English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
Aidez à traduire ce guide !
Le Guide de Conception de Systèmes

Motivation
Apprenez à concevoir des systèmes à grande échelle.>
Préparez-vous à l'entretien de conception de systèmes.
Apprenez à concevoir des systèmes à grande échelle
Apprendre à concevoir des systèmes évolutifs vous aidera à devenir un meilleur ingénieur.
La conception de systèmes est un sujet vaste. Il existe une énorme quantité de ressources dispersées sur le web concernant les principes de conception de systèmes.
Ce dépôt est une collection organisée de ressources pour vous aider à apprendre à construire des systèmes à grande échelle.
Apprenez de la communauté open source
C'est un projet open source continuellement mis à jour.
Les contributions sont les bienvenues !
Préparez-vous à l'entretien de conception de systèmes
En plus des entretiens de programmation, la conception de systèmes est une composante obligatoire du processus d'entretien technique dans de nombreuses entreprises technologiques.
Exercez-vous sur des questions courantes d’entretien de conception de systèmes et comparez vos résultats avec des solutions exemples : discussions, code et diagrammes.
Sujets supplémentaires pour la préparation à l’entretien :
- Guide d’étude
- Comment aborder une question d’entretien de conception de systèmes
- Questions d'entretien sur la conception système, avec solutions
- Questions d'entretien sur la conception orientée objet, avec solutions
- Questions supplémentaires d'entretien sur la conception système
Flashcards Anki
Les paquets de flashcards Anki fournis utilisent la répétition espacée pour vous aider à retenir les concepts clés de la conception système.
- Paquet conception système
- Paquet exercices conception système
- Paquet exercices conception orientée objet
Ressource de codage : Défis de codage interactifs
Vous cherchez des ressources pour vous préparer à l'entretien de codage ?
Découvrez le dépôt frère Interactive Coding Challenges, qui contient un paquet Anki supplémentaire :
Contribution
Apprenez de la communauté.
N'hésitez pas à soumettre des pull requests pour aider à :
- Corriger des erreurs
- Améliorer des sections
- Ajouter de nouvelles sections
- Traduire
Consultez les Lignes directrices de contribution.
Index des sujets de conception de systèmes
Résumés de divers sujets de conception de systèmes, incluant avantages et inconvénients. Tout est un compromis.
Chaque section contient des liens vers des ressources plus approfondies.
- Sujets de conception de systèmes : commencez ici
- Étape 1 : revoir la vidéo sur la scalabilité
- Étape 2 : revoir l’article sur la scalabilité
- Étapes suivantes
- Performance vs scalabilité
- Latence vs débit
- Disponibilité vs cohérence
- Théorème CAP
- CP – cohérence et tolérance aux partitions
- AP – disponibilité et tolérance aux partitions
- Modèles de cohérence
- Cohérence faible
- Cohérence éventuelle
- Cohérence forte
- Modèles de disponibilité
- Basculement (fail-over)
- Réplication
- Disponibilité en chiffres
- Système de noms de domaine
- Réseau de distribution de contenu
- CDN push
- CDN pull
- Équilibreur de charge
- Actif-passif
- Actif-actif
- Équilibrage de charge de couche 4
- Équilibrage de charge de couche 7
- Mise à l’échelle horizontale
- Proxy inverse (serveur web)
- Équilibreur de charge vs proxy inverse
- Couche application
- Microservices
- Découverte de service
- Base de données
- Système de gestion de base de données relationnelle (SGBDR)
- Réplication maître-esclave
- Réplication maître-maître
- Fédération
- Sharding
- Dénormalisation
- Optimisation SQL
- NoSQL
- Magasin clé-valeur
- Magasin de documents
- Magasin à colonnes larges
- Base de données graphe
- SQL ou NoSQL
- Cache
- Cache client
- Cache CDN
- Cache serveur web
- Cache base de données
- Cache application
- Cache au niveau des requêtes de base de données
- Cache au niveau des objets
- Quand mettre à jour le cache
- Cache-aside
- Écriture directe
- Écriture différée (write-back)
- Rafraîchissement anticipé
- Asynchronisme
- Files de messages
- Files d'attente de tâches
- Rétropression
- Communication
- Protocole de contrôle de transmission (TCP)
- Protocole de datagramme utilisateur (UDP)
- Appel de procédure distante (RPC)
- Transfert d'état représentatif (REST)
- Sécurité
- Annexe
- Table des puissances de deux
- Nombres de latence que tout programmeur devrait connaître
- Questions supplémentaires d'entretien de conception système
- Architectures du monde réel
- Architectures d'entreprise
- Blogs d'ingénierie d'entreprise
- En cours de développement
- Crédits
- Informations de contact
- Licence
Guide d'étude
Sujets suggérés à réviser en fonction de votre calendrier d'entretien (court, moyen, long).
Q : Pour les entretiens, dois-je tout savoir ici ?
R : Non, vous n'avez pas besoin de tout savoir ici pour préparer l'entretien.
Ce qui vous est demandé lors d'un entretien dépend de variables telles que :
- Votre niveau d'expérience
- Votre formation technique
- Les postes pour lesquels vous postulez
- Les entreprises avec lesquelles vous passez des entretiens
- La chance
Commencez large et approfondissez quelques domaines. Il est utile de connaître un peu divers sujets clés de la conception de systèmes. Ajustez ce guide en fonction de votre calendrier, de votre expérience, des postes pour lesquels vous passez des entretiens, et des entreprises avec lesquelles vous passez des entretiens.
- Calendrier court - Visez la largeur avec les sujets de conception de systèmes. Entraînez-vous en résolvant quelques questions d'entretien.
- Calendrier moyen - Visez la largeur et une certaine profondeur avec les sujets de conception de systèmes. Entraînez-vous en résolvant beaucoup de questions d'entretien.
- Calendrier long - Visez la largeur et une plus grande profondeur avec les sujets de conception de systèmes. Entraînez-vous en résolvant la plupart des questions d'entretien.
Comment aborder une question d’entretien de conception de système
Comment aborder une question d’entretien de conception de système.
L’entretien de conception de système est une conversation ouverte. Vous êtes censé la diriger.
Vous pouvez utiliser les étapes suivantes pour guider la discussion. Pour aider à solidifier ce processus, travaillez la section Questions d’entretien de conception de système avec solutions en suivant les étapes ci-dessous.
Étape 1 : Définir les cas d’utilisation, contraintes et hypothèses
Recueillez les exigences et délimitez le problème. Posez des questions pour clarifier les cas d’utilisation et les contraintes. Discutez des hypothèses.
- Qui va l’utiliser ?
- Comment vont-ils l’utiliser ?
- Combien y a-t-il d’utilisateurs ?
- Que fait le système ?
- Quelles sont les entrées et sorties du système ?
- Quelle quantité de données attendons-nous de gérer ?
- Combien de requêtes par seconde attendons-nous ?
- Quel est le ratio attendu lecture/écriture ?
Étape 2 : Créer un design de haut niveau
Esquissez un design de haut niveau avec tous les composants importants.
- Esquissez les principaux composants et connexions
- Justifiez vos idées
Étape 3 : Concevoir les composants principaux
Plongez dans les détails de chaque composant principal. Par exemple, si on vous demande de concevoir un service de raccourcissement d’URL, discutez :
- Générer et stocker un hash de l’URL complète
- MD5 et Base62
- Collisions de hash
- SQL ou NoSQL
- Schéma de base de données
- Traduire une URL hachée en URL complète
- Recherche en base de données
- API et conception orientée objet
Étape 4 : Mettre à l’échelle la conception
Identifiez et traitez les goulets d’étranglement, compte tenu des contraintes. Par exemple, avez-vous besoin des éléments suivants pour résoudre les problèmes de scalabilité ?
- Équilibreur de charge
- Scalabilité horizontale
- Mise en cache
- Partitionnement de base de données (sharding)
Calculs approximatifs
Il se peut qu’on vous demande de faire quelques estimations à la main. Reportez-vous à l’Annexe pour les ressources suivantes :
- Utiliser des calculs approximatifs
- Table des puissances de deux
- Temps de latence que tout programmeur devrait connaître
Source(s) et lectures complémentaires
Consultez les liens suivants pour mieux comprendre à quoi vous attendre :
- Comment réussir un entretien de conception de systèmes
- L'entretien de conception de système
- Introduction aux entretiens d'architecture et de conception de systèmes
- Modèle de conception de système
Questions d'entretien de conception de système avec solutions
Questions courantes d'entretien de conception de système avec discussions, code et diagrammes d'exemple.>
Solutions liées au contenu dans le dossier solutions/.| Question | | |---|---| | Concevoir Pastebin.com (ou Bit.ly) | Solution | | Concevoir la timeline et la recherche Twitter (ou le fil d'actualité et la recherche Facebook) | Solution | | Concevoir un robot d'exploration web | Solution | | Concevoir Mint.com | Solution | | Concevoir les structures de données pour un réseau social | Solution | | Concevoir un magasin clé-valeur pour un moteur de recherche | Solution | | Concevoir la fonctionnalité de classement des ventes par catégorie d'Amazon | Solution | | Concevoir un système évolutif pour des millions d'utilisateurs sur AWS | Solution | | Ajouter une question de conception de système | Contribuer |
Concevoir Pastebin.com (ou Bit.ly)
Voir l'exercice et la solution
Concevoir la timeline et la recherche Twitter (ou le fil d'actualité et la recherche Facebook)
Voir l'exercice et la solution
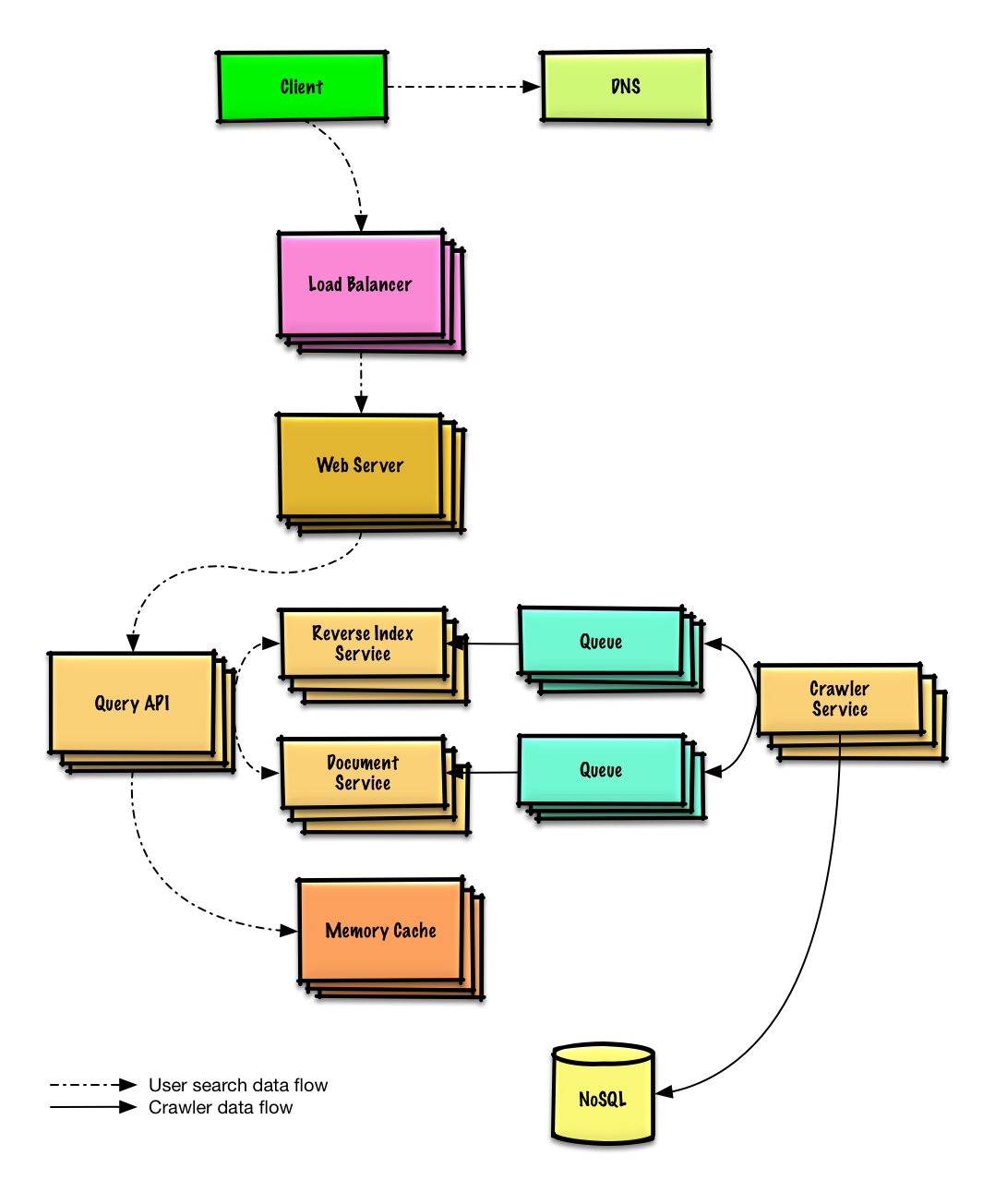
Concevoir un robot d'exploration web
Voir l'exercice et la solution
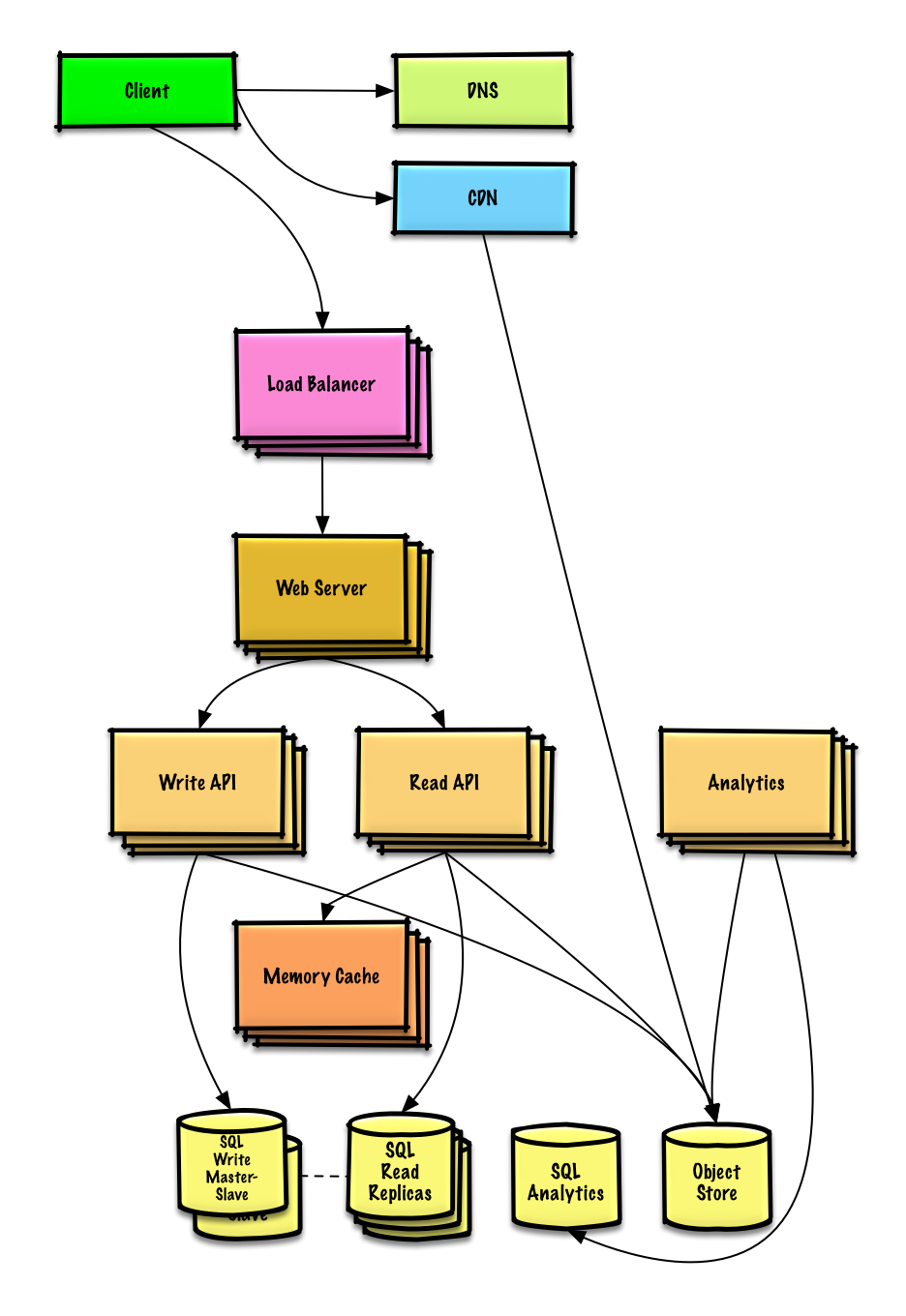
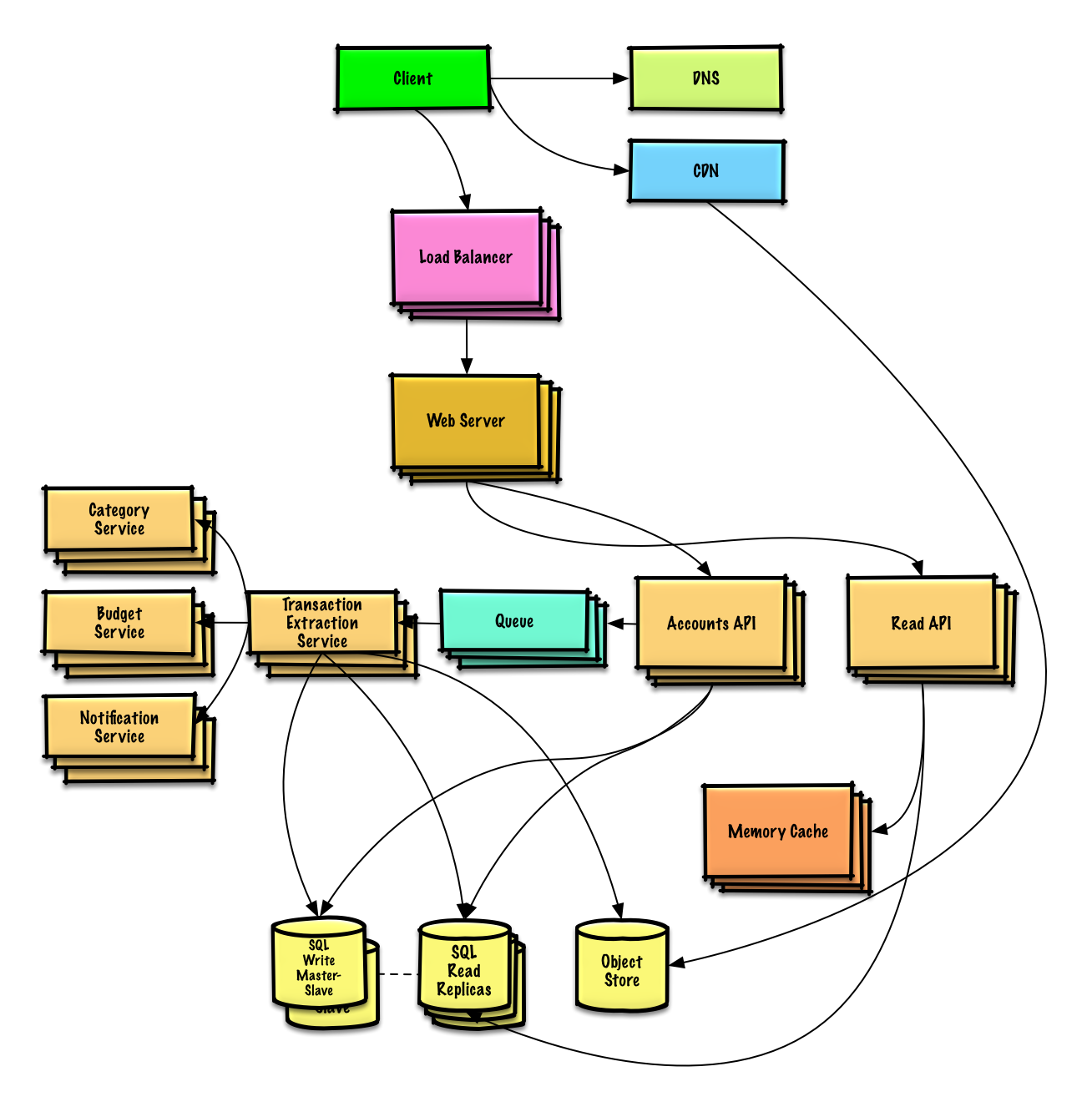
Design Mint.com
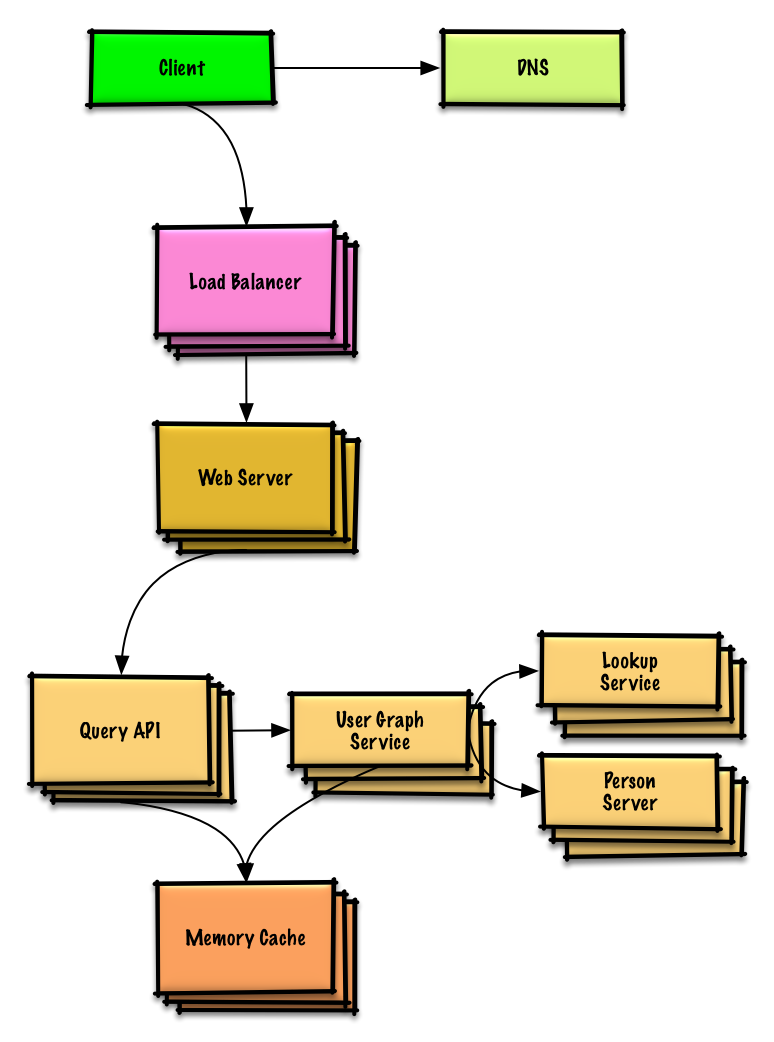
Design the data structures for a social network
Design a key-value store for a search engine
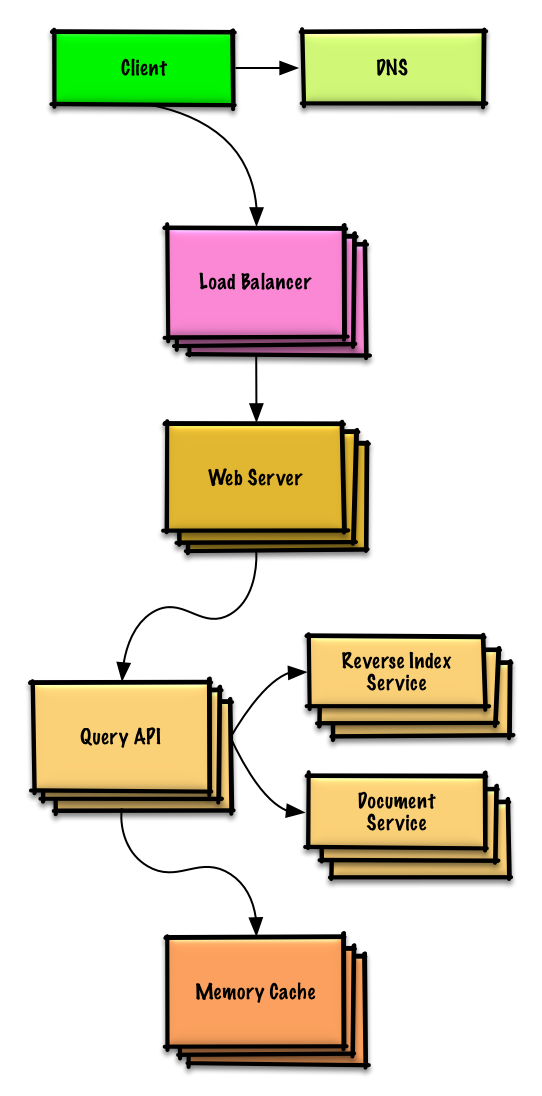
Design Amazon's sales ranking by category feature
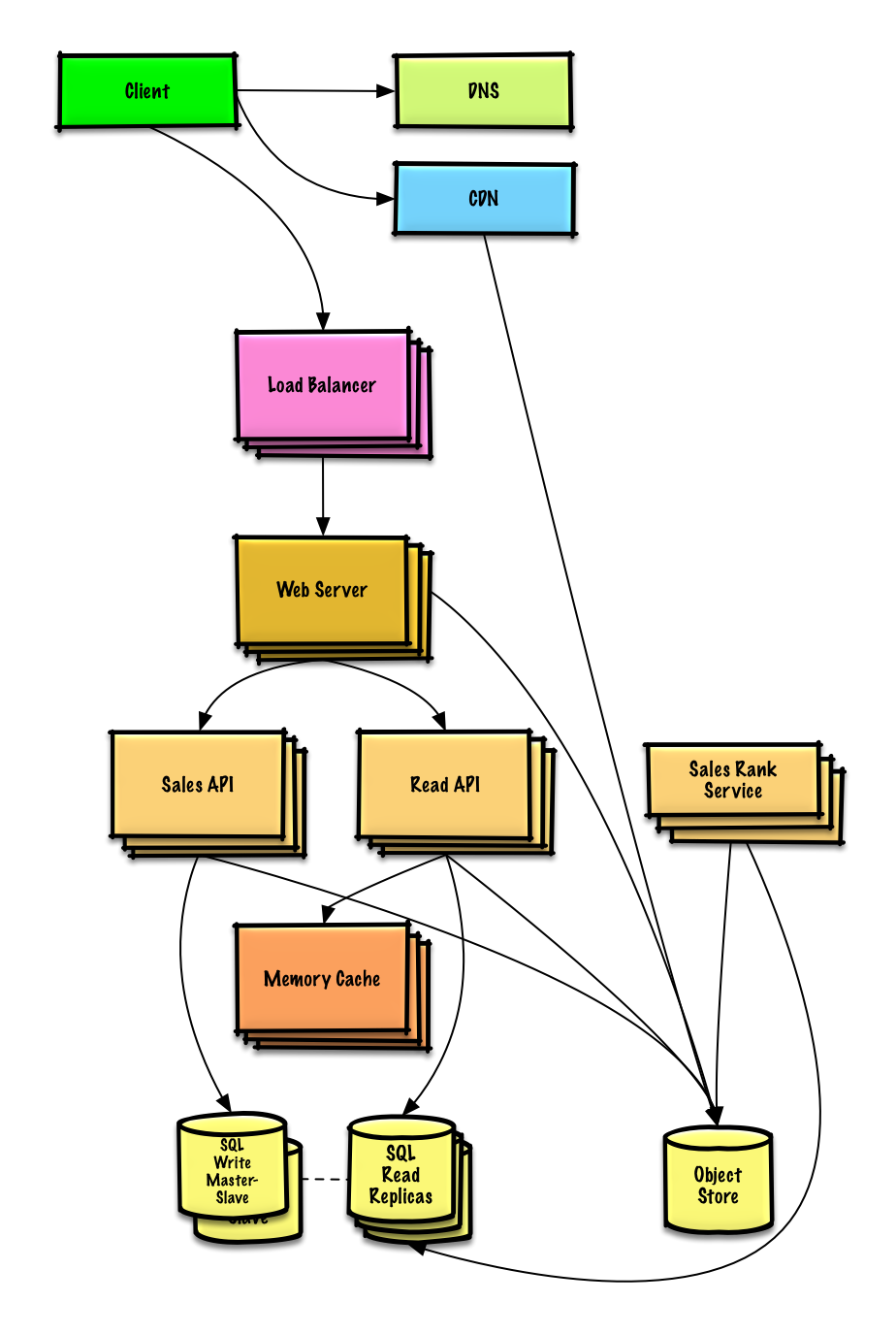
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | Concevoir une table de hachage | Solution | | Concevoir un cache LRU (least recently used) | Solution | | Concevoir un centre d'appels | Solution | | Concevoir un jeu de cartes | Solution | | Concevoir un parking | Solution | | Concevoir un serveur de chat | Solution | | Concevoir un tableau circulaire | Contribuer | | Ajouter une question de conception orientée objet | Contribuer |
Sujets de conception de système : commencez ici
Nouveau en conception de système ?
D'abord, vous aurez besoin d'une compréhension de base des principes courants, apprendre ce qu'ils sont, comment ils sont utilisés, et leurs avantages et inconvénients.
Étape 1 : Revoir la conférence vidéo sur la scalabilité
Conférence sur la scalabilité à Harvard
- Sujets abordés :
- Scalabilité verticale
- Scalabilité horizontale
- Mise en cache
- Équilibrage de charge
- Réplication de base de données
- Partitionnement de base de données
Étape 2 : Revoir l'article sur la scalabilité
- Sujets abordés :
- Clones
- Bases de données
- Caches
- Asynchronisme
Étapes suivantes
Ensuite, nous examinerons les compromis de haut niveau :
- Performance vs scalabilité
- Latence vs débit
- Disponibilité vs cohérence
Puis, nous plongerons dans des sujets plus spécifiques tels que DNS, CDN et équilibreurs de charge.
Performance vs scalabilité
Un service est scalable s’il entraîne une augmentation de la performance de manière proportionnelle aux ressources ajoutées. Généralement, augmenter la performance signifie traiter plus d’unités de travail, mais cela peut aussi être pour gérer des unités de travail plus importantes, comme lorsque les jeux de données grandissent.1
Une autre façon de voir la performance vs scalabilité :
- Si vous avez un problème de performance, votre système est lent pour un seul utilisateur.
- Si vous avez un problème de scalabilité, votre système est rapide pour un seul utilisateur mais lent sous forte charge.
Source(s) et lectures complémentaires
Latence vs débit
La latence est le temps nécessaire pour effectuer une action ou produire un résultat.
Le débit est le nombre de ces actions ou résultats par unité de temps.
Généralement, vous devez viser un débit maximal avec une latence acceptable.
Source(s) et lectures complémentaires
Disponibilité vs cohérence
Théorème CAP
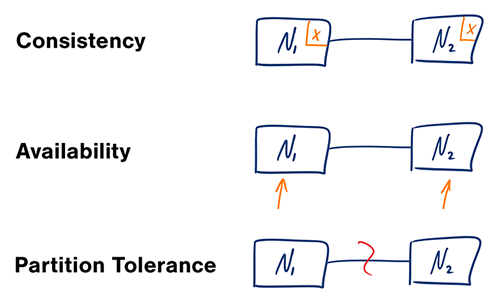
Source : Théorème CAP revisité
Dans un système informatique distribué, vous ne pouvez garantir que deux des trois garanties suivantes :
- Cohérence - Chaque lecture reçoit la dernière écriture ou une erreur
- Disponibilité - Chaque requête reçoit une réponse, sans garantie qu'elle contienne la version la plus récente de l'information
- Tolérance au partitionnement - Le système continue de fonctionner malgré un partitionnement arbitraire dû à des défaillances réseau
#### CP - cohérence et tolérance au partitionnement
Attendre une réponse du nœud partitionné peut entraîner une erreur de délai d’attente. CP est un bon choix si vos besoins métiers nécessitent des lectures et écritures atomiques.
#### AP - disponibilité et tolérance au partitionnement
Les réponses retournent la version des données la plus facilement disponible sur n’importe quel nœud, qui peut ne pas être la plus récente. Les écritures peuvent prendre un certain temps à se propager lorsque le partitionnement est résolu.
AP est un bon choix si le métier doit permettre la cohérence éventuelle ou quand le système doit continuer à fonctionner malgré des erreurs externes.
Source(s) et lectures complémentaires
Modèles de cohérence
Avec plusieurs copies des mêmes données, nous sommes confrontés à des options pour les synchroniser afin que les clients aient une vue cohérente des données. Rappelons la définition de la cohérence dans le théorème CAP - Chaque lecture reçoit la dernière écriture ou une erreur.
Cohérence faible
Après une écriture, les lectures peuvent ou non la voir. Une approche de meilleure tentative est adoptée.
Cette approche se retrouve dans des systèmes comme memcached. La cohérence faible fonctionne bien dans les cas d’utilisation en temps réel tels que VoIP, visioconférence et jeux multijoueurs en temps réel. Par exemple, si vous êtes en appel téléphonique et perdez la réception pendant quelques secondes, lorsque vous récupérez la connexion, vous n’entendez pas ce qui a été dit pendant la perte de connexion.
Cohérence éventuelle
Après une écriture, les lectures la verront finalement (typiquement en quelques millisecondes). Les données sont répliquées de manière asynchrone.
Cette approche est observée dans des systèmes tels que DNS et le courrier électronique. La cohérence éventuelle fonctionne bien dans les systèmes hautement disponibles.
Cohérence forte
Après une écriture, les lectures la verront. Les données sont répliquées de manière synchrone.
Cette approche est observée dans les systèmes de fichiers et les SGBDR. La cohérence forte fonctionne bien dans les systèmes nécessitant des transactions.
Source(s) et lectures complémentaires
Modèles de disponibilité
Il existe deux modèles complémentaires pour supporter une haute disponibilité : basculement et réplication.
Basculement
#### Actif-passif
Avec le basculement actif-passif, des signaux de vie sont envoyés entre le serveur actif et le serveur passif en attente. Si le signal de vie est interrompu, le serveur passif prend l'adresse IP de l'actif et reprend le service.
La durée d'indisponibilité est déterminée par le fait que le serveur passif fonctionne déjà en veille « chaude » ou s'il doit démarrer depuis une veille « froide ». Seul le serveur actif gère le trafic.
Le basculement actif-passif peut aussi être appelé basculement maître-esclave.
#### Actif-actif
En actif-actif, les deux serveurs gèrent le trafic, répartissant la charge entre eux.
Si les serveurs sont exposés au public, le DNS doit connaître les adresses IP publiques des deux serveurs. Si les serveurs sont internes, la logique applicative doit connaître les deux serveurs.
Le basculement actif-actif peut aussi être appelé basculement maître-maître.
Inconvénient(s) : basculement
- La bascule ajoute plus de matériel et une complexité supplémentaire.
- Il y a un risque de perte de données si le système actif tombe en panne avant que les nouvelles données écrites puissent être répliquées sur le système passif.
Réplication
#### Maître-esclave et maître-maître
Ce sujet est abordé plus en détail dans la section Base de données :
Disponibilité en chiffres
La disponibilité est souvent quantifiée par le temps de fonctionnement (ou d’arrêt) en pourcentage du temps pendant lequel le service est disponible. La disponibilité est généralement mesurée en nombre de 9 -- un service avec une disponibilité de 99,99 % est décrit comme ayant quatre 9.
#### Disponibilité à 99,9 % - trois 9
| Durée | Temps d’arrêt acceptable | |---------------------|-------------------------| | Temps d’arrêt par an | 8h 45min 57s | | Temps d’arrêt par mois| 43m 49,7s | | Temps d’arrêt par semaine | 10m 4,8s | | Temps d’arrêt par jour| 1m 26,4s |
#### Disponibilité à 99,99 % - quatre 9
| Durée | Temps d’arrêt acceptable | |---------------------|-------------------------| | Temps d’arrêt par an | 52min 35,7s | | Temps d’arrêt par mois| 4m 23s | | Temps d’arrêt par semaine | 1m 5s | | Temps d’arrêt par jour| 8,6s |
#### Disponibilité en parallèle vs en séquence
Si un service est composé de plusieurs composants susceptibles de tomber en panne, la disponibilité globale du service dépend de si les composants sont en séquence ou en parallèle.
###### En séquence
La disponibilité globale diminue lorsque deux composants avec une disponibilité < 100 % sont en série :
Availability (Total) = Availability (Foo) * Availability (Bar)Si Foo et Bar avaient chacun une disponibilité de 99,9 %, leur disponibilité totale en séquence serait de 99,8 %.
###### En parallèle
La disponibilité globale augmente lorsque deux composants avec une disponibilité < 100 % sont en parallèle :
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Si à la fois Foo et Bar avaient chacun une disponibilité de 99,9 %, leur disponibilité totale en parallèle serait de 99,9999 %.
Système de noms de domaine
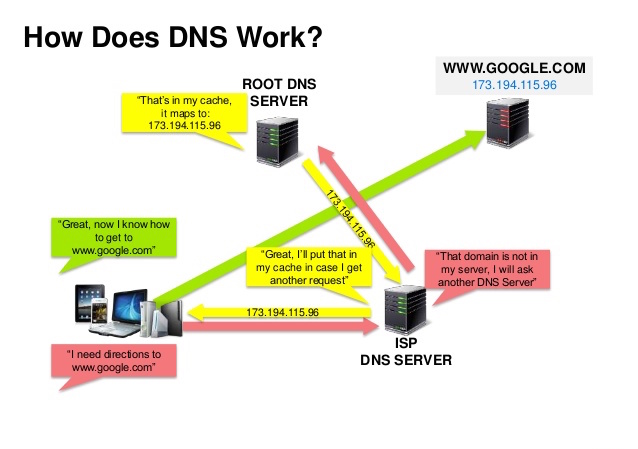
Source : Présentation sur la sécurité DNS
Un système de noms de domaine (DNS) traduit un nom de domaine tel que www.example.com en une adresse IP.
Le DNS est hiérarchique, avec quelques serveurs faisant autorité au niveau supérieur. Votre routeur ou FAI fournit des informations sur les serveurs DNS à contacter lors d'une recherche. Les serveurs DNS de niveau inférieur mettent en cache les correspondances, qui peuvent devenir obsolètes à cause des délais de propagation DNS. Les résultats DNS peuvent également être mis en cache par votre navigateur ou votre système d'exploitation pendant une certaine période, déterminée par le temps de vie (TTL).
- Enregistrement NS (serveur de noms) - Spécifie les serveurs DNS pour votre domaine/sous-domaine.
- Enregistrement MX (échange de courrier) - Spécifie les serveurs de messagerie pour accepter les messages.
- Enregistrement A (adresse) - Lie un nom à une adresse IP.
- CNAME (canonique) - Lie un nom à un autre nom ou
CNAME(exemple.com vers www.example.com) ou à un enregistrementA.
- Round robin pondéré
- Empêcher le trafic d'aller vers des serveurs en maintenance
- Équilibrer entre différentes tailles de clusters
- Tests A/B
- Basé sur la latence
- Basé sur la géolocalisation
Inconvénient(s) : DNS
- Accéder à un serveur DNS introduit un léger délai, bien que réduit par la mise en cache décrite ci-dessus.
- La gestion des serveurs DNS peut être complexe et est généralement assurée par les gouvernements, les FAI et les grandes entreprises.
- Les services DNS ont récemment été la cible de attaques DDoS, empêchant les utilisateurs d'accéder à des sites comme Twitter sans connaître les adresses IP de Twitter.
Source(s) et lectures complémentaires
Réseau de diffusion de contenu
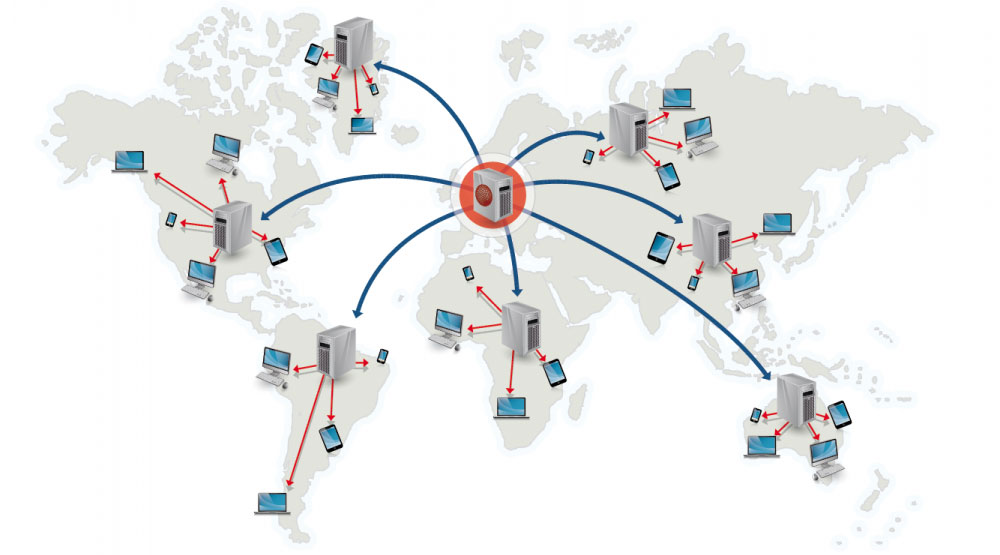
Source : Pourquoi utiliser un CDN
Un réseau de diffusion de contenu (CDN) est un réseau mondialement distribué de serveurs proxy, servant le contenu depuis des emplacements plus proches de l'utilisateur. Généralement, des fichiers statiques tels que HTML/CSS/JS, photos, et vidéos sont servis depuis le CDN, bien que certains CDN comme CloudFront d'Amazon supportent du contenu dynamique. La résolution DNS du site indique aux clients quel serveur contacter.
Servir du contenu depuis des CDN peut significativement améliorer les performances de deux façons :
- Les utilisateurs reçoivent le contenu depuis des centres de données proches d’eux
- Vos serveurs n’ont pas à traiter les requêtes que le CDN satisfait
CDN push
Les CDN push reçoivent du nouveau contenu chaque fois qu’un changement se produit sur votre serveur. Vous assumez entièrement la responsabilité de fournir le contenu, en le téléchargeant directement vers le CDN et en réécrivant les URLs pour pointer vers le CDN. Vous pouvez configurer la durée d’expiration du contenu et quand il est mis à jour. Le contenu est téléchargé uniquement lorsqu’il est nouveau ou modifié, minimisant le trafic, mais maximisant le stockage.
Les sites avec peu de trafic ou des sites dont le contenu est rarement mis à jour fonctionnent bien avec les CDN push. Le contenu est placé sur le CDN une fois, au lieu d’être récupéré à intervalles réguliers.
CDN pull
Les CDN pull récupèrent le nouveau contenu depuis votre serveur lorsque le premier utilisateur demande ce contenu. Vous laissez le contenu sur votre serveur et réécrivez les URLs pour pointer vers le CDN. Cela entraîne une requête plus lente jusqu’à ce que le contenu soit mis en cache sur le CDN.
Un temps de vie (TTL) détermine la durée pendant laquelle le contenu est mis en cache. Les CDN pull minimisent l’espace de stockage sur le CDN, mais peuvent générer un trafic redondant si les fichiers expirent et sont récupérés avant d’avoir réellement changé.
Les sites à fort trafic fonctionnent bien avec les CDN pull, car le trafic est réparti plus uniformément avec seulement le contenu récemment demandé restant sur le CDN.
Inconvénient(s) : CDN
- Les coûts de CDN peuvent être significatifs selon le trafic, bien que cela doive être mis en balance avec les coûts supplémentaires que vous encourriez sans utiliser de CDN.
- Le contenu peut être obsolète s’il est mis à jour avant l’expiration du TTL.
- Les CDN nécessitent de modifier les URLs du contenu statique pour pointer vers le CDN.
Source(s) et lectures complémentaires
Équilibreur de charge
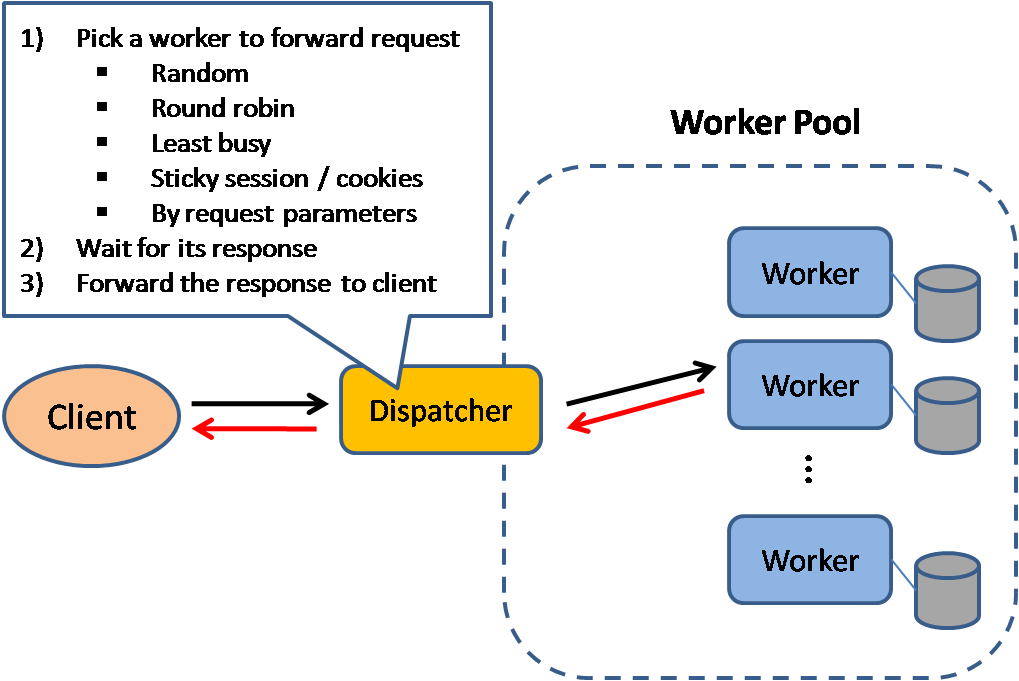
Source : Modèles de conception de systèmes évolutifs
Les équilibreurs de charge distribuent les requêtes entrantes des clients vers des ressources informatiques telles que les serveurs d'application et les bases de données. Dans chaque cas, l'équilibreur de charge renvoie la réponse de la ressource informatique au client approprié. Les équilibreurs de charge sont efficaces pour :
- Empêcher que les requêtes ne soient envoyées à des serveurs défaillants
- Éviter la surcharge des ressources
- Aider à éliminer un point de défaillance unique
Les avantages supplémentaires incluent :
- Terminaison SSL - Décrypter les requêtes entrantes et chiffrer les réponses du serveur afin que les serveurs backend n'aient pas à effectuer ces opérations potentiellement coûteuses
- Supprime la nécessité d'installer des certificats X.509 sur chaque serveur
- Persistance de session - Émettre des cookies et acheminer les requêtes d'un client spécifique vers la même instance si les applications web ne gèrent pas les sessions
Les équilibreurs de charge peuvent acheminer le trafic en fonction de divers critères, notamment :
- Aléatoire
- Le moins chargé
- Session/cookies
- Round robin ou round robin pondéré
- Couche 4
- Couche 7
Équilibrage de charge de couche 4
Les équilibreurs de charge de couche 4 examinent les informations à la couche transport pour décider comment distribuer les requêtes. Généralement, cela implique les adresses IP source et destination, ainsi que les ports dans l'en-tête, mais pas le contenu du paquet. Les équilibreurs de charge de couche 4 transmettent les paquets réseau vers et depuis le serveur en amont, en effectuant une traduction d'adresse réseau (NAT).
Équilibrage de charge de couche 7
Les équilibreurs de charge de couche 7 examinent la couche application pour décider comment répartir les requêtes. Cela peut impliquer le contenu des en-têtes, des messages et des cookies. Les équilibreurs de charge de couche 7 terminent le trafic réseau, lisent le message, prennent une décision de répartition de charge, puis ouvrent une connexion vers le serveur sélectionné. Par exemple, un équilibreur de charge de couche 7 peut diriger le trafic vidéo vers des serveurs hébergeant des vidéos tout en dirigeant le trafic plus sensible de facturation utilisateur vers des serveurs renforcés en sécurité.
Au prix d'une flexibilité moindre, l'équilibrage de charge de couche 4 nécessite moins de temps et de ressources informatiques que la couche 7, bien que l'impact sur les performances puisse être minimal sur du matériel standard moderne.
Mise à l'échelle horizontale
Les équilibreurs de charge peuvent également aider à la mise à l'échelle horizontale, améliorant les performances et la disponibilité. Monter en charge en utilisant des machines standard est plus rentable et offre une meilleure disponibilité que d'augmenter la capacité d'un seul serveur sur du matériel plus coûteux, appelé mise à l'échelle verticale. Il est aussi plus facile de recruter des talents pour travailler sur du matériel standard que pour des systèmes d'entreprise spécialisés.
#### Inconvénient(s) : mise à l'échelle horizontale
- La mise à l'échelle horizontale introduit de la complexité et implique le clonage des serveurs
- Les serveurs doivent être sans état : ils ne doivent pas contenir de données utilisateur comme des sessions ou des photos de profil
- Les sessions peuvent être stockées dans un magasin de données centralisé tel qu'une base de données (SQL, NoSQL) ou un cache persistant (Redis, Memcached)
- Les serveurs en aval, comme les caches et bases de données, doivent gérer plus de connexions simultanées à mesure que les serveurs en amont se multiplient
Inconvénient(s) : équilibreur de charge
- L'équilibreur de charge peut devenir un goulot d'étranglement en termes de performances s'il ne dispose pas de ressources suffisantes ou s'il n'est pas configuré correctement.
- Introduire un équilibreur de charge pour éliminer un point de défaillance unique entraîne une complexité accrue.
- Un seul équilibreur de charge est un point de défaillance unique, configurer plusieurs équilibreurs augmente encore la complexité.
Source(s) et lectures complémentaires
- Architecture NGINX
- Guide d'architecture HAProxy
- Scalabilité
- Wikipedia)
- Équilibrage de charge couche 4
- Équilibrage de charge couche 7
- Configuration du listener ELB
Proxy inverse (serveur web)
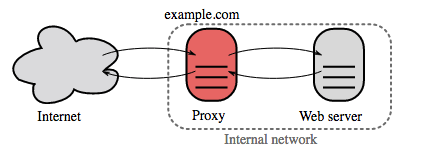
{kind=link}
Un reverse proxy est un serveur web qui centralise les services internes et fournit des interfaces unifiées au public. Les requêtes des clients sont transmises à un serveur capable de les satisfaire avant que le reverse proxy ne renvoie la réponse du serveur au client.
Avantages supplémentaires :
- Sécurité accrue - Masquer les informations sur les serveurs backend, bloquer des IP, limiter le nombre de connexions par client
- Scalabilité et flexibilité accrues - Les clients ne voient que l'IP du reverse proxy, ce qui permet de faire évoluer les serveurs ou de changer leur configuration
- Terminaison SSL - Déchiffrer les requêtes entrantes et chiffrer les réponses du serveur afin que les serveurs backend n’aient pas à effectuer ces opérations potentiellement coûteuses
- Élimine le besoin d’installer des certificats X.509 sur chaque serveur
- Compression - Compresser les réponses du serveur
- Mise en cache - Retourner la réponse pour les requêtes en cache
- Contenu statique - Servir directement du contenu statique
- HTML/CSS/JS
- Photos
- Vidéos
- Etc.
Équilibreur de charge vs reverse proxy
- Déployer un équilibreur de charge est utile lorsque vous avez plusieurs serveurs. Souvent, les équilibreurs de charge dirigent le trafic vers un ensemble de serveurs remplissant la même fonction.
- Les reverse proxies peuvent être utiles même avec un seul serveur web ou serveur d’application, offrant les avantages décrits dans la section précédente.
- Des solutions telles que NGINX et HAProxy peuvent supporter à la fois le reverse proxy de couche 7 et l’équilibrage de charge.
Inconvénient(s) : reverse proxy
- L’introduction d’un reverse proxy entraîne une complexité accrue.
- Un reverse proxy unique constitue un point de défaillance unique, la configuration de plusieurs reverse proxies (c’est-à-dire un basculement)) augmente encore la complexité.
Sources et lectures complémentaires
Couche application
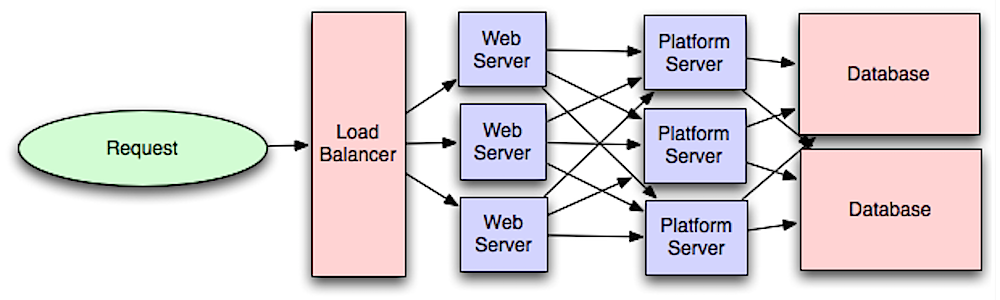
Source : Introduction à l’architecture des systèmes à grande échelle
Séparer la couche web de la couche application (également appelée couche plateforme) permet de faire évoluer et de configurer les deux couches indépendamment. Ajouter une nouvelle API se traduit par l’ajout de serveurs d’application sans forcément ajouter de serveurs web supplémentaires. Le principe de responsabilité unique prône des services petits et autonomes qui collaborent. De petites équipes avec de petits services peuvent planifier de manière plus agressive une croissance rapide.
Les workers dans la couche application aident aussi à permettre l’asynchronisme.
Microservices
En lien avec cette discussion, les microservices peuvent être décrits comme une suite de services petits, modulaires et déployables indépendamment. Chaque service exécute un processus unique et communique via un mécanisme léger bien défini pour servir un objectif métier. 1
Pinterest, par exemple, pourrait avoir les microservices suivants : profil utilisateur, abonné, flux, recherche, téléchargement de photo, etc.
Découverte de service
Des systèmes tels que Consul, Etcd et Zookeeper peuvent aider les services à se trouver en gardant la trace des noms, adresses et ports enregistrés. Les vérifications de santé aident à vérifier l’intégrité des services et sont souvent réalisées via un point d’accès HTTP. Consul et Etcd disposent tous deux d’un magasin clé-valeur intégré, utile pour stocker des valeurs de configuration et d’autres données partagées.
Inconvénient(s) : couche application
- Ajouter une couche application avec des services faiblement couplés nécessite une approche différente d’un point de vue architecture, opérations et processus (par rapport à un système monolithique).
- Les microservices peuvent ajouter de la complexité en termes de déploiements et d’opérations.
Source(s) et lectures complémentaires
- Introduction à l’architecture des systèmes à grande échelle
- Réussir l’entretien de conception système
- Architecture orientée services
- Introduction à Zookeeper
- Ce que vous devez savoir sur la construction de microservices
Base de données
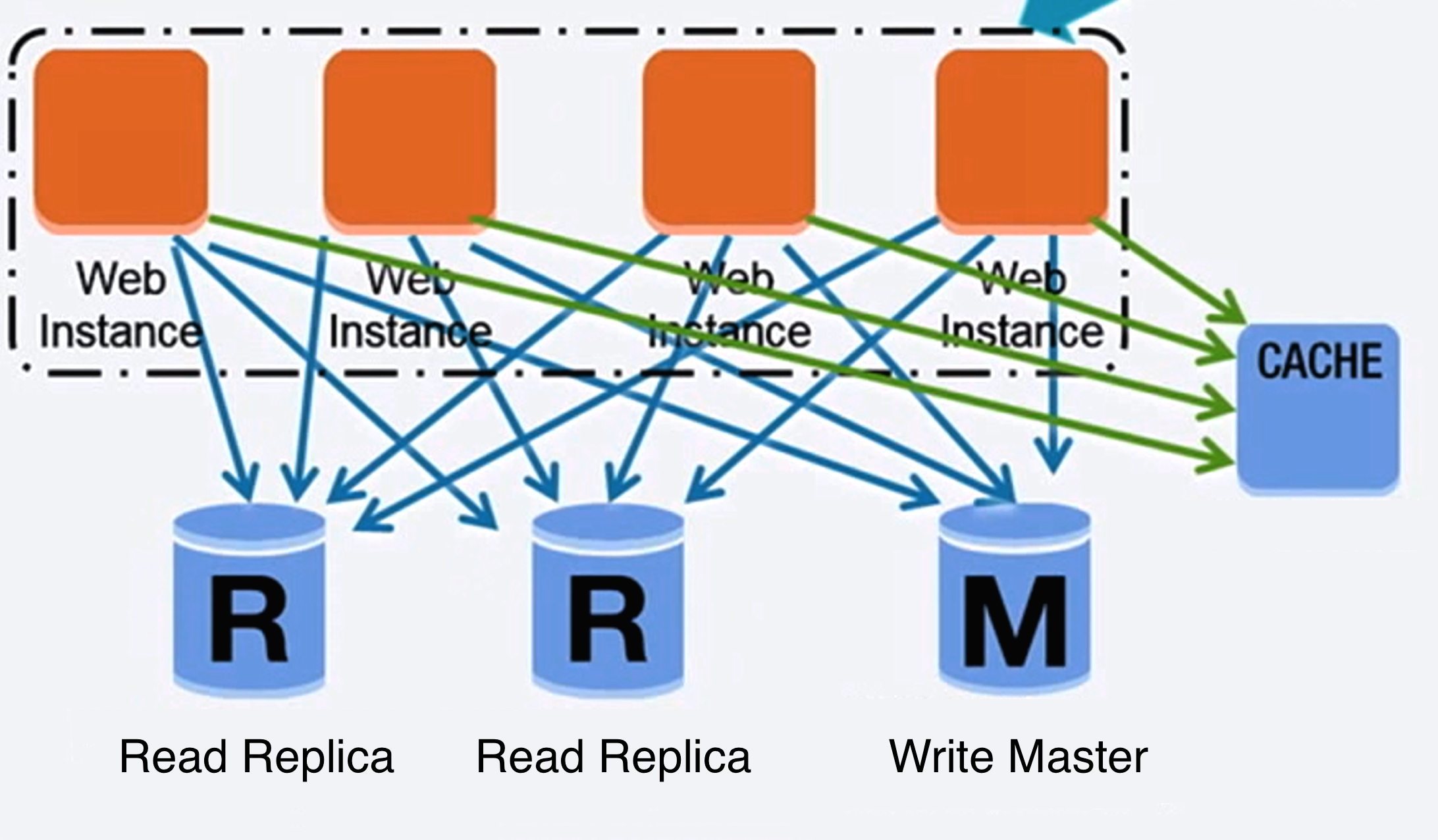
Source : Monter en charge jusqu’à vos premiers 10 millions d’utilisateurs
Système de gestion de base de données relationnelle (SGBDR)
Une base de données relationnelle comme SQL est une collection d'éléments de données organisés en tables.
ACID est un ensemble de propriétés des transactions dans une base de données relationnelle.
- Atomicité - Chaque transaction est tout ou rien
- Cohérence - Toute transaction amène la base de données d'un état valide à un autre
- Isolation - L'exécution concurrente des transactions produit les mêmes résultats que leur exécution en série
- Durabilité - Une fois qu'une transaction est validée, elle le reste
#### Réplication maître-esclave
Le maître gère les lectures et écritures, répliquant les écritures vers un ou plusieurs esclaves, qui ne servent que les lectures. Les esclaves peuvent aussi répliquer vers d'autres esclaves en forme d'arbre. Si le maître est hors ligne, le système peut continuer à fonctionner en mode lecture seule jusqu'à ce qu'un esclave soit promu maître ou qu'un nouveau maître soit provisionné.
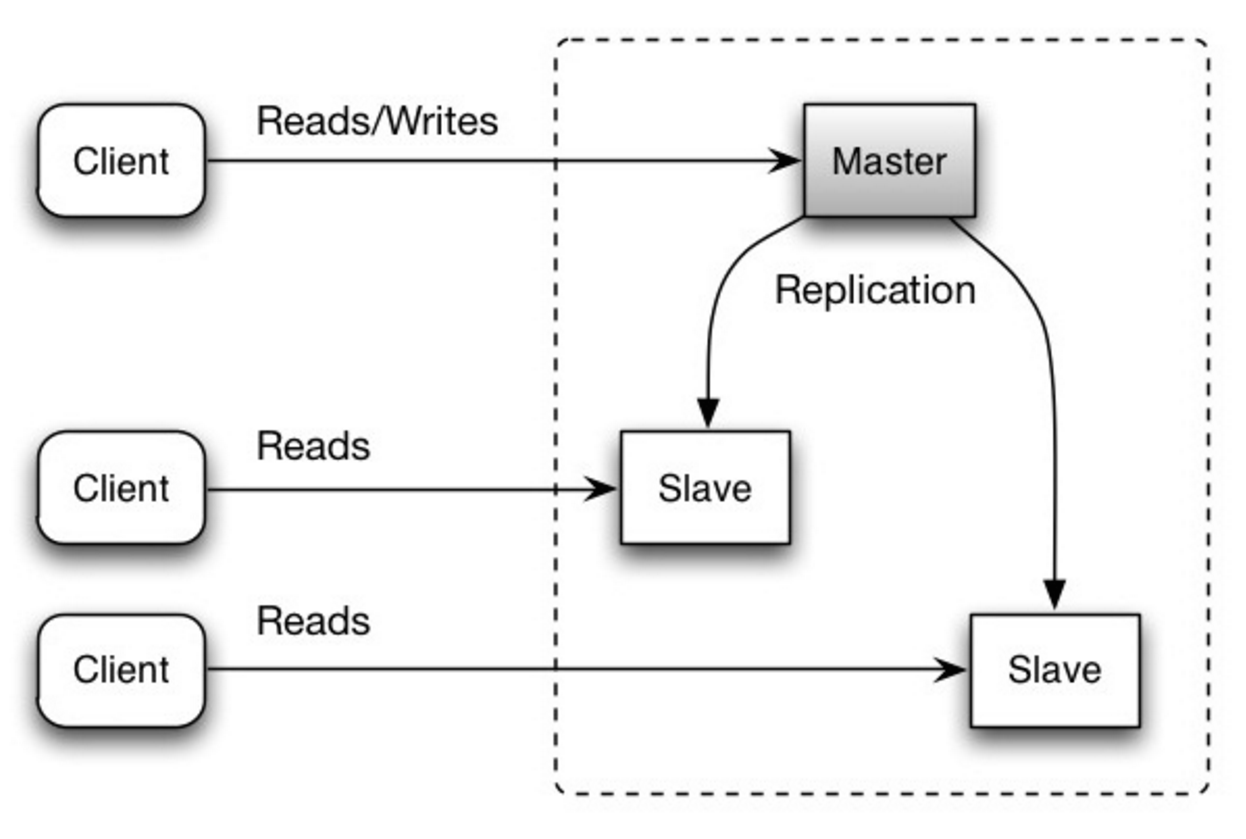
Source : Scalability, availability, stability, patterns
##### Inconvénient(s) : réplication maître-esclave
- Une logique supplémentaire est nécessaire pour promouvoir un esclave en maître.
- Voir Inconvénient(s) : réplication pour les points liés à la fois maître-esclave et maître-maître.
Les deux maîtres gèrent lectures et écritures et se coordonnent sur les écritures. Si l'un des maîtres tombe en panne, le système peut continuer à fonctionner avec lectures et écritures.
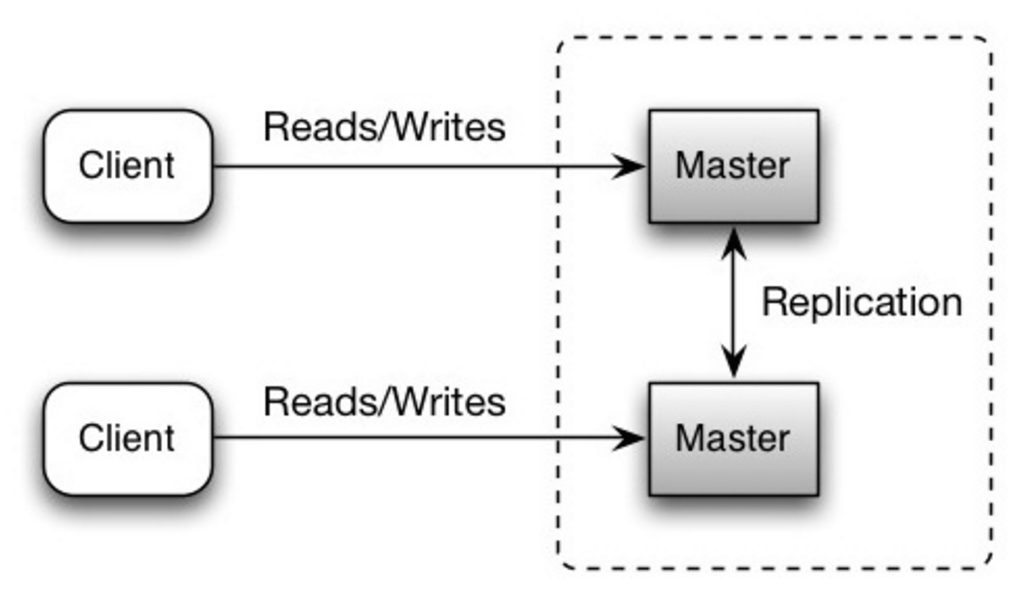
Source : Scalability, availability, stability, patterns
##### Inconvénient(s) : réplication maître-maître
- Vous aurez besoin d'un répartiteur de charge ou devrez modifier la logique de votre application pour déterminer où écrire.
- La plupart des systèmes maître-maître sont soit faiblement cohérents (violation d’ACID) soit ont une latence d’écriture augmentée due à la synchronisation.
- La résolution des conflits intervient davantage à mesure que le nombre de nœuds d’écriture augmente et que la latence s’accroît.
- Voir Inconvénient(s) : réplication pour les points relatifs à la fois maître-esclave et maître-maître.
- Il existe un risque de perte de données si le maître tombe en panne avant que les nouvelles données écrites aient pu être répliquées sur d’autres nœuds.
- Les écritures sont rejouées sur les réplicas en lecture. S’il y a beaucoup d’écritures, les réplicas en lecture peuvent être encombrés par le rejouement des écritures et ne peuvent pas effectuer autant de lectures.
- Plus il y a de réplicas en lecture, plus il faut répliquer, ce qui entraîne un décalage plus important dans la réplication.
- Sur certains systèmes, l’écriture sur le maître peut générer plusieurs threads pour écrire en parallèle, alors que les réplicas en lecture ne supportent l’écriture que séquentielle avec un seul thread.
- La réplication ajoute du matériel et une complexité supplémentaire.
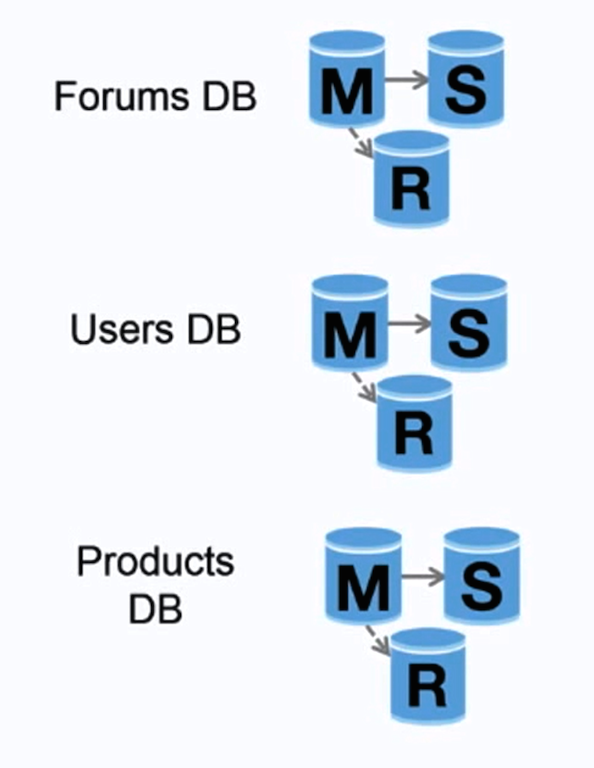
Source : Monter en charge jusqu’à vos premiers 10 millions d’utilisateurs
La fédération (ou partition fonctionnelle) divise les bases de données par fonction. Par exemple, au lieu d’une base de données monolithique unique, vous pourriez avoir trois bases de données : forums, utilisateurs et produits, ce qui réduit le trafic de lecture et d’écriture sur chaque base et donc le décalage de réplication. Des bases de données plus petites permettent de stocker davantage de données en mémoire, ce qui se traduit par plus de hits en cache grâce à une meilleure localité de cache. Sans maître central unique sérialisant les écritures, vous pouvez écrire en parallèle, augmentant ainsi le débit.
##### Inconvénient(s) : fédération
- La fédération n’est pas efficace si votre schéma nécessite de très grandes fonctions ou tables.
- Vous devrez mettre à jour la logique de votre application pour déterminer quelle base de données lire et écrire.
- Joindre des données provenant de deux bases est plus complexe avec un lien serveur.
- La fédération ajoute du matériel et une complexité supplémentaire.
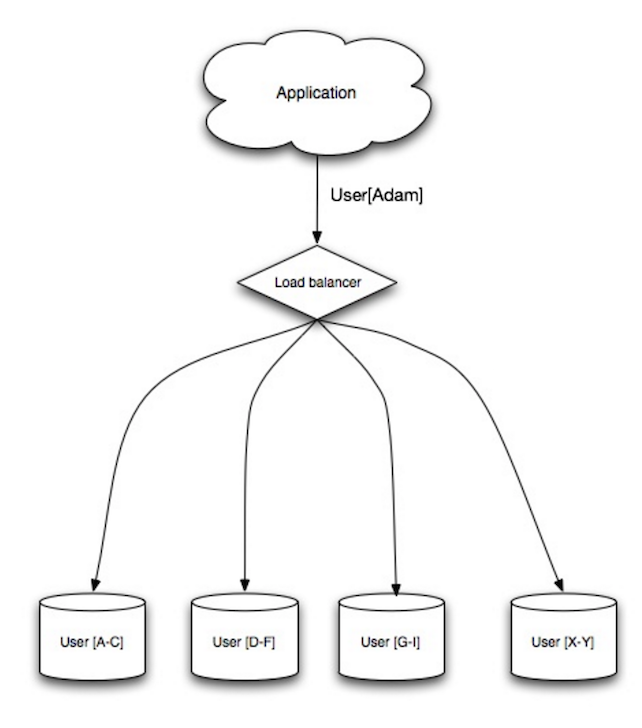
Source : Scalabilité, disponibilité, stabilité, modèles
Le sharding distribue les données à travers différentes bases de données de sorte que chaque base ne gère qu’un sous-ensemble des données. En prenant une base de données d’utilisateurs comme exemple, à mesure que le nombre d’utilisateurs augmente, plus de shards sont ajoutés au cluster.
Semblable aux avantages de la fédération, le sharding entraîne moins de trafic en lecture et écriture, moins de réplication, et plus de cache hits. La taille des index est également réduite, ce qui améliore généralement les performances avec des requêtes plus rapides. Si un shard tombe en panne, les autres shards restent opérationnels, bien que vous souhaitiez ajouter une forme de réplication pour éviter la perte de données. Comme pour la fédération, il n’y a pas de maître central unique qui sérialise les écritures, vous permettant d’écrire en parallèle avec un débit accru.
Les façons courantes de sharder une table d’utilisateurs sont soit par l’initiale du nom de famille de l’utilisateur, soit par la localisation géographique de l’utilisateur.
##### Inconvénient(s) : sharding
- Vous devrez mettre à jour la logique de votre application pour fonctionner avec des shards, ce qui pourrait entraîner des requêtes SQL complexes.
- La distribution des données peut devenir déséquilibrée dans un shard. Par exemple, un groupe d’utilisateurs intensifs sur un shard pourrait entraîner une charge accrue sur ce shard par rapport aux autres.
- Le rééquilibrage ajoute une complexité supplémentaire. Une fonction de sharding basée sur le hachage cohérent peut réduire la quantité de données transférées.
- Joindre des données provenant de plusieurs shards est plus complexe.
- Le sharding ajoute plus de matériel et de complexité supplémentaire.
La dénormalisation tente d’améliorer les performances en lecture au détriment de certaines performances en écriture. Des copies redondantes des données sont écrites dans plusieurs tables pour éviter des jointures coûteuses. Certains SGBDR comme PostgreSQL et Oracle supportent les vues matérialisées qui gèrent le travail de stockage des informations redondantes et maintiennent la cohérence des copies redondantes.
Une fois que les données sont distribuées avec des techniques telles que la fédération et le sharding, gérer des jointures entre centres de données augmente encore la complexité. La dénormalisation pourrait contourner le besoin de telles jointures complexes.
Dans la plupart des systèmes, les lectures peuvent dépasser largement les écritures, dans un rapport de 100:1 voire 1000:1. Une lecture résultant en une jointure complexe de base de données peut être très coûteuse, passant un temps significatif en opérations disque.
##### Inconvénient(s) : dénormalisation
- Les données sont dupliquées.
- Les contraintes peuvent aider les copies redondantes d’informations à rester synchronisées, ce qui augmente la complexité de la conception de la base de données.
- Une base de données dénormalisée sous une lourde charge d’écriture pourrait avoir des performances inférieures à son homologue normalisée.
L'optimisation SQL est un sujet vaste et de nombreux livres ont été écrits à titre de référence.
Il est important de mesurer les performances et de profiler pour simuler et déceler les goulets d'étranglement.
- Mesurer les performances - Simuler des situations de forte charge avec des outils tels que ab.
- Profiler - Activer des outils tels que le journal des requêtes lentes pour aider à suivre les problèmes de performance.
##### Resserrez le schéma
- MySQL écrit sur disque en blocs contigus pour un accès rapide.
- Utilisez
CHARau lieu deVARCHARpour les champs de longueur fixe. CHARpermet effectivement un accès rapide et aléatoire, tandis qu'avecVARCHAR, il faut trouver la fin d'une chaîne avant de passer à la suivante.- Utilisez
TEXTpour de grands blocs de texte comme les articles de blog.TEXTpermet aussi des recherches booléennes. Utiliser un champTEXTimplique de stocker un pointeur sur disque qui sert à localiser le bloc de texte. - Utilisez
INTpour les nombres plus grands jusqu'à 2^32 ou 4 milliards. - Utilisez
DECIMALpour les devises afin d'éviter les erreurs de représentation en virgule flottante. - Évitez de stocker de gros
BLOB, stockez plutôt l'emplacement où récupérer l'objet. VARCHAR(255)est le nombre maximal de caractères pouvant être comptés dans un nombre sur 8 bits, maximisant souvent l'utilisation d'un octet dans certains SGBDR.- Appliquez la contrainte
NOT NULLquand c'est possible pour améliorer les performances de recherche.
- Les colonnes que vous interrogez (
SELECT,GROUP BY,ORDER BY,JOIN) peuvent être plus rapides avec des index. - Les index sont généralement représentés sous forme d'arbres B auto-équilibrés qui maintiennent les données triées et permettent recherches, accès séquentiels, insertions et suppressions en temps logarithmique.
- Placer un index peut permettre de garder les données en mémoire, ce qui demande plus d’espace.
- Les écritures peuvent aussi être plus lentes car l’index doit être mis à jour.
- Lors du chargement de grandes quantités de données, il peut être plus rapide de désactiver les index, charger les données, puis reconstruire les index.
- Dénormalisez lorsque la performance l’exige.
- Séparer une table en mettant les points chauds dans une table distincte pour aider à la maintenir en mémoire.
- Dans certains cas, le cache de requêtes peut entraîner des problèmes de performance.
- Conseils pour optimiser les requêtes MySQL
- Y a-t-il une bonne raison pour voir VARCHAR(255) utilisé si souvent ?
- Comment les valeurs nulles affectent-elles les performances ?
- Journal des requêtes lentes
NoSQL
NoSQL est un ensemble d’éléments de données représentés dans un magasin clé-valeur, magasin de documents, magasin à colonnes larges, ou une base de données graphe. Les données sont dénormalisées, et les jointures sont généralement effectuées dans le code de l’application. La plupart des magasins NoSQL ne disposent pas de véritables transactions ACID et privilégient la cohérence éventuelle.
BASE est souvent utilisé pour décrire les propriétés des bases de données NoSQL. En comparaison avec le théorème CAP, BASE choisit la disponibilité plutôt que la cohérence.
- Basicamente disponible - le système garantit la disponibilité.
- État mou - l’état du système peut changer dans le temps, même sans entrée.
- Cohérence éventuelle - le système deviendra cohérent sur une période de temps, à condition que le système ne reçoive pas d’entrée pendant cette période.
#### Magasin clé-valeur
Abstraction : table de hachage
Un magasin clé-valeur permet généralement des lectures et écritures en O(1) et est souvent basé sur la mémoire ou le SSD. Les magasins de données peuvent maintenir les clés en ordre lexicographique, permettant une récupération efficace des plages de clés. Les magasins clé-valeur peuvent permettre le stockage de métadonnées avec une valeur.
Les magasins clé-valeur offrent des performances élevées et sont souvent utilisés pour des modèles de données simples ou pour des données en évolution rapide, comme une couche de cache en mémoire. Comme ils n’offrent qu’un ensemble limité d’opérations, la complexité est transférée à la couche applicative si des opérations supplémentaires sont nécessaires.
Un magasin clé-valeur est la base de systèmes plus complexes tels qu’un magasin de documents, et dans certains cas, une base de données graphe.
##### Source(s) et lectures complémentaires : magasin clé-valeur
- Base de données clé-valeur
- Inconvénients des magasins clé-valeur
- Architecture Redis
- Architecture de Memcached
Abstraction : magasin clé-valeur avec des documents stockés en tant que valeurs
Un magasin de documents est centré autour des documents (XML, JSON, binaire, etc.), où un document contient toutes les informations pour un objet donné. Les magasins de documents fournissent des API ou un langage de requête pour interroger en fonction de la structure interne du document lui-même. Notez que de nombreux magasins clé-valeur incluent des fonctionnalités pour travailler avec les métadonnées d'une valeur, brouillant ainsi les frontières entre ces deux types de stockage.
Selon l'implémentation sous-jacente, les documents sont organisés par collections, tags, métadonnées ou répertoires. Bien que les documents puissent être organisés ou regroupés, ils peuvent contenir des champs complètement différents les uns des autres.
Certains magasins de documents comme MongoDB et CouchDB fournissent également un langage de type SQL pour effectuer des requêtes complexes. DynamoDB supporte à la fois les paires clé-valeur et les documents.
Les magasins de documents offrent une grande flexibilité et sont souvent utilisés pour travailler avec des données qui changent occasionnellement.
##### Source(s) et lectures complémentaires : magasin de documents
- Base de données orientée document
- Architecture MongoDB
- Architecture CouchDB
- Architecture Elasticsearch
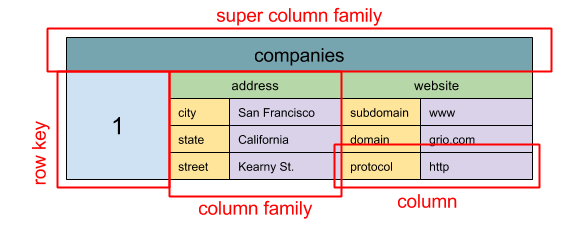
Source : SQL & NoSQL, une brève histoire
Abstraction : carte imbriquée ColumnFamily> L'unité de base des données dans un magasin à colonnes larges est une colonne (paire nom/valeur). Une colonne peut être regroupée en familles de colonnes (analogue à une table SQL). Les super familles de colonnes regroupent davantage les familles de colonnes. Vous pouvez accéder à chaque colonne indépendamment via une clé de ligne, et les colonnes avec la même clé forment une ligne. Chaque valeur contient un horodatage pour la gestion des versions et la résolution des conflits.
Google a introduit Bigtable comme premier magasin à colonnes larges, qui a influencé l'open source HBase souvent utilisé dans l'écosystème Hadoop, ainsi que Cassandra de Facebook. Des magasins tels que BigTable, HBase et Cassandra maintiennent les clés en ordre lexicographique, permettant une récupération efficace de plages de clés sélectives.
Les magasins à colonnes larges offrent une haute disponibilité et une grande scalabilité. Ils sont souvent utilisés pour des ensembles de données très volumineux.
##### Source(s) et lectures complémentaires : magasin à colonnes larges
#### Base de données graphe
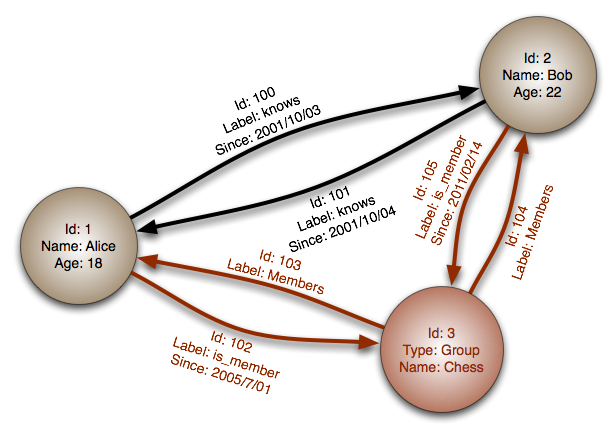
Source : Base de données graphe
{kind=link}
Abstraction : graphe
Dans une base de données graphe, chaque nœud est un enregistrement et chaque arc est une relation entre deux nœuds. Les bases de données graphe sont optimisées pour représenter des relations complexes avec de nombreuses clés étrangères ou des relations plusieurs-à-plusieurs.
Les bases de données graphe offrent de hautes performances pour des modèles de données avec des relations complexes, comme un réseau social. Elles sont relativement récentes et ne sont pas encore largement utilisées ; il peut être plus difficile de trouver des outils de développement et des ressources. De nombreux graphes ne peuvent être accessibles qu’avec des API REST.
##### Source(s) et lectures complémentaires : graphe
#### Source(s) et lectures complémentaires : NoSQL- Explication de la terminologie BASE
- Bases de données NoSQL : enquête et guide de décision
- Scalabilité
- Introduction au NoSQL
- Patrons NoSQL
SQL ou NoSQL
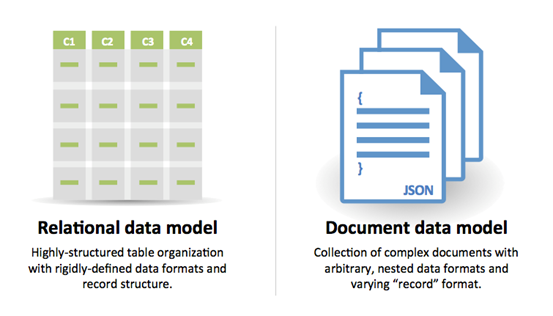
Source : Transition des SGBDR vers NoSQL
Raisons pour SQL :
- Données structurées
- Schéma strict
- Données relationnelles
- Besoin de jointures complexes
- Transactions
- Modèles clairs pour la montée en charge
- Plus établi : développeurs, communauté, code, outils, etc.
- Les recherches par index sont très rapides
- Données semi-structurées
- Schéma dynamique ou flexible
- Données non relationnelles
- Pas besoin de jointures complexes
- Stocker plusieurs To (ou Po) de données
- Charge de travail très intensive en données
- Très haut débit pour les IOPS
- Ingestion rapide de données de clickstream et de logs
- Données de classement ou de score
- Données temporaires, comme un panier d’achat
- Tables fréquemment consultées (« chaudes »)
- Tables de métadonnées/de recherches
Cache
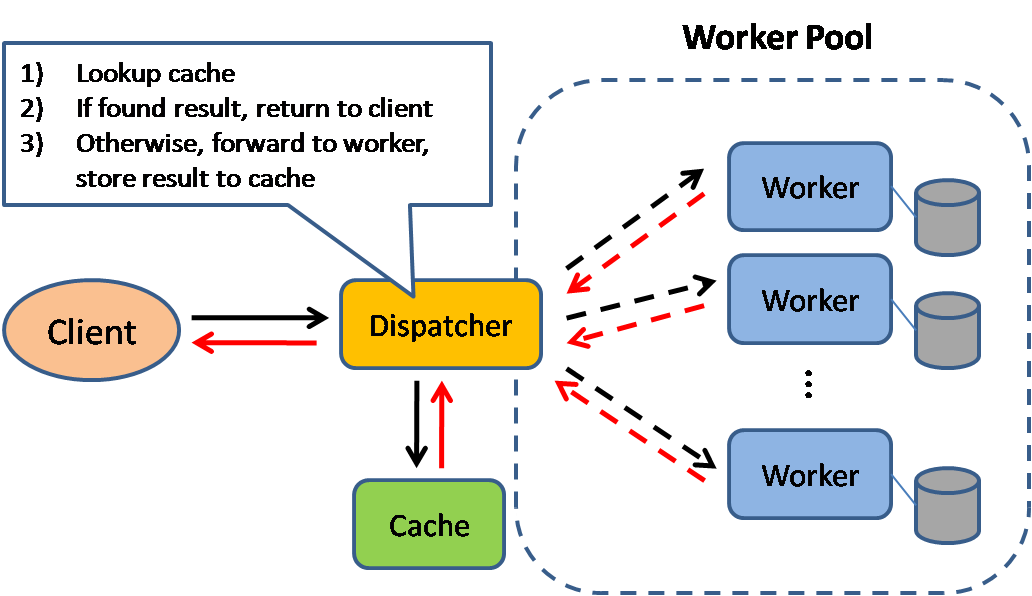
Source : Modèles de conception de systèmes évolutifs
La mise en cache améliore les temps de chargement des pages et peut réduire la charge sur vos serveurs et bases de données. Dans ce modèle, le répartiteur cherchera d'abord si la requête a déjà été effectuée et essaiera de trouver le résultat précédent à retourner, afin d'économiser l'exécution réelle.
Les bases de données bénéficient souvent d'une répartition uniforme des lectures et écritures sur leurs partitions. Les éléments populaires peuvent fausser cette répartition, causant des goulots d'étranglement. Placer un cache devant une base de données peut aider à absorber les charges inégales et les pics de trafic.
Mise en cache côté client
Les caches peuvent être situés côté client (système d'exploitation ou navigateur), côté serveur, ou dans une couche de cache distincte.
Mise en cache CDN
Les CDN sont considérés comme un type de cache.
Mise en cache côté serveur web
Les reverse proxies et caches tels que Varnish peuvent servir directement du contenu statique et dynamique. Les serveurs web peuvent également mettre en cache les requêtes, retournant des réponses sans avoir à contacter les serveurs d’application.
Mise en cache côté base de données
Votre base de données inclut généralement un certain niveau de mise en cache en configuration par défaut, optimisé pour un cas d'utilisation générique. Ajuster ces paramètres pour des schémas d’utilisation spécifiques peut améliorer encore les performances.
Mise en cache côté application
Les caches en mémoire tels que Memcached et Redis sont des magasins clé-valeur entre votre application et votre stockage de données. Puisque les données sont conservées en RAM, c’est beaucoup plus rapide que les bases de données typiques où les données sont stockées sur disque. La RAM est plus limitée que le disque, donc les algorithmes de validation de cache tels que le moins récemment utilisé (LRU)) peuvent aider à invalider les entrées « froides » et garder les données « chaudes » en RAM.
Redis dispose des fonctionnalités supplémentaires suivantes :
- Option de persistance
- Structures de données intégrées telles que ensembles triés et listes
- Niveau ligne
- Niveau requête
- Objets entièrement formés et sérialisables
- HTML entièrement rendu
Mise en cache au niveau des requêtes de base de données
Chaque fois que vous interrogez la base de données, hachez la requête en tant que clé et stockez le résultat dans le cache. Cette approche souffre de problèmes d'expiration :
- Difficile de supprimer un résultat mis en cache avec des requêtes complexes
- Si une donnée change, comme une cellule de table, vous devez supprimer toutes les requêtes mises en cache qui pourraient inclure la cellule modifiée
Mise en cache au niveau de l'objet
Considérez vos données comme un objet, similaire à ce que vous faites avec votre code applicatif. Faites en sorte que votre application assemble le jeu de données depuis la base de données dans une instance de classe ou une structure(s) de données :
- Supprimez l'objet du cache si ses données sous-jacentes ont changé
- Permet un traitement asynchrone : les workers assemblent les objets en consommant le dernier objet mis en cache
- Sessions utilisateur
- Pages web entièrement rendues
- Flux d'activité
- Données du graphe utilisateur
Quand mettre à jour le cache
Comme vous ne pouvez stocker qu'une quantité limitée de données dans le cache, vous devez déterminer quelle stratégie de mise à jour du cache convient le mieux à votre cas d'utilisation.
#### Cache-aside
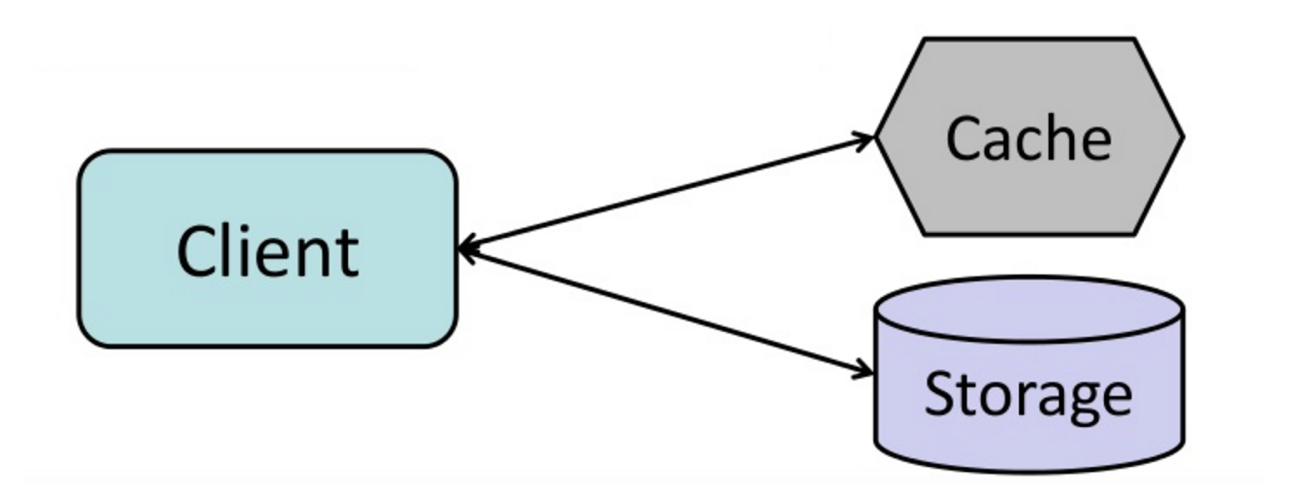
Source : From cache to in-memory data grid
L'application est responsable de la lecture et de l'écriture dans le stockage. Le cache n'interagit pas directement avec le stockage. L'application fait ce qui suit :
- Recherche l'entrée dans le cache, ce qui aboutit à un cache miss
- Charge l'entrée depuis la base de données
- Ajoute l'entrée au cache
- Retourne l'entrée
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached est généralement utilisé de cette manière.
Les lectures ultérieures des données ajoutées au cache sont rapides. Cache-aside est également appelé chargement paresseux. Seules les données demandées sont mises en cache, ce qui évite de remplir le cache avec des données non demandées.
##### Inconvénient(s) : cache-aside
- Chaque absence de cache entraîne trois allers-retours, ce qui peut provoquer un délai notable.
- Les données peuvent devenir obsolètes si elles sont mises à jour dans la base de données. Ce problème est atténué en définissant un temps de vie (TTL) qui force une mise à jour de l'entrée de cache, ou en utilisant l'écriture directe.
- Lorsqu'un nœud échoue, il est remplacé par un nouveau nœud vide, augmentant la latence.
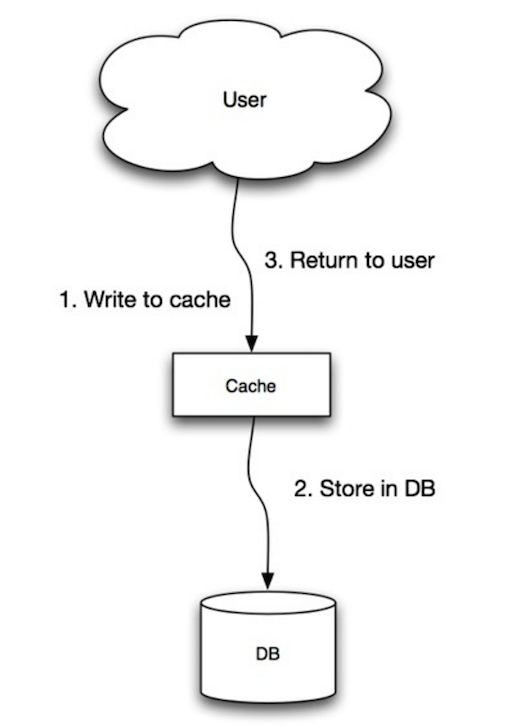
Source : Scalabilité, disponibilité, stabilité, modèles
L'application utilise le cache comme magasin principal de données, lisant et écrivant les données dedans, tandis que le cache est responsable de la lecture et de l'écriture dans la base de données :
- L'application ajoute/actualise une entrée dans le cache
- Le cache écrit de manière synchrone l'entrée dans le magasin de données
- Retour
set_user(12345, {"foo":"bar"})Code cache :
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)L'écriture directe (write-through) est une opération globale lente en raison de l'opération d'écriture, mais les lectures suivantes des données fraîchement écrites sont rapides. Les utilisateurs tolèrent généralement mieux la latence lors de la mise à jour des données que lors de la lecture des données. Les données dans le cache ne sont pas obsolètes.
##### Inconvénient(s) : write-through
- Lorsqu'un nouveau nœud est créé en raison d'une défaillance ou d'une montée en charge, le nouveau nœud ne mettra pas en cache les entrées tant que l'entrée n'aura pas été mise à jour dans la base de données. Cache-aside en conjonction avec write-through peut atténuer ce problème.
- La plupart des données écrites pourraient ne jamais être lues, ce qui peut être minimisé avec un TTL.
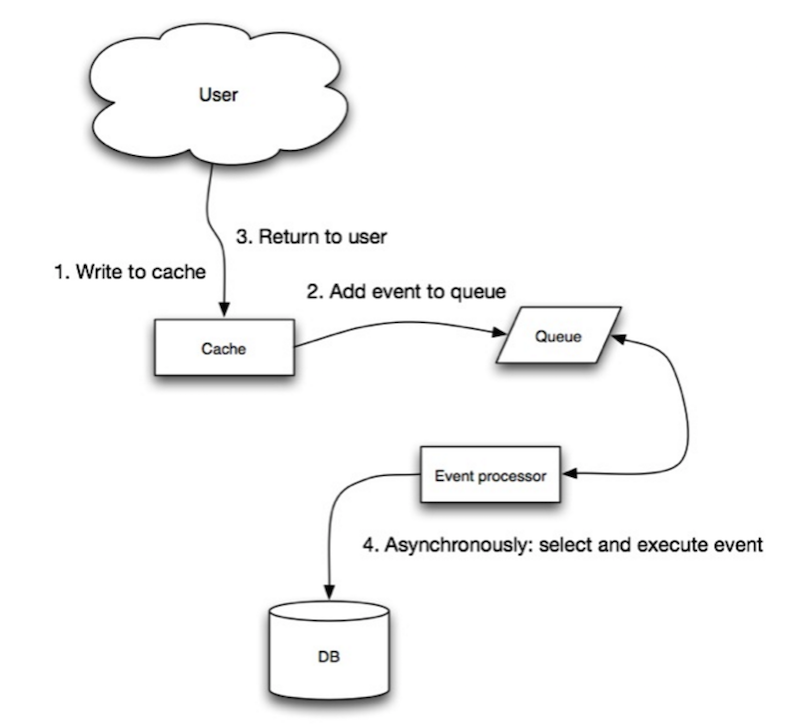
Source : Scalabilité, disponibilité, stabilité, modèles
Dans l'écriture différée, l'application fait ce qui suit :
- Ajouter/mettre à jour une entrée dans le cache
- Écrire de manière asynchrone l'entrée dans le magasin de données, améliorant les performances d'écriture
- Il pourrait y avoir une perte de données si le cache tombe en panne avant que son contenu n'atteigne le magasin de données.
- Il est plus complexe de mettre en œuvre l'écriture différée que de mettre en œuvre cache-aside ou write-through.
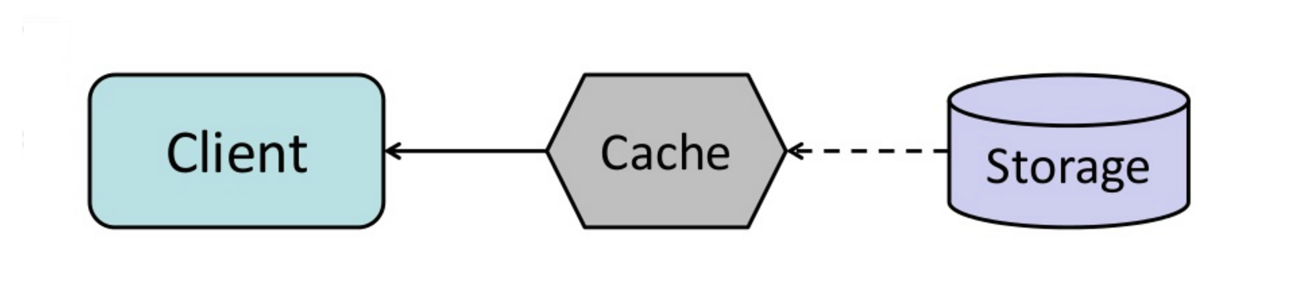
Source : Du cache à la grille de données en mémoire
Vous pouvez configurer le cache pour rafraîchir automatiquement toute entrée de cache récemment accédée avant son expiration.
Le rafraîchissement anticipé peut entraîner une réduction de la latence par rapport au read-through si le cache peut prédire avec précision quels éléments seront probablement nécessaires à l'avenir.
##### Inconvénient(s) : refresh-ahead
- Ne pas prédire avec précision les éléments susceptibles d’être nécessaires à l’avenir peut entraîner des performances réduites par rapport à une absence de rafraîchissement anticipé.
Inconvénient(s) : cache
- Nécessité de maintenir la cohérence entre les caches et la source de vérité comme la base de données via l’invalidation de cache.
- L’invalidation de cache est un problème difficile, il y a une complexité supplémentaire liée au moment de la mise à jour du cache.
- Nécessité d’apporter des modifications à l’application, comme l’ajout de Redis ou memcached.
Source(s) et lectures complémentaires
- Du cache à la grille de données en mémoire
- Modèles de conception de systèmes évolutifs
- Introduction à l’architecture des systèmes pour l’échelle
- Évolutivité, disponibilité, stabilité, modèles
- Évolutivité
- Stratégies AWS ElastiCache
- Wikipedia)
Asynchronisme
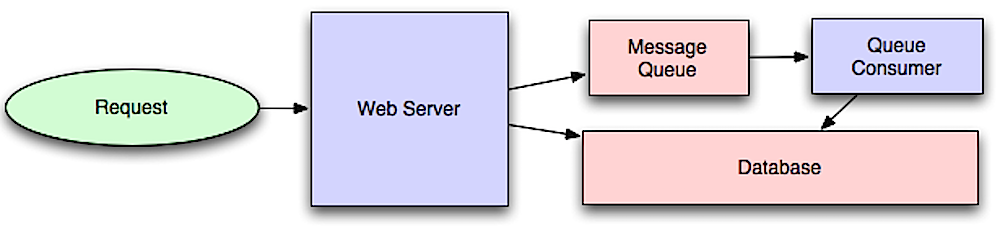
Source : Introduction à l’architecture des systèmes pour l’échelle
Les workflows asynchrones aident à réduire les temps de requête pour les opérations coûteuses qui seraient autrement effectuées en ligne. Ils peuvent également aider en réalisant à l’avance des travaux chronophages, tels que l’agrégation périodique des données.
Files de messages
Les files de messages reçoivent, retiennent et livrent les messages. Si une opération est trop lente à effectuer en ligne, vous pouvez utiliser une file de messages avec le workflow suivant :
- Une application publie un travail dans la file, puis informe l’utilisateur de l’état du travail
- Un worker récupère le travail de la file, le traite, puis signale que le travail est terminé
Redis est utile en tant que simple broker de messages mais des messages peuvent être perdus.
RabbitMQ est populaire mais nécessite de s’adapter au protocole 'AMQP' et de gérer vos propres nœuds.
Amazon SQS est hébergé mais peut présenter une latence élevée et la possibilité que des messages soient livrés deux fois.
Files de tâches
Les files de tâches reçoivent des tâches et leurs données associées, les exécutent, puis livrent leurs résultats. Elles peuvent prendre en charge la planification et peuvent être utilisées pour exécuter des travaux intensifs en calcul en arrière-plan.
Celery prend en charge la planification et supporte principalement Python.
Rétropression (Back pressure)
Si les files d’attente commencent à croître de manière significative, la taille de la file peut dépasser la mémoire, entraînant des défauts de cache, des lectures sur disque et des performances encore plus lentes. La rétropression peut aider en limitant la taille de la file, maintenant ainsi un débit élevé et de bons temps de réponse pour les tâches déjà en attente. Une fois la file remplie, les clients reçoivent un statut serveur occupé ou HTTP 503 pour réessayer plus tard. Les clients peuvent réessayer la requête ultérieurement, peut-être avec un exponential backoff.
Inconvénient(s) : asynchronisme
- Les cas d’utilisation tels que les calculs peu coûteux et les flux de travail en temps réel pourraient être mieux adaptés aux opérations synchrones, car l’introduction de files d’attente peut ajouter des délais et de la complexité.
Source(s) et lectures complémentaires
- It's all a numbers game
- Applying back pressure when overloaded
- Little's law
- Quelle est la différence entre une file de messages et une file de tâches ?
Communication
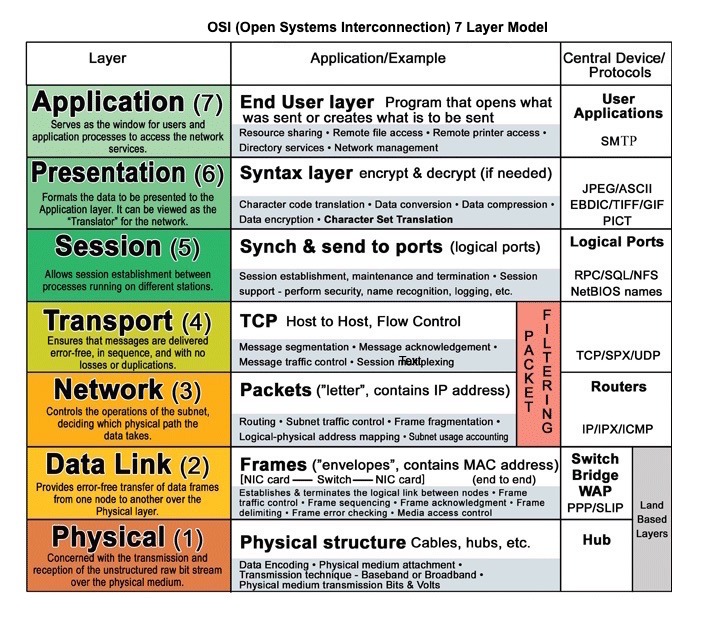
Source : modèle OSI en 7 couches
Protocole de transfert hypertexte (HTTP)
HTTP est une méthode pour encoder et transporter des données entre un client et un serveur. C’est un protocole requête/réponse : les clients émettent des requêtes et les serveurs renvoient des réponses avec le contenu pertinent et des informations sur le statut de la requête. HTTP est autonome, permettant aux requêtes et réponses de transiter par de nombreux routeurs et serveurs intermédiaires qui effectuent équilibrage de charge, mise en cache, chiffrement et compression.
Une requête HTTP basique se compose d’un verbe (méthode) et d’une ressource (point de terminaison). Voici les verbes HTTP courants :
| Verbe | Description | Idempotent* | Sûr | Mise en cache |
| GET | Lit une ressource | Oui | Oui | Oui | | POST | Crée une ressource ou déclenche un processus qui traite les données | Non | Non | Oui si la réponse contient des informations de fraîcheur | | PUT | Crée ou remplace une ressource | Oui | Non | Non | | PATCH | Met à jour partiellement une ressource | Non | Non | Oui si la réponse contient des informations de fraîcheur | | DELETE | Supprime une ressource | Oui | Non | Non |
*Peut être appelé plusieurs fois sans résultats différents.
HTTP est un protocole de couche application reposant sur des protocoles de niveau inférieur tels que TCP et UDP.
#### Source(s) et lectures complémentaires : HTTP
Protocole de contrôle de transmission (TCP)
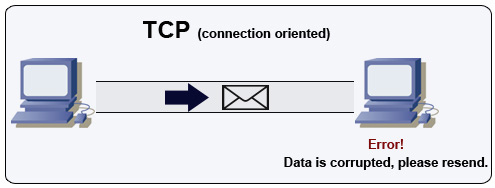
Source : Comment créer un jeu multijoueur
TCP est un protocole orienté connexion sur un réseau IP. La connexion est établie et terminée via une poignée de main (handshake). Tous les paquets envoyés sont garantis d’atteindre la destination dans l’ordre initial et sans corruption grâce à :
- Des numéros de séquence et des champs de somme de contrôle pour chaque paquet
- Des paquets de reconnaissance (acknowledgement)) et la retransmission automatique
Pour garantir un débit élevé, les serveurs web peuvent garder un grand nombre de connexions TCP ouvertes, ce qui entraîne une utilisation élevée de la mémoire. Il peut être coûteux d’avoir un grand nombre de connexions ouvertes entre les threads du serveur web et par exemple, un serveur memcached. Le pooling de connexions peut aider en plus du passage à UDP lorsque cela est applicable.
TCP est utile pour les applications nécessitant une haute fiabilité mais moins critiques en temps. Quelques exemples incluent les serveurs web, les bases de données, SMTP, FTP et SSH.
Utilisez TCP plutôt que UDP lorsque :
- Vous avez besoin que toutes les données arrivent intactes
- Vous souhaitez automatiquement faire une meilleure estimation de l’utilisation du débit réseau
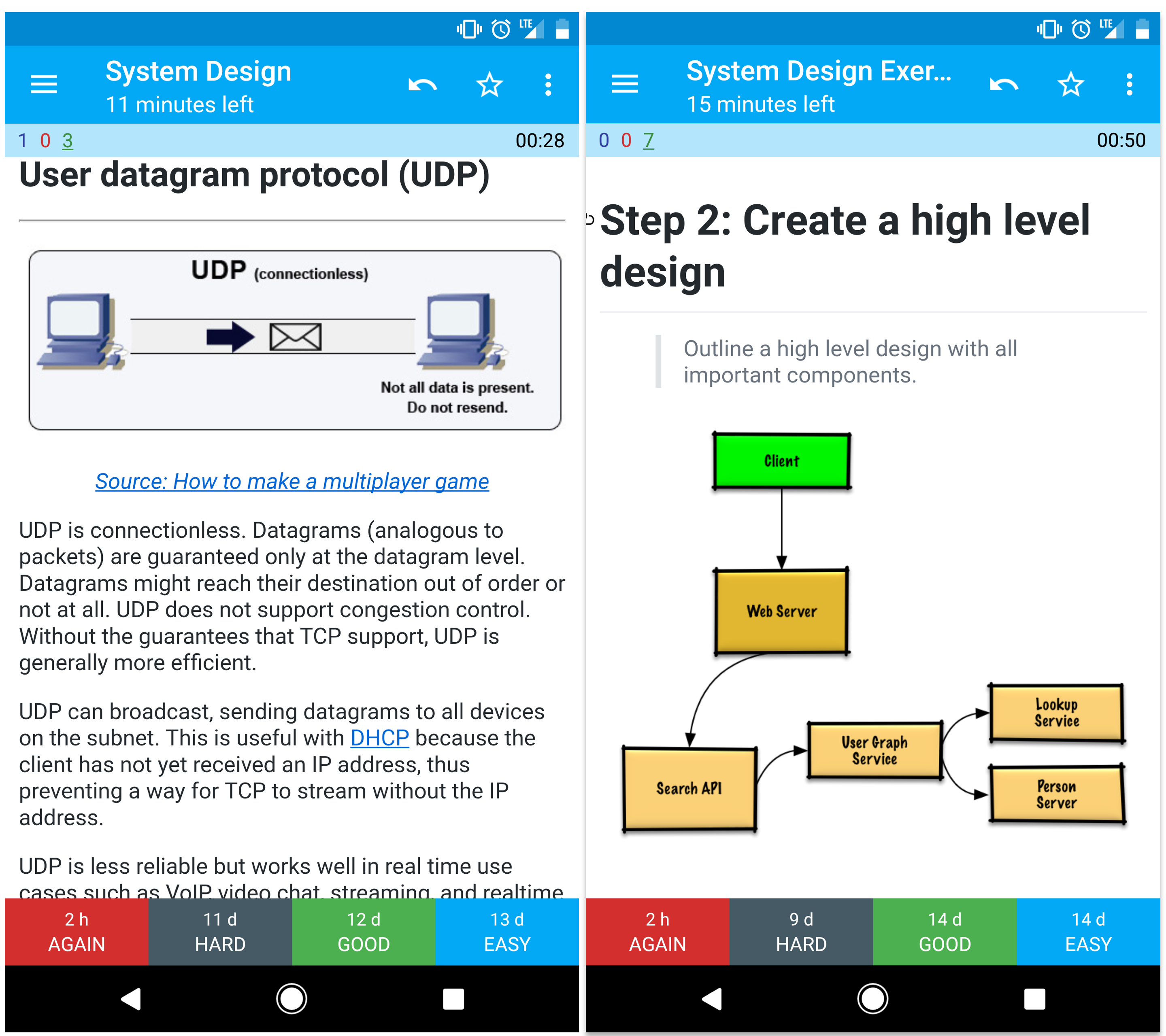
Protocole datagramme utilisateur (UDP)
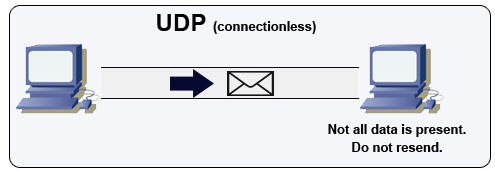
Source : Comment créer un jeu multijoueur
UDP est sans connexion. Les datagrammes (analogues aux paquets) sont garantis uniquement au niveau du datagramme. Les datagrammes peuvent arriver à destination dans le désordre ou pas du tout. UDP ne supporte pas le contrôle de congestion. Sans les garanties que TCP offre, UDP est généralement plus efficace.
UDP peut diffuser, envoyant des datagrammes à tous les appareils sur le sous-réseau. Ceci est utile avec DHCP car le client n'a pas encore reçu d'adresse IP, empêchant ainsi TCP de diffuser sans adresse IP.
UDP est moins fiable mais fonctionne bien dans des cas d'utilisation en temps réel tels que VoIP, chat vidéo, streaming et jeux multijoueurs en temps réel.
Utilisez UDP plutôt que TCP quand :
- Vous avez besoin de la latence la plus faible
- Les données tardives sont pires que la perte de données
- Vous souhaitez implémenter votre propre correction d'erreur
- Mise en réseau pour la programmation de jeux
- Principales différences entre les protocoles TCP et UDP
- Différence entre TCP et UDP
- Protocole de contrôle de transmission
- Protocole datagramme utilisateur
- Mise à l'échelle de memcache chez Facebook
Appel de procédure distante (RPC)
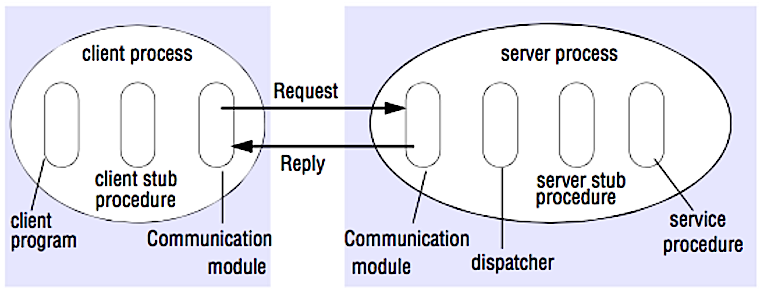
Source : Réussir l'entretien de conception système
Dans un RPC, un client déclenche l'exécution d'une procédure dans un espace d'adressage différent, généralement un serveur distant. La procédure est codée comme s'il s'agissait d'un appel de procédure local, masquant les détails de la communication avec le serveur au programme client. Les appels distants sont généralement plus lents et moins fiables que les appels locaux, il est donc utile de distinguer les appels RPC des appels locaux. Les frameworks RPC populaires incluent Protobuf, Thrift, et Avro.
RPC est un protocole requête-réponse :
- Programme client - Appelle la procédure stub client. Les paramètres sont poussés sur la pile comme un appel de procédure local.
- Procédure stub client - Sérialise (emballe) l’identifiant de la procédure et les arguments dans un message de requête.
- Module de communication client - Le système d’exploitation envoie le message du client vers le serveur.
- Module de communication serveur - Le système d’exploitation transmet les paquets entrants à la procédure stub serveur.
- Procédure stub serveur - Désérialise les résultats, appelle la procédure serveur correspondant à l’identifiant de la procédure et transmet les arguments donnés.
- La réponse du serveur répète les étapes ci-dessus dans l’ordre inverse.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC se concentre sur l'exposition des comportements. Les RPC sont souvent utilisés pour des raisons de performance dans les communications internes, car vous pouvez créer manuellement des appels natifs pour mieux adapter vos cas d'utilisation.
Choisissez une bibliothèque native (également appelée SDK) lorsque :
- Vous connaissez votre plateforme cible.
- Vous souhaitez contrôler la manière dont votre "logique" est accessible.
- Vous souhaitez contrôler la gestion des erreurs en dehors de votre bibliothèque.
- La performance et l'expérience utilisateur finale sont vos principales préoccupations.
#### Inconvénient(s) : RPC
- Les clients RPC deviennent étroitement liés à l'implémentation du service.
- Une nouvelle API doit être définie pour chaque nouvelle opération ou cas d'utilisation.
- Il peut être difficile de déboguer les RPC.
- Vous pourriez ne pas être en mesure de tirer parti des technologies existantes directement. Par exemple, cela peut nécessiter un effort supplémentaire pour garantir que les appels RPC sont correctement mis en cache sur des serveurs de cache tels que Squid.
Représentation de transfert d'état (REST)
REST est un style architectural imposant un modèle client/serveur où le client agit sur un ensemble de ressources gérées par le serveur. Le serveur fournit une représentation des ressources et des actions qui peuvent soit manipuler, soit obtenir une nouvelle représentation des ressources. Toute communication doit être sans état et mise en cache.
Il y a quatre qualités d'une interface RESTful :
- Identifier les ressources (URI en HTTP) - utiliser la même URI quel que soit l'opération.
- Changer avec les représentations (Verbes en HTTP) - utiliser des verbes, des en-têtes et un corps.
- Message d'erreur auto-descriptif (réponse de statut en HTTP) - utiliser les codes d'état, ne pas réinventer la roue.
- HATEOAS (interface HTML pour HTTP) - votre service web doit être entièrement accessible dans un navigateur.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### Inconvénient(s) : REST
- REST étant axé sur l'exposition des données, il pourrait ne pas convenir si les ressources ne sont pas naturellement organisées ou accessibles dans une hiérarchie simple. Par exemple, retourner tous les enregistrements mis à jour au cours de la dernière heure correspondant à un ensemble particulier d'événements n'est pas facilement exprimé comme un chemin. Avec REST, cela est souvent implémenté avec une combinaison de chemin URI, de paramètres de requête et éventuellement du corps de la requête.
- REST s'appuie généralement sur quelques verbes (GET, POST, PUT, DELETE et PATCH) qui ne correspondent pas toujours à votre cas d'utilisation. Par exemple, déplacer des documents expirés vers le dossier d'archive ne s'intègre pas proprement dans ces verbes.
- Récupérer des ressources complexes avec des hiérarchies imbriquées nécessite plusieurs allers-retours entre le client et le serveur pour afficher des vues uniques, par exemple récupérer le contenu d'une entrée de blog et les commentaires sur cette entrée. Pour les applications mobiles fonctionnant dans des conditions réseau variables, ces multiples allers-retours sont très indésirables.
- Avec le temps, davantage de champs peuvent être ajoutés à une réponse d'API et les clients plus anciens recevront tous les nouveaux champs de données, même ceux dont ils n'ont pas besoin, ce qui gonfle la taille de la charge utile et entraîne des latences plus importantes.
Comparaison des appels RPC et REST
| Opération | RPC | REST |
|---|---|---|
| Inscription | POST /signup | POST /persons |
| Démission | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| Lire une personne | GET /readPerson?personid=1234 | GET /persons/1234 |
| Lire la liste d'articles d'une personne | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| Ajouter un article à la liste d'articles d'une personne | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| Mettre à jour un article | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| Supprimer un article | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
Source : Savez-vous vraiment pourquoi vous préférez REST à RPC
#### Source(s) et lectures complémentaires : REST et RPC
- Savez-vous vraiment pourquoi vous préférez REST à RPC
- Quand les approches de type RPC sont-elles plus appropriées que REST ?
- REST vs JSON-RPC
- Démystifier les mythes de RPC et REST
- Quels sont les inconvénients de l'utilisation de REST
- Réussir l'entretien de conception de système
- Thrift
- Pourquoi REST pour un usage interne et pas RPC
Sécurité
Cette section pourrait être mise à jour. Envisagez de contribuer !
La sécurité est un sujet vaste. À moins que vous n'ayez une expérience considérable, un background en sécurité, ou que vous postuliez à un poste nécessitant des connaissances en sécurité, vous n'aurez probablement pas besoin de connaître plus que les bases :
- Chiffrez les données en transit et au repos.
- Nettoyez toutes les entrées utilisateur ou tout paramètre d'entrée exposé à l'utilisateur pour prévenir les XSS et les injections SQL.
- Utilisez des requêtes paramétrées pour éviter les injections SQL.
- Appliquez le principe du moindre privilège.
Source(s) et lectures complémentaires
Annexe
Il vous sera parfois demandé de faire des estimations rapides. Par exemple, vous pourriez devoir déterminer combien de temps il faudra pour générer 100 miniatures d’images à partir du disque ou combien de mémoire une structure de données occupera. Le tableau des puissances de deux et les chiffres de latence que tout programmeur devrait connaître sont des références utiles.
Tableau des puissances de deux
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### Source(s) et lectures complémentaires
Nombres de latence que tout programmeur devrait connaître
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Métriques pratiques basées sur les chiffres ci-dessus :
- Lecture séquentielle depuis un HDD à 30 Mo/s
- Lecture séquentielle depuis un Ethernet 1 Gbps à 100 Mo/s
- Lecture séquentielle depuis un SSD à 1 Go/s
- Lecture séquentielle depuis la mémoire principale à 4 Go/s
- 6-7 allers-retours mondiaux par seconde
- 2 000 allers-retours par seconde au sein d’un centre de données
#### Source(s) et lectures complémentaires
- Chiffres de latence que tout programmeur devrait connaître - 1
- Chiffres de latence que tout programmeur devrait connaître - 2
- Conceptions, leçons et conseils issus de la construction de grands systèmes distribués
- Conseils en ingénierie logicielle issus de la construction de systèmes distribués à grande échelle
Questions supplémentaires d’entretien de conception système
Questions courantes d’entretien de conception système, avec des liens vers des ressources pour résoudre chacune.
| Question | Référence(s) |
|---|---|
| Concevoir un service de synchronisation de fichiers comme Dropbox | youtube.com |
| Concevoir un moteur de recherche comme Google | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| Concevoir un robot d’indexation web évolutif comme Google | quora.com |
| Concevoir Google Docs | code.google.com
neil.fraser.name |
| Concevoir un magasin clé-valeur comme Redis | slideshare.net |
| Concevoir un système de cache comme Memcached | slideshare.net |
| Concevoir un système de recommandation comme celui d’Amazon | hulu.com
ijcai13.org |
| Concevoir un système tinyurl comme Bitly | n00tc0d3r.blogspot.com |
| Concevoir une application de chat comme WhatsApp | highscalability.com
| Concevoir un système de partage de photos comme Instagram | highscalability.com
highscalability.com |
| Concevoir la fonction fil d’actualité de Facebook | quora.com
quora.com
slideshare.net |
| Concevoir la fonction timeline de Facebook | facebook.com
highscalability.com |
| Concevoir la fonction chat de Facebook | erlang-factory.com
facebook.com |
| Concevoir une fonction de recherche de graphe comme celle de Facebook | facebook.com
facebook.com
facebook.com |
| Concevoir un réseau de diffusion de contenu comme CloudFlare | figshare.com |
| Concevoir un système de sujets tendance comme celui de Twitter | michael-noll.com
snikolov.wordpress.com |
| Concevoir un système de génération d’identifiants aléatoires | blog.twitter.com
github.com |
| Retourner les k requêtes les plus fréquentes durant un intervalle de temps | cs.ucsb.edu
wpi.edu |
| Concevoir un système qui sert des données depuis plusieurs centres de données | highscalability.com |
| Concevoir un jeu de cartes multijoueur en ligne | indieflashblog.com
buildnewgames.com |
| Concevoir un système de collecte des déchets (garbage collection) | stuffwithstuff.com
washington.edu |
| Concevoir un limiteur de débit d’API | https://stripe.com/blog/ |
| Concevoir une Bourse (comme NASDAQ ou Binance) | Jane Street
Golang Implementation
Go Implementation |
| Ajouter une question de conception système | Contribuer |
Architectures du monde réel
Articles sur la manière dont les systèmes réels sont conçus.
Source : Échelles des timelines Twitter
Ne vous concentrez pas sur les détails techniques dans les articles suivants, mais plutôt :
- Identifier les principes partagés, technologies communes et motifs dans ces articles
- Étudier les problèmes résolus par chaque composant, où cela fonctionne, où cela ne fonctionne pas
- Revoir les leçons apprises
Architectures d’entreprises
| Entreprise | Référence(s) |
|---|---|
| Amazon | Architecture Amazon |
| Cinchcast | Production de 1 500 heures d’audio chaque jour |
| DataSift | Datamining en temps réel à 120 000 tweets par seconde |
| Dropbox | Comment nous avons fait évoluer Dropbox |
| ESPN | Fonctionnement à 100 000 duh nuh nuhs par seconde |
| Google | Architecture Google |
| Instagram | 14 millions d’utilisateurs, des téraoctets de photos
Ce qui alimente Instagram |
| Justin.tv | Architecture de diffusion vidéo en direct de Justin.Tv |
| Facebook | Mise à l’échelle de memcached chez Facebook
TAO : magasin de données distribué de Facebook pour le graphe social
Stockage des photos chez Facebook
Comment Facebook diffuse en direct à 800 000 spectateurs simultanés |
| Flickr | Architecture Flickr |
| Mailbox | De 0 à un million d’utilisateurs en 6 semaines |
| Netflix | Vue à 360 degrés de toute la pile Netflix
Netflix : que se passe-t-il quand vous appuyez sur play ? |
| Pinterest | De 0 à des dizaines de milliards de pages vues par mois
18 millions de visiteurs, croissance de 10x, 12 employés |
| Playfish | 50 millions d’utilisateurs mensuels et en croissance |
| PlentyOfFish | Architecture PlentyOfFish |
| Salesforce | Comment ils gèrent 1,3 milliard de transactions par jour |
| Stack Overflow | Architecture Stack Overflow |
| TripAdvisor | 40 millions de visiteurs, 200 millions de pages dynamiques vues, 30 To de données |
| Tumblr | 15 milliards de pages vues par mois |
| Twitter | Rendre Twitter 10 000 % plus rapide
Stocker 250 millions de tweets par jour avec MySQL
150 millions d’utilisateurs actifs, 300 000 QPS, un firehose de 22 Mo/s
Timelines à grande échelle
Données grandes et petites chez Twitter
Opérations chez Twitter : montée en charge au-delà de 100 millions d’utilisateurs
Comment Twitter gère 3 000 images par seconde |
| Uber | Comment Uber met à l’échelle sa plateforme de marché en temps réel
Leçons apprises de la montée en charge d’Uber à 2 000 ingénieurs, 1 000 services et 8 000 dépôts Git |
| WhatsApp | L’architecture WhatsApp que Facebook a achetée pour 19 milliards de dollars |
| YouTube | Scalabilité YouTube
Architecture YouTube |
Blogs d'ingénierie des entreprises
Architectures pour les entreprises avec lesquelles vous passez des entretiens.>
Les questions que vous rencontrez peuvent provenir du même domaine.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Blog d'ingénierie Twilio
- Ingénierie Twitter
- Blog d'ingénierie Uber
- Blog d'ingénierie Yahoo
- Blog d'ingénierie Yelp
- Blog d'ingénierie Zynga
Vous souhaitez ajouter un blog ? Pour éviter de dupliquer le travail, envisagez d'ajouter le blog de votre entreprise dans le dépôt suivant :
En cours de développement
Intéressé à ajouter une section ou à aider à en compléter une en cours ? Contribuez !
- Calcul distribué avec MapReduce
- Hachage cohérent
- Scatter gather
- Contribuez
Crédits
Les crédits et sources sont fournis tout au long de ce dépôt.
Remerciements particuliers à :
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- Fiche mémo design système
- Une liste de lectures sur les systèmes distribués
- Réussir l'entretien de conception de système
Infos de contact
N’hésitez pas à me contacter pour discuter de tout problème, question ou commentaire.
Mes coordonnées se trouvent sur ma page GitHub.
Licence
Je vous fournis le code et les ressources de ce dépôt sous une licence open source. Puisqu’il s’agit de mon dépôt personnel, la licence que vous recevez pour mon code et mes ressources vient de moi et non de mon employeur (Facebook).
Copyright 2017 Donne Martin
Licence Creative Commons Attribution 4.0 International (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---