggiornare la logica dell'applicazione per determinare quale database leggere e scrivere.
- Unire dati da due database è più complesso con un collegamento server.
- La federazione aggiunge più hardware e ulteriore complessità.
Fonte: Scalability, availability, stability, patterns
Lo sharding distribuisce i dati tra diversi database in modo che ciascun database possa gestire solo un sottoinsieme dei dati. Prendendo come esempio un database utenti, man mano che il numero di utenti aumenta, si aggiungono altri shard al cluster.
Simile ai vantaggi della federazione, lo sharding comporta meno traffico di lettura e scrittura, meno replicazione e più cache hit. Anche la dimensione dell'indice si riduce, migliorando generalmente le prestazioni con query più veloci. Se uno shard si guasta, gli altri shard continuano a funzionare, anche se è consigliabile aggiungere una forma di replica per evitare la perdita di dati. Come la federazione, non esiste un unico master centrale che serializza le scritture, permettendo di scrivere in parallelo con maggiore throughput.
I modi comuni per shardare una tabella di utenti sono tramite l'iniziale del cognome dell'utente o la posizione geografica dell'utente.
##### Svantaggi: sharding
- Sarà necessario aggiornare la logica dell'applicazione per lavorare con gli shard, il che può comportare query SQL complesse.
- La distribuzione dei dati può diventare squilibrata in uno shard. Ad esempio, un gruppo di power user su uno shard potrebbe causare un carico maggiore su quello shard rispetto agli altri.
- Il riequilibrio aggiunge ulteriore complessità. Una funzione di sharding basata su consistent hashing può ridurre la quantità di dati trasferiti.
- Unire dati da più shard è più complesso.
- Lo sharding aggiunge più hardware e maggiore complessità.
La denormalizzazione cerca di migliorare le prestazioni di lettura a scapito di quelle di scrittura. Copie ridondanti dei dati vengono scritte in più tabelle per evitare join costosi. Alcuni RDBMS come PostgreSQL e Oracle supportano le materialized views che gestiscono il lavoro di memorizzazione delle informazioni ridondanti e mantengono le copie ridondanti coerenti.
Quando i dati vengono distribuiti con tecniche come federazione e sharding, la gestione dei join tra data center aumenta ulteriormente la complessità. La denormalizzazione può evitare la necessità di join così complessi.
Nella maggior parte dei sistemi, le letture possono superare di gran lunga le scritture, anche 100:1 o 1000:1. Una lettura che comporta un join complesso nel database può essere molto costosa, spendendo una notevole quantità di tempo in operazioni su disco.
##### Svantaggi: denormalizzazione
- I dati sono duplicati.
- I vincoli possono aiutare le copie ridondanti dell'informazione a rimanere sincronizzate, aumentando la complessità della progettazione del database.
- Un database denormalizzato sotto carico di scrittura intenso potrebbe avere prestazioni peggiori rispetto a uno normalizzato.
L'ottimizzazione SQL è un argomento ampio e molti libri sono stati scritti come riferimento.
È importante misurare e profilare per simulare e individuare i colli di bottiglia.
- Misurazione - Simula situazioni di alto carico con strumenti come ab.
- Profilazione - Abilita strumenti come il registro delle query lente per aiutare a tracciare problemi di performance.
##### Ottimizza lo schema
- MySQL esporta su disco in blocchi contigui per accesso veloce.
- Usa
CHARinvece diVARCHARper campi a lunghezza fissa. CHARpermette un accesso casuale veloce, mentre conVARCHARbisogna trovare la fine della stringa prima di passare alla successiva.- Usa
TEXTper grandi blocchi di testo come post di blog.TEXTconsente anche ricerche booleane. Usando un campoTEXTsi memorizza un puntatore su disco che viene usato per trovare il blocco di testo. - Usa
INTper numeri grandi fino a 2^32 o 4 miliardi. - Usa
DECIMALper le valute per evitare errori di rappresentazione dei numeri in virgola mobile. - Evita di memorizzare grandi
BLOB, salva invece la posizione dove reperire l'oggetto. VARCHAR(255)è il numero massimo di caratteri che può essere conteggiato in un numero a 8 bit, spesso ottimizzando l'uso di un byte in alcuni RDBMS.- Imposta il vincolo
NOT NULLdove applicabile per migliorare le prestazioni di ricerca.
- Le colonne che interroghi (
SELECT,GROUP BY,ORDER BY,JOIN) possono essere più veloci con indici. - Gli indici sono solitamente rappresentati come B-tree autobilancianti che mantengono i dati ordinati e consentono ricerche, accesso sequenziale, inserimenti e cancellazioni in tempo logaritmico.
- Posizionare un indice può mantenere i dati in memoria, richiedendo più spazio.
- Le scritture possono essere più lente poiché anche l'indice deve essere aggiornato.
- Quando si caricano grandi quantità di dati, potrebbe essere più veloce disabilitare gli indici, caricare i dati e poi ricostruire gli indici.
- Denormalizza dove le prestazioni lo richiedono.
- Suddividi una tabella inserendo i punti caldi in una tabella separata per aiutare a mantenerla in memoria.
- In alcuni casi, la cache delle query potrebbe causare problemi di prestazioni.
- Suggerimenti per ottimizzare le query MySQL
- C'è una buona ragione per cui vedo spesso VARCHAR(255)?
- Come influenzano le prestazioni i valori null?
- Slow query log
NoSQL
NoSQL è una collezione di elementi dati rappresentati in un key-value store, document store, wide column store o un graph database. I dati sono denormalizzati, e le join generalmente vengono effettuate nel codice dell'applicazione. La maggior parte degli archivi NoSQL non offre vere transazioni ACID e privilegia la consistenza eventuale.
BASE viene spesso utilizzato per descrivere le proprietà dei database NoSQL. In confronto al Teorema CAP, BASE sceglie la disponibilità rispetto alla consistenza.
- Fondamentalmente disponibile - il sistema garantisce la disponibilità.
- Stato morbido - lo stato del sistema può cambiare nel tempo, anche senza input.
- Consistenza eventuale - il sistema diventerà consistente nel tempo, purché non riceva input durante quel periodo.
#### Key-value store
Astrazione: tabella hash
Un key-value store generalmente consente letture e scritture O(1) ed è spesso supportato da memoria o SSD. Gli archivi dati possono mantenere le chiavi in ordine lessicografico, permettendo il recupero efficiente di intervalli di chiavi. I key-value store possono consentire la memorizzazione di metadati insieme a un valore.
I key-value store offrono alte prestazioni e sono spesso utilizzati per modelli dati semplici o per dati che cambiano rapidamente, come uno strato di cache in memoria. Poiché offrono solo un set limitato di operazioni, la complessità viene spostata al livello applicativo se sono necessarie operazioni aggiuntive.
Un key-value store è la base per sistemi più complessi come un document store, e in alcuni casi, un graph database.
##### Fonte(i) e ulteriori letture: key-value store
#### Document storeAstrazione: archivio chiave-valore con documenti memorizzati come valori
Un document store è incentrato sui documenti (XML, JSON, binari, ecc.), dove un documento memorizza tutte le informazioni relative a un determinato oggetto. I document store forniscono API o un linguaggio di query per interrogare sulla base della struttura interna del documento stesso. Nota, molti archivi chiave-valore includono funzionalità per lavorare con i metadati di un valore, sfumando la distinzione tra questi due tipi di archiviazione.
In base all'implementazione sottostante, i documenti sono organizzati in collezioni, tag, metadati o directory. Anche se i documenti possono essere organizzati o raggruppati insieme, i documenti possono avere campi completamente diversi tra loro.
Alcuni document store come MongoDB e CouchDB offrono anche un linguaggio simile a SQL per effettuare query complesse. DynamoDB supporta sia chiave-valore che documenti.
I document store offrono grande flessibilità e sono spesso utilizzati per lavorare con dati che cambiano occasionalmente.
##### Fonte(e) e ulteriori letture: document store
- Database orientato ai documenti
- Architettura MongoDB
- Architettura CouchDB
- Architettura Elasticsearch
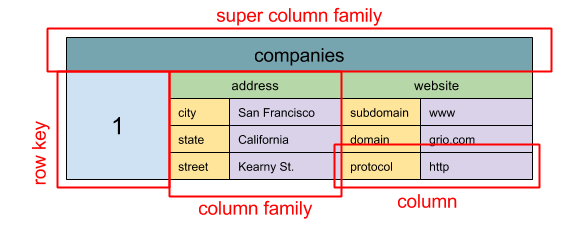
Fonte: SQL & NoSQL, una breve storia
Astrazione: mappa annidata ColumnFamily> L'unità base di dati di un wide column store è una colonna (coppia nome/valore). Una colonna può essere raggruppata in famiglie di colonne (analogo a una tabella SQL). Le super column families raggruppano ulteriormente le famiglie di colonne. Puoi accedere a ciascuna colonna indipendentemente tramite una chiave di riga, e le colonne con la stessa chiave di riga formano una riga. Ogni valore contiene un timestamp per la versioning e la risoluzione dei conflitti.
Google ha introdotto Bigtable come primo wide column store, che ha influenzato l'open-source HBase spesso usato nell'ecosistema Hadoop, e Cassandra di Facebook. Archivi come BigTable, HBase e Cassandra mantengono le chiavi in ordine lessicografico, consentendo un recupero efficiente di intervalli selettivi di chiavi.
I wide column store offrono alta disponibilità e grande scalabilità. Sono spesso utilizzati per set di dati molto grandi.
##### Fonte(e) e ulteriori letture: wide column store
#### Database a grafo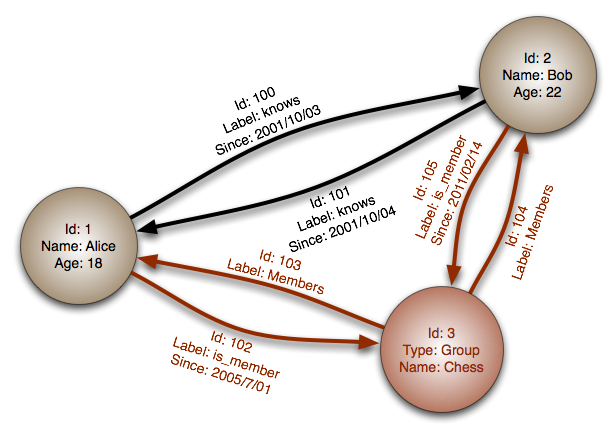
{kind=link}
{kind=link}
Astrazione: grafo
In un database a grafo, ogni nodo è un record e ogni arco è una relazione tra due nodi. I database a grafo sono ottimizzati per rappresentare relazioni complesse con molte chiavi esterne o relazioni molti-a-molti.
I database a grafo offrono prestazioni elevate per modelli di dati con relazioni complesse, come una rete sociale. Sono relativamente nuovi e non sono ancora ampiamente utilizzati; potrebbe essere più difficile trovare strumenti di sviluppo e risorse. Molti grafi possono essere accessibili solo tramite REST API.
##### Fonte/i e ulteriori letture: grafo
#### Fonte/i e ulteriori letture: NoSQL- Spiegazione della terminologia base
- Database NoSQL: panoramica e guida alle decisioni
- Scalabilità
- Introduzione ai NoSQL
- Pattern NoSQL
SQL o NoSQL
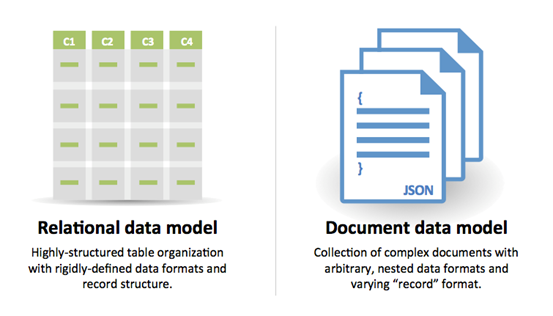
Fonte: Transizione da RDBMS a NoSQL
Motivi per SQL:
- Dati strutturati
- Schema rigoroso
- Dati relazionali
- Necessità di join complessi
- Transazioni
- Schemi chiari per lo scaling
- Più consolidato: sviluppatori, comunità, codice, strumenti, ecc.
- Le ricerche tramite indice sono molto veloci
- Dati semi-strutturati
- Schema dinamico o flessibile
- Dati non relazionali
- Nessuna necessità di join complessi
- Memorizzazione di molti TB (o PB) di dati
- Carico di lavoro molto intensivo sui dati
- Altissimo throughput per IOPS
- Ingestione rapida di dati clickstream e log
- Dati di classifiche o punteggi
- Dati temporanei, come un carrello della spesa
- Tabelle frequentemente accessibili ('hot')
- Tabelle di metadati/lookup
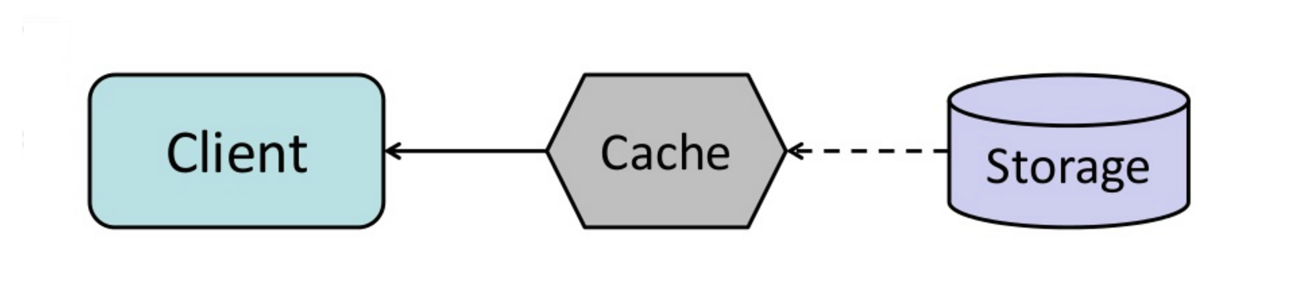
Cache
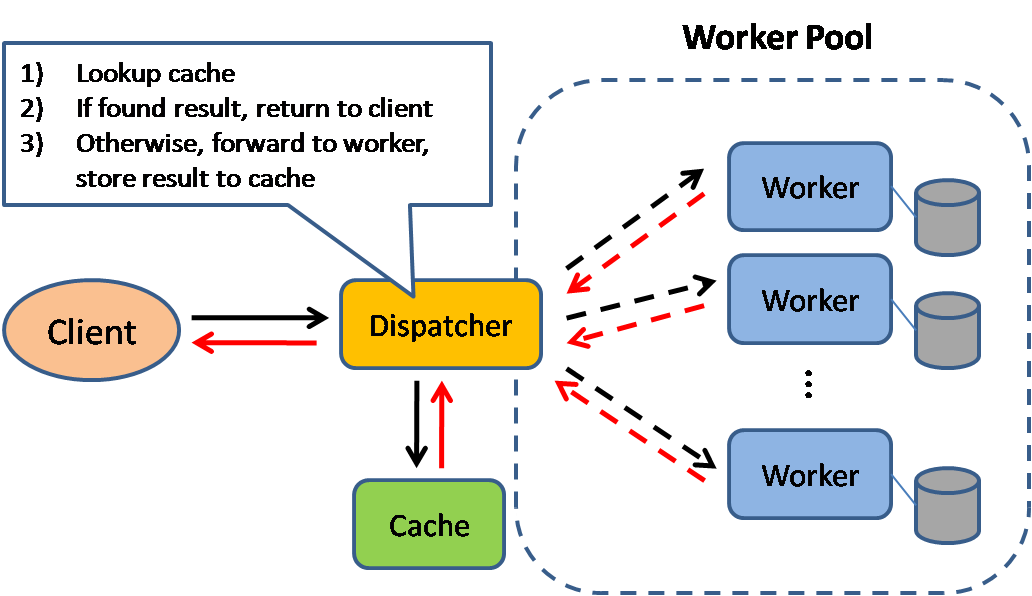
Fonte: Scalable system design patterns
La cache migliora i tempi di caricamento della pagina e può ridurre il carico sui server e sui database. In questo modello, il dispatcher controllerà prima se la richiesta è già stata effettuata e cercherà di trovare il risultato precedente da restituire, al fine di evitare l'esecuzione effettiva.
I database spesso beneficiano di una distribuzione uniforme di letture e scritture tra le sue partizioni. Gli elementi popolari possono alterare la distribuzione, causando colli di bottiglia. Mettere una cache davanti a un database può aiutare ad assorbire carichi irregolari e picchi di traffico.
Cache lato client
Le cache possono essere posizionate lato client (OS o browser), lato server, o in un livello di cache distinto.
Cache CDN
Le CDN sono considerate un tipo di cache.
Cache del web server
Reverse proxy e cache come Varnish possono servire direttamente contenuti statici e dinamici. I web server possono anche memorizzare le richieste in cache, restituendo risposte senza dover contattare i server applicativi.
Cache del database
Il tuo database di solito include un certo livello di cache nella configurazione predefinita, ottimizzata per un uso generico. Modificare queste impostazioni per specifici modelli di utilizzo può aumentare ulteriormente le prestazioni.
Cache applicativa
Le cache in memoria come Memcached e Redis sono archivi chiave-valore tra la tua applicazione e il tuo storage dati. Poiché i dati sono tenuti in RAM, sono molto più veloci rispetto ai database tipici dove i dati sono su disco. La RAM è più limitata del disco, quindi algoritmi di invalidazione della cache come least recently used (LRU)) possono aiutare a invalidare le voci "fredde" e mantenere i dati "caldi" in RAM.
Redis offre le seguenti funzionalità aggiuntive:
- Opzione di persistenza
- Strutture dati integrate come insiemi ordinati e liste
- Livello riga
- Livello query
- Oggetti serializzabili completi
- HTML completamente renderizzato
Caching a livello di query del database
Ogni volta che interroghi il database, usa l'hash della query come chiave e memorizza il risultato nella cache. Questo approccio presenta problemi di scadenza:
- Difficile eliminare un risultato memorizzato in cache con query complesse
- Se una parte dei dati cambia, come una cella di tabella, devi eliminare tutte le query memorizzate in cache che potrebbero includere la cella modificata
Caching a livello di oggetto
Vedi i tuoi dati come oggetti, simile a come fai con il codice della tua applicazione. Fai sì che la tua applicazione assembli il set di dati dal database in un'istanza di classe o in una/e struttura/e dati:
- Rimuovi l'oggetto dalla cache se i suoi dati sottostanti sono cambiati
- Permette l'elaborazione asincrona: i worker assemblano oggetti consumando l'ultimo oggetto memorizzato in cache
- Sessioni utente
- Pagine web completamente renderizzate
- Stream di attività
- Dati del grafo utente
Quando aggiornare la cache
Poiché puoi memorizzare solo una quantità limitata di dati in cache, dovrai determinare quale strategia di aggiornamento della cache funziona meglio per il tuo caso d'uso.
#### Cache-aside
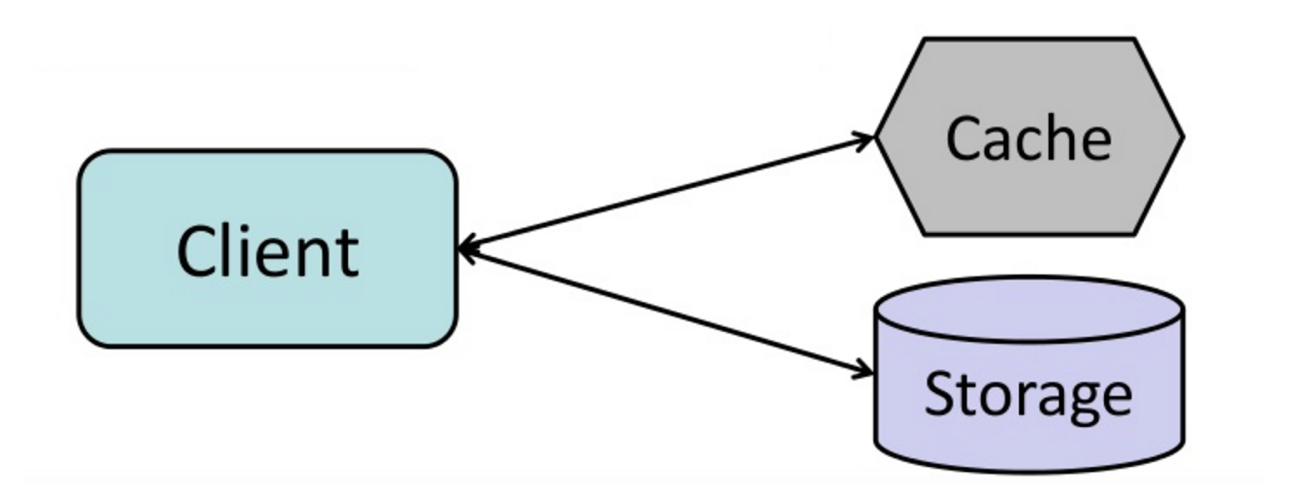
Fonte: From cache to in-memory data grid
L'applicazione è responsabile della lettura e scrittura dallo storage. La cache non interagisce direttamente con lo storage. L'applicazione esegue le seguenti operazioni:
- Cerca una voce in cache, ottenendo un cache miss
- Carica la voce dal database
- Aggiunge la voce alla cache
- Restituisce la voce
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached viene generalmente utilizzato in questo modo.
Le letture successive dei dati aggiunti alla cache sono veloci. Il cache-aside è anche chiamato lazy loading. Solo i dati richiesti vengono memorizzati nella cache, evitando di riempire la cache con dati che non vengono richiesti.
##### Svantaggio/i: cache-aside
- Ogni mancanza nella cache comporta tre passaggi, il che può causare un ritardo evidente.
- I dati possono diventare obsoleti se vengono aggiornati nel database. Questo problema viene mitigato impostando un time-to-live (TTL) che forza l’aggiornamento della voce in cache, oppure utilizzando il write-through.
- Quando un nodo fallisce, viene sostituito da un nodo nuovo e vuoto, aumentando la latenza.
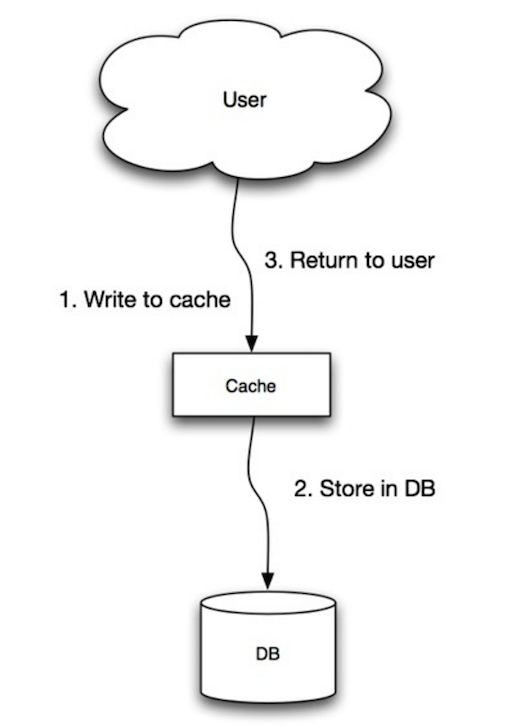
Fonte: Scalability, availability, stability, patterns
L’applicazione utilizza la cache come principale archivio dati, leggendo e scrivendo dati su di essa, mentre la cache si occupa di leggere e scrivere sul database:
- L’applicazione aggiunge/aggiorna la voce nella cache
- La cache scrive sincronicamente la voce nell’archivio dati
- Ritorno
set_user(12345, {"foo":"bar"})Codice cache:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Svantaggio/i: write-through
- Quando viene creato un nuovo nodo a seguito di un guasto o di uno scaling, il nuovo nodo non memorizzerà le voci in cache finché la voce non verrà aggiornata nel database. Cache-aside insieme a write-through può mitigare questo problema.
- La maggior parte dei dati scritti potrebbe non essere mai letta, cosa che può essere minimizzata con un TTL.
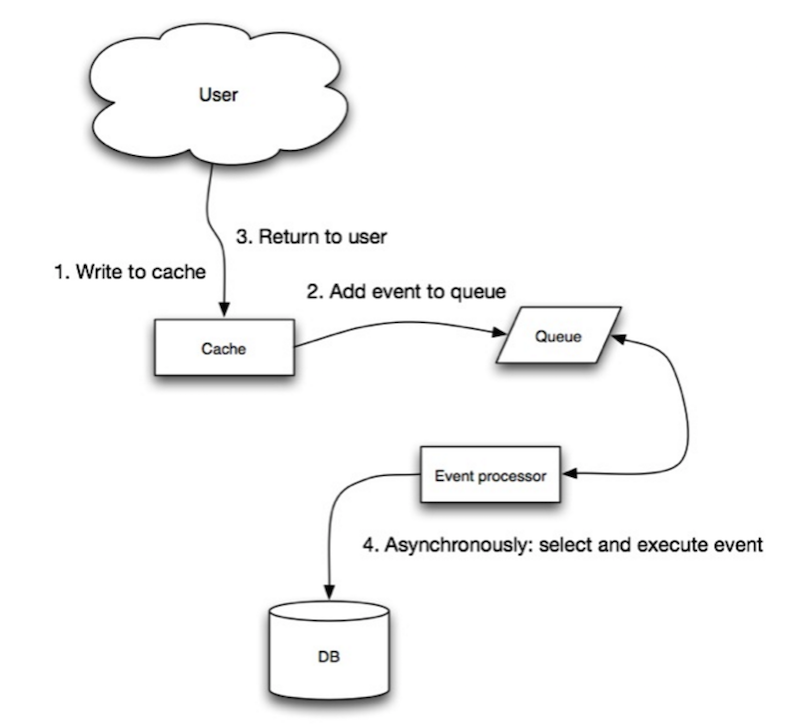
Fonte: Scalability, availability, stability, patterns
Nel write-behind, l'applicazione esegue le seguenti operazioni:
- Aggiunge/aggiorna la voce nella cache
- Scrive la voce nel data store in modo asincrono, migliorando le prestazioni di scrittura
- Potrebbe esserci perdita di dati se la cache si interrompe prima che il suo contenuto venga scritto nel data store.
- Implementare il write-behind è più complesso rispetto a cache-aside o write-through.
Fonte: From cache to in-memory data grid
È possibile configurare la cache affinché aggiorni automaticamente qualsiasi voce della cache recentemente acceduta prima della sua scadenza.
Il refresh-ahead può comportare una latenza ridotta rispetto al read-through se la cache riesce a prevedere accuratamente quali elementi saranno necessari in futuro.
##### Svantaggio/i: refresh-ahead
- Non prevedere accuratamente quali elementi potrebbero essere necessari in futuro può comportare prestazioni inferiori rispetto all'assenza di refresh-ahead.
Svantaggio(i): cache
- È necessario mantenere la coerenza tra le cache e la fonte di verità come il database tramite invalidazione della cache.
- L'invalidazione della cache è un problema difficile, vi è una complessità aggiuntiva relativa a quando aggiornare la cache.
- È necessario apportare modifiche all'applicazione come l'aggiunta di Redis o memcached.
Fonte(i) e letture aggiuntive
- From cache to in-memory data grid
- Scalable system design patterns
- Introduction to architecting systems for scale
- Scalability, availability, stability, patterns
- Scalability
- AWS ElastiCache strategies
- Wikipedia)
Asincronismo
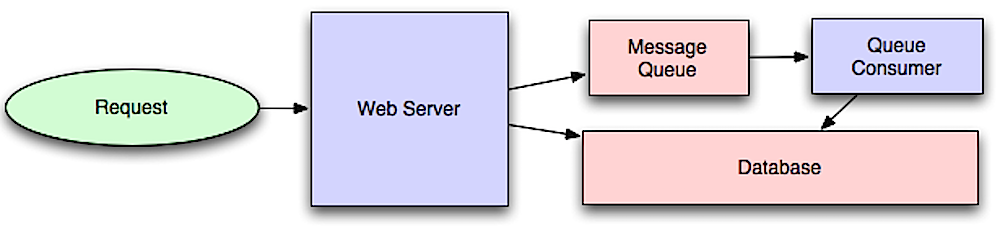
Fonte: Introduzione all’architettura di sistemi scalabili
I flussi di lavoro asincroni aiutano a ridurre i tempi di richiesta per operazioni costose che altrimenti verrebbero eseguite in linea. Possono anche aiutare effettuando in anticipo lavori che richiedono tempo, come l'aggregazione periodica dei dati.
Code di messaggi
Le code di messaggi ricevono, trattengono e consegnano messaggi. Se un'operazione è troppo lenta per essere eseguita in linea, è possibile utilizzare una coda di messaggi con il seguente flusso:
- Un'applicazione pubblica un lavoro nella coda, quindi notifica all'utente lo stato del lavoro
- Un worker preleva il lavoro dalla coda, lo elabora e segnala il completamento
Redis è utile come semplice message broker, ma i messaggi possono andare persi.
RabbitMQ è popolare, ma richiede di adattarsi al protocollo 'AMQP' e di gestire i propri nodi.
Amazon SQS è ospitato ma può avere alta latenza e la possibilità che i messaggi vengano consegnati due volte.
Code di attività
Le code di attività ricevono le attività e i relativi dati, le eseguono e poi ne consegnano i risultati. Possono supportare la pianificazione e vengono utilizzate per eseguire lavori computazionalmente intensivi in background.
Celery supporta la pianificazione ed è principalmente compatibile con python.
Pressione inversa (Back pressure)
Se le code iniziano a crescere significativamente, la dimensione della coda può superare la memoria, causando cache miss, letture da disco e prestazioni ancora più lente. La pressione inversa può aiutare limitando la dimensione della coda, mantenendo così un alto tasso di throughput e buoni tempi di risposta per i lavori già in coda. Una volta che la coda è piena, i client ricevono un messaggio di server occupato o lo status code HTTP 503 per riprovare più tardi. I client possono ripetere la richiesta successivamente, magari con exponential backoff.
Svantaggio(i): asincronismo
- Casi d'uso come calcoli poco costosi e flussi di lavoro in tempo reale potrebbero essere più adatti per operazioni sincrone, poiché l'introduzione di code può aggiungere ritardi e complessità.
Fonte(e) e ulteriori letture
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- Qual è la differenza tra una message queue e una task queue?
Comunicazione
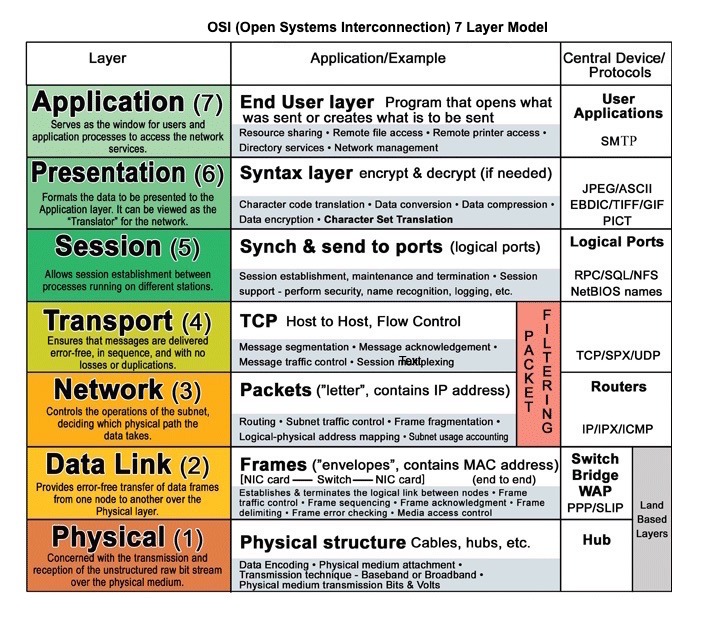
Fonte: modello OSI a 7 livelli
Hypertext transfer protocol (HTTP)
HTTP è un metodo per codificare e trasportare dati tra un client e un server. È un protocollo request/response: i client inviano richieste e i server rispondono con contenuti rilevanti e informazioni sullo stato di completamento della richiesta. HTTP è autonomo, consentendo che richieste e risposte fluiscano attraverso router e server intermedi che eseguono bilanciamento del carico, caching, crittografia e compressione.
Una richiesta HTTP di base consiste in un verbo (metodo) e una risorsa (endpoint). Di seguito sono riportati i verbi HTTP più comuni:
| Verbo | Descrizione | Idempotente* | Sicuro | Caching | |---|---|---|---|---| | GET | Legge una risorsa | Sì | Sì | Sì | | POST | Crea una risorsa o avvia un processo che gestisce dati | No | No | Sì se la risposta contiene info sulla freschezza | | PUT | Crea o sostituisce una risorsa | Sì | No | No | | PATCH | Aggiorna parzialmente una risorsa | No | No | Sì se la risposta contiene info sulla freschezza | | DELETE | Elimina una risorsa | Sì | No | No |
*Può essere chiamato molte volte senza risultati diversi.
HTTP è un protocollo di livello applicazione che si basa su protocolli di livello inferiore come TCP e UDP.
#### Fonte(e) e ulteriori letture: HTTP
Transmission control protocol (TCP)
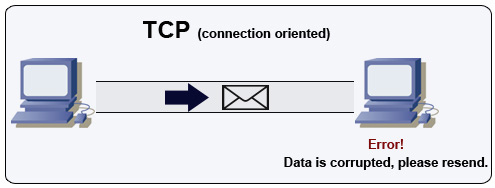
Fonte: Come realizzare un gioco multiplayer
TCP è un protocollo orientato alla connessione su una rete IP. La connessione viene stabilita e terminata tramite una stretta di mano. Tutti i pacchetti inviati sono garantiti di raggiungere la destinazione nell'ordine originale e senza corruzione tramite:
- Numeri di sequenza e campi checksum per ogni pacchetto
- Pacchetti di acknowledgement) e ritrasmissione automatica
Per garantire un'elevata velocità di trasmissione, i server web possono mantenere aperte molte connessioni TCP, con conseguente elevato utilizzo di memoria. Può essere costoso avere molte connessioni aperte tra i thread del server web e, ad esempio, un server memcached. Il connection pooling può aiutare oltre alla commutazione su UDP dove applicabile.
TCP è utile per applicazioni che richiedono alta affidabilità ma sono meno critiche in termini di tempo. Alcuni esempi includono server web, info di database, SMTP, FTP e SSH.
Usa TCP invece di UDP quando:
- Hai bisogno che tutti i dati arrivino integri
- Vuoi stimare automaticamente il miglior utilizzo della larghezza di banda di rete
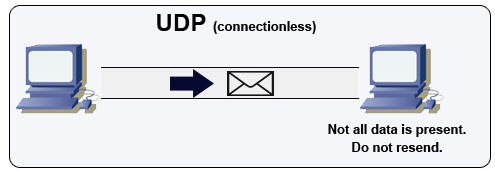
Protocollo User Datagram (UDP)
Fonte: How to make a multiplayer game
UDP è senza connessione. I datagrammi (analoghi ai pacchetti) sono garantiti solo a livello di datagramma. I datagrammi possono arrivare a destinazione fuori ordine o non arrivare affatto. UDP non supporta il controllo della congestione. Senza le garanzie offerte da TCP, UDP è generalmente più efficiente.
UDP può trasmettere in broadcast, inviando datagrammi a tutti i dispositivi sulla sottorete. Questo è utile con DHCP perché il client non ha ancora ricevuto un indirizzo IP, impedendo così a TCP di trasmettere senza l’indirizzo IP.
UDP è meno affidabile, ma funziona bene in casi d’uso in tempo reale come VoIP, videochat, streaming e giochi multiplayer in tempo reale.
Usa UDP invece di TCP quando:
- Hai bisogno della latenza più bassa
- I dati in ritardo sono peggiori della perdita di dati
- Vuoi implementare la tua correzione degli errori
- Networking per la programmazione di giochi
- Differenze chiave tra i protocolli TCP e UDP
- Differenza tra TCP e UDP
- Transmission control protocol
- User datagram protocol
- Scaling memcache at Facebook
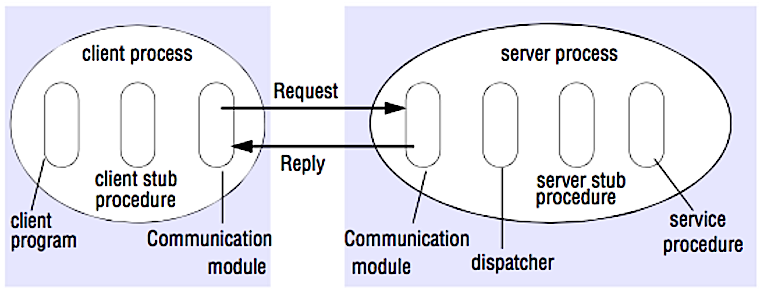
Remote procedure call (RPC)
Fonte: Crack the system design interview
In una RPC, un client fa eseguire una procedura su uno spazio di indirizzi diverso, di solito un server remoto. La procedura è scritta come se fosse una chiamata locale, astrarre i dettagli di come comunicare con il server dal programma client. Le chiamate remote sono solitamente più lente e meno affidabili delle chiamate locali, quindi è utile distinguere tra chiamate RPC e chiamate locali. Framework RPC popolari includono Protobuf, Thrift, e Avro.
RPC è un protocollo richiesta-risposta:
- Programma client - Chiama la procedura stub del client. I parametri vengono inseriti nello stack come in una chiamata di procedura locale.
- Procedura stub del client - Marsha (impacchetta) l'id della procedura e gli argomenti in un messaggio di richiesta.
- Modulo di comunicazione del client - Il sistema operativo invia il messaggio dal client al server.
- Modulo di comunicazione del server - Il sistema operativo passa i pacchetti in arrivo alla procedura stub del server.
- Procedura stub del server - Demarsha i risultati, chiama la procedura del server corrispondente all'id della procedura e passa gli argomenti forniti.
- La risposta del server ripete i passaggi sopra descritti in ordine inverso.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC si concentra sull'esposizione dei comportamenti. Gli RPC vengono spesso utilizzati per motivi di prestazioni nelle comunicazioni interne, poiché è possibile creare chiamate native su misura per adattarsi meglio ai propri casi d'uso.
Scegli una libreria nativa (nota anche come SDK) quando:
- Conosci la tua piattaforma di destinazione.
- Vuoi controllare come viene acceduta la tua "logica".
- Vuoi controllare come avviene la gestione degli errori al di fuori della tua libreria.
- Le prestazioni e l'esperienza dell'utente finale sono la tua principale preoccupazione.
#### Svantaggio/i: RPC
- I client RPC diventano strettamente accoppiati all'implementazione del servizio.
- Deve essere definita una nuova API per ogni nuova operazione o caso d'uso.
- Può essere difficile eseguire il debug degli RPC.
- Potresti non essere in grado di sfruttare tecnologie esistenti immediatamente. Ad esempio, potrebbe essere necessario uno sforzo aggiuntivo per garantire che le chiamate RPC siano correttamente memorizzate nella cache su server di caching come Squid.
Trasferimento di stato rappresentazionale (REST)
REST è uno stile architetturale che applica un modello client/server in cui il client agisce su un insieme di risorse gestite dal server. Il server fornisce una rappresentazione delle risorse e azioni che possono manipolare o ottenere una nuova rappresentazione delle risorse. Tutta la comunicazione deve essere senza stato e cacheabile.
Ci sono quattro qualità di un'interfaccia RESTful:
- Identificare le risorse (URI in HTTP) - utilizzare lo stesso URI indipendentemente dall'operazione.
- Cambiare con le rappresentazioni (Verbi in HTTP) - usare verbi, header e body.
- Messaggio di errore auto-descrittivo (risposta di stato in HTTP) - utilizzare i codici di stato, non reinventare la ruota.
- HATEOAS (interfaccia HTML per HTTP) - il tuo servizio web dovrebbe essere completamente accessibile tramite browser.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
REST è focalizzato sull’esposizione dei dati. Minimizza il coupling tra client/server ed è spesso utilizzato per API HTTP pubbliche. REST utilizza un metodo più generico e uniforme per esporre le risorse tramite URI, rappresentazione tramite header e azioni tramite verbi come GET, POST, PUT, DELETE e PATCH. Essendo stateless, REST è ottimo per lo scaling orizzontale e il partizionamento.
#### Svantaggio(i): REST
- Poiché REST è focalizzato sull’esposizione dei dati, potrebbe non essere adatto se le risorse non sono naturalmente organizzate o accessibili in una gerarchia semplice. Ad esempio, restituire tutti i record aggiornati nell’ultima ora che corrispondono a un particolare insieme di eventi non è facilmente esprimibile come un percorso. Con REST, è probabile che venga implementato con una combinazione di percorso URI, parametri di query e possibilmente il corpo della richiesta.
- REST tipicamente si basa su pochi verbi (GET, POST, PUT, DELETE e PATCH) che a volte non si adattano al tuo caso d’uso. Ad esempio, spostare documenti scaduti nella cartella archivio potrebbe non rientrare perfettamente in questi verbi.
- Recuperare risorse complesse con gerarchie annidate richiede più round trip tra client e server per rendere singole viste, ad es. recuperare il contenuto di una voce di blog e i commenti su quella voce. Per applicazioni mobili che operano in condizioni di rete variabili, questi roundtrip multipli sono altamente indesiderabili.
- Nel tempo, potrebbero essere aggiunti più campi alla risposta di un’API e i client più vecchi riceveranno tutti i nuovi campi dati, anche quelli di cui non hanno bisogno; di conseguenza, il payload si gonfia e comporta latenze maggiori.
Confronto tra chiamate RPC e REST
| Operazione | RPC | REST |
|---|---|---|
| Registrazione | POST /signup | POST /persons |
| Dimissioni | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Leggi una persona | GET /readPerson?personid=1234 | GET /persons/1234 |
| Leggi la lista oggetti di una persona | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Aggiungi un oggetto alla lista di una persona | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Aggiorna un oggetto | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Elimina un oggetto | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Fonte: Do you really know why you prefer REST over RPC
#### Fonte/i e ulteriori letture: REST e RPC
- Do you really know why you prefer REST over RPC
- Quando gli approcci RPC sono più appropriati rispetto a REST?
- REST vs JSON-RPC
- Sfatare i miti di RPC e REST
- Quali sono gli svantaggi dell’utilizzo di REST
- Crack the system design interview
- Thrift
- Perché REST per uso interno e non RPC
Sicurezza
Questa sezione potrebbe necessitare di aggiornamenti. Prendi in considerazione di contribuire!
La sicurezza è un argomento ampio. A meno che tu non abbia una notevole esperienza, un background in sicurezza, o stia facendo domanda per una posizione che richiede conoscenze di sicurezza, probabilmente non avrai bisogno di sapere più delle basi:
- Crittografa i dati in transito e a riposo.
- Sanifica tutti gli input dell'utente o qualsiasi parametro di input esposto all'utente per prevenire XSS e iniezione SQL.
- Usa query parametrizzate per prevenire l'iniezione SQL.
- Usa il principio del privilegio minimo.
Fonte(e) e ulteriori letture
Appendice
A volte ti verrà chiesto di fare stime "a spanne". Ad esempio, potresti dover determinare quanto tempo ci vorrà per generare 100 miniature di immagini da disco o quanta memoria occuperà una struttura dati. La tabella delle potenze di due e i numeri di latenza che ogni programmatore dovrebbe conoscere sono riferimenti utili.
Tabella delle potenze di due
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Fonte(e) e ulteriori letture
Numeri di latenza che ogni programmatore dovrebbe conoscere
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- Lettura sequenziale da HDD a 30 MB/s
- Lettura sequenziale da Ethernet 1 Gbps a 100 MB/s
- Lettura sequenziale da SSD a 1 GB/s
- Lettura sequenziale dalla memoria principale a 4 GB/s
- 6-7 viaggi di andata e ritorno in tutto il mondo al secondo
- 2.000 viaggi di andata e ritorno al secondo all'interno di un data center
#### Fonte/i e letture aggiuntive
- Numeri di latenza che ogni programmatore dovrebbe conoscere - 1
- Numeri di latenza che ogni programmatore dovrebbe conoscere - 2
- Progetti, lezioni e consigli dalla realizzazione di grandi sistemi distribuiti
- Consigli di ingegneria del software dalla costruzione di sistemi distribuiti su larga scala
Ulteriori domande per colloqui di progettazione di sistemi
Domande comuni dei colloqui di progettazione di sistemi, con link a risorse su come risolverle.
| Domanda | Riferimento/i |
|---|---|
| Progetta un servizio di sincronizzazione file come Dropbox | youtube.com |
| Progetta un motore di ricerca come Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Progetta un web crawler scalabile come Google | quora.com |
| Progetta Google docs | code.google.com
neil.fraser.name |
| Progetta un key-value store come Redis | slideshare.net |
| Progetta un sistema di cache come Memcached | slideshare.net |
| Progetta un sistema di raccomandazione come quello di Amazon | hulu.com
ijcai13.org |
| Progetta un sistema tinyurl come Bitly | n00tc0d3r.blogspot.com |
| Progetta un'app di chat come WhatsApp | highscalability.com
| Progetta un sistema di condivisione immagini come Instagram | highscalability.com
highscalability.com |
| Progetta la funzione news feed di Facebook | quora.com
quora.com
slideshare.net |
| Progetta la funzione timeline di Facebook | facebook.com
highscalability.com |
| Progetta la funzione chat di Facebook | erlang-factory.com
facebook.com |
| Progetta una funzione di ricerca su grafi come quella di Facebook | facebook.com
facebook.com
facebook.com |
| Progetta una content delivery network come CloudFlare | figshare.com |
| Progetta un sistema di argomenti di tendenza come quello di Twitter | michael-noll.com
snikolov .wordpress.com |
| Progetta un sistema di generazione di ID casuali | blog.twitter.com
github.com |
| Restituisci le top k richieste durante un intervallo di tempo | cs.ucsb.edu
wpi.edu |
| Progetta un sistema che serve dati da più data center | highscalability.com |
| Progetta un gioco di carte multiplayer online | indieflashblog.com
buildnewgames.com |
| Progetta un sistema di garbage collection | stuffwithstuff.com
washington.edu |
| Progetta un sistema di limitazione delle API | https://stripe.com/blog/ |
| Progetta una Borsa Valori (come NASDAQ o Binance) | Jane Street
Golang Implementation
Go Implementation |
| Aggiungi una domanda di system design | Contribuisci |
Architetture del mondo reale
Articoli su come sono progettati i sistemi nel mondo reale.
Fonte: Twitter timelines at scale
Non concentrarti sui dettagli minuziosi per i seguenti articoli, invece:
- Identifica principi condivisi, tecnologie comuni e pattern all'interno di questi articoli
- Studia quali problemi vengono risolti da ciascun componente, dove funziona e dove no
- Rivedi le lezioni apprese
Architetture aziendali
| Azienda | Riferimento/i |
|---|---|
| Amazon | Architettura Amazon |
| Cinchcast | Produzione di 1.500 ore di audio ogni giorno |
| DataSift | Datamining in tempo reale a 120.000 tweet al secondo |
| Dropbox | Come abbiamo scalato Dropbox |
| ESPN | Operatività a 100.000 duh nuh nuhs al secondo |
| Google | Architettura Google |
| Instagram | 14 milioni di utenti, terabyte di foto
Cosa alimenta Instagram |
| Justin.tv | Architettura di trasmissione video live di Justin.Tv |
| Facebook | Scalare memcached su Facebook
TAO: Data store distribuito di Facebook per il social graph
Lo storage delle foto su Facebook
Come Facebook Live trasmette a 800.000 spettatori simultanei |
| Flickr | Architettura Flickr |
| Mailbox | Da 0 a un milione di utenti in 6 settimane |
| Netflix | Vista a 360 gradi dell'intero stack Netflix
Netflix: cosa succede quando premi Play? |
| Pinterest | Da 0 a decine di miliardi di pageview al mese
18 milioni di visitatori, crescita 10x, 12 dipendenti |
| Playfish | 50 milioni di utenti mensili e in crescita |
| PlentyOfFish | Architettura PlentyOfFish |
| Salesforce | Come gestiscono 1,3 miliardi di transazioni al giorno |
| Stack Overflow | Architettura Stack Overflow |
| TripAdvisor | 40M visitatori, 200M pageview dinamiche, 30TB dati |
| Tumblr | 15 miliardi di pageview al mese |
| Twitter | Rendere Twitter il 10000 percento più veloce
Memorizzare 250 milioni di tweet al giorno usando MySQL
150M utenti attivi, 300K QPS, un firehose da 22 MB/S
Timeline su larga scala
Big e small data su Twitter
Operazioni su Twitter: scaling oltre 100 milioni di utenti
Come Twitter gestisce 3.000 immagini al secondo |
| Uber | Come Uber scala la propria piattaforma di mercato in tempo reale
Lezioni apprese scalando Uber a 2000 ingegneri, 1000 servizi e 8000 repository Git |
| WhatsApp | L'architettura di WhatsApp che Facebook ha acquistato per 19 miliardi di dollari |
| YouTube | Scalabilità di YouTube
Architettura YouTube |
Blog di ingegneria aziendale
Architetture delle aziende con cui stai facendo colloqui.>
Le domande che incontri potrebbero provenire dallo stesso dominio.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Vuoi aggiungere un blog? Per evitare di duplicare il lavoro, considera di aggiungere il blog della tua azienda al seguente repository:
In fase di sviluppo
Sei interessato ad aggiungere una sezione o aiutare a completarne una in corso? Contribuisci!
- Calcolo distribuito con MapReduce
- Hashing consistente
- Scatter gather
- Contribuisci
Crediti
I crediti e le fonti sono forniti in tutto questo repository.
Un ringraziamento speciale a:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Info di contatto
Sentiti libero di contattarmi per discutere qualsiasi problema, domanda o commento.
Le mie informazioni di contatto sono disponibili sulla mia pagina GitHub.
Licenza
Sto fornendo codice e risorse in questo repository sotto una licenza open source. Poiché questo è il mio repository personale, la licenza che ricevi per il mio codice e le risorse proviene da me e non dal mio datore di lavoro (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---