English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation इस गाइड को अनुवाद करने में मदद करें!
सिस्टम डिज़ाइन प्राइमर

प्रेरणा
जानें कि बड़े पैमाने की प्रणालियों को कैसे डिज़ाइन करें।>
सिस्टम डिज़ाइन साक्षात्कार की तैयारी करें।
जानें कि बड़े पैमाने की प्रणालियों को कैसे डिज़ाइन करें
स्केलेबल सिस्टम डिज़ाइन करना सीखना आपको बेहतर इंजीनियर बनने में मदद करेगा।
सिस्टम डिज़ाइन एक व्यापक विषय है। सिस्टम डिज़ाइन सिद्धांतों पर इंटरनेट पर बड़ी मात्रा में संसाधन फैले हुए हैं।
यह रिपॉजिटरी आपको बड़े पैमाने पर सिस्टम बनाने में मदद करने के लिए संसाधनों का एक संगठित संग्रह है।
ओपन सोर्स समुदाय से सीखें
यह निरंतर अपडेट होने वाला, ओपन सोर्स प्रोजेक्ट है।
योगदान स्वागत योग्य हैं!
सिस्टम डिज़ाइन साक्षात्कार की तैयारी करें
कोडिंग साक्षात्कार के अलावा, सिस्टम डिज़ाइन कई टेक कंपनियों में तकनीकी साक्षात्कार प्रक्रिया का एक अनिवार्य हिस्सा है।
आम सिस्टम डिज़ाइन साक्षात्कार प्रश्नों का अभ्यास करें और अपने परिणामों की नमूना समाधानों के साथ तुलना करें: चर्चाएँ, कोड और आरेख।
साक्षात्कार तैयारी के लिए अतिरिक्त विषय:
- अध्ययन गाइड
- सिस्टम डिज़ाइन साक्षात्कार प्रश्न का दृष्टिकोण कैसे बनाएं
- सिस्टम डिज़ाइन इंटरव्यू प्रश्न, समाधान सहित
- ऑब्जेक्ट-ओरिएंटेड डिज़ाइन इंटरव्यू प्रश्न, समाधान सहित
- अतिरिक्त सिस्टम डिज़ाइन इंटरव्यू प्रश्न
Anki फ्लैशकार्ड्स
दिए गए Anki फ्लैशकार्ड डेक्स स्पेस्ड रिपीटीशन का उपयोग करते हैं ताकि आप प्रमुख सिस्टम डिज़ाइन अवधारणाओं को याद रख सकें।
चलते-फिरते उपयोग के लिए शानदार।कोडिंग संसाधन: इंटरएक्टिव कोडिंग चुनौतियाँ
क्या आप कोडिंग इंटरव्यू की तैयारी के लिए संसाधन ढूंढ रहे हैं?
सिस्टर रिपॉजिटरी देखें इंटरएक्टिव कोडिंग चुनौतियाँ, जिसमें एक अतिरिक्त Anki डेक शामिल है:
सहयोग
समुदाय से सीखें।
सहायता के लिए स्वतंत्र रूप से पुल रिक्वेस्ट सबमिट करें:
- त्रुटियाँ सुधारें
- सेक्शन बेहतर बनाएं
- नई अनुभाग जोड़ें
- अनुवाद करें
योगदान दिशा-निर्देश की समीक्षा करें।
सिस्टम डिज़ाइन विषयों की सूची
विभिन्न सिस्टम डिज़ाइन विषयों का सारांश, जिसमें फायदे और नुकसान शामिल हैं। हर चीज़ में समझौता है।>
प्रत्येक अनुभाग में अधिक गहन संसाधनों के लिंक हैं।
- सिस्टम डिज़ाइन विषय: यहाँ से शुरू करें
- चरण 1: स्केलेबिलिटी वीडियो व्याख्यान की समीक्षा करें
- चरण 2: स्केलेबिलिटी लेख की समीक्षा करें
- अगले कदम
- प्रदर्शन बनाम स्केलेबिलिटी
- विलंबता बनाम थ्रूपुट
- उपलब्धता बनाम स्थिरता
- CAP प्रमेय
- CP - स्थिरता और विभाजन सहिष्णुता
- AP - उपलब्धता और विभाजन सहिष्णुता
- स्थिरता पैटर्न
- कमजोर स्थिरता
- अंततः स्थिरता
- मजबूत स्थिरता
- उपलब्धता पैटर्न
- फेल-ओवर
- प्रतिकृति
- संख्याओं में उपलब्धता
- डोमेन नाम प्रणाली
- सामग्री वितरण नेटवर्क
- पुश CDN
- पुल CDN
- लोड बैलेंसर
- सक्रिय-निष्क्रिय
- सक्रिय-सक्रिय
- लेयर 4 लोड बैलेंसिंग
- लेयर 7 लोड बैलेंसिंग
- क्षैतिज स्केलिंग
- रिवर्स प्रॉक्सी (वेब सर्वर)
- लोड बैलेंसर बनाम रिवर्स प्रॉक्सी
- एप्लिकेशन लेयर
- माइक्रोसर्विसेस
- सर्विस डिस्कवरी
- डाटाबेस
- रिलेशनल डाटाबेस मैनेजमेंट सिस्टम (RDBMS)
- मास्टर-स्ले रिप्लिकेशन
- मास्टर-मास्टर रिप्लिकेशन
- फेडरेशन
- शार्डिंग
- डिनॉर्मलाइजेशन
- SQL ट्यूनिंग
- NoSQL
- की-वैल्यू स्टोर
- डॉक्यूमेंट स्टोर
- वाइड कॉलम स्टोर
- ग्राफ डाटाबेस
- SQL या NoSQL
- कैश
- क्लाइंट कैशिंग
- CDN कैशिंग
- वेब सर्वर कैशिंग
- डाटाबेस कैशिंग
- एप्लिकेशन कैशिंग
- डाटाबेस क्वेरी स्तर पर कैशिंग
- ऑब्जेक्ट स्तर पर कैशिंग
- कैश कब अपडेट करें
- कैश-असाइड
- राइट-थ्रू
- राइट-बिहाइंड (राइट-बैक)
- रिफ्रेश-अहेड
- असिंक्रोनस
- मैसेज क्यूज़
- टास्क कतारें
- बैक प्रेशर
- संचार
- ट्रांसमिशन कंट्रोल प्रोटोकॉल (TCP)
- यूज़र डेटाग्राम प्रोटोकॉल (UDP)
- रिमोट प्रोसीजर कॉल (RPC)
- रिप्रेजेंटेशनल स्टेट ट्रांसफर (REST)
- सुरक्षा
- परिशिष्ट
- दो के घातों की तालिका
- हर प्रोग्रामर को ज्ञात होने वाली विलंब संख्याएँ
- अतिरिक्त सिस्टम डिज़ाइन साक्षात्कार प्रश्न
- वास्तविक दुनिया की वास्तुकलाएँ
- कंपनी वास्तुकलाएँ
- कंपनी इंजीनियरिंग ब्लॉग्स
- विकासाधीन
- श्रेय
- संपर्क जानकारी
- लाइसेंस
अध्ययन मार्गदर्शिका
आपके साक्षात्कार समयरेखा (संक्षिप्त, मध्यम, लंबी) के आधार पर समीक्षा के लिए सुझाए गए विषय।
प्र: क्या इंटरव्यू के लिए मुझे यहाँ सब कुछ जानना आवश्यक है?
उ: नहीं, इंटरव्यू की तैयारी के लिए आपको यहाँ सब कुछ जानना आवश्यक नहीं है।
इंटरव्यू में आपसे क्या पूछा जाएगा, यह इन कारकों पर निर्भर करता है:
- आपके पास कितना अनुभव है
- आपका तकनीकी पृष्ठभूमि क्या है
- आप किस पद के लिए इंटरव्यू दे रहे हैं
- आप किन कंपनियों में इंटरव्यू दे रहे हैं
- भाग्य
चौड़ा शुरू करें और कुछ क्षेत्रों में गहराई में जाएँ। विभिन्न प्रमुख सिस्टम डिज़ाइन विषयों के बारे में थोड़ा जानना मददगार होता है। निम्नलिखित मार्गदर्शिका को अपनी समयसीमा, अनुभव, जिन पदों के लिए आप इंटरव्यू दे रहे हैं, और जिन कंपनियों के लिए आप इंटरव्यू दे रहे हैं, के अनुसार समायोजित करें।
- कम समयसीमा - सिस्टम डिज़ाइन विषयों में चौड़ाई का लक्ष्य रखें। कुछ इंटरव्यू प्रश्नों को हल करके अभ्यास करें।
- मध्यम समयसीमा - सिस्टम डिज़ाइन विषयों में चौड़ाई और कुछ गहराई का लक्ष्य रखें। कई इंटरव्यू प्रश्नों को हल करके अभ्यास करें।
- लंबी समयसीमा - सिस्टम डिज़ाइन विषयों में चौड़ाई और अधिक गहराई का लक्ष्य रखें। अधिकांश इंटरव्यू प्रश्नों को हल करके अभ्यास करें।
सिस्टम डिज़ाइन इंटरव्यू प्रश्न को कैसे हल करें
सिस्टम डिज़ाइन इंटरव्यू प्रश्न को कैसे हल करें।
सिस्टम डिज़ाइन इंटरव्यू एक खुली बातचीत है। आपसे अपेक्षा की जाती है कि आप इसका नेतृत्व करेंगे।
आप चर्चा को मार्गदर्शित करने के लिए निम्नलिखित चरणों का उपयोग कर सकते हैं। इस प्रक्रिया को मजबूत करने के लिए, सिस्टम डिज़ाइन इंटरव्यू प्रश्नों के समाधान अनुभाग पर इन चरणों के साथ काम करें।
चरण 1: उपयोग के मामले, बाधाएँ, और मान्यताओं की रूपरेखा बनाएं
आवश्यकताएँ एकत्र करें और समस्या का दायरा तय करें। उपयोग के मामले और बाधाओं को स्पष्ट करने के लिए प्रश्न पूछें। मान्यताओं पर चर्चा करें।
- कौन इसका उपयोग करेगा?
- वे इसका उपयोग कैसे करेंगे?
- कितने उपयोगकर्ता हैं?
- सिस्टम क्या करता है?
- सिस्टम के इनपुट और आउटपुट क्या हैं?
- हमें कितने डेटा की उम्मीद है?
- हमें प्रति सेकंड कितनी अनुरोधों की उम्मीद है?
- अपेक्षित पढ़ने और लिखने का अनुपात क्या है?
चरण 2: उच्च स्तरीय डिज़ाइन बनाएं
सभी महत्वपूर्ण घटकों के साथ एक उच्च स्तरीय डिज़ाइन की रूपरेखा बनाएं।
- मुख्य घटकों और कनेक्शनों का स्केच बनाएं
- अपने विचारों का औचित्य सिद्ध करें
चरण 3: मुख्य घटकों का डिज़ाइन करें
प्रत्येक मुख्य घटक के लिए विवरण में जाएं। उदाहरण के लिए, यदि आपसे एक URL शॉर्टनिंग सेवा डिज़ाइन करने के लिए कहा जाए, तो चर्चा करें:
- पूर्ण URL का हैश जनरेट करना और स्टोर करना
- MD5 और Base62
- हैश टकराव
- SQL या NoSQL
- डेटाबेस स्कीमा
- हैश किए गए URL को पूर्ण URL में ट्रांसलेट करना
- डेटाबेस लुकअप
- API और ऑब्जेक्ट-ओरिएंटेड डिज़ाइन
चरण 4: डिज़ाइन को स्केल करें
बॉटलनेक्स की पहचान करें और सीमाओं को ध्यान में रखते हुए उनका समाधान करें। उदाहरण के लिए, क्या आपको स्केलेबिलिटी समस्याओं के समाधान के लिए निम्नलिखित की आवश्यकता है?
- लोड बैलेंसर
- क्षैतिज स्केलिंग
- कैशिंग
- डेटाबेस शार्डिंग
अनुमानित गणनाएँ (Back-of-the-envelope calculations)
आपसे हाथ से कुछ अनुमान लगाने के लिए कहा जा सकता है। निम्नलिखित संसाधनों के लिए परिशिष्ट देखें:
- Back-of-the-envelope गणनाओं का उपयोग करें
- दो की घातों की तालिका
- प्रत्येक प्रोग्रामर को ज्ञात लेटेंसी संख्याएँ
स्रोत और आगे पढ़ाई
अधिक अच्छे से समझने के लिए निम्नलिखित लिंक देखें:
- सिस्टम डिज़ाइन इंटरव्यू में कैसे सफल हों
- सिस्टम डिज़ाइन इंटरव्यू
- आर्किटेक्चर और सिस्टम डिज़ाइन इंटरव्यू का परिचय
- सिस्टम डिज़ाइन टेम्पलेट
सिस्टम डिज़ाइन इंटरव्यू प्रश्न और उनके समाधान
सामान्य सिस्टम डिज़ाइन इंटरव्यू प्रश्नों के लिए नमूना चर्चा, कोड, और चित्र।>
समाधान solutions/ फ़ोल्डर में दिए गए कंटेंट से जुड़े हैं।| प्रश्न | | |---|---| | Pastebin.com (या Bit.ly) डिज़ाइन करें | समाधान | | ट्विटर टाइमलाइन और सर्च (या फेसबुक फीड और सर्च) डिज़ाइन करें | समाधान | | वेब क्रॉलर डिज़ाइन करें | समाधान | | Mint.com डिज़ाइन करें | समाधान | | सोशल नेटवर्क के लिए डेटा संरचना डिज़ाइन करें | समाधान | | सर्च इंजन के लिए की-वैल्यू स्टोर डिज़ाइन करें | समाधान | | अमेज़न के सेल्स रैंकिंग बाय कैटेगरी फीचर को डिज़ाइन करें | समाधान | | AWS पर लाखों यूज़र्स को स्केल करने वाली प्रणाली डिज़ाइन करें | समाधान | | एक सिस्टम डिज़ाइन प्रश्न जोड़ें | योगदान करें |
Pastebin.com (या Bit.ly) डिज़ाइन करें
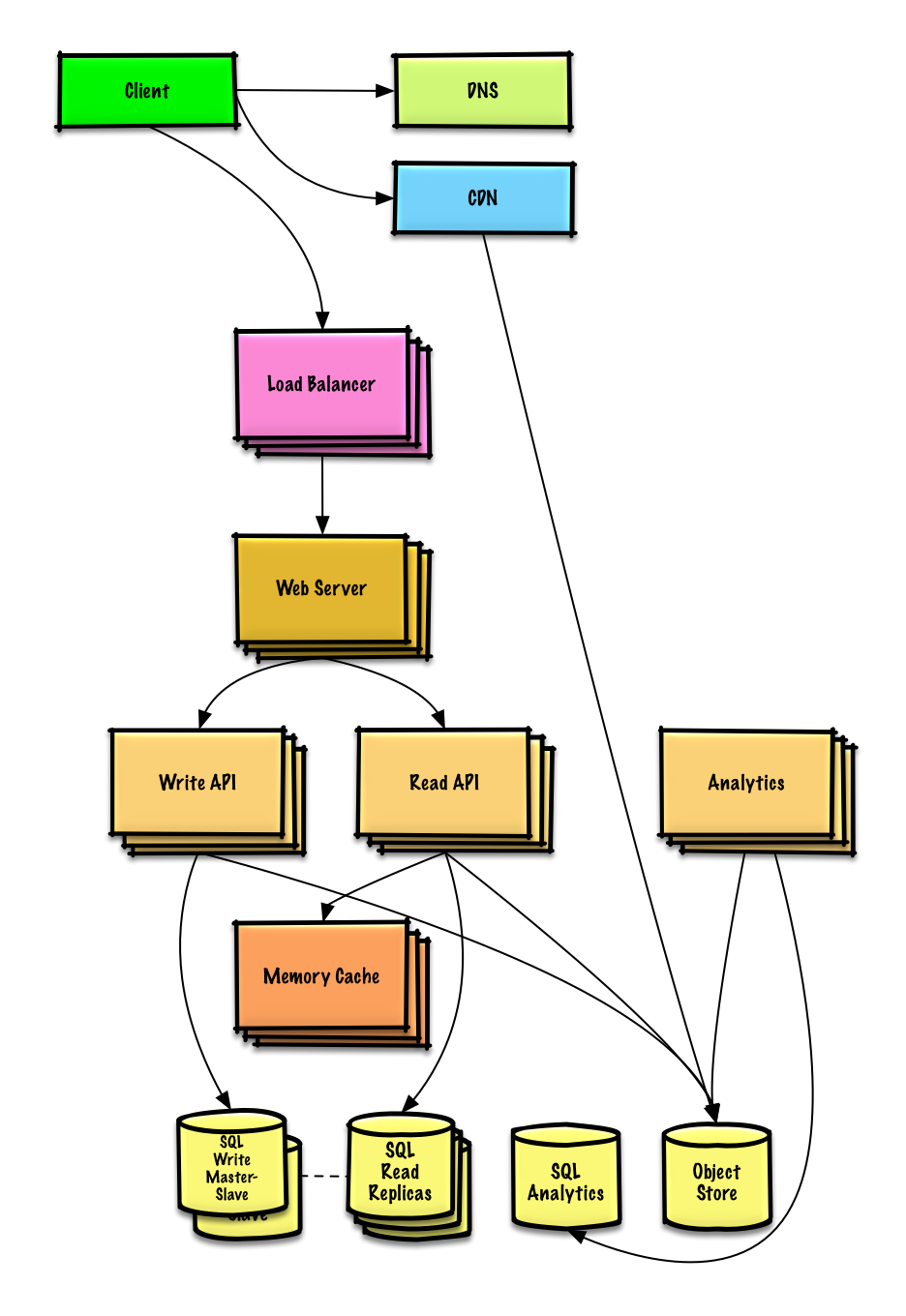
ट्विटर टाइमलाइन और सर्च (या फेसबुक फीड और सर्च) डिज़ाइन करें
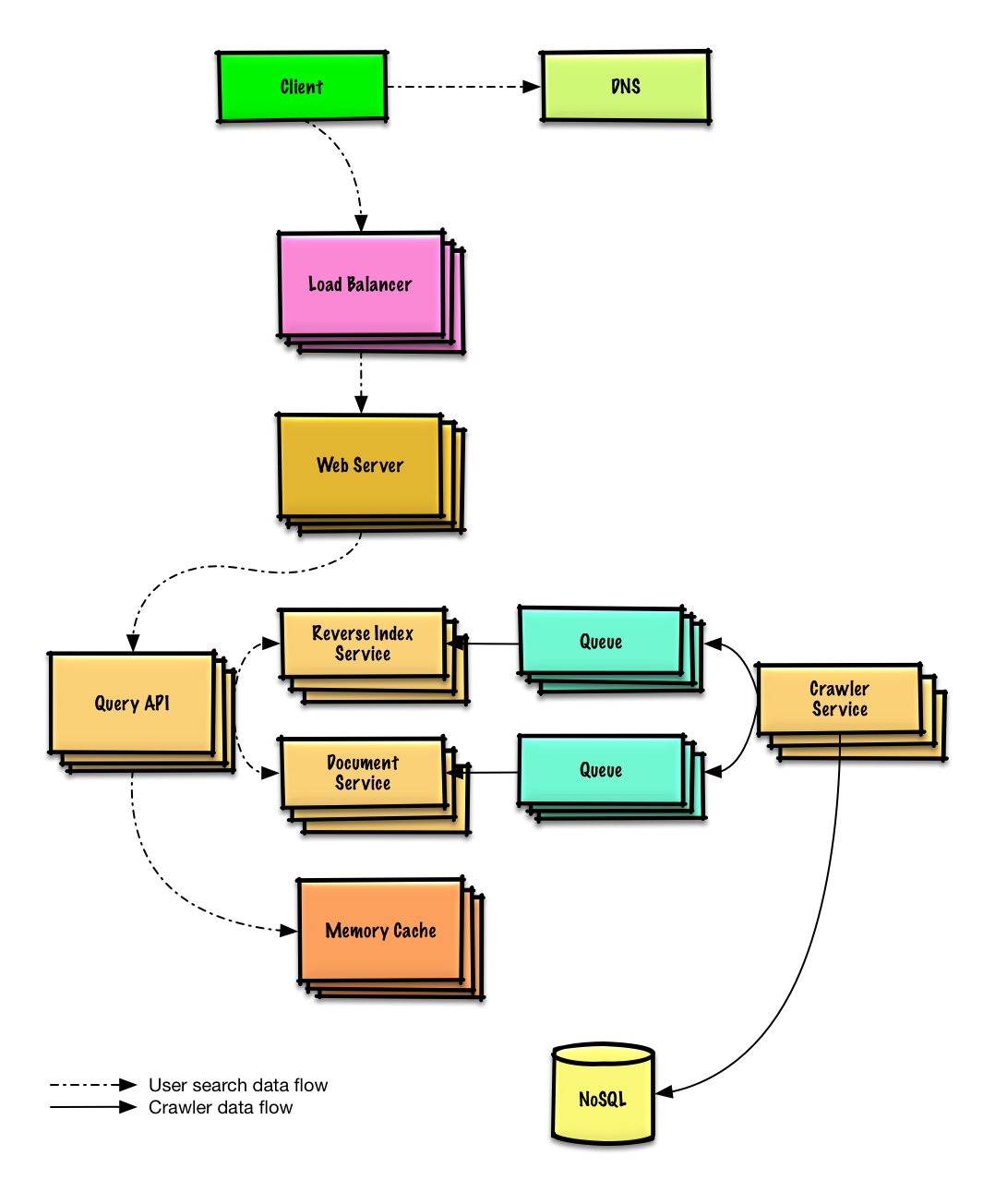
वेब क्रॉलर डिज़ाइन करें
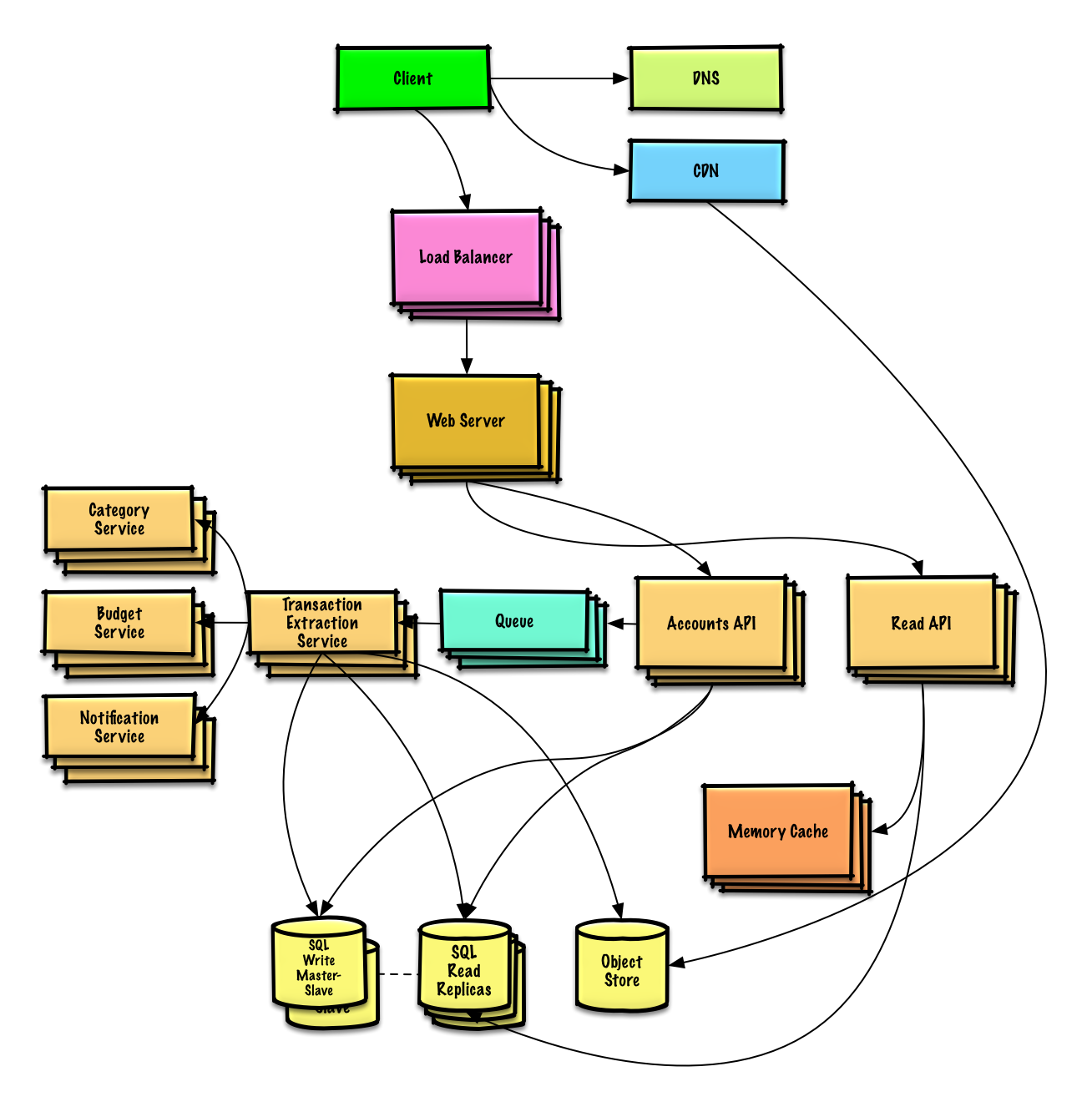
Design Mint.com
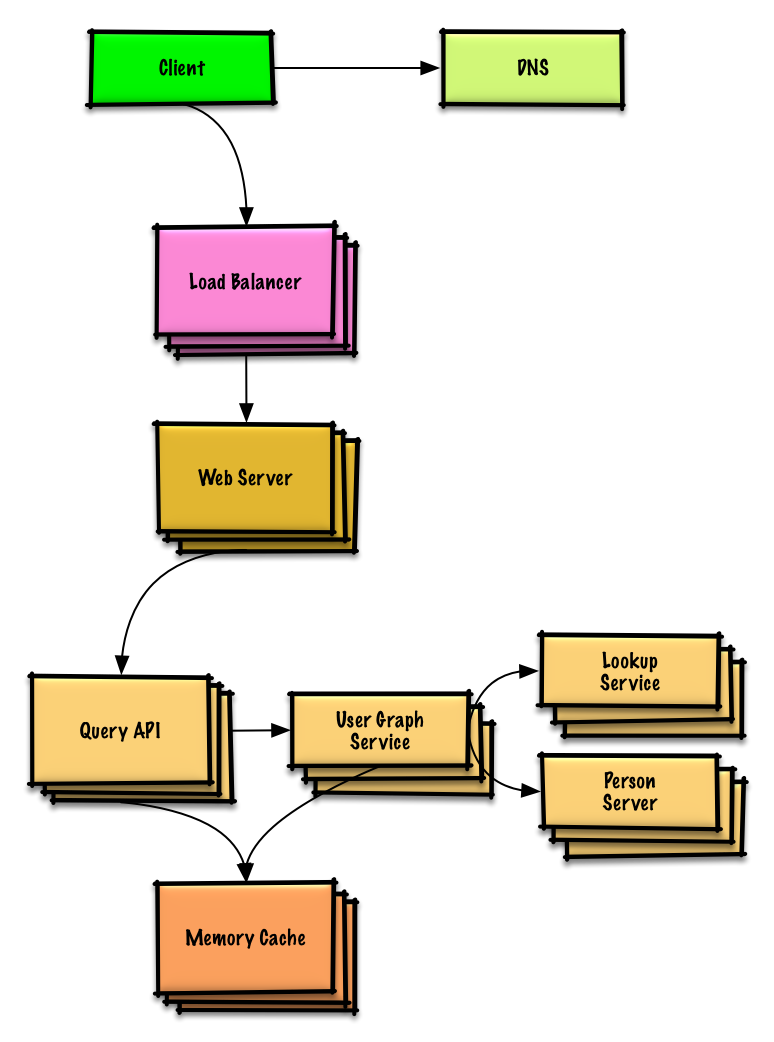
Design the data structures for a social network
Design a key-value store for a search engine
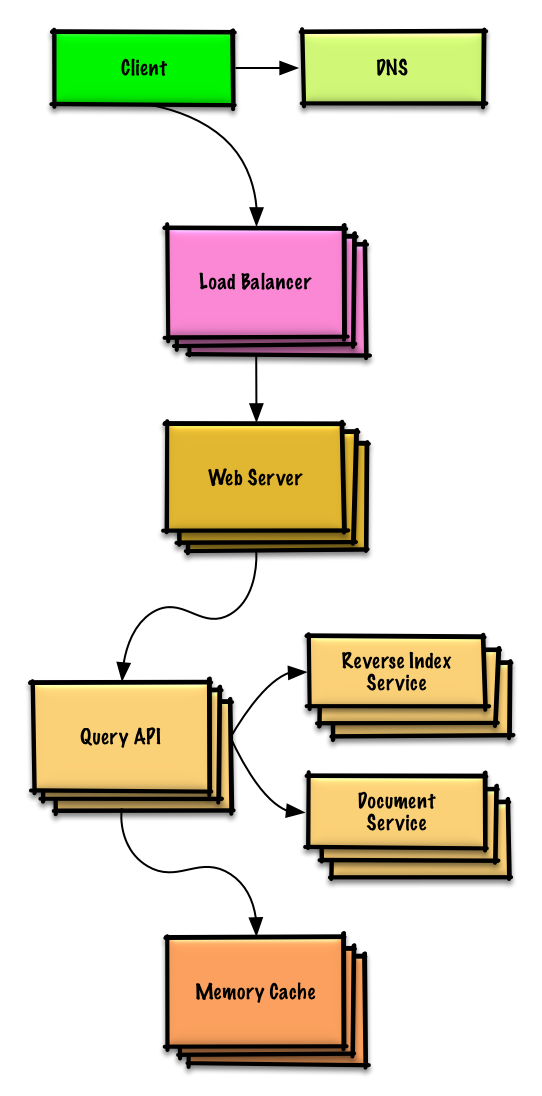
Design Amazon's sales ranking by category feature
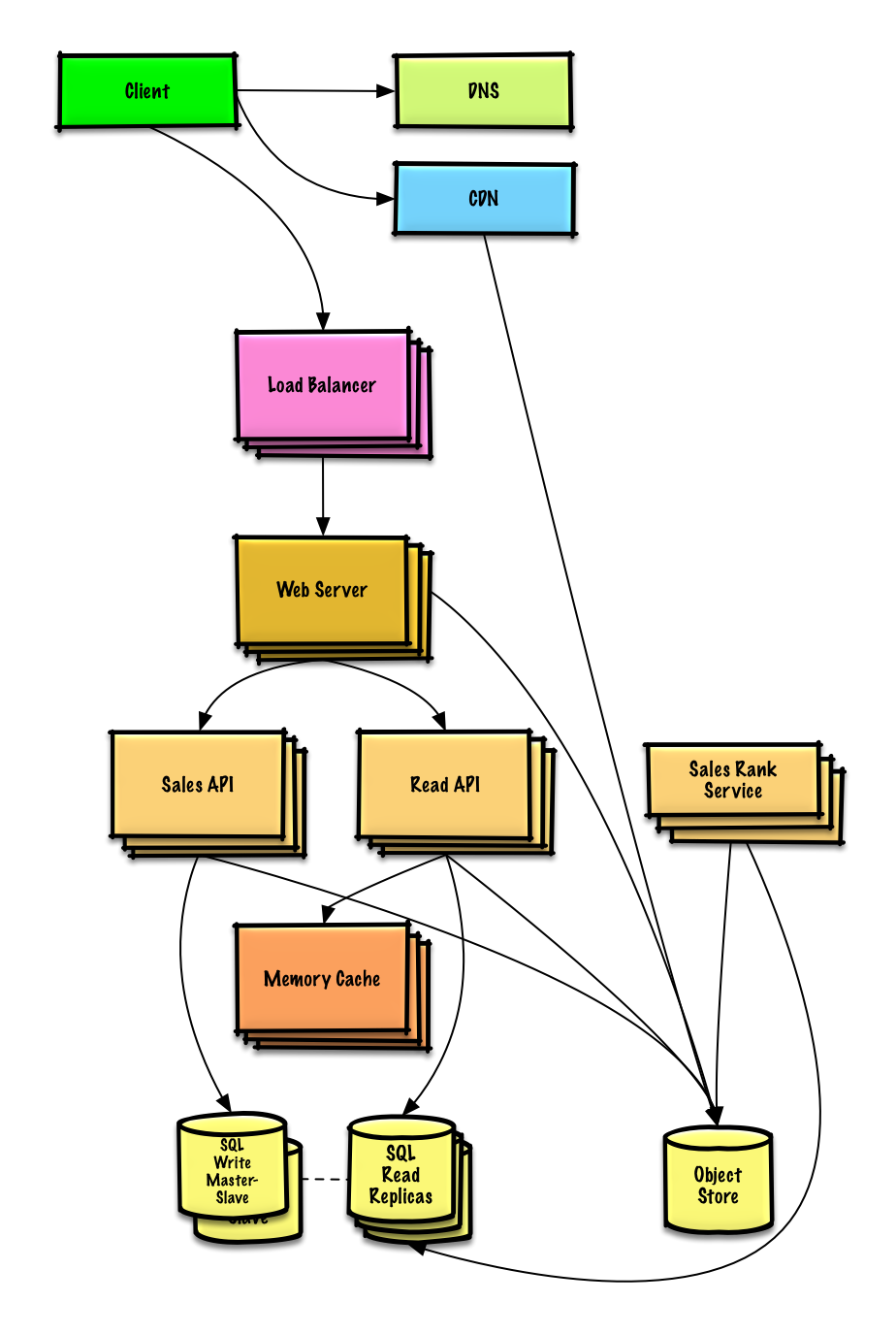
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | हैश मैप डिज़ाइन करें | समाधान | | कम से कम हाल ही में उपयोग की गई कैश डिज़ाइन करें | समाधान | | कॉल सेंटर डिज़ाइन करें | समाधान | | कार्ड्स की गड्डी डिज़ाइन करें | समाधान | | पार्किंग लॉट डिज़ाइन करें | समाधान | | चैट सर्वर डिज़ाइन करें | समाधान | | सर्कुलर एरे डिज़ाइन करें | योगदान करें | | एक ऑब्जेक्ट-ओरिएंटेड डिज़ाइन प्रश्न जोड़ें | योगदान करें |
सिस्टम डिज़ाइन विषय: यहाँ से शुरू करें
सिस्टम डिज़ाइन में नए हैं?
सबसे पहले, आपको सामान्य सिद्धांतों की मूल समझ की आवश्यकता होगी, जानें कि वे क्या हैं, उनका उपयोग कैसे किया जाता है, और उनके फायदे और नुकसान क्या हैं।
चरण 1: स्केलेबिलिटी वीडियो व्याख्यान की समीक्षा करें
हार्वर्ड में स्केलेबिलिटी व्याख्यान
- शामिल विषय:
- वर्टिकल स्केलिंग
- हॉरिजॉन्टल स्केलिंग
- कैशिंग
- लोड बैलेंसिंग
- डेटाबेस प्रतिकृति
- डेटाबेस विभाजन
चरण 2: स्केलेबिलिटी लेख की समीक्षा करें
- शामिल विषय:
- क्लोन्स
- डेटाबेस
- कैशेज़
- असिंक्रोनिज़्म
अगले कदम
अब हम उच्च-स्तरीय ट्रेड-ऑफ़्स देखेंगे:
- प्रदर्शन (Performance) बनाम स्केलेबिलिटी (scalability)
- विलंबता (Latency) बनाम थ्रूपुट (throughput)
- उपलब्धता (Availability) बनाम स्थिरता (consistency)
फिर हम DNS, CDN और लोड बैलेंसर जैसे विशिष्ट विषयों में गहराई से जाएंगे।
प्रदर्शन बनाम स्केलेबिलिटी
कोई सेवा स्केलेबल है अगर वह जोड़े गए संसाधनों के अनुपात में प्रदर्शन बढ़ाती है। सामान्यतः, प्रदर्शन बढ़ाना मतलब और अधिक कार्य इकाइयों को सेवा देना है, लेकिन यह बड़े कार्य इकाइयों को संभालने के लिए भी हो सकता है, जैसे कि डेटासेट का आकार बढ़ना।1
प्रदर्शन बनाम स्केलेबिलिटी को देखने का एक और तरीका:
- अगर आपके पास प्रदर्शन की समस्या है, तो आपका सिस्टम एकल उपयोगकर्ता के लिए धीमा है।
- अगर आपके पास स्केलेबिलिटी की समस्या है, तो आपका सिस्टम एकल उपयोगकर्ता के लिए तेज है लेकिन भारी लोड में धीमा हो जाता है।
स्रोत और आगे पढ़ें
विलंबता बनाम थ्रूपुट
विलंबता (Latency) वह समय है जो कोई कार्य करने या कोई परिणाम उत्पन्न करने में लगता है।
थ्रूपुट (Throughput) एक निश्चित समय में किए गए ऐसे कार्यों या परिणामों की संख्या है।
सामान्यतः, आपको अधिकतम थ्रूपुट के साथ स्वीकार्य विलंबता का लक्ष्य रखना चाहिए।
स्रोत और आगे पढ़ें
उपलब्धता बनाम स्थिरता
CAP प्रमेय
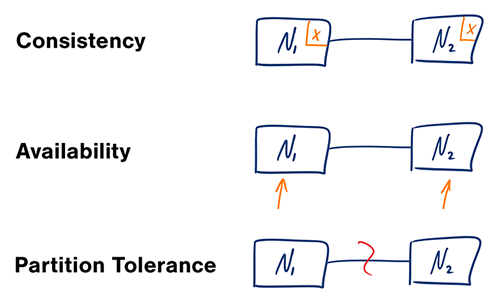
एक वितरित कंप्यूटर प्रणाली में, आप केवल निम्नलिखित में से दो गारंटी ही समर्थन कर सकते हैं:
- संगति (Consistency) - हर रीड को सबसे हाल की राइट या एक त्रुटि प्राप्त होती है
- उपलब्धता (Availability) - हर अनुरोध को एक प्रतिक्रिया मिलती है, बिना यह गारंटी कि इसमें जानकारी का सबसे हालिया संस्करण है
- विभाजन सहिष्णुता (Partition Tolerance) - प्रणाली नेटवर्क विफलताओं के कारण मनमाने विभाजन के बावजूद संचालन जारी रखती है
#### CP - संगति और विभाजन सहिष्णुता
विभाजित नोड से प्रतिक्रिया का इंतजार करना एक टाइमआउट त्रुटि का कारण बन सकता है। यदि आपके व्यापारिक आवश्यकताओं को परमाणु रीड और राइट की आवश्यकता है तो CP एक अच्छा विकल्प है।
#### AP - उपलब्धता और विभाजन सहिष्णुता
प्रतिक्रियाएँ किसी भी नोड पर उपलब्ध डेटा का सबसे आसानी से उपलब्ध संस्करण लौटाती हैं, जो सबसे नया नहीं भी हो सकता है। जब विभाजन हल हो जाता है तो राइट्स के प्रचार में कुछ समय लग सकता है।
AP एक अच्छा विकल्प है यदि व्यापारिक आवश्यकताएँ अंततः संगति की अनुमति देती हैं या जब प्रणाली को बाहरी त्रुटियों के बावजूद काम करना जारी रखना होता है।
स्रोत और आगे पढ़ाई
संगति पैटर्न
एक ही डेटा की कई प्रतियों के साथ, हमारे पास विकल्प होते हैं कि उन्हें कैसे सिंक्रोनाइज़ करें ताकि क्लाइंट्स को डेटा का संगत दृश्य मिले। CAP प्रमेय से संगति की परिभाषा याद रखें - हर रीड को सबसे हाल की राइट या एक त्रुटि प्राप्त होती है।
कमजोर संगति
एक राइट के बाद, रीड्स उसे देख सकते हैं या नहीं भी देख सकते हैं। इसमें सर्वश्रेष्ठ प्रयास किया जाता है।
यह दृष्टिकोण ऐसे सिस्टम्स में देखा जाता है जैसे मेमकैश्ड। कमजोर संगति वास्तविक समय के उपयोग के मामलों में अच्छी तरह काम करती है जैसे VoIP, वीडियो चैट, और रीयलटाइम मल्टीप्लेयर गेम्स। उदाहरण के लिए, यदि आप फोन कॉल पर हैं और कुछ सेकंड के लिए सिग्नल खो देते हैं, जब आप फिर से कनेक्शन प्राप्त करते हैं तो आप वह नहीं सुनते जो कनेक्शन के दौरान कहा गया था।
इवैंचुअल कंसिस्टेंसी
एक लिखने (write) के बाद, पढ़ने (read) में वह अंततः दिखाई देगा (आमतौर पर मिलीसेकंड्स में)। डेटा को असिंक्रोनस रूप से दोहराया जाता है।
यह दृष्टिकोण DNS और ईमेल जैसी प्रणालियों में देखा जाता है। इवैंचुअल कंसिस्टेंसी उच्च उपलब्धता वाली प्रणालियों में अच्छी तरह काम करती है।
स्ट्रॉन्ग कंसिस्टेंसी
एक लिखने के बाद, पढ़ने में वह दिखाई देगा। डेटा को सिंक्रोनस रूप से दोहराया जाता है।
यह दृष्टिकोण फाइल सिस्टम और RDBMS में देखा जाता है। स्ट्रॉन्ग कंसिस्टेंसी उन प्रणालियों में अच्छी तरह काम करती है जिन्हें ट्रांजैक्शन्स की आवश्यकता होती है।
स्रोत और आगे पढ़ें
उपलब्धता पैटर्न्स
उच्च उपलब्धता को समर्थन देने के लिए दो पूरक पैटर्न्स हैं: फेल-ओवर और रिप्लिकेशन।
फेल-ओवर
#### एक्टिव-पैसिव
एक्टिव-पैसिव फेल-ओवर में, एक्टिव और स्टैंडबाय पर मौजूद पैसिव सर्वर के बीच हार्टबीट भेजी जाती है। यदि हार्टबीट बाधित हो जाती है, तो पैसिव सर्वर एक्टिव का आईपी पता ले लेता है और सेवा फिर से शुरू कर देता है।
डाउनटाइम की अवधि इस बात पर निर्भर करती है कि पैसिव सर्वर पहले से 'हॉट' स्टैंडबाय में चल रहा है या 'कोल्ड' स्टैंडबाय से स्टार्ट होना है। केवल एक्टिव सर्वर ही ट्रैफिक को संभालता है।
एक्टिव-पैसिव फेल-ओवर को मास्टर-स्लेव फेल-ओवर भी कहा जा सकता है।
#### एक्टिव-एक्टिव
एक्टिव-एक्टिव में, दोनों सर्वर ट्रैफिक को संभाल रहे होते हैं, और लोड को आपस में बांटते हैं।
यदि सर्वर सार्वजनिक हैं, तो DNS को दोनों सर्वरों के सार्वजनिक आईपी के बारे में पता होना चाहिए। यदि सर्वर आंतरिक हैं, तो एप्लिकेशन लॉजिक को दोनों सर्वरों की जानकारी होनी चाहिए।
एक्टिव-एक्टिव फेल-ओवर को मास्टर-मास्टर फेल-ओवर भी कहा जा सकता है।
नुकसान: फेल-ओवर
- फेल-ओवर अतिरिक्त हार्डवेयर और अतिरिक्त जटिलता जोड़ता है।
- यदि सक्रिय सिस्टम विफल हो जाता है तो डेटा की हानि की संभावना होती है, खासकर जब कोई नया डेटा निष्क्रिय सिस्टम में दोहराया नहीं गया हो।
प्रतिकृति (Replication)
#### मास्टर-स्लेव और मास्टर-मास्टर
इस विषय पर डेटाबेस अनुभाग में विस्तार से चर्चा की गई है:
उपलब्धता संख्याओं में
उपलब्धता को अक्सर अपटाइम (या डाउनटाइम) के प्रतिशत के रूप में मापा जाता है कि सेवा कितने समय तक उपलब्ध है। उपलब्धता को आमतौर पर 9 की संख्या में मापा जाता है—99.99% उपलब्धता वाली सेवा को चार 9 वाली सेवा कहा जाता है।
#### 99.9% उपलब्धता - तीन 9
| अवधि | स्वीकार्य डाउनटाइम| |---------------------|--------------------| | सालाना डाउनटाइम | 8घंटा 45मिनट 57सेकंड| | मासिक डाउनटाइम | 43मिनट 49.7सेकंड | | साप्ताहिक डाउनटाइम | 10मिनट 4.8सेकंड | | दैनिक डाउनटाइम | 1मिनट 26.4सेकंड |
#### 99.99% उपलब्धता - चार 9
| अवधि | स्वीकार्य डाउनटाइम| |---------------------|--------------------| | सालाना डाउनटाइम | 52मिनट 35.7सेकंड | | मासिक डाउनटाइम | 4मिनट 23सेकंड | | साप्ताहिक डाउनटाइम | 1मिनट 5सेकंड | | दैनिक डाउनटाइम | 8.6सेकंड |
#### समानांतर बनाम अनुक्रम में उपलब्धता
यदि किसी सेवा में कई घटक होते हैं जो विफल हो सकते हैं, तो सेवा की कुल उपलब्धता इस बात पर निर्भर करती है कि घटक अनुक्रम में हैं या समानांतर में।
###### अनुक्रम में
जब दो घटक जिनकी उपलब्धता < 100% है, अनुक्रम में होते हैं तो समग्र उपलब्धता कम हो जाती है:
Availability (Total) = Availability (Foo) * Availability (Bar)यदि Foo और Bar दोनों की उपलब्धता 99.9% है, तो अनुक्रम में उनकी कुल उपलब्धता 99.8% होगी।
###### समानांतर में
जब दो घटक जिनकी उपलब्धता < 100% है, समानांतर में होते हैं तो कुल उपलब्धता बढ़ जाती है:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo और Bar की उपलब्धता 99.9% हो, तो उनकी कुल उपलब्धता पैरेलल में 99.9999% होगी।डोमेन नाम प्रणाली
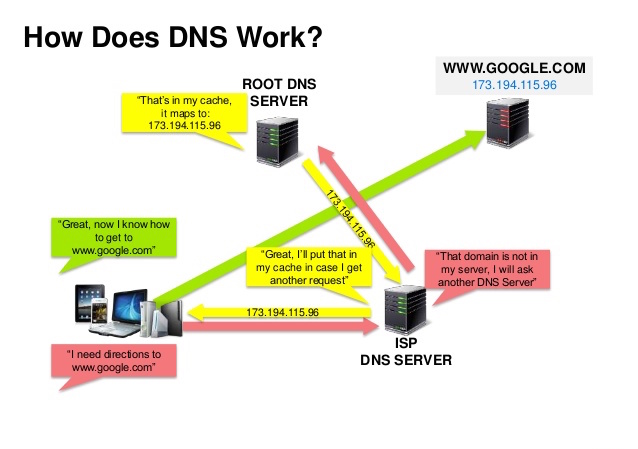
डोमेन नाम प्रणाली (DNS) एक डोमेन नाम जैसे www.example.com को IP पता में बदलती है।
DNS पदानुक्रमिक है, जिसके शीर्ष स्तर पर कुछ अधिकृत सर्वर होते हैं। आपका राउटर या ISP यह जानकारी देता है कि खोज के समय किस DNS सर्वर(सर्वरों) से संपर्क करना है। निम्न स्तर के DNS सर्वर मैपिंग को कैश करते हैं, जो DNS प्रचार विलंब के कारण पुराना हो सकता है। DNS परिणाम आपके ब्राउज़र या OS द्वारा भी एक निश्चित समय के लिए कैश किए जा सकते हैं, जो टाइम टू लाइव (TTL) द्वारा निर्धारित होता है।
- NS रिकॉर्ड (नेम सर्वर) - आपके डोमेन/सबडोमेन के लिए DNS सर्वरों को निर्दिष्ट करता है।
- MX रिकॉर्ड (मेल एक्सचेंज) - संदेश स्वीकार करने के लिए मेल सर्वरों को निर्दिष्ट करता है।
- A रिकॉर्ड (पता) - नाम को IP पते से जोड़ता है।
- CNAME (कैनोनिकल) - नाम को दूसरे नाम या
CNAME(example.com से www.example.com) या किसीAरिकॉर्ड से जोड़ता है।
- वेटेड राउंड रॉबिन
- रखरखाव में चल रहे सर्वरों को ट्रैफ़िक जाने से रोकना
- विभिन्न क्लस्टर आकारों के बीच संतुलन
- A/B परीक्षण
- लेटेंसी आधारित
- जियोलोकेशन आधारित
नुकसान: DNS
- DNS सर्वर तक पहुँचने में थोड़ा विलंब होता है, जिसे ऊपर वर्णित कैशिंग द्वारा कम किया जा सकता है।
- DNS सर्वर प्रबंधन जटिल हो सकता है और आमतौर पर सरकारों, ISP और बड़ी कंपनियों द्वारा प्रबंधित किया जाता है।
- हाल ही में DNS सेवाओं पर DDoS हमला हुआ है, जिससे उपयोगकर्ता Twitter जैसी वेबसाइटों तक नहीं पहुँच पाए, जब तक कि उन्हें Twitter के IP पते न पता हों।
स्रोत एवं आगे पढ़ें
- DNS वास्तुकला.aspx)
- विकिपीडिया
- DNS लेख
कंटेंट डिलीवरी नेटवर्क
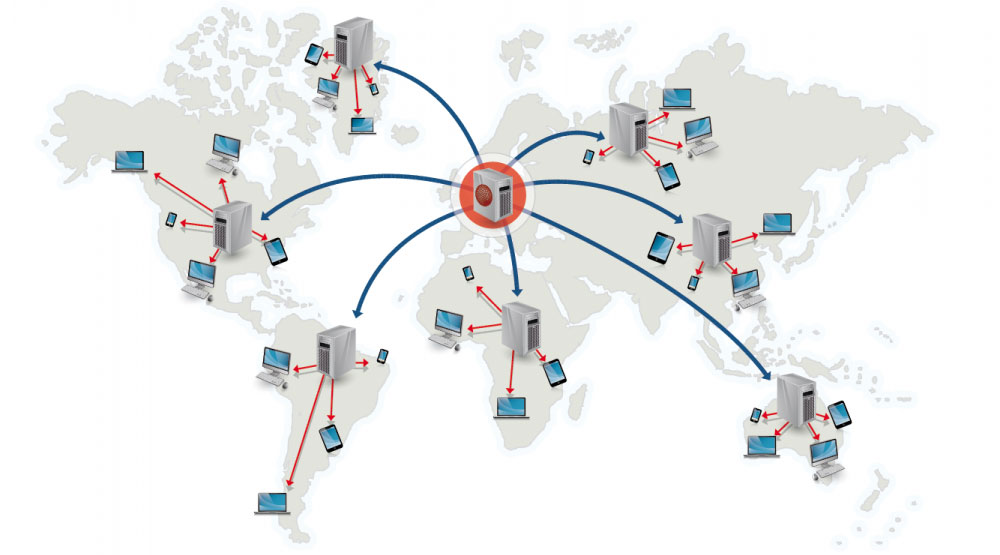
स्रोत: CDN का उपयोग क्यों करें
एक कंटेंट डिलीवरी नेटवर्क (CDN) प्रॉक्सी सर्वरों का वैश्विक रूप से वितरित नेटवर्क है, जो उपयोगकर्ता के करीब स्थानों से कंटेंट प्रदान करता है। आमतौर पर, स्थैतिक फाइलें जैसे HTML/CSS/JS, फोटो और वीडियो CDN से सर्व होती हैं, हालांकि कुछ CDN जैसे अमेज़न का CloudFront डायनामिक कंटेंट को भी सपोर्ट करते हैं। साइट का DNS रेज़ॉल्यूशन क्लाइंट्स को बताएगा कि किस सर्वर से संपर्क करें।
CDN से कंटेंट सर्व करने से प्रदर्शन दो तरीकों से काफी बेहतर हो सकता है:
- उपयोगकर्ता को डेटा सेंटर से कंटेंट मिलता है जो उनके करीब होता है
- आपके सर्वरों को उन रिक्वेस्ट्स को सर्व नहीं करना पड़ता जिन्हें CDN पूरा करता है
पुश CDN
पुश CDN आपके सर्वर पर बदलाव होते ही नया कंटेंट प्राप्त करता है। आप कंटेंट प्रदान करने की पूरी जिम्मेदारी लेते हैं, सीधे CDN पर अपलोड करते हैं और URL को CDN की ओर इंगित करने के लिए री-राइट करते हैं। आप नियंत्रित कर सकते हैं कि कंटेंट कब एक्सपायर हो और कब अपडेट हो। कंटेंट केवल तब अपलोड होता है जब वह नया या बदला हुआ हो, जिससे ट्रैफिक कम होता है, लेकिन स्टोरेज अधिकतम होती है।
कम ट्रैफिक वाली साइट्स या ऐसी साइट्स जिनका कंटेंट अक्सर अपडेट नहीं होता, पुश CDN के साथ अच्छी तरह काम करती हैं। कंटेंट एक बार CDN पर रखा जाता है, बजाय इसके कि नियमित अंतराल पर बार-बार खींचा जाए।
पुल CDN
पुल CDN आपके सर्वर से नया कंटेंट तब प्राप्त करता है जब पहला उपयोगकर्ता उस कंटेंट की मांग करता है। आप कंटेंट अपने सर्वर पर ही रखते हैं और URLs को CDN की ओर इंगित करने के लिए री-राइट करते हैं। इससे पहली बार अनुरोध थोड़ा धीमा होता है जब तक कि कंटेंट CDN पर कैश नहीं हो जाता।
एक टाइम-टू-लिव (TTL) यह निर्धारित करता है कि कंटेंट कितने समय तक कैश रहेगा। पुल CDN CDN पर स्टोरेज स्पेस को कम करता है, लेकिन यदि फाइलें एक्सपायर हो जाती हैं और वे वास्तव में बदलने से पहले पुनः खींच ली जाती हैं तो यह अनावश्यक ट्रैफिक उत्पन्न कर सकता है।
भारी ट्रैफिक वाली साइट्स पुल CDN के साथ अच्छी तरह काम करती हैं, क्योंकि ट्रैफिक अधिक समान रूप से फैल जाता है और केवल हाल ही में अनुरोधित कंटेंट ही CDN पर रहता है।
नुकसान: CDN
- ट्रैफिक के अनुसार CDN लागत महत्वपूर्ण हो सकती है, हालांकि इसकी तुलना उस अतिरिक्त लागत से करनी चाहिए जो CDN का उपयोग न करने पर आती।
- यदि कंटेंट TTL समाप्त होने से पहले अपडेट किया जाता है तो वह पुराना हो सकता है।
- CDN के लिए स्थैतिक कंटेंट के URLs को बदलकर CDN की ओर इंगित करना आवश्यक होता है।
स्रोत और आगे पढ़ें
लोड बैलेंसर
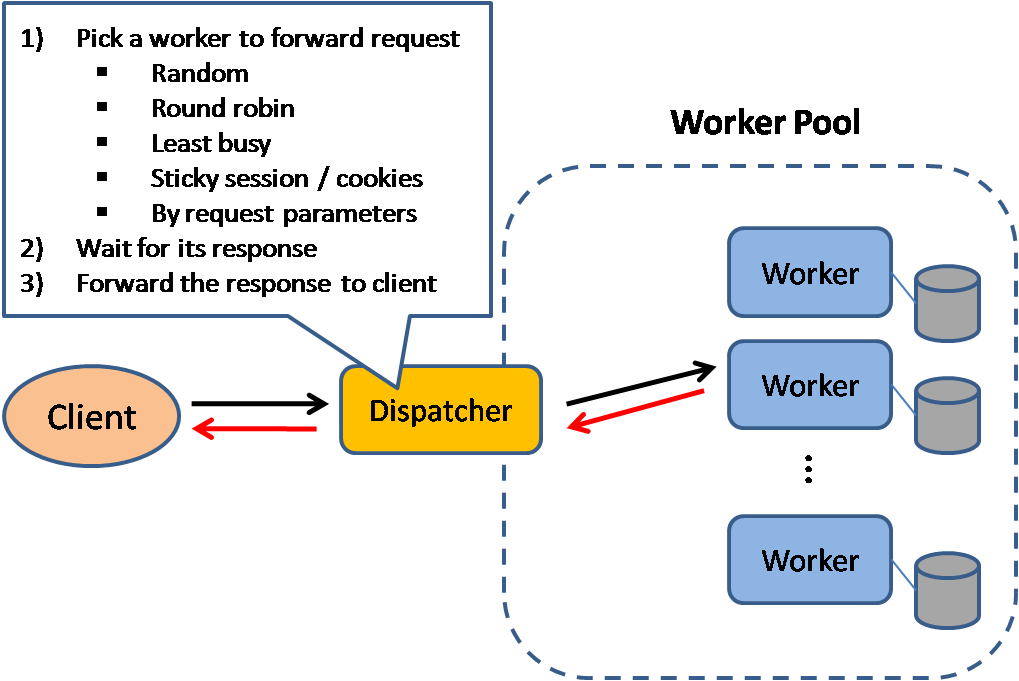
स्रोत: स्केलेबल सिस्टम डिजाइन पैटर्न
लोड बैलेंसर इनकमिंग क्लाइंट अनुरोधों को कंप्यूटिंग संसाधनों जैसे एप्लीकेशन सर्वर और डेटाबेस में वितरित करते हैं। प्रत्येक मामले में, लोड बैलेंसर कंप्यूटिंग संसाधन से प्रतिक्रिया को उपयुक्त क्लाइंट को लौटाता है। लोड बैलेंसर इन कार्यों में प्रभावी होते हैं:
- अस्वस्थ सर्वर को अनुरोध भेजने से रोकना
- संसाधनों के ओवरलोडिंग को रोकना
- एकल बिंदु विफलता को खत्म करने में मदद करना
अतिरिक्त लाभों में शामिल हैं:
- SSL समाप्ति - इनकमिंग अनुरोधों को डिक्रिप्ट करना और सर्वर प्रतिक्रियाओं को एन्क्रिप्ट करना ताकि बैकएंड सर्वरों को ये संभावित रूप से महंगे ऑपरेशन न करने पड़ें
- प्रत्येक सर्वर पर X.509 प्रमाणपत्र स्थापित करने की आवश्यकता को समाप्त करता है
- सत्र स्थायित्व - कुकीज जारी करना और यदि वेब ऐप्स सत्र ट्रैक नहीं रखते हैं तो विशिष्ट क्लाइंट के अनुरोधों को उसी इंस्टेंस पर रूट करना
लोड बैलेंसर विभिन्न मापदंडों के आधार पर ट्रैफिक को रूट कर सकते हैं, जिनमें शामिल हैं:
- रैंडम
- सबसे कम लोडेड
- सत्र/कुकीज
- राउंड रोबिन या वेटेड राउंड रोबिन
- लेयर 4
- लेयर 7
लेयर 4 लोड बैलेंसिंग
लेयर 4 लोड बैलेंसर ट्रांसपोर्ट लेयर पर जानकारी देखकर तय करते हैं कि अनुरोधों को कैसे वितरित किया जाए। आमतौर पर इसमें हेडर में स्रोत, गंतव्य IP एड्रेस और पोर्ट शामिल होते हैं, लेकिन पैकेट की सामग्री नहीं। लेयर 4 लोड बैलेंसर नेटवर्क पैकेट्स को अपस्ट्रीम सर्वर तक फॉरवर्ड करते हैं, नेटवर्क एड्रेस ट्रांसलेशन (NAT) करते हैं।
लेयर 7 लोड बैलेंसिंग
लेयर 7 लोड बैलेंसर एप्लिकेशन लेयर को देखता है ताकि यह तय कर सके कि अनुरोधों को कैसे वितरित किया जाए। इसमें हेडर, संदेश और कुकीज़ की सामग्री शामिल हो सकती है। लेयर 7 लोड बैलेंसर नेटवर्क ट्रैफिक को समाप्त करता है, संदेश पढ़ता है, लोड-बैलेंसिंग का निर्णय लेता है, फिर चयनित सर्वर के लिए एक कनेक्शन खोलता है। उदाहरण के लिए, एक लेयर 7 लोड बैलेंसर वीडियो ट्रैफिक को उन सर्वरों पर निर्देशित कर सकता है जो वीडियो होस्ट करते हैं, जबकि अधिक संवेदनशील उपयोगकर्ता बिलिंग ट्रैफिक को सुरक्षा-सुदृढ़ सर्वरों पर भेजता है।लचीलापन की कीमत पर, लेयर 4 लोड बैलेंसिंग लेयर 7 की तुलना में कम समय और कंप्यूटिंग संसाधनों की आवश्यकता होती है, हालांकि आधुनिक सामान्य हार्डवेयर पर प्रदर्शन प्रभाव न्यूनतम हो सकता है।
क्षैतिज स्केलिंग
लोड बैलेंसर क्षैतिज स्केलिंग में भी सहायता कर सकते हैं, जिससे प्रदर्शन और उपलब्धता बेहतर होती है। सामान्य मशीनों का उपयोग करके स्केल आउट करना अधिक लागत प्रभावी है और महंगे हार्डवेयर पर एकल सर्वर को स्केल अप करने की तुलना में अधिक उपलब्धता मिलती है, जिसे वर्टिकल स्केलिंग कहा जाता है। सामान्य हार्डवेयर पर काम करने वाली प्रतिभा को नियुक्त करना भी विशेष एंटरप्राइज सिस्टम की तुलना में आसान है।
#### नुकसान: क्षैतिज स्केलिंग
- क्षैतिज रूप से स्केलिंग करने से जटिलता आती है और सर्वरों को क्लोन करना शामिल होता है
- सर्वरों को स्टेटलेस होना चाहिए: उनमें कोई उपयोगकर्ता-संबंधित डेटा जैसे सत्र या प्रोफाइल चित्र नहीं होने चाहिए
- सत्र को केंद्रीकृत डेटा स्टोर जैसे डेटाबेस (SQL, NoSQL) या स्थायी कैश (Redis, Memcached) में संग्रहीत किया जा सकता है
- डाउनस्ट्रीम सर्वरों जैसे कैश और डेटाबेस को अधिक समकालिक कनेक्शन संभालने होंगे जब अपस्ट्रीम सर्वर स्केल आउट होते हैं
नुकसान: लोड बैलेंसर
- यदि लोड बैलेंसर के पास पर्याप्त संसाधन नहीं हैं या इसे ठीक से कॉन्फ़िगर नहीं किया गया है, तो यह प्रदर्शन की बाधा बन सकता है।
- एकल विफलता बिंदु को समाप्त करने के लिए लोड बैलेंसर को पेश करने से जटिलता बढ़ जाती है।
- एकल लोड बैलेंसर एकल विफलता बिंदु है, कई लोड बैलेंसर को कॉन्फ़िगर करना जटिलता को और बढ़ाता है।
स्रोत एवं आगे पढ़ें
- NGINX वास्तुकला
- HAProxy वास्तुकला गाइड
- स्केलेबिलिटी
- विकिपीडिया)
- लेयर 4 लोड बैलेंसिंग
- लेयर 7 लोड बैलेंसिंग
- ELB लिसनर कॉन्फ़िगरेशन
रिवर्स प्रॉक्सी (वेब सर्वर)
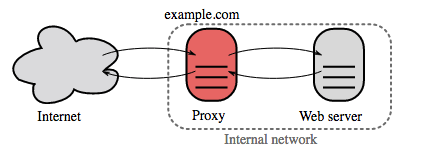
रिवर्स प्रॉक्सी एक वेब सर्वर है जो आंतरिक सेवाओं को केंद्रीकृत करता है और सार्वजनिक रूप से एकीकृत इंटरफेस प्रदान करता है। क्लाइंट से अनुरोध उस सर्वर को अग्रेषित किया जाता है जो उसे पूरा कर सकता है, इसके बाद रिवर्स प्रॉक्सी सर्वर की प्रतिक्रिया क्लाइंट को लौटाता है।
अतिरिक्त लाभों में शामिल हैं:
- सुरक्षा में वृद्धि - बैकएंड सर्वरों की जानकारी छुपाएँ, IP को ब्लैकलिस्ट करें, प्रति क्लाइंट कनेक्शन की संख्या सीमित करें
- स्केलेबिलिटी और लचीलापन में वृद्धि - क्लाइंट केवल रिवर्स प्रॉक्सी का IP देखते हैं, जिससे आप सर्वरों को स्केल या उनकी कॉन्फ़िगरेशन बदल सकते हैं
- SSL टर्मिनेशन - इनकमिंग अनुरोधों को डिक्रिप्ट करें और सर्वर प्रतिक्रियाओं को एन्क्रिप्ट करें ताकि बैकएंड सर्वरों को ये महंगे ऑपरेशन करने की आवश्यकता न हो
- प्रत्येक सर्वर पर X.509 प्रमाणपत्र स्थापित करने की आवश्यकता समाप्त करता है
- कम्प्रेशन - सर्वर प्रतिक्रियाओं को कम्प्रेस करें
- कैशिंग - कैश किए गए अनुरोधों के लिए प्रतिक्रिया लौटाएँ
- स्टैटिक कंटेंट - स्टैटिक कंटेंट सीधे प्रदान करें
- HTML/CSS/JS
- फोटो
- वीडियो
- आदि
लोड बैलेंसर बनाम रिवर्स प्रॉक्सी
- जब आपके पास कई सर्वर होते हैं तो लोड बैलेंसर को डिप्लॉय करना उपयोगी होता है। अक्सर, लोड बैलेंसर ट्रैफिक को एक सेट सर्वरों तक रूट करते हैं जो समान कार्य करते हैं।
- रिवर्स प्रॉक्सी एक वेब सर्वर या एप्लिकेशन सर्वर के साथ भी उपयोगी हो सकता है, जिससे पिछले सेक्शन में बताए गए लाभ मिलते हैं।
- NGINX और HAProxy जैसी सॉल्यूशंस दोनों लेयर 7 रिवर्स प्रॉक्सीइंग और लोड बैलेंसिंग को सपोर्ट कर सकती हैं।
नुकसान(न): रिवर्स प्रॉक्सी
- रिवर्स प्रॉक्सी को लागू करने से जटिलता बढ़ जाती है।
- एक सिंगल रिवर्स प्रॉक्सी एक सिंगल पॉइंट ऑफ फेल्योर है, कई रिवर्स प्रॉक्सी (जैसे फेलओवर) को कॉन्फ़िगर करने से जटिलता और बढ़ जाती है।
स्रोत(स) और आगे पढ़ने के लिए
एप्लिकेशन लेयर
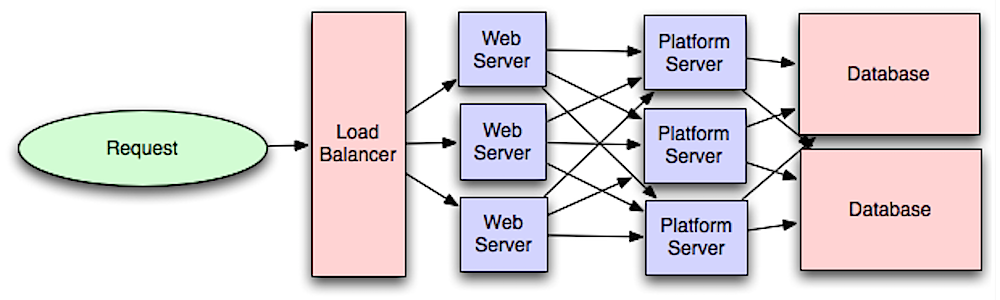
स्रोत: स्केल के लिए सिस्टम आर्किटेक्टिंग का परिचय
वेब लेयर को एप्लिकेशन लेयर (जिसे प्लेटफॉर्म लेयर भी कहा जाता है) से अलग करना आपको दोनों लेयर को स्वतंत्र रूप से स्केल और कॉन्फ़िगर करने की अनुमति देता है। एक नया API जोड़ने से एप्लिकेशन सर्वर जोड़ने पड़ते हैं, जरूरी नहीं कि अतिरिक्त वेब सर्वर भी जोड़ने पड़ें। सिंगल रेस्पॉन्सिबिलिटी प्रिंसिपल छोटे और स्वायत्त सेवाओं के पक्ष में है जो एक साथ काम करती हैं। छोटी टीमें छोटी सेवाओं के साथ तेजी से वृद्धि की योजना बना सकती हैं।
एप्लिकेशन लेयर में वर्कर्स एसिंक्रोनिज़्म को सक्षम करने में भी मदद करते हैं।
माइक्रोसर्विसेज
इस चर्चा से संबंधित हैं माइक्रोसर्विसेज, जिन्हें स्वतंत्र रूप से डिप्लॉय करने योग्य, छोटी, मॉड्यूलर सेवाओं का एक सूट कहा जा सकता है। प्रत्येक सेवा एक विशिष्ट प्रक्रिया चलाती है और व्यापारिक उद्देश्य को पूरा करने के लिए एक अच्छी तरह से परिभाषित, हल्के मैकेनिज्म के माध्यम से संचार करती है। 1
Pinterest, उदाहरण के लिए, निम्नलिखित माइक्रोसर्विसेज हो सकती हैं: यूजर प्रोफाइल, फॉलोवर, फीड, सर्च, फोटो अपलोड, आदि।
सेवा खोज (Service Discovery)
Consul, Etcd, और Zookeeper जैसे सिस्टम सेवाओं को एक-दूसरे को ढूंढने में मदद करते हैं, पंजीकृत नाम, पता, और पोर्ट का ट्रैक रखते हैं। हेल्थ चेक्स सेवा की अखंडता की पुष्टि करने में मदद करते हैं और अक्सर HTTP एंडपॉइंट का उपयोग करके किए जाते हैं। Consul और Etcd दोनों में एक इन-बिल्ट की-वैल्यू स्टोर होता है, जो कॉन्फ़िगरेशन वैल्यू और अन्य साझा डेटा को स्टोर करने के लिए उपयोगी हो सकता है।
नुकसान: एप्लिकेशन लेयर
- लूजली कपल्ड सेवाओं के साथ एप्लिकेशन लेयर जोड़ना आर्किटेक्चर, ऑपरेशन्स और प्रक्रिया के दृष्टिकोण से एक अलग अप्रोच की आवश्यकता होती है (मोनोलिथिक सिस्टम की तुलना में)।
- माइक्रोसर्विसेज डिप्लॉयमेंट और ऑपरेशन्स के मामले में जटिलता जोड़ सकती हैं।
स्रोत और आगे पढ़ें
- स्केल के लिए सिस्टम आर्किटेक्टिंग का परिचय
- सिस्टम डिजाइन इंटरव्यू कैसे क्रैक करें
- सर्विस ओरिएंटेड आर्किटेक्चर
- Zookeeper का परिचय
- माइक्रोसर्विसेज बनाने के बारे में आपको क्या जानना चाहिए
डेटाबेस
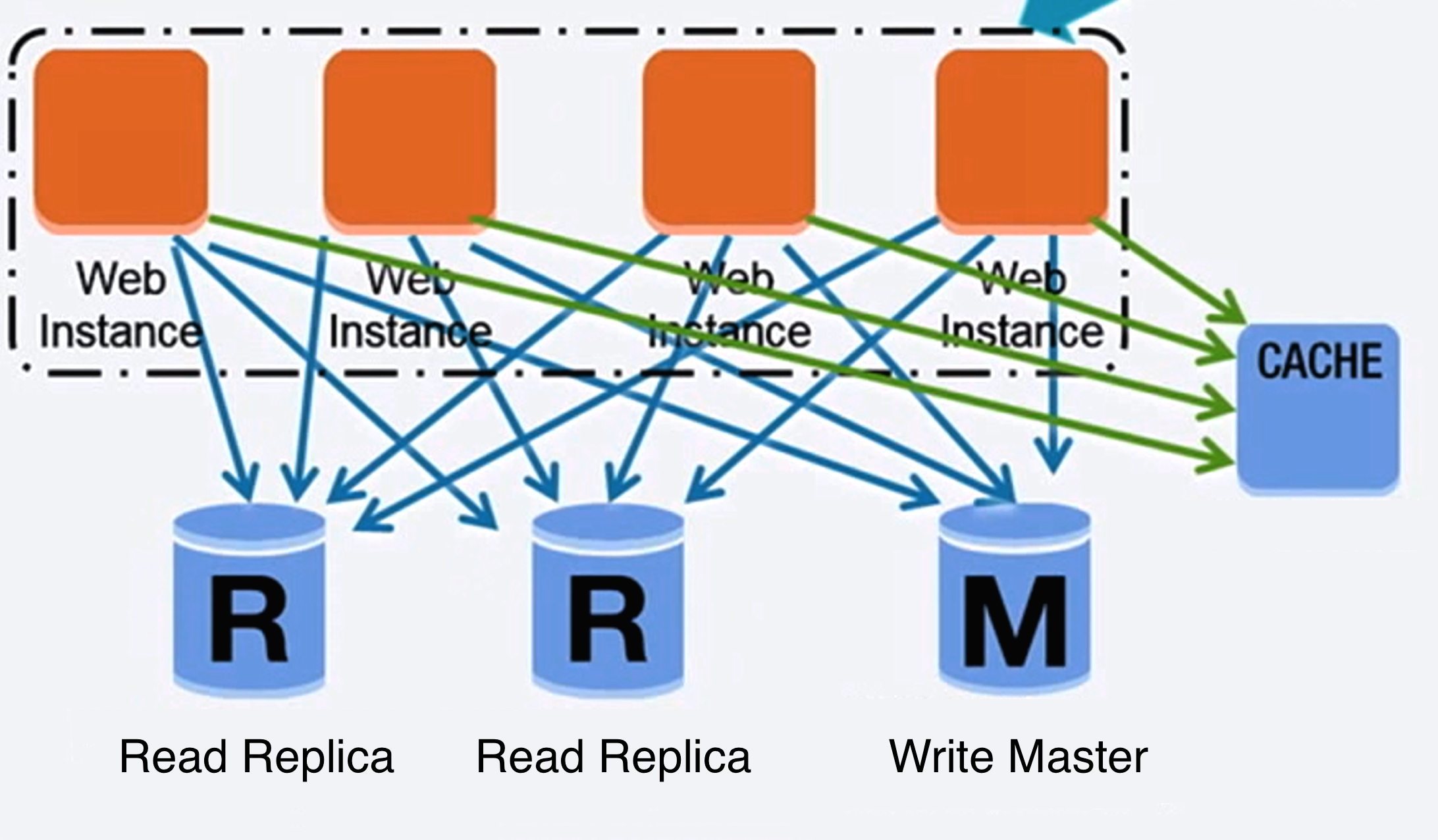
स्रोत: पहले 10 मिलियन उपयोगकर्ताओं तक स्केलिंग
रिलेशनल डेटाबेस मैनेजमेंट सिस्टम (RDBMS)
SQL जैसी रिलेशनल डेटाबेस डेटा आइटम्स का संग्रह है जो तालिकाओं में व्यवस्थित होती है।
ACID रिलेशनल डेटाबेस लेन-देन की गुणधर्मों का एक समूह है।
- परमाणुता - प्रत्येक लेन-देन सब कुछ या कुछ भी नहीं है
- संगतता - कोई भी लेन-देन डेटाबेस को एक मान्य स्थिति से दूसरी मान्य स्थिति में लाएगा
- पृथक्करण - लेन-देन को एक साथ निष्पादित करने के परिणाम वही हैं, जैसे कि उन्हें क्रमशः निष्पादित किया गया हो
- स्थायित्व - एक बार लेन-देन प्रतिबद्ध हो जाने के बाद, वह वैसा ही रहेगा
#### मास्टर-स्लेव प्रतिकृति
मास्टर रीड और राइट दोनों सर्व करता है, और राइट्स को एक या अधिक स्लेव्स में प्रतिकृत करता है, जो केवल रीड सर्व करते हैं। स्लेव्स अतिरिक्त स्लेव्स को भी वृक्ष के रूप में प्रतिकृत कर सकते हैं। यदि मास्टर ऑफलाइन हो जाता है, तो सिस्टम केवल पढ़ने की स्थिति में चल सकता है जब तक कि किसी स्लेव को मास्टर में प्रोमोट नहीं किया जाता या नया मास्टर प्रोविजन नहीं किया जाता।
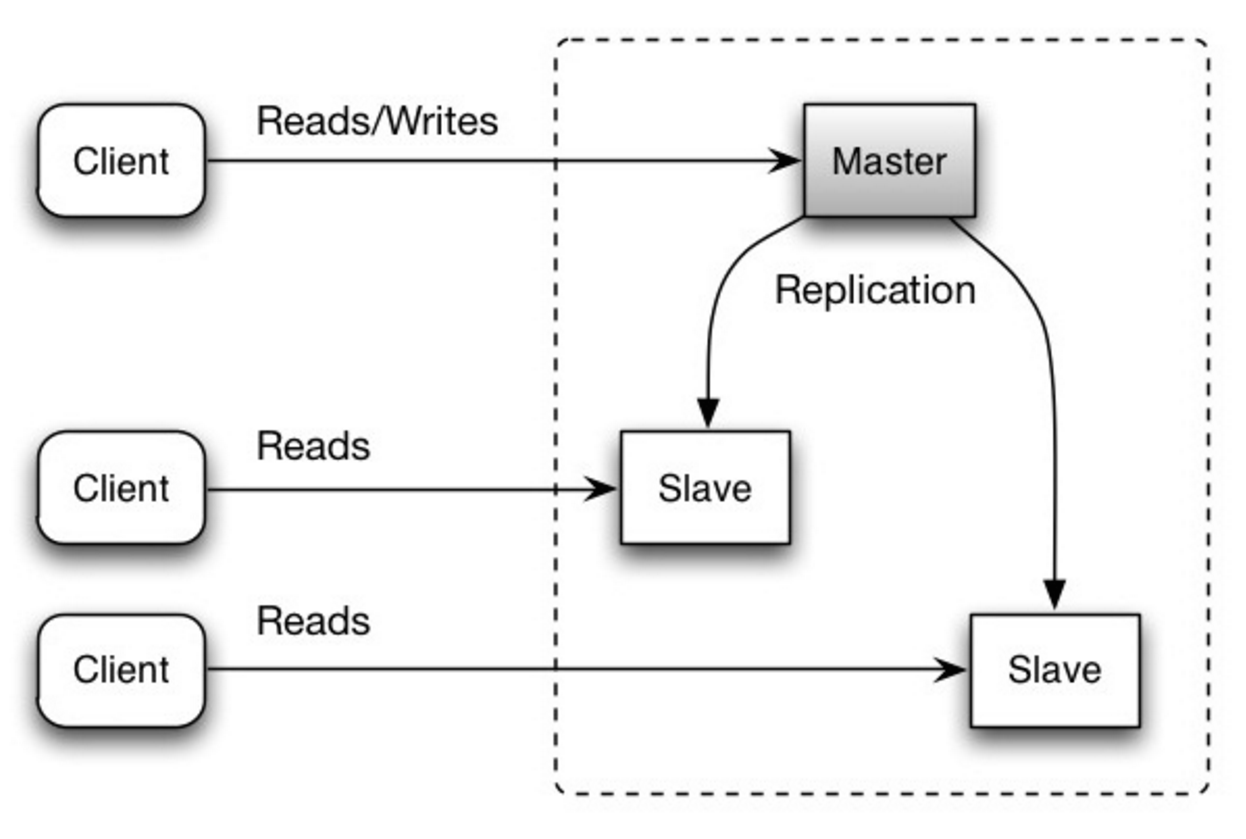
स्रोत: स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न्स
##### नुकसानों: मास्टर-स्लेव प्रतिकृति
- स्लेव को मास्टर में प्रोमोट करने के लिए अतिरिक्त लॉजिक की आवश्यकता होती है।
- नुकसानों: प्रतिकृति देखें, जो दोनों मास्टर-स्लेव और मास्टर-मास्टर से संबंधित बिंदुओं के लिए है।
दोनों मास्टर रीड और राइट सर्व करते हैं और राइट्स पर एक-दूसरे के साथ समन्वय करते हैं। अगर कोई मास्टर डाउन हो जाए, तो सिस्टम रीड और राइट दोनों के साथ कार्य करना जारी रख सकता है।
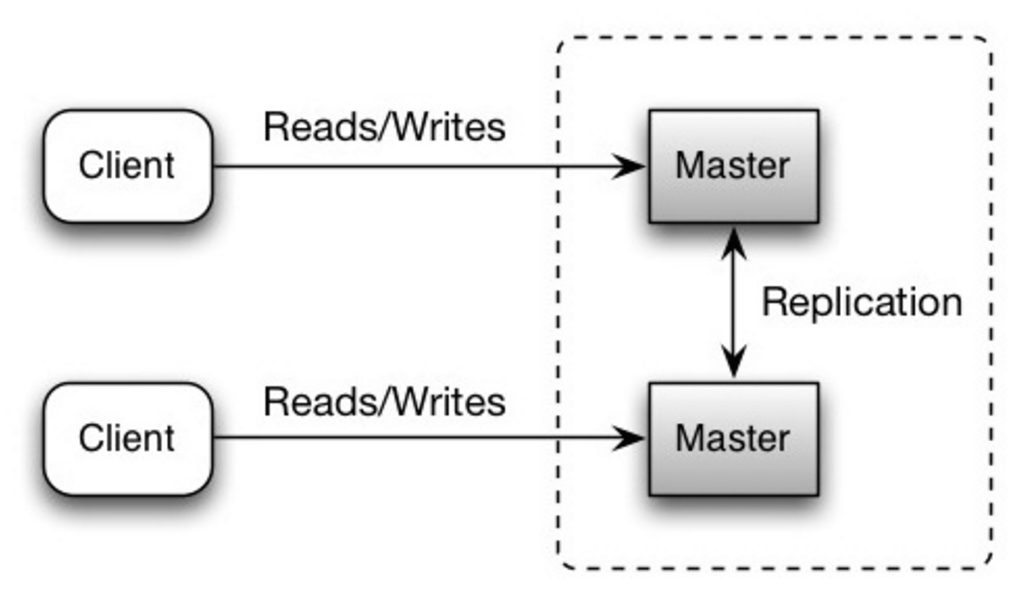
स्रोत: स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न्स
##### नुकसानों: मास्टर-मास्टर प्रतिकृति
- आपको एक लोड बैलेंसर की आवश्यकता होगी या आपको अपने एप्लीकेशन लॉजिक में बदलाव करने होंगे ताकि यह निर्धारित किया जा सके कि कहाँ लिखना है।
- अधिकांश मास्टर-मास्टर सिस्टम या तो ढीली संगतता रखते हैं (ACID का उल्लंघन करते हैं) या सिंक्रोनाइज़ेशन के कारण राइट लेटेंसी बढ़ जाती है।
- जैसे-जैसे अधिक write नोड्स जोड़े जाते हैं और latency बढ़ती है, संघर्ष समाधान (conflict resolution) अधिक महत्वपूर्ण हो जाता है।
- दोनों master-slave और master-master से संबंधित बिंदुओं के लिए नुकसान: प्रतिकृति देखें।
- यदि मास्टर विफल हो जाता है इससे पहले कि कोई नया लिखा गया डेटा अन्य नोड्स पर प्रतिकृति हो सके, तो डेटा खोने की संभावना रहती है।
- लिखे गए डेटा को पढ़ने वाले रिप्लिका पर फिर से चलाया जाता है। यदि बहुत सारे लिखे होते हैं, तो पढ़ने वाले रिप्लिका लिखे दोहराने में व्यस्त हो सकते हैं और उतनी पढ़ाई नहीं कर सकते।
- जितने अधिक पढ़ने वाले स्लेव्स, उतनी अधिक प्रतिकृति करनी होगी, जिससे प्रतिकृति में विलंब बढ़ता है।
- कुछ प्रणालियों में, मास्टर को लिखने पर समानांतर में लिखने के लिए अनेक थ्रेड्स बन सकते हैं, जबकि पढ़ने वाले रिप्लिका केवल एकल थ्रेड के साथ अनुक्रमिक रूप से लिखना समर्थन करते हैं।
- प्रतिकृति अधिक हार्डवेयर और अतिरिक्त जटिलता जोड़ती है।
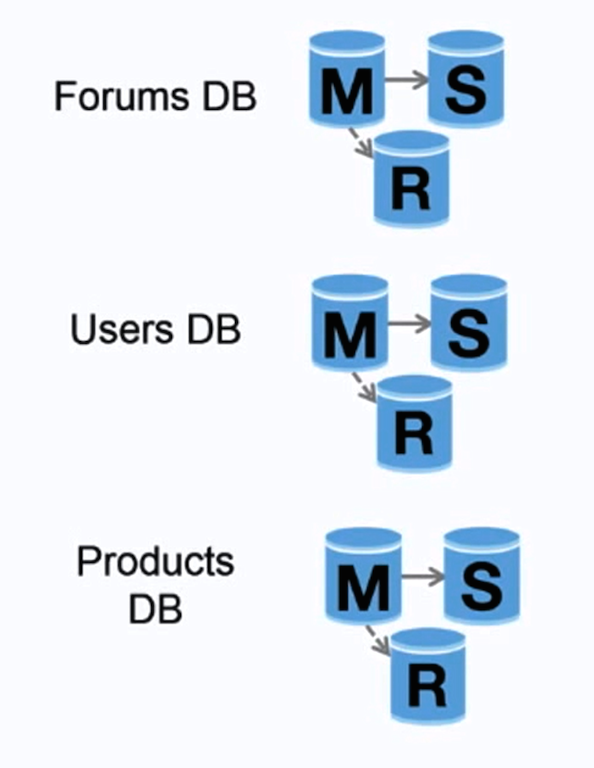
स्रोत: Scaling up to your first 10 million users
फेडरेशन (या फंक्शनल पार्टीशनिंग) डेटाबेस को कार्य के अनुसार विभाजित करता है। उदाहरण के लिए, एक एकल, एकीकृत डेटाबेस की बजाय, आप तीन डेटाबेस रख सकते हैं: forums, users, और products। इससे प्रत्येक डेटाबेस पर पढ़ने और लिखने का ट्रैफिक कम होता है और प्रतिकृति में विलंब भी कम होता है। छोटे डेटाबेस का अर्थ है अधिक डेटा मेमोरी में समा सकता है, जिससे कैश locality बेहतर होने के कारण अधिक कैश हिट्स मिलती हैं। किसी एकल केंद्रीय मास्टर द्वारा लिखाई को अनुक्रमित न करने से आप समांतर रूप से लिख सकते हैं, जिससे throughput बढ़ता है।
##### नुकसान: फेडरेशन
- यदि आपकी schema को बड़े functions या tables की आवश्यकता है तो फेडरेशन प्रभावी नहीं है।
- आपको अपनी एप्लिकेशन लॉजिक को यह निर्धारित करने के लिए अपडेट करना होगा कि किस डेटाबेस से पढ़ना और लिखना है।
- दो डेटाबेस से डेटा जोड़ना सर्वर लिंक के साथ अधिक जटिल है।
- फेडरेशन अधिक हार्डवेयर और अतिरिक्त जटिलता जोड़ता है।
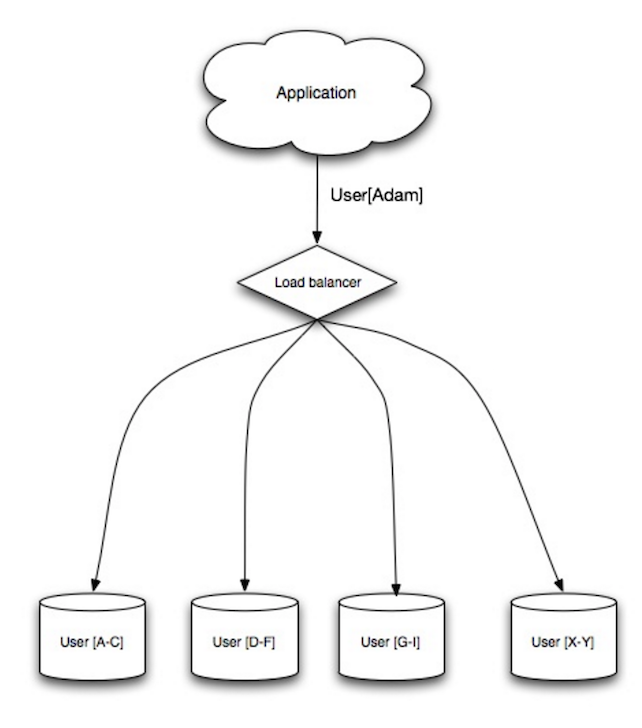
स्रोत: स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न
शार्डिंग डेटा को विभिन्न डेटाबेसों में वितरित करता है ताकि प्रत्येक डेटाबेस केवल डेटा के एक उपसमुच्चय को ही प्रबंधित कर सके। उदाहरण के लिए, जब उपयोगकर्ताओं की संख्या बढ़ती है, तो क्लस्टर में और शार्ड जोड़े जाते हैं।
फेडरेशन के लाभों के समान, शार्डिंग से पढ़ने और लिखने का ट्रैफिक कम होता है, कम रेप्लिकेशन होता है, और अधिक कैश हिट्स मिलते हैं। इंडेक्स का आकार भी छोटा होता है, जिससे आमतौर पर क्वेरीज़ तेज़ हो जाती हैं और प्रदर्शन सुधरता है। यदि कोई एक शार्ड डाउन हो जाता है, तो अन्य शार्ड्स चालू रहते हैं, हालांकि डेटा लॉस से बचाव के लिए आपको किसी प्रकार का रेप्लिकेशन जोड़ना होगा। फेडरेशन की तरह, यहां कोई एक केंद्रीय मास्टर नहीं होता जो लिखावटों को सीरियलाइज़ करे, जिससे आप समानांतर में अधिक थ्रूपुट के साथ लिख सकते हैं।
उपयोगकर्ताओं की तालिका को शार्ड करने के सामान्य तरीके या तो उपयोगकर्ता के अंतिम नाम के प्रारंभिक अक्षर या उपयोगकर्ता के भौगोलिक स्थान के आधार पर होते हैं।
##### नुकसान: शार्डिंग
- आपको अपने एप्लिकेशन लॉजिक को शार्ड्स के साथ काम करने के लिए अपडेट करना पड़ेगा, जिससे जटिल SQL क्वेरी बन सकती हैं।
- एक शार्ड में डेटा वितरण असमान हो सकता है। उदाहरण के लिए, यदि किसी शार्ड पर कई पावर यूज़र हैं, तो उस शार्ड पर लोड अन्य शार्ड्स की तुलना में अधिक हो सकता है।
- रीबैलेंसिंग में अतिरिक्त जटिलता जुड़ जाती है। कंसिस्टेंट हैशिंग पर आधारित शार्डिंग फंक्शन ट्रांसफर किए गए डेटा की मात्रा को कम कर सकता है।
- कई शार्ड्स से डेटा को जोड़ना अधिक जटिल हो जाता है।
- शार्डिंग अतिरिक्त हार्डवेयर और जटिलता जोड़ता है।
डीनॉर्मलाइज़ेशन पढ़ने के प्रदर्शन को बेहतर बनाने का प्रयास करता है, हालांकि इससे कुछ लिखने के प्रदर्शन में गिरावट आ सकती है। महंगे जॉइन से बचने के लिए डेटा की अतिरिक्त प्रतियां कई तालिकाओं में लिखी जाती हैं। कुछ RDBMS जैसे PostgreSQL और Oracle मटेरियलाइज़्ड व्यूज़ का समर्थन करते हैं, जो अतिरिक्त जानकारी को संग्रहीत करने और प्रतियों को समन्वित रखने का कार्य संभालते हैं।
एक बार जब डेटा को फेडरेशन और शार्डिंग जैसी तकनीकों से वितरित कर दिया जाता है, तो डेटा सेंटर्स के बीच जॉइन्स को प्रबंधित करना और भी अधिक जटिल हो जाता है। डीनॉर्मलाइज़ेशन ऐसी जटिल जॉइन्स की आवश्यकता को टाल सकता है।
अधिकांश प्रणालियों में, पढ़ने की दर लिखने से बहुत अधिक होती है, जैसे 100:1 या यहां तक कि 1000:1। एक पढ़ाई जो जटिल डेटाबेस जॉइन में बदलती है, वह बहुत महंगी हो सकती है और इसमें डिस्क ऑपरेशन्स पर काफी समय लग सकता है।
##### नुकसान: डीनॉर्मलाइज़ेशन
- डेटा डुप्लिकेट हो जाता है।
- प्रतिबंध (constraints) अतिरिक्त प्रतियों को समन्वित रखने में मदद कर सकते हैं, जिससे डेटाबेस डिज़ाइन की जटिलता बढ़ जाती है।
- भारी लिखावट लोड में डीनॉर्मलाइज़्ड डेटाबेस का प्रदर्शन सामान्यीकृत डेटाबेस से भी खराब हो सकता है।
SQL ट्यूनिंग एक व्यापक विषय है और कई पुस्तकों को संदर्भ के रूप में लिखा गया है।
बॉटलनेक्स को उजागर करने और अनुकरण करने के लिए बेंचमार्क और प्रोफाइल करना महत्वपूर्ण है।
- बेंचमार्क - उच्च-लोड स्थितियों का अनुकरण करने के लिए ab जैसे टूल का उपयोग करें।
- प्रोफाइल - प्रदर्शन समस्याओं को ट्रैक करने में मदद के लिए slow query log जैसे टूल सक्षम करें।
##### स्कीमा को कसें
- MySQL तेज़ एक्सेस के लिए डिस्क पर लगातार ब्लॉक्स में डंप करता है।
- निश्चित-लंबाई वाले फ़ील्ड्स के लिए
CHARका उपयोग करें बजायVARCHARके। CHARप्रभावी रूप से तेज़, रैंडम एक्सेस की अनुमति देता है, जबकिVARCHARमें आपको अगले स्ट्रिंग पर जाने से पहले उसकी समाप्ति ढूंढनी होती है।- बड़े टेक्स्ट ब्लॉक्स जैसे ब्लॉग पोस्ट के लिए
TEXTका उपयोग करें।TEXTबूलियन सर्च की अनुमति देता है।TEXTफ़ील्ड का उपयोग करने पर डिस्क पर एक पॉइंटर स्टोर होता है जिससे टेक्स्ट ब्लॉक का स्थान मिलता है। - बड़े नंबरों के लिए 2^32 या 4 बिलियन तक के लिए
INTका उपयोग करें। - मुद्रा के लिए
DECIMALका उपयोग करें ताकि फ्लोटिंग पॉइंट रिप्रेजेंटेशन की गलतियों से बचा जा सके। - बड़े
BLOBको स्टोर करने से बचें, वस्तु का स्थान स्टोर करें। VARCHAR(255)8 बिट नंबर में गिने जा सकने वाले कैरेक्टर्स की अधिकतम संख्या है, जो कुछ RDBMS में एक बाइट का सर्वोत्तम उपयोग करती है।- जहाँ लागू हो वहाँ
NOT NULLकन्स्ट्रेंट सेट करें ताकि सर्च प्रदर्शन सुधारें।
- वो कॉलम जिनका आप क्वेरी कर रहे हैं (
SELECT,GROUP BY,ORDER BY,JOIN), इंडेक्स के साथ तेज़ हो सकते हैं। - इंडेक्स सामान्यतः सेल्फ-बैलेंसिंग B-tree के रूप में होते हैं, जो डेटा को सॉर्टेड रखते हैं और खोज, अनुक्रमिक एक्सेस, इनसर्शन, डिलीशन को लॉगरिदमिक समय में संभव बनाते हैं।
- इंडेक्स लगाने पर डेटा मेमोरी में रह सकता है, जिससे अधिक स्थान लगेगा।
- लिखाई भी धीमी हो सकती है क्योंकि इंडेक्स को भी अपडेट करना होता है।
- जब बड़ी मात्रा में डेटा लोड कर रहे हों, तो इंडेक्स को डिसेबल करना, डेटा लोड करना, फिर इंडेक्स को रीबिल्ड करना तेज़ हो सकता है।
- प्रदर्शन की मांग होने पर डिनॉर्मलाइज़ करें।
- एक तालिका को विभाजित करें, गर्म स्थानों को अलग तालिका में डालें ताकि इसे मेमोरी में रखने में मदद मिले।
- कुछ मामलों में, क्वेरी कैश प्रदर्शन संबंधी समस्याओं का कारण बन सकता है।
- MySQL क्वेरी को ऑप्टिमाइज़ करने के टिप्स
- क्या कोई अच्छा कारण है कि मैं VARCHAR(255) का उपयोग बार-बार देखता हूँ?
- NULL मान प्रदर्शन को कैसे प्रभावित करते हैं?
- धीमी क्वेरी लॉग
NoSQL
NoSQL डेटा आइटम्स का एक संग्रह है, जो की-वैल्यू स्टोर, डॉक्युमेंट स्टोर, वाइड कॉलम स्टोर, या ग्राफ डाटाबेस में दर्शाया जाता है। डेटा डीनॉर्मलाइज़्ड होता है, और आमतौर पर जॉइन एप्लिकेशन कोड में किए जाते हैं। अधिकांश NoSQL स्टोर्स में वास्तविक ACID ट्रांजैक्शन नहीं होते और वे eventual consistency को प्राथमिकता देते हैं।
BASE शब्द का उपयोग अक्सर NoSQL डाटाबेस की विशेषताओं को बताने के लिए किया जाता है। CAP प्रमेय की तुलना में, BASE स्थिरता की बजाय उपलब्धता चुनता है।
- मूल रूप से उपलब्ध - सिस्टम उपलब्धता की गारंटी देता है।
- सॉफ्ट स्टेट - सिस्टम की स्थिति समय के साथ बदल सकती है, भले ही कोई इनपुट न हो।
- इवैंचुअल कंसिस्टेंसी - सिस्टम एक निश्चित समय के बाद स्थिर हो जाएगा, बशर्ते उस दौरान कोई इनपुट न मिले।
#### की-वैल्यू स्टोर
अमूर्तता: हैश टेबल
एक की-वैल्यू स्टोर आमतौर पर O(1) रीड और राइट की अनुमति देता है और अक्सर मेमोरी या SSD द्वारा समर्थित होता है। डेटा स्टोर्स lexicographic क्रम में कीज़ को रख सकते हैं, जिससे की रेंज को कुशलता से प्राप्त किया जा सकता है। की-वैल्यू स्टोर्स किसी वैल्यू के साथ मेटाडेटा स्टोर करने की अनुमति दे सकते हैं।
की-वैल्यू स्टोर्स उच्च प्रदर्शन प्रदान करते हैं और आमतौर पर सरल डेटा मॉडल या तेजी से बदलने वाले डेटा के लिए उपयोग किए जाते हैं, जैसे कि इन-मेमोरी कैश लेयर। चूंकि वे केवल सीमित ऑपरेशन सेट प्रदान करते हैं, अगर अतिरिक्त ऑपरेशन की आवश्यकता हो तो जटिलता एप्लिकेशन लेयर में स्थानांतरित हो जाती है।
एक की-वैल्यू स्टोर अधिक जटिल सिस्टम जैसे कि डॉक्युमेंट स्टोर, और कुछ मामलों में ग्राफ डाटाबेस का आधार होता है।
##### स्रोत(स) और आगे की पढ़ाई: की-वैल्यू स्टोर
#### डॉक्युमेंट स्टोरअमूर्तता: कुंजी-मूल्य स्टोर जिसमें डॉक्युमेंट्स को मूल्यों के रूप में संग्रहीत किया जाता है
एक डॉक्युमेंट स्टोर डॉक्युमेंट्स (XML, JSON, बाइनरी आदि) के इर्द-गिर्द केंद्रित होता है, जहाँ एक डॉक्युमेंट दिए गए ऑब्जेक्ट की सारी जानकारी संग्रहीत करता है। डॉक्युमेंट स्टोर्स API या क्वेरी भाषा प्रदान करते हैं ताकि डॉक्युमेंट की आंतरिक संरचना के आधार पर क्वेरी की जा सके। नोट, कई की-वैल्यू स्टोर्स में वैल्यू के मेटाडाटा के साथ काम करने की सुविधाएँ होती हैं, जिससे इन दो प्रकार के स्टोरेज के बीच की सीमाएँ धुंधली हो जाती हैं।
आधारभूत कार्यान्वयन के आधार पर, डॉक्युमेंट्स को संग्रह, टैग, मेटाडाटा या निर्देशिकाओं द्वारा व्यवस्थित किया जाता है। हालांकि डॉक्युमेंट्स को व्यवस्थित या समूहित किया जा सकता है, डॉक्युमेंट्स में ऐसे क्षेत्र हो सकते हैं जो एक-दूसरे से पूरी तरह भिन्न हों।
कुछ डॉक्युमेंट स्टोर्स जैसे MongoDB और CouchDB जटिल क्वेरी करने के लिए SQL-जैसी भाषा भी प्रदान करते हैं। DynamoDB दोनों की-वैल्यू और डॉक्युमेंट्स को सपोर्ट करता है।
डॉक्युमेंट स्टोर्स उच्च लचीलापन प्रदान करते हैं और अक्सर कभी-कभी बदलने वाले डेटा के साथ काम करने के लिए इस्तेमाल किए जाते हैं।
##### स्रोत और आगे पढ़ें: डॉक्युमेंट स्टोर
#### वाइड कॉलम स्टोर
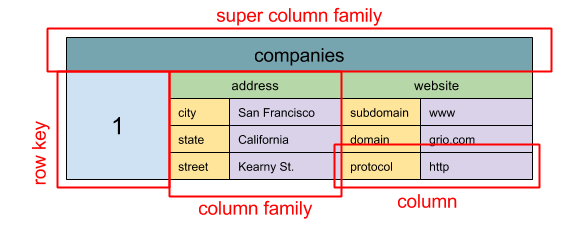
स्रोत: SQL & NoSQL, एक संक्षिप्त इतिहास
अमूर्तता: नेस्टेड मैप ColumnFamily> वाइड कॉलम स्टोर की मूल डेटा इकाई एक कॉलम (नाम/मूल्य जोड़ी) है। एक कॉलम को कॉलम परिवारों में समूहित किया जा सकता है (SQL टेबल के समान)। सुपर कॉलम परिवार आगे कॉलम परिवारों को समूहित करते हैं। आप प्रत्येक कॉलम को स्वतंत्र रूप से एक रो कुंजी द्वारा एक्सेस कर सकते हैं, और एक ही रो कुंजी वाले कॉलम एक रो बनाते हैं। प्रत्येक मूल्य में संस्करणिंग और संघर्ष समाधान के लिए एक टाइमस्टैम्प होता है।
Google ने Bigtable को पहला वाइड कॉलम स्टोर के रूप में पेश किया, जिसने ओपन-सोर्स HBase को प्रभावित किया जो अक्सर Hadoop इकोसिस्टम में उपयोग होता है, और Cassandra को Facebook ने बनाया। BigTable, HBase, और Cassandra जैसे स्टोर्स कुंजियों को लेक्सिकोग्राफिक क्रम में रखते हैं, जिससे चयनित कुंजी रेंज को कुशलतापूर्वक प्राप्त किया जा सकता है।
वाइड कॉलम स्टोर्स उच्च उपलब्धता और उच्च स्केलेबिलिटी प्रदान करते हैं। इन्हें अक्सर बहुत बड़े डेटा सेट्स के लिए इस्तेमाल किया जाता है।
##### स्रोत और आगे पढ़ें: वाइड कॉलम स्टोर
#### ग्राफ डेटाबेस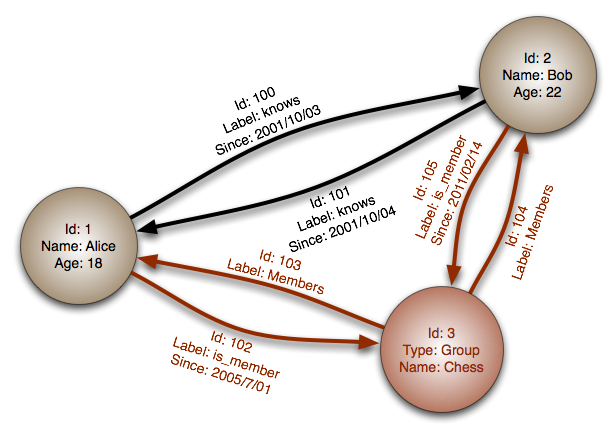
अमूर्तता: ग्राफ
ग्राफ डेटाबेस में, प्रत्येक नोड एक रिकॉर्ड होता है और प्रत्येक आर्क दो नोड्स के बीच संबंध होता है। ग्राफ डेटाबेस कई विदेशी कुंजियों या कई-से-कई संबंधों के साथ जटिल संबंधों का प्रतिनिधित्व करने के लिए अनुकूलित होते हैं।
ग्राफ डेटाबेस जटिल संबंधों वाले डेटा मॉडल के लिए उच्च प्रदर्शन प्रदान करते हैं, जैसे कि एक सोशल नेटवर्क। ये अपेक्षाकृत नए हैं और अभी तक व्यापक रूप से उपयोग नहीं किए जाते; विकास टूल और संसाधन ढूंढना कठिन हो सकता है। कई ग्राफ्स केवल REST APIs के साथ ही एक्सेस किए जा सकते हैं।
##### स्रोत और आगे पढ़ाई: ग्राफ
#### स्रोत और आगे पढ़ाई: NoSQL- बेस शब्दावली की व्याख्या
- NoSQL डेटाबेस सर्वेक्षण और निर्णय मार्गदर्शन
- स्केलेबिलिटी
- NoSQL का परिचय
- NoSQL पैटर्न
SQL या NoSQL
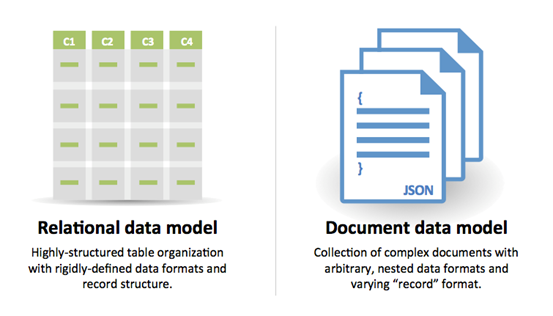
स्रोत: RDBMS से NoSQL की ओर संक्रमण
SQL के लिए कारण:
- संरचित डेटा
- कड़ा स्कीमा
- रिलेशनल डेटा
- जटिल जॉइनों की आवश्यकता
- ट्रांजेक्शन्स
- स्केलिंग के लिए स्पष्ट पैटर्न
- अधिक स्थापित: डेवलपर्स, समुदाय, कोड, टूल्स आदि
- इंडेक्स द्वारा लुकअप बहुत तेज़ हैं
- अर्ध-संरचित डेटा
- डायनामिक या लचीला स्कीमा
- गैर-रिलेशनल डेटा
- जटिल जॉइनों की आवश्यकता नहीं
- कई TB (या PB) डेटा स्टोर करना
- बहुत डेटा-गहन वर्कलोड
- IOPS के लिए बहुत उच्च थ्रूपुट
- क्लिकस्ट्रीम और लॉग डेटा का तेज़ इनजेस्ट
- लीडरबोर्ड या स्कोरिंग डेटा
- अस्थायी डेटा, जैसे शॉपिंग कार्ट
- बार-बार एक्सेस की जाने वाली ('हॉट') टेबल्स
- मेटाडेटा/लुकअप टेबल्स
कैश
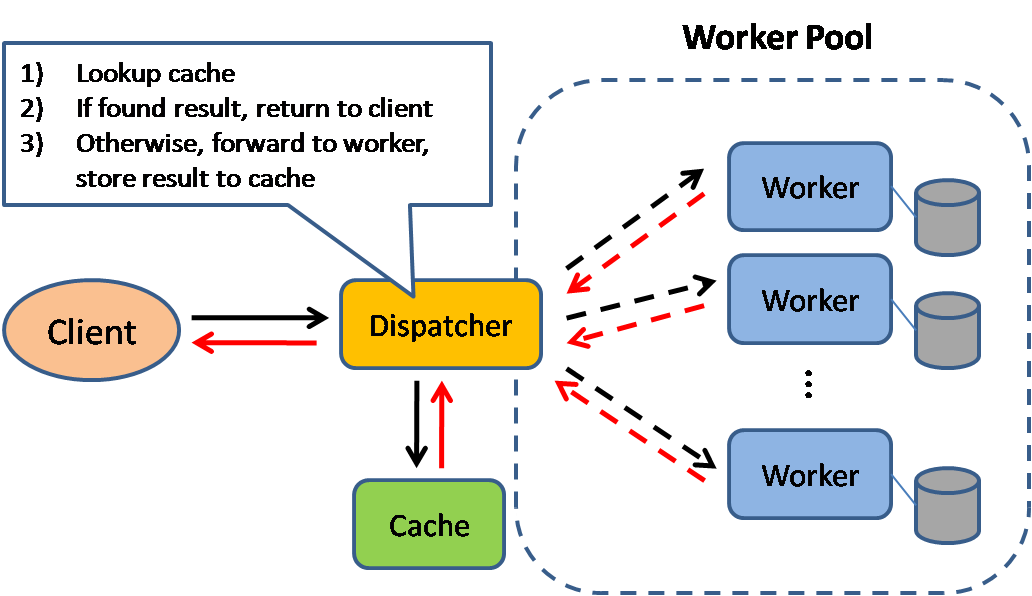
स्रोत: स्केलेबल सिस्टम डिजाइन पैटर्न्स
कैशिंग पृष्ठ लोड समय को बेहतर बनाती है और आपके सर्वर और डेटाबेस पर लोड को कम कर सकती है। इस मॉडल में, डिस्पैचर पहले यह देखेगा कि अनुरोध पहले किया गया है या नहीं, और पिछले परिणाम को वापस करने का प्रयास करेगा, ताकि वास्तविक निष्पादन को बचाया जा सके।
डेटाबेस अक्सर अपने विभाजनों में रीड और राइट्स के समान वितरण से लाभान्वित होते हैं। लोकप्रिय आइटम वितरण को असमान कर सकते हैं, जिससे बॉटलनेक उत्पन्न होते हैं। डेटाबेस के आगे कैश लगाना असमान लोड और ट्रैफिक स्पाइक्स को संभालने में मदद कर सकता है।
क्लाइंट कैशिंग
कैश क्लाइंट साइड (OS या ब्राउज़र), सर्वर साइड, या अलग कैश लेयर में स्थित हो सकते हैं।
CDN कैशिंग
CDN को कैश का एक प्रकार माना जाता है।
वेब सर्वर कैशिंग
रिवर्स प्रॉक्सी और Varnish जैसे कैश स्टैटिक और डायनामिक कंटेंट को सीधे सर्व कर सकते हैं। वेब सर्वर भी अनुरोधों को कैश कर सकते हैं, जिससे एप्लिकेशन सर्वर से संपर्क किए बिना ही प्रतिक्रिया दी जा सकती है।
डेटाबेस कैशिंग
आपका डेटाबेस आम तौर पर डिफॉल्ट कॉन्फ़िगरेशन में किसी स्तर की कैशिंग शामिल करता है, जो सामान्य उपयोग के लिए अनुकूलित होती है। इन सेटिंग्स को विशिष्ट उपयोग पैटर्न के लिए बदलने से प्रदर्शन और बढ़ सकता है।
एप्लिकेशन कैशिंग
इन-मेमोरी कैश जैसे Memcached और Redis आपके एप्लिकेशन और डेटा स्टोरेज के बीच की-वैल्यू स्टोर होते हैं। चूंकि डेटा RAM में रखा जाता है, यह सामान्य डेटाबेस की तुलना में काफी तेज होता है जहां डेटा डिस्क में रखा जाता है। RAM डिस्क की तुलना में सीमित होती है, इसलिए कैश इनवैलिडेशन एल्गोरिदम जैसे Least Recently Used (LRU)) 'कोल्ड' एंट्रीज़ को हटाने और 'हॉट' डेटा को RAM में रखने में मदद करते हैं।
Redis में निम्नलिखित अतिरिक्त विशेषताएं हैं:
- परसिस्टेंस विकल्प
- इन-बिल्ट डेटा संरचनाएं जैसे सॉर्टेड सेट और लिस्ट
- रो स्तर
- क्वेरी स्तर
- पूरी तरह से निर्मित सीरियलाइज़ेबल ऑब्जेक्ट्स
- पूरी तरह से रेंडर की गई HTML
डेटाबेस क्वेरी स्तर पर कैशिंग
जब भी आप डेटाबेस से क्वेरी करते हैं, क्वेरी को एक कुंजी के रूप में हैश करें और परिणाम को कैश में संग्रहित करें। इस विधि में एक्सपाइरी से जुड़ी समस्याएँ होती हैं:
- जटिल क्वेरी के साथ कैश किए गए परिणाम को हटाना कठिन है
- यदि डेटा का कोई भाग बदलता है, जैसे कि कोई टेबल सेल, तो आपको उन सभी कैश की गई क्वेरीज़ को हटाना होगा, जिनमें बदला हुआ सेल शामिल हो सकता है
ऑब्जेक्ट स्तर पर कैशिंग
अपने डेटा को एक ऑब्जेक्ट के रूप में देखें, जैसा कि आप अपने एप्लिकेशन कोड के साथ करते हैं। अपने एप्लिकेशन को डेटाबेस से डेटा सेट को एक क्लास इंस्टेंस या डेटा स्ट्रक्चर(s) में असेंबल करने दें:
- यदि ऑब्जेक्ट के अंतर्निहित डेटा में बदलाव होता है, तो ऑब्जेक्ट को कैश से हटा दें
- एसिंक्रोनस प्रोसेसिंग की अनुमति देता है: वर्कर नवीनतम कैश किए गए ऑब्जेक्ट को लेकर ऑब्जेक्ट्स को असेंबल करते हैं
- यूज़र सेशंस
- पूर्ण रूप से रेंडर किए गए वेब पेजेज़
- गतिविधि स्ट्रीम्स
- यूज़र ग्राफ डेटा
कैश को कब अपडेट करें
चूंकि आप कैश में सीमित मात्रा में डेटा ही संग्रहित कर सकते हैं, आपको यह निर्धारित करना होगा कि आपके उपयोग के मामले के लिए कौन सी कैश अपडेट स्ट्रैटेजी सबसे उपयुक्त है।
#### कैश-असाइड
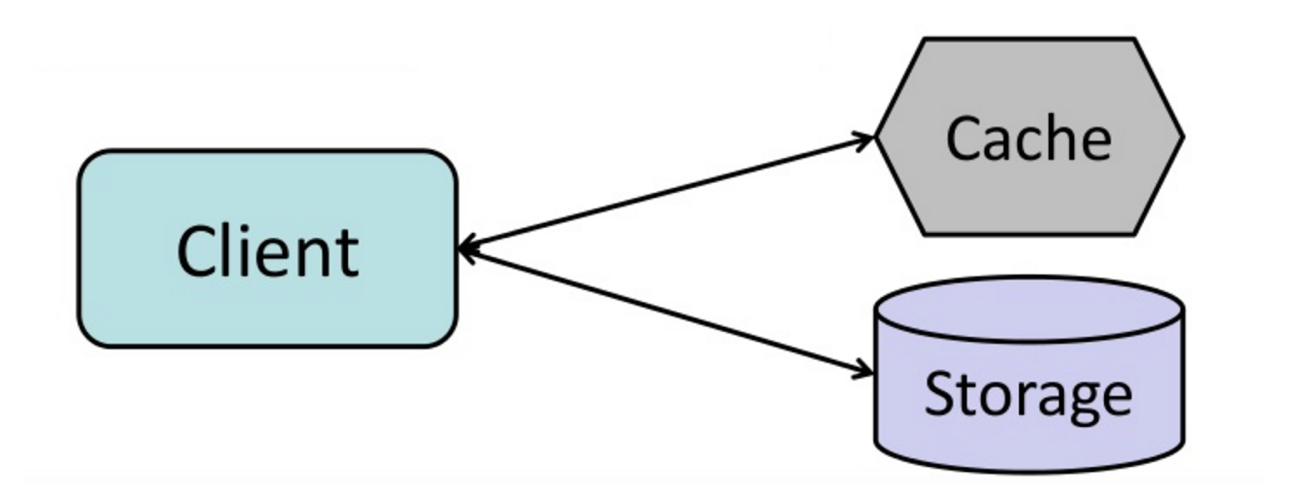
स्रोत: कैश से इन-मेमोरी डेटा ग्रिड तक
एप्लिकेशन स्टोरेज से पढ़ने और लिखने के लिए जिम्मेदार होता है। कैश सीधे स्टोरेज के साथ इंटरैक्ट नहीं करता। एप्लिकेशन निम्न कार्य करता है:
- कैश में एंट्री खोजें, जिससे कैश मिस होती है
- डेटाबेस से एंट्री लोड करें
- एंट्री को कैश में जोड़ें
- एंट्री लौटाएँ
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached आमतौर पर इस तरीके से उपयोग किया जाता है।
कैश में जोड़ा गया डेटा की बाद की रीड्स तेज़ होती हैं। कैश-असाइड को लेज़ी लोडिंग भी कहा जाता है। केवल अनुरोधित डेटा ही कैश होता है, जिससे ऐसे डेटा से कैश नहीं भरता जिसकी मांग नहीं है।
##### नुकसान: कैश-असाइड
- हर कैश मिस के लिए तीन ट्रिप्स होते हैं, जिससे ध्यान देने योग्य विलंब हो सकता है।
- अगर डेटाबेस में डेटा अपडेट होता है तो वह पुराना हो सकता है। इस समस्या को टाइम-टू-लाइव (TTL) सेट करके हल किया जा सकता है, जिससे कैश एंट्री अपडेट होती है, या राइट-थ्रू का उपयोग किया जाता है।
- जब कोई नोड फेल हो जाता है, तो उसकी जगह एक नया, खाली नोड आ जाता है, जिससे लेटेंसी बढ़ती है।
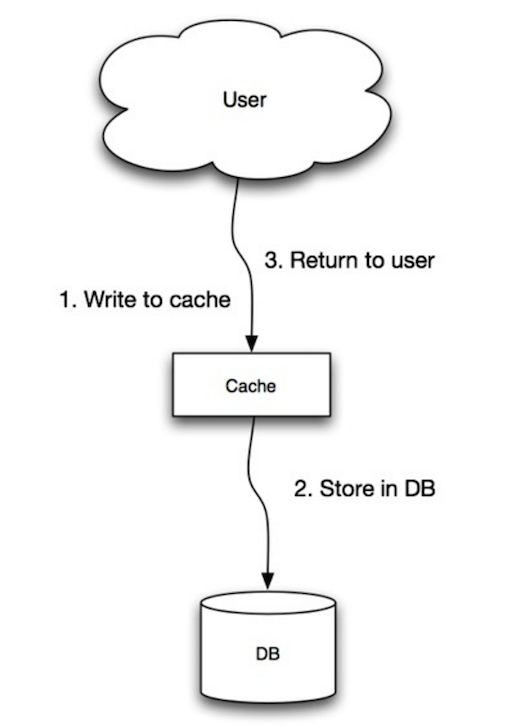
स्रोत: स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न्स
एप्लिकेशन मुख्य डाटा स्टोर के रूप में कैश का उपयोग करती है, इसमें डेटा पढ़ती और लिखती है, जबकि कैश डेटाबेस में पढ़ने और लिखने के लिए जिम्मेदार होता है:
- एप्लिकेशन कैश में एंट्री जोड़ती/अपडेट करती है
- कैश सिंक्रोनसली एंट्री को डाटा स्टोर में लिखता है
- रिटर्न
set_user(12345, {"foo":"bar"})कैश कोड:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### नुकसान: राइट-थ्रू
- जब कोई नया नोड फेल होने या स्केलिंग के कारण बनाया जाता है, तो नया नोड तब तक एंट्री को कैश नहीं करेगा जब तक कि वह एंट्री डेटाबेस में अपडेट न हो जाए। कैश-असाइड को राइट-थ्रू के साथ मिलाकर इस समस्या को कम किया जा सकता है।
- अधिकांश लिखा गया डेटा शायद कभी पढ़ा ही न जाए, जिसे TTL के उपयोग से कम किया जा सकता है।
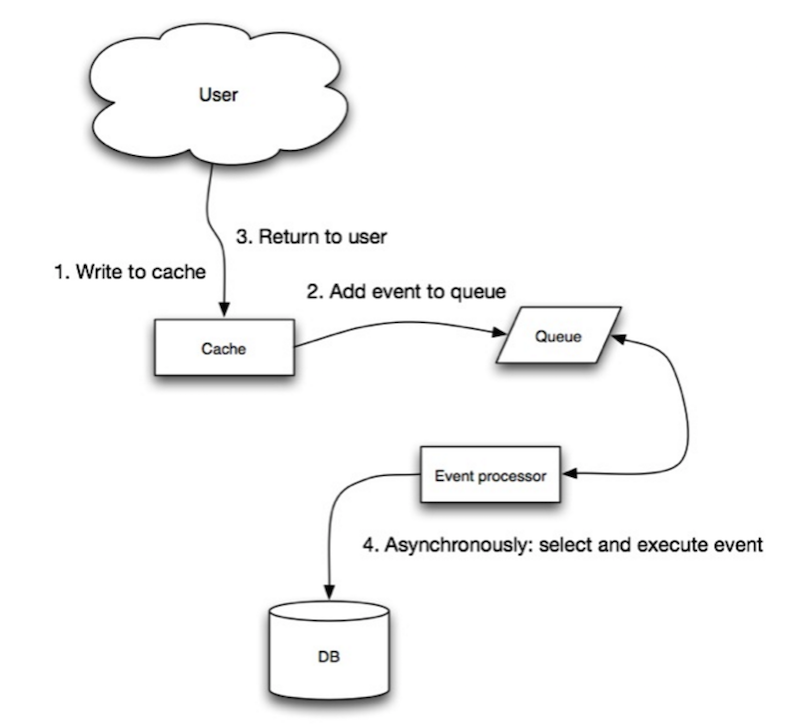
स्रोत: स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न्स
राइट-बिहाइंड में, एप्लिकेशन निम्नलिखित करता है:
- एंट्री को कैश में जोड़ना/अपडेट करना
- डेटा स्टोर में एंट्री को असिंक्रोनस रूप से लिखना, जिससे लिखने की परफॉर्मेंस बेहतर होती है
- अगर कैश अपने कंटेंट को डेटा स्टोर तक भेजने से पहले डाउन हो जाता है तो डेटा लॉस हो सकता है।
- राइट-बिहाइंड को लागू करना कैश-असाइड या राइट-थ्रू की तुलना में अधिक जटिल है।
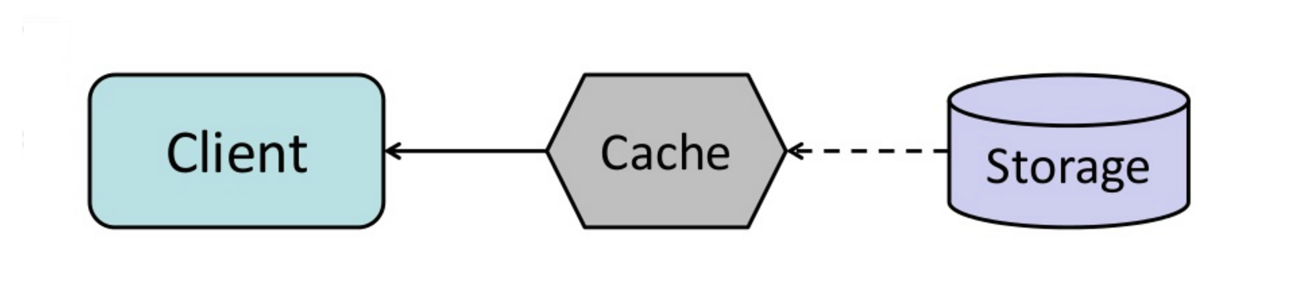
स्रोत: कैश से इन-मेमोरी डेटा ग्रिड तक
आप कैश को इस प्रकार कॉन्फ़िगर कर सकते हैं कि हाल ही में एक्सेस की गई किसी भी कैश एंट्री को उसकी समाप्ति से पहले स्वतः रिफ्रेश कर दे।
यदि कैश यह सही-सही अनुमान लगा सकता है कि भविष्य में किन आइटम्स की आवश्यकता हो सकती है, तो रिफ्रेश-अहेड रीड-थ्रू की तुलना में लेटेंसी को कम कर सकता है।
##### नुकसान: रिफ्रेश-अहेड
- भविष्य में किन वस्तुओं की आवश्यकता होगी, इसका सही पूर्वानुमान न लगाना, refresh-ahead के बिना प्रदर्शन को कम कर सकता है।
नुकसान(नुकसान): कैश
- कैश और सत्य के स्रोत जैसे डेटाबेस के बीच कैश इनवैलिडेशन द्वारा स्थिरता बनाए रखना आवश्यक है।
- कैश इनवैलिडेशन एक कठिन समस्या है, इसमें कैश को कब अपडेट करना है, इससे जुड़ी अतिरिक्त जटिलता होती है।
- एप्लिकेशन में बदलाव करना आवश्यक है जैसे कि Redis या memcached जोड़ना।
स्रोत और आगे पढ़ने के लिए
- कैश से इन-मेमोरी डेटा ग्रिड तक
- स्केलेबल सिस्टम डिज़ाइन पैटर्न
- स्केल के लिए सिस्टम आर्किटेक्चर का परिचय
- स्केलेबिलिटी, उपलब्धता, स्थिरता, पैटर्न
- स्केलेबिलिटी
- AWS ElastiCache रणनीतियाँ
- विकिपीडिया)
असिंक्रोनिज़्म
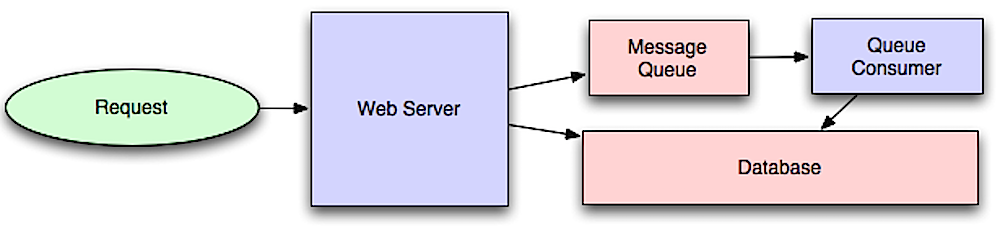
स्रोत: स्केल के लिए सिस्टम आर्किटेक्चर का परिचय
असिंक्रोनस वर्कफ़्लो महंगे ऑपरेशनों के लिए अनुरोध समय को कम करने में मदद करते हैं, जो अन्यथा इन-लाइन किए जाते। ये समय लेने वाले कार्य जैसे डेटा का आवधिक एग्रीगेशन पहले से करके भी सहायता करते हैं।
संदेश कतारें
संदेश कतारें संदेश प्राप्त, संग्रहित और वितरित करती हैं। यदि कोई ऑपरेशन इन-लाइन करने के लिए बहुत धीमा है, तो आप निम्नलिखित वर्कफ़्लो के साथ संदेश कतार का उपयोग कर सकते हैं:
- एक एप्लिकेशन कतार में एक जॉब प्रकाशित करता है, फिर उपयोगकर्ता को जॉब की स्थिति की सूचना देता है
- एक वर्कर कतार से जॉब उठाता है, उसे प्रोसेस करता है, फिर संकेत देता है कि जॉब पूर्ण हो गई है
Redis एक साधारण संदेश ब्रोकर के रूप में उपयोगी है लेकिन संदेश खो सकते हैं।
RabbitMQ लोकप्रिय है लेकिन इसके लिए 'AMQP' प्रोटोकॉल को अपनाना और अपने नोड्स का प्रबंधन करना पड़ता है। Amazon SQS होस्टेड है लेकिन इसमें उच्च विलंबता हो सकती है और संदेशों के दो बार वितरित होने की संभावना रहती है।
टास्क कतारें
टास्क कतारें कार्य और उनके संबंधित डेटा प्राप्त करती हैं, उन्हें चलाती हैं, फिर उनके परिणाम वितरित करती हैं। ये शेड्यूलिंग का समर्थन कर सकती हैं और बैकग्राउंड में गणनात्मक रूप से गहन कार्य चलाने के लिए उपयोग की जा सकती हैं।
Celery शेड्यूलिंग का समर्थन करता है और मुख्य रूप से पायथन के लिए उपलब्ध है।
बैक प्रेशर
अगर कतारें काफी बढ़ने लगती हैं, तो कतार का आकार मेमोरी से बड़ा हो सकता है, जिससे कैश मिस, डिस्क रीड्स और प्रदर्शन में और भी अधिक गिरावट आ सकती है। बैक प्रेशर कतार का आकार सीमित कर उच्च थ्रूपुट दर और कतार में पहले से मौजूद कार्यों के लिए अच्छा प्रतिक्रिया समय बनाए रखने में मदद करता है। एक बार कतार भर जाने पर, क्लाइंट्स को सर्वर बिजी या HTTP 503 स्टेटस कोड मिलता है, जिससे वे बाद में पुनः प्रयास करें। क्लाइंट्स अनुरोध को बाद में फिर से भेज सकते हैं, संभवतः एक्सपोनेंशियल बैकऑफ के साथ।
नुकसान: असिंक्रोनिज्म
- सस्ते गणना वाले और रियलटाइम वर्कफ़्लो जैसे उपयोग के मामले सिंक्रोनस ऑपरेशन के लिए अधिक उपयुक्त हो सकते हैं, क्योंकि कतारें जोड़ने से विलंबता और जटिलता बढ़ सकती है।
स्रोत और आगे की पढ़ाई
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- What is the difference between a message queue and a task queue?
संचार
{kind=link}
{kind=link}
हाइपरटेक्स्ट ट्रांसफर प्रोटोकॉल (HTTP)
HTTP क्लाइंट और सर्वर के बीच डेटा को एन्कोड और ट्रांसपोर्ट करने की एक विधि है। यह अनुरोध/प्रतिक्रिया प्रोटोकॉल है: क्लाइंट अनुरोध भेजते हैं और सर्वर प्रासंगिक कंटेंट और अनुरोध की स्थिति जानकारी के साथ प्रतिक्रिया भेजते हैं। HTTP स्व-निहित है, जिससे अनुरोध और प्रतिक्रिया कई मध्यवर्ती राउटर और सर्वरों से होकर जा सकती है, जो लोड बैलेंसिंग, कैशिंग, एन्क्रिप्शन और कंप्रेशन करते हैं।
एक बेसिक HTTP अनुरोध में एक क्रिया (विधि) और एक संसाधन (एंडपॉइंट) होता है। नीचे सामान्य HTTP क्रियाएं दी गई हैं:
| क्रिया | विवरण | आइडेम्पोटेंट* | सुरक्षित | कैश करने योग्य | |---|---|---|---|---|
| GET | एक संसाधन को पढ़ता है | हाँ | हाँ | हाँ | | POST | एक संसाधन बनाता है या डेटा को संभालने वाली प्रक्रिया को ट्रिगर करता है | नहीं | नहीं | हाँ, अगर प्रतिक्रिया में ताजगी की जानकारी हो | | PUT | एक संसाधन बनाता या बदलता है | हाँ | नहीं | नहीं | | PATCH | एक संसाधन को आंशिक रूप से अपडेट करता है | नहीं | नहीं | हाँ, अगर प्रतिक्रिया में ताजगी की जानकारी हो | | DELETE | एक संसाधन को हटाता है | हाँ | नहीं | नहीं |
*अलग परिणामों के बिना कई बार कॉल किया जा सकता है।
HTTP एक एप्लीकेशन लेयर प्रोटोकॉल है, जो TCP और UDP जैसे निम्न-स्तरीय प्रोटोकॉल पर निर्भर करता है।
#### स्रोत(स) और आगे पढ़ें: HTTP
ट्रांसमिशन कंट्रोल प्रोटोकॉल (TCP)
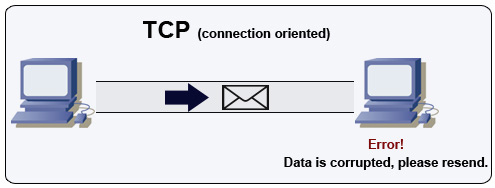
स्रोत: मल्टीप्लेयर गेम कैसे बनाएं
TCP एक कनेक्शन-ओरिएंटेड प्रोटोकॉल है जो IP नेटवर्क पर चलता है। कनेक्शन को स्थापित और समाप्त करने के लिए हैंडशेक का उपयोग किया जाता है। सभी भेजे गए पैकेट गारंटी के साथ बिना किसी भ्रष्टाचार के और मूल क्रम में गंतव्य तक पहुँचते हैं:
- प्रत्येक पैकेट के लिए अनुक्रम संख्या और चेकसम फ़ील्ड्स
- स्वीकृति) पैकेट और स्वचालित पुन:प्रेषण
उच्च थ्रूपुट सुनिश्चित करने के लिए, वेब सर्वर कई TCP कनेक्शन खुले रख सकते हैं, जिससे उच्च मेमोरी उपयोग होता है। वेब सर्वर थ्रेड्स और जैसे memcached सर्वर के बीच कई खुले कनेक्शन होना महंगा हो सकता है। कनेक्शन पूलिंग मदद कर सकती है, साथ ही जहां संभव हो UDP में स्विच करना भी।
TCP उन एप्लिकेशन के लिए उपयोगी है जिन्हें उच्च विश्वसनीयता की आवश्यकता होती है लेकिन वे समय की दृष्टि से कम महत्वपूर्ण होती हैं। कुछ उदाहरण हैं वेब सर्वर, डेटाबेस जानकारी, SMTP, FTP, और SSH।
TCP का उपयोग UDP के ऊपर करें जब:
- आपको सभी डेटा सही-सलामत पहुँचने की आवश्यकता हो
- आप स्वचालित रूप से नेटवर्क थ्रूपुट का सर्वोत्तम अनुमान लगाना चाहते हैं
यूज़र डेटाग्राम प्रोटोकॉल (UDP)
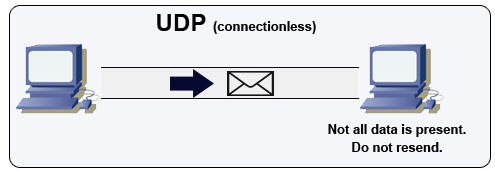
स्रोत: मल्टीप्लेयर गेम कैसे बनाएं
UDP कनेक्शनलेस है। डेटाग्राम (पैकेट के समान) केवल डेटाग्राम स्तर पर ही गारंटीकृत होते हैं। डेटाग्राम अपने गंतव्य तक गलत क्रम में पहुँच सकते हैं या बिल्कुल भी नहीं पहुँच सकते। UDP कंजेशन कंट्रोल का समर्थन नहीं करता। TCP द्वारा प्रदान की गई गारंटी के बिना, UDP आमतौर पर अधिक प्रभावी होता है।
UDP ब्रॉडकास्ट कर सकता है, जिससे सबनेट के सभी डिवाइसों को डेटाग्राम भेजे जा सकते हैं। यह DHCP के साथ उपयोगी है क्योंकि क्लाइंट ने अभी तक IP पता प्राप्त नहीं किया है, जिससे TCP को IP पते के बिना स्ट्रीम करने का तरीका नहीं मिल पाता।
UDP कम विश्वसनीय है लेकिन वॉयस ओवर IP, वीडियो चैट, स्ट्रीमिंग, और रीयलटाइम मल्टीप्लेयर गेम्स जैसे वास्तविक समय के उपयोग मामलों में अच्छी तरह काम करता है।
TCP के बजाय UDP का प्रयोग करें जब:
- आपको सबसे कम विलंबता चाहिए
- देर से प्राप्त डेटा, डेटा की हानि से भी खराब है
- आप अपनी खुद की त्रुटि सुधार लागू करना चाहते हैं
- गेम प्रोग्रामिंग के लिए नेटवर्किंग
- TCP और UDP प्रोटोकॉल के बीच मुख्य अंतर
- TCP और UDP के बीच अंतर
- ट्रांसमिशन कंट्रोल प्रोटोकॉल
- यूज़र डेटाग्राम प्रोटोकॉल
- फेसबुक पर मेमकैश को स्केल करना
रिमोट प्रोसीजर कॉल (RPC)
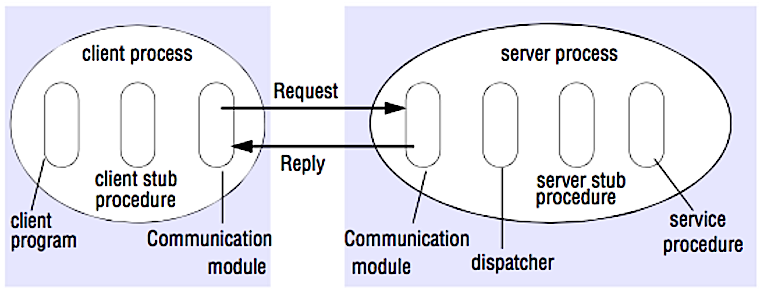
स्रोत: सिस्टम डिजाइन इंटरव्यू कैसे क्रैक करें
RPC में, एक क्लाइंट किसी अन्य एड्रेस स्पेस पर, आमतौर पर रिमोट सर्वर पर, एक प्रक्रिया को निष्पादित कराता है। प्रक्रिया को ऐसे कोड किया जाता है जैसे यह लोकल प्रक्रिया कॉल हो, जिससे क्लाइंट प्रोग्राम से सर्वर के साथ संवाद करने का विवरण अमूर्त हो जाता है। रिमोट कॉल आमतौर पर लोकल कॉल की तुलना में धीमे और कम विश्वसनीय होते हैं, इसलिए RPC कॉल को लोकल कॉल से अलग पहचानना सहायक होता है। लोकप्रिय RPC फ्रेमवर्क में Protobuf, Thrift, और Avro शामिल हैं।
RPC एक रिक्वेस्ट-रिस्पॉन्स प्रोटोकॉल है:
- क्लाइंट प्रोग्राम - क्लाइंट स्टब प्रक्रिया को कॉल करता है। पैरामीटर स्टैक पर एक स्थानीय प्रक्रिया कॉल की तरह पुश किए जाते हैं।
- क्लाइंट स्टब प्रक्रिया - प्रक्रिया आईडी और आर्ग्युमेंट्स को रिक्वेस्ट संदेश में मार्शल (पैक) करती है।
- क्लाइंट कम्युनिकेशन मॉड्यूल - OS क्लाइंट से सर्वर तक संदेश भेजता है।
- सर्वर कम्युनिकेशन मॉड्यूल - OS इनकमिंग पैकेट्स को सर्वर स्टब प्रक्रिया को पास करता है।
- सर्वर स्टब प्रक्रिया - परिणामों को अनमार्शल करती है, प्रक्रिया आईडी से मेल खाने वाली सर्वर प्रक्रिया को कॉल करती है और दिए गए आर्ग्युमेंट्स पास करती है।
- सर्वर प्रतिक्रिया उपरोक्त चरणों को उल्टे क्रम में दोहराती है।
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
देशी लाइब्रेरी (जिसे SDK भी कहा जाता है) चुनें जब:
- आप अपने लक्षित प्लेटफ़ॉर्म को जानते हैं।
- आप नियंत्रित करना चाहते हैं कि आपकी "लॉजिक" तक कैसे पहुंचा जाए।
- आप नियंत्रित करना चाहते हैं कि आपकी लाइब्रेरी के बाहर त्रुटि नियंत्रण कैसे हो।
- प्रदर्शन और अंतिम उपयोगकर्ता अनुभव आपकी प्राथमिक चिंता है।
#### नुकसान: RPC
- RPC क्लाइंट्स सेवा कार्यान्वयन से बहुत अधिक जुड़े होते हैं।
- हर नए ऑपरेशन या उपयोग मामले के लिए एक नया API परिभाषित करना पड़ता है।
- RPC को डिबग करना कठिन हो सकता है।
- आप मौजूदा तकनीकों का सीधे लाभ नहीं उठा सकते। उदाहरण के लिए, यह सुनिश्चित करने के लिए अतिरिक्त प्रयास की आवश्यकता हो सकती है कि RPC कॉल्स को ठीक से कैश किया जाए जैसे कैशिंग सर्वर पर Squid।
प्रतिनिधित्वात्मक स्थिति हस्तांतरण (REST)
REST एक वास्तुशिल्प शैली है जो क्लाइंट/सर्वर मॉडल को लागू करती है जहाँ क्लाइंट सर्वर द्वारा प्रबंधित संसाधनों के सेट पर कार्य करता है। सर्वर संसाधनों का प्रतिनिधित्व और क्रियाएं प्रदान करता है जो या तो संसाधनों को बदल सकती हैं या उनका नया प्रतिनिधित्व प्राप्त कर सकती हैं। सभी संचार स्टेटलेस और कैश करने योग्य होने चाहिए।
RESTful इंटरफेस की चार विशेषताएं हैं:
- संसाधनों की पहचान करें (HTTP में URI) - किसी भी ऑपरेशन के बावजूद एक ही URI का उपयोग करें।
- प्रतिनिधित्व के साथ बदलें (HTTP में क्रियाएं) - क्रियाओं, हेडर और बॉडी का उपयोग करें।
- स्व-वर्णनात्मक त्रुटि संदेश (HTTP में स्थिति प्रतिक्रिया) - स्थिति कोड का उपयोग करें, पहिया फिर से न बनाएं।
- HATEOAS (HTTP के लिए HTML इंटरफेस) - आपकी वेब सेवा पूरी तरह ब्राउज़र में सुलभ होनी चाहिए।
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### REST की कमी(याँ):
- चूंकि REST डेटा को उजागर करने पर केंद्रित है, यह उपयुक्त नहीं हो सकता यदि संसाधन स्वाभाविक रूप से सरल पदानुक्रम में व्यवस्थित या एक्सेस नहीं होते। उदाहरण के लिए, पिछले घंटे के सभी अद्यतन रिकॉर्ड को लौटाना जो किसी विशेष घटनाओं से मेल खाते हैं, एक पथ के रूप में आसानी से व्यक्त नहीं किया जा सकता। REST के साथ, इसे URI पथ, क्वेरी पैरामीटर, और संभवतः रिक्वेस्ट बॉडी के संयोजन से लागू करना पड़ सकता है।
- REST आमतौर पर कुछ क्रियाओं (GET, POST, PUT, DELETE, और PATCH) पर निर्भर करता है जो कभी-कभी आपके उपयोग के मामले में फिट नहीं बैठते। उदाहरण के लिए, समाप्त दस्तावेज़ों को आर्काइव फ़ोल्डर में स्थानांतरित करना इन क्रियाओं में ठीक से फिट नहीं बैठता।
- जटिल संसाधनों को नेस्टेड पदानुक्रम के साथ प्राप्त करना क्लाइंट और सर्वर के बीच कई राउंड ट्रिप की आवश्यकता होती है ताकि एकल व्यू प्रस्तुत किया जा सके, जैसे कि ब्लॉग प्रविष्टि की सामग्री और उस प्रविष्टि पर टिप्पणियाँ प्राप्त करना। मोबाइल एप्लिकेशन के लिए जो परिवर्तनीय नेटवर्क स्थितियों में काम करते हैं, ये अनेक राउंड ट्रिप अत्यंत अवांछनीय हैं।
- समय के साथ, API प्रतिक्रिया में अधिक फ़ील्ड जोड़े जा सकते हैं और पुराने क्लाइंट्स सभी नए डेटा फ़ील्ड प्राप्त करेंगे, भले ही उन्हें उनकी आवश्यकता न हो, परिणामस्वरूप पेलोड आकार बढ़ जाता है और विलंबता अधिक हो जाती है।
RPC और REST कॉल की तुलना
| ऑपरेशन | RPC | REST |
|---|---|---|
| साइनअप | POST /signup | POST /persons |
| इस्तीफा | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| व्यक्ति पढ़ें | GET /readPerson?personid=1234 | GET /persons/1234 |
| व्यक्ति की वस्तुओं की सूची पढ़ें | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| व्यक्ति की वस्तुओं में एक वस्तु जोड़ें | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| वस्तु अपडेट करें | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| वस्तु हटाएँ | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
स्रोत: क्या आप वास्तव में जानते हैं कि आप RPC पर REST क्यों पसंद करते हैं
#### स्रोत(स्रोत) और आगे पढ़ें: REST और RPC
- क्या आप वास्तव में जानते हैं कि आप RPC पर REST क्यों पसंद करते हैं
- कब RPC-जैसी विधियाँ REST से अधिक उपयुक्त होती हैं?
- REST बनाम JSON-RPC
- RPC और REST के मिथकों का भंडाफोड़
- RESTful API का उपयोग करने के नुकसान क्या हैं
- सिस्टम डिजाइन इंटरव्यू क्रैक करें
- Thrift
- आंतरिक उपयोग के लिए REST और RPC क्यों नहीं
सुरक्षा
इस अनुभाग को कुछ अपडेट की आवश्यकता हो सकती है। कृपया योगदान करने पर विचार करें!
सुरक्षा एक व्यापक विषय है। जब तक आपके पास पर्याप्त अनुभव, सुरक्षा पृष्ठभूमि, या ऐसी स्थिति के लिए आवेदन नहीं कर रहे हैं जिसमें सुरक्षा का ज्ञान आवश्यक हो, आपको शायद मूल बातें जानने की ही आवश्यकता होगी:
- ट्रांजिट में और विश्राम के दौरान डेटा को एन्क्रिप्ट करें।
- सभी यूजर इनपुट या उपयोगकर्ता को दिखाए गए किसी भी इनपुट पैरामीटर को सैनिटाइज करें ताकि XSS और SQL injection से बचा जा सके।
- SQL injection को रोकने के लिए पैरेमिट्राइज्ड क्वेरीज़ का उपयोग करें।
- न्यूनतम विशेषाधिकार के सिद्धांत का पालन करें।
स्रोत और आगे पढ़ने के लिए
परिशिष्ट
कभी-कभी आपसे 'बैक-ऑफ-द-एंवेलप' अनुमान लगाने के लिए कहा जाएगा। उदाहरण के लिए, आपको यह निर्धारित करना पड़ सकता है कि डिस्क से 100 इमेज थंबनेल बनाने में कितना समय लगेगा या कोई डेटा संरचना कितनी मेमोरी लेगी। दो की घात तालिका और प्रत्येक प्रोग्रामर को पता होनी चाहिए लेटेंसी संख्याएँ उपयोगी संदर्भ हैं।
दो की घात तालिका
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### स्रोत और आगे पढ़ने के लिए
विलंबता संख्याएँ जिन्हें हर प्रोग्रामर को जानना चाहिए
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- HDD से अनुक्रमिक रूप से पढ़ना 30 MB/s पर
- 1 Gbps ईथरनेट से अनुक्रमिक रूप से पढ़ना 100 MB/s पर
- SSD से अनुक्रमिक रूप से पढ़ना 1 GB/s पर
- मुख्य मेमोरी से अनुक्रमिक रूप से पढ़ना 4 GB/s पर
- प्रति सेकंड 6-7 विश्व-व्यापी राउंड ट्रिप्स
- एक डेटा सेंटर के भीतर प्रति सेकंड 2,000 राउंड ट्रिप्स
#### स्रोत(स) और आगे पढ़ें
- हर प्रोग्रामर को जानने योग्य लेटेंसी नंबर - 1
- हर प्रोग्रामर को जानने योग्य लेटेंसी नंबर - 2
- बड़े वितरित सिस्टम बनाने से डिज़ाइन, सबक और सलाह
- बड़े पैमाने पर वितरित सिस्टम बनाने से सॉफ्टवेयर इंजीनियरिंग सलाह
अतिरिक्त सिस्टम डिज़ाइन इंटरव्यू प्रश्न
सामान्य सिस्टम डिज़ाइन इंटरव्यू प्रश्न, प्रत्येक को हल करने के लिए संसाधनों के लिंक के साथ।
| प्रश्न | संदर्भ(स) |
|---|---|
| ड्रॉपबॉक्स जैसी फाइल सिंक सेवा डिज़ाइन करें | youtube.com |
| गूगल जैसा सर्च इंजन डिज़ाइन करें | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| गूगल जैसा स्केलेबल वेब क्रॉलर डिज़ाइन करें | quora.com |
| गूगल डॉक्स डिज़ाइन करें | code.google.com
neil.fraser.name |
| रेडिस जैसी की-वैल्यू स्टोर डिज़ाइन करें | slideshare.net |
| मेमकैश्ड जैसी कैश सिस्टम डिज़ाइन करें | slideshare.net |
| अमेज़न जैसी सिफारिश प्रणाली डिज़ाइन करें | hulu.com
ijcai13.org |
| बिटली जैसी टिनीयूआरएल प्रणाली डिज़ाइन करें | n00tc0d3r.blogspot.com |
| व्हाट्सएप जैसी चैट ऐप डिज़ाइन करें | highscalability.com
| इंस्टाग्राम जैसी फोटो शेयरिंग प्रणाली डिज़ाइन करें | highscalability.com
highscalability.com |
| फेसबुक न्यूज़ फीड फंक्शन डिज़ाइन करें | quora.com
quora.com
slideshare.net |
| फेसबुक टाइमलाइन फंक्शन डिज़ाइन करें | facebook.com
highscalability.com |
| फेसबुक चैट फंक्शन डिज़ाइन करें | erlang-factory.com
facebook.com |
| फेसबुक की तरह एक ग्राफ़ खोज फ़ंक्शन डिज़ाइन करें | facebook.com
facebook.com
facebook.com |
| CloudFlare जैसा कंटेंट डिलीवरी नेटवर्क डिज़ाइन करें | figshare.com |
| ट्विटर जैसा ट्रेंडिंग टॉपिक सिस्टम डिज़ाइन करें | michael-noll.com
snikolov .wordpress.com |
| रैंडम आईडी जेनरेशन सिस्टम डिज़ाइन करें | blog.twitter.com
github.com |
| एक समय अंतराल के दौरान शीर्ष k अनुरोध लौटाएँ | cs.ucsb.edu
wpi.edu |
| एक सिस्टम डिज़ाइन करें जो कई डेटा सेंटर्स से डेटा सर्व करता है | highscalability.com |
| एक ऑनलाइन मल्टीप्लेयर कार्ड गेम डिज़ाइन करें | indieflashblog.com
buildnewgames.com |
| एक गार्बेज कलेक्शन सिस्टम डिज़ाइन करें | stuffwithstuff.com
washington.edu |
| एक API रेट लिमिटर डिज़ाइन करें | https://stripe.com/blog/ |
| एक स्टॉक एक्सचेंज (NASDAQ या Binance जैसा) डिज़ाइन करें | Jane Street
Golang Implementation
Go Implementation |
| एक सिस्टम डिज़ाइन प्रश्न जोड़ें | Contribute |
वास्तविक दुनिया की आर्किटेक्चर
वास्तविक दुनिया की प्रणालियाँ कैसे डिज़ाइन की जाती हैं, इस पर लेख।
स्रोत: ट्विटर टाइमलाइन बड़े पैमाने पर
निम्नलिखित लेखों के लिए सूक्ष्म विवरणों पर ध्यान न दें, बल्कि:
- इन लेखों में साझा सिद्धांतों, सामान्य तकनीकों और पैटर्न की पहचान करें
- अध्ययन करें कि प्रत्येक घटक कौन सी समस्याओं को हल करता है, कहाँ काम करता है, कहाँ नहीं
- सीखे गए पाठों की समीक्षा करें
कंपनी आर्किटेक्चर
| कंपनी | संदर्भ(संदर्भ) |
|---|---|
| Amazon | Amazon आर्किटेक्चर |
| Cinchcast | हर दिन 1,500 घंटे ऑडियो का निर्माण |
| DataSift | 120,000 ट्वीट प्रति सेकंड पर रीयलटाइम डेटा माइनिंग |
| Dropbox | हमने Dropbox को कैसे स्केल किया |
| ESPN | 100,000 duh nuh nuhs प्रति सेकंड पर ऑपरेटिंग |
| Google | Google आर्किटेक्चर |
| Instagram | 14 मिलियन उपयोगकर्ता, टेराबाइट्स फोटो
Instagram को क्या शक्ति देता है |
| Justin.tv | Justin.tv का लाइव वीडियो प्रसारण आर्किटेक्चर |
| Facebook | Facebook में Memcached का स्केलिंग
TAO: Facebook का वितरित डेटा स्टोर सोशल ग्राफ के लिए
Facebook की फोटो स्टोरेज
Facebook लाइव स्ट्रीम 800,000 समानांतर दर्शकों को कैसे भेजता है |
| Flickr | Flickr आर्किटेक्चर |
| Mailbox | 6 हफ्तों में 0 से 1 मिलियन उपयोगकर्ताओं तक |
| Netflix | नेटफ्लिक्स स्टैक का 360 डिग्री दृश्य
Netflix: जब आप प्ले दबाते हैं तब क्या होता है? |
| Pinterest | 0 से हर महीने 10 अरब पेज व्यू तक
18 मिलियन विज़िटर, 10x वृद्धि, 12 कर्मचारी |
| Playfish | 50 मिलियन मासिक उपयोगकर्ता और बढ़ रहे हैं |
| PlentyOfFish | PlentyOfFish आर्किटेक्चर |
| Salesforce | वे रोज़ाना 1.3 अरब ट्रांज़ैक्शन कैसे संभालते हैं |
| Stack Overflow | Stack Overflow आर्किटेक्चर |
| TripAdvisor | 40M विज़िटर, 200M डायनामिक पेज व्यू, 30TB डेटा |
| Tumblr | हर महीने 15 अरब पेज व्यू |
| Twitter | Twitter को 10000 प्रतिशत तेज़ बनाना
MySQL का उपयोग कर रोज़ाना 250 मिलियन ट्वीट स्टोर करना
150M सक्रिय उपयोगकर्ता, 300K QPS, 22 MB/S फायरहोज़
स्केल पर टाइमलाइन
Twitter में बड़ा और छोटा डेटा
Twitter में ऑपरेशन: 100 मिलियन उपयोगकर्ताओं से आगे स्केलिंग
Twitter प्रति सेकंड 3,000 इमेज कैसे संभालता है |
| Uber | Uber अपने रीयलटाइम मार्केट प्लेटफॉर्म को कैसे स्केल करता है
Uber को 2000 इंजीनियर्स, 1000 सेवाएँ, और 8000 Git रिपॉजिटरी तक स्केल करने से सीखे गए सबक |
| WhatsApp | WhatsApp आर्किटेक्चर जिसे Facebook ने 19 अरब डॉलर में खरीदा |
| YouTube | YouTube स्केलेबिलिटी
YouTube आर्किटेक्चर |
कंपनी इंजीनियरिंग ब्लॉग्स
उन कंपनियों के आर्किटेक्चर जिनके लिए आप इंटरव्यू दे रहे हैं।>
आपके सामने आने वाले प्रश्न उसी डोमेन से हो सकते हैं।
- एयरबीएनबी इंजीनियरिंग
- एटलसियन डेवलपर्स
- एडब्ल्यूएस ब्लॉग
- बिटली इंजीनियरिंग ब्लॉग
- बॉक्स ब्लॉग्स
- क्लाउडेरा डेवलपर ब्लॉग
- ड्रॉपबॉक्स टेक ब्लॉग
- क्वोरा में इंजीनियरिंग
- ईबे टेक ब्लॉग
- एवरनोट टेक ब्लॉग
- एटसी कोड ऐज़ क्राफ्ट
- फेसबुक इंजीनियरिंग
- फ्लिकर कोड
- फोरस्क्वेयर इंजीनियरिंग ब्लॉग
- गिटहब इंजीनियरिंग ब्लॉग
- गूगल रिसर्च ब्लॉग
- ग्रुपऑन इंजीनियरिंग ब्लॉग
- हेरोकू इंजीनियरिंग ब्लॉग
- हबस्पॉट इंजीनियरिंग ब्लॉग
- हाई स्केलेबिलिटी
- इंस्टाग्राम इंजीनियरिंग
- इंटेल सॉफ्टवेयर ब्लॉग
- जेन स्ट्रीट टेक ब्लॉग
- लिंक्डइन इंजीनियरिंग
- माइक्रोसॉफ्ट इंजीनियरिंग
- माइक्रोसॉफ्ट पायथन इंजीनियरिंग
- नेटफ्लिक्स टेक ब्लॉग
- पेपल डेवलपर ब्लॉग
- पिनटेरेस्ट इंजीनियरिंग ब्लॉग
- रेडिट ब्लॉग
- सेल्सफोर्स इंजीनियरिंग ब्लॉग
- स्लैक इंजीनियरिंग ब्लॉग
- स्पॉटिफाई लैब्स
- स्ट्राइप इंजीनियरिंग ब्लॉग
- Twilio इंजीनियरिंग ब्लॉग
- Twitter इंजीनियरिंग
- Uber इंजीनियरिंग ब्लॉग
- Yahoo इंजीनियरिंग ब्लॉग
- Yelp इंजीनियरिंग ब्लॉग
- Zynga इंजीनियरिंग ब्लॉग
ब्लॉग जोड़ना चाहते हैं? काम को दोहराने से बचने के लिए, अपने कंपनी ब्लॉग को निम्नलिखित रिपो में जोड़ने पर विचार करें:
विकासाधीन
कोई अनुभाग जोड़ने या किसी प्रगति पर काम कर रहे अनुभाग को पूरा करने में रुचि है? योगदान दें!
- मैप-रिड्यूस के साथ वितरित कंप्यूटिंग
- कंसिस्टेंट हैशिंग
- स्कैटर गैदर
- योगदान दें
श्रेय
इस रिपो में पूरे स्रोत और श्रेय प्रदान किए गए हैं।
विशेष धन्यवाद:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
संपर्क जानकारी
कृपया किसी भी समस्या, प्रश्न या टिप्पणी पर चर्चा करने के लिए मुझसे संपर्क करने में संकोच न करें।
मेरी संपर्क जानकारी मेरे GitHub पृष्ठ पर मिल सकती है।
लाइसेंस
मैं आपको इस रिपॉजिटरी में कोड और संसाधन एक ओपन सोर्स लाइसेंस के तहत प्रदान कर रहा हूँ। क्योंकि यह मेरी व्यक्तिगत रिपॉजिटरी है, आपको मेरे कोड और संसाधनों का लाइसेंस मुझसे मिलता है, न कि मेरे नियोक्ता (Facebook) से।
कॉपीराइट 2017 डॉन मार्टिन
क्रिएटिव कॉमन्स एट्रिब्यूशन 4.0 इंटरनेशनल लाइसेंस (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---