English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français | Add Translation
برای ترجمه این راهنما کمک کنید!
راهنمای طراحی سیستم

انگیزه
یاد بگیرید چگونه سیستمهای بزرگمقیاس را طراحی کنید.>
برای مصاحبه طراحی سیستم آماده شوید.
یاد بگیرید چگونه سیستمهای بزرگمقیاس را طراحی کنید
یادگیری طراحی سیستمهای مقیاسپذیر به شما کمک میکند مهندس بهتری شوید.
طراحی سیستم موضوعی گسترده است. منابع فراوانی در سراسر وب در مورد اصول طراحی سیستم وجود دارد.
این مخزن یک مجموعه سازمانیافته از منابع است تا به شما کمک کند یاد بگیرید چگونه سیستمها را در مقیاس بزرگ بسازید.
یادگیری از جامعه متنباز
این پروژه به صورت متنباز و به طور مداوم بهروزرسانی میشود.
مشارکتها خوشآمدید!
آمادگی برای مصاحبه طراحی سیستم
علاوه بر مصاحبههای برنامهنویسی، طراحی سیستم یک جزء الزامی در فرآیند مصاحبه فنی بسیاری از شرکتهای فناوری است.
تمرین پرسشهای رایج مصاحبه طراحی سیستم و مقایسه نتایج خود با نمونه راهحلها: بحثها، کد، و نمودارها.
موضوعات اضافی برای آمادگی مصاحبه:
- راهنمای مطالعه
- چگونه به پرسش مصاحبه طراحی سیستم نزدیک شویم
- سوالات مصاحبه طراحی سیستم، به همراه راهحلها
- سوالات مصاحبه طراحی شیءگرا، به همراه راهحلها
- سوالات اضافی مصاحبه طراحی سیستم
فلشکارتهای Anki
دستههای فلشکارت Anki ارائهشده از تکرار فاصلهدار برای حفظ مفاهیم کلیدی طراحی سیستم استفاده میکنند.
عالی برای استفاده در حین حرکت.منبع کدنویسی: چالشهای تعاملی کدنویسی
دنبال منبعی برای آمادگی مصاحبه کدنویسی هستید؟
مخزن خواهر چالشهای تعاملی کدنویسی را بررسی کنید که شامل یک دسته Anki اضافی است:
مشارکت
از جامعه یاد بگیرید.
در ارسال pull request برای کمک کردن آزاد هستید:
- رفع خطاها
- بهبود بخشها
- افزودن بخشهای جدید
- ترجمه
راهنمای مشارکت را مرور کنید.
فهرست موضوعات طراحی سیستم
خلاصهای از موضوعات مختلف طراحی سیستم، شامل مزایا و معایب. همه چیز معامله است.>
هر بخش شامل لینکهایی به منابع عمیقتر میباشد.
- موضوعات طراحی سیستم: از اینجا شروع کنید
- مرحله ۱: ویدیوی آموزشی مقیاسپذیری را مرور کنید
- مرحله ۲: مقاله مقیاسپذیری را مرور کنید
- گامهای بعدی
- کارایی در مقابل مقیاسپذیری
- تاخیر در مقابل توان عملیاتی
- دردسترس بودن در مقابل سازگاری
- قضیه CAP
- CP - سازگاری و تحمل تقسیمبندی
- AP - دردسترس بودن و تحمل تقسیمبندی
- الگوهای سازگاری
- سازگاری ضعیف
- سازگاری نهایی
- سازگاری قوی
- الگوهای دردسترس بودن
- Fail-over
- تکثیر
- دردسترس بودن با اعداد
- سیستم نام دامنه
- شبکه تحویل محتوا
- CDNهای فشاری
- CDNهای کششی
- تعادل بار (Load balancer)
- فعال-غیرفعال (Active-passive)
- فعال-فعال (Active-active)
- تعادل بار لایه ۴
- تعادل بار لایه ۷
- مقیاسپذیری افقی
- پراکسی معکوس (سرور وب)
- تفاوت تعادل بار و پراکسی معکوس
- لایه کاربردی
- ریزسرویسها (Microservices)
- کشف سرویس
- پایگاه داده
- سیستم مدیریت پایگاه داده رابطهای (RDBMS)
- تکثیر استاد-برده
- تکثیر استاد-استاد
- فدراسیون
- شاردینگ
- غیرنرمالسازی
- بهینهسازی SQL
- NoSQL
- ذخیرهسازی کلید-مقدار
- ذخیرهسازی سندی
- ذخیرهسازی ستونی گسترده
- پایگاه داده گرافی
- SQL یا NoSQL
- کش (Cache)
- کش سمت کلاینت
- کش CDN
- کش سرور وب
- کش پایگاه داده
- کش برنامه
- کش در سطح پرسوجوی پایگاه داده
- کش در سطح شیء
- زمان بهروزرسانی کش
- کش-کناری (Cache-aside)
- نوشتن همزمان (Write-through)
- نوشتن در پسزمینه (write-back)
- پیشبارگذاری (Refresh-ahead)
- غیربلادرنگ بودن (Asynchronism)
- صفهای پیام
- صفهای وظیفه
- فشار برگشتی
- ارتباطات
- پروتکل کنترل انتقال (TCP)
- پروتکل دیتاگرام کاربر (UDP)
- فراخوانی رویه از راه دور (RPC)
- انتقال وضعیت نمایشی (REST)
- امنیت
- ضمیمه
- جدول توانهای دو
- اعداد تأخیر که هر برنامهنویسی باید بداند
- سؤالات تکمیلی مصاحبه طراحی سیستم
- معماریهای دنیای واقعی
- معماریهای شرکتها
- وبلاگهای مهندسی شرکتها
- در حال توسعه
- اعتبارات
- اطلاعات تماس
- مجوز
راهنمای مطالعه
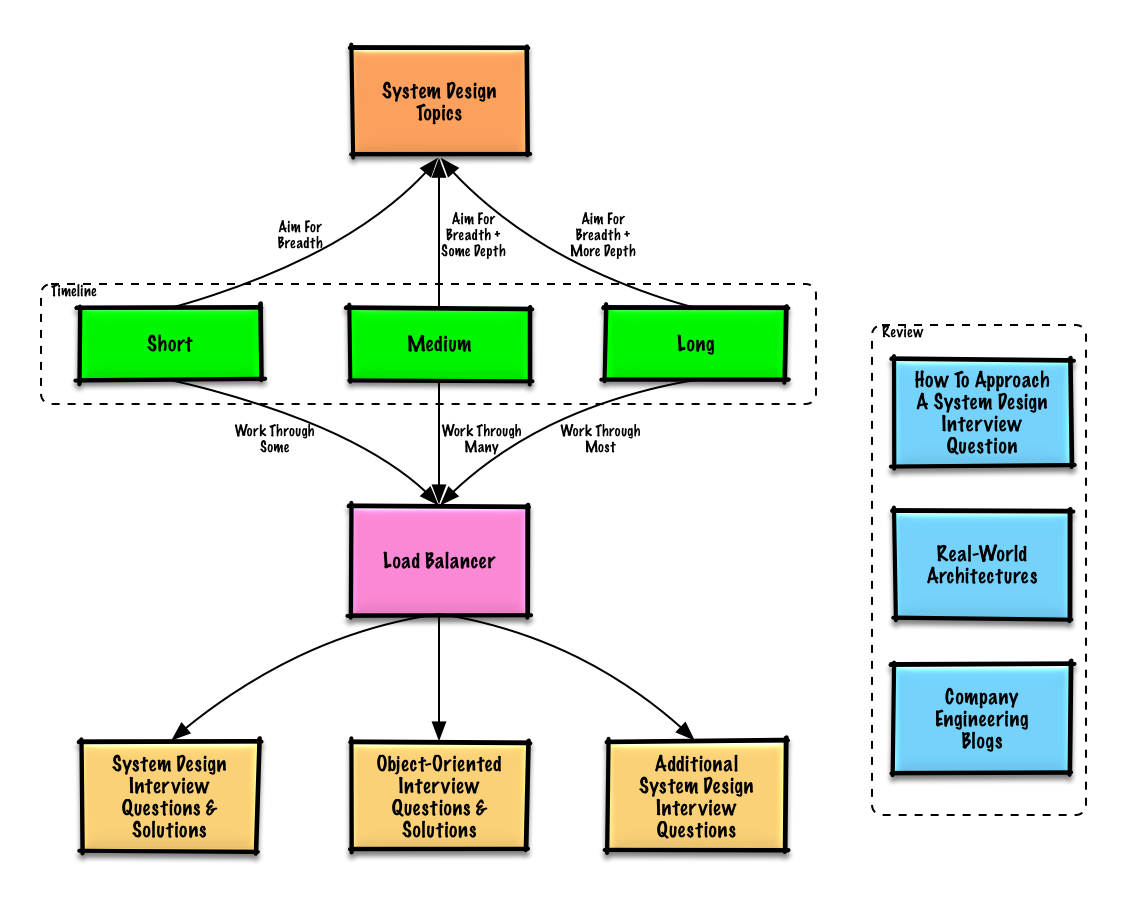
موضوعات پیشنهادی برای مرور بر اساس زمانبندی مصاحبه شما (کوتاهمدت، میانمدت، بلندمدت).
س: آیا برای مصاحبه باید همه چیز اینجا را بدانم؟
ج: خیر، برای آمادگی مصاحبه لازم نیست همه مطالب اینجا را بدانید.
سؤالاتی که در مصاحبه مطرح میشود بستگی به متغیرهایی مانند:
- میزان تجربه شما
- پیشزمینه فنی شما
- موقعیتهایی که برای آنها مصاحبه میدهید
- شرکتهایی که با آنها مصاحبه میکنید
- شانس
از گسترده شروع کنید و در برخی حوزهها عمیقتر شوید. دانستن کمی درباره موضوعات کلیدی طراحی سیستم کمککننده است. راهنمای زیر را بر اساس زمانبندی، تجربه، موقعیتهای شغلی مورد مصاحبه و شرکتهایی که با آنها مصاحبه دارید، تنظیم کنید.
- زمانبندی کوتاه - هدف خود را بر گستردگی موضوعات طراحی سیستم قرار دهید. با حل تعدادی سوال مصاحبه تمرین کنید.
- زمانبندی متوسط - هدف خود را بر گستردگی و کمی عمق در موضوعات طراحی سیستم قرار دهید. با حل سوالات بیشتری تمرین کنید.
- زمانبندی طولانی - هدف خود را بر گستردگی و عمق بیشتر موضوعات طراحی سیستم قرار دهید. با حل اکثر سوالات مصاحبه تمرین کنید.
چگونه به یک سوال مصاحبه طراحی سیستم نزدیک شویم
چگونه یک سوال مصاحبه طراحی سیستم را حل کنیم.
مصاحبه طراحی سیستم یک گفتگوی باز است. انتظار میرود شما آن را هدایت کنید.
میتوانید از مراحل زیر برای هدایت بحث استفاده کنید. برای تثبیت این فرایند، بخش سوالات مصاحبه طراحی سیستم با راهحل را با استفاده از مراحل زیر تمرین کنید.
مرحله ۱: شرح موارد استفاده، محدودیتها و فرضیات
نیازمندیها را جمعآوری و دامنه مسئله را مشخص کنید. برای شفافسازی موارد استفاده و محدودیتها سوال بپرسید. فرضیات را بحث کنید.
- چه کسانی قرار است از آن استفاده کنند؟
- چگونه از آن استفاده خواهند کرد؟
- چند کاربر دارد؟
- سیستم چه کاری انجام میدهد؟
- ورودیها و خروجیهای سیستم چیست؟
- انتظار داریم چه مقدار داده را مدیریت کنیم؟
- انتظار چند درخواست در ثانیه را داریم؟
- نسبت خواندن به نوشتن مورد انتظار چقدر است؟
مرحله ۲: ایجاد یک طراحی سطح بالا
یک طراحی سطح بالا با تمام اجزای مهم را ترسیم کنید.
- اجزای اصلی و ارتباطات را رسم کنید
- ایدههای خود را توجیه کنید
مرحله ۳: طراحی اجزای اصلی
جزئیات هر جزء اصلی را بررسی کنید. برای مثال، اگر از شما خواسته شد یک سرویس کوتاهکننده URL طراحی کنید، بحث کنید:
- تولید و ذخیره هش از URL کامل
- MD5 و Base62
- برخورد هشها
- SQL یا NoSQL
- طرح پایگاه داده
- تبدیل URL هش شده به URL کامل
- جستجو در پایگاه داده
- طراحی API و شیگرایی
مرحله ۴: مقیاسدهی طراحی
گلوگاهها را با توجه به محدودیتها شناسایی و رفع کنید. برای مثال، آیا برای رفع مشکلات مقیاسپذیری به موارد زیر نیاز دارید؟
- متعادلکننده بار
- مقیاس افقی
- کشینگ
- قطعهبندی پایگاه داده
محاسبات سرانگشتی
ممکن است از شما خواسته شود برخی برآوردها را دستی انجام دهید. به ضمیمه برای منابع زیر مراجعه کنید:
منبع(ها) و مطالعه بیشتر
برای آشنایی بیشتر با انتظارات، به لینکهای زیر مراجعه کنید:
- چگونه در مصاحبه طراحی سیستم موفق شویم
- مصاحبه طراحی سیستم
- مقدمهای بر معماری و مصاحبههای طراحی سیستم
- قالب طراحی سیستم
سوالات مصاحبه طراحی سیستم با راهحلها
سوالات رایج مصاحبه طراحی سیستم با نمونه بحثها، کد و نمودارها.>
راهحلها به محتوای پوشه solutions/ لینک شدهاند.| سوال | | |---|---| | طراحی Pastebin.com (یا Bit.ly) | راهحل | | طراحی تایملاین و جستجوی توییتر (یا فید و جستجوی فیسبوک) | راهحل | | طراحی یک وبکراولر | راهحل | | طراحی Mint.com | راهحل | | طراحی ساختار دادهها برای یک شبکه اجتماعی | راهحل | | طراحی یک فروشگاه کلید-مقدار برای موتور جستجو | راهحل | | طراحی ویژگی رتبهبندی فروش آمازون بر اساس دستهبندی | راهحل | | طراحی سیستمی که به میلیونها کاربر در AWS مقیاسپذیر باشد | راهحل | | افزودن سوال طراحی سیستم | مشارکت |
طراحی Pastebin.com (یا Bit.ly)
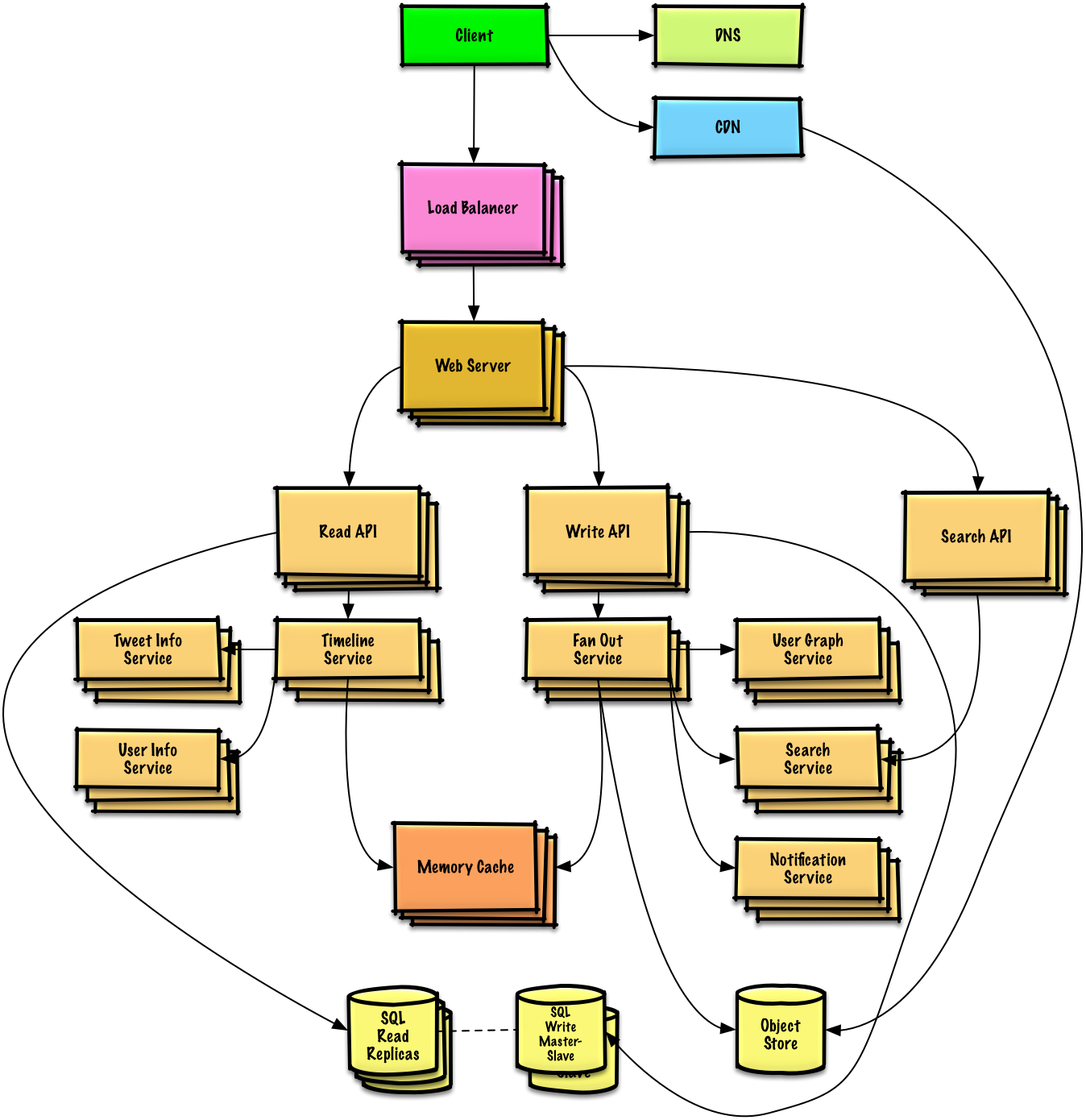
طراحی تایملاین و جستجوی توییتر (یا فید و جستجوی فیسبوک)
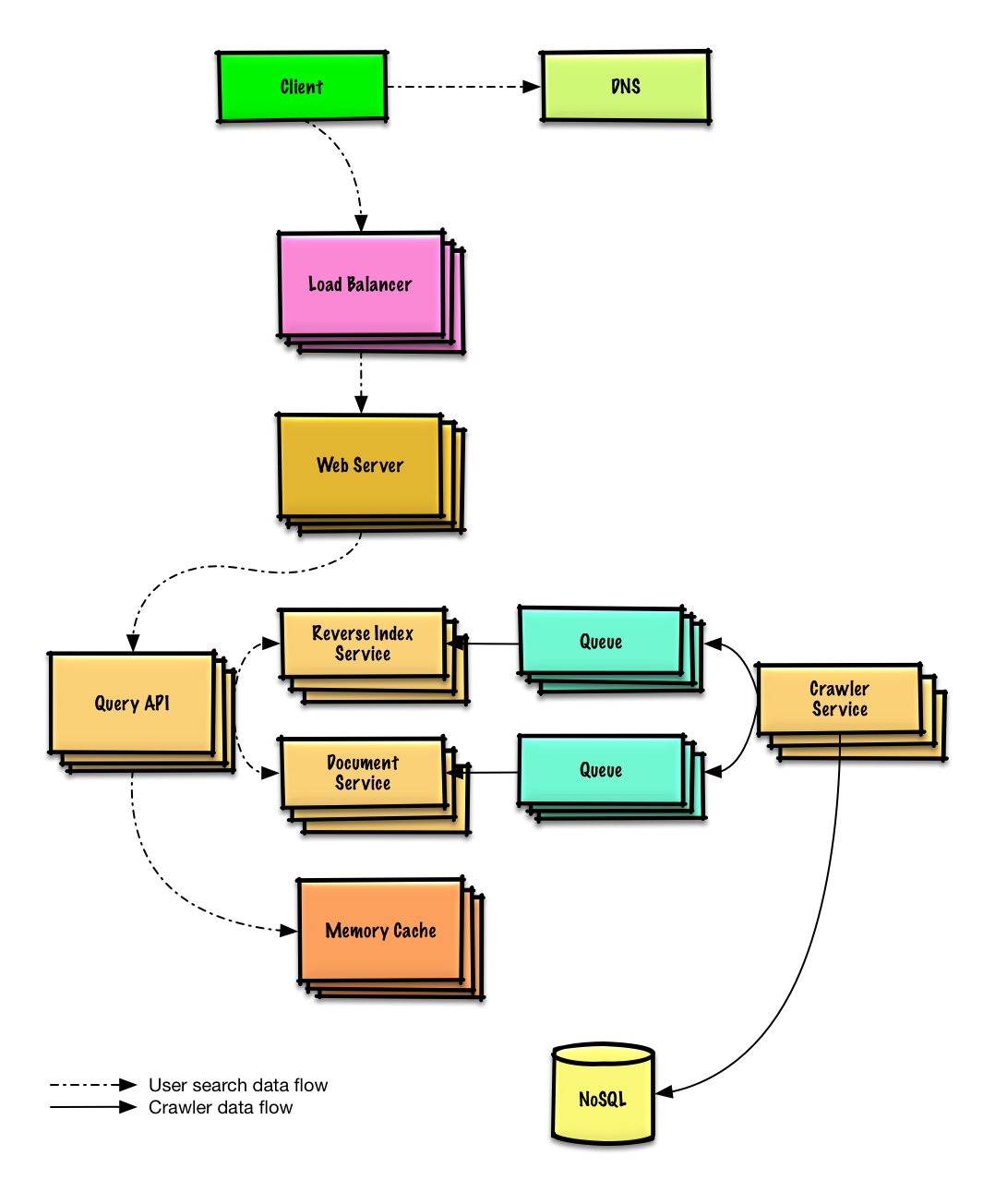
طراحی یک وبکراولر
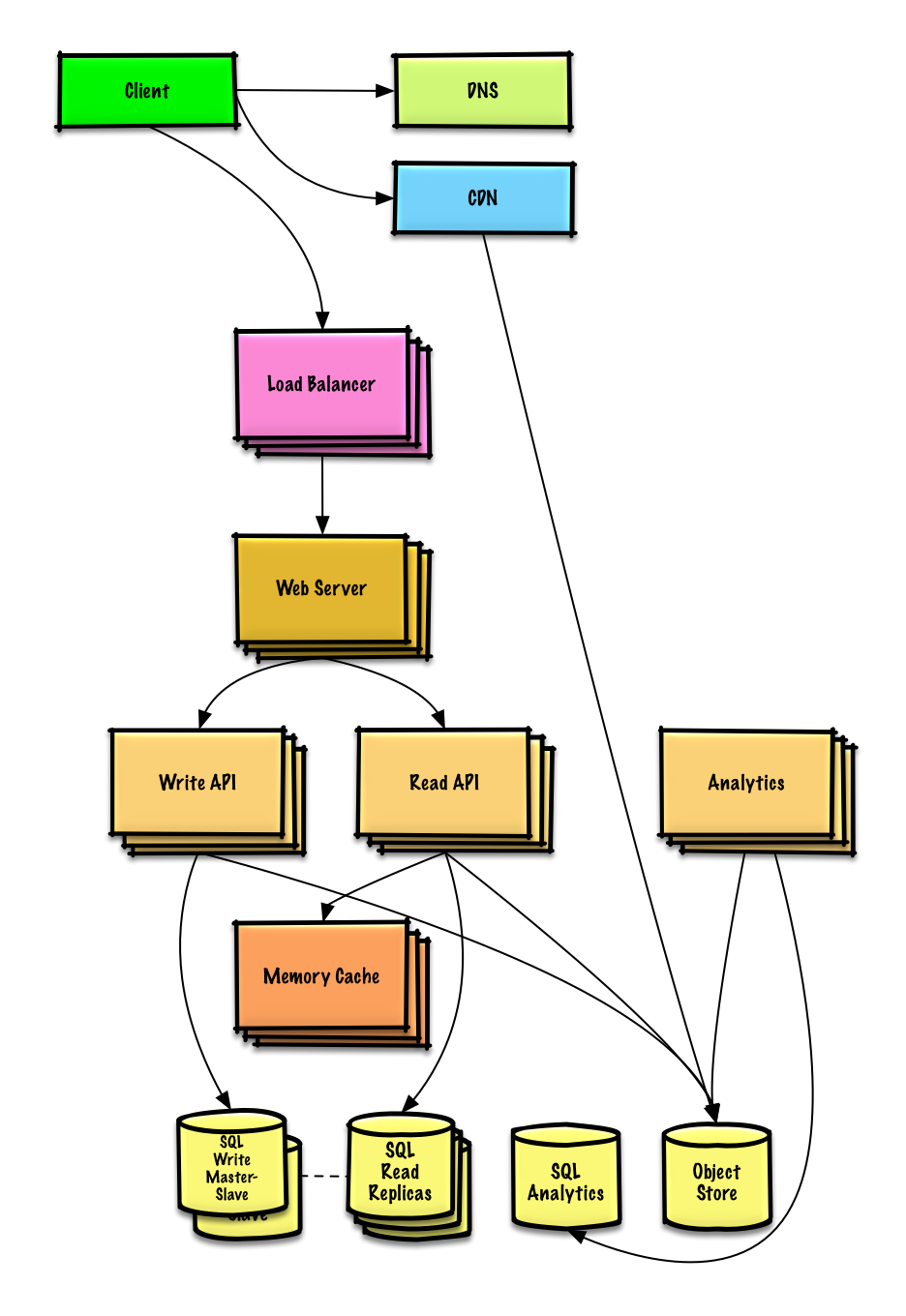
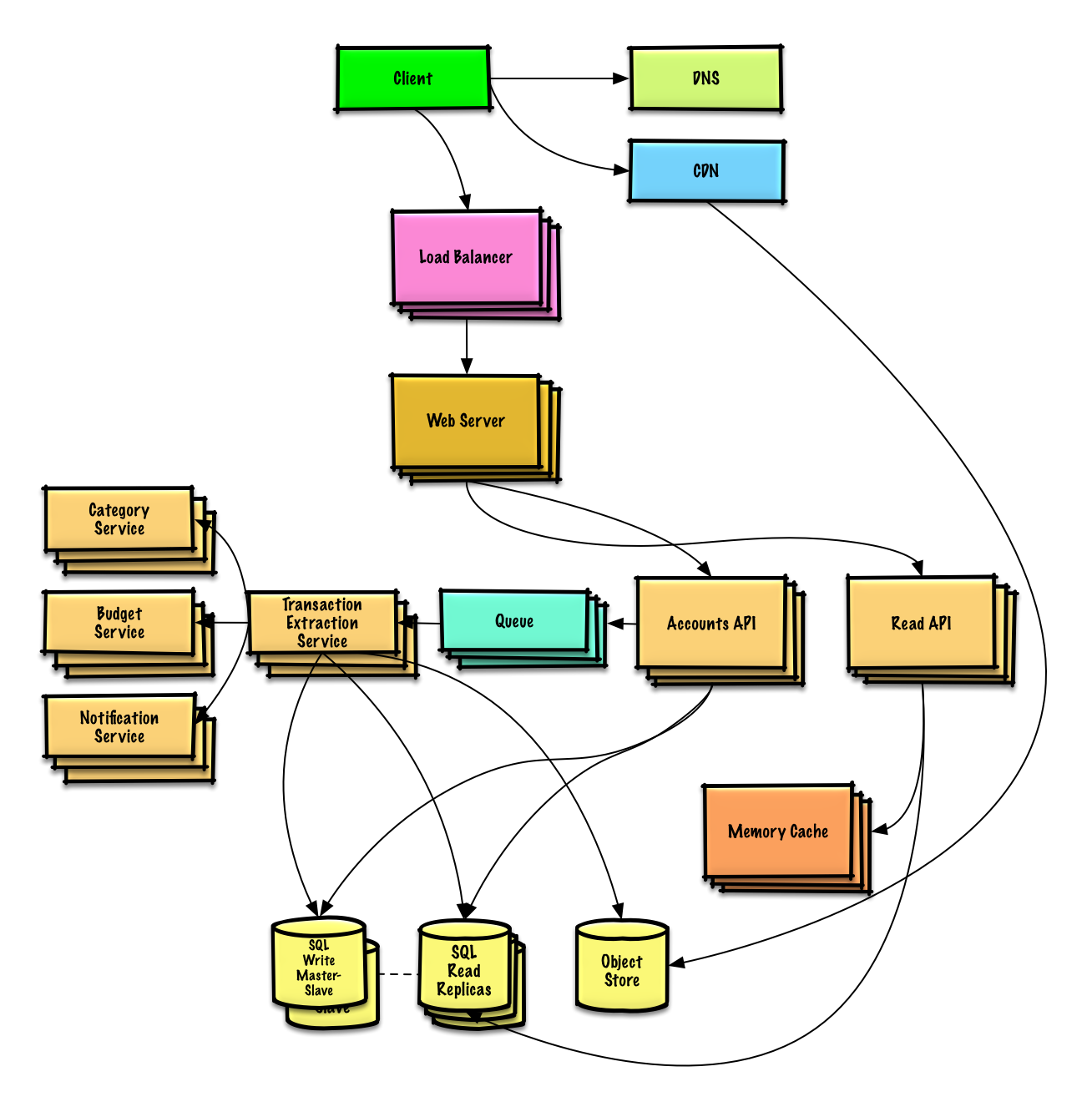
Design Mint.com
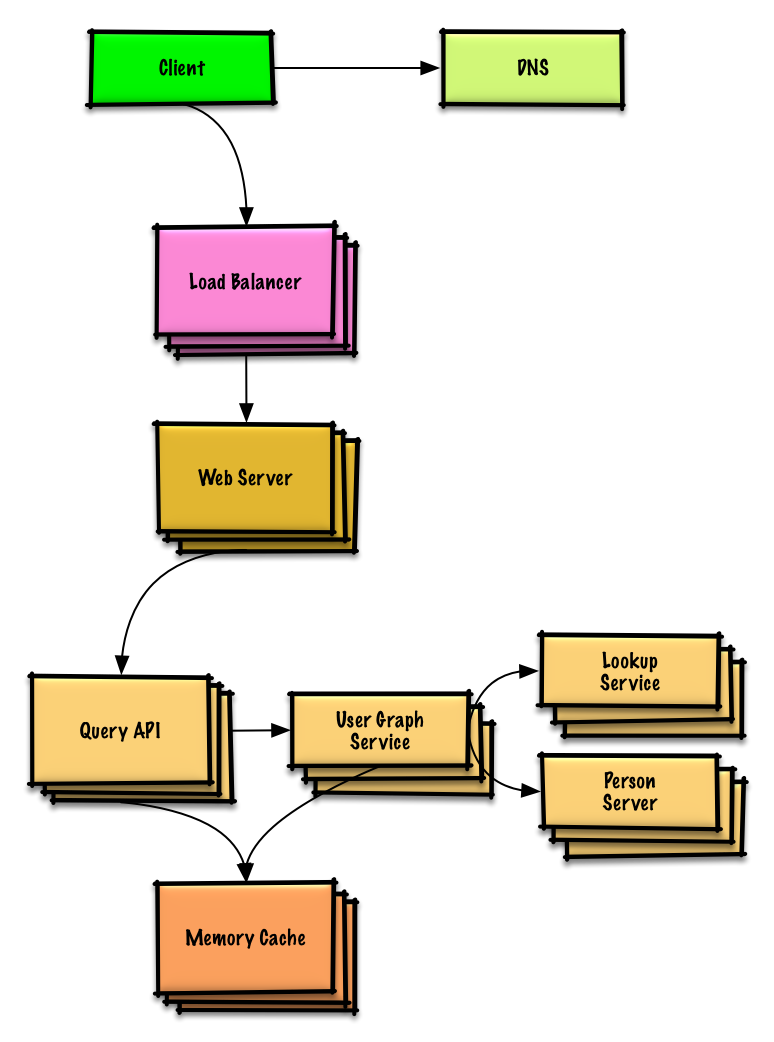
Design the data structures for a social network
Design a key-value store for a search engine
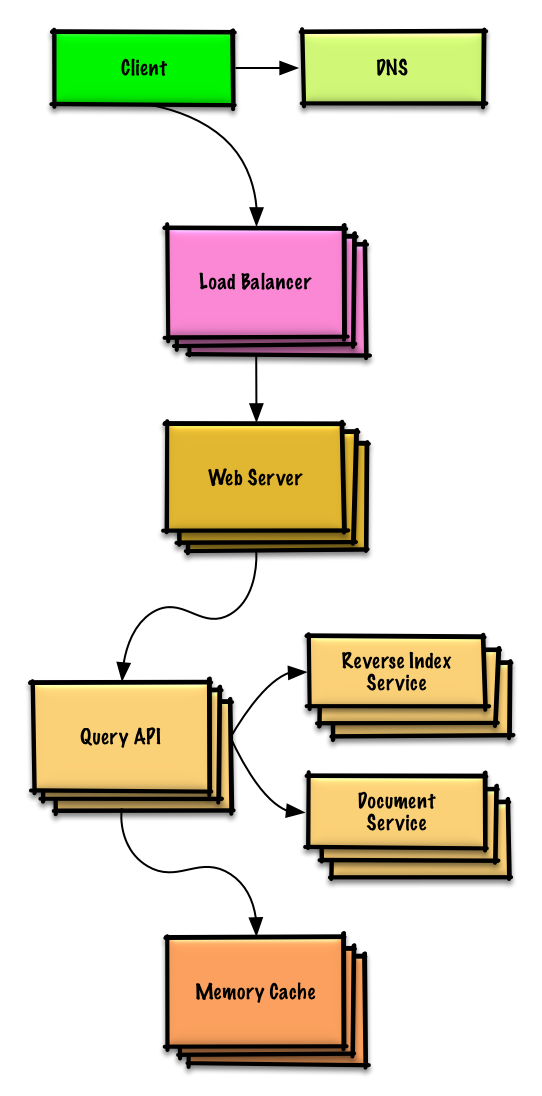
Design Amazon's sales ranking by category feature
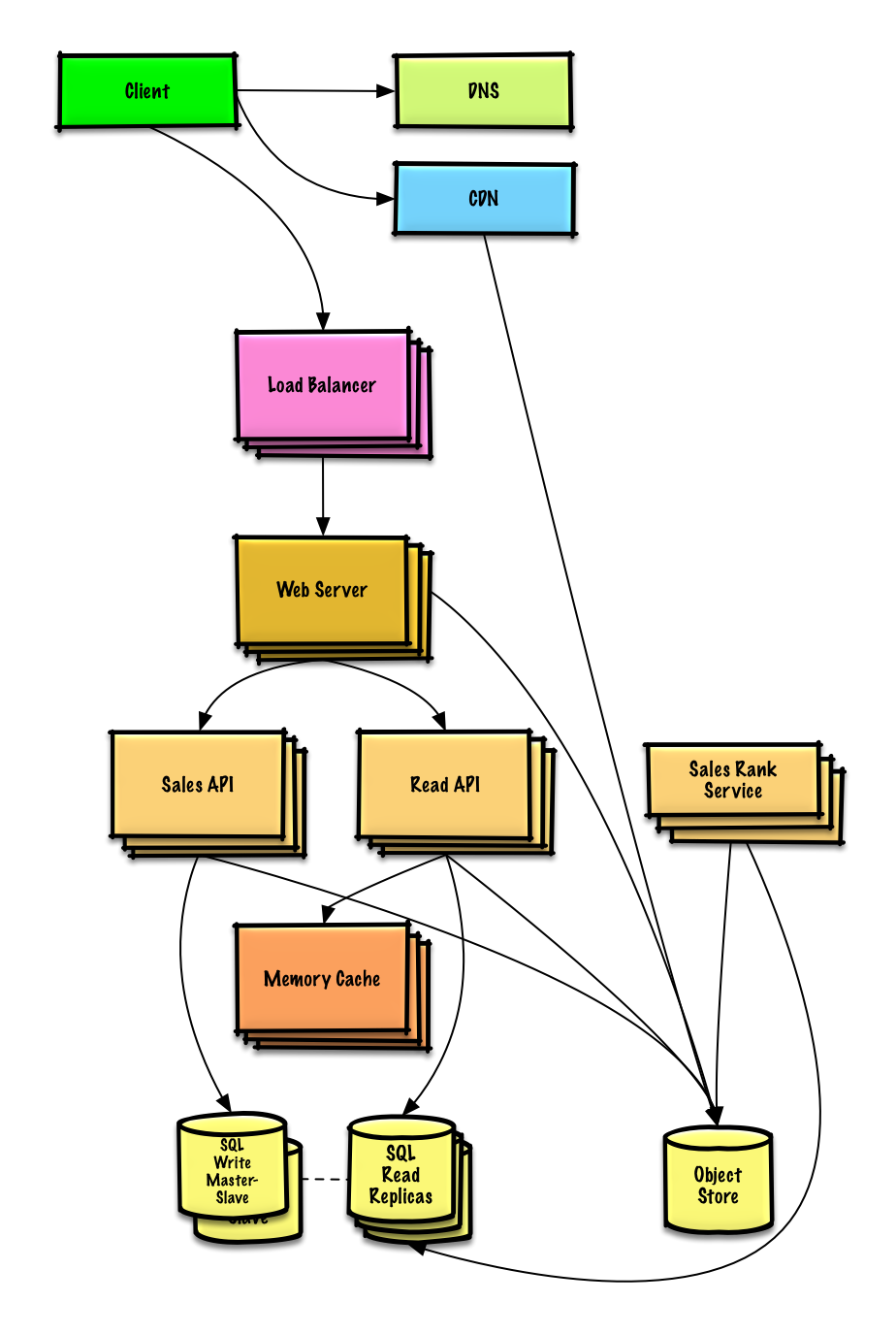
Design a system that scales to millions of users on AWS
Object-oriented design interview questions with solutions
Common object-oriented design interview questions with sample discussions, code, and diagrams.>
Solutions linked to content in the solutions/ folder.>Note: This section is under development
| Question | | |---|---| | طراحی یک هشمپ | راهحل | | طراحی یک حافظه کش با سیاست کمترین استفاده اخیر | راهحل | | طراحی یک مرکز تماس | راهحل | | طراحی یک دسته کارت | راهحل | | طراحی یک پارکینگ | راهحل | | طراحی یک سرور گفتوگو | راهحل | | طراحی یک آرایه دایرهای | مشارکت | | افزودن یک سوال طراحی شیءگرا | مشارکت |
موضوعات طراحی سیستم: از اینجا شروع کنید
تازهوارد به طراحی سیستم هستید؟
ابتدا باید دانش پایهای از اصول رایج کسب کنید، درباره اینکه چه هستند، چگونه استفاده میشوند و مزایا و معایبشان یاد بگیرید.
مرحله ۱: مرور ویدیو سخنرانی مقیاسپذیری
سخنرانی مقیاسپذیری در دانشگاه هاروارد
- موضوعات پوشش داده شده:
- مقیاسپذیری عمودی
- مقیاسپذیری افقی
- کشینگ
- تعادل بار
- تکرار پایگاه داده
- پارتیشنبندی پایگاه داده
مرحله ۲: مرور مقاله مقیاسپذیری
- موضوعات پوشش داده شده:
- کلونها
- پایگاههای داده
- کشها
- غیربلوکی بودن
گامهای بعدی
در ادامه به بررسی مبادلات سطح بالا خواهیم پرداخت:
- کارایی در مقابل قابلیت گسترشپذیری
- تاخیر در مقابل توان عملیاتی
- دردسترس بودن در مقابل یکپارچگی
سپس به موضوعات خاصتری مانند DNS، CDNها و متعادلکنندههای بار خواهیم پرداخت.
کارایی در مقابل قابلیت گسترشپذیری
یک سرویس زمانی گسترشپذیر است که افزایش کارایی آن متناسب با منابع اضافه شده باشد. معمولاً افزایش کارایی به معنی سرویسدهی به تعداد بیشتری کار است، اما میتواند به معنی پردازش واحدهای بزرگتر کار نیز باشد، مانند زمانی که مجموعه دادهها رشد میکنند.1
یک راه دیگر برای نگاه کردن به کارایی در مقابل قابلیت گسترشپذیری:
- اگر مشکل کارایی دارید، سیستم شما برای یک کاربر کند است.
- اگر مشکل گسترشپذیری دارید، سیستم شما برای یک کاربر سریع است اما تحت بار سنگین کند میشود.
منابع و مطالعه بیشتر
تاخیر در مقابل توان عملیاتی
تاخیر مدت زمانی است که برای انجام یک عمل یا تولید یک نتیجه صرف میشود.
توان عملیاتی تعداد چنین اعمال یا نتایج در واحد زمان است.
معمولاً باید برای بیشترین توان عملیاتی با تاخیر قابل قبول هدفگذاری کنید.
منابع و مطالعه بیشتر
دردسترس بودن در مقابل یکپارچگی
قضیه CAP
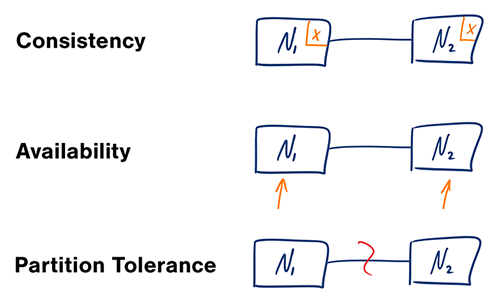
در یک سیستم کامپیوتری توزیعشده، شما فقط میتوانید دو مورد از تضمینهای زیر را پشتیبانی کنید:
- یکپارچگی (Consistency) - هر خوانش جدیدترین نوشتار را دریافت میکند یا با خطا مواجه میشود
- دسترسیپذیری (Availability) - هر درخواست پاسخی دریافت میکند، بدون تضمین اینکه شامل جدیدترین نسخه اطلاعات است
- تحمل تقسیمبندی (Partition Tolerance) - سیستم علیرغم تقسیمبندیهای دلخواه بهدلیل خرابیهای شبکه به کار خود ادامه میدهد
#### CP - یکپارچگی و تحمل تقسیمبندی
منتظر ماندن برای پاسخ از گره تقسیمشده ممکن است منجر به خطای زمانبندی شود. CP گزینه خوبی است اگر نیازهای تجاری شما به خوانش و نوشتار اتمی نیاز دارد.
#### AP - دسترسیپذیری و تحمل تقسیمبندی
پاسخها نسخهای از دادهها را که در هر گره در دسترستر است بازمیگردانند، که ممکن است جدیدترین نباشد. نوشتارها ممکن است زمانبر باشند تا زمانی که تقسیمبندی رفع شود.
AP انتخاب خوبی است اگر نیازهای تجاری اجازه یکپارچگی نهایی را بدهد یا زمانی که سیستم باید علیرغم خطاهای خارجی به کار خود ادامه دهد.
منبع(ها) و مطالعه بیشتر
الگوهای یکپارچگی
با وجود چندین نسخه از دادههای یکسان، با گزینههایی برای همگامسازی آنها روبرو هستیم تا کلاینتها دید یکپارچهای از دادهها داشته باشند. تعریف یکپارچگی را از قضیه CAP به یاد آورید - هر خوانش جدیدترین نوشتار را دریافت میکند یا با خطا مواجه میشود.
یکپارچگی ضعیف
پس از یک نوشتار، خوانشها ممکن است آن را ببینند یا نبینند. یک روش مبتنی بر تلاش بهترین اتخاذ میشود.
این رویکرد در سیستمهایی مانند memcached دیده میشود. یکپارچگی ضعیف در کاربردهای بلادرنگ مانند VoIP، چت ویدیویی، و بازیهای چندنفره بلادرنگ خوب عمل میکند. برای مثال، اگر در تماس تلفنی باشید و چند ثانیه آنتندهی را از دست بدهید، زمانی که دوباره اتصال برقرار شود، چیزی که در زمان قطع شدن گفته شده را نمیشنوید.
سازگاری نهایی (Eventual consistency)
پس از یک عملیات نوشتن، عملیات خواندن در نهایت آن را مشاهده خواهند کرد (معمولاً در عرض چند میلیثانیه). دادهها به صورت غیرهمزمان تکثیر میشوند.
این روش در سیستمهایی مانند DNS و ایمیل دیده میشود. سازگاری نهایی در سیستمهایی با دسترسیپذیری بالا به خوبی عمل میکند.
سازگاری قوی (Strong consistency)
پس از یک عملیات نوشتن، عملیات خواندن آن را مشاهده خواهند کرد. دادهها به صورت همزمان تکثیر میشوند.
این روش در سیستمهای فایل و پایگاههای داده رابطهای (RDBMS) دیده میشود. سازگاری قوی در سیستمهایی که نیاز به تراکنش دارند به خوبی عمل میکند.
منبع(ها) و مطالعه بیشتر
الگوهای دسترسیپذیری
دو الگوی مکمل برای پشتیبانی از دسترسیپذیری بالا وجود دارد: سوئیچپذیری (fail-over) و تکثیر (replication).
سوئیچپذیری (Fail-over)
#### فعال-غیرفعال (Active-passive)
در سوئیچپذیری فعال-غیرفعال، سیگنالهای ضربان قلب بین سرور فعال و سرور غیرفعال در حالت آماده باش ارسال میشود. اگر سیگنال قطع شود، سرور غیرفعال آدرس IP فعال را میگیرد و خدمات را ادامه میدهد.
طول زمان خاموشی به این بستگی دارد که آیا سرور غیرفعال از قبل در حالت آماده باش 'داغ' اجرا میشود یا باید از حالت آماده باش 'سرد' راهاندازی شود. تنها سرور فعال ترافیک را مدیریت میکند.
سوئیچپذیری فعال-غیرفعال همچنین میتواند به عنوان سوئیچپذیری استاد-غلام (master-slave) شناخته شود.
#### فعال-فعال (Active-active)
در حالت فعال-فعال، هر دو سرور ترافیک را مدیریت میکنند و بار را بین خود تقسیم میکنند.
اگر سرورها برای عموم قابل مشاهده باشند، DNS باید از IPهای عمومی هر دو سرور آگاه باشد. اگر سرورها داخلی باشند، منطق برنامه باید از هر دو سرور مطلع باشد.
سوئیچپذیری فعال-فعال همچنین میتواند به عنوان سوئیچپذیری استاد-استاد (master-master) شناخته شود.
معایب: سوئیچپذیری (failover)
- فِیلاوِر نیازمند سختافزار بیشتر و پیچیدگی اضافی است.
- در صورت خرابی سیستم فعال پیش از تکثیر دادههای جدید به سیستم غیرفعال، امکان از دست رفتن داده وجود دارد.
تکرار (Replication)
#### ارباب-برده و ارباب-ارباب
این موضوع در بخش پایگاه داده بیشتر مورد بحث قرار گرفته است:
دسترسیپذیری به صورت عددی
دسترسیپذیری معمولاً با زمان آپتایم (یا داونتایم) به عنوان درصد زمانی که سرویس در دسترس است سنجیده میشود. دسترسیپذیری معمولاً با تعداد عدد ۹ اندازهگیری میشود--سرویسی با ۹۹.۹۹٪ دسترسیپذیری به عنوان چهار عدد ۹ شناخته میشود.
#### ۹۹.۹٪ دسترسیپذیری - سه عدد ۹
| مدت زمان | داونتایم قابل قبول| |---------------------|--------------------| | داونتایم سالانه | ۸ساعت ۴۵دقیقه ۵۷ثانیه| | داونتایم ماهانه | ۴۳دقیقه ۴۹.۷ثانیه | | داونتایم هفتگی | ۱۰دقیقه ۴.۸ثانیه | | داونتایم روزانه | ۱دقیقه ۲۶.۴ثانیه |
#### ۹۹.۹۹٪ دسترسیپذیری - چهار عدد ۹
| مدت زمان | داونتایم قابل قبول| |---------------------|--------------------| | داونتایم سالانه | ۵۲دقیقه ۳۵.۷ثانیه | | داونتایم ماهانه | ۴دقیقه ۲۳ثانیه | | داونتایم هفتگی | ۱دقیقه ۵ثانیه | | داونتایم روزانه | ۸.۶ثانیه |
#### دسترسیپذیری موازی در مقابل ترتیبی
اگر یک سرویس از چندین مؤلفه آسیبپذیر در برابر خرابی تشکیل شده باشد، دسترسیپذیری کلی سرویس بستگی به ترتیبی یا موازی بودن مؤلفهها دارد.
###### به صورت ترتیبی در دسترس بودن کلی کاهش مییابد زمانی که دو مؤلفه با دسترسپذیری کمتر از ۱۰۰٪ به صورت متوالی قرار گرفته باشند:
Availability (Total) = Availability (Foo) * Availability (Bar)Foo و Bar هرکدام ۹۹.۹٪ دسترسیپذیری داشته باشند، دسترسیپذیری کل آنها به صورت دنبالهای ۹۹.۸٪ خواهد بود.###### به صورت موازی
دسترسیپذیری کلی زمانی افزایش مییابد که دو مؤلفه با دسترسیپذیری کمتر از ۱۰۰٪ به صورت موازی باشند:
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))Foo و Bar دارای دسترسیپذیری ۹۹.۹٪ باشند، دسترسیپذیری کلی آنها در حالت موازی ۹۹.۹۹۹۹٪ خواهد بود.سامانه نام دامنه (DNS)
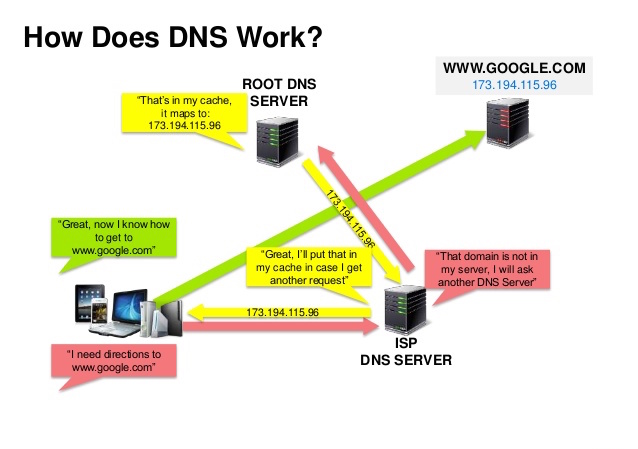
سامانه نام دامنه (DNS) یک نام دامنه مانند www.example.com را به یک آدرس IP ترجمه میکند.
DNS ساختاری سلسلهمراتبی دارد و تعداد کمی سرور معتبر در بالاترین سطح آن قرار دارند. روتر یا ISP شما اطلاعاتی در مورد اینکه هنگام جستجو به کدام سرور DNS مراجعه شود، ارائه میدهد. سرورهای DNS سطح پایینتر نگاشتها را کش میکنند که ممکن است به دلیل تأخیر در انتشار DNS، منسوخ شوند. نتایج DNS میتواند توسط مرورگر یا سیستمعامل شما برای مدت معینی که توسط زمان حیات (TTL) تعیین میشود، کش شوند.
- رکورد NS (نام سرور) - سرورهای DNS دامنه/زیر دامنه شما را مشخص میکند.
- رکورد MX (تبادل ایمیل) - سرورهای ایمیل را برای دریافت پیامها تعیین میکند.
- رکورد A (آدرس) - یک نام را به یک آدرس IP اشاره میدهد.
- CNAME (نام متعارف) - یک نام را به نام دیگر یا
CNAME(مثلاً example.com به www.example.com) یا به یک رکوردAاشاره میدهد.
- چرخش دورانی وزنی
- جلوگیری از ارسال ترافیک به سرورهای در حال نگهداری
- توازن بین اندازههای مختلف کلاستر
- تست A/B
- بر پایه تأخیر
- بر پایه موقعیت جغرافیایی
معایب: DNS
- دسترسی به یک سرور DNS تا حدی تأخیر دارد، اگرچه این موضوع با کشینگ که در بالا توضیح داده شد، کاهش مییابد.
- مدیریت سرورهای DNS میتواند پیچیده باشد و عموماً توسط دولتها، ارائهدهندگان اینترنت و شرکتهای بزرگ مدیریت میشود.
- خدمات DNS اخیراً مورد حملات DDoS قرار گرفتهاند که مانع از دسترسی کاربران به وبسایتهایی مانند توییتر بدون دانستن آدرس IP توییتر شدهاند.
منابع و مطالعه بیشتر
- معماری DNS.aspx)
- ویکیپدیا
- مقالات DNS
شبکه تحویل محتوا
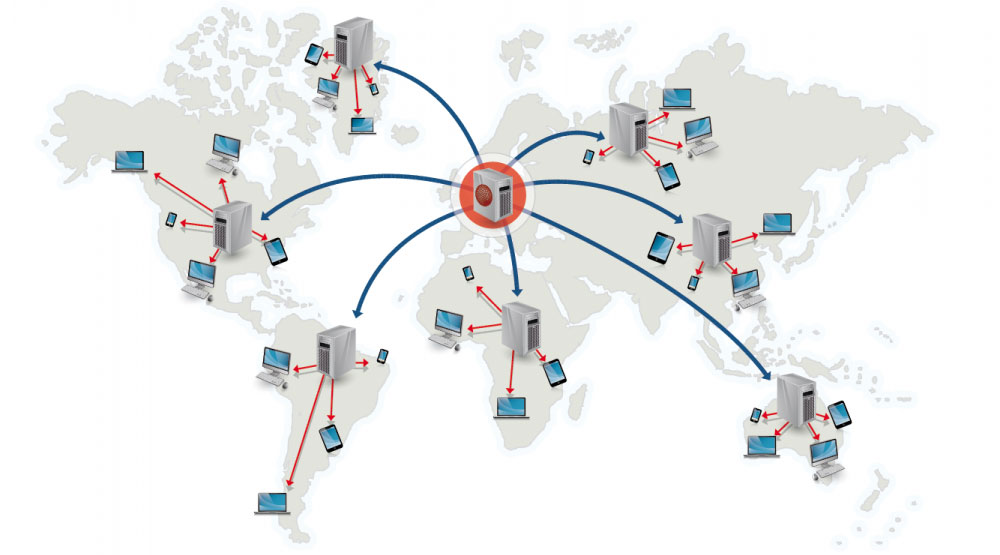
شبکه تحویل محتوا (CDN) یک شبکه پراکنده جهانی از سرورهای پروکسی است که محتوا را از مکانهایی نزدیکتر به کاربر ارائه میدهد. معمولاً فایلهای ثابت مانند HTML/CSS/JS، عکسها و ویدئوها از CDN ارائه میشوند، اگرچه برخی CDNها مانند CloudFront آمازون از محتوای پویا نیز پشتیبانی میکنند. حل DNS سایت به مشتریان میگوید با کدام سرور تماس بگیرند.
ارائه محتوا از طریق CDNها میتواند عملکرد را به دو روش به طور قابل توجهی بهبود بخشد:
- کاربران محتوا را از دیتاسنترهای نزدیک خود دریافت میکنند
- سرورهای شما مجبور نیستند درخواستهایی که CDN پاسخ میدهد را سرویس دهند
CDNهای Push
CDNهای Push محتوای جدید را هر زمان که تغییری در سرور شما رخ دهد دریافت میکنند. شما مسئولیت کامل ارائه محتوا را دارید، محتوا را مستقیماً به CDN آپلود میکنید و URLها را طوری بازنویسی میکنید که به CDN اشاره کنند. شما میتوانید زمان انقضا و بروزرسانی محتوا را پیکربندی کنید. محتوا فقط زمانی که جدید یا تغییر یافته باشد آپلود میشود، که ترافیک را به حداقل میرساند اما فضای ذخیرهسازی را به حداکثر میرساند.
سایتهایی با میزان ترافیک کم یا سایتهایی که محتوا به ندرت بهروزرسانی میشود برای CDNهای Push مناسب هستند. محتوا فقط یک بار روی CDN قرار میگیرد، به جای اینکه در فواصل منظم مجدداً بارگیری شود.
CDNهای Pull
CDNهای Pull زمانی که اولین کاربر محتوا را درخواست کند، محتوای جدید را از سرور شما دریافت میکنند. شما محتوا را روی سرور خود نگه میدارید و URLها را طوری بازنویسی میکنید که به CDN اشاره کنند. این باعث میشود اولین درخواست کندتر باشد تا زمانی که محتوا روی CDN کش شود.
یک زمان عمر (TTL) تعیین میکند محتوا چه مدت کش میشود. CDNهای Pull فضای ذخیرهسازی را روی CDN به حداقل میرسانند، اما اگر فایلها منقضی شوند و قبل از تغییر مجدداً دریافت شوند، میتوانند ترافیک تکراری ایجاد کنند.
سایتهایی با ترافیک سنگین برای CDNهای Pull مناسب هستند، زیرا ترافیک به طور یکنواختتر پخش میشود و فقط محتوای اخیراً درخواست شده روی CDN باقی میماند.
معایب: CDN
- هزینه CDN بسته به میزان ترافیک میتواند قابل توجه باشد، اگرچه این هزینه باید با هزینههای اضافی عدم استفاده از CDN مقایسه شود.
- محتوا ممکن است منسوخ باشد اگر قبل از انقضای TTL بروزرسانی شود.
- CDNها نیازمند تغییر URLهای محتوای ثابت برای اشاره به CDN هستند.
منابع و مطالعه بیشتر
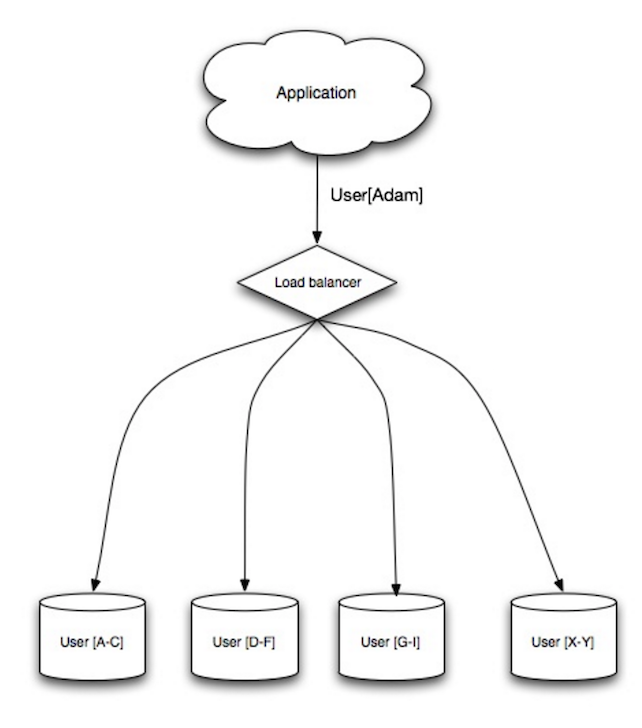
متعادلکننده بار (Load balancer)
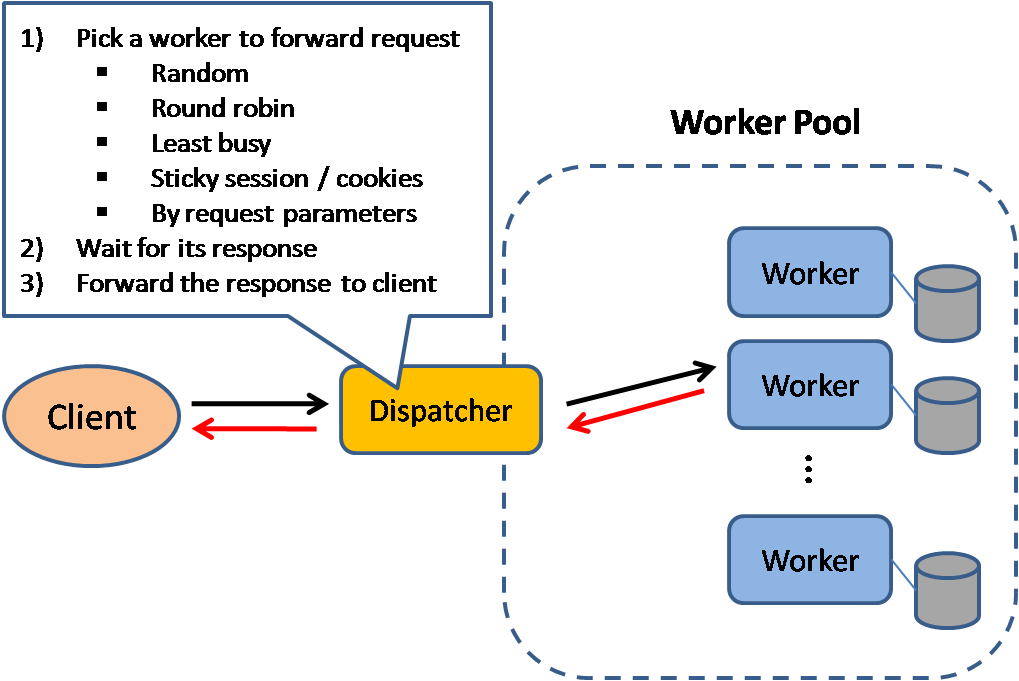
منبع: الگوهای طراحی سیستم مقیاسپذیر
متعادلکنندههای بار درخواستهای ورودی مشتری را به منابع محاسباتی مانند سرورهای برنامه و پایگاههای داده توزیع میکنند. در هر حالت، متعادلکننده بار پاسخ منابع محاسباتی را به مشتری مناسب بازمیگرداند. متعادلکنندههای بار در موارد زیر مؤثر هستند:
- جلوگیری از ارسال درخواستها به سرورهای ناسالم
- جلوگیری از بارگذاری بیش از حد منابع
- کمک به حذف نقطه شکست واحد
مزایای اضافی عبارتند از:
- پایاندهی SSL - رمزگشایی درخواستهای ورودی و رمزگذاری پاسخهای سرور تا سرورهای پشتی مجبور نباشند این عملیات پرهزینه را انجام دهند
- حذف نیاز به نصب گواهینامههای X.509 روی هر سرور
- پایداری نشست (Session persistence) - صدور کوکی و هدایت درخواستهای یک مشتری خاص به همان نمونه اگر برنامههای وب جلسات را پیگیری نمیکنند
متعادلکنندههای بار میتوانند ترافیک را بر اساس معیارهای مختلفی هدایت کنند، از جمله:
- تصادفی
- کمبارترین
- نشست/کوکیها
- گردش نوبتی یا گردش نوبتی وزنی
- لایه ۴
- لایه ۷
متعادلسازی بار در لایه ۴
متعادلکنندههای بار لایه ۴ اطلاعات موجود در لایه انتقال را برای تصمیمگیری درباره نحوه توزیع درخواستها بررسی میکنند. معمولاً این شامل آدرسهای IP مبدأ و مقصد و پورتها در سربرگ است، اما محتوای بسته را شامل نمیشود. متعادلکنندههای بار لایه ۴ بستههای شبکه را به سرور بالادستی ارسال و دریافت میکنند و عملیات ترجمه آدرس شبکه (NAT) را انجام میدهند.
متعادلسازی بار در لایه ۷
تعادلکنندههای بار لایه ۷ به لایه کاربرد نگاه میکنند تا تصمیم بگیرند چگونه درخواستها را توزیع کنند. این میتواند شامل محتوای هدر، پیام و کوکیها باشد. تعادلکنندههای بار لایه ۷ ترافیک شبکه را خاتمه میدهند، پیام را میخوانند، تصمیم تعادل بار را میگیرند و سپس یک اتصال به سرور منتخب باز میکنند. برای مثال، تعادلکننده بار لایه ۷ میتواند ترافیک ویدئو را به سرورهایی که ویدئوها را میزبانی میکنند هدایت کند، در حالی که ترافیک حساستر صورتحساب کاربر را به سرورهایی با امنیت بیشتر هدایت کند.
در ازای انعطافپذیری، تعادل بار لایه ۴ نسبت به لایه ۷ زمان و منابع محاسباتی کمتری نیاز دارد، اگرچه تأثیر عملکرد روی سختافزارهای کالایی مدرن میتواند حداقل باشد.
مقیاسبندی افقی
تعادلکنندههای بار میتوانند به مقیاسبندی افقی نیز کمک کنند و عملکرد و دسترسپذیری را بهبود بخشند. مقیاسبندی با استفاده از ماشینهای کالایی مقرون بهصرفهتر بوده و دسترسپذیری بیشتری نسبت به ارتقاء یک سرور واحد با سختافزار گرانتر دارد که به آن مقیاسبندی عمودی گفته میشود. همچنین استخدام نیروی کار برای سختافزار کالایی آسانتر از سیستمهای سازمانی خاص است.
#### معایب: مقیاسبندی افقی
- مقیاسبندی افقی پیچیدگی ایجاد میکند و شامل کلون کردن سرورهاست
- سرورها باید بدون حالت باشند: نباید دادههای مرتبط با کاربر مثل نشستها یا تصاویر پروفایل را داشته باشند
- نشستها میتوانند در یک مخزن داده مرکزی مثل پایگاه داده (SQL، NoSQL) یا کش دائمی (ردیس، ممکش) ذخیره شوند
- سرورهای پاییندستی مانند کش و پایگاه داده باید اتصالات همزمان بیشتری را با افزایش سرورهای بالادستی مدیریت کنند
معایب: تعادلکننده بار
- اگر تعادلکننده بار منابع کافی نداشته باشد یا به درستی پیکربندی نشده باشد، میتواند به گلوگاه عملکرد تبدیل شود.
- اضافه کردن تعادلکننده بار برای حذف نقطه شکست منفرد منجر به افزایش پیچیدگی میشود.
- یک تعادلکننده بار منفرد خود یک نقطه شکست منفرد است، پیکربندی چند تعادلکننده بار پیچیدگی را بیشتر میکند.
منابع و مطالعه بیشتر
- معماری NGINX
- راهنمای معماری HAProxy
- مقیاسپذیری
- ویکیپدیا)
- تعادل بار لایه ۴
- تعادل بار لایه ۷
- پیکربندی شنونده ELB
پراکسی معکوس (وب سرور)
پروکسی معکوس یک وبسرور است که خدمات داخلی را متمرکز کرده و واسطهای یکپارچهای را به عموم ارائه میدهد. درخواستهای مشتریان به سروری که قادر به پاسخگویی است ارسال میشود، سپس پروکسی معکوس پاسخ سرور را به مشتری بازمیگرداند.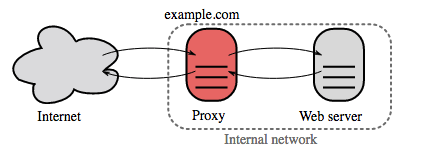
مزایای اضافی شامل:
- افزایش امنیت - مخفی کردن اطلاعات مربوط به سرورهای پشتی، لیست سیاه کردن آیپیها، محدود کردن تعداد اتصالات هر مشتری
- افزایش مقیاسپذیری و انعطافپذیری - مشتریان فقط آیپی پروکسی معکوس را میبینند، بنابراین میتوانید سرورها را مقیاسدهی یا پیکربندی آنها را تغییر دهید
- پایاندهی SSL - رمزگشایی درخواستهای ورودی و رمزگذاری پاسخهای سرور تا سرورهای پشتی نیازی به انجام این عملیات پرهزینه نداشته باشند
- حذف نیاز به نصب گواهی X.509 روی هر سرور
- فشردهسازی - فشردهسازی پاسخهای سرور
- کشینگ - بازگرداندن پاسخ برای درخواستهای کش شده
- محتوای ایستا - ارائه مستقیم محتوای ایستا
- HTML/CSS/JS
- عکسها
- ویدئوها
- غیره
متعادلکننده بار در مقابل پروکسی معکوس
- استفاده از متعادلکننده بار زمانی مفید است که چندین سرور داشته باشید. غالباً متعادلکنندههای بار ترافیک را به مجموعهای از سرورهای دارای عملکرد مشابه هدایت میکنند.
- پروکسیهای معکوس حتی با وجود یک وبسرور یا سرور برنامه نیز مفید هستند و مزایای بخش قبلی را ارائه میدهند.
- راهکارهایی مانند NGINX و HAProxy میتوانند هم پروکسی معکوس لایه ۷ و هم متعادلسازی بار را پشتیبانی کنند.
معایب: پروکسی معکوس
- معرفی پروکسی معکوس باعث افزایش پیچیدگی میشود.
- یک پروکسی معکوس واحد نقطه شکست واحد است و پیکربندی چندین پروکسی معکوس (مثلاً failover) پیچیدگی بیشتری ایجاد میکند.
منابع و مطالعه بیشتر
لایه برنامه
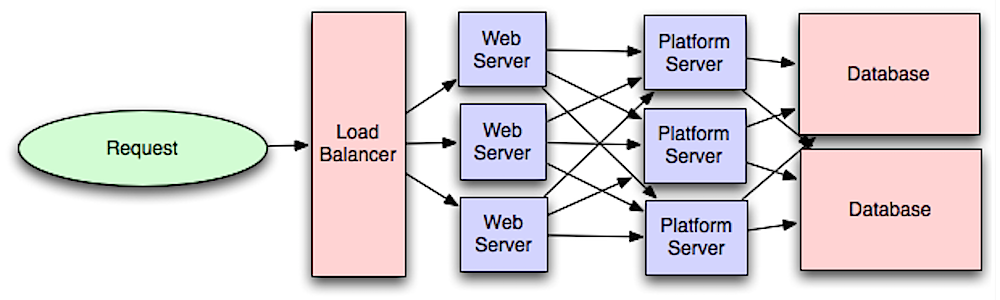
منبع: مقدمهای بر معماری سیستمها برای مقیاسپذیری
جدا کردن لایه وب از لایه برنامه (که به عنوان لایه پلتفرم نیز شناخته میشود) این امکان را میدهد تا هر دو لایه را به طور مستقل مقیاسبندی و پیکربندی کنید. اضافه کردن یک API جدید منجر به افزودن سرورهای برنامه بدون لزوم اضافه کردن سرورهای وب بیشتر میشود. اصل مسئولیت واحد طرفدار خدمات کوچک و مستقل است که با هم کار میکنند. تیمهای کوچک با سرویسهای کوچک میتوانند برای رشد سریعتر برنامهریزی تهاجمیتری داشته باشند.
کارگران در لایه برنامه همچنین به فعالسازی غیرهمزمانی کمک میکنند.
میکروسرویسها
مرتبط با این بحث، میکروسرویسها هستند که به عنوان مجموعهای از سرویسهای کوچک، مدولار و مستقل که به طور جداگانه قابل استقرار هستند، توصیف میشوند. هر سرویس یک فرآیند منحصربهفرد را اجرا میکند و از طریق یک مکانیزم سبک و با تعریف دقیق با دیگر سرویسها برای تحقق هدف کسبوکار ارتباط برقرار میکند. 1
برای مثال، Pinterest میتواند میکروسرویسهایی مانند پروفایل کاربر، دنبالکننده، خوراک، جستجو، بارگذاری عکس و غیره داشته باشد.
کشف سرویس
سیستمهایی مانند Consul، Etcd، و Zookeeper میتوانند با ردیابی نامها، آدرسها و پورتهای ثبتشده به سرویسها در یافتن یکدیگر کمک کنند. بررسی سلامت به اعتبار سرویس کمک میکند و اغلب با استفاده از یک نقطه پایانی HTTP انجام میشود. هر دو Consul و Etcd دارای ذخیرهساز کلید-مقدار داخلی هستند که میتواند برای ذخیره مقادیر پیکربندی و دادههای مشترک دیگر مفید باشد.
معایب: لایه برنامه
- افزودن یک لایه برنامه با سرویسهای ضعیفاً متصل نیازمند رویکرد متفاوتی از نظر معماری، عملیات و فرآیند (در مقایسه با سیستم یکپارچه) است.
- میکروسرویسها میتوانند پیچیدگی را از نظر استقرار و عملیات افزایش دهند.
منابع و مطالعات بیشتر
- مقدمهای بر معماری سیستمها برای مقیاسپذیری
- مصاحبه طراحی سیستم را بشکنید
- معماری مبتنی بر سرویس
- مقدمهای بر Zookeeper
- آنچه باید درباره ساخت میکروسرویسها بدانید
پایگاه داده
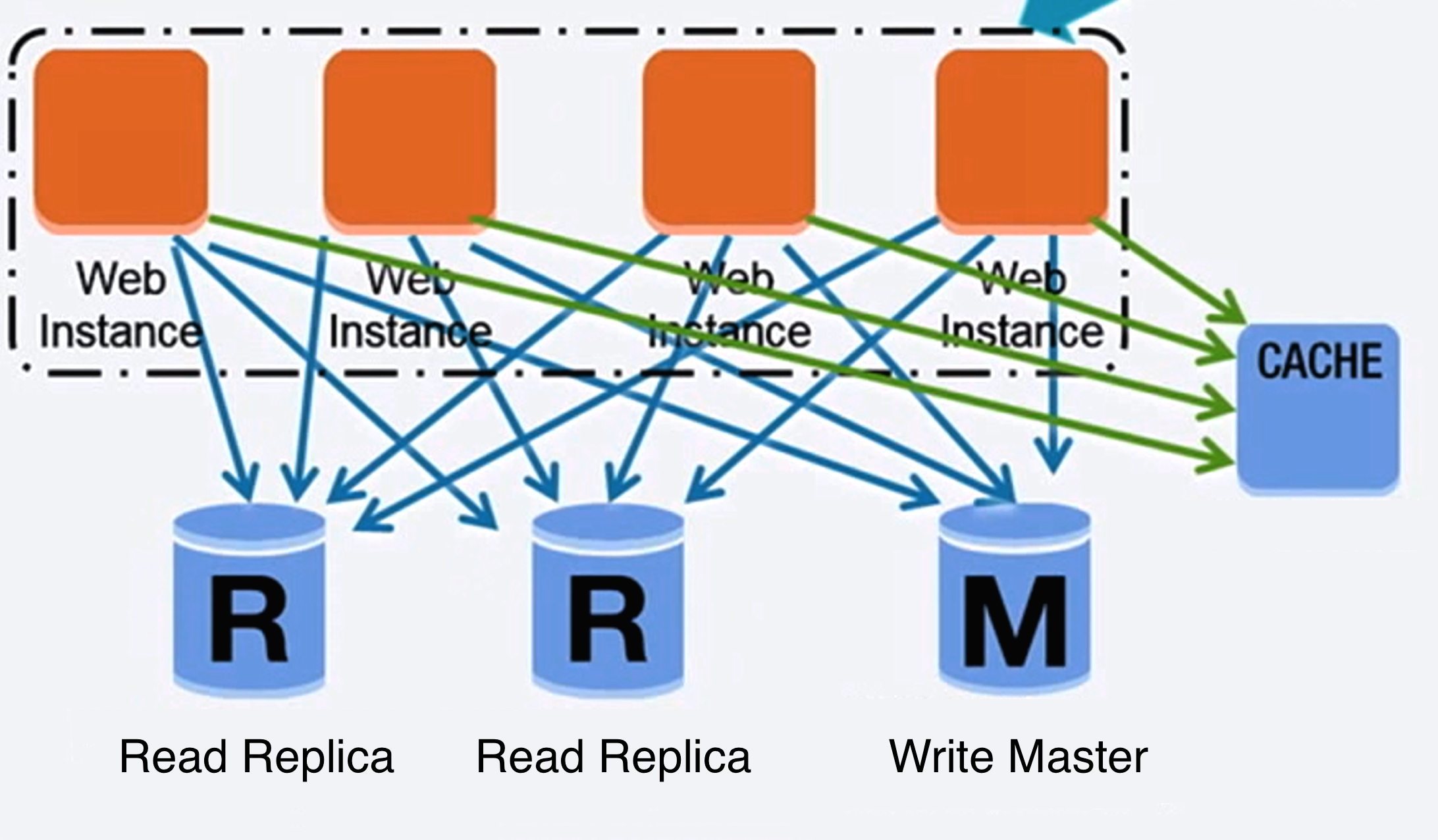
منبع: مقیاسدهی تا اولین ۱۰ میلیون کاربر
سیستم مدیریت پایگاه داده رابطهای (RDBMS)
یک پایگاه داده رابطهای مانند SQL مجموعهای از دادهها است که در جداول سازماندهی شدهاند.
ACID مجموعهای از ویژگیهای تراکنشهای پایگاه داده رابطهای است.
- اتمی بودن - هر تراکنش یا کاملاً انجام میشود یا اصلاً انجام نمیشود
- سازگاری - هر تراکنش پایگاه داده را از یک حالت معتبر به حالت معتبر دیگر منتقل میکند
- جداسازی - اجرای همزمان تراکنشها همان نتایجی را دارد که اگر تراکنشها به صورت سریالی اجرا شوند
- ماندگاری - پس از آنکه یک تراکنش ثبت شد، باقی خواهد ماند
#### تکثیر master-slave
سرور master عملیات خواندن و نوشتن را انجام میدهد و نوشتنها را به یک یا چند سرور slave تکثیر میکند؛ سرورهای slave فقط عملیات خواندن را انجام میدهند. slaveها میتوانند به صورت درختی به slaveهای بیشتری تکثیر شوند. اگر master آفلاین شود، سیستم میتواند تا زمانی که یک slave به master ارتقا یابد یا master جدیدی فراهم شود، به صورت فقط خواندنی به کار خود ادامه دهد.
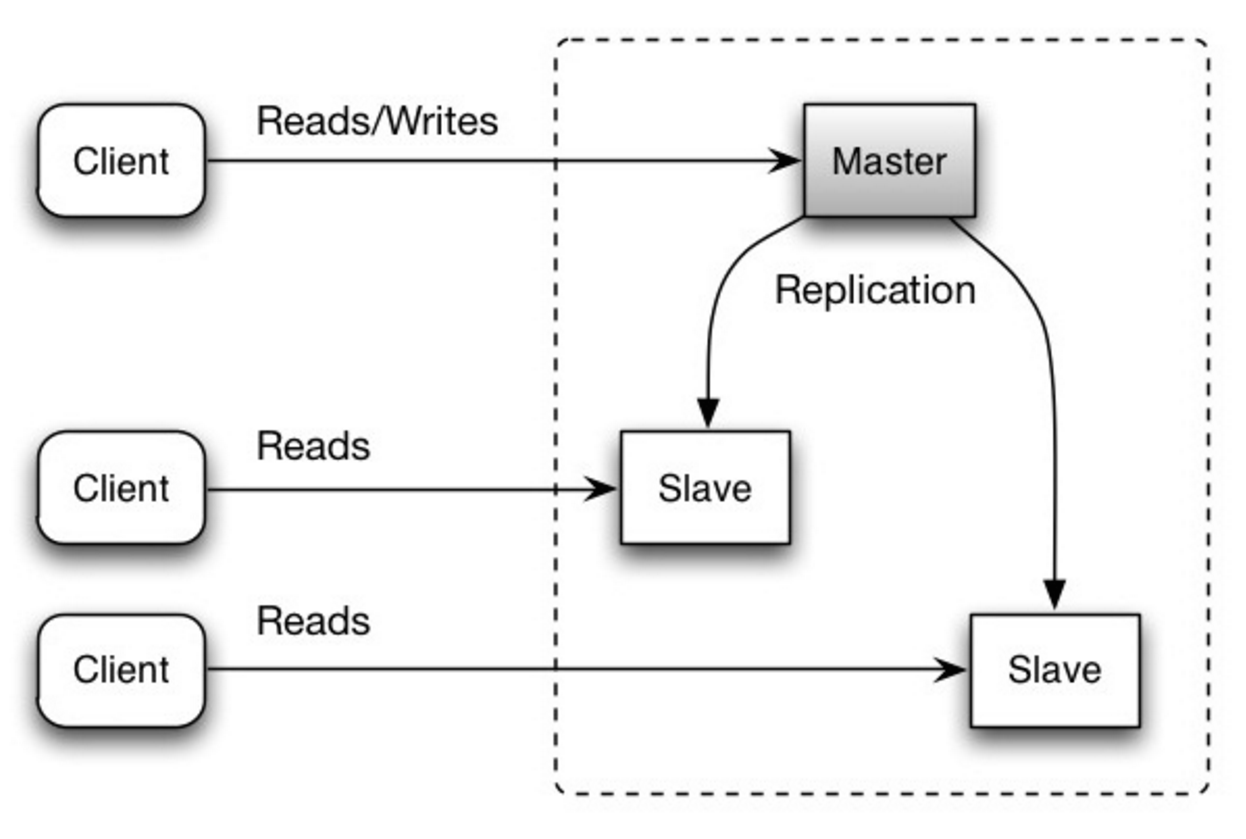
منبع: الگوهای مقیاسپذیری، دسترسیپذیری، پایداری
##### معایب: تکثیر master-slave
- منطق اضافی برای ارتقای یک slave به master مورد نیاز است.
- برای نکات مرتبط با هر دو master-slave و master-master به معایب: تکثیر مراجعه کنید.
هر دو سرور master عملیات خواندن و نوشتن را انجام داده و در نوشتنها با یکدیگر هماهنگ میشوند. اگر یکی از masterها از دسترس خارج شود، سیستم میتواند با حفظ هر دو عملیات خواندن و نوشتن به کار خود ادامه دهد.
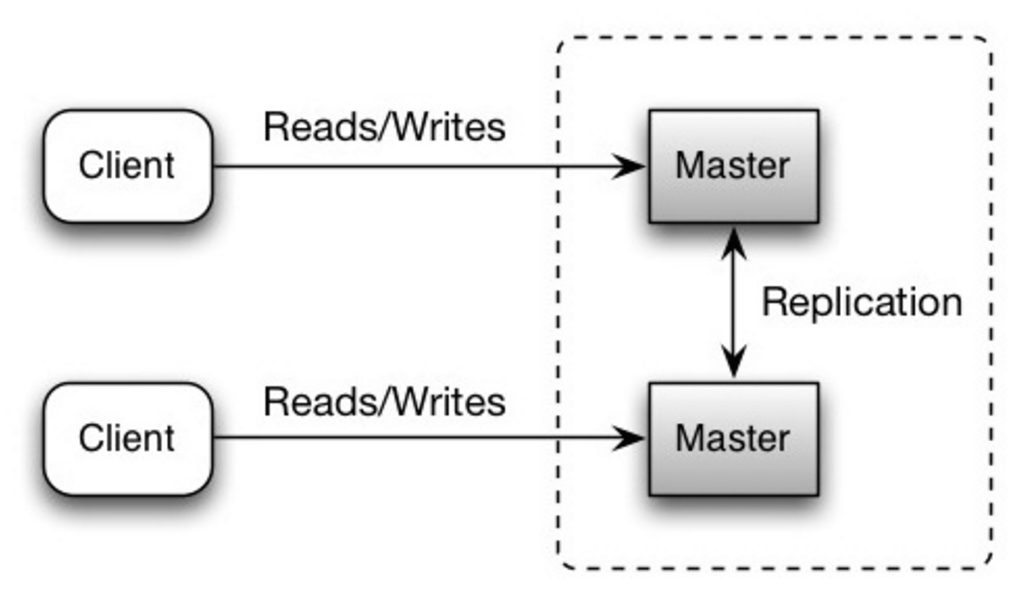
منبع: الگوهای مقیاسپذیری، دسترسیپذیری، پایداری
##### معایب: تکثیر master-master
- به یک load balancer نیاز دارید یا باید تغییراتی در منطق برنامه خود ایجاد کنید تا محل نوشتن مشخص شود.
- بیشتر سیستمهای master-master یا به طور ضعیف سازگارند (نقض ACID) یا دارای تأخیر بیشتر در نوشتن به دلیل همگامسازی هستند.
- حل تعارض بیشتر زمانی مطرح میشود که تعداد گرههای نوشتن افزایش یابد و تأخیر بیشتر شود.
- برای نکاتی که مربوط به هر دو حالت master-slave و master-master هستند، به معایب: تکرار مراجعه کنید.
- احتمال از دست رفتن داده وجود دارد اگر مستر قبل از اینکه دادهی جدید نوشته شده بتواند به گرههای دیگر تکرار شود، از کار بیفتد.
- نوشتنها برای تکرار به رپلیکایهای خواندن بازپخش میشوند. اگر تعداد نوشتنها زیاد باشد، رپلیکایهای خواندن ممکن است با بازپخش نوشتنها سنگین شده و نتوانند به اندازه کافی عملیات خواندن انجام دهند.
- هر چه تعداد گرههای خواندن بیشتر باشد، باید بیشتر تکرار شود که این باعث افزایش تاخیر در تکرار میگردد.
- در برخی سیستمها، نوشتن در مستر میتواند چندین رشته را برای نوشتن موازی راهاندازی کند، در حالی که رپلیکایهای خواندن فقط از نوشتن ترتیبی با یک رشته پشتیبانی میکنند.
- تکرار سختافزار بیشتر و پیچیدگی اضافی ایجاد میکند.
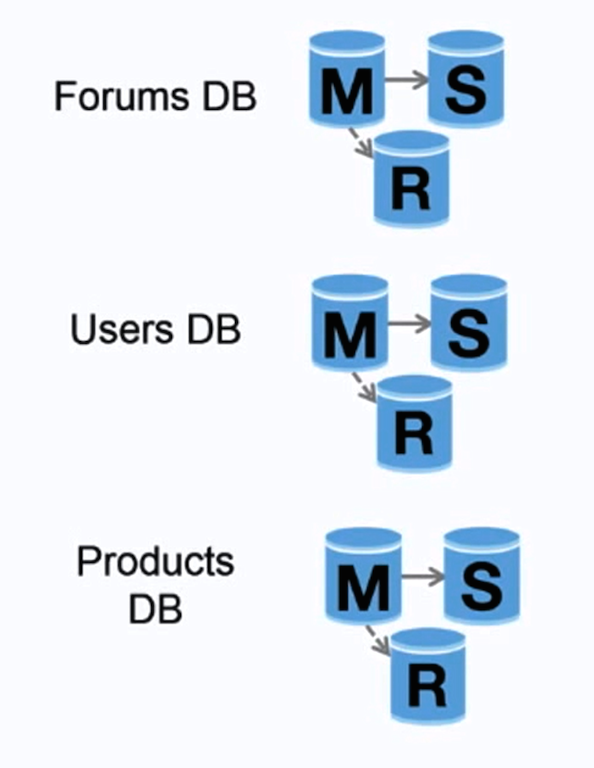
منبع: مقیاسبندی تا اولین ۱۰ میلیون کاربر شما
فدراسیون (یا تقسیمبندی عملکردی) پایگاههای داده را بر اساس عملکرد تقسیم میکند. برای مثال، به جای یک پایگاه داده یکپارچه، میتوانید سه پایگاه داده داشته باشید: تالارها، کاربران و محصولات که منجر به ترافیک خواندن و نوشتن کمتر برای هر پایگاه داده و در نتیجه تاخیر کمتر در تکرار میشود. پایگاههای داده کوچکتر باعث میشود دادههای بیشتری در حافظه جای بگیرند که به نوبه خود منجر به افزایش برخورد کش به دلیل بهبود محلی بودن کش میشود. با حذف یک مستر مرکزی برای ترتیبدهی نوشتنها، میتوانید به صورت موازی بنویسید و توان عملیاتی را افزایش دهید.
##### معایب: فدراسیون
- فدراسیون اگر طرح شما نیاز به جداول یا توابع بزرگ داشته باشد، مؤثر نیست.
- باید منطق برنامه خود را بروزرسانی کنید تا مشخص کند از کدام پایگاه داده باید خواند یا نوشت.
- پیوستن داده از دو پایگاه داده با لینک سرور پیچیدهتر است.
- فدراسیون سختافزار بیشتر و پیچیدگی اضافی ایجاد میکند.
منبع: الگوهای مقیاسپذیری، دسترسیپذیری، پایداری
شاردینگ دادهها را بین پایگاههای داده مختلف توزیع میکند به طوری که هر پایگاه داده فقط میتواند زیرمجموعهای از دادهها را مدیریت کند. به عنوان مثال، با افزایش تعداد کاربران در یک پایگاه داده کاربران، شاردهای بیشتری به کلاستر اضافه میشوند.
مشابه مزایای فدراسیون، شاردینگ منجر به ترافیک کمتر خواندن و نوشتن، تکرار کمتر و تعداد بیشتر اصابت کش میشود. اندازه ایندکس نیز کاهش مییابد که معمولاً عملکرد را با پرسوجوهای سریعتر بهبود میدهد. اگر یک شارد از کار بیفتد، سایر شاردها همچنان فعال هستند، اگرچه بهتر است نوعی تکرار داده برای جلوگیری از فقدان داده اضافه کنید. مانند فدراسیون، هیچ سرور مرکزی واحدی برای سریالسازی نوشتنها وجود ندارد، که به شما امکان نوشتن موازی با توان عملیاتی بیشتر میدهد.
روشهای رایج برای شارد کردن جدول کاربران معمولاً براساس حرف اول نام خانوادگی کاربر یا موقعیت جغرافیایی کاربر انجام میشود.
##### معایب: شاردینگ
- باید منطق برنامه خود را به گونهای بهروزرسانی کنید که با شاردها کار کند، که ممکن است منجر به پرسوجوهای SQL پیچیده شود.
- توزیع داده در یک شارد میتواند نامتوازن شود. برای مثال، مجموعهای از کاربران پرمصرف روی یک شارد میتواند بار آن شارد را نسبت به سایرین افزایش دهد.
- متعادلسازی مجدد پیچیدگی اضافی دارد. تابع شاردینگ مبتنی بر هشینگ پایدار میتواند مقدار داده انتقال یافته را کاهش دهد.
- اتصال داده از چندین شارد پیچیدهتر است.
- شاردینگ سختافزار بیشتری و پیچیدگی بیشتری اضافه میکند.
دنرمالسازی تلاش میکند تا عملکرد خواندن را به قیمت کاهش عملکرد نوشتن بهبود دهد. نسخههای تکراری از دادهها در چندین جدول نوشته میشوند تا از پیوندهای پرهزینه جلوگیری شود. برخی RDBMSها مانند PostgreSQL و Oracle از نماهای مادیشده پشتیبانی میکنند که وظیفه ذخیره اطلاعات تکراری و هماهنگ نگه داشتن نسخههای تکراری را به عهده دارند.
زمانی که دادهها با تکنیکهایی مانند فدراسیون و شاردینگ توزیع میشوند، مدیریت پیوندها بین مراکز داده پیچیدگی بیشتری ایجاد میکند. دنرمالسازی ممکن است نیاز به چنین پیوندهای پیچیدهای را برطرف کند.
در اکثر سیستمها، تعداد خواندنها بسیار بیشتر از نوشتنهاست؛ نسبت ۱۰۰ به ۱ یا حتی ۱۰۰۰ به ۱. یک خواندن که منجر به پیوند پایگاه داده پیچیده شود میتواند بسیار پرهزینه باشد و زمان قابل توجهی صرف عملیات دیسک کند.
##### معایب: دنرمالسازی
- دادهها تکرار میشوند.
- محدودیتها میتوانند به هماهنگ ماندن نسخههای تکراری اطلاعات کمک کنند، که پیچیدگی طراحی پایگاه داده را افزایش میدهد.
- پایگاه داده دنرمالشده تحت بار سنگین نوشتن ممکن است عملکردی کمتر از نسخه نرمالشده خود داشته باشد.
بهینهسازی SQL یک موضوع گسترده است و بسیاری از کتابها به عنوان مرجع نوشته شدهاند.
مهم است که بنچمارک و پروفایل انجام دهید تا نقاط گلوگاه را شبیهسازی و کشف کنید.
- بنچمارک - شبیهسازی موقعیتهای بارگذاری بالا با ابزارهایی مانند ab.
- پروفایل - فعالسازی ابزارهایی مانند لاگ پرسوجوی کند برای پیگیری مشکلات عملکرد.
##### بهبود ساختار پایگاه داده
- MySQL دادهها را به صورت بلوکهای متوالی روی دیسک ذخیره میکند تا دسترسی سریع داشته باشید.
- از
CHARبه جایVARCHARبرای فیلدهای با طول ثابت استفاده کنید. CHARاجازه دسترسی تصادفی سریع را میدهد، در حالی که درVARCHARباید انتهای رشته را پیدا کنید تا به بعدی بروید.- از
TEXTبرای بلوکهای بزرگ متن مانند پستهای وبلاگ استفاده کنید.TEXTهمچنین امکان جستجوی بولی را فراهم میکند. استفاده از فیلدTEXTباعث ذخیرهسازی یک اشارهگر روی دیسک میشود که برای یافتن بلوک متن استفاده میشود. - از
INTبرای اعداد بزرگ تا ۲^۳۲ یا ۴ میلیارد استفاده کنید. - برای جلوگیری از خطاهای نمایش اعشاری، از
DECIMALبرای مقادیر پولی استفاده کنید. - از ذخیرهسازی
BLOBهای بزرگ خودداری کنید، و به جای آن محل دریافت شی را ذخیره نمایید. VARCHAR(255)بیشترین تعداد کاراکتری است که میتوان با یک عدد ۸ بیتی شمارش کرد و اغلب استفاده بهینه از یک بایت را در برخی RDBMSها فراهم میکند.- محدودیت
NOT NULLرا در صورت امکان تنظیم کنید تا عملکرد جستجو را بهبود دهید.
- ستونهایی که پرسوجو میشوند (
SELECT,GROUP BY,ORDER BY,JOIN) با ایندکسها سریعتر خواهند بود. - ایندکسها معمولاً به صورت درخت B خودمتعادل نمایش داده میشوند که دادهها را مرتب نگه میدارد و امکان جستجو، دسترسی ترتیبی، درج و حذف را در زمان لگاریتمی فراهم میکند.
- قرار دادن ایندکس میتواند دادهها را در حافظه نگه دارد و نیازمند فضای بیشتر باشد.
- نوشتن دادهها ممکن است کندتر شود زیرا ایندکس نیز باید بهروزرسانی شود.
- هنگام بارگذاری حجم زیاد داده، ممکن است سریعتر باشد که ایندکسها را غیرفعال کنید، دادهها را بارگذاری کنید و سپس ایندکسها را دوباره بسازید.
- غیراستانداردسازی را زمانی که عملکرد ایجاب کند انجام دهید.
- یک جدول را با قرار دادن نقاط داغ در جدولی جداگانه تقسیم کنید تا به حفظ آن در حافظه کمک کند.
- در برخی موارد، کش پرسوجو میتواند منجر به مشکلات عملکردی شود.
- نکاتی برای بهینهسازی پرسوجوهای MySQL
- آیا دلیل خوبی وجود دارد که VARCHAR(255) اینقدر زیاد استفاده میشود؟
- مقدارهای null چگونه بر عملکرد تأثیر میگذارند؟
- گزارش پرسوجوی کند
NoSQL
NoSQL مجموعهای از آیتمهای داده است که در قالب ذخیرهسازی کلید-مقدار، ذخیرهسازی سندی، ستون گسترده یا پایگاه داده گرافی نمایش داده میشوند. دادهها غیرنرمالسازی شدهاند و پیوندها معمولاً در کد برنامه انجام میشوند. بیشتر پایگاههای NoSQL تراکنشهای واقعی ACID ندارند و به توافق نهایی گرایش دارند.
BASE اغلب برای توصیف ویژگیهای پایگاه دادههای NoSQL استفاده میشود. در مقایسه با قضیه CAP، BASE ترجیح میدهد قابلیت دسترسی را بر سازگاری مقدم بدارد.
- اساساً قابل دسترسی - سیستم قابلیت دسترسی را تضمین میکند.
- حالت نرم - وضعیت سیستم ممکن است در طول زمان حتی بدون ورودی تغییر کند.
- توافق نهایی - سیستم در طول زمان سازگار خواهد شد، به شرطی که سیستم در آن دوره ورودی دریافت نکند.
#### ذخیرهسازی کلید-مقدار
انتزاع: جدول هش
یک ذخیرهسازی کلید-مقدار معمولاً امکان خواندن و نوشتن O(1) را فراهم میکند و اغلب مبتنی بر حافظه یا SSD است. مخازن داده میتوانند کلیدها را در ترتیب واژهنامهای نگه دارند، که بازیابی موثر محدوده کلیدها را ممکن میسازد. ذخیرهسازی کلید-مقدار میتواند امکان ذخیره متادیتا همراه با مقدار را فراهم کند.
ذخیرهسازی کلید-مقدار عملکرد بالایی ارائه میدهد و اغلب برای مدلهای داده ساده یا دادههایی که به سرعت تغییر میکنند، مانند لایه کش حافظهای استفاده میشود. از آنجا که تنها مجموعه محدودی از عملیات را ارائه میدهد، پیچیدگی در صورت نیاز به عملیات بیشتر به لایه برنامه منتقل میشود.
ذخیرهسازی کلید-مقدار پایهای برای سیستمهای پیچیدهتر مانند ذخیرهسازی سندی و در برخی موارد پایگاه داده گرافی است.
##### منبع(ها) و مطالعه بیشتر: ذخیرهسازی کلید-مقدار
#### پایگاه داده اسنادانتزاع: ذخیرهساز کلید-مقدار با اسناد به عنوان مقدارها
یک پایگاه داده اسنادی حول محور اسناد (XML، JSON، باینری و غیره) شکل گرفته است، جایی که یک سند تمام اطلاعات مربوط به یک شی را ذخیره میکند. پایگاههای داده اسنادی API یا زبان پرسوجو برای جستجو بر اساس ساختار داخلی خود سند ارائه میدهند. توجه داشته باشید، بسیاری از ذخیرهسازهای کلید-مقدار ویژگیهایی برای کار با فراداده مقدار ارائه میدهند که مرز بین این دو نوع ذخیرهسازی را کمرنگ میکند.
بر اساس پیادهسازی زیرین، اسناد توسط مجموعهها، برچسبها، فراداده یا دایرکتوریها سازماندهی میشوند. اگرچه اسناد میتوانند سازماندهی یا گروهبندی شوند، اما ممکن است فیلدهای اسناد کاملاً با هم متفاوت باشند.
برخی پایگاههای داده اسنادی مانند MongoDB و CouchDB همچنین زبان مشابه SQL برای انجام پرسوجوهای پیچیده ارائه میدهند. DynamoDB از هر دو مدل کلید-مقدار و سند پشتیبانی میکند.
پایگاههای داده اسنادی انعطافپذیری بالایی ارائه میدهند و اغلب برای دادههایی با تغییرات گاهبهگاه استفاده میشوند.
##### منبع(ها) و مطالعه بیشتر: پایگاه داده اسناد
#### پایگاه داده ستونی گسترده
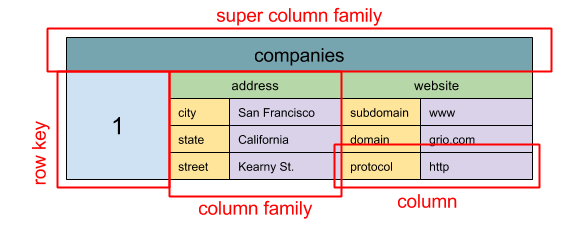
منبع: SQL & NoSQL، تاریخچهای مختصر
انتزاع: نگاشت تو در تو ColumnFamily> واحد پایه داده در پایگاه داده ستونی گسترده یک ستون (جفت نام/مقدار) است. یک ستون میتواند در خانواده ستونها (مشابه جدول SQL) گروهبندی شود. خانوادههای ستون فوق، خانوادههای ستون را بیشتر گروهبندی میکنند. شما میتوانید هر ستون را با کلید ردیف به طور مستقل دسترسی داشته باشید و ستونهایی با کلید ردیف یکسان یک ردیف را تشکیل میدهند. هر مقدار شامل یک زمانسنج برای نسخهبندی و رفع تضاد است.
گوگل Bigtable را به عنوان اولین پایگاه داده ستونی گسترده معرفی کرد که بر HBase متنباز که در اکوسیستم Hadoop استفاده میشود و Cassandra از فیسبوک تأثیر گذاشت. پایگاههایی مانند BigTable، HBase و Cassandra کلیدها را به صورت واژهنامهای مرتب میکنند که امکان بازیابی کارآمد بازههای انتخابی کلید را فراهم میکند.
پایگاههای داده ستونی گسترده، دسترسیپذیری و مقیاسپذیری بالایی ارائه میدهند. آنها اغلب برای مجموعه دادههای بسیار بزرگ استفاده میشوند.
##### منبع(ها) و مطالعه بیشتر: پایگاه داده ستونی گسترده
#### پایگاه داده گراف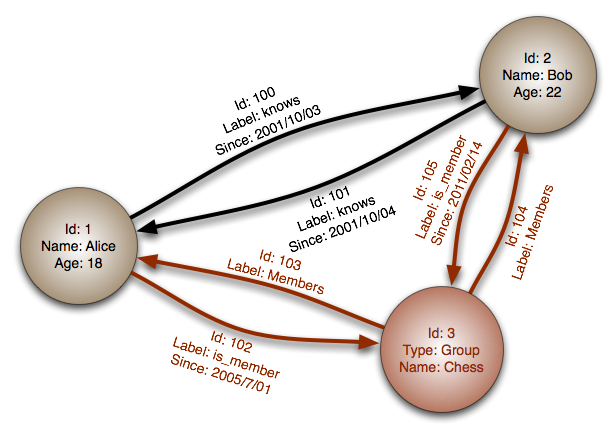
انتزاع: گراف
در پایگاه داده گراف، هر گره یک رکورد است و هر یال یک رابطه بین دو گره میباشد. پایگاههای داده گراف برای نمایش روابط پیچیده با کلیدهای خارجی متعدد یا روابط چند به چند بهینه شدهاند.
پایگاههای داده گراف عملکرد بالایی برای مدلهای داده با روابط پیچیده، مانند شبکههای اجتماعی، ارائه میدهند. این نوع پایگاه داده نسبتاً جدید بوده و هنوز فراگیر نشدهاند؛ ممکن است یافتن ابزارهای توسعه و منابع دشوارتر باشد. بسیاری از گرافها فقط با REST APIها قابل دسترسی هستند.
##### منبع(ها) و مطالعات بیشتر: گراف
#### منبع(ها) و مطالعات بیشتر: NoSQL- توضیح اصطلاحات پایه
- پایگاههای داده NoSQL: یک بررسی و راهنمای تصمیمگیری
- مقیاسپذیری
- معرفی NoSQL
- الگوهای NoSQL
SQL یا NoSQL
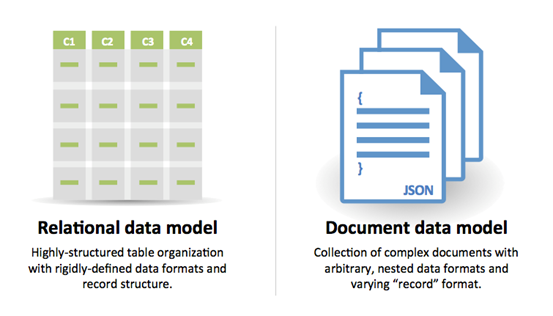
دلایل استفاده از SQL:
- دادههای ساختیافته
- طرحوارهی سختگیرانه
- دادههای رابطهای
- نیاز به پیوندهای پیچیده
- تراکنشها
- الگوهای مشخص برای مقیاسپذیری
- بیشتر تثبیت شده: توسعهدهندگان، جامعه، کد، ابزارها و غیره
- جستجوهای مبتنی بر ایندکس بسیار سریع هستند
- دادههای نیمهساختیافته
- طرحوارهی پویا یا انعطافپذیر
- دادههای غیر رابطهای
- عدم نیاز به پیوندهای پیچیده
- ذخیره حجم بالای داده (چندین ترابایت یا پتابایت)
- حجم کاری بسیار سنگین داده
- کارایی بسیار بالا برای عملیات ورودی/خروجی
- دریافت سریع دادههای کلیکاستریم و لاگ
- دادههای جدول امتیازات یا رتبهبندی
- دادههای موقت مانند سبد خرید
- جداولی که اغلب مورد دسترسی قرار میگیرند (جداول ‘داغ’)
- جداول متادیتا/جستجو
کش
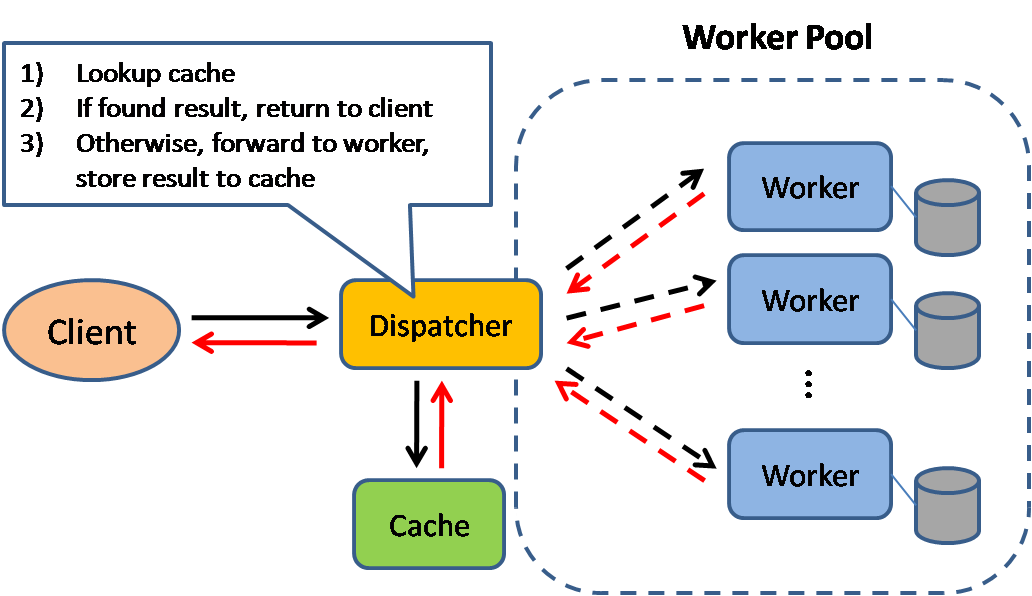
منبع: الگوهای طراحی سیستم مقیاسپذیر
کشینگ باعث بهبود زمان بارگذاری صفحات شده و میتواند بار روی سرورها و پایگاههای داده شما را کاهش دهد. در این مدل، دیسپچر ابتدا بررسی میکند که آیا درخواست قبلاً انجام شده است یا خیر و سعی میکند نتیجه قبلی را پیدا کرده و بازگرداند تا از اجرای واقعی صرفهجویی شود.
پایگاههای داده معمولاً از توزیع یکنواخت خواندن و نوشتن در سراسر پارتیشنهای خود سود میبرند. اقلام محبوب میتوانند این توزیع را بههم زده و باعث ایجاد گلوگاه شوند. قرار دادن کش جلوی پایگاه داده میتواند بارهای نامتعادل و جهشهای ترافیک را جذب کند.
کشینگ سمت کلاینت
کشها میتوانند در سمت کلاینت (سیستمعامل یا مرورگر)، سمت سرور، یا در یک لایه کش مجزا قرار گیرند.
کشینگ CDN
CDNها نوعی کش محسوب میشوند.
کشینگ وبسرور
پراکسیهای معکوس و کشهایی مانند Varnish میتوانند محتوای ایستا و پویا را مستقیماً ارائه دهند. وبسرورها همچنین میتوانند درخواستها را کش کنند و پاسخها را بدون نیاز به تماس با سرورهای اپلیکیشن بازگردانند.
کشینگ پایگاه داده
پایگاه داده شما معمولاً در پیکربندی پیشفرض خود سطحی از کشینگ دارد که برای یک مورد استفاده عمومی بهینه شده است. تنظیم این تنظیمات برای الگوهای استفاده خاص میتواند عملکرد را بیشتر افزایش دهد.
کشینگ اپلیکیشن
کشهای درون حافظه مانند Memcached و Redis فروشگاههای کلیدی-مقداری بین اپلیکیشن و ذخیرهسازی دادههای شما هستند. از آنجا که دادهها در RAM نگهداری میشوند، بسیار سریعتر از پایگاههای داده معمولی هستند که دادهها را روی دیسک ذخیره میکنند. RAM محدودتر از دیسک است، بنابراین الگوریتمهای ابطال کش مانند کمترین استفاده شده اخیر (LRU)) میتوانند به ابطال دادههای سرد و نگه داشتن دادههای داغ در RAM کمک کنند.
Redis ویژگیهای اضافی زیر را دارد:
- گزینه پایداری
- ساختارهای داده داخلی مانند مجموعههای مرتب شده و لیستها
- سطح سطر
- سطح پرسوجو
- اشیاء سریالایز شده کاملاً تشکیل شده
- HTML کاملاً رندر شده
کش کردن در سطح پرسوجوی پایگاه داده
هر زمان که پایگاه داده را پرسوجو میکنید، پرسوجو را بهعنوان یک کلید هش کرده و نتیجه را در کش ذخیره کنید. این رویکرد با مشکلات انقضا روبرو است:
- حذف نتیجه کش شده با پرسوجوهای پیچیده دشوار است
- اگر یک بخش از داده مانند یک سلول جدول تغییر کند، باید تمام پرسوجوهای کش شدهای که ممکن است سلول تغییر یافته را شامل شوند حذف کنید
کش کردن در سطح شیء
دادههای خود را بهعنوان یک شیء ببینید، مشابه کاری که با کد برنامه انجام میدهید. برنامه شما مجموعه داده را از پایگاه داده گرفته و به یک نمونه کلاس یا ساختار دادهای تبدیل میکند:
- اگر داده زیرین شیء تغییر کند، شیء را از کش حذف کنید
- امکان پردازش غیرهمزمان را فراهم میکند: کارگرها با مصرف آخرین شیء کش شده، اشیا را میسازند
- نشستهای کاربری
- صفحات وب کاملاً رندر شده
- جریانهای فعالیت
- دادههای گراف کاربر
زمان بهروزرسانی کش
از آنجا که میتوانید تنها مقدار محدودی داده را در کش ذخیره کنید، باید تعیین کنید کدام استراتژی بهروزرسانی کش برای مورد استفاده شما مناسبتر است.
#### کش-کناری
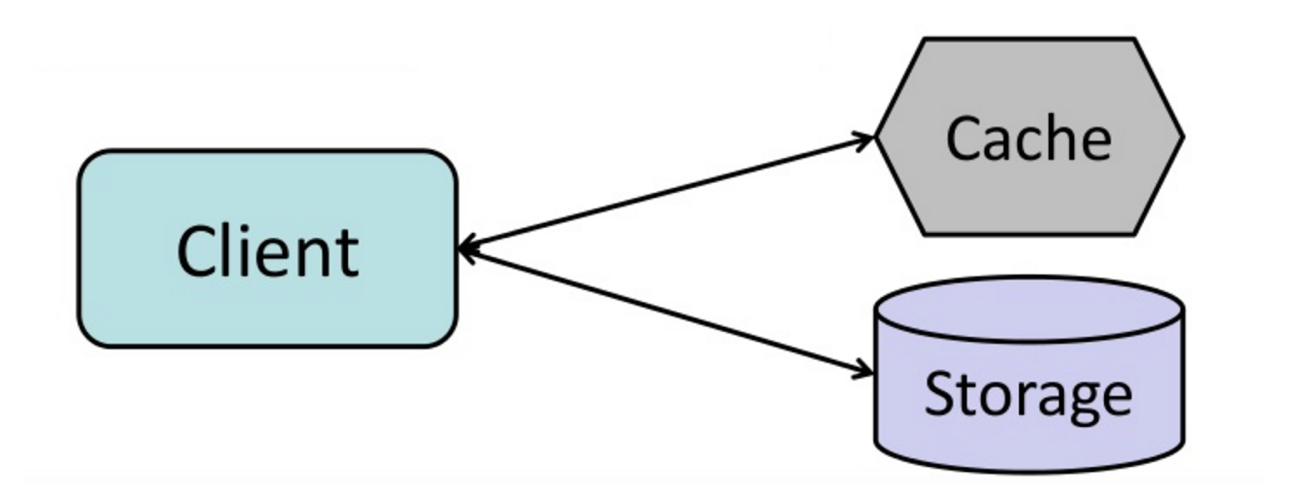
منبع: از کش تا شبکه داده در حافظه
برنامه مسئول خواندن و نوشتن از حافظه است. کش مستقیماً با حافظه تعامل ندارد. برنامه اقدامات زیر را انجام میدهد:
- جستجوی ورودی در کش، در نتیجه خطای کش (cache miss)
- بارگذاری ورودی از پایگاه داده
- افزودن ورودی به کش
- بازگرداندن ورودی
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return userMemcached معمولاً به این صورت استفاده میشود.
خواندنهای بعدی دادهای که به کش افزوده شدهاند سریع هستند. کش-کناری همچنین به عنوان بارگذاری تنبل شناخته میشود. فقط دادههای درخواستشده کش میشوند که از پر شدن کش با دادههایی که درخواست نشدهاند جلوگیری میکند.
##### معایب: کش-کناری
- هر بار از دست دادن کش منجر به سه رفتوآمد میشود که میتواند باعث تأخیر قابل توجهی شود.
- دادهها ممکن است اگر در پایگاه داده بهروزرسانی شوند، قدیمی شوند. این مشکل با تعیین مدت زمان اعتبار (TTL) که بهروزرسانی ورودی کش را اجبار میکند، یا با استفاده از نوشتن-همزمان کاهش مییابد.
- وقتی یک نود از کار میافتد، با یک نود جدید و خالی جایگزین میشود که تأخیر را افزایش میدهد.
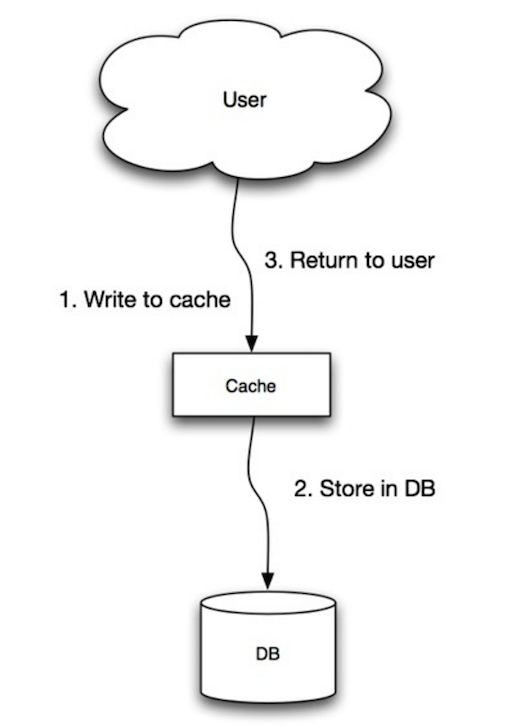
منبع: الگوهای مقیاسپذیری، دسترسیپذیری، پایداری
برنامه از کش به عنوان منبع اصلی داده استفاده میکند و دادهها را خوانده و مینویسد، در حالی که کش مسئول خواندن و نوشتن در پایگاه داده است:
- برنامه ورودی را در کش اضافه/بهروزرسانی میکند
- کش به طور همزمان ورودی را در منبع داده مینویسد
- بازگشت
set_user(12345, {"foo":"bar"})کد کش:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)##### معایب: نوشتن-همزمان
- زمانی که یک نود جدید به دلیل خرابی یا مقیاسبندی ایجاد میشود، نود جدید تا زمانی که ورودی در پایگاه داده بهروزرسانی نشود، ورودیها را کش نمیکند. استفاده همزمان از Cache-aside با نوشتن-همزمان میتواند این مشکل را کاهش دهد.
- بیشتر دادههایی که نوشته میشوند ممکن است هرگز خوانده نشوند، که میتوان این مورد را با تعیین TTL کاهش داد.
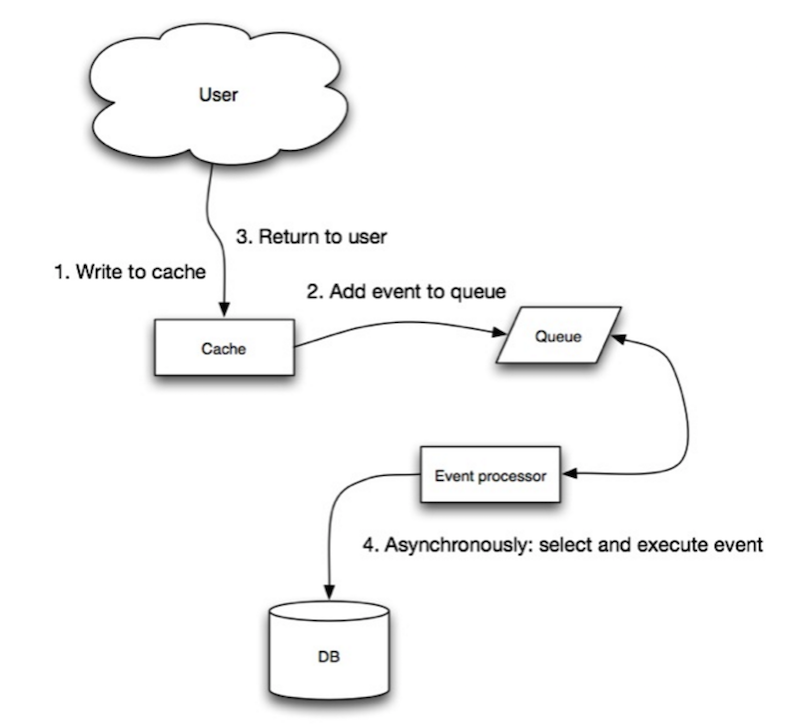
منبع: الگوهای مقیاسپذیری، دسترسیپذیری، پایداری
در نوشتن-پسزمینه، برنامه کاربردی اقدامات زیر را انجام میدهد:
- افزودن/بهروزرسانی ورودی در کش
- نوشتن غیرهمزمان ورودی در مخزن داده، که باعث بهبود عملکرد نوشتن میشود
- ممکن است از دست رفتن داده رخ دهد اگر کش قبل از رسیدن محتوای آن به مخزن داده از کار بیفتد.
- پیادهسازی نوشتن-پسزمینه پیچیدهتر از پیادهسازی cache-aside یا نوشتن-همزمان است.
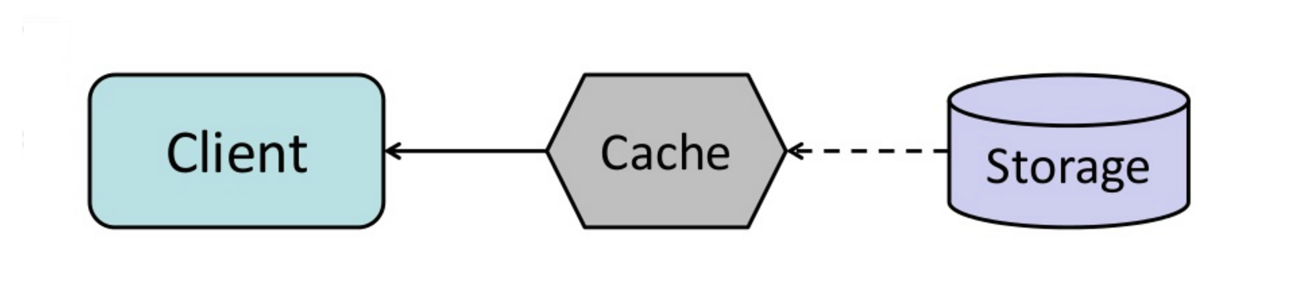
منبع: از کش تا شبکه داده درونحافظهای
میتوانید کش را طوری پیکربندی کنید که هر ورودی کشی که اخیراً مورد دسترسی قرار گرفته است را قبل از انقضایش به طور خودکار تازهسازی کند.
تازهسازی-پیشاپیش میتواند منجر به کاهش تأخیر نسبت به خواندن-همزمان شود اگر کش بتواند به درستی پیشبینی کند کدام آیتمها احتمالاً در آینده مورد نیاز خواهند بود.
##### معایب: تازهسازی-پیشاپیش
- پیشبینی نادرست اینکه کدام آیتمها احتمالاً در آینده مورد نیاز خواهند بود میتواند منجر به عملکرد پایینتر نسبت به حالت بدون refresh-ahead شود.
معایب: کش
- نیاز به حفظ سازگاری بین کشها و منبع حقیقت مانند پایگاه داده از طریق باطلسازی کش.
- باطلسازی کش یک مشکل دشوار است، پیچیدگی بیشتری در ارتباط با زمان بهروزرسانی کش وجود دارد.
- نیاز به ایجاد تغییرات در برنامه مانند افزودن Redis یا memcached.
منابع و مطالعه بیشتر
- از کش تا شبکه داده درونحافظهای
- الگوهای طراحی سیستم مقیاسپذیر
- مقدمهای بر معماری سیستمها برای مقیاس
- مقیاسپذیری، دسترسیپذیری، پایداری، الگوها
- مقیاسپذیری
- استراتژیهای AWS ElastiCache
- ویکیپدیا)
غیرهمزمانی
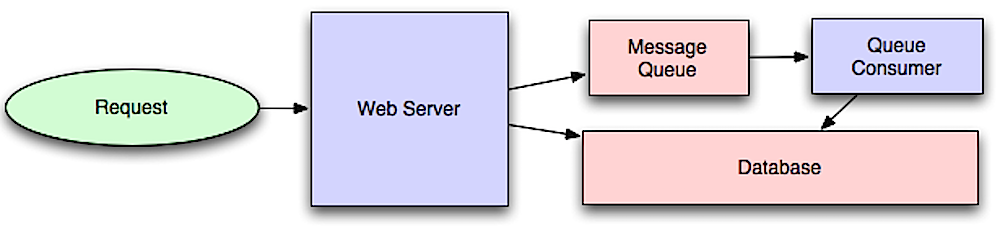
منبع: مقدمهای بر معماری سیستمها برای مقیاس
گردشکارهای غیرهمزمان به کاهش زمان درخواست برای عملیاتهای پرهزینه که در غیر این صورت به صورت درونخطی انجام میشوند کمک میکنند. همچنین میتوانند با انجام کارهای زمانبر از پیش، مانند تجمیع دورهای دادهها، مفید باشند.
صفهای پیام
صفهای پیام، پیامها را دریافت، نگهداری و تحویل میدهند. اگر یک عملیات برای انجام درونخطی خیلی کند است، میتوانید از صف پیام با گردش کار زیر استفاده کنید:
- یک برنامه شغلی را در صف منتشر میکند، سپس وضعیت شغل را به کاربر اطلاع میدهد
- یک کارگر شغل را از صف دریافت کرده، پردازش میکند و سپس سیگنال تکمیل شغل را ارسال میکند
Redis به عنوان یک پیامرسان ساده مفید است اما پیامها ممکن است از دست بروند.
RabbitMQ محبوب است اما نیاز دارد که با پروتکل 'AMQP' سازگار شوید و گرههای خودتان را مدیریت کنید. Amazon SQS میزبانی شده است اما ممکن است تاخیر بالایی داشته باشد و امکان تحویل دوباره پیامها وجود دارد.
صفهای وظیفه
صفهای وظیفه وظایف و دادههای مرتبط با آنها را دریافت میکنند، آنها را اجرا میکنند و سپس نتایج را تحویل میدهند. این صفها قابلیت زمانبندی دارند و میتوانند برای اجرای کارهای محاسباتی سنگین در پسزمینه استفاده شوند.
Celery از زمانبندی پشتیبانی میکند و عمدتاً برای پایتون مناسب است.
فشار معکوس (Back pressure)
اگر صفها به طور قابل توجهی رشد کنند، اندازه صف میتواند از حافظه بزرگتر شود که منجر به خطاهای کش، خواندن دیسک و عملکرد کندتر میشود. فشار معکوس میتواند با محدود کردن اندازه صف کمک کند، و با این کار نرخ گذردهی بالا و زمان پاسخ مناسب برای کارهای موجود در صف حفظ میشود. وقتی صف پر شود، کلاینتها وضعیت سرور مشغول یا کد وضعیت HTTP 503 دریافت میکنند تا بعداً دوباره تلاش کنند. کلاینتها میتوانند درخواست را در زمان دیگری دوباره ارسال کنند، شاید با بازگشت نمایی.
معایب: غیرهمزمانی
- موارد استفادهای مانند محاسبات کمهزینه و جریانهای کاری بلادرنگ ممکن است برای عملیات همزمان مناسبتر باشند، زیرا افزودن صفها میتواند تاخیر و پیچیدگی ایجاد کند.
منابع و مطالعات بیشتر
ارتباط
{kind=link}
{kind=link}
پروتکل انتقال ابرمتن (HTTP)
HTTP روشی برای کدگذاری و انتقال داده بین کلاینت و سرور است. این یک پروتکل درخواست/پاسخ است: کلاینتها درخواست ارسال میکنند و سرورها پاسخهایی با محتوای مرتبط و اطلاعات وضعیت تکمیل درخواست صادر میکنند. HTTP مستقل از محیط است و به درخواستها و پاسخها اجازه میدهد از مسیرهای مختلف، روترها و سرورهای واسط که عمل بارگذاری، کش، رمزنگاری و فشردهسازی انجام میدهند، عبور کنند.
یک درخواست HTTP پایه شامل یک فعل (method) و یک منبع (endpoint) است. در زیر افعال رایج HTTP آورده شده است:
| فعل | توضیحات | ایندموتنت* | امن | قابل کش شدن |
| GET | خواندن یک منبع | بله | بله | بله | | POST | ایجاد یک منبع یا راهاندازی فرایندی که دادهها را پردازش میکند | خیر | خیر | بله اگر پاسخ شامل اطلاعات تازگی باشد | | PUT | ایجاد یا جایگزینی یک منبع | بله | خیر | خیر | | PATCH | بهروزرسانی جزئی یک منبع | خیر | خیر | بله اگر پاسخ شامل اطلاعات تازگی باشد | | DELETE | حذف یک منبع | بله | خیر | خیر |
میتواند چندین بار فراخوانی شود بدون نتایج متفاوت.
HTTP یک پروتکل لایه کاربردی است که بر پروتکلهای سطح پایینتر مانند TCP و UDP تکیه دارد.
#### منبع(ها) و مطالعه بیشتر: HTTP
پروتکل کنترل انتقال (TCP)
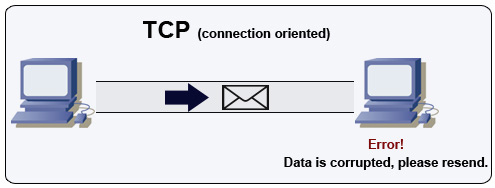
منبع: چگونه یک بازی چند نفره بسازیم
TCP یک پروتکل مبتنی بر اتصال روی یک شبکه IP است. اتصال با استفاده از دستدهی برقرار و قطع میشود. تمام بستههایی که ارسال میشوند تضمین میشود که به مقصد برسند، به همان ترتیب اصلی و بدون خرابی از طریق:
- شمارههای ترتیبی و فیلدهای بررسی مجموع برای هر بسته
- بستههای تأیید دریافت) و ارسال مجدد خودکار
برای تضمین سرعت انتقال بالا، سرورهای وب میتوانند تعداد زیادی اتصال TCP باز نگه دارند که منجر به مصرف حافظه زیاد میشود. داشتن تعداد زیادی اتصال باز بین رشتههای سرور وب و مثلاً یک سرور memcached میتواند پرهزینه باشد. تجمیع اتصال میتواند کمک کند، علاوه بر اینکه در موارد مناسب به UDP سوئیچ شود.
TCP برای برنامههایی که به قابلیت اطمینان بالا نیاز دارند اما حساسیت زمانی کمتری دارند مفید است. برخی مثالها شامل سرورهای وب، اطلاعات پایگاه داده، SMTP، FTP و SSH هستند.
TCP را به جای UDP استفاده کنید زمانی که:
- نیاز دارید تمام دادهها بهطور کامل و سالم برسند
- میخواهید به طور خودکار بهترین تخمین از بهرهبرداری شبکه را داشته باشید
پروتکل دیتاگرام کاربر (UDP)
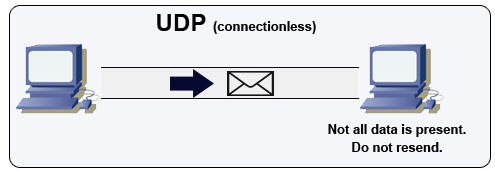
منبع: چگونه یک بازی چندنفره بسازیم
UDP بدون اتصال است. دیتاگرامها (مشابه بستهها) فقط در سطح دیتاگرام تضمین شدهاند. دیتاگرامها ممکن است خارج از ترتیب به مقصد برسند یا اصلاً نرسند. UDP کنترل تراکم را پشتیبانی نمیکند. بدون تضمینهایی که TCP ارائه میدهد، UDP معمولاً کارآمدتر است.
UDP میتواند پخش کند، دیتاگرامها را به همه دستگاههای زیرشبکه ارسال کند. این امر با DHCP مفید است زیرا کلاینت هنوز آدرس IP دریافت نکرده است و بنابراین راهی برای TCP جهت ارسال جریان بدون آدرس IP وجود ندارد.
UDP کمتر قابل اعتماد است اما در کاربردهای بلادرنگ مانند VoIP، چت ویدیویی، استریم و بازیهای چندنفره بلادرنگ خوب عمل میکند.
زمانی از UDP به جای TCP استفاده کنید که:
- به کمترین تأخیر نیاز دارید
- داده دیرتر بدتر از از دست رفتن داده است
- میخواهید تصحیح خطا را خودتان پیادهسازی کنید
- شبکه برای برنامهنویسی بازی
- تفاوتهای کلیدی بین پروتکلهای TCP و UDP
- تفاوت بین TCP و UDP
- پروتکل کنترل انتقال
- پروتکل دیتاگرام کاربر
- مقیاسبندی ممکش در فیسبوک
فراخوانی رویه از راه دور (RPC)
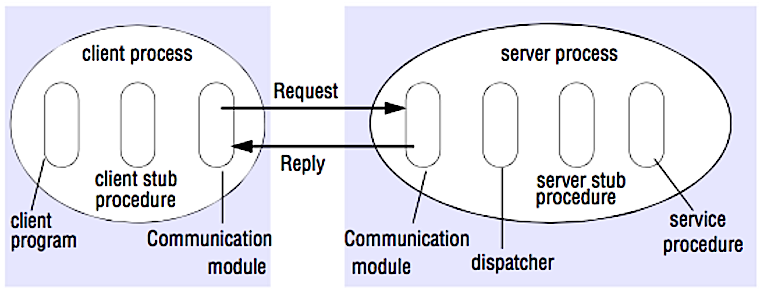
منبع: مصاحبه طراحی سیستم را حل کنید
در RPC، یک کلاینت باعث اجرای یک رویه در فضای آدرس متفاوت، معمولاً یک سرور راه دور، میشود. این رویه به گونهای کدنویسی شده است که گویی یک فراخوانی رویه محلی است و جزئیات نحوه ارتباط با سرور را از برنامه کلاینت انتزاع میکند. فراخوانیهای راه دور معمولاً کندتر و کمتر قابل اعتمادتر از فراخوانیهای محلی هستند، بنابراین تشخیص فراخوانیهای RPC از فراخوانیهای محلی مفید است. چارچوبهای RPC محبوب شامل Protobuf، Thrift و Avro هستند.
RPC یک پروتکل درخواست-پاسخ است:
- برنامه کلاینت - رویه استاب کلاینت را فراخوانی میکند. پارامترها مانند فراخوانی یک رویه محلی روی پشته قرار میگیرند.
- رویه استاب کلاینت - شناسه رویه و آرگومانها را در یک پیام درخواست بستهبندی (مارشال) میکند.
- ماژول ارتباطی کلاینت - سیستمعامل پیام را از کلاینت به سرور ارسال میکند.
- ماژول ارتباطی سرور - سیستمعامل بستههای دریافتی را به رویه استاب سرور انتقال میدهد.
- رویه استاب سرور - نتایج را بازبستهبندی (آنمارشال) کرده، رویه سرور مطابق با شناسه رویه را فراخوانی میکند و آرگومانهای داده شده را ارسال میکند.
- پاسخ سرور مراحل بالا را به صورت معکوس تکرار میکند.
GET /someoperation?data=anIdPOST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
یک کتابخانه بومی (یا SDK) را زمانی انتخاب کنید که:
- پلتفرم هدف خود را میدانید.
- میخواهید کنترل کنید که "منطق" شما چگونه در دسترس قرار میگیرد.
- میخواهید کنترل کنید که کنترل خطاها چگونه خارج از کتابخانه شما انجام شود.
- عملکرد و تجربه کاربری نهایی دغدغه اصلی شماست.
#### معایب: RPC
- کلاینتهای RPC به شدت به پیادهسازی سرویس وابسته میشوند.
- برای هر عملیات یا مورد استفاده جدید باید یک API جدید تعریف شود.
- دیباگ کردن RPC میتواند دشوار باشد.
- ممکن است نتوانید به راحتی از فناوریهای موجود استفاده کنید؛ به عنوان مثال، ممکن است نیاز به تلاش اضافی برای اطمینان از اینکه فراخوانیهای RPC به درستی کش شوند بر روی سرورهای کش مانند Squid باشد.
انتقال وضعیت نمایشی (REST)
REST یک سبک معماری است که مدل کلاینت/سرور را تحمیل میکند، جایی که کلاینت بر روی مجموعهای از منابع که توسط سرور مدیریت میشوند عمل میکند. سرور نمایشهایی از منابع و اقداماتی را فراهم میکند که میتوانند منابع را تغییر دهند یا نمای جدیدی از منابع به دست آورند. تمام ارتباطات باید بدون حالت و قابل کش شدن باشند.
چهار ویژگی برای یک رابط RESTful وجود دارد:
- شناسایی منابع (URI در HTTP) - صرفنظر از عملیات، از همان URI استفاده کنید.
- تغییر با نمایشها (افعال در HTTP) - از افعال، هدرها و بدنه استفاده کنید.
- پیام خطای خودتوصیف (پاسخ وضعیت در HTTP) - از کدهای وضعیت استفاده کنید، دوباره چرخ را اختراع نکنید.
- HATEOAS (رابط HTML برای HTTP) - سرویس وب شما باید به طور کامل در مرورگر قابل دسترسی باشد.
GET /someresources/anIdPUT /someresources/anId
{"anotherdata": "another value"}
#### معایب: REST
- با توجه به اینکه REST بر ارائه دادهها متمرکز است، ممکن است اگر منابع به صورت طبیعی در یک سلسلهمراتب ساده سازماندهی یا قابل دسترسی نباشند، گزینهی مناسبی نباشد. برای مثال، بازگرداندن تمام رکوردهای بهروزرسانیشده در یک ساعت گذشته که مطابق با مجموعهای از رویدادهای خاص هستند، به راحتی به عنوان یک مسیر قابل بیان نیست. در REST معمولاً این کار با ترکیبی از مسیر URI، پارامترهای کوئری، و احتمالاً بدنه درخواست انجام میشود.
- REST معمولاً بر تعداد کمی فعل (GET، POST، PUT، DELETE و PATCH) تکیه دارد که گاهی اوقات با نیاز شما همخوانی ندارد. به عنوان مثال، انتقال اسناد منقضی شده به پوشه آرشیو ممکن است به شکل مناسبی در این افعال قرار نگیرد.
- دریافت منابع پیچیده با سلسلهمراتب تو در تو، نیازمند چندین رفت و برگشت بین کلاینت و سرور برای ارائه یک نما است، مثلاً دریافت محتوای یک مطلب وبلاگ و نظرات آن مطلب. برای اپلیکیشنهای موبایل در شرایط متغیر شبکه، این رفت و برگشتها بسیار نامطلوب هستند.
- با گذشت زمان، ممکن است فیلدهای بیشتری به پاسخ API افزوده شوند و کلاینتهای قدیمی تمام دادههای جدید را دریافت کنند، حتی آنهایی که به آنها نیاز ندارند، که نتیجه آن افزایش حجم payload و تاخیر بیشتر است.
مقایسه فراخوانیهای RPC و REST
| عملیات | RPC | REST |
|---|---|---|
| ثبتنام | POST /signup | POST /persons |
| استعفا | POST /resign
{
"personid": "1234"
} | DELETE /persons/1234 |
| خواندن یک فرد | GET /readPerson?personid=1234 | GET /persons/1234 |
| خواندن لیست آیتمهای یک فرد | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| افزودن آیتم به لیست آیتمهای یک فرد | POST /addItemToUsersItemsList
{
"personid": "1234";
"itemid": "456"
} | POST /persons/1234/items
{
"itemid": "456"
} |
| بهروزرسانی یک آیتم | POST /modifyItem
{
"itemid": "456";
"key": "value"
} | PUT /items/456
{
"key": "value"
} |
| حذف یک آیتم | POST /removeItem
{
"itemid": "456"
} | DELETE /items/456 |
منبع: آیا واقعاً میدانید چرا REST را به RPC ترجیح میدهید؟
#### منابع و مطالعه بیشتر: REST و RPC
- آیا واقعاً میدانید چرا REST را به RPC ترجیح میدهید؟
- چه زمانی رویکردهای شبیه به RPC مناسبتر از REST هستند؟
- REST در مقابل JSON-RPC
- افسانهزدایی از RPC و REST
- معایب استفاده از REST
- مصاحبه طراحی سیستم را ترک کنید
- Thrift
- چرا REST برای استفاده داخلی و نه RPC
امنیت
این بخش نیاز به بروزرسانی دارد. برای مشارکت اقدام کنید!
امنیت موضوعی گسترده است. مگر اینکه تجربه قابل توجهی داشته باشید، سابقهای در زمینه امنیت داشته باشید، یا برای موقعیتی درخواست دهید که نیاز به دانش امنیتی دارد، احتمالاً بیش از اصول اولیه نیازی به دانستن ندارید:
- رمزنگاری دادهها در حالت انتقال و ذخیرهشده.
- پاکسازی تمام ورودیهای کاربر یا هر پارامتر ورودی که در معرض کاربر قرار میگیرد برای جلوگیری از XSS و تزریق SQL.
- استفاده از پرسوجوهای پارامتری برای جلوگیری از تزریق SQL.
- استفاده از اصل کمترین سطح دسترسی.
منبع(ها) و مطالعه بیشتر
ضمیمه
گاهی اوقات از شما خواسته میشود که تخمینهای سرانگشتی انجام دهید. برای مثال، ممکن است لازم باشد تعیین کنید تولید ۱۰۰ تصویر بندانگشتی از دیسک چقدر زمان میبرد یا یک ساختار داده چه مقدار حافظه نیاز دارد. جدول توانهای دو و اعداد تأخیر که هر برنامهنویسی باید بداند منابع مفیدی هستند.
جدول توانهای دو
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB#### منبع(ها) و مطالعه بیشتر
اعداد تأخیر که هر برنامهنویسی باید بداند
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 msNotes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
- خواندن ترتیبی از HDD با سرعت ۳۰ مگابایت بر ثانیه
- خواندن ترتیبی از اترنت ۱ گیگابیت بر ثانیه با سرعت ۱۰۰ مگابایت بر ثانیه
- خواندن ترتیبی از SSD با سرعت ۱ گیگابایت بر ثانیه
- خواندن ترتیبی از حافظه اصلی با سرعت ۴ گیگابایت بر ثانیه
- ۶-۷ رفت و برگشت جهانی در هر ثانیه
- ۲,۰۰۰ رفت و برگشت در هر ثانیه درون یک دیتاسنتر
#### منبع(ها) و مطالعه بیشتر
- اعداد تأخیر که هر برنامهنویس باید بداند - ۱
- اعداد تأخیر که هر برنامهنویس باید بداند - ۲
- طراحیها، درسها و توصیهها از ساخت سیستمهای توزیعشده بزرگ
- توصیههای مهندسی نرمافزار از ساخت سیستمهای توزیعشده در مقیاس بزرگ
پرسشهای تکمیلی مصاحبه طراحی سیستم
پرسشهای رایج مصاحبه طراحی سیستم، همراه با لینکهایی برای منابع حل هر یک.
| پرسش | مرجع(ها) |
|---|---|
| طراحی سرویس همگامسازی فایل مانند Dropbox | youtube.com |
| طراحی موتور جستجو مانند گوگل | queue.acm.org
stackexchange.com
ardendertat.com
stanford.edu |
| طراحی خزنده وب مقیاسپذیر مانند گوگل | quora.com |
| طراحی Google docs | code.google.com
neil.fraser.name |
| طراحی فروشگاه کلید-مقدار مانند Redis | slideshare.net |
| طراحی سیستم کش مانند Memcached | slideshare.net |
| طراحی سیستم توصیهگر مانند آمازون | hulu.com
ijcai13.org |
| طراحی سیستم tinyurl مانند Bitly | n00tc0d3r.blogspot.com |
| طراحی اپلیکیشن چت مانند WhatsApp | highscalability.com
| طراحی سیستم اشتراکگذاری عکس مانند Instagram | highscalability.com
highscalability.com |
| طراحی تابع خبرخوان فیسبوک | quora.com
quora.com
slideshare.net |
| طراحی تابع timeline فیسبوک | facebook.com
highscalability.com |
| طراحی تابع چت فیسبوک | erlang-factory.com
facebook.com |
| یک تابع جستجوی گراف مانند فیسبوک طراحی کنید | facebook.com
facebook.com
facebook.com |
| یک شبکه تحویل محتوا مانند CloudFlare طراحی کنید | figshare.com |
| یک سیستم موضوعات ترند مانند توییتر طراحی کنید | michael-noll.com
snikolov .wordpress.com |
| یک سیستم تولید شناسه تصادفی طراحی کنید | blog.twitter.com
github.com |
| درخواستهای برتر k را در یک بازه زمانی بازگردانید | cs.ucsb.edu
wpi.edu |
| یک سیستم که دادهها را از چندین مرکز داده ارائه میدهد طراحی کنید | highscalability.com |
| یک بازی کارت چندنفره آنلاین طراحی کنید | indieflashblog.com
buildnewgames.com |
| یک سیستم جمعآوری زباله طراحی کنید | stuffwithstuff.com
washington.edu |
| یک محدودکننده نرخ API طراحی کنید | https://stripe.com/blog/ |
| یک بورس اوراق بهادار (مانند NASDAQ یا Binance) طراحی کنید | Jane Street
Golang Implementation
Go Implementation |
| یک سوال طراحی سیستم اضافه کنید | Contribute |
معماریهای واقعی دنیا
مقالاتی درباره نحوه طراحی سیستمهای واقعی دنیا.
منبع: مقیاسپذیری تایملاین توییتر
به جزئیات ریز در مقالات زیر تمرکز نکنید، بلکه:
- اصول مشترک، فناوریهای رایج و الگوها را در این مقالات شناسایی کنید
- بررسی کنید هر مولفه چه مشکلی را حل میکند، کجا کار میکند، کجا نمیکند
- درسهای آموخته شده را مرور کنید
معماری شرکتها
| شرکت | مرجع(ها) |
|---|---|
| آمازون | معماری آمازون |
| Cinchcast | تولید ۱۵۰۰ ساعت صوت در هر روز |
| DataSift | دادهکاوی بلادرنگ با ۱۲۰،۰۰۰ توییت در ثانیه |
| Dropbox | چگونه Dropbox را مقیاسبندی کردیم |
| ESPN | عملیات با ۱۰۰،۰۰۰ duh nuh nuhs در ثانیه |
| گوگل | معماری گوگل |
| اینستاگرام | ۱۴ میلیون کاربر، ترابایتها عکس
چه چیزی اینستاگرام را قدرت میدهد |
| Justin.tv | معماری پخش زنده ویدیوی Justin.tv |
| فیسبوک | مقیاسبندی memcached در فیسبوک
TAO: مخزن داده توزیعشده فیسبوک برای گراف اجتماعی
ذخیرهسازی عکس فیسبوک
چگونه فیسبوک پخش زنده را به ۸۰۰،۰۰۰ بیننده همزمان میرساند |
| Flickr | معماری Flickr |
| Mailbox | از ۰ تا یک میلیون کاربر در ۶ هفته |
| Netflix | نمای ۳۶۰ درجه از کل پشته Netflix
Netflix: چه اتفاقی میافتد وقتی پلی را فشار میدهید؟ |
| Pinterest | از ۰ تا دهها میلیارد بازدید صفحه در ماه
۱۸ میلیون بازدیدکننده، رشد ۱۰ برابری، ۱۲ کارمند |
| Playfish | ۵۰ میلیون کاربر ماهانه و رو به رشد |
| PlentyOfFish | معماری PlentyOfFish |
| Salesforce | چگونه روزانه ۱.۳ میلیارد تراکنش را مدیریت میکنند |
| Stack Overflow | معماری Stack Overflow |
| TripAdvisor | ۴۰M بازدیدکننده، ۲۰۰M بازدید پویا، ۳۰TB داده |
| Tumblr | ۱۵ میلیارد بازدید صفحه در ماه |
| توییتر | سریعتر کردن توییتر به میزان ۱۰۰۰۰ درصد
ذخیرهسازی ۲۵۰ میلیون توییت در روز با MySQL
۱۵۰ میلیون کاربر فعال، ۳۰۰K QPS، فایرهوس ۲۲ MB/S
تایملاینها در مقیاس
دادههای بزرگ و کوچک در توییتر
عملیات در توییتر: مقیاسبندی فراتر از ۱۰۰ میلیون کاربر
چگونه توییتر ۳۰۰۰ تصویر در ثانیه را مدیریت میکند |
| Uber | چگونه Uber پلتفرم بازار بلادرنگ خود را مقیاسبندی میکند
درسهایی از مقیاسبندی Uber تا ۲۰۰۰ مهندس، ۱۰۰۰ سرویس و ۸۰۰۰ مخزن Git |
| WhatsApp | معماری WhatsApp که فیسبوک با ۱۹ میلیارد دلار خرید |
| یوتیوب | مقیاسپذیری یوتیوب
معماری یوتیوب |
وبلاگهای مهندسی شرکتها
معماریهایی برای شرکتهایی که در حال مصاحبه با آنها هستید.>
سوالاتی که با آنها مواجه میشوید ممکن است از همان حوزه باشند.
- مهندسی Airbnb
- توسعهدهندگان Atlassian
- وبلاگ AWS
- وبلاگ مهندسی Bitly
- وبلاگهای Box
- وبلاگ توسعهدهندگان Cloudera
- وبلاگ فنی Dropbox
- مهندسی در Quora
- وبلاگ فنی Ebay
- وبلاگ فنی Evernote
- Etsy Code as Craft
- مهندسی Facebook
- Flickr Code
- وبلاگ مهندسی Foursquare
- وبلاگ مهندسی GitHub
- وبلاگ تحقیقات Google
- وبلاگ مهندسی Groupon
- وبلاگ مهندسی Heroku
- وبلاگ مهندسی Hubspot
- High Scalability
- مهندسی Instagram
- وبلاگ نرمافزار Intel
- وبلاگ فنی Jane Street
- مهندسی LinkedIn
- مهندسی Microsoft
- مهندسی پایتون Microsoft
- وبلاگ فنی Netflix
- وبلاگ توسعهدهندگان Paypal
- وبلاگ مهندسی Pinterest
- وبلاگ Reddit
- وبلاگ مهندسی Salesforce
- وبلاگ مهندسی Slack
- Spotify Labs
- وبلاگ مهندسی Stripe
- وبلاگ مهندسی Twilio
- مهندسی توییتر
- وبلاگ مهندسی Uber
- وبلاگ مهندسی یاهو
- وبلاگ مهندسی Yelp
- وبلاگ مهندسی Zynga
دنبال اضافه کردن یک وبلاگ هستید؟ برای جلوگیری از تکرار کار، وبلاگ شرکت خود را به مخزن زیر اضافه کنید:
در حال توسعه
علاقهمند به اضافه کردن یک بخش یا کمک به تکمیل یکی از بخشهای در حال پیشرفت هستید؟ مشارکت کنید!
- محاسبات توزیعشده با MapReduce
- هشینگ سازگار
- Scatter gather
- مشارکت کنید
اعتبارها
اعتبارها و منابع در سراسر این مخزن ارائه شدهاند.
تشکر ویژه از:
- Hired in tech
- Cracking the coding interview
- High scalability
- checkcheckzz/system-design-interview
- shashank88/system_design
- mmcgrana/services-engineering
- System design cheat sheet
- A distributed systems reading list
- Cracking the system design interview
اطلاعات تماس
در صورت تمایل میتوانید برای بحث در مورد هرگونه مشکل، سؤال یا نظر با من تماس بگیرید.
اطلاعات تماس من را میتوانید در صفحه گیتهاب من پیدا کنید.
مجوز
من کد و منابع موجود در این مخزن را تحت یک مجوز متنباز در اختیار شما قرار میدهم. از آنجا که این مخزن شخصی من است، مجوزی که برای کد و منابع دریافت میکنید از طرف من است و نه کارفرمای من (فیسبوک).
کپیرایت ۲۰۱۷ دون مارتین
مجوز بینالمللی کریتیو کامنز انتساب 4.0 (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/
--- Tranlated By Open Ai Tx | Last indexed: 2025-08-09 ---