English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Bantu terjemahkan panduan ini!
The System Design Primer

Motivasi
Pelajari cara merancang sistem skala besar.>
Persiapkan diri untuk wawancara desain sistem.
Pelajari cara merancang sistem skala besar
Mempelajari cara merancang sistem yang dapat diskalakan akan membantu Anda menjadi engineer yang lebih baik.
Desain sistem adalah topik yang luas. Ada sangat banyak sumber daya yang tersebar di seluruh web mengenai prinsip-prinsip desain sistem.
Repo ini adalah kumpulan sumber daya yang terorganisir untuk membantu Anda belajar membangun sistem berskala besar.
Belajar dari komunitas open source
Ini adalah proyek open source yang terus diperbarui.
Kontribusi sangat diterima!
Persiapan untuk wawancara desain sistem
Selain wawancara coding, desain sistem adalah komponen yang wajib dalam proses wawancara teknis di banyak perusahaan teknologi.
Latih pertanyaan umum wawancara desain sistem dan bandingkan hasil Anda dengan solusi contoh: diskusi, kode, dan diagram.
Topik tambahan untuk persiapan wawancara:
- Panduan belajar
- Cara mendekati pertanyaan wawancara desain sistem
- Pertanyaan wawancara desain sistem, dengan solusi
- Pertanyaan wawancara desain berorientasi objek, dengan solusi
- Pertanyaan wawancara desain sistem tambahan
Kartu flash Anki
Deck kartu flash Anki yang disediakan menggunakan pengulangan berspasi untuk membantu Anda mengingat konsep desain sistem utama.
Sangat cocok digunakan saat bepergian.Sumber Coding: Tantangan Coding Interaktif
Mencari sumber daya untuk membantu Anda mempersiapkan Wawancara Coding?
Lihat repo saudara Tantangan Coding Interaktif, yang juga memiliki deck Anki tambahan:
Kontribusi
Belajar dari komunitas.
Jangan ragu untuk mengirimkan pull request untuk membantu:
- Memperbaiki kesalahan
- Meningkatkan bagian
- Tambahkan bagian baru
- Terjemahkan
Tinjau Pedoman Kontribusi.
Indeks topik desain sistem
Ringkasan berbagai topik desain sistem, termasuk kelebihan dan kekurangan. Semua adalah pertukaran.>
Setiap bagian berisi tautan ke sumber daya yang lebih mendalam.
- Topik desain sistem: mulai di sini
- Langkah 1: Tinjau video kuliah skalabilitas
- Langkah 2: Tinjau artikel skalabilitas
- Langkah berikutnya
- Performa vs skalabilitas
- Latensi vs throughput
- Ketersediaan vs konsistensi
- Teorema CAP
- CP - konsistensi dan toleransi partisi
- AP - ketersediaan dan toleransi partisi
- Pola konsistensi
- Konsistensi lemah
- Konsistensi eventual
- Konsistensi kuat
- Pola ketersediaan
- Fail-over
- Replikasi
- Ketersediaan dalam angka
- Sistem nama domain
- Jaringan pengiriman konten
- Push CDN
- Pull CDN
- Load balancer
- Aktif-pasif
- Aktif-aktif
- Load balancing Layer 4
- Load balancing Layer 7
- Skalabilitas horizontal
- Reverse proxy (web server)
- Load balancer vs reverse proxy
- Lapisan aplikasi
- Mikroservis
- Penemuan layanan
- Basis data
- Sistem manajemen basis data relasional (RDBMS)
- Replikasi master-slave
- Replikasi master-master
- Federasi
- Sharding
- Denormalisasi
- Pengaturan SQL (SQL tuning)
- NoSQL
- Penyimpanan key-value
- Penyimpanan dokumen
- Penyimpanan kolom lebar
- Basis Data Graf
- SQL atau NoSQL
- Cache
- Caching klien
- Caching CDN
- Caching server web
- Caching basis data
- Caching aplikasi
- Caching di tingkat query basis data
- Caching di tingkat objek
- Kapan memperbarui cache
- Cache-aside
- Write-through
- Write-behind (write-back)
- Refresh-ahead
- Asinkronisme
- Antrian pesan
- Antrean tugas
- Tekanan balik
- Komunikasi
- Protokol kontrol transmisi (TCP)
- Protokol datagram pengguna (UDP)
- Panggilan prosedur jarak jauh (RPC)
- Transfer status representasional (REST)
- Keamanan
- Lampiran
- Tabel pangkat dua
- Angka latensi yang harus diketahui setiap programmer
- Pertanyaan tambahan wawancara desain sistem
- Arsitektur dunia nyata
- Arsitektur perusahaan
- Blog teknik perusahaan
- Dalam pengembangan
- Kredit
- Info kontak
- Lisensi
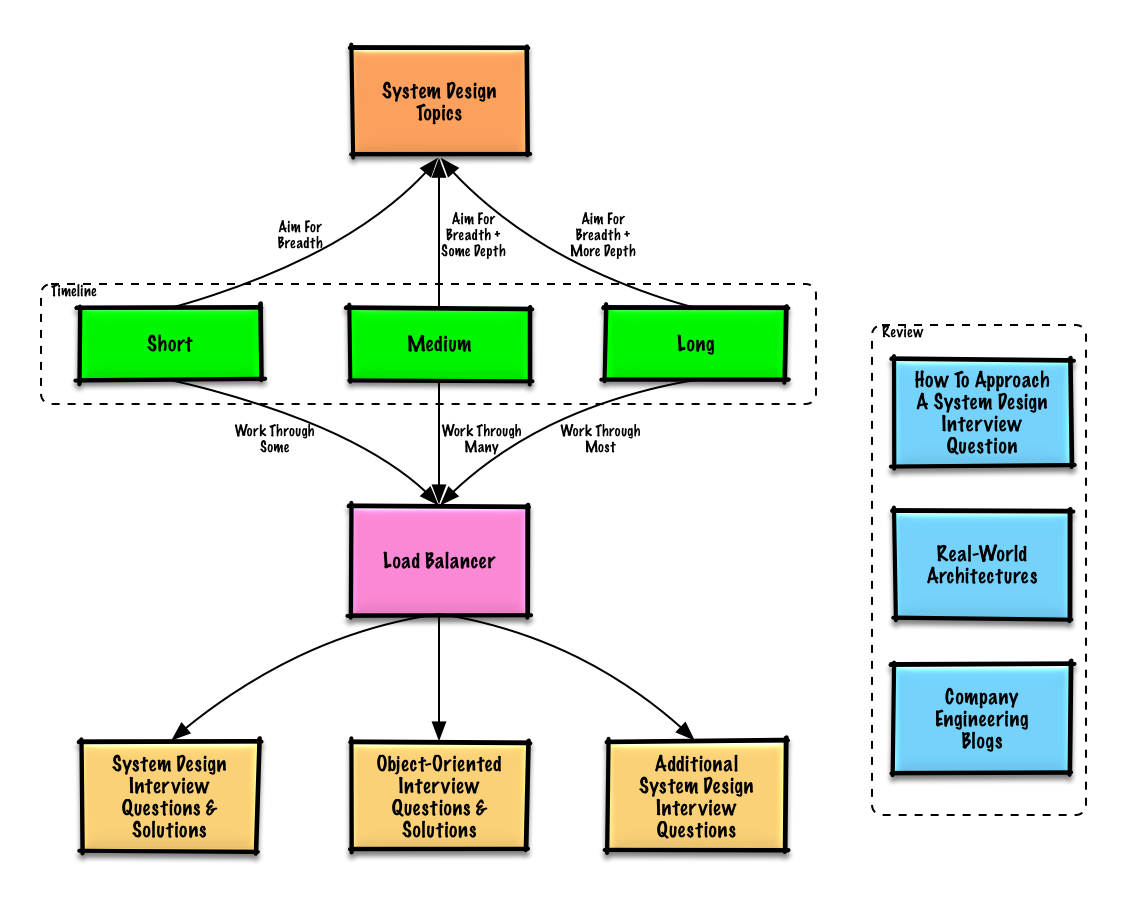
Panduan belajar
Topik yang disarankan untuk ditinjau berdasarkan waktu wawancara Anda (pendek, sedang, panjang).
Q: Untuk wawancara, apakah saya perlu tahu semua yang ada di sini?
A: Tidak, Anda tidak perlu tahu semuanya di sini untuk mempersiapkan wawancara.
Pertanyaan yang diajukan dalam wawancara tergantung pada variabel seperti:
- Seberapa banyak pengalaman yang Anda miliki
- Apa latar belakang teknis Anda
- Untuk posisi apa Anda wawancara
- Dengan perusahaan mana Anda wawancara
- Keberuntungan
Mulai dari yang luas dan perdalam di beberapa area. Penting untuk mengetahui sedikit tentang berbagai topik desain sistem utama. Sesuaikan panduan berikut berdasarkan timeline Anda, pengalaman, posisi yang Anda lamar, dan perusahaan tempat Anda melamar.
- Timeline pendek - Fokus pada luas topik desain sistem. Latihan dengan mengerjakan beberapa pertanyaan wawancara.
- Timeline sedang - Fokus pada luas dan sedikit mendalam topik desain sistem. Latihan dengan mengerjakan banyak pertanyaan wawancara.
- Timeline panjang - Fokus pada luas dan lebih mendalam topik desain sistem. Latihan dengan mengerjakan sebagian besar pertanyaan wawancara.
Cara menghadapi pertanyaan wawancara desain sistem
Cara menghadapi pertanyaan wawancara desain sistem.
Wawancara desain sistem adalah percakapan terbuka. Anda diharapkan untuk memimpinnya.
Anda dapat menggunakan langkah-langkah berikut untuk memandu diskusi. Untuk membantu memperkuat proses ini, kerjakan bagian Pertanyaan wawancara desain sistem beserta solusi menggunakan langkah-langkah berikut.
Langkah 1: Garis besar use case, batasan, dan asumsi
Kumpulkan kebutuhan dan tentukan ruang lingkup masalah. Ajukan pertanyaan untuk memperjelas use case dan batasan. Diskusikan asumsi.
- Siapa yang akan menggunakannya?
- Bagaimana mereka akan menggunakannya?
- Berapa banyak pengguna yang ada?
- Apa yang dilakukan sistem?
- Apa input dan output dari sistem?
- Berapa banyak data yang diperkirakan akan ditangani?
- Berapa banyak permintaan per detik yang diperkirakan?
- Berapa rasio baca terhadap tulis yang diharapkan?
Langkah 2: Buat desain tingkat tinggi
Gambarkan desain tingkat tinggi dengan semua komponen penting.
- Sketsa komponen utama dan koneksinya
- Justifikasi ide Anda
Langkah 3: Rancang komponen inti
Masuk ke detail untuk setiap komponen inti. Misalnya, jika Anda diminta untuk merancang layanan pemendek url, diskusikan:
- Membuat dan menyimpan hash dari url lengkap
- MD5 dan Base62
- Tabrakan hash
- SQL atau NoSQL
- Skema basis data
- Menerjemahkan url yang telah di-hash ke url lengkap
- Pencarian basis data
- Desain API dan berorientasi objek
Langkah 4: Skalakan desain
Identifikasi dan atasi kemacetan, sesuai dengan batasan yang ada. Misalnya, apakah Anda membutuhkan hal berikut untuk mengatasi masalah skalabilitas?
- Load balancer
- Skalabilitas horizontal
- Caching
- Sharding basis data
Perhitungan kasar di atas kertas
Anda mungkin diminta untuk melakukan beberapa estimasi secara manual. Lihat Lampiran untuk sumber daya berikut:
- Gunakan perhitungan kasar di atas kertas
- Tabel pangkat dua
- Angka latensi yang harus diketahui setiap programmer
Sumber dan bacaan lanjutan
Lihat tautan berikut untuk mendapatkan gambaran lebih baik tentang apa yang diharapkan:
- Cara sukses dalam wawancara desain sistem
- Wawancara desain sistem
- Pengantar Arsitektur dan Wawancara Desain Sistem
- Template desain sistem
Pertanyaan wawancara desain sistem beserta solusi
Pertanyaan umum wawancara desain sistem dengan diskusi, kode, dan diagram contoh.>
Solusi terhubung ke konten di folder solutions/.| Pertanyaan | | |---|---| | Desain Pastebin.com (atau Bit.ly) | Solusi | | Desain linimasa dan pencarian Twitter (atau feed dan pencarian Facebook) | Solusi | | Desain web crawler | Solusi | | Desain Mint.com | Solusi | | Desain struktur data untuk jejaring sosial | Solusi | | Desain penyimpanan key-value untuk mesin pencari | Solusi | | Desain fitur peringkat penjualan Amazon berdasarkan kategori | Solusi | | Desain sistem yang dapat diskalakan ke jutaan pengguna di AWS | Solusi | | Tambahkan pertanyaan desain sistem | Kontribusi |
Desain Pastebin.com (atau Bit.ly)
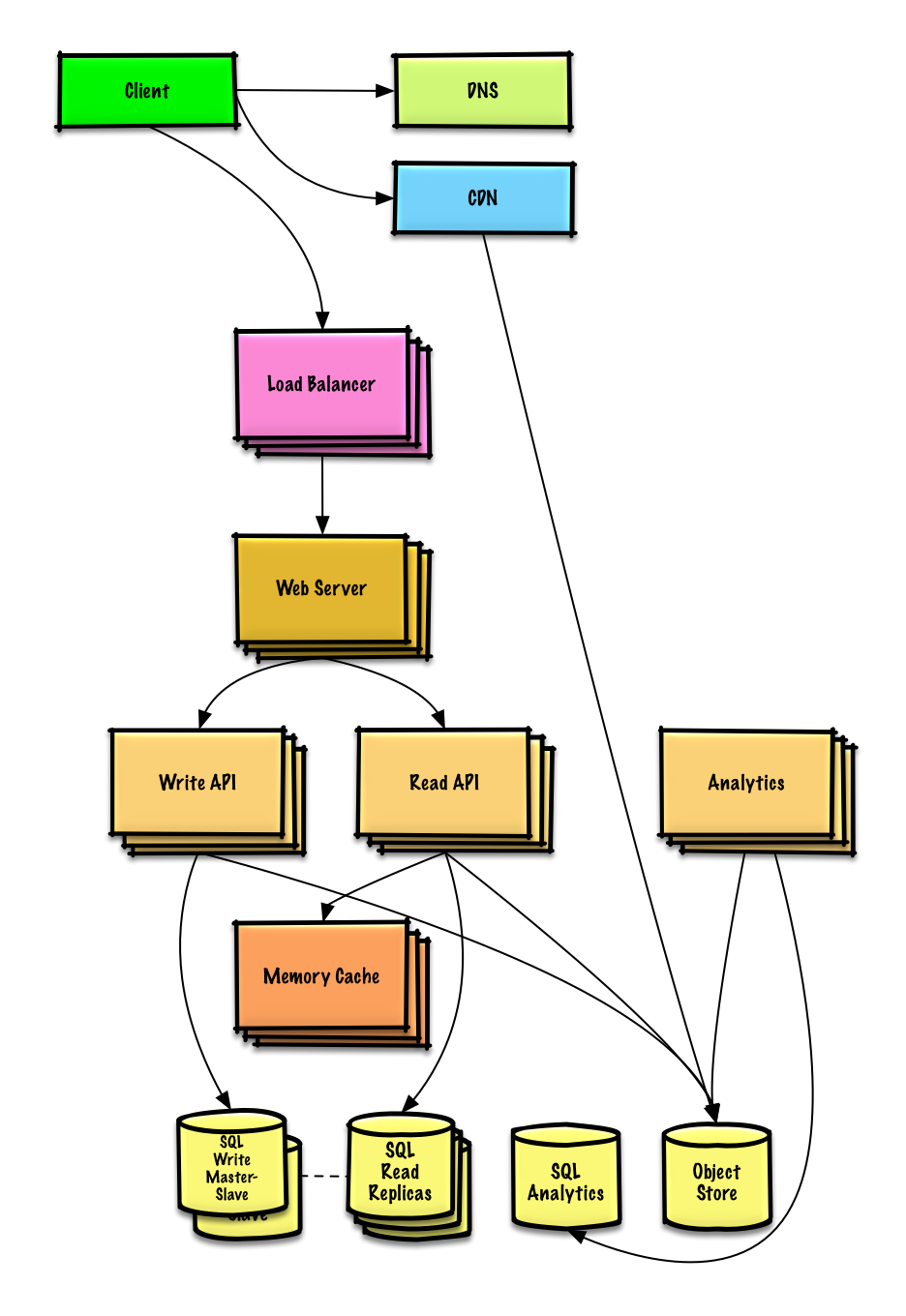
Desain linimasa dan pencarian Twitter (atau feed dan pencarian Facebook)
Desain web crawler
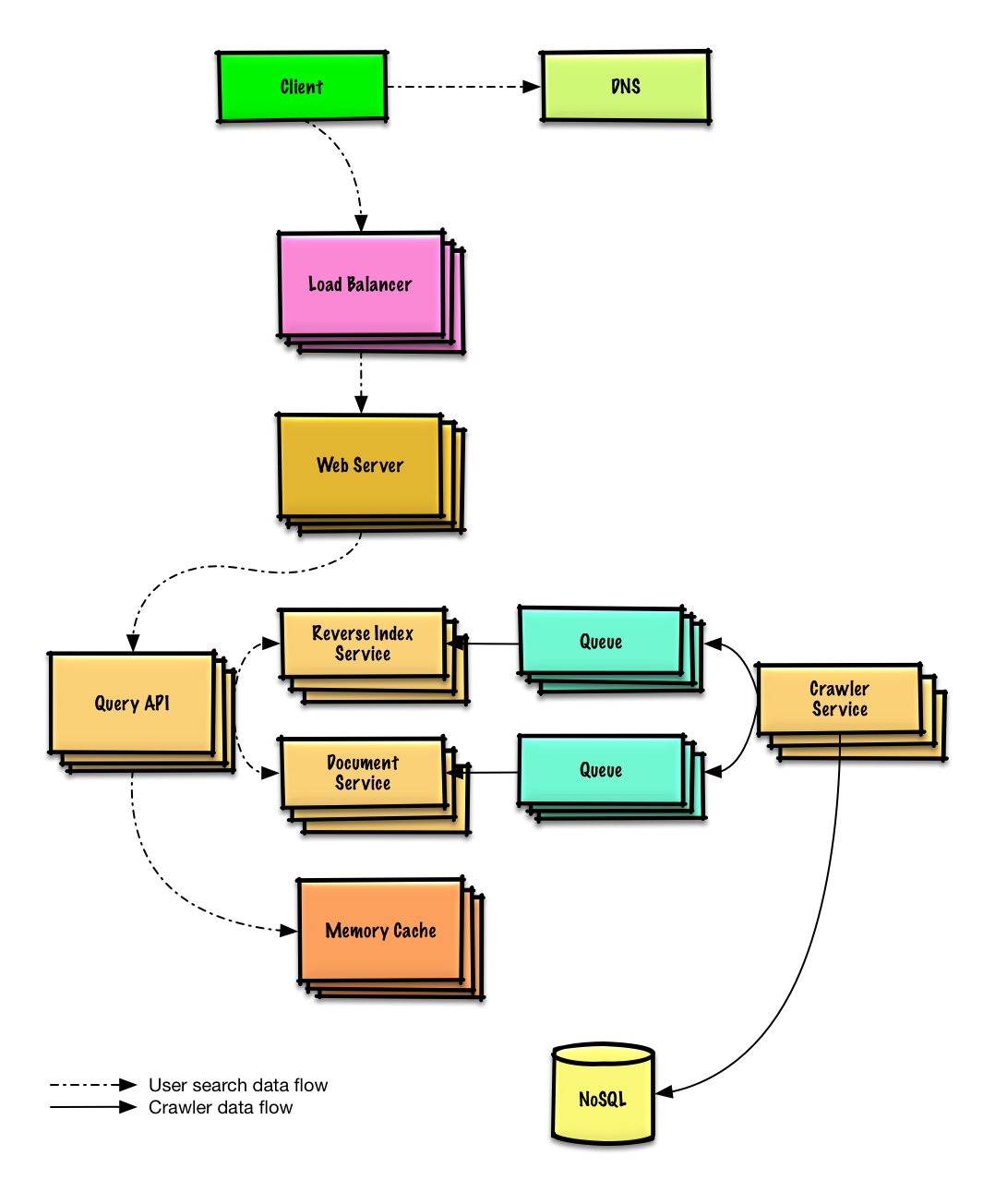
Design Mint.com
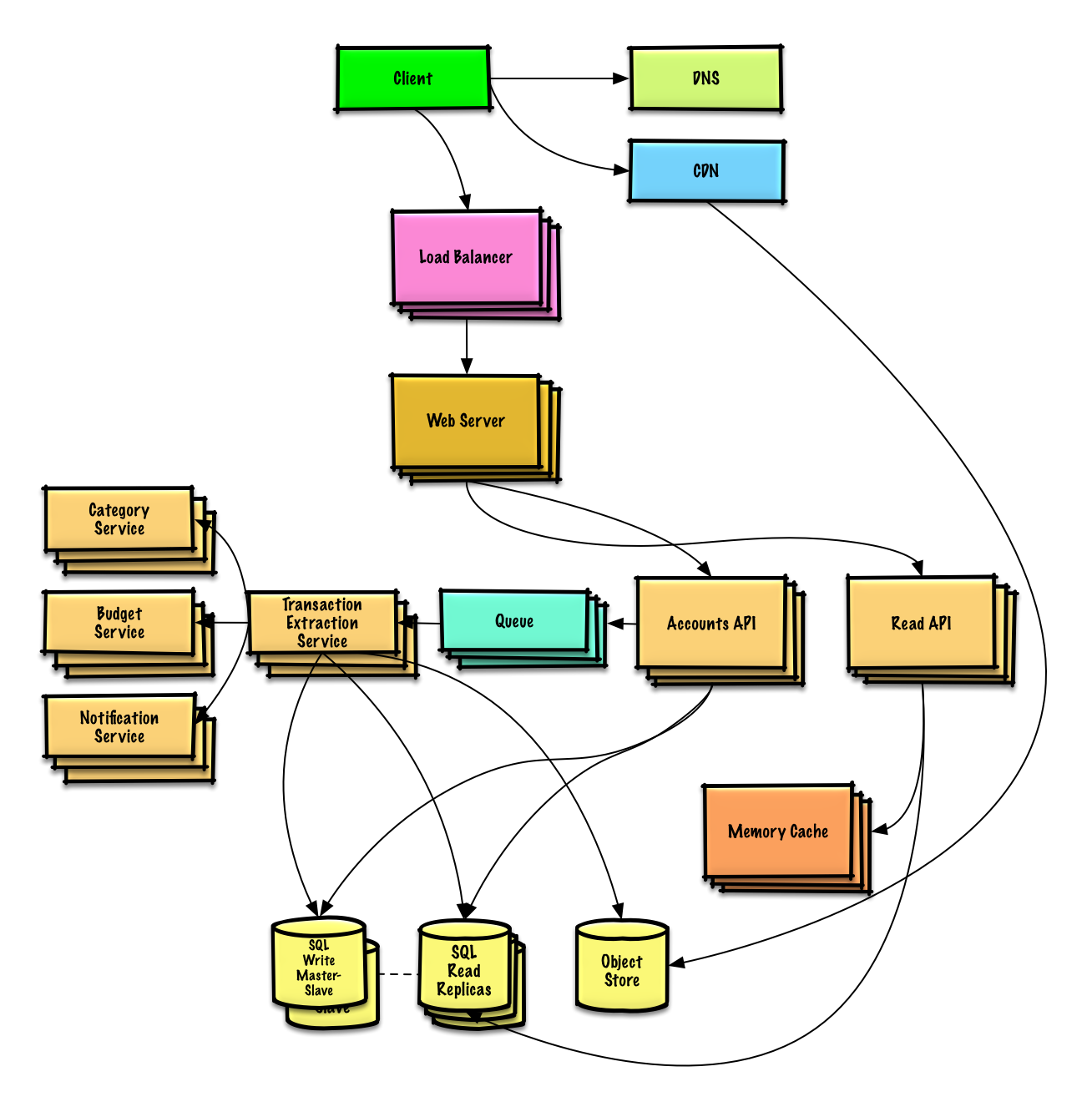
Design the data structures for a social network
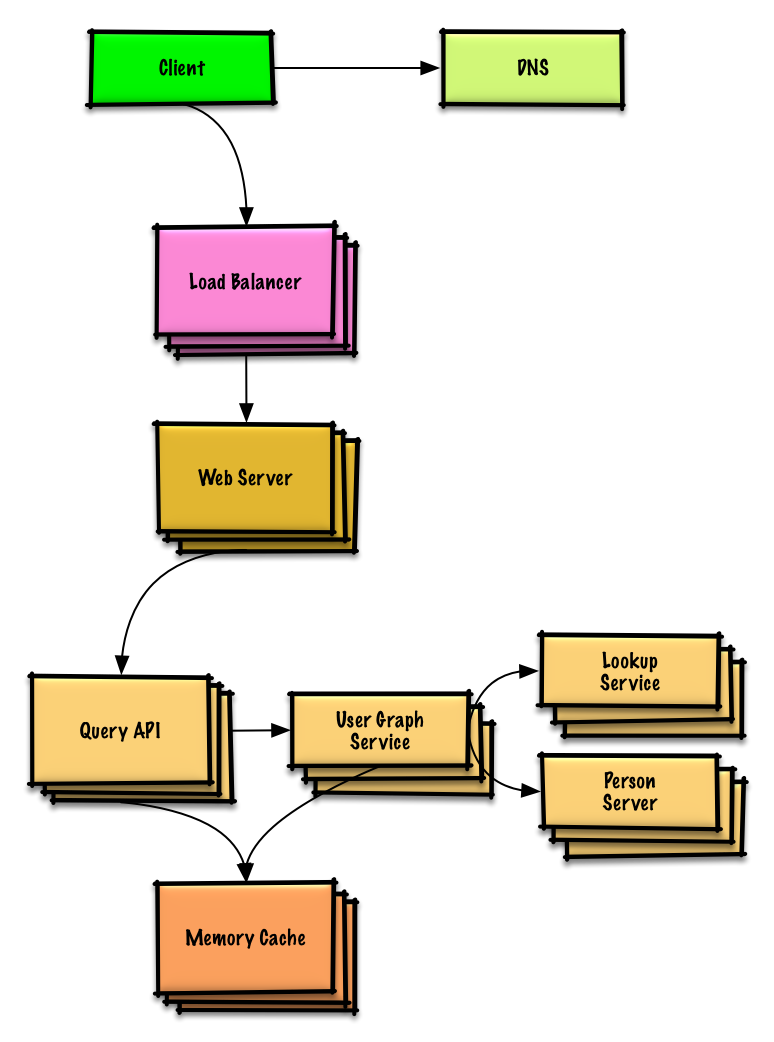
Design a key-value store for a search engine
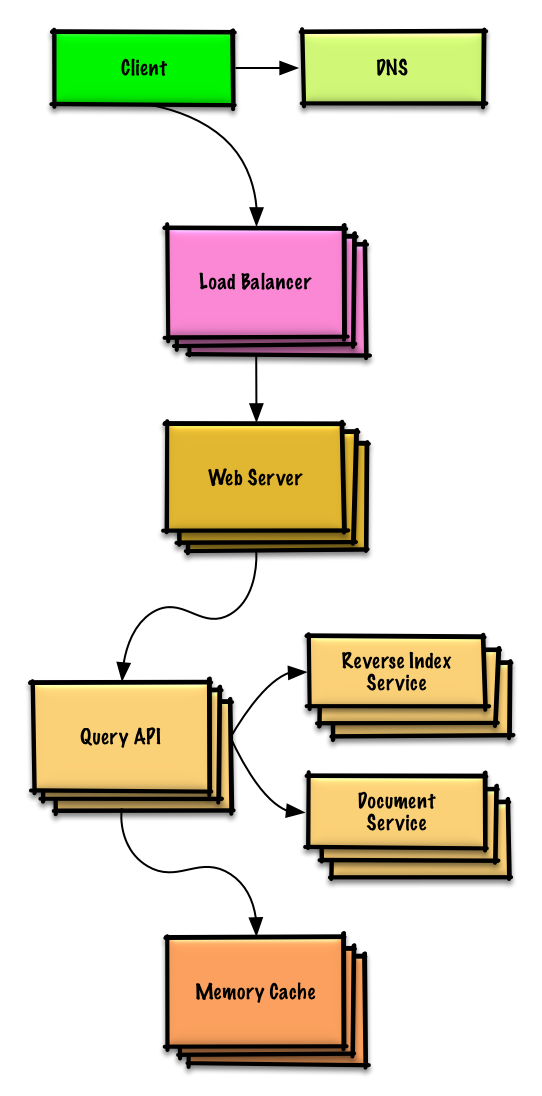
Design Amazon's sales ranking by category feature
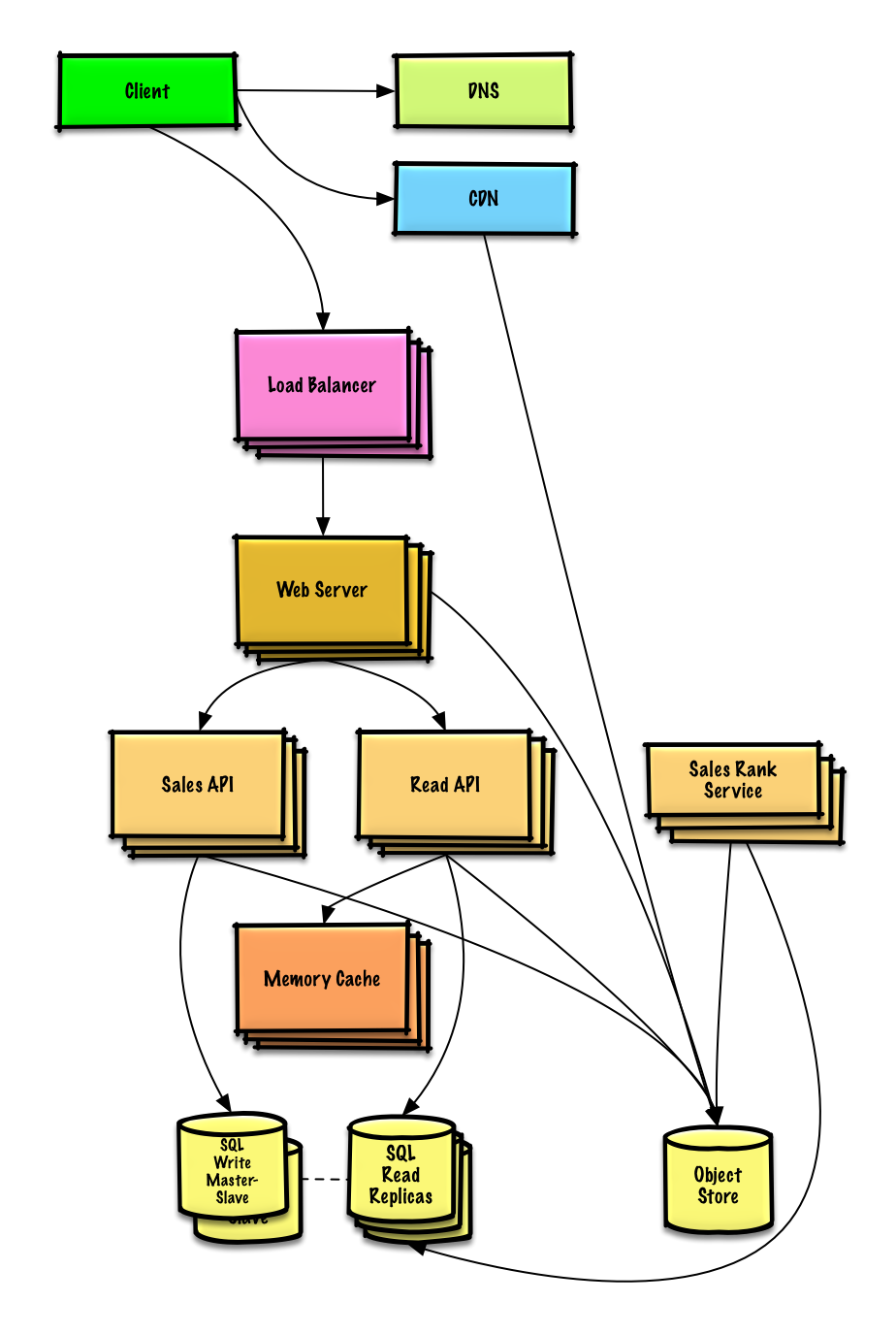
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Desain hash map | Solusi | | Desain cache least recently used | Solusi | | Desain call center | Solusi | | Desain setumpuk kartu | Solusi | | Desain tempat parkir | Solusi | | Desain server chat | Solusi | | Desain array melingkar | Kontribusi | | Tambahkan pertanyaan desain berorientasi objek | Kontribusi |
Topik desain sistem: mulai di sini
Baru dalam desain sistem?
Pertama, Anda perlu pemahaman dasar tentang prinsip umum, mempelajari apa itu, bagaimana digunakan, serta kelebihan dan kekurangannya.
Langkah 1: Tinjau kuliah video skalabilitas
Kuliah Skalabilitas di Harvard
- Topik yang dibahas:
- Vertical scaling
- Horizontal scaling
- Caching
- Load balancing
- Replikasi basis data
- Partisi basis data
Langkah 2: Tinjau artikel skalabilitas
- Topik yang dibahas:
- Clones
- Database
- Cache
- Asynchronism
Langkah selanjutnya
Selanjutnya, kita akan melihat pertukaran tingkat tinggi:
- Performa vs skalabilitas
- Latensi vs throughput
- Ketersediaan vs konsistensi
Kemudian kita akan membahas topik yang lebih spesifik seperti DNS, CDN, dan load balancer.
Performa vs skalabilitas
Sebuah layanan dikatakan skalabel jika menghasilkan peningkatan performa secara proporsional dengan sumber daya yang ditambahkan. Secara umum, meningkatkan performa berarti melayani lebih banyak unit kerja, tetapi juga bisa untuk menangani unit kerja yang lebih besar, seperti ketika kumpulan data bertambah.1
Cara lain untuk melihat performa vs skalabilitas:
- Jika Anda memiliki masalah performa, sistem Anda lambat untuk satu pengguna.
- Jika Anda memiliki masalah skalabilitas, sistem Anda cepat untuk satu pengguna tetapi lambat di bawah beban berat.
Sumber dan bacaan lebih lanjut
Latensi vs throughput
Latensi adalah waktu yang dibutuhkan untuk melakukan suatu tindakan atau menghasilkan suatu hasil.
Throughput adalah jumlah tindakan atau hasil tersebut per satuan waktu.
Secara umum, Anda harus mengupayakan throughput maksimal dengan latensi yang dapat diterima.
Sumber dan bacaan lebih lanjut
Ketersediaan vs konsistensi
Teorema CAP
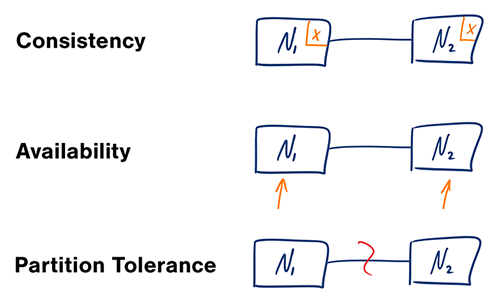
Dalam sistem komputer terdistribusi, Anda hanya dapat mendukung dua dari jaminan berikut:
- Konsistensi - Setiap pembacaan menerima penulisan terbaru atau terjadi error
- Ketersediaan - Setiap permintaan menerima respons, tanpa jaminan bahwa respons tersebut berisi versi informasi terbaru
- Toleransi Partisi - Sistem tetap beroperasi meskipun terjadi partisi sembarangan akibat kegagalan jaringan
#### CP - konsistensi dan toleransi partisi
Menunggu respons dari node yang terpartisi dapat menghasilkan error timeout. CP adalah pilihan yang baik jika kebutuhan bisnis Anda mengharuskan pembacaan dan penulisan atomik.
#### AP - ketersediaan dan toleransi partisi
Respons mengembalikan versi data yang paling mudah tersedia di node manapun, yang mungkin bukan yang terbaru. Penulisan mungkin memerlukan waktu untuk menyebar setelah partisi teratasi.
AP adalah pilihan yang baik jika kebutuhan bisnis mengizinkan konsistensi eventual atau ketika sistem harus tetap berfungsi meskipun terjadi error eksternal.
Sumber dan bacaan lebih lanjut
- CAP theorem revisited
- Pendahuluan CAP theorem dalam bahasa Inggris sederhana
- CAP FAQ
- The CAP theorem
Pola konsistensi
Dengan beberapa salinan data yang sama, kita dihadapkan pada pilihan tentang bagaimana menyinkronkan mereka agar klien memiliki pandangan data yang konsisten. Ingat definisi konsistensi dari CAP theorem - Setiap pembacaan menerima penulisan terbaru atau terjadi error.
Konsistensi lemah
Setelah penulisan, pembacaan mungkin bisa melihatnya atau tidak. Pendekatan yang diambil adalah usaha terbaik.
Pendekatan ini ditemukan pada sistem seperti memcached. Konsistensi lemah bekerja dengan baik pada kasus penggunaan waktu nyata seperti VoIP, video chat, dan game multipemain realtime. Misalnya, jika Anda sedang melakukan panggilan telepon dan kehilangan sinyal beberapa detik, ketika Anda kembali terhubung Anda tidak mendengar apa yang diucapkan selama kehilangan koneksi.
Konsistensi eventual
Setelah penulisan, pembacaan pada akhirnya akan melihatnya (biasanya dalam hitungan milidetik). Data direplikasi secara asinkron.
Pendekatan ini digunakan dalam sistem seperti DNS dan email. Konsistensi eventual bekerja dengan baik pada sistem yang sangat tersedia.
Konsistensi kuat
Setelah penulisan, pembacaan akan melihatnya. Data direplikasi secara sinkron.
Pendekatan ini digunakan dalam sistem berkas dan RDBMS. Konsistensi kuat bekerja dengan baik pada sistem yang membutuhkan transaksi.
Sumber dan bacaan lebih lanjut
Pola ketersediaan
Ada dua pola yang saling melengkapi untuk mendukung ketersediaan tinggi: fail-over dan replikasi.
Fail-over
#### Aktif-pasif
Dengan fail-over aktif-pasif, heartbeat dikirim antara server aktif dan server pasif yang siaga. Jika heartbeat terputus, server pasif mengambil alih alamat IP server aktif dan melanjutkan layanan.
Lamanya downtime ditentukan oleh apakah server pasif sudah berjalan dalam mode siaga 'hot' atau perlu memulai dari mode siaga 'cold'. Hanya server aktif yang menangani trafik.
Fail-over aktif-pasif juga dapat disebut sebagai failover master-slave.
#### Aktif-aktif
Pada aktif-aktif, kedua server menangani trafik, membagi beban di antara mereka.
Jika server bersifat publik, DNS perlu mengetahui tentang alamat IP publik kedua server. Jika server bersifat internal, logika aplikasi perlu mengetahui tentang kedua server.
Fail-over aktif-aktif juga dapat disebut sebagai failover master-master.
Kekurangan: failover
- Fail-over menambah perangkat keras dan kompleksitas tambahan.
- Ada potensi kehilangan data jika sistem aktif gagal sebelum data baru yang ditulis dapat direplikasi ke sistem pasif.
Replikasi
#### Master-slave dan master-master
Topik ini dibahas lebih lanjut pada bagian Database:
Ketersediaan dalam angka
Ketersediaan sering dihitung berdasarkan waktu aktif (atau waktu tidak aktif) sebagai persentase waktu layanan tersedia. Ketersediaan umumnya diukur dalam jumlah angka 9--layanan dengan ketersediaan 99,99% disebut memiliki empat angka 9.
#### Ketersediaan 99,9% - tiga angka 9
| Durasi | Waktu tidak aktif yang dapat diterima | |---------------------|---------------------------------------| | Waktu tidak aktif per tahun | 8j 45mnt 57d | | Waktu tidak aktif per bulan | 43mnt 49,7d | | Waktu tidak aktif per minggu | 10mnt 4,8d | | Waktu tidak aktif per hari | 1mnt 26,4d |
#### Ketersediaan 99,99% - empat angka 9
| Durasi | Waktu tidak aktif yang dapat diterima | |---------------------|---------------------------------------| | Waktu tidak aktif per tahun | 52mnt 35,7d | | Waktu tidak aktif per bulan | 4mnt 23d | | Waktu tidak aktif per minggu | 1mnt 5d | | Waktu tidak aktif per hari | 8,6d |
#### Ketersediaan secara paralel vs secara berurutan
Jika suatu layanan terdiri dari beberapa komponen yang rawan gagal, ketersediaan keseluruhan layanan bergantung pada apakah komponen tersebut berurutan atau paralel.
###### Secara berurutan Ketersediaan keseluruhan menurun ketika dua komponen dengan ketersediaan < 100% berada dalam urutan:
Availability (Total) = Availability (Foo) * Availability (Bar)Foo maupun Bar masing-masing memiliki ketersediaan 99,9%, total ketersediaan mereka secara berurutan adalah 99,8%.###### Secara paralel
Ketersediaan keseluruhan meningkat ketika dua komponen dengan ketersediaan < 100% berada secara paralel:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo maupun Bar masing-masing memiliki ketersediaan 99,9%, total ketersediaan mereka secara paralel akan menjadi 99,9999%.Sistem nama domain
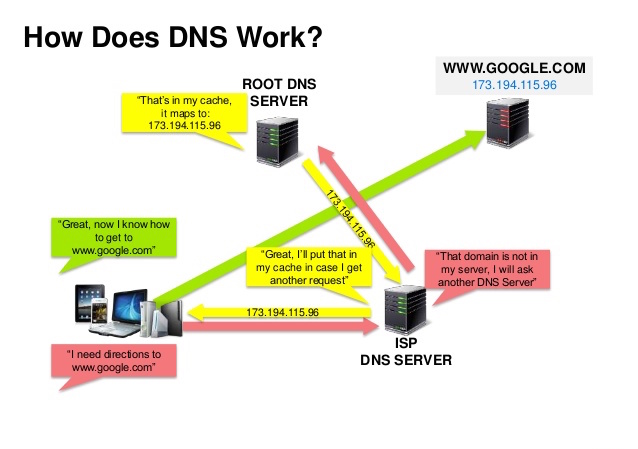
Sumber: Presentasi keamanan DNS
Sistem Nama Domain (DNS) menerjemahkan nama domain seperti www.example.com menjadi alamat IP.
DNS bersifat hierarkis, dengan beberapa server otoritatif di tingkat atas. Router atau ISP Anda menyediakan informasi tentang server DNS mana yang harus dihubungi saat melakukan lookup. Server DNS tingkat bawah melakukan cache pemetaan, yang bisa menjadi usang karena keterlambatan propagasi DNS. Hasil DNS juga dapat di-cache oleh browser atau OS Anda untuk jangka waktu tertentu, yang ditentukan oleh time to live (TTL).
- NS record (name server) - Menentukan server DNS untuk domain/subdomain Anda.
- MX record (mail exchange) - Menentukan server surat untuk menerima pesan.
- A record (address) - Menunjukkan nama ke alamat IP.
- CNAME (canonical) - Menunjukkan nama ke nama lain atau
CNAME(example.com ke www.example.com) atau ke recordA.
- Weighted round robin
- Mencegah lalu lintas menuju server yang sedang dalam perawatan
- Menyeimbangkan antara ukuran cluster yang bervariasi
- Pengujian A/B
- Latency-based
- Geolocation-based
Kekurangan: DNS
- Mengakses server DNS memperkenalkan sedikit penundaan, walau dapat dikurangi dengan cache seperti dijelaskan di atas.
- Manajemen server DNS bisa rumit dan umumnya diatur oleh pemerintah, ISP, dan perusahaan besar.
- Layanan DNS belakangan ini menjadi sasaran serangan DDoS, sehingga pengguna tidak dapat mengakses situs seperti Twitter tanpa mengetahui alamat IP Twitter.
Sumber dan bacaan lebih lanjut
Jaringan pengiriman konten
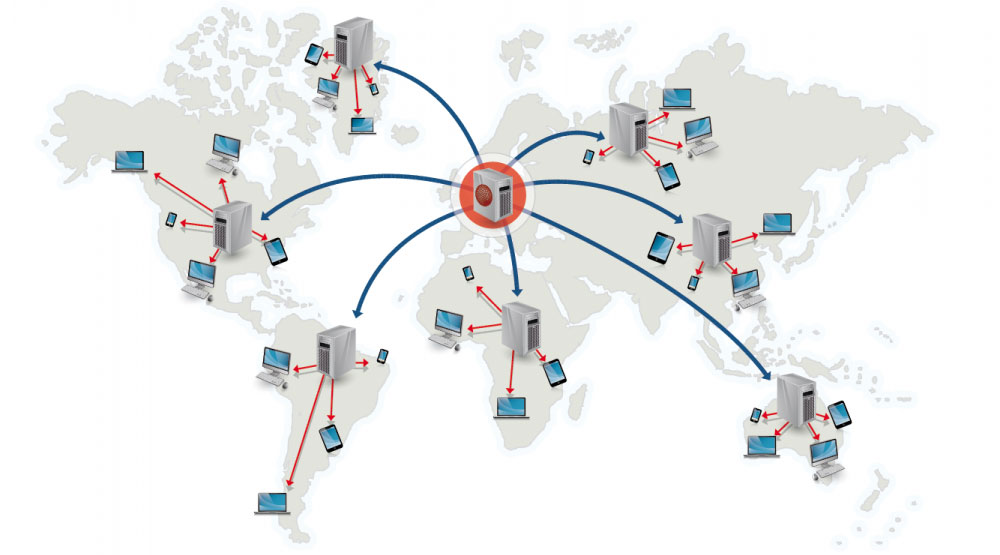
Sumber: Mengapa menggunakan CDN
Jaringan pengiriman konten (CDN) adalah jaringan server proxy yang tersebar secara global, melayani konten dari lokasi yang lebih dekat dengan pengguna. Umumnya, file statis seperti HTML/CSS/JS, foto, dan video disajikan dari CDN, meskipun beberapa CDN seperti CloudFront milik Amazon mendukung konten dinamis. Resolusi DNS situs akan memberi tahu klien server mana yang harus dihubungi.
Penyajian konten dari CDN dapat secara signifikan meningkatkan performa dengan dua cara:
- Pengguna menerima konten dari pusat data yang dekat dengan mereka
- Server Anda tidak perlu melayani permintaan yang telah dipenuhi oleh CDN
Push CDN
Push CDN menerima konten baru setiap kali terjadi perubahan pada server Anda. Anda bertanggung jawab penuh untuk menyediakan konten, mengunggah langsung ke CDN dan menulis ulang URL agar mengarah ke CDN. Anda dapat mengatur kapan konten kedaluwarsa dan kapan diperbarui. Konten diunggah hanya ketika konten baru atau berubah, sehingga meminimalkan lalu lintas, tetapi memaksimalkan penyimpanan.
Situs dengan sedikit lalu lintas atau situs dengan konten yang jarang diperbarui sangat cocok menggunakan Push CDN. Konten ditempatkan di CDN sekali saja, bukan ditarik ulang secara berkala.
Pull CDN
Pull CDN mengambil konten baru dari server Anda ketika pengguna pertama kali meminta konten tersebut. Anda membiarkan konten tetap di server Anda dan menulis ulang URL agar mengarah ke CDN. Hal ini menyebabkan permintaan pertama lebih lambat hingga konten di-cache di CDN.
Time-to-live (TTL) menentukan berapa lama konten di-cache. Pull CDN meminimalkan ruang penyimpanan di CDN, tetapi dapat menciptakan lalu lintas berulang jika file kedaluwarsa dan ditarik sebelum benar-benar berubah.
Situs dengan lalu lintas tinggi sangat cocok menggunakan Pull CDN, karena lalu lintas tersebar lebih merata dengan hanya konten yang baru saja diminta tetap berada di CDN.
Kelemahan: CDN
- Biaya CDN bisa signifikan tergantung pada lalu lintas, meskipun ini harus dibandingkan dengan biaya tambahan jika tidak menggunakan CDN.
- Konten bisa menjadi usang jika diperbarui sebelum TTL habis.
- CDN memerlukan perubahan URL untuk konten statis agar mengarah ke CDN.
Sumber dan bacaan lebih lanjut
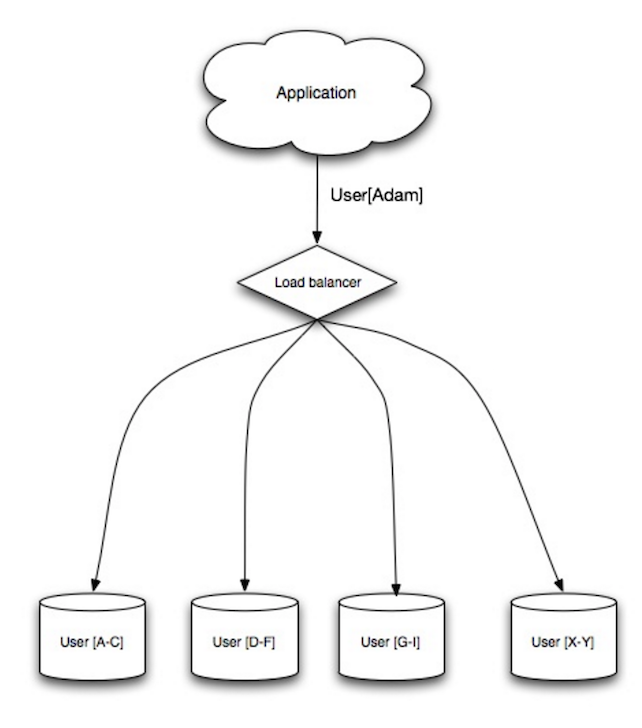
Penyeimbang beban
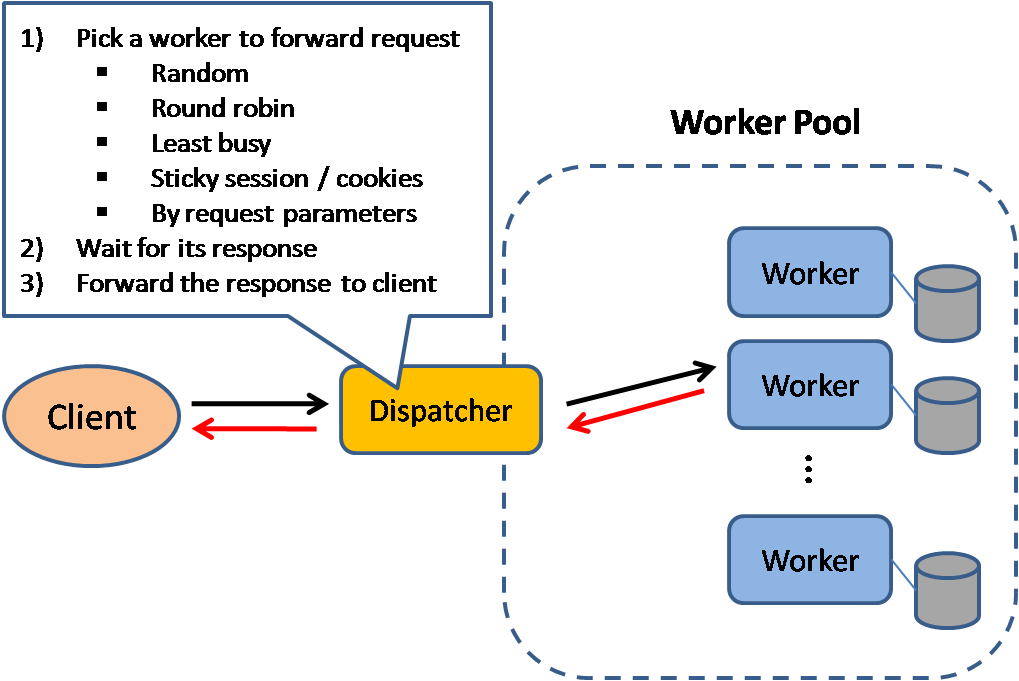
Sumber: Pola desain sistem yang skalabel
Penyeimbang beban mendistribusikan permintaan klien yang masuk ke sumber daya komputasi seperti server aplikasi dan basis data. Dalam setiap kasus, penyeimbang beban mengembalikan respons dari sumber daya komputasi ke klien yang sesuai. Penyeimbang beban efektif untuk:
- Mencegah permintaan masuk ke server yang tidak sehat
- Mencegah sumber daya kelebihan beban
- Membantu menghilangkan titik kegagalan tunggal
Manfaat tambahan meliputi:
- Terminasi SSL - Mendekripsi permintaan masuk dan mengenkripsi respons server sehingga server backend tidak perlu melakukan operasi yang berpotensi mahal ini
- Menghilangkan kebutuhan untuk menginstal sertifikat X.509 pada setiap server
- Persistensi sesi - Mengeluarkan cookie dan mengarahkan permintaan klien tertentu ke instance yang sama jika aplikasi web tidak melacak sesi
Penyeimbang beban dapat mengarahkan lalu lintas berdasarkan berbagai metrik, termasuk:
- Acak
- Beban paling ringan
- Sesi/cookie
- Round robin atau weighted round robin
- Layer 4
- Layer 7
Penyeimbangan beban Layer 4
Penyeimbang beban Layer 4 melihat informasi pada lapisan transport untuk memutuskan bagaimana mendistribusikan permintaan. Umumnya, ini melibatkan alamat IP sumber, tujuan, dan port dalam header, tetapi tidak isi paket. Penyeimbang beban Layer 4 meneruskan paket jaringan ke dan dari server hulu, melakukan Network Address Translation (NAT).
Penyeimbangan beban Layer 7
Penyeimbang beban Layer 7 melihat pada lapisan aplikasi untuk memutuskan bagaimana mendistribusikan permintaan. Ini dapat melibatkan isi header, pesan, dan cookie. Penyeimbang beban Layer 7 menghentikan lalu lintas jaringan, membaca pesan, membuat keputusan penyeimbangan beban, lalu membuka koneksi ke server yang dipilih. Sebagai contoh, penyeimbang beban layer 7 dapat mengarahkan lalu lintas video ke server yang menyimpan video sementara mengarahkan lalu lintas penagihan pengguna yang lebih sensitif ke server yang telah diperkuat keamanannya.Dengan mengorbankan fleksibilitas, penyeimbangan beban layer 4 membutuhkan waktu dan sumber daya komputasi yang lebih sedikit daripada Layer 7, meskipun dampak kinerjanya bisa minimal pada perangkat keras komoditas modern.
Pensakalan horizontal
Penyeimbang beban juga dapat membantu penskalaan horizontal, meningkatkan kinerja dan ketersediaan. Melakukan penskalaan keluar menggunakan mesin komoditas lebih hemat biaya dan menghasilkan ketersediaan yang lebih tinggi dibandingkan dengan penskalaan ke atas satu server pada perangkat keras yang lebih mahal, yang disebut Pensakalan Vertikal. Selain itu, lebih mudah merekrut talenta yang bekerja pada perangkat keras komoditas daripada pada sistem perusahaan khusus.
#### Kerugian: penskalaan horizontal
- Pensakalan secara horizontal memperkenalkan kompleksitas dan melibatkan penggandaan server
- Server harus stateless: mereka tidak boleh berisi data terkait pengguna seperti sesi atau foto profil
- Sesi dapat disimpan di pusat data terpusat seperti database (SQL, NoSQL) atau cache persisten (Redis, Memcached)
- Server hilir seperti cache dan database perlu menangani lebih banyak koneksi simultan seiring server hulu melakukan penskalaan keluar
Kerugian: penyeimbang beban
- Penyeimbang beban dapat menjadi hambatan kinerja jika tidak memiliki sumber daya yang cukup atau jika tidak dikonfigurasi dengan benar.
- Memperkenalkan penyeimbang beban untuk membantu menghilangkan satu titik kegagalan mengakibatkan peningkatan kompleksitas.
- Satu penyeimbang beban adalah satu titik kegagalan, mengonfigurasi beberapa penyeimbang beban lebih lanjut meningkatkan kompleksitas.
Sumber dan bacaan lebih lanjut
- Arsitektur NGINX
- Panduan arsitektur HAProxy
- Skalabilitas
- Wikipedia)
- Penyeimbangan beban Layer 4
- Penyeimbangan beban Layer 7
- Konfigurasi listener ELB
Proksi balik (web server)
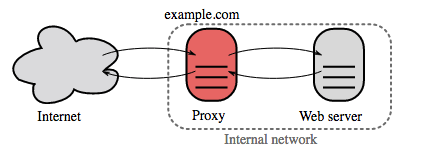
Reverse proxy adalah server web yang memusatkan layanan internal dan menyediakan antarmuka terpadu kepada publik. Permintaan dari klien diteruskan ke server yang dapat memenuhinya sebelum reverse proxy mengembalikan respons server ke klien.
Manfaat tambahan meliputi:
- Keamanan meningkat - Menyembunyikan informasi tentang server backend, memblokir IP, membatasi jumlah koneksi per klien
- Skalabilitas dan fleksibilitas meningkat - Klien hanya melihat IP reverse proxy, memungkinkan Anda meningkatkan jumlah server atau mengubah konfigurasinya
- Terminasi SSL - Mendekripsi permintaan masuk dan mengenkripsi respons server sehingga server backend tidak perlu melakukan operasi yang berpotensi mahal ini
- Menghilangkan kebutuhan untuk memasang sertifikat X.509 di setiap server
- Kompresi - Mengompresi respons server
- Caching - Mengembalikan respons untuk permintaan yang telah di-cache
- Konten statis - Menyajikan konten statis secara langsung
- HTML/CSS/JS
- Foto
- Video
- Dll
Load balancer vs reverse proxy
- Men-deploy load balancer berguna ketika Anda memiliki banyak server. Seringkali, load balancer mengarahkan traffic ke sekumpulan server yang melayani fungsi yang sama.
- Reverse proxy bisa berguna bahkan hanya dengan satu server web atau server aplikasi, membuka manfaat seperti yang dijelaskan pada bagian sebelumnya.
- Solusi seperti NGINX dan HAProxy dapat mendukung reverse proxy layer 7 dan load balancing.
Kekurangan: reverse proxy
- Menambahkan reverse proxy menyebabkan peningkatan kompleksitas.
- Satu reverse proxy adalah titik kegagalan tunggal, mengonfigurasi beberapa reverse proxy (misalnya failover) semakin meningkatkan kompleksitas.
Sumber dan bacaan lanjutan
Lapisan aplikasi
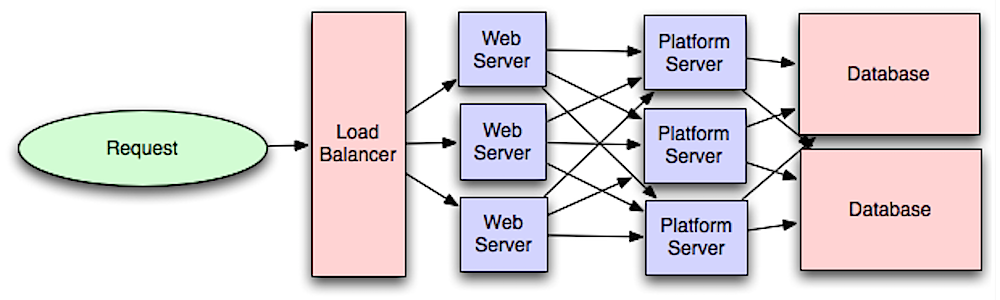
Sumber: Intro to architecting systems for scale
Memisahkan lapisan web dari lapisan aplikasi (juga dikenal sebagai lapisan platform) memungkinkan Anda untuk menskalakan dan mengonfigurasi kedua lapisan secara independen. Menambahkan API baru berarti menambahkan server aplikasi tanpa harus menambah server web tambahan. Prinsip tanggung jawab tunggal menganjurkan layanan-layanan kecil dan otonom yang bekerja bersama-sama. Tim kecil dengan layanan kecil dapat merencanakan pertumbuhan cepat secara lebih agresif.
Pekerja di lapisan aplikasi juga membantu memungkinkan asinkronisme.
Microservices
Terkait dengan pembahasan ini adalah microservices, yang dapat digambarkan sebagai rangkaian layanan kecil, modular, dan dapat di-deploy secara independen. Setiap layanan menjalankan proses unik dan berkomunikasi melalui mekanisme yang terdefinisi dengan baik dan ringan untuk mencapai tujuan bisnis. 1
Pinterest, sebagai contoh, dapat memiliki microservices seperti: profil pengguna, pengikut, feed, pencarian, unggah foto, dll.
Service Discovery
Sistem seperti Consul, Etcd, dan Zookeeper dapat membantu layanan saling menemukan dengan melacak nama, alamat, dan port yang terdaftar. Health checks membantu memverifikasi integritas layanan dan sering dilakukan menggunakan endpoint HTTP. Baik Consul maupun Etcd memiliki key-value store bawaan yang dapat berguna untuk menyimpan nilai konfigurasi dan data bersama lainnya.
Kerugian: lapisan aplikasi
- Menambahkan lapisan aplikasi dengan layanan yang saling terhubung secara longgar membutuhkan pendekatan berbeda dari sudut pandang arsitektur, operasi, dan proses (dibandingkan sistem monolitik).
- Microservices dapat menambah kompleksitas dalam hal deployment dan operasi.
Sumber dan bacaan lebih lanjut
- Intro to architecting systems for scale
- Crack the system design interview
- Arsitektur berbasis layanan
- Pengenalan Zookeeper
- Inilah yang perlu Anda ketahui tentang membangun microservices
Database
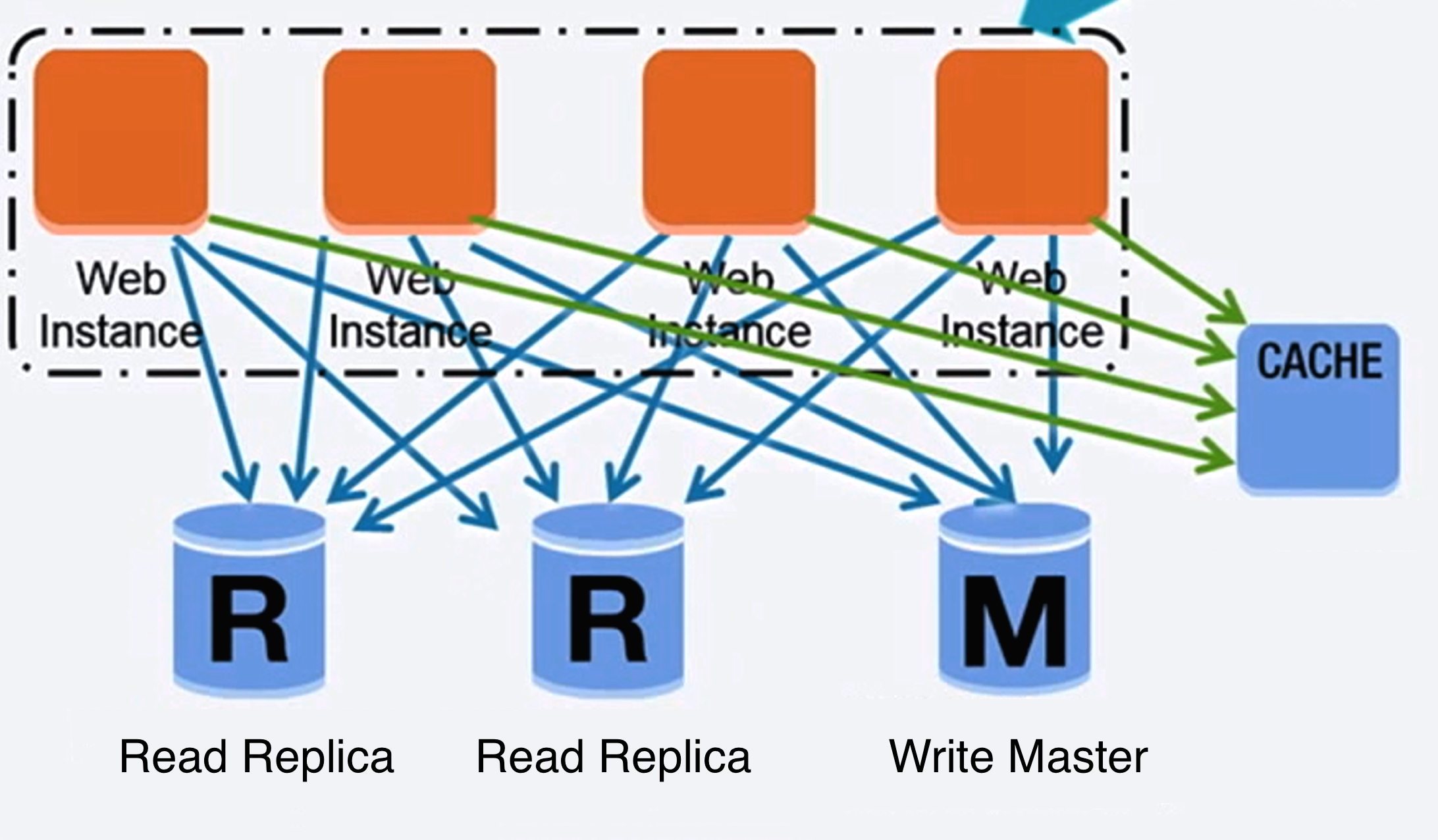
Sumber: Scaling up to your first 10 million users
Sistem manajemen basis data relasional (RDBMS)
Database relasional seperti SQL adalah kumpulan item data yang diorganisir dalam tabel.
ACID adalah seperangkat properti dari transaksi database relasional.
- Atomicity - Setiap transaksi dilakukan secara keseluruhan atau tidak sama sekali
- Consistency - Setiap transaksi akan membawa database dari satu keadaan yang valid ke keadaan valid lainnya
- Isolation - Menjalankan transaksi secara bersamaan menghasilkan hasil yang sama seperti jika transaksi dijalankan secara serial
- Durability - Setelah transaksi dikomitmen, maka akan tetap demikian
#### Replikasi master-slave
Master melayani pembacaan dan penulisan, mereplikasi penulisan ke satu atau lebih slave, yang hanya melayani pembacaan. Slave juga dapat mereplikasi ke slave tambahan secara bertingkat. Jika master offline, sistem dapat terus beroperasi dalam mode hanya-baca sampai slave dipromosikan sebagai master atau master baru disediakan.
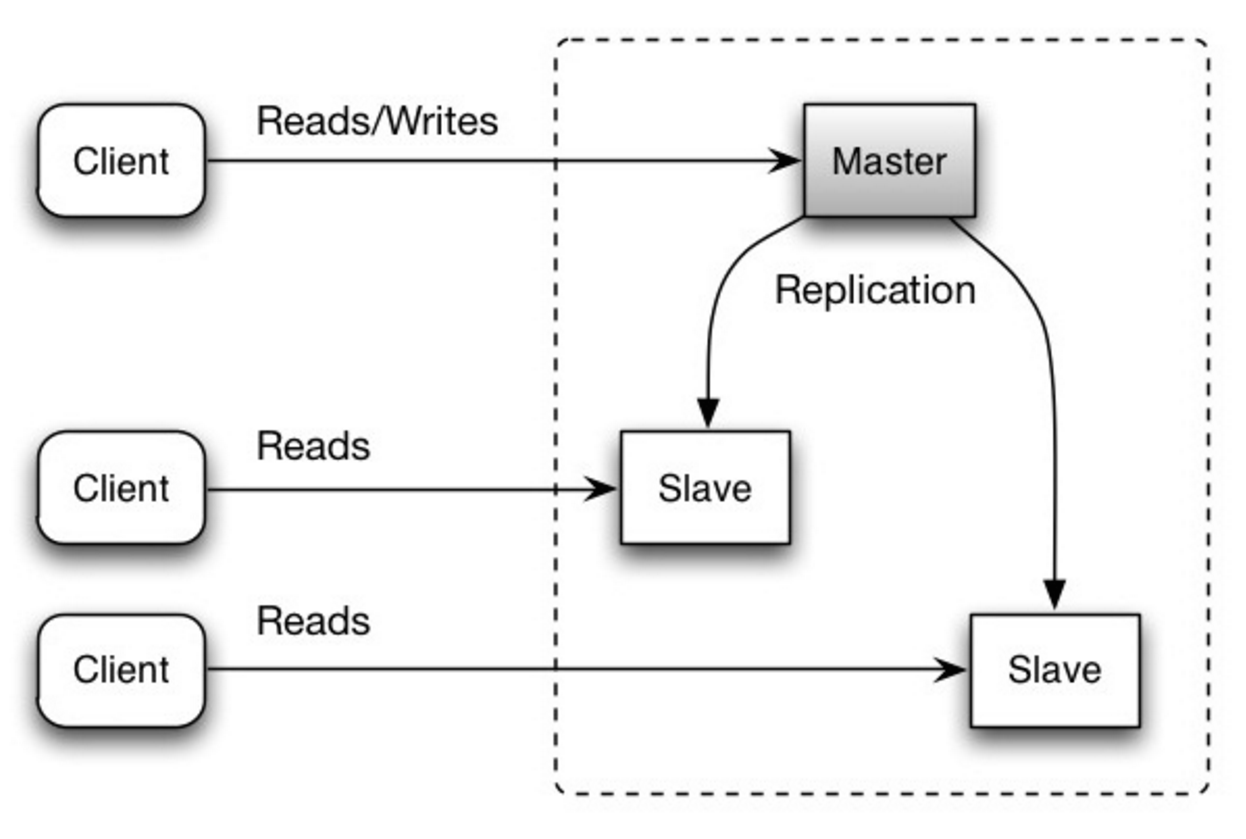
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
##### Kekurangan: replikasi master-slave
- Logika tambahan dibutuhkan untuk mempromosikan slave menjadi master.
- Lihat Kekurangan: replikasi untuk poin terkait baik master-slave maupun master-master.
Kedua master melayani pembacaan dan penulisan dan berkoordinasi satu sama lain untuk penulisan. Jika salah satu master turun, sistem dapat terus beroperasi dengan pembacaan dan penulisan.
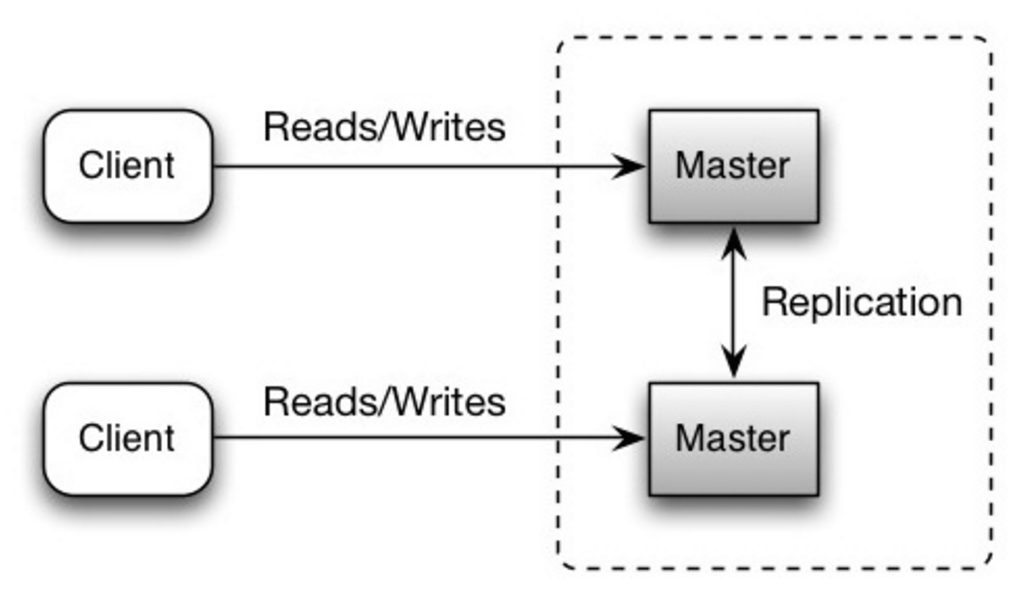
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
##### Kekurangan: replikasi master-master
- Anda membutuhkan penyeimbang beban atau Anda perlu mengubah logika aplikasi untuk menentukan di mana menulis.
- Sebagian besar sistem master-master baik konsistensinya longgar (melanggar ACID) atau memiliki latensi penulisan yang lebih tinggi akibat sinkronisasi.
- Resolusi konflik semakin sering terjadi ketika semakin banyak node penulis ditambahkan dan saat latensi meningkat.
- Lihat Kerugian: replikasi untuk poin-poin yang berkaitan dengan baik master-slave maupun master-master.
- Ada potensi kehilangan data jika master gagal sebelum data yang baru ditulis dapat direplikasi ke node lain.
- Penulisan diulang ke replika baca. Jika terdapat banyak penulisan, replika baca dapat menjadi lambat karena harus memutar ulang penulisan dan tidak dapat melakukan banyak pembacaan.
- Semakin banyak slave baca, semakin banyak yang harus direplikasi, yang menyebabkan keterlambatan replikasi lebih besar.
- Pada beberapa sistem, penulisan ke master dapat memunculkan beberapa thread untuk penulisan paralel, sedangkan replika baca hanya mendukung penulisan secara berurutan dengan satu thread.
- Replikasi menambah perangkat keras dan kompleksitas tambahan.
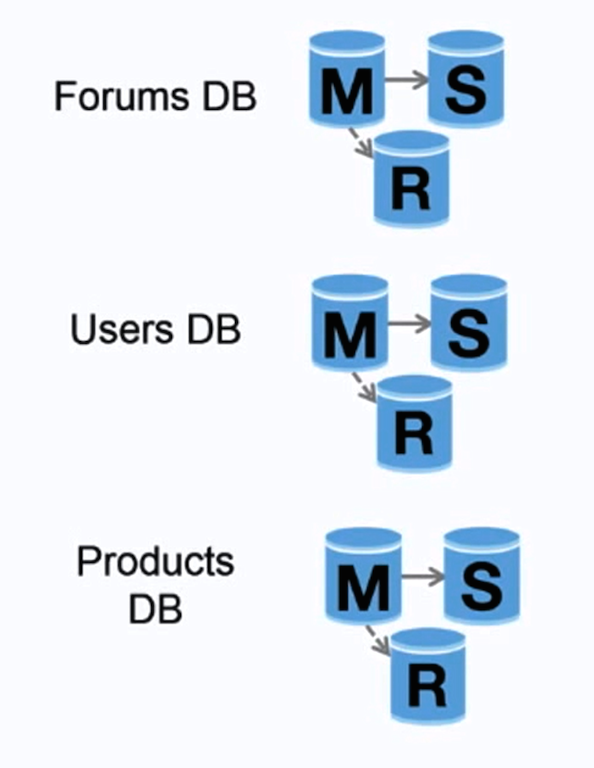
Sumber: Scaling up to your first 10 million users
Federasi (atau pemartisian fungsional) membagi basis data berdasarkan fungsi. Misalnya, daripada satu basis data monolitik, Anda dapat memiliki tiga basis data: forums, users, dan products, sehingga lalu lintas baca dan tulis ke masing-masing basis data lebih sedikit dan mengurangi keterlambatan replikasi. Basis data yang lebih kecil memungkinkan lebih banyak data masuk ke memori, yang menghasilkan lebih banyak cache hit karena peningkatan lokalitas cache. Tanpa satu master pusat yang menserialisasi penulisan, Anda dapat menulis secara paralel, meningkatkan throughput.
##### Kerugian: federasi
- Federasi tidak efektif jika skema Anda membutuhkan fungsi atau tabel yang besar.
- Anda perlu memperbarui logika aplikasi untuk menentukan basis data mana yang akan dibaca dan ditulis.
- Menggabungkan data dari dua basis data lebih kompleks dengan server link.
- Federasi menambah perangkat keras dan kompleksitas tambahan.
Sumber: Pola Skalabilitas, Ketersediaan, Stabilitas
Sharding mendistribusikan data ke berbagai basis data sehingga setiap basis data hanya dapat mengelola sebagian data. Sebagai contoh basis data pengguna, saat jumlah pengguna meningkat, lebih banyak shard ditambahkan ke klaster.
Mirip dengan keuntungan dari federasi, sharding menghasilkan lalu lintas baca dan tulis yang lebih sedikit, replikasi yang lebih sedikit, dan cache hit yang lebih banyak. Ukuran indeks juga berkurang, yang umumnya meningkatkan performa dengan kueri yang lebih cepat. Jika satu shard mati, shard lain tetap berjalan, meskipun Anda sebaiknya menambahkan bentuk replikasi untuk menghindari kehilangan data. Seperti federasi, tidak ada satu master pusat yang melakukan serialisasi penulisan, sehingga Anda dapat menulis secara paralel dengan throughput yang lebih tinggi.
Cara umum untuk melakukan shard pada tabel pengguna adalah berdasarkan inisial nama belakang pengguna atau lokasi geografis pengguna.
##### Kerugian: sharding
- Anda perlu memperbarui logika aplikasi agar dapat bekerja dengan shard, yang dapat menghasilkan kueri SQL yang kompleks.
- Distribusi data dapat menjadi tidak merata dalam sebuah shard. Misalnya, sekelompok pengguna aktif pada satu shard dapat menyebabkan beban pada shard tersebut lebih tinggi dibanding shard lain.
- Rebalancing menambah kompleksitas tambahan. Fungsi sharding berbasis consistent hashing dapat mengurangi jumlah data yang dipindahkan.
- Menggabungkan data dari beberapa shard menjadi lebih kompleks.
- Sharding menambah kebutuhan perangkat keras dan kompleksitas tambahan.
Denormalisasi berusaha meningkatkan performa baca dengan mengorbankan sebagian performa tulis. Salinan data yang redundan ditulis di beberapa tabel untuk menghindari join yang mahal. Beberapa RDBMS seperti PostgreSQL dan Oracle mendukung materialized view yang menangani penyimpanan informasi redundan dan menjaga konsistensi salinan redundan.
Setelah data terdistribusi dengan teknik seperti federasi dan sharding, pengelolaan join antar data center semakin menambah kompleksitas. Denormalisasi dapat menghindari kebutuhan akan join kompleks tersebut.
Di sebagian besar sistem, operasi baca bisa jauh lebih banyak daripada tulis, bahkan dengan rasio 100:1 atau 1000:1. Operasi baca yang menghasilkan join database kompleks bisa sangat mahal, menghabiskan banyak waktu untuk operasi disk.
##### Kerugian: denormalisasi
- Data menjadi duplikat.
- Constraint dapat membantu salinan informasi yang redundan tetap sinkron, yang menambah kompleksitas desain basis data.
- Basis data yang didenormalisasi di bawah beban tulis berat mungkin berperforma lebih buruk daripada basis data yang dinormalisasi.
Penyetelan SQL adalah topik yang luas dan banyak buku telah ditulis sebagai referensi.
Penting untuk melakukan benchmark dan profiling untuk mensimulasikan serta menemukan hambatan.
- Benchmark - Simulasikan situasi beban tinggi dengan alat seperti ab.
- Profiling - Aktifkan alat seperti slow query log untuk membantu melacak masalah kinerja.
##### Perketat skema
- MySQL menulis ke disk dalam blok yang berdekatan untuk akses cepat.
- Gunakan
CHARdaripadaVARCHARuntuk field berdimensi tetap. CHARmemungkinkan akses acak cepat, sedangkan denganVARCHAR, Anda harus menemukan akhir string sebelum pindah ke berikutnya.- Gunakan
TEXTuntuk blok teks besar seperti posting blog.TEXTjuga memungkinkan pencarian boolean. Penggunaan fieldTEXTmengakibatkan penyimpanan pointer di disk yang digunakan untuk menemukan blok teks. - Gunakan
INTuntuk angka besar hingga 2^32 atau 4 miliar. - Gunakan
DECIMALuntuk mata uang agar terhindar dari kesalahan representasi floating point. - Hindari menyimpan
BLOBbesar, simpan lokasi objek untuk mengambilnya. VARCHAR(255)adalah jumlah karakter terbesar yang dapat dihitung dalam angka 8 bit, sering memaksimalkan penggunaan byte pada beberapa RDBMS.- Atur batasan
NOT NULLjika memungkinkan untuk meningkatkan performa pencarian.
- Kolom yang Anda query (
SELECT,GROUP BY,ORDER BY,JOIN) bisa lebih cepat dengan indeks. - Indeks biasanya diwakili sebagai B-tree self-balancing yang menjaga data tetap terurut dan memungkinkan pencarian, akses berurutan, penyisipan, dan penghapusan dalam waktu logaritmik.
- Penempatan indeks bisa menjaga data tetap di memori, sehingga membutuhkan lebih banyak ruang.
- Penulisan juga bisa lebih lambat karena indeks perlu diperbarui.
- Saat memuat data dalam jumlah besar, mungkin lebih cepat untuk menonaktifkan indeks, memuat data, lalu membangun ulang indeks.
- Denormalisasi jika tuntutan kinerja membutuhkannya.
- Pisahkan sebuah tabel dengan menempatkan titik-titik panas (hot spots) dalam tabel terpisah untuk membantu agar tetap berada di memori.
- Dalam beberapa kasus, cache query bisa menyebabkan masalah kinerja.
- Tips untuk mengoptimalkan query MySQL
- Apakah ada alasan bagus VARCHAR(255) sering digunakan?
- Bagaimana nilai null mempengaruhi kinerja?
- Log query lambat
NoSQL
NoSQL adalah kumpulan item data yang direpresentasikan dalam key-value store, document store, wide column store, atau graph database. Data didenormalisasi, dan join biasanya dilakukan dalam kode aplikasi. Sebagian besar penyimpanan NoSQL tidak memiliki transaksi ACID yang sesungguhnya dan lebih memilih konsistensi eventual.
BASE sering digunakan untuk mendeskripsikan sifat database NoSQL. Dibandingkan dengan Teorema CAP, BASE memilih ketersediaan daripada konsistensi.
- Basically available - sistem menjamin ketersediaan.
- Soft state - status sistem dapat berubah seiring waktu, bahkan tanpa input.
- Eventual consistency - sistem akan menjadi konsisten dalam jangka waktu tertentu, asalkan tidak menerima input selama periode tersebut.
#### Key-value store
Abstraksi: hash table
Key-value store umumnya memungkinkan baca dan tulis O(1) dan sering didukung oleh memori atau SSD. Penyimpanan data dapat mempertahankan kunci dalam urutan leksikografis, memungkinkan pengambilan rentang kunci secara efisien. Key-value store dapat memungkinkan penyimpanan metadata bersama sebuah nilai.
Key-value store memberikan kinerja tinggi dan sering digunakan untuk model data sederhana atau data yang cepat berubah, seperti lapisan cache dalam memori. Karena hanya menawarkan operasi terbatas, kompleksitas akan berpindah ke lapisan aplikasi jika dibutuhkan operasi tambahan.
Key-value store adalah dasar bagi sistem yang lebih kompleks seperti document store, dan dalam beberapa kasus, graph database.
##### Sumber dan bacaan lanjutan: key-value store
#### Penyimpanan dokumenAbstraksi: penyimpanan key-value dengan dokumen sebagai nilai
Penyimpanan dokumen berpusat pada dokumen (XML, JSON, biner, dll), di mana dokumen menyimpan semua informasi untuk suatu objek tertentu. Penyimpanan dokumen menyediakan API atau bahasa query untuk melakukan query berdasarkan struktur internal dokumen itu sendiri. Catatan, banyak penyimpanan key-value yang menyertakan fitur untuk bekerja dengan metadata nilai, sehingga memperburam batas antara kedua tipe penyimpanan ini.
Berdasarkan implementasi dasarnya, dokumen diorganisasi berdasarkan koleksi, tag, metadata, atau direktori. Meskipun dokumen dapat diorganisasi atau dikelompokkan bersama, dokumen dapat memiliki field yang benar-benar berbeda satu sama lain.
Beberapa penyimpanan dokumen seperti MongoDB dan CouchDB juga menyediakan bahasa mirip SQL untuk melakukan query kompleks. DynamoDB mendukung baik key-value maupun dokumen.
Penyimpanan dokumen memberikan fleksibilitas tinggi dan sering digunakan untuk data yang kadang berubah.
##### Sumber dan bacaan lebih lanjut: penyimpanan dokumen
#### Wide column store
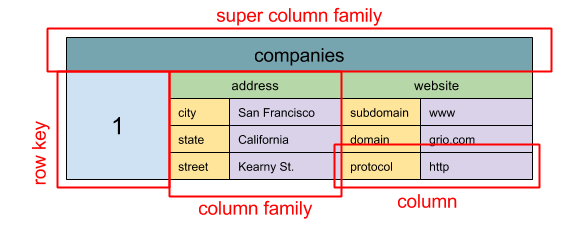
Sumber: SQL & NoSQL, sejarah singkat
Abstraksi: peta bersarang ColumnFamily> Unit dasar data pada wide column store adalah kolom (pasangan nama/nilai). Kolom dapat dikelompokkan dalam column family (analog dengan tabel SQL). Super column family lebih lanjut mengelompokkan column family. Anda dapat mengakses setiap kolom secara independen dengan row key, dan kolom dengan row key yang sama membentuk sebuah baris. Setiap nilai mengandung timestamp untuk versi dan penyelesaian konflik.
Google memperkenalkan Bigtable sebagai wide column store pertama, yang mempengaruhi HBase open-source yang sering digunakan dalam ekosistem Hadoop, dan Cassandra dari Facebook. Penyimpanan seperti BigTable, HBase, dan Cassandra mempertahankan key dalam urutan leksikografis, memungkinkan pengambilan rentang key secara efisien.
Wide column store menawarkan ketersediaan tinggi dan skalabilitas tinggi. Mereka sering digunakan untuk set data yang sangat besar.
##### Sumber dan bacaan lebih lanjut: wide column store
#### Basis data graf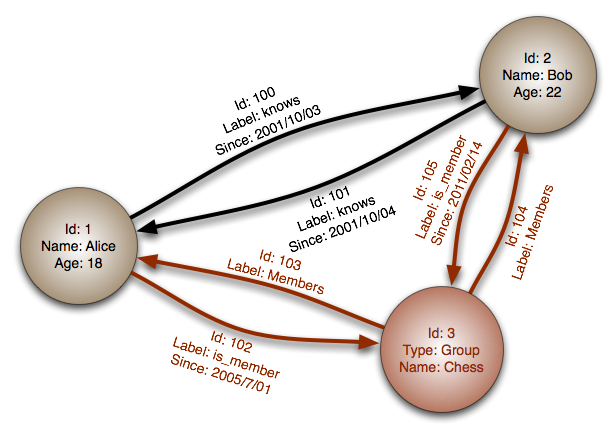
Abstraksi: graf
Dalam basis data graf, setiap node adalah sebuah record dan setiap arc adalah hubungan antara dua node. Basis data graf dioptimalkan untuk merepresentasikan hubungan kompleks dengan banyak kunci asing atau relasi banyak-ke-banyak.
Basis data graf menawarkan performa tinggi untuk model data dengan hubungan kompleks, seperti jejaring sosial. Mereka relatif baru dan belum banyak digunakan; mungkin lebih sulit untuk menemukan alat pengembangan dan sumber daya. Banyak graf hanya dapat diakses dengan REST APIs.
##### Sumber dan bacaan lanjutan: graf
#### Sumber dan bacaan lanjutan: NoSQL- Penjelasan terminologi dasar
- Basis data NoSQL: survei dan panduan pengambilan keputusan
- Skalabilitas
- Pengantar NoSQL
- Pola-pola NoSQL
SQL atau NoSQL
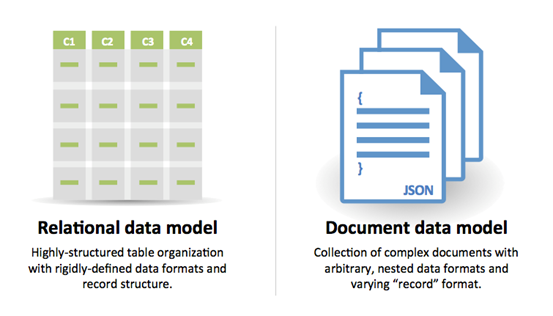
Sumber: Transisi dari RDBMS ke NoSQL
Alasan untuk SQL:
- Data terstruktur
- Skema ketat
- Data relasional
- Membutuhkan join kompleks
- Transaksi
- Pola yang jelas untuk skalabilitas
- Lebih mapan: pengembang, komunitas, kode, alat, dll
- Pencarian berdasarkan indeks sangat cepat
- Data semi-terstruktur
- Skema dinamis atau fleksibel
- Data non-relasional
- Tidak perlu join kompleks
- Menyimpan banyak TB (atau PB) data
- Beban kerja sangat intensif data
- Throughput sangat tinggi untuk IOPS
- Pengambilan data clickstream dan log yang cepat
- Data papan peringkat atau skor
- Data sementara, seperti keranjang belanja
- Tabel yang sering diakses ('panas')
- Tabel metadata/lookup
Cache
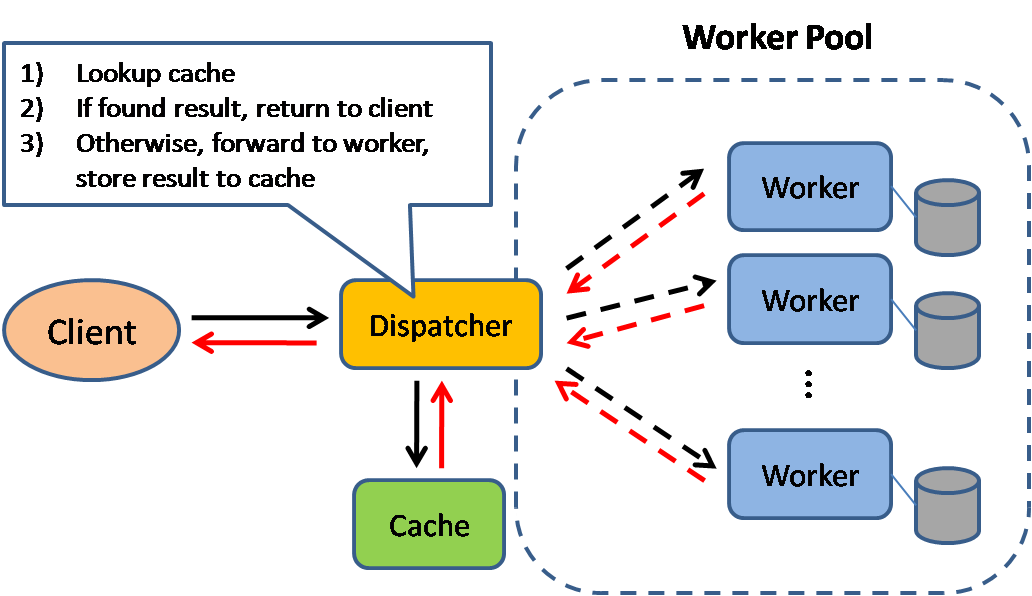
Sumber: Pola desain sistem yang dapat diskalakan
Caching meningkatkan waktu pemuatan halaman dan dapat mengurangi beban pada server dan basis data Anda. Dalam model ini, dispatcher akan terlebih dahulu memeriksa apakah permintaan sudah pernah dilakukan sebelumnya dan mencoba menemukan hasil sebelumnya untuk dikembalikan, guna menghemat eksekusi yang sebenarnya.
Basis data sering mendapat manfaat dari distribusi bacaan dan penulisan yang merata di seluruh partisinya. Item populer dapat mengacaukan distribusi, menyebabkan kemacetan. Menempatkan cache di depan basis data dapat membantu menyerap beban yang tidak merata dan lonjakan lalu lintas.
Caching klien
Cache dapat ditempatkan di sisi klien (OS atau browser), sisi server, atau pada lapisan cache yang berbeda.
Caching CDN
CDN dianggap sebagai jenis cache.
Caching server web
Reverse proxy dan cache seperti Varnish dapat melayani konten statis dan dinamis secara langsung. Server web juga dapat melakukan cache permintaan, mengembalikan respons tanpa harus menghubungi server aplikasi.
Caching basis data
Basis data Anda biasanya sudah menyertakan tingkat caching tertentu dalam konfigurasi default, dioptimalkan untuk kasus penggunaan umum. Menyesuaikan pengaturan ini untuk pola penggunaan spesifik dapat semakin meningkatkan performa.
Caching aplikasi
Cache dalam memori seperti Memcached dan Redis adalah penyimpanan key-value antara aplikasi Anda dan penyimpanan data Anda. Karena data disimpan di RAM, kecepatannya jauh lebih tinggi dibandingkan basis data biasa yang menyimpan data di disk. RAM lebih terbatas daripada disk, sehingga algoritma cache invalidation seperti least recently used (LRU)) dapat membantu menghapus entri 'dingin' dan menjaga data 'panas' tetap di RAM.
Redis memiliki fitur tambahan berikut:
- Opsi persistensi
- Struktur data bawaan seperti sorted sets dan lists
- Level baris
- Level kueri
- Objek serializable yang sudah terbentuk penuh
- HTML yang sudah dirender sepenuhnya
Caching di tingkat query database
Setiap kali Anda melakukan query ke database, hash query tersebut sebagai kunci dan simpan hasilnya ke cache. Pendekatan ini memiliki masalah terkait masa berlaku:
- Sulit menghapus hasil cache dengan query yang kompleks
- Jika satu data berubah seperti sel tabel, Anda harus menghapus semua query cache yang mungkin memuat sel yang berubah tersebut
Caching di tingkat objek
Lihat data Anda sebagai sebuah objek, mirip dengan yang Anda lakukan pada kode aplikasi Anda. Biarkan aplikasi Anda merangkai dataset dari database ke dalam instance kelas atau struktur data:
- Hapus objek dari cache jika data dasarnya berubah
- Memungkinkan pemrosesan asinkron: worker merangkai objek dengan mengambil objek terbaru dari cache
- Sesi pengguna
- Halaman web yang telah dirender sepenuhnya
- Stream aktivitas
- Data grafik pengguna
Kapan melakukan update cache
Karena Anda hanya dapat menyimpan sejumlah data terbatas di cache, Anda perlu menentukan strategi update cache mana yang paling cocok untuk kasus penggunaan Anda.
#### Cache-aside
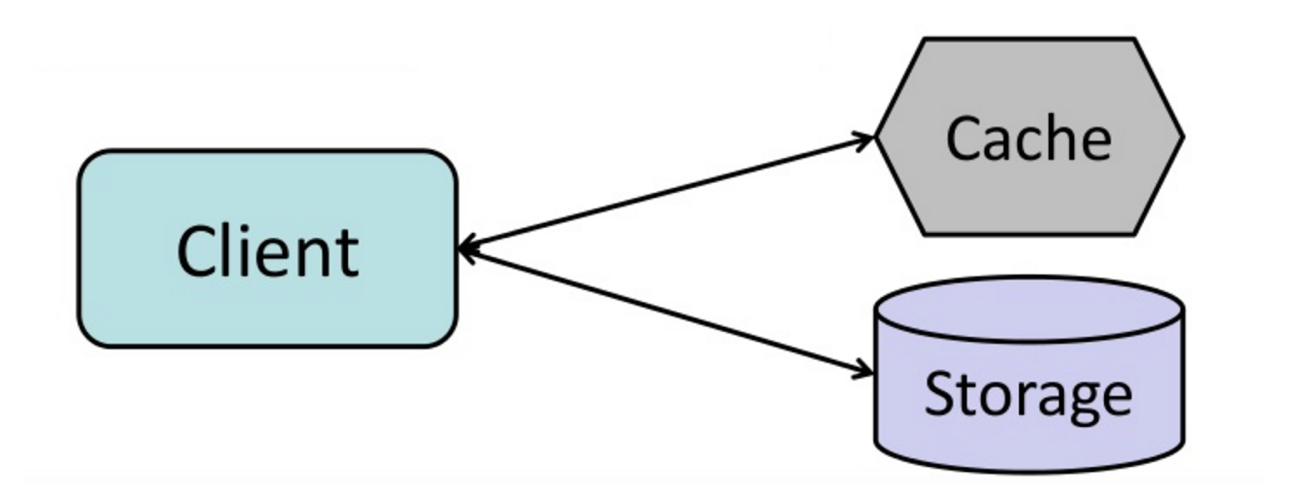
Sumber: From cache to in-memory data grid
Aplikasi bertanggung jawab untuk membaca dan menulis dari storage. Cache tidak berinteraksi langsung dengan storage. Aplikasi melakukan hal berikut:
- Mencari entri di cache, menghasilkan cache miss
- Memuat entri dari database
- Menambahkan entri ke cache
- Mengembalikan entri
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userPembacaan data berikutnya yang ditambahkan ke cache menjadi cepat. Cache-aside juga disebut sebagai lazy loading. Hanya data yang diminta yang di-cache, sehingga menghindari cache terisi oleh data yang tidak diminta.
##### Kekurangan: cache-aside
- Setiap cache miss menghasilkan tiga perjalanan, yang dapat menyebabkan penundaan yang terasa.
- Data bisa menjadi usang jika diperbarui di database. Masalah ini dapat diatasi dengan mengatur time-to-live (TTL) yang memaksa pembaruan entri cache, atau dengan menggunakan write-through.
- Ketika sebuah node gagal, node baru yang kosong akan menggantikan, sehingga meningkatkan latensi.
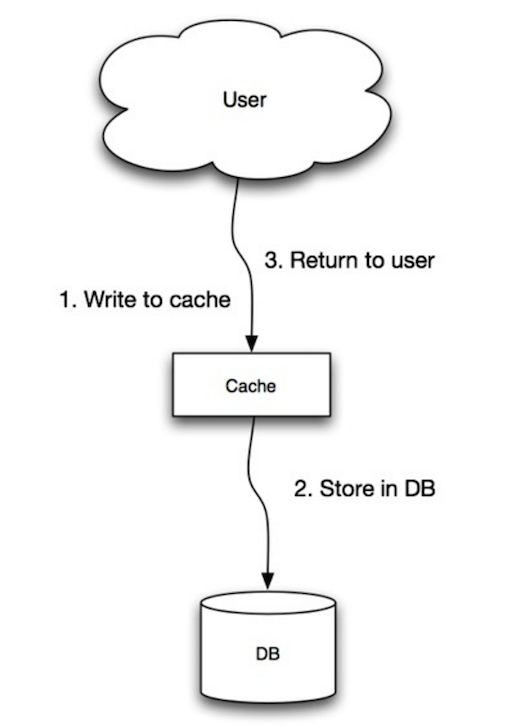
Sumber: Skalabilitas, ketersediaan, stabilitas, pola
Aplikasi menggunakan cache sebagai tempat penyimpanan data utama, membaca dan menulis data ke sana, sementara cache bertanggung jawab untuk membaca dan menulis ke database:
- Aplikasi menambah/memperbarui entri di cache
- Cache secara sinkron menulis entri ke penyimpanan data
- Kembali
set_user(12345, {"foo":"bar"})Kode cache:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### Kekurangan: write-through
- Ketika node baru dibuat karena kegagalan atau skalabilitas, node baru tersebut tidak akan melakukan cache pada entri sampai entri tersebut diperbarui di database. Cache-aside bersama dengan write-through dapat mengurangi masalah ini.
- Sebagian besar data yang ditulis mungkin tidak pernah dibaca, yang dapat diminimalkan dengan TTL.
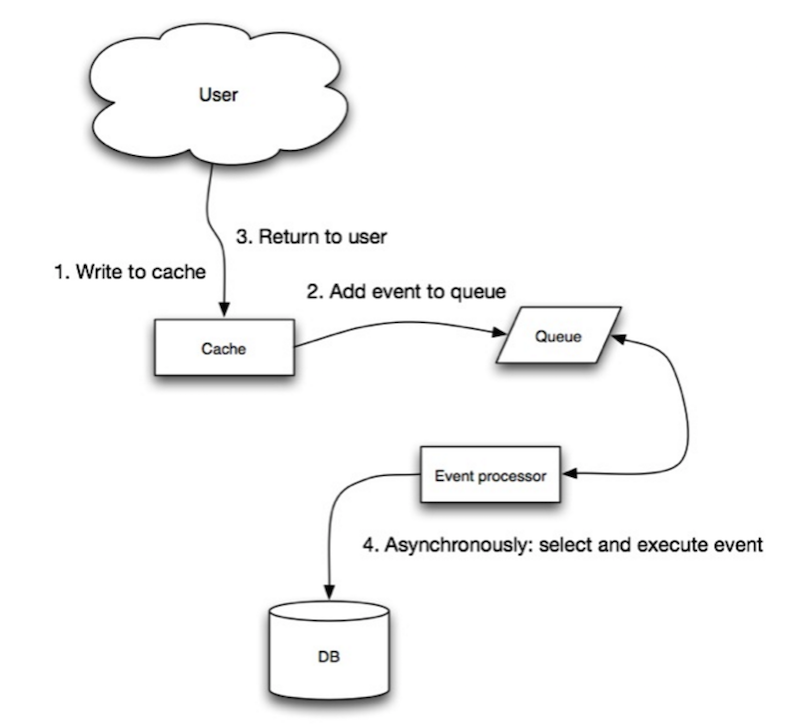
Sumber: Scalability, availability, stability, patterns
Pada write-behind, aplikasi melakukan hal berikut:
- Menambah/memperbarui entri di cache
- Menulis entri ke data store secara asinkron, meningkatkan performa penulisan
- Bisa terjadi kehilangan data jika cache down sebelum isinya masuk ke data store.
- Implementasi write-behind lebih kompleks dibandingkan cache-aside atau write-through.
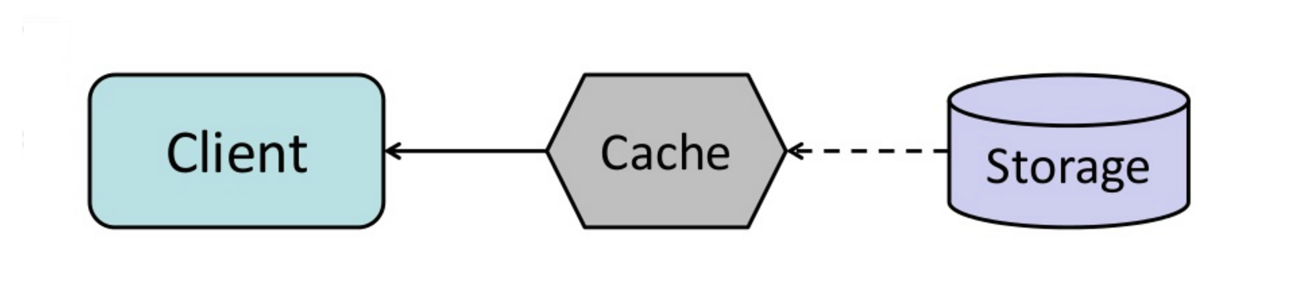
Sumber: From cache to in-memory data grid
Anda dapat mengonfigurasi cache untuk secara otomatis menyegarkan entri cache yang baru saja diakses sebelum masa kedaluwarsanya.
Refresh-ahead dapat menghasilkan latensi yang lebih rendah dibandingkan read-through jika cache dapat secara akurat memprediksi item mana yang kemungkinan akan dibutuhkan di masa depan.
##### Kekurangan: refresh-ahead
- Tidak secara akurat memprediksi item mana yang kemungkinan akan dibutuhkan di masa depan dapat menghasilkan kinerja yang lebih rendah daripada tanpa refresh-ahead.
Kekurangan: cache
- Perlu menjaga konsistensi antara cache dan sumber kebenaran seperti database melalui invalidasi cache.
- Invalidasi cache merupakan masalah yang sulit, ada kompleksitas tambahan terkait kapan harus memperbarui cache.
- Perlu melakukan perubahan aplikasi seperti menambahkan Redis atau memcached.
Sumber dan bacaan lebih lanjut
- Dari cache ke in-memory data grid
- Pola desain sistem yang skalabel
- Pengantar arsitektur sistem untuk skala
- Skalabilitas, ketersediaan, stabilitas, pola
- Skalabilitas
- Strategi AWS ElastiCache
- Wikipedia)
Asinkronisme
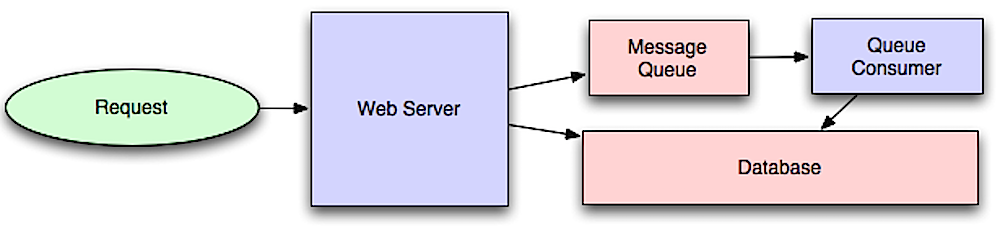
Sumber: Intro to architecting systems for scale
Alur kerja asinkron membantu mengurangi waktu permintaan untuk operasi yang mahal yang seharusnya dilakukan secara in-line. Mereka juga dapat membantu dengan melakukan pekerjaan yang memakan waktu di muka, seperti agregasi data secara berkala.
Message queues
Message queue menerima, menyimpan, dan mengirimkan pesan. Jika suatu operasi terlalu lambat untuk dilakukan secara in-line, Anda dapat menggunakan message queue dengan alur kerja berikut:
- Aplikasi mempublikasikan pekerjaan ke antrian, lalu memberi tahu pengguna tentang status pekerjaan
- Seorang pekerja mengambil pekerjaan dari antrian, memprosesnya, lalu memberi sinyal bahwa pekerjaan telah selesai
Redis berguna sebagai message broker sederhana namun pesan bisa hilang.
RabbitMQ populer tetapi mengharuskan Anda menyesuaikan dengan protokol 'AMQP' dan mengelola node Anda sendiri. Amazon SQS dihosting namun dapat memiliki latensi tinggi dan kemungkinan pesan dikirim dua kali.
Antrian tugas
Antrian tugas menerima tugas dan data terkait, menjalankannya, lalu mengirimkan hasilnya. Mereka dapat mendukung penjadwalan dan digunakan untuk menjalankan pekerjaan yang membutuhkan komputasi intensif di latar belakang.
Celery mendukung penjadwalan dan utamanya mendukung bahasa python.
Tekanan balik (Back pressure)
Jika antrian mulai tumbuh secara signifikan, ukuran antrian bisa lebih besar dari memori, yang mengakibatkan cache miss, pembacaan disk, dan kinerja yang semakin lambat. Tekanan balik dapat membantu dengan membatasi ukuran antrian, sehingga mempertahankan tingkat throughput tinggi dan waktu respons yang baik untuk pekerjaan yang sudah ada di antrian. Setelah antrian penuh, klien akan menerima server busy atau kode status HTTP 503 untuk mencoba lagi nanti. Klien dapat mencoba ulang permintaan di lain waktu, mungkin dengan exponential backoff.
Kelemahan: asinkronisme
- Kasus penggunaan seperti perhitungan murah dan alur kerja realtime mungkin lebih cocok untuk operasi sinkron, karena penggunaan antrian dapat menambah penundaan dan kompleksitas.
Sumber dan bacaan lebih lanjut
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- Apa perbedaan antara message queue dan task queue?
Komunikasi
{kind=link}
{kind=link}
Hypertext transfer protocol (HTTP)
HTTP adalah metode untuk mengenkode dan mengirimkan data antara klien dan server. Ini adalah protokol request/response: klien mengirim permintaan dan server mengirim respons dengan konten relevan dan info status penyelesaian tentang permintaan tersebut. HTTP bersifat mandiri, memungkinkan permintaan dan respons mengalir melalui banyak router dan server perantara yang melakukan load balancing, caching, enkripsi, dan kompresi.
Permintaan HTTP dasar terdiri dari kata kerja (metode) dan sumber daya (endpoint). Berikut adalah kata kerja HTTP yang umum:
| Verb | Deskripsi | Idempotent* | Aman | Dapat di-cache |
| GET | Membaca sebuah sumber daya | Ya | Ya | Ya | | POST | Membuat sebuah sumber daya atau memicu proses yang menangani data | Tidak | Tidak | Ya jika respons berisi info kesegaran | | PUT | Membuat atau mengganti sebuah sumber daya | Ya | Tidak | Tidak | | PATCH | Memperbarui sebagian sumber daya | Tidak | Tidak | Ya jika respons berisi info kesegaran | | DELETE | Menghapus sebuah sumber daya | Ya | Tidak | Tidak |
*Dapat dipanggil berkali-kali tanpa hasil yang berbeda.
HTTP adalah protokol lapisan aplikasi yang bergantung pada protokol tingkat bawah seperti TCP dan UDP.
#### Sumber dan bacaan lebih lanjut: HTTP
Protokol kontrol transmisi (TCP)
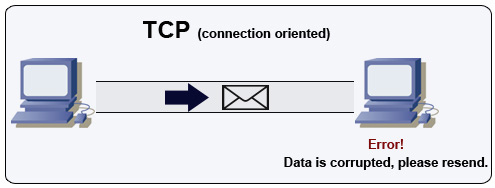
Sumber: How to make a multiplayer game
TCP adalah protokol berorientasi koneksi di atas jaringan IP. Koneksi dibuat dan diakhiri menggunakan handshake. Semua paket yang dikirim dijamin sampai ke tujuan dalam urutan asli dan tanpa korupsi melalui:
- Nomor urut dan field checksum untuk setiap paket
- Paket acknowledgement) dan retransmisi otomatis
Untuk memastikan throughput tinggi, server web dapat menjaga banyak koneksi TCP tetap terbuka, yang menyebabkan penggunaan memori tinggi. Menjaga banyak koneksi terbuka antara thread server web dan misalnya, server memcached bisa mahal. Connection pooling dapat membantu selain beralih ke UDP jika memungkinkan.
TCP bermanfaat untuk aplikasi yang membutuhkan keandalan tinggi namun tidak terlalu kritis waktu. Beberapa contoh termasuk server web, info database, SMTP, FTP, dan SSH.
Gunakan TCP dibanding UDP saat:
- Anda membutuhkan semua data tiba utuh
- Anda ingin secara otomatis memperkirakan penggunaan throughput jaringan
User datagram protocol (UDP)
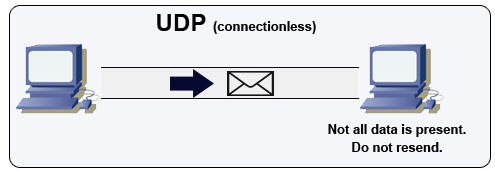
Sumber: How to make a multiplayer game
UDP bersifat connectionless. Datagram (analog dengan paket) hanya dijamin pada tingkat datagram. Datagram dapat tiba di tujuan dalam urutan yang salah atau bahkan tidak sampai sama sekali. UDP tidak mendukung kontrol kemacetan. Tanpa jaminan seperti pada TCP, UDP umumnya lebih efisien.
UDP dapat melakukan broadcast, mengirimkan datagram ke semua perangkat di subnet. Ini berguna untuk DHCP karena klien belum menerima alamat IP, sehingga mencegah TCP melakukan streaming tanpa alamat IP.
UDP kurang andal tetapi bekerja dengan baik untuk kasus penggunaan waktu nyata seperti VoIP, video chat, streaming, dan permainan multipemain waktu nyata.
Gunakan UDP daripada TCP ketika:
- Anda membutuhkan latensi serendah mungkin
- Data yang terlambat lebih buruk daripada kehilangan data
- Anda ingin mengimplementasikan koreksi kesalahan sendiri
- Networking for game programming
- Key differences between TCP and UDP protocols
- Difference between TCP and UDP
- Transmission control protocol
- User datagram protocol
- Scaling memcache at Facebook
Remote procedure call (RPC)
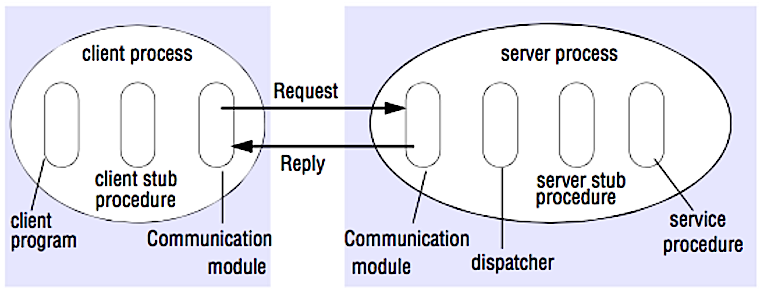
Sumber: Crack the system design interview
Dalam RPC, sebuah klien menyebabkan sebuah prosedur dijalankan pada ruang alamat yang berbeda, biasanya pada server jarak jauh. Prosedur tersebut dikodekan seolah-olah merupakan pemanggilan prosedur lokal, sehingga merangkum detail tentang bagaimana berkomunikasi dengan server dari program klien. Panggilan jarak jauh biasanya lebih lambat dan kurang andal dibandingkan panggilan lokal sehingga membantu untuk membedakan panggilan RPC dari panggilan lokal. Framework RPC populer meliputi Protobuf, Thrift, dan Avro.
RPC adalah protokol request-response:
- Program klien - Memanggil prosedur client stub. Parameter dimasukkan ke dalam stack seperti pemanggilan prosedur lokal.
- Prosedur client stub - Melakukan marshaling (pengemasan) id prosedur dan argumen ke dalam pesan permintaan.
- Modul komunikasi klien - OS mengirimkan pesan dari klien ke server.
- Modul komunikasi server - OS meneruskan paket yang masuk ke prosedur server stub.
- Prosedur server stub - Melakukan unmarshalling hasil, memanggil prosedur server yang sesuai dengan id prosedur dan memberikan argumen yang diberikan.
- Respons server mengulangi langkah-langkah di atas dengan urutan terbalik.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC berfokus pada pemaparan perilaku. RPC sering digunakan untuk alasan performa dalam komunikasi internal, karena Anda dapat merancang panggilan native secara khusus agar lebih sesuai dengan kebutuhan Anda.
Pilihlah pustaka native (alias SDK) ketika:
- Anda mengetahui platform target Anda.
- Anda ingin mengontrol bagaimana "logika" Anda diakses.
- Anda ingin mengontrol bagaimana penanganan kesalahan terjadi di luar pustaka Anda.
- Performa dan pengalaman pengguna akhir adalah perhatian utama Anda.
#### Kerugian: RPC
- Klien RPC menjadi sangat terkait erat dengan implementasi layanan.
- API baru harus didefinisikan untuk setiap operasi atau kasus penggunaan baru.
- Debug RPC bisa menjadi sulit.
- Anda mungkin tidak dapat memanfaatkan teknologi yang sudah ada secara langsung. Misalnya, mungkin diperlukan upaya tambahan untuk memastikan panggilan RPC di-cache dengan benar di server cache seperti Squid.
Representational state transfer (REST)
REST adalah gaya arsitektur yang menerapkan model client/server di mana klien bertindak pada sekumpulan sumber daya yang dikelola oleh server. Server menyediakan representasi sumber daya dan tindakan yang dapat memanipulasi atau memperoleh representasi baru dari sumber daya. Semua komunikasi harus bersifat stateless dan dapat di-cache.
Ada empat kualitas antarmuka RESTful:
- Identifikasi sumber daya (URI dalam HTTP) - gunakan URI yang sama terlepas dari operasi apapun.
- Perubahan dengan representasi (Verba dalam HTTP) - gunakan verba, header, dan body.
- Pesan kesalahan yang deskriptif (respons status dalam HTTP) - Gunakan kode status, jangan membuat ulang standar yang sudah ada.
- HATEOAS (antarmuka HTML untuk HTTP) - layanan web Anda harus sepenuhnya dapat diakses di browser.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Kekurangan: REST
- Karena REST berfokus pada penyajian data, mungkin tidak cocok jika sumber daya tidak secara alami terorganisir atau diakses dalam hierarki sederhana. Misalnya, mengembalikan semua catatan yang diperbarui dalam satu jam terakhir yang cocok dengan serangkaian event tertentu tidak mudah diekspresikan sebagai path. Dengan REST, hal ini kemungkinan diimplementasikan dengan kombinasi path URI, parameter query, dan mungkin body permintaan.
- REST biasanya mengandalkan beberapa kata kerja (GET, POST, PUT, DELETE, dan PATCH) yang kadang tidak sesuai dengan kasus penggunaan Anda. Misalnya, memindahkan dokumen kadaluarsa ke folder arsip mungkin tidak cocok dengan kata kerja tersebut.
- Mengambil sumber daya yang kompleks dengan hierarki bertingkat memerlukan beberapa perjalanan bolak-balik antara klien dan server untuk menampilkan satu tampilan, misalnya mengambil konten entri blog dan komentar pada entri tersebut. Untuk aplikasi mobile yang beroperasi dalam kondisi jaringan yang bervariasi, perjalanan bolak-balik ini sangat tidak diinginkan.
- Seiring waktu, lebih banyak field mungkin ditambahkan ke respons API dan klien lama akan menerima semua field data baru, bahkan yang tidak mereka butuhkan, sehingga membengkakkan ukuran payload dan menyebabkan latensi yang lebih tinggi.
Perbandingan panggilan RPC dan REST
| Operasi | RPC | REST |
|---|---|---|
| Signup | POST /signup | POST /persons |
| Resign | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Baca data seseorang | GET /readPerson?personid=1234 | GET /persons/1234 |
| Baca daftar item seseorang | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Tambah item ke daftar item seseorang | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Update item | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Hapus item | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Sumber: Do you really know why you prefer REST over RPC
#### Sumber dan bacaan lanjut: REST dan RPC
- Do you really know why you prefer REST over RPC
- Kapan pendekatan RPC lebih sesuai daripada REST?
- REST vs JSON-RPC
- Membantah mitos RPC dan REST
- Apa saja kekurangan penggunaan REST
- Crack the system design interview
- Thrift
- Mengapa REST untuk penggunaan internal dan bukan RPC
Keamanan
Bagian ini membutuhkan beberapa pembaruan. Pertimbangkan untuk berkontribusi!
Keamanan adalah topik yang luas. Kecuali Anda memiliki pengalaman yang cukup, latar belakang keamanan, atau melamar posisi yang memerlukan pengetahuan keamanan, Anda mungkin hanya perlu mengetahui dasar-dasarnya:
- Enkripsi saat transit dan saat diam.
- Sanitasi semua masukan pengguna atau parameter masukan apa pun yang terbuka untuk pengguna guna mencegah XSS dan SQL injection.
- Gunakan query terparameter untuk mencegah SQL injection.
- Gunakan prinsip hak akses paling minimal.
Sumber dan bacaan lebih lanjut
Lampiran
Terkadang Anda akan diminta melakukan estimasi 'back-of-the-envelope'. Misalnya, Anda mungkin perlu menentukan berapa lama waktu yang dibutuhkan untuk menghasilkan 100 thumbnail gambar dari disk atau berapa banyak memori yang akan digunakan oleh sebuah struktur data. Tabel pangkat dua dan Angka latensi yang harus diketahui setiap programmer adalah referensi yang berguna.
Tabel pangkat dua
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Sumber dan bacaan lebih lanjut
Angka latensi yang harus diketahui setiap programmer
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Metode praktis berdasarkan angka di atas:
- Membaca secara berurutan dari HDD pada 30 MB/s
- Membaca secara berurutan dari Ethernet 1 Gbps pada 100 MB/s
- Membaca secara berurutan dari SSD pada 1 GB/s
- Membaca secara berurutan dari memori utama pada 4 GB/s
- 6-7 perjalanan keliling dunia per detik
- 2.000 perjalanan bolak-balik per detik dalam satu pusat data
#### Sumber dan bacaan lanjutan
- Angka latensi yang harus diketahui setiap programmer - 1
- Angka latensi yang harus diketahui setiap programmer - 2
- Desain, pelajaran, dan saran dari membangun sistem terdistribusi besar
- Saran Rekayasa Perangkat Lunak dari Membangun Sistem Terdistribusi Skala Besar
Pertanyaan tambahan wawancara desain sistem
Pertanyaan umum wawancara desain sistem, dengan tautan ke sumber daya cara menyelesaikan masing-masing.
| Pertanyaan | Referensi |
|---|---|
| Desain layanan sinkronisasi file seperti Dropbox | youtube.com |
| Desain mesin pencari seperti Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Desain perayap web yang skalabel seperti Google | quora.com |
| Desain Google docs | code.google.com
neil.fraser.name |
| Desain penyimpanan key-value seperti Redis | slideshare.net |
| Desain sistem cache seperti Memcached | slideshare.net |
| Desain sistem rekomendasi seperti Amazon | hulu.com
ijcai13.org |
| Desain sistem tinyurl seperti Bitly | n00tc0d3r.blogspot.com |
| Desain aplikasi chat seperti WhatsApp | highscalability.com
| Desain sistem berbagi foto seperti Instagram | highscalability.com
highscalability.com |
| Desain fungsi umpan berita Facebook | quora.com
quora.com
slideshare.net |
| Desain fungsi linimasa Facebook | facebook.com
highscalability.com |
| Desain fungsi chat Facebook | erlang-factory.com
facebook.com |
| Rancang fungsi pencarian grafik seperti Facebook | facebook.com
facebook.com
facebook.com |
| Rancang jaringan pengiriman konten seperti CloudFlare | figshare.com |
| Rancang sistem topik trending seperti Twitter | michael-noll.com
snikolov .wordpress.com |
| Rancang sistem pembuatan ID acak | blog.twitter.com
github.com |
| Kembalikan permintaan top k selama interval waktu | cs.ucsb.edu
wpi.edu |
| Rancang sistem yang melayani data dari beberapa pusat data | highscalability.com |
| Rancang permainan kartu multipemain online | indieflashblog.com
buildnewgames.com |
| Rancang sistem garbage collection | stuffwithstuff.com
washington.edu |
| Rancang pembatas laju API | https://stripe.com/blog/ |
| Rancang Bursa Saham (seperti NASDAQ atau Binance) | Jane Street
Golang Implementation
Go Implementation |
| Tambahkan pertanyaan desain sistem | Kontribusi |
Arsitektur dunia nyata
Artikel tentang bagaimana sistem dunia nyata dirancang.
Sumber: Timeline Twitter dalam skala besar
Jangan fokus pada detail teknis mendalam untuk artikel berikut, melainkan:
- Identifikasi prinsip yang sama, teknologi umum, dan pola dalam artikel-artikel tersebut
- Pelajari masalah apa yang diselesaikan oleh setiap komponen, di mana berfungsi, di mana tidak
- Tinjau pelajaran yang didapat
Arsitektur Perusahaan
| Perusahaan | Referensi |
|---|---|
| Amazon | Arsitektur Amazon |
| Cinchcast | Memproduksi 1.500 jam audio setiap hari |
| DataSift | Penambangan data real-time 120.000 tweet per detik |
| Dropbox | Bagaimana kami menskalakan Dropbox |
| ESPN | Beroperasi pada 100.000 duh nuh nuh per detik |
| Google | Arsitektur Google |
| Instagram | 14 juta pengguna, terabyte foto
Apa yang mendukung Instagram |
| Justin.tv | Arsitektur siaran video langsung Justin.Tv |
| Facebook | Scaling memcached di Facebook
TAO: Penyimpanan data terdistribusi Facebook untuk grafik sosial
Penyimpanan foto Facebook
Bagaimana Facebook Live Menyiarkan ke 800.000 Penonton Secara Bersamaan |
| Flickr | Arsitektur Flickr |
| Mailbox | Dari 0 ke satu juta pengguna dalam 6 minggu |
| Netflix | Pandangan 360 Derajat Seluruh Stack Netflix
Netflix: Apa yang Terjadi Ketika Anda Menekan Play? |
| Pinterest | Dari 0 ke puluhan miliar tampilan halaman per bulan
18 juta pengunjung, pertumbuhan 10x, 12 karyawan |
| Playfish | 50 juta pengguna bulanan dan terus bertambah |
| PlentyOfFish | Arsitektur PlentyOfFish |
| Salesforce | Bagaimana mereka menangani 1,3 miliar transaksi per hari |
| Stack Overflow | Arsitektur Stack Overflow |
| TripAdvisor | 40M pengunjung, 200M tampilan halaman dinamis, 30TB data |
| Tumblr | 15 miliar tampilan halaman per bulan |
| Twitter | Membuat Twitter 10000 persen lebih cepat
Menyimpan 250 juta tweet per hari menggunakan MySQL
150M pengguna aktif, 300K QPS, 22 MB/S firehose
Timeline pada skala besar
Big dan small data di Twitter
Operasi di Twitter: scaling lebih dari 100 juta pengguna
Bagaimana Twitter Menangani 3.000 Gambar Per Detik |
| Uber | Bagaimana Uber menskalakan platform pasar real-time mereka
Pelajaran dari scaling Uber ke 2000 engineer, 1000 layanan, dan 8000 repositori Git |
| WhatsApp | Arsitektur WhatsApp yang dibeli Facebook seharga $19 miliar |
| YouTube | Skalabilitas YouTube
Arsitektur YouTube |
Blog Teknik Perusahaan
Arsitektur untuk perusahaan tempat Anda sedang wawancara.>
Pertanyaan yang Anda temui mungkin berasal dari domain yang sama.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
Ingin menambahkan blog? Untuk menghindari duplikasi pekerjaan, pertimbangkan untuk menambahkan blog perusahaan Anda ke repo berikut:
Sedang dikembangkan
Tertarik menambahkan bagian atau membantu menyelesaikan bagian yang sedang berlangsung? Kontribusi!
- Komputasi terdistribusi dengan MapReduce
- Consistent hashing
- Scatter gather
- Kontribusi
Kredit
Kredit dan sumber diberikan di seluruh repo ini.
Terima kasih khusus kepada:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
Info kontak
Silakan hubungi saya untuk mendiskusikan masalah, pertanyaan, atau komentar apa pun.
Informasi kontak saya dapat ditemukan di Halaman GitHub saya.
Lisensi
Saya menyediakan kode dan sumber daya dalam repositori ini kepada Anda di bawah lisensi sumber terbuka. Karena ini adalah repositori pribadi saya, lisensi yang Anda terima untuk kode dan sumber daya saya berasal dari saya dan bukan dari pemberi kerja saya (Facebook).
Hak Cipta 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---